
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Battle Royale Optimization with Fuzzy Deep Learning for Arabic Sentiment Classification
1 Department of Computer and Self Development, Preparatory Year Deanship, Prince Sattam bin Abdulaziz University, AlKharj, Saudi Arabia
2 Department of Applied Linguistics, College of Languages, Princess Nourah bint Abdulrahman University, P.O. Box 84428, Riyadh, 11671, Saudi Arabia
3 Department of Industrial Engineering, College of Engineering at Alqunfudah, Umm Al-Qura University, Makkah 24211, Saudi Arabia
4 Department of Computer Science, Faculty of Computers and Information Technology, Future University in Egypt, New Cairo, 11835, Egypt
5 Department of Information System, College of Computer Engineering and Sciences, Prince Sattam bin Abdulaziz University, AlKharj, Saudi Arabia
* Corresponding Author: Manar Ahmed Hamza. Email:
Computer Systems Science and Engineering 2023, 46(2), 2619-2635. https://doi.org/10.32604/csse.2023.034519
Received 19 July 2022; Accepted 14 September 2022; Issue published 09 February 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Aspect-Based Sentiment Analysis (ABSA) on Arabic corpus has become an active research topic in recent days. ABSA refers to a fine-grained Sentiment Analysis (SA) task that focuses on the extraction of the conferred aspects and the identification of respective sentiment polarity from the provided text. Most of the prevailing Arabic ABSA techniques heavily depend upon dreary feature-engineering and pre-processing tasks and utilize external sources such as lexicons. In literature, concerning the Arabic language text analysis, the authors made use of regular Machine Learning (ML) techniques that rely on a group of rare sources and tools. These sources were used for processing and analyzing the Arabic language content like lexicons. However, an important challenge in this domain is the unavailability of sufficient and reliable resources. In this background, the current study introduces a new Battle Royale Optimization with Fuzzy Deep Learning for Arabic Aspect Based Sentiment Classification (BROFDL-AASC) technique. The aim of the presented BROFDL-AASC model is to detect and classify the sentiments in the Arabic language. In the presented BROFDL-AASC model, data pre-processing is performed at first to convert the input data into a useful format. Besides, the BROFDL-AASC model includes Discriminative Fuzzy-based Restricted Boltzmann Machine (DFRBM) model for the identification and categorization of sentiments. Furthermore, the BRO algorithm is exploited for optimal fine-tuning of the hyperparameters related to the FBRBM model. This scenario establishes the novelty of current study. The performance of the proposed BROFDL-AASC model was validated and the outcomes demonstrate the supremacy of BROFDL-AASC model over other existing models.Keywords
The advancements in web technologies have provided novel opportunities for the communication of user-generated content such as website reviews, blogs, forums, social networking sites and so on [1]. The extraordinary increase in the generation of data and the process of dealing with intricate unstructured text in natural language involve both organizations and persons in the domain of data mining. Sentiment Analysis (SA) (emotional analysis or opinion mining) can be defined as a computer-generated analytical procedure to assess different types of emotions, opinions and moods of the human beings [2]. It is helpful in deciding the attitude of a researcher, about a particular piece of content, on the basis of the subject of interest [3]. SA results categorizes the opinions and polarities of the text corpus (i.e., news, review, or tweet) as neutral, positive and negative. For Arabic SA, three techniques are used in general such as hybrid-based, corpus-based, lexicon-based and hybrid-based techniques (in which both corpus and lexicon techniques are combined) [4,5].
The intension of the common SA mechanism is to decide a single sentiment polarity for every review or an opinionated sentence [6]. However, this cannot be always useful or practical in nature since a sentence or a review might consist of numerous opinions covering diverse aspects of the topic under study. Moreover, such opinions may also contradict or conflict with each other [7,8]. For instance, a reviewer may simply praise the performance of a graphics card in a computer while disparage the lifetime of the battery [9]. Due to these multi-faceted opinions, there is a need exists for a fine-grained analysis of the sentiments and it is fulfilled by Aspect-Based or feature-based SA (ABSA) [10]. ABSA is an extension of SA that considers all the types of opinions in a sentence or a review with entities and aspects under target along with its sentiment polarity values [11]. ABSA is highly helpful at instances as discussed above. Owing to its significance, ABSA was highly focused at workshops like SemEval and high-profile Natural Language Processing (NLP) conferences [12]. SemEval is an annual NLP workshop that provides several insights to the scientific community in terms of testing SA mechanisms [13]. DL is a highly-recommended method in ML technique to handle several NLP complexities like SA machine translation called speech recognition and entity recognition [14]. Apart from its prodigious performance, DL has an additional advantage i.e., it does not depend on external resources or hand-crafted features.
Bensoltane et al. [15] attempted to overcome such limitations by offering Transfer Learning (TL) techniques with the help of pre-trained language methods. This was accomplished to perform two Aspect-Based Sentiment Analysis (ABSA) errands in the Arabic language like Aspect Category Detection (ACD) and Aspect Term Extraction (ATE). The presented methods were constructed based on the Arabic version (AraBERT) of the BERT method. The study compared diverse executions of the BERT method such as feature-oriented and fine-tuning approaches. The primary finding of this study was that fine-tuning is highly appropriate in low-resource backgrounds. Then, if the downstream layers are modelled in a customized manner, it enhances the outcomes of the default finely-tuned BERT method. Kumar et al. [16] recommended an effective technique for SA by efficiently merging three processes into one. The first process was the formation of ontology to extract the semantic features. The second process utilized Word2vec to transform the processed corpus and at last, CNN was utilized for the purpose of opinion mining. In order to fine-tune the CNN parameters, a multi-objective function was resolved for non-dominant Pareto front optimum values, utilizing PSO. Alshammari et al. [17] conducted a survey of the research works conducted earlier upon SA that utilized ML, DL and lexicon-related approaches in English and Arabic language tweets. The authors reported the outcomes for both DL as well as ML-SA methods on Arabic tweets for the extraction of sentiments of Saudi telecommunication firms’ customers. The author evaluated the impact of Word Embedding and Part of Speech (POS) methods upon the performances of DL approaches.
Ishaq et al. [18] granted a real technique for sentiment analysis. In this technique, three functions were compiled such as the implementation of CNN, mining of the semantic features and the transformation of the derived corpus with the help of Word2vec for opinion mining. GA was used to fine-tune the CNN hyper-parameters. Ma et al. [19] offered an effective solution for battered aspect-related SA, particularly paying attention to the application of common-sense knowledge in deep neural series method. In order to derive the implications of the dependent sentiment, the authors augmented LSTM with a stacked attention system that comprises of attention methods for sentence- and target-levels. For a precise compilation of the implicit and explicit knowledges, the authors offered an extension of LSTM in the name of Sentic LSTM. The protracted LSTM cell had an isolated output gate that incorporates both concept as well as input token level memory. Moreover, the author recommended an extension of Sentic LSTM by creating a hybrid of recurrent additive networks and LSTM which pretends like Sentic paradigms. Though several works are available in the literature, only a few works have concentrated on hyperparameter tuning processes with the help of optimization algorithms.
The current study introduces a new Battle Royale Optimization with Fuzzy Deep Learning for Arabic Aspect Based Sentiment Classification (BROFDL-AASC) technique. The aim of the presented BROFDL-AASC model is to detect and classify the sentiments found in the Arabic language. In the presented BROFDL-AASC model, data pre-processing is performed at the initial stage to convert the input data into a useful format. Besides, the BROFDL-AASC model performs Discriminative Fuzzy-based Restricted Boltzmann Machine (DFRBM) model for the identification and categorization of sentiments. Furthermore, the BRO algorithm is exploited for optimal fine-tuning of the hyperparameters related to the FBRBM model. The performance of the proposed BROFDL-AASC model was experimentally validated under different measures.
In this study, a new BROFDL-AASC technique has been developed for Arabic aspect-based sentiment classification. The presented BROFDL-AASC model detects and classifies the sentiments expressed in the Arabic language. Fig. 1 displays the block diagram of BROFDL-AASC approach.
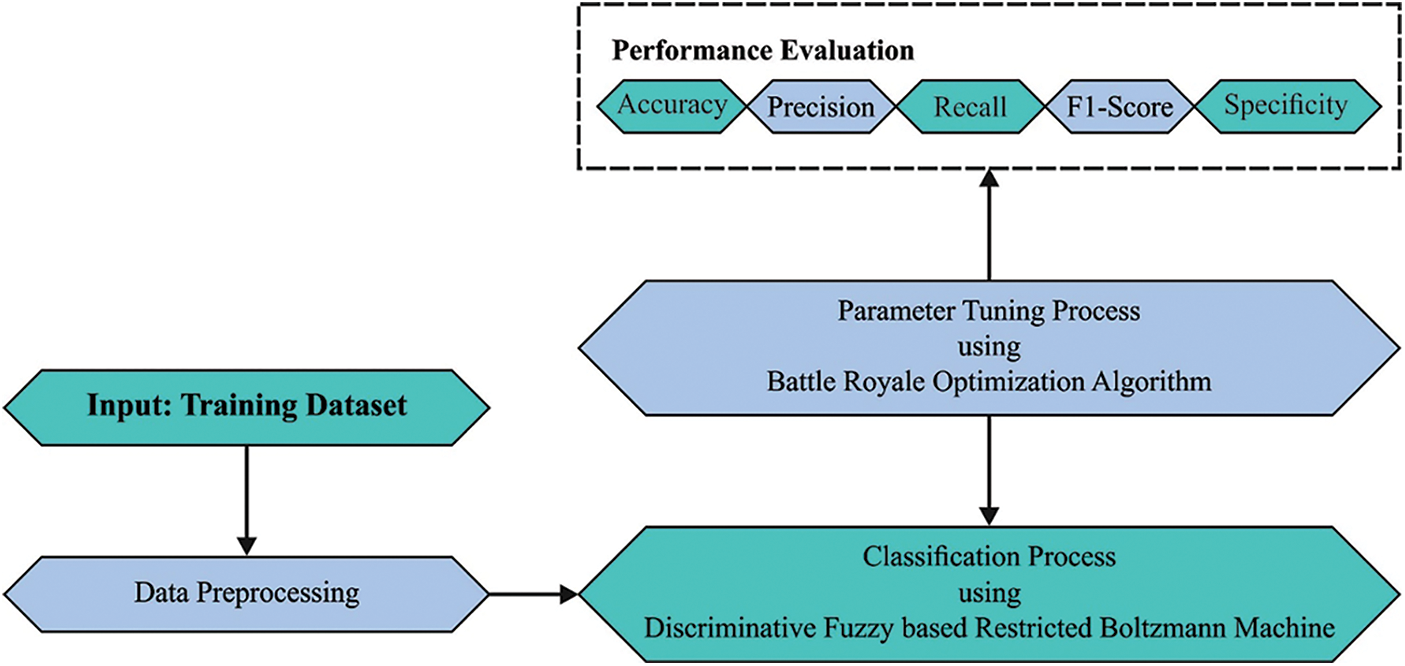
Figure 1: Block diagram of BROFDL-AASC approach
In the presented BROFDL-AASC model, data pre-processing is conducted at the initial stage to convert the input data into a useful format. The steps involved are given herewith [20]:
i) Increase a space between conjunction letters, commas and special characters with that of the subsequent word such as (عوضوملا، و يلاتلاب → عوضوملا ،يلاتلابو).
ii) Eliminate every diacritic i.e., ْعَّتَمَتَي→عتمتي.
iii) Eliminate the repeated characters, for instance (عوضوملا→عوـــــضوملا)
iv) Eliminate the unwanted additional spaces (صقن رارضأ صقن→رارضأ)
v) Eliminate unusual entries such as poems (ىَوِّللا ِطْقِسِب ِلِزْنَمو ٍبيِبَح ىَرْكِذ ْنِم ِكْبَن اَفِق ِلَمْوَحَف ِلوُخَّدلا َنْيَب),
vi) In this study, the BERT model is applied for word embedding process.
2.2 Sentiment Analysis Using DFRBM Model
In current study, the proposed BROFDL-AASC model makes use of the DFRBM model for identification and the categorization of the sentiments. FRBM is developed by substituting the real value parameters of RBM with symmetric triangular fuzzy numbers [21]. However, the architecture is retained similar to RBM as shown below.
In Eq. (1), the weight
Here,
Here,
Here,
Now,
In Eq. (6),
where
Besides Eq. (4), the update rule for the parameter of label unit in DFRBM is shown below.
where
Once a novel sample x is given for classification, the subsequent two condition likelihoods are calculated.
and
Here,
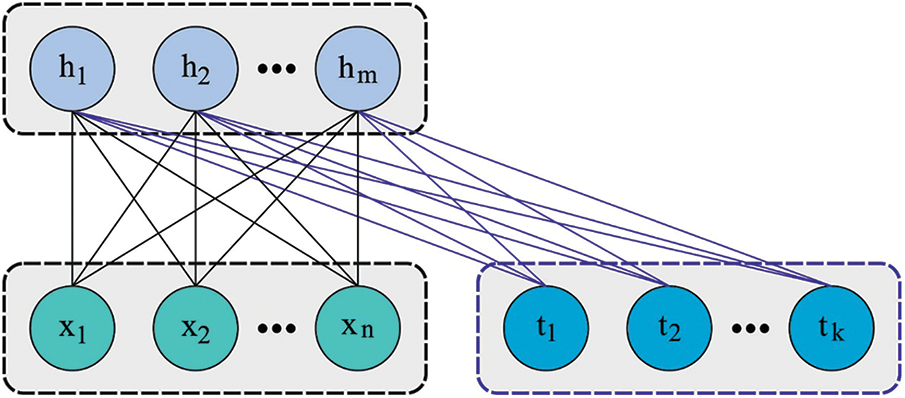
Figure 2: Structure of DFRBM
Accordingly, the label of the sample x is defined using the maximal probability

2.3 Hyperparameter Tuning Using BRO Algorithm
Finally, the BRO algorithm is exploited for optimal fine-tuning of the hyperparameters involved in FBRBM model. In a certain version of the Battle Royale game, the player starts the game by jumping from a plane and parachutes down to the map. Likewise, BRO is initiated through a random population that is distributed uniformly across the problems, like other swarm-based approaches [22]. Then, every individual (either a player or a soldier) attempts to hurt the nearby soldier by shooting them using a weapon. Therefore, a soldier in the best position causes harm to the nearby neighbours. If a soldier is hurt by others, their damage level increases by one. This interaction is arithmetically evaluated for each
In Eq. (10), r denotes a randomly-produced value that is distributed uniformly within 0 and1 and
In Eq. (11),
This interaction contributes towards exploration and exploitation phases. Hence, the lower and the upper bounds are upgraded as given below.
Now,

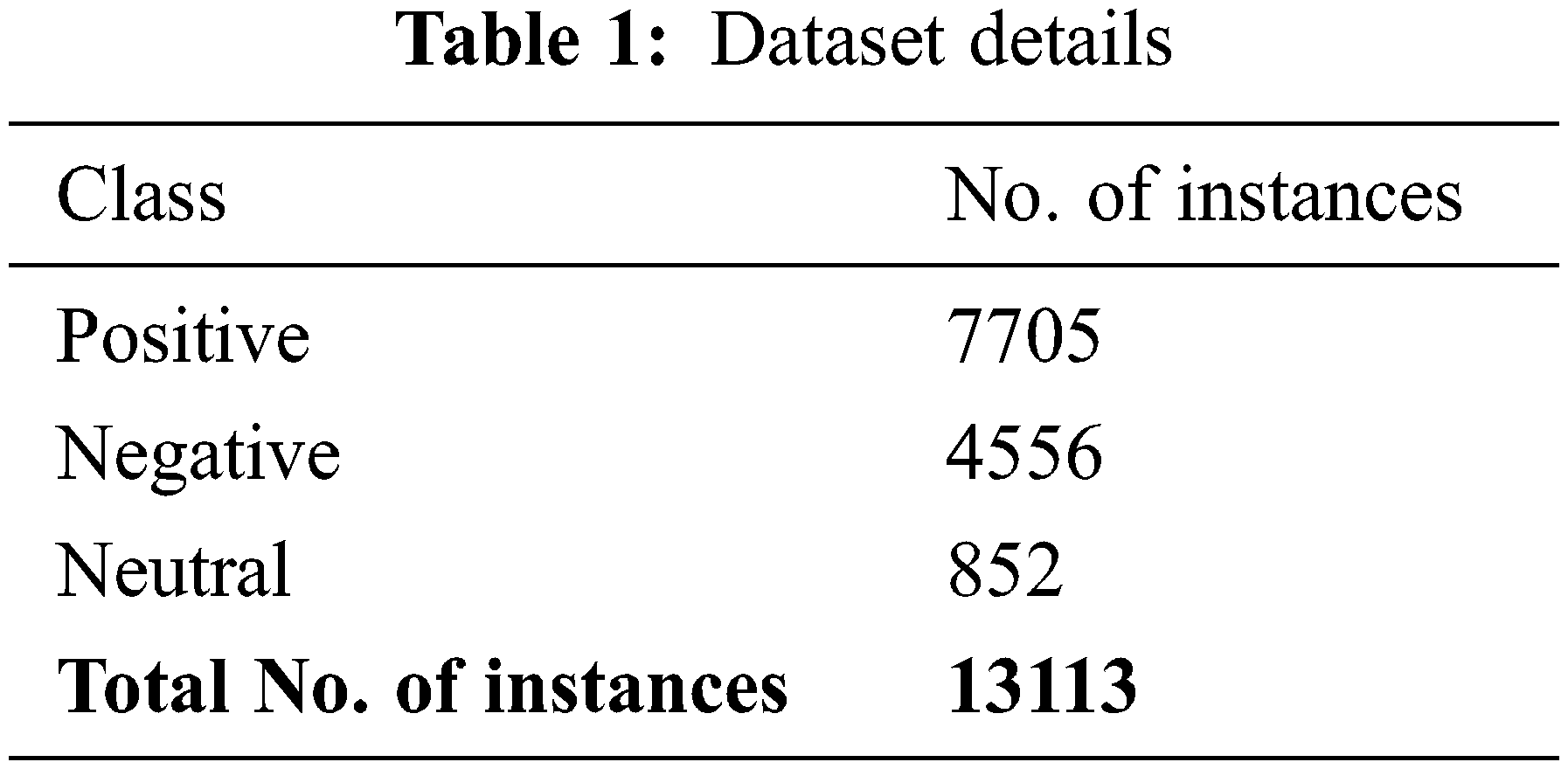
In this section, the presented model was experimentally validated using Arabic SemEval-2016 dataset. The dataset has a total of 13,113 samples under three class labels as illustrated in Table 1. The results were examined under different aspects such as a) 80% of TR data, (b) 20% of TS data, (c) 70% of TR data, and (d) 30% of TS data.
The confusion matrices generated by the proposed BROFDL-AASC model under different aspects are illustrated in Fig. 3. On 80% of TR data, the proposed BROFDL-AASC model identified 5,934, 3,428 and 517 samples as positive, negative and neutral classes respectively. In addition to this, on 20% of TS data, the presented BROFDL-AASC method classified 1,516, 830, and 125 samples under positive, negative and neutral classes correspondingly. Moreover, on 70% of TR data, the proposed BROFDL-AASC algorithm categorized 5,228, 2975 and 395 samples under positive, negative and neutral classes correspondingly.
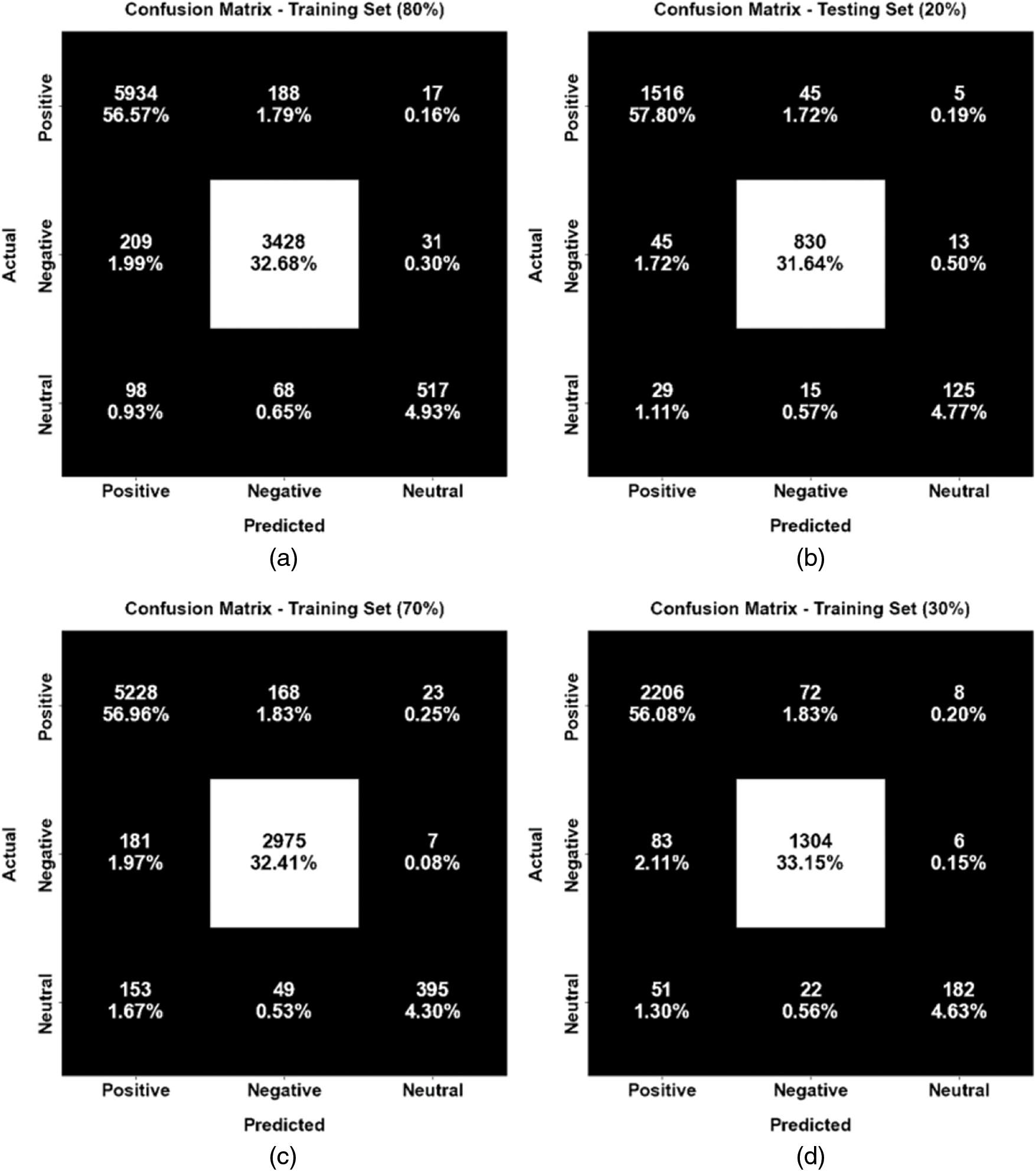
Figure 3: Confusion matrices of BROFDL-AASC approach (a) 80% of TR data, (b) 20% of TS data, (c) 70% of TR data, and (d) 30% of TS data
Table 2 and Fig. 4 show the analytical outcomes achieved by the proposed BROFDL-AASC model on 80% of TR data. In positive class, the presented BROFDL-AASC model attained
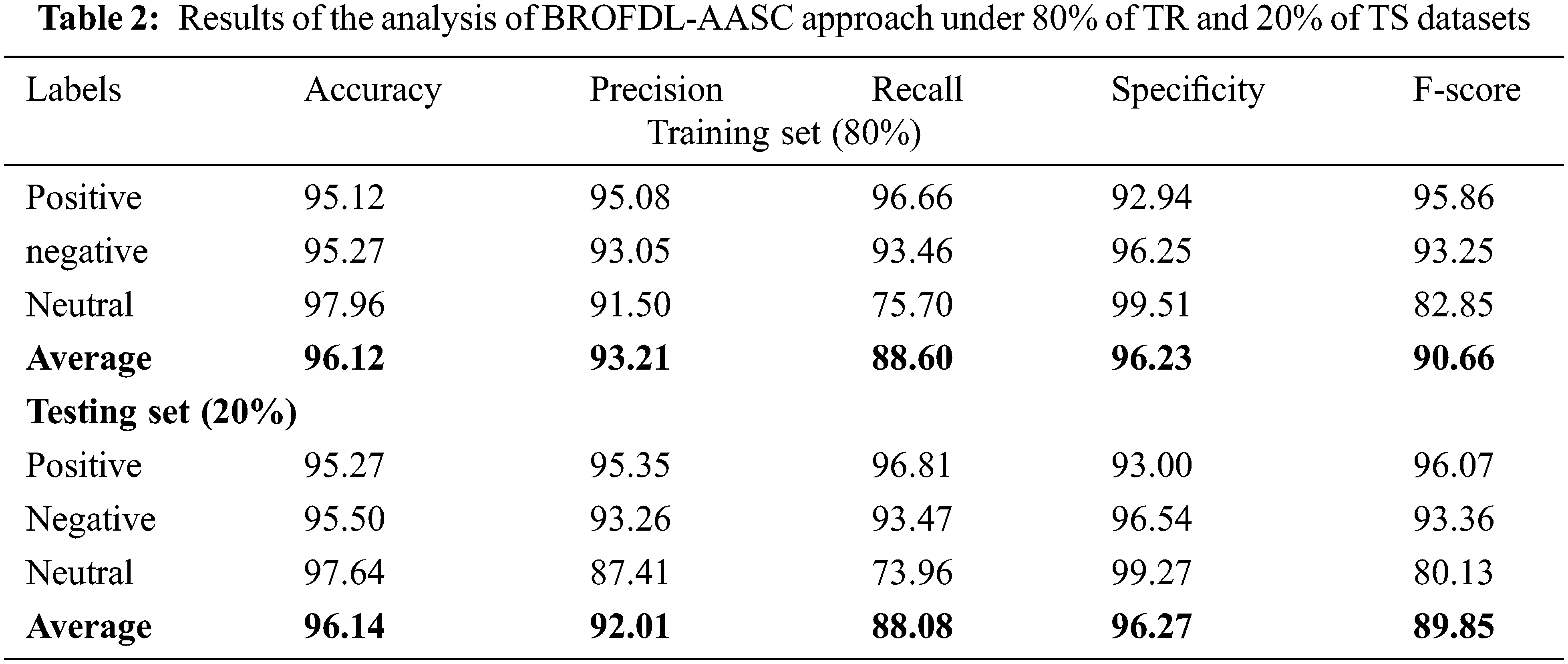
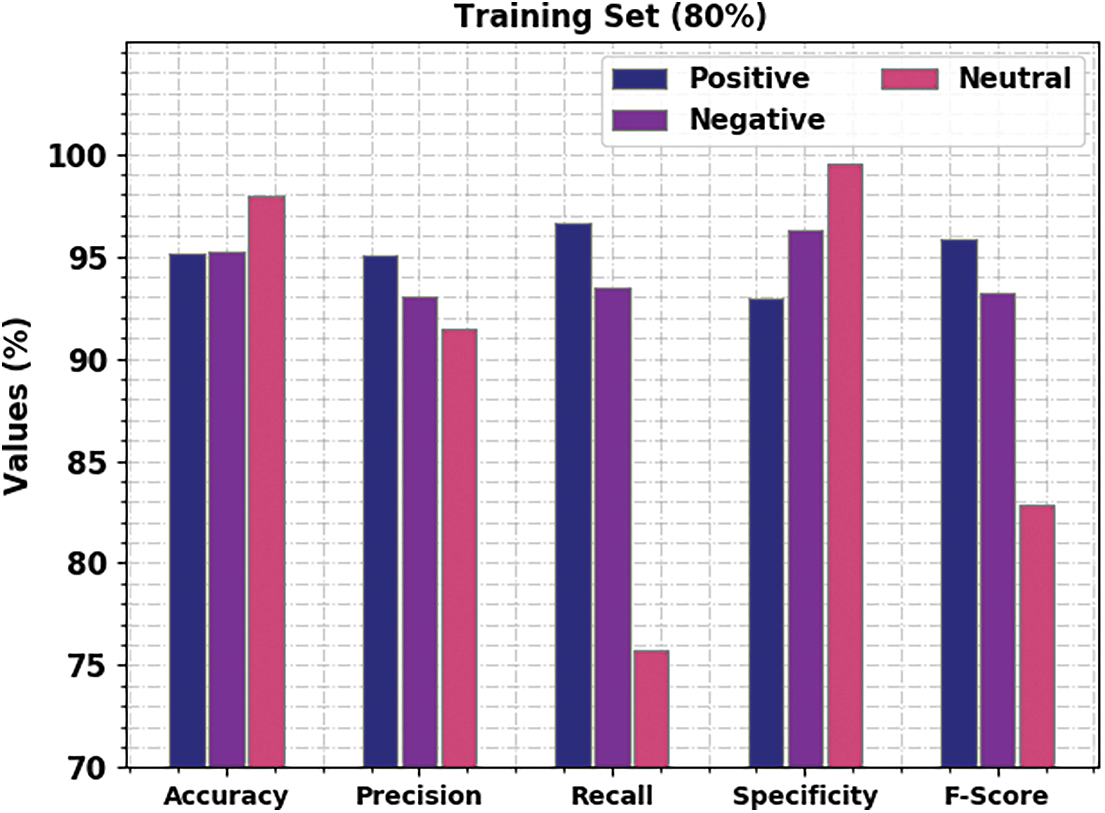
Figure 4: Results of the analysis of BROFDL-AASC approach under 80% of TR data
Fig. 5 presents the results of the analysis accomplished by BROFDL-AASC approach on 20% of TS data. On positive class, the proposed BROFDL-AASC approach accomplished
Figure 5: Results of the analysis of BROFDL-AASC approach under 20% of TS data
Table 3 and Fig. 6 display the comprehensive analytical results attained by the proposed BROFDL-AASC approach on 70% of TR data. On positive class, the presented BROFDL-AASC technique achieved
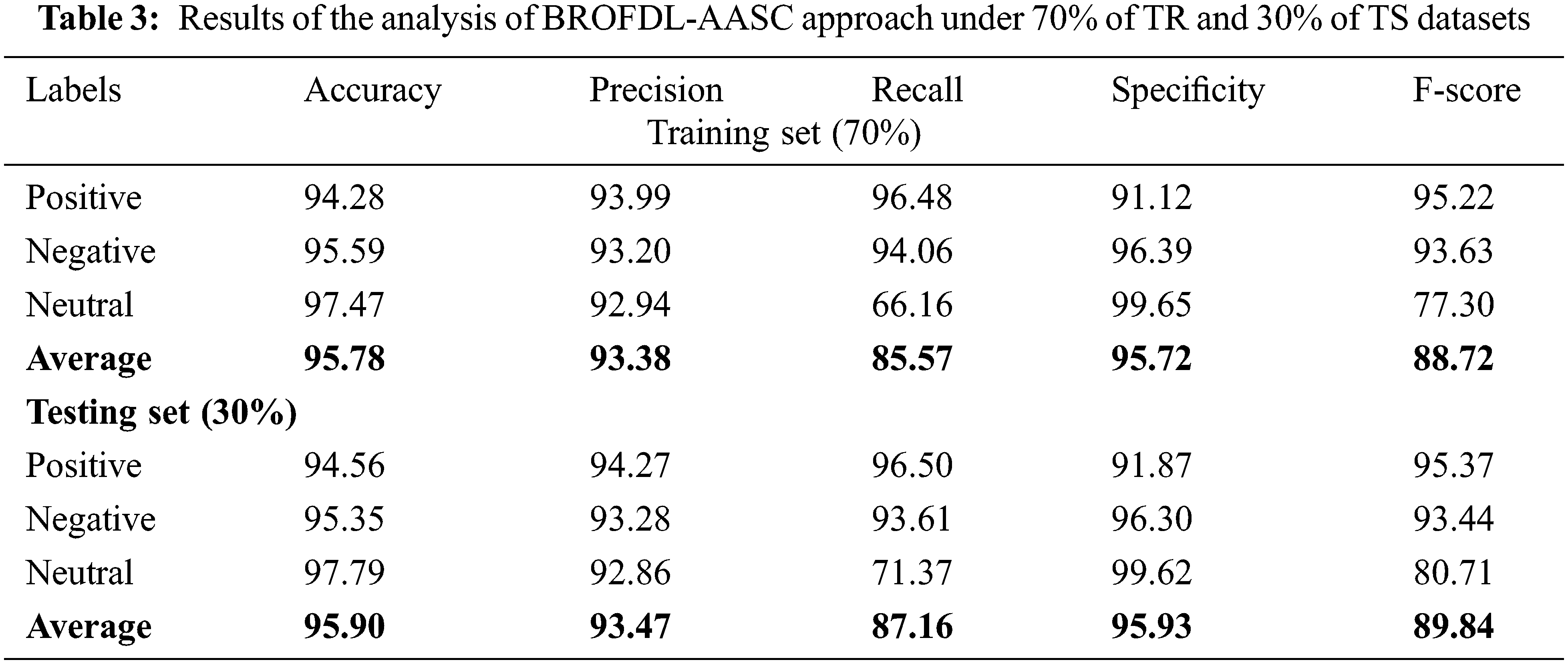
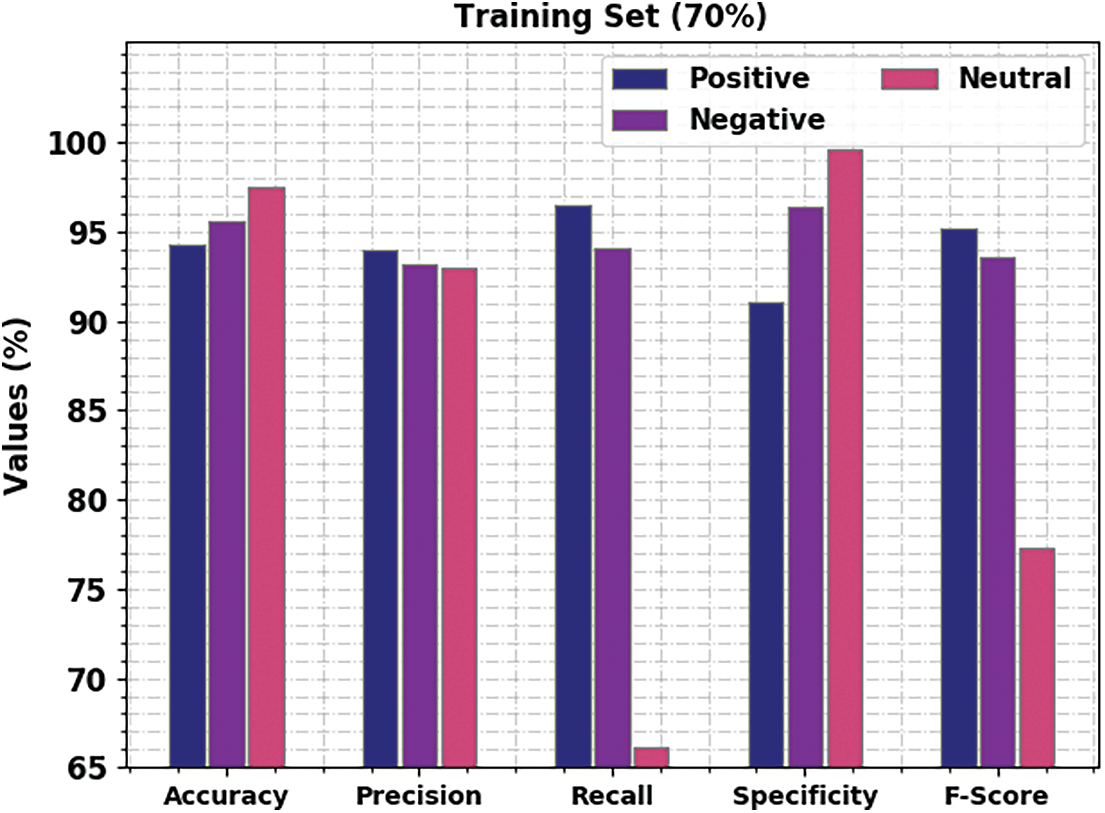
Figure 6: Results of the analysis of BROFDL-AASC approach under 70% of TR data
Fig. 7 portrays the analytical results attained by BROFDL-AASC approach on 30% of TS data. On positive class, the proposed BROFDL-AASC method attained
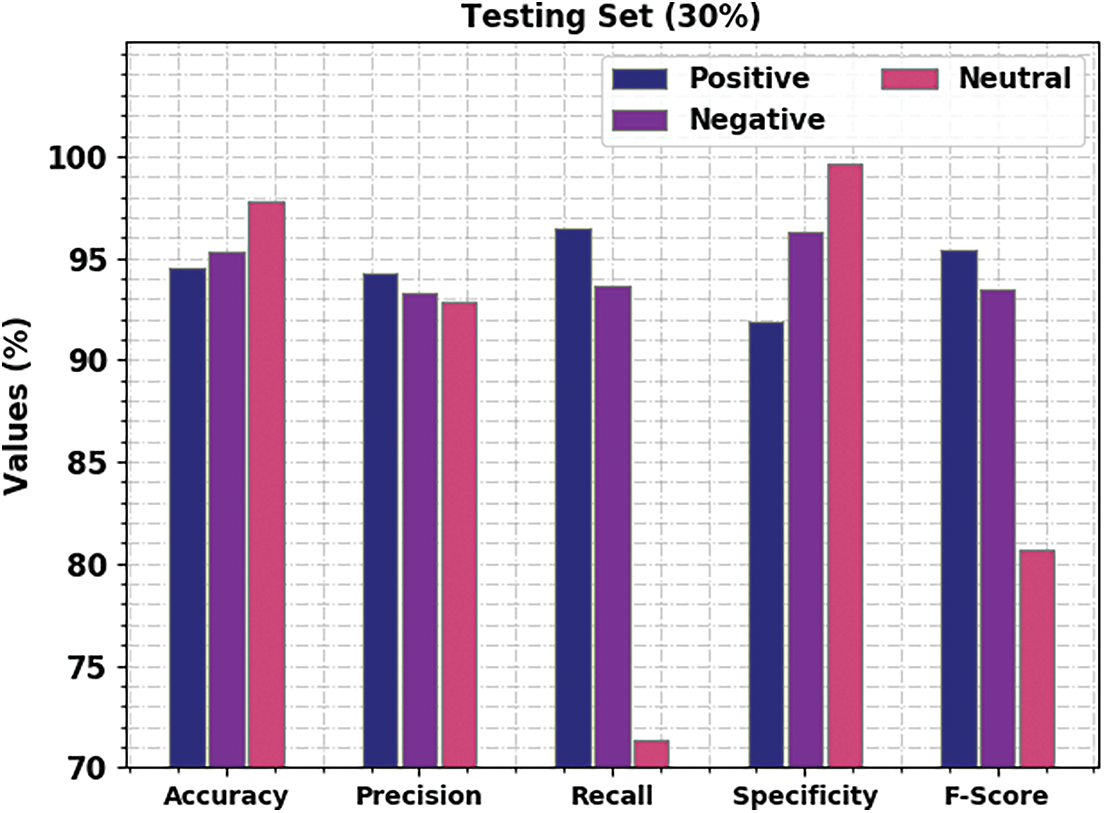
Figure 7: Results of the analysis of BROFDL-AASC approach under 30% of TS data
Both Training Accuracy (TRA) and Validation Accuracy (VLA) values, attained by the proposed BROFDL-AASC methodology on test dataset, are depicted in Fig. 8. The experimental outcomes infer that the proposed BROFDL-AASC approach obtained the maximum TRA and VLA values whereas VLA values were higher than TRA.
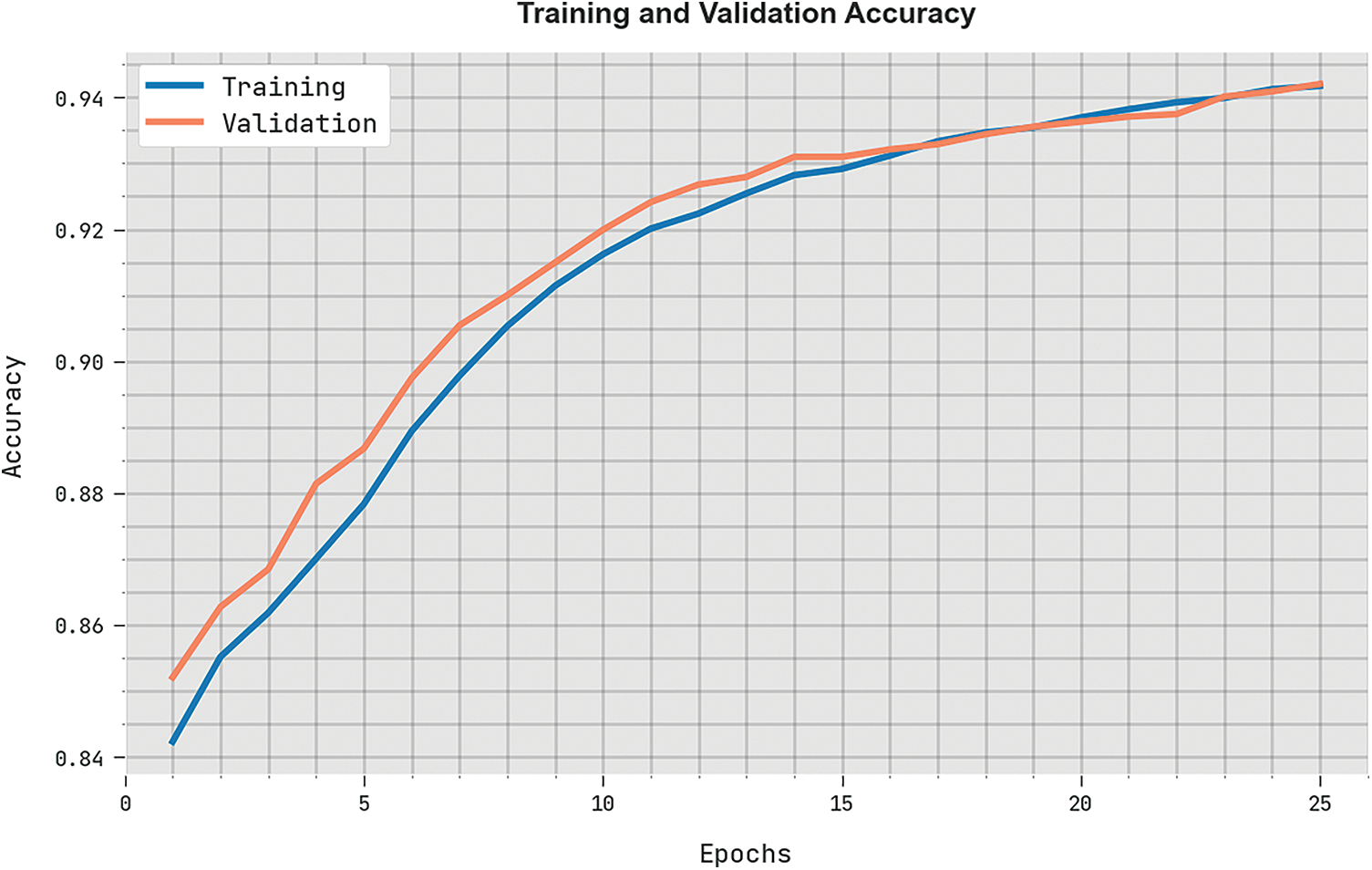
Figure 8: TRA and VLA analyses results of BROFDL-AASC approach
Both Training Loss (TRL) and Validation Loss (VLL) values, obtained by BROFDL-AASC methodology on test dataset, are depicted in Fig. 9. The experimental outcomes imply that the proposed BROFDL-AASC approach achieved the minimal TRL and VLL values whereas VLL values were lower than TRL.
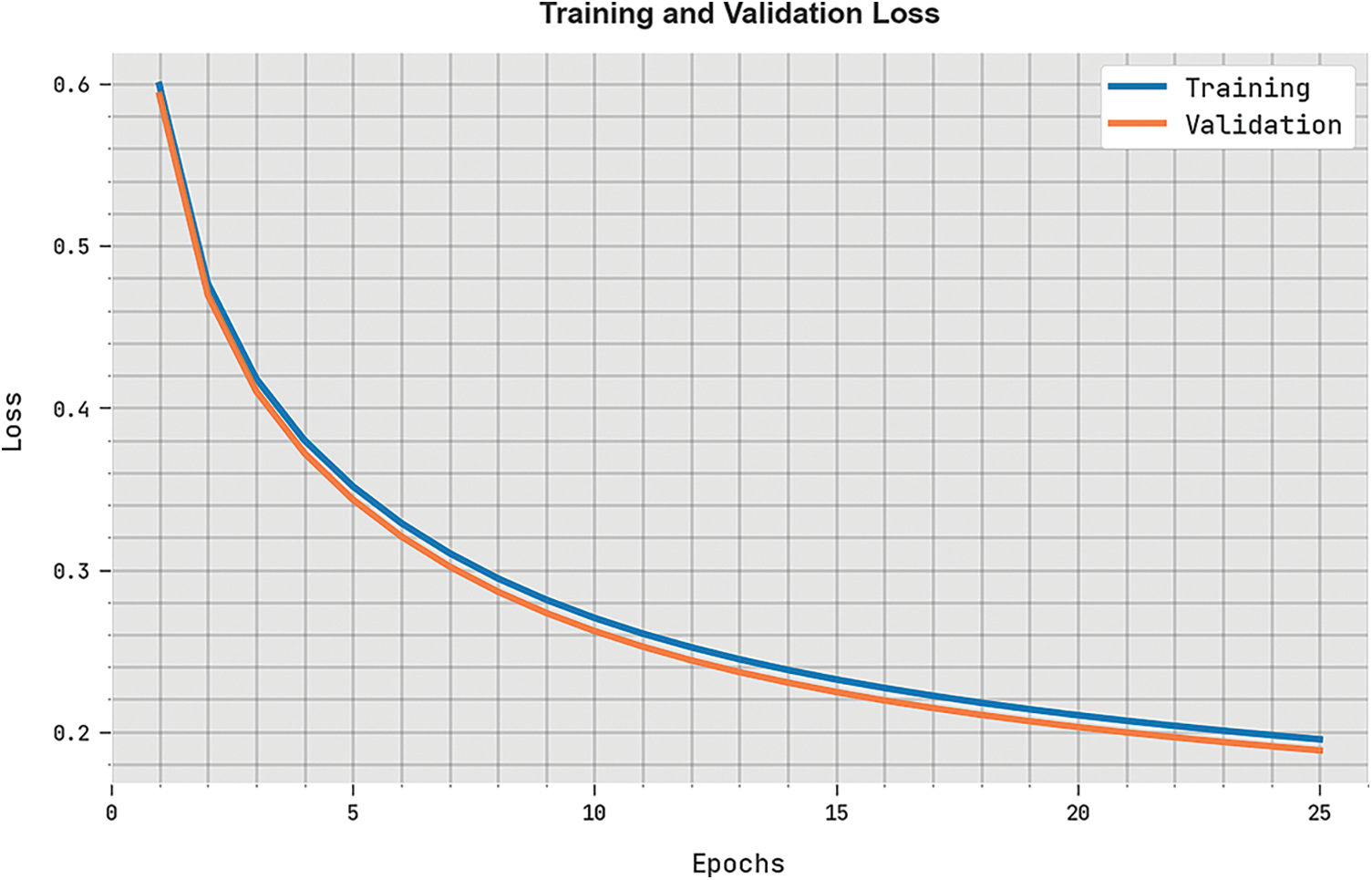
Figure 9: TRL and VLL analyses results of BROFDL-AASC approach
A clear precision-recall analysis was conducted upon BROFDL-AASC approach on test dataset and the results are displayed in Fig. 10. The figure represents that BROFDL-AASC algorithm achieved enhanced precision-recall values under all the classes.
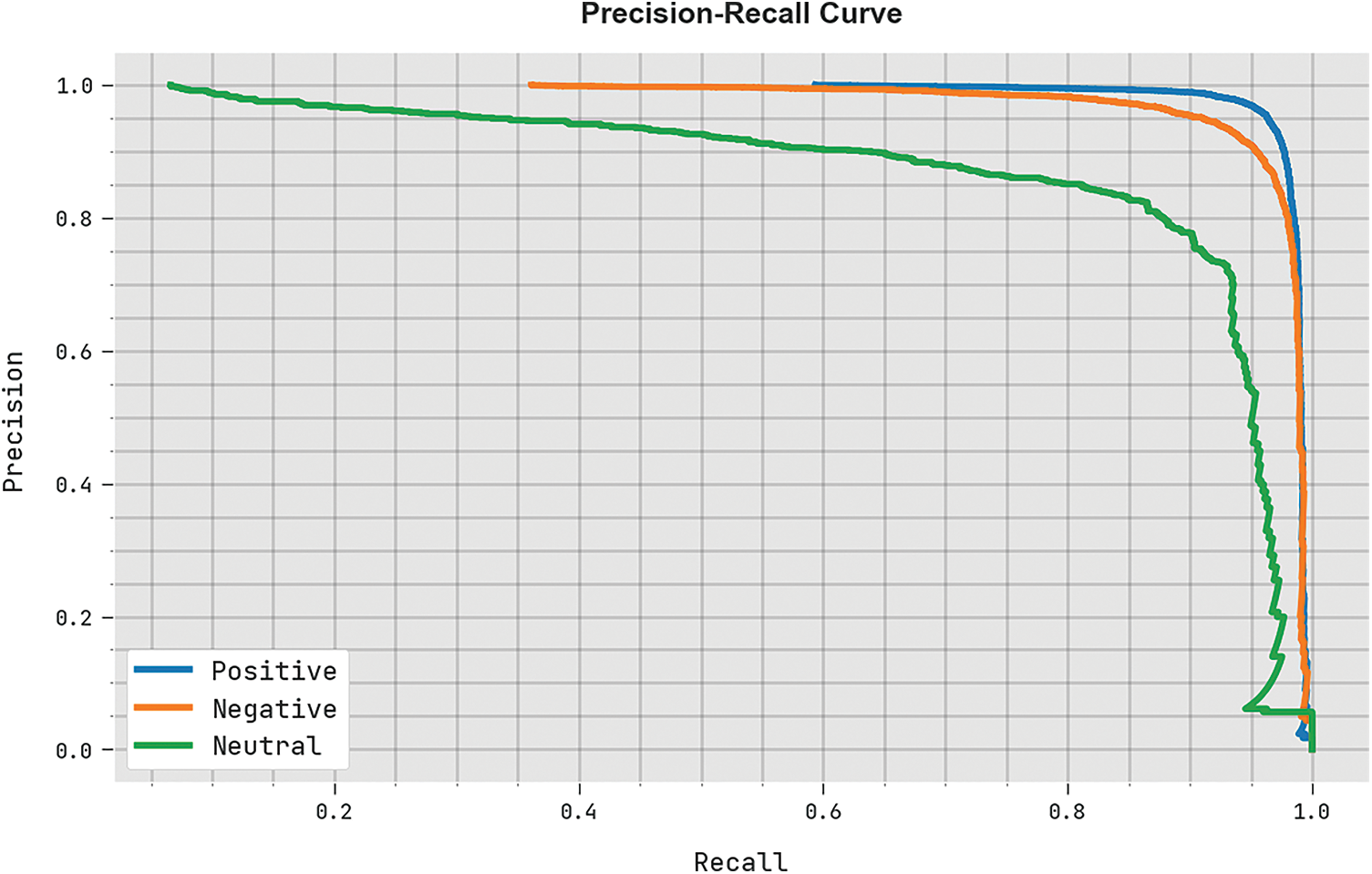
Figure 10: Precision-recall analysis results of BROFDL-AASC approach
A brief ROC analysis was conducted upon BROFDL-AASC algorithm on test dataset and the results are portrayed in Fig. 11. The results imply that the proposed BROFDL-AASC technique exhibited its ability in categorizing the test dataset under distinct classes.
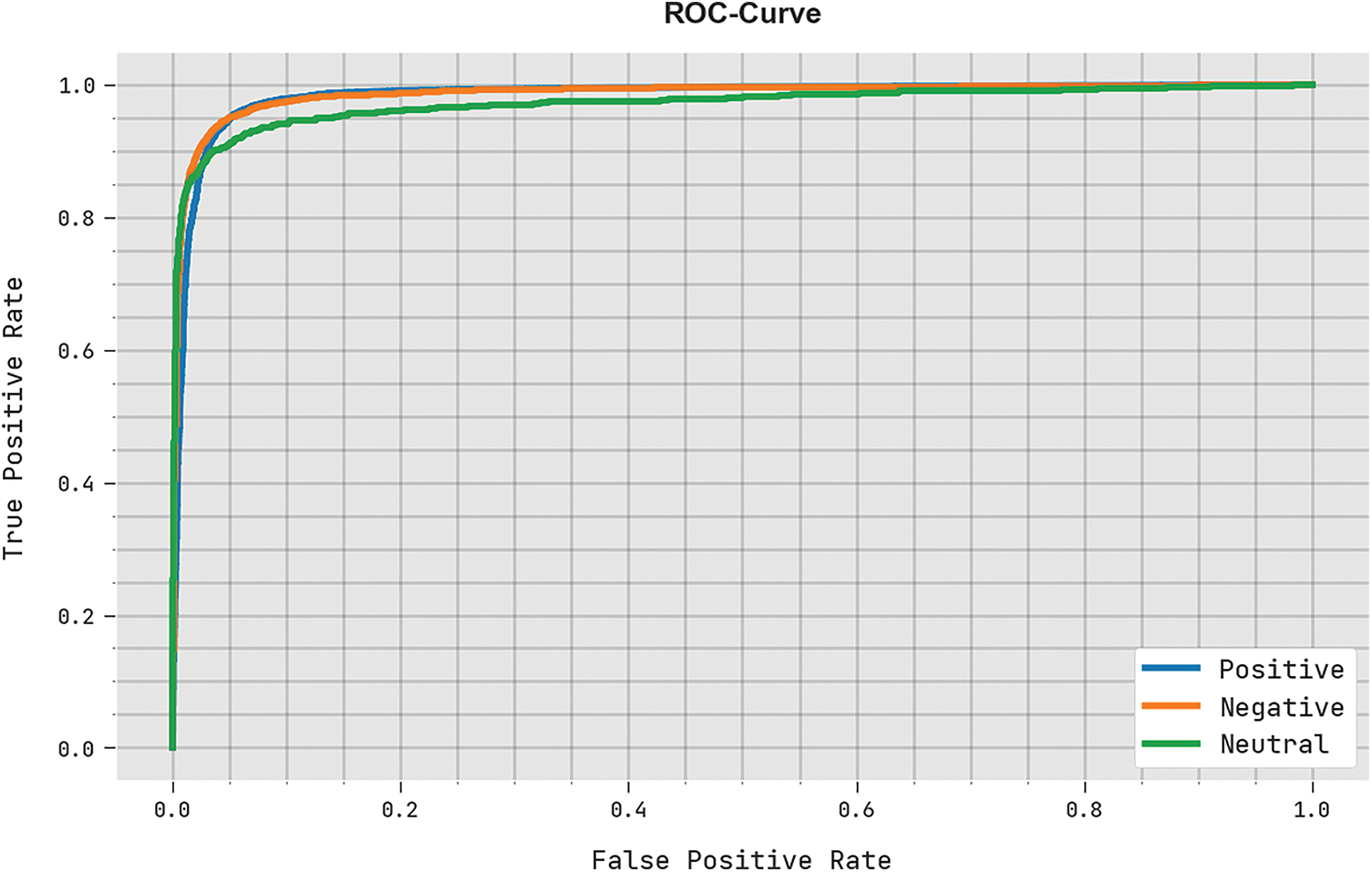
Figure 11: ROC analysis results of BROFDL-AASC approach
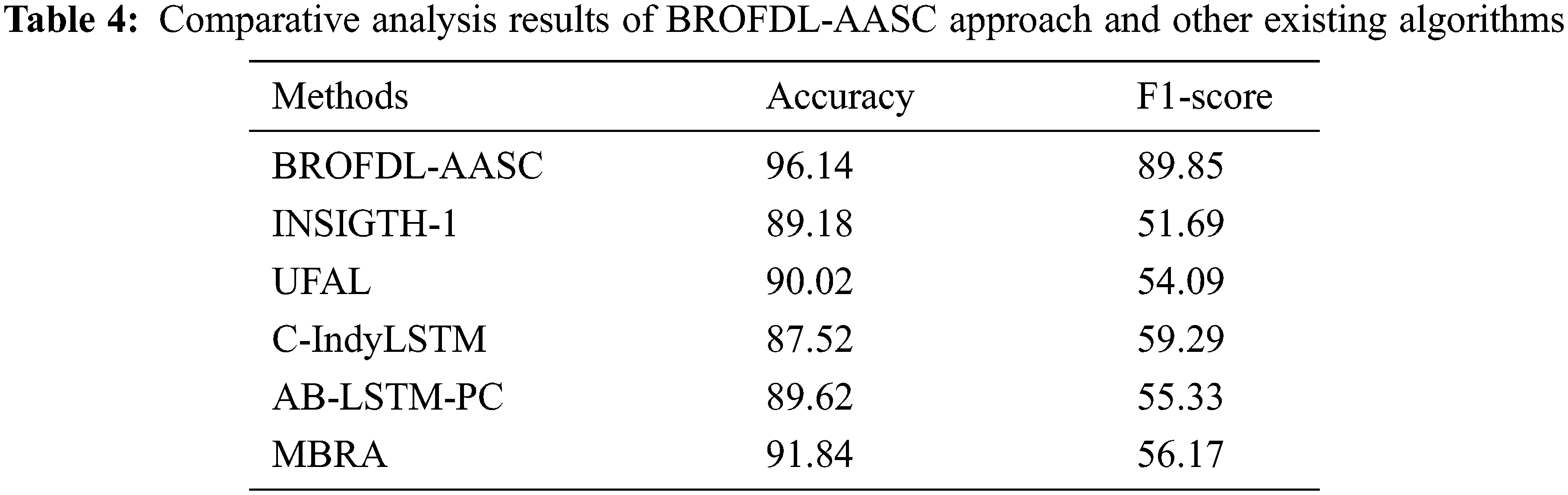
At last, a comparison study was conducted between BROFDL-AASC model and other recent models and the results are demonstrated in Table 4 and [7]. The experimental outcomes infer that the proposed BROFDL-AASC model outperformed other methods. With respect to
In this study, a new BROFDL-AASC technique has been developed for Arabic Aspect Based Sentiment Classification. The aim of the presented BROFDL-AASC model is to detect and classify the sentiments expressed in the Arabic language. In the presented BROFDL-AASC model, data pre-processing is performed at first to convert the input data into a useful format. Besides, the BROFDL-AASC model involves DFRBM model for identification and the categorization of sentiments. Furthermore, the BRO algorithm is exploited for optimal fine-tuning of the hyperparameters related to the FBRBM model. The performance of the proposed BROFDL-AASC model was experimentally validated and the results demonstrate the supremacy of BROFDL-AASC model over other existing models. In future, the performance of the proposed BROFDL-AASC model can be improved using hybrid metaheuristics.
Funding Statement: Princess Nourah bint Abdulrahman University Researchers Supporting Project Number (PNURSP2022R281), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia. The authors would like to thank the Deanship of Scientific Research at Umm Al-Qura University for supporting this work by Grant Code: 22UQU4340237DSR52.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. M. A. Smadi, B. Talafha, M. Al-Ayyoub and Y. Jararweh, “Using long short-term memory deep neural networks for aspect-based sentiment analysis of arabic reviews,” International Journal of Machine Learning and Cybernetics, vol. 10, no. 8, pp. 2163–2175, 2019. [Google Scholar]
2. S. Behdenna, F. Barigou and G. Belalem, “Towards semantic aspect-based sentiment analysis for arabic reviews,” International Journal of Information Systems in the Service Sector, vol. 12, no. 4, pp. 1–13, 2020. [Google Scholar]
3. M. A. Smadi, M. A. Ayyoub, Y. Jararweh and O. Qawasmeh, “Enhancing aspect-based sentiment analysis of arabic hotels’ reviews using morphological, syntactic and semantic features,” Information Processing & Management, vol. 56, no. 2, pp. 308–319, 2019. [Google Scholar]
4. F. N. Al-Wesabi, “A smart English text zero-watermarking approach based on third-level order and word mechanism of markov model,” Computers, Materials & Continua, vol. 65, no. 2, pp. 1137–1156, 2020. [Google Scholar]
5. A. Alharbi, M. Taileb and M. Kalkatawi, “Deep learning in arabic sentiment analysis: An overview,” Journal of Information Science, vol. 47, no. 1, pp. 129–140, 2019. [Google Scholar]
6. F. N. Al-Wesabi, “Proposing high-smart approach for content authentication and tampering detection of arabic text transmitted via internet,” IEICE Transactions on Information and Systems, vol. E103.D, no. 10, pp. 2104–2112, 2020. [Google Scholar]
7. T. Sana, B. Ines, J. Salma and Y. B. Ayed, “A hybrid method for arabic aspect-based sentiment analysis,” International Journal of Hybrid Intelligent Systems, vol. 16, no. 2, pp. 99–110, 2020. [Google Scholar]
8. F. N. Al-Wesabi, “A hybrid intelligent approach for content authentication and tampering detection of arabic text transmitted via internet,” Computers, Materials & Continua, vol. 66, no. 1, pp. 195–211, 2021. [Google Scholar]
9. D. K. Tayal, S. K. Yadav and D. Arora, “Personalized ranking of products using aspect-based sentiment analysis and plithogenic sets,” Multimedia Tools and Applications, pp. 1–27. https://doi.org/10.1007/s11042-022-13315-y. [Google Scholar]
10. F. N. Al-Wesabi, “Entropy-based watermarking approach for sensitive tamper detection of arabic text,” Computers, Materials & Continua, vol. 67, no. 3, pp. 3635–3648, 2021. [Google Scholar]
11. S. Al-Dabet, S. Tedmori and M. AL-Smadi, “Enhancing arabic aspect-based sentiment analysis using deep learning models,” Computer Speech & Language, vol. 69, pp. 101224, 2021. [Google Scholar]
12. M. Alassaf and A. M. Qamar, “Aspect-based sentiment analysis of arabic tweets in the education sector using a hybrid feature selection method,” in 14th Int. Conf. on Innovations in Information Technology (IIT), Al Ain, United Arab Emirates, pp. 178–185, 2020. [Google Scholar]
13. A. Alnawas and N. Arıcı, “The corpus based approach to sentiment analysis in modern standard arabic and arabic dialects: A literature review,” Journal of Polytechnic, 2018. https://doi.org/10.2339/politeknik.403975. [Google Scholar]
14. M. Al-Smadi, O. Qawasmeh, M. Al-Ayyoub, Y. Jararweh and B. Gupta, “Deep recurrent neural network vs. support vector machine for aspect-based sentiment analysis of arabic hotels’ reviews,” Journal of Computational Science, vol. 27, pp. 386–393, 2018. [Google Scholar]
15. R. Bensoltane and T. Zaki, “Towards arabic aspect-based sentiment analysis: A transfer learning-based approach,” Social Network Analysis and Mining, vol. 12, no. 1, pp. 1–16, 2021. [Google Scholar]
16. R. Kumar, H. S. Pannu and A. K. Malhi, “Aspect-based sentiment analysis using deep networks and stochastic optimization,” Neural Computing and Applications, vol. 32, no. 8, pp. 3221–3235, 2020. [Google Scholar]
17. N. F. Alshammari and A. A. AlMansour, “Aspect-based sentiment analysis for arabic content in social media,” in Int. Conf. on Electrical, Communication, and Computer Engineering (ICECCE), Istanbul, Turkey, pp. 1–6, 2020. [Google Scholar]
18. A. Ishaq, S. Asghar and S. A. Gillani, “Aspect-based sentiment analysis using a hybridized approach based on cnn and ga,” IEEE Access, vol. 8, pp. 135499–135, 2020. [Google Scholar]
19. Y. Ma, H. Peng, T. Khan, E. Cambria and A. Hussain, “Sentic lstm: A hybrid network for targeted aspect-based sentiment analysis,” Cognitive Computation, vol. 10, no. 4, pp. 639–650, 2018. [Google Scholar]
20. M. Al-Maleh and S. Desouki, “Arabic text summarization using deep learning approach,” Journal of Big Data, vol. 7, no. 1, pp. 109, 2020. [Google Scholar]
21. C. Chen and S. Feng, “Generative and discriminative fuzzy restricted boltzmann machine learning for text and image classification,” IEEE Transactions on Cybernetics, vol. 50, no. 5, pp. 2237–2248, 2020. [Google Scholar]
22. T. R. Farshi, “Battle royale optimization algorithm,” Neural Computing and Applications, vol. 33, no. 4, pp. 1139–1157, 2021. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools