DOI:10.32604/csse.2022.023051
| Computer Systems Science & Engineering DOI:10.32604/csse.2022.023051 | |
| Article |
A Model for Cross-Domain Opinion Target Extraction in Sentiment Analysis
Department of Computer Engineering, Eskisehir Technical University, Eskisehir, Turkiye
*Corresponding Author: Muhammet Yasin PAK. Email: mypak@eskisehir.edu.tr
Received: 26 August 2021; Accepted: 09 October 2021
Abstract: Opinion target extraction is one of the core tasks in sentiment analysis on text data. In recent years, dependency parser–based approaches have been commonly studied for opinion target extraction. However, dependency parsers are limited by language and grammatical constraints. Therefore, in this work, a sequential pattern-based rule mining model, which does not have such constraints, is proposed for cross-domain opinion target extraction from product reviews in unknown domains. Thus, knowing the domain of reviews while extracting opinion targets becomes no longer a requirement. The proposed model also reveals the difference between the concepts of opinion target and aspect, which are commonly confused in the literature. The model consists of two stages. In the first stage, the aspects of reviews are extracted from the target domain using the rules automatically generated from source domains. The aspects are also transferred from the source domains to a target domain. Moreover, aspect pruning is applied to further improve the performance of aspect extraction. In the second stage, the opinion target is extracted among the aspects extracted at the former stage using the rules automatically generated for opinion target extraction. The proposed model was evaluated on several benchmark datasets in different domains and compared against the literature. The experimental results revealed that the opinion targets of the reviews in unknown domains can be extracted with higher accuracy than those of the previous works.
Keywords: Opinion target extraction; aspect extraction; sentiment analysis
Nowadays, people can easily share their ideas through the Internet and also have the opportunity to benefit from other people's ideas. With the influence of social media, people make more comments on products, services, or anything. Appropriate analysis and interpretation of these comments play an important role in decision-making regarding a topic or problem. Sentiment analysis, also called opinion mining, aims to make a detailed analysis of sentiments, or opinions, about products and services [1–3].
Sentiment analysis is carried out at three different levels: document, sentence, and aspect level [4]. Sentiment analysis at the document level aims to find the dominant opinion in the document. At the sentence level, each sentence of the document is handled separately and a subjectivity analysis of the sentences is also made. On the other hand, aspect-level sentiment analysis aims to find the expressed opinion of each aspect or feature of an entity (product or service) with a more detailed analysis than those of document and sentence levels [5]. The opinion can be expressed regarding the whole entity or some aspects of the entity. For example, in the sentence “I am quite happy with the camera”, a positive opinion is expressed about the “camera” entity in general. On the contrary, in the review “This camera has a major design flaw”, a negative opinion is expressed about the “design” aspect of the “camera”.
The aspect-level sentiment analysis is carried out in two stages. First, the opinion target is extracted. Then, in the sentiment classification phase, the sentiment expressed about each opinion target is classified as either positive or negative. The opinion target refers to an aspect in which an opinion is expressed [5]. For instance, battery, camera, and screen are some examples of aspects of the phone entity. In the review “The phone has an amazing battery”, “battery” is the opinion target because opinion is expressed about it. In the review “Smartphone screens now extend up to about 7 inches”, “screen” is an aspect of the phone, but it is not an opinion target since no opinion is specified. While “lens” and “viewfinder” are aspects in the review “the lens is visible in the viewfinder when the lens is set to the wide-angle”, only the “viewfinder” is the opinion target. The problem of opinion target extraction has been studying intensively in recent years [6,7]. The same problem is expressed as opinion target extraction or aspect extraction problem in many studies and opinion target is expressed in different terms. While some studies can use the term of aspect [8,9], feature [10,11], and object feature [12], aspect and opinion target were used interchangeably [13]. Most of the recent studies [14–16] still do not consider aspects that are not opinion target in the sentence. Therefore, it is not possible to use these aspects in training for opinion target extraction. However, in [17], aspect extraction aims to create a list or dictionary of aspects belonging to the entity for a given entity, whereas the opinion target extraction aims to extract opinion targets in each review.
In the aspect extraction problem, the aspect to be extracted is expressed as an explicit aspect if it is present in the review. Otherwise, it is expressed as an implicit aspect [18]. For example, “food” and “screen” are explicit aspects in the reviews “The food of the hotel was delicious to eat” and “Smartphone screens now extend up to about 7 inches”, respectively. On the other hand, for the review “The hotel was too expensive”, the “price” is an implicit aspect since it does not appear in the review. Most of the related studies in the literature have been dealt with explicit aspects [6].
Supervised opinion target extraction models show high performance; however, the success of supervised models depends on the availability of labeled data. There are a wide range and variety of products and services being reviewed in different domains. However, collecting labeled data for each domain is a difficult task. Unsupervised or semi-supervised models are preferred to reduce the need for labeled data. Another way is to use labeled data from other domains. The need for labeled data can be reduced to establish a system that can be easily transferred among domains [19]. Cross-domain transfer learning models can be applied to transfer knowledge learned from a labeled source domain to any target domain with very little or no labeled data. In the absence of any labeled data for the target domain, unlabeled data of the target domain can be used. However, if the domain of the document is unknown, it is not possible to use any data belonging to the target domain. In studies of opinion target extraction, various information has been transferred from source domains to target domains. The syntactic relations among aspect and opinion words and common opinion words can be transferred from source domains to the target domain [20]. Besides, there is a great number of common aspects across domains although every domain is different [21]. These aspects can be transferred between the source and target domains.
Dependency parser–based extraction rules have been commonly studied in recent years for opinion target extraction [22–24]. However, these dependency parsers are limited by language and grammatical constraints. Since review authors do not feel obliged to comply with such limitations and can write as they wish, the dependency parsers may lead to wrong dependencies. An alternative way to extract opinion targets without using a dependency parser is to use sequential pattern-based rules. Though there have been some efforts on sequential pattern-based rules, these efforts extract the rules manually and have just a limited number of rules [25–28].
In our study, a sequential pattern-based rule mining model is proposed for cross-domain opinion target extraction. N-gram-based sequential rule mining is applied for the opinion target extraction problem by analyzing the patterns in product reviews. It is assumed that the domain of the review is unknown. Thus, it is not possible to use labeled or unlabeled data for the unknown target domain and only the data from the source domains can be used to generate rules. In the proposed model, the opinion target extraction is carried out in two stages unlike current sequential pattern-based rule mining approaches since the aspect is defined separately from the opinion target in our work. In the first stage, the aspects are extracted from the review using the aspect extraction rules automatically generated from the labeled data in source domains. The common aspects are transferred to the target domain from the source domains. Also, the aspect pruning process is applied. In the second stage, opinion targets are extracted from the aspects, which are extracted in the first stage, using the opinion target extraction rules automatically generated from source domains. Thanks to the two-stage approach, the aspects, which are actually not opinion targets, can be also used in the automatic rule generation process during the aspect extraction stage. The proposed model was evaluated by a thorough experimental work on seven different datasets and compared to the other approaches in the literature. The experimental results indicated that the proposed model outperforms the previous works on opinion target extraction and for the opinion targets particularly composed of noun phrases.
The research objectives of this work are:
• to design a sequential pattern-based model to generate rules automatically for extracting opinion targets in product reviews,
• to reveal the difference between the concepts of opinion target and aspect,
• to use the aspects, which are actually not opinion targets, in the rule generation process for aspect extraction,
• to adapt a cross-domain approach to extract opinion targets in unknown domains.
The remainder of the paper is organized as follows: Section 2 describes aspect and opinion extraction approaches in the sentiment analysis. In Section 3, the definitions of some basic concepts are explained with examples. The proposed model for cross-domain aspect and opinion target extraction is introduced in Section 4. The experimental work and the related results are presented and discussed in Section 5 and Section 6. Finally, the conclusions and future work are given in Section 7.
Opinion target extraction studies can be grouped as unsupervised, supervised, and semi-supervised depending on the use of labeled data. The unsupervised models aim to extract opinion targets using only unlabeled data while supervised models use labeled data. Semi-supervised models additionally can use a seed list of opinion words or aspects and opinion word lexicons. Also, manually created rules and external sources such as web search engines are used.
The topic modeling is an unsupervised learning model that assumes each document consists of a mixture of topics that can cover both aspects and sentiment words [29]. Brody et al. [19] propose an unsupervised local topic model to identify aspects and aspect-specific sentiment words. García et al. [30] propose an almost unsupervised aspect-based sentiment analysis system for multidomain and multilingual based on topic modeling. They used a minimal set of seed words that consist of just one seed word per domain aspect plus one positive and negative opinion word. Ekinci et al. [31] incorporated semantic knowledge into a model, which is called Concept-LDA, for aspect-based sentiment analysis. The topic models are more suitable for grouping and extracting aspects from large documents instead of extracting the opinion target in the review.
The frequency-based models are unsupervised models that assume frequently used nouns are usually important aspects. In study of Hu et al. [32], the frequent aspects were used to find adjacent opinion words, and infrequent aspects were extracted using opinion words. Pointwise mutual information (PMI) score was computed for each aspect in another study [33]. It was aimed to improve the precision of frequency-based models by pruning some candidate aspects. Some rules were manually defined to extract opinion words using syntactic dependencies that reveal the relationship between aspects and opinion words. Li et al. [34] propose a frequency-based model with PMI-IR to improve the performance of opinion target extraction. The experiments were carried out on Chinese product reviews.
Unsupervised rule-based models aim to extract rules by using the relationships between aspects and opinion words. The aspects related to any opinion word are tried to be extracted as opinion targets. The double-propagation is a bootstrapping-based model extracting both sentiment words and aspects simultaneously using syntactic dependencies [13]. A key advantage of this model is that it only needs an initial opinion lexicon to start the bootstrapping process. The model can be seen as a semi-supervised model due to the use of the seeds. The opinion words and opinion targets are extracted using seed opinion words. Then, the extracted words and targets are used for further opinion word and opinion target extraction. This process repeats until there is no new word left to add. However, the bootstrapping-based models cause the error propagation problem [35]. The opinion target and opinion words extracted incorrectly in the first iterations probably cause new errors in the next iterations. Finally, those errors accumulate gradually with the increasing iterations. Also, the success of syntactic-based models depends on the success of the dependency parser. The reviews with grammatical errors may fail in the parsing process. Poria et al. [36] propose a fully unsupervised rule-based approach to detect both implicit and explicit aspects using common-sense knowledge and syntactic dependencies. The opinion targets were extracted using hand-crafted dependency rules and an opinion lexicon. Kang et al. [37] extended double-propagation [13] with the definition of objective aspects by combining part-whole relation and review-specific patterns. Association rule mining [38] and word-based translation model [35] are other unsupervised models used to create a relationship between aspect and opinion targets.
The sequence models are supervised and address the problem of opinion extraction as a sequence labeling problem because of the reason that the aspects and opinion words are usually interdependent and in the sequence in a review [39]. Hidden Markov models [10] and conditional random fields (CRFs) [12] are examples of the sequence models. The CRF needs a huge number of features to work properly and depends on the grammatical accuracy of reviews [9]. The supervised rule-based models are also used for opinion target extraction. After labeling the opinion targets in reviews, the rules were generated for opinion target extraction. In terms of being rule-based, these models are similar to language rule-based approaches. However, they use labeled data instead of seed words for the labeling process. Since these models are supervised, they are similar to sequence models. Hu et al. [40] propose a supervised sequential pattern mining model to find language patterns to extract opinion targets from pros and cons reviews, which are short phrases that include the aspect and usually the opinion word. This was the first work that mines and uses such rules. The aspects of pros and cons reviews were extracted as opinion targets since these reviews are assumed to contain opinion. After the review was tagged by the POS tagger, opinion targets were labeled with the label of “feature”. N-gram approach was used to produce shorter segments for 3-gram (3 words with their POS tags). The class sequential pattern mining model, also called sequential rule mining, was applied to find all language patterns [41]. The rules were selected according to the minimum support value and these rules are used to identify features in the test review. Although the model produces rules in the form of n-grams, it allows gaps in the rule. The rule providing the highest confidence is selected. Rana et al. [42] propose a supervised model based on sequential pattern mining for opinion target extraction. The extraction is carried out in three stages. First, the opinion targets and opinion words in the review are labeled with the “aspect” and “opinion” labels. Then, sequential patterns are generated using the PrefixSpan algorithm. Opinion target rules expressing the relationship between aspect and opinion words are defined manually by analyzing sequential patterns in the second stage. Finally, explicit aspects are extracted using the opinion target rules. Samha et al. [43] presents an approach to extract frequent sets, which consisted of frequent tags that define the product aspects. Some studies [25–28] benefits from manual patterns to extract product features and opinion words.
Recently, supervised deep learning (DL) models have been successfully implemented for opinion target extraction as well [44,45]. For a system to be successful in opinion target extraction, it usually needs manually labeled data and language-specific resources for training on a particular domain and language, particularly for the DL models. The computational resources and processing time are other issues in DL when compared to traditional machine learning algorithms [46].
In recent years, the number of studies has increased on the domain adaptation problem to reduce the need for labeled data for opinion target extraction. Most of the cross-domain transfer learning studies use labeled data about the source domains and unlabeled data about the target domain [20,47–49]. In some studies [8], no data from the target domain is used. Cross-domain transfer learning refers to the transfer of labeled data for supervised approaches [50]. Marcacini et al. [8] present a heterogeneous network-based model, where labeled aspects of the source domain, linguistic features, and unlabeled aspects of the target domain are all mapped as nodes in a heterogeneous network. The opinion target extraction was performed for the target domain using other source domains when the target domain is unknown. In another approach [51], a linear-chain CRF with hand-engineered features (e.g., POS tags and dependencies) is applied for opinion target extraction in cross-domain settings. In another study [52], a cross-domain recurrent neural network model is proposed. The model integrates auxiliary tasks that are composed from manually defined rules. Wang et al. [47] propose a dependency-tree-based RNN for domain adaptation with GRU which incorporates an auto-encoder in the auxiliary task to reduce label noise. Wang et al. [48] extend previous work [47] and integrate a conditional domain adversarial network that takes both word features syntactic head relations as input. In another study [53], a model is proposed for incorporating external linguistic information into a self-attention mechanism coupled with the BERT model. Another domain adaptation approach is lifelong learning that aims to benefits from the knowledge or information learned in the past to help future learning [21,54]. While cross-domain approaches transfer only labeled data to the target domain, lifelong learning approaches can use unlabeled data in source domains [55–57].
In study of Dragoni et al. [58], the structure of the grammar dependencies is analyzed for extracting the connections between aspects and opinions. A set of rules are applied for aspect extraction. Luo et al. [59] define a new problem of extracting prominent aspects from customer review corpora. They also create a new evaluation dataset for prominent aspects extraction. Al-Smadi et al. [60] presents a research for aspect-based sentiment analysis of hotels’ reviews in Arabic. Supervised machine learning approaches of a set of classifiers are employed for opinion target extraction.
An opinion is expressed directly about an entity itself or its aspect. In the review “the hotel was amazing”, “hotel” is the entity and the opinion is about the entity itself. In the review “the food of the hotel was delicious”, “food” is the aspect and the opinion is about the aspect of the entity. In aspect extraction studies, an entity is generally not considered. The term “aspect” includes both the entity and the aspect [6].
In the aspect extraction problem, the aspect to be extracted is expressed as an explicit aspect if it is present in the review. Otherwise, it is expressed as an implicit aspect. While the “food” is an explicit aspect in the review “The food of the hotel was very delicious”, the “price” is an implicit aspect in the review “The hotel was very expensive”. The explicit aspects usually consist of nouns or noun phrases [4]. A review can contain one or more noun or noun phrases, however, some of them are aspects. The opinion may be expressed about one or more of the aspects, but opinion may not be expressed about all the aspects. If an opinion is expressed about an aspect, this aspect is called the “opinion target”. Sample reviews labeled with the opinion targets are given in Tab. 1. In review 1, “price” and “service” are both aspects and also opinion targets. “Zoom” and “optical zoom” are the aspects in review 2, but “optical zoom” is specified as an opinion target. In review 3, the words “lens”, “viewfinder”, “angle” and “wide-angle” are seen as nouns and noun phrases. While “lens” and “viewfinder” are aspects in these nouns and noun phrases, “viewfinder”, about which opinion is expressed, is the opinion target. While review 4 has “phone”, “photo” and “photo quality” as the aspects, there is no opinion target because no opinion is expressed in the review. As a result, the aspect set is a subset of the noun and noun phrases set, and the opinion target set is a subset of the aspect set in the review.

The problem of opinion target extraction is handled in two stages, namely aspect extraction, and opinion target extraction. In the aspect extraction stage, it is aimed to extract the aspects in a given review in the target domain using sequential pattern-based aspect extraction rules. The aspects of the source domains are also transferred to the target domain. In the opinion target extraction stage, the opinion targets are determined among the aspects extracted in the first stage by using sequential pattern-based opinion target extraction rules. The aspect extraction and opinion target extraction rules are automatically generated using source domains and selected based on their support and confidence values. This model is semi-supervised since it does not use labeled data and only uses an opinion lexicon. A general scheme of the proposed model is shown in Fig. 1. The aspect extraction, the opinion target extraction, and the rule generation for aspect and opinion target extraction are described in detail in the following subsections.

Figure 1: A general scheme of the proposed model
In this stage, the review is first tagged by a Part-Of-Speech (POS) tagger. Then, some preprocessing steps are carried out and opinion words are labeled using opinion word lexicon [61]. The candidate aspects are determined using the tag patterns and the aspect scores are computed using the sequential pattern-based aspect extraction rules. Finally, the candidate aspects with the highest scores are extracted as aspects. If candidate aspects are included in the aspects transferred from the source domains, they are directly considered as aspects.
The POS tagger analyzes text and assigns a tag to each word. Thus, the word space consisting of thousands of words is represented by a limited number of tags. This process makes it easy to extract relationships of words by grouping them. However, the process may cause undesired information loss in some cases as well. For example, prepositions and subordinating conjunctions are represented by the same “IN” tag although these words have different roles in the review. To prevent loss of information, the tagging was not applied for “IN”, “DT” tags. A sample review and its tagged version are given in Tab. 2a.

The words are handled sequentially and consecutively to extract the relationships between them. Some preprocessing steps are taken to extract the relationships more effectively. The preprocessing steps for sample review are presented in Tabs. 2b–2e.
Handling Parenthesis: Parentheses between two consecutive words make it difficult to extract the relationships. Therefore, parentheses are removed and the expressions in parentheses are added to the end of the review.
Removing Negation: Since negative expressions do not affect aspect extraction, they are removed from the review. The following transformations are first carried out. Then, the remaining “not” and “n't” statements are removed.
{wo, MD} {n't, RB}→{will, MD} {does, VBZ} {not/n't, RB} {operate, VB}→{operate, VBZ}
{ca, MD} {n't, RB}→{can, MD} {does, VBZ} {not/n't, RB} {have, VB}→{has, VBP}
{do, VB} {not/n't, RB}→{} {did, VBD} {not/n't, RB} {work, VB}→{work, VBD}
Handling Phrasal Verbs:Phrasal verbs composed of more than one word are converted into a single word.
Handling Phrases:Phrases are converted into a single word using a manually created phrase list. “in fact”, “a few days ago”, “i have to say” are a few examples of those phrases.
The opinion words are labeled with the OP label using the opinion word list generated from an opinion lexicon [61]. The tag information of the opinion word is also added to the label since the opinion words with different tags have different roles in a review. For example, the word “good” is converted to “good/JJ” in tagging, then “good/JJ/OP-JJ” in labeling as shown in Tab. 2f.
4.1.4 Extracting Tag Patterns and Candidate Aspects
The aspects/opinion targets can be represented by several tags in a review. These tags are called “tag patterns”. The opinion targets and corresponding tag patterns for sample reviews are given in Tab. 3. For example, the tag pattern of “viewfinder” is “NN” in review 1 and it is “VB” for “use” in review 2. The opinion targets can be also found in the form of phrases. “NN NN”, “JJ NN”, “NN NN NN” are tag patterns for phrases in reviews 5–7 respectively. If a tag pattern is common to all source domains, it is selected as a general tag pattern. The general tag patterns are also divided into tag groups manually based on their roles in the review. The general tag patterns with the tag groups used in this study are listed in Tab. 4. The words and phrases corresponding to the general tag patterns are extracted as the candidate aspects in the tagged and labeled review (Tab. 2) as follows:


NN: memory, card, phone, gb, today; NN NN: memory card; JJ NN:new phone; VBZ:is; JJ:new;
The candidate aspects are extracted from certain tag patterns, but some of those candidates may be redundant or incorrect. Aspect pruning aims to remove these types of candidate aspects [62]. For example, “today”, “new phone”, “new”, “is” are examples of redundant or incorrect aspects for the sample review in Tab. 2. The pruning word list is obtained for each target domain using the tagged and labeled (aspect and opinion word) data and aspects in source domains. First of all, candidate aspects are extracted for each source domain. If a candidate aspect is common in most of the source domains and this candidate aspect is also not an aspect in any of the source domains, it is added to the pruning word list. If the extracted candidate aspect or its subset is in the pruning word list, this candidate aspect is pruned from the candidate aspects.
For the abovementioned example, since the words “today”, “new”, “is” and the subset of the word “new phone” are in the pruning word list, these words are removed. Sample words from the pruning word list common to all source domains are listed in Tab. 5.

A review may contain many candidate aspects; however, one or more of them can be aspects. The aspect score is calculated for each candidate aspect using particular rules and the candidate aspects with the highest scores are then selected as the actual aspects. The sequential pattern-based rule generation for aspect extraction is explained in Section 4.3.1. The test rules are extracted for each candidate aspect to compute its aspect score. First, the tagged and labeled review is converted into word sequences at the word and tag level. The candidate aspect whose score is to be computed is labeled with the label “A-CAND”. As an example, let's compute the aspect score of the candidate aspect “memory card”. “memory card” is labeled with A-CAND. Then, the word level and tag level sequences are generated as shown in Tab. 6. For the specified n, the subsequences of length n containing the A-CAND label are the test rules for the candidate aspect. The general model for applying the test rules is presented. According to this model, the word level rules take precedence over tag level rules and the rules with longer rule lengths take precedence over the rules with a shorter length. Considering these priorities, the rule sets are constituted and the order of applying those rule sets is determined. The model for applying rule sets for n = 4 (with sample test rules) and the corresponding rules for aspect extraction for the candidate aspect “memory card” are illustrated in Fig. 2.

Figure 2: The model for rule sets for n = 4 with sample test rules and the corresponding rules for aspect extraction for a candidate word

The calculation of the aspect score for the candidate aspect is carried out as follows: The rules corresponding to the test rules are matched with the generated rules for aspect extraction. The matching process starts from Rule Set 1 and continues until Rule Set 4. If any rule in Rule Set 1 does not match the generated rules, then the processing continues from Rule Set 2, and so on. The maximum of the confidence values of the rules in the matching rule set is defined as the aspect score for the candidate aspect. If there is no match for any rules in the rule sets, the aspect score of the candidate aspect is assumed to be 0.
The aspect score is computed for each candidate aspect. The minimum aspect score for aspect extraction is obtained by multiplying the maximum of the aspect scores by a certain tolerance rate. Assuming that the scores calculated for the candidate aspects in the sample review are: {memory card: 0.90, memory: 0.85, phone: 0.75, card: 0.70}, if the tolerance rate is selected as 0.90, the minimum aspect score is then calculated as 0.90 × 0.90 = 0.81. The candidate aspects with a score higher than the minimum aspect score are selected as aspects. In the sample review, “memory card” and “memory” are selected as aspects. Besides, the aspects of the source domains are transferred to the target domain. Although the aspect score of the candidate aspect “phone” is not higher than the minimum aspect score, “phone” is selected as an aspect because it is transferred from the source domains. As a result, “memory card”, “memory” and “phone” are extracted as the aspects in the aspect extraction stage for the sample review.
As mentioned earlier, some of the candidate aspects in a given review are extracted as the aspects in the aspect extraction stage. Hence, it is assumed that there is at least one opinion target in that review. Therefore, if only one aspect is extracted, that aspect is considered an opinion target. If the review has more than one aspect, the opinion target/targets are selected among the aspects in the opinion target extraction stage. Not every aspect has to be an opinion target because an opinion may not be expressed in each aspect. The tagging and preprocessing steps are the same as the aspect extraction step. The extracted aspects in the previous step are labeled with the “ASPECT” label and their tag group in the aspect labeling process. However, a conflict may occur if an aspect is a subset of another aspect. For example, the aspect “memory” is a subset of the aspect “memory card”. Therefore, it is not possible to label both aspects at the same time. As a solution to this problem, “memory card”, which is the superset aspect, is selected for labeling. The labeling of opinion words is carried out in the same way as the aspect extraction step. As an example, let's compute the opinion target score of the candidate opinion target “memory card”. A sequence of words for the word and tag level is generated and the candidate opinion target “memory card” is labeled with OT-CAND label. The other aspects are labeled with the ASPECT label. The generated sequences for the test review are presented in Tab. 7. The subsequences are obtained similar to the aspect extraction stage and these subsequences are used as the test rules based on the model shown in Fig. 2. The candidate opinion target scores are calculated using the sequential pattern-based opinion target rules for each opinion target. The opinion target is often located close to the opinion word in a review. Based on this assumption, the opinion target score value is also increased by a certain amount (e.g., 0.10) according to the proximity of the candidate opinion target to the opinion words. Consequently, the candidate opinion targets with the highest score are selected as the actual opinion targets.

The sequential pattern-based rules for aspect extraction and opinion target extraction are automatically generated and selected based on certain criteria. First, a rule must appear in at least two source domains to be selected to constitute a domain-independent model. The support and confidence values are then calculated for each rule. While selecting the rules, minimum confidence and minimum support values are determined empirically.
4.3.1 Automatic Rule Generation for Aspect Extraction
The tagged and aspect-labeled reviews of source domains are required to obtain the sequential pattern-based aspect extraction rules. After the preprocessing and tagging steps, the aspects are labeled with the “ASPECT” label with a tag group of aspects. Then, the opinion words in the reviews are labeled. The aspects for the source domain are obtained by bringing the opinion target of each review together. Finally, the tagged and labeled reviews are converted into the sequences at the word and tag level. The N-gram subsequences containing the label “ASPECT” and the n-gram subsequences containing the tag patterns are extracted from the sequences for the word-level and tag level. The number of occurrences of each n-gram subsequence in all reviews of the source domain is calculated. Each n-gram subsequence containing the label “ASPECT” is a candidate rule for the aspect extraction. The support and confidence values are calculated to generate a rule for the aspect extraction for the target domain TD as in the formulations given below:
Let
Let
Let RA be the rule for aspect extraction for TD. Then, the support and confidence values for the rule RA are calculated as in Eqs. (1) and (2):
As a numerical example, the frequencies of the sequences for some sample rules in the source domains D1-D3 are given in Tab. 8, where the target domain is D4. The number of sentences in the source domains are assumed to be 100, 200, 500. Then, the support and confidence values of a generated rule for the aspect extraction can be calculated as shown in Tab. 9.


4.3.2 Automatic Rule Generation for Opinion Target Extraction
The sequential pattern-based opinion target rules are automatically generated using the tagged and opinion target-labeled data of the source domains. The opinion targets are set manually for each review in the labeled data. After the preprocessing, tagging, and labeling opinion words are completed, the opinion targets in the review are labeled with the “OP.TARGET” label with the tag group. The aspects are also labeled with the “ASPECT” label in the review in the same way as the rule generation for aspect extraction. After the sequences are generated and subsequences are extracted, the frequency of subsequences containing “ASPECT” or “OP.TARGET” labels in all source domains is calculated. The support and confidence values are calculated to generate a rule for the opinion target extraction for the target domain TD as in the formulations given below:
Let
Let
Let ROT be the rule for opinion target extraction for TD. Then, the support and confidence values for the rule ROT are calculated as in Eqs. (3) and (4):
As a numerical example, the frequencies of the sequences for some sample rules in the source domains D1-D3 are given in Tab. 8, where the target domain is D4. The number of sentences in the source domains are assumed to be 100, 200, 500. Then, the support and confidence values of a generated rule for the opinion target extraction can be calculated as shown in Tab. 10.

The proposed model has several contributions to the literature. First of all, the concepts of “aspect” and “opinion target”, which have been confused in many of the previous works, were clearly defined. On this baseline, the opinion target extraction problem was handled in two stages: aspect extraction and opinion target extraction. Most of the works in the literature only label opinion targets in reviews and do not consider the aspects that are not opinion targets. In our work, however, the use of aspects in reviews was provided for the rule generation and the aspects in the source domains were also transferred to the target domain in the aspect extraction stage. Unlike previous works, some tags were not included in the tagging process, and the loss of information caused by tagging was also reduced. While labeling opinion words, aspects, and opinion targets in a review, the defined tag groups were considered. Hence, the labels were customized according to the POS tag information of the word in that review. In our study, unlike the previous works obtaining the rules manually, sequential pattern-based rules were generated automatically for opinion target extraction.
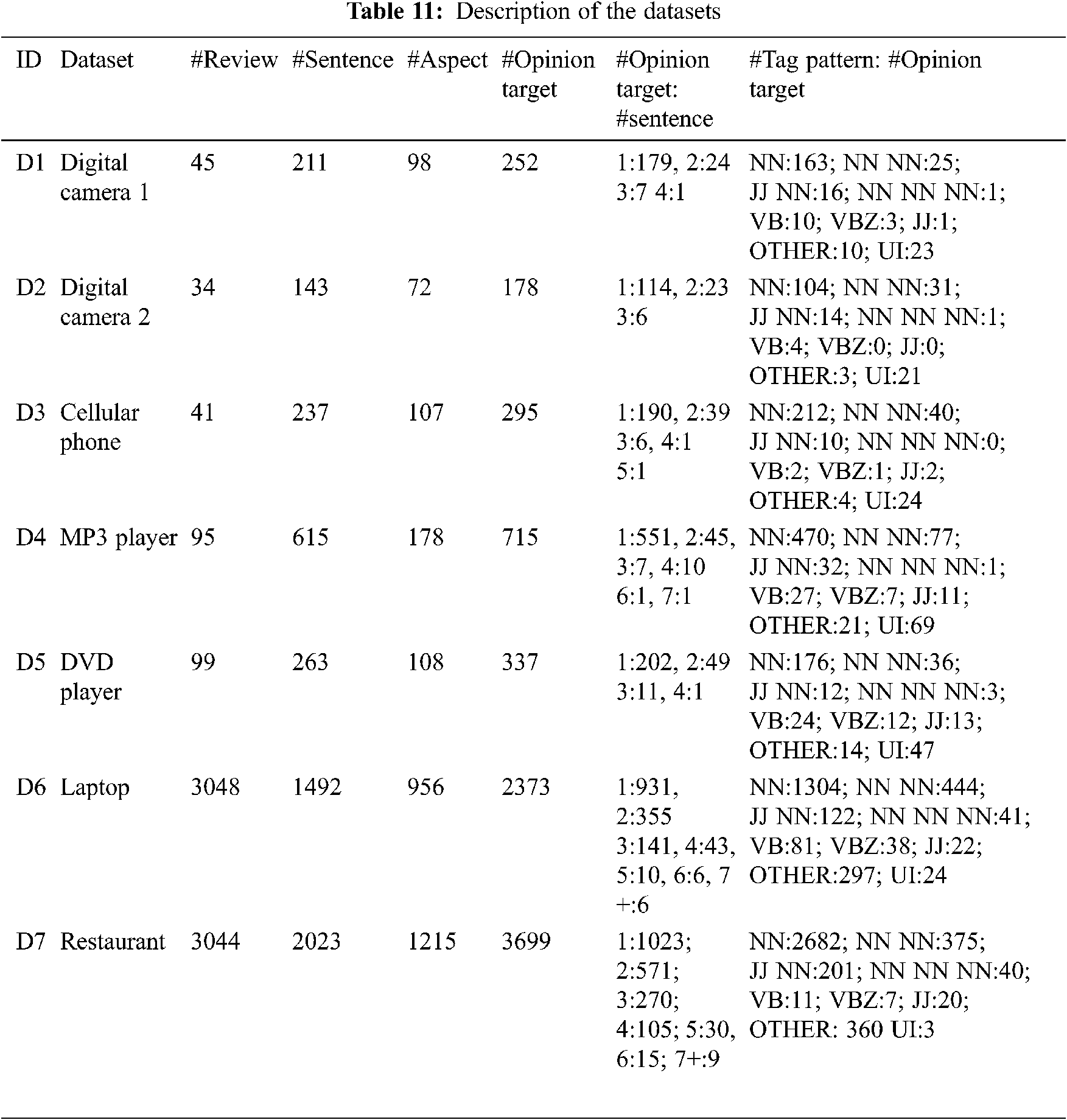
The experiments were carried out using seven well-known datasets [61,63]. The attributes of these datasets are summarized in Tab. 11. Since this study deals with explicit aspect extraction, the sentences with implicit aspects were removed from the datasets. The opinion targets, which cannot be found directly in a review, are expressed as unidentified and their tag pattern is shown with the abbreviation “UI”. Some examples of unidentified opinion targets are as follows:
• picture quality##downloading pictures is quick and a breeze, and the quality is astounding.
• picture, ease of use##it takes excellent pics and is very easy to use, if you read the manual.
• no-off button##the on-off button feels somewhat flimsy, and has an awkward …
• speakerphone##i like the speakphone function a lot.
The proposed model handles each one of those seven datasets as the target domain while the remaining six datasets are treated as the source domains. Since the number of works, which addresses the unknown target domain in cross-domain studies for opinion target extraction, is quite limited in the literature, the experimental results were compared against a recent cross-domain extraction model, namely CD-ALPHN [8] and five well-known classifiers including decision tree (DT), k-nearest neighbor (kNN), multi-layer perceptron (MLP), naïve Bayes (NB), and support vector machine (SVM). The minimum confidence and support values used in the rule selection process were determined experimentally. The experiments were carried out with the confidence values of {0.10, 0.20, …, 0.90}, and the support values in the range of {0.0001–0.02}. Another parameter is the tolerance rate that allows us to extract more than one opinion target in a given review. For the tolerance rate, the values of {0.10, 0.20, …, 0.90} were used. The opinion targets may consist of one or more words and can be expressed with different tag patterns as shown in Tab. 4. The experimental results were obtained using both the entire dataset and its subsets to be able to compare the proposed model appropriately. Specifically, three subsets of the dataset were constituted: the reviews that contain the tag patterns in only the group NN (NN, NN NN, JJ NN, NN NN NN), the reviews excluding the unidentified reviews, and the intersection of those two subsets.
Precision, recall, and F1-measure were used as the success metrics to evaluate the performance of the proposed model. During the evaluation phase, certain rules were determined while the extracted aspect was compared with the real aspect. The aspect/opinion target extraction process is considered correct if the real aspect/opinion target is the singular form of the extracted aspect/opinion target or the real aspect/opinion target is the subset of the extracted aspect/opinion target. The following reviews are given as examples of correct extraction.
• picture##the highest optical zoom pictures are perfect. Extracted: pictures
• camera##this is a great camera for you! Extracted: camera
• lcd##the moveable lcd screen is great. Extracted: lcd screen
• depth## i can live with is the extreme depth of field obtainable … Extracted: extreme depth
• customer service##… their customer service line is always busy. Extracted: customer service line
In other cases, the extracted aspects/opinion targets were considered incorrect. The following reviews are given as examples of incorrect extraction.
• four megapixel##four megapixels is great. Extracted: megapixels
• zoomed image##… the zoomed images are quite impressive. Extracted: images
• pickels and slaw##lunch came with pickels and slaw, no extra charge. Extracted: pickels, slaw
• glass of wine##… let me finish my glass of wine before offering another. Extracted: wine
• picture quality##great quality picture and features. Extracted: quality picture
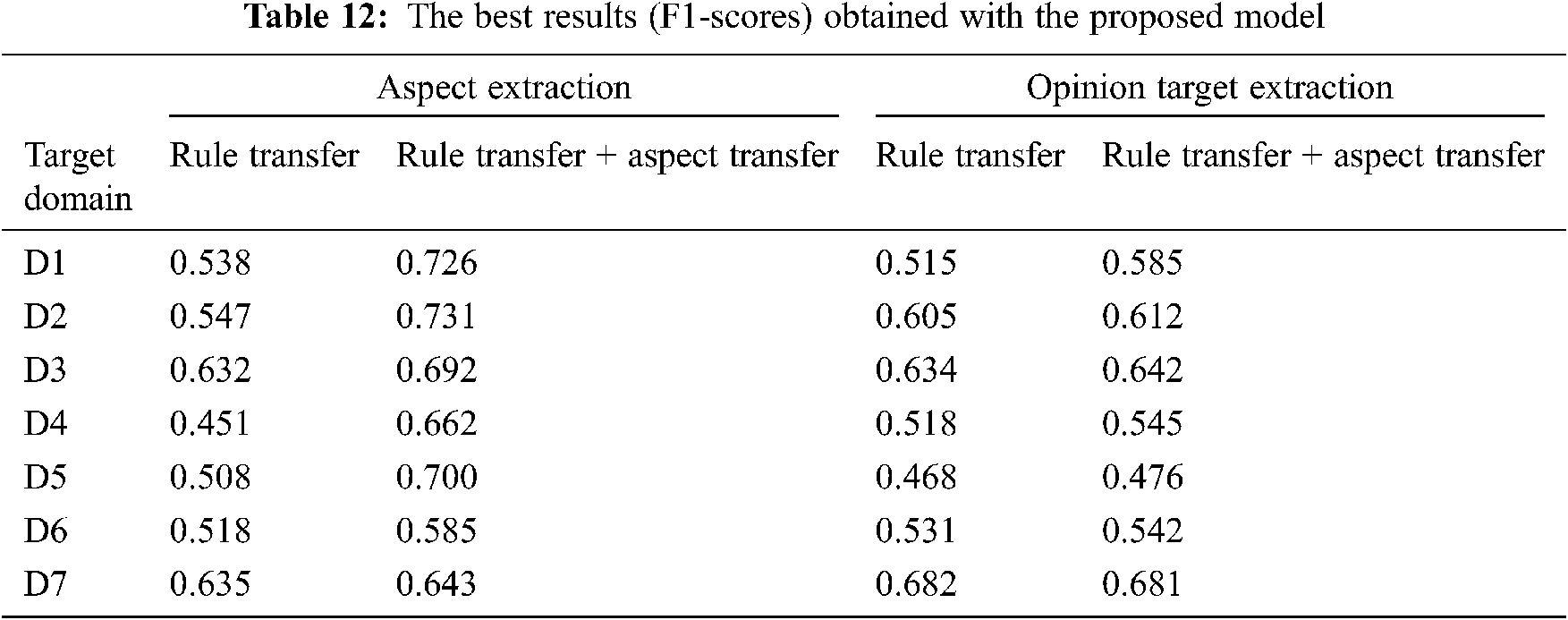
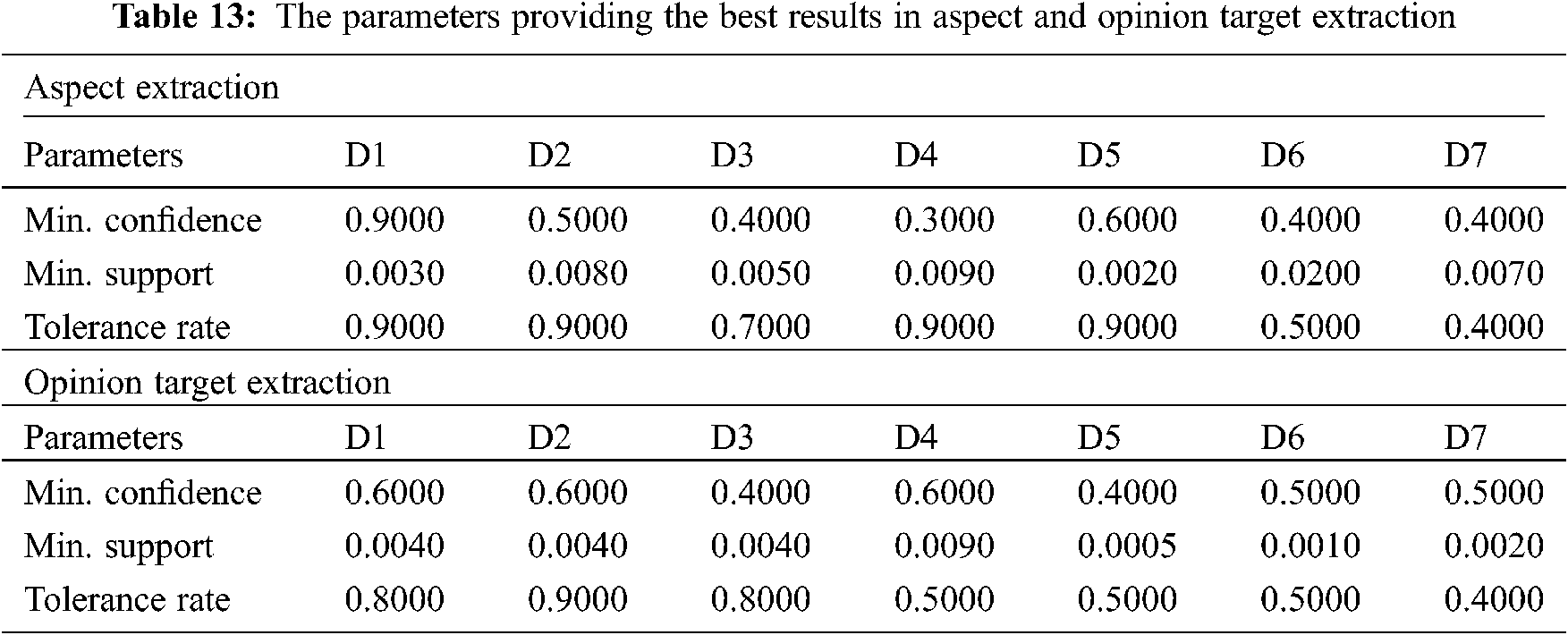
The best results for the aspect extraction and opinion target extraction are presented in Tab. 12. During the experiments, it was also aimed to see the effect of the rule transfer and aspect transfer over the results. One can note that the aspect transfer improves the success of aspect extraction as well as the success of opinion target extraction. Since the domains contain common aspects, it can be stated that the aspect transfer affects the aspect extraction stage more. However, since domain D7 has different aspects than the other domains, the success of aspect extraction depends on the rule transfer rather than the aspect transfer. While the aspect transfer significantly improves the success of opinion target extraction for the domains D1 and D4, it has less effect on the other domains. For domain D7, the rule transfer is sufficient for a successful opinion target extraction. The parameters specified in Tab. 13 are the ones providing the best results in the case of rule and aspect transfer for all tag patterns. The parameters providing the best results were found to be different for each domain. Enough rules cannot be generated when the confidence values are chosen high, so the best results are obtained for low confidence values. It was also observed that the tolerance rate gets smaller in the domains, where the number of opinion targets per sentence is rather large.
The experiments were repeated for different support values while the other parameters remain the same considering the parameters in Tab. 13. The corresponding results are presented in Fig. 3 for each domain. It was observed that the best results for each domain are clustered around different support values. For example, considering the results of domain D1, the best results were obtained when the support value for aspect extraction was 0.003 and the support value for opinion target extraction was selected in the range of {0.003–0.007}.

Figure 3: F1-scores for the minimum support values in aspect extraction (AE) and opinion target extraction (OTE) with the parameters providing the best results for each domain
The results of the opinion target extraction are comparatively summarized in Tab. 14, where the best results are indicated in bold. The proposed model is superior for the domains particularly containing common aspects when using all of the tag patterns. For example, it offers better performance for the domains D1, D2, and D3 than those of the other approaches.
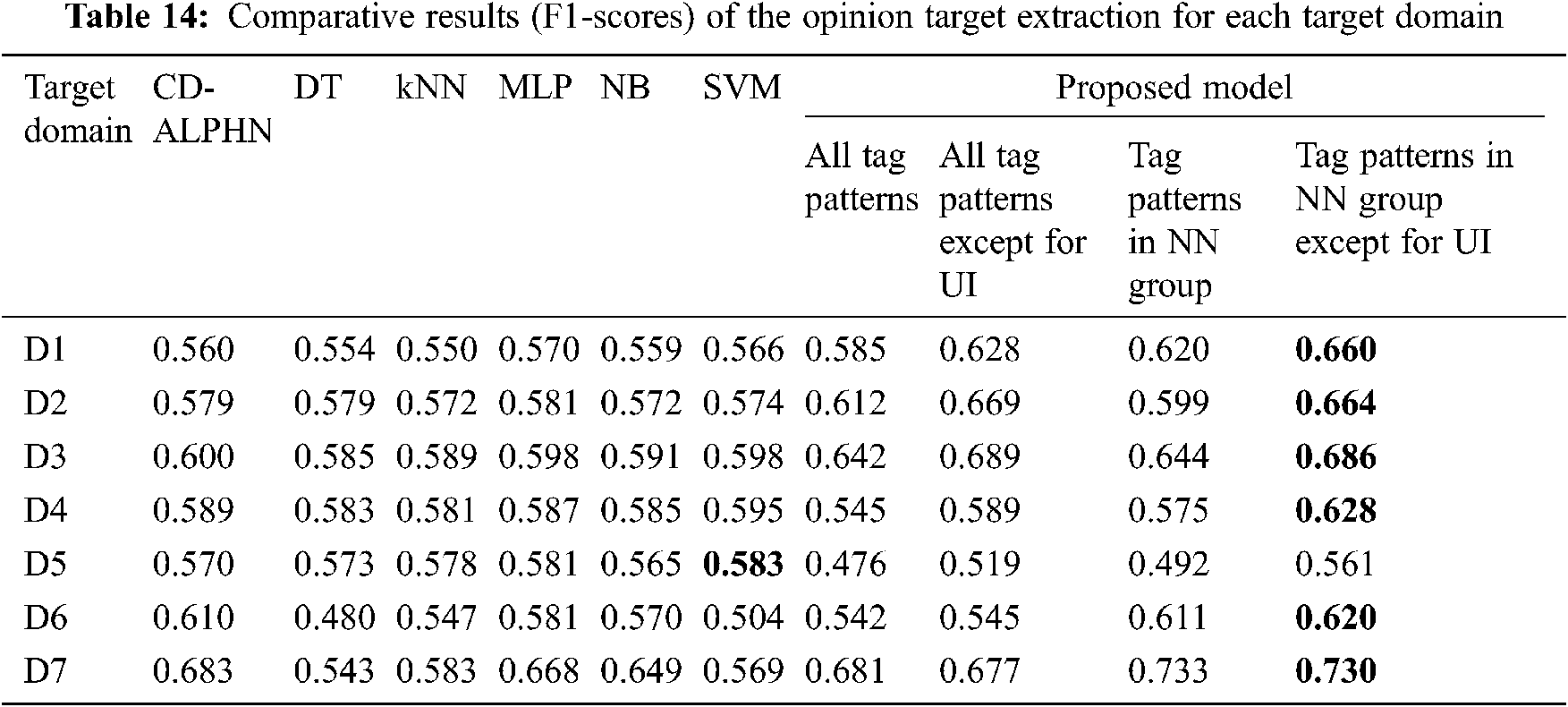
The reason for the low results for the other domains is that these domains have a higher number of sentences with the tag pattern “OTHER” and with the “VB” and “JJ” groups. Since the extraction process can be performed only for the general tag patterns in Tab. 4, the opinion targets with the tag pattern “OTHER” cannot be extracted from the review in the target domain. Also, the groups “VB” and “JJ” are observed rarely in the datasets unlike the tag patterns in the group “NN”. Therefore, if the training data from source domains is not sufficient at all, a small number of rules can be generated for these groups. These rules are not enough for successful opinion target extraction for the target domain. In addition to the results obtained using all tag patterns, the results obtained with the removal of “UI” opinion targets or only the tag patterns in the group “NN” are presented as well. The removal of unidentified opinion targets improves the success of opinion target extraction except for domain D7. This domain contains almost no “UI” opinion targets so the process of removal does not positively affect the result. Since removing “UI” opinion targets leads to a decrease in the training data from source domains, the success of opinion target extraction decreases for domain D7. The use of only the group “NN” improves the success of opinion target extraction. For example, it offers better performance for domains D6 and D7 than those of the other approaches. When using only the group “NN” after removing the “UI” opinion targets, the best results were obtained for all domains except for domain D5 when compared to the other approaches.
In Tab. 15, the proposed model is compared to the other cross-domain models in terms of extraction model, dataset attributes, and performance of opinion target extraction. Conditional random fields [51,64], heterogeneous network-based [8], recursive neural network [47–48,52,64], self-attention mechanism with the BERT model [53] were the models used in opinion target extraction whereas our study proposed a sequential rule-based model. One can observe from the same table that datasets consisting of a relatively small number of domains were used in most of the previous works. On the other hand, a total of 6406 reviews were used for 7 domains in our study. Considering that only one source domain vs. one target domain was handled in the studies [47–48,51–53,64], all combinations of one target domain vs. all the remaining source domains were tested in our study. Finally, considering the performances of previous cross-domain studies [8,47,48,51–53,64], the proposed model offered significantly high F-scores for opinion target extraction.

In this work, a sequential pattern-based rule mining model is proposed for cross-domain opinion target extraction in sentiment analysis. Unlike many previous works, the difference between the concepts of aspect and opinion target, which has been used interchangeably, was revealed. Thanks to the two-step approach, in the aspect extraction stage, not only the opinion targets but also the aspects of reviews were included. Besides, it was observed that the success of aspect extraction improves by transferring the aspects belonging to the source domains. Also, new approaches were proposed for the tagging and labeling processes as well.
Experimental results verified that the proposed model offers a promising performance for opinion target extraction regardless of the domain of reviews. It is competitive or even better than previous works and well-known classifiers. Considering all the results in different scenarios, the proposed model increases the success of opinion target extraction substantially. Furthermore, it is observed that product reviews have common patterns, even in different domains. This outcome indicates that sequential pattern-based rule mining approaches can be used for domain-independent opinion target extraction systems in decision support systems.
While the proposed model focuses particularly on opinion target extraction, a system for aspect-based opinion summarization may be established by adding the sentiment classification stage in future work. Last but not least, the proposed model can be applied to languages other than English.
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. A. Keramatfar and H. Amirkhani, “Bibliometrics of sentiment analysis literature,” Journal of Information Science, vol. 45, no. 1, pp. 3–15, 2019. [Google Scholar]
2. W. N. Chan and T. Thein, “Sentiment analysis system in big data environment,” Computer Systems Science and Engineering, vol. 33, no. 3, pp. 187–202, 2018. [Google Scholar]
3. Z. Lin, L. Wang, X. Cui and Y. Gu, “Fast sentiment analysis algorithm based on double model fusion,” Computer Systems Science and Engineering, vol. 36, no. 1, pp. 175–188, 2021. [Google Scholar]
4. B. Liu, “Sentiment analysis and opinion mining,” Synthesis Lectures on Human Language Technologies, vol. 5, no. 1, pp. 1–167, 2012. [Google Scholar]
5. B. Liu, “Many facets of sentiment analysis,” in A Practical Guide to Sentiment Analysis, Springer, Cham, pp. 11–39, 2017. [Google Scholar]
6. T. A. Rana and Y. N. Cheah, “Aspect extraction in sentiment analysis: Comparative analysis and survey,” Artificial Intelligence Review, vol. 46, no. 4, pp. 459–483, 2016. [Google Scholar]
7. M. Tubishat, N. Idris and M. A. Abushariah, “Implicit aspect extraction in sentiment analysis: Review, taxonomy, opportunities, and open challenges,” Information Processing & Management, vol. 54, no. 4, pp. 545–563, 2018. [Google Scholar]
8. R. M. Marcacini, R. G. Rossi, I. P. Matsuno and S. O. Rezende, “Cross-domain aspect extraction for sentiment analysis: A transductive learning approach,” Decision Support Systems, vol. 114, pp. 70–80, 2018. [Google Scholar]
9. P. Ray and A. Chakrabarti, “A mixed approach of deep learning method and rule-based method to improve aspect level sentiment analysis,” Applied Computing and Informatics, 2020 (in-press). [Google Scholar]
10. W. Jin, H. H. Ho and R. K. Srihari, “A novel lexicalized HMM-based learning framework for web opinion mining,” in Proc. of the 26th Annual Int. Conf. on Machine Learning, Montreal, Canada, pp. 465–472, 2009. [Google Scholar]
11. L. Zhang, B. Liu, S. H. Lim and E. O'Brien-Strain, “Extracting and ranking product features in opinion documents,” in Proc. of the Coling 2010: Posters, Beijing, China, pp. 1462–1470, 2010. [Google Scholar]
12. F. Li, C. Han, M. Huang, X. Zhu, Y. Xia et al., “Structure-aware review mining and summarization,” in Proc. of the 23rd Int. Conf. on Computational Linguistics (Coling 2010Beijing, China, pp. 653–661, 2010. [Google Scholar]
13. G. Qiu, B. Liu, J. Bu and C. Chen, “Opinion word expansion and target extraction through double propagation,” Computational Linguistics, vol. 37, no. 1, pp. 9–27, 2011. [Google Scholar]
14. H. Yang, B. Zeng, J. Yang, Y. Song and R. Xu, “A multi-task learning model for Chinese-oriented aspect polarity classification and aspect term extraction,” Neurocomputing, vol. 419, pp. 344–356, 2021. [Google Scholar]
15. G. S. Chauhan, Y. K. Meena, D. Gopalani and R. Nahta, “A two-step hybrid unsupervised model with attention mechanism for aspect extraction,” Expert Systems with Applications, vol. 161, pp. 113673, 2020. [Google Scholar]
16. L. Augustyniak, T. Kajdanowicz and P. Kazienko, “Comprehensive analysis of aspect term extraction methods using various text embeddings,” Computer Speech & Language, vol. 69, pp. 101217, 2021. [Google Scholar]
17. Y. Wang, W. He, M. Jiang, Y. Huang and P. Qiu, “CHOpinionminer: An unsupervised system for Chinese opinion target extraction,” Concurrency and Computation: Practice and Experience, vol. 32, no. 7, pp. e5582, 2020. [Google Scholar]
18. V. Ganganwar and R. Rajalakshmi, “Implicit aspect extraction for sentiment analysis: A survey of recent approaches,” Procedia Computer Science, vol. 165, pp. 485–491, 2019. [Google Scholar]
19. S. Brody and N. Elhadad, “An unsupervised aspect-sentiment model for online reviews,” in Proc. of the Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics, pp. 804–812, 2010. [Google Scholar]
20. W. Wang and S. J. Pan, “Transferable interactive memory network for domain adaptation in fine-grained opinion extraction,” in Proc. of the AAAI Conf. on Artificial Intelligence, Hawaii, USA, pp. 7192–7199, 2019. [Google Scholar]
21. L. Shu, B. Liu, H. Xu and A. Kim, “Supervised opinion aspect extraction by exploiting past extraction results,” arXiv Prepr. arXiv 1612.07940, 2016. [Google Scholar]
22. D. Anand and B. S. Mampilli, “A novel evolutionary approach for learning syntactic features for cross domain opinion target extraction,” Applied Soft Computing, vol. 102, pp. 107086, 2021. [Google Scholar]
23. M. Venugopalan and D. Gupta, “An unsupervised hierarchical rule based model for aspect term extraction augmented with pruning strategies,” Procedia Computer Science, vol. 171, pp. 22–31, 2020. [Google Scholar]
24. M. Tubishat, N. Idris and M. Abushariah, “Explicit aspects extraction in sentiment analysis using optimal rules combination,” Future Generation Computer Systems, vol. 114, pp. 448–480, 2021. [Google Scholar]
25. S. S. Htay and K. T. Lynn, “Extracting product features and opinion words using pattern knowledge in customer reviews,” The Scientific World Journal, vol. 2013, pp. 1–5, 2013. [Google Scholar]
26. W. Maharani, D. H. Widyantoro and M. L. Khodra, “Aspect extraction in customer reviews using syntactic pattern,” Procedia Computer Science, vol. 59, pp. 244–253, 2015. [Google Scholar]
27. M. Z. Asghar, A. Khan, S. R. Zahra, S. Ahmad and F. M. Kundi, “Aspect-based opinion mining framework using heuristic patterns,” Cluster Computing, vol. 22, no. 3, pp. 7181–7199, 2019. [Google Scholar]
28. T. A. Rana and Y. N. Cheah, “Sequential patterns-based rules for aspect-based sentiment analysis,” Advanced Science Letters, vol. 24, no. 2, pp. 1370–1374, 2018. [Google Scholar]
29. X. Li and L. Lei, “A bibliometric analysis of topic modelling studies (2000–2017),” Journal of Information Science, vol. 47, no. 2, pp. 161–175, 2021. [Google Scholar]
30. A. García-Pablos, M. Cuadros and G. Rigau, “W2VLDA: Almost unsupervised system for aspect based sentiment analysis,” Expert Systems with Applications, vol. 91, pp. 127–137, 2018. [Google Scholar]
31. E. Ekinci and S. Ilhan Omurca, “Concept-lDA: Incorporating babelfy into LDA for aspect extraction,” Journal of Information Science, vol. 46, no. 3, pp. 406–418, 2020. [Google Scholar]
32. M. Hu and B. Liu, “Mining opinion features in customer reviews,” in Proc. of the AAAI, San Jose, California, pp. 755–760, 2004. [Google Scholar]
33. A. M. Popescu and O. Etzioni, “Extracting product features and opinions from reviews,” in Natural Language Processing and Text Mining, Springer, London, pp. 9–28, 2007. [Google Scholar]
34. S. Li, L. Zhou and Y. Li, “Improving aspect extraction by augmenting a frequency-based method with web-based similarity measures,” Information Processing & Management, vol. 51, no. 1, pp. 58–67, 2015. [Google Scholar]
35. K. Liu, L. Xu and J. Zhao, “Opinion target extraction using word-based translation model,” in Proc. of the 2012 Joint Conf. on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Jeju Island, Korea, pp. 1346–1356, 2012. [Google Scholar]
36. S. Poria, E. Cambria, L. W. Ku, C. Gui and A. Gelbukh, “A rule-based approach to aspect extraction from product reviews,” in Proc. of the Second Workshop on Natural Language Processing for Social Media (SocialNLPDublin, Ireland, pp. 28–37, 2014. [Google Scholar]
37. Y. Kang and L. Zhou, “Rube: Rule-based methods for extracting product features from online consumer reviews,” Information & Management, vol. 54, no. 2, pp. 166–176, 2017. [Google Scholar]
38. Z. Hai, K. Chang and J. J. Kim, “Implicit feature identification via co-occurrence association rule mining,” in Proc. of the Int. Conf. on Intelligent Text Processing and Computational Linguistics, Tokyo, Japan, pp. 393–404, 2011. [Google Scholar]
39. L. Zhang and B. Liu, “Aspect and entity extraction for opinion mining,” in Data Mining and Knowledge Discovery for Big Data, Springer, Berlin, Heidelberg, pp. 1–40, 2014. [Google Scholar]
40. M. Hu and B. Liu, “Opinion feature extraction using class sequential rules,” in AAAI Spring Symposium: Computational Approaches to Analyzing Weblogs, Stanford, USA, pp. 61–66, 2006. [Google Scholar]
41. B. Liu, “Web data mining: Exploring hyperlinks, contents, and usage data,” in Science & Business Media, Springer, Berlin, Heidelberg, 2007. [Google Scholar]
42. T. A. Rana and Y. N. Cheah, “Sequential patterns rule-based approach for opinion target extraction from customer reviews,” Journal of Information Science, vol. 45, no. 5, pp. 643–655, 2019. [Google Scholar]
43. A. K. Samha, Y. Li and J. Zhang, “Aspect-based opinion extraction from customer reviews,” arXiv Prepr. arXiv 14041982, 2014. [Google Scholar]
44. H. H. Do, P. Prasad, A. Maag and A. Alsadoon, “Deep learning for aspect-based sentiment analysis: A comparative review,” Expert Systems with Applications, vol. 118, pp. 272–299, 2019. [Google Scholar]
45. A. Alharbi, M. Taileb and M. Kalkatawi, “Deep learning in arabic sentiment analysis: An overview,” Journal of Information Science, vol. 47, no. 1, pp. 129–140, 2021. [Google Scholar]
46. M. Al-Smadi, O. Qawasmeh, M. Al-Ayyoub, Y. Jararweh and B. Gupta, “Deep recurrent neural network vs. support vector machine for aspect-based sentiment analysis of arabic hotels’ reviews,” Journal of Computational Science, vol. 27, pp. 386–393, 2018. [Google Scholar]
47. W. Wang and S. J. Pan, “Recursive neural structural correspondence network for cross-domain aspect and opinion co-extraction,” in Proc. of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long PapersMelbourne, Australia, pp. 2171–2181, 2018. [Google Scholar]
48. W. Wang and S. J. Pan, “Syntactically meaningful and transferable recursive neural networks for aspect and opinion extraction,” Computational Linguistics, vol. 45, no. 4, pp. 705–736, 2020. [Google Scholar]
49. Z. Li, X. Li, Y. Wei, L. Bing, Y. Zhang et al., “Transferable end-to-end aspect-based sentiment analysis with selective adversarial learning,” arXiv Prepr. arXiv 1910.14192, 2019. [Google Scholar]
50. R. Liu, Y. Shi, C. Ji and M. Jia, “A survey of sentiment analysis based on transfer learning,” IEEE Access, vol. 7, pp. 85401–85412, 2019. [Google Scholar]
51. N. Jakob and I. Gurevych, “Extracting opinion targets in a single and cross-domain setting with conditional random fields,” in Proc. of the 2010 Conf. on Empirical Methods in Natural Language Processing, pp. 1035–1045, 2010. [Google Scholar]
52. Y. Ding, J. Yu and J. Jiang, “Recurrent neural networks with auxiliary labels for cross-domain opinion target extraction,” in Proc. of the AAAI Conf. on Artificial Intelligence, San Francisco, California, USA, pp. 3436–3442, 2017. [Google Scholar]
53. O. Pereg, D. Korat and M. Wasserblat, “Syntactically aware cross-domain aspect and opinion terms extraction,” in Proc. of the 28th Int. Conf. on Computational Linguistics, Barcelona, Spain, pp. 1772–1777, 2020. [Google Scholar]
54. L. Shu, H. Xu and B. Liu, “Lifelong learning crf for supervised aspect extraction,” arXiv Prepr. arXiv 170500251, 2017. [Google Scholar]
55. Z. Hai, K. Chang, J. J. Kim and C. C. Yang, “Identifying features in opinion mining via intrinsic and extrinsic domain relevance,” IEEE Transactions on Knowledge and Data Engineering, vol. 26, no. 3, pp. 623–634, 2013. [Google Scholar]
56. C. Quan and F. Ren, “Unsupervised product feature extraction for feature-oriented opinion determination,” Information Sciences, vol. 272, pp. 16–28, 2014. [Google Scholar]
57. Z. Chen, A. Mukherjee and B. Liu, “Aspect extraction with automated prior knowledge learning,” in Proc. of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long PapersBaltimore, Maryland, USA, pp. 347–358, 2014. [Google Scholar]
58. M. Dragoni, M. Federici and A. Rexha, “An unsupervised aspect extraction strategy for monitoring real-time reviews stream,” Information Processing & Management, vol. 56, no. 3, pp. 1103–1118, 2019. [Google Scholar]
59. Z. Luo, S. Huang and K. Q. Zhu, “Knowledge empowered prominent aspect extraction from product reviews,” Information Processing & Management, vol. 56, no. 3, pp. 408–423, 2019. [Google Scholar]
60. M. Al-Smadi, M. Al-Ayyoub, Y. Jararweh and O. Qawasmeh, “Enhancing aspect-based sentiment analysis of arabic hotels’ reviews using morphological, syntactic and semantic features,” Information Processing & Management, vol. 56, no. 2, pp. 308–319, 2019. [Google Scholar]
61. M. Hu and B. Liu, “Mining and summarizing customer reviews,” in Proc. of the Tenth ACM SIGKDD Int. Conf. on Knowledge Discovery and Data Mining, Seattle, Washington, USA, pp. 168–177, 2004. [Google Scholar]
62. A. Bagheri, M. Saraee and F. De Jong, “Care more about customers: Unsupervised domain-independent aspect detection for sentiment analysis of customer reviews,” Knowledge-Based Systems, vol. 52, pp. 201–213, 2013. [Google Scholar]
63. M. Pontiki, D. Galanis, J. Pavlopoulos, H. Papageorgiou, I. Androutsopoulos et al., “SemEval-2014 Task 4: Aspect Based Sentiment Analysis,” in Proc. of the 8th International Workshop on Semantic Evaluation (SemEval 2014), Dublin,Ireland, pp. 27–35, 2014. [Google Scholar]
64. W. Wang, S. J. Pan, D. Dahlmeier and X. Xiao, “Recursive neural conditional random fields for aspect-based sentiment analysis,” arXiv Prepr. arXiv 1603.06679, 2016. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |