
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Aspect-Based Sentiment Analysis for Social Multimedia: A Hybrid Computational Framework
1 University Institute of Information Technology–PMAS Arid Agriculture University, Rawalpindi, 46000, Pakistan
2 Department of Creative Technologies, Air University, Islamabad, 44000, Pakistan
3 Computer Engineering and Science Department, Faculty of Computer Science and Information Technology, Al Baha University, Al Baha, 65799, Saudi Arabia
4 Digital Health Institute, King Abdulaziz City for Science and Technology, Riyadh, 11442, Saudi Arabia
* Corresponding Authors: Muhammad Rizwan Rashid Rana. Email: ; Abdullah Almuhaimeed. Email:
Computer Systems Science and Engineering 2023, 46(2), 2415-2428. https://doi.org/10.32604/csse.2023.035149
Received 09 August 2022; Accepted 08 December 2022; Issue published 09 February 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
People utilize microblogs and other social media platforms to express their thoughts and feelings regarding current events, public products and the latest affairs. People share their thoughts and feelings about various topics, including products, news, blogs, etc. In user reviews and tweets, sentiment analysis is used to discover opinions and feelings. Sentiment polarity is a term used to describe how sentiment is represented. Positive, neutral and negative are all examples of it. This area is still in its infancy and needs several critical upgrades. Slang and hidden emotions can detract from the accuracy of traditional techniques. Existing methods only evaluate the polarity strength of the sentiment words when dividing them into positive and negative categories. Some existing strategies are domain-specific. The proposed model incorporates aspect extraction, association rule mining and the deep learning technique Bidirectional Encoder Representations from Transformers (BERT). Aspects are extracted using Part of Speech Tagger and association rule mining is used to associate aspects with opinion words. Later, classification was performed using BER. The proposed approach attained an average of 89.45% accuracy, 88.45% precision and 85.98% recall on different datasets of products and Twitter. The results showed that the proposed technique achieved better than state-of-the-art sentiment analysis techniques.Keywords
Social media has become a key source of knowledge on various subjects because of its role as a platform for information exchange [1]. Media resources posted on social media sites, such as YouTube, Facebook and Twitter, are known as “social multimedia” [2]. A massive amount of multimedia data is created in all social networks every minute in the era of big data. Several exciting applications rely on understanding the knowledge contained within social multimedia, such as analyzing and predicting user behavior [3]. Sentiment analysis (also known as opinion mining) can be used for many purposes, such as stock market forecasting, box office forecasting, political vote projections and public opinion monitoring, to name a few [4–6]. Sentiment analysis of multimedia information in social networks has become increasingly significant because it aids in perception, planning, reasoning, creativity and decision-making across various domains [7,8]. Figs. 1 and 2 depict examples of positive and negative reviews, respectively.

Figure 1: Review showing positive sentiments

Figure 2: Review showing negative sentiments
Sentiment analysis is identifying, assessing and extracting sentiments, feelings and views represented in a piece of writing [9]. Because of the widespread use of social networking sites (including Twitter, Facebook, Twitter, Weibo, etc.), multimedia material, such as photographs and videos, is becoming increasingly crucial for disseminating thoughts and opinions on social networks [10]. Consequently, the study of sentiment analysis in social multimedia is no longer limited to natural language processing but also touches on Decision Support Systems (DSS), Expert systems and other areas of artificial intelligence. Although social multimedia sentiment analysis is still in its infancy and the topic is somewhat contentious, the multimediatization of social networks is apparent and this field is gaining increasing attention. There are two types of reviews: comments classified as numeric sentiment and categorical sentiment. A rating framework in web-based business locales is a typical illustration of numeric sentiments. This rating system is used to assess people’s opinions. Classifying a comment or review into separate classes is known as classification. Paired (positive, negative) and ternary (positive, negative and neutral) and various classes are among them (Anger, Sad, Glad, happy and so on).
Aspect-based sentiment analysis (ABSA) is the most modern technique to identify sentiment polarities about specific aspects of the text [8]. Many traditional approaches to natural language processing have been replaced by deep learning models [9] due to deep learning’s growing popularity and the advancements in computer hardware. Deep learning models have attained state-of-the-art performance on serval tasks, including sentiment analysis, named entity identification, classification, image synthesis and image segmentation. Many deep learning approaches for ABSA tasks have been developed in recent years that are more scalable than classic feature-based methods [10–15]. BERT [16] uses semantic combination functions to handle sentiment analysis’s complicated combinatorial nature. To increase prediction accuracy, BERT models encode sentence sequence information, obtain remote dependencies and build representations of phrases.
ABSA is a challenging and demanding research subject because of the complexity of viewpoints and the range of elements. Efforts have been made to address this issue. When a lot of slang and hidden emotions are present in customer evaluations (text data), the accuracy of old methodologies significantly decreases. The polarity intensity of emotion words is not considered by existing approaches, which divide sentiment words into negative and positive categories. In some instances, current methods are domain-specific [17]; when applied to a dataset from a different domain, these approaches lose their accuracy [18,19]. The following is a list of the research’s key findings:
• In this research, an optimal and efficient aspect extraction approach was proposed.
• Polarity intensity is calculated instead of just classifying a review as either positive or negative.
• The proposed technique is evaluated on multiple domain datasets to check its reliability.
The main goal of this research is to propose an efficient technique for aspects extraction and classification using rule mining-based deep leaning. The remaining sections are grouped as follows: Section 2 provides an overview of the existing sentiment analysis approaches. Section 3 shows the suggested conceptual model for ABSA, which contains data preprocessing, aspect extraction, refinement and classification. Experiment outcomes and comparisons to existing approaches are presented and discussed in Section 4. Paper concludes in Section 5; finally, some directions for future work are given in Section 6.
In the last two decades, a large amount of study has been conducted on sentiment analysis. Sentiment analysis approaches have been used to classify algorithms for various purposes, including medical diagnosis and treatment, banking, DSS, etc. Several currently available strategies are reviewed in depth in this section.
Wadawadagi et al. presented for ABSA a method including the extraction and classification of aspect phrases [20]. The suggested model extracts aspect terms, while the novel Polarity Enriched Attention Neural (PEAN) model is used to classify sentiments. Experiments were run using two different benchmark datasets, and the outcomes show that applying the PEAN model to ABSA significantly improved its overall performance. Another research presented a novel method for measuring consumer satisfaction based on agricultural product assessments using BERT [21]. The agrarian assessment classification approach described in this study efficiently recognized the emotion transmitted in the text, making it easier to analyze the data from network evaluations, extract meaningful information and exhibit sentiment.
Zhao et al. developed the knowledge-enabled language representation model BERT to analyze sentiments from user text data [22]. The novelty of the proposed model is the use of external knowledge to boost the performance of ABSA. The proposed model is equipped with a knowledge layer that captures knowledge features, contains sentiment from the review and sends them to the embedding module. Experiments were performed on data collected from two Chinese university MOOC platforms. The dataset was randomly divided into three parts: 70% training dataset, 25% testing and 5% validation set. The proposed model achieved 85% accuracy and a 78% f-measure. Results are also compared with some state of art techniques of sentiment analysis. They are KNEE, CG-BERT and BERT+Liner. Comparisons show that the proposed approach outperforms existing methods in terms of accuracy and macro-F1.
Zhao et al. proposed a novel machine learning approach named “Local Search Improvised Bat Algorithm based Elman Neural Network” (LSIBA-ENN) for the sentiment analysis of product reviews [23]. The proposed model consists of four phases. They are the collection of product reviews, preprocessing of these reviews, extraction and selection of features and sentiment classification. Reviews were collected using a web scrapper from various e-commerce websites (Amazon, E-bay). Preprocessing techniques like tokenization, lemmatization, snowball stemming, etc., are applied to remove unwanted data. LTF-MICF and HMEWA algorithms are applied for feature extraction and feature selection. Later on, the classification of reviews is performed using LSIBA-ENN. LSIBA-ENN is a combination of a search-based algorithm and neural network that classifies the reviews into three classes: positive, negative and neutral. The proposed technique achieved 90.9% precision and 90.01% recall. Results are compared with classifiers (Naive Bayes, Support vector machine, Elman neural network) which show the proposed technique achieved better results.
Kumar et al. introduced a novel Intelligent Senti-net-based lexicon-generating approach for classifying sentiments in social media text data [24]. The proposed technique revolves around data preprocessing, lexicon construction, feature extraction and classification using SentiNet and neural networks. For optimization of features, an enhanced version of the sea loin algorithm named SI-SLnO (Self-Improved Sea loin algorithm) is proposed. This study uses an optimized neural network to classify texts, with the training conducted by a new SI-SLnO algorithm that selects the optimal weights. Classification is performed using two ways: lexicon and neural work. Both lexicon and neural network outputs are synthesized to attain the final sentiment. The proposed method was evaluated using these two standard datasets: Judge and Customer Support on Twitter. This method achieved 88.26% accuracy and 78.90% precision on the judge dataset, while 89.05% accuracy and 81% precision on the twcs.csv dataset. Results are compared with two baseline techniques for sentiment analysis: SLnO and neural networks. Results revealed the effectiveness of the proposed technique by showing an improvement in sentiment classification performance.
Mowlaei et al. developed extensions of two lexicon generation methods for aspect-based problems; Aspect-Based Frequency (ABF) based Sentiment Analysis and Adaptive Lexicon learning using a Genetic Algorithm (ALGA) [25]. ABF uses statistical methods and ALGA uses a genetic algorithm. Three different datasets are used, Canon G3 (Camera) Reviews, Creative Zen (MP3 Player) Reviews and Nokia 6610 (Cellphone). Experimental results show that the proposed model achieved 91.0% precision, 91.1% recall and 91.0% F-measure. Nawaz et al. presented an aspect-based sentiment analysis technique using a POS tagger, Visuwords and a rational classifier [26]. Dey et al. presented a work with a better rate of accuracy and faster recognition time for monitoring the emotional state of humans [27]. The proposed deep convolution neural network (DCNN) with a custom Gabor filter recognizes emotions with an accuracy of 85.8%. Chen et al. developed a method for constructing an ensemble classifier utilizing sentiment in Chinese news at the phrase level and technical indicators to forecast stock market changes [28]. This ensemble classifier is comprised of these three classifiers. The results indicate that the proposed method is more accurate than the existing approaches. Ahmed et al., describe a fuzzy classification-based deep attention model that exploits the linguistic characteristics of patient letters to construct emotional lexicons [29]. The experimental findings indicate that emotion-based augmentation enhances test accuracy and contributes to developing quality standards.
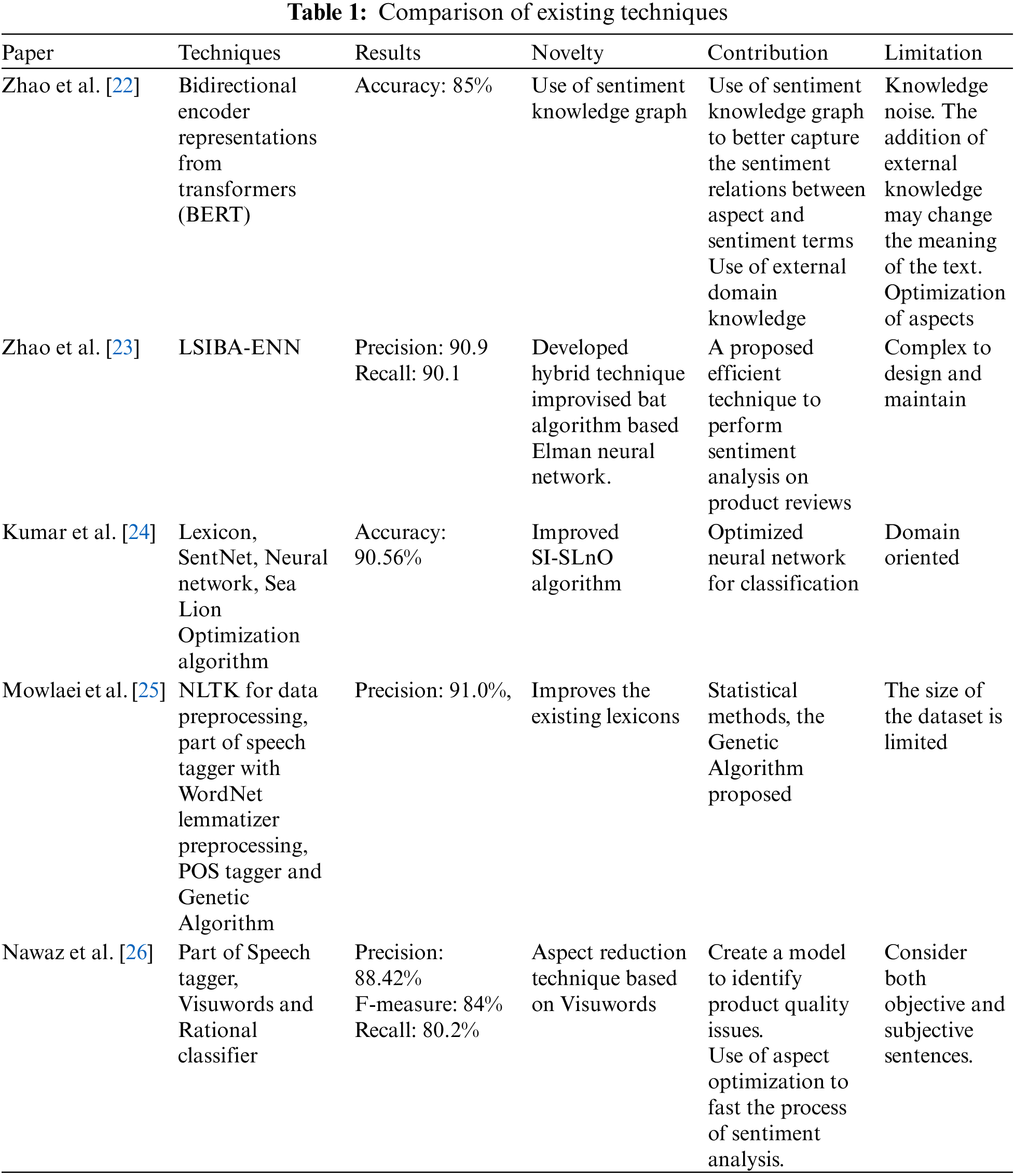
Detail comparison of some existing techniques of sentiment analysis on products and social media is shown in Table 1.
This study builds an integrated model using hybrid computational techniques of lexicons and a classifier to preprocess, extract features, classify the tweets, and depict the sentiment analysis results. The data preprocessing, aspect extraction, aspect refinement and classification processes are the core components of the model that has been suggested. The different stages of the proposed model are broken down into more specific steps and described in further depth in the following subsections. Fig. 3 presents the suggested concept with a graphical representation.

Figure 3: Proposed methodology for judging public attitudes. (a) Twitter data source, (b) data preprocessing, (c) aspects extraction, (d) refining and association, (e) classification using BERT
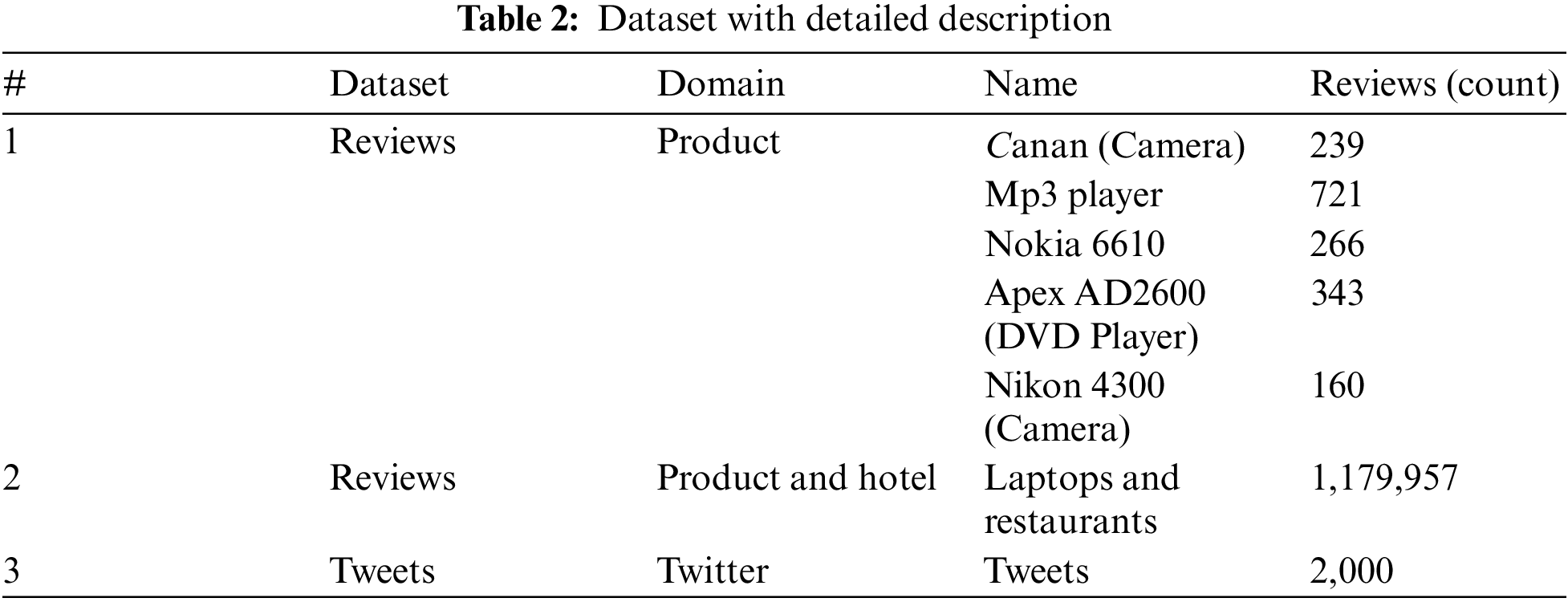
Data Collection and data selection are essential in any experiment. Here, our study has five benchmark datasets of product reviews already used in Bing Liu’s study [30]. These products are Canan (Camera), MP3 Player, Nokia 6610, Apex AD2600 (DVD Player) and Nikon 4300 (Camera). Our proposed method’s reliability was further tested using data from other domains. One of the famous benchmark datasets is “SemEval-2014” [31]. Last, some tweets were collected using Twitter API and created new datasets consisting of 2000 tweets from different regions. All datasets are in the English language. Table 2 shows the distribution of datasets.
Data preprocessing involves cleaning and preparing text for classification. Typically, online works include a lot of noise and irrelevant content, such as HTML tags and advertisements [32]. Moreover, many of the text’s words have little impact on classification. These words increase the issue’s dimensionality, making the classification more complicated since each word in the text is considered a different dimension [33]. Here is the assumption of properly preprocessing the data: minimizing text noise should enhance the classifier’s effectiveness and accelerate the classification process, hence permitting real-time sentiment analysis [34]. The whole approach consists of many steps: online text cleaning, elimination of white space, expansion of abbreviations, Binning, stemming, elimination of stop words and feature selection. Stemming is a cycle where words are diminished to a root by eliminating emphasis through dropping superfluous characters, generally a postfix. There are a few stemming models, including Porter and Snowball. The outcomes can be utilized to recognize connections and shared traits across enormous datasets. The expression “stemming” alludes to the decrease of words to their underlying foundations. All previous processes are referred to as transformations, whereas the last phase of applying functions to choose the proper patterns is known as filtering.
3.3 Aspect Extraction and Association
We used association rule mining (ARM) in conjunction with POS pattern heuristics to discover our datasets’ explicit single and multiword features. In addition, the Stanford Dependency Parser (SDP) approach is utilized to extract implicit aspects, which consider the relationship between the opinion and aspects. Rule mining approaches are very much used in past literature for sentiment analysis [13,19,35]. The following sections go into detail about each of these components. Associative rule mining is applied to identify the essential aspects of a given target.
‘If/Then’ patterns are frequently found in the data and these patterns are used to develop association rules. The criteria and confidence levels are applied in the next step to finding the most significant associations. To put it another way, the ‘if/then’ statements have been proven valid several times and the supporting criteria show how often the items appear in the database. Some tags with descriptions are given below in Fig. 4.

Figure 4: Tags with description [13]
Association rule mining (ARM) is used to identify the most significant multiword and single-word features of the target entities provided [36–39]. The importance of an aspect was determined by how frequently it appeared in more than 1% of the sentences. This experiment applied the ARM based on the Apriori algorithm [40]. By analyzing the transactions, the Apriori algorithm identifies the most frequent (important) characteristics of a set of transactions that meet a user-specified minimum level of support.
Bidirectional Encoder Representations from Transformers, or BERT for short, is a deep learning approach created by Google for natural language processing (NLP). BERT is a transformer-based deep technique. There are two versions of the BERT available [41], the BERT (basic) and the BERT (large). The BERT (basic) model has twelve encoders and twelve bidirectional self-attention heads. In contrast, the BERT (big) model has twenty-four encoders and sixteen bidirectional self-attention heads. These models have already undergone preliminary training using unlabeled data acquired from the English Wikipedia, which has 2,500 million words and the Book Corpus, which contains 800 million words [42,43]. BERT can figure out how much weight each item of data should have to depend on how related it is to the other pieces of data by using Transformers, a deep learning model.
The BERT (base) system is used in the suggested method. This system has twelve bidirectional self-attention heads along with twelve encoders. During the training phase, the loss function is used to adjust the weights so that the fitting BERT may be created by minimizing the loss function. The probabilities of probable labels in forward propagation are the model’s outputs. These probabilities are then evaluated with any additional target labels provided. A penalty is then computed by the loss function for each divergence between the model’s outputs and the target label. During backpropagation, the trainable weights are modified by adding the partial derivative of the loss function for each weight individually. It results in an altered value for the trainable weight. In this particular instance, sentiment classification is represented by a function that maps the input feature space to the label space.
where,
• N is the number of training instances
• M is the number of classes
•
•
• fm is the m’th element of f
In the ideal situation, if the classifier’s output matches the actual target, then it is 100% accurate for the training example and the loss is zero.
The dataset is distributed in training, test and validation datasets. The graph in Fig. 5 shows the training and validation set accuracy. The model is trained to 10 epochs and at the end, we achieved an accuracy of 98 percent on the training dataset and 89 percent on the validation set. As the training approaches ten epochs, the training accuracy increases to 98 percent; it may be better after more finetuning of the parameters.

Figure 5: Training and testing of the dataset
Table 3 shows the outcomes of the proposed method, which depicts that it obtained 92.09% precision, 91.84% recall and 93.06% accuracy on the product review dataset. At the same time, Movie reviews had an accuracy of 88.76% and 87.02% recall, whereas 87.98% precision, 89.02% accuracy, 88.11% recall and 88.74% precision on the data set of Twitter. The findings suggest that our method has enhanced accuracy, precision and recall. Graphically it is shown in Fig. 6.
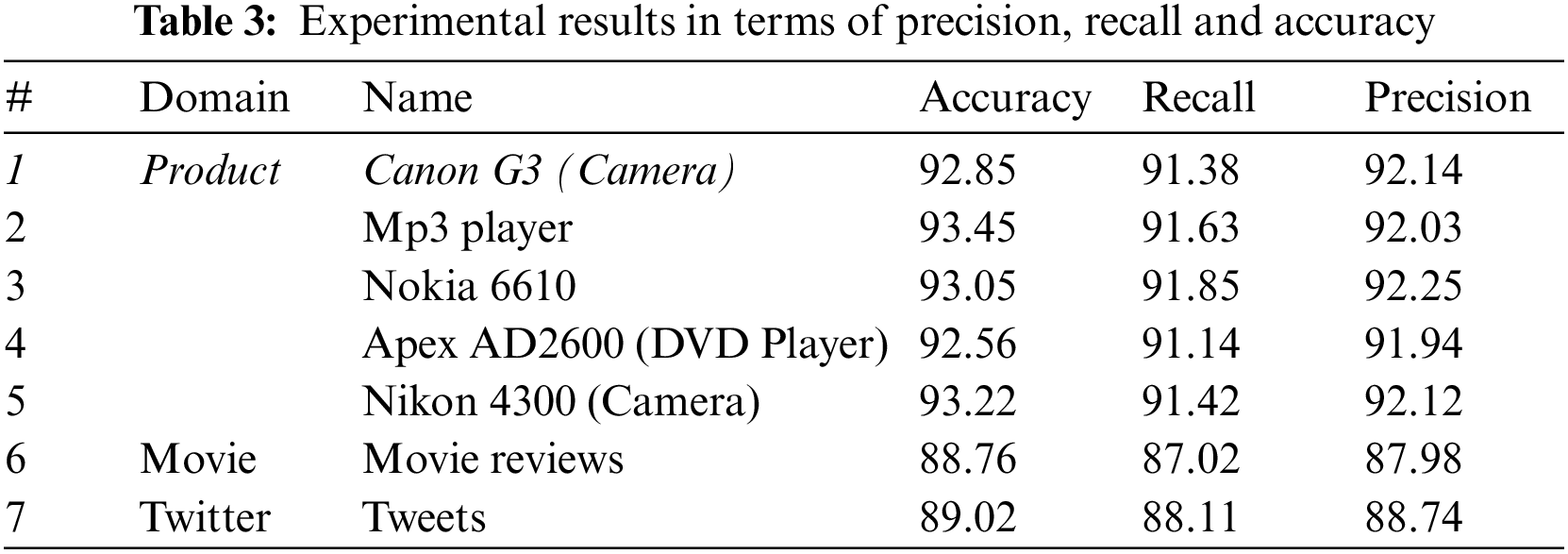

Figure 6: Experimental results
Table 4 demonstrates the effectiveness of association rule mining for extracting aspects. The proposed technique of aspects extraction is compared with some state of art techniques of aspects extraction [13,21,43]. The outcomes of the proposed methods for aspects extractions are compared with some aspects extractions from parts of speech and with various state-of-the-art techniques of aspects extractions. Graphically it is shown in Fig. 7.

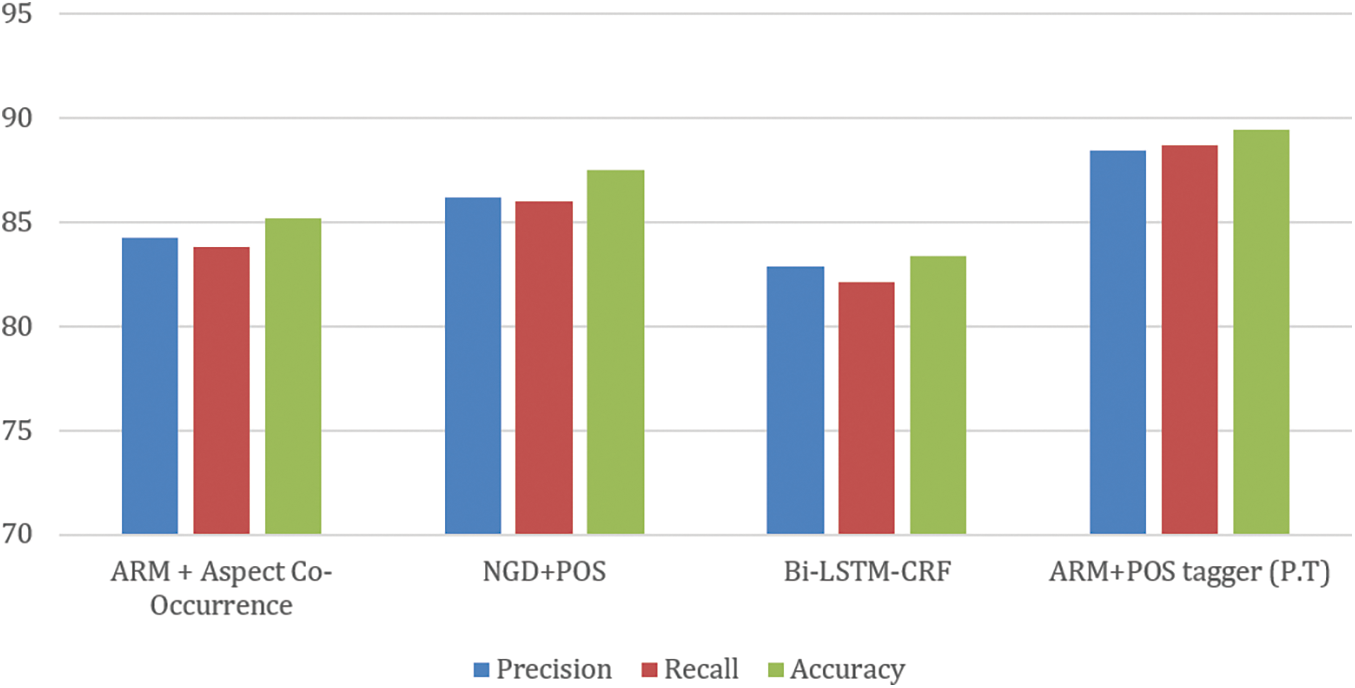
Figure 7: Comparison with state-of-the-art techniques in terms of aspects extraction
The paradigm of social media has altered dramatically due to internet accessibility. Sentiment analysis has significantly improved all aspects of e-commerce. ICT (Information and Communication Technologies) plays a significant role in society today. Literature from the past shows that the traditional ABSA methods take a long time and are hard for the public to use. The proposed association rules-based BERT model overcomes all these issues by introducing classification using BERT, extraction and ranking using association rules. This research also presents a web-based intelligent system that uses machine learning techniques to identify sentiments. The outcomes of the proposed approach demonstrate that it requires less time for aspect selection and extraction. Moreover, the effectiveness of the proposed model has also been evaluated using accuracy, precision and recall. A comparison is also performed to validate the proposed aspect extraction technique with the state-of-the-art approach.
Deep learning models have been used extensively in sentiment analysis in recent years. Existing machine learning models are flawed and there is room for performance enhancement. In this study, a novel method for evaluating the polarity of sentiments has been developed using BERT and association rule mining. The proposed approach is applied to each word of opinionated reviews/tweets from several domain datasets to categorize reviews. The experimental findings predicted the work’s precision, recall and accuracy developments. Results showed that the proposed technique achieved an average of 89.45% accuracy, 88.45% precision and 88.67% recall on different domain datasets. One of the limitations of this study is the usage of every aspect and opinion term, which reduces the effectiveness of the proposed methodology on large datasets.
In the future, this method might alleviate concerns with aspect-based sentiment analysis. Future success will depend on efforts to combine existing research with machine learning techniques to extract complex characteristics and sentiment analysis. Other potential improvements include forecasting presidential elections, designing complex ontologies, designing complex ontologies, predicting rising stars in the entertainment industry, early bug detection in the software industry and improving the quality assurance process for brands and products. Future studies may investigate the effect of customer sentiments on any product. It will provide a clear picture of customer satisfaction; through this, one can keep an eye on the quality of the product or service.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. M. R. R. Rana, A. Nawaz and J. Iqbal, “A survey on sentiment classification algorithms, challenges and applications,” Acta Universitatis Sapientiae, Informatica, vol. 10, no. 2, pp. 58–72, 2018. [Google Scholar]
2. M. Tubishat, N. Idris and M. Abushariah, “Explicit aspects extraction in sentiment analysis using optimal rules combination,” Future Generation Computer Systems, vol. 114, no. 1, pp. 448–480, 2021. [Google Scholar]
3. M. R. R. Rana, S. U. Rehman, A. Nawaz, T. Ali and M. Ahmed, “A conceptual model for decision support systems using aspect based sentiment analysis,” Proceedings of the Romanian Academy Series A-Mathematics Physics Technical Sciences Information Science, vol. 22, pp. 381–390, 2021. [Google Scholar]
4. R. Bhaskaran, S. Saravanan, M. Kavitha, C. Jeyalakshmi, S. Kadry et al., “Intelligent machine learning with metaheuristics based sentiment analysis and classification,” Computer Systems Science and Engineering, vol. 44, no. 1, pp. 235–247, 2023. [Google Scholar]
5. A. Yanie, A. Hasibuan, I. Ishak, M. Marsono, S. Lubis et al., “Web based application for decision support system with ELECTRE method,” In Journal of Physics: Conference Series, vol. 1028, no. 1, pp. 012054, 2018. [Google Scholar]
6. R. Madhumathi, A. M. Kowshalya and R. Shruthi, “Assessment of sentiment analysis using information gain based feature selection approach,” Computer Systems Science and Engineering, vol. 43, no. 2, pp. 849–860, 2020. [Google Scholar]
7. A. Sharma and H. Wehrheim, “Higher income, larger loan? monotonicity testing of machine learning models,” in Proc. of the 29th Int. Symp. on Software Testing and Analysis, New York, USA, pp. 200–210, 2020. [Google Scholar]
8. A. I. Canhoto and F. Clear, “Artificial intelligence and machine learning as business tools: A framework for diagnosing value destruction potential,” Business Horizons, vol. 63, no. 2, pp. 183–193, 2020. [Google Scholar]
9. J. Papathanasiou, N. Ploskas and I. Linden, “Computerized decision support case study research: Concepts and suggestions, in Real-World Decision Support Systems: Case Studies, vol. 37, Switzerland: Springer, pp. 1–13, 2016. [Google Scholar]
10. M. Jabreel, N. Maaroof, A. Valls and A. Moreno, “Introducing sentiment analysis of textual reviews in a multi-criteria decision aid system,” Applied Sciences, vol. 11, no. 1, pp. 216, 2021. [Google Scholar]
11. M. L. B. Estrada, R. Z. Cabada, R. O. Bustillos and M. Graff, “Opinion mining and emotion recognition applied to learning environments,” Expert Systems with Applications, vol. 150, no. 1, pp. 113265, 2020. [Google Scholar]
12. P. Bhardwaj, S. Gautam and P. Pahwa, “A novel approach to analyze the sentiments of tweets related to TripAdvisor,” Journal of Information and Optimization Sciences, vol. 39, no. 2, pp. 591–605, 2018. [Google Scholar]
13. A. Banjar, Z. Ahmed, A. Daud, R. A. Abbasi and H. Dawood, “Aspect-based sentiment analysis for polarity estimation of customer reviews on twitter,” CMC-Computers, Materials & Continua, vol. 67, no. 2, pp. 2203–2225, 2021. [Google Scholar]
14. S. H. Janjua, G. F. Siddiqui, M. A. Sindhu and U. Rashid, “Multi-level aspect based sentiment classification of Twitter data: Using hybrid approach in deep learning,” PeerJ Computer Science, vol. 7, no. 1, pp. e433, 2021. [Google Scholar]
15. M. Birjali, M. Kasri and A. Beni-Hssane, “A comprehensive survey on sentiment analysis: Approaches, challenges and trends,” Knowledge-Based Systems, vol. 226, no. 1, pp. 107134, 2021. [Google Scholar]
16. J. Mir and A. Mahmood, “Movie aspects identification model for aspect based sentiment analysis,” Information Technology and Control, vol. 49, no. 4, pp. 564–582, 2020. [Google Scholar]
17. A. Ishaq, S. Asghar and S. A. Gillani, “Aspect-based sentiment analysis using a hybridized approach based on CNN and GA,” IEEE Access, vol. 8, no. 1, pp. 135499–135512, 2020. [Google Scholar]
18. N. Nandal, R. Tanwar and J. Pruthi, “Machine learning based aspect level sentiment analysis for Amazon products,” Spatial Information Research, vol. 28, no. 5, pp. 601–607, 2020. [Google Scholar]
19. A. Nawaz, T. Ali, Y. Hafeez and M. R. Rashid, “Mining public opinion: A sentiment based forecasting for democratic elections of Pakistan,” Spatial Information Research, vol. 30, no. 1, pp. 169–181, 2022. [Google Scholar]
20. R. Wadawadagi and V. Pagi, “Polarity enriched attention network for aspect-based sentiment analysis,” International Journal of Information Technology, vol. 14, no. 1, pp. 2767–2778, 2022. [Google Scholar]
21. Y. Cao, Z. Sun, L. Li and W. Mo, “A study of sentiment analysis algorithms for agricultural product reviews based on improved bert model,” Symmetry, vol. 14, no. 8, pp. 1604, 2022. [Google Scholar]
22. A. Zhao and Y. Yu, “Knowledge-enabled BERT for aspect-based sentiment analysis,” Knowledge-Based Systems, vol. 227, no. 1, pp. 107220, 2021. [Google Scholar]
23. H. Zhao, Z. Liu, X. Yao and Q. Yang, “A machine learning-based sentiment analysis of online product reviews with a novel term weighting and feature selection approach,” Information Processing & Management, vol. 58, no. 5, pp. 102656, 2021. [Google Scholar]
24. K. E. Naresh Kumar and V. Uma, “Intelligent sentinet-based lexicon for context-aware sentiment analysis: Optimized neural network for sentiment classification on social media,” The Journal of Supercomputing, vol. 77, no. 11, pp. 12801–12825, 2021. [Google Scholar]
25. M. E. Mowlaei, M. S. Abadeh and H. Keshavarz, “Aspect-based sentiment analysis using adaptive aspect-based lexicons,” Expert Systems with Applications, vol. 148, no. 1, pp. 113234, 2020. [Google Scholar]
26. A. Nawaz, A. A. Awan, T. Ali and M. R. R. Rana, “Product’s behaviour recommendations using free text: An aspect based sentiment analysis approach,” Cluster Computing, vol. 23, no. 2, pp. 1267–1279, 2020. [Google Scholar]
27. A. Dey and K. Dasgupta, “Emotion recognition using deep learning in pandemic with real-time email alert,” in Proc. of Third Int. Conf. on Communication, Computing and Electronics Systems, Singapore, pp. 175–190, 2022. [Google Scholar]
28. C. H. Chen, P. Y. Chen and L. J. Chun-Wei, “An ensemble classifier for stock trend prediction using sentence-level Chinese news sentiment and technical indicators,” International Journal of Interactive Multimedia and Artificial Intelligence, vol. 7, no. 3, pp. 53–64, 2022. [Google Scholar]
29. U. Ahmed, R. H. Jhaveri, G. Srivastava and J. C. W. Lin, “Explainable deep attention active learning for sentimental analytics of mental disorder,” Transactions on Asian and Low-Resource Language Information Processing, pp. 1–20, 2022. [Google Scholar]
30. M. Pontiki, D. Galanis, H. Papageorgiou, I. Androutsopoulos, S. Manandhar et al., “Semeval-2016 task 5: Aspect based sentiment analysis,” in Int. Workshop on Semantic Evaluation, San Diego, California, USA, pp. 19–30, 2016. [Google Scholar]
31. V. Chang, L. Liu, Q. Xu, T. Li and C. H. Hsu, “An improved model for sentiment analysis on luxury hotel review,” Expert Systems, vol. 1, no. 1, pp. e12580, 2020. [Google Scholar]
32. T. Gui, Q. Zhang, H. Huang, M. Peng and X. J. Huang, “Part-of-speech tagging for twitter with adversarial neural networks,” in Proc. of the 2017 Conf. on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, pp. 2411–2420, 2017. [Google Scholar]
33. X. Zhu, X. Yang, Y. Huang, Q. Guo and B. Zhang, “Measuring similarity and relatedness using multiple semantic relations in WordNet,” Knowledge and Information Systems, vol. 62, no. 4, pp. 1539–1569, 2020. [Google Scholar]
34. K. M. Hamdia, X. Zhuang and T. Rabczuk, “An efficient optimization approach for designing machine learning models based on genetic algorithm,” Neural Computing and Applications, vol. 33, no. 6, pp. 1923–1933, 2021. [Google Scholar]
35. S. Matharaarachchi, M. Domaratzki, A. Katz and S. Muthukumarana, “Discovering long covid symptom patterns: Association rule mining and sentiment analysis in social media tweets,” JMIR Formative Research, vol. 6, no. 9, pp. e37984, 2022. [Google Scholar]
36. W. Gan, J. C. W. Lin, P. Fournier-Viger, H. C. Chao and P. S. Yu, “A survey of parallel sequential pattern mining,” ACM Transactions on Knowledge Discovery from Data (TKDD), vol. 13, no. 3, pp. 1–34, 2019. [Google Scholar]
37. W. Gan, J. C. W. Lin, H. C. Chao and J. Zhan, “Data mining in distributed environment: A survey,” Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, vol. 7, no. 6, pp. e1216, 2017. [Google Scholar]
38. P. Fournier-Viger, G. He, C. Cheng, J. Li, M. Zhou et al., “A survey of pattern mining in dynamic graphs,” Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, vol. 10, no. 6, pp. e1372, 2020. [Google Scholar]
39. P. Fournier-Viger, J. C. W. Lin, B. Vo, T. T. Chi, J. Zhang et al., “A survey of itemset mining,” Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, vol. 7, no. 4, pp. e1207, 2017. [Google Scholar]
40. H. Wei, H. Bao and X. Ruan, “Genetic algorithm-driven discovery of unexpected thermal conductivity enhancement by disorder,” Nano Energy, vol. 71, no. 1, pp. 104619, 2020. [Google Scholar]
41. J. L. Kwan, L. Lo, J. Ferguson, H. Goldberg, J. P. Diaz-Martinez et al., “Computerised clinical decision support systems and absolute improvements in care: Meta-analysis of controlled clinical trials,” BMJ, vol. 370, no. 1, pp. 1–11, 2020. [Google Scholar]
42. Z. Xiong, Y. Cui, Z. Liu, Y. Zhao, H. Hu et al., “Evaluating explorative prediction power of machine learning algorithms for materials discovery using k-fold forward cross-validation,” Computational Materials Science, vol. 171, no. 1, pp. 109203, 2020. [Google Scholar]
43. M. A. Ullah, S. A. Marium and N. S. Dipa, “An algorithm and method for sentiment analysis using the text and emoticon,” ICT Express, vol. 6, no. 4, pp. 357–360, 2020. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools