
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Double Deep Q-Network Method for Energy Efficiency and Throughput in a UAV-Assisted Terrestrial Network
1 University Grenoble Alpes, CNRS, Grenoble INP, LIG, DRAKKAR Teams, 38000, Grenoble, France
2 Laboratoire d’informatique Médical, Université de Bejaia, Targa Ouzemour, Q22R+475, Algeria
3 Department of Information Technology, College of Computer and Information Sciences, Princess Nourah bint Abdulrahman University, P.O.Box 84428, Riyadh, 11671, Saudi Arabia
4 Department of Research and Development, Centre for Space Research, School of Electronics and Electrical Engineering, Lovely Professional University, Phagwara, 144411, India
5 Department of Communication and Electronics, Delta Higher Institute of Engineering and Technology, Mansoura, Egypt
6 Electrical Engineering Department, College of Engineering, Taif University, P. O. BOX 11099, Taif, 21944, Saudi Arabia
* Corresponding Author: Reem Alkanhel. Email:
Computer Systems Science and Engineering 2023, 46(1), 73-92. https://doi.org/10.32604/csse.2023.034461
Received 18 July 2022; Accepted 22 September 2022; Issue published 20 January 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Increasing the coverage and capacity of cellular networks by deploying additional base stations is one of the fundamental objectives of fifth-generation (5G) networks. However, it leads to performance degradation and huge spectral consumption due to the massive densification of connected devices and simultaneous access demand. To meet these access conditions and improve Quality of Service, resource allocation (RA) should be carefully optimized. Traditionally, RA problems are nonconvex optimizations, which are performed using heuristic methods, such as genetic algorithm, particle swarm optimization, and simulated annealing. However, the application of these approaches remains computationally expensive and unattractive for dense cellular networks. Therefore, artificial intelligence algorithms are used to improve traditional RA mechanisms. Deep learning is a promising tool for addressing resource management problems in wireless communication. In this study, we investigate a double deep Q-network-based RA framework that maximizes energy efficiency (EE) and total network throughput in unmanned aerial vehicle (UAV)-assisted terrestrial networks. Specifically, the system is studied under the constraints of interference. However, the optimization problem is formulated as a mixed integer nonlinear program. Within this framework, we evaluated the effect of height and the number of UAVs on EE and throughput. Then, in accordance with the experimental results, we compare the proposed algorithm with several artificial intelligence methods. Simulation results indicate that the proposed approach can increase EE with a considerable throughput.Keywords
In recent years, unmanned aerial vehicle (UAV)-assisted fifth-generation (5G) communication has provided an attractive way to connect users with different devices and improve network capacity. However, data traffic on cellular networks increases exponentially, Thus, resource allocation (RA) is becoming increasingly critical [1]. Industrial spectrum bands experience increased demand for channels, leading to a spectrum scarcity situation. In the context of 5G, mmWave is considered a potential solution to meet this demand [2,3]. Moreover, other techniques, such as beamforming, multi-input multi-output (MIMO), and advanced power control, are introduced as promising solutions in the design of future networks [4]. Despite all these attempts to satisfy this demand, RA remains a priority to accommodate users in terms of Quality of Service (QoS). RA problems are often formulated as nonconvex problems requiring proper management [5,6]. Optimal solutions are obtained by implementing heuristic methods, such as genetic algorithm, particle swarm optimization, and simulated annealing [7,8]. However, such solutions end up with quasioptimal solutions and converge relatively slowly. Therefore, alternative solutions and flexible algorithms that exploit late development in artificial intelligence are desirable to explore. Recently, deep learning (DL) [9] has emerged as an effective tool to increase flexibility and optimize RA in complex wireless communication networks. First, DL-based RA is flexible because the same deep neural network (DNN) can be implemented to achieve different design objectives by modifying the loss function [10]. Second, the computation time required by DL to obtain RA results is lower than that of conventional algorithms [11]. Finally, DL can receive complex high-dimensional information as input and allocate the optimal action for each input statistic in a particular condition [10]. On the basis of the above analysis, DL can be chosen as an accurate method for RA.
As an emerging technology, DL has been used in several research studies to improve RA for terrestrial networks. For instance, the authors in [12] investigated the deep reinforcement learning (DRL)-based time division duplex configuration to allocate radio resources dynamically in an online manner and with high mobility. In [1], Lee et al. proposed deep power control based on a convolutional neural network to maximize spectral efficiency (SE) and energy efficiency (EE). In this study, a comparison between the DL model and a conventional weighted minimum mean square error was realized. In the same context, [13] performed a max-min and max-prod power allocation in downlink massive MIMO. To maximize EE, a deep artificial neural network scheme was applied in [14], where interference and system propagation channels were considered. Deep Q-learning (DQL)-based RA has also attracted much attention in recent literature. In [15], the authors studied the RA problem to enhance EE. The proposed method formulated a combined optimization problem, considering EE and QoS. More recently, a supervised DL approach in 5G multitier networks was adopted in [16] to solve the joint RA and remote–radio–head association. For this model, efficient subchannel and power allocation were used to generate training data. According to the decentralized RA mechanism, the authors in [17] developed a novel decentralized DL for vehicle-to-vehicle communications. The main objective was to determine the optimal sub-band and power level for transmission without requiring or waiting for global information. The authors used a DRL-based power control to investigate the problem of spectrum sharing in a cognitive radio system. The aim of this framework is that the secondary user shares the common spectrum with the primary user. Instead of unsupervised learning, the authors in [18] introduced supervised learning to maximize the throughput of device-to-device with maximum power constraint. The authors in [19] presented a comprehensive approach and considered DRL to maximize the total network throughput. However, this work did not include EE for optimization. Majority of the learning algorithms introduced above do not incorporate constraints directly into the training cost functions. Nowadays, literatures focus on RA in UAV-assisted cellular networks based on artificial intelligence. In reference [20], authors proposed a multiagent reinforcement learning framework to study the dynamic RA of multiple UAVs. The objective of this investigation was to maximize long-term rewards. However, the work did not consider UAV height. In [21], the authors used deep Q-network to solve the RA for UAV-assisted ultradense networks. To maximize system EE, a link selection strategy was proposed to allow users to select the optimal communication links. The authors did not consider the influence of SE on EE. In addition, the authors in [22] studied the RA problem of UAV-assisted wireless-powered Internet of Things systems, aiming to allocate optimal energy resources for wireless power transfer. In [23], the authors thoroughly investigated deep Q-network (DQN), invoking the difference of convex-based optimization method for multicooperative UAV-assisted wireless networks. This work assumed beamforming technique to serve users simultaneously in the same spectrum and maximize the sum user achievable rate. However, the work was not focused on EE. Another DQN work in [24] was presented to study the low utilization rate of resources. A novel DQN-based method was introduced to address the complex problem. The authors in [25] analyzed RA for bandwidth, throughput, and power consumption in different scenarios for multi-UAV-assisted IoT networks. On the basis of machine learning, authors considered DRL to address the joint RA problem. Although the proposed approach remained efficient, it did not consider ground network, EE and total throughput. In the present study, we aim to optimize EE and total throughput in UAV-assisted terrestrial networks subject to the constraints on transmission power and UAV height. Our main efforts are to apply a double deep Q-network (DDQN) that obtains optimal rewards better than DQN [26].
Existing research on RA in UAV-assisted 5G networks focuses on single objective optimization and considers the DQN algorithm to generate data. Following the previous analysis, we investigate the RA problem in UAV-assisted cellular networks that maximize EE and total network throughput. Especially, DDQN is proposed to address intelligent RA. The main contributions of this study are listed below.
(1) We formulate EE and total throughput in mmWave scenario while ensuring the minimum QoS requirements for all users according to the environment. However, the optimization problem is formulated as a mixed integer nonlinear program. Multiple constraints, such as the path loss model, number of users, channel gains, beamforming, and signal-to-interference-plus-noise ratio (SINR) issues, are used to describe the environment.
(2) We investigate a multiagent DDQN algorithm to optimize EE and total throughput. We assume that each user equipment (UE) behaves as an agent and performs optimization decisions on environmental information.
(3) We compare the performance of the proposed algorithm, QL, and the DQN approaches already proposed in terms of RA.
The remainder of this paper is organized as follows: An overview for DRL is presented in Section 2, and the system model is introduced in Section 3. Then, the DDQN algorithm is discussed in Section 4, followed by simulation and results in Section 5. Lastly, conclusions and perspectives are drawn in Section 6.
DRL is a prominent case of machine learning and thus a class of artificial intelligence. It allows agents to identify the ideal performance based on its own experience, rather than depending on a supervisor [27]. In this approach, a neural network is used as an agent that learns by interacting with the environment and solves the process by determining an optimal action. Compared with the standard ML, namely supervised and unsupervised learning [28], DRL does not depend on data acquisition. Thus, sequential decision making occurs, and the next input is based on the decision of the learner or system. Moreover, in DRL, the Markov decision process (MDP) is formalized as a mathematical approach to modeling and decision-making situations. The reinforcement learning process operates as follows [29]: the agent begins in a specific state within its environment
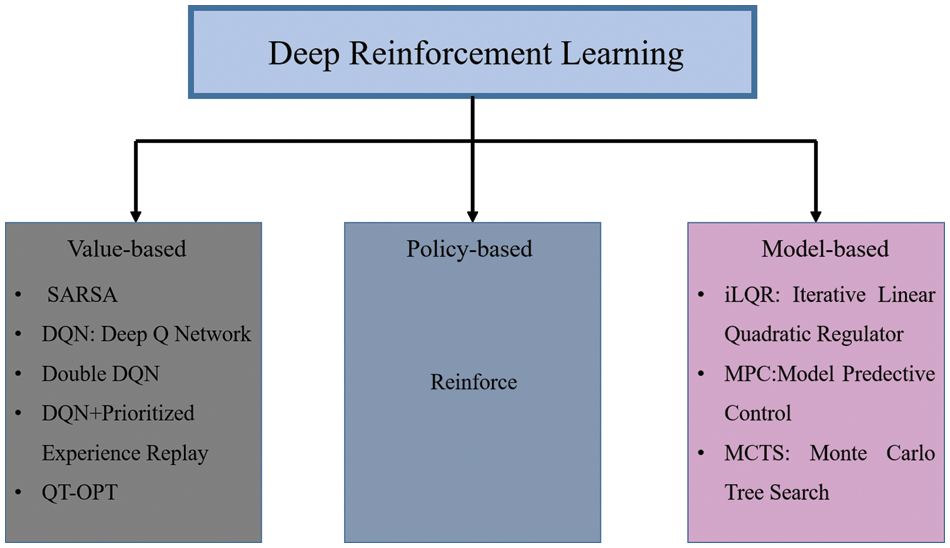
Figure 1: DRL algorithms
As a popular branch of machine learning, Q-learning is based on the main concept of the action value function
where
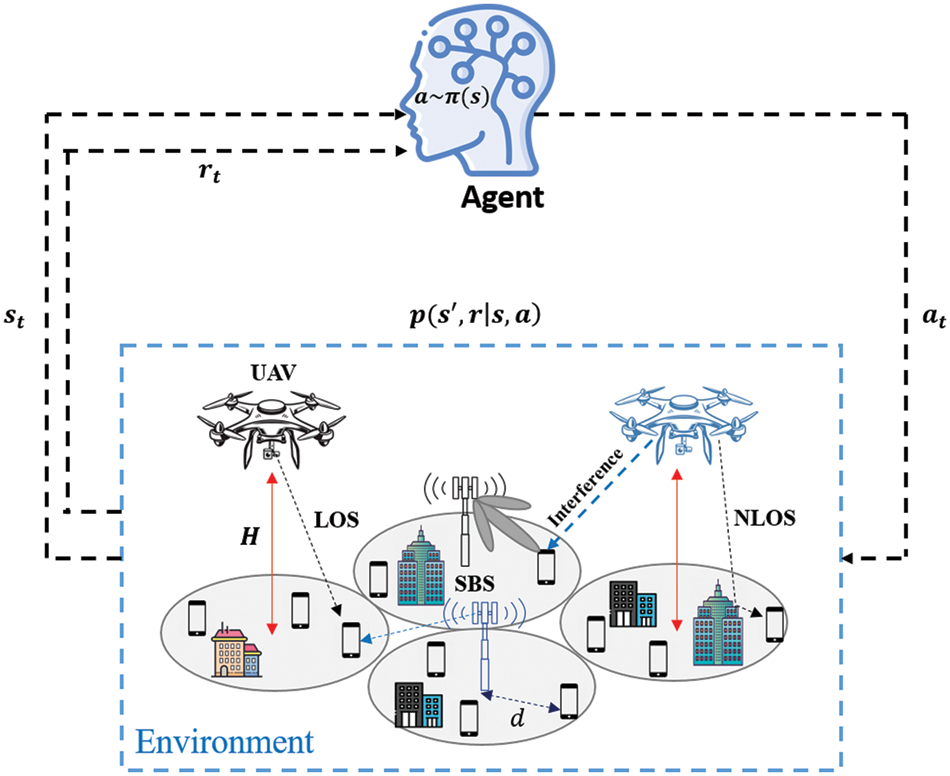
Figure 2: Q-learning algorithm for UAV-assisted SBS
As stated above, the Q-learning algorithm faces difficulties in obtaining the optimal policy when the action and state spaces become exceptionally large [33]. This constraint is often observed in the RA approaches of cellular networks. To solve this problem, the DQN algorithm, which connects the traditional Q-learning algorithm to a convolutional neural network, was proposed [34]. The main difference with the Q-learning algorithm is the replacement of the table with the function approximator called DNN; this process attempts to approximate the Q values. Approximators have two types: a linear function and a nonlinear function [35]. However, in a nonlinear DNN, the new Q function is defined as
To train the DQN, iterative updating of the weight
3 System Model and Problem Formulation
In the proposed model, we consider the downlink communication of a UAV-assisted cellular network comprising a set of small base stations (SBSs) denoted as
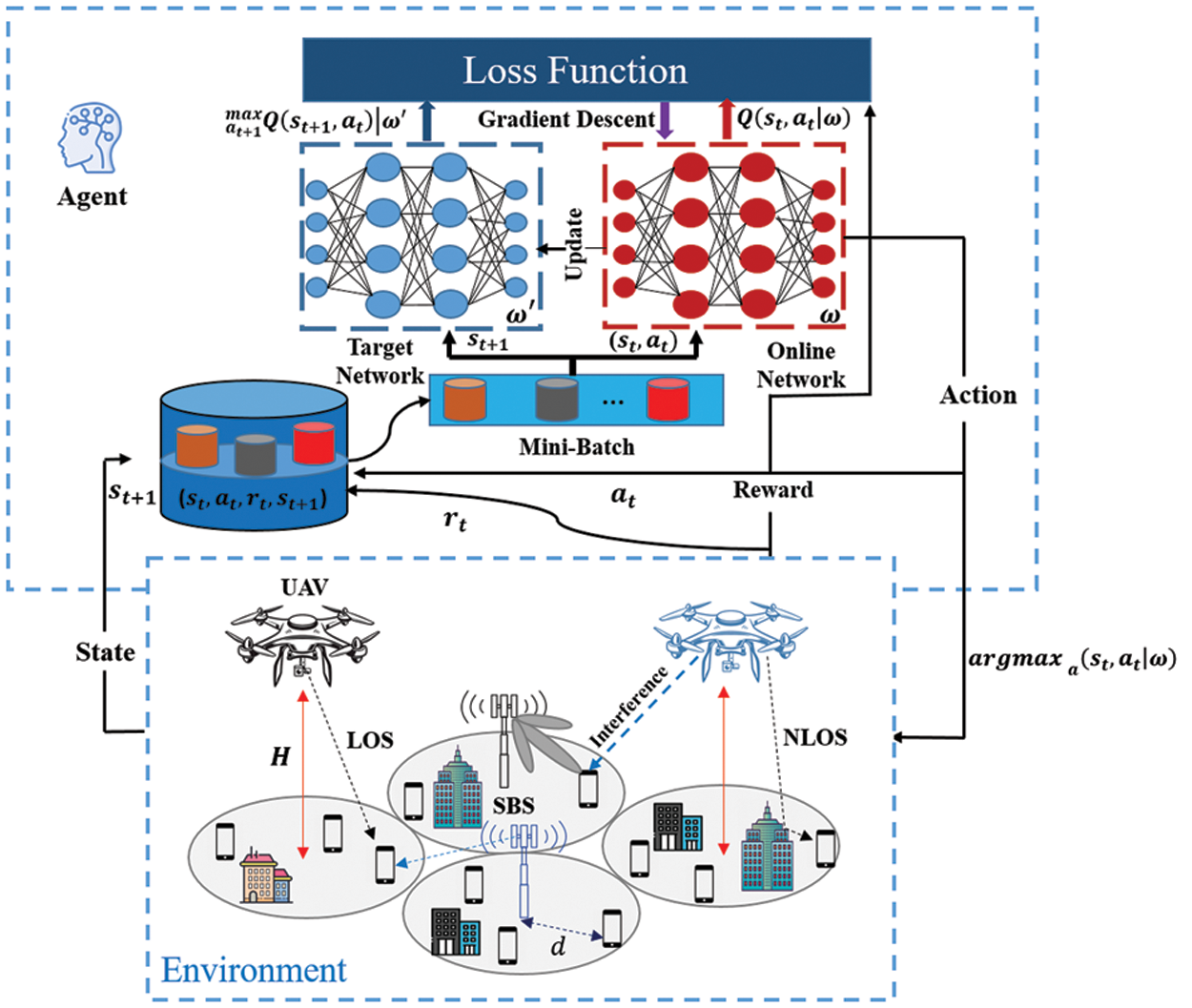
Figure 3: DQN architecture for UAV-assisted SBS
3.1 Fading and Achievable Data Rate
The channel between the base station and UE can be fixed or time varying. Fading is defined as the fluctuation in received signal strength with respect to time, and it occurs due to several factors, including transmitter and receiver movement, propagation environment, and atmospheric condition. Similar to [38], we model the channel in a way that it can capture small-scale and large-scale fading. At each time slot
where
where b and c are constants that depend on the network environment, and
where
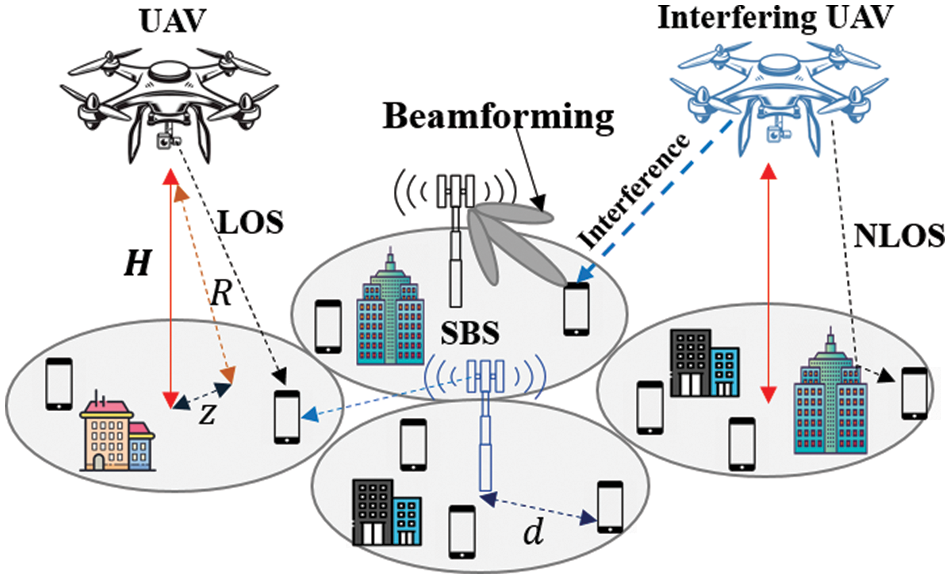
Figure 4: UAV-assisted terrestrial network (SBS)
Adding additional gain to the system remains necessary due to the propagation losses that occur at mm-wave frequencies. One of the main solutions proposed by several research for future wireless networks is beamforming [41]. The fundamental principle of beamforming is to control the direction of a wavefront toward the UE. According to [42], UAV and SBS serve UE through beamforming technology. In this manner, the SINR of UE from UAV at time slot t can be written as
where
Without loss of generality, different properties are displayed in terms of propagation. For air-to-ground communication, the path loss of LoS and NLoS links at time slot t can be experienced depending on additional path losses in LoS and NLoS links
Similarly, we define the SINR when UE is associated with SBS. In this case, we adopt the standard power-law path loss model with the mean
The SINR additional loss at the typical UE when it is connected to SBS is given by (13), where
3.3 Spectral Efficiency and Energy Efficiency
SE and EE are the key metrics to evaluate any wireless communication system. SE is defined as the efficiency capability of a given channel bandwidth. In other words, it represents the transmission rate per unit of bandwidth and is measured in bits per second per hertz. The EE metric is used to evaluate the total energy consumption for a network. It is defined as a ratio of the total transferred bits to the total power consumption. Nevertheless, EE and SE have a fundamental relationship. Let
where
For UAV
For SBS
The proper performance of EE approaches is of paramount importance in UAV-assisted terrestrial networks because it is directly related to the choice of objectives and constraints for relevant optimization problems. In this work, we aim to optimize two specific objectives for RA, namely, the maximization of EE and throughput. From the SE perspective, the EE maximization problem can be formulated as
s.t.
Constraint
s.t.
The constraint in
4 Double Deep Q-Network Algorithm
In this section, we present a DRL algorithm-based EE and throughput RA framework to address the network problems of (17) and (18). The task of the DRL agent is to learn an optimal policy from state to action, thus maximizing the utility function. We formulate the optimization problem as a fully observable Markov decision process. Similar to literature, we consider a tuple (

Figure 5: DDQN architecture
At each time t, the weighted parameters
The state describes a specific configuration of the environment. At time slot
where
In our problem, each agent must choose an appropriate base station (i.e., UAV or SBS), power transmission, UAV height, and LoS/NLoS link probability. At time step
where
Reinforcement learning is based on the reward function, stating that the agent (UAV and SBS) is guided toward an optimal policy. As mentioned above, we model this problem as a fully observable MDP to maximize EE and throughput. Therefore, the reward of j can be computed as
where

This section discusses the simulation and results for EE and throughput in the downlink UAV-assisted terrestrial network comprising eight SBSs with a radius of 500 m and five UAVs deployed randomly in the area. The cell contains
5.1 Energy Efficiency Analysis
In this subsection, we show some results of EE, which are obtained using DDNQ. For improved performance validation, we compare our proposed algorithm with the DQN and QL architectures. Moreover, the effect of UE demand, number of UAVs, and beamforming on maximum power
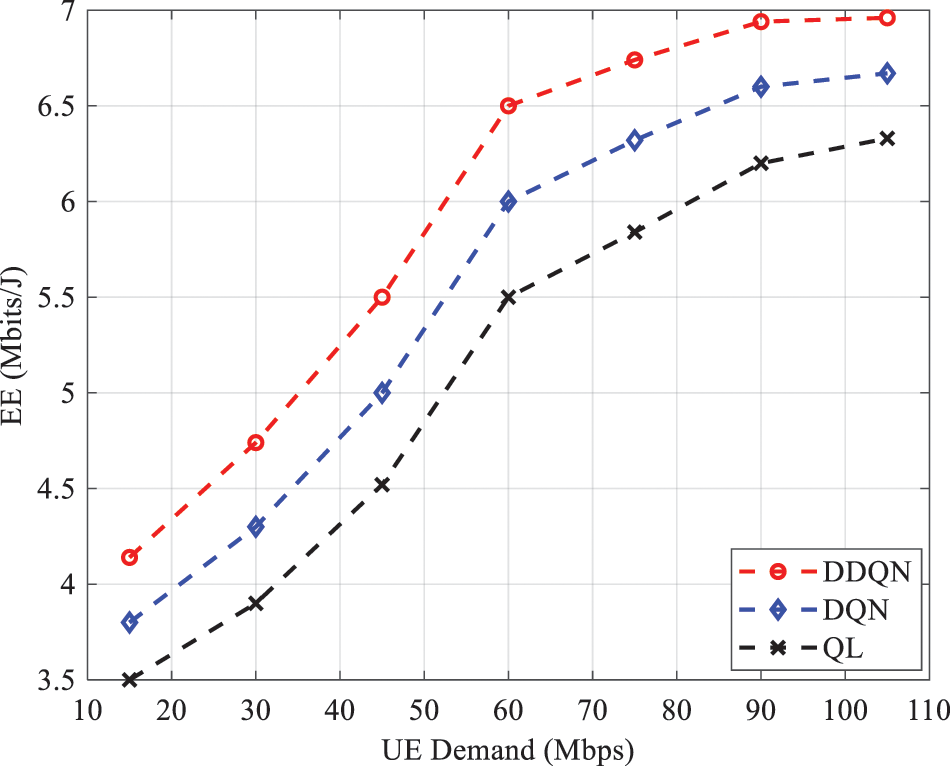
Figure 6: EE as a function of UE demand for different algorithms
This result is obtained because when UE demand increases considerably (
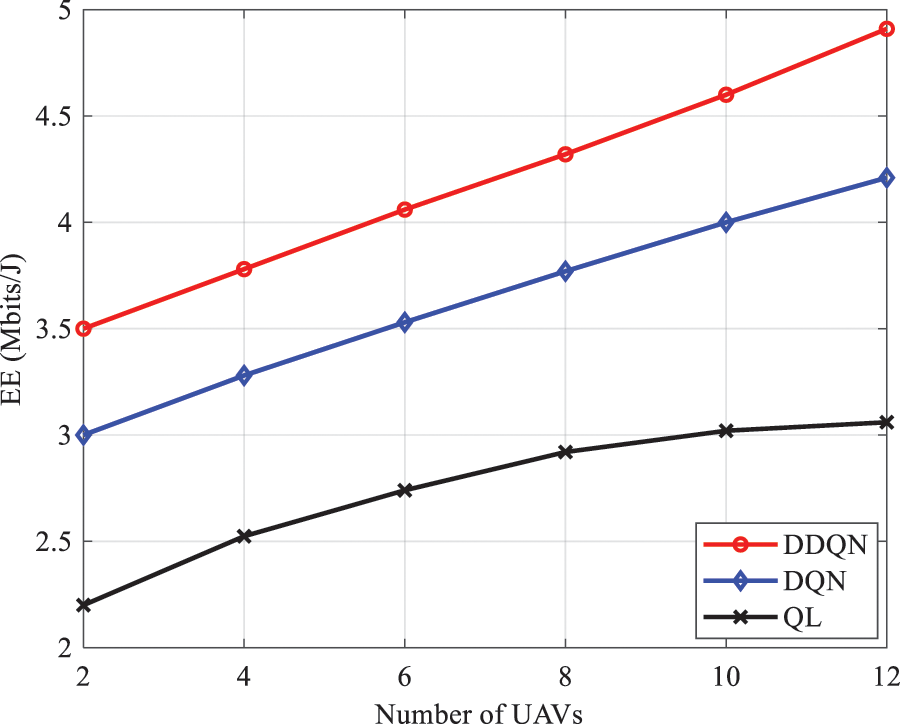
Figure 7: EE as a function of number of UAVs for different algorithms
Moreover, Fig. 7 demonstrates that the DDQN algorithm outperforms DQN and QL by 13.3% on EE because traditional RL algorithms use a one-actor network to train multiple agents; thus, conflicts between agents are recorded. Next, EE is plotted as a function of the number of UE for different UAV height (
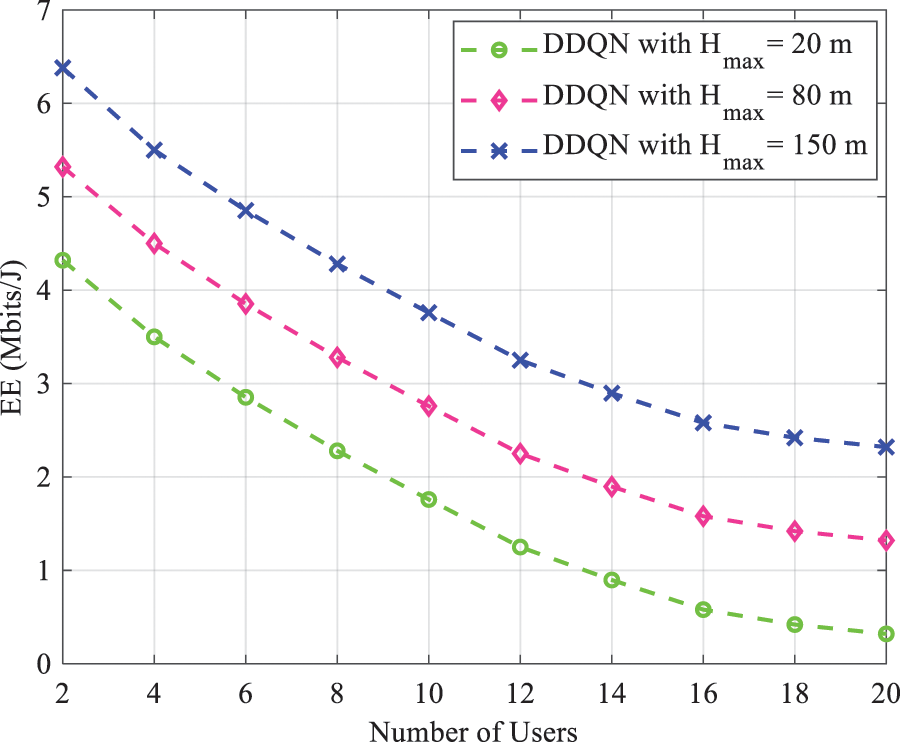
Figure 8: EE as a function of number of users for different
As the number of UE increases, the power assigned to UE declines. Therefore, the increase in height compensates this shortcoming. Fig. 9 shows EE vs. the maximum power of UAV
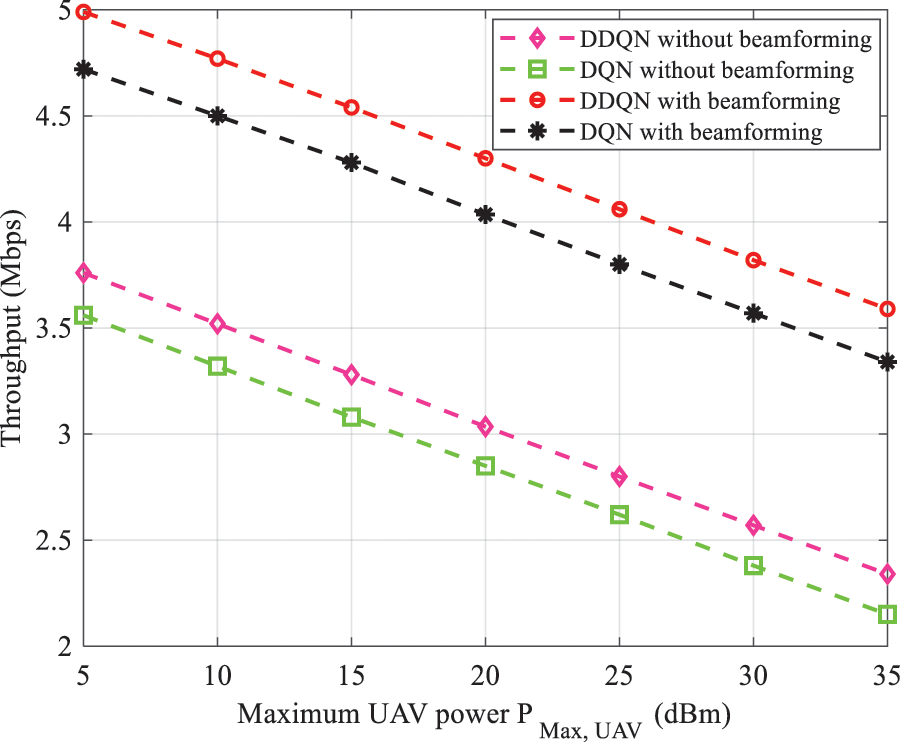
Figure 9: EE vs. maximum UAV power transmission with and without beamforming
To validate the accuracy of our approach, we analyze the total throughput (second objective) according to the number of UAVs deployed, UAV height
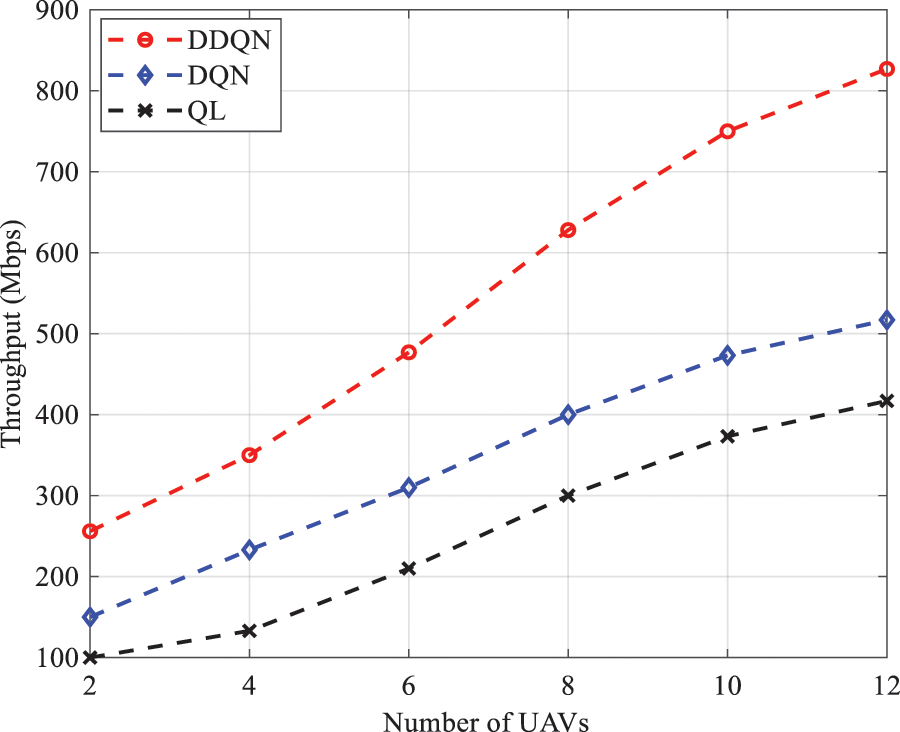
Figure 10: Throughput as a function of number of UAVs with different algorithms
Fig. 11 illustrates the variation of throughput vs. UAV height in different AI algorithms. According to Fig. 11, throughput increases with maximization of altitude
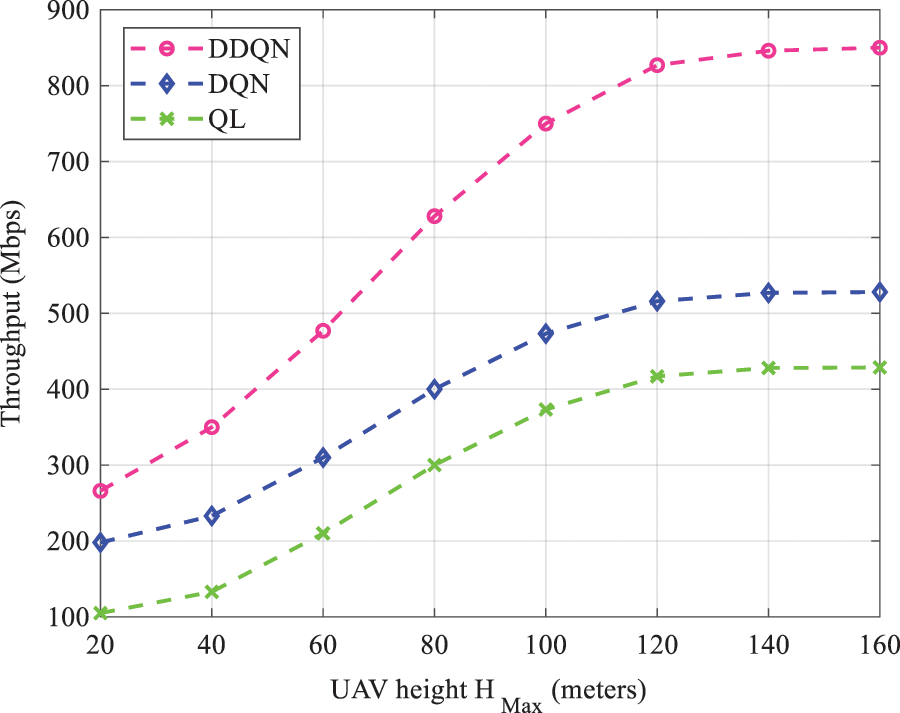
Figure 11: Throughput analysis as a function of UAV height
Fig. 12 shows the variation of the throughput vs. maximum UAV power. As expected, the total throughput increases as
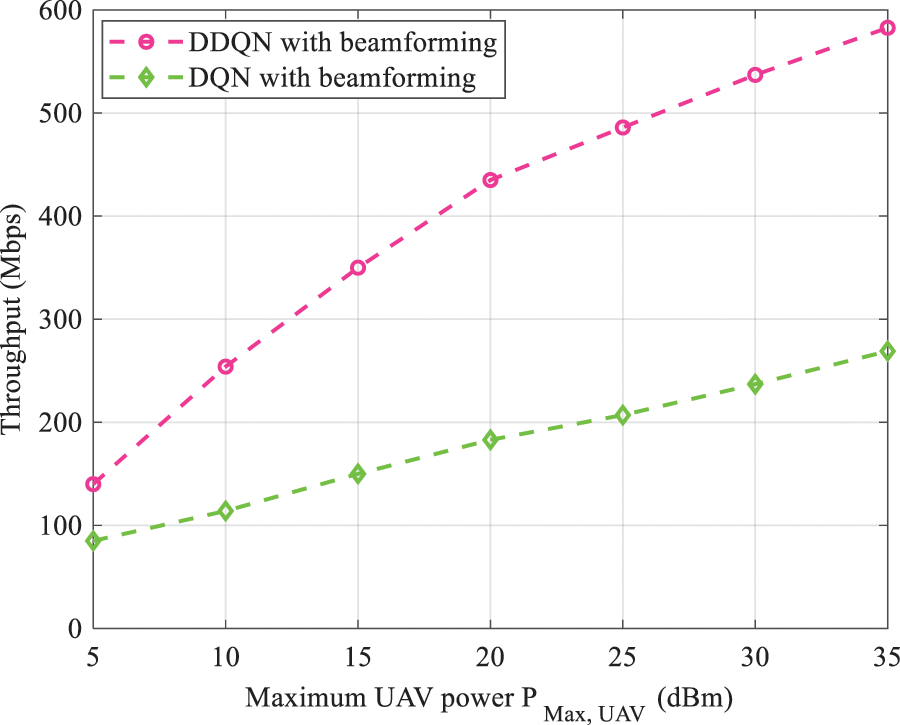
Figure 12: Throughput as a function of UAV power with beamforming
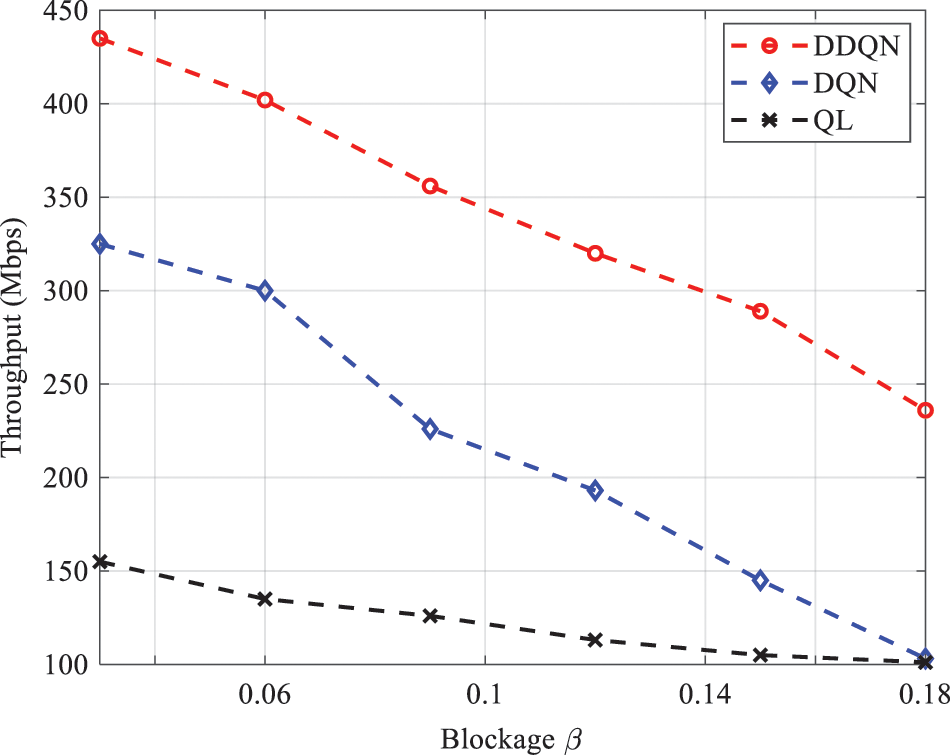
Figure 13: Throughput vs. blockage parameter
In this study, we proposed a DDQN scheme for RA optimization in UAV-assisted terrestrial networks. The problem is formulated as EE and throughput maximization. Initially, we provided a general overview of deep reinforcement architectures. Then, we presented the network architecture where the base stations use the beamforming technique during transmission. The proposed EE and throughput were assessed under the number of UAVs, beamforming, maximum UAV power transmission, and blockage parameter. The algorithm accuracy of the obtained EE and throughput was demonstrated by a comparison with deep Q-network and Q-learning. Our results indicate that EE can be affected by the number of UAVs to be deployed in the coverage area, as well as the maximum altitude variation (constraint). Moreover, the use of beamforming can be cost effective in improving EE. Our investigation also revealed other useful conclusions. For throughput analysis, the blockage parameter has a dominant influence on the throughput, and an optimal value can be selected. In terms of convergences, our DDQN consistently outperforms DQN and QL. In future work, other issues can be explored and investigated. For instance, UAV mobility can be considered, and an optimal mobility model can be selected to maximize throughput. Interference coordination may also be introduced between tiers.
Acknowledgement: The authors would like to acknowledge the financial support received from Princess Nourah bint Abdulrahman University Researchers Supporting Project Number (PNURSP2022R323), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia and Taif University Researchers Supporting Project Number TURSP-2020/34), Taif, Saudi Arabia.
Funding Statement: This work was supported by Princess Nourah bint Abdulrahman University Researchers Supporting Project Number (PNURSP2022R323), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia, and Taif University Researchers Supporting Project Number TURSP-2020/34), Taif, Saudi Arabia.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. Z. Sylia, G. Cédric, O. M. Amine and K. Abdelkrim, “Resource allocation in a multi-carrier cell using scheduler algorithms,” in 4th Int. Conf. on Optimization and Applications (ICOA), Mohammedia, Morocco, pp. 1–5, 2018. [Google Scholar]
2. T. O. Olwal, K. Djouani and A. M. Kurien, “A survey of resource management toward 5G radio access networks,” IEEE Communications Surveys & Tutorials, vol. 18, no. 3, pp. 1656–1686, 2016. [Google Scholar]
3. T. S. Rappaport, “Millimeter wave mobile communications for 5G cellular: It will work!,” IEEE Access, vol. 1, pp. 335–349, 2013. [Google Scholar]
4. M. A. Ouamri, M. E. Oteşteanu, A. Isar and M. Azni, “Coverage, handoff and cost optimization for 5G heterogeneous network,” Physical Communication, vol. 39, pp. 1–8, 2020. [Google Scholar]
5. C. Sun, C. She, C. Yang, T. Q. S. Quek, Y. Li et al., “Optimizing resource allocation in the short blocklength regime for ultra-reliable and low-latency communications,” IEEE Transactions on Wireless Communications, vol. 18, no. 1, pp. 402–415, Jan. 2019. [Google Scholar]
6. Y. Hu, M. Ozmen, M. C. Gursoy and A. Schmeink, “Optimal power allocation for QoS-constrained downlink multi-user networks in the finite blocklength regime,” IEEE Transactions on Wireless Communications, vol. 17, no. 9, pp. 5827–5840, Sept. 2018. [Google Scholar]
7. L. Zhu, J. Zhang, Z. Xiao, X. Cao, D. O. Wu et al., “Joint Tx-Rx beamforming and power allocation for 5G millimeter-wave non-orthogonal multiple access networks,” IEEE Transactions on Communications, vol. 67, no. 7, pp. 5114–5125, July 2019. [Google Scholar]
8. S. O. Oladejo and O. E. Falowo, “Latency-aware dynamic resource allocation scheme for multi-tier 5G network: A network slicing-multitenancy scenario,” IEEE Access, vol. 8, pp. 74834–74852, 2020. [Google Scholar]
9. L. Lei, Y. Yuan, T. X. Vu, S. Chatzinotas and B. Ottersten, “Learning-based resource allocation: Efficient content delivery enabled by convolutional neural network,” in IEEE 20th Int. Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Cannes, France, pp. 1–5, 2019. [Google Scholar]
10. K. I. Ahmed, H. Tabassum and E. Hossain, “Deep learning for radio resource allocation in multi-cell networks,” IEEE Network, vol. 33, no. 6, pp. 188–195, Dec. 2019. [Google Scholar]
11. L. Liang, H. Ye, G. Yu and G. Y. Li, “Deep-learning-based wireless resource allocation with application to vehicular networks,” Proceedings of the IEEE, vol. 108, no. 2, pp. 341–356, Feb. 2020. [Google Scholar]
12. F. Tang, Y. Zhou and N. Kato, “Deep reinforcement learning for dynamic uplink/downlink resource allocation in high mobility 5G HetNet,” IEEE Journal on Selected Areas in Communications, vol. 38, no. 12, pp. 2773–2782, 2020. [Google Scholar]
13. L. Sanguinetti, A. Zappone and M. Debbah, “Deep learning power allocation in massive MIMO,” in 2018 52nd Asilomar Conf. on Signals, Systems, and Computers, USA, pp. 1257–1261, 2018. [Google Scholar]
14. A. Zappone, M. Debbah and Z. Altman, “Online energy-efficient power control in wireless networks by deep neural networks,” in IEEE 19th Int. Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Greece, pp. 1–5, 2018. [Google Scholar]
15. H. Li, H. Gao, T. Lv and Y. Lu, “Deep Q-learning based dynamic resource allocation for self-powered ultra-dense networks, in IEEE Int. Conf. on Communications Workshops (ICC Workshops), USA, pp. 1–6, 2018. [Google Scholar]
16. S. Ali, A. Haider, M. Rahman, M. Sohail and Y. B. Zikria, “Deep learning (DL) based joint resource allocation and RRH association in 5G-multi-tier networks,” IEEE Access, vol. 9, pp. 118357–118366, 2021. [Google Scholar]
17. H. Ye, G. Y. Li and B. F. Juang, “Deep reinforcement learning based resource allocation for V2V communications,” IEEE Transactions on Vehicular Technology, vol. 68, no. 4, pp. 3163–3173, April 2019. [Google Scholar]
18. D. Ron and J. -R. Lee, “DRL-based sum-rate maximization in D2D communication underlaid uplink cellular networks,” IEEE Transactions on Vehicular Technology, vol. 70, no. 10, pp. 11121–11126, Oct. 2021. [Google Scholar]
19. R. Amiri, M. A. Almasi, J. G. Andrews and H. Mehrpouyan, “Reinforcement learning for self organization and power control of two-tier heterogeneous networks,” IEEE Transactions on Wireless Communications, vol. 18, no. 8, pp. 3933–3947, Aug. 2019. [Google Scholar]
20. J. Cui, Y. Liu and A. Nallanathan, “Multi-agent reinforcement learning-based resource allocation for UAV networks,” IEEE Transactions on Wireless Communications, vol. 19, no. 2, pp. 729–743, Feb. 2020. [Google Scholar]
21. X. Chen, X. Liu, Y. Chen, L. Jiao and G. Min, “Deep Q-Network based resource allocation for UAV-assisted Ultra-Dense Networks,” Computer Networks, vol. 196, pp. 1–10, 2021. [Google Scholar]
22. B. Liu, H. Xu and X. Zhou, “Resource allocation in unmanned aerial vehicle (UAV)-assisted wireless-powered internet of things,” Sensors, vol. 19, no. 8, pp. 1908–1928, 2019. [Google Scholar]
23. P. Luong, F. Gagnon, L. -N. Tran and F. Labeau, “Deep reinforcement learning-based resource allocation in cooperative UAV-assisted wireless networks,” IEEE Transactions on Wireless Communications, vol. 20, no. 11, pp. 7610–7625, Nov. 2021. [Google Scholar]
24. W. Min, P. Chen, Z. Cao and Y. Chen, “Reinforcement learning-based UAVs resource allocation for integrated sensing and communication (ISAC) system,” Electronics, vol. 11, no. 3, pp. 441, 2022. [Google Scholar]
25. Y. Y. Munaye, R. -T. Juang, H. -P. Lin and G. B. Tarekegn, “Resource allocation for multi-UAV assisted IoT networks: A deep reinforcement learning approach,” in Int. Conf. on Pervasive Artificial Intelligence (ICPAI), Taiwan, pp. 15–22, 2020. [Google Scholar]
26. H. van Hasselt, A. Guez and D. Silver, “Deep reinforcement learning with double Q-learning,” in Proc. AAAI Conf. Artif. Intell., Phoenix, Arizona, USA, pp. 2094–2100, Sep. 2016. [Google Scholar]
27. H. A. Shah, L. Zhao and I. -M. Kim, “Joint network control and resource allocation for space-terrestrial integrated network through hierarchal deep actor-critic reinforcement learning,” IEEE Transactions on Vehicular Technology, vol. 70, no. 5, pp. 4943–4954, May 2021. [Google Scholar]
28. M. M. Sande, M. C. Hlophe and B. T. Maharaj, “Access and radio resource management for IAB networks using deep reinforcement learning,” IEEE Access, vol. 9, pp. 114218–114234, 2021. [Google Scholar]
29. M. Agiwal, A. Roy and N. Saxena, “Next generation 5G wireless networks: A comprehensive survey,” IEEE Communications Surveys & Tutorials, vol. 18, no. 3, pp. 1617–1655, 2016. [Google Scholar]
30. L. Liang, H. Ye, G. Yu and G. Y. Li, “Deep-learning-based wireless resource allocation with application to vehicular networks,” in Proc. of the IEEE, vol. 108, no. 2, pp. 341–356, Feb. 2020. [Google Scholar]
31. A. Iqbal, M. -L. Tham and Y. C. Chang, “Double deep Q-network-based energy-efficient resource allocation in cloud radio access network,” IEEE Access, vol. 9, pp. 20440–20449, 2021. [Google Scholar]
32. Y. Zhang, X. Wang and Y. Xu, “Energy-efficient resource allocation in uplink NOMA systems with deep reinforcement learning,” in 11th Int. Conf. on Wireless Communications and Signal Processing (WCSP), Xi’an, China, pp. 1–6, 2019. [Google Scholar]
33. X. Lai, Q. Hu, W. Wang, L. Fei and Y. Huang, “Adaptive resource allocation method based on deep Q network for industrial internet of things,” IEEE Access, vol. 8, pp. 27426–27434, 2020. [Google Scholar]
34. F. Hussain, S. A. Hassan, R. Hussain and E. Hossain, “Machine learning for resource management in cellular and IoT networks: Potentials current solutions, and open challenges,” IEEE Communications Surveys & Tutorials, vol. 22, no. 2, pp. 1251–1275, 2021. [Google Scholar]
35. S. Yu, X. Chen, Z. Zhou, X. Gong and D. Wu, “When deep reinforcement learning meets federated learning: Intelligent multitimescale resource management for multiaccess edge computing in 5G ultradense network,” IEEE Internet of Things Journal, vol. 8, no. 4, pp. 2238–2251, 2021. [Google Scholar]
36. J. Zhang, Y. Zeng and R. Zhang, “Multi-antenna UAV data harvesting: Joint trajectory and communication optimization,” Journal of Communications and Information Networks, vol. 5, no. 1, pp. 86–99, March 2020. [Google Scholar]
37. A. Pratap, R. Misra and S. K. Das, “Maximizing fairness for resource allocation in heterogeneous 5G networks,” IEEE Transactions on Mobile Computing, vol. 20, no. 2, pp. 603–619, Feb. 2021. [Google Scholar]
38. Y. Fu, X. Yang, P. Yang, A. K. Y. Wong, Z. Shi, et al.,, “Energy-efficient offloading and resource allocation for mobile edge computing enabled mission-critical internet-of-things systems,” EURASIP Journal on Wireless Communications and Networking, vol. 2021, no. 1, 2021. [Google Scholar]
39. A. Al-Hourani, S. Kandeepan and S. Lardner, “Optimal LAP altitude for maximum coverage,” IEEE Wireless Commun. Lett., vol. 3, no. 6, pp. 569–572, Dec. 2014. [Google Scholar]
40. M. A. Ouamri, M. E. Oteşteanu, G. Barb and C. Gueguen “Coverage analysis and efficient placement of drone-BSs in 5G networks,” Engineering Proceedings, vol. 14, no. 1, pp. 1–8, 2022. [Google Scholar]
41. Md. A. Ouamri “Stochastic geometry modeling and analysis of downlink coverage and rate in small cell network,” Telecommun Syst, vol. 77, no. 4, pp. 767–779, 2021. [Google Scholar]
42. D. Alkama, M. A. Ouamri, M. S. Alzaidi, R. N. Shaw, M. Azni et al., “Downlink performance analysis in MIMO UAV-cellular communication with LoS/NLoS propagation under 3D beamforming,” IEEE Access, vol. 10, pp. 6650–6659, 2022. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools