
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Implementation of Hybrid Deep Reinforcement Learning Technique for Speech Signal Classification
1 Department of Electronics and Communication Engineering, Sri Ramakrishna Institute of Technology, Coimbatore, 641020, India
2 Department of Electrical and Electronics Engineering, Sri Ramakrishna Institute of Technology, Coimbatore, 641020, India
* Corresponding Author: R. Gayathri. Email:
Computer Systems Science and Engineering 2023, 46(1), 43-56. https://doi.org/10.32604/csse.2023.032491
Received 19 May 2022; Accepted 27 August 2022; Issue published 20 January 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Classification of speech signals is a vital part of speech signal processing systems. With the advent of speech coding and synthesis, the classification of the speech signal is made accurate and faster. Conventional methods are considered inaccurate due to the uncertainty and diversity of speech signals in the case of real speech signal classification. In this paper, we use efficient speech signal classification using a series of neural network classifiers with reinforcement learning operations. Prior classification of speech signals, the study extracts the essential features from the speech signal using Cepstral Analysis. The features are extracted by converting the speech waveform to a parametric representation to obtain a relatively minimized data rate. Hence to improve the precision of classification, Generative Adversarial Networks are used and it tends to classify the speech signal after the extraction of features from the speech signal using the cepstral coefficient. The classifiers are trained with these features initially and the best classifier is chosen to perform the task of classification on new datasets. The validation of testing sets is evaluated using RL that provides feedback to Classifiers. Finally, at the user interface, the signals are played by decoding the signal after being retrieved from the classifier back based on the input query. The results are evaluated in the form of accuracy, recall, precision, f-measure, and error rate, where generative adversarial network attains an increased accuracy rate than other methods: Multi-Layer Perceptron, Recurrent Neural Networks, Deep belief Networks, and Convolutional Neural Networks.Keywords
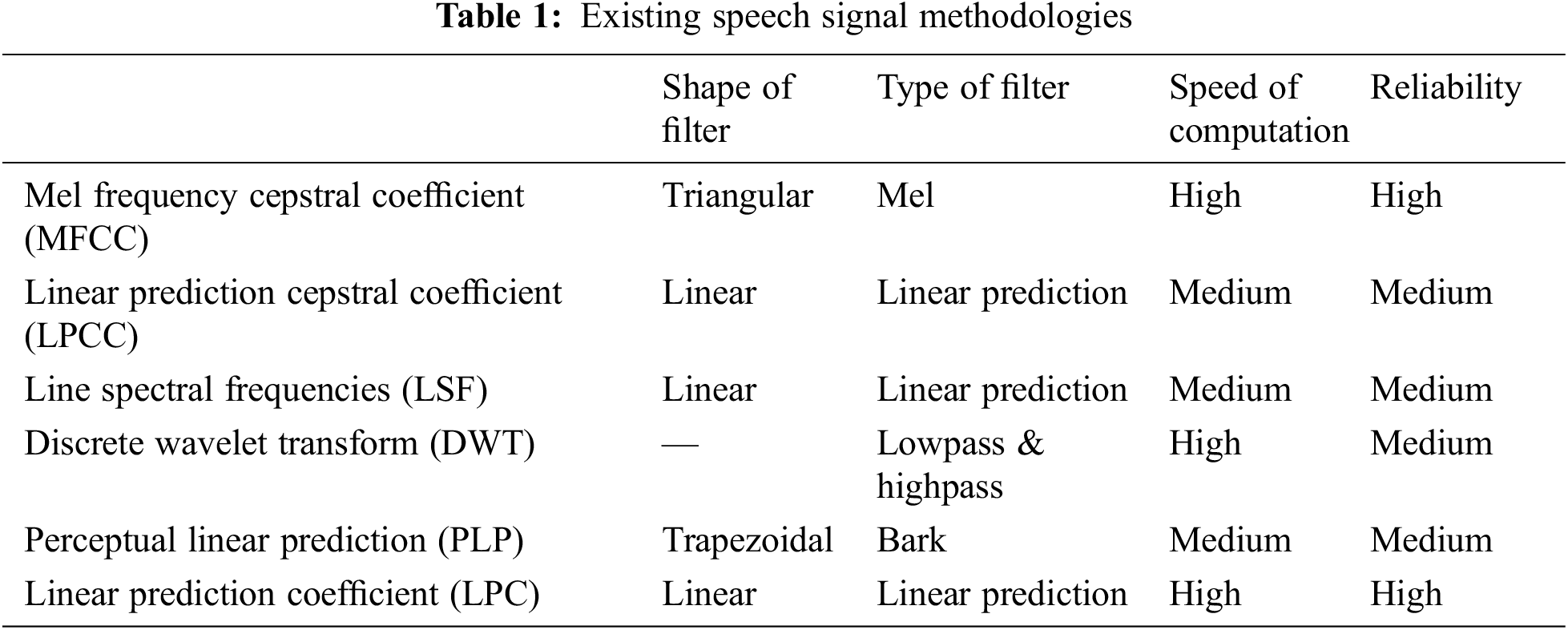
Speech recognition belongs to the class of speech processing, where the speech from individuals is recognized and translated using specific methodologies in Table 1 [1,2]. These approaches usually separate any spoken word and add a series of processing steps to obtain features that will be mapped to a particular word [3–6].
The Artificial Neural Network (ANN) is a major advancement in machine learning, which made an improving Human-machine-interface as in [7–10], through a mixture of Recurrent Neural Networks (RNNs) and Convolutional Neural Networks (CNNs). Levenberg-Marquardt (LM) algorithm [11,12] is an algorithm for training the CNN and ANN. In comparison with the LM algorithm, there exist no standard procedures or algorithms to train the other Deep Neural Networks (DNN). ANN is the biochemical mechanism that enables the intensity of neuronal interactions to be changed according to the relative time of the production and spiking behavior of a single neuron. This is a training approach-based network specifically for unsupervised learning [13]. It has been deployed on many simulation and hardware platforms, including SpiNNaker. For static input signals like images, STDP has proven very effective and robust [14–21]. But in processing time-specific signals like audio samples, it is harder to enforce.
The main contribution of the paper involves the following:
• The study classifies the speech signal using a series of Generative Adversarial Networks (GAN) with feedback obtained from reinforcement learning.
• The study uses Cepstral Analysis to extract the features before the classification of speech signal classification and the extracted features obtained from the speech waveform provides a parametric representation at a relatively minimized data rate for optimal classification.
• The study uses Generative Adversarial Networks (GAN) to validate the speech signal classification and compares it with other existing deep learning classifiers namely: Deep Belief Network (DBN), Multi-Layer Perceptron (MLP) Recurrent Neural Networks (RNN), and Convolutional Neural Networks (CNN).
The outline of the paper is given below: Section 2 provides the related works. Section 3 discusses the details of the proposed classification engine. Section 4 evaluates the entire work and Section 5 concludes the work with the possible direction of future scope.
In this section, we proposed a speech classification using a series of hybrid neural network classifiers with reinforcement learning. The feature extraction uses Cepstral Analysis to extract the features prior to speech signal classification and the extracted features provide parametric representation at a relatively minimized data rate. The classification is conducted using various classifiers including GAN to validate the speech signal classification and finds the optimal classifier. Fig. 1. shows the architecture of Speech Signal Classification
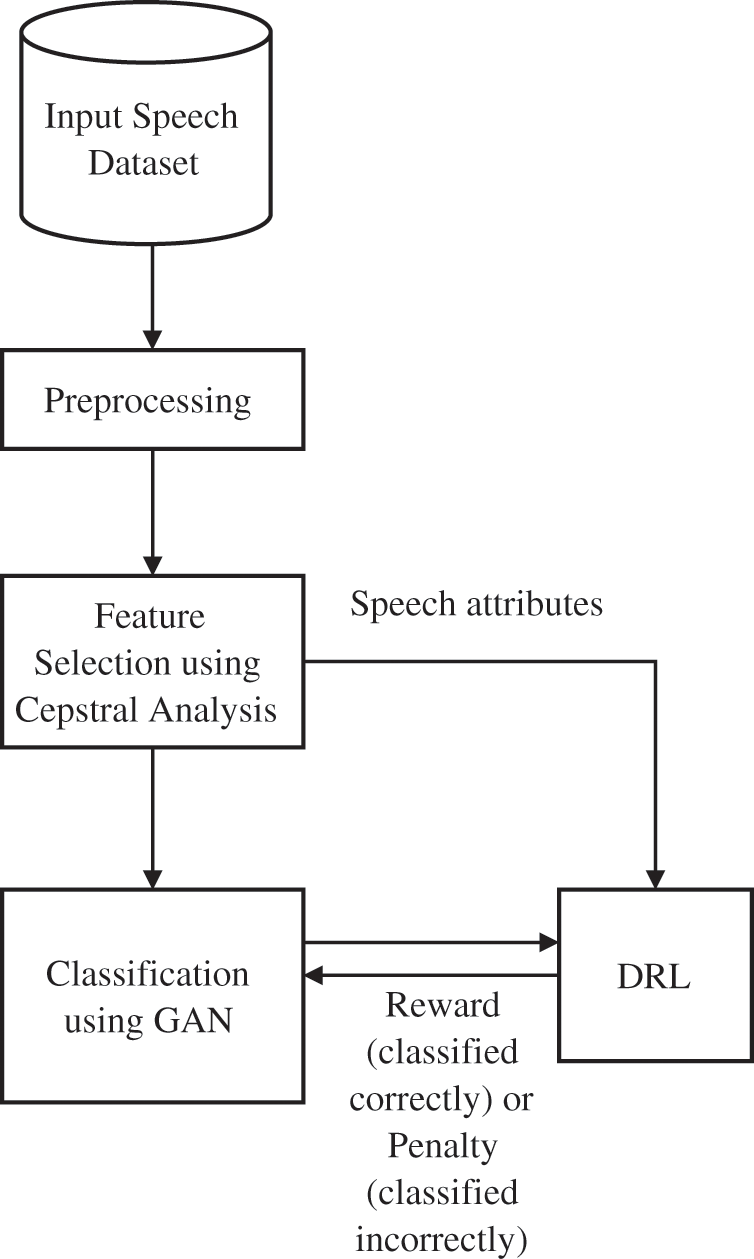
Figure 1: Architecture of speech signal classification
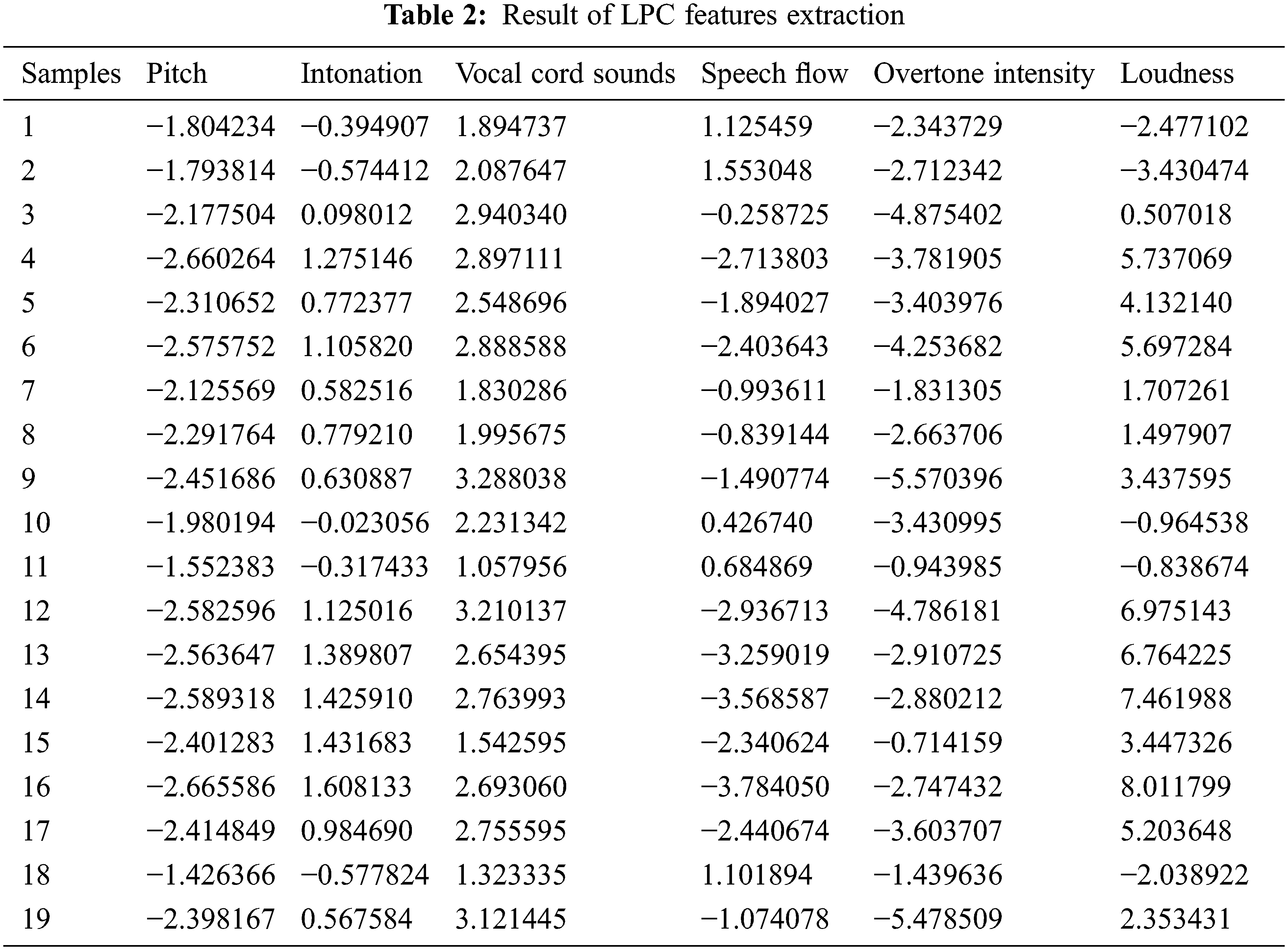
Pre-processing of speech processing is performed to improve the accuracy of speech classification algorithms. This involves resampling, amplifying, and framing, and the audio recordings are sampled at 16 kHz for this analysis. The pitch of the audio recordings is normalized such that the signal spectrum of dynamics lies between −1.0 and +1.0 regardless of changes in voice intensity and microphone distance. The normalization of amplitude is reached after splitting the voice data using the absolute maximum magnitude. Speech signals are required to be analyzed in a short interval since they belong to the class of non-stationary signals. Framing is the method of splitting a signal into short frames. The resulting amplitude sampled under a 16-kHz scale is split into 256 sampled frames with 80% overlap. Thus, the process of overlapping in short frames enhances the process of classification. Formants are resonance bands within the speaking signal frequency range. The resonance bands reflect the signal significantly. In this proposed methodology, the formant extraction algorithm is carried out using Linear Prediction Coding (LPC). LPC provides a smooth estimation of the power spectrum that yields the results of the extracted features as given in Table 2. Here, 19 different samples are used for the extraction of the features.
The formant extraction is dependent on signal propagation within the frequency field. The locations of the formants are selected to balance this energy distribution. These formants are prominent bandwidth frequencies of less than 400 Hz within the spectrum. Therefore, the formants are high-energy bands with less concentration of about 400 Hz in their bandwidth.
The coefficients obtained from LPCs are translated into polar form. The coefficient phases are derived from the spectrum as resonant bands with bandwidths below 400 Hz and a positive phase. The formants are called these constructive processes. The centroid formants are regarded as the weighted averages in the short frequency range of formants in each frame. The center formant is an indicator of how the strength of an audio signal is centralized in the frequency spectrum. For instance, the centroid formant is situated in the HF range if the remainder of the spectral resides lies in the high-frequency range. However, the centroid formants are located at a low-frequency range, if the bulk of power remains in low-frequency components.
The most widely used technique used to obtain spectral characteristics is Cepstral Coefficients (CC). CCs used to detect speech are built on a Mel Scale frequency domain that is based on the human ear and is one of the most widely known strategies for extracting features. The features considered for the study include pitch, intonation, vocal cord sounds (voiced and unvoiced), speech flow, overtone intensity, loudness, and breaks between the speeches. CCs are considered to be frequency domain features, which are much more reliable than time domain features.
The first step on the input signal is to determine the cepstral coefficient. The power spectrum is obtained using Eq. (1).
where,
It is important to convert at the Mel Log bank using Discrete Cosine Transform. Finally, it is called the Cepstral Coefficient that the log Mel spectrum returns into the period. By using this cepstral coefficient, the spectral properties of the signal are well reflected.
Pre-Emphasis: The sample rate of the audio signals is 16 kHz. Each word is stored in an audio file in its own right. The pre-emphasis of speech signal for signal energy at high frequencies is included in this process. The Filter discrepancy in the pre-emphasis filter is shown in Eq. (2).
Framing and Windowing: The signal is dynamic in nature and used for stationary framing. Framing is the next stage after pre-empting: this signal is divided into smaller, overlapping frames. Windowing is used after framing to eliminate discontinuities at panel edges. The windowing system used in this study is the hamming window. The Hamming Window is given as below:
where,
N-total samples present in a frame.
Fast Fourier Transform (FFT): FFT estimates the discrete Fourier transform (DFT) of the speech signal. The results which transform the speech signal into its relevant frequency domain and the estimations of FFT are defined as below:
where, N is the size of FFT.
Mel Filter Bank: Mel Filter Bank: The Mel filter bank transforms the frequency domain signal from Hertz to Mel Scale and the spectral power is hence converted into mel scale with triangular-shaped filter banks of overlapping ones.
Discrete Cosine Transform (DCT): The DCT is applied after considering the logarithm of the Mel-filter bank output.
Delta Energy: The DE considers the base of 10 of the previous stage DCT output. The calculation of energy is important because the human ear response at the signal level of the acoustic speech is not linear, and human ears are not very sensitive to amplitude differences at higher amplitudes. The benefit of the logarithmic function is that the action of the human ear is usually duplicated. The estimation of energy using Eq. (5) is given as below:
The above equation tends to provide cepstral coefficients.
Classification
This section uses GAN to classify the instances obtained from feature extraction.
GAN is an alternative model of maximum likelihood technique that behaves as an unsupervised model with two neural networks acting in contrast with each other. One acts as a generator and the other act as a discriminator. The former generates the classes from features and the latter checks the correctness of the classes obtained. The process repeats until the generator output produces error-less outputs, which it is expressed as below:
2.3 Feedback from Reinforcement Learning
Reinforcement learning is considered as the process of collection of agents to assess the actions of the classifier and its error analysis for reward or penalizing the classifier’s decision actions.
Algorithm 1 provides the details of how the classifier is rewarded or penalized.

The output of reinforcement learning is sent to the classifier that determines whether the classifier has correctly or incorrectly identified the speech instances on each dataset. This is carried out to reduce the classification error, where the classifier tries to reduce its error rate while classifying the speech instances.
This section verifies the accuracy levels of various classifiers on speech signal datasets. The experiments are conducted on various performance metrics that include accuracy, precision, recall, F-measure, and MSE, and the formula for estimating the metrics is given below:
where:
TP-true positive tweets
TN-true negative tweets
FP-false positive tweets
FN-false negative tweets
Analysis
This section provides the results of various classifiers (DBN, MLP, RNN, CNN, and proposed GAN) in terms of five different performance metrics over 9 different datasets that include RAVDESS, TED-LIUM corpus, Google Audio set, LibriSpeech ASR Corpus, CSS10, BACKBONE Pedagogic Corpus of Video-Recorded Interviews, Arabic Speech Corpus, Nijmegen Corpus of Casual French and Free-Spoken Digit Dataset. The first four datasets belong to General Voice Recognition Datasets and the remaining datasets belong to Multilingual Speech Data. The study uses 80% of the datasets for training and reaming 20% of the datasets for testing with 5-fold cross-validation. The total number of speech samples collected in each database is given in Table 1 over various datasets. Further, brief overviews of various existing classifiers are given below:
MLP is a feedforward neural network that helps in the classification of speech signals using the features extracted. The MLP has a single input, multi-hidden, and output layer. The architecture of MLP for classification is given below:
where
yј is the parameter moved to subsequent layer
n is the amount of moving edges to node j,
xi is the input
θj is the bias node.
The RBM is a building block that offers multi-layer learning and this is formed from the stacks of restricted Boltzmann machines. The restricted Boltzmann machine is a two-level model with visible layer units and hidden layers. DBN comprises multiple layered hidden units with suitable interconnections between them. In the case of classifying the speech signal, the connection links are not made between the units of each layer.
RNN uses Elman architecture, where it uses output via hidden unit layers and it is expressed as below:
where
x is considered as the input vector,
h is considered as the hidden layer vectors,
y is considered as the output vectors,
b is considered as the bias vector and
w and u are considered as the weight matrices.
The process is conducted in a loop manner, which allows the data to pass in one step.
The architecture of CNN for classification is a three-layered architecture that consists of Convolution, max-pooling, and classification. The first two form the lower and middle leveled network. The max-pooling is the odd-numbered layers and convolutional layers are regarded as the even-numbered layers. For classification, the study includes convolutional and maximum pooling layers, which are considered feature mapping. Table 3 shows the combination of two or more layers in each plan enables faster computation of classes from the features of the speech signal.

Table 4 shows the results of Classifiers on speech signals with RAVDESS. The results of various performance metrics show an improved performance by GAN than other classifiers with cepstral coefficient extraction of features.
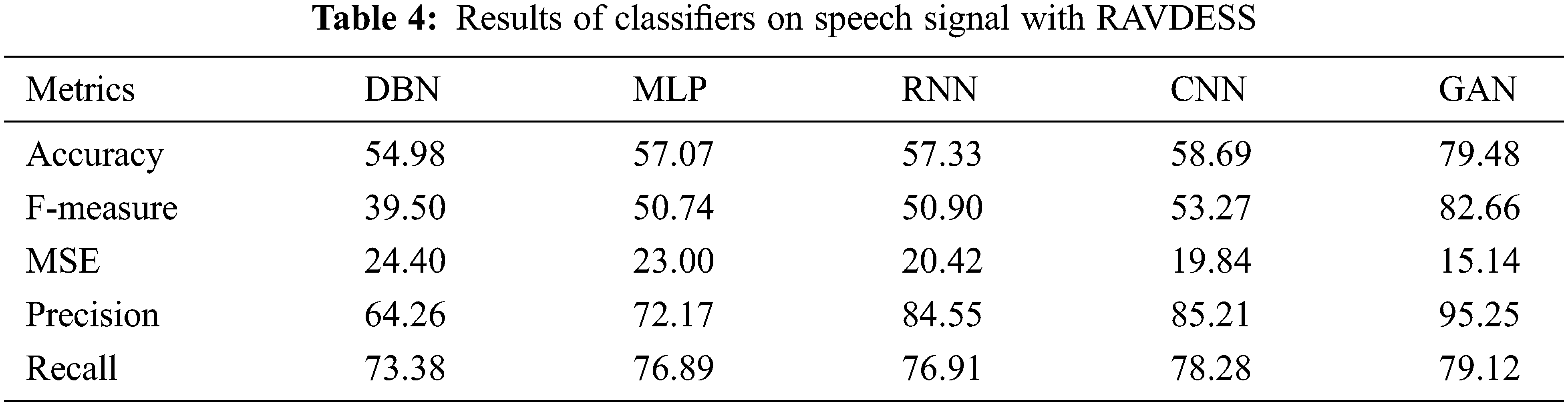
Table 5 shows the results of Classifiers on speech signals with TED-LIUM corpus. The results of various performance metrics show an improved performance by GAN than other classifiers with cepstral coefficient extraction of features.
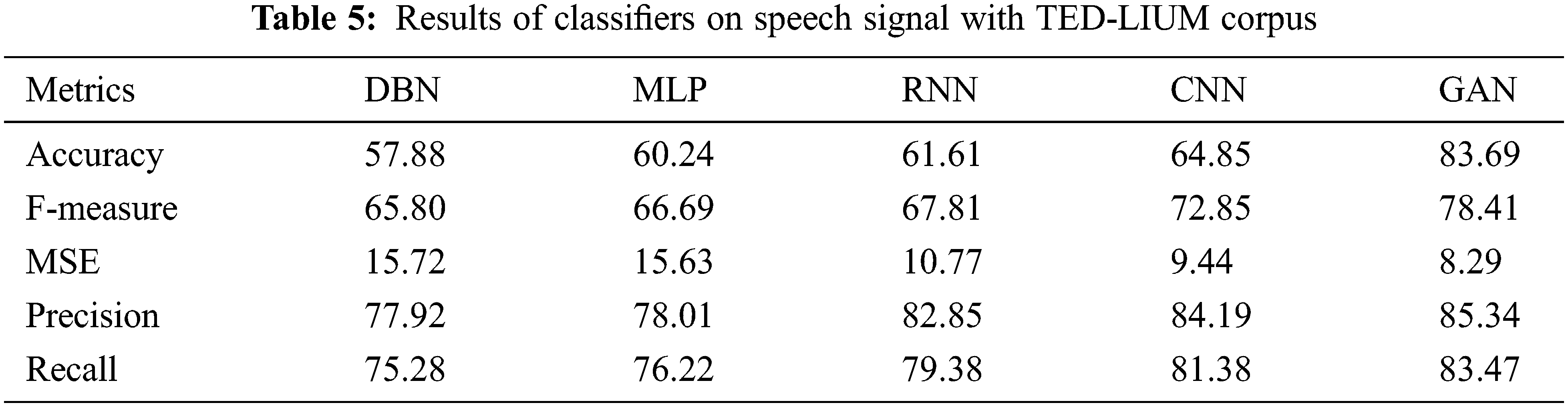
Table 6 shows the results of Classifiers on speech signal with Google Audio set. The results of various performance metrics show an improved performance by GAN than other classifiers with cepstral coefficient extraction of features.
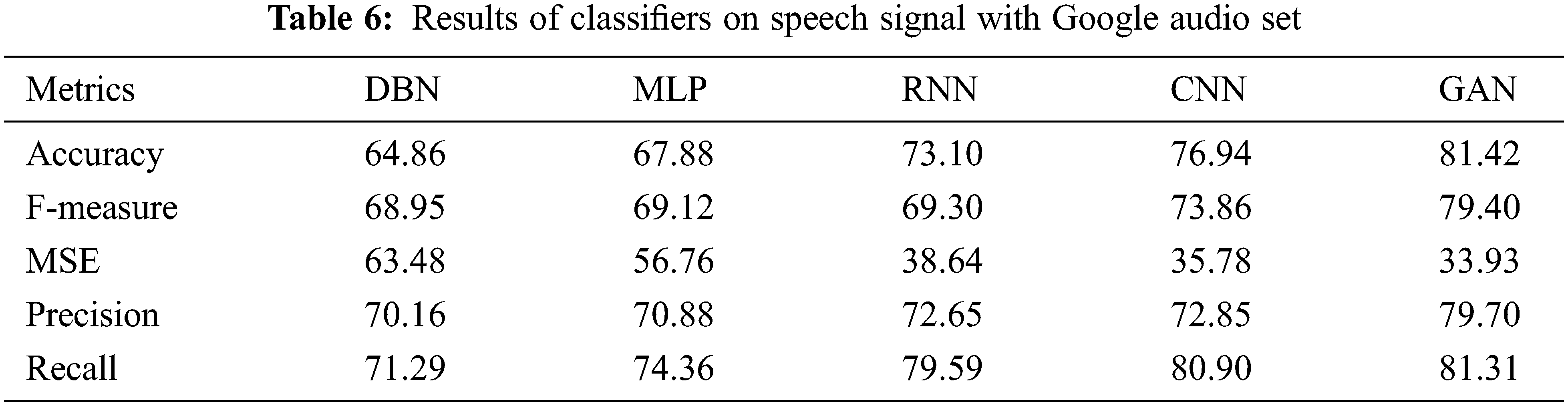
Table 7 shows the results of Classifiers on speech signals with LibriSpeech ASR Corpus. The results of various performance metrics show an improved performance by GAN than other classifiers with cepstral coefficient extraction of features.
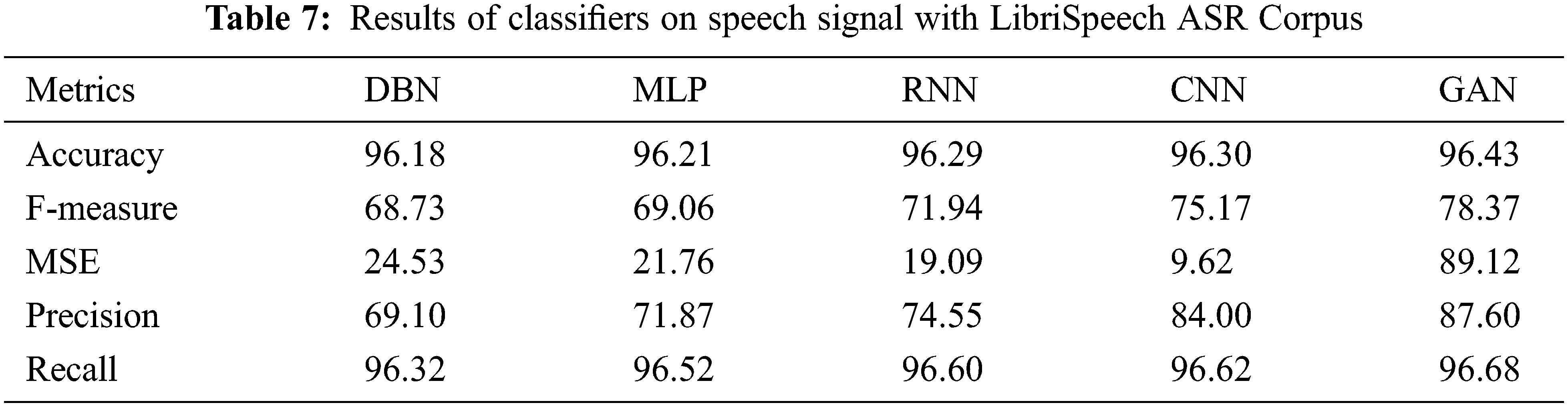
Table 8 shows the results of Classifiers on speech signal with CSS10. The results of various performance metrics show an improved performance by GAN than other classifiers with cepstral coefficient extraction of features.
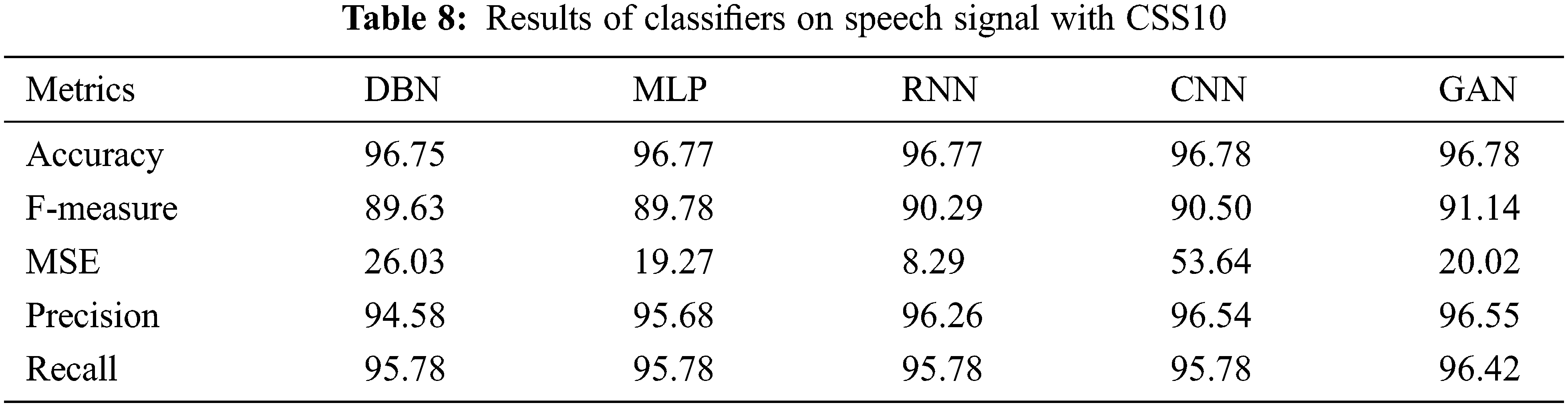
Table 9 shows the results of Classifiers on speech signals with backbone Pedagogic Corpus of Video-Recorded Interviews. The results of various performance metrics show an improved performance by GAN than other classifiers with cepstral coefficient extraction of features.
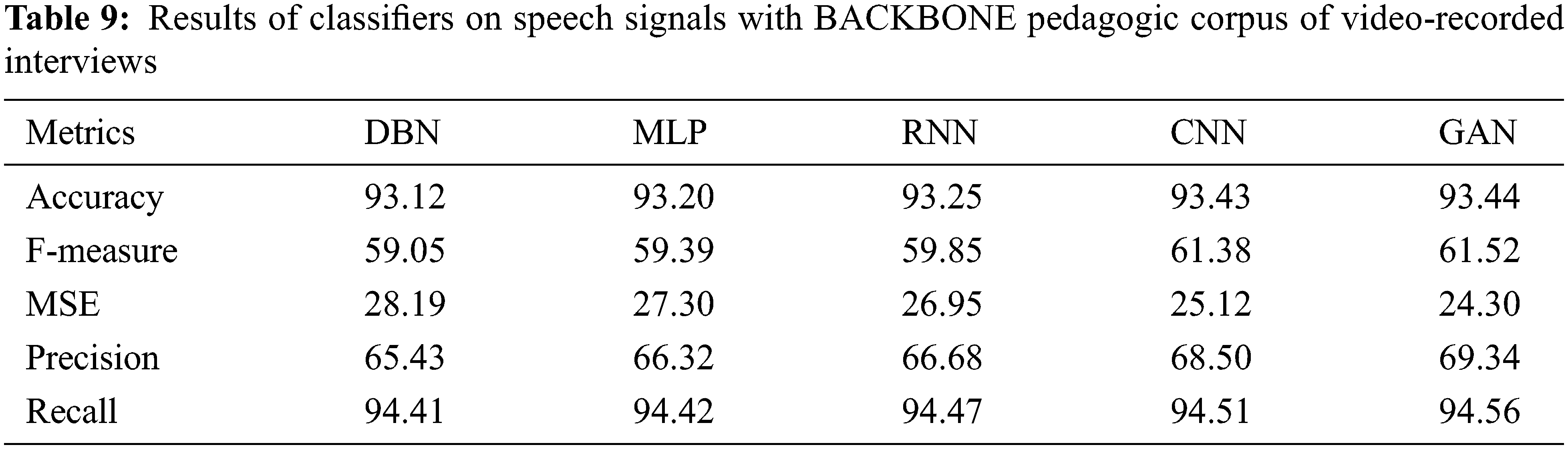
Table 10 shows the results of Classifiers on speechs signal with Arabic Speech Corpus. The results of various performance metrics show an improved performance by GAN than other classifiers with cepstral coefficient extraction of features.
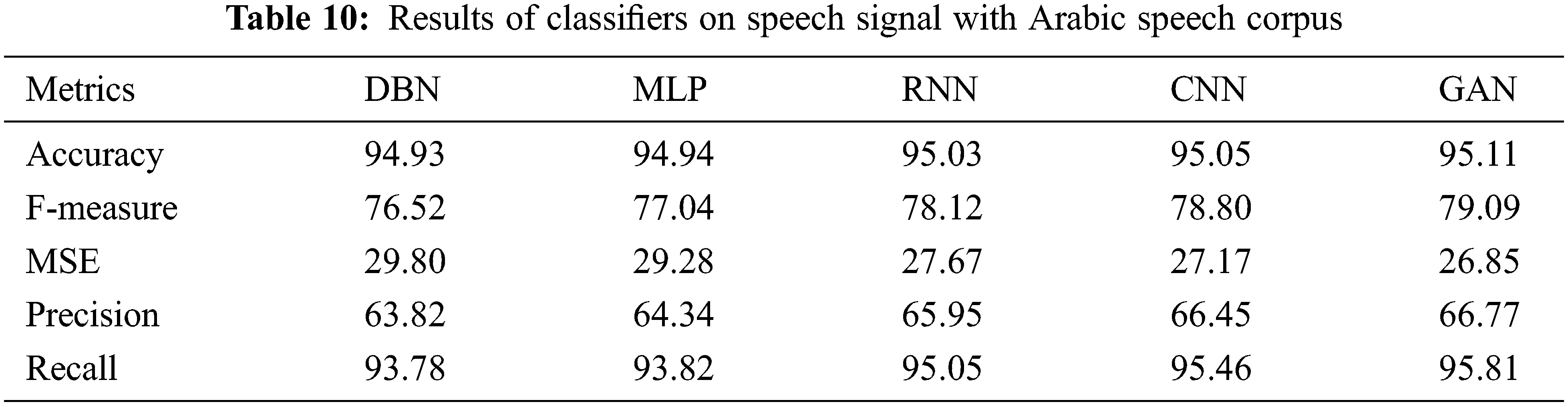
Table 11 shows the results of Classifiers on speech signals with Nijmegen Corpus of Casual French. The results of various performance metrics show an improved performance by GAN than other classifiers with cepstral coefficient extraction of features.
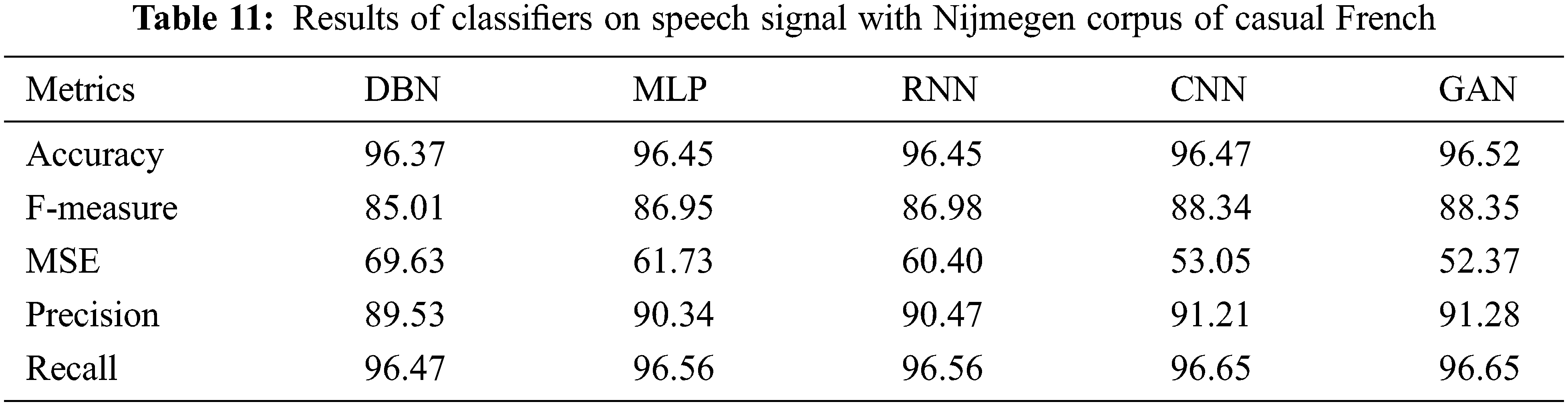
Table 12 shows the results of Classifiers on speech signal with Free Spoken Digit Dataset. The results of various performance metrics show an improved performance by GAN than other classifiers with cepstral coefficient extraction of features. Fig. 2 shows the accuracy (Training/Testing) over various datasets. Fig. 3 shows the Confusion Matrix.
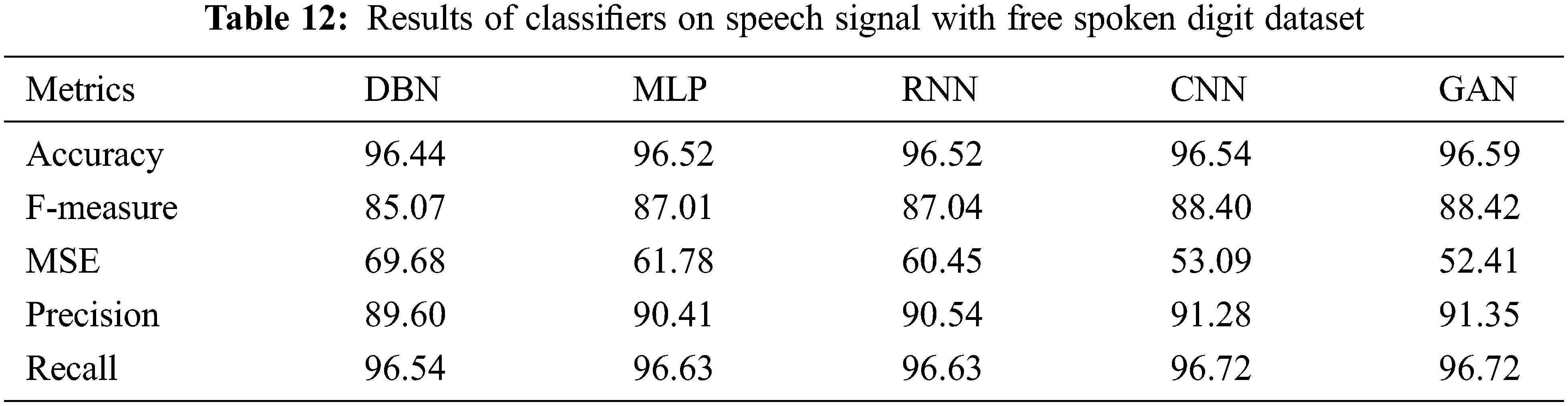
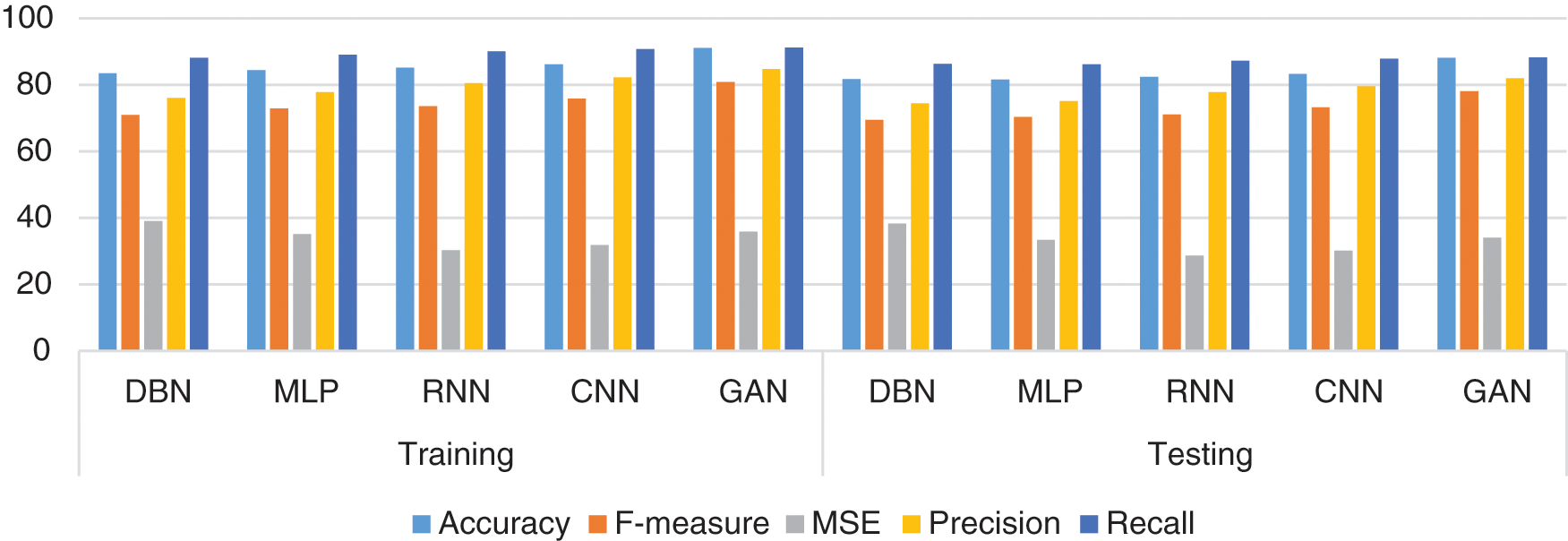
Figure 2: Accuracy (training/testing) over various datasets
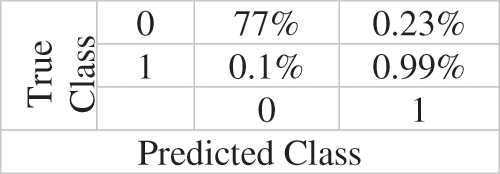
Figure 3: Confusion matrix
In this paper, the Classification of the speech signal is conducted with different DNN classifiers m where reinforcement learning checks the accuracy of classification. The extraction of essential features using cepstral coefficient analysis enables accurate classification of instances by the neural network classifiers. The use of reinforcement learning as a feedback mechanism helps in correcting the errors made by a classifier. The use of different classifiers including MLP, DBN, RNN, GAN, and CNN offer improved results in terms of reduced errors. As a result of which, the deep learning classifier namely RNN, CNN, and GAN achieve reduced penalties than DBN and MLP. The results of classification further show that the proposed speech signal classification engine offers higher classification accuracy with GAN than CNN, RNN, and the other two machine learning classifiers. The use of the cepstral coefficient also has improved the performance of the classification engine due to the proper extraction of features from the pre-processed speech signal. The other performance metrics show that the GAN obtains improved precision, recall, f-measure, and MSE. In the future, the ensemble of all these classifiers can be used as a multi-modal speech signal classification engine over a large speech signal dataset.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. S. Kannan, G. Dhiman, A. Sharma, S. N. Mohanty, M. Soni et al., “Ubiquitous vehicular ad-hoc network computing using deep neural network with IoT-based bat agents for traffic management,” Electronics, vol. 10, no. 7, pp. 785, 2021. [Google Scholar]
2. T. Stafylakis, M. H. Khan and G. Tzimiropoulos, “Pushing the boundaries of audiovisual word recognition using residual networks and LSTMs,” Computer Vision and Image Understanding, vol. 176, pp. 22–32, 2018. [Google Scholar]
3. K. I. Iso and T. Watanabe, “Speaker-independent word recognition using a neural prediction model,” in Proc. Int. Conf. on Acoustics, Speech, and Signal Processing, Albuquerque, NM, USA, pp. 441–444, 1990. [Google Scholar]
4. S. Furui, “Speaker-independent isolated word recognition using dynamic features of speech spectrum,” IEEE Transactions on Acoustics, Speech, and Signal Processing, vol. 34, no. 1, pp. 52–59, 1986. [Google Scholar]
5. K. Srihari, G. Dhiman, K. Somasundaram, A. Sharma, S. Rajeskannan et al., “Nature-inspired-based approach for automated cyberbullying classification on multimedia social networking,” Mathematical Problems in Engineering, vol. 2021, no. 6644652, pp. 12, 2021. [Google Scholar]
6. P. McGuire, J. Fritsch, J. J. Steil, F. Rothling, G. A. Fink et al., “Multi-modal human-machine communication for instructing robot grasping tasks,” in Proc. IEEE/RSJ Int. Conf. of Intelligent Robots and Systems, 2002, Lausanne, Switzerland, vol. 2, pp. 1082–1088, 2002. [Google Scholar]
7. O. Russakovsky, L. J. Li and L. Fei-Fei, “Best of both worlds: Human machine collaboration for object annotation,” in Proc. IEEE Conf. on Computer Vision and Pattern Recognition, Boston, MA, USA, pp. 2121–2131, 2015. [Google Scholar]
8. R. Collobert, C. Puhrsch and G. Synnaeve, “Wav2letter: An endto-end convnet-based speech recognition system,” in Proc. IEEE Conf. on Machine Learning, New York, USA, pp. 1–12, 2016. [Google Scholar]
9. A. V. D. Oord, S. Dieleman, H. Zen, K. Simonyan, O. Vinyals et al., “Wavenet: A generative model for raw audio,” in Proc. IEEE Conf. on Machine Learning, New York, USA, pp. 34–39, 2016. [Google Scholar]
10. M. T. Hagan and M. B. Menhaj, “Training feed forward networks with the marquardt algorithm,” IEEE Transactions on Neural Networks, vol. 5, no. 6, pp. 989–993, 1994. [Google Scholar]
11. P. U. Diehl and M. Cook, “Efficient implementation of STDP rules on SpiNNakerneuromorphic hardware,” in Proc. Int. Conf. on Neural Networks, Beijing, China, pp. 4288–4295, 2014. [Google Scholar]
12. S. R. Kheradpisheh, M. Ganjtabesh, S. J. Thorpe and T. Masquelier, “STDP-based spiking deep neural networks for object recognition,” in Proc. IEEE Conf. on Machine Learning, New York, USA, vol. 3, 2016. [Google Scholar]
13. J. P. D. Morales, A. J. Fernandez, A. R. Navarro, E. C. Escudero, D. G. Galan et al., “Multilayer spiking neural network for audio samples classification using SpiNNaker,” in Proc. Int. Conf. on Artificial Neural Networks, Barcelona, Spain, pp. 6–9, 2016. [Google Scholar]
14. Z. Hu, T. Wang and X. Hu, “An STDP-based supervised learning algorithm for spiking neural networks,” in Proc. Int. Conf. on Neural Information Processing, Guangzhou, China, pp. 92–100, 2017. [Google Scholar]
15. T. Moraitis, A. Sebastian, I. Boybat, M. L. Gallo, T. Tuma et al., “Fatiguing STDP: Learning from spike-timing codes in the presence of rate codes,” in Proc. 2017 Int. Joint Conf. on Neural Networks (IJCNN), Anchorage, AK, USA, pp. 1823–1830, 2017. [Google Scholar]
16. W. Sun, G. C. Zhang, X. R. Zhang, X. Zhang and N. N. Ge, “Fine-grained vehicle type classification using lightweight convolutional neural network with feature optimization and joint learning strategy,” Multimedia Tools and Applications, vol. 80, no. 20, pp. 30803–30816, 2021. [Google Scholar]
17. W. Sun, X. Chen, X. R. Zhang, G. Z. Dai, P. S. Chang et al., “A Multi-feature learning model with enhanced local attention for vehicle re-identification,” Computers, Materials & Continua, vol. 69, no. 3, pp. 3549–3560, 2021. [Google Scholar]
18. H. Sun and R. Grishman, “Lexicalized dependency paths based supervised learning for relation extraction,” Computer Systems Science and Engineering, vol. 43, no. 3, pp. 861–870, 2022. [Google Scholar]
19. C. R. Rathish and A. Rajaram, “Efficient path reassessment based on node probability in wireless sensor network,” International Journal of Control Theory and Applications, vol. 34, pp. 817–832, 2016. [Google Scholar]
20. C. R. Rathish and A. Rajaram, “Sweeping inclusive connectivity based routing in wireless sensor networks,” ARPN Journal of Engineering and Applied Sciences, vol. 3, no. 5. pp. 1752–1760, 2018. [Google Scholar]
21. A. Rajaram and K. Sathiyaraj, “An improved optimization technique for energy harvesting system with grid connected power for green house management,” Journal of Electrical Engineering & Technology, vol. 2022, pp. 1–13, 2022. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools