DOI:10.32604/csse.2023.025256
| Computer Systems Science & Engineering DOI:10.32604/csse.2023.025256 | |
| Article |
Hybridization of Metaheuristics Based Energy Efficient Scheduling Algorithm for Multi-Core Systems
1Department of Computer Science & Engineering, St. Joseph’s College of Engineering, Chennai, 600119, India
2Department of Computer Science and Engineering, Saveetha School of Engineering, SIMATS, Chennai, 602 105, India
3Department of Electronics and Communication Engineering, K. Ramakrishnan College of Engineering, Tiruchirappalli, 621112, India
4Department of Electronics and Communication Engineering, Sona College of Technology, Salem, 636 005, India
5Department of Computer Engineering, College of Computers and Information Technology, Taif University, Taif, 21944, Saudi Arabia
6Department of Biomedical Engineering, College of Engineering, Princess Nourah bint Abdulrahman University, Riyadh, 11671, Saudi Arabia
7Department of Computer and Self Development, Preparatory Year Deanship, Prince Sattam bin Abdulaziz University, AlKharj, Saudi Arabia
*Corresponding Author: Manar Ahmed Hamza. Email: ma.hamza@psau.edu.sa
Received: 17 November 2021; Accepted: 20 December 2021
Abstract: The developments of multi-core systems (MCS) have considerably improved the existing technologies in the field of computer architecture. The MCS comprises several processors that are heterogeneous for resource capacities, working environments, topologies, and so on. The existing multi-core technology unlocks additional research opportunities for energy minimization by the use of effective task scheduling. At the same time, the task scheduling process is yet to be explored in the multi-core systems. This paper presents a new hybrid genetic algorithm (GA) with a krill herd (KH) based energy-efficient scheduling technique for multi-core systems (GAKH-SMCS). The goal of the GAKH-SMCS technique is to derive scheduling tasks in such a way to achieve faster completion time and minimum energy dissipation. The GAKH-SMCS model involves a multi-objective fitness function using four parameters such as makespan, processor utilization, speedup, and energy consumption to schedule tasks proficiently. The performance of the GAKH-SMCS model has been validated against two datasets namely random dataset and benchmark dataset. The experimental outcome ensured the effectiveness of the GAKH-SMCS model interms of makespan, processor utilization, speedup, and energy consumption. The overall simulation results depicted that the presented GAKH-SMCS model achieves energy efficiency by optimal task scheduling process in MCS.
Keywords: Task scheduling; energy efficiency; multi-core systems; fitness function; makespan
The evolution of Multi-Core Systems (MCS) has been a major advancement for previous models of computer structure. Thus, the merits and demerits of this study pose the significance of the newly proposed method and efficiency in handling thermal dispersion and the inexistence of proficient scheduling approaches. In general, the major theme of a chip is processed in similar clock application, clock frequency, and computing voltage [1]. But the system is not processed in a similar frequency. Hence, retaining the performance symmetry between heterogeneous operating values is a significant problem and developers have managed to resolve the issues. Also, 2 plausible solutions for predefined problems namely, dynamic voltage circuitry for each core (hardware solution), and Schedule tasks between cores to activate the cores to process on similar clock frequency (software solution). The previous compensation principle is shown power exhaustion at maximum frequencies and escalates the thermal throttling. On behalf of the challenging factor, the second solution is unknown from the perception of scheduling [2]. Followed by, the applied workload is divided into cores with the aid of operating on identical cores operating on identical clock frequency for high power conservation. The new processing units offer an interface to modify voltage for optimal energy application. Hence, voltage tailoring on implementation is named Dynamic Voltage Scaling (DVS), which is a productive approach used for reducing energy consumption.
Here, dynamic clock as well as voltage modifications imply the cropping edge of energy reducing abilities in Complementary metal–oxide–semiconductor (CMOS) motherboard [3]. The correlation among frequency and voltage exhibits a base for DVS in smart processors. Hypothetically, a unique processor is a key material that provides frequent voltage levels. But, the application of continuous changing voltages is impossible due to the switching burden and support various operational levels. Hence, the advanced processing units are applicable to support a static value of discrete-level that enhances the speed among traditional and present levels. In [2], it is reported that the energy-speed curve is convex by default. Based on the statement of Jensen’s inequality, the deadline limitations are satisfied and energy effective models are used for implementing tasks at ideal speed when compared with differential speed for individual operations. Fig. 1 illustrates the common process of scheduling system.
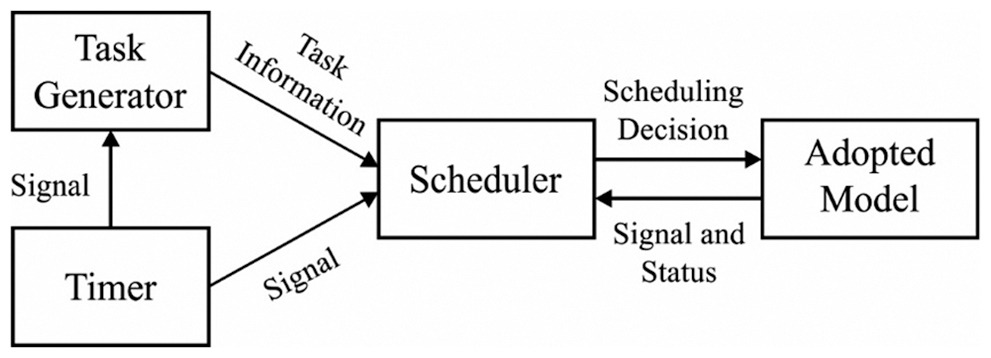
Figure 1: General process of scheduling
Furthermore, the simulation outcome is relevant to explore the feasibility of computing equal speed for the cores by using a processor that supports the maximum count of discrete power voltage levels. The first priority of a process denotes the concentration provides to the task while making scheduling decisions. Usually, real-time applications were not applied completely. Hence, the systems are challenging to use DVS and its scheduling methods. Under the application of the DVS model, complete maintenance has to be provided for task scheduling and numerous outcomes are attained [4].
The prominently applied policy for scheduling real-time process is a priority-based module which has been categorized into 2 classes namely, Fixed priority and Dynamic priority [3]. The first approach allocates a static value for the priority of all processes in a task, which has to be varied from the priorities allocated to jobs emanated by alternate tasks in the system. The second module has no limitations where the priorities are allocated to a single process. Even though dynamic approaches are assumed theoretically, it is unpredictable if a transient burden exists [5].
This paper presents a new hybrid genetic algorithm (GA) with a krill herd (KH) based energy-efficient scheduling technique for multi-core systems (GAKH-SMCS). GA is an evolutionary algorithm using the searching approaches for the identification of nearest optimal solutions. To resolve the issue of ineffective information flow between different generations in GA, the KH algorithm is incorporated into GA by altering the GA cycle and operators, appending swarm intelligence (SI) and rousing from Krill movements. The GAKH-SMCS model involves a multi-objective fitness function using four parameters such as makespan, processor utilization, speedup, and energy consumption to schedule tasks proficiently. The performance of the GAKH-SMCS model has been validated against two datasets namely random dataset and benchmark dataset. In short, the paper contributions can be summarized as follows
• Design an energy-efficient task scheduling algorithm using a hybrid metaheuristic technique for MCS
• Hybridizing GA with KH algorithms for improving the information flow among generations in GA
• Derive a multi-objective fitness function using four variables namely
• Validate the results of the GAKH-SMCS model against random and benchmark dataset.
The remaining sections are planned as follows. Section 2 briefs the existing scheduling techniques developed for MCS. Next, the proposed GAKH-SMCS model is designed in Section 3. At last, Section 4 performs the simulation process and Section 5 concludes the work.
2 Existing Scheduling Approaches for MCS
Most proposals have reported task scheduling for MCS with realistic limitations. Increasing the proficiency of theoretical applications in real-time overhead is projected in [4] to schedule the periodic soft real-time jobs. In the case of periodic application, Moulik et al. [5] presented a variable energy-aware real-time scheduling device with 3 levels of hierarchical resource assignment. Initially, the scheduler determines a pair of fragments for execution and schedules the task for enabling better execution value, and manufacture the processing frequencies for each core and reduce the power utilization. Next, the extended approach [6] has considered the system-wide power application for considering the best frequency selection technique. Chwa et al. [7] applied fully-migrative frameworks of 2-type heterogeneous MCS named Hetero-Fair.
Tang et al. [8] developed a task scheduling method for combining hard periodic as well as soft aperiodic real-time jobs. Firstly, a periodic operation is scheduled by offline technique and periodic tasks are scheduled dynamically with the help of residual slack time data for a resource. Lin et al. [9] projected a processor mapping approach according to the Integer Linear Programming (ILP) mechanism for practical time streaming models. To serve the global optimization of throughput, delay, and computational cost, a global ILP approach has been deployed and suitable solutions are identified with the help of a GA. In contrast, the developed approach assumes real-time features of the method and power attributes of task requests and advents. At this point, dynamic voltage/frequency scaling (DVFS) is applied for limiting the power application and sample scheduling methods practically with the help of the benchmark system. Hence, task scheduling models consider that energy is applied for heterogeneous MCS. Next, power reducing processor allocation for the periodic real-time process was projected [10], in which the solution for the ILP approach is retrieved using greedy methods and reduces power utilization.
A task scheduling framework is developed in [11] that assumes the implementation time for process and power utilization in the ILP scheme. Here, a task is labeled as graphical form and it can be allocated to maximum priority level with limited execution time and power application. Yu et al. [12] proposed an ILP-based static resource allocation approach in which the voltage levels of computing elements were assumed to be the attribute in ILP problem formulation for power minimization. Zhang et al. [13] executed Shuffled Frog Leaping Algorithm (SFLA) for realistic periodic task scheduling in which the objective is to reduce the power utilization during the deadline completion. Hung et al. [14] define an energy-effective scheduling framework for the DVS model and non-DVS processing units, in which the objectives are reducing power consumption and enhance energy savings. Followed by, power consumption is classified by 2 diverse cases in which the non-DVS processing element is either based on burden or non-burden. Thus, the newly developed approaches are approximation models that depend upon ILP.
Also, Baruah et al. [15] deployed an ILP development-based dividing framework for limited-deadline processes on heterogeneous processing units. Awan et al. [16] reported task assignment on DVFS based heterogeneous MCS that reduces the total power utilization of the system considering draining energy and dynamic energy. Afterward, a task-to-core mapping approach has been depicted and evaluate the sleep condition as well as processing frequency-level of a core for the autonomous sporadic process. Lin et al. [17] presented an energy-effective task scheduling model which is operated under 2 execution models namely, Batch mode and Online mode. Initial mode, a greedy based application has been applied for reducing the overall cost in which the cost is composed of time and power utilization, computational rate, and money spent for waiting by individuals while in the second mode, a novel task has been produced typically and developed to the model. The tasks go to 2 types of online mode: Interactive and Non-interactive operations. Initially, interactive tasks require limited response time while the non-interactive process does not consider the response time. Hence, a method for online mode is employed for completing the interactive operations with limited response time and to reduce the non-interactive task implementation duration.
3 Proposed GAKH Based Scheduling Technique for MCS
GA is an evolutionary algorithm using the searching approaches for the identification of nearest optimal solutions. To resolve the issue of ineffective information flow between different generations in GA, the KH algorithm is incorporated to GA by altering the GA cycle and operators, appending SI and rousing from Krill movements. The proposed GAKH-SMCS algorithm utilizes a multi-objective fitness function using four parameters for the optimal task scheduling process.
In this study, a pair of
Followed by, LPP is devised as shown below:
Minimize
Maximize
Maximize
Subjected to
The following units are employed to define the newly projected approach:
The implementation time
where
The original start time,
The releasing time of a processor
The finish time
3.2 Hybridization of GA with KH Algorithm
In traditional GA, considering the absence of robust data flow among parents and children generations, the attained results are inferior in a few issues. In the newly developed GAKH technique, reasonable enhancement is accomplished by combining GA and KH methods. The major cause for presenting the change is that the GA approach does not provide optimal outcomes when compared with alternate approaches as KH lacks robust data flow and KH genetic operators are unfit in exhibiting the final outcomes. The major intension of this framework is to resolve the vulnerability of KH and GA and solve the clustering issues by KH [18]. The steps involved in newly presented approaches are given in the following.
(1) Initialization: Develop a population randomly in a search space.
(2) Fitness estimation: Estimating the fitness of a candidate.
(3) Motion Operators:
a. Cumulative
b. Local
c. Random
(4) Substitution
(5) Maximize the population
(6) Follow step 3 until reaching the termination criteria
(7) End.
Step 3: Fitness estimation
Step 4: Under the application of GA operators and including self–organization, parent data flow, the maximum and minimum objective functions and final outcome of existing generation for the operators and change the population development in GA and the final generations offer considerable outcomes when compared with former generations. Obviously, a chromosome resembles the krill’s hierarchy by the movements defined above.
Cumulative movement. It is referred to as krill based movement. It manages to retain maximum density and go nearby group’s maximum collection.
Suppose the operator
In cross-over operator is used on 2 chromosomes
Where rand value of considered from , 1
where rand is among , 1
where
The local movement is evolved by the foraging behavior of krill. Here, krill from a former place of food seeks food. Operator mutation is
where
Random diffusion is developed by the random movement of krill. During this approach, the presented approach every generation generates
where
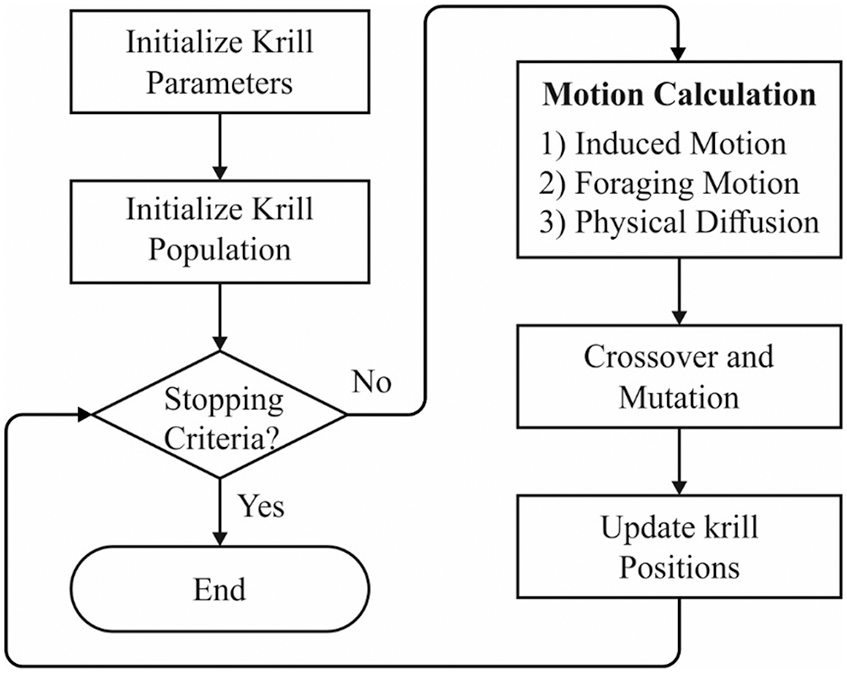
Figure 2: The flowchart of KH algorithm
3.3 Application of GAKH Algorithm for Task Scheduling in MCS
The projected model named GAKH based scheduling in MCS is composed of the objectives given in the following.
3.3.1 Representing Chromosomes
Chromosomes must offer better solutions to the applied problems. In this model, they are defined as a string of arbitrarily created processor value. The basic population is developed by arbitrarily produced
For deriving the fitness score, 3 objectives have been applied namely, reduction of makespan, increment in processor application, and improvisation of speedup value. In this model, a chromosome is estimated using a fitness score and identifies an optimal solution for the applied problem.
Reduction of Makespan: A task
where
Increment of Processor application: It is considered as the ratio among average time where the processors are engaged by complete system schedule time and determined as given below:
Then, the second objective is recommended as:
Improvisation of Speedup: A speedup factor is considered as the ratio among sequential implementation time by makespan as depicted in the following:
Reduction of energy consumption (EC): It is defined as the amount of energy spent for communication purposes.
Here, the Weighted Sum Approach (WSA) has been applied for computing Fitness Function (FF). WSA is defined as a traditional application used to optimize the MCS by task scheduling problem, in which the objective is allocated with weight [19]. The main aim of this framework is to select the solution with a reduced fitness score. Assume the parameter weight as
The major objective is to reduce fitness value. In a crossover, 2 parent chromosomes combine and generate 2 child chromosomes. There are maximum crossover operations such as 1-point, 2-point, hybrid, and so on. Hence, the crossover process is processed after mutation, in which child chromosomes undergo mutation for a better solution. Under the mutation process, the gene position is selected arbitrarily and the value is interchanged by the alternate valuable score. In the case of the selection process, optimal chromosomes are decided based on fitness measures.
To examine the performance of the GAKH-SMCS model, a series of simulations were takes place on Intel i7 3.4 GHz CPU with 4 GB of RAM. To select the parents depending upon the fitness value, Roulette Wheel Selection is used. Also, the weighted sum approach (WSM) is used to determine the fitness of the presented model. The results are examined using a random and benchmark dataset [20]. A comparative analysis with Priority-aware Genetic Algorithm (PGA), hybrid heuristicgenetic algorithm with adaptive parameter (HGAAP), GA based scheduling (GA-SC), and Genetic Algorithm in Heterogeneous Distributed Computing System (GAHDCS).
4.1 Analysis of Scheduling Results on Random Dataset
The GAKH-SMCS model is tested against 4 arbitrarily created datasets such as Set 1: 100 tasks with 3 processors (100 × 3), Set 2: 200 tasks with 3 processors (200 × 3), Set 3: 500 tasks with 5 processors (500 × 5), and Set 4: 1000 tasks with 10 processors (1000 × 10). In this case, the task sizes are arbitrarily created and utilized the weights of 0.5, 0.3, 0.2 to determine the fitness value. Tab. 1 and Figs. 3, 4 showcases the results obtained by the GAKH-SMCS model on the applied random dataset for distinct measures.
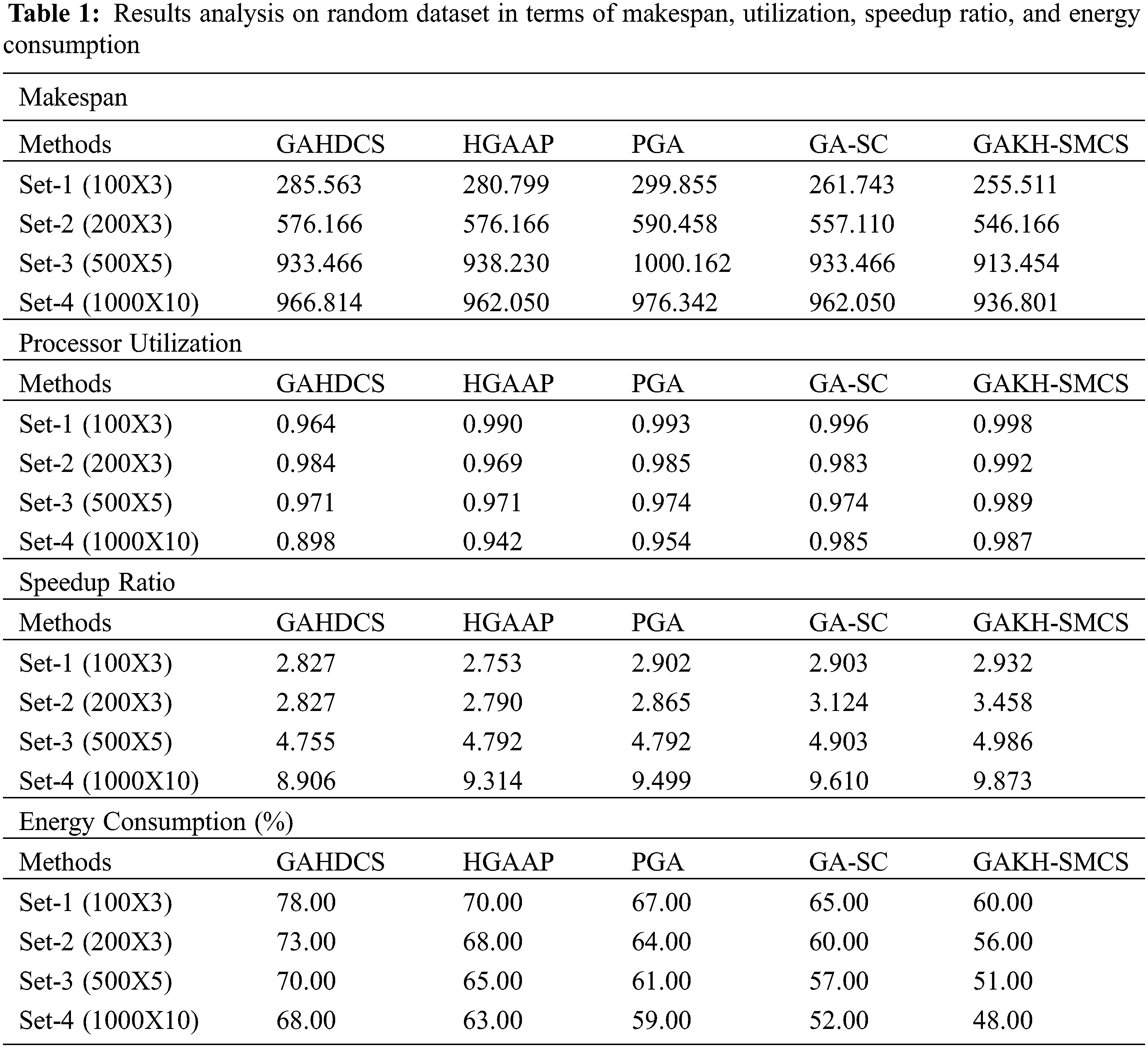
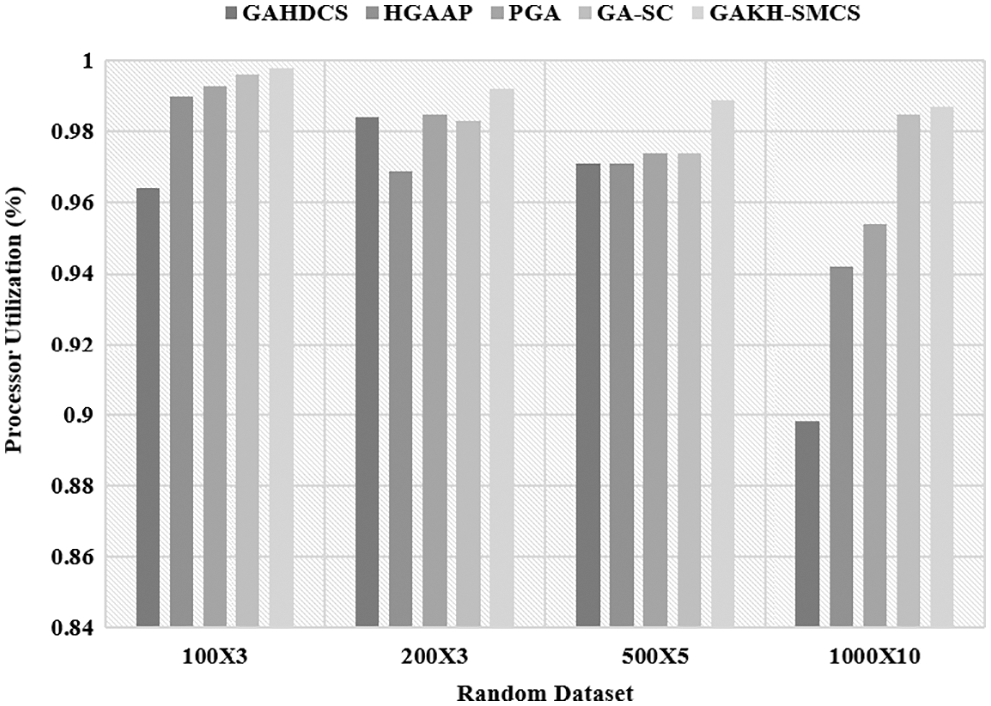
Figure 3: Processor utilization analysis on random dataset
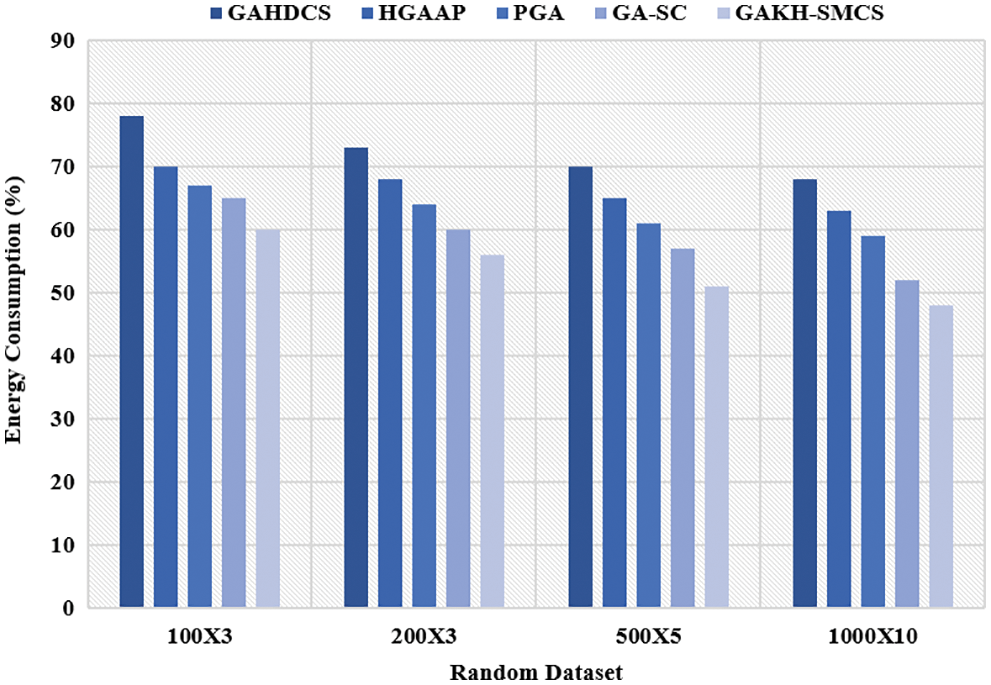
Figure 4: Energy efficiency analysis on random dataset
An analysis of makespan results indicated that the GAHDCS model has depicted poor performance by obtaining maximum makespan over the compared methods. Besides, the HGAAP and PGA models have resulted in a slightly better makespan over the GAHDCS model. Though the GA-SC model has showcased competitive performance, the presented GAKH-SMCS model has outperformed the other methods by achieving minimum makespan. For instance, on the applied set-4 (1000 × 10), the presented GAKH-SMCS model reached a minimum makespan of 936.801 whereas the GAHDCS, HGAAP, PGA, and GA-SC models have attained higher makespan of 285.563, 280.799, 299.855, and 261.743 respectively.
On determining results to processor utilization, it is evident that the GAHDCS model is the worst performer over the compared methods by offering the least processor utilization whereas the HGAAP, PGA, and GA-SC models have exhibited slightly better utilization over the GAHDCS. However, the presented GAKH-SMCS model has demonstrated supreme results by obtaining maximum processor utilization. For instance, on the applied Set-4 (1000 × 10) dataset, the presented GAKH-SMCS model has depicted higher processor utilization of 0.998 whereas the GAHDCS, HGAAP, PGA, and GA-SC models have demonstrated lower processor utilization of 0.898, 0.942, 0.954, and 0.985 respectively.
The analysis of power consumption results depicted that the GAHDCS method has demonstrated inferior performance by accomplishing high power consumption over the traditional approaches. Followed by, the HGAAP and PGA methodologies have exhibited considerable power consumption than the GAHDCS model. Even though the GA-SC technique has implied a competing function, the proposed GAKH-SMCS framework has surpassed the alternate models by accomplishing lower power utilization. For sample, on the given set-4 (1000 × 10), the newly GAKH-SMCS deployed technology has attained the least power consumption of 48% while the GAHDCS, HGAAP, PGA, and GA-SC methodologies have accomplished maximum power consumption of 68%, 63%, 59%, and 52% correspondingly.
On examining the final outcome utilizing the speedup ratio, it is clear that the GAHDCS method has identified inferior performers when compared with other modes by exhibiting a lower speedup ratio while the HGAAP, PGA, and GA-SC methodologies have showcased moderate utilization over the GAHDCS. Therefore, the developed GAKH-SMCS framework has depicted qualified outcomes by attaining a high speedup ratio. For example, on the given Set-4 (1000 × 10) dataset, the projected GAKH-SMCS framework has illustrated a maximum speedup ratio of 0.998 while the GAHDCS, HGAAP, PGA, and GA-SC frameworks have showcased limited speedup ratio of 8.906, 9.314, 9.499, and 9.610 respectively.
4.2 Analysis of Scheduling Results on the Benchmark Dataset
In this study, 2 datasets 256 tasks on 8 processors (256 × 8) and 512 tasks on 16 processors (512 × 16) were assumed to verify the process [20]. The samples are represented as u_x_yyzz where u implies samples produced by the uniform distribution, x signifies the consistency, yy indicates heterogeneity, and zz depicts the heterogeneity. Here, the performance is validated interms of distinct evaluation measures.
Tab. 2 and Figs. 5, 6 implies the results attained by the GAKH-SMCS method on the given benchmark dataset employing various metrics. An analysis of makespan results pointed out that the GAHDCS approach has illustrated inferior performance by gaining high makespan over the traditional models. On the other hand, the HGAAP and PGA approaches have concluded with acceptable makespan over the GAHDCS scheme. Even though the GA-SC framework has showcased competing performance, the projected GAKH-SMCS model has performed well with the alternate models by accomplishing the least makespan. For sample, on the given ushihi dataset, the newly GAKH-SMCS approach attained a low makespan of 24768088 and the GAHDCS, HGAAP, PGA, and GA-SC models have obtained optimal makespan of 27234317, 25499658, 27147584, and 26106788 respectively.

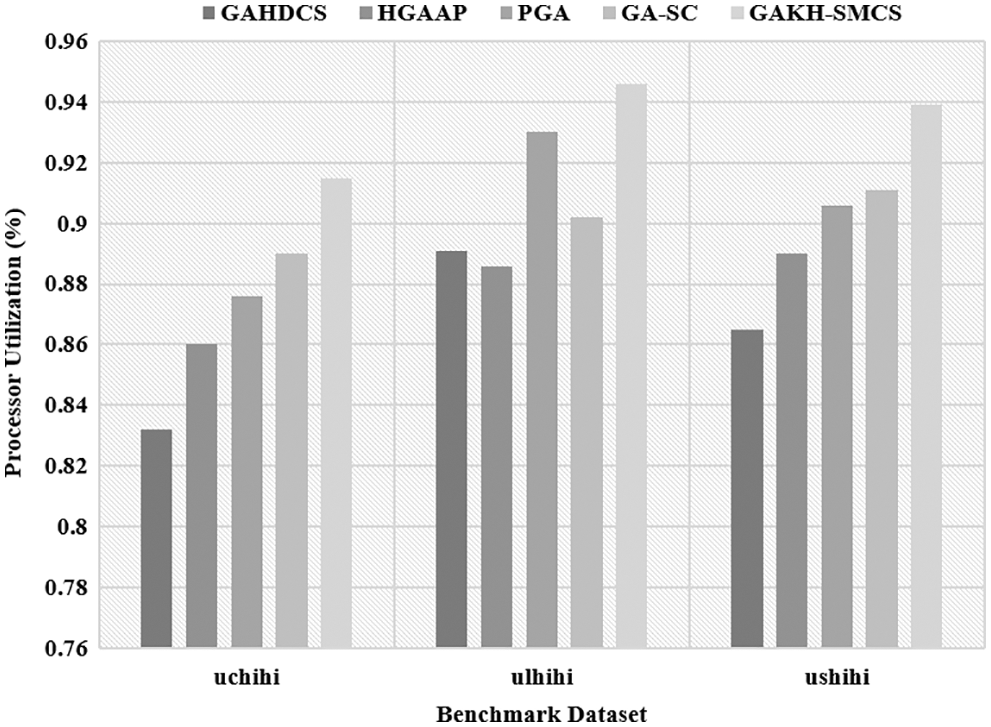
Figure 5: Processor utilization analysis on benchmark dataset
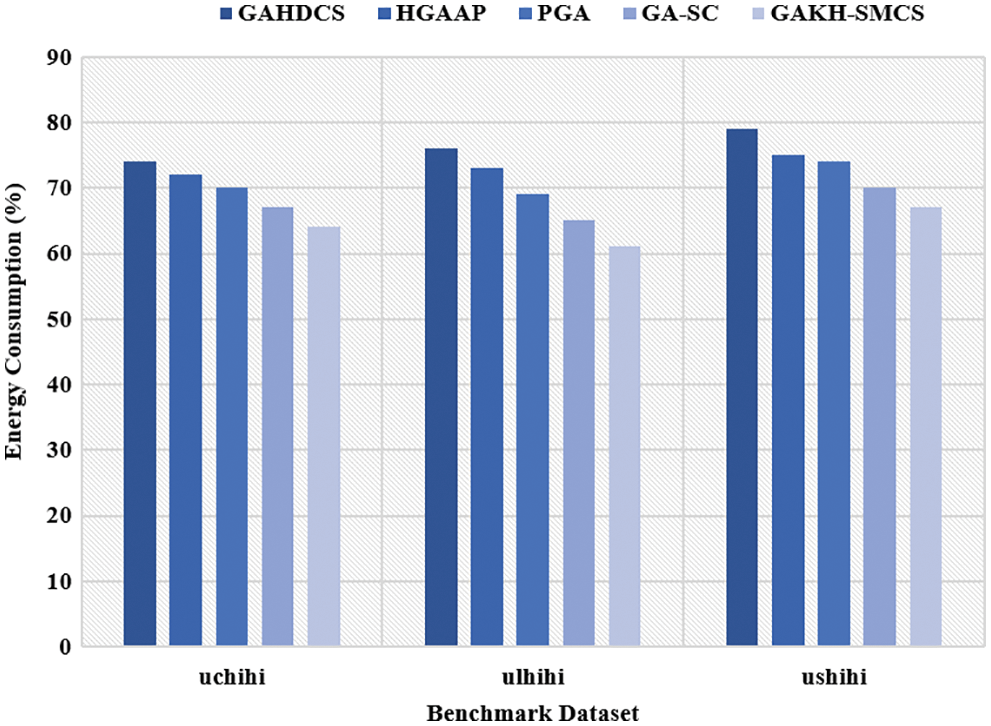
Figure 6: Energy efficiency analysis on benchmark dataset
On examining the final outcome utilizing processor utilization, it is clear that the GAHDCS approach has been meant to be the worst performer over the earlier models by generating minimum processor utilization while the HGAAP, PGA, and GA-SC models have depicted moderate application when compared with GAHDCS. Therefore, the projected GAKH-SMCS framework has depicted qualified results by gaining higher processor utilization. For sample, on the applied ushihi dataset, the projected GAKH-SMCS approach has showcased maximum processor utilization of 0.939 whereas the GAHDCS, HGAAP, PGA, and GA-SC models have demonstrated least processor utilization of 0.865, 0.890, 0.906, and 0.911 respectively.
An examination of energy consumption results pointed out that the GAHDCS method has illustrated inferior performance by achieving high energy consumption over the classical models. Also, the HGAAP and PGA frameworks have attained moderate energy consumption over the GAHDCS scheme. Although the GA-SC technique has implied competing performance, the proposed GAKH-SMCS model has surpassed the alternate methods by accomplishing lower energy consumption. For example, on the applied ushihi dataset, the presented GAKH-SMCS model reached a limited energy consumption of 67% whereas the GAHDCS, HGAAP, PGA, and GA-SC models have attained maximum energy consumption of 78%, 75%, 74%, and 70% respectively.
On examining results for speedup ratio, it is apparent that the GAHDCS method has been identified to be the poor performer over the classical models by providing minimum speedup ratio while the HGAAP, PGA, and GA-SC methodologies have depicted acceptable consumption over the GAHDCS. Thus, the projected GAKH-SMCS framework has illustrated qualified results by gaining a high speedup ratio. For sample, on the applied ushihi dataset, the presented GAKH-SMCS technology has shown a maximal speedup ratio of 7.682 whereas the GAHDCS, HGAAP, PGA, and GA-SC technologies have illustrated least speedup ratio of 6.765, 7.020, 7.147, and 7.211 respectively.
This paper has designed an energy-efficient task scheduling algorithm using GAKH-SMCS. The goal of the GAKH-SMCS technique is to derive scheduling tasks in such a way to achieve faster completion time and minimum energy dissipation. The GAKH algorithm is introduced to resolve the problem of ineffective information flow between different generations in GA by altering the GA cycle and operators, appending SI, and rousing from Krill movements. The GAKH-SMCS model comprises a multi-objective fitness function by the use of four parameters such as makespan, processor utilization, speedup, and energy consumption to schedule tasks competently. To validate the performance of the GAKH-SMCS model, a series of experiments were conducted on the random dataset and benchmark dataset. The experimental results depicted that the presented GAKH-SMCS model achieves energy efficiency by optimal task scheduling process in MCS. As a part of the future scope, the performance of the GAKH-SMCS model can be improved using optimal data aggregation techniques.
Funding Statement: This work was supported by Taif University Researchers Supporting Program (Project Number: TURSP-2020/195), Taif University, Saudi Arabia. Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2022R203), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. X. Huang, K. L. Li and R. Li, “A energy efficient scheduling base on dynamic voltage and frequency scaling for multi-core embedded real-time system,” in Algorithms and Architectures for Parallel Processing, Lecture Notes in Computer Science book series, Springer, Switzerland, vol. 5574, pp. 137–145, 2009. [Google Scholar]
2. T. Ishihara and H. Yasuura, “Voltage scheduling problem for dynamically variable voltage processors,” in Proc. of the 1998 Int. Symp. on Low Power Electronics and Design-ISLPED ’98, Monterey, California, United States, pp. 197–202, 1998. [Google Scholar]
3. J. W. S. Liu, Real Time Systems. Upper Saddle River: Prentice Hall, 2000. [Google Scholar]
4. J. M. Calandrino, D. Baumberger, T. Li, S. Hahn and J. H. Anderson, “Soft real-time scheduling on performance asymmetric multicore platforms,” in 13th IEEE Real Time and Embedded Technology and Applications Symp. (RTAS'07), Bellevue, WA, USA, pp. 101–112, 2007. [Google Scholar]
5. S. Moulik, R. Devaraj and A. Sarkar, “HEART: A heterogeneous energy-aware real-time scheduler,” in 2019 32nd Int. Conf. on VLSI Design and 2019 18th Int. Conf. on Embedded Systems (VLSID), Delhi, NCR, India, pp. 476–481, 2019. [Google Scholar]
6. S. Moulik, R. Devaraj and A. Sarkar, “HEALERS: a heterogeneous energy-aware low-overhead real-time scheduler,” IET Computers & Digital Techniques, vol. 13, no. 6, pp. 470–480, 2019. [Google Scholar]
7. H. S. Chwa, J. Seo, J. Lee and I. Shin, “Optimal real-time scheduling on two-type heterogeneous multicore platforms,” in 2015 IEEE Real-Time Systems Symp., San Antonio, Texas, pp. 119–129, 2015. [Google Scholar]
8. H. Tang, P. Ramanathan and K. Compton, “Combining hard periodic and soft aperiodic real-time task scheduling on heterogeneous compute resources,” in 2011 Int. Conf. on Parallel Processing, Taipei City, Taiwan, pp. 753–762, 2011. [Google Scholar]
9. J. Lin, A. Srivatsa, A. Gerstlauer and B. L. Evans, “Heterogeneous multiprocessor mapping for real-time streaming systems,” in 2011 IEEE Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP), Czech Republic, pp. 1605–1608, 2011. [Google Scholar]
10. J. Chen, A. Schranzhofer and L. Thiele, “Energy minimization for periodic real-time tasks on heterogeneous processing units,” in 2009 IEEE Int. Symp. on Parallel & Distributed Processing, Rome, pp. 1–12, 2009. [Google Scholar]
11. L. Wenjing and W. Lisheng, “Energy-considered scheduling algorithm based on heterogeneous multi-core processor,” in 2011 Int. Conf. on Mechatronic Science, Electric Engineering and Computer (MEC), Jilin, China, pp. 1151–1154, 2011. [Google Scholar]
12. Y. Yu and V. K. Prasanna, “Power-aware resource allocation for independent tasks in heterogeneous real-time systems,” in Proc. Ninth Int. Conf. on Parallel and Distributed Systems, 2002, Taiwan, China, pp. 341–348, 2002. [Google Scholar]
13. W. Zhang, E. Bai, H. He and A. Cheng, “Solving energy-aware real-time tasks scheduling problem with shuffled frog leaping algorithm on heterogeneous platforms,” Sensors, vol. 15, no. 6, pp. 13778–13804, 2015. [Google Scholar]
14. C. Hung, J. Chen and T. Kuo, “Energy-efficient real-time task scheduling for a dvs system with a non-dvs processing element,” in 2006 27th IEEE Int. Real-Time Systems Symp. (RTSS'06), Rio de Janeiro, pp. 303–312, 2006. [Google Scholar]
15. S. K. Baruah, V. Bonifaci, R. Bruni and A. M. Spaccamela, “ILP models for the allocation of recurrent workloads upon heterogeneous multiprocessors,” Journal of Scheduling, vol. 22, no. 2, pp. 195–209, 2019. [Google Scholar]
16. M. A. Awan, P. M. Yomsi, G. Nelissen and S. M. Petters, “Energy-aware task mapping onto heterogeneous platforms using DVFS and sleep states,” Real-Time Systems, vol. 52, no. 4, pp. 450–485, 2016. [Google Scholar]
17. C. C. Lin, Y. C. Syu, C. J. Chang, J. J. Wu, P. Liu et al., “Energy-efficient task scheduling for multi-core platforms with per-core DVFS,” Journal of Parallel and Distributed Computing, vol. 86, no. 4, pp. 71–81, 2015. [Google Scholar]
18. M. Akbari and H. Izadkhah, “Hybrid of genetic algorithm and krill herd for software clustering problem,” in 2019 5th Conf. on Knowledge Based Engineering and Innovation (KBEI), Tehran, Iran, pp. 565–570, 2019. [Google Scholar]
19. A. Bose, T. Biswas and P. Kuila, “A novel genetic algorithm based scheduling for multi-core systems,” in Smart Innovations in Communication and Computational Sciences, Singapore: Springer, pp. 45–54, 2019. [Google Scholar]
20. T. D. Braun, H. J. Siegel, N. Beck, L. L. Bölöni, M. Maheswaran et al., “A comparison of eleven static heuristics for mapping a class of independent tasks onto heterogeneous distributed computing systems,” Journal of Parallel and Distributed Computing, vol. 61, no. 6, pp. 810–837, 2001. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |