
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

IoT-Driven Optimal Lightweight RetinaNet-Based Object Detection for Visually Impaired People
1 Department of Computer Science, College of Sciences and Humanities-Aflaj, Prince Sattam bin Abdulaziz University, Saudi Arabia
2 King Salman Center for Disability Research, Riyadh, Al-Hayāṯim 16273, Saudi Arabia
3 Department of Information Technology, College of Computers and Information Technology, Taif University, P.O. Box 11099, Taif, 21944, Saudi Arabia
4 Department of Special Education, College of Education, King Saud University, Riyadh, 12372, Saudi Arabia
5 Department of Computer Science, College of Science & Arts, King Khaled University, Ar-Riyad 12372, Saudi Arabia
6 Department of Computer and Self Development, Preparatory Year Deanship, Prince Sattam bin Abdulaziz University, AlKharj, Saudi Arabia
* Corresponding Author: Mesfer Alduhayyem. Email:
Computer Systems Science and Engineering 2023, 46(1), 475-489. https://doi.org/10.32604/csse.2023.034067
Received 05 July 2022; Accepted 11 October 2022; Issue published 20 January 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Visual impairment is one of the major problems among people of all age groups across the globe. Visually Impaired Persons (VIPs) require help from others to carry out their day-to-day tasks. Since they experience several problems in their daily lives, technical intervention can help them resolve the challenges. In this background, an automatic object detection tool is the need of the hour to empower VIPs with safe navigation. The recent advances in the Internet of Things (IoT) and Deep Learning (DL) techniques make it possible. The current study proposes IoT-assisted Transient Search Optimization with a Lightweight RetinaNet-based object detection (TSOLWR-ODVIP) model to help VIPs. The primary aim of the presented TSOLWR-ODVIP technique is to identify different objects surrounding VIPs and to convey the information via audio message to them. For data acquisition, IoT devices are used in this study. Then, the Lightweight RetinaNet (LWR) model is applied to detect objects accurately. Next, the TSO algorithm is employed for fine-tuning the hyperparameters involved in the LWR model. Finally, the Long Short-Term Memory (LSTM) model is exploited for classifying objects. The performance of the proposed TSOLWR-ODVIP technique was evaluated using a set of objects, and the results were examined under distinct aspects. The comparison study outcomes confirmed that the TSOLWR-ODVIP model could effectually detect and classify the objects, enhancing the quality of life of VIPs.Keywords
Visual impairment is one of the major health complications that affect humankind across the globe. Vision loss or vision impairment is characterized by loss of visual capacity or visual-sensing capability of an individual and is incurable by wearing spectacles [1]. In such cases, navigation in unknown locations is highly challenging for Visually Impaired Persons (VIPs) other than in their own house. Vision impairment occurs for multiple reasons, such as retinopathy, uncorrected refractive errors, glaucoma, age-related eye problems, diabetic trachoma, cataracts, unaddressed presbyopia and corneal opacity [2]. People use several aids for social inclusion, rehabilitation, education and work, excluding medical treatment. VIPs depend on their auditory perceptions and somatosensation—basically sound and braille—to obtain information from their environment. VIPs use assistive gadgets like canes to recognize their impediments [3]. However, nearly 28.22% of the global population are VIPs, whereas VIP-accessible facilities are not globally implemented. This leads to social discrimination problems since their activities have constraints. To be specific, VIPs cannot independently handle unpredictable circumstances outdoors. It limits their activities and movements indoors or in neighborhoods [4].
VIPs face important difficulties in their day-to-day activities: object detection and recognition, mobility/navigation and safety, translation, identification of currency and textual information (signs, symbols) [5]. In literature, various methods, applications, systems and devices have been proposed, developed and validated in assistive technologies to facilitate VIPs in executing a task. These solutions usually consist of electronic gadgets equipped with microprocessors, cameras and sensors. These gadgets can take decisions and offer auditory or tactile feedback to the end-user, i.e., VIPs [6,7]. Though the existing object detection and recognition mechanisms are highly accurate, it lacks in presenting essential data and the associated attributes to track VIPs and ensure their safe movement. Since blind persons do not know the type of objects in their surroundings, such devices are highly helpful.
Moreover, a tracking system should be developed using which the VIPs’ family members can monitor their movements [8]. Various authors have proposed numerous methods for developing assistive gadgets for VIPs. The following technologies are used in the prevailing gadgets such as low-energy Bluetooth beacons, vision-based sensors (camera), non-vision sensors (magnetic sensing, infrared, inertial and ultrasonic, etc.), and many more [9]. In the past, several research works attempted to address the following challenges: the nature and position of obstacles in a travelling path, understanding the environment, raising perception and easing VIPs in indoor and outdoor environments. Generally, advanced technologies have functions to choose routes and detect problems automatically [10]. Yet, there is a demand to develop and design intelligent systems that are helpful in object detection and recognition and enable the secure movement of VIPs.
The current study develops an IoT-assisted Transient Search Optimization with a Lightweight RetinaNet-based object detection (TSOLWR-ODVIP) model to help VIPs. For data acquisition, IoT devices are used in this study. Lightweight RetinaNet (LWR) model is applied to detect objects accurately. Next, the TSO algorithm is employed for fine-tuning the hyperparameters involved in the LWR model. Finally, the Long Short-Term Memory (LSTM) model is exploited for classifying objects. The performance of the proposed TSOLWR-ODVIP technique was validated using a set of objects, and the results were examined under distinct aspects.
Liu et al. [11] modelled a fuzzy-enabled solution for vision challenges. This study leveraged a fuzzy-aided mechanism for the detection of targets that are poorly tracked with the help of response matrices of the samples. In poor tracking, the target tends to get relocated under the stored template. The solution was tested using an OTB100 data set, and the experimental outcomes reveal that the auxiliary solution was effective for vision challenges. Alon et al. [12] utilized different gadgets for multiple purposes, such as a Pi camera as a capturing device, Raspberry Pi 4 as a microcontroller and a speaker for audio to declare an identified bill. EyeBill-PH was performed with an overall testing accuracy of 86.3%. Su et al. [13] formulated finger-worn gadgets—called Chinese FingerReader—that were realistically installed in VIPs to recognize conventional Chinese characters over micro Internet of Things (IoT) processors. The Chinese FingerReader, installed on the index finger, has small buttons and a camera. In this device, the small camera captures the images by finding the relative place of the index finger in the printed text. The buttons are implemented for VIPs to capture the images, whereas the audio output of the respective Chinese characters is provided to the VIPs in the form of a voice prompt.
In literature [14], the authors executed a new indoor object detector with the help of a Deep Convolutional Neural Network (CNN)-based structure. The structure was constructed based on a deep CNN called ‘RetinaNet’. The proposed model was validated through several backbones such as VGGNet, ResNet, and DenseNet to enhance the processing time and detection performance. Bai et al. [15] introduced a wearable assistive device that empowers VIPs to navigate quickly and safely in strange ambiences and to recognize objects in outdoor and indoor environments. A lightweight CNN-related object recognition mechanism was formulated and deployed on the smartphone to increase the perception capability of VIPs and promote their navigation systems. Jiang et al. [16] innovatively used the image quality assessment method to select the images captured via vision sensors. This method could ensure the quality of the input scene for the final identification mechanism. Primarily, binocular vision sensors were used in this method to capture the images in a fixed frequency and choose the informative ones based on stereo image quality values. Then, the captured images were forwarded to the cloud for further computation processes. Specifically, the identification and automatic outcomes were obtained for all images from earlier stages. Then, big data-related CNN was used in this study.
3 The Proposed Object Detection Model
In this study, a new TSOLWR-ODVIP technique has been developed to detect and classify objects for VIPs. The major aim of the presented TSOLWR-ODVIP technique is to identify different objects surrounding the VIP and convey the information via an audio message.
3.1 Object Detection: LWR Model
In this study, the LWR model is applied to detect objects [17] accurately. RetinaNet structure encompasses Feature Pyramid Network (FPN), a detection backend and a backbone, as shown in Fig. 1. Initially, the images are managed using a backbone, which is generally a ResNet structure. It is important to note that though MobileNet efficiency is on par excellent with ResNet in terms of classification, it is not accurate enough to be observed as a corresponding replacement for ResNet. In this perspective, MobileNet is utilized as the backbone for detection tasks though it suffers from reduced accuracy in terms of classification outcomes. The primary purpose of MobileNet is that the confidence score of the MobileNet-based backbone can be decreased by trading off with low computation cost. As a result, it is not considered the desired choice as a backbone of a highly-accurate object detection network. Both backbone and the following FPN combine to form encoder and decoder networks. FPN has an advantage, i.e., it combines the characteristics of successive layers from the roughest to the finest level so that the features in different scales and levels are efficiently transmitted to the subsequent layer. Next, the multiple scale pyramid feature (P3-P7) feeds into the backend in which two detection subdivisions are applied for object classification and bounding box regression.
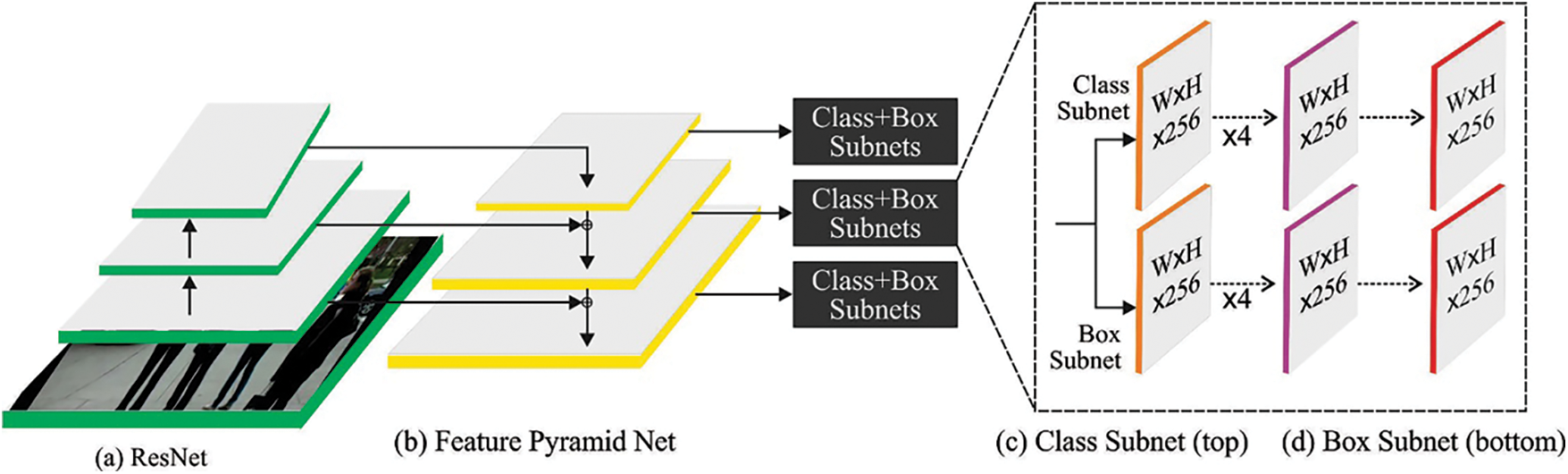
Figure 1: Structure of RetinaNet
Instinctively, the filter size is reduced to achieve FLOP reduction. Now, the D-blockv1 employs the MobileNet structure. A 1 × 1 convolution layer and a 3 × 3 depthwise (DW) convolutional layer replace one original layer. The D-block-v2 consecutively places 1 × 1 as well as 3 × 3 kernels. Based on YOLOv1, 3 × 3 kernels are replaced without presenting the residual blocks. In this study, the number of filters is fixed to a constant value across the layers. The D-block-v3 is highly aggressive because it substitutes each 3 × 3 convolution with a 1 × 1 convolution. In this scenario, the lightweight block experiences a decline in accuracy to trade off less computational cost. A lightweight detection block is a trade-off between low computation difficulty and a decline in accuracy. To indemnify the reduced accuracy, the fully-shared weight system is replaced with a partially-shared weight system in the new RetinaNet model. A partially-shared weight system primarily has two benefits. D3 has an independent weight parameter which learns additionally-tailored characteristics for the branch and can compensate for the reduced accuracy by low computation difficulty. For others, it allows the users not to touch the remaining network through heavy bottleneck blocks that are simply resolved.
3.2 Hyperparameter Tuning: TSO Algorithm
In this stage, the TSO algorithm is employed for fine-tuning the hyperparameters involved in the LWR model [18]. TSO procedure is modelled as follows; 1) initialize the search agents between the upper and lower limits of the search area; 2) identify the optimal solution (Exploration), and 3) obtain the optimal solution or steady-state (Exploitation) phase. At first, the initialization of the searching agent is arbitrarily produced. Then, the exploration behaviour of TSO is followed based on the oscillation of the second order
In this expression,

3.3 Object Classification: LSTM Model
Finally, the LSTM model is exploited for classifying objects [19]. Recurrent Neural Network (RNN) is a new Artificial Intelligence technique applied in real-time applications. A conventional RNN is generally employed to forecast the trained temporal dataset. However, it faces many challenges in terms of dealing with gradient explosion datasets. To resolve these issues, the LSTM method was developed. The LSTM method applies a memory function to substitute the hidden RNN unit. Fig. 2 shows the architecture of the LSTM mechanism which detects intrusions in IoT data. The LSTM technique has three major gates: output, forget, and input.
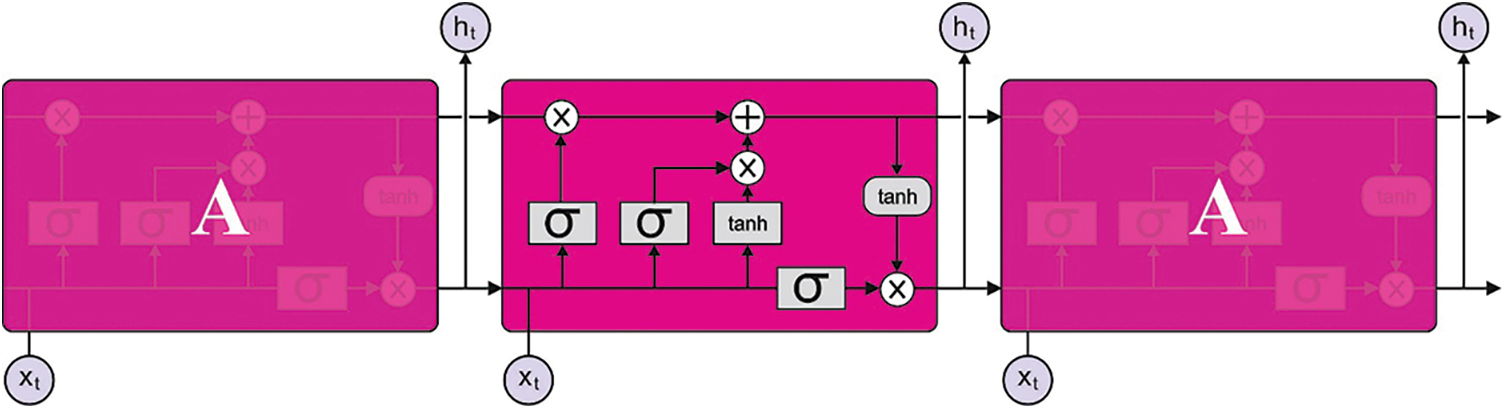
Figure 2: LSTM model
The forget gate identifies the forgotten datasets, whereas
Here,
The cell state
In Eq. (11),
The current section experimentally validates the proposed TSOLWR-ODVIP model using a dataset that is composed of 1,600 samples. The dataset has a total of eight distinct classes. Table 1 provides the details regarding the dataset. The proposed model was simulated in Python 3.6.5 tool, whereas the PC configurations are as follows; i5-8600 k, GeForce 1050Ti 4 GB, 16 GB RAM, 250 GB SSD, and 1 TB HDD. The parameter settings are given herewith: learning rate: 0.01, dropout: 0.5, batch size: 5, epoch count: 50, and activation: ReLU.
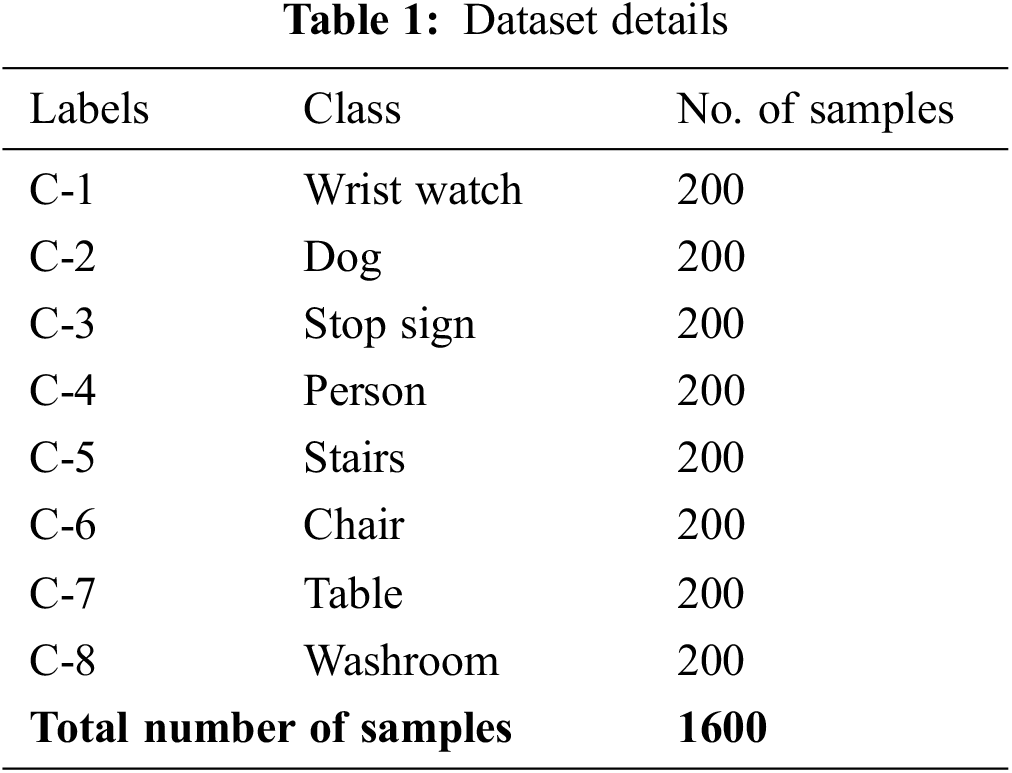
Fig. 3 illustrates the confusion matrices offered by the TSOLWR-ODVIP model upon the entire Training (TR) and Testing (TS) datasets. The results demonstrate that the proposed TSOLWR-ODVIP model recognized all the class labels proficiently.
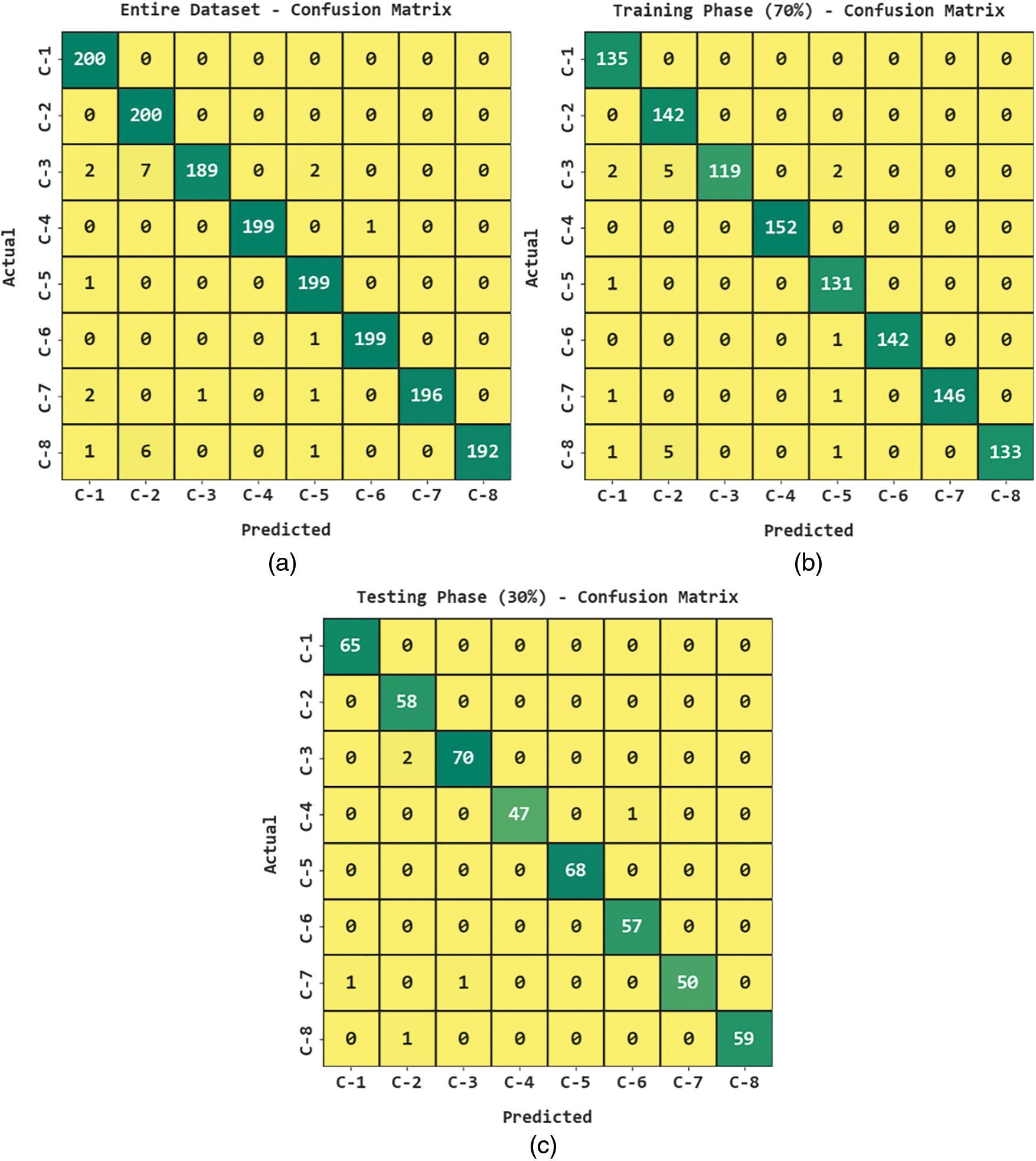
Figure 3: Confusion matrices of TSOLWR-ODVIP model (a) entire dataset, (b) 70% of TR data and (c) 30% of TS data
Table 2 provides the comprehensive object detection outcomes achieved by the proposed TSOLWR-ODVIP model. Fig. 4 portrays the results accomplished by the TSOLWR-ODVIP model on the entire dataset under distinct classes. TSOLWR-ODVIP model categorized C-1 samples with
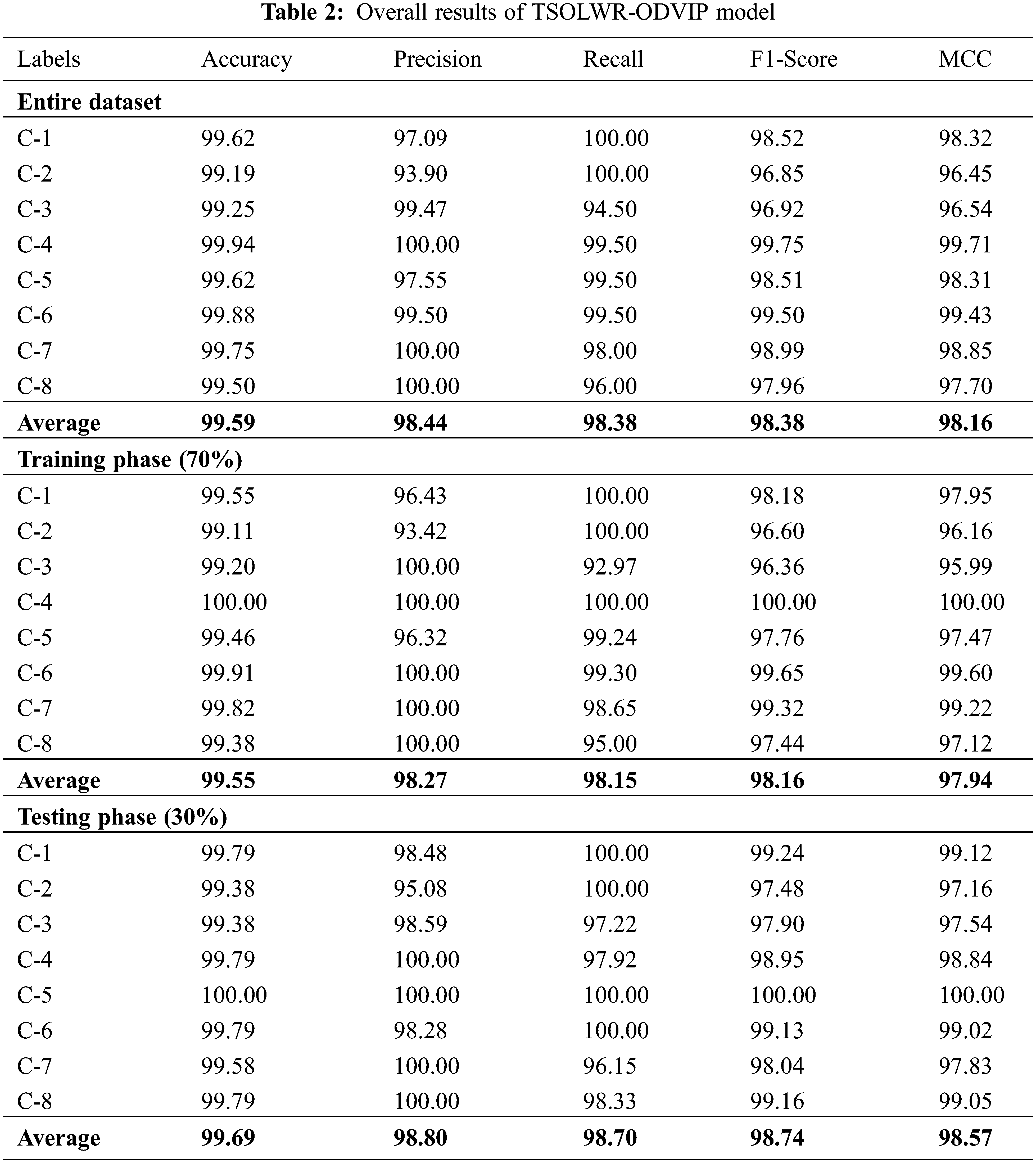
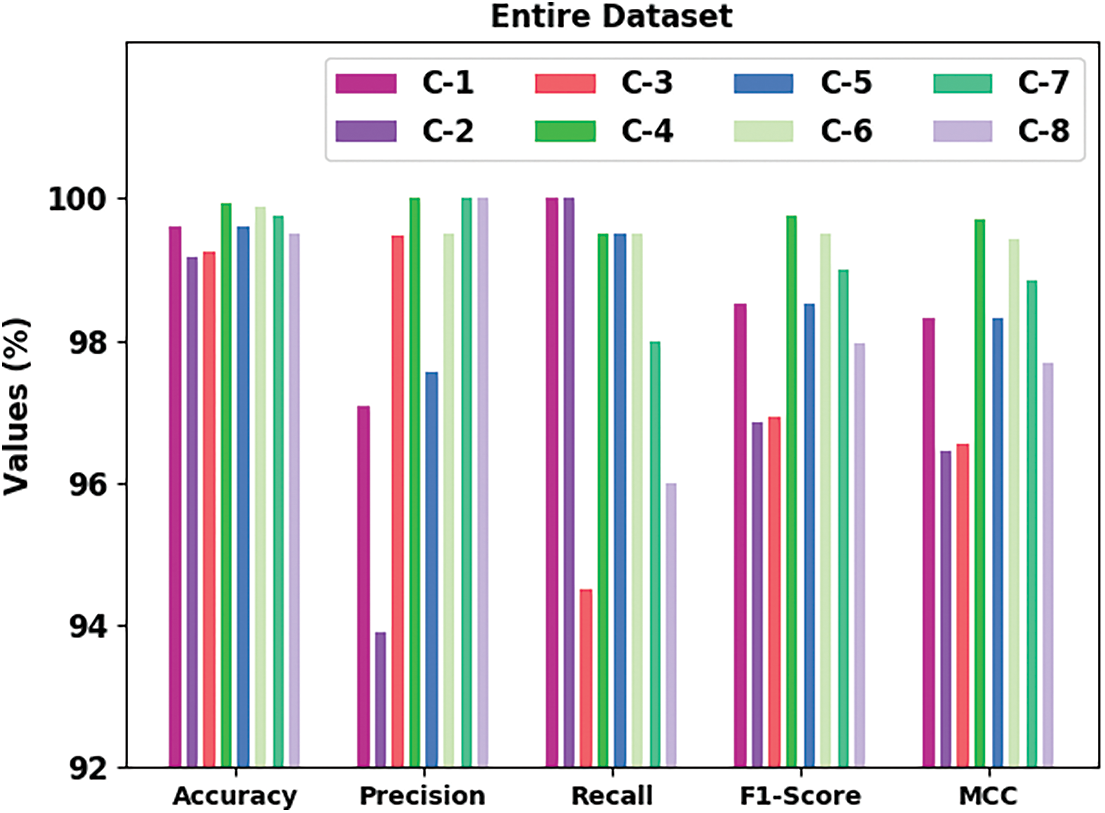
Figure 4: Overall results of the TSOLWR-ODVIP model on the entire dataset
Fig. 5 shows the outcomes accomplished by the proposed TSOLWR-ODVIP approach on dissimilar classes of 70% TR data. The presented TSOLWR-ODVIP system classified C-1 samples with
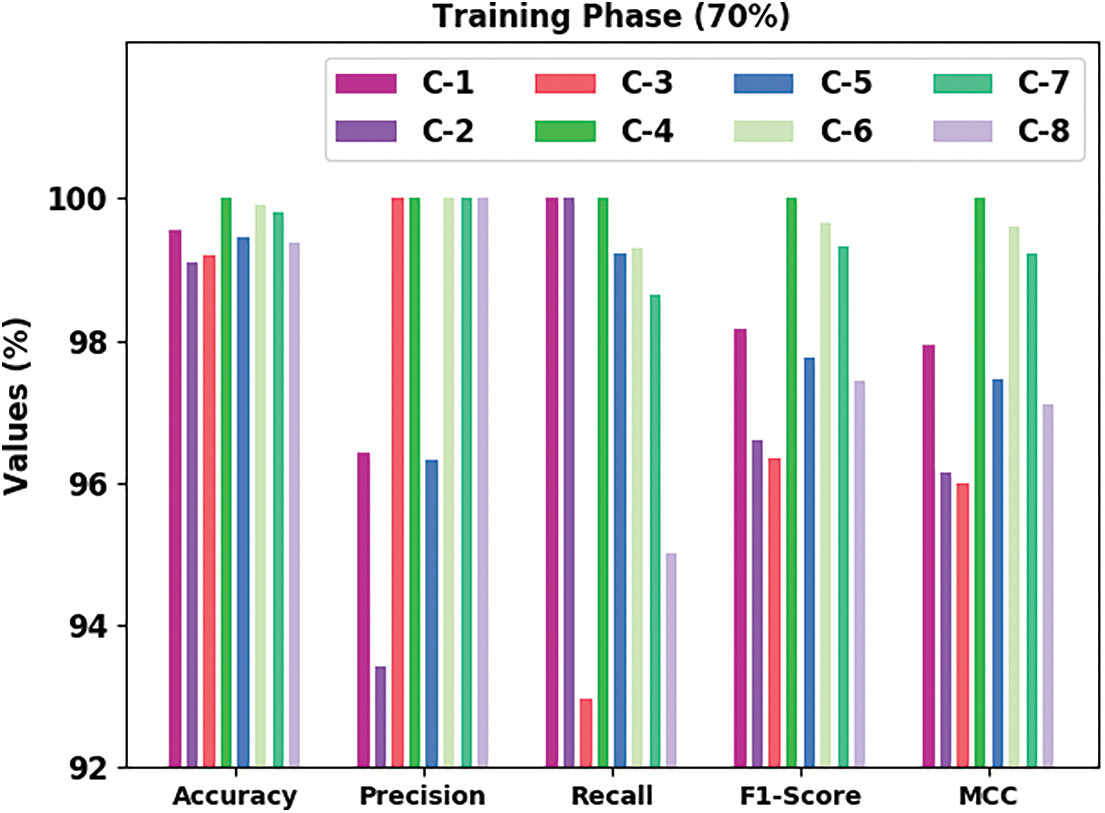
Figure 5: Overall results of TSOLWR-ODVIP model on 70% of TR dataset
Fig. 6 reviews the outcomes achieved by TSOLWR-ODVIP algorithm on dissimilar classes of 30% TS data. The proposed TSOLWR-ODVIP approach categorized C-1 samples with
Figure 6: Overall results of the TSOLWR-ODVIP model on 30% of testing dataset
Fig. 7 provides the ROC curve examination results of the TSOLWR-ODVIP model. The figure demonstrates that the proposed TSOLWR-ODVIP model accomplished enhanced ROC values under all the classes.
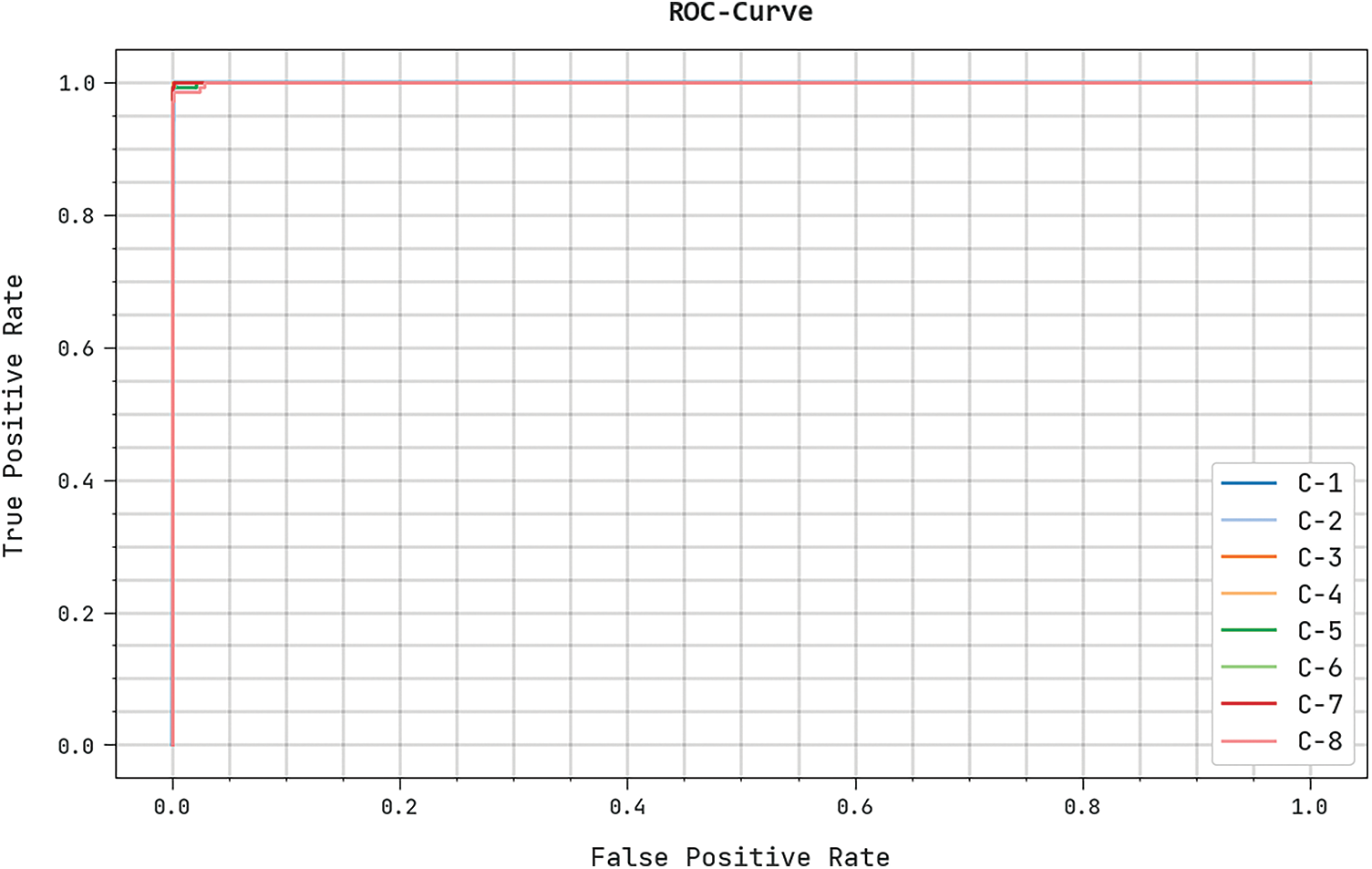
Figure 7: ROC analysis results of the TSOLWR-ODVIP model
At last, Table 3 provides an overview of the detailed comparative analysis results achieved by the proposed TSOLWR-ODVIP model and other existing DL models. Fig. 8 portrays the comparative analysis outcomes offered by the TSOLWR-ODVIP model and other DL models in terms of
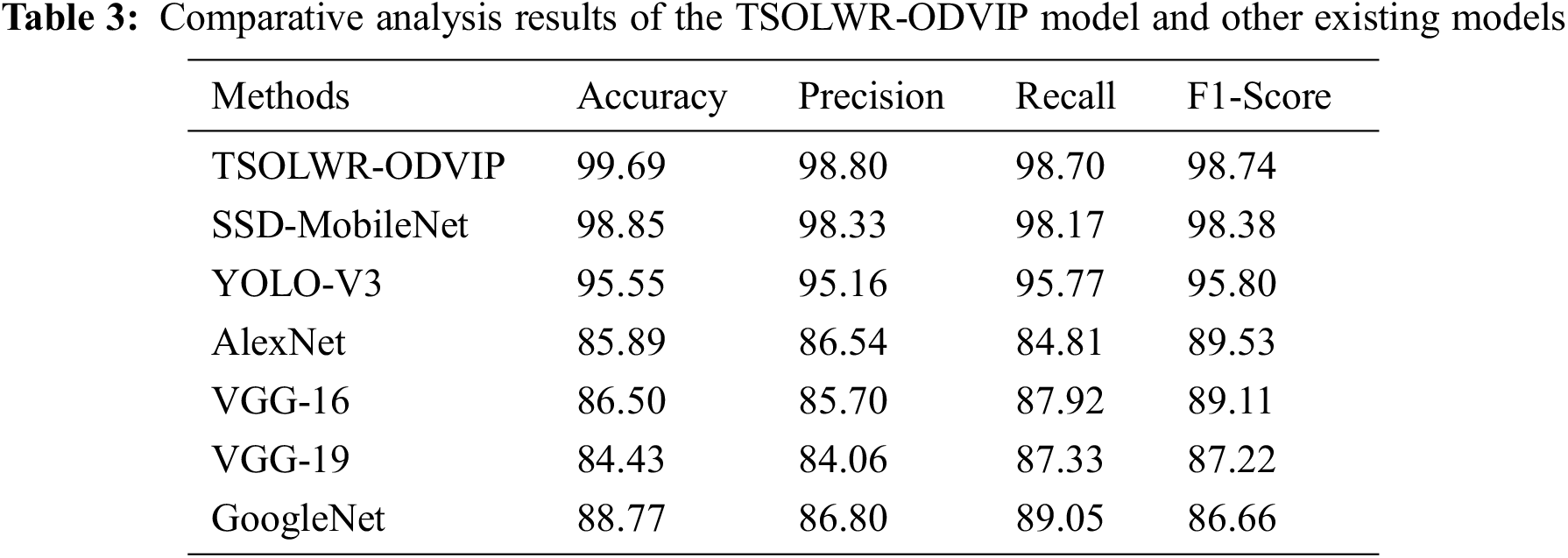
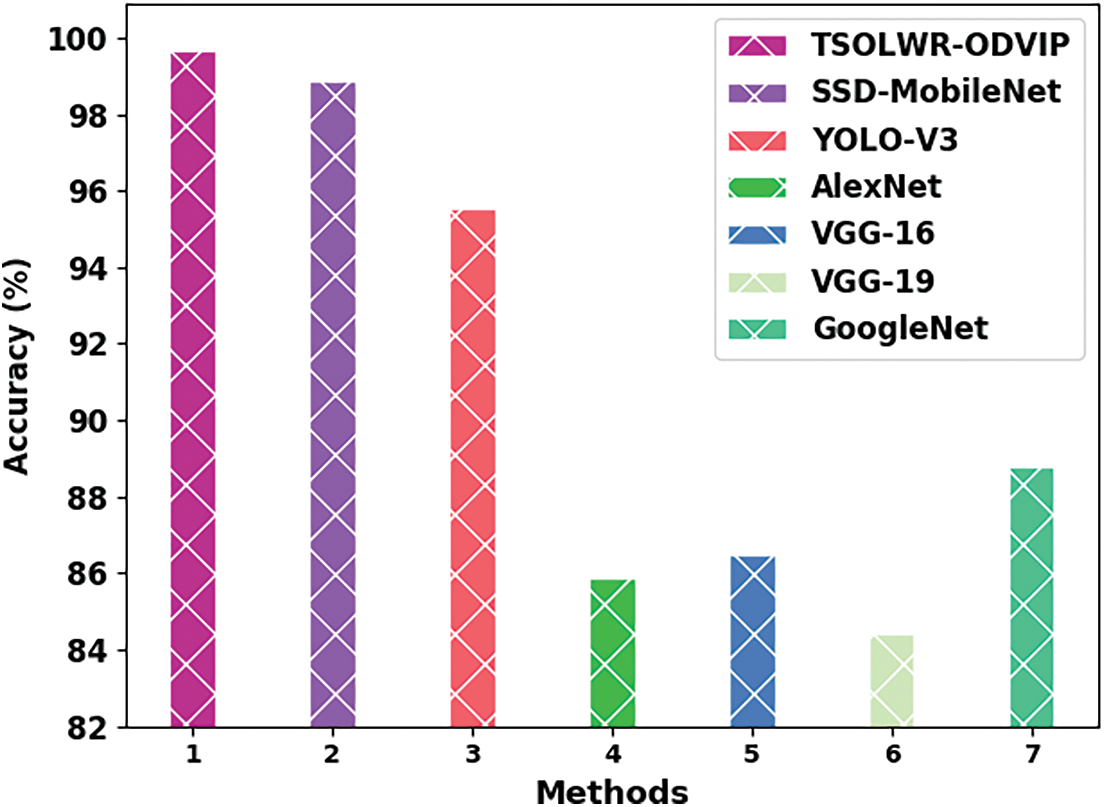
Figure 8: Comparative
Fig. 9 shows the comparative analysis results of the proposed TSOLWR-ODVIP and other DL techniques in terms of
Figure 9: Comparative
Fig. 10 shows the comparative analysis outcomes of TSOLWR-ODVIP and other DL methods in terms of
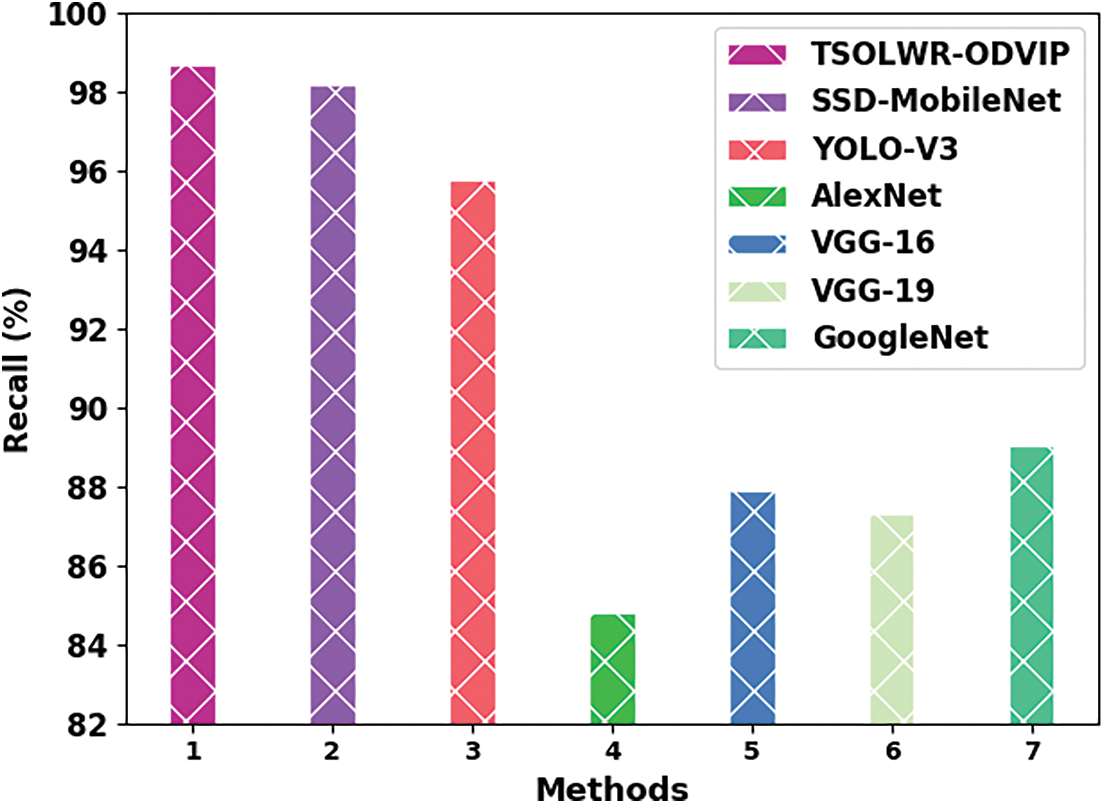
Figure 10: Comparative
Fig. 11 portrays the comparative analysis results, in terms of
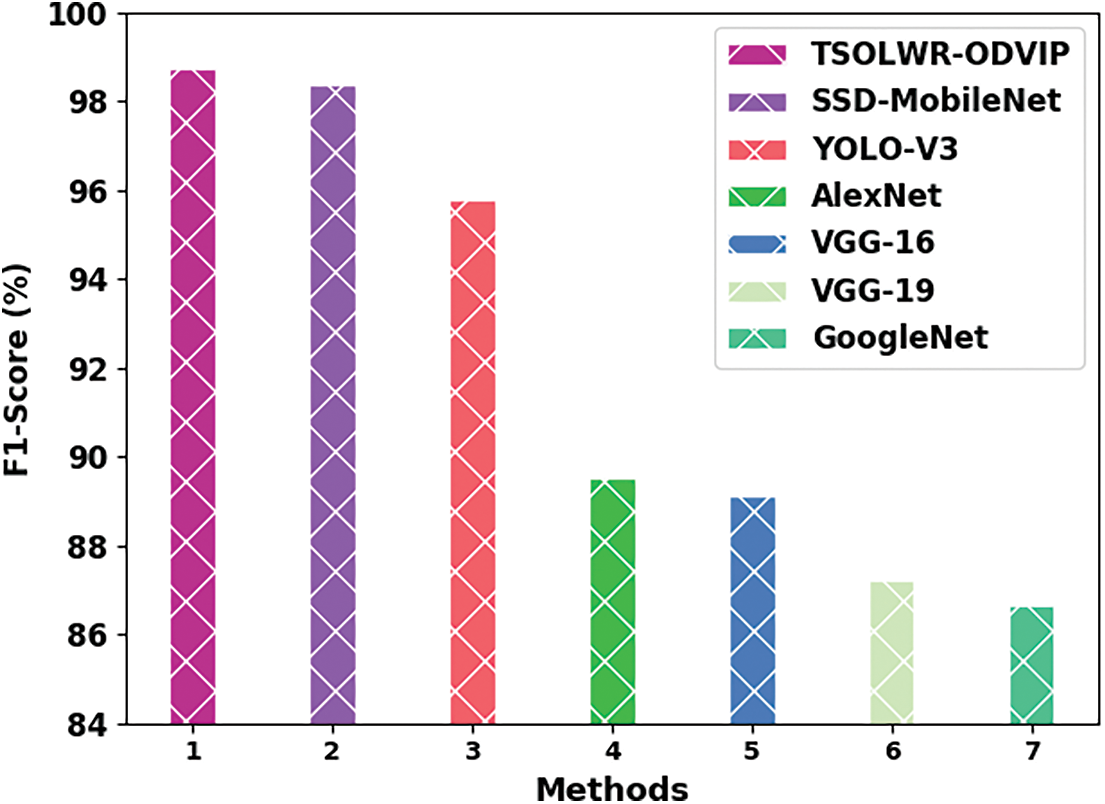
Figure 11: Comparative
In this study, a new TSOLWR-ODVIP technique has been developed to detect and classify objects to help VIPs. The major aim of the presented TSOLWR-ODVIP technique is to identify different objects surrounding the VIPs and convey the information to them via audio messages. For data acquisition, IoT devices are used in this study. Followed by LWR model is applied for the accurate detection of the objects. Then, the TSO algorithm is employed for fine-tuning the hyperparameters involved in LWR model. At last, the LSTM model is exploited for the classification of objects. The performance of the proposed TSOLWR-ODVIP technique was validated using a set of objects and the results were examined under distinct aspects. The proposed model achieved a high accuracy of 99.69%. The comparison study outcomes confirmed that the TSOLWR-ODVIP model detects and effectually classifies the objects. So, it can be exploited to enhance the quality of life of VIPs. In future, hybrid DL models can be used to boost the detection efficacy of the TSOLWR-ODVIP technique.
Funding Statement: The authors extend their appreciation to the King Salman center for Disability Research for funding this work through Research Group no KSRG-2022-030.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. R. R. A. Bourne, S. R. Flaxman and T. Braithwaite, “Magnitude, temporal trends, and projections of the global prevalence of blindness and distance and near vision impairment: A systematic review and meta-analysis,” The Lancet Global Health, vol. 5, no. 9, pp. 888–897, 2017. [Google Scholar]
2. E. Cardillo, V. Di Mattia, G. Manfredi, P. Russo, A. De Leo et al. “An electromagnetic sensor prototype to assist visually impaired and blind people in autonomous walking,” IEEE Sensors Journal, vol. 18, no. 6, pp. 2568–2576, 2018. [Google Scholar]
3. O. Arslan and D. E. Koditschek, “Sensor-based reactive navigation in unknown convex sphere worlds,” The International Journal of Robotics Research, vol. 38, no. 2–3, pp. 196–223, 2019. [Google Scholar]
4. S. Caraiman, O. Zvoristeanu, A. Burlacu and P. Herghelegiu, “Stereo vision based sensory substitution for the visually impaired,” Sensors, vol. 19, no. 12, pp. 2771, 2019. [Google Scholar]
5. R. A. Z. Daou, J. Chehade, G. A. Haydar, A. Hayek, J. Boercsoek et al. “Design and implementation of smart shoes for blind and visually impaired people for more secure movements,” in 32nd Int. Conf. on Microelectronics (ICM), Aqaba, Jordan, pp. 1–6, 2020. [Google Scholar]
6. S. Shaikh, “Assistive object recognition system for visually impaired,” International Journal of Engineering and Technical Research, vol. V9, no. 9, pp. 736–140, 2020. [Google Scholar]
7. V. V. Meshram, K. Patil, V. A. Meshram and F. C. Shu, “An astute assistive device for mobility and object recognition for visually impaired people,” IEEE Transactions on Human-Machine Systems, vol. 49, no. 5, pp. 449–460, 2019. [Google Scholar]
8. M. M. Islam, M. S. Sadi, K. Z. Zamli and M. M. Ahmed, “Developing walking assistants for visually impaired people: A review,” IEEE Sensors Journal, vol. 19, no. 8, pp. 2814–2828, 2019. [Google Scholar]
9. S. S. A. Zaidi, M. S. Ansari, A. Aslam, N. Kanwal, M. Asghar et al. “A survey of modern deep learning based object detection models,” Digital Signal Processing, vol. 126, pp. 103514, 2022. [Google Scholar]
10. P. M. Kumar, U. Gandhi, R. Varatharajan, G. Manogaran and T. Vadivel “Intelligent face recognition and navigation system using neural learning for smart security in internet of things,” Cluster Computing, vol. 22, no. S4, pp. 7733–7744, 2019. [Google Scholar]
11. S. Liu, X. Liu, S. Wang and K. Muhammad, “Fuzzy-aided solution for out-of-view challenge in visual tracking under IoT-assisted complex environment,” Neural Computing and Applications, vol. 33, no. 4, pp. 1055–1065, 2021. [Google Scholar]
12. A. S. Alon, R. M. Dellosa, N. U. Pilueta, H. D. Grimaldo and E. T. Manansala, “EyeBill-PH: A machine vision of assistive philippine bill recognition device for visually impaired,” in 11th IEEE Control and System Graduate Research Colloquium (ICSGRC), Shah Alam, Malaysia, pp. 312–317, 2020. [Google Scholar]
13. Y. S. Su, C. H. Chou, Y. L. Chu and Z. Y. Yang, “A Finger-worn device for exploring Chinese printed text with using cnn algorithm on a micro iot processor,” IEEE Access, vol. 7, pp. 116529–116, 2019. [Google Scholar]
14. M. Afif, R. Ayachi, Y. Said, E. Pissaloux and M. Atri, “An evaluation of retinanet on indoor object detection for blind and visually impaired persons assistance navigation,” Neural Processing Letters, vol. 51, no. 3, pp. 2265–2279, 2020. [Google Scholar]
15. J. Bai, Z. Liu, Y. Lin, Y. Li and S. Lian, “Wearable travel aid for environment perception and navigation of visually impaired people,” Electronics, vol. 8, no. 6, pp. 1–27, 2019. [Google Scholar]
16. B. Jiang, J. Yang, Z. Lv and H. Song, “Wearable vision assistance system based on binocular sensors for visually impaired users,” IEEE Internet of Things Journal, vol. 6, no. 2, pp. 1375–1383, 2019. [Google Scholar]
17. Y. Li, A. Dua and F. Ren, “Lightweight retinanet for object detection on edge devices,” in IEEE 6th World Forum on Internet of Things (WF-IoT), New Orleans, LA, USA, pp. 1–6, 2020. [Google Scholar]
18. M. H. Qais, H. M. Hasanien and S. Alghuwainem, “Transient search optimization: A new meta-heuristic optimization algorithm,” Applied Intelligence, vol. 50, no. 11, pp. 3926–3941, 2020. [Google Scholar]
19. F. Karim, S. Majumdar, H. Darabi and S. Chen, “LSTM fully convolutional networks for time series classification,” IEEE Access, vol. 6, pp. 1662–1, 2018. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools