
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Web Intelligence with Enhanced Sunflower Optimization Algorithm for Sentiment Analysis
Department of Information Technology, College of Computer and Information Sciences, Princess Nourah bint Abdulrahman University, P.O.Box 84428, Riyadh, 11671, Saudi Arabia
* Corresponding Author: Abeer D. Algarni. Email:
Computer Systems Science and Engineering 2023, 47(1), 1233-1247. https://doi.org/10.32604/csse.2022.026915
Received 06 January 2022; Accepted 11 February 2022; Issue published 26 May 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Exponential increase in the quantity of user generated content in websites and social networks have resulted in the emergence of web intelligence approaches. Several natural language processing (NLP) tools are commonly used to examine the large quantity of data generated online. Particularly, sentiment analysis (SA) is an effective way of classifying the data into different classes of user opinions or sentiments. The latest advances in machine learning (ML) and deep learning (DL) approaches offer an intelligent way of analyzing sentiments. In this view, this study introduces a web intelligence with enhanced sunflower optimization based deep learning model for sentiment analysis (WIESFO-DLSA) technique. The major intention of the WIESFO-DLSA technique is to identify the expressions or sentiments that exist in the social networking data. The WIESFO-DLSA technique initially performs pre-processing and word2vec feature extraction processes to generate a meaningful set of features. At the same time, bidirectional long short term memory (BiLSTM) model is applied for classification of sentiments into different class labels. Moreover, an enhanced sunflower optimization (ESFO) algorithm is exploited to optimally adjust the hyperparameters of the BiLSTM model. A wide range of simulation analyses is performed to report the better outcomes of the WISFO-DLSA technique and the experimental outcomes ensured its promising performance under several measures.Keywords
The integration of Web Intelligence with data mining, business analytics, infrastructure data visualization, best practices, and data tools, assist organizations to make further data-driven decisions [1]. Practically, current company intelligence has a common assumption of our organization’s information and makes use of that information to eliminate inefficiencies, quickly adapt, and drive change to supply or market changes. Web intelligence constitutes the use of worldwide web (WWW) as a phenomenon of data retrieval from data storage in a smarter way. Generally, Sentiment Analysis (SA) is the method of categorizing and identifying the polarization of a text at phrase, document, and sentence levels [2]. This method has been utilized in several domains such as politics, e-commerce, healthcare, entertainment, and so on. For instance, SA is beneficial to businesses for monitoring user opinion about the product, and consumer select the good products according to public opinion [3]. The major process in Twitter SA is to describe the opinions of Twitter as negative or positive opinions. The major problems of twitter SA are: (a) abbreviations and acronyms are commonly utilized on twitter (b) tweet posts are usually written in informal language and (c) short message shows limited cues regarding their sentiments [4,5]. Fig. 1 showcases the process involved in SA.
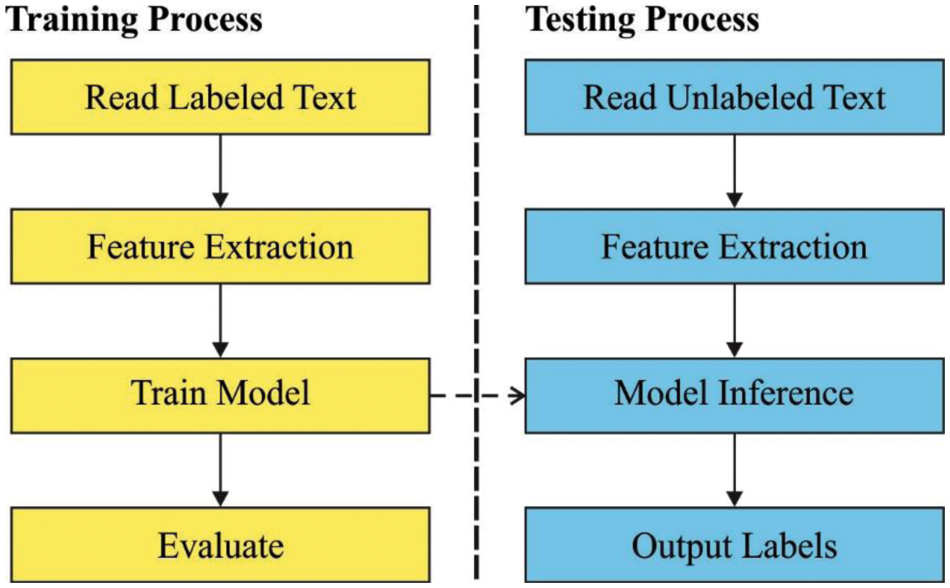
Figure 1: Process in sentiment analysis
Because of the increasing textual data, there has been a necessity for analyzing the concepts of expressing sentiment and calculating the insight to explore businesses [6]. Advertising companies and Business owners frequently employ SA to determine advertising campaigns and new business strategies. The machine learning (ML) algorithm is highly useful in classifying and predicting documents that represent positive or negative sentiments. The ML method is considered as supervised and unsupervised ML methods. Supervised approach employs labeled datasets in which all the documents of training set are labeled using relevant sentiments [7]. While unsupervised learning includes unlabelled datasets in which text isn’t labeled using relevant sentiments. The research mostly considered supervised learning techniques on labeled datasets. Usually, SA can be performed on document, aspect, and sentence levels. Sentence level sentiment classification considers the polarity of single sentence of a document. Document Level sentiment classification focus on categorizing the whole topic or document as negative or positive. Aspect level sentiment classification recognizes the divergent aspect of corpus and for all the documents, the polarity is estimated by the attained aspect [8].
Conventional methods based on automatic feature engineering, i.e., time consuming. At the same time, deep learning (DL) method is a promising alternative to conventional models [9]. It proved outstanding efficiency in NLP tasks, including SA. The primary concept of DL methods is to learn complicated features extracted from information with minimal external contributions with deep neural network (DNN) model. This algorithm doesn’t want to be passed automatically crafted feature: they manually learn new feature [10]. Nonetheless, a representative feature of DL method is that they require massive number of information to be well performed. The availability of resources and automated feature extraction is vital while comparing the conventional ML and DL approaches.
Yoo et al. [11] presented the Polaris, the system to analyze and predict users’ sentimental trajectory to event analyzing from real time out of huge social media content, and demonstrate the outcomes of initial validation work is completed. Araque et al. [12] progressed a DL based sentiment classification utilizing a word embedded technique and linear ML technique. This classifier serves as baseline for comparing with following outcomes. Secondary can be presented 2 ensemble approaches that aggregate our baseline classifiers with other surface classifiers extremely utilized in SA.
Jawad et al. [13] related the efficiency of distinct ML and DL techniques, besides presenting a novel hybrid technique that utilizes text mining and NNs to sentimental classification. The data set utilized during this work has more than 1 million tweets gathered from 5 domains. Chen et al. [14] utilized the Military life PTT board of Taiwan’s main online forum as source of their experimental data. The drive of this analysis is for constructing a SA structure and procedures to social media for proposing a self-developed military sentiment dictionary to increase sentimental classification and analyzing the efficacy of several DL techniques with different parameter calibration combinations. The experimental outcomes illustrate that the accuracy and F1-score of this technique which integrates present sentiment dictionary and the self-developed military sentimental dictionaries are superior to the outcomes in utilizing present sentimental dictionary only.
Valencia et al. [15] presented the procedure of general ML tools and accessible social media information to forecast the price effort of Bitcoin, Ethereum, Ripple, and Litecoin cryptocurrency market movement. It can be related to the consumption of NN, SVM, and RF but utilizing components in Twitter and market data as input features. Vashishtha et al. [16] compute the sentimental of social media posts utilizing a novel group of fuzzy rules containing several lexicons and data sets. The presented fuzzy system combines NLP approaches and Word Sense Disambiguation utilizing a novel unsupervised 9 fuzzy rule based systems for classifying the posts as positive, negative, or neutral sentimental classes.
This article develops a novel web intelligence with enhanced sunflower optimization based deep learning model for sentiment analysis (WIESFO-DLSA) technique. The WIESFO-DLSA technique initially performs pre-processing and word2vec feature extraction processes to generate a meaningful set of features. Besides, bidirectional long short term memory (BiLSTM) model is applied for classification of sentiments into different class labels. In addition, an enhanced sunflower optimization (ESFO) algorithm is exploited to optimally adjust the hyperparameters of the BiLSTM model and the ESFO algorithm is devised by integrating the concepts of SFO algorithm with Hill climbing (HC) concept. An extensive set of experiments were carried out to highlight the betterment of the WISFO-DLSA technique.
The rest of the paper is arranged as follows. Section 2 offers the proposed model, Section 3 provides the experimental analysis, and Section 4 draws the conclusion.
In this study, a new WIESFO-DLSA technique has been developed to identify the expressions or sentiments that exist in the social networking data. The WIESFO-DLSA technique initially performs pre-processing and word2vec feature extraction processes to generate a meaningful set of features. Followed by, the ESFO with BiLSTM model is applied for classification of sentiments into different class labels where ESFO algorithm is exploited to optimally adjust the hyperparameters of the BiLSTM model. Fig. 2 demonstrates the block diagram of WIESFO-DLSA technique.
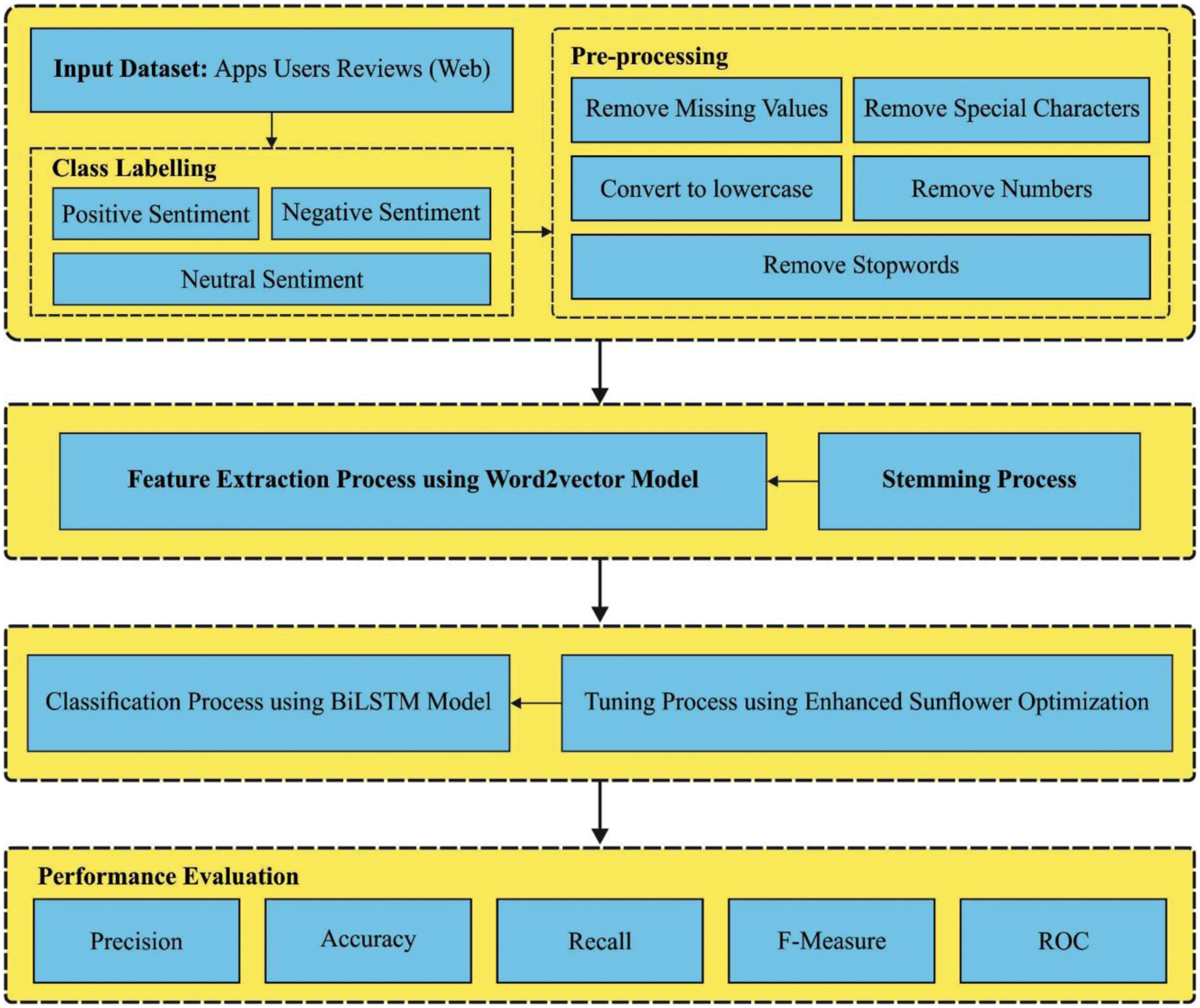
Figure 2: Overall process of WIESFO-DLSA technique
Frequently, the dataset has noise from the procedure of unwanted information which doesn’t give near the classifier and requires that cleaned. The data pre-processed is the technique utilized for removing noisy and insufficient data. The pre-processed roles an important play in improving the accuracy [17]. The dataset utilized under this analysis involves a huge count of unwanted data which is not playing some role in the forecast. As training as well as testing time improves once the dataset is superior, thus, eliminating unwanted data is speeds up the trained model as well. The pre-process contains the phases implemented for cleaning the data thus the learning efficacy of this technique is improved. Therefore, the natural language tool kit (NLTK) of Python was employed. It can be set of text processing libraries that are utilized for a variety of process tasks and it can be utilized NLTK 3.5b1 with Python 3. In the primary phase, every review with missing value is recognized and distant as missing data is reduce the efficiency of the classifier. Afterward, a numerical value is eliminated in the text as it does not give to learned classifiers. It decreases the effort of trained classifiers. Sometimes, analyses have special symbols as hear sign, thumb sign, and so on, which require that eliminate for decreasing feature dimensional and higher efficiency. Then, the subsequent punctuation []() /|, ; . ’ has been eliminated in the review considering the detail which it doesn’t give to text analysis. In the next stage, word is changed to lowercase as the text study has case sensitive. When this stage is not applied, the ML techniques are counted for instance ‘Excellent’ and ‘excellent’ as 2 distinct words that is eventually move the classifier efficacy. Finally, stemming was implemented. It can be essential pre-processed stage which eliminates the affixes in the words. It alters the extended word as to their base procedures. i.e., ‘loves’, ‘loved’, and ‘loving’ is the altered procedures of ‘love’. The stemming alters these words as to original or root method and uses for increasing the efficiency of classifier.
2.2 Word2Vec Model for Feature Extraction
The similarity measure (SM) is a function in which the data of 2 ontology entities are utilized as input and real values among [0, 1] is outputted to characterize the similarity [18]. SM is a significant portion of the ontology matching procedure. Exploiting distinct SMs affect the outcomes of ontology alignment. In the study, we used two classes of SMs to compute the similarity value of two entities, that is., cosine similarity and linguistic-based measures utilizing the Word2Vec models. Word2Vec is a language model of Natural Language Processing (NLP) in which phrases or words are characterized as real value vectors. Usually, similar words are mapped to the same region and have the proximity of vectors [18]. Regarding this, the ontology depiction in vector space, it implies that property or class of ontologies is characterized in dimension of the vector space. Especially, distinct properties or classes are characterized uniquely in the vector space. The vector space covers each class and property in ontology. In the study, the dimension of the vector space is defined by each class and property in the two ontologies. It can be determined by the following equation:
Whereas
2.3 Sentiment Classification Using BiLSTM Model
Once the features are derived, they are passed into the BiLSTM model to classify the sentiments. The BiLSTM method [19] is a discrete version of RNN. LSTM is particularly proposed to avoid long-term dependency problems. It comprises of constant memory cell, input, forget, and output gates. The LSTM based sequential method follows this equation in which it, ft and 0t represents the input, forget, and output gates, correspondingly:
Now tanh denotes the nonlinear hyperbolic function and
The decoder comprises the sequential LSTM that takes input from the encoder. Now,
Then, an attention-based bi-LSTM has been proposed as an encoder.
2.4 Design of ESFO Algorithm for Hyperparameter Tuning
For boosting the classification efficiency of the BiLSTM technique, the ESFO algorithm is derived. The sunflower life process is consistent: as the needles of clock, it rises and follows the sun daily. It can be moved alternate way at night for awaiting its disappearance the subsequent morning [20]. The inverse square law radiation is other key nature based optimized. The amount of heat Q obtained by all plants are provided as:
where P implies the source powers and ri stands for the distance between the current paramount and the plant i. The direction of sunflowers near the sun is as:
The sunflowers stride from the way s has computed as:
where λ indicates the perpetual value that determines a. “inertial” dislocation of plants, Pi(||Xi − Xi−1||) has the probability of pollinations. The maximal stage is determined as:
where Xmax and Xmin represents the upper and lower boundary, and Npop stands for the entire amount of plants. The latest plantation as:
The technique begins with generating the population of people that is even or arbitrary. The respective individual rating assists us in choosing that one is altered as to sun. But, it can be supposed to comprise the capability to function with many suns from a future edition, it can be now restricted to separate under this study. Afterward, similar to the sunflowers, every further entity places itself near the sun and move from an arbitrary controlled method. The paramount plant is pollinated nearby the sun.
The presented ESFO approach is named local search, which is a basic version of local improvement method. It starts with one arbitrary solution (x), proceed repeatedly by shifting in the existing solution to optimal neighboring solution until it reaches a local optimal (that is., the local optimum solution doesn’t have optimal neighboring solution, no development in FF). It takes downhill development in which the FF of neighboring solution must be superior to the existing solution [21]. Subsequently, it converges to the local optimal suddenly and fasts. But it rapidly gets stuck in local optimal that in most situations isn’t acceptable. Afterward producing the early solution x and the iterative development method, a collection of neighboring solutions is produced by employing the process Improve (N(x)). Algorithm 1 presents the pseudocode of the HC approach. This process search for discovering the better neighboring solution from the collection of neighbors using satisfactory rules like random walk, first improvement, best improvement, and sidewalk. However, all the above rules are terminated in local optimal.

In this section, the performance validation of the WIESFO-DLSA technique takes place using the dataset, comprising user reviews from the Google apps in the English language. It is available at https://www.kaggle.com/lava18/google-playstore-apps. It holds 64,295 instances with 23,998 positive reviews, 8271 negative and 5158 neutral reviews in the dataset.
Fig. 3 demonstrates three confusion matrices produced by the WIESFO-DLSA technique under distinct epochs. With 500 epochs, the WIESFO-DLSA technique has identified 23877 instances into positive, 8072 instances into negative, and 4883 instances into neutral class. Similarly, with 1500 epochs, the WIESFO-DLSA technique has identified 23875 instances into positive, 8111 instances into negative, and 4947 instances into neutral class.
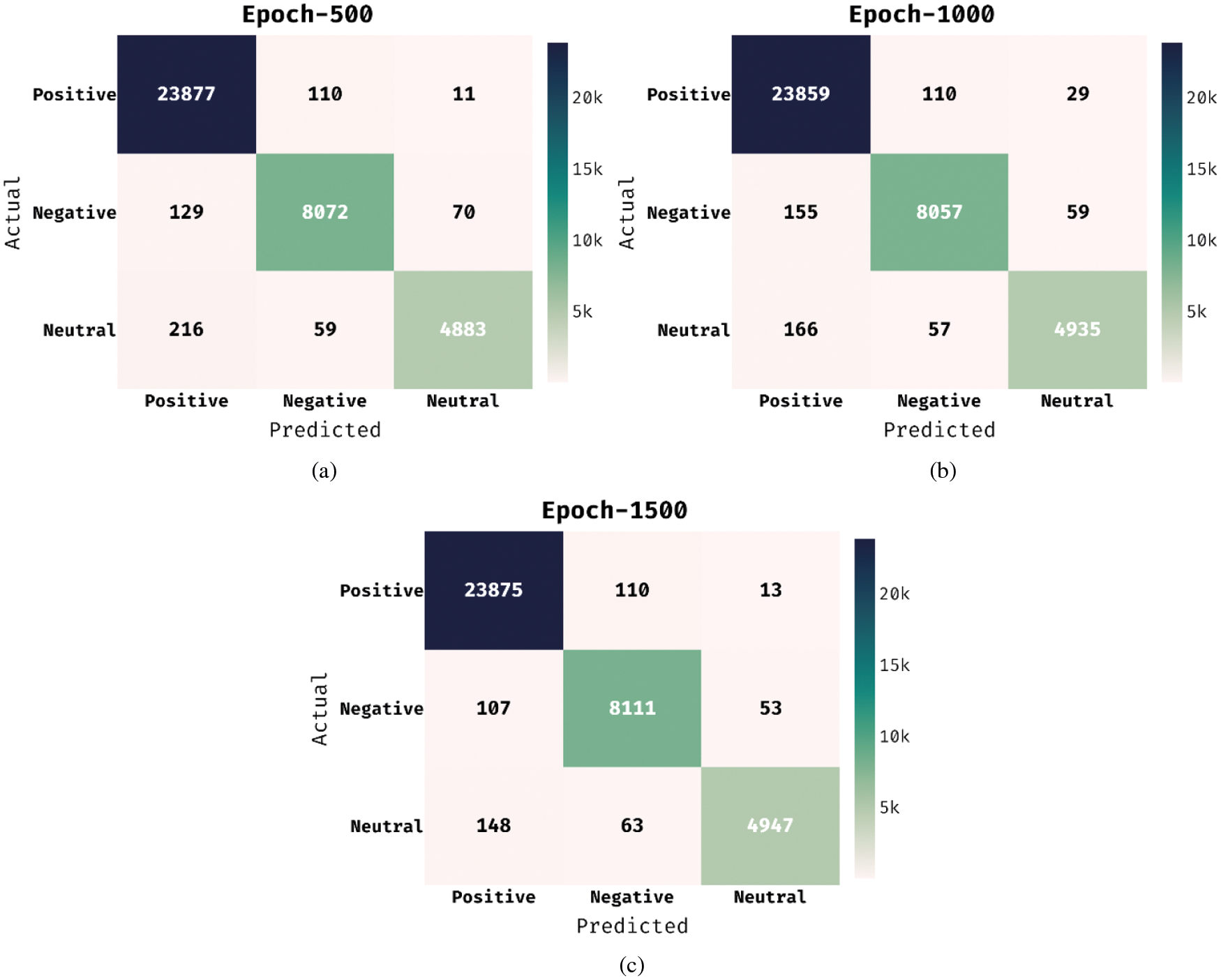
Figure 3: Confusion matrix analysis of WIESFO-DLSA technique
Table 1 provides a comprehensive classification result analysis of the WIESFO-DLSA technique under distinct class labels and epochs. The results notified that the WIESFO-DLSA technique has the ability to classify all the instances effectively.
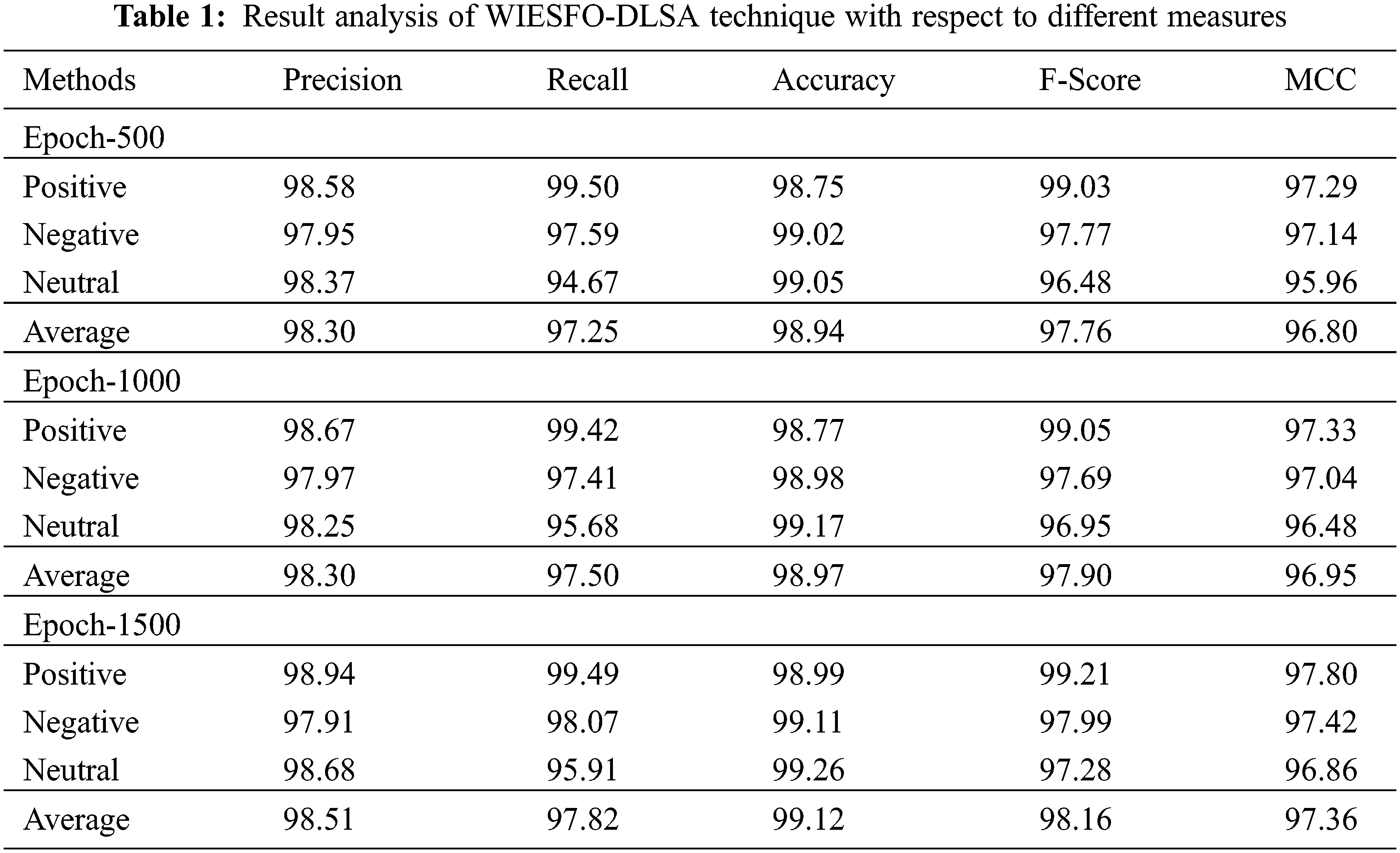
Overall classifier results of the WIESFO-DLSA technique under distinct epochs are offered in Table 2 and Fig. 4. The experimental values denoted the betterment of the WIESFO-DLSA technique under all epochs. For instance, with 500 epochs, the WIESFO-DLSA technique has resulted to precn, recal, accuy, Fscore, and MCC of 98.30%, 97.25%, 98.94%, 97.76%, and 96.80% respectively. At the same time, with 1000 epochs, the WIESFO-DLSA technique has accomplished precn, recal, accuy, Fscore, and MCC of 98.30%, 97.50%, 98.97%, 97.89%, and 96.95% respectively. Furthermore, with 1500 epochs, the WIESFO-DLSA technique has led to precn, recal, accuy, Fscore, and MCC of 98.51%, 97.82%, 99.12%, 98.16%, and 97.36% respectively.

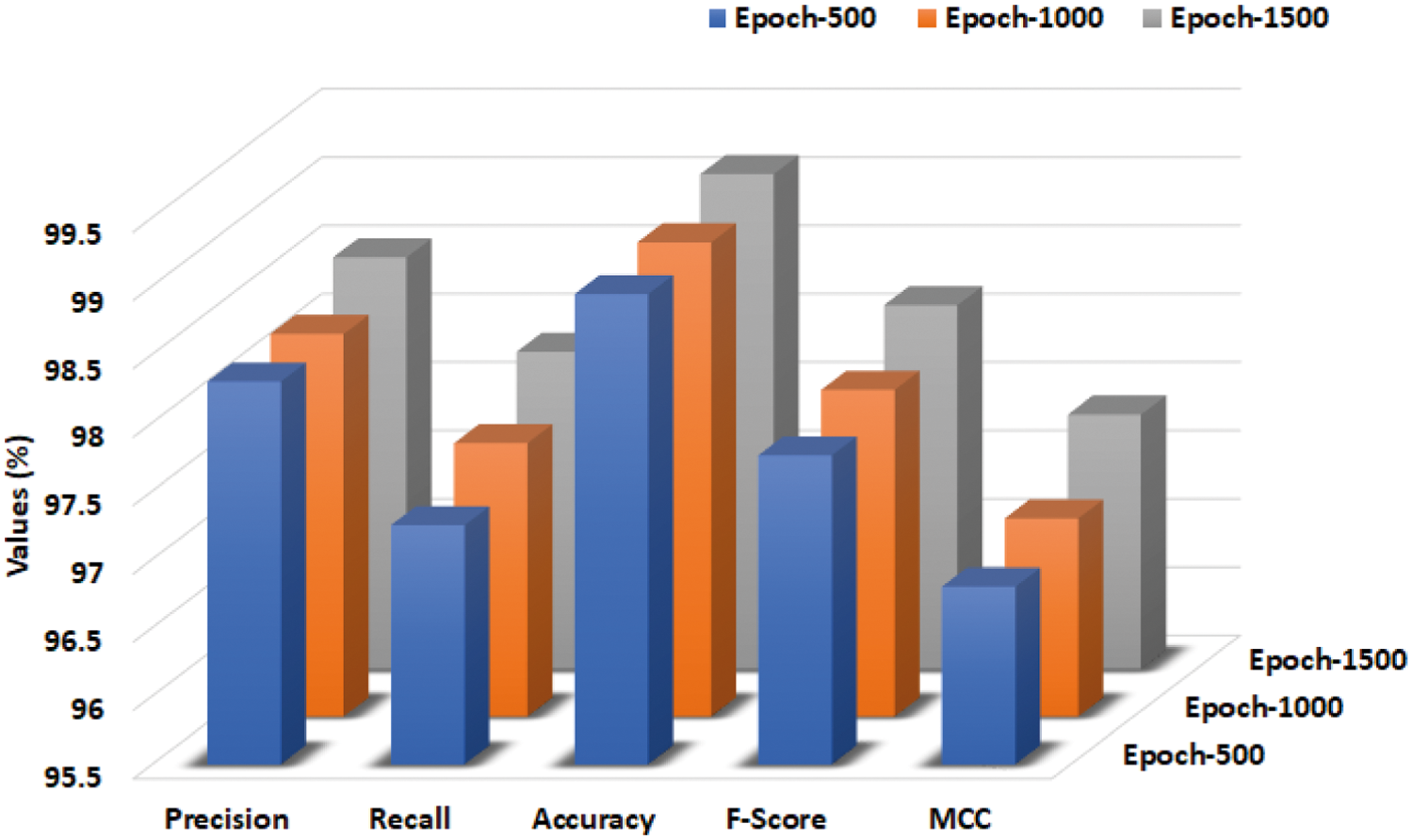
Figure 4: Overall analysis of WIESFO-DLSA technique
Fig. 5 demonstrates the ROC analysis of the WIESFO-DLSA technique under epoch of 500. The figure exposed that the WIESFO-DLSA technique has reached enhanced outcome with the minimum ROC of 99.7821.
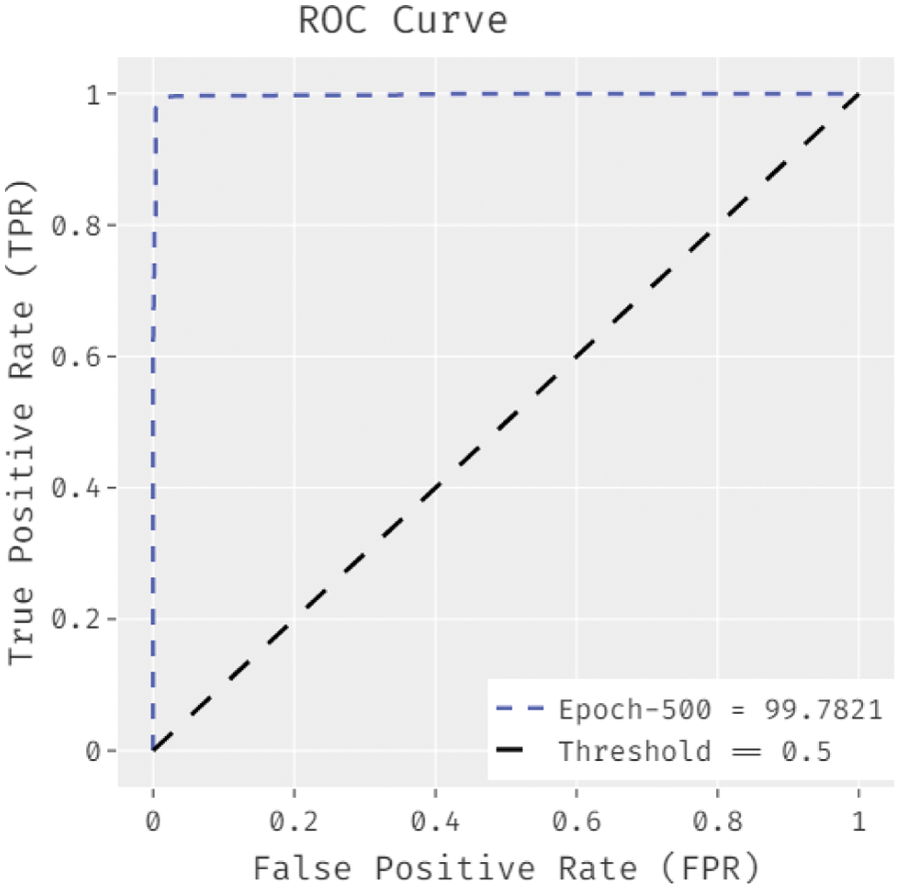
Figure 5: ROC analysis of WIESFO-DLSA technique under epoch of 500
Fig. 6 depicts the ROC analysis of the WIESFO-DLSA approach under epoch of 1000. The figure demonstrated that the WIESFO-DLSA algorithm has attained increased results with the minimum ROC of 99.6295.
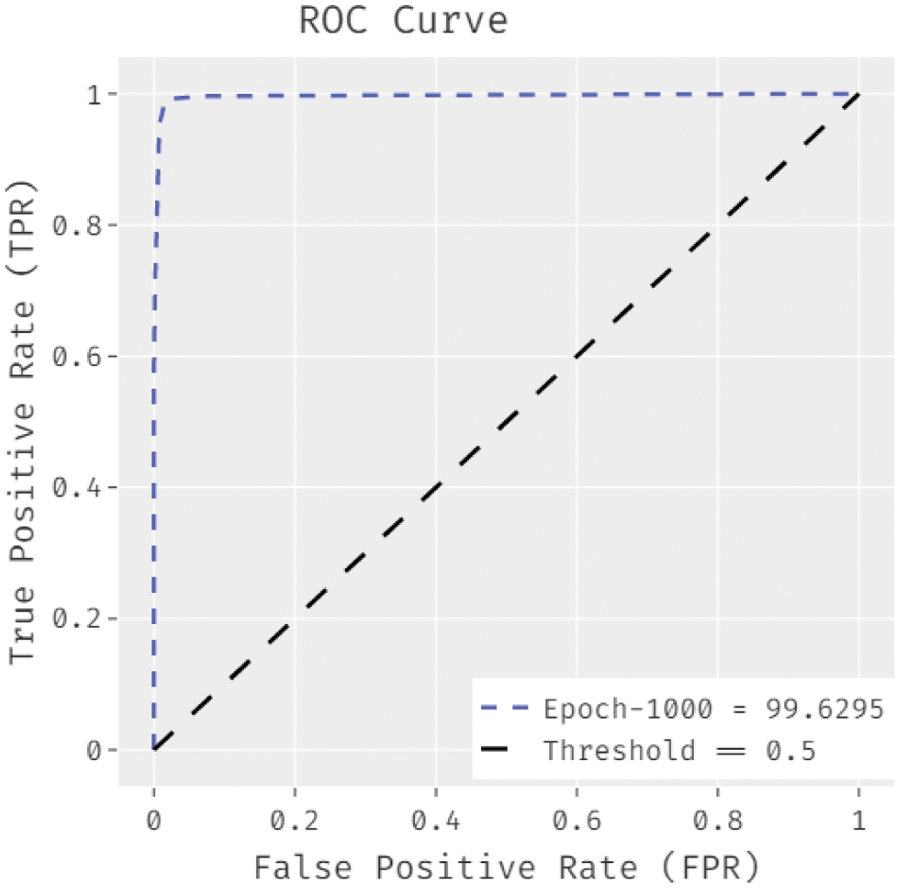
Figure 6: ROC analysis of WIESFO-DLSA technique under epoch of 1000
Fig. 7 illustrates the ROC analysis of the WIESFO-DLSA approach under epoch of 1500. The figure revealed that the WIESFO-DLSA method has gained improved outcomes with the minimal ROC of 99.8517.
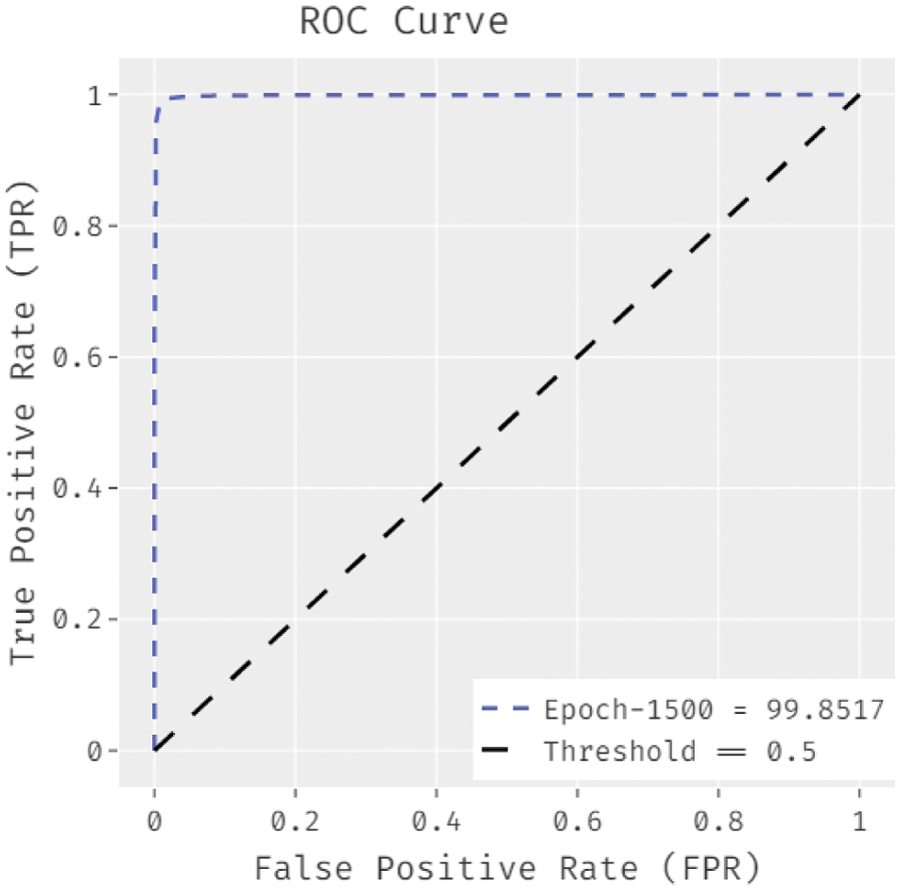
Figure 7: ROC analysis of WIESFO-DLSA technique under epoch of 1500
Table 3 and Fig. 8 illustrate the comparative result analysis of the WIESFO-DLSA technique with recent methods on the classification of positive instances. The experimental results stated that the LOGR-CM technique has exhibited least outcome with the minimal values of precn, recal, and Fscore. In addition, the GBM-CM and SVM-CM techniques have resulted in slightly enhanced values of precn, recal, and Fscore. In line with, the GBSVM-CM and RANDFO-CM techniques have accomplished reasonable values of precn, recal, and Fscore. However, the WIESFO-DLSA technique has obtained effective results with the precn, recal, and Fscore of 98.94%, 99.49%, and 99.21% respectively.
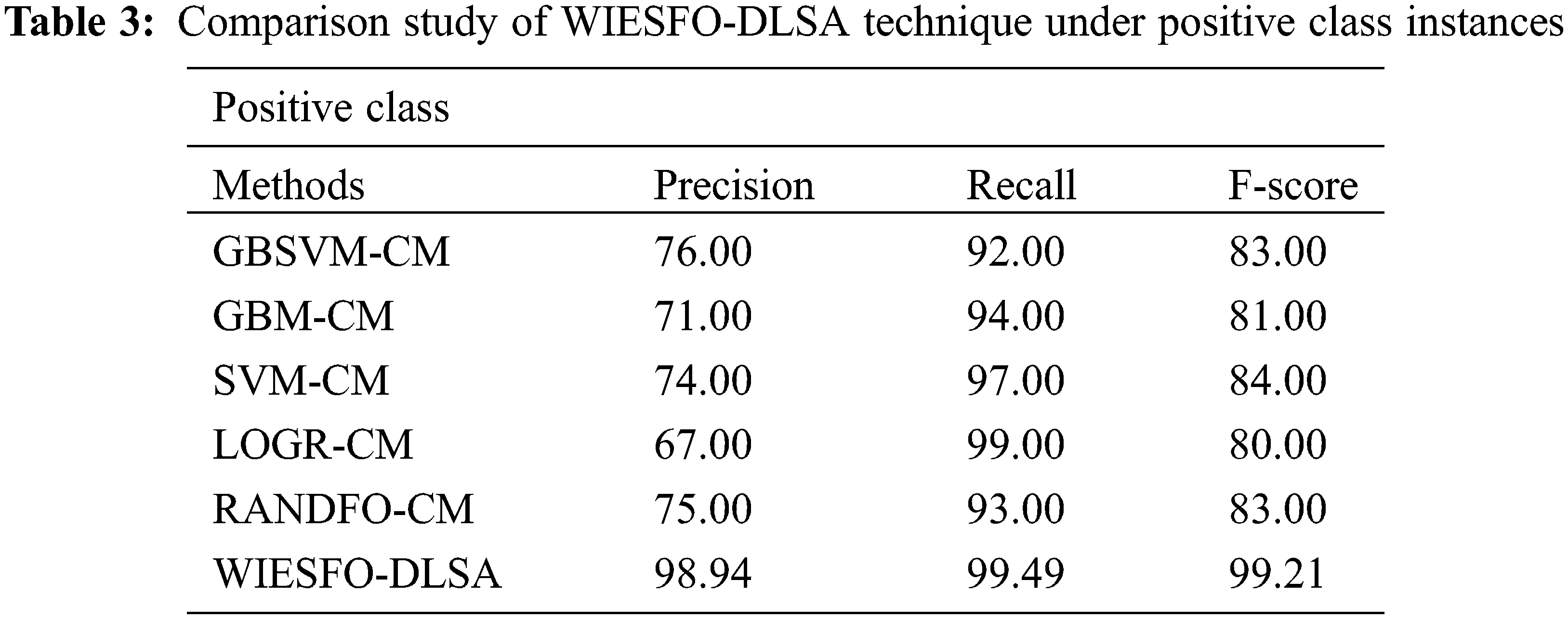
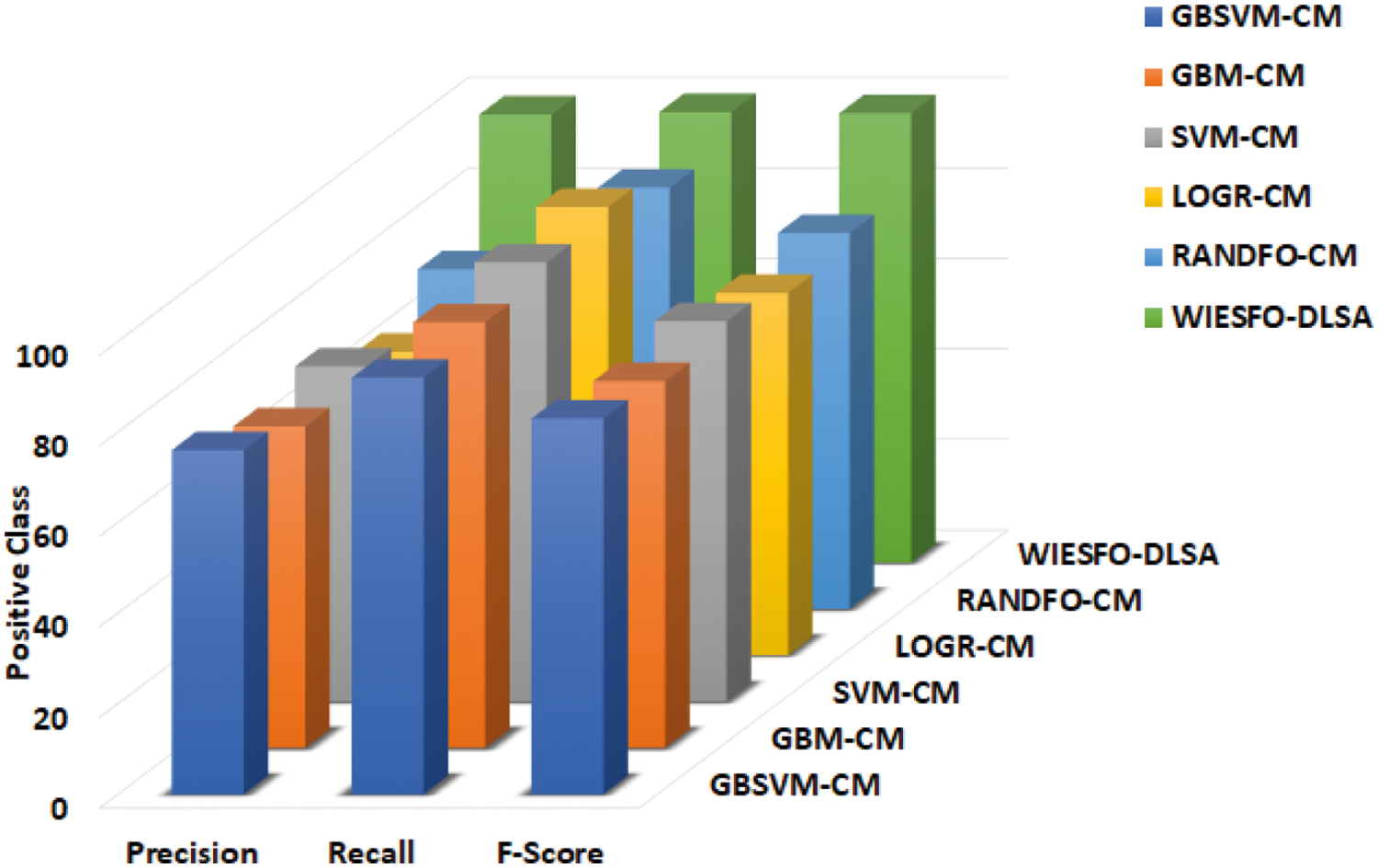
Figure 8: Comparative analysis of WIESFO-DLSA technique under positive class
Table 4 and Fig. 9 depict the comparative outcome analysis of the WIESFO-DLSA approach with existing approaches on the classification of negative instances. The experimental outcomes revealed that the LOGR-CM technique has exhibited least outcome with the minimal values of precn, recal, and Fscore. Also, the GBM-CM and SVM-CM methods have resulted in somewhat increased values of precn, recal, and Fscore. Followed by, the GBSVM-CM and RANDFO-CM techniques have accomplished reasonable values of precn, recal, and Fscore. At last, the WIESFO-DLSA approach has obtained effective outcomes with the precn, recal, and Fscore of 97.91%, 98.07%, and 97.99% correspondingly.
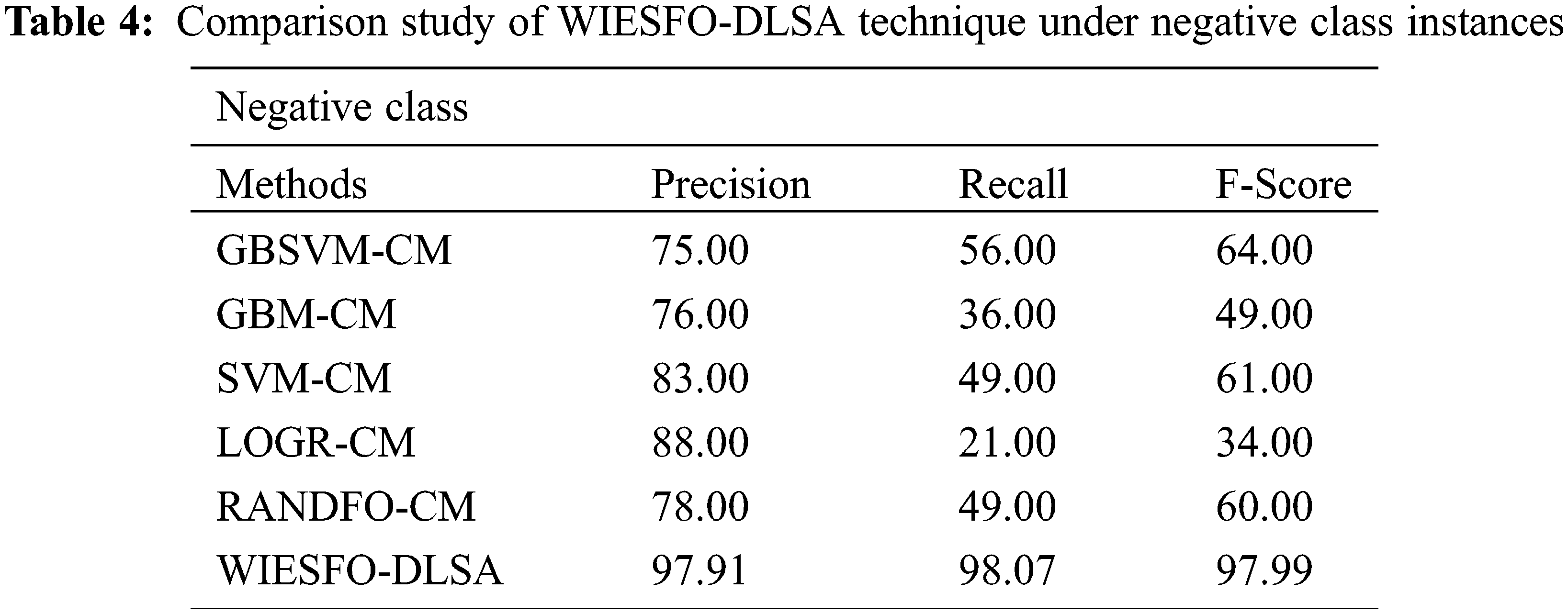
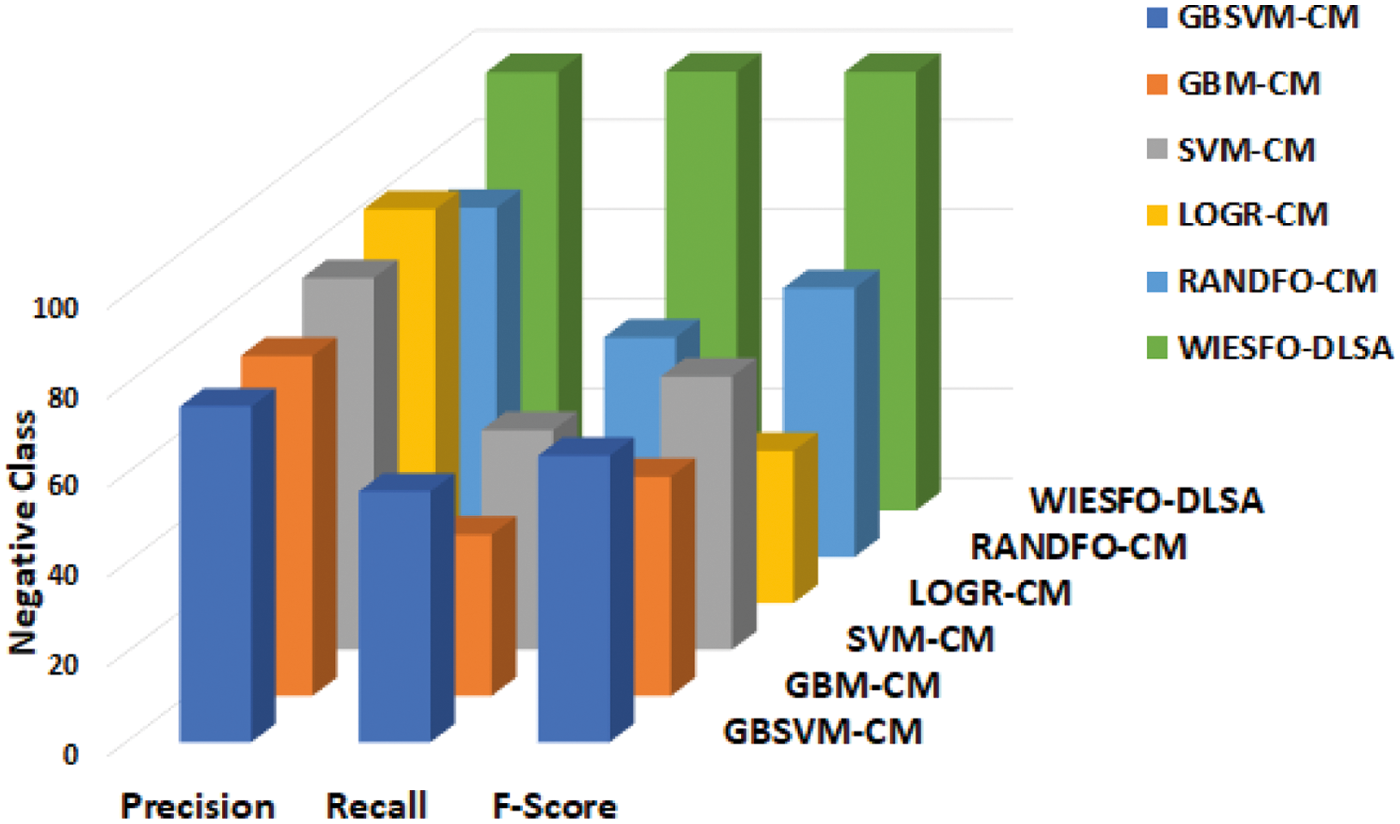
Figure 9: Comparative analysis of WIESFO-DLSA technique under negative class
Table 5 and Fig. 10 demonstrates the comparative result analysis of the WIESFO-DLSA technique with recent methods on the classification of neutral instances. The experimental outcomes revealed that the LOGR-CM technique has exhibited worse outcome with the minimal values of precn, recal, and Fscore. Furthermore, the GBM-CM and SVM-CM approaches have resulted in slightly enhanced values of precn, recal, and Fscore. Similarly, the GBSVM-CM and RANDFO-CM algorithms have accomplished reasonable values of precn, recal, and Fscore. Finally, the WIESFO-DLSA methodology has achieved effectual outcomes with the precn, recal, and Fscore of 98.68%, 95.91%, and 97.28% correspondingly.
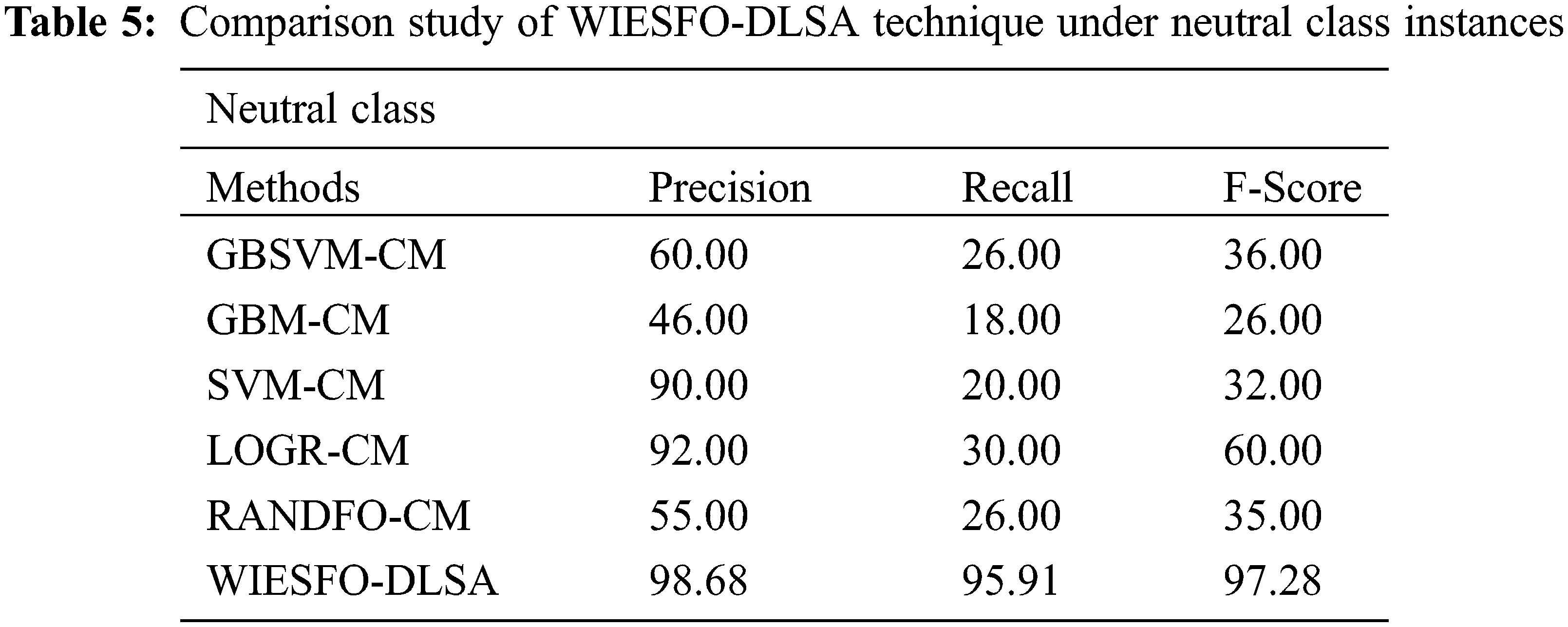
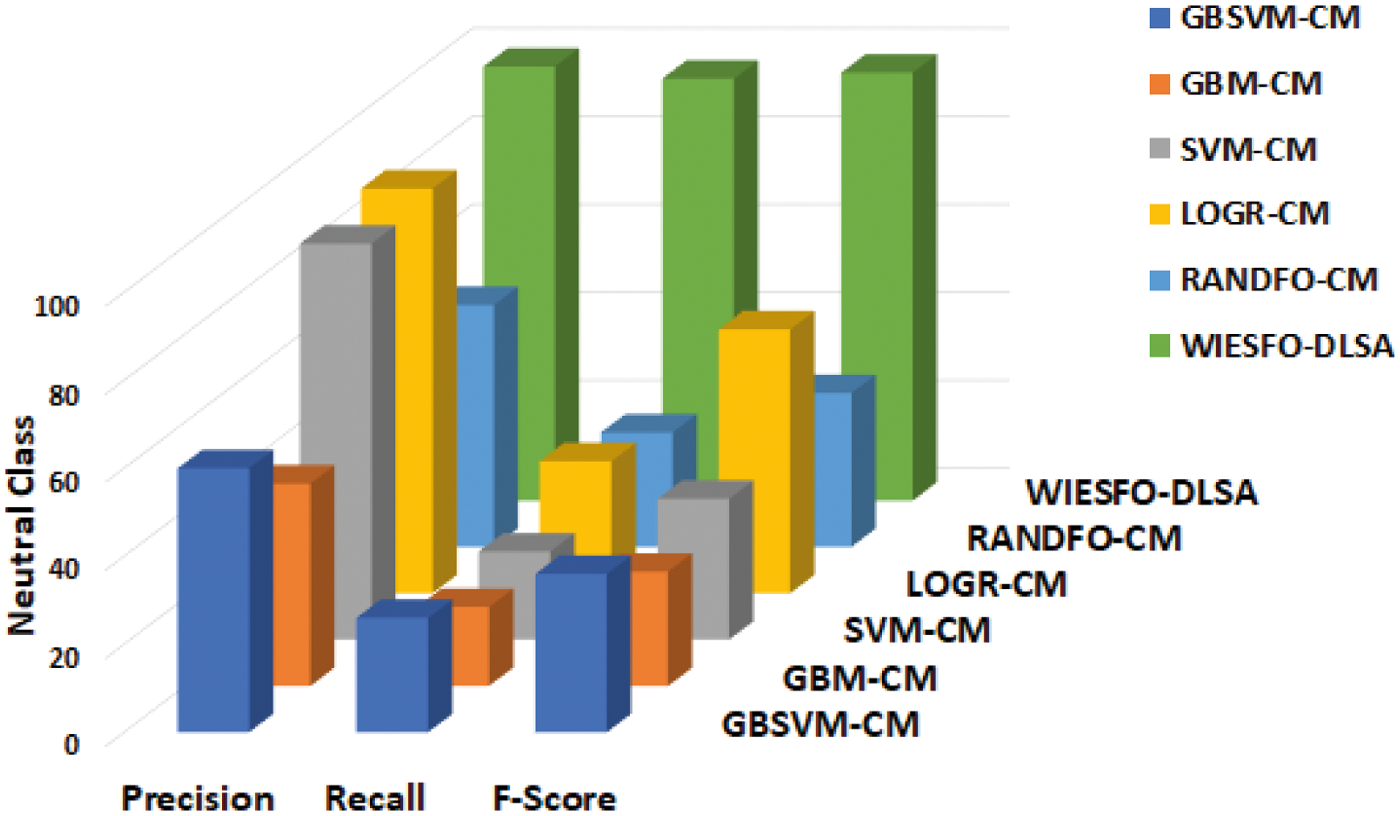
Figure 10: Comparative analysis of WIESFO-DLSA technique under neutral class
Finally, a comparative accuy analysis of the WIESFO-DLSA technique with recent approaches [17] are offered in Table 6 and Fig. 11. The results notified that the LOGR-CM and GBM-CM techniques have obtained lower accuy values of 68% and 70% respectively. Also, the RANDFO-CM, GBSVM-CM, and SVM-CM techniques have resulted in moderately closer accuy values of 73%, 75%, and 75% respectively. However, the WIESFO-DLSA technique has accomplished improved outcomes with the maximum accuy of 99.12%. By looking into the abovementioned tables and figures, it can be ensured that the WIESFO-DLSA technique has appeared as an effective tool for SA.
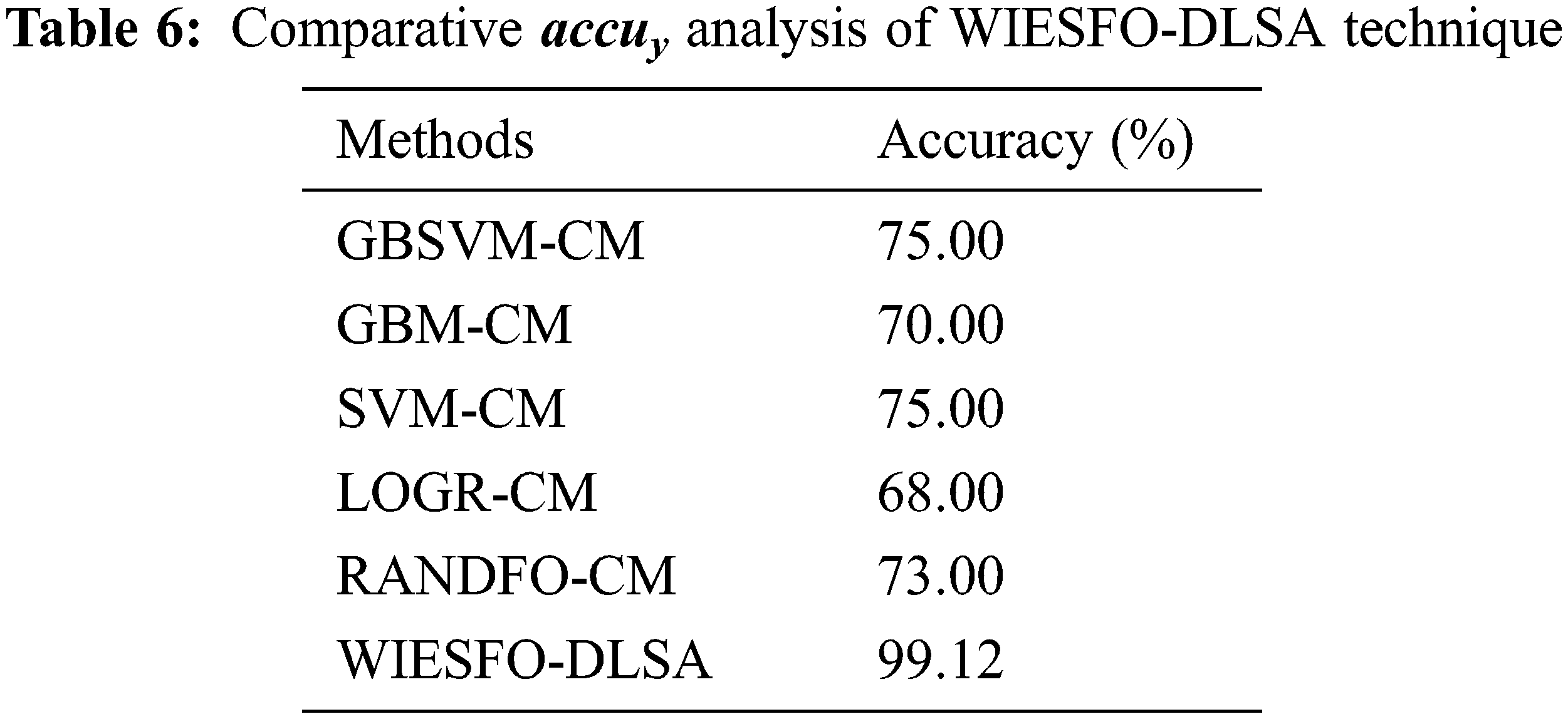
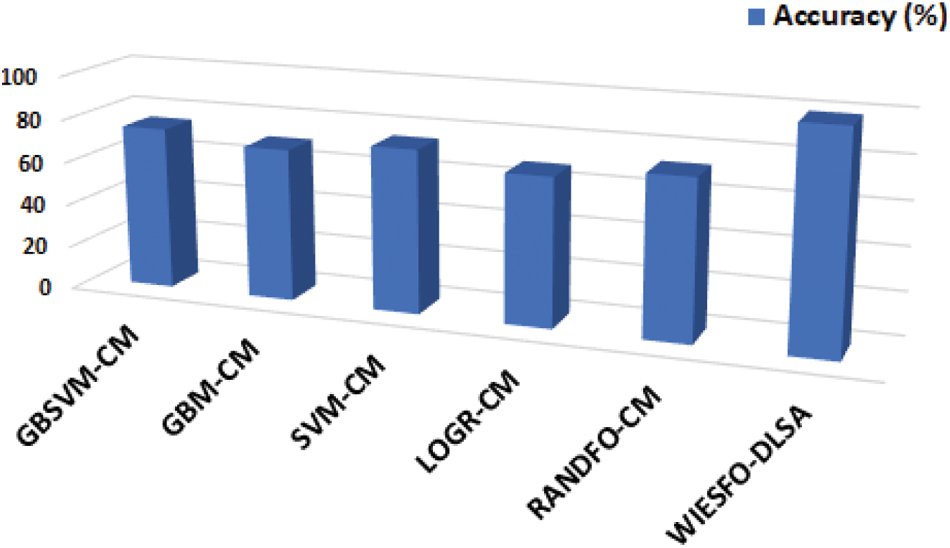
Figure 11: Accuracy analysis of WIESFO-DLSA technique with recent algorithms
In this study, a new WIESFO-DLSA technique has been developed for identifying the expressions or sentiments that exist in the social networking data. The WIESFO-DLSA technique initially performs pre-processing and word2vec feature extraction processes to generate a meaningful set of features. Followed by, the ESFO with BiLSTM model is applied for classification of sentiments into different class labels where ESFO technique was exploited to optimally adjust the hyperparameters of the BiLSTM model. Finally, the ESFO algorithm is devised by integrating the concepts of SFO algorithm with HC. An extensive set of experiments were carried out to highlight the betterment of the WISFO-DLSA technique. The experimental outcomes ensured its promising performance over the recent state of art approaches under several measures. Therefore, the WISFO-DLSA technique can be utilized as an effective tool to analyze sentiments. In the future, it can be deployed in smartphone applications to enable real time data processing.
Funding Statement: Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2023R51), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. D. M. E. D. M. Hussein, “A survey on sentiment analysis challenges,” Journal of King Saud University-Engineering Sciences, vol. 30, no. 4, pp. 330–338, 2018. [Google Scholar]
2. M. Luca and G. Zervas, “Fake it till you make it: Reputation, competition, and yelp review fraud,” Management Science, vol. 62, no. 12, pp. 3412–3427, 2016. [Google Scholar]
3. F. Rustam, I. Ashraf, A. Mehmood, S. Ullah and G. Choi, “Tweets classification on the base of sentiments for us airline companies,” Entropy, vol. 21, no. 11, pp. 1078, 2019. [Google Scholar]
4. A. Ortigosa, J. M. Martín and R. M. Carro, “Sentiment analysis in Facebook and its application to e-learning,” Computers in Human Behavior, vol. 31, pp. 527–541, 2014. [Google Scholar]
5. R. Duwairi and M. El-Orfali, “A study of the effects of preprocessing strategies on sentiment analysis for Arabic text,” Journal of Information Science, vol. 40, no. 4, pp. 501–513, 2014. [Google Scholar]
6. V. Kalra and R. Aggarwal, “Importance of text data preprocessing & implementation in rapidminer,” in the Proc. of the First Int. Conf. on Information Technology and Knowledge Management, pp. 71–75, 2018. [Google Scholar]
7. D. Agnihotri, K. Verma, P. Tripathi and B. K. Singh, “Soft voting technique to improve the performance of global filter based feature selection in text corpus,” Applied Intelligence, vol. 49, no. 4, pp. 1597–1619, 2019. [Google Scholar]
8. S. Yang and H. Zhang, “Text mining of twitter data using a latent dirichlet allocation topic model and sentiment analysis,” World Academy of Science, Engineering and Technology International Journal of Computer and Information Engineering, vol. 12, no. 7, pp. 525–529, 2018. [Google Scholar]
9. R. Zhao and K. Mao, “Fuzzy bag-of-words model for document representation,” IEEE Transactions on Fuzzy Systems, vol. 26, no. 2, pp. 794–804, 2018. [Google Scholar]
10. Ankit and N. Saleena, “An ensemble classification system for twitter sentiment analysis,” Procedia Computer Science, vol. 132, pp. 937–946, 2018. [Google Scholar]
11. S. Yoo, J. Song and O. Jeong, “Social media contents based sentiment analysis and prediction system,” Expert Systems with Applications, vol. 105, pp. 102–111, 2018. [Google Scholar]
12. O. Araque, I. C. Platas, J. F. S. Rada and C. A. Iglesias, “Enhancing deep learning sentiment analysis with ensemble techniques in social applications,” Expert Systems with Applications, vol. 77, pp. 236–246, 2017. [Google Scholar]
13. M. H. A. E. Jawad, R. Hodhod and Y. M. K. Omar, “Sentiment analysis of social media networks using machine learning,” in 2018 14th Int. Computer Engineering Conf. (ICENCO), Cairo, Egypt, pp. 174–176, 2018. [Google Scholar]
14. L. C. Chen, C. M. Lee and M. Y. Chen, “Exploration of social media for sentiment analysis using deep learning,” Soft Computing, vol. 24, no. 11, pp. 8187–8197, 2020. [Google Scholar]
15. F. Valencia, A. G. Espinosa and B. V. Aguirre, “Price movement prediction of cryptocurrencies using sentiment analysis and machine learning,” Entropy, vol. 21, no. 6, pp. 589, 2019 [Google Scholar] [PubMed]
16. S. Vashishtha and S. Susan, “Fuzzy rule based unsupervised sentiment analysis from social media posts,” Expert Systems with Applications, vol. 138, pp. 112834, 2019. [Google Scholar]
17. M. Khalid, I. Ashraf, A. Mehmood, S. Ullah, M. Ahmad et al., “GBSVM: Sentiment classification from unstructured reviews using ensemble classifier,” Applied Sciences, vol. 10, no. 8, pp. 2788, 2020. [Google Scholar]
18. X. Xue, H. Wang, J. Zhang, Y. Huang, M. Li et al., “Matching transportation ontologies with word2vec and alignment extraction algorithm,” Journal of Advanced Transportation, vol. 2021, pp. 1–9, 2021. [Google Scholar]
19. T. Chen, R. Xu, Y. He and X. Wang, “Improving sentiment analysis via sentence type classification using BiLSTM-CRF and CNN,” Expert Systems with Applications, vol. 72, pp. 221–230, 2017. [Google Scholar]
20. G. F. Gomes, S. S. da Cunha and A. C. Ancelotti, “A sunflower optimization (SFO) algorithm applied to damage identification on laminated composite plates,” Engineering with Computers, vol. 35, no. 2, pp. 619–626, 2019. [Google Scholar]
21. M. Shehab, H. Alshawabkah, L. Abualigah and N. AL-Madi, “Enhanced a hybrid moth-flame optimization algorithm using new selection schemes,” Engineering with Computers, vol. 37, no. 4, pp. 2931–2956, 2021. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools