DOI:10.32604/csse.2023.027502
| Computer Systems Science & Engineering DOI:10.32604/csse.2023.027502 | |
| Article |
Optimal Weighted Extreme Learning Machine for Cybersecurity Fake News Classification
1Department of Computer Science and Information Systems, College of Applied Sciences, AlMaarefa University, Ad Diriyah, Riyadh, 13713, Kingdom of Saudi Arabia
2Department of Computer Science, Prince Sultan University, Riyadh, 11586, Kingdom of Saudi Arabia
3Department of Computer Engineering, College of Computers and Information Technology, Taif University, Taif, 21944, Kingdom of Saudi Arabia
4Department of Computing, Arabeast Colleges, Riyadh, 11583, Kingdom of Saudi Arabia
5Department of Archives and Communication, King Faisal University, Al Ahsa, Hofuf, 31982, Kingdom of Saudi Arabia
*Corresponding Author: Ashit Kumar Dutta. Email: adotta@mcst.edu.sa
Received: 19 January 2022; Accepted: 23 March 2022
Abstract: Fake news and its significance carried the significance of affecting diverse aspects of diverse entities, ranging from a city lifestyle to a country global relativity, various methods are available to collect and determine fake news. The recently developed machine learning (ML) models can be employed for the detection and classification of fake news. This study designs a novel Chaotic Ant Swarm with Weighted Extreme Learning Machine (CAS-WELM) for Cybersecurity Fake News Detection and Classification. The goal of the CAS-WELM technique is to discriminate news into fake and real. The CAS-WELM technique initially pre-processes the input data and Glove technique is used for word embedding process. Then, N-gram based feature extraction technique is derived to generate feature vectors. Lastly, WELM model is applied for the detection and classification of fake news, in which the weight value of the WELM model can be optimally adjusted by the use of CAS algorithm. The performance validation of the CAS-WELM technique is carried out using the benchmark dataset and the results are inspected under several dimensions. The experimental results reported the enhanced outcomes of the CAS-WELM technique over the recent approaches.
Keywords: Cybersecurity; cybercrime; fake news; data classification; machine learning; metaheuristics
Online data is often accessible as a result of few clicks away. With the unique independence provided to users for sharing stories, the complexity to describe the root of false data increases gradually. The existence of dramatic headlines and clickbait titles is at its highest point that assists in the broadcast of inaccurate and unprofessional news in response to advertising revenues. User, wants to be part of this hot discussion or topic, adapt the innovative message with intention or by mistake that eventually results in the distribution of rumor on the internet. Fake news is inscribed for a hoax that leads to political or gains or financial spreading data disguised as propaganda [1], one might be utilized to influence public perception towards falseness. Even this encourages the beliefs and people ideology to some range that might create several damages [2]. This persuading is popular when a news story breaks out, whereby the supporter usually tends to share data in its complete originality, while the one opinion doesn’t bring into line with the information mentioned resorting to share that similar data with few adjustments. Currently, media outlets are the only information resources. Specific contribution in news sharing has significantly developed over the last decade where it become ever more complex to discriminate news that originate from a reliable source from the one that is invented [3]. Consequently, fake news has gained several interests recently by organizations like Google, Twitter, Facebook, and by various authors, who are making continuous attempts in opposing the spread of fake stories. Fig. 1 illustrates the platform to detect fake news.

Figure 1: Platform to detect fake news
Artificial intelligence (AI) technique is the evolving technology that has transformed the view at business problems [4]. An increasing amount of businesses are transforming to innovative analysis and machine learning to resolve problems. With this development, natural language processing (NLP) describes great potential for business that is concerned with understanding human sentiment via the current information. NLP functions with each kind of social and natural communication, involving text, audio, and video. In order to identify trends and many valuable patterns in the textual data set, text mining assisted to perform in this way [5]. In present market setting, strategic use of NLP assist business to obtain relative benefits. AI and NLP assist in combating the large unstructured data of various fields involving education, healthcare, business sectors, fake news, trust and security, opinion from the public in the government sector [6]. The NLP assists human-to-machine communication very efficiently that sequentially improves the overall efficiency and decision-making of the businesses. The NLP relates to how individual interacts, that consist of emotions, speech, and text. Fake news detection has gained much consideration in the NLP research field to mitigate the time-consuming human activity and burdensome data verification [7]. Despite that, the process of estimating the validity of news remains a challenge even for automatic systems.
Kumar et al. [8] gather 1356 news samples from different clients through media sources and Twitter including PolitiFact and construct various data sets for the fake and real news stories. We compared many advanced methods including attention mechanism, convolution neural network (CNN), long short term memory (LSTM), and ensemble approaches. Roy et al. [9] developed deep learning (DL) algorithms to identify fake news and classify them to the pre-determined fine-grained classes. Firstly, we designed CNN and bidirectional LSTM (Bi-LSTM) based systems. The representation attained from these two methods is given to a multilayer perceptron (MLP) for the last classification.
Aslam et al. [10] presented an ensemble-based DL method for classifying news as real or fake. Because of the nature of dataset traits, two DL methods have been employed. For the textual attributes “statement,” Bi-LSTM-gated recurrent unit (GRU)-dense DL method has been utilized, for the residual characteristics, dense DL algorithm has been employed.
In Agarwal et al. [11], researchers have experimented and discussed word embedding (GloVe) for text pre-processing to establish lingual relationships and create a vector space of words. The presented method is the combination of CNN and recurrent neural network (RNN) frameworks that have accomplished standard outcomes in predicting fake news, with the effectiveness of word embedding complementing the overall method. Furthermore, to guarantee the prediction quality, several model parameters were recorded and tuned for the optimal result.
Khanam et al. [12] make research analytics based fake news detection and examine the conventional machine learning (ML) methods for choosing the best, to construct a method of a product using supervised ML method, which could categorize fake news as false or true, by utilizing python scikit-learn, NLP for text analysis. Bangyal et al. [13] developed a precise model for SA of fake news. The fake news datasets contain fake news; the study initiates by data pre-processing (replaces the stemming, tokenization, noise removal, and missing value). The study employed a semantic method with inverse document frequency and term frequency weighting for representing information. In the evaluation and measuring stage, we employed 8 ML approaches.
This study designs a novel Chaotic Ant Swarm with Weighted Extreme Learning Machine (CAS-WELM) for Cybersecurity Fake News Detection and Classification. The goal of the CAS-WELM system is to discriminate news into fake and real. The CAS-WELM technique initially pre-processes the input data and Glove technique is used for word embedding process. Then, N-gram based feature extraction technique is derived to generate feature vectors. Lastly, WELM model is applied for the detection and classification of fake news, in which the weight value of the WELM model can be optimally adjusted by the use of CAS algorithm. The performance validation of the CAS-WELM technique is carried out using the benchmark dataset and the results are inspected under several dimensions.
In this study, a novel CAS-WELM technique has been developed for Cybersecurity Fake News Detection and Classification. The CAS-WELM technique mainly intends to discriminate news into fake and real. The CAS-WELM technique undergoes different stages of operations namely pre-processing, Glove based word embedding, N-gram based feature extraction, WELM based classification, and CAS based parameter optimization. Besides, the weight value of the WELM model can be optimally adjusted by the use of CAS algorithm.
The data set is considered into two groups, true category, and false category. Data visualization assists in comprehending comparative data mean by demonstrating information in visual contexts, namely graphs or maps. This makes it easy to spot outliers, trends, and patterns in massive datasets by creating the data to analyze for the human mind. The data set is categorized into two classes, original and fake news. The fake news class is denoted as ‘0’ and true news class is denoted as ‘1’. When certain words exist in the group of a corpus, then the word is removed [14]. Data pre-processing is a major phase that includes data manipulation beforehand it is implemented, to improve efficacy. It includes data transformation and cleansing. To remove the stop word from the sentence, the text can be separated into words, and then it is verified to understand whether the word exist in the Natural Language Toolkit (NLTK) list of stop words. Stemming represents the extraction of word root or stems form that may or may not completely reflects semantic intellectual. The procedure of lemmatization is the decrease of inflectional format generally useful word-to common form. Glove embedding and Keras embedding layer, utilized to train NN system on textual information. This is a flexible layer, utilized for loading pre-trained GloVe embedding of hundred dimensions.
2.2 N-gram Based Feature Extraction
Consider
Now, the comma represents row vector concatenation. A filter
whereas
Here,
Beforehand elaborating on the WELM, firstly presented the fundamental extreme learning machine (ELM). Using the mapping datasets

Figure 2: Structure of WELM
In which
In which
Here, the
The aim of trained SLFN is to reduce the output errors, that is, approximate the input sample with zero error
Whereas
Aimed at ELM, the bias
The optimum solution of Eq. (11) is
Whereas
While constructing the ELM classification, we determine a
Next, Eq. (13) becomes
Mainly, it consists of two systems to assign the weight to the sample of the two classes:
Or
Here,
2.4 Parameter Optimization Using CAS Algorithm
For tuning the weight values of the WELM model, the CAS is used. Recently, a SI optimization method named CAS approach is presented for solving the optimization issue according to chaos concept [18]. The CAS algorithm is mathematically modelled by the following equation:
In which
Lastly, with the impact of
To support ant to have a distinct organization variable, fix
The experimental result analysis of the CAS-WELM technique is validated using benchmark dataset. The initial dataset is named as ISOT Fake News Dataset [19] (Sample Set-1), comprising 44,898 articles (21,417 instances under truthful articles and 23,481 under fake articles). The second Kaggle dataset [20] (Sample Set-2) includes 20,386 articles employed to train the dataset and 5,126 articles are applied to test the dataset. The third dataset [21] (sample set-3) comprises 3,352 articles, both fake and true. The final dataset (Sample Set-4) includes the combination of the dataset.
Tab. 1 and Fig. 3 demonstrate the accuracy analysis of the CAS-WELM technique with other ones [22]. The results indicated that the k-nearest neighbor (KNN) model has attained worse classification results than the other methods. In addition, the logistic regression (LR) model has obtained slightly improved classification performance over the KNN model. Moreover, the Localized Support Vector Machine (LSVM), MLP, and Bagging-decision tree (DT) model has accomplished moderately increased outcomes. Though the random forest (RF) model has resulted in competitive outcome, the CAS-WELM technique has outperformed the other methods with the higher accuracy of 99.46%, 96.32%, 96.58%, and 94.89% on the test sample sets 1–4 respectively.


Figure 3: Accuracy analysis of CAS-WELM technique with existing approaches
Tab. 2 and Fig. 4 illustrate the precision analysis of the CAS-WELM approach with other ones. The results indicated that the KNN technique has attained least classification outcomes over the other methods. Besides, the LR approach has reached somewhat higher classification performance over the KNN technique. Moreover, the LSVM, MLP, and Bagging-DT methodology have accomplished moderately increased outcomes. Then, the RF system has resulted in competitive outcome, the CAS-WELM system has demonstrated the other methods with the superior precision of 99.61%, 95.74%, 99.24%, and 95.35% on the test sample sets 1–4 correspondingly.


Figure 4: Precision analysis of CAS-WELM technique with existing approaches
Tab. 3 and Fig. 5 showcases the recall analysis of the CAS-WELM approach with other ones. The outcomes referred that the KNN algorithm has gained poor classification results over the other methods. Similarly, the LR technique has obtained slightly enhanced classification performance over the KNN technique. Likewise, the LSVM, MLP, and Bagging-DT approach has accomplished moderately increased outcomes. Eventually, the RF system has resulted in competitive outcome, the CAS-WELM method has exhibited the other techniques with the maximal recall of 100%, 98.24%, 100%, and 95.84% on the test sample sets 1–4 correspondingly.
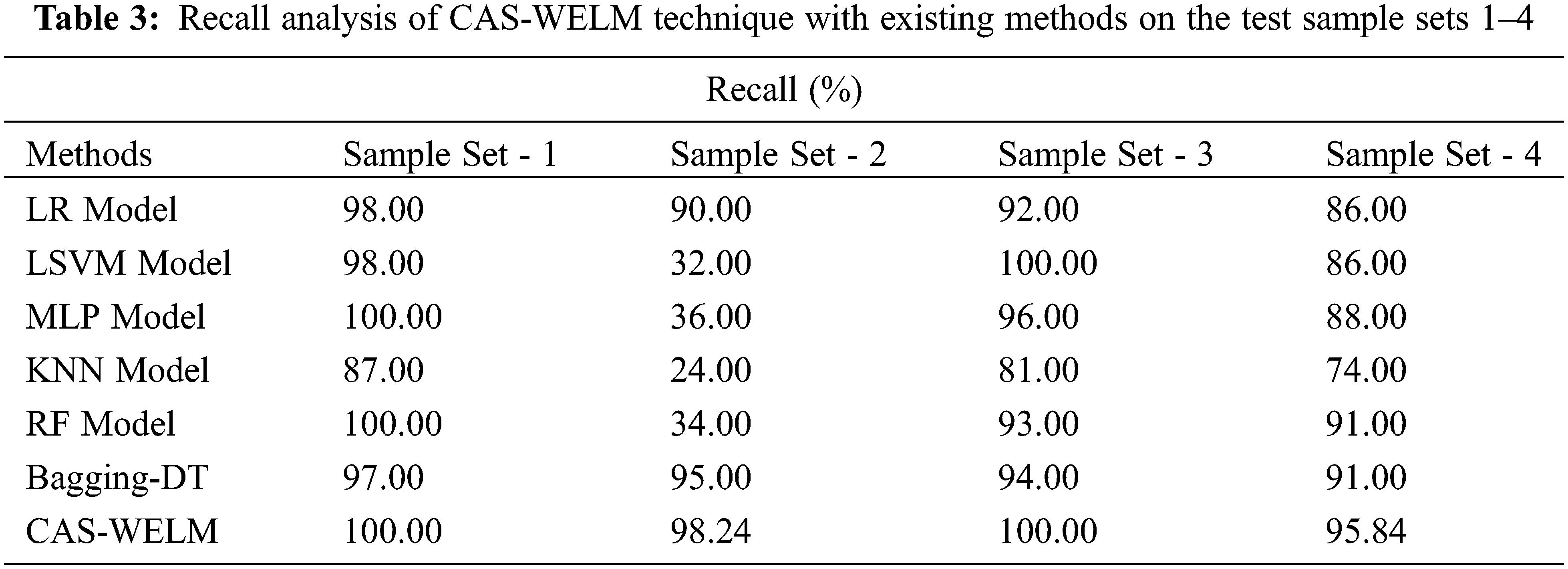

Figure 5: Recall analysis of CAS-WELM technique with existing approaches on test sample sets 1–4
Tab. 4 and Fig. 6 illustrates the F-score analysis of the CAS-WELM technique with other ones. The results show that the KNN method has gained minimal classification outcomes over the other approaches. Besides, the LR technique has obtained somewhat enhanced classification performance over the KNN technique. Moreover, the LSVM, MLP, and Bagging-DT approach has accomplished moderately higher outcomes. At last, the RF system has resulted in competitive outcome, the CAS-WELM technique has outperformed the other methods with the increased F-score of 99.36%, 96.48%, 98.88%, and 96.23% on the test sample sets 1–4 correspondingly.
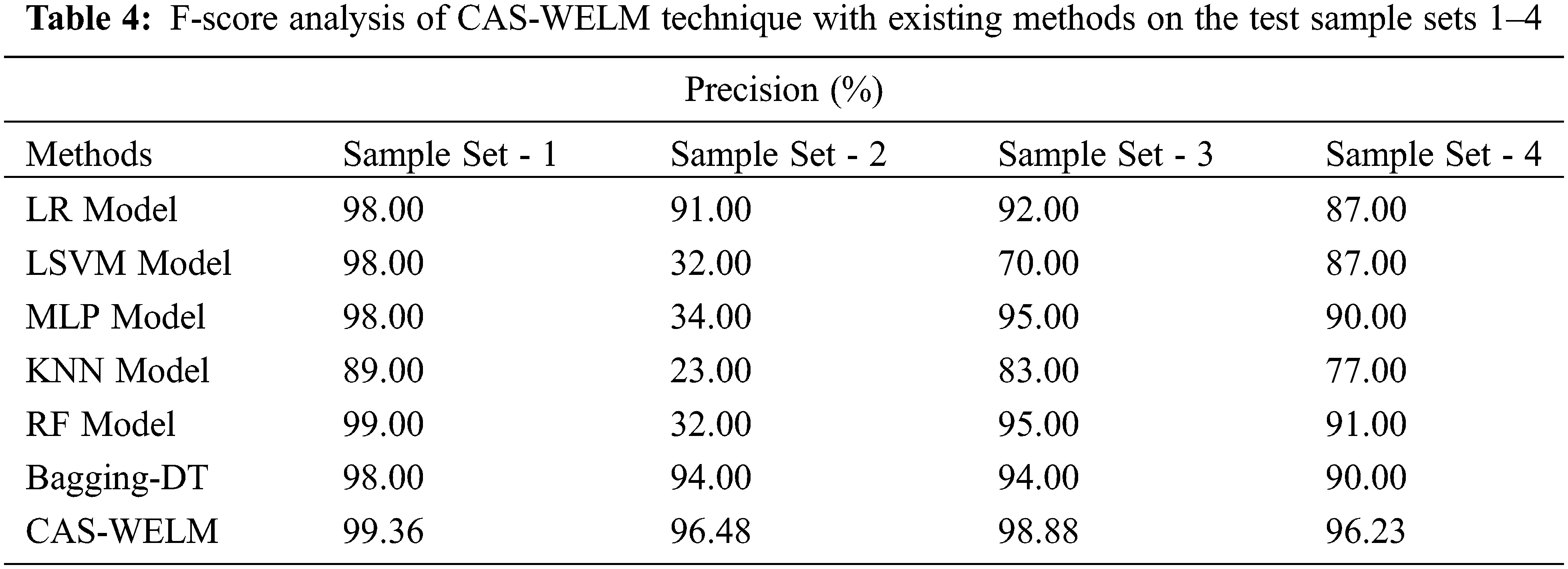

Figure 6: F-score analysis of CAS-WELM technique with existing approaches on test sample sets 1–4
Fig. 7 demonstrates the accuracy and loss graph analysis of the CAS-WELM technique on the test sample sets 1 and 2. The results show that the accuracy value tends to increase and loss value tends to decrease with an increase in epoch count. It is also observed that the training loss is low and validation accuracy is high on test sample sets 1 and 2.

Figure 7: Accuracy and loss analysis of CAS-WELM technique under test sample sets 1 and 2
Fig. 8 offers the accuracy and loss graph analysis of the CAS-WELM methodology on the test sample sets 3 and 4. The outcomes demonstrated that the accuracy value tends to be higher and loss value tends to lower with higher epoch count. It is also experiential that the training loss is minimum and validation accuracy is high on the test sample sets 3 and 4.

Figure 8: Accuracy and loss analysis of CAS-WELM technique under test sample sets 3 and 4
In this study, a novel CAS-WELM technique has been developed for Cybersecurity Fake News Detection and Classification. The CAS-WELM technique mainly intends to discriminate news into fake and real. The CAS-WELM technique undergoes different stages of operations namely pre-processing, Glove based word embedding, N-gram based feature extraction, WELM based classification, and CAS based parameter optimization. Besides, the weight value of the WELM model can be optimally adjusted by the use of CAS algorithm. The performance validation of the CAS-WELM technique is carried out using the benchmark dataset and the results are inspected under several dimensions. The experimental results reported the enhanced outcomes of the CAS-WELM technique over the recent approaches. In the future, advanced deep learning models can be utilized to classify and detect fake news in social networking platform.
Acknowledgement: The authors deeply acknowledge the Researchers supporting program (TUMA-Project-2021-27) Almaarefa University, Riyadh, Saudi Arabia for supporting steps of this work. The authors would like to acknowledge the support of Prince Sultan University for paying the Article Processing Charges (APC) of this publication.
Funding Statement: This research was supported by the Researchers Supporting Program (TUMA-Project-2021-27) Almaarefa University, Riyadh, Saudi Arabia. Taif University Researchers Supporting Project number (TURSP-2020/161), Taif University, Taif, Saudi Arabia.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. S. A. García, G. G. García, M. S. Prieto, A. J. M. Guerrero and C. R. Jiménez, “The impact of term fake news on the scientific community scientific performance and mapping in web of science,” Social Sciences, vol. 9, no. 5, pp. 73, 2020. [Google Scholar]
2. T. Hopp, “Fake news self-efficacy, fake news identification, and content sharing on Facebook,” Journal of Information Technology & Politics, pp. 1–24, 2021. https://doi.org/10.1080/19331681.2021.1962778. [Google Scholar]
3. N. K. Conroy, V. L. Rubin and Y. Chen, “Automatic deception detection: Methods for finding fake news,” Proceedings of the American Society for Information Science and Technology, vol. 52, no. 1, pp. 1–4, 2015. [Google Scholar]
4. A. Robb, “Anatomy of a fake news scandal,” Rolling Stone, vol. 1301, pp. 28–33, 2017. [Google Scholar]
5. H. Allcott and M. Gentzkow, “Social media and fake news in the 2016 Election,” Journal of Economic Perspectives, vol. 31, no. 2, pp. 211–236, 2017. [Google Scholar]
6. V. Rubin, N. Conroy, Y. Chen and S. Cornwell, “Fake news or truth? using satirical cues to detect potentially misleading news,” in Proc. of the Second Workshop on Computational Approaches to Deception Detection, San Diego, California, pp. 7–17, 2016. [Google Scholar]
7. K. Shu, A. Sliva, S. Wang, J. Tang and H. Liu, “Fake news detection on social media: A data mining perspective,” ACM SIGKDD Explorations Newsletter, vol. 19, no. 1, pp. 22–36, 2017. [Google Scholar]
8. S. Kumar, R. Asthana, S. Upadhyay, N. Upreti and M. Akbar, “Fake news detection using deep learning models: A novel approach,” Transactions on Emerging Telecommunications Technologies, vol. 31, no. 2, pp. 1–23, 2020. [Google Scholar]
9. A. Roy, K. Basak, A. Ekbal and P. Bhattacharyya, “A deep ensemble framework for fake news detection and classification,” arXiv preprint arXiv: 1811.04670, 2018. [Google Scholar]
10. N. Aslam, I. U. Khan, F. Alotaibi, L. Aldaej and A. Aldubaikil, “Fake Detect: A deep learning ensemble model for fake news detection,” Complexity, vol. 2021, no. 4, pp. 1–8, 2021. [Google Scholar]
11. A. Agarwal, M. Mittal, A. Pathak and L. M. Goyal, “Fake news detection using a blend of neural networks: An application of deep learning,” SN Computer Science, vol. 1, no. 3, pp. 143, 2020. [Google Scholar]
12. Z. Khanam, B. N. Alwasel, H. Siraf and M. Rashid, “Fake news detection using machine learning approaches,” IOP Conference Series: Materials Science and Engineering, vol. 1099, no. 1, pp. 012040, 2021. [Google Scholar]
13. W. H. Bangyal, R. Qasim, N. U. Rehman, Z. Ahmad, H. Dar et al., “Detection of fake news text classification on covid-19 using deep learning approaches,” Computational and Mathematical Methods in Medicine, vol. 2021, no. 12, pp. 1–14, 2021. [Google Scholar]
14. T. Chauhan and H. Palivela, “Optimization and improvement of fake news detection using deep learning approaches for societal benefit,” International Journal of Information Management Data Insights, vol. 1, no. 2, pp. 100051, 2021. [Google Scholar]
15. C. Zhou, C. Sun, Z. Liu and F. Lau, “A C-LSTM neural network for text classification,” arXiv preprint arXiv: 1511.08630, 2015. [Google Scholar]
16. S. Ding, H. Zhao, Y. Zhang, X. Xu and R. Nie, “Extreme learning machine: Algorithm, theory and applications,” Artificial Intelligence Review, vol. 44, no. 1, pp. 103–115, 2015. [Google Scholar]
17. Z. Xu, J. Liu, X. Luo, Z. Yang, Y. Zhang et al., “Software defect prediction based on kernel PCA and weighted extreme learning machine,” Information and Software Technology, vol. 106, no. 6, pp. 182–200, 2019. [Google Scholar]
18. M. Wan, C. Wang, L. Li and Y. Yang, “Chaotic ant swarm approach for data clustering,” Applied Soft Computing, vol. 12, no. 8, pp. 2387–2393, 2012. [Google Scholar]
19. H. Ahmed, I. Traore and S. Saad, “Detecting opinion spams and fake news using text classification,” Security and Privacy, vol. 1, no. 1, pp. e9, 2018. [Google Scholar]
20. Kaggle, Fake News, Kaggle. San Francisco, CA, USA, 2018. [Online]. Available: https://www.kaggle.com/c/fake-news. [Google Scholar]
21. Kaggle, Fake News Detection, Kaggle. San Francisco, CA, USA, 2018. [Online]. Available: https://www.kaggle.com/jruvika/fake-news-detection. [Google Scholar]
22. I. Ahmad, M. Yousaf, S. Yousaf and M. O. Ahmad, “Fake news detection using machine learning ensemble methods,” Complexity, vol. 2020, no. 5, pp. 1–11, 2020. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |