
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Heterogeneous Ensemble Feature Selection Model (HEFSM) for Big Data Analytics
1 Department of Information Technology, Sri Ramakrishna Engineering College, Coimbatore, Tamilnadu, India
2 Department of Computer Science & Engineering, RVS College of Engineering and Technology, Coimbatore, Tamilnadu, India
* Corresponding Author: M. Priyadharsini. Email:
Computer Systems Science and Engineering 2023, 45(2), 2187-2205. https://doi.org/10.32604/csse.2023.031115
Received 11 April 2022; Accepted 13 June 2022; Issue published 03 November 2022
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Big Data applications face different types of complexities in classifications. Cleaning and purifying data by eliminating irrelevant or redundant data for big data applications becomes a complex operation while attempting to maintain discriminative features in processed data. The existing scheme has many disadvantages including continuity in training, more samples and training time in feature selections and increased classification execution times. Recently ensemble methods have made a mark in classification tasks as combine multiple results into a single representation. When comparing to a single model, this technique offers for improved prediction. Ensemble based feature selections parallel multiple expert’s judgments on a single topic. The major goal of this research is to suggest HEFSM (Heterogeneous Ensemble Feature Selection Model), a hybrid approach that combines multiple algorithms. The major goal of this research is to suggest HEFSM (Heterogeneous Ensemble Feature Selection Model), a hybrid approach that combines multiple algorithms. Further, individual outputs produced by methods producing subsets of features or rankings or voting are also combined in this work. KNN (K-Nearest Neighbor) classifier is used to classify the big dataset obtained from the ensemble learning approach. The results found of the study have been good, proving the proposed model’s efficiency in classifications in terms of the performance metrics like precision, recall, F-measure and accuracy used.Keywords
IS (Intelligent Systems) have been growing rapidly in recent years encompassing the areas of commerce, science and medicine [1]. DM (Data Mining) defined in short as knowledge explorations identify trends, patterns and relationships in data and convert raw data into meaningful information [1]. AI (Artificial Intelligence) based techniques have been useful in normalizing incomplete DM datasets. DMTs (DM techniques) have been exploited in business decisions and organizational priorities. DM tasks include pre-processing, pattern assessments and presentations [2] using Cluster analysis, Time-series mining, ARM (Association Rules Mining) and classifications [3]. Thus, classification techniques play the underlying role in all DM tasks. Classifications grow in complexity when it involves high dimensional data like Big data where dimension is referred to the number of parameter values taken into consideration. As this count increases it increases the computational time required for processing where dimensionality reductions of the data is executed to increase the speed of the processing techniques.
Feature Selection is an efficient method of dimensionality reductions [4]. These selections select a subset with required features from the base set based on an evaluation criteria. The results thus better learning performances in terms of accuracy or classifications. These selections search for minimal representation of features and evaluate thus selected subsets in classification performances [5]. Feature selection methods also contribute towards generalizations of classifiers [6]. These approaches are oriented towards redundancy minimizations and relevance maximizations of labelling classes for classifications. The selected feature subsets retain their original forms and offer better readability and interpretability. When information is labelled, it helps in distinguishing relevant features. Thus these methods can be categorized into supervised, unsupervised and semi-supervised methods for feature selections [7].
Supervised Feature Selections can be viewed as filters, wrappers and embeddings in modelling systems [8,9]. Filters separate unwanted features for classifiers to learn while wrappers use predictive accuracies of previous learning for selecting quality features in data sets. Wrappers are expensive in their executions where metaheuristic algorithms reduce these computational times reasonably. Most metaheuristic algorithms have a problem of getting caught in a local optimum. Evolutionary algorithms have helped overcome this problem in their operations where PSO, GA (Genetic Algorithm), DD (Differential Development), ACO (Ant Colony Optimization), GWO and EHO algorithms are examples in this category. Hybrid techniques aim to use individual algorithmic powers for increased explorations [10].
This paper proposes a new hybrid wrapper for feature selection using FWGWO (Fuzzy Weight Grey Wolf Optimization) and EHO algorithms. Features are selected based on a fuzzy weight that minimizes the subset’s length and increases classification accuracy in parallel. The proposed HEFSM uses multiple algorithms. TCM (Tent Chaotic Map) is the wrapper used to jump local optima while optimizing search capabilities. FWGWO is an easy to implement algorithm which operates with fewer parameters. The algorithm considers location of individual wolves for its solutions. Thus, this work uses EHO in updating positional locations. A binary transformation normalizes continuous features which are then classified by the KNN classifier.
Consider Sharawi et al. [11] used WOA (Whale Optimization Algorithm) in their proposed feature selection system. Their meta-heuristic optimization algorithm mimicked the behavior of humpback whales. The proposed model applies the wrapper-based method to reach the optimal subset of features. They compared their technique with the PSO and GA algorithms on sixteen different datasets with multiple parameters. Experimental results demonstrate the proposed algorithm’s ability to optimize feature selections.
Sayed et al. [12] embedded a chaotic search in WOA iterations. Their scheme called CWOA (Chaotic Whale Optimization Algorithm) used TCM’s for improving WOA outputs. Their chaotic exploration operators outperformed other similar techniques. PSO was proposed by Chen et al. [13] in their HPSO-SSM (Hybrid Particle Swarm Optimization with a Spiral-Shaped Mechanism) selected optimal feature subsets for classification using wrappers. Their experimental results showed good performance in searching feature feasibility by selecting informative attributes for classifications.
PSO variant was used by Gu et al. [14] in their study which proposed CSO (Competitive Swarm Optimize) for large-scale optimizations of features in high-dimensional data. Their experimental results of six benchmark datasets showed a better performance than PSO based algorithms. Their CSO selected lesser number of features which could be classified better. Tu et al. [15] proposed HSGWO (Hierarchy Strengthened GWO) as their feature selection technique where wolves were classified as omega and dominant. The technique’s learning used dominant wolves to prevent low ranked wolves and improve cumulative efficiency. This is followed by a hybrid GWO and DE (Differential Evolution) strategy for omega wolves to evade local optimums. Their use of a perturbed operator improved exploration of the diverse population. Their results proved the algorithm’s superiority in convergences and solution quality.
Dimensions were learnt by Haiz et al. [16] with a generalized learning on PSO selected features. They included cardinality of subsets by extending dimension velocity. Their 2D-learning framework retained key features of PSO selections while learning dimensions. When evaluated with NB (Naive–Bayes) and KNN classifications their feature subsets ran faster evaluating its usefulness.
GWO was combined with Antlion Optimization in the study of Zawbaa et al. [17]. The scheme called ALO-GWO (Antlion Optimization -Grey Wolf Optimization) algorithm learnt from fewer examples and used it to select important features from large sets that could improve classification accuracy. The proposal showed promising results in comparison with PSO and GA. APSO (Accelerated Particle Swarm Optimization) proposed by Fong et al. [18] was a lightweight feature selection technique. It was designed specifically for mining streamed data for achieving enhanced analytical accuracy with lesser processing time. The scheme when tested on high dimensionality sets showed its improved performance.
Two-phase Mutation figured in the study of Abdel-Basset et al. [19] based on GWO algorithm. They selected features with wrappers. Their sigmoid function transformed search spaces into a binary form for feature selections. Statistical analysis proved the technique’s effectiveness. Li et al. [20] integrated GWO with a Kernel Extreme Learning Machine in their study. Their framework called (IGWO-KELM) was applied in medical diagnostics. GWO and GA were evaluated in its comparisons for predicting common diseases. Their performance metrics showed improvements in classification accuracy, sensitivity, specificity, precision, G-mean, F-measure and selected feature sizes. GWSO’s binary variant was exploited by ElHasnony et al. [21] in their study. Their technique called GWO-PSO found optimal solutions and used KNN for classifications on wrapper selected features where Euclidean separation matrices found optimal solutions.
Wang et al. [22] proposed a new technique SA-EFS (Sort aggregation-Ensemble Feature Selection) for high-dimensional datasets. The technique used Chi-Square, maximum information coefficient and XGBoost for aggregations. They integrated arithmetic and geometric mean aggregations for analyzing classification and predictive performances of the technique’s selected feature subsets. Their experimental results showed arithmetic mean aggregation ensemble feature selections effectively improved classification accuracy and that threshold intervals of 0.1 performed better. An empirical study in Pes [23] included many types of selection algorithms in different application domains. Eighteen heterogeneous classification tasks were evaluated with different cardinality feature subsets where ensemble approaches performed better even on single selectors.
Despite numerous attempts to develop an efficient model for characteristic choice in Big Data applications, the complexity of handling such data remains a significant barrier. As a result of the large volume and intricacy of large data sets, the data mining operation may be hampered. The characteristic choice method is a required pre-processing phase to reduce dataset dimensionality for the most useful characteristics and categorization performance improvement. It takes time to conduct a comprehensive analysis for important traits. In this paper, a new Heterogeneous Ensemble Feature Selection Model) which includes several algorithms in a hybrid combination is proposed. To determine the best answers, a K-nearest neighbour classifier with Euclidean separation matrices is utilised.
This work proposes feature selections based on sorted aggregations using ensembles in its approach. Three feature selection methods are executed in HEFSM to obtain multiple optimal feature subsets. Filtering is done by ReliefF, InfoG (Information Gain), and GR (Gain Ratio) methods. The proposed work also embeds SVM-t (Support Vector Machine- t-statistics). A new binary variant of wrappers based on the FWGWO and EHO is used in feature selections. Individual outputs of the used methods are learnt based on rules for getting multiple optimal feature subset candidate sets which are then aggregated to produce optimized feature subsets. The proposed algorithm of this work is verified using KNN classification. Fig. 1 depicts the flow of this research work.
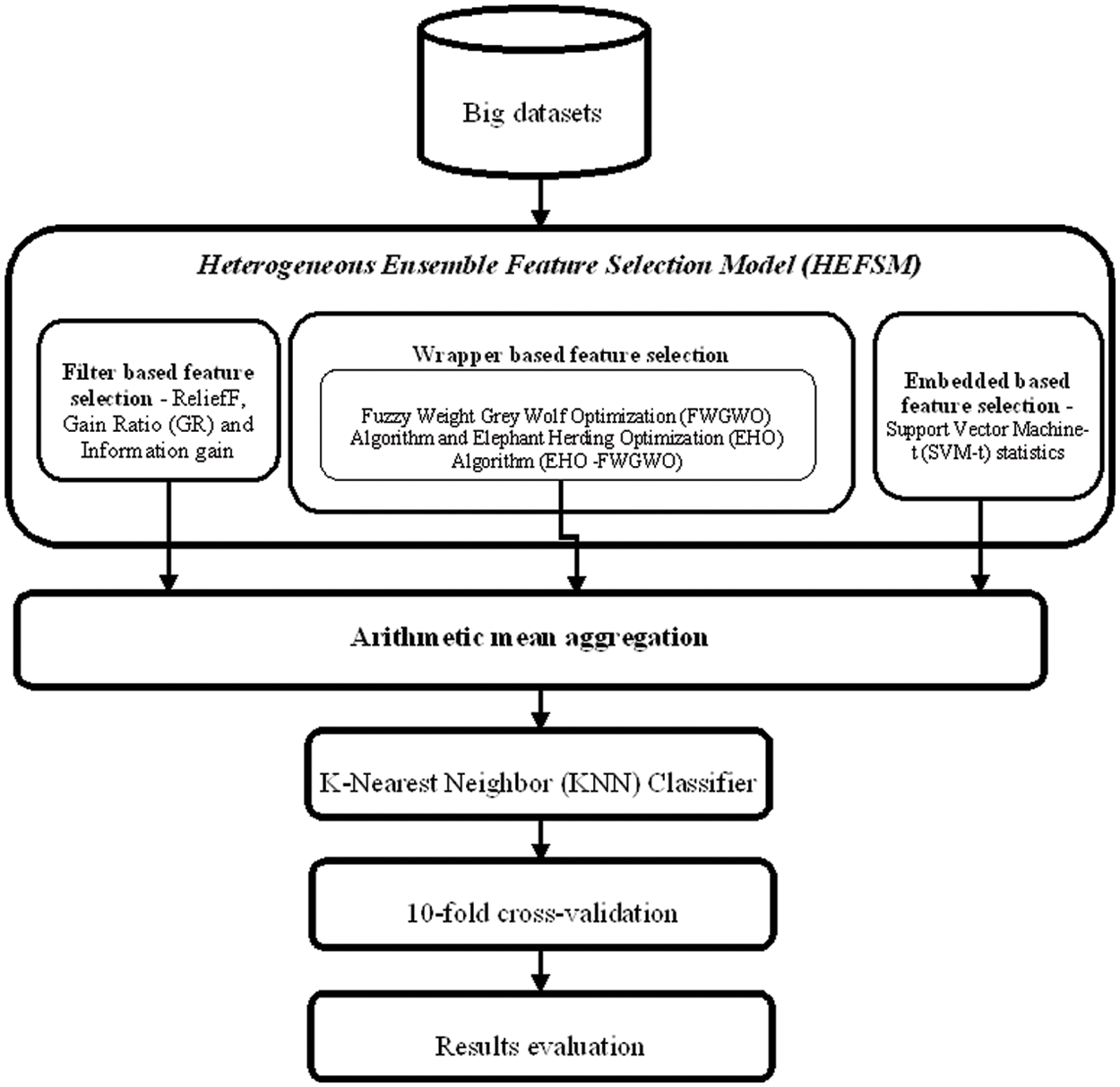
Figure 1: Flow of the proposed system
Ensembles learn better in ML by combining different ML learning models [24,25]. They are better than singular ML models as they effectively output multiple optimal features. Hence, this work uses ensembles for better feature selections by using combinations of filters, wrappers and an embedded algorithm.
Data Filtering in this work are based on three functions namely ReliefF, InfoG, and GR [25].
ReliefF differentiates data points that are near to each other in a feature space. A sample drawn instance’s value is compared with instances near to it. A relevance score is then assigned to each feature as good features have a constant value within their class. This process is recursive and features’ scores in iterations are updated. This helps weighing nearest neighbours based on their distance. ReliefF which can handle noisy and incomplete data values is limited to two classes in this work. It randomly selects an instance

InfoG is based on entropy where the weight of each feature is derived by evaluating the extent to which it decreases the class entropy or in reducing class predictions. Entropy can be calculated [25] using Eq. (1):
where IG(C, F)-information of feature F in class C, H(C)–class entropy and H (C|F)-conditional class entropy. InfoG is the number of bits saved when the class is transformed. Conditional entropy, depicted in Eqs. (2) and (3) can be computed by splitting the dataset into groups for each observed value of F and the sum of the ratio of examples in the class multiplied by the group’s entropy [25].
GR is also based on entropy, but differs from InfoG in normalizing InfoG’s bias towards greater values. Normalizations are done by dividing InfoG with attribute entropy in a class; as a result it reduces the bias of InfoG algorithm. GR can be computed using Eq. (4) [26].
when features count in a subset increases, difference are more clear and pronounced.
Wrappers use ML for their search of possible feature subsets and evaluate each subset based on quality. This work uses FWGWO (Algorithm 1) with EHO (Algorithm 2) as a wrapper in its operations.
Techniques based on Grey wolves are an advanced implementation of optimizations as they easily close on optimal selection of features (prey) from a dataset. This work uses metaheuristic algorithms which mimic attacking grey wolves for closing in on a prey (optimal selection of features) [27]. Wolves exist in packs of 5–12 and have four levels of leadership hierarchy namely alpha (

Figure 2: The leadership hierarchy of wolfs
The
where
where
where
The weight vector
Membership values for each weight in
where,
Wolves change their positions for catching a prey where |A| < 1.

Proposed Elephant Herding Optimization (EHO)-FWGWO Model
The proposed algorithm for addressing feature selection problems is examined in this section (see Fig. 3). The model is mainly initialized, evaluated, transformed, and iterated.
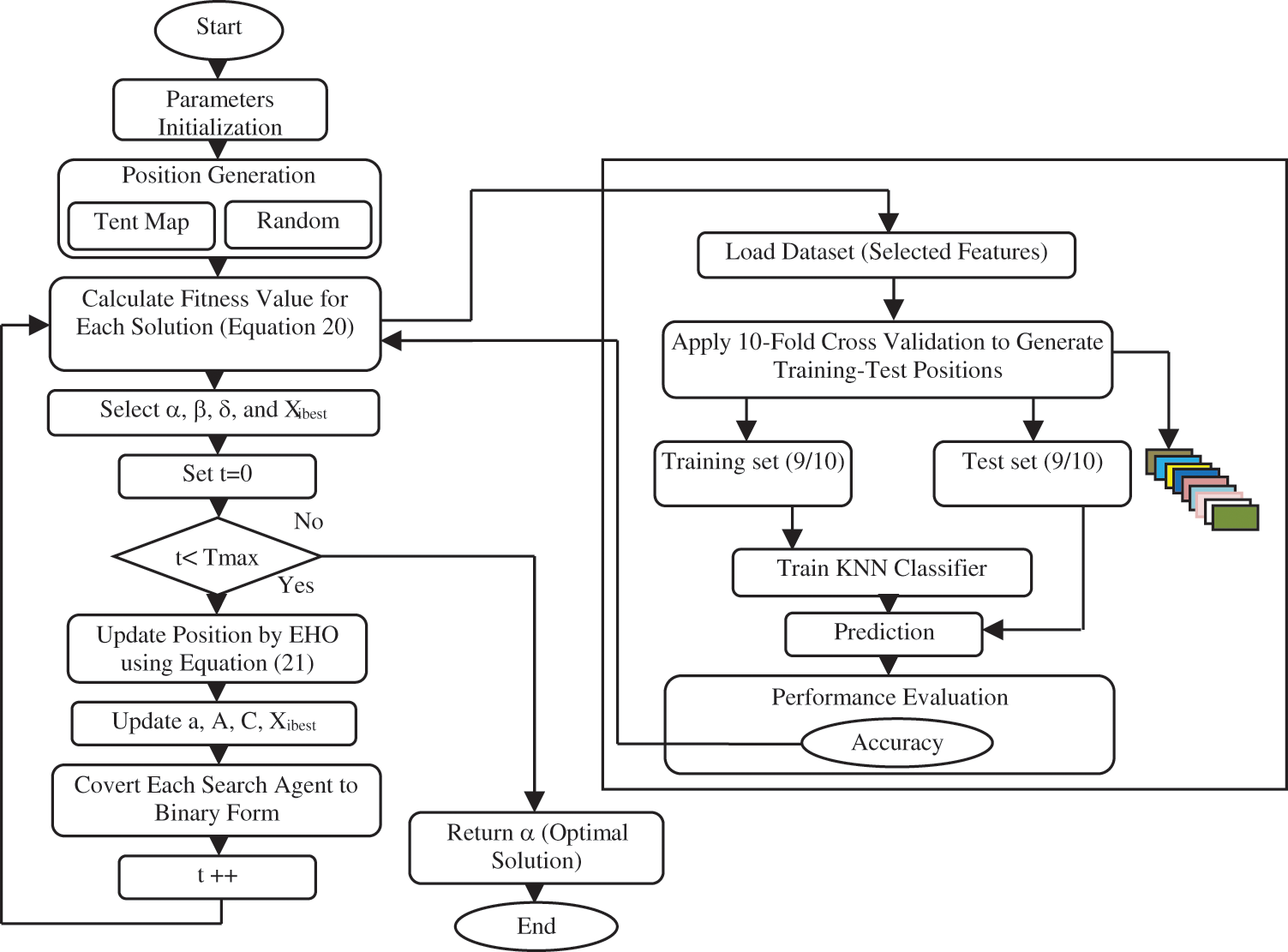
Figure 3: Block diagram for the proposed model
Initialization
In this stage randomly generated n wolves are initialized. These wolves or search agents represent a solution whose length d equates to the features count in the original dataset. Fig. 4 displays a probable dataset solution with 11 features. Relevant features have a value of 1 while ignored features take a value of 0.

Figure 4: Solution representation
A logistic map generated the initial PSO population where feature convergences in the proposed algorithm rely on random sequences that execute the algorithm using different parameters. The proposed work’s TCM is depicted as Eq. (19).
where,
Evaluation
The fitness function used in this work evaluates goals using Eq. (20),
where,
Position Updating
FWGWO considers the second and third-best locations of wolves for learning location information on specific wolves and in doing so a wolf’s information on own experience is ignored. Hence, the proposed work uses EHO to update positions. FWGWO update are performed based on a clan operator which uses grey wolf’s position in a clan for updates based on the relationship to the operator. EHO methods for updates described by the authors of [29] are used in this study for updating grey wolf positions. Assuming ci denotes a grey wolf clan its subsequent position in the clan is updated using Eq. (21):
where,
The issue in the above equation is the absence of a reference source. Hence, information from all individuals in ci is used to create the new best
where,
where,

This work embeds SVM-t for statistically analyzing features from a dataset for selection as SVMs create a maximal hyper plane from feature vectors to find classes in a dataset. The proposed SVM-t takes advantage of the most significant feature subsets in a dataset using Eq. (27). Two-sample t-statistics in two directions evaluate variances in the determined classes and thus minimizes variations between them for classifying data points into classes.
where, n+ (resp., n−)–number of support vectors designed for class + 1 (resp., −1). Compute mean
Fig. 5 depicts the overall framework of HEFSM in feature selections. HEFSM uses filters, wrappers and embedding for selecting significant features and then orders them based on their importance to produce many sorted optimal feature subsets namely
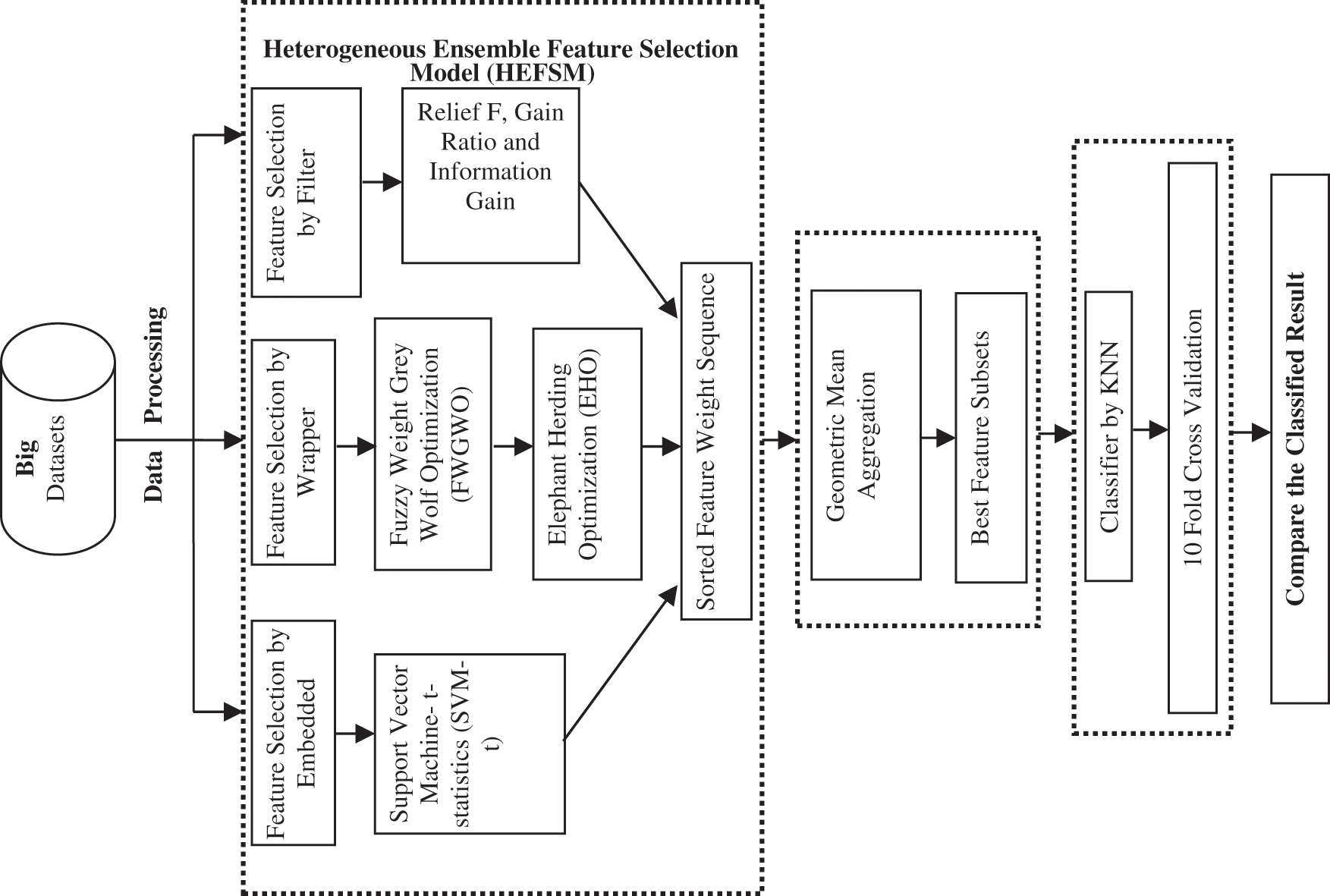
Figure 5: Overall framework of HEFSM method
Geometric mean is obtained by dividing the sum of logarithmic values by the number of features as shown in Eq. (28),
A threshold percentage th% selects features from this sorted sequences to create an optimal feature subset. All feature selection methods results are joined for forming a single input for the KNN classifier which then validates the proposed scheme’s selected feature sets.
KNN uses Euclidean distances for finding nearest neighbours to data points [30] using Eq. (29).
where,
This section displays experimental results of the proposed HEFSM is implemented on MATLAB (2014a) and on an intel core i7/16Gb running 64 bit windows 10. The proposed scheme was examined using known datasets (listed in Tab. 1) with feature selection issues for its ability to select optimal feature sets from datasets. These datasets were obtained from the UCI Machine Learning Repository website [32]–[34]. Breast cancer Wisconsin data collection, characteristics are determined from a digitized representation of a fine needle aspirate (FNA) of a breast mass. They explain the existence of the cell nuclei features that are in the picture. It contains information on the source, donor, clinical studies, id number, diagnosis (malignant = M, Benign = B) and distribution of grades. Ten real-valued functions are determined for each cell nucleus as pursues: radius, texture, perimeter, area, smoothness, compactness, concavity, concave points, symmetry and fractal dimension (See Tab. 1).
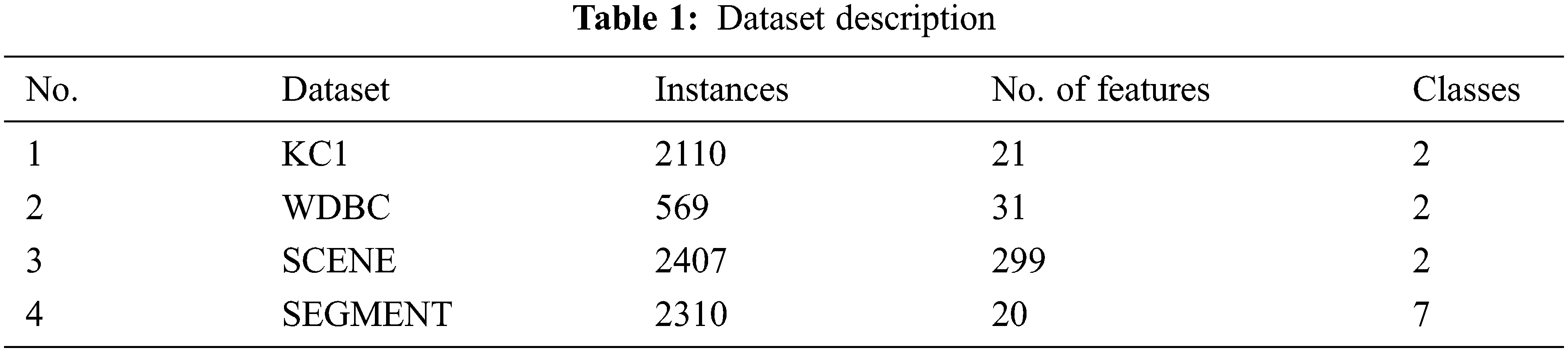
All the characteristics are measured for the mean, regular error, and “worst” or highest (mean of the three highest values). 80% of the training data and 20% of the evaluation data are included in the categorization phase for the assigned series of data. Data source of Chronic Kidney Disease (CKD) consist of 400 occurrences with 25 characteristics. This dataset is also used to assess CKD and can be obtained approximately within 8 weeks of time from the hospital (Tab. 2). The scene dataset is an image classification task where labels like Beach, Mountain, Field, and Urban are assigned to each image. Segment instances were drawn randomly from a database of 7 outdoor images. The images were hand-segmented to create a classification for every pixel. Each instance is a 3 × 3 region.

In this case, recall is specified as the quantity of true positives divided by the overall elements truly belonging to the positive class. It is defined in Eq. (31)
F-measure is defined as combination of precision and recall. It is defined in Eq. (32)
Classification accuracy is the ratio of correct predictions to total predictions made. It is often described in Eq. (33),
The classification accuracy of the KNN classifier conducted in Tab. 3. The resulted accuracies in most datasets approved the superiority of the proposed model. In the scene and segment dataset, the HEFSM achieved better results of 92.85% and 97.23% which is better than other methods. The results in Tab. 3 graphically modelled in the following Figs 6–10. Combining experiments were performed using four feature selection methods and four datasets, shown as 3.
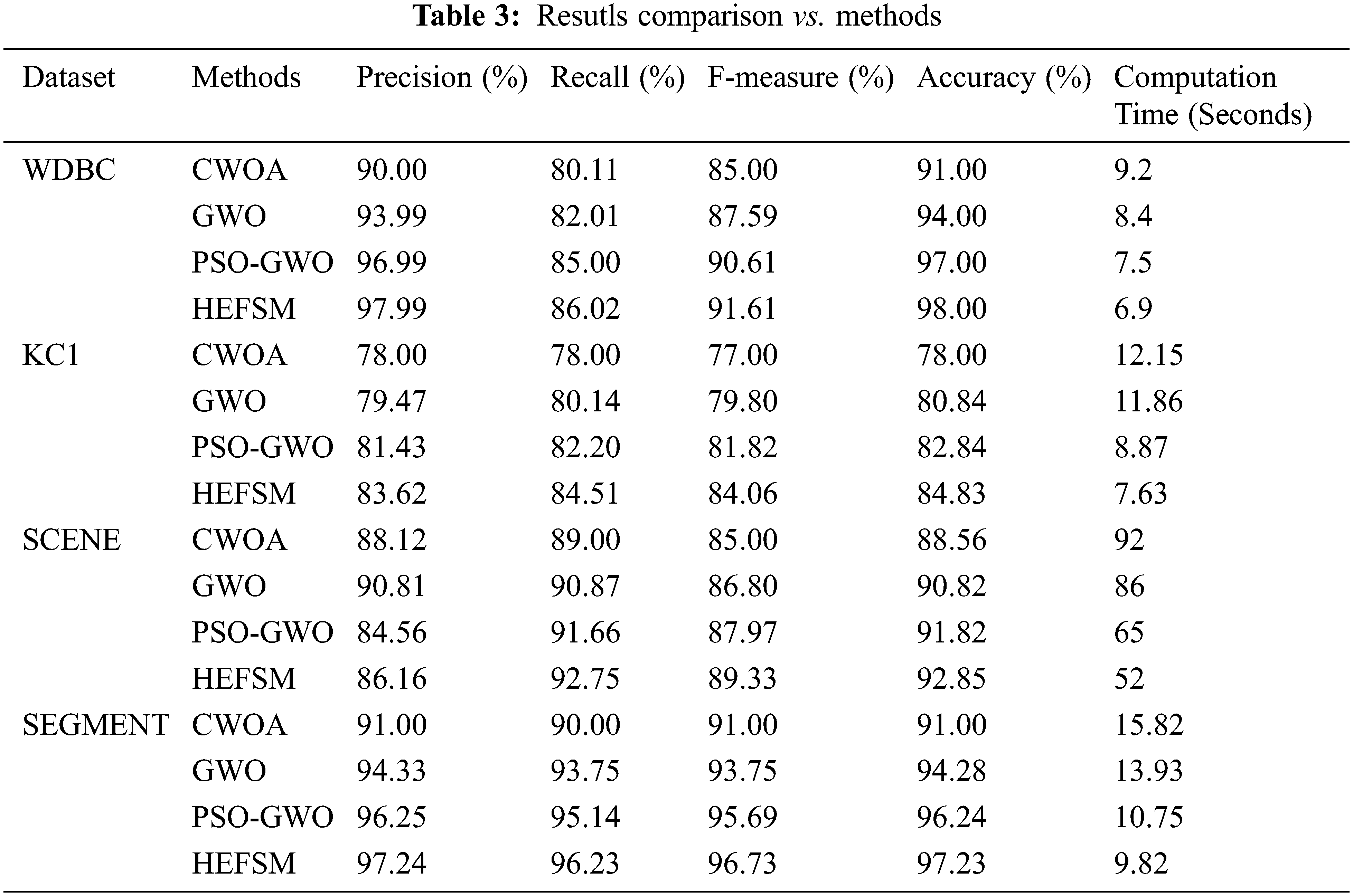
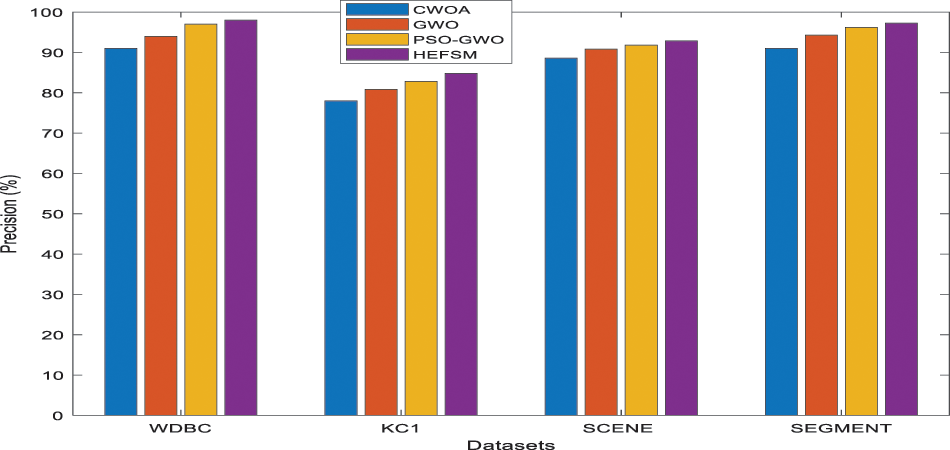
Figure 6: Precision comparison of feature selection methods vs. datasets
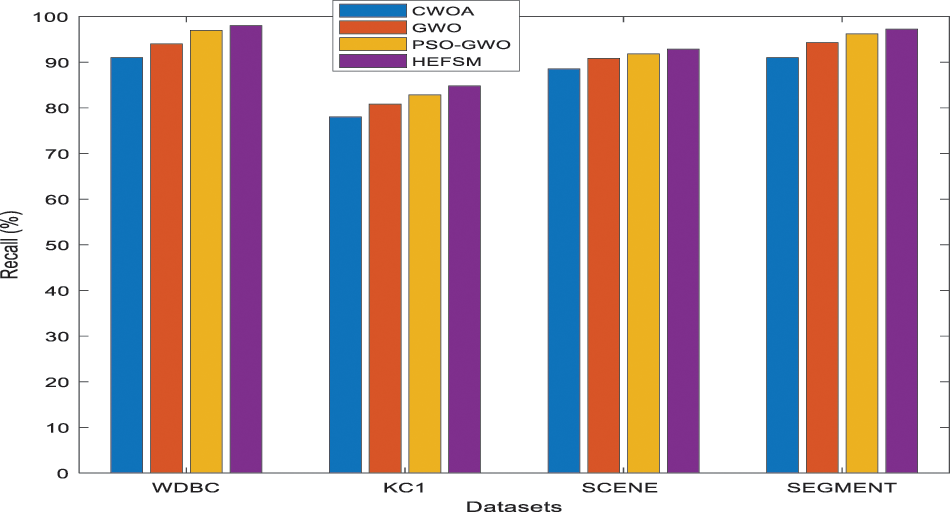
Figure 7: Recall comparison of feature selection methods vs. datasets
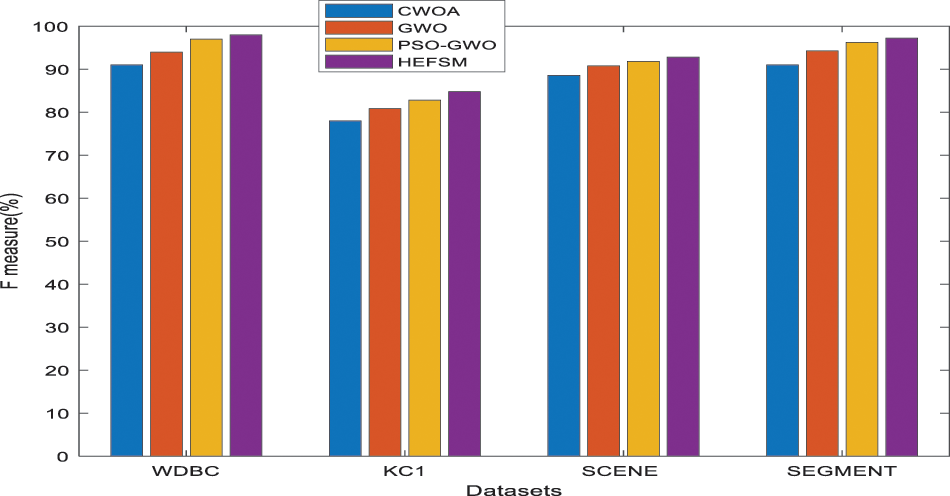
Figure 8: F-Measure comparison of feature selection methods vs. datasets
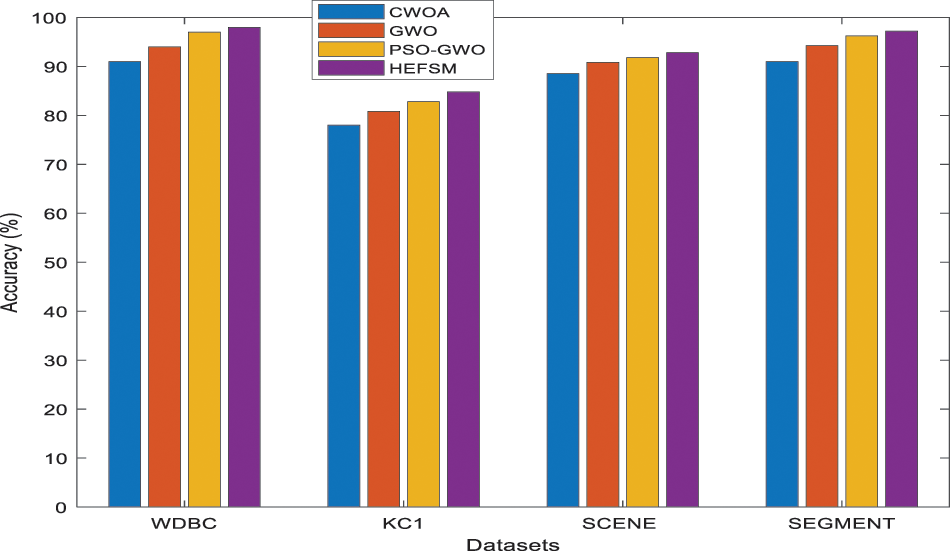
Figure 9: Accuracy comparison of feature selection methods vs. datasets
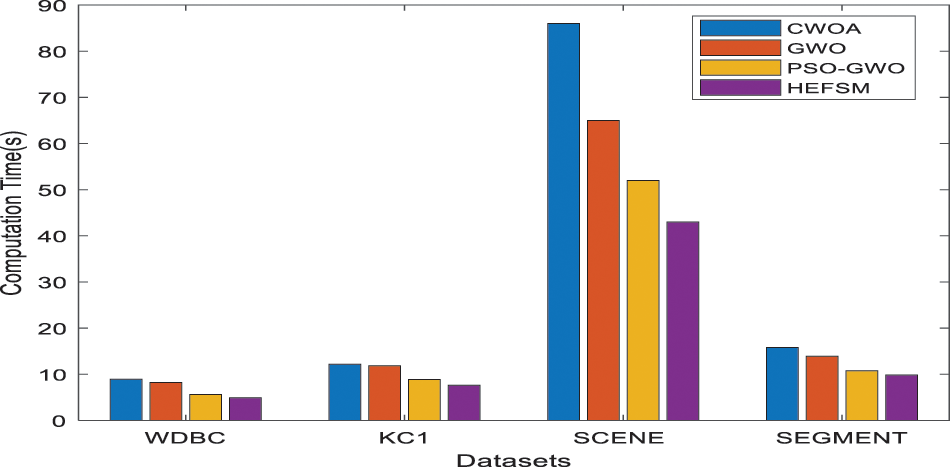
Figure 10: Computational time comparison of feature selection methods vs. datasets
Fig. 6 shows the precision comparison among the proposed HEFSM system and other algorithms concerning the KNN classifier. Fig. 6, the precision result of proposed HEFSM system gives higher results of 97.99% whereas other methods such as CWOA, GWO and PSO-GWO gives lesser precision results of 90.00%, 93.99%, and 96.99% respectively at WDBC dataset. The recall results of feature selection methods are graphically explained in Fig. 7. The proposed model achieved higher recall results of 86.02%, whereas other methods such as CWOA, GWO and PSO-GWO algorithm gives recall result of 80.11%, 82.01% and 85.00% respectively at WDBC dataset concerning the KNN classifier. F-measure results of proposed system and existing feature selection algorithms via KNN classifier are graphically shown in Fig. 8. The proposed model gives improved f-measure results of 91.61%, whereas other methods such as CWOA, GWO and PSO-GWO algorithm gives f-measure result of 85.00%, 87.59% and 90.61% respectively at WDBC dataset concerning the KNN classifier. From the total number of features in all datasets, the proposed HEFSM model via three feature selection methods gives best features which give improved accuracy results. Fig. 9 shows a comparison among the proposed model and other algorithms concerning the accuracy. Tab. 3 shows the accuracy for experiment computations. The results graphically explained in Fig. 9. The proposed model achieved higher accuracy. The accuracy for all datasets has increased when compared to other feature selection methods respectively. Accuracy results of proposed system and existing feature selection algorithms via KNN classifier are graphically shown in Fig. 9. The proposed model gives improved accuracy results of 98.00%, whereas other methods such as CWOA, GWO and PSO-GWO algorithm gives accuracy result of 91.00%, 94.00% and 97.00% respectively at WDBC dataset via KNN classifier. From the total number of features in all datasets, the proposed HEFSM model via three feature selection methods gives best features which give improved accuracy results.
Fig. 10 shows the comparison time among the proposed model and other algorithms concerning the KNN classifier. Tab. 3 shows the elapsed time for experiment computations. The proposed model achieved less computation time of 6.9 s for WDBC dataset. The total time is 9.2 s for CWOA, 8.4 s for GWO and PSO-GWO equals to 7.5 s.
This paper has proposed and implemented an ensemble learning method HEFSM for selecting optimal feature sets from high dimensional datasets. Multiple techniques and algorithms are used in this proposed work. It uses filters, wrappers and embedding in its architecture. Filtering is based on ReliefF, InfoG and GR. SVM-t is embedded for statistical evaluations and selections. A new binary variant of wrapper functions in feature selection is executed by integrating FWGWO and EHO algorithms for achieving better performances and achieving a better trade-off between predictive performance and stability. The ensemble paradigm has been introduced in the framework for improving robustness of feature selections, specifically for high-dimensional or minimal sampled datasets or data where extracting stable features is complex and difficult. The proposed scheme’s aggregate learning from multiple optimal feature subsets results in higher stability especially while handling high dimensional data in HEFSM. This framework’s EHO-FWGWO algorithm overcomes local optima issues by its random initializations, use of TCM and features weights generated by a fuzzy function. Moreover, the application of a sigmoid function in converting the search space to a binary form increases the proposed systems ability. HEFSM technique could find best feature subsets for maximizing classifier accuracy as proved by the results of KNN classifications on the selected optimal feature subsets. For instance, the proposed model gives improved accuracy results of 98.00%, whereas other methods such as CWOA, GWO and PSO-GWO algorithm gives accuracy result of 91.00%, 94.00% and 97.00% respectively at WDBC dataset via KNN classifier. Invest a significant amount of time in data to increase the model’s reliability and performance. KNN classifier, accuracy depends on the quality of the data and for larger dataset the prediction stage might be slow. In future some other classifiers such Support Vector Machine (SVM), deep learning methods and fuzzy methods have been developed for classification which is left as scope of the future work.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. K. Hi’ovská and P. Koncz, “Application of artificial intelligence and data mining techniques to financial markets,” Economic Studies & Analyses/Acta VSFS, vol. 6, no. 1, pp. 1–15, 2012. [Google Scholar]
2. M. Qiu, S. Y. Kung and Q. Yang, “Secure sustainable green smart computing,” in IEEE Transactions on Sustainable Computing, vol. 4, no. 2, pp. 142–144, 2019. [Google Scholar]
3. B. Johnson, Algorithmic Trading & DMA: An introduction to direct access trading strategies, 1st ed., London: Myeloma Press, pp. 574, 2011. [Google Scholar]
4. J. Cai, J. Luo, S. Wang and S. Yang, “Feature selection in machine learning: A new perspective,” Neuro Computing, vol. 3, pp. 70–79, 2018. [Google Scholar]
5. E. Emary and H. M. Zawbaa, “Feature selection via lèvy antlion optimization,” Pattern Analysis and Applications, vol. 22, no. 3, pp. 857–876, 2018. [Google Scholar]
6. R. C. Chen, C. Dewi, S. W. Huang and R. E. Caraka, “Selecting critical features for data classification based on machine learning methods,” Journal of Big Data, vol. 7, no. 1, pp. 1–26, 2020. [Google Scholar]
7. J. C. Ang, A. Mirzal, H. Haron and H. N. A. Hamed, “Supervised, unsupervised, and semi-supervised feature selection: A review on gene selection,” IEEE/ACM Transactions on Computational Biology and Bioinformatics, vol. 13, no. 5, pp. 971–989, 2015. [Google Scholar]
8. P. Smialowski, D. Frishman and S. Kramer, “Pitfalls of supervised feature selection,” Bioinformatics, vol. 26, no. 3, pp. 440–443, 2010. [Google Scholar]
9. S. H. Huang, “Supervised feature selection: A tutorial,” Artificial Intelligence Research, vol. 4, no. 2, pp. 22–37, 2015. [Google Scholar]
10. N. Hoque, M. Singh and D. K. Bhattacharyya, “EFS-MI: An ensemble feature selection method for classification,” Complex & Intelligent Systems, vol. 4, no. 2, pp. 105–118, 2018. [Google Scholar]
11. M. Sharawi, H. M. Zawbaa and E. Emary, “Feature selection approach based on whale optimization algorithm,” in 2017 Ninth Int. Conf. on Advanced Computational Intelligence (ICACI), Doha, Qatar, pp. 163–168, 2017. [Google Scholar]
12. G. I. Sayed, A. Darwish and A. E. Hassanien, “A new chaotic whale optimization algorithm for features selection,” Journal of Classification, vol. 35, no. 2, pp. 300–344, 2018. [Google Scholar]
13. K. Chen, F. Y. Zhou and X. F. Yuan, “Hybrid particle swarm optimization with spiral-shaped mechanism for feature selection,” Expert Systems with Applications, vol. 128, pp. 140–156, 2019. [Google Scholar]
14. S. Gu, R. Cheng and Y. Jin, “Feature selection for high-dimensional classification using a competitive swarm optimizer,” Soft Computing, vol. 22, no. 3, pp. 811–822, 2018. [Google Scholar]
15. Q. Tu, X. Chen and X. Liu, “Hierarchy strengthened grey wolf optimizer for numerical optimization and feature selection,” IEEE Access, vol. 7, pp. 78012–78028, 2019. [Google Scholar]
16. F. Haiz, A. Swain, N. Patel and C. Naik, “A Two-dimensional (2-D) learning framework for particle swarm based feature selection,” Pattern Reorganization, vol. 76, pp. 416–433, 2018. [Google Scholar]
17. H. M. Zawbaa, E. Emary, C. Grosan and V. Snasel, “Large-dimensionality small-instance set feature selection: A hybrid bio-inspired heuristic approach,’’ Swarm Evolution Computer, vol. 42, pp. 29–42, 2018. [Google Scholar]
18. S. Fong, R. Wong and A. Vasilakos, “Accelerated PSO swarm search feature selection for data stream mining big data,” IEEE Transaction. Services Computer, vol. 9, no. 1, pp. 33–45, 2016. [Google Scholar]
19. M. Abdel-Basset, D. El-Shahat, I. El-henawy, V. H. C. de Albuquerque and S. Mirjalili, “A new fusion of grey wolf optimizer algorithm with a two-phase mutation for feature selection,” Expert Systems with Applications, vol. 139, pp. 1–14, 2020. [Google Scholar]
20. Q. Li, H. Chen, H. Huang, X. Zhao, Z. Cai et al., “An enhanced grey wolf optimization based feature selection wrapped kernel extreme learning machine for medical diagnosis,” Computer Mathematics Methods, vol. 2017, pp. 1–15, 2017. [Google Scholar]
21. I. M. El-Hasnony, S. I. Barakat, M. Elhoseny and R. R. Mostafa, “Improved feature selection model for big data analytics,” IEEE Access, vol. 8, pp. 66989–67004, 2018. [Google Scholar]
22. J. Wang, J. Xu, C. Zhao, Y. Peng and H. Wang, “An ensemble feature selection method for high-dimensional data based on sort aggregation,” Systems Science & Control Engineering, vol. 7, no. 2, pp. 32–39, 2019. [Google Scholar]
23. B. Pes, “Ensemble feature selection for high-dimensional data: A stability analysis across multiple domains,” Neural Computing and Applications, vol. 32, pp. 1–23, 2019. [Google Scholar]
24. I. H. Witten, E. Frank, M. A. Hall and C. J. Pal, Data Mining: Practical Machine Learning Tools and Techniques, Burlington: Morgan Kaufmann, vol. 2, pp. 1–664, 2016. [Google Scholar]
25. I. Kavakiotis, O. Tsave, A. Salifoglou, N. Maglaveras, I. Vlahavas et al., “Machine learning and data mining methods in diabetes research,” Computational and Structural Biotechnology Journal, vol. 15, pp. 104–116, 2017. [Google Scholar]
26. H. Dağ, K. E. Sayin, I. Yenidoğan, S. Albayrak and C. Acar, “Comparison of feature selection algorithms for medical data,” in 2012 Int. Symp. on Innovations in Intelligent Systems and Applications, Karadeniz Technical University, pp. 1–5, 2012. [Google Scholar]
27. S. Mirjalili, S. M. Mirjalili and A. Lewis, “Grey wolf optimizer,” Advances in Engineering Software, vol. 69, pp. 46–61, 2014. [Google Scholar]
28. Z. J. Teng, J. L. Jv and L. W. Guo, “An improved hybrid grey wolf optimization algorithm,” Soft Computing, vol. 23, no. 15, pp. 6617–6631, 2019. [Google Scholar]
29. G. G. Wang, S. Deb and L. D. S. Coelho, “Elephant herding optimization,” in 2015 3rd Int. Symp. on Computational and Business Intelligence (ISCBI), Indonesia, pp. 1–5, 2015. [Google Scholar]
30. J. Gou, H. Ma, W. Ou, S. Zeng, Y. Rao et al. “A generalized mean distance-based k-nearest neighbor classifier,’’ Expert System Applied, vol. 115, pp. 356–372, 2019. [Google Scholar]
31. T. T. Wong and P. Y. Yeh, “Reliable accuracy estimates from k-fold cross validation,” IEEE Transtions Knowledge Data Engineerng, Early Access, vol. 2, pp. 635–651, 2019. [Google Scholar]
32. E. D. Dheeru and K. Taniskidou, “UCI machine learning repository,” Technical Representation, vol. 5, pp. 586–592, 2017. [Google Scholar]
33. W. Sun, X. Chen, X. R. Zhang, G. Z. Dai, P. S. Chang et al., “A Multi-feature learning model with enhanced local attention for vehicle re-identification,” Computers, Materials & Continuous, vol. 69, no. 3, pp. 3549–3560, 2021. [Google Scholar]
34. W. Sun, G. C. Zhang, X. R. Zhang, X. Zhang and N. N. Ge, “Fine-grained vehicle type classification using lightweight convolutional neural network with feature optimization and joint learning strategy,” Multimedia Tools and Applications, vol. 80, no. 20, pp. 30803–30816, 2021. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools