
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Sentiment Analysis with Tweets Behaviour in Twitter Streaming API
1 Computer Science and Engineering, I. T. S Engineering College, Greater Noida, 201310, India
2 Computer Science and Engineering, DPG Institute of Technology and Management, Gurgaon, 122004, India
3 Computer Science and Engineering, National Institute of Technology Srinagar, Jammu and Kashmir, India
4 Department of Computer Science and Engineering, SRM University, Amaravati, Andhra Pradesh, 522240, India
5 School of Computer Science SCS, Taylor’s University, Subang Jaya, 47500, Malaysia
6 Department of Computer Science, College of Computers and Information Technology, Taif University, P. O. Box 11099, Taif, 21944, Saudi Arabia
* Corresponding Author: NZ Jhanjhi. Email:
Computer Systems Science and Engineering 2023, 45(2), 1113-1128. https://doi.org/10.32604/csse.2023.030842
Received 03 April 2022; Accepted 08 June 2022; Issue published 03 November 2022
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Twitter is a radiant platform with a quick and effective technique to analyze users’ perceptions of activities on social media. Many researchers and industry experts show their attention to Twitter sentiment analysis to recognize the stakeholder group. The sentiment analysis needs an advanced level of approaches including adoption to encompass data sentiment analysis and various machine learning tools. An assessment of sentiment analysis in multiple fields that affect their elevations among the people in real-time by using Naive Bayes and Support Vector Machine (SVM). This paper focused on analysing the distinguished sentiment techniques in tweets behaviour datasets for various spheres such as healthcare, behaviour estimation, etc. In addition, the results in this work explore and validate the statistical machine learning classifiers that provide the accuracy percentages attained in terms of positive, negative and neutral tweets. In this work, we obligated Twitter Application Programming Interface (API) account and programmed in python for sentiment analysis approach for the computational measure of user’s perceptions that extract a massive number of tweets and provide market value to the Twitter account proprietor. To distinguish the results in terms of the performance evaluation, an error analysis investigates the features of various stakeholders comprising social media analytics researchers, Natural Language Processing (NLP) developers, engineering managers and experts involved to have a decision-making approach.Keywords
Sentiment analysis, also known as opinion mining, indicates the utilization of Natural Language Processing (NLP), text mining and computational linguistics to recognize and evaluate emotional states [1]. Sentiment analysis is an approach to assess a user in correspondence with a customer support. The current analytical tools are competent to squeeze with incredible measurements of customer criticism constantly and accurately. The sentiment analysis efforts to control the temper of a speaker or opponent might be an assessment of enthusiastic responses. Sentiment mining is a task that analyzes a widespread number of archives to accumulate the sentiments of remarks postured [2] and integrates various approaches, including computational and information retrieval [3].
Twitter is a social network where rapid user sentiments have leading social media analytical frequencies. It generates billions of Application Programming Interface (API) screams where Twitter sentiments have a massive extent to comprehend user’s perceptions and provide early warnings occurrence [4,5]. Twitter key sentiment inputs have various sentiment divergence (positive, negative or neutral) that allows users to communicate with other users and share their ideas, feelings, etc., with steadiness and approaches [6]. A posted tweet can be visible by default to the users unless they revolute their confidentialities to make it understandable by the followers on Twitter incline [7]. The eminence of tweet sentiment polarity classifications has information and emerging analytics applications [8]. In this research work, a novel approach is proposed to represent expressions in the semantic direction, based on data abstraction, pre-processing of extracted data and classification on Twitter.
Twitter sentiment analysis tools developed in social media include API-based tools subscription that comprises feasible stand-alone tools and integrated trained tools [9]. API-based tools can be downloaded as system applications appropriate to unlabelled forms to evaluate Chatterbox, Sentiment, TextAnalytics, Anonymous, SentimentAnalyzer, TextProcessing, Machine Learning Analyzer, etc. through API [10]. Sentiment analysis uses an accomplished machine learning classifier created on a vast Twitter corpus of positive and negative tweets [11], which are based on the presence of emoticons.
Objectives and Motivation
Research is structured speculation of a delinquent to gain a solution to a real problem. In this work, the objective is vibrant and transitory, providing direction to examine the variables. The research objective of this work is specified as outlined to achieve the work that includes,
• Study sentiment analysis.
• Analyze the sentiment techniques to understand the user’s behaviour that can decide the mental situation going on.
• Find the accuracy of the user’s tweets status and measure the perception using python programming.
• Awareness of how to deal with tweet data.
• Develop a computational tool for sentiment analysis.
• Relate the sentiment analysis knowledge with real-time life experience.
• Prospect to study advanced properties that may respond something triumph to do definite fertile to the researchers.
Nowadays, the furthermost distinguished area among the people is to analyze user’s sentiments can have conspicuous study to have attracted the future planning and creation of innovative concepts. The political ideas or campaigns, people’s opinions or perceptions on the social media are the informal approaches to accessing the sentiments through the tweets, which can have predictions for various events on social media.
Yadav et al. [12] presented various techniques to analyze the behaviour of the tweets as positive, negative or neutral for the evaluation and satisfy the sentiments. Asghar et al. [13] presented a unified framework for classifying tweets to enhance the performance of Twitter-based sentiment analysis that classifies precise accuracy. Abbasi et al. [14] proposed using sentiment analysis to classify web environment opinions in various languages to predict the sentiments. Anber et al. [15] presented information exploration to analyze different hashtags, Twitter’s network topology and identification of influence sentiment. Kumar et al. [16] proposed approaches for binding Twitter data to discover solutions to complicate searches. Da Silva et al. [17] presented the uses of sentiment analysis to search the products to monitor the public sentiment toward their brands. Devika [18] presented a sentiment analysis tool to extract the information to competence the collective sentiments of the reviews. Chenaghlu et al. [19] presented information epoch consequences of data in various forms and modalities to discover instructive information. Ho et al. [20] proposed a data analytic approach consisting of machine learning algorithms and combinatorial fusion. Tan et al. [21] observed the emergent issues within the sentiment variation related to the causes behind the deviations. Dubey et al. [22] presented text mining-based tweets generated for various personalities on different opinions and issues. Fu et al. [23] proposed a novel crawler that incorporates sentiment information to enhance the collection of rich web content for a particular issue. Marcel et al. [24] presented the performance of a social network that allows users to distribute real-time hypermedia and data to localize prospective attention. Mostafa et al. [25] presented machine learning classifier algorithms are applied on crawled Twitter data to encode techniques to accomplish the accuracy. Hassan et al. [26] proposed a sentiment to elaborate bootstrapping ensemble and depictive abundance issues. Bermingham et al. [27] proposed classifying the sentiment in microblogs as more relaxed than in blogs and relating to supervised learning research. Goodchild et al. [28] presented that data quality generates trusted data.
In this study, the Twitter dataset collected tweets to anticipate the valuation to find the characteristics of tweets. The tweet collection phase as an input dataset uses the beginning of tweets that have to pre-process to extract the phases to receive estimation and analysis of the data classification. The framework of the tweet data analysis is shown in Fig. 1 represents the process from data collection to evaluate the results.

Figure 1: Framework of Tweet analysis mechanism
Tweets through web-based networking are imperative opinion can break down individuals’ sensitivity and sentiments by such type of social media. In this work, tweet datasets can compose the data and be detached into the testing and training to the datasets that measure the performance calculation of the developed model. This model can categorize newly generated tweets that can be elevated from the Twitter API development account into the tweets to categorize the modules [18], as shown in the proposed flowchart in Fig. 2.
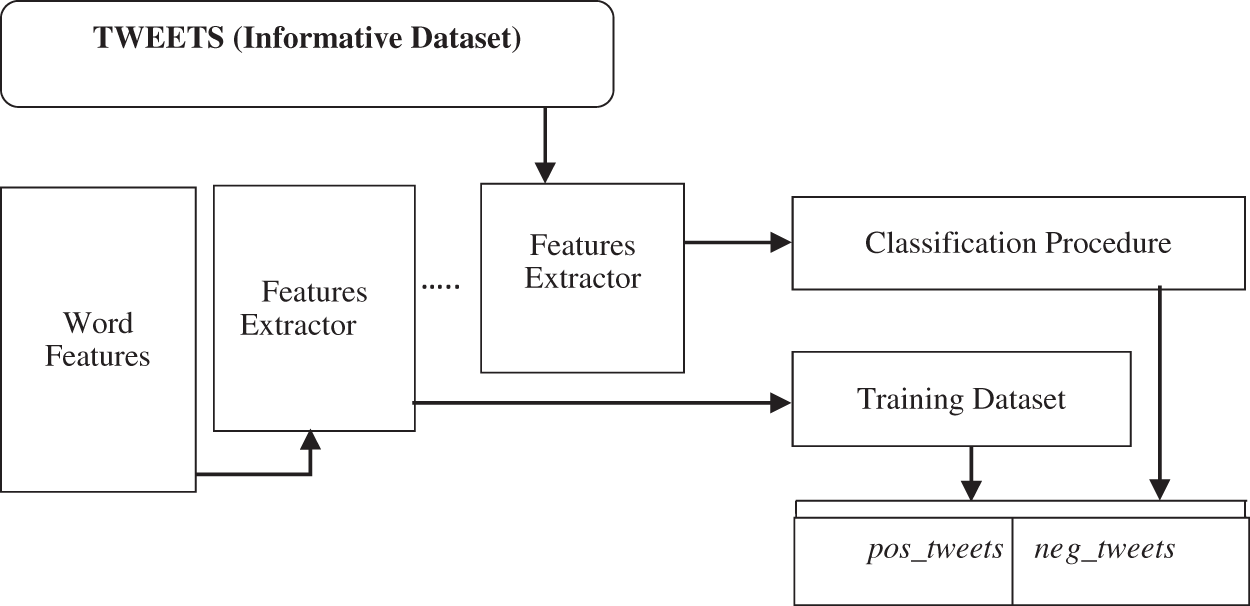
Figure 2: Proposed flowchart based on a generated tweets dataset
The tweet preprocessing filters the dataset and reduces the clatter from it. The vital data processing algorithm of verbal uses NLP that includes;
(i) Assigned sentiment variance to the tweets [19] with a lexicon-based approach [20,21] and
(ii) The dataset is trained such as Naive Bayes and Support Vector Machine (SVM) to measure the accuracy [22].
The subsequent collectives are having lexicon for sentiment analysis to represent a framework that explains the procedure from the level of raw data which is capable to analyze the tweets at various levels and apply a machine learning approach to provide appropriate results at the end as shown in Fig. 3.
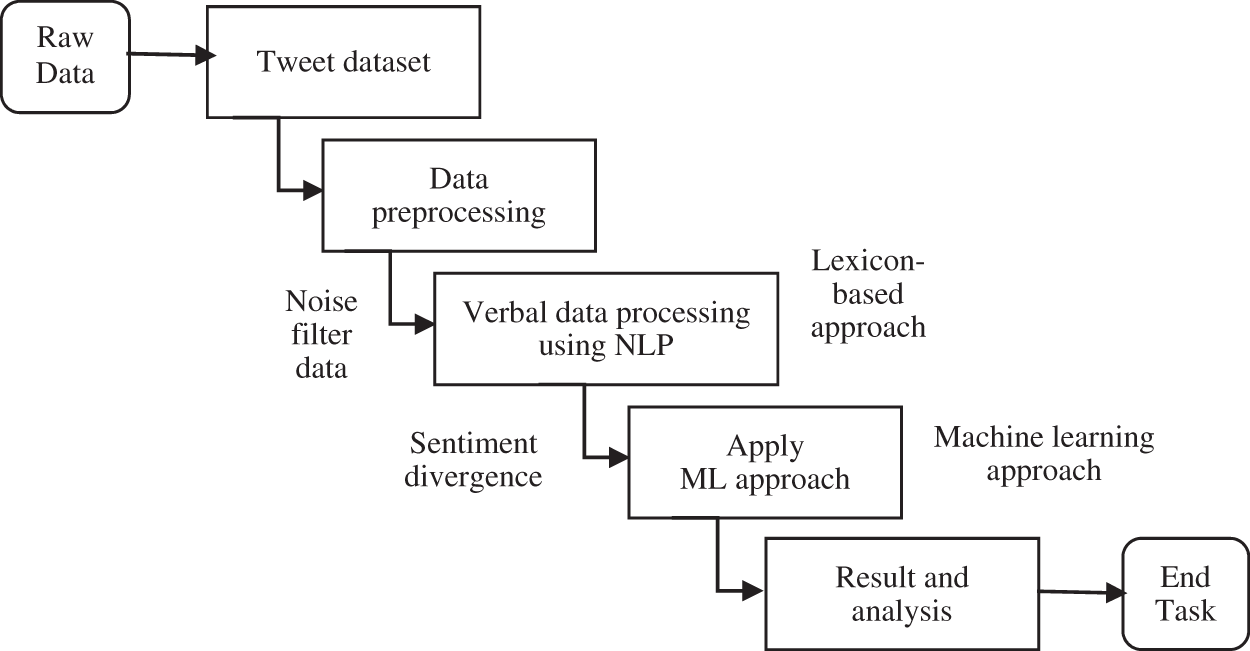
Figure 3: Framework of sentiment analysis using various approaches
5 Sentiment Analysis on Twitter
This study analyses users’ estimation, sentiment, assessment, impudence, and emotions from transcribed language [23] with the help of NLP and artificial intelligence analysis, categorized as positive, negative, expectation, anxiety, happiness, and wonder, as shown in Fig. 4.
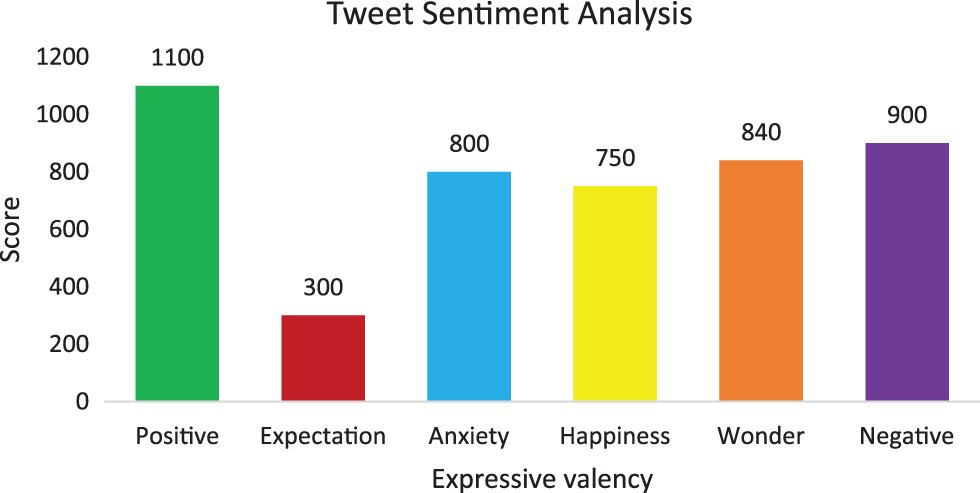
Figure 4: Various emocation using Twitter sentiment analysis
Here, the proposed text dataset notch for positive tweets are reasonably developed other sentiments whereas anticipated as negative and cannot be categorized known as neutral tweets. People’s views on the level of arrangement on a particular topic, product, service or even political elections are imminent under sentiment analysis [23]. The increasing distinctiveness of social media has become informal and more accessible to crawl the user’s feedback [24,25] and analyze their sentiments as positive, negative or neutral [26–28] tweet approaches. There are two specific approaches are employed to acquire the sentiment analysis comprises,
(i) NLP Approach: This approach is the interface between computers and human languages to assess users’ sentiment. In this work, various features are used effectively to interpret the sentiments of users where a sentence has two different meanings in which one entity is interpreted with positive and another entity is interpreted with a negative sentiment tag showing a tweet has a varied sentiment.
(ii) Machine Learning Approach: Machine learning regulates the formation of the sentiment concept to study algorithms [29,30] and learn from various datasets to analyze [31] the sentiment of Twitter users [32].
5.1 Semantic Features for Sentiment Analysis
The semantic feures integrate into the sentiment analysis method that extracts from tweets to measure the overall correlation of entities along with sentiment polarity [33,34]. It helps to recognize tweet sentiment containing any of the entities which are incapable of looking in the training dataset and composed with their possibilities in positive and negative tweets [35]. Various methods are possible with sentiment analysis to Naive Bayes probabilistic classifier [36,37] where a scheme of a sentiment class c can be classified with a specified tweet tw which is calculated and given as,
where,
In polynomial Naive Bayes,
where,
N denotes a comprehensive number of tweets.
where,
5.2 Tweet Classification Framework
Twitter sentiments framework that process with contemplates tweet collection and tweet analysis that is forwarded by users (as hashtag) to swift their sentiments [38] and accumulates the retrieved tweets to pre-process the dataset. To understand the sentiments of the tweets at an optimum level, need to find the maximum accuracy for polarity and bias calculator to use sentiment analyzers that include,
(i) Textblob: The essential features of NLP are used to analyze the polarity and bias calculation of tweets [39].
(ii) SentiWordNet: Accessible analyzer that is extracted from a wordnet database of the English language that comprehends the sentiments.
(iii) Word Sense Disambiguation: Able to find the accurate word sense within a definite framework for vibrant senates for the polarity calculation. It is effective other than NLP framework recognition functions due to a problem identification discrepancy.
Each classifier is enabled to obtain the training dataset which is tested on a classification model using Naive Bayes and SVM classifier [40] to provide an optimal accuracy [41]. The apparatuses and procedures maintained in sentiment analysis are represented as a framework shown in Figs. 5a and 5b.
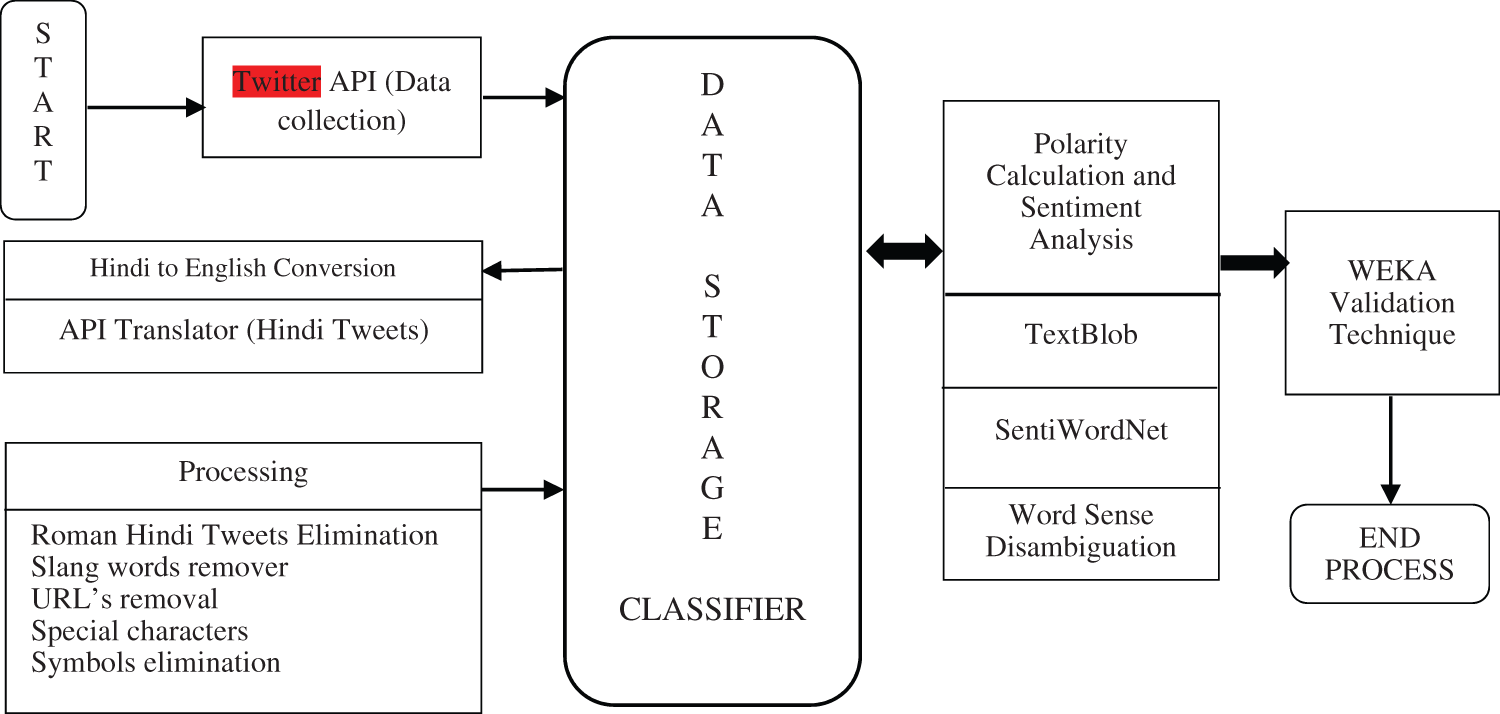
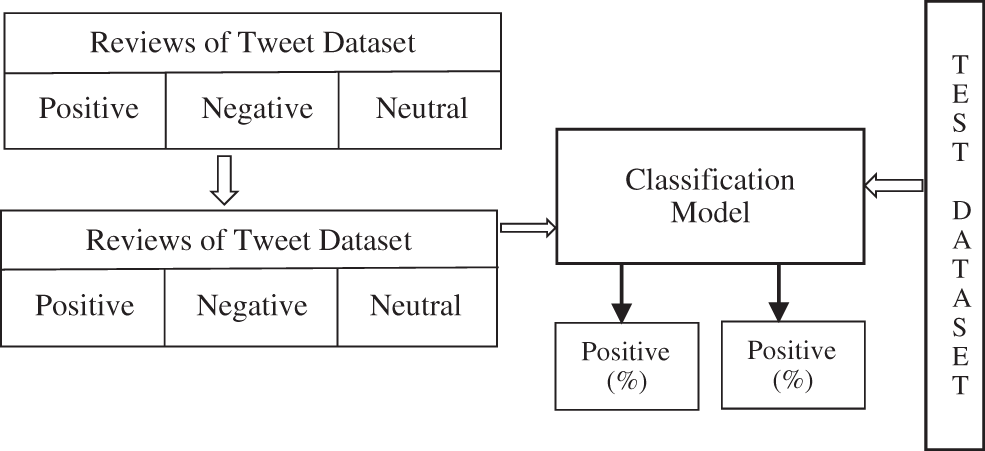
Figure 5: (a) Twitter API classification using data classifier with sentiment analysis (b) Framework of tweet classification and sentiment analysis
5.3 Polarity Calculation and Sentiment Analysis
In social media platforms, the sentiment analysis has precious sensitivities with a level of the dataset that characterizes in unstructured performance of sense with sentiments. Though using polarity, each tweet allocates a notch (−1 to 1) with words in sentences representing a positive sentiment while the ‘0’ value is measured as a neutral sentiment. While adding the Hindi tweets converts into English accomplishes additional tasks for pre-processing as flowchart is shown in Fig. 6.
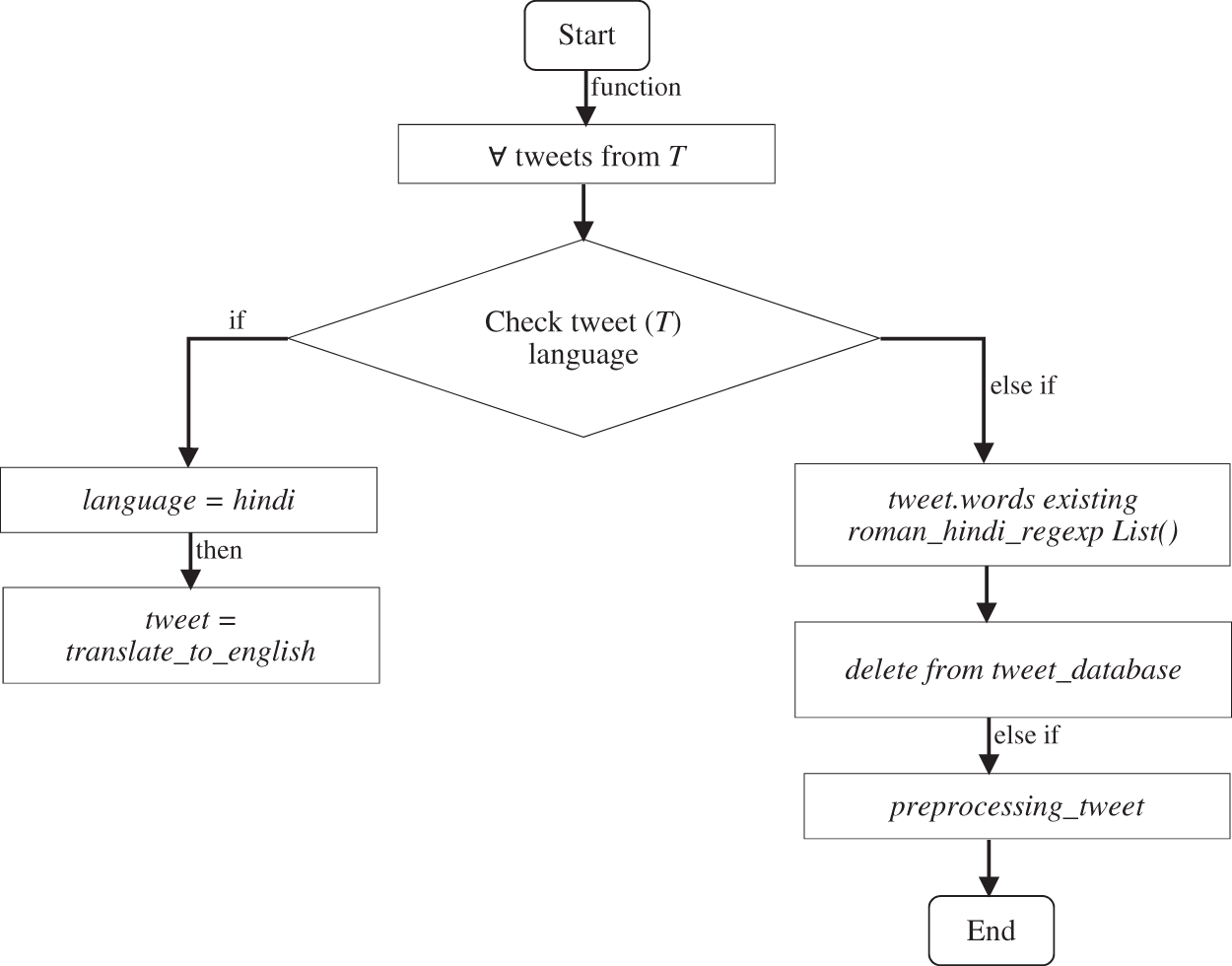
Figure 6: Tweet conversion and tasks for pre-processing approach
Each sentiment analyzer uses bias and polarity of processed tweets (sentiment of polarity such as
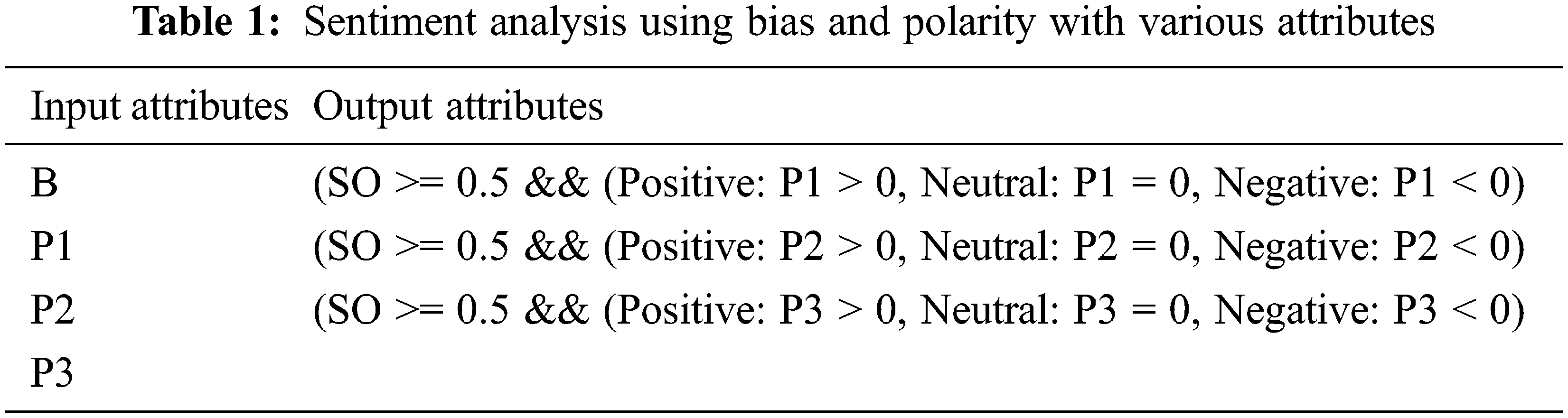
where,
PT: Pre-processed tweets from the database.
B: Biased control of the statements.
P1 and S1:
P2 and S2:
P3 and S3:
6 Various Approached Used in Sentiment Analysis
This work regulates the solution of tweet segmentation in positive or negative classification which is essential to applying a lexicon-based approach along with machine learning for sentiment analysis on Twitter.
This approach is the sentiment of a text which is resolute by its leading sentiment words that contain phrases in a verbal situation which has different approaches includes;
(i) Simple Word Count (SWC): A sentiment lexicon l, a document
The sentiment alignment of d (where, 1 denotes → “positive” and −1 denotes → “negative”) can be defined as,
To find appropriate the problem, necessary to allocate an arbitrary label to d when the sentiment word sum is ‘0’.
(ii) Feature Counting (FC): A sentiment lexicon l having enumeration function of a feature f plots a feature to a real-valued number that is described as,
The enumeration function not only outlines the polarity of the sentiment features, but also has a degree of freedom. The data with
By choosing an edge
To apt the problem, d is the sum value between threshold intervals where the enumeration process extracts the features to describe an effective enumeration function and find a precise edge of accuracy.
6.2 Twitter Sentiment Analysis Using Supervised Approaches
In this approach, the labeled datasets are dependent and use the machine learning process during the training to train the models and achieved considerable results. Twitter sentiment analyzes the performance to classify [42] and train data to extract the feature sets [43]. The supervised machine learning approach for Twitter sentiment analysis is shown in Fig. 7 stipulates the data training and data testing procedure along with labels as classifiers.
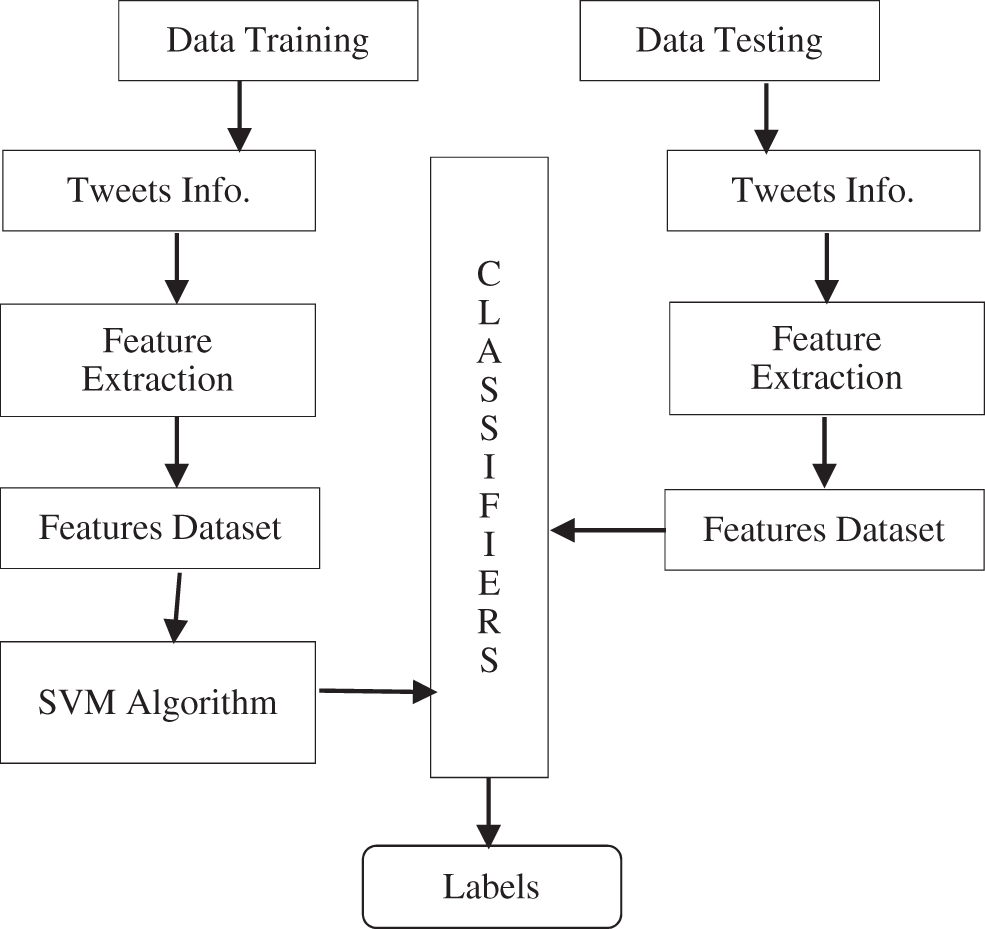
Figure 7: Supervised machine learning algorithms with tweet sentiment analysis
Tweet data uses prediction algorithms (such as SVM and Bayesian classifier) to resolve the sentiment polarity of tweets’ performance. Binary classification of the dataset is having sentiment analysis problem to organize the dataset into positive and negative tweets based on the regulation approach with emoticons which is applied in Twitter API to have tweet citations.
Polarity state defines the positivity or negativity of text is focused on emotions expressed in the statement. It depends on the assessment which can be easily counted and applied Naive Bayes algorithm with the positive and negative words. A sentiment analysis task depends on the words and divides the text into a single word so that evaluation or the computation makes informal then only, Naive Bayes algorithm search for words that can express sentiment in a tweet. The Naive Bayes algorithm works with a bag of words and prerequisite to find out all the positive or negative words which are illustrated and listed below,
| Positive words | Prosper, flourishes, applause, praise, cooperative, accommodating, accomplished, truthful, precisely, accurately, reachable, attainment, accomplishment, successes, possible |
| Negative words | anomalous, eradicate, offensive, atrociously, abhor, outrage, abort, abandon, scrape, harsh, unexpected, brusquely, nonattendance, absconder, irrational, mishandling |
Those bags of words are used to find out the text, whether the tweet is positive or negative, each tweet will get 1 indentation that is,
Tweet data indentation = tweets positive – tweets negative
For e.g., a tweet “here is a pretty good climate.”
For this we achieve an indentation: positive tweets = pretty (1) + good (1) = 2;
Negative tweets = 0
So, the tweet indentation for this tweet is;
Tweet data indentation = 2 − 0 = 2
All tweets having positive and negative indentation that contains tweet value ‘0’ includes under a neutral tweet. The positive and negative words analyze the difference and get tweet scores to create a histogram plot of various tweets. Now, to track the polarity class database, a polarity class bar diagram is shown in Fig. 8 to analyze the sentiment of tweets.
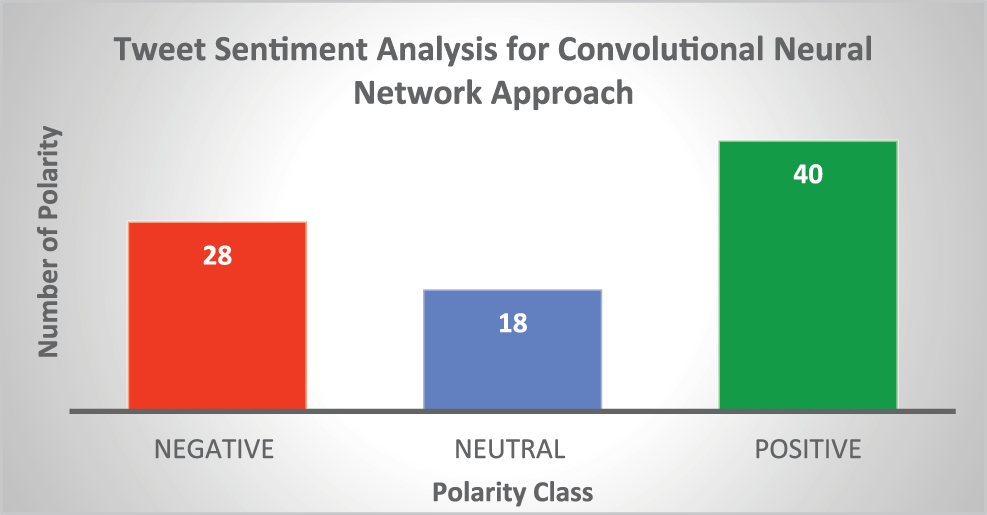
Figure 8: Polarity class bar diagram for tweet sentiment analysis
7.2 Influences of Tweet Data in Unambiguous Mode
7.2.1 Tweet Performance on Real-Time Dataset
In this research work, this execution contributes to representing an authenticate performance of the targeted Twitter account where the primary task provides authentication by the Twitter API account after receiving a confirmation mail from Twitter. The positive and negative tweets (in %) are shown recent few tweets (data taken while running the python code and auto-generated output used recent last 50000 tweets). To generate tweet percentage, need to use various keys which are auto-generated by the API developer account and used in python code. The generated output is shown as,

While using Twitter graphical view is required to have authentication as shown below;
| 1. import tweepy |
| 2. consumer_key = 'EoJKizEYz8aud3TGIhKvjP4jG' |
| 3. consumer_secret = 'JcxWYvqdFx199UwPvSZM18Ru2tHQmKqcCsGPzN5TTApXVXOo3g' |
| 4. access_token = '2701416409-U8I93Za4BubFSFnJ7mGJlJmKM9Q9PgNzJFwjVIB' |
| 5. access_secret = 'FiOOSKJr6py6jZ21WlUFERc0HZrwzAAXNPF13wIXRRjl0' |
| 6. auth = tweepy.OAuthHandler(consumer_key, consumer_secret) |
| 7. auth.set_access_token(access_token, access_secret) |
| 8. our_api = tweepy.API(auth) |
| 9. print('Authenticated',our_api) |
Authenticated <tweepy.api.API object at 0x00000191A05FFD00>
natgeo_tweets [0]
(‘@dadanhrn not until @CraigWeekend says so’, 59, 1269)
It is to be informed that the above complete output is taken, just for a demonstration purpose in this research work that delivers the strength of work.
7.2.2 Positive and Negative Influences of Tweet Data
The influence of tweet data is presented as a positive and negative response that determine the status of tweets in the bar chart method and acquires more accuracy to comprehend the prediction of the intellectual position of the users as given in Tab. 2.

The result shows the performance status of the initiated Twitter account that demonstrates the positive and negative status of tweets on their account as shown in Fig. 9.
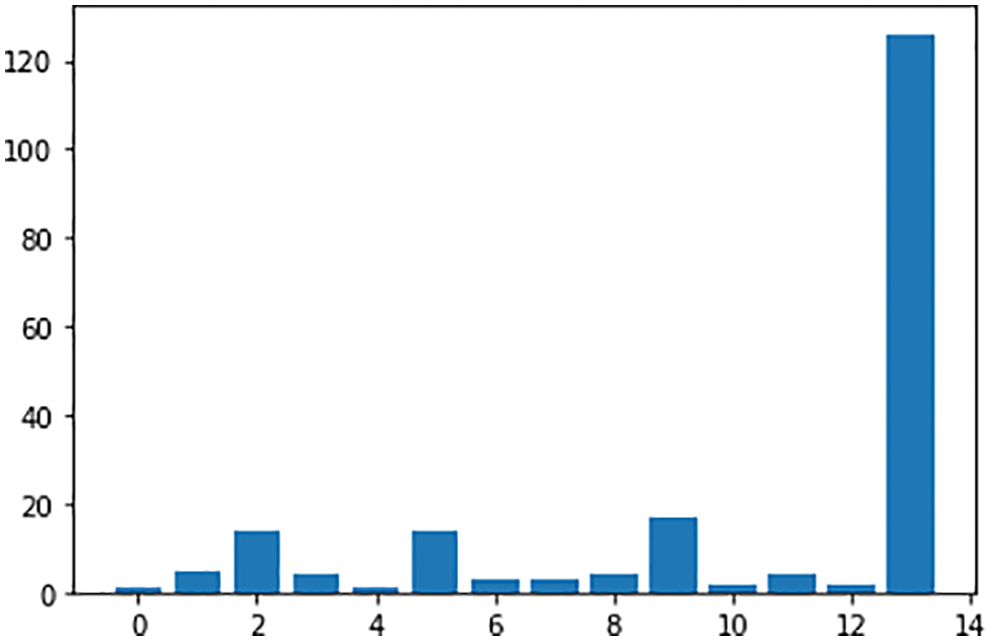
Figure 9: Performance status of tweets in Twitter account
7.3 Analysis of Resolute Accuracy with Polarity Calculation
In this section, the detailed experiment is conducted with sentiment assignment to justify the results that determine the accuracy which is evaluated from various sentiment analyzers. The sentiment analyzers have various distinctions for comparison of their accuracies. Tab. 3 represents tweets evaluation to transmit the data with a similar type of sentiments with the total number of tweets such as 2076, as experimented below,
The tweet data is gathered from users’ accounts only where preprocessing with 7650 tweets among the various sentiment analyzers and compared with various tweet rates which have been found the TextBlob had the uppermost positive tweets rate 4283 (in number), SentiWordNet produced 3650 the maximum negative sentiment tweet rate are given in Tab. 4 and represented in Fig. 10 respectively.
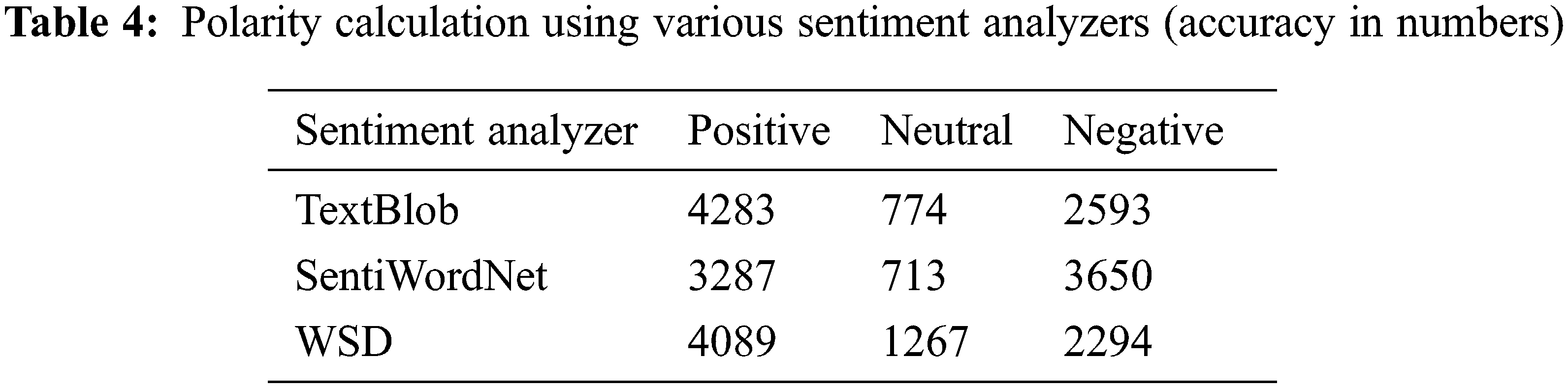
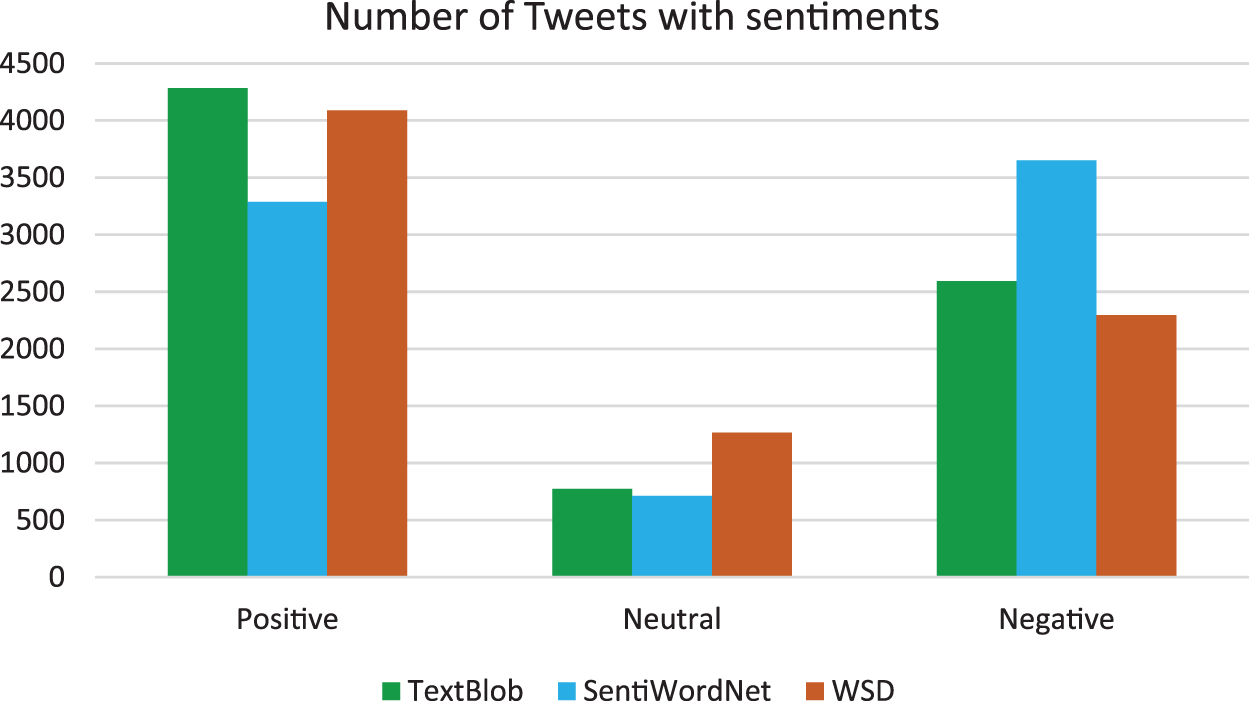
Figure 10: Sentiment analysis of tweet data using polarity computation
The validation of tweet data is extracted from various sentiment analyzers are used Naive Bayes classifier on a 2560 training set of 1280 positive and 1280 negative tweets analyzed by respective sentiment analyzers as given in Tab. 5.

As a result, Word Sense Disambiguation (WSD) had the highest accuracy rate are found to have a predicted determination sentiment analysis using the Naive Bayes classifier to provide accurate instances which are shown in Fig. 11.
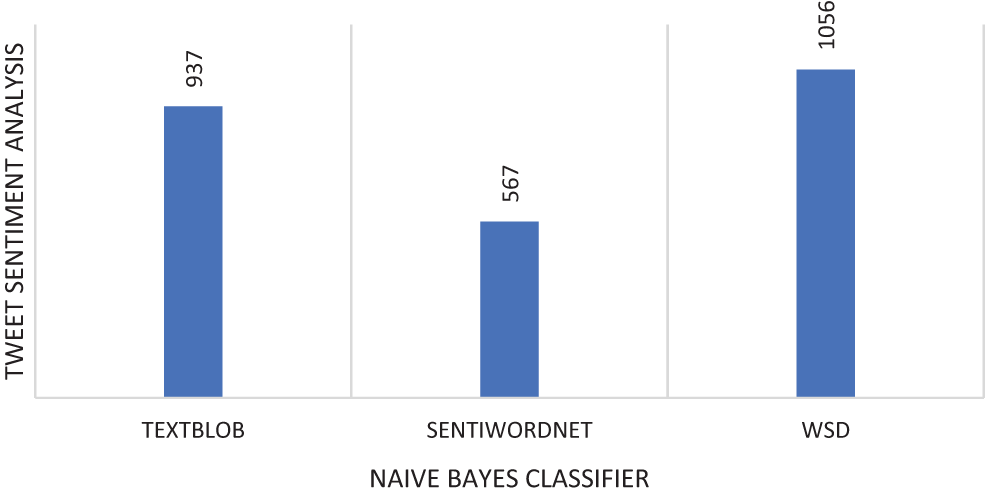
Figure 11: Sentiment analyzer with the Naive Bayes classifier (inaccuracy)
In this research work, we investigate the sentiment analysis that occurs while communicating with tweet data that represent the happening moment around the world. Also, this work analyzed to predict sentiment in Twitter that contributes outperform features and kernel models to accomplish the sentiments using machine learning algorithms. This research is focused on the various sentiment analyzers with the utmost accuracy rate for learning about tweet sentiments on social media. The results are examined using the polarity method which is calculated based on the semantic score of a certain word using a lexicon-based approach. Though, the approach of machine learning is essentially intended to categorize the text by using Naive Bayes and SVM algorithms that provided evaluation between sentiment lexicons to adopt sentiment analysis. A hybrid approach for sentiment analysis has learned to use word sense which can accumulate tweet data that afford statistical sentimental structure of the search keyword and obtain high-efficiency results on social media. The expected consequences of this research are,
(i) Search tweets using keywords of a particular account or random statistics,
(ii) Users can perceive trending sizzling issues,
(iii) Enable to analyze data themselves from twitter and
(iv) Outputs are possibly be observed as histogram plots or bar diagrams or chart basis.
In the future scope, need to compare Twitter analysis with other spheres that prerequisite further research to know how to apply and solve the real-time problems of the society in terms of elections, product reputation evaluation, etc. would dive into the Twitter sentiment analysis aspects in near future. In sentiment analysis, researchers are working on the accuracy of the algorithm and used in commercial aspects or to do further research to find out more customer satisfaction based on tweets.
Funding Statement: This work was supported by Taif University Researchers Supporting Project (TURSP) under number (TURSP-2020/73), Taif University, Taif, Saudi Arabia.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. A. Alsaeedi and M. Z. Khan, “A study on sentiment analysis techniques of Twitter data,” International Journal of Advanced Computer Science and Applications, vol. 10, no. 2, pp. 361–374, 2019. [Google Scholar]
2. M. Anjaria and R. M. R. Guddeti, “Influence factor-based opinion mining of Twitter data using supervised learning,” in Proc. 6th Int. Conf. on Communication Systems and Networks, Bangalore, India, pp. 1–8, 2014. [Google Scholar]
3. S. Umer, P. P. Mohanta, R. K. Rout and H. M. Pandey, “Machine learning method for cosmetic product recognition: A visual searching approach,” Multimedia Tools and Applications, vol. 80, no. 28, pp. 34997–35023, 2021. [Google Scholar]
4. A. DuVander, “Which APIs are handling billions of requests per day?,” Programmable Web, 2012. https://www.programmableweb.com/news/which-apis-are-handling-billions-requests-day/2012/05/23. [Google Scholar]
5. K. N. Alam, M. S. Khan, A. R. Dhruba, M. M. Khan and J. F. Al-Amri, “Deep learning-based sentiment analysis of COVID-19 vaccination responses from Twitter data,” Computational and Mathematical Methods in Medicine, vol. 2021, no. 1, pp. 1–15, 2021. [Google Scholar]
6. H. U. Khan, S. Nasir, K. Nasim, D. Shabbir and A. Mahmood, “Twitter trends: A ranking algorithm analysis on real-time data,” Expert Systems with Applications, vol. 164, no. 3, pp. 113990, 2021. [Google Scholar]
7. A. Hasan, S. Moin, A. Karim and S. Shamshirband, “Machine learning-based sentiment analysis for Twitter accounts,” Mathematical and Computational Applications, vol. 23, no. 1, pp. 1–15, 2018. [Google Scholar]
8. K. Chouhan, A. Singh, A. Srivastava, S. Agrawal, B. D. Shukla et al., “Structural support vector machine for speech recognition classification with CNN approach,” in Proc. 9th Int. Conf. on Information Technology for Cyber and IT Service Management, Bengkulu, Indonesia, Inspec no. 21297945, 2021. [Google Scholar]
9. Developers, “Twitter rest API,” 2018. [Online]. Available: https://dev.twitter.com/rest/public. [Google Scholar]
10. I. Twitter, “Second quarter report,” 2016. [Google Scholar]
11. K. P. Murphy, Naive Bayes Classifiers, vol. 18, Vancouver, BC V6T 1Z4, Canada: University of British Columbia, 2006. [Google Scholar]
12. N. Yadav, O. Kudale, S. Gupta, A. Rao and A. K. Shitole, “Twitter sentiment analysis using machine learning for product evaluation,” in Proc. 5th Int. Conf. on Inventive Computation Technologies, Coimbatore, India, pp. 181–185, 2020. [Google Scholar]
13. M. Z. Asghar, F. M. Kundi, S. Ahmad, A. Khan and F. Khan, “T-SAF: Twitter sentiment analysis framework using a hybrid classification scheme,” Expert Systems, vol. 35, no. 1, pp. 42–55, 2018. [Google Scholar]
14. A. Abbasi, H. Chen and A. Salem, “Sentiment analysis in multiple languages: Feature selection for opinion classification in web forums,” ACM Transactions on Information Systems, vol. 26, no. 3, pp. 1–34, 2008. [Google Scholar]
15. H. Anber, A. Salah and A. A. A. El-Aziz, “A literature review on Twitter data analysis,” International Journal of Computer and Electrical Engineering, vol. 8, no. 3, pp. 241–249, 2016. [Google Scholar]
16. S. Kumar, F. Morstatter and H. Liu, Twitter data analytics, New York: Springer, 2014. [Google Scholar]
17. N. F. F. Da Silva and E. R. Hruschka, “Tweet sentiment analysis with classifier ensembles,” Decision Support Systems, vol. 66, no. C, pp. 170–179, 2014. [Google Scholar]
18. M. D. S. C. Devika, “Sentiment analysis: A comparative study on different approaches,” Procedia Computer Science, vol. 87, no. 4, pp. 44–49, 2016. [Google Scholar]
19. M. A. Chenaghlu, M. R. F. Derakhshi, L. Farzinvash, M. A. Balafar and C. Motamed, “Topic detection and tracking techniques on Twitter: A systematic review,” Hindawi Complexity, vol. 21, pp. 1–15, 2021. [Google Scholar]
20. J. Ho, D. Ondusko, B. Roy and D. F. Hsu, “Sentiment analysis on tweets using machine learning and combinatorial fusion,” in Int. Conf. on Dependable, Autonomic and Secure Computing, Pervasive Intelligence and Computing, Cloud and Big Data Computing, Fukuoka, Japan, Cyber Science and Technology Congress, 2019. [Google Scholar]
21. S. Tan, Y. Li, H. Sun, Z. Guan, X. Yan et al., “Interpreting the public sentiment variations on Twitter,” IEEE Transactions on Knowledge and Data Engineering, vol. 26, no. 5, pp. 1158–1170, 2013. [Google Scholar]
22. G. Dubey, S. Chawla and K. Kaur, “Social media opinion analysis for Indian political diplomats,” in Proc. 7th Int. Conf. on Cloud Computing, Data Science and Engineering-Confluence, Noida, India, pp. 681–686, 2017. [Google Scholar]
23. T. Fu, A. Abbasi, D. Zeng and H. Chen, “Sentimental spidering: Leveraging opinion information in focused crawlers,” ACM Transactions on Information Systems, vol. 30, no. 4, pp. 1–30, 2012. [Google Scholar]
24. K. Marcel, H. Safa and M. Masud, “WhatsUpNow: Urban social application with real-time peer-to-peer ambient and sensory data exchanges,” Multimedia Tools and Applications, vol. 75, no. 21, pp. 13349–13374, 2016. [Google Scholar]
25. G. Mostafa, I. Ahmed and M. S. Junayed, “Investigation of different machine learning algorithms to determine human sentiment using Twitter data,” International Journal of Information Technology and Computer Science, vol. 2, pp. 38–48, 2021. [Google Scholar]
26. A. Hassan, A. Abbasi and D. Zeng, “Twitter sentiment analysis: A bootstrap ensemble framework,” in Proc. ASE/IEEE Int. Conf. on Social Computing, Alexandria, VA, USA, pp. 357–364, 2013. [Google Scholar]
27. A. Bermingham and A. Smeaton, “Classifying sentiment in microblogs: Is brevity an advantage?,” in Proc. 19th Int. Conf. on Information and Knowledge Management and Co-located Workshops, Toronto, Ontario, Canada, pp. 1833–1836, 2010. [Google Scholar]
28. M. F. Goodchild and J. A. Glennon, “Crowd sourcing geographic information for disaster response: A research frontier,” International Journal of Digital Earth, vol. 3, no. 3, pp. 231–241, 2010. [Google Scholar]
29. S. Hossain, S. Umer, V. Asari and R. K. Rout, “A unified framework of deep learning-based facial expression recognition system for diversified applications,” Applied Sciences, vol. 11, no. 19, pp. 1–26, 2021. [Google Scholar]
30. S. H. Biradar, J. V. Gorabal and G. Gupta, “Machine learning tool for exploring sentimental analysis, on Twitter data,” Materials Today Proceedings, vol. 56, pp. 1927–1934, 2022. [Google Scholar]
31. S. Umer, R. K. Rout, C. Pero and M. Nappi, “Facial expression recognition with trade-offs between data augmentation and deep learning features,” Journal of Ambient Intelligence and Humanized Computing, vol. 13, pp. 721–735, 2021. [Google Scholar]
32. S. Bahri, P. Bahri and S. Lal, “A novel approach of sentiment classification using emoticons,” in Int. Conf. on Computational Intelligence and Data Science, Gurugram, India, pp. 1–10, 2018. [Google Scholar]
33. A. Abirami and V. Gayathri, “A survey on sentiment analysis methods and approach,” in Proc. 8th Int. Conf. on Advanced Computing, Chennai, India, pp. 72–76, 2017. [Google Scholar]
34. Sentiment classifier. 2022. [Online]. Available: https://github.com/kevincobain2000/sentiment_classifier. [Google Scholar]
35. N. C. Dang, M. N. M. Garcia and F. D. L. Prieta, “Sentiment analysis based on deep learning: A comparative study,” Electronics, vol. 9, no. 3, pp. 1– 29, 2020. [Google Scholar]
36. V. Sahayak, V. Shete, A. Pathan and A. Pathan, “Sentiment analysis on Twitter data,” International Journal of Innovative Research in Advanced Engineering, vol. 2, no. 1, pp. 178– 183, 2015. [Google Scholar]
37. S. Jawale and S. D. Sawarkar, “Interpretable sentiment analysis based on deep learning: An overview,” in IEEE Pune Section Int. Conf., Pune, India, 2020. [Google Scholar]
38. W. Medhat, A. Hassan and H. Korashy, “Sentiment analysis algorithms and applications: A survey,” Ain Shams Engineering Journal, vol. 5, no. 4, pp. 1093–1113, 2014. [Google Scholar]
39. P. Ray and A. Chakrabarti, “A mixed approach of deep learning method and rule-based method to improve aspect level sentiment analysis,” Applied Computing and Informatics, vol. 18, no. 1/2, pp. 163–178, 2022. [Google Scholar]
40. S. Umer, R. Mondal, H. M. Pandey and R. K. Rout, “Deep features based convolutional neural network model for text and non-text region segmentation from document images,” Applied Soft Computing, vol. 113, no. 3, pp. 107917, 2021. [Google Scholar]
41. K. Chouhan, A. Kumar, A. K. Chakraverti and R. R. Cholla, “Human fall detection analysis with image recognition using convolutional neural network approach,” in Proc. Int. Conf. on Trends in Computational and Cognitive Engineering, Singapore, Springer Nature, vol. 376, pp. 95–106, 2022. [Google Scholar]
42. R. K. Rout, S. S. Hassan, S. S. S. Umer, K. S. Sahoo and A. Gandomi, “Feature-extraction and analysis based on spatial distribution of amino acids for SARS-CoV-2 protein sequences,” Computers in Biology and Medicine, vol. 141, pp. 105024, 2022. [Google Scholar]
43. S. S. Hassan, R. K. Rout, K. S. Sahoo, N. Jhanjhi and S. Umer, “A vicenary analysis of SARS-CoV-2 genomes,” Computers, Materials and Continua, vol. 69, no. 3, pp. 3477–3493, 2021. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools