
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Securing Cloud Computing from Flash Crowd Attack Using Ensemble Intrusion Detection System
1 Department of Computer Science, Faculty of Science, Northern Border University (NBU), Arar, 73222, Saudi Arabia
2 Remote Sensing Unit, Northern Border University (NBU), Arar, 73222, Saudi Arabia
3 Deparment of Cybersecurity, American University of Madaba (AUM), Amman, 11821, Jordan
4 School of Engineering and Computing, University of West of Scotland, Paisley, PA1 2BE, UK
* Corresponding Author: Yousef Sanjalawe. Email:
(This article belongs to the Special Issue: Artificial Intelligence for Cyber Security)
Computer Systems Science and Engineering 2023, 47(1), 453-469. https://doi.org/10.32604/csse.2023.039207
Received 14 January 2023; Accepted 10 March 2023; Issue published 26 May 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Flash Crowd attacks are a form of Distributed Denial of Service (DDoS) attack that is becoming increasingly difficult to detect due to its ability to imitate normal user behavior in Cloud Computing (CC). Botnets are often used by attackers to perform a wide range of DDoS attacks. With advancements in technology, bots are now able to simulate DDoS attacks as flash crowd events, making them difficult to detect. When it comes to application layer DDoS attacks, the Flash Crowd attack that occurs during a Flash Event is viewed as the most intricate issue. This is mainly because it can imitate typical user behavior, leading to a substantial influx of requests that can overwhelm the server by consuming either its network bandwidth or resources. Therefore, identifying these types of attacks on web servers has become crucial, particularly in the CC. In this article, an efficient intrusion detection method is proposed based on White Shark Optimizer and ensemble classifier (Convolutional Neural Network (CNN) and LighGBM). Experiments were conducted using a CICIDS 2017 dataset to evaluate the performance of the proposed method in real-life situations. The proposed IDS achieved superior results, with 95.84% accuracy, 96.15% precision, 95.54% recall, and 95.84% F1 measure. Flash crowd attacks are challenging to detect, but the proposed IDS has proven its effectiveness in identifying such attacks in CC and holds potential for future improvement.Keywords
Cloud Computing (CC) has enhanced the computational approaches that involve the use of virtualization. The literature presented various definitions of CC. Specifically, the National Institute of Standards and Technology (NIST) [1] described CC as “a virtualized pay-as-you-go computing model to assist the prevalent, efficient, and desired network access to a shared pool of customizable computing resources that could be distributed at a high rate with the lowest management action or service provider interaction”. Examples of these resources include storage, networks, servers, services, and applications. Although adversaries are aiming at numerous CC attributes, such as high demand and flexibility, the cloud environment is vulnerable to a diverse range of security threats [2]. Provided that the cloud offers on-demand usage to its provided services [3], attackers attempt to begin an organized Distributed Denial of Service (DDoS) attack on the CC servers that resemble an authorized flash crowd event, which could affect the availability of cloud services. This action enables the attacker to succeed in initiating the attack without being caught. The absence of services has a significant impact on the revenue and business of the service providers, considering the high possibility of transitioning to other service providers due to dissatisfaction regarding the Quality of Service (QoS) [4].
A flash crowd refers to a significant number of individuals who gather in one location for the same purpose in a short period. In computer networks, flash crowd denotes the increased website traffic within a relatively brief time. This situation occurs as a result of unique phenomena, which include breaking news and the delivery of a popular product. In some cases, a flash event happens when a well-known site is connected to a smaller site, which leads to a substantial rise in traffic identified as a flash-dot effect [5].
Flash events and flash-dot impact the server operation of websites and network infrastructure, considering that overcrowding at the network layer could prevent several user requests from reaching the server. The requests may arrive at the server after a significant delay due to requests for resending and packet loss. Certain web server configurations and descriptions are not capable of managing the number of flash event demands [6]. As a result, the users who attempt to access the website in a flash event would be dissatisfied due to the long wait or inability of the event to achieve the target. The severity of the phenomenon increases upon an attacker’s attempt to avoid the defense mechanism by imitating the traffic pattern of authorized users in a flash event [7]. As illustrated in Fig. 1, these categories of attacks occurring during flash events are described as flash crowd attacks.
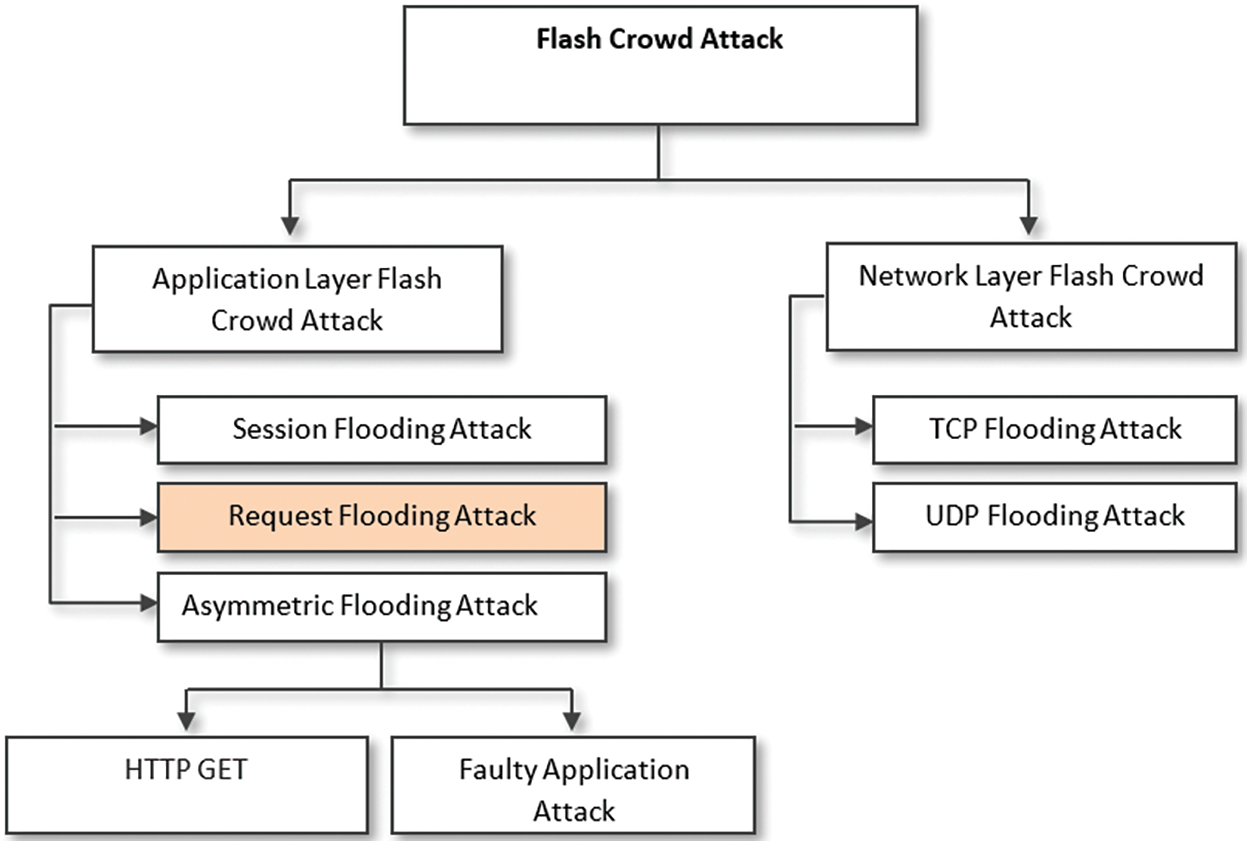
Figure 1: Classes of flash crowd attack
Detecting flash crowd attacks during flash events in CC is a primary challenge for web servers, as they need to differentiate between legitimate user requests for the event and malicious demands. This differentiation is difficult to achieve using existing methods, which can result in delayed feedback to authorized users or even the entire web server crashing. To overcome this challenge, this article proposes a new approach to detect flash crowd attacks with greater accuracy. The contributions of this approach are:
• Enhancing the current body of literature concerning the detection of flash crowd in CC.
• Proposing an adapted version of the White Shark Optimizer (WSO) for selecting the most significant feature subset.
• Adaptation version of Principal Component Analysis (PCA) for reducing the dimensionality of selected features.
• Adaptation of LightGBM and Convolutional Neural Network (CNN) for the detection of flash crowd attacks with superior performance.
The other sections of this article begin with Section 2, which analyses the existing related works and highlights the research gaps. Section 3 discusses the approach proposed in this research in detail. Section 4 presents the findings and their discussion. This article ends with a conclusion in Section 5.
CC assists the auto-scaling feature in scaling the resources on-demand in a dynamic manner. However, this attribute causes critical financial losses to customers when attacks take place on their purchased instances. Among the most critical and most employed attacks on the cloud are the TCP SYN EDOS attacks [8]. Notable initiatives have been performed in the previous decade as a defense against these attacks. Several simulation platforms were suggested for the measurement and analysis of the effect of EDOS attacks on CCE. To identify the traffic anomaly and prevent the emerging categories of DDoS attacks, various techniques are employed, including the artificial intelligence-based approach [9–11], statistical anomaly identification [12–14], machine learning-based approach [15,16], data mining approach [17–21], classifiers-based [22,23], hybrid anomaly detection [24,25], and signature-based detection [26,27]. Based on the comparative summary of all the methods presented in Table 1, machine learning anomaly identification is applied in this article.

Anomaly detection using statistical methods is a useful technique for identifying unusual traffic patterns, especially in terms of resource and computation efficiency. This method involves comparing incoming network traffic statistics to normal network traffic patterns to identify any anomalies. Once an anomaly is detected, statistical inference tests are utilized to assess the reliability of the patterns [28]. However, this method is not considered “adaptive,” as shown in Table 1. There have been efforts by researchers to develop methods that combine the efficiency of statistical anomaly detection with the adaptive nature of Software-Defined Networking (SDN). In the context of defending against DDoS attacks, a popular approach is the use of TCP SYN cookies [29], which can effectively block TCP SYN flooding attacks on a server. This technique can be implemented on a cloud instance to prevent such attacks while also reducing the financial cost of the instance due to resource usage. When a TCP SYN attack with a payload is used, the inbound traffic accepted by the instance may require a large amount of bandwidth. After accepting a large number of TCP SYN requests, the instance processes these packets to identify the attack, which may also consume instance resources and result in charges for resource usage for the client.
Gaurav et al. [30] proposed a method called EDOS-Shield to mitigate E-DoS attacks, which uses a virtual firewall that maintains lists of client IP addresses as either “whitelisted” or “blacklisted” based on their classification using a Graphic Turing Test (GTT). Clients who pass the GTT are included in the whitelist, while those who fail are added to the blacklist. However, this approach has the disadvantage of creating overhead, causing delays for legitimate users trying to access the CC. Shawahna et al. [31] proposed a reactive method called EDOS-Attack Defense Shell (ADS), which is designed to block NAT-based attackers by using the port number and IP address of the attacker device and blocking requests from that port number. The authors used a trust factor calculation based on the GTT to determine whether a request was an attack or not. EDOS-ADS can identify clients using their port number and IP address, and it also effectively handles IP spoofing to allow legitimate users to access services. However, there are several issues with this approach. One issue is that when the attacker starts a new request, the NAT router assigns a different port number to the attacker, allowing them to continue the attack from a different port. Another issue is that the GTT involves a different channel assignment for every request, causing the server to generate numerous puzzles for a high number of requests, which could accumulate the attack if the puzzle is not solved in time. The GTT feedback duration is 13.06 s, allowing illegal users to generate massive volume of requests from one source and use massive number of channels for the GTT. Additionally, URL redirection adds an overhead of 0.63 s.
Bawa et al. [32] introduced an IDS, called EDOSEMM, to detect EDOS attacks in a CC. The model consists of three main modules, one of which is the data preparation module, which processes and organizes the flows of incoming packets, which can create overhead. This module deals with both UDP and HTTP attack traffic as well as legitimate traffic. The model uses Hellinger distance and entropy approaches to accurately detect anomalies. A mitigation approach for SYN flooding was suggested by Mendonça et al. [33], which is based on SDN and is executed on a controller. This approach involves utilizing a threshold value to identify and prevent TCP SYN attackers. Once the controller detects that the number of SYN requests from a specific host has exceeded the threshold value, it automatically blacklists and blocks the host. However, this method is solely dependent on the threshold value, which may lead to the blocking of legitimate users due to network disturbances or other related factors.
In [34], a proposal was made to enhance security measures for the Industrial Internet of Things (IIoT) because of its decentralized architecture. The authors suggested a prediction model that utilizes Deep Learning (DL) and is based on sparse evolutionary training (SET) to forecast various types of cybersecurity attacks, including intrusion detection, data type probing, and DoS. The SET-based model that was proposed achieved high performance within a short timeframe (i.e., 2.29 ms). Furthermore, in a real scenario of IIoT security, the performance in terms of detection rate was enhanced by an average of 6.25% in comparison with state-of-the-art models. In addition, [35] explores the application of SDN in enhancing intelligent machine learning methodologies for IDS. The authors propose a new IDS called HFS-LGBM IDS for SDN that utilizes a hybrid Feature Selection (FS) algorithm to obtain the optimal subset of network traffic features and a LightGBM algorithm to detect attacks, aiming to address security concerns associated with SDN. Based on the experimental outcomes from the NSL-KDD benchmark dataset, the proposed system surpasses current methods in terms of accuracy, precision, recall, and F-measure. The authors emphasize the importance of having accurate, high-performing, and real-time systems to tackle the risks linked to SDN.
The paper [36] puts forward a DL-based IDS that can detect diverse kinds of attacks on IoT devices. According to the proposed IDS, it has demonstrated excellent effectiveness in identifying various types of attacks, with a detection accuracy of 93.74% for both simulated and real intrusions. The overall detection rate of this IDS is 93.21%, which is deemed satisfactory in terms of enhancing the security of IoT networks. On the other hand, [37] introduces a new FS technique thatimproves the performance of Deep Neural Network-based IDS. This approach prunes features based on their importance, which is derived from a fusion of statistical importance. The performance of this approach has been evaluated on various datasets and through statistical tests, providing evidence of its effectiveness. The proposed approach provided important contributions to the field of securing IoT and a novel technique to enhance performance and improve security against vulnerabilities and threats.
After a long while since the first “Full-Scale High-Rate Flooding” (HRF) DDoS attacks against the Internet, several types of attacks continue to comprise a malicious threat to different Internet-based environments. Further, the detection of attacks efficiently remains a significant challenging issue. In this section, an attempt to propose an efficient solution to detect the flash crowd attack in flash events in a cloud computing environment is discussed, and the detailed design of the corresponding IDS, as depicted in Fig. 2, is comprehensively presented. The proposed IDS contains six main stages, namely: (i) data preprocessing, (ii) feature selection, (iii) dimensionality reduction, (iv) hybrid classifier, (v) flash crowd detection, and (vi) performance evaluation.
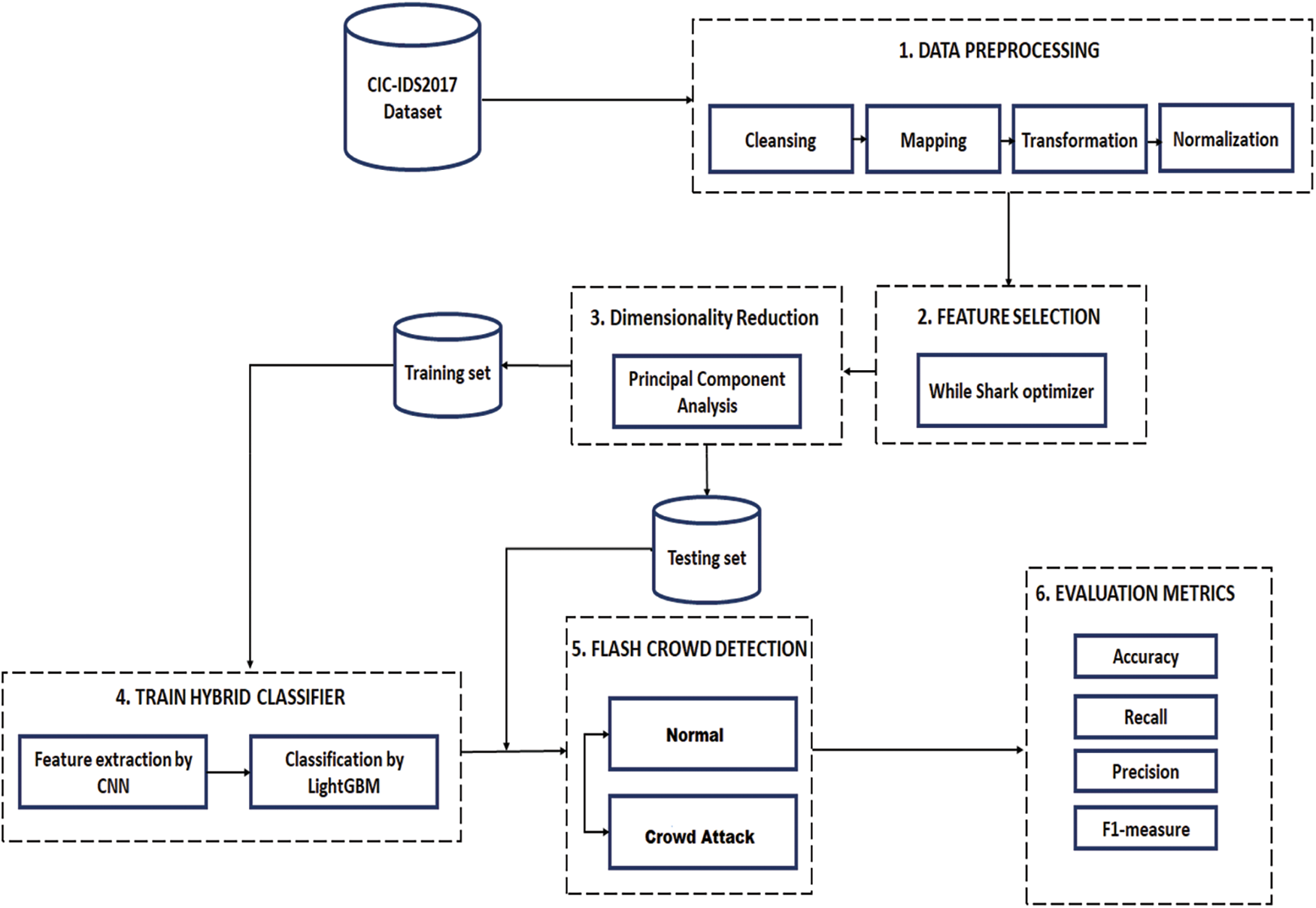
Figure 2: Architecture of proposed IDS
To develop a precise IDS model, several actions should be conducted before the data is included to train the model. Notably, pre-processing is crucial for developing an effective IDS method and reducing the computationally intensive processes. In this study, the following actions were conducted for data preparation:
To compare the attributes, which had different ranges, the data was standardized using Z-score normalization (as shown in Eq. (1)) to transform it onto a different scale. This resulted in the standardized data having a standard deviation of 1 and a mean value of 0 [38].
where M denotes the mean, and
Normalization is a process applied to dataset samples in IDS to standardize them, making them more consistent and easier to analyze. This includes techniques such as scaling, centering, transforming, and removing outliers and missing data. This article presents both binary and multiclass categorizations. In the binary experiment, normal strings were given a binary value of 0, while all malicious packet was given a value of 1. Each attack in the multiple class categorization was assigned a distinct digit value.
CNN requires input in the form of an image with 3-D: width, channel, and height. However, network traffic is in the form of 1-D dimension, which is not compliance with the architecture of CNN. Therefore, a transformation is necessary to convert the shape of the input packet to the resolution dimensions required by a CNN. For the subset of 48 attributes, the 48-D vector was converted into8 × 6 images, while the 9-dimensional vector input was converted into 3 × 3 images. Since this article only uses grayscale images with a single channel, the channel number was set to 1.
The WSO is an algorithm that uses mathematical models based on the characteristics of great white sharks to solve optimization problems within a fixed search space [39]. It is a meta-heuristic algorithm that aims to balance the exploration process and exploitation process of the search space, using the search agents to find the best results. The process and pseudocode of WSO are illustrated in Figs. 3 and 4 respectively. The key concepts and foundations of WSO are inspired by the hunting behaviors of great white sharks, such as their highly developed senses of smell and hearing, which they use to locate and pursue their prey.

Figure 3: Stages of SWO

Figure 4: Pseudocode of WSO [39]
Three characteristics of white sharks were adapted to locate their prey (e.g., the optimal food source). These characteristics are: (1) the movement towards prey based on the wave hesitation that occurs after the prey moves, which involves the white shark using its senses of smell and hearing to make an undulating movement towards the prey; (2) scavenging for prey in deep ocean areas, where the white shark navigates to the prey’s location and gets close to the optimal prey; and (3) detecting the prey once it is within close-proximity, using fish school behavior to move towards the best white shark in the vicinity of the optimal prey. If the prey is not found, the location of each white shark would determine the optimal solution.
3.3 Principal Component Analysis
PCA is a technique used to decrease the number of dimensions in a dataset by identifying Principal Components (PCs), which are the directions that explain the highest variance in the data. It is a linear, unsupervised transformation technique that creates new features in a new subspace using orthogonal axes [40]. Fig. 5 demonstrates that the 1st PC has the largest variance, followed by lower variances for the subsequent PCs. The purpose of PCA is to retain as much information from the initial data as feasible while reducing its dimensionality.

Figure 5: Pseudocode of PCA
PCA is used to minimize the dimensionality of a given benchmark dataset by transforming the initial d-dimensional dataset X into a new k-dimensional space Y (where k ≤ d) using a transformation matrix W [41]. The method used to obtain this transformation matrix is the linear Eigen-decomposition technique, which involves calculating the Eigenvalues and Eigenvectors (PCs) of the covariance matrix (X.X T). The Eigenvectors represent the directions of the data, and the Eigenvalues represent the magnitude of the data. To obtain the columns in the matrix W, each Eigenvector is assigned to a column, with the Eigenvalues being used to determine their order [42]. The Eigen-decomposition method is defined by breaking down the covariance matrix into three other matrices:
In the definition of Eigen-decomposition, B is a square matrix (d × d) consisting of the Eigenvectors, and D is a diagonal matrix (d × d) with all elements except for those on the core diagonal set to zero. These elements represent the specific Eigenvalues, and BT is the transpose of matrix B.
CNN is a neural network architecture used for computer vision tasks, which utilizes a technique called convolution to efficiently process visual data. As shown in Fig. 6, the CNN architecture has three core layers: the first is pooling layer, the second is convolution, and the last is fully connected layers [43]. In the convolution layer, a filter is applied to the input data by multiplying it with a set of weights, creating a new two-dimensional array called a feature map. The filter is moved over the input using a step size called the “stride”, which determines the size of the output feature map. This process is repeated, creating multiple feature maps, which are then processed by the next layers of the CNN, as illustrated by Eq. (3).
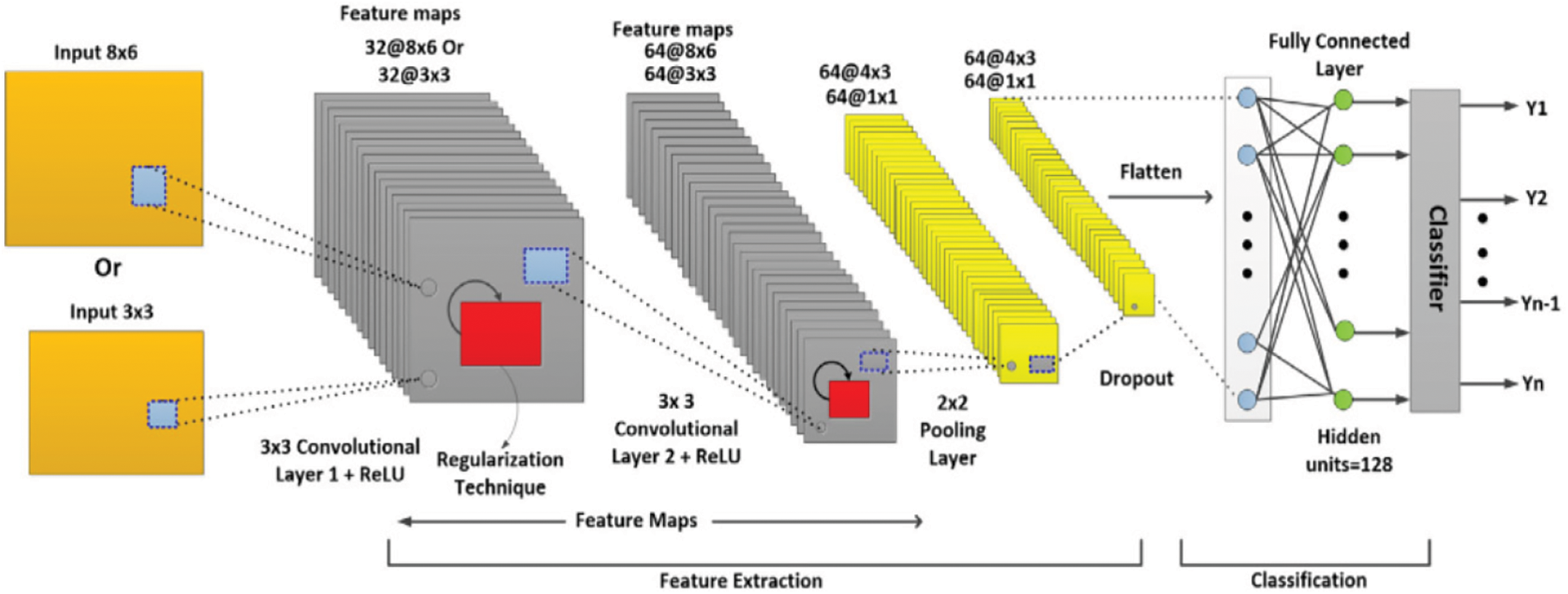
Figure 6: Architecture of CNN
The convolution equation involves various elements, such as θ, representing the non-linear activation function, x, representing the input data, b, which is the bias term, s, which denotes the feature map, and w, indicating the weight of the kernel function. In CNN, the Relu function is commonly used to set all negative values in the feature map to zero, thereby increasing the level of non-linearity in the convolutional layers. A CNN typically includes multiple convolutional layers, with the initial layer designed to detect basic features like edges or corners, while the later layers capture more advanced features. However, multiple convolutional layers may cause the output dimension to become smaller than the input, resulting in loss of information after a certain number of iterations. To address this issue, the padding technique can be employed by adding a border around the image. Two types of padding exist: “same” and “valid.” The “same” padding method involves adding a border around the image to ensure that the input and output images are the same size. The padding size should satisfy the following equation to be valid:
where
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools