
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Artificial Fish Swarm Optimization with Deep Learning Enabled Opinion Mining Approach
1 Department of Information Systems, College of Computing and Information System, Umm Al-Qura University, Mecca, 24382, Saudi Arabia
2 Department of Computer Sciences, College of Computer and Information Sciences, Princess Nourah Bint Abdulrahman University, Riyadh, 11671, Saudi Arabia
3 Department of Computer Science, College of Science & Art at Mahayil, King Khalid University, Abha, 62529, Saudi Arabia
4 Department of Computer and Self Development, Preparatory Year Deanship, Prince Sattam bin Abdulaziz University, Al-Kharj, 16278, Saudi Arabia
5 Department of Mathematics, Faculty of Science, Cairo University, Giza, 12613, Egypt
* Corresponding Author: Manar Ahmed Hamza. Email:
Computer Systems Science and Engineering 2023, 45(1), 737-751. https://doi.org/10.32604/csse.2023.030170
Received 20 March 2022; Accepted 26 April 2022; Issue published 16 August 2022
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Sentiment analysis or opinion mining (OM) concepts become familiar due to advances in networking technologies and social media. Recently, massive amount of text has been generated over Internet daily which makes the pattern recognition and decision making process difficult. Since OM find useful in business sectors to improve the quality of the product as well as services, machine learning (ML) and deep learning (DL) models can be considered into account. Besides, the hyperparameters involved in the DL models necessitate proper adjustment process to boost the classification process. Therefore, in this paper, a new Artificial Fish Swarm Optimization with Bidirectional Long Short Term Memory (AFSO-BLSTM) model has been developed for OM process. The major intention of the AFSO-BLSTM model is to effectively mine the opinions present in the textual data. In addition, the AFSO-BLSTM model undergoes pre-processing and TF-IFD based feature extraction process. Besides, BLSTM model is employed for the effectual detection and classification of opinions. Finally, the AFSO algorithm is utilized for effective hyperparameter adjustment process of the BLSTM model, shows the novelty of the work. A complete simulation study of the AFSO-BLSTM model is validated using benchmark dataset and the obtained experimental values revealed the high potential of the AFSO-BLSTM model on mining opinions.Keywords
With recent advancements of the Internet, people groups, social networks, the ascent in their applications, and number of clients of interpersonal organizations, the volume of information produced has expanded [1]. In this way, it makes significant data extraction really testing. Then again, individuals are eager and glad to share their lives, information, and experience, and the immense measure of data has turned into an alluring asset for associations to screen the opinions of clients, and interpersonal organizations have been a suitable system for offering clients’ viewpoints and thoughts in different applied fields and a rich asset for clients’ opinions mining (OM) and sentiment analysis (SA) [2]. Thus, mining such information helps extricate pragmatic examples which are valuable for business, applications, and shoppers [3].
Since the world has been immersed with the rising measure of traveller information, the travel industry associations and businesses should keep side by side about vacationer experience and perspectives about the business, item, and administration [4]. Acquiring bits of knowledge into these fields can work with the improvement of the power system that can upgrade traveller experience and further lift vacationer dedication and suggestions. Generally, businesses depend on the organized quantitative methodology, for instance, rating vacationer fulfilment level in view of the Likert Scale [5]. Albeit this approach is viable to demonstrate or negate existing speculation, the shut finished questions can’t uncover accurate traveller experience and sensations of the items or administrations, which hampers acquiring bits of knowledge from sightseers. All things considered, businesses have previously applied complex and progressed approaches, for example, text mining and SA, to unveil the examples taken cover behind the information and the primary subjects [6].
OM is an exploration field that arrangements with data recovery and information location from the text utilizing information mining and regular language handling strategies [7]. Information mining is an interaction that utilizes information examination apparatuses to reveal and observe examples and connections among information that might prompt extraction of new data from an enormous data set. The motivation behind OM is research on opinions and contemplations, recognizable proof of arising social polarities in light of the perspectives, sentiments, states of mind, mentalities, and assumptions for the recipient gatherings or most individuals. By and large, the goal is to perceive clients’ mentalities involving investigation of their sentences in substance shipped off networks [8]. The mentalities are grouped by their polarities, in particular sure, unbiased and negative. Programmed help from the investigation interaction is vital, and because of the great volume of data, this sort of help is one of the fundamental difficulties. OM can be considered as a programmed information location whose objective is to track down secret examples in numerous thoughts, web journals, and tweets [9]. Lately, many examinations have been acted in various fields of OM in interpersonal organizations. By researching the techniques proposed in this space was defined that the principal challenges are maximum preparation cost in light of time or memory utilized, absence of advanced dictionaries, maximum elements of highlights’ space, and vagueness in sure or negative discovery of certain sentences in these strategies [10].
Zervoudakis et al. [11] propose OpinionMine, a Bayesian based structure for OM, developing Twitter Data. Primarily, the structure imports Tweets extremely by utilizing Twitter application programming interface (API). Afterward, the import Tweet is more managed automatically to construct the group of untrained rules and arbitrary variables. Next, the training method is utilized to estimate of novel Tweet. At last, the created method is retraining incrementally, so developing further robust. In [12], analysis of many tweets compared with the no plastic campaign has been executed for predicting the degree of polarity and subjectivity of tweets. The analysis was separated as to stages namely removing data, pre-processed, cleaning, eliminating stop word, and computation of sentiment score. The Machine Learning (ML) technique was executed on data set compared with the no plastic campaign and analysis was completed.
Yadav et al. [13] purposes for predicting the outcome of vote from Haryana in the tweet written in the English language. It can be utilized the Twitter Archiving Google Sheet (TAGS) tool and Twitter API utilizing R for obtaining the tweet. R is an extremely strong programming language and is satisfyingly employed from data interpretation and SA. Eshmawi et al. [14] concentrate on the scheme of automated OM method utilizing deer hunting optimization algorithm (DHOA) with fuzzy neural network (FNN), named as DHOA-FNN technique. The presented DHOA-FNN approach contains 4 various phases pre-processed, feature extracting, classifier, and parameter tuning procedures. Also, the DHOA-FNN approach contains 2 phases of feature extracting like Glove and N-gram techniques. Furthermore, the FNN system was employed as a classifier method, and parameter optimized procedure occurs by GTOA.
In this paper, a new Artificial Fish Swarm Optimization with Bidirectional Long Short Term Memory (AFSO-BLSTM) model has been developed for OM process. The major intention of the AFSO-BLSTM model is to effectively mine the opinions present in the textual data. In addition, the AFSO-BLSTM model undergoes pre-processing and TF-IFD based feature extraction process. Besides, BLSTM model is employed for the effectual detection and classification of opinions. Finally, the AFSO algorithm is utilized for effective hyperparameter adjustment process of the BLSTM model. A complete simulation study of the AFSO-BLSTM model is validated using benchmark dataset and the obtained experimental values revealed the high potential of the AFSO-BLSTM model on mining opinions.
In this article, a novel AFSO-BLSTM model has been developed for OM process. The AFSO-BLSTM model undergoes pre-processing and TF-IFD based feature extraction process. Moreover, BLSTM model is employed for the effectual detection and classification of opinions. Then, the AFSO algorithm is utilized for effective hyperparameter adjustment process of the BLSTM model. Fig. 1 illustrates the block diagram of proposed AFSO-BLSTM technique.
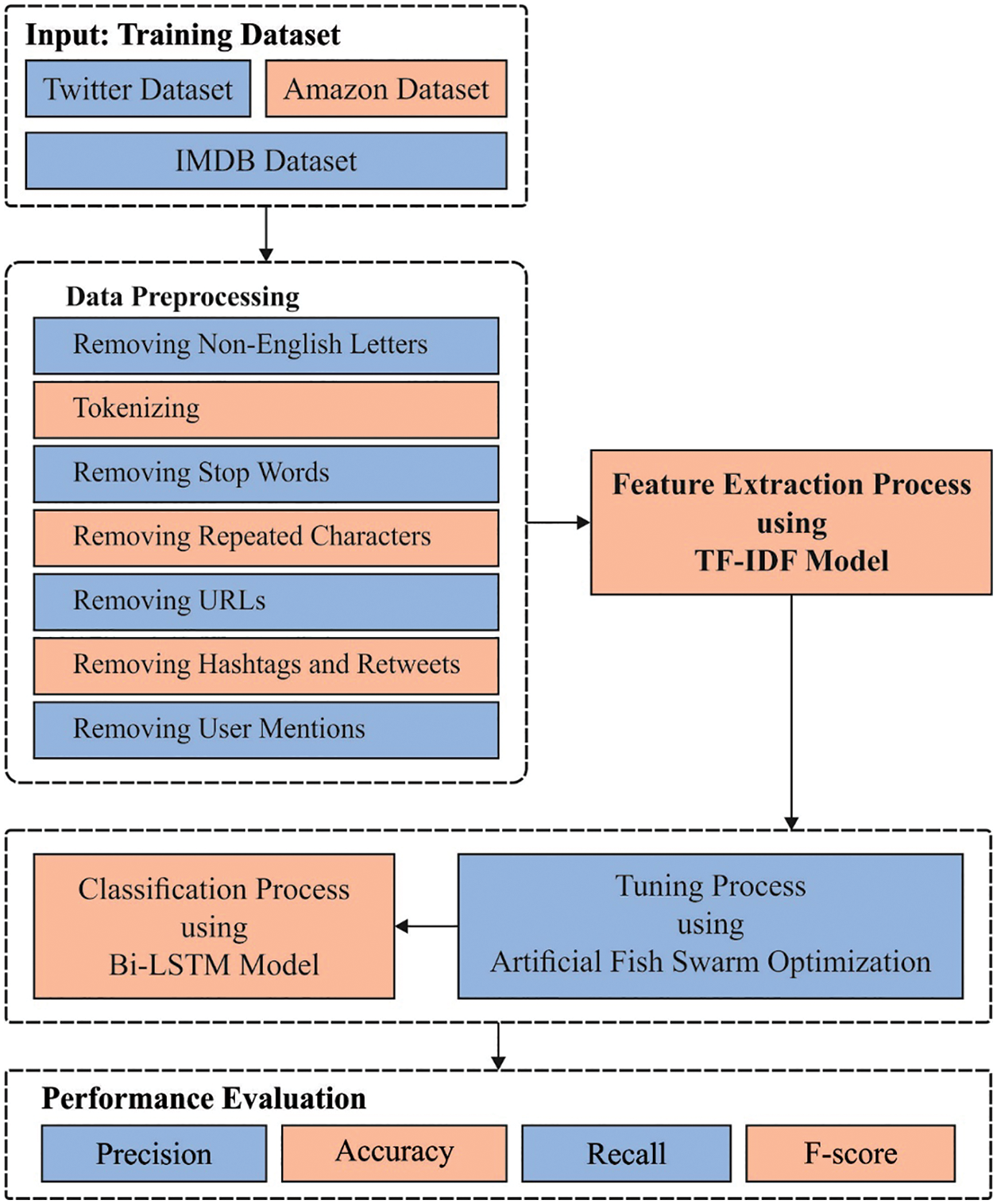
Figure 1: Block diagram of AFSO-BLSTM technique
2.1 Pre-processing and TF-IDF Model
At the initial stage, the AFSO-BLSTM model undergoes pre-processing and TF-IFD based feature extraction process [15]. TF-IDF is most generally employed feature extracting manner on text analysis. Amongst the 2 important tasks of index and weighted to text analysis, TF-IDF controls the weighting. It defines the weighted of offered term
whereas
The weighted of every term employing the TF-IDF is calculated by:
In which
2.2 Process Involved in BLSTM Model
Next to feature extraction, the BLSTM model is employed for the effectual detection and classification of opinions [16,17]. The BLSTM approach receives the feature is input for recognizing the class label of activities. The LSTM improves Memory Cell infrastructures from the neural nodes of hidden layer of RNN to store the previous data and added 3 gate infrastructures such as Forget, Output, and Input gates, to handle the procedure of previous data [16]. LSTM is transfer useful information from the subsequent time computation. The
The calculation equation is provided from the subsequent formulas:
In which
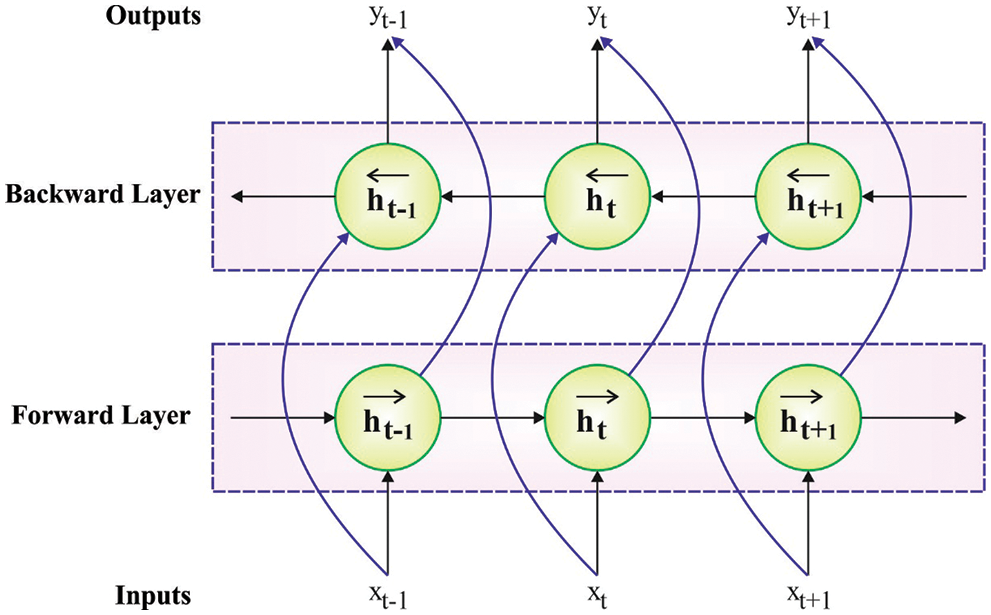
Figure 2: Framework of BiLSTM
Long short term memory (LSTM) is only learned from the abovementioned data of time sequence, BLSTM generates a more increase dependent upon LSTM, for instance, developed up of reverse as well as forward LSTM network, offering the context data of time sequence. At this point,
The final outcome
In the abovementioned formulas, it calculates the outcome at every moment, and later reach the final output
2.3 Process Involved in AFSO Based Parameter Optimization
At the final stage of OM, the AFSO algorithm is utilized for effective hyperparameter adjustment process of the BLSTM model [17]. AFSO algorithm is a type of SI technique depending upon the performance of animals. Is baseline being the stimulation of clustering, collision, and foraging behaviors of fish and the cooperative provision in a fish swarm to understand a global optimal point. The maximum distance passed by the artificial fish technique is defined as Step, the obvious distance passes by the artificial fish is defined as Visual, the repeat quantity signifies the
while rand (0–1) characterizes an arbitrary value amongst zero & one. After
After it does not
To avoid over-crowding, an artificial current place
Otherwise, it begins to accomplish the prey behavior.
The current place of artificial fish swarm is described as
It allows artificial fish to accomplish food and company over a great region. A place is subjectively selected, along with artificial fish moved to them.
Through the searching region of
In which
In this section, the performance validation of the AFSO-BLSTM model is tested using three benchmark datasets namely IMDB Dataset [18], Amazon Products Dataset [19], and Twitter Dataset [20]. All these three datasets comprises two class labels namely positive and negative.
Tab. 1 and Fig. 3 illustrate a comprehensive comparative study of the AFSO-BLSTM model on the test IMDB dataset [21,22]. The outcomes indicated that the AFSO-BLSTM model has showcased enhanced performance over the other models under distinct feature extraction techniques. With unigram features, the AFSO-BLSTM model has offered
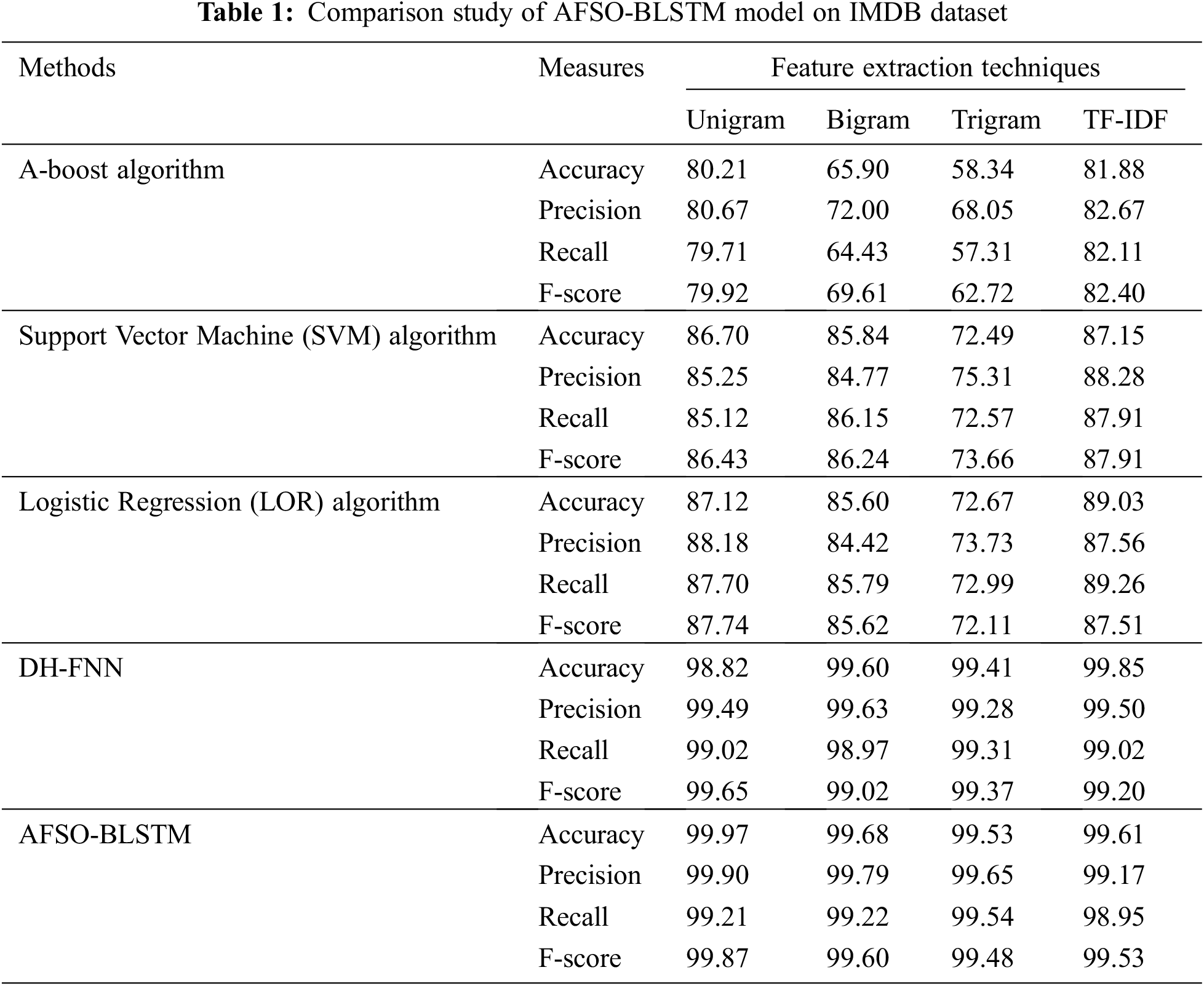
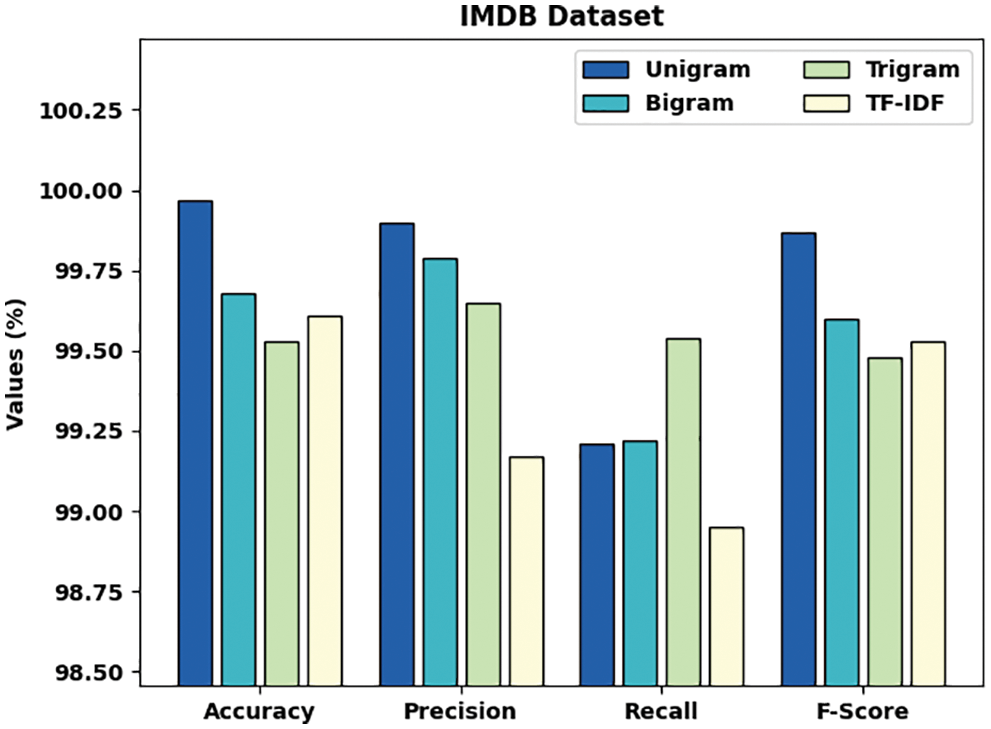
Figure 3: Comparative analysis of AFSO-BLSTM technique on IMDB dataset
Fig. 4 illustrates the training and validation accuracy inspection of the AFSO-BLSTM model on IMDB dataset. The figure conveyed that the AFSO-BLSTM model has offered maximum training/validation accuracy on classification process.
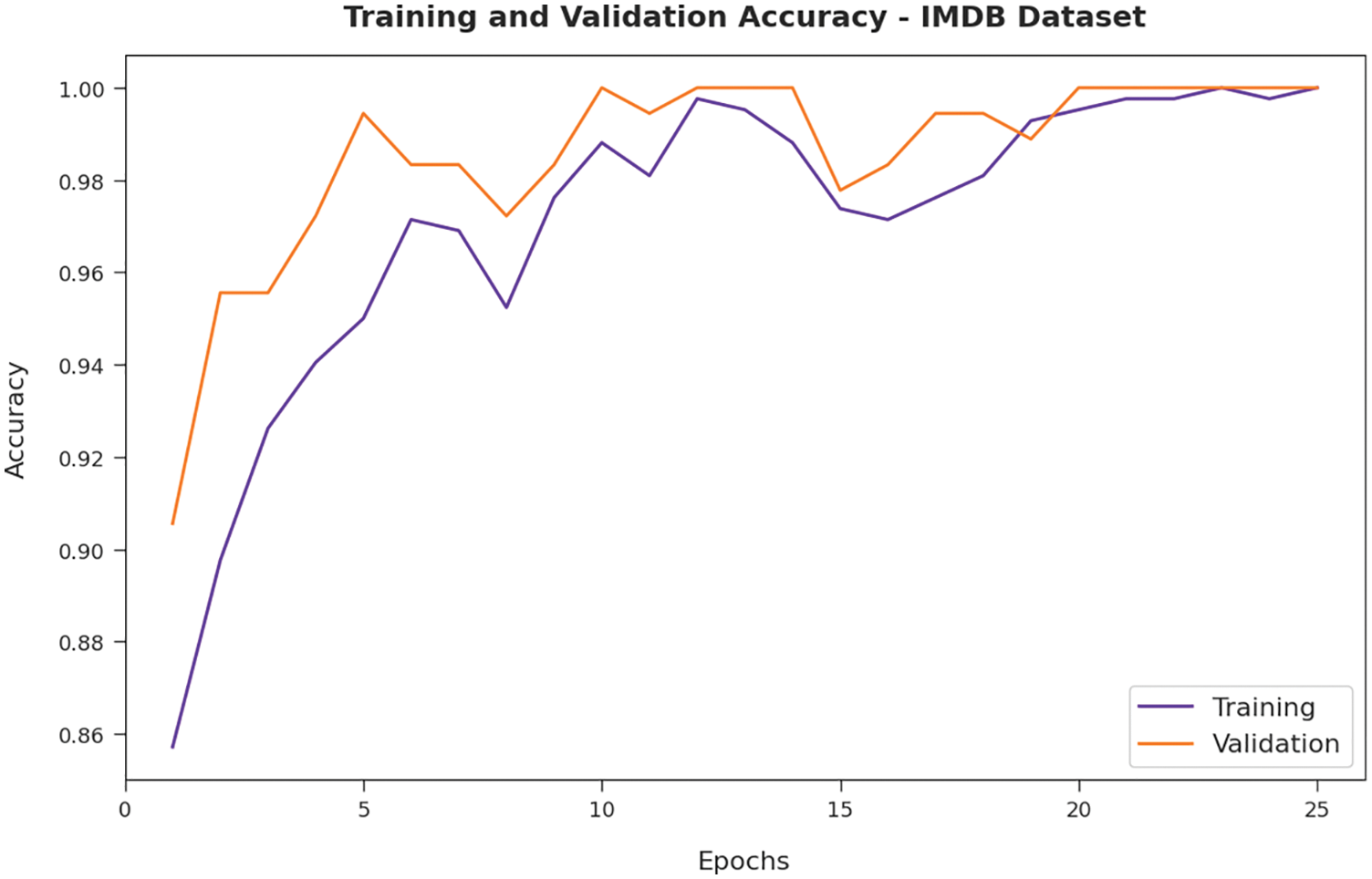
Figure 4: Accuracy analysis of AFSO-BLSTM technique under IMDB dataset
Next, Fig. 5 exemplifies the training and validation loss inspection of the AFSO-BLSTM model on IMDB dataset. The figure reported that the AFSO-BLSTM model has offered reduced training/accuracy loss on the classification process of test data.
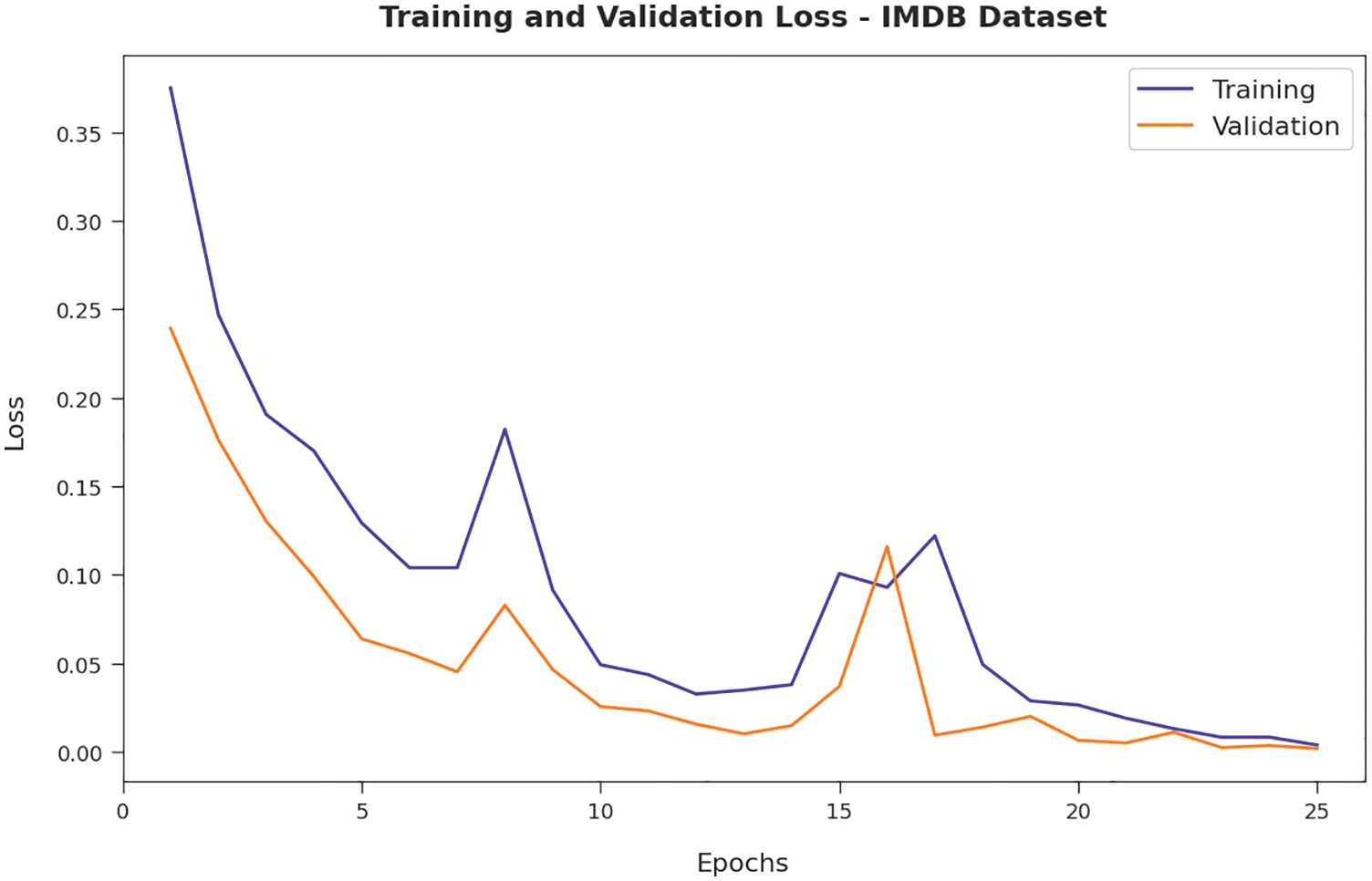
Figure 5: Loss analysis of AFSO-BLSTM technique under IMDB dataset
Tab. 2 and Fig. 6 demonstrate a comprehensive comparative study of the AFSO-BLSTM model on the test Amazon dataset. The outcomes referred that the AFSO-BLSTM model has showcased enhanced performance over the other models under distinct feature extraction techniques. With unigram features, the AFSO-BLSTM method has offered
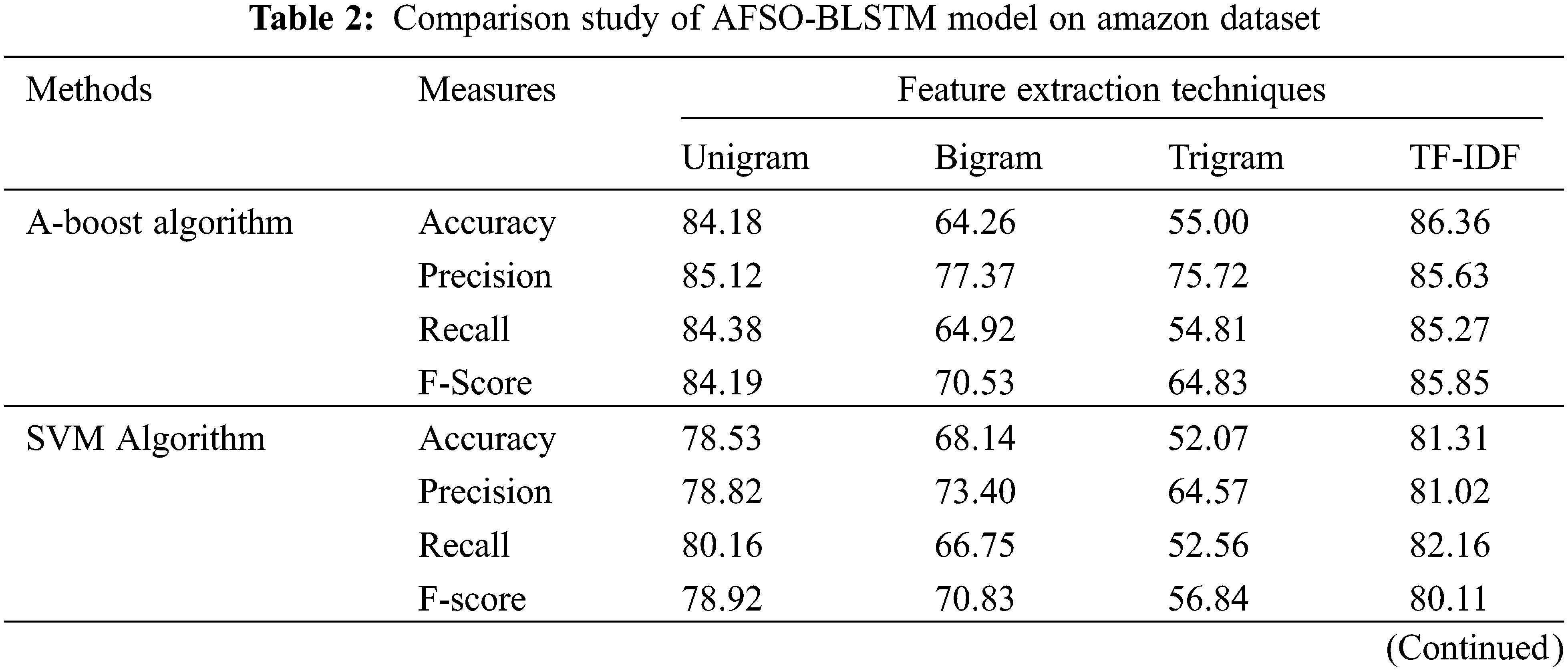
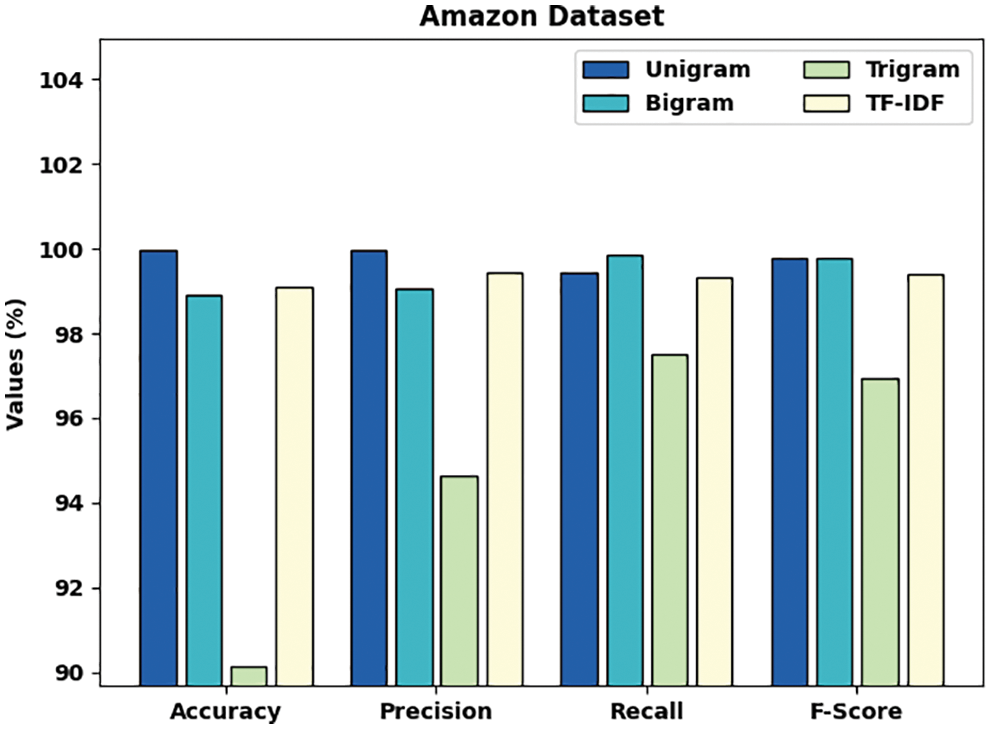
Figure 6: Comparative analysis of AFSO-BLSTM technique on Amazon dataset
Fig. 7 showcases the training and validation accuracy inspection of the AFSO-BLSTM method on Amazon dataset. The figure exposed that the AFSO-BLSTM model has offered maximum training/validation accuracy on classification process.
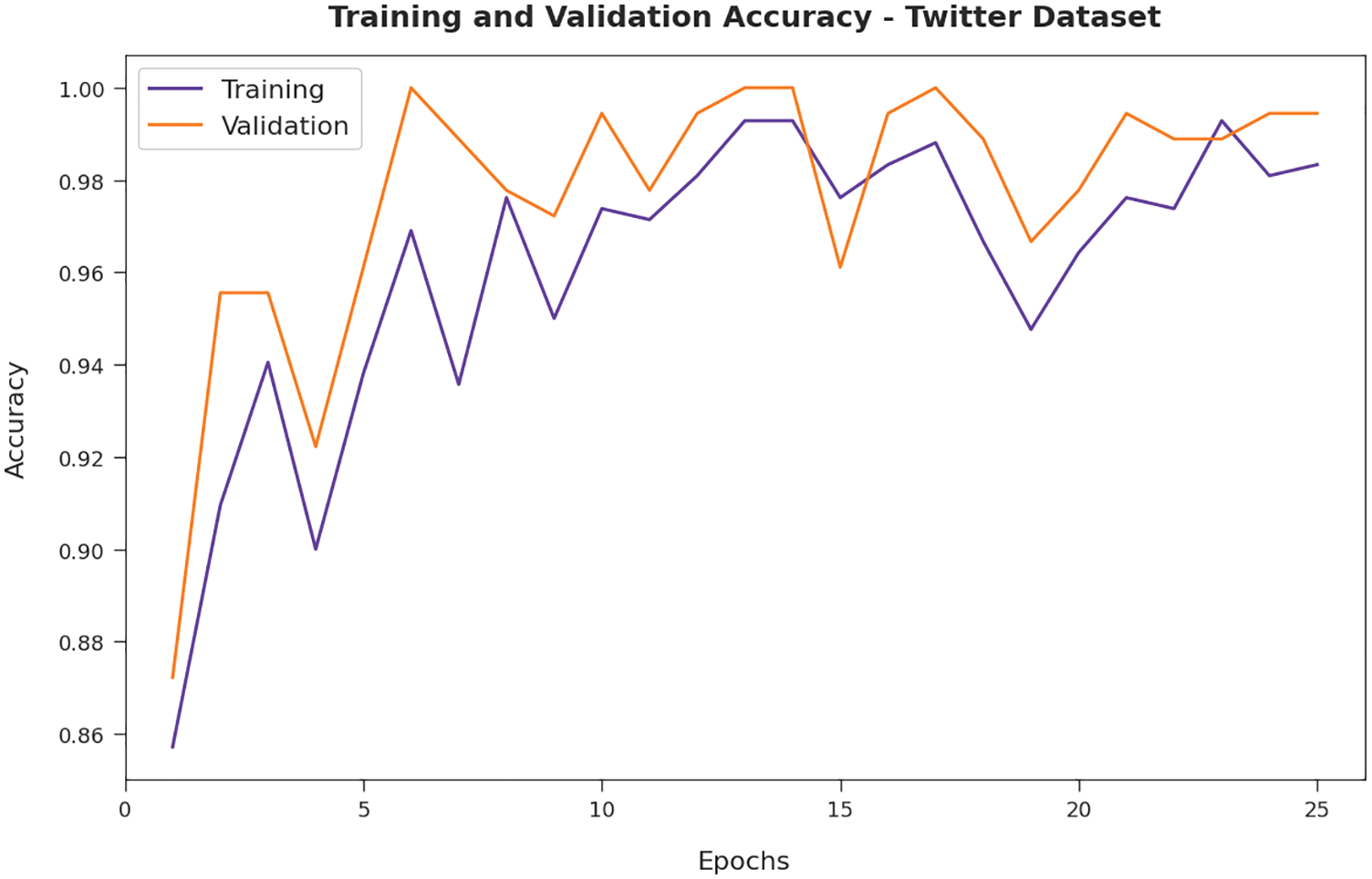
Figure 7: Accuracy analysis of AFSO-BLSTM technique under Amazon dataset
Afterward, Fig. 8 exemplifies the training and validation loss inspection of the AFSO-BLSTM technique on Amazon dataset. The figure revealed that the AFSO-BLSTM system has offered reduced training/accuracy loss on the classification process of test data.
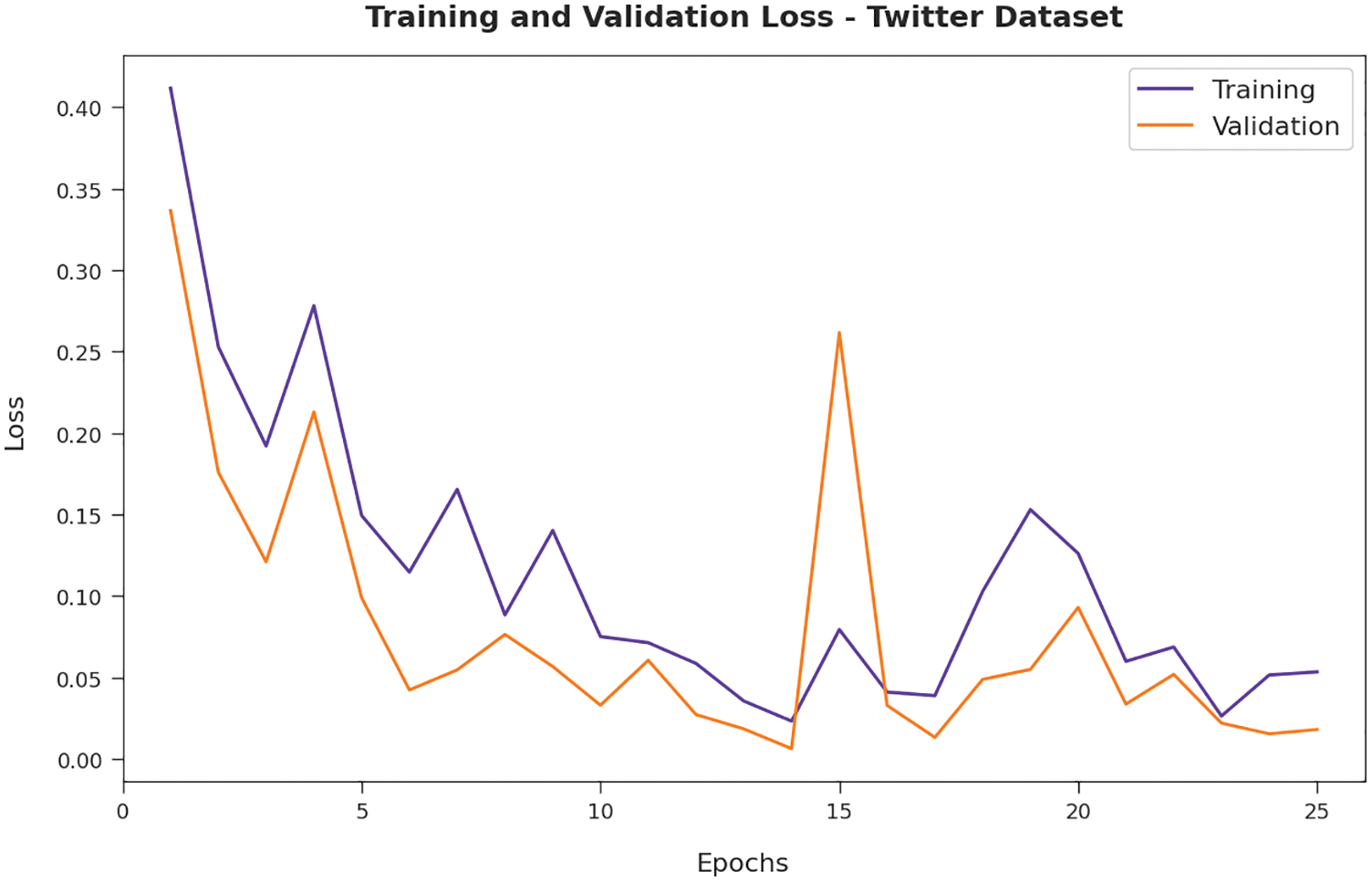
Figure 8: Loss analysis of AFSO-BLSTM technique under Amazon dataset
Tab. 3 and Fig. 9 demonstrate a comprehensive comparative study of the AFSO-BLSTM approach on the test Twitter dataset. The outcomes represented that the AFSO-BLSTM model has showcased enhanced performance over the other techniques under distinct feature extraction techniques. With unigram features, the AFSO-BLSTM model has offered
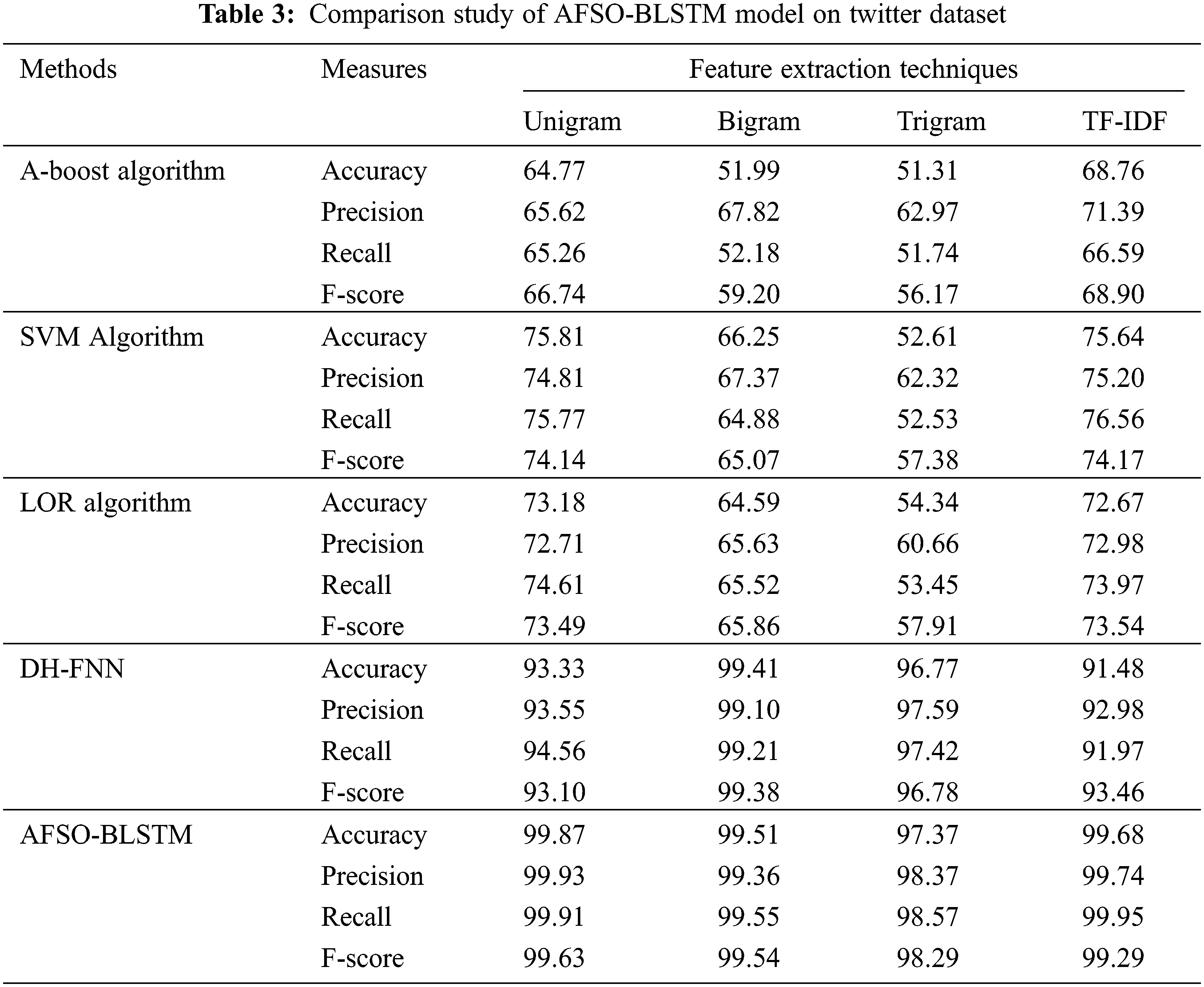
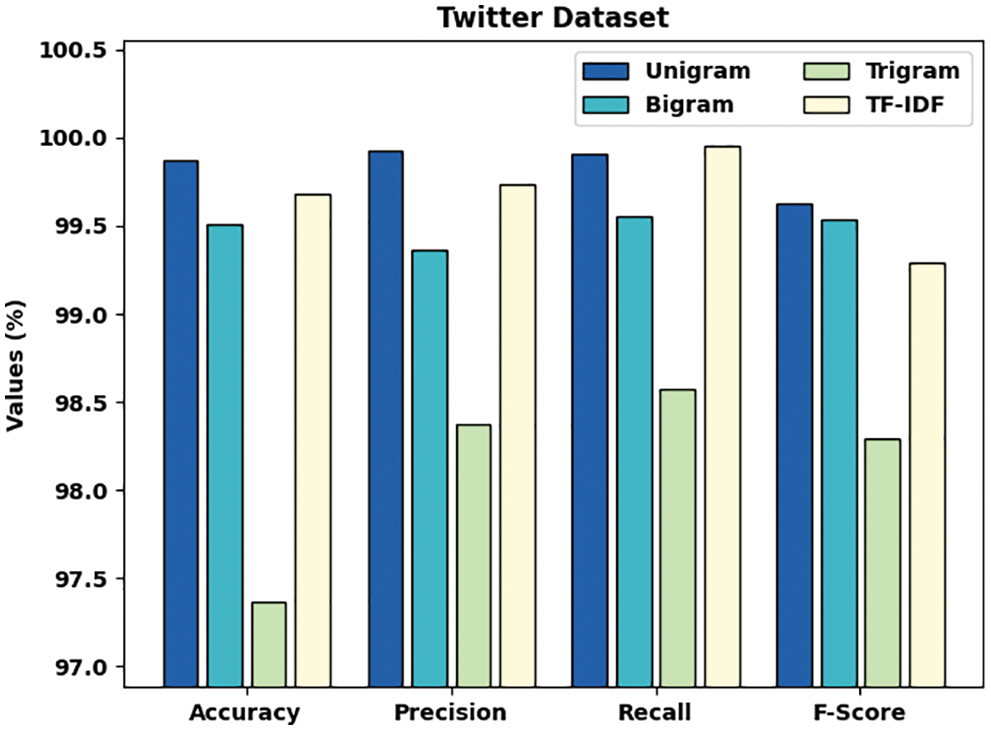
Figure 9: Comparative analysis of AFSO-BLSTM technique on Twitter dataset
Fig. 10 depicts the training and validation accuracy inspection of the AFSO-BLSTM approach on Twitter dataset. The figure conveyed that the AFSO-BLSTM model has offered maximal training/validation accuracy on classification process.
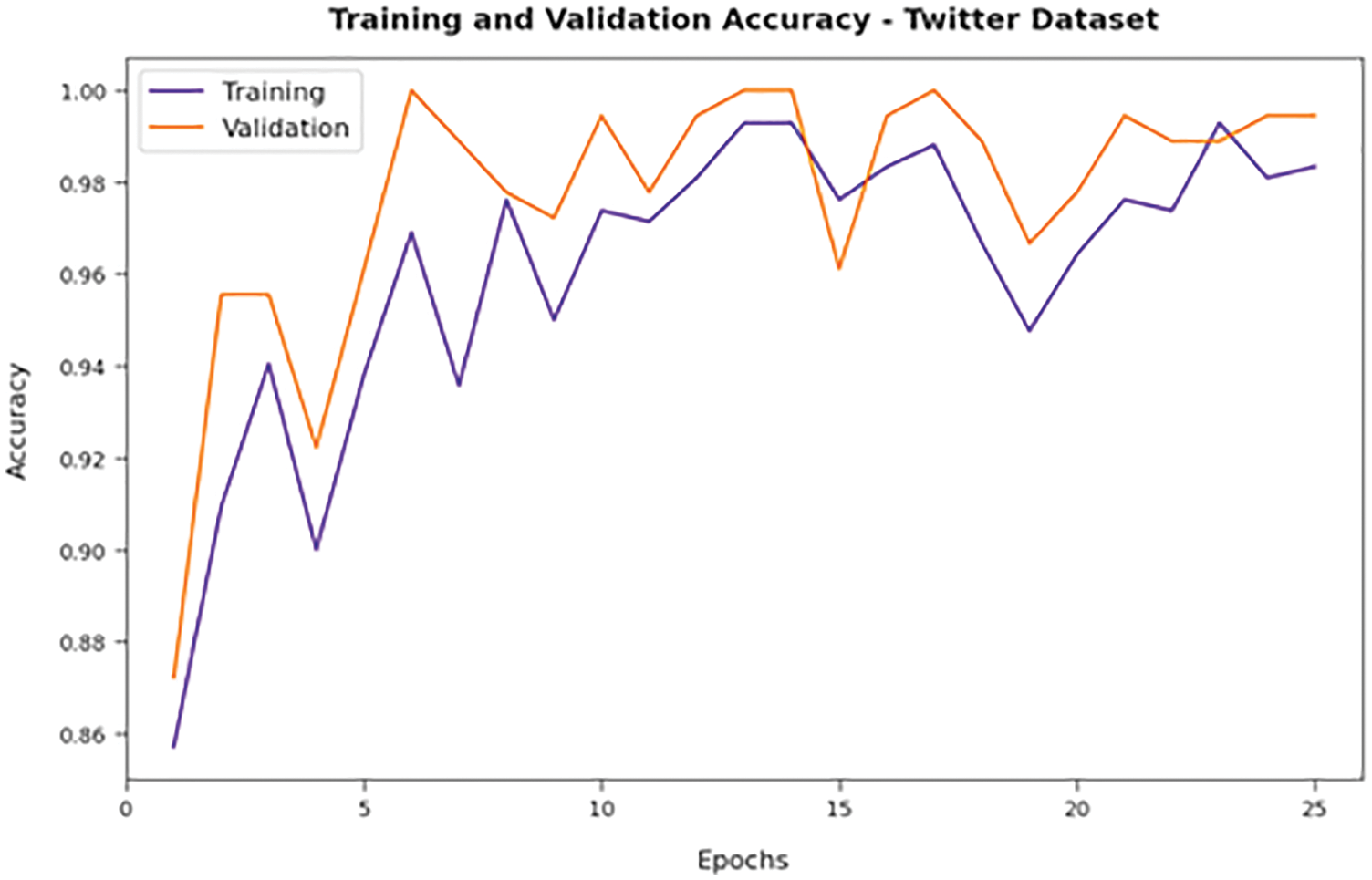
Figure 10: Accuracy analysis of AFSO-BLSTM technique under Twitter dataset
Then, Fig. 11 typifies the training and validation loss inspection of the AFSO-BLSTM approach on Twitter dataset. The figure reported that the AFSO-BLSTM model has offered reduced training/accuracy loss on the classification process of test data.
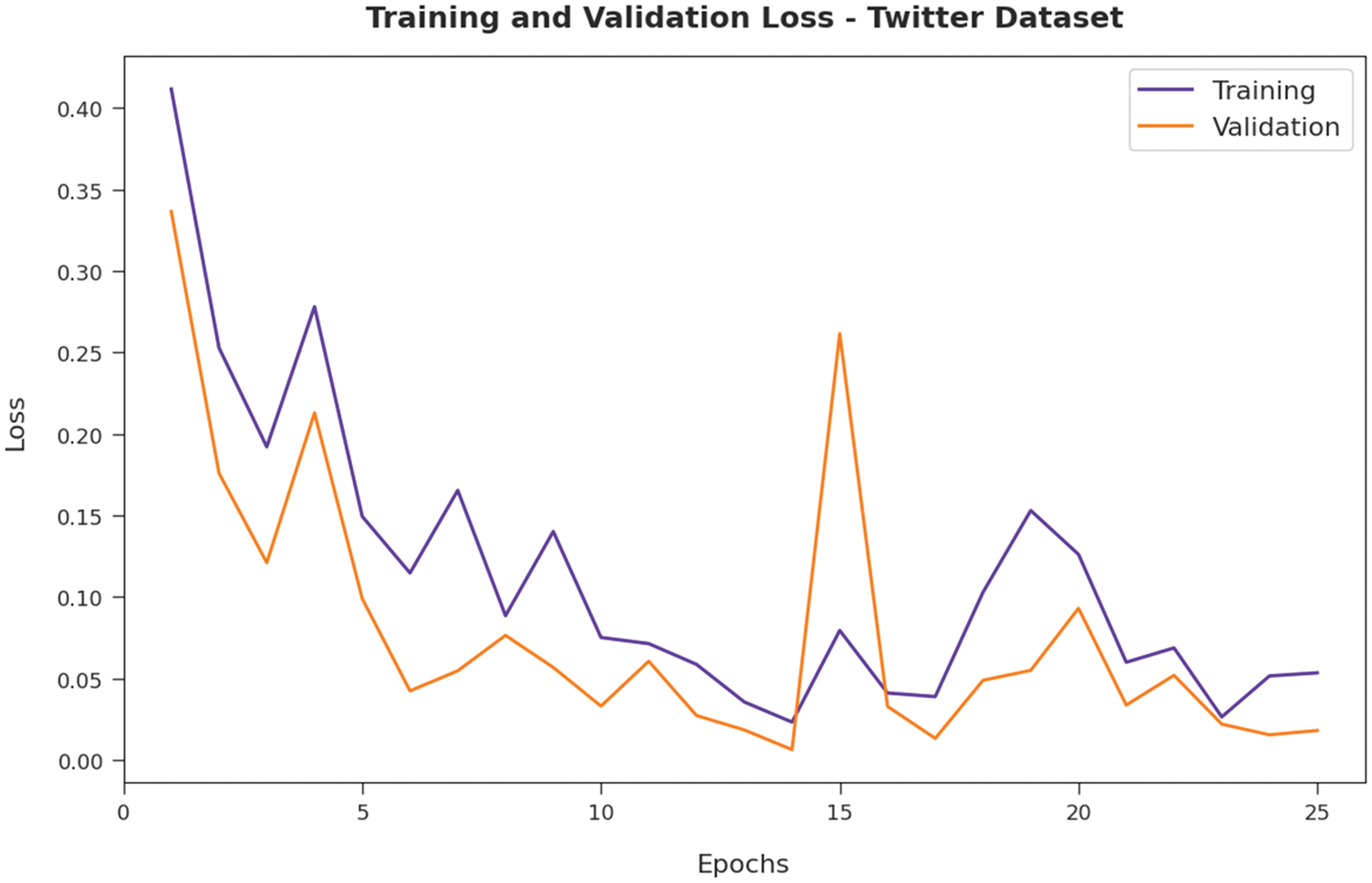
Figure 11: Loss analysis of AFSO-BLSTM technique under Twitter dataset
The above mentioned results and discussion indicated the supremacy of the AFSO-BLSTM model on the OM tasks.
In this article, a novel AFSO-BLSTM model has been developed for OM process. The major intention of the AFSO-BLSTM model is to effectively mine the opinions present in the textual data. In addition, the AFSO-BLSTM model undergoes pre-processing and TF-IFD based feature extraction process. Besides, BLSTM model is employed for the effectual detection and classification of opinions. Finally, the AFSO algorithm is utilized for effective hyperparameter adjustment process of the BLSTM model. A complete simulation study of the AFSO-BLSTM model is validated using benchmark dataset and the obtained experimental values revealed the high potential of the AFSO-BLSTM model on mining opinions. In future, hybrid DL models can be included to further boost the classification efficiency of the BLSTM model.
Funding Statement: The authors extend their appreciation to the Deanship of Scientific Research at King Khalid University for funding this work under grant number (RGP 2/142/43).
Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2022R161), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
The authors would like to thank the Deanship of Scientific Research at Umm Al-Qura University for supporting this work by Grant Code: (22UQU4210118DSR08).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. M. Keyvanpour, Z. K. Zandian and M. Heidarypanah, “OMLML: A helpful opinion mining method based on lexicon and machine learning in social networks,” Social Network Analysis and Mining, vol. 10, no. 1, pp. 10, 2020. [Google Scholar]
2. M. L. B. Estrada, R. Z. Cabada, R. O. Bustillos and M. Graff, “Opinion mining and emotion recognition applied to learning environments,” Expert Systems with Applications, vol. 150, pp. 113265, 2020. [Google Scholar]
3. R. Alfrjani, T. Osman and G. Cosma, “A hybrid semantic knowledgebase-machine learning approach for opinion mining,” Data & Knowledge Engineering, vol. 121, no. 7, pp. 88–108, 2019. [Google Scholar]
4. B. Lin, N. Cassee, A. Serebrenik, G. Bavota, N. Novielli et al., “Opinion mining for software development: A systematic literature review,” ACM Transactions on Software Engineering and Methodology, vol. 31, no. 3, pp. 1–41, 2022. [Google Scholar]
5. W. Cherif, A. Madani and M. Kissi, “Supervised classification by thresholds: Application to automated text categorization and opinion mining,” Concurrency and Computation: Practice and Experience, vol. 34, no. 4, pp. e6613, 2022. [Google Scholar]
6. S. R. George, P. S. Kumar and S. K. George, “Conceptual framework model for opinion mining for brands in facebook engagements using machine learning tools,” in: ICT Analysis and Applications, Lecture Notes in Networks and Systems Book Series, vol. 154, Singapore: Springer, pp. 115–121, 2021. [Google Scholar]
7. F. Bi, X. Ma, W. Chen, W. Fang, H. Chen et al., “Review on video object tracking based on deep learning,” Journal of New Media, vol. 1, no. 2, pp. 63–74, 2019. [Google Scholar]
8. W. Sun, X. Chen, X. R. Zhang, G. Z. Dai, P. S. Chang et al., “A multi-feature learning model with enhanced local attention for vehicle re-identification,” Computers, Materials & Continua, vol. 69, no. 3, pp. 3549–3561, 2021. [Google Scholar]
9. M. Susmitha and R. L. Pranitha, “Performance assessment using supervised machine learning algorithms of opinion mining on social media dataset,” in Proc. of Second Int. Conf. on Advances in Computer Engineering and Communication Systems, Algorithms for Intelligent Systems Book Series, Singapore, Springer, pp. 419–427, 202. [Google Scholar]
10. M. S. Jacobnd and P. S. Rajendran, “Deceptive product review identification framework using opinion mining and machine learning,” in Mobile Radio Communications and 5G Networks, Lecture Notes in Networks and Systems Book Series, vol. 339, Singapore: Springer, pp. 57–72, 2022. [Google Scholar]
11. S. Zervoudakis, E. Marakakis, H. Kondylakis and S. Goumas, “OpinionMine: A bayesian-based framework for opinion mining using twitter data,” Machine Learning with Applications, vol. 3, no. 3, pp. 100018, 2021. [Google Scholar]
12. N. A. Surabhi and A. K. Jain, “Twitter sentiment analysis on Indian Government schemes using machine learning models,” International Journal of Swarm Intelligence, vol. 7, no. 1, pp. 39, 2022. [Google Scholar]
13. D. Yadav, A. Sharma, S. Ahmad and U. Chandra, “Political sentiment analysis: Case study of haryana using machine learning,” in Mobile Radio Communications and 5G Networks, Lecture Notes in Networks and Systems Book Series, vol. 339, Singapore: Springer, pp. 479–499, 2022. [Google Scholar]
14. A. A. Eshmawi, H. Alhumyani, S. A. Khalek, R. A. Saeed, M. Ragab et al., “Design of automated opinion mining model using optimized fuzzy neural network,” Computers, Materials & Continua, vol. 71, no. 2, pp. 2543–2557, 2022. [Google Scholar]
15. W. Zhang, T. Yoshida and X. Tang, “A comparative study of TF*IDF, LSI and multi-words for text classification,” Expert Systems with Applications, vol. 38, no. 3, pp. 2758–2765, 2011. [Google Scholar]
16. T. Chen, R. Xu, Y. He and X. Wang, “Improving sentiment analysis via sentence type classification using BiLSTM-CRF and CNN,” Expert Systems with Applications, vol. 72, no. 8, pp. 221–230, 2017. [Google Scholar]
17. M. Neshat, G. Sepidnam, M. Sargolzaei and A. N. Toosi, “Artificial fish swarm algorithm: A survey of the state-of-the-art, hybridization, combinatorial and indicative applications,” Artificial Intelligence Review, vol. 42, no. 4, pp. 965–997, 2014. [Google Scholar]
18. A. L. Maas, R. E. Daly, P. T. Pham, D. Huang, A. Y. Ng et al., “Learning word vectors for sentiment analysis,” in Proc. of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, Oregon, USA, pp. 19–24, 2011. [Google Scholar]
19. D. Kotzias, M. Denil, N. de Freitas and P. Smyth, “From group to individual labels using deep features,” in Proc. of the 21th ACM SIGKDD Int. Conf. on Knowledge Discovery and Data Mining, Sydney, NSW Australia, pp. 597–606, 2015. [Google Scholar]
20. Twitter Sentiment Analysis Training Corpus (Datasethttp://thinknook.com/twittersentiment-analysis-training-corpus-dataset-2012-09-22/. [Google Scholar]
21. R. Alfrjani, T. Osman and G. Cosma, “A hybrid semantic knowledgebase-machine learning approach for opinion mining,” Data & Knowledge Engineering, vol. 121, no. 7, pp. 88–108, 2019. [Google Scholar]
22. D. Gamal, M. Alfonse, E. S. M. E. Horbaty and A. B. M. Salem, “Analysis of machine learning algorithms for opinion mining in different domains,” Machine Learning and Knowledge Extraction, vol. 1, no. 1, pp. 224–234, 2018. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools