
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Adaptive Partial Task Offloading and Virtual Resource Placement in SDN/NFV-Based Network Softwarization
1 Department of Software Convergence, Soonchunhyang University, Asan, 31538, Korea
2 Department of Computer Software Engineering, Soonchunhyang University, Asan, 31538, Korea
* Corresponding Author: Seokhoon Kim. Email:
Computer Systems Science and Engineering 2023, 45(2), 2141-2154. https://doi.org/10.32604/csse.2023.030984
Received 07 April 2022; Accepted 27 June 2022; Issue published 03 November 2022
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Edge intelligence brings the deployment of applied deep learning (DL) models in edge computing systems to alleviate the core backbone network congestions. The setup of programmable software-defined networking (SDN) control and elastic virtual computing resources within network functions virtualization (NFV) are cooperative for enhancing the applicability of intelligent edge softwarization. To offer advancement for multi-dimensional model task offloading in edge networks with SDN/NFV-based control softwarization, this study proposes a DL mechanism to recommend the optimal edge node selection with primary features of congestion windows, link delays, and allocatable bandwidth capacities. Adaptive partial task offloading policy considered the DL-based recommendation to modify efficient virtual resource placement for minimizing the completion time and termination drop ratio. The optimization problem of resource placement is tackled by a deep reinforcement learning (DRL)-based policy following the Markov decision process (MDP). The agent observes the state spaces and applies value-maximized action of available computation resources and adjustable resource allocation steps. The reward formulation primarily considers task-required computing resources and action-applied allocation properties. With defined policies of resource determination, the orchestration procedure is configured within each virtual network function (VNF) descriptor using topology and orchestration specification for cloud applications (TOSCA) by specifying the allocated properties. The simulation for the control rule installation is conducted using Mininet and Ryu SDN controller. Average delay and task delivery/drop ratios are used as the key performance metrics.Keywords
1.1 Motivation and Problem Statement
With future aspects of enabling network automation, the 3rd generation partnership project (3GPP), a global organization for standard telecommunications, released technical specifications of various use cases, which includes the procedures of gathering primary network data features, machine learning (ML) model training, and request-response interactions in the network data analytics function (NWDAF) [1]. In addition, European telecommunications standards institute (ETSI) contributes reference models and promising concepts in generic autonomic network architecture (GANA) and experiential networked intelligence (ENI) for enabling artificial intelligence (AI) algorithms, including ML/deep learning (DL) and self-organizing deployment policies [2,3]. With the preliminaries of superior testbeds and architectural systems, the decision-making and management entities of intelligent modules can be deployed within specified interfaces and network service demands which interact with operations support system (OSS)/business support system (BSS). Therefore, the confluence of network functions virtualization (NFV), software-defined networking (SDN), and edge computing allows an adaptive configuration of intelligent model policies on resource pooling adjustment, networking abstractions, and efficient slicing capabilities in multi-type Quality-of-Service (QoS) indicators with different criticality requirements [4–7].
Applying intelligent models in SDN-based architecture has been converged for multiple purposes, such as flow rules optimization, flow-aware classifications, estimation of QoS performances, and resource orchestration by enabling the interaction interfaces between classifiers and controllers [8,9]. However, in the era of the massive Internet of Things (IoT), the user equipment (UE) consists of low battery life and resource constraints for abstracting and training the intelligent collaborative learning model. Partial offloading policies can be considered for optimizing the completion time of local computation-intensive tasks [10]. With task sizes exceeding the local resource properties, the available local power and processing capacities have to consider executing a portion of the task, while another portion is offloaded to the optimal edge node. The combined local execution, offloading time, and edge computing time are primary elements to be critically forecasted and observed in order to alleviate the high possibility of task termination. Therefore, the optimal edge node selection, virtual resource placement, and task offloading scheduling are the major statement to tackle for further enhancement. To optimize this problem statement, partial offloading decisions and scheduling policy determination can be handled for energy-efficient and communication-efficient aspects by an optimization approach such as the convex technique [11,12]. However, deep reinforcement learning (DRL)-based optimization approaches are used for enabling intelligent resource allocation and offloading decisions by tackling the minimization of weighted sum completion time, consumed energy, and closed-loop resource control policies in systematic edge computing platforms [13–15].
In this paper, a working flow on deep Q-learning (DQL)-enhanced virtual resource orchestration (DQL-eVRO) policies are set on SDN/NFV-based architecture to observe the primary states, action-based orchestration, and rewards which consider the minimization of weighted sum task termination ratio. A deep neural network (DNN)-based classifier module (DNN-bCM) for delay-aware edge task computing in terms of congestion windows, link delays, and bandwidth capacities to recommend optimal edge nodes is proposed for labeling the efficiencies of available edge resources in the particular time slot. The confluence of DQL-eVRO and DNN-bCM responds to an enhancement for adaptive partial task offloading and virtual resource placement (APTOV) scheme in collaborative control softwarization, which raised one deployment scenario in learning model interactions. The simulation is conducted to indicate the performances of the proposed and reference schemes.
The paper is organized as follows. Section 2 presents the system architecture of the proposed approach, including the architectural framework for the control softwarization, communication model, computation model, and primary components of the agent. Section 3 describes the algorithm flows and enhanced controller/orchestrator perspective, which is the main functional softwarization of the proposed APTOV approach in collaborative SDN/NFV-based control. Section 4 shows the simulation setup and result discussions. Section 5 presents the summary conclusion of the paper.
To estimate the optimal edge node, the DNN model can be formulated by feeding the network data collected by OpenFlow (OF) based device/resource abstractions with support modules. Within NFV-based architecture, edge servers (ES) in virtualized infrastructure manager (VIM) consist of virtualization layers that abstract the computing resources and isolate multi-pools based on different critical computing tasks. With well-classified offloading tasks, the orchestration of virtual resource placement for edge computing is considered by allocated virtual machine (VM) properties.
The equipped extra server capacities within the edge node, small base stations (SBS), are presented for assisting partial task offloading policies. Each local UE notifies the remaining energy and computing resources as a portion of state spaces for the proposed DQL-eVRO agent. In the partition phase, the existing available local capacity is a primary feature to consider before determining the edge offloading task size. In the system model, each task consists of primary variables from task profilers such as task sizes, required computing resources, and maximum available execution delay, which are denoted as a three-tuple
Let
In the partial offloading aspect, the local computing, offloading, and edge computing delays are critical for taking into consideration; however, the total number of subtask execution in different entities has to be acutely tackled. Eqs (3) and (4) present the primary formulation of local and edge computing delays, which are mainly based on the available resource in local UE
The full task computing delay at local UE
In this approach, the main objective of joint minimizing the partial offloading computation in a particular entire local task, presented in Eq. (8), is by selecting the optimal edge node
The edge node recommendation is used to enhance the solution efficiencies by approximating the delay-aware queuing and congestion states if local UE decides to offload several subtasks for computing in edge node
2.4 Primary Components of Agent
With the setup environment following communication and computation models of the learning tasks, sets of states, actions, and rewards are required in this approach to be well-observed, applied as policy orchestration, and formulated as an achievement estimation in the proposed agent control, respectively. To acquire these requirements, the setup environment and three primary components of the agent, including epsilon (
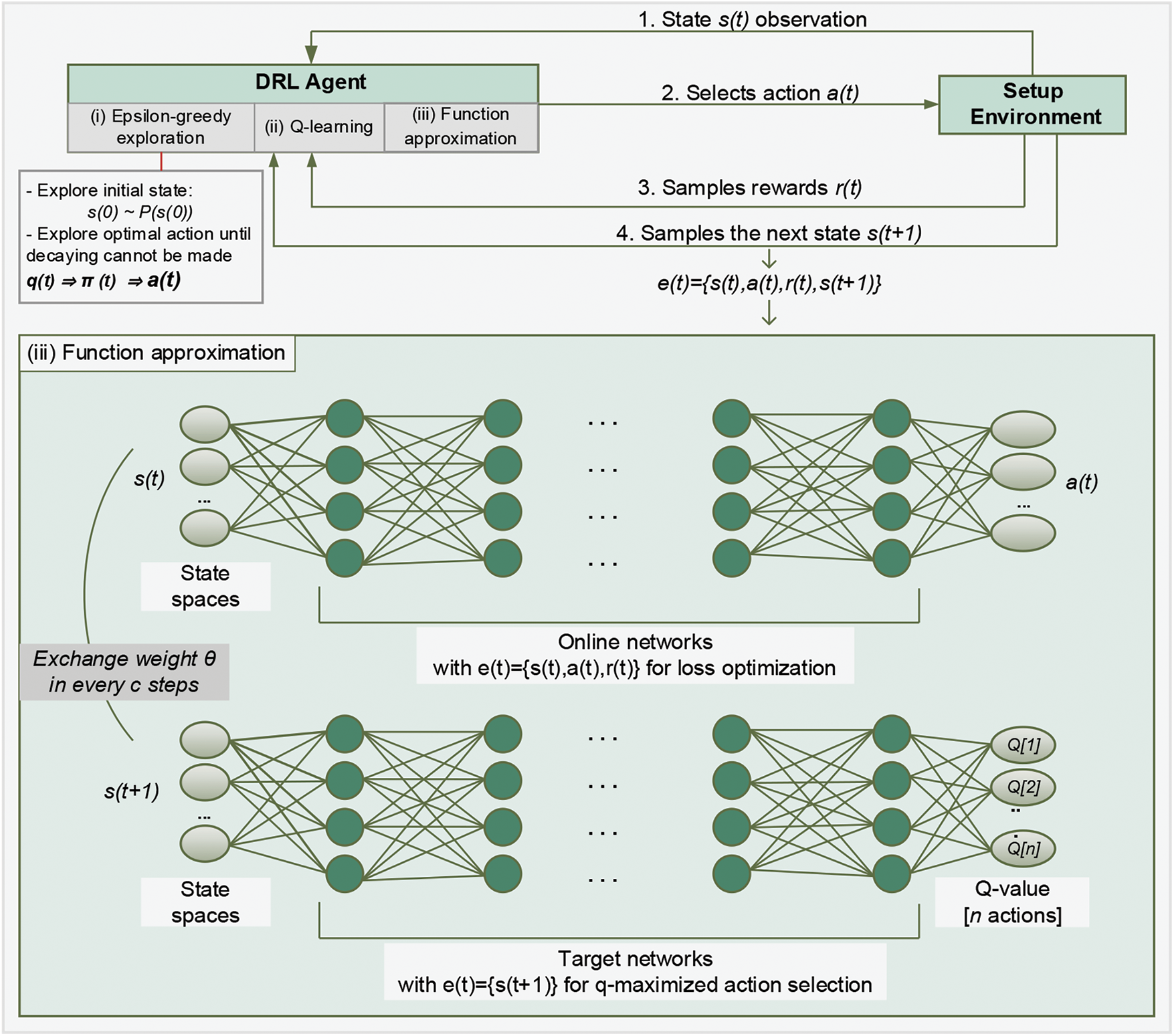
Figure 1: Interaction of primary components in DRL agent
Batch experience at step
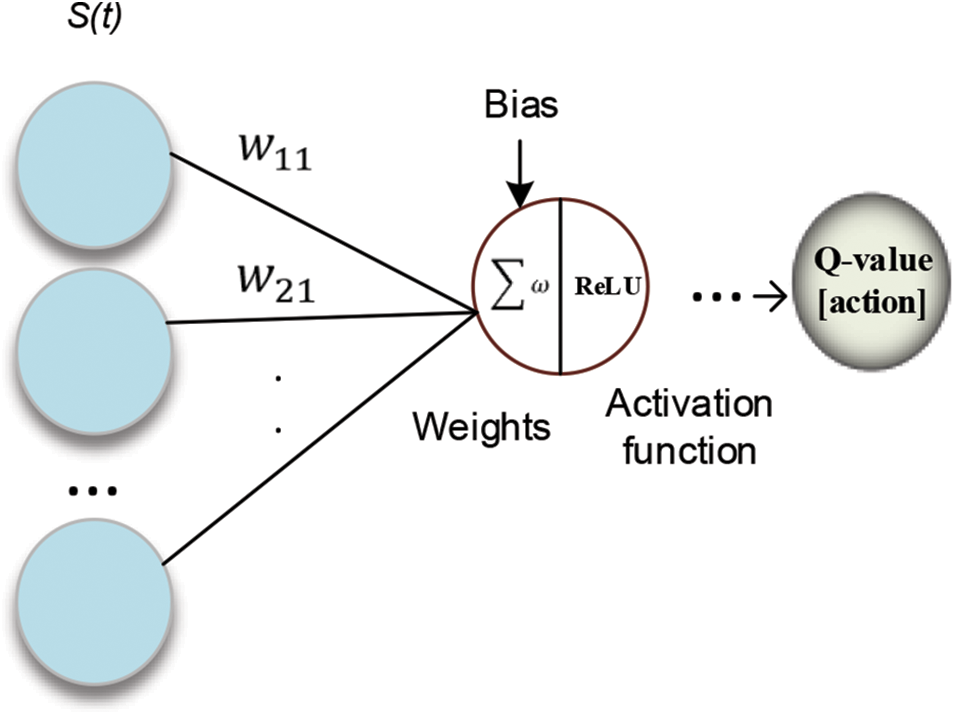
Figure 2: Learning model in a particular node
3 Adaptive Partial Task Offloading and Virtual Resource Placement
In this section, the primary aspects of the proposed approach are described. The convergence of DNN-bCM and DQL-eVRO for an enhancement of APTOV scheme in collaborative SDN/NFV network softwarization is emphasized by illustrating the algorithm flows of each aspect and enhanced controller/orchestrator perspective, which is the main functional control policy softwarization.
3.1 A Deep Neural Network-Based Classifier Module
In this classifier module, the primary phases to indicate the class labels of prioritization and policy-configured output for optimizing ES selection are shown. Fig. 3 illustrates the interactions between the five main stages in the control entity, including the collection, data adjustment, training/validation/testing, and recommendation phases, with the data plane. With OF-based protocol interfaces, the data plane and control plane are communicated with capabilities of device/resource gathering and programmable rule installations. The support modules are utilized in this system to observe the UE and ES information. In the collection phase, the features are accumulated for abstracting as a batch of the input dataset. The data adjustment phase carries on the procedure by detecting and eliminating the inadequate or dummy variables. With sufficient adjustment, the training labels for the learning model are obtained with specific indications of partitioned task criticality levels.
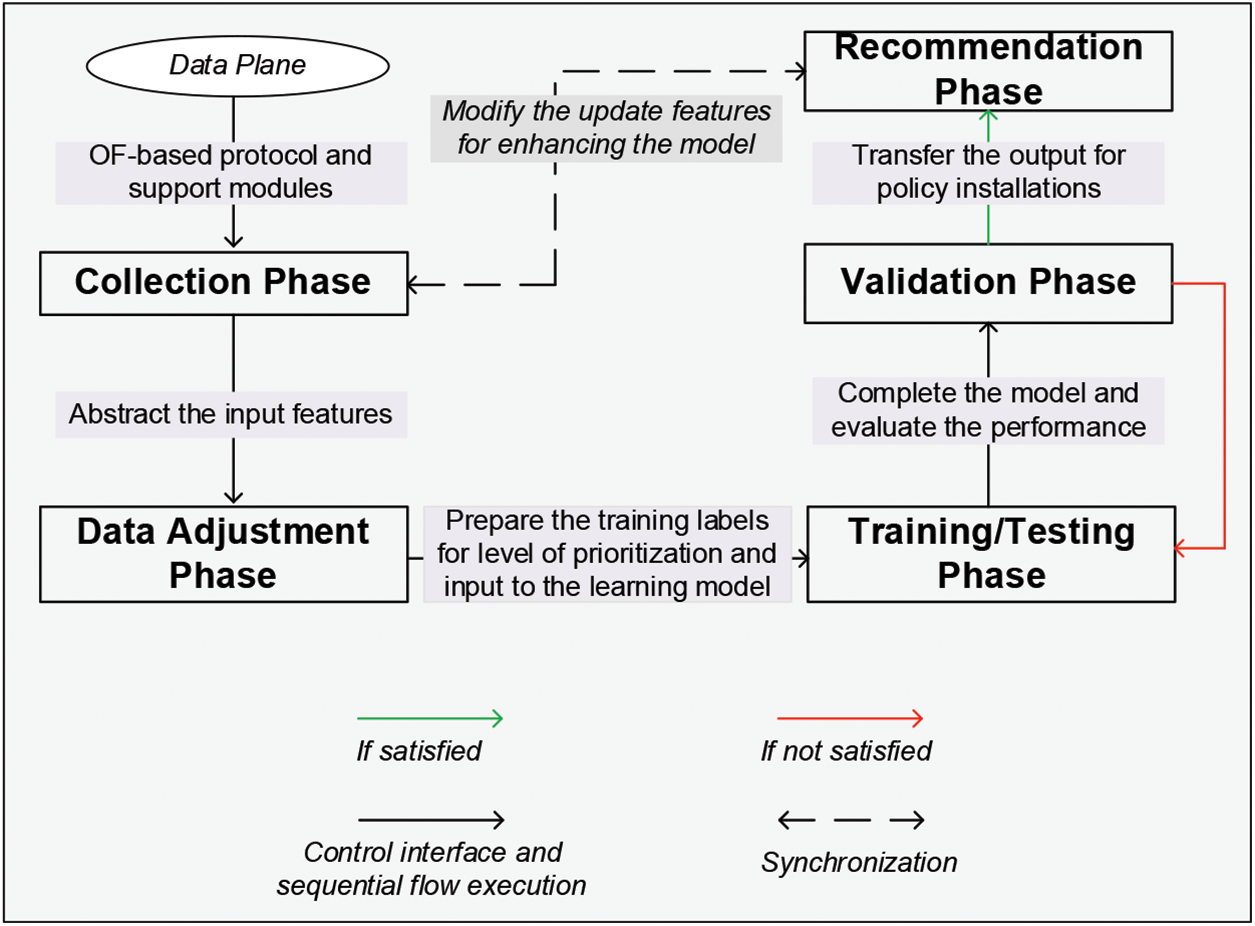
Figure 3: Interactions between the data and control planes with flow connectivity of the five primary phases: collection, data adjustment, training/testing, validation, and recommendation phase

The priority determination is assisted by the maximum endurable termination delay
3.2 Deep Q-Learning-Enhanced Virtual Resource Orchestration
To enhance the elasticity and adaptability of the proposed softwarization framework, the recommendation of an optimal edge node is converged with the DQL-enhanced VM allocation for advancing adaptive partial task computation. This section delivers the primary aspect of the allocation statement by describing the procedure of agent interaction with the proposed states, actions, and reward indication. The implicit mechanisms for agent controller/orchestrator are configured for long-term control.
In the initialization and setup environment phases, the hyperparameters and elements of the DQL-based model have to be well designed and adjusted in order to emerge with the state conditions. The elements of DQL-based approaches, q-value function, DNN online/target approximation, and experience replay for training an optimal policy of the proposed scheme are presented. To adaptively control the communication and computation resources for partial task offloading, the state observation in the proposed environment is significant to gather for the proposed agent, including the resource statuses, task information, and communication values. The collective state observations in
With
However, the DQL-based model consisted of unstable training episodes with insufficient reward accumulation. In every 1000 steps, the proposed scheme formulates the collected batches for future optimization. The proposed controller and orchestrator leverage the resources with the weight-assisted offloading task. The virtual deployment unit (VDU) capabilities and properties are parameterized for configuring each VNF descriptor based on the modified weights of the network approximation. The discrete state priorities of the collected experience batch are classified for the prior adjustment of computational resource utilization. VNFFG descriptor includes the forwarding path of defined properties, policies, and VNF forwarders with connection point/virtual link capabilities for rendering into service chains. The predetermined resources in the edge server and each VNF placement are updated for intermediate reward calculation. Therefore, each virtual resource pool is defined as specific slicing with clustered model service types. The local model computation efficiency rate in each edge server is improved by instruction sets of each clustered traffic flow and virtualization extraction. The model interactivity between proposed action spaces and orchestrator is considered to express the triggering chains on gathering virtual resource pools in order to serve the partial model task communication and computation based on specific congestion states. The collection of functions that map accordingly to the virtual blocks of resources in the perspective of model actions is tackled for long-term end-to-end sufficiency. Therefore, the execution of partial task offloading feasible accesses an optimal edge server with adequate resource pools.
To efficiently simulate the APTOV approach, connectivity between agent output and SDN/NFV-based environment has to consider; however, with constraints of virtual interfaces, the output-configured relation is applied between DQL-based agent and mininet/mini-nfv/Ryu orchestration topology [7,23]. With partial task creation and offloading experiment, the consideration of task amounts, number of ES, virtual pool capacities, transmission bandwidth, server resources, local resources, and partial task sizes are included to evaluate the performance and proposed environment setup. Within 100 full local tasks, the partial division with the size of 450 KB is executed. In this environment, the number of ES is 5. The transmission bandwidth and server resources are 5 MHz and 15 GHz, respectively [24,33]. The transmission power is in the range of 40 mW to 100 mW. The simulation of computation and communication models for
With 310 slot times, the agent applied four different learning rate values for best fitting the conditional environment. The cumulative negative/positive rewards in each episode of OpenAI-Gym-based DQL agent are obtained for evaluating the agent execution. The agent used the initialization function to gather vectors of state possibilities and the approximation function to generate the exploration. The allocation function optimizes the percentage of resource placement. In each episode, the intermediate rewards have been calculated numerous times and accumulated to illustrate the model efficiencies and enhancement. With the output of the proposed APTOV agent, the controller/orchestrator configuration is made to show the QoS indicators. The outputs are configured into the descriptors corresponding to the
With partial task offloading decisions and resource determination, the flow rule installation and life-cycle orchestration are made within the controller and create/update/delete functions in the VNF manager. The reference schemes are defined by indicating the differences between various policies for offloading and resource adjustment in terms of experience-based, resource-maximized, and single DNN-based approaches, which are denoted as EB-A, RM-A, and DNNB-A, respectively. The primary features of congestion windows, link delays, and allocatable bandwidth capacities in the dataset are gathered by simulation software, which is collected at each ES corresponding with each UE. The data was inputted into the DL mechanism to extract the features and optimize the model parameters. The train, validation, and test sizes are adjusted to 70%, 15%, and 15%, respectively. The loss and accuracy of model training/inference are evaluated before configuring the class labels in the DQL-eVRO. By using TensorFlow/Keras platform, the overall accuracy of the final learning model reached 99.86%. The experience-based approach offloaded the partial tasks based on the latency-maximized experience within the batch container comparison, which adjusts the resources corresponding to experience replay. The resource-maximized approach considered the resource allocation policies, which supervised placing the adjustable available resources at every congestion condition. For single DNN-based approaches, the resource features and local task information are gathered; however, the edge recommendation is fixed, and the VM capacities have challenging functionality to adaptively place and map in high congestion states.
Fig. 4 illustrates the graphical delay comparison between APTOV and reference approaches. In terms of delay, the proposed approach considered the congestion state by deploying the setup environment and proposed agent with the capability of configuring allocation actions to orchestrate the communication resource in peak-hour intervals and accelerate the offloading process. In this aspect, the delay-critical evaluation determined the partial offloading success rate without fully taking risks of high termination drops. Within SDN/NFV-based softwarization architecture, the elastic computing resource mapping and programmable rule installation enhance the optimal edge selection for resource-efficient and latency-efficient objectives. APTOV achieved an average delay of 9.4612 ms within 310 sconds experiment, which is 95.6222, 81.9085, and 30.2743 ms lower than EB-A, RM-A, and DNNB-A, respectively.
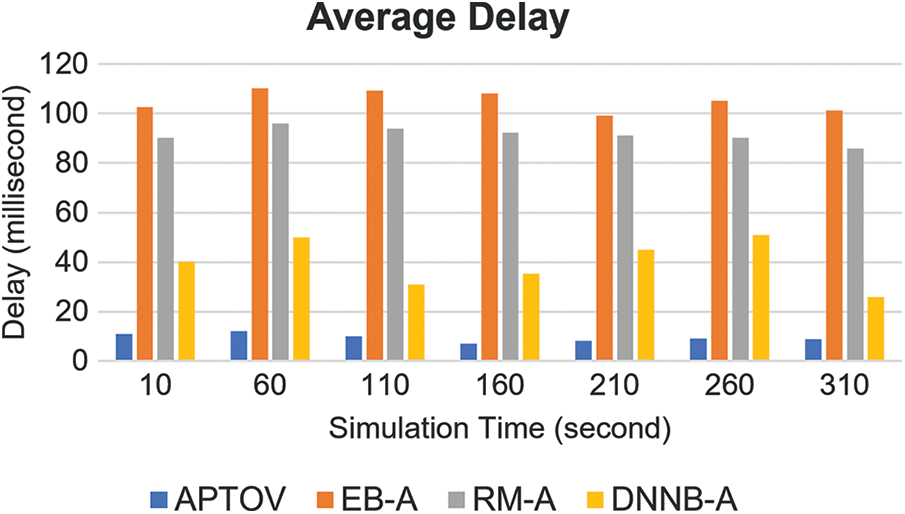
Figure 4: Comparison of average delay
Fig. 5 presents the partial task delivery ratio of APTOV and reference approaches within 310 s of simulation. This performance metric covers the successful rates of subtask
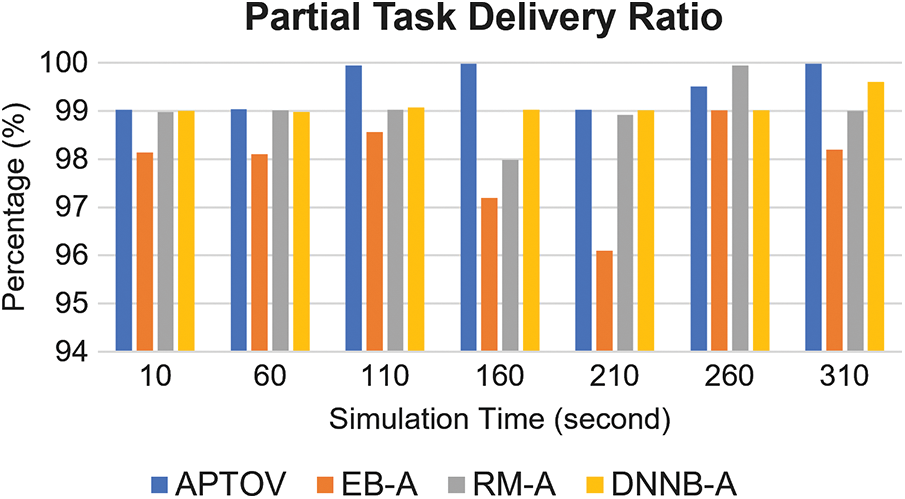
Figure 5: Comparison of partial task delivery ratio
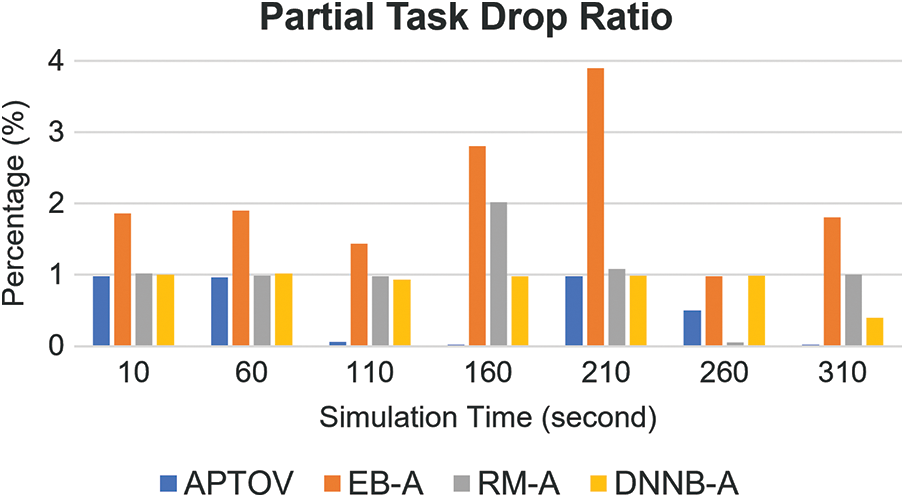
Figure 6: Comparison of partial task drop ratio
In this paper, an adaptive decision with efficient virtual resource allocation for partial task offloading is presented by collecting and adjusting the data within leveraged edge computing and SDN/NFV-based network softwarization. The system model for training/testing the optimal edge recommendation in DNN-bCM considered the interaction between local devices, ES, and SDN/NFV-based control with proposed DQL-eVRO to tackle the alternative offloading destination with a modified flow rule setup. The confluence between DNN-bCM and DQL-eVRO introduced the APTOV approaches for adaptive task offloading and efficient resource mapping, followed by the reward formulation by minimization models of partial task computation delay in local, offloading delay towards selected edge node, and computation delay in recommended ES. The proposed simulation correspondingly configured and orchestrated the agent actions to enhance the QoS performances for time-sensitive networking applications, particularly in high congestion and peak-hour conditions. DQL-based approach aimed to offer the self-managing closed-loop control in network virtualization and softwarization environment.
In future studies, the virtual link connectivity for mininet/mini-nfv/Ryu and DQL-based agents will be further extended. Moreover, the scheduling and partition procedure with task profiler information will be further studied by using double deep-q-networks and artificial neural networks to meet the ultra-reliable low-latency QoS requirements for mission-critical applications.
Funding Statement: This work was funded by BK21 FOUR (Fostering Outstanding Universities for Research) (No. 5199990914048), and this research was supported by Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education (NRF-2020R1I1A3066543). In addition, this work was supported by the Soonchunhyang University Research Fund.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. T. K. Le, U. Salim and F. Kaltenberger, “An overview of physical layer design for ultra-reliable low-latency communications in 3GPP releases 15, 16, and 17,” IEEE Access, vol. 9, pp. 433–444, 2021. [Google Scholar]
2. R. Chanparadza, T. B. Meriem, B. Radier, S. Szott and M. Wodczak, “SDN enablers in the ETSI AFI GANA reference model for autonomic management & control (emerging standardand virtualization impact,” in 2013 IEEE Globecom Workshops (GC Wkshps), Atlanta, GA, USA, pp. 818–823, 2013. [Google Scholar]
3. Y. Wang, R. Forbes, U. Elzur, J. Strassner, A. Gamelas et al., “From design to practice: ETSI ENI reference architecture and instantiation for network management and orchestration using artificial intelligence,” IEEE Communications Standards Magazine, vol. 4, no. 3, pp. 38–45, 2020. [Google Scholar]
4. X. Yin, B. Cheng, M. Wang and J. Chen, “Availability-aware service function chain placement in mobile edge computing,” in 2020 IEEE World Congress on Services (SERVICES), Beijing, China, pp. 69–74, 2020. [Google Scholar]
5. T. Rausch and S. Dustdar, “Edge Intelligence: The convergence of humans, things, and AI,” in 2019 IEEE Int. Conf. on Cloud Engineering (IC2E), Prague, Czech Republic, pp. 86–96, 2019. [Google Scholar]
6. W. Zhuang, Q. Ye, F. Lyu, N. Cheng and J. Ren, “SDN/NFV-empowered future IoV with enhanced communication, computing, and caching,” Proceedings of the IEEE, vol. 108, no. 2, pp. 274–291, 2020. [Google Scholar]
7. P. Tam, S. Math, C. Nam and S. Kim, “Adaptive resource optimized edge federated learning in real-time image sensing classifications,” IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 14, pp. 10929–10940, 2021. [Google Scholar]
8. G. Zhao, H. Xu, Y. Zhao, C. Qiao and L. Huang, “Offloading tasks with dependency and service caching in mobile edge computing,” IEEE Transactions on Parallel and Distributed Systems, vol. 32, no. 11, pp. 2777–2792, 2021. [Google Scholar]
9. R. Amin, E. Rojas, A. Aqdus, S. Ramzan, D. Casillas-Perez et al., “A survey on machine learning techniques for routing optimization in SDN,” IEEE Access, vol. 9, pp. 104582–104611, 2021. [Google Scholar]
10. Z. Kuang, L. Li, J. Gao, L. Zhao and A. Liu, “Partial offloading scheduling and power allocation for mobile edge computing systems,” IEEE Internet of Things Journal, vol. 6, no. 4, pp. 6774–6785, 2019. [Google Scholar]
11. S. Boyd and L. Vandenberghe, Convex Optimization. Cambridge, U.K: Cambridge Univ. Press, 2004. [Online]. Available at: https://web.stanford.edu/~boyd/cvxbook/bv_cvxbook.pdf. [Google Scholar]
12. S. Math, P. Tam and S. Kim, “Intelligent real-time IoT traffic steering in 5G edge networks,” Computers, Materials & Continua, vol. 67, no. 3, pp. 3433–3450, 2021. [Google Scholar]
13. K. Haseeb, I. Ahmad, I. I. Awan, J. Lloret and I. Bosch, “A machine learning SDN-enabled big data model for IoMT systems,” Electronics, vol. 10, no. 18, pp. 2228, 2021. [Google Scholar]
14. H. Park and Y. Lim, “Deep reinforcement learning based resource allocation with radio remote head grouping and vehicle clustering in 5G vehicular networks,” Electronics, vol. 10, no. 23, pp. 3015, 2021. [Google Scholar]
15. Y. Y. Munaye, R. -T. Juang, H. -P. Lin, G. B. Tarekegn and D.-B. Lin, “Deep reinforcement learning based resource management in UAV-assisted IoT networks,” Applied Science, vol. 11, no. 5, pp. 2163, 2021. [Google Scholar]
16. H. Li, F. Fang and Z. Ding, “DRL-assisted resource allocation for NOMA-MEC offloading with hybrid SIC,” Entropy, vol. 23, no. 5, pp. 613, 2021. [Google Scholar]
17. X. Han, X. Meng, Z. Yu and D. Zhai, “A dynamic adjustment method of service function chain resource configuration,” KSII Transactions on Internet and Information Systems, vol. 15, no. 8, pp. 2783–2804, 2021. [Google Scholar]
18. G. Zhao, H. Xu, Y. Zhao, C. Qiao and L. Huang, “Offloading tasks with dependency and service caching in mobile edge computing,” IEEE Transactions on Parallel and Distributed Systems, vol. 32, no. 11, pp. 2777–2792, 2021. [Google Scholar]
19. Z. Jin, C. Zhang, G. Zhao, Y. Jin and L. Zhang, “A context-aware task offloading scheme in collaborative vehicular edge computing systems,” KSII Transactions on Internet and Information Systems, vol. 15, no. 2, pp. 383–403, 2021. [Google Scholar]
20. I. A. Elgendy, W. -Z. Zhang, Y. Zeng, H. He, Y. -C. Tian et al., “Efficient and secure multi-user multi-task computation offloading for mobile-edge computing in mobile iot networks,” IEEE Transactions on Network and Service Management, vol. 17, no. 4, pp. 2410–2422, 2020. [Google Scholar]
21. O. Adamuz-Hinojosa, J. Ordonez-Lucena, P. Ameigeiras, J. J. Ramos-Munoz, D. Lopez et al., “Automated network service scaling in NFV: Concepts, mechanisms and scaling workflow,” IEEE Communications Magazine, vol. 56, no. 7, pp. 162–169, 2018. [Google Scholar]
22. M. Abu-Alhaija, N. M. Turab and A. Hamza, “Extensive study of cloud computing technologies, threats and solutions prospective,” Computer Systems Science and Engineering, vol. 41, no. 1, pp. 225–240, 2022. [Google Scholar]
23. P. Tam, S. Math, A. Lee and S. Kim, “Multi-agent deep Q-networks for efficient edge federated learning communications in software-defined IoT,” Computers, Materials & Continua, vol. 71, no. 2, pp. 3319–3335, 2022. [Google Scholar]
24. K. Xiao, Z. Gao, C. Yao, Q. Wang, Z. Mo et al., “Task offloading and resources allocation based on fairness in edge computing,” in Proc. IEEE Wireless Communications and Networking Conf. (WCNC), Marrakesh, Morocco, pp. 1–6, 2019. [Google Scholar]
25. R. Amiri, M. A. Almasi, J. G. Andrews and H. Mehrpouyan, “Reinforcement learning for self organization and power control of two-tier heterogeneous networks,” IEEE Transactions on Wireless Communications, vol. 18, no. 8, pp. 3933–3947, 2019. [Google Scholar]
26. B. Li, R. Zhang, X. Tian and Z. Zhu, “Multi-agent and cooperative deep reinforcement learning for scalable network automation in multi-domain SD-EONs,” IEEE Transactions on Network and Service Management, vol. 18, no. 4, pp. 4801–4813, 2021. [Google Scholar]
27. J. Pei, P. Hong, K. Xue and D. Li, “Resource aware routing for service function chains in SDN and NFV-enabled network,” IEEE Transactions on Services Computing, vol. 14, no. 4, pp. 985–997, 2021. [Google Scholar]
28. Z. Lv and W. Xiu, “Interaction of edge-cloud computing based on SDN and NFV for next generation IoT,” IEEE Internet of Things Journal, vol. 7, no. 7, pp. 5706–5712, 2020. [Google Scholar]
29. I. Kalphana and T. Kesavamurthy, “Convolutional neural network auto encoder channel estimation algorithm in MIMO-OFDM system,” Computer Systems Science and Engineering, vol. 41, no. 1, pp. 171–185, 2022. [Google Scholar]
30. C. Pham, D. T. Nguyen, N. H. Tran, K. K. Nguyen and M. Cheriet, “Optimized IoT service chain implementation in edge cloud platform: A deep learning framework,” IEEE Transactions on Network and Service Management, vol. 18, no. 1, pp. 538–551, 2021. [Google Scholar]
31. K. Praveen kumar and P. Sivanesan, “Cost optimized switching of routing protocol scheme for IoT applications,” Computer Systems Science and Engineering, vol. 41, no. 1, pp. 67–82, 2022. [Google Scholar]
32. C. She, C. Sun, Z. Gu, Y. Li, C. Yang et al., “A tutorial on ultrareliable and low-latency communications in 6G: Integrating domain knowledge into deep learning,” Proceedings of the IEEE, vol. 109, no. 3, pp. 204–246, 2021. [Google Scholar]
33. X. Wu, “A dynamic QoS adjustment enabled and load-balancing-aware service composition method for multiple requests,” KSII Transactions on Internet and Information Systems, vol. 15, no. 3, pp. 891–910, 2021. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools