DOI:10.32604/csse.2023.025969
| Computer Systems Science & Engineering DOI:10.32604/csse.2023.025969 | |
| Article |
Speech Separation Methodology for Hearing Aid
1Meenakshi Sundararajan Engineering College, Chennai, Tamil nadu, India
2R. M. K. Engineering College, Kavaraipettai, Tamil nadu, India
*Corresponding Author: Joseph Sathiadhas Esra. Email: josephesra.phd@gmail.com
Received: 21 January 2022; Accepted: 03 March 2022
Abstract: In the design of hearing aids (HA), the real-time speech-enhancement is done. The digital hearing aids should provide high signal-to-noise ratio, gain improvement and should eliminate feedback. In generic hearing aids the performance towards different frequencies varies and non uniform. Existing noise cancellation and speech separation methods drops the voice magnitude under the noise environment. The performance of the HA for frequency response is non uniform. Existing noise suppression methods reduce the required signal strength also. So, the performance of uniform sub band analysis is poor when hearing aid is concern. In this paper, a speech separation method using Non-negative Matrix Factorization (NMF) algorithm is proposed for wavelet decomposition. The Proposed non-uniform filter-bank was validated by parameters like band power, Signal-to-noise ratio (SNR), Mean Square Error (MSE), Signal to Noise and Distortion Ratio (SINAD), Spurious-free dynamic range (SFDR), error and time. The speech recordings before and after separation was evaluated for quality using objective speech quality measures International Telecommunication Union -Telecommunication standard ITU-T P.862.
Keywords: Speech separation; wavelet filter; independent component analysis (ICA); non-negative matrix factorization (NMF); fejer-korovkin (FK); signal-to-noise ratio (SNR)
About 500 million people were suffering from hearing loss. Their quality of life can be enhanced by using Digital Hearing Aid. The hearing aid is used by only 30% of the patients. This percentage can be increased by designing hearing aid device with low noise and improved sound quality. Obviously, the cost is the important factor too. The different hearing aids based on placement Behind-The-Ear (BTE) HA, Receiver-In-Canal (RIC) HA, In-The-Canal (ITC) HA and the In-The-Ear (ITE) HA, have same structures for collection and sound regeneration. The Main functions of hearing aid are shown in Fig. 1 [1]. In the frequency band, the frequency out of audio range was removed using the low pass and high pass filter [2]. This type of noise cancellation will enhance the digital hearing aids that could have a series of advantages such as; high signal-to-noise ratio, higher gain, immune to electromagnetic interference and feedback elimination [3–5]. The components of the digital hearing aids are microphone, an Analog-to-Digital converter (A/D), an amplifier, a Digital Signal Processor (DSP), a Digital-to-Analog converter (D/A), a speaker, and a battery. The existing HA structure adopts a built-in DSP for voice processing. In noise removal process sub-band are selected by using reconfigurable filter bank [6,7]. The Basic hearing aid is given in Fig. 1a Even though the hearing aid manufacturers miniaturized the device, it lags in battery capacity. The improved listening capacity have increased the cost which not affordable by all. Speech separation becomes an important element in binaural HA system. Building an analog filter with multiple stages is difficult when compared to the digital filter [8]. Liu et al. [9] designed a de-noising filter to remove the mixed impulsive and Gaussian noises. The noise suppression circuit is a cascaded filter with similar co-efficients. Chandra Sekhar Yadav et al. [10] tested a Wiener filter to remove the Gaussian noise from the input signal. Abbasa et al. [11] presented the separation of speech mixtures that are often be referred to as the cocktail party problem. The Independent component analysis (ICA) and binary time frequency masking is the two source separation techniques which has been combined to solve the speech separation process [12]. There are several works in literature dedicated for speech separation process which includes fusion framework [13] and NMF-based Target Source Separation [14]. Sean Wood et al. [15] presented a hybrid blind source separation algorithm which was a combination of non-negative matrix factorization (NMF) and generalized cross correlation (GCC) method.

Figure 1: (a) Basic digital hearing aid, (b) Block diagram of Digital Hearing aid
The Hearing aid should recognize the speech signals out of the environmental noise. Some of the noise is produced by speech babbles, instrumentation noise and other unnecessary sounds. Too much of reverberation will reduce speech intelligibility and the overall sound quality. If the noise magnitude is more than the voice, the efficiency of speech processing unit will be poor. So, the alternative method can be developed for noise reduction in hearing aid. The Noise is removed independently in binaural. Hearing aid (HA), which differs from the two systems since it processes noise independently. In spite of the advances in Hearing aid (HA) technology, improving the speech intelligibility is a challenge. In recent years, hearing aids are connected to android, iPhone Operating System (IOS), and Bluetooth-enabled phones. In most cases the collected sound is directional. If the noise strength is more compared to the required signal, it’s very difficult to remove the same. In addition, the frequency response of hearing aids should be uniform throughout the audio spectrum. The Performance of the HA for frequency response is non uniform. Existing noise suppression methods reduce the required signal strength also along with noise. So the performance of uniform sub band analysis is poor when hearing aid is concern. On the other hand, source separation is one of the important issues in the Digital Hearing Aid (DHA). The Microphone in the Digital Hearing Aid (DHA) continuously receives the ‘N’ number of incoming speech signals. The Hearing-impaired people couldn’t understand the collapsed incoming speech signals.
In this research work, sub band analysis using Fejer-Korovkin (FK) wavelet based decomposition Methodology is proposed. The Wavelet based de-noising algorithm minimizes the Gaussian noises present in the input signal. If the number of stages in the filter bank is more, the rejection ratio will be more. It is better in performance when compared to the existing two stage wavelet filter bank and tree structured wavelet filter banks. For speech separation Non-negative Matrix Factorization (NMF) algorithm is used. The Proposed filter bank architecture is compared with other architectures. The Proposed methods Error and time calculation for different divergence are measured. For evaluation of the proposed method and existing method, mixed audio sources were used for speech separation. Different parameters like Signal to Noise Ratio (SNR), Signal to Distortion Ratio (SDR), Signal to Noise and Distortion Ratio (SINAD), Spurious-free dynamic range (SFDR), Mean Square Error (MSE), and Band Power were used for evaluation.
The Filter bank is an important functional block in digital hearing aids that decomposes the input signal into different bands [16,17]. The Gain of individual stages can be varied based on the band requirements.
2.1 Wavelet Based Non-Uniform Filter Bank
The Discrete input signal is applied to filter bank to produce a set of sub-band signals [18]. The term uniform filter bank (UFB) is defined to emphasize that all the sub-band signals are at the same rate. Shakya et al. [19] The Discrete Wavelet Transform (DWT) for multi-resolution analysis can be viewed as non-uniform filter bank. In terms of this methodology a low-pass filter corresponds to scaling function and the subsequent high-pass corresponds to wavelet function [20]. The corresponding non-uniform filter bank is possible through repetitive application on the low-pass channel [21].
2.2 Two Channel Wavelet Filter Bank
For speech processing two band ortho normal wavelet is used which can be associated with ortho normal filter bank [22]. Speech processing of hearing aid can be possible using filter bank which has equal bandwidth and perfect reconstruction features. The connection between discrete and continuous wavelet bases enhances the design of the filter banks like equal bandwidth, two-channel, Perfect Reconstruction Quadrature Mirror Filter (PR-QMF) banks [23,24]. Eqs. (1) and (2) represents the ortho-normality state of wavelet and scaling bases with its relations to the discrete-time filter banks.
(1) In intra- and inter-scales, the wavelets are ortho-normal as,
(2) The corresponding scaling function of wavelet theory has only intra-scale ortho-normality as,
(3) The corresponding property for all values of m, n, m′, and n′ in wavelet and scaling bases is given in Eq. (3).
In Eq. (4), ho(n), hl(n) represent the two-band discrete-time Perfect Reconstruction Quadrature Mirror Filter (PR-QMF) bank with the additional property of H,(eh) = 0 at o = x.
The wavelet δ(t) and scaling functions β(t) are build to maintain ortho-normality. The filter function h0(n) and hl(n) have finite duration [25]. The design of a two-band discrete-time para-unitary filter bank are advantages and is been used for channel diagnolization [26].
2.3 Tree Structured Wavelet Filter Bank
In tree-structured filter banks, the inputs pass through two or more filters and the output is downsampled [27]. The Eq. (5) defines the analytic wavelets.
Here j represents the unit imaginary.
Among the wide variety of sound separation algorithms, the unsupervised Non-negative Matrix Factorization (NMF) dictionary learning algorithm suits well for the delineation of sound mixture [28,29]. The Cost function of Non-negative Matrix Factorization (NMF) will decompose their spectrogram into two non-negative matrices such as; a dictionary matrix Wfd and a coefficient matrix Hdt. Hence the product of both the Non-negative Matrix Factorization (NMF) function is ∧ = WH approximates V. various measures of reconstruction error have been used, several of which generalize to the divergence Dβ (V|∧), defined by Eq. (6).
The Speech regeneration may be the right choice of NMF algorithm which includes the Euclidian distance (β = 2) [30] and the generalized Kullback-Leibler divergence (β = 1) [31]. The Coefficient sparsity is used by [32] for Itakura-Saito divergence (β = 0). Hence the normalization will have such kind of l1 norms that is typically used for coefficient sparsity which is shown by [33]. At the point of initialization technique, the multiplicative update rules are then defined as W and H. In Eq. (7) and Eq. (8) the update rules for Dβ (V|∧) are given.
where X is the Hadamard product. Fig. 2 represents the left and right input in the case of stereo audio signals that has been concatenated in time [34] where Fig. 2a shows the single dictionary of spectral atoms which is used to encode both channels via the two coefficient matrices Hldt and Hrdt shown in Fig. 2b. Speech emotion recognition was presented in literature [35,36].

Figure 2: The coefficient of stereo channel with the hearing aid can be represented such that the negative decomposition of left channels is taken on the combination of Hldt and Hrdt. It shows the non-negative matrix factorization (NMF) decomposition of a stereo mixture of speech signals. a) The Non-negative matrix factorization (NMF) dictionary Wfd, with cube root compression applied for clarity, consisting of atoms that are nonnegative functions of frequency. A subset is shown in detail on the right. b) non-negative atom coefficients for the left and right channels
4 Proposed Speech Separation with Filter Bank and NMF
The Proposed speech separation method using filter bank and NMF is shown in Fig. 3.

Figure 3: Block diagram of proposed speech separation algorithm
4.1 Sub Band Analysis Filter Bank Using Proposed Fejer-Korovkin Wavelet Filter Bank
The Fejer-Korovkin (FK) wavelet is used to design the proposed filter bank architecture which is shown in Fig. 4. The speech signals are decomposed using the proposed filter bank into non-uniform sub-bands. The Architecture of abalysis and synthesis filter is shown in Figs. 4a and 4b.

Figure 4: (a) Proposed analysis filter bank, (b) Proposed synthesis filter bank
In Eq. (9) shows the Fejer-Korovkin (FK) wavelet filter that defines kernel Kn which is used to separate the raw time series into a high frequency (HF) component and a low frequency (LF) component.
The Kn(ξ) can be simplified and expressed in Eq. (10) and θn(k) can be expressed in Eq. (11) and Eq. (12).
With
We define the Fejer-Korovkin filters by Eq. (13).
Then m0n has degree n + 1 if n is odd and degree n if n is even. γρ( m0n) = O(1/n).
The filter bank plot of |m0n|2 for n = 2, 4,….12 with following Fig. 5. Hence the Fejer-Korovkin (FK) kernals K2n

Figure 5: The fejer-korovkin (FK) filters for n = 2, 4,…, 12
The Figs. 6 and 7 show the scaling function and wavelet generated by the Fejer-Korovkin (FK) filter of length 12.

Figure 6: The scaling function generated by the fejer-korovkin filer

Figure 7: The wavelet function generated by the fejer-korovkin (FK) filer
4.2 Source Separation by Non-Negative Matrix Factorization (NMF) Algorithm
The Non-negative Matrix Factorization (NMF) is used for blind source separation which is closely approximated by a constant frequency with the magnitude spectrogram X of the mixture. The corresponding audio source is separated into I channels with their corresponding spectrograms Ci, 1 ≤ i ≤ I. This Algorithm is based on vector Bi and a time varying gain Gi of the single speech. In Eq. (14) the spectrogram Ci is shown.
The Ci is rank one and the low pass characteristics is found in rows Gi. The Separation of Non-negative Matrix Factorization (NMF) algorithm is improved due to the continuous nature and is shown in Eq. (15).
In Eqs. (16)–(20) shows the multiplicative update rules
The Eqs. (21)–(23) shows the following numerical stability for normalized Bi and Gi in each iteration to ensure equal energy.
Fig. 8 shows the Non-negative Matrix Factorization (NMF) based source separation method where the separation can be improved by using clustering.

Figure 8: The signal flow of the proposed non-negative matrix factorization (NMF) separation algorithm
The Proposed clustering method can be used to cluster any number of sub clusters. For more independent sources the clustering can be done using hierarchical clustering. Here two clusters are created for N number of channels. The clusters m, m∼ ∈ {1, 2} are separated using the vectors a∼, a∼(i) ∈ {1, 2}. The estimated energy E∼m∼ of the spectrograms of both clusters are given by
For uncorrelated sources, the energy is estimated from the mixture signals. Further we assume that one cluster corresponds to one source, and the other cluster contains the remaining sources. Therefore, we expect that the first separated source esm1 corresponds to the cluster with lowest energy because the other cluster corresponds to multiple sources:
The Process repeats until all channels are clustered into two. The process terminates once the sources are clustered.
5.1 Analysis of Two Channel Wavelet Filter Bank
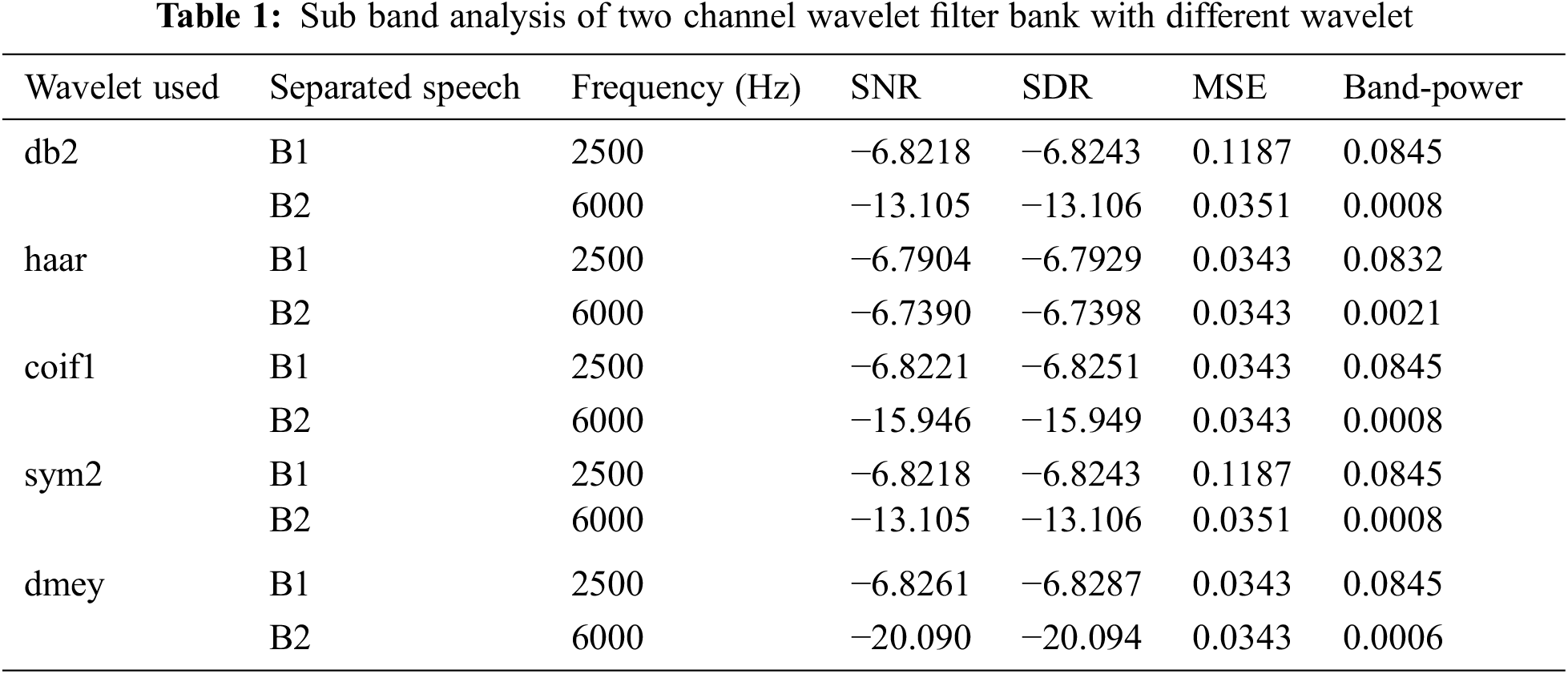
Tab. 1 shows the subband analysis of the two channel filter-bank implemented using different wavelets such as db2, haar, coif1, sym2 and dmey. Various parameters such as Signal-to-noise ratio (SNR), SDR, Mean Square Error (MSE) and band power are observed.
5.2 Analysis of Tree Structured Wavelet Filter Bank
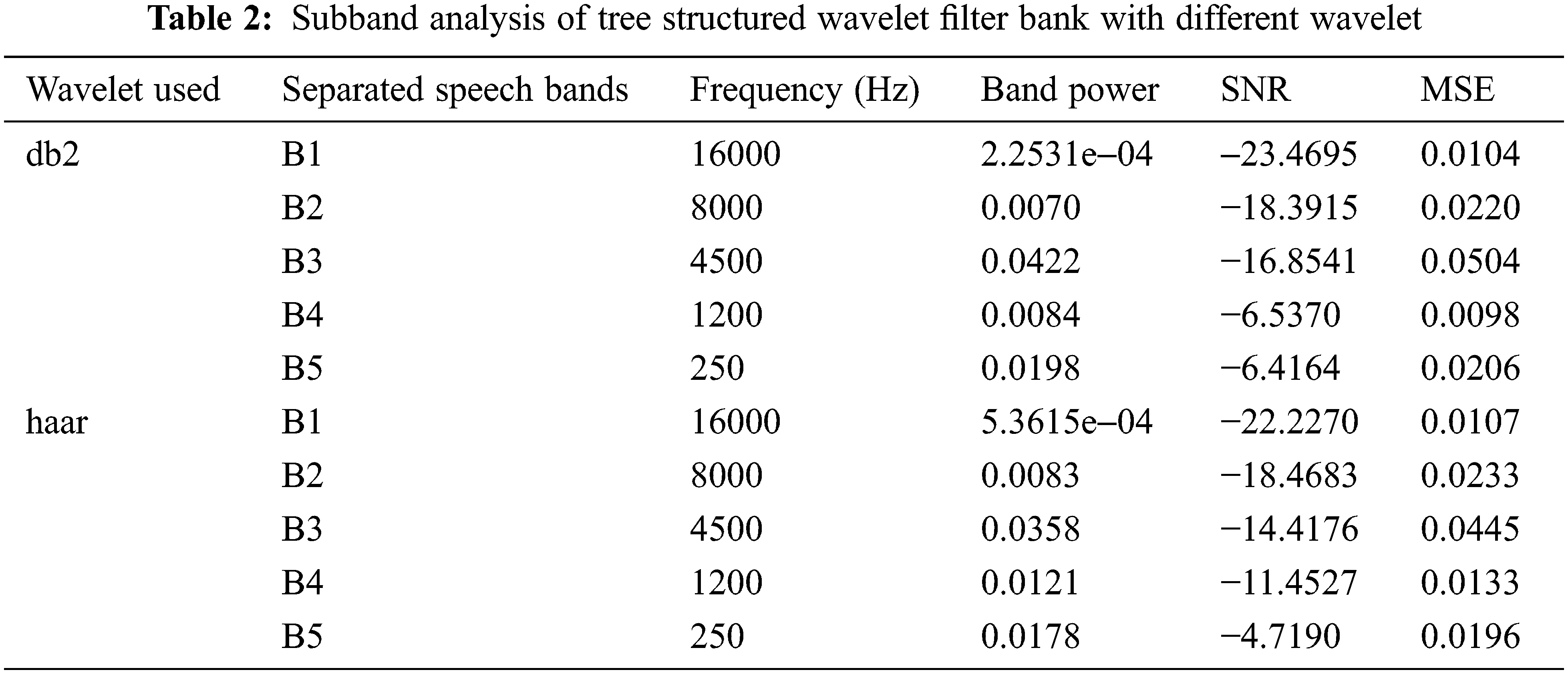
Tab. 2 shows the subband analysis of the Tree structured wavelet filter bank implemented using different wavelets. Various parameters are observed.
5.3 Analysis of Proposed Fejer-Korovkin (FK) Wavelet Filter Bank
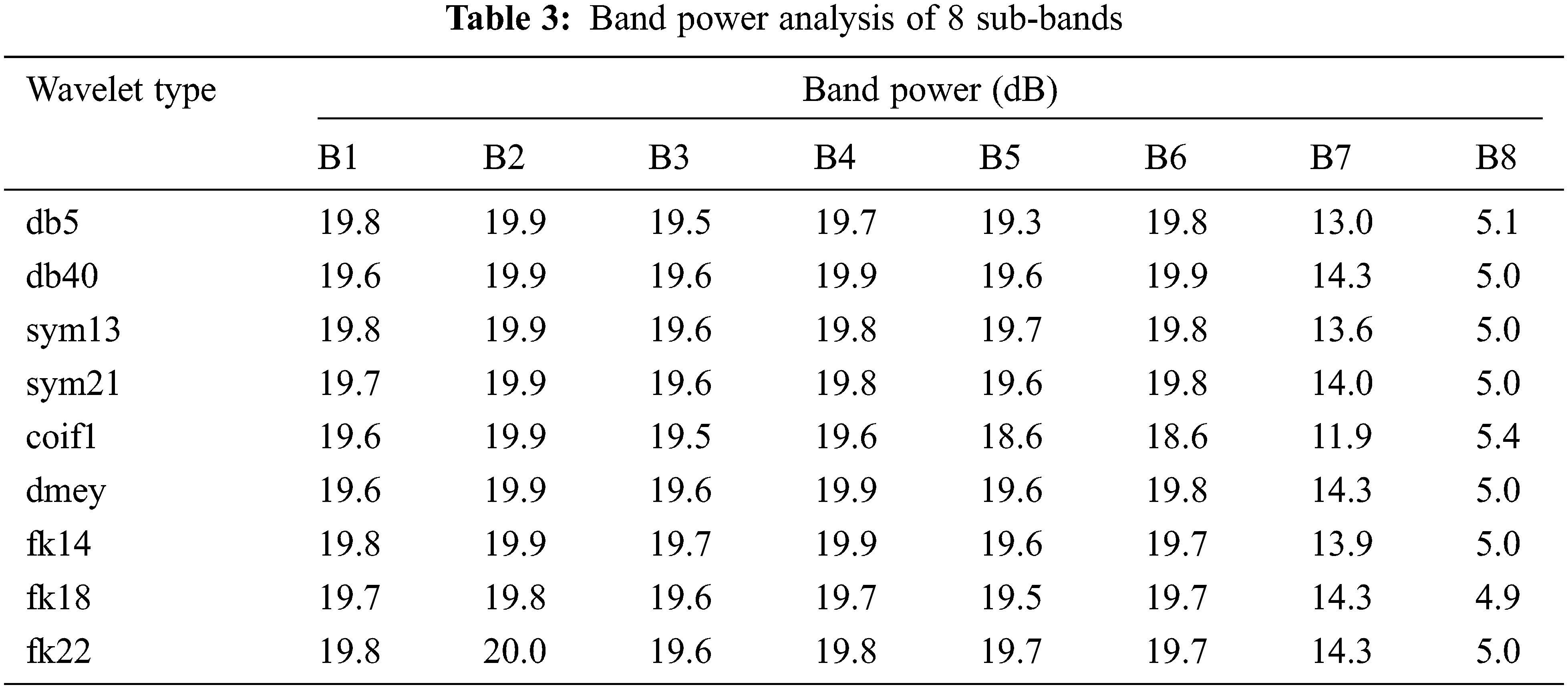
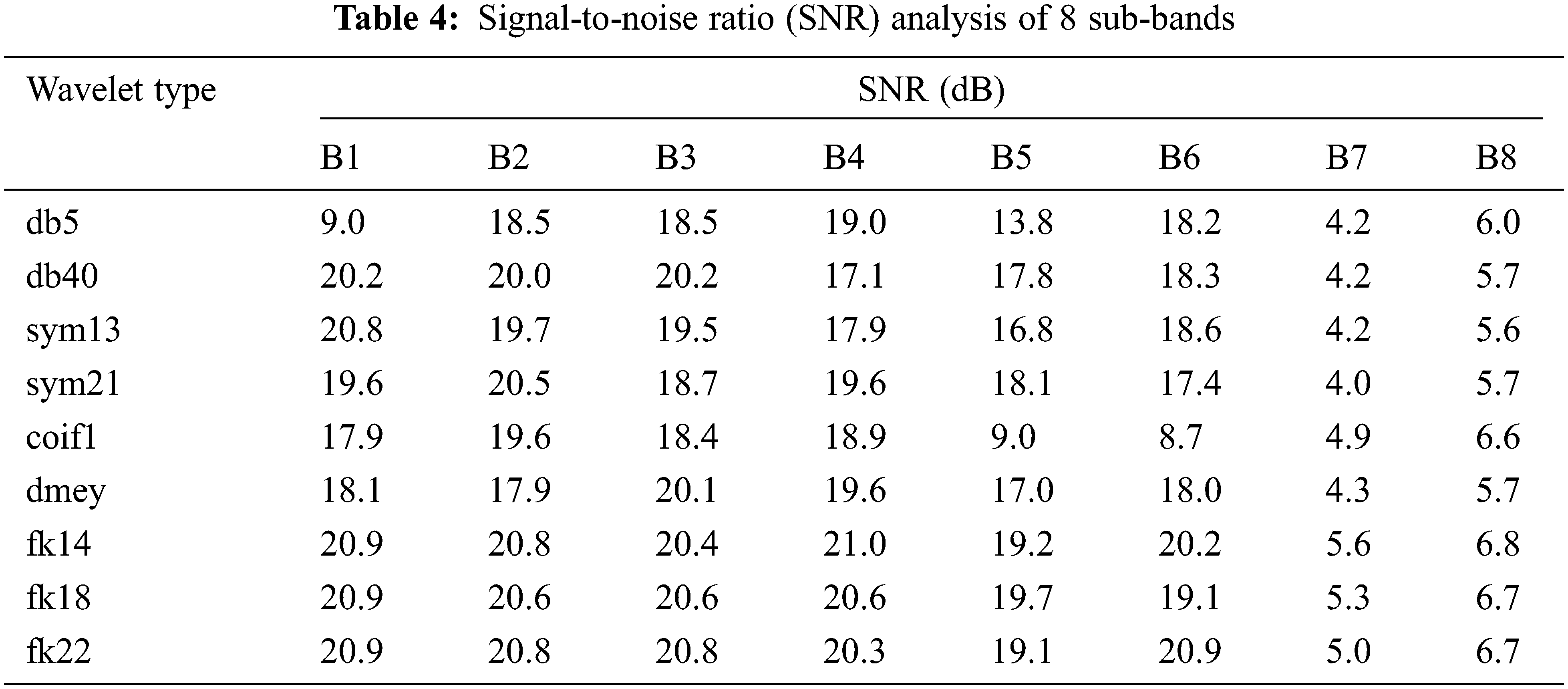
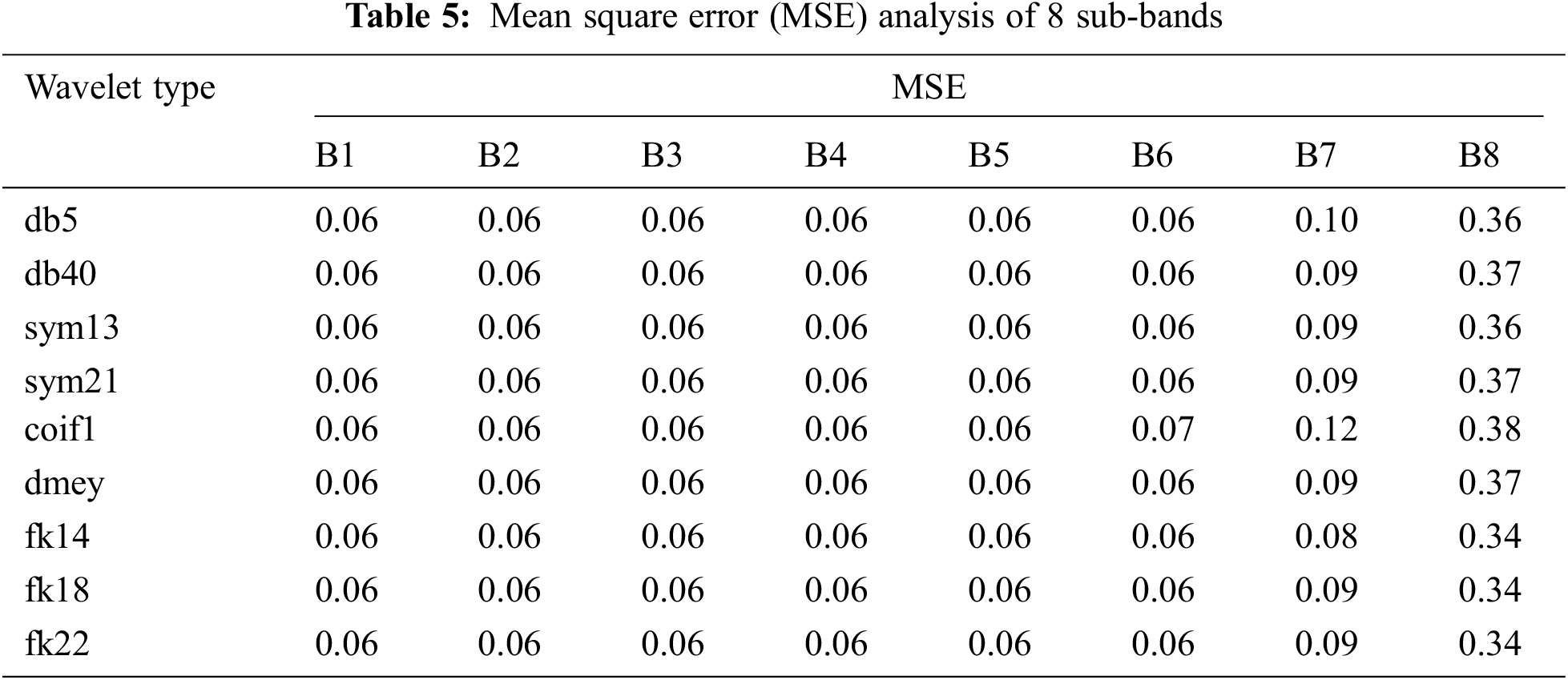
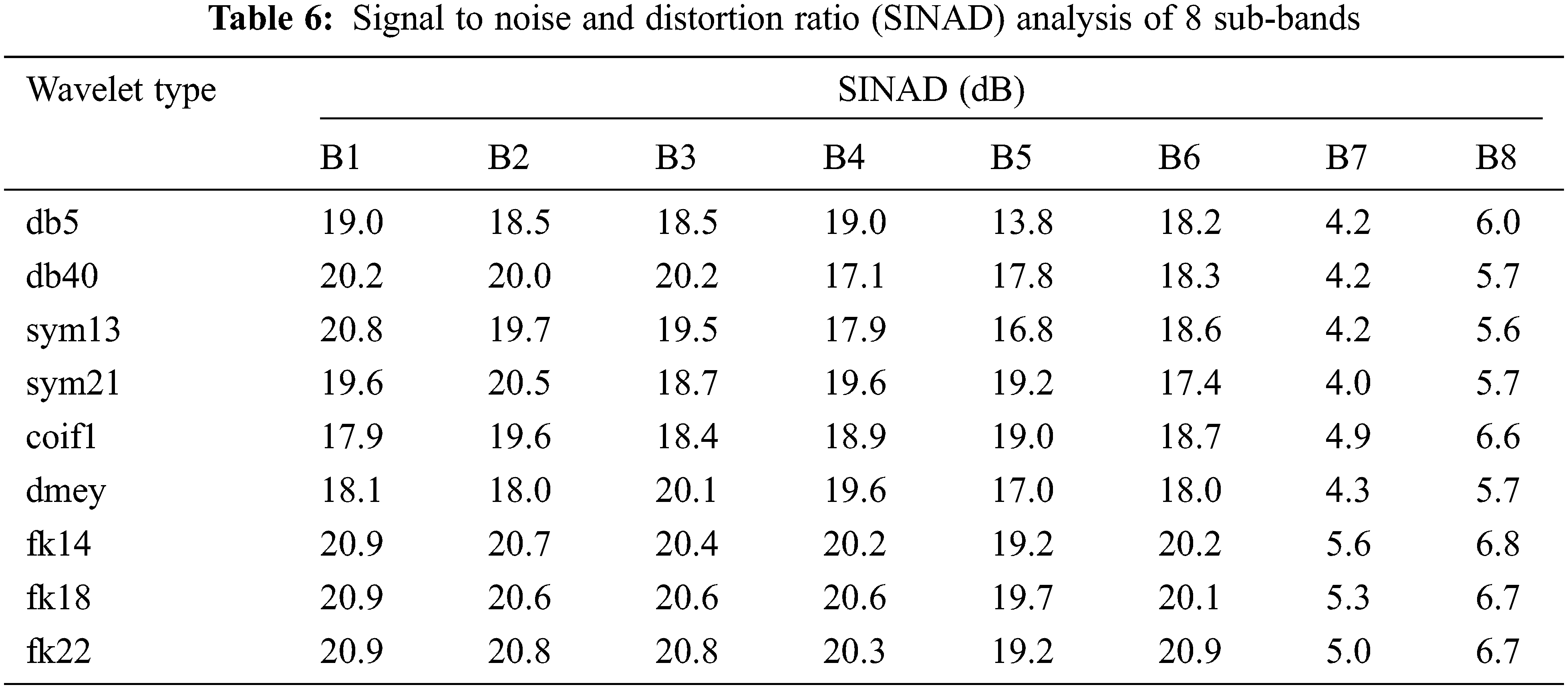
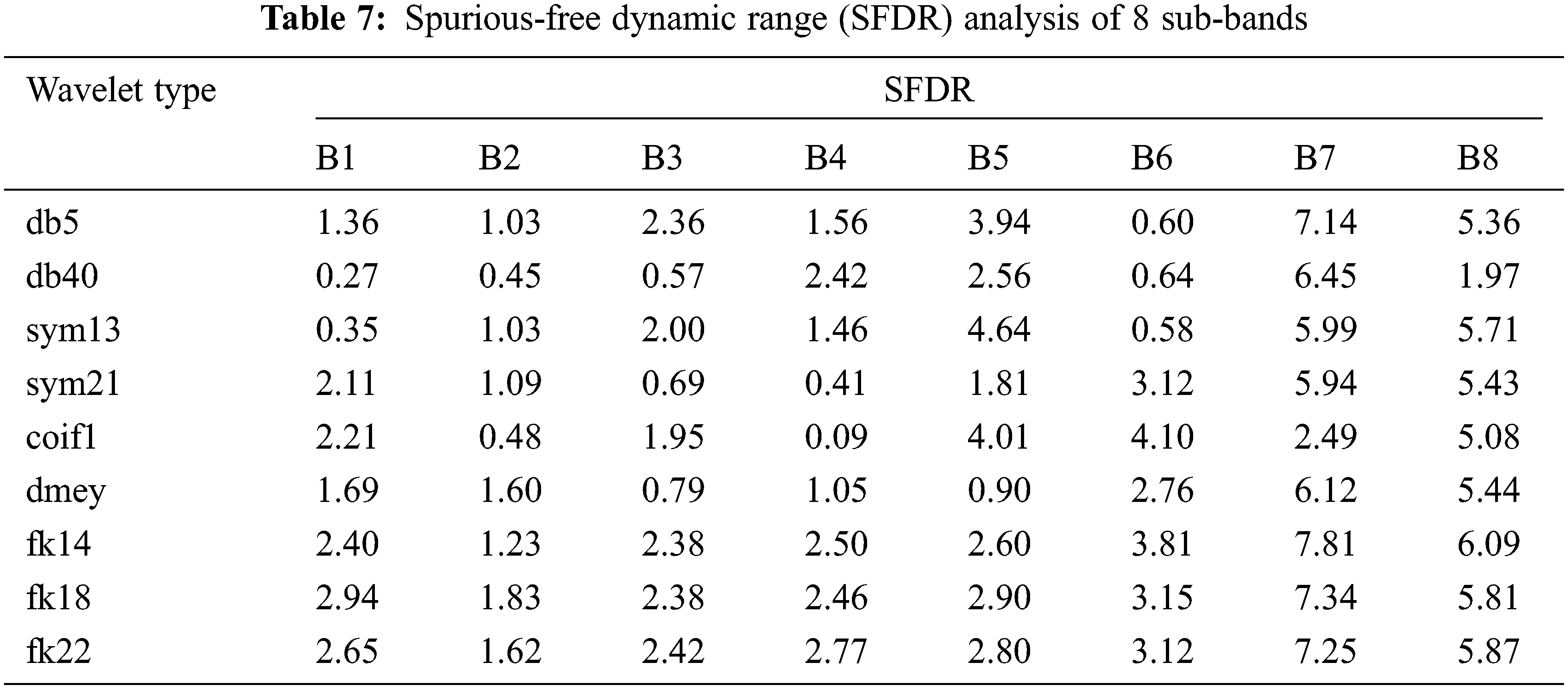
The Analysis of the proposed filter bank using Fk wavelet is done by evaluating the spectrum of noisy signal and input Fig. 9a. The Different decomposition stages are presented in Fig. 9b. Tabs. 3–7 presents the various analysis of the subband filter. The Comparative analysis is presented from Figs. 9(c–f).


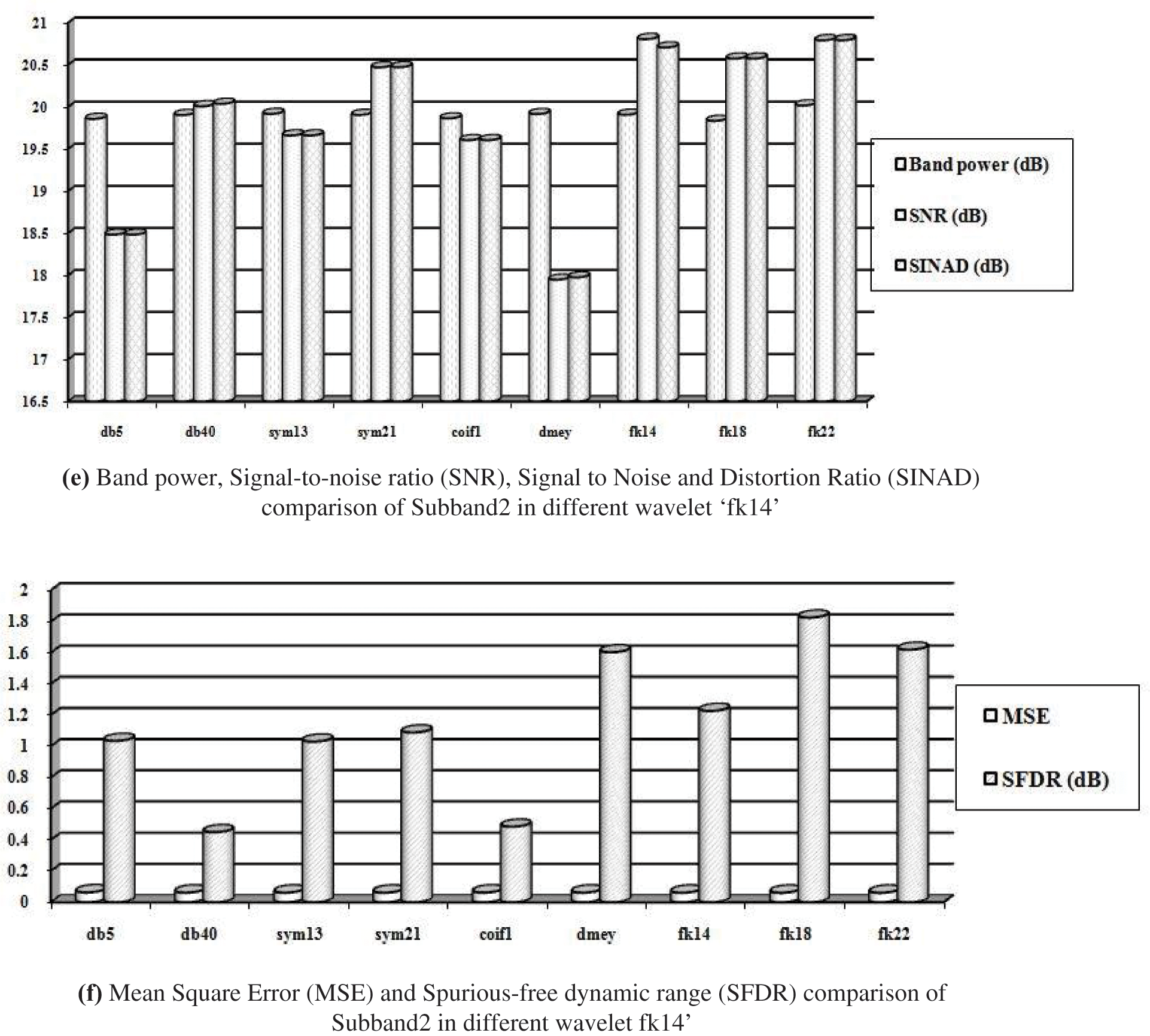
Figure 9: (a) Spectrum of input and noisy speech signal, (b): Decomposition of noised speech signal by using fejer-korovkin(FK) wavelet ‘fk14’, (c) Band power, signal-to-noise ratio (SNR), signal to noise and distortion ratio (SINAD) comparison of subband1 in different wavelet ‘fk14’, (d) Mean square error (MSE) and spurious-free dynamic range (SFDR) comparison of subband1 in different wavelet ‘fk14’, (e) Band power, signal-to-noise ratio (SNR), signal to noise and distortion ratio (SINAD) comparison of subband2 in different wavelet ‘fk14’, (f) Mean square error (MSE) and spurious-free dynamic range(SFDR) comparison of subband2 in different wavelet fk14’
5.4 Independent Component Analysis (ICA)
The Sources in the hearing aid system are statistically independent and the linear mixtures are separated using Independent component analysis (ICA) and Blind Source Separation (BSS). The Experimental setup uses two speech signal and noise. It is a microphone which records with proximities a1 and b1 for male and female voices respectively. Hence they can be source separated using ICA. The linear mixture observed data is given as x (Eq. (26)).
where, A is some unknown invertible that mixes the components as A = [a1 b1]. Eq. (27) shows the estimation of underlying source which will construct a new matrix W as linear transformed data,
The Unmixing matrix has the approximate value of A−1 so that

Figure 10: (a) Mixed audio source (mixednumbers.wav file), (b) Separation of two speech recordings in mixed audio source by existing independent component analysis (ICA), (c) Separation of Two speech recordings in mixed audio source by proposed method
5.5 Analysis of NMF Algorithm for BSS
The Input signals are analyzed using the Non-negative Matrix Factorization (NMF) algorithm and the source matrix are generated W and H. Error and time calculation of Proposed NMF source separation algorithm with different divergence are presented in Tab. 8. Perceptual Evaluation of Speech Quality (PESQ) parameters are analyzed in this work.
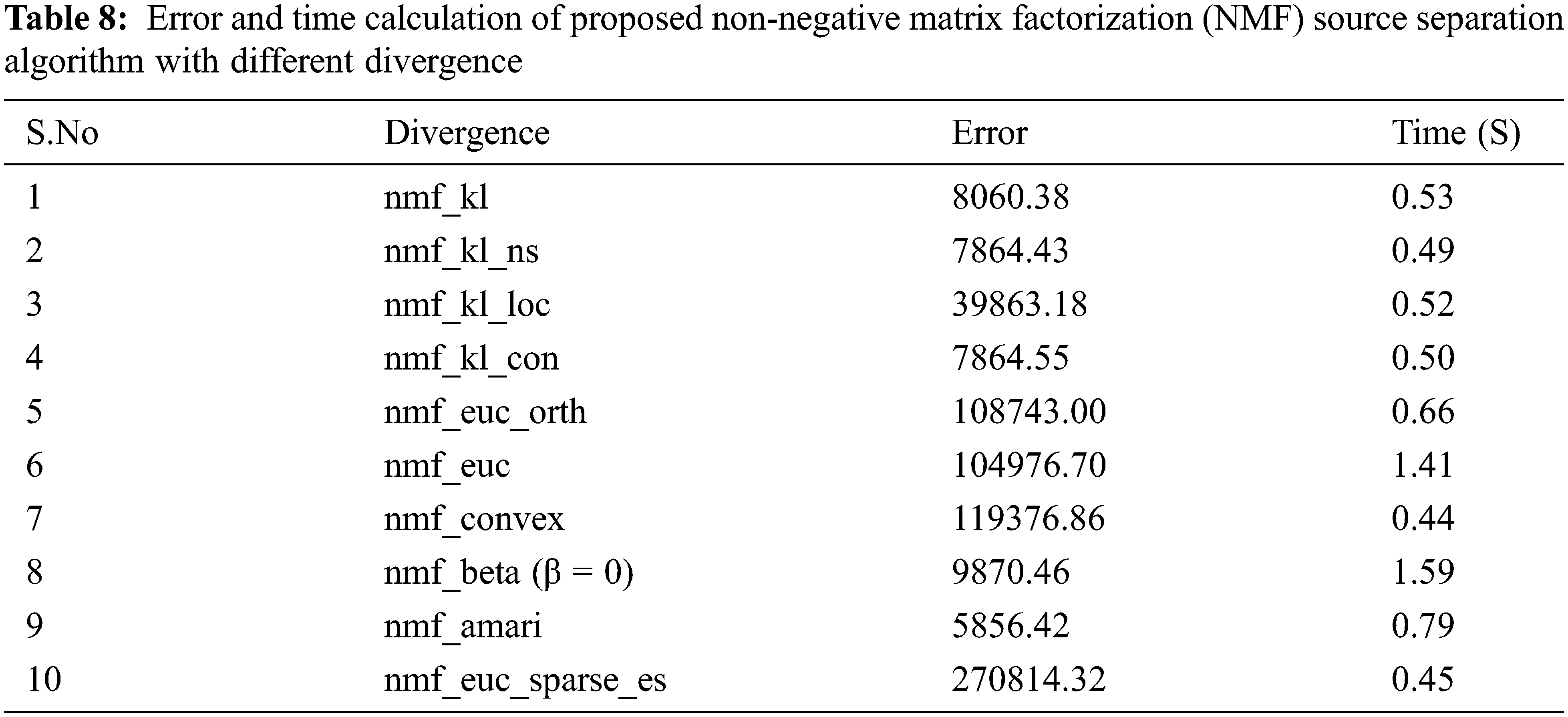
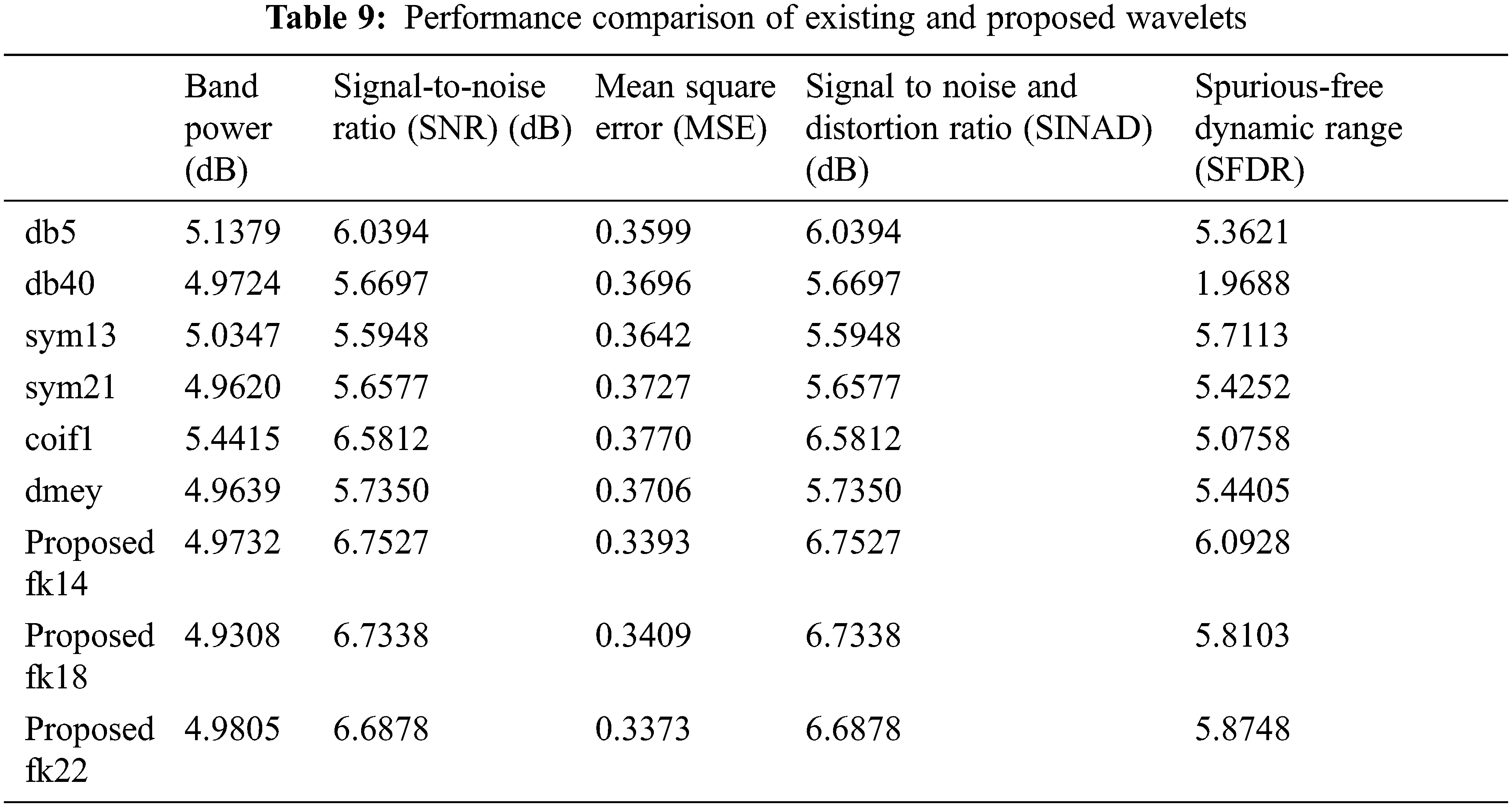
The performance comparison of the existing and proposed method is shown in Tab. 9.
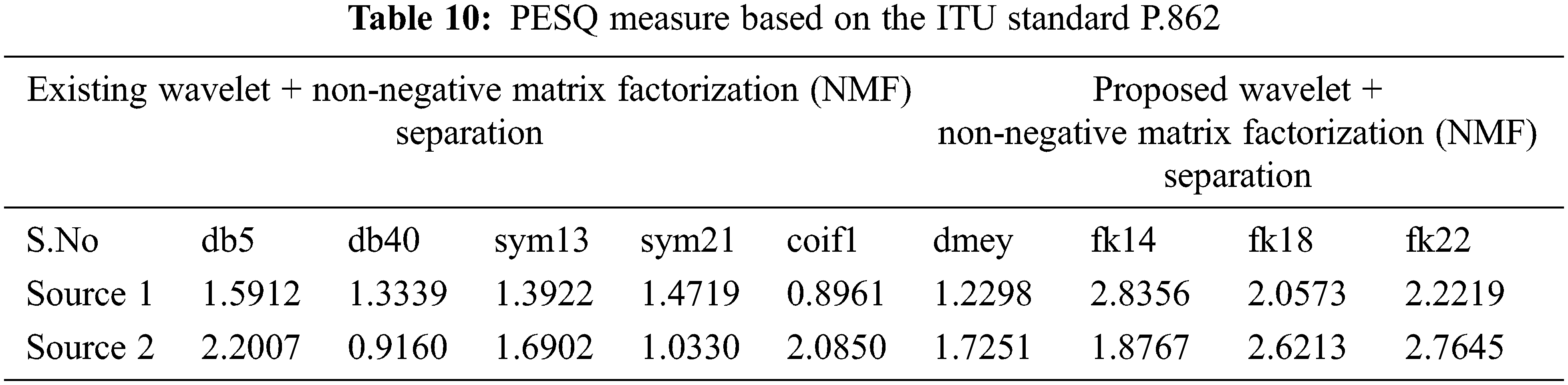
The Speech recordings before and after separation are evaluated for quality using objective speech quality measures such as ITU-T P.862 for objectivity (Tab. 10).
The paper presents a new method for speech separation in Hearing aids which provide high signal-to-noise ratio. The Wavelet based decomposition Methodology using Fejer-Korovkin (FK) algorithm is better in performance when compared to the existing decomposition in two stage wavelet filter bank and tree structured wavelet filter bank db. For speech separation Non-negative Matrix Factorization (NMF) algorithm is used. The proposed methods Error and time calculation for different divergence are measured. For evaluation of the proposed method and existing method on speech separation mixed audio sources are used and ITU standard P.862 is utilized for the evaluation. Different parameters like Signal to Noise Ratio (SNR), Signal to Distortion Ratio (SDR), Signal to Noise and Distortion Ratio (SINAD), Spurious-free dynamic range (SFDR), Mean Square Error (MSE), and Band Power were used for evaluation. In future deep learning methods will be proposed for this application. The hardware implementation will be carried out using new semiconductor devices.
Acknowledgement: We acknowledge our family friends and organization for their support in carrying the research work.
Funding Statement: No specific funding for this study is received by the authors for this work.
Conflicts of Interest: The authors declare that we have no conflicts of interest to report regarding the present study.
1. K. J. Ballard, F. S. M. Halaki, K. Paul, A. Daliri and D. A. Robin, “An investigation of compensation and adaptation to auditory perturbations in individuals with acquired apraxia of speech,” Frontiers in Human Neuroscience, vol. 12, pp. 1–14, 2018. [Google Scholar]
2. J. T. George and E. Elias, “A 16-band reconfigurable hearing Aid using variable bandwidth filters,” Global Journal of Researches in Engineering, vol. 14, no. 1, pp. 1–8, 2014. [Google Scholar]
3. L. N. L. Wong, Y. Chen, Q. Wang and V. Kuehnel, “Efficacy of a hearing Aid noise reduction function,” Trends in Hearing, vol. 22, pp. 1–14, 2018. [Google Scholar]
4. H. Levitt, “Noise reduction in hearing aids: A review,” Journal of Rehabilitation Research and Development, vol. 38, no. 1, pp. 111–121, 2001. [Google Scholar]
5. U. Shrawankar and V. Thakare, “Noise estimation and noise removal techniques for speech recognition,” IFIP International Federation for Information Processing, vol. 340, pp. 336–342, 2010. [Google Scholar]
6. G. P. Prajapati and A. Devani, “Review paper on noise reduction using different techniques,” International Research Journal of Engineering and Technology (IRJET), vol. 4, no. 3, pp. 522–524, 2017. [Google Scholar]
7. Y. Wei and D. Liu, “A reconfigurable digital filterbank for hearing-aid systems with a variety of sound wave decomposition plans,” IEEE Transactions on Biomedical Engineering, vol. 60, no. 6, pp. 1628–1635, 2013. [Google Scholar]
8. A. Schasse, “Two-stage filter-bank system for improved single-channel noise reduction in hearing aids,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 23, no. 2, pp. 383–393, 2015. [Google Scholar]
9. H. Liu, R. Zhang, Y. Zhou, X. Jing and T. K. Truong, “Speech denoising using transform domains in the presence of impulsive and Gaussian noises,” IEEE Access, vol. 5, pp. 21193–21203, 2017. [Google Scholar]
10. G. V. P. Chandra Sekhar Yadav, B. A. Krishna and Kamaraju, “Performance of wiener filter and adaptive filter for noise cancellation in real-time environment,” International Journal of Computer Applications, vol. 97, no. 15, pp. 16–23, 2014. [Google Scholar]
11. N. A. M. Abbasa and H. M. Salman, “Independent component analysis based on quantum particle swarm optimization,” Egyptian Informatics Journal, vol. 19, no. 2, pp. 101–105, 2018. [Google Scholar]
12. M. S. Pedersen, D. Wang, J. Larsen and U. Kjems, “Two-microphone separation of speech mixtures,” IEEE Transactions on Neural Networks, vol. 19, no. 3, pp. 475–492, 2008. [Google Scholar]
13. X. Jaureguiberry, E. Vincent and G. Richard, “Fusion methods for speech enhancement and audio source separation,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 24, no. 7, pp. 1266–1279, 2016. [Google Scholar]
14. T. G. Kang, K. Kwon, J. W. Shin and N. S. Kim, “NMF-Based target source separation using deep neural network,” IEEE Signal Processing Letters, vol. 22, no. 2, pp. 229–233, 2015. [Google Scholar]
15. U. N. S. Wood, J. Rouat, S. Dupont and G. Pironkov, “Blind speech separation and enhancement with GCC-NMF,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 25, no. 4, pp. 745–755, 2017. [Google Scholar]
16. S. Raj and A. Shaji, “Design of reconfigurable digital filter bank for hearing Aid,” International Journal of Science and Research (IJSR), vol. 5, no. 7, pp. 450–454, 2016. [Google Scholar]
17. N. Yang, M. Usman, X. He, M. A. Jan and L. Zhang, “Time-frequency filter bank: A simple approach for audio and music separation,” IEEE Access, vol. 5, pp. 27114–27125, 2017. [Google Scholar]
18. A. S. Kang and R. Vig, “Performance analysis of near perfect reconstruction filter bank in cognitive radio environment,” Interanational Journal of Advanced Networking and Applications, vol. 8, no. 3, pp. 3070–3083, 2016. [Google Scholar]
19. S. Shakya and J. Ogale, “Design and analysis of uniform-band and octave-band tree-structured filter bank,” International Journal of Signal Processing Systems, vol. 4, no. 2, pp. 162–167, 2016. [Google Scholar]
20. I. Missaoui and Z. Lachiri, “Blind speech separation based on undecimated wavelet packetperceptual filterbanks and independent component analysis,” IJCSI International Journal of Computer Science Issues, vol. 8, no. 1, pp. 265–272, 2011. [Google Scholar]
21. K. Tripathi and K. S. Rao, “VEP detection for read, extempore and conversation speech,” IETE Journal of Research, 2020. [Google Scholar]
22. J. Indra, R. K. Shankar, N. Kasthuri and S. Geetha manjuri, “A modified tunable – Q wavelet transform approach for tamil speech enhancement,” IETE Journal of Research, 2020. [Google Scholar]
23. K. K. Shukla and A. K. Tiwari, “Efficient algorithms for discrete wavelet transform,” Springer Briefs in Computer Science, 2013. [Google Scholar]
24. N. Trivedi, V. Kumar, S. Singh, S. Ahuja and R. Chadha, “Speech recognition by wavelet analysis,” International Journal of Computer Applications, vol. 15, no. 8, pp. 27–32, 2011. [Google Scholar]
25. A. Kumar and R. Sunkaria, “Two-channel perfect reconstruction (PR) quadrature mirror filter (QMF) bank design using logarithmic window function and spline function,” Signal, Image and Video Processing, vol. 10, no. 8, pp. 1473–1480, 2016. [Google Scholar]
26. A. N. Akansu and R. A. Haddad, Multi-resolution Signal Decomposition: Transforms, Subbands, and Wavelets, Academic Press: Newark, NJ, 2nd ed., 2000. [Google Scholar]
27. G. P. Vouras and T. Tran, “Paraunitary filter bank design using derivative constraints,” in IEEE Int. Conf. on Acoustics, Speech and Signal Processing - ICASSP ‘07, Honolulu, pp. 1453–1456, 2007. [Google Scholar]
28. K. M. Ribeiro, R. A. Braga, T. Safadi and G. Horgan, “Comparison between Fourier and wavelets transforms in biospeckle signals,” Applied Mathematics, vol. 4, pp. 11–22, 2013. [Google Scholar]
29. T. Si-Nguyen and W. H. Brian Ng, “Critically sampled discrete wavelet transforms with rational dilation factor of 3/2,” in 10th Int. Conf. on Signal Processing Proc., Beijing, China, pp. 199–202, 2010. [Google Scholar]
30. D. L. Wang and J. Chen, “Supervised speech separation based on deep learning: An overview,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 26, no. 10, pp. 1–27, 2018. [Google Scholar]
31. J. Glass, “Towards unsupervised speech processing,” in 11th Int. Conf. on Information Science, Signal Processing and Their Applications (ISSPA), Montreal, Quebec, Canada, pp. 1–4, 2012. [Google Scholar]
32. Y. Xue, C. S. Tong and T. Li, “Evaluation of distance measures for NMF-based face image applications,” Journal of Computers, vol. 9, no. 7, pp. 1704–1711, 2014. [Google Scholar]
33. Z. Yang, H. Zhang, Z. Yuan and E. Oja, “Kullback-leibler divergence for nonnegative matrix factorization,” in Int. Conf. on Artificial Neural Networks (ICANN), Berlin, Heidelberg, pp. 250–257, 2011. [Google Scholar]
34. A. Adewusi, K. A. Amusa and A. R. Zubair, “Itakura-saito divergence non negative matrix factorization with application to monaural speech separation,” International Journal of Computer Applications, vol. 153, no. 9, pp. 17–22, 2016. [Google Scholar]
35. Mustaqeem and S. Kwon, “CLSTM: Deep feature-based speech emotion recognition using the hierarchical ConvLSTM network,” Mathematics, vol. 8, pp. 2133, 2020. [Google Scholar]
36. Mustaqeem and S. Kwon, “Optimal feature selection based speech emotion recognition using Two-stream deep convolutional neural network,” International Journal Intelligent System, vol. 36, no. 9, pp. 1–20, 2021. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |