
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Improved Attentive Recurrent Network for Applied Linguistics-Based Offensive Speech Detection
1 Department of Computer and Self Development, Preparatory Year Deanship, Prince Sattam bin Abdulaziz University, AlKharj, Saudi Arabia
2 Department of Applied Linguistics, College of Languages, Princess Nourah Bint Abdulrahman University, P.O. Box 84428, Riyadh, 11671, Saudi Arabia
3 Department of Computer Sciences, College of Computing and Information System, Umm Al-Qura University, Makkah, Saudi Arabia
4 Department of Information Systems, Faculty of Computing and Information Technology, King Abdulaziz University, Jeddah, Saudi Arabia
5 Department of Digital Media, Faculty of Computers and Information Technology, Future University in Egypt, New Cairo, 11835, Egypt
6 Department of English, College of Science & Humanities, Prince Sattam bin Abdulaziz University, AlKharj, Saudi Arabia
* Corresponding Author: Manar Ahmed Hamza. Email:
Computer Systems Science and Engineering 2023, 47(2), 1691-1707. https://doi.org/10.32604/csse.2023.034798
Received 27 July 2022; Accepted 13 November 2022; Issue published 28 July 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Applied linguistics is one of the fields in the linguistics domain and deals with the practical applications of the language studies such as speech processing, language teaching, translation and speech therapy. The ever-growing Online Social Networks (OSNs) experience a vital issue to confront, i.e., hate speech. Amongst the OSN-oriented security problems, the usage of offensive language is the most important threat that is prevalently found across the Internet. Based on the group targeted, the offensive language varies in terms of adult content, hate speech, racism, cyberbullying, abuse, trolling and profanity. Amongst these, hate speech is the most intimidating form of using offensive language in which the targeted groups or individuals are intimidated with the intent of creating harm, social chaos or violence. Machine Learning (ML) techniques have recently been applied to recognize hate speech-related content. The current research article introduces a Grasshopper Optimization with an Attentive Recurrent Network for Offensive Speech Detection (GOARN-OSD) model for social media. The GOARN-OSD technique integrates the concepts of DL and metaheuristic algorithms for detecting hate speech. In the presented GOARN-OSD technique, the primary stage involves the data pre-processing and word embedding processes. Then, this study utilizes the Attentive Recurrent Network (ARN) model for hate speech recognition and classification. At last, the Grasshopper Optimization Algorithm (GOA) is exploited as a hyperparameter optimizer to boost the performance of the hate speech recognition process. To depict the promising performance of the proposed GOARN-OSD method, a widespread experimental analysis was conducted. The comparison study outcomes demonstrate the superior performance of the proposed GOARN-OSD model over other state-of-the-art approaches.Keywords
Brand advertising and mass communication about the products and services of a company have been digitalized in this modern era. This phenomenon made several companies pay more attention to hate speech content than ever before [1]. Online hate speech content can be described as messages conveyed in discriminatory or pejorative language. Though the companies can control the content released on their social media channels and their website, it is impossible for them to completely control the online users’ comments or their posts regarding their brand [2]. In simple terms, hate speech can be found in written communication, behaviour, or speech. It uses or attacks an individual or a group of people, or an organization using discriminatory or pejorative language about certain delicate data or protected features [3]. Such protected features include colour, religion, nationality, health status, ethnicity, disability, sexual orientation, marital status, descent, gender or race and other identity factors [4]. Hate speech is an illegal and dangerous act that should be discouraged at all levels. In addition to the content, both sounds and images are also utilized in the distribution of hate speech [5]. Hence, computer-based text classification is considered an optimal solution to overcome this issue.
There is no universal definition available for hate speech. Because precise and clear hate speech definition can shorten the annotator’s effort, increasing the annotator’s agreement rate [6]. However, it is hard to distinguish hate speech from normal speech. So, it is challenging to provide a universal and precise definition for hate speech [7]. Cyberbullying is a type of online-based harassment that involves repeated hostile behaviour towards a person or a group of individuals who are unable to defend themselves, mostly adolescents. This hostile behaviour is deliberately expressed upon the victims to hurt or threaten them [8]. Cyberbullying is also considered a type of hate speech if a victim’s sensitive features are targeted during the assault. Hate speech can be differentiated from cyber-bullying in such a manner that hate speech affects an individual and has consequences for society or a whole group [9]. Hate speech is a complex and multi-faceted concept that is difficult to understand by computer systems and human beings. The prevailing literature contains numerous Deep Learning (DL) techniques for detecting hate speech [10].
In this background, the authors have offered various DL models with the help of Neural Network (NN) elements such as the Convolutional Neural Network (CNN) and Long Short-Term Memory (LSTM) model. The existing DL methods generally utilize a single NN element and a set of certain user-defined features as additional features. In general, different DL elements are effective over different types of datasets. Automatic hate speech recognition becomes essential for avoiding spreading hate speech, mainly in social media. Several approaches have been presented to carry out the offensive speech detection process, comprising the latest DL-based models advancements. Various datasets have also been developed, exemplifying various manifestations of the hate-speech detection problem.
In the earlier study [11], the author used a multilingual and multi-task technique relevant to the newly-projected Transformer Neural Network to resolve three sub-tasks for hate speech recognition. These tasks are nothing but the tasks shared on Hate Speech and Offensive Content (HASOC) detection in Indo-European languages during the year 2019. The author expanded the submissions to the competition using multitasking techniques. These techniques can be trained with the help of three techniques: multilingual training, multitask learning with distinct task heads, and the back-translation method. Khan et al. [12] introduced a hate detection technique for mass media with a multi-label complexity. For this purpose, the author devised a CNN-related service structure called ‘HateClassify’ to categorize the mass media content as hate speech, non-offensive and offensive.
In literature [13], the author presented a Transfer Learning (TL) method for hate speech recognition based on an existing pre-trained language method called BERT (Bidirectional Encoder Representations from Transformers) model. The study evaluated the presented method using two publicly-available Twitter datasets that had content with hate or offensive content, racism and sexism. Then, the author presented a bias alleviation system to mitigate the impact of the bias upon the trained set when fine-tuning the pre-trained BERT-related technique for hate speech identification. In the study conducted earlier [14], the researchers collected the hate speech content, i.e., English-Odia code-varied data, from a public page on Facebook. Then, the data were classified into three classes. The hate speech recognition models use a group of extracted features and Machine Learning (ML) method. A few approaches, such as Random Forest (RF), Support Vector Machine (SVM) and Naïve Bayes (NB), were trained well using the complete data with the extracted features relevant to word unigram, Term Frequency-Inverse Document Frequency (TF-IDF), bigram, combined n-grams, word2vec, combined n-grams weighted by Term Frequency Inverse Dense Frequency (TF-IDF) and trigram for datasets. Perifanos et al. [15] presented an innovative method for hate speech recognition by combining Natural Language Processing (NLP) and Computer Vision (CV) techniques to identify offensive content. This work focused on racist, hateful and xenophobic Twitter messages about Greek migrants and refugees. The author compiled the TL method and the finely-tuned Bidirectional Encoder Representations from Transformers (BERT) and Residual Neural Networks (Resnet) models in this method.
Das et al. [16] projected a common NLP tool, i.e., encoder–decoder-related ML approach, to classify Bengali users’ comments on Facebook pages. In this study, the one-dimensional convolutional layer was employed to encode and extract the local features from the comments. At last, the attention systems such as the GRU-related decoders and the LSTM approach were employed to estimate the hate speech classes. Al-Makhadmeh et al. [17] presented a technique in which a hybrid of NLP and ML methods was used to determine the hate speech on mass media sites. In this study, the hate speech content was accumulated. The data went through different processes such as character removal, stemming, inflection elimination and token splitting, before executing the hate speech identification procedure. Then, the gathered data was scrutinized using an ensemble deep learning technique. The model identified the hate speech on Social Networking Sites (SNS) with the help of a proficient learning procedure that categorized the messages into hate language, neutral and violent.
Though several models are available in the literature for offensive speech detection, it is still needed to improve the detection performance. Since the trial-and-error hyperparameter tuning process is tedious, metaheuristic algorithms can be employed. Therefore, the current research article introduces a Grasshopper Optimization with an Attentive Recurrent Network for Offensive Speech Detection (GOARN-OSD) model for social media. The presented GOARN-OSD technique integrates the concepts of DL and metaheuristic algorithms for hate speech detection. In the proposed GOARN-OSD technique, data pre-processing and word embedding are carried out in the primary stage. The ARN model is utilized in this study for hate speech recognition and its classification. At last, the Grasshopper Optimization Algorithm (GOA) is exploited as a hyperparameter optimizer to boost the performance of hate speech recognition, showing the novelty of the work. A widespread experimental analysis was conducted to establish the promising performance of the proposed GOARN-OSD technique.
2 Proposed Offensive Speech Detection Model
In this article, a new GOARN-OSD method has been developed to detect offensive speeches on social media. The presented GOARN-OSD technique integrates the concepts of DL and metaheuristic algorithms for hate speech detection. Fig. 1 illustrates the block diagram of the proposed GOARN-OSD approach.
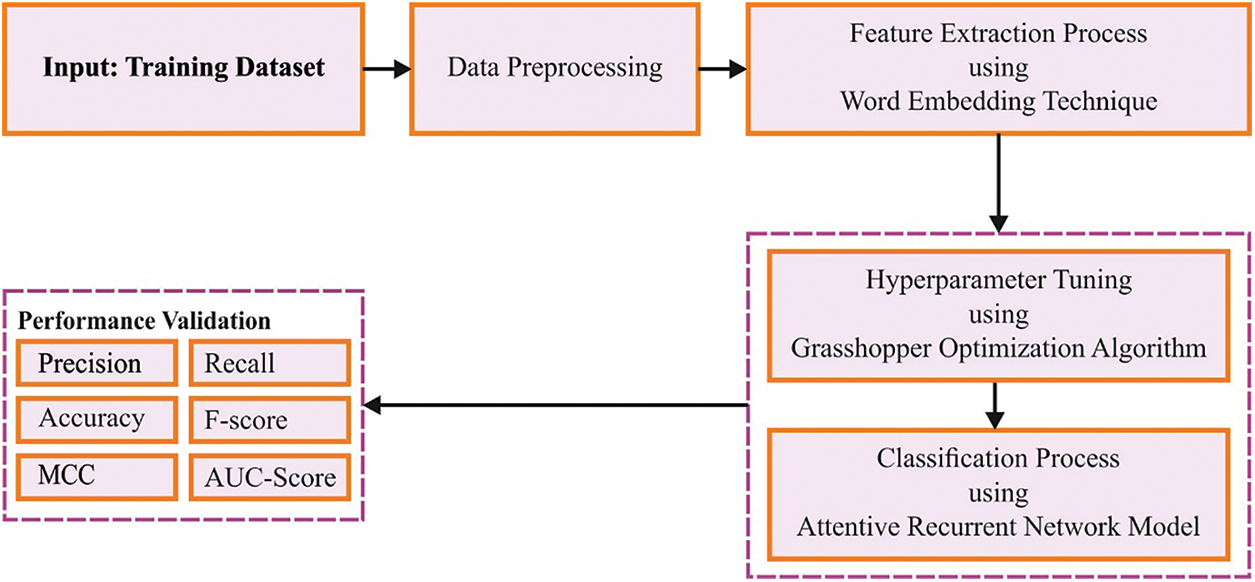
Figure 1: Block diagram of the GOARN-OSD approach
In the proposed GOARN-OSD technique, the data is pre-processed in the primary stage. The pre-processing step filters the irrelevant and noisy contents from the data. At first, all the duplicate tweets are filtered since it does not feed any dataset to the module. During the pre-processing stage, different Twitter-specific symbols and noises, namely, mention (@), retweets (RT), hashtags (#) and the URLs, are filtered. Furthermore, the alphanumeric symbols such as dots, ampersands, non-ASCII characters, stop-words and commas are filtered to prevent noisy content from being used. At last, the pre-processed tweets are transformed into lower case to avoid ambiguity.
Most DL approaches for text classification exploit the word embedding approach to extract effective and discriminative characteristics. It is a process of mapping the words into real, fixed and dimension vectors to capture the syntactic and semantic dataset for the words and initialize the weight of the first NNS layer. Its superiority considerably impacts the learner’s performance [18]. The author-trained CNN classifier is used for contextualized word embedding (MBert and AraBert) and non-contextualized word embedding (FastText-SkipGram) processes.
FastText-SkipGram: It is trained using large Arabic corpora viz., a group of Wikipedia dump containing three million Arabic sentences, United Nations corpora of 6.5 million Arabic tweets, and other corpora of 9.9 million Arabic sentences. The embedded words contain word vectors with more than a million words under 300 dimensions.
Multilingual Bert: It is a contextualized word-embedding process that works on sub-word levels to generate the feature vectors for the words. Unlike the static non-contextualized word-embedding process, this Bert process captures both long- and short-span contextual dependencies in the input text using a bidirectional self-attention transformer. In this work, the multilingual version of the Bert (MBert) is employed with a pre-trained monolingual Wikipedia corpus of 104 languages.
AraBert: This process employs a novel Arabic-contextualized word-embedding training process. AraBert is employed to accomplish a remarkable outcome in three Arabic NLP tasks and eight distinct data sets.
2.3 Hate Speech Classification Using ARN Model
The ARN model is utilized in this study to recognize and classify hate speech content. The Recurrent Neural Network (RNN) model efficiently mines datasets containing features. The hidden layer of the RNN model, with long-term sequence storage, has a loop that integrates the present moment’s output with the following moment’s input [19]. Consequently, the RNN model is considered fit to process the log datasets that differ with sedimentary faces in the in-depth direction. But, gradient explosion and disappearance problems tend to occur in real-time applications due to the fundamental structure of the RNN model. So, it has a memory function for short-term datasets. Regarding the issues mentioned earlier, the RNN variants of the Gated Recurrent Unit (GRU) and the LSTM technique are projected. The LSTM model has three gating units: the output, forget and input gates to update the input dataset and attain the capability of a long-term memory dataset. But the hidden unit of the LSTM model not only has various parameters and a complex structure and takes a long training time. In contrast to the LSTM system, the reset and update gates of the GRU model can shorten the training time, improve the network’s generalization ability and decrease the number of network training parameters based on the assumption of guaranteeing the predictive performance.
The architecture of the GRU model integrates the output of the hidden state at
In these expressions,
Even though the neural network efficiently handles the text classification tasks, a considerable shortcoming cannot be disregarded in the ‘black box’ methodology. In this study, a Bi-LSTM structure is described using an attention layer that permits the neork to consider words in a sentence based on their intrinsic importance. The attention LSTM mechanism can extract a portion of the subset of the presented input. At the same time, its importae can be understood on the phrase- or word-level significance of the specified queries. The intermediate outcomes of the NN output are exploited for an effectual feature selection (viz., attentiveord weight) to help the rule-based methodology construct an explainable and interpretable text classification solution.
Consider a sentence S is classified into t words,
Then, a word-level neural depiction is attained for the provided word
The Bi-LSTM neural unit summarizes the data of the entire sentence, S. In the conventional LSTM method, the vectors
Now
In Eq. (10), s represents a high-level depiction of the sentence that is applied as a concluding feature for the prediction of a label y to the classification of a sentence using a
In Eq. (11),
Eq. (12), k denotes the index of the sentence, j shows the index of the class,
2.4 Hyperparameter Optimization
At last, the GOA is exploited as a hyperparameter optimizer to boost hate speech recognition performance. In this work, the GOA method integrates the behaviour of Grasshoppers (GH) [20]. Grasshopper is a parasite that affects farming and agricultural practices. Its lifespan encompasses three phases such as adulthood, egg and the nymph. In the first phase, the grasshoppers exhibit running and hopping behaviours in spinning barrels (at a slow motion with small increments) for ingratiation; they eat plants originating during their migration. The grasshoppers migrate to a long distance as colonies in their adult lifespan with long and unexpected movements. This phenomenon is shown in the following equation.
In Eq. (13),
In Eq. (14),
In Eq. (15), w and b show the attractive distance scale and attractiveness threshold. In Eq. (13),
In Eq. (16), q and y denote the constant gravitation and the drifting constant, while
In Eq. (17),
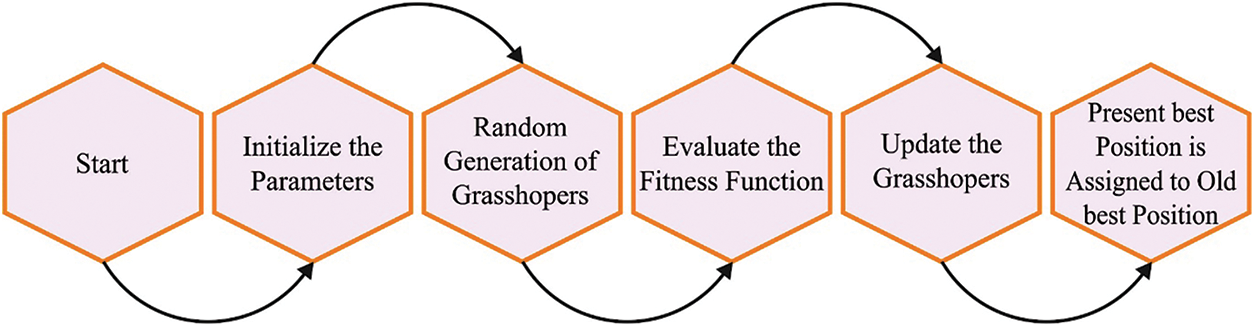
Figure 2: Flowchart of the GOA approach
Now, z refers to a critical factor that significantly decreases the zone of attraction, the comfort zone and the region of repellence, as given below.
In Eq. (18),
The pseudocode of the GOA approach involves Algorithm 1, whereas the GH begins with the implementation of an arbitrary population
1. Standardization of the distance for solution A within [1,4].
2. Update

This section examines the classification performance of the GOARN-OSD model on the Twitter dataset. The dataset has a total of 2,000 tweets under two class labels and the details about the dataset are depicted in Table 1.

In Fig. 3, the confusion matrices generated by the proposed GOARN-OSD model are depicted under distinct Training (TR) and Testing (TS) dataset values. On 80% of TR data, the GOARN-OSD model recognized 738 samples as hate class and 742 samples as normal class. Moreover, on 20% of TS data, the proposed GOARN-OSD approach categorized 205 samples under the hate class and 174 samples under the normal class. Along with that, on 70% of TR data, the GOARN-OSD approach classified 697 samples under hate class and 624 samples under normal class. Then, on 30% of TS data, the GOARN-OSD method recognized 293 samples as hate class and 270 samples as normal class.
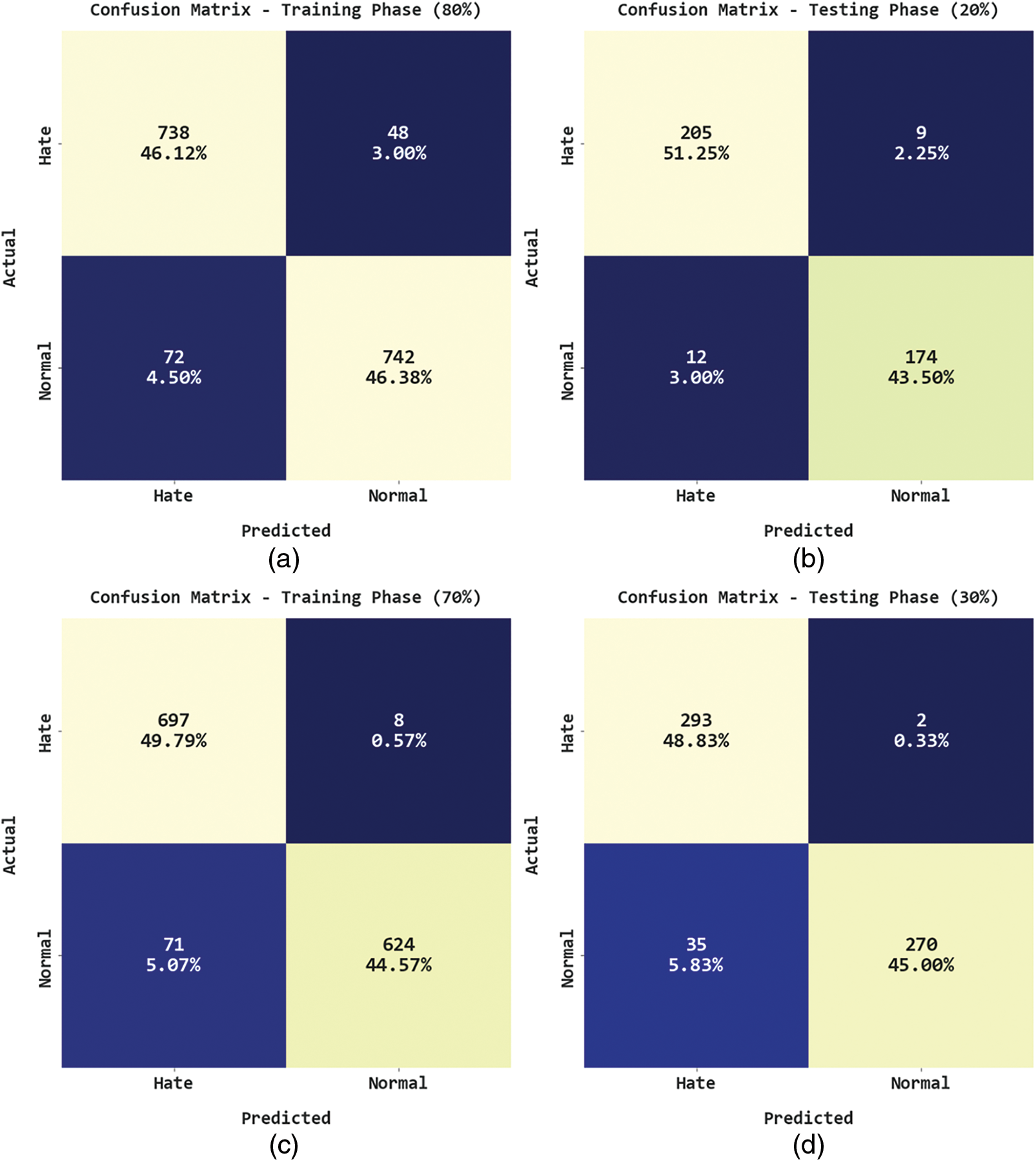
Figure 3: Confusion matrices of the GOARN-OSD approach (a) 80% of TR data, (b) 20% of TS data, (c) 70% of TR data, and (d) 30% of TS data
Table 2 presents the overall experimental results of the proposed GOARN-OSD method on 80% of TR data and 20% of TS datasets.
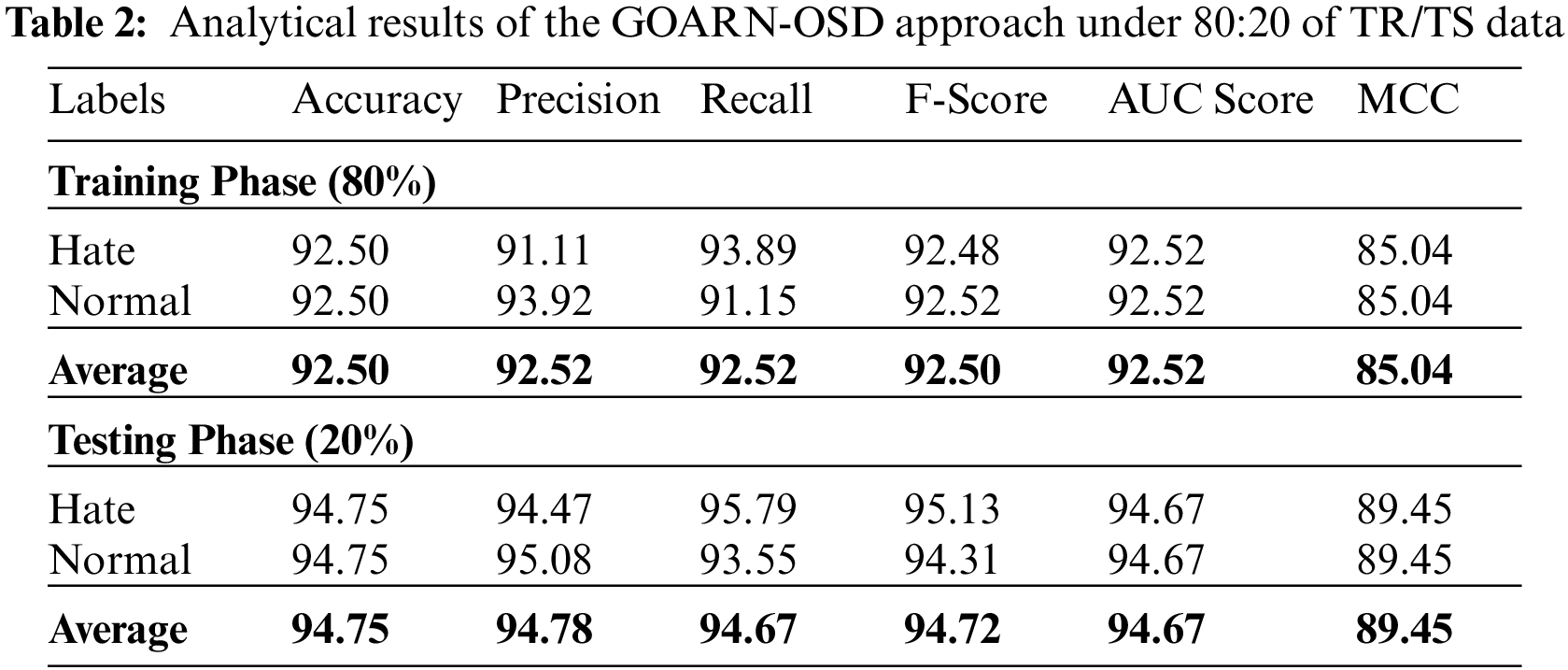
Fig. 4 reveals the overall offensive speech classification performance of the GOARN-OSD model on 80% of TR data. The GOARN-OSD model recognized the samples into hate class with

Figure 4: Average analysis results of the GOARN-OSD approach under 80% of TR data
Fig. 5 shows the complete offensive speech classification performance achieved by the proposed GOARN-OSD technique on 20% of TS data. The GOARN-OSD methodology recognized the samples into hate class with

Figure 5: Average analysis results of the GOARN-OSD approach under 20% of TS data
Table 3 presents the detailed experimental results of the GOARN-OSD method on 80% of TR data and 20% of TS datasets. Fig. 6 displays the detailed offensive speech classification performance of the proposed GOARN-OSD technique on 70% of TR data. The GOARN-OSD approach recognized the samples under hate class with


Figure 6: Average analysis results of the GOARN-OSD approach under 70% of TR data
Fig. 7 demonstrates the complete offensive speech classification performance achieved by the proposed GOARN-OSD approach on 30% of TS data. The GOARN-OSD methodology recognized the samples as hate class with

Figure 7: Average analysis results of the GOARN-OSD approach under 30% of TS data
Both Training Accuracy (TRA) and Validation Accuracy (VLA) values, gained by the proposed GOARN-OSD methodology on the test dataset, are shown in Fig. 8. The experimental results denote that the proposed GOARN-OSD approach attained the maximal TRA and VLA values whereas the VLA values were superior to TRA values.

Figure 8: TRA and VLA analyses results of the GOARN-OSD approach
Both Training Loss (TRL) and Validation Loss (VLL) values, obtained by the GOARN-OSD method on the test dataset, are displayed in Fig. 9. The experimental results represent that the GOARN-OSD technique exhibited the minimal TRL and VLL values while the VLL values were lesser than the TRL values.

Figure 9: TRL and VLL analyses results of the GOARN-OSD approach
A clear precision-recall analysis was conducted upon the GOARN-OSD algorithm using the test dataset and the results are presented in Fig. 10. The figure denotes that the GOARN-OSD methodology produced enhanced precision-recall values under all the classes.

Figure 10: Precision-recall analysis results of the GOARN-OSD approach
A brief ROC study was conducted upon the GOARN-OSD technique using the test dataset and the results are portrayed in Fig. 11. The outcomes denote that the proposed GOARN-OSD method displayed its ability to categorize the test dataset under distinct classes.

Figure 11: ROC analysis results of the GOARN-OSD approach
The enhanced hate speech detection outcomes of the proposed GOARN-OSD model along with the results of other models were compared and the results are given in Table 4 and Fig. 12 [21]. These table values imply that the proposed GOARN-OSD model achieved a better performance over other models. For instance, in terms of
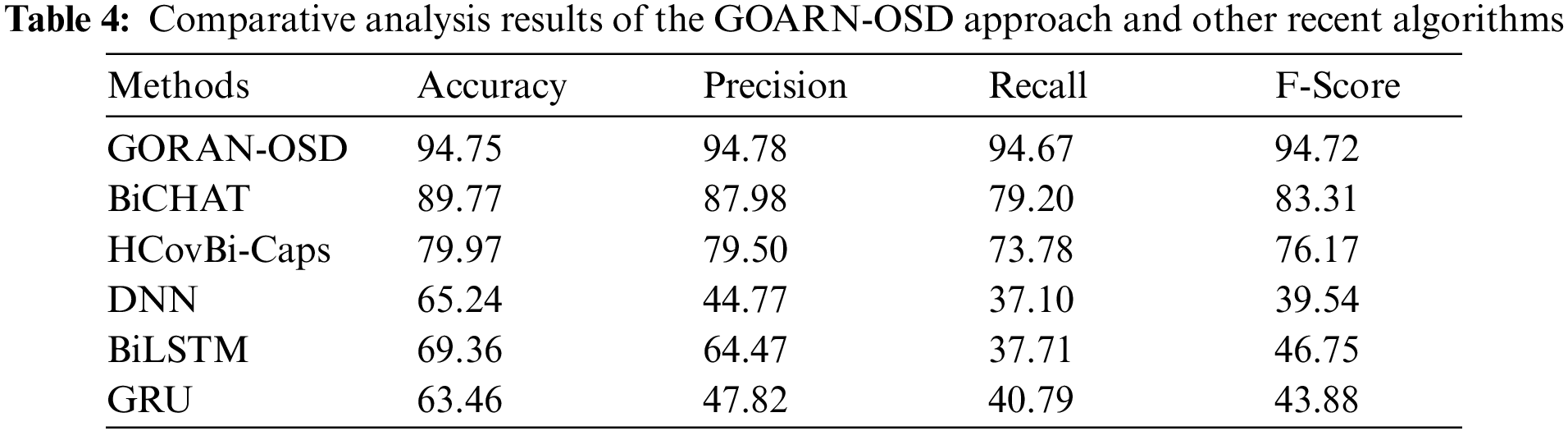

Figure 12: Comparative analysis results of the GOARN-OSD approach and other recent algorithms
Finally, in terms of
Therefore, it can be inferred that the proposed GOARN-OSD model produced enhanced offensive speech detection performance than the existing models.
In this article, a new GOARN-OSD technique has been developed for offensive speech detection on social media. The proposed GOARN-OSD technique integrates the concepts of DL technique and metaheuristic algorithm for the purpose of hate speech detection. In the proposed GOARN-OSD technique, the data is pre-processed and word embedding is carried out in the primary stage. For hate speech recognition and classification, the ARN model is utilized in this study. At last, the GOA approach is exploited as a hyperparameter optimizer to boost the hate speech recognition performance. To depict the promising performance of the proposed GOARN-OSD method, a widespread experimental analysis was executed. The comparative study outcomes established the superior performance of the proposed GOARN-OSD method compared to the existing approaches. In the future, the GOARN-OSD technique can be elaborated for sarcasm detection process too.
Acknowledgement: The authors thank to the support of Princess Nourah bint Abdulrahman University, Umm Al-Qura University, and Prince Sattam bin Abdulaziz University for their funding support to this work.
Funding Statement: Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2023R281), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia. The authors would like to thank the Deanship of Scientific Research at Umm Al-Qura University for supporting this work by Grant Code: (22UQU4331004DSR031). This study is supported via funding from Prince Sattam bin Abdulaziz University project number (PSAU/2023/R/1444).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. G. Kovács, P. Alonso and R. Saini, “Challenges of hate speech detection in social media,” SN Computer Science, vol. 2, no. 2, pp. 1–15, 2021. [Google Scholar]
2. S. Modha, T. Mandl, P. Majumder and D. Patel, “Tracking hate in social media: Evaluation, challenges and approaches,” SN Computer Science, vol. 1, no. 2, pp. 1–16, 2020. [Google Scholar]
3. B. Mathew, P. Saha, S. M. Yimam, C. Biemann, P. Goyal et al., “Hatexplain: A benchmark dataset for explainable hate speech detection,” in Proc. of the AAAI Conf. on Artificial Intelligence, vol. 35, no. 17, pp. 14867–14875, 2021. [Google Scholar]
4. B. Vidgen and T. Yasseri, “Detecting weak and strong Islamophobic hate speech on social media,” Journal of Information Technology & Politics, vol. 17, no. 1, pp. 66–78, 2020. [Google Scholar]
5. N. Vashistha and A. Zubiaga, “Online multilingual hate speech detection: Experimenting with Hindi and English social media,” Information, vol. 12, no. 1, pp. 5, 2020. [Google Scholar]
6. M. Mondal, L. A. Silva, D. Correa and F. Benevenuto, “Characterizing usage of explicit hate expressions in social media,” New Review of Hypermedia and Multimedia, vol. 24, no. 2, pp. 110–130, 2018. [Google Scholar]
7. M. Corazza, S. Menini, E. Cabrio, S. Tonelli and S. Villata, “A multilingual evaluation for online hate speech detection,” ACM Transactions on Internet Technology, vol. 20, no. 2, pp. 1–22, 2020. [Google Scholar]
8. T. Davidson, D. Warmsley, M. Macy and I. Weber, “Automated hate speech detection and the problem of offensive language,” in Proc. of the Int. AAAI Conf. on Web and Social Media, Canada, vol. 11, no. 1, pp. 512–515, 2017 [Google Scholar]
9. T. T. A. Putri, S. Sriadhi, R. D. Sari, R. Rahmadani and H. D. Hutahaean, “A comparison of classification algorithms for hate speech detection,” in Iop Conf. Series: Materials Science and Engineering, India, vol. 830, no. 3, pp. 032006, 2020. [Google Scholar]
10. G. K. Pitsilis, H. Ramampiaro and H. Langseth, “Effective hate-speech detection in Twitter data using recurrent neural networks,” Applied Intelligence, vol. 48, no. 12, pp. 4730–4742, 2018. [Google Scholar]
11. S. Mishra, S. Prasad and S. Mishra, “Exploring multi-task multilingual learning of transformer models for hate speech and offensive speech identification in social media,” SN Computer Science, vol. 2, no. 2, pp. 1–19, 2021. [Google Scholar]
12. M. U. Khan, A. Abbas, A. Rehman and R. Nawaz, “Hateclassify: A service framework for hate speech identification on social media,” IEEE Internet Computing, vol. 25, no. 1, pp. 40–49, 2020. [Google Scholar]
13. M. Mozafari, R. Farahbakhsh and N. Crespi, “Hate speech detection and racial bias mitigation in social media based on BERT model,” PLoS One, vol. 15, no. 8, pp. e0237861, 2020. [Google Scholar] [PubMed]
14. S. K. Mohapatra, S. Prasad, D. K. Bebarta, T. K. Das, K. Srinivasan et al., “Automatic hate speech detection in English-odia code mixed social media data using machine learning techniques,” Applied Sciences, vol. 11, no. 18, pp. 8575, 2021. [Google Scholar]
15. K. Perifanos and D. Goutsos, “Multimodal hate speech detection in Greek social media,” Multimodal Technologies and Interaction, vol. 5, no. 7, pp. 34, 2021. [Google Scholar]
16. A. K. Das, A. Al Asif, A. Paul and M. N. Hossain, “Bangla hate speech detection on social media using attention-based recurrent neural network,” Journal of Intelligent Systems, vol. 30, no. 1, pp. 578–591, 2021. [Google Scholar]
17. Z. Al-Makhadmeh and A. Tolba, “Automatic hate speech detection using killer natural language processing optimizing ensemble deep learning approach,” Computing, vol. 102, no. 2, pp. 501–522, 2020. [Google Scholar]
18. S. Safari, S. Sadaoui and M. Mouhoub, “Deep learning ensembles for hate speech detection,” in 32nd Int. Conf. on Tools with Artificial Intelligence ICTAI, U.S., pp. 526–531, 2020. [Google Scholar]
19. Z. He, C. Y. Chow and J. D. Zhang, “STANN: A spatiotemporal attentive neural network for traffic prediction,” IEEE Access, vol. 7, pp. 4795–4806, 2018. [Google Scholar]
20. B. S. Yildiz, N. Pholdee, S. Bureerat, A. R. Yildiz and S. M. Sait, “Robust design of a robot gripper mechanism using new hybrid grasshopper optimization algorithm,” Expert Systems, vol. 38, no. 3, pp. e12666, 2021. [Google Scholar]
21. S. Khan, M. Fazil, V. K. Sejwal, M. A. Alshara, R. M. Alotaibi et al., “Bichat: BiLSTM with deep CNN and hierarchical attention for hate speech detection,” Journal of King Saud University-Computer and Information Sciences, vol. 34, no. 7, pp. 4335–4344, 2022. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools