DOI:10.32604/csse.2022.021635
| Computer Systems Science & Engineering DOI:10.32604/csse.2022.021635 | |
| Article |
Emotion Recognition with Capsule Neural Network
1School of Information and Communication Technology, Hanoi University of Science and Technology, Hanoi, 10000, Vietnam
2Faculty of Information Technology, University of Transport and Communications, Hanoi, 10000, Vietnam
*Corresponding Author: Quang H. Nguyen. Email: quangnh@soict.hust.edu.vn
Received: 08 July 2021; Accepted: 13 August 2021
Abstract: For human-machine communication to be as effective as human-to-human communication, research on speech emotion recognition is essential. Among the models and the classifiers used to recognize emotions, neural networks appear to be promising due to the network’s ability to learn and the diversity in configuration. Following the convolutional neural network, a capsule neural network (CapsNet) with inputs and outputs that are not scalar quantities but vectors allows the network to determine the part-whole relationships that are specific 6 for an object. This paper performs speech emotion recognition based on CapsNet. The corpora for speech emotion recognition have been augmented by adding white noise and changing voices. The feature parameters of the recognition system input are mel spectrum images along with the characteristics of the sound source, vocal tract and prosody. For the German emotional corpus EMO-DB, the average accuracy score for 4 emotions, neutral, boredom, anger and happiness, is 99.69%. For Vietnamese emotional corpus BKEmo, this score is 94.23% for 4 emotions, neutral, sadness, anger and happiness. The accuracy score is highest when combining all the above feature parameters, and this score increases significantly when combining mel spectrum images with the features directly related to the fundamental frequency.
Keywords: Emotion recognition; CapsNet; data augmentation; mel spectrum image; fundamental frequency
Today, robots are present in many places and different areas where people gather. In mass production lines, robots ensure uniformity of manufactured products. It can be said that robots think no less than humans when playing chess. However, for robots, the ability to express emotions through body language, facial expressions, and especially through voice is also limited. Emotional expression is a very subtle human behavior, but at present, robots are very inferior. To achieve the goal of human-machine interaction similar to human-human interaction, there is clearly considerable research needed. Emotional recognition of speech is a research aspect that needs to be considered to achieve that goal.
Neural networks, in addition to being designed to simulate the activity of human neurons, are even more special because of their ability to mimic human perception of the world around them. To identify objects through the visual system, people can quickly and accurately capture information through the part-whole relationship of the object. Therefore, for humans, it is not difficult to exactly identify one object in different poses. The part-whole relationship exists in different objects and is also a specific feature for those objects. The capsule neural network (CapsNet) was proposed to focus on exploiting this feature [1–3]. When explaining the capsule neural network exploiting this feature, some authors often take the example of human face descriptions. The relative position of the eyes, nose and mouth on the human face is that the eyes and nose are positioned above the mouth, and the nose and mouth are arranged on the vertical symmetrical axis of the face. This is one of the characteristics of the spatial relationships of objects to correctly identify the human face, and these relationships are equivariant. This paper is based on a capsule neural network used to identify images to perform emotion recognition of speech. The input of the recognition system is mel spectrum. A part-whole relationship to the mel spectrum of the speech signal can be taken as an example for the case of the syllable, including a fricative consonant [s] preceding a voiced sound [ε], for example. The mel spectrum of syllable [sε] is given in Fig. 1.
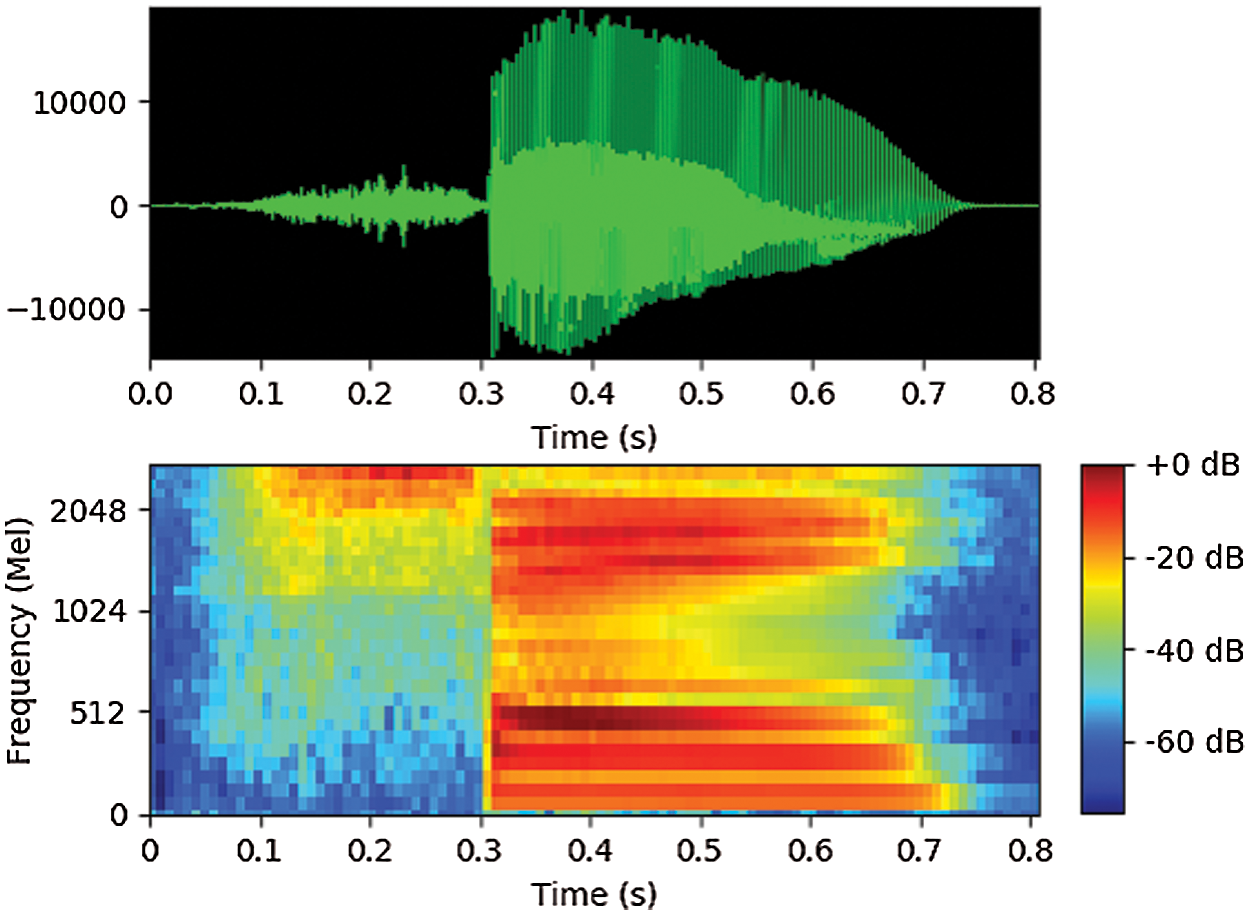
Figure 1: Mel spectrum of syllable [sε]
From Fig. 1, the characteristic of the mel spectrum for a fricative sound is that spectral energy is concentrated mainly in the high-frequency domain (the upper part of the mel spectrum), whereas for voiced sounds, the spectral energy is focused more on low-order formants (the lower part of the mel spectrum). Thus, it can be said that in the mel spectrum, the spatial relationship of the energy concentration sections between the fricative sound and the voiced sound is the upper left-the lower right. This also means that the part-whole relationship that CapsNet exploited also exists in the mel spectrum of the speech signal.
The rest of the paper is organized as follows. Section 2 describes related work. The emotional corpora used in this paper, and data augmentation are presented in Section 3. Section 4 details the configuration of the capsule neural network for emotion recognition. The experimental results are provided in Section 5. Finally, Section 6 presents the discussion and conclusion.
If only considering the field of research, such as speech processing, there have been some CapsNet-based studies. In [4], the capsule network was applied to capture the spatial relationship and pose information of speech spectrogram features in both frequency and time axes. The authors showed that the end-to-end speech recognition system with capsule networks on one-second speech commands dataset achieves better results on both clean and noise-added tests than baseline convolutional neural network models. A capsule network for low resource spoken language understanding was proposed for command-and-control applications in [5]. For small quantities of data, the proposed model is shown to significantly outperform the previous state-of-the-art model.
The literature [6–9] provided an overview of speech emotion recognition, including models, used classifiers and corpus, specific parameters and corresponding recognition accuracy. The different classifiers may be Gaussian mixture models (GMM), support vector machines (SVM), artificial neural networks (ANN), k-nearest neighbor classifier, Bayes classifier, linear discriminant analysis with Gaussian probability distribution, and hidden Markov models (HMM). The feature parameters can be classified into 3 groups. The first group includes parameters directly related to the sound source. The second group is the parameters of the vocal tract, while the third group is related to the prosody. For the sound source, the feature parameters may be LP (linear prediction) residual energy or LP residual, glottal excitation signal. The parameters of the vocal tract include MFCC (mel frequency cepstral coefficients), LPCC (linear predictive cepstral coefficients), and RASTA (Relative Spectra) PLP (perceptual linear predictive) coefficients, formants and their bandwidth and spectral features. The prosodic parameters consist of pitch, energy, duration and voice quality features. In addition to these parameters, statistical features such as mean, StdDev, min, and max have been used. Until recently, GMM, HMM, and SVM were still used to recognize emotional speech [10–17] or GMM and DNN, and GMM and SVM have been combined [18–20]. Sequential minimal optimization (SMO), J48, and random forest have been used for testing the adaptive data boosting (ADB) technique [21]. For ANN, it can be seen that the models used are ANN with 3 layers [22], DNN [23], progressive neural network [24], recurrent neural network [12,25], backpropagation neural network [26], deep convolutional recurrent network [27], coupled deep convolutional neural network (CDCNN) [28], deep belief networks (DBNs) [29], combination of SVM and belief networks [30], CNN [31], convolutional recurrent neural network (CRNN) [32], deep learning [33,34], a combination of convolutional and recurrent layers for reusing ASR (automatic speech recognition) network [35] and LSTM (long short-term memory) network [36]. A number of issues have also been raised for emotion recognition of speech, such as transfer learning [37–39], using cross-corpus [27,40], and adversarial training [41].
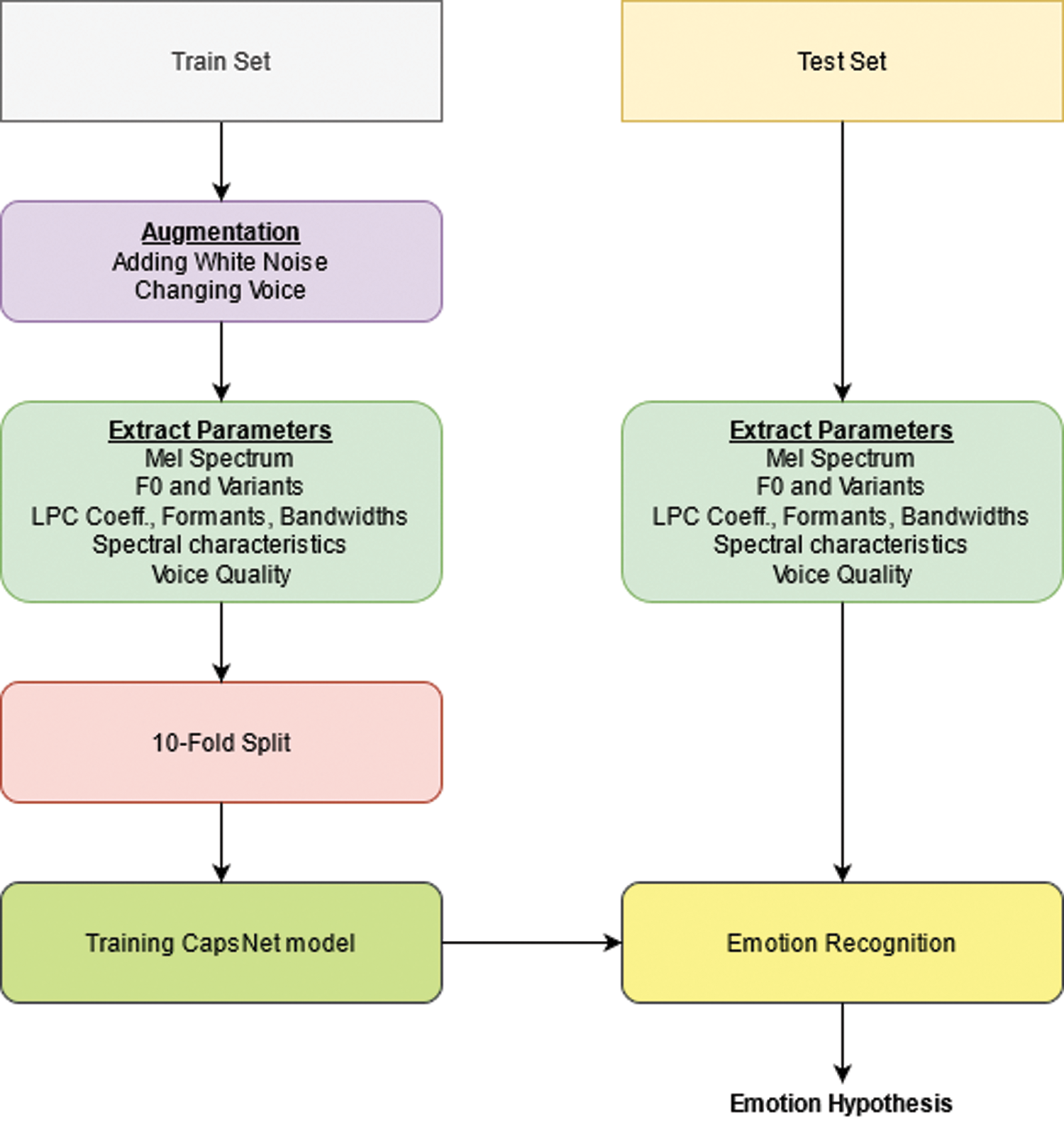
Figure 2: Overall architecture of our proposal method
For Vietnamese emotion recognition, SVM was used in [42] to classify emotions using the EEG signal. An average accuracy of 70.5% was achieved in real-time for five emotional states. Research in [43] used the GMM model to recognize 6 emotions: happiness, neutrality, sadness, surprise, anger, and fear. In this research, two male voices and two female voices expressed 6 emotions for 6 different sentences. The feature parameters were MFCC, short-term energy, pitch, and formants. The highest recognition score was 96.5% for neutral emotion, and the lowest was 76.5% for sad emotion. In [44], the corpus included 6 voices and 20 sentences and the same number of emotions as in [43]. The recognition score on the Vietnamese language was 96.5% for neutrality and dropped to 84.1% for surprise using SVM with Im-SFLA (improved shuffled frog leaping algorithm). The authors in [45,46] used GMM and CNN to recognize 4 emotions with Vietnamese emotional corpus BKEmo. Details of this study and the corpus BKEmo are briefly presented in the following sections.
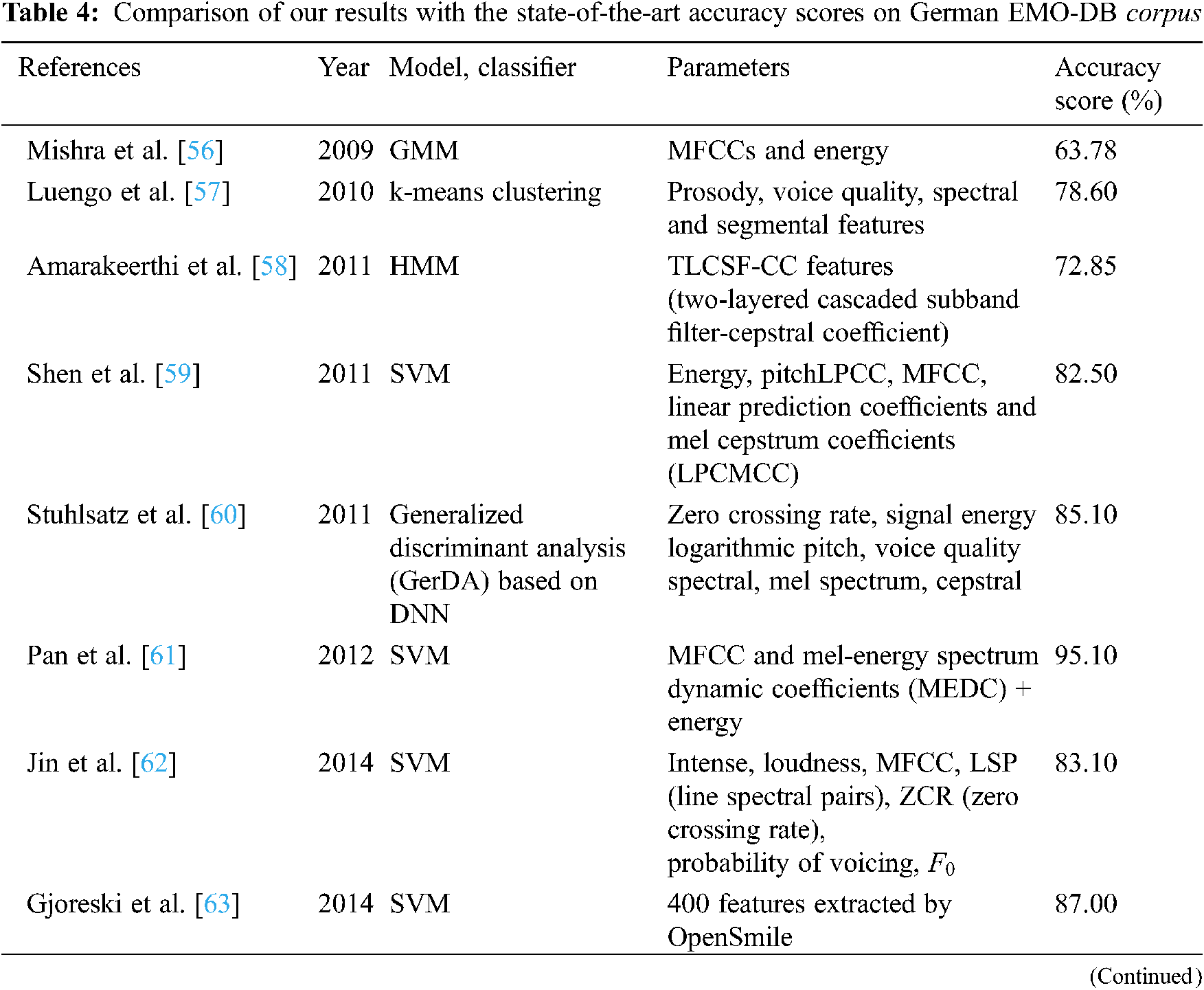
In this paper, the EMO-DB corpus was also used to perform emotion recognition using CapsNet. Since its appearance, there have been many emotional speech recognition studies using this corpus. In the context of this paper, we review most of the research conducted in the last more 10 years using EMO-DB (Tab. 4). From the review, most studies with EMO-DB also use models, classifiers and feature parameters, as mentioned above. In addition, EMO-DB is also used in cross-corpus and transfer learning studies [47].
Overall architecture of our proposal method is shown in Fig. 2 which has composed: data augmentation module, parameter extraction module, CapsNet module. These modules are presented as following.
It is well known that for the classification problem or in machine learning in general, the more available data, the better the classification performance. Therefore, if data are insufficient, data augmentation is necessary. In addition, data enhancement is one method to avoid overfitting. Ocquaye et al. [48] implemented data augmentation for EMO-DB by adding background noise as proposed in [49]. For data augmentation in our case, adding white noise and changing voices were made for BKEmo and specifically for EMO-DB because the existing EMO-DB is not a corpus of sufficiently large size.
Fig. 3 illustrates the addition of white noise to the augmented corpus and the magnified noise.
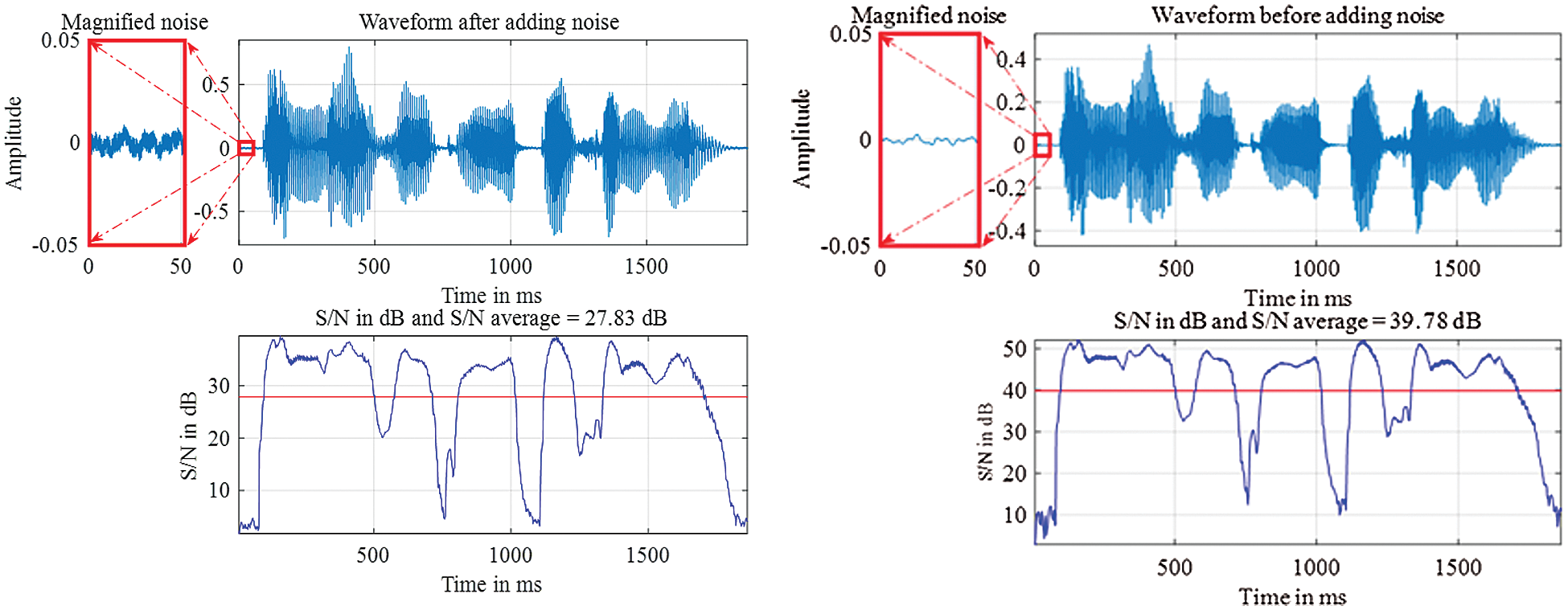
Figure 3: Example to illustrate the addition of white noise for data augmentation
The example illustrates that after adding white noise, the average signal-to-noise ratio decreases by 11.95 dB. The signal-to-noise ratio is calculated using the Eq. (1):
where
That means on average
Fig. 4 illustrates changing the voices for the augmented corpus. If it is a male voice, the formant is raised towards the high frequency so that the male voice is closer to a female voice. If it is a female voice, the formant is lowered towards the low frequency to be closer to a male voice. Translation of formant is performed with Praat toolkits [50]. For the formant lifting case, the lift coefficient used in Praat is 1.1, while for the formant reduction, the reduction factor used in Praat is 0.909.
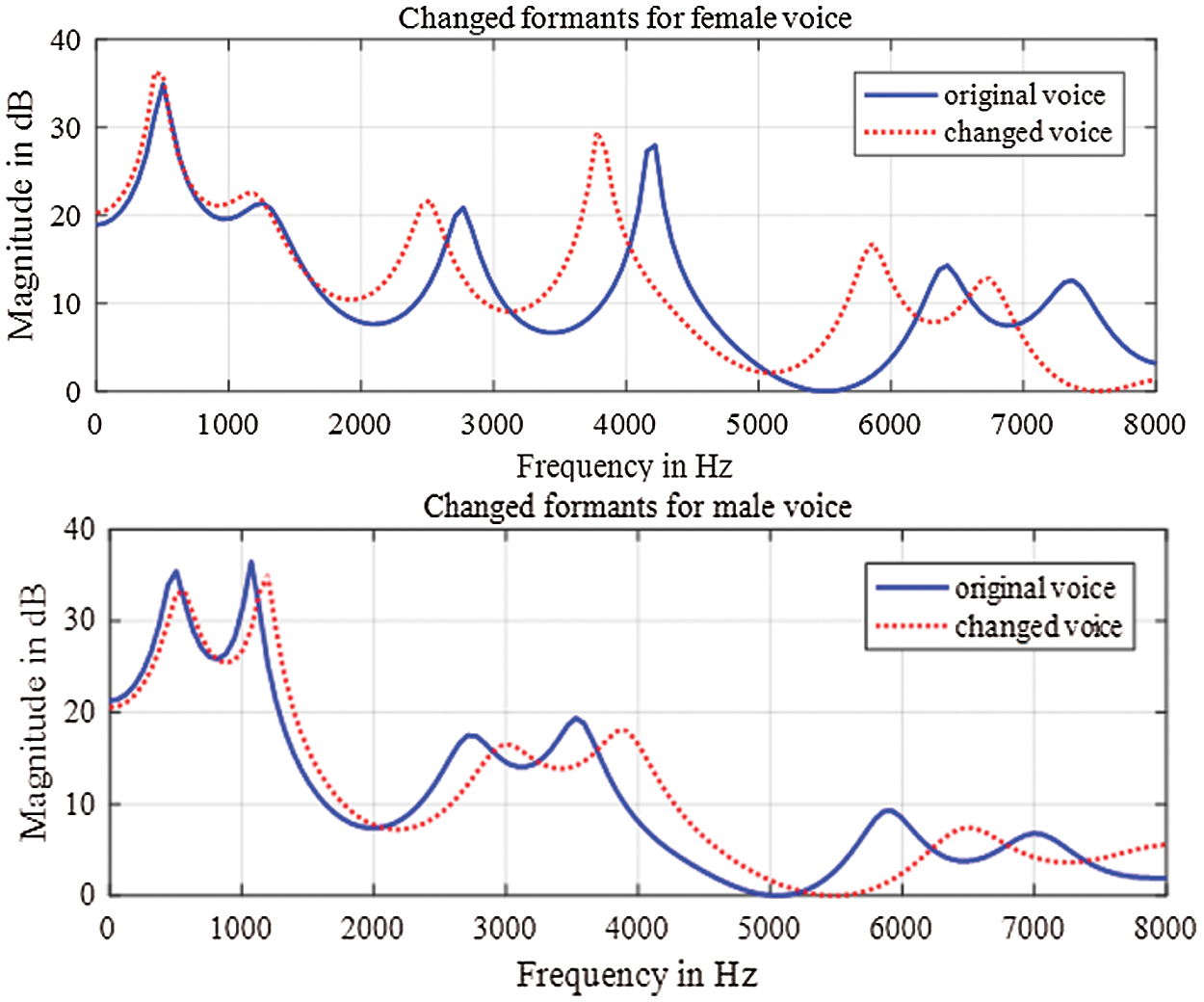
Figure 4: Illustrating changing voices for data augmentation
The mel spectrum image is extracted from sound file with the fixed size 260
Beside 260 mel spectral coefficients such as baseline, we added 8 parameters related to fundamental frequency
• Derivation of
• Normalization of
• Normalization of
• Normalization of
• Normalization of
• Normalization of
• Normalization of
We also added 28 other parameters related to the vocal tract, spectral characteristics and voice quality, so there are 296 parameters in total. These 28 parameters are listed in Tab. 1. This parameter set is named MELSPEC_F0_OTHER.

For the basic discrete-time model for speech production, the vocal tract’s transfer function is
Other parameters, such as harmonicity, center of gravity, central moment, skewness, and kurtosis, were explained based on Praat and are presented in [45]. ANOVA and T-test were used in [52] to evaluate the corpus BKEmo. The P-value = 0.05 is used in the majority of cases [53], and this value is also used as the cutoff for significance in our case. If the P-value is less than 0.05, a significant difference for a pair of emotions does exist. The T-test results from [52] showed that the emotion pairs of BKEmo are best distinguished for most of the above feature parameters. All feature parameters are calculated using Praat toolkits [50].
A capsule is a group of neurons in which the inputs and outputs of the capsule are vectors [1]. To illustrate the basic activity of the capsule neural network to be used in the paper, we take an example of a capsule neural network consisting of M capsules in the higher level and N capsules in the lower level, as denoted in Fig. 5. Capsule 1 in the higher level has an output vector
Before entering capsule j at the higher level, the output vector
Capsule j in the higher level performs the sum:
The output vector
Vector output
where bij are the log prior probabilities that capsule i should be coupled to capsule j.
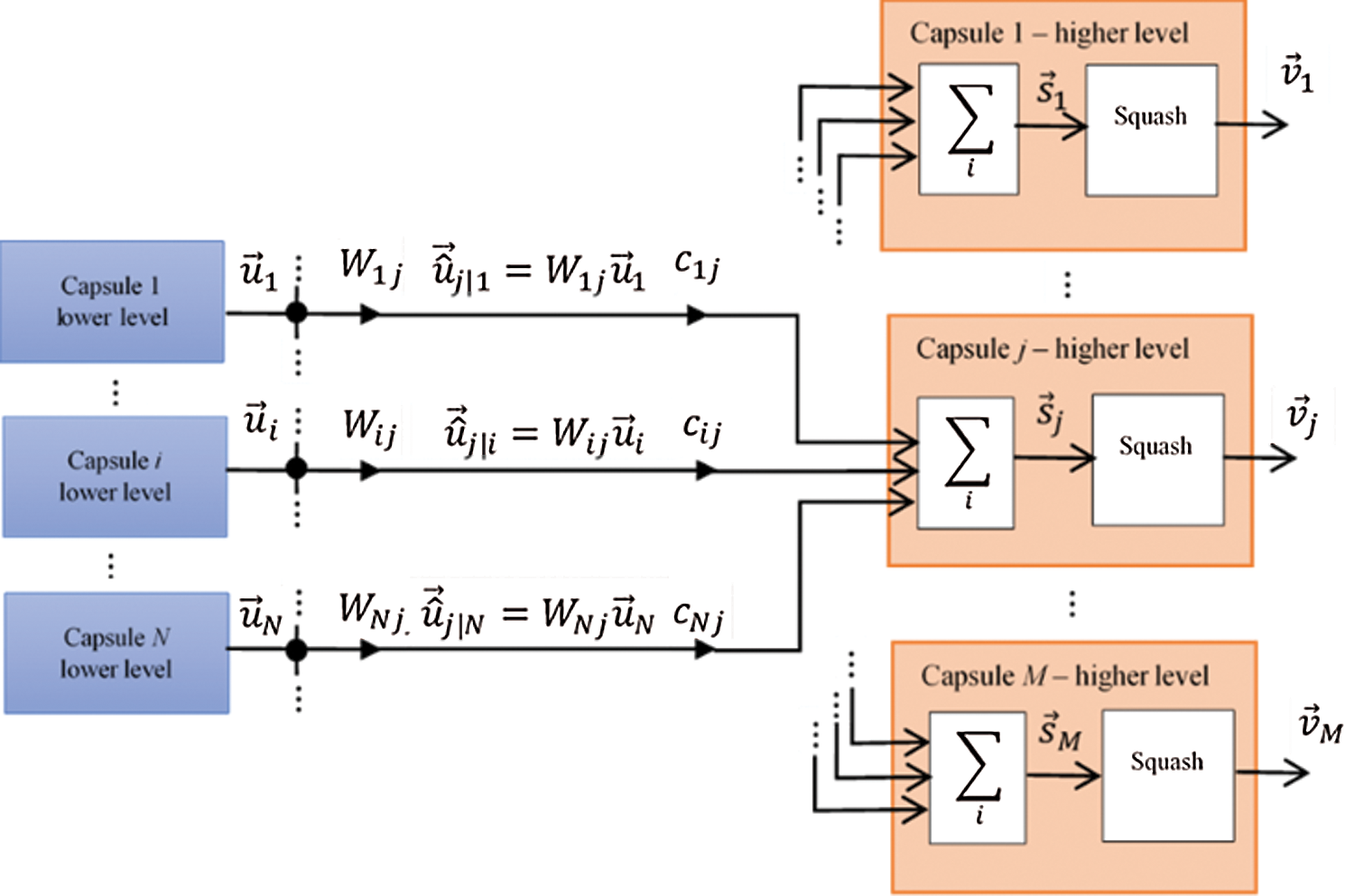
Figure 5: A capsule neural network consisting of M capsules in the higher level and N capsules in the lower level
The basis of dynamic routing algorithms proposed in [2] is that the capsule in the lower level sends its input to a higher-level capsule that agrees with that input. The result of the algorithm with a certain number of routing iterations (usually equal to 3) gives a set of routing coefficients that best match the output from the capsule in the lower level with the output of the capsules at a higher level.
CapsNet computes the margin loss for class k as following:
where Tk = 1 if an entity of class k is present and
3.3.2 Configuration of Capsule Neural Network for Emotion Recognition
The neural network used to recognize the four emotions in this paper consists of two parts: the first part is 5 CNN layers, and the second part is a capsule neural network. Take the configuration example of the neural network for the case of 296 parameters
• Layer 1: Convolution 2D, input (296, 296,1), output (148, 148, 64), kernel (3
• Layer 2: Convolution 2D, input (148, 148, 64), output (74, 74, 16), kernel (2
• Layer 3: Convolution 2D, input (74, 74, 16), output (37, 37, 16), kernel (2
• Layer 4: Convolution 2D, input (37, 37, 16), output (19, 19, 16), kernel (2
• Layer 5: Convolution 2D, input (19, 19, 16), output (10, 10, 16), kernel (2
The output of layer 5 is the input of the primary capsule in Fig. 6. The configuration of the CapsNet is basically inspired by the CapsNet configuration proposed by [2], but the parameters have been changed to suit our case.
Fig. 6 is an illustration of the primary and secondary capsules (capsule layer). In nature, the primary capsule layer is similar to the convolutional layer. This layer reduces the spatial dimension from 10 × 10 to 5 × 5 by using kernel 9 × 9 with stride 2 and no padding. The primary capsule layer uses 8 × 32 kernels to generate 32 8-D capsules, i.e., 8 output neurons are grouped together to form a capsule. The output of the primary capsule layer is reshaped to (800 (=5 × 5 × 32), 8). Next, the capsule layer applies a transformation matrix
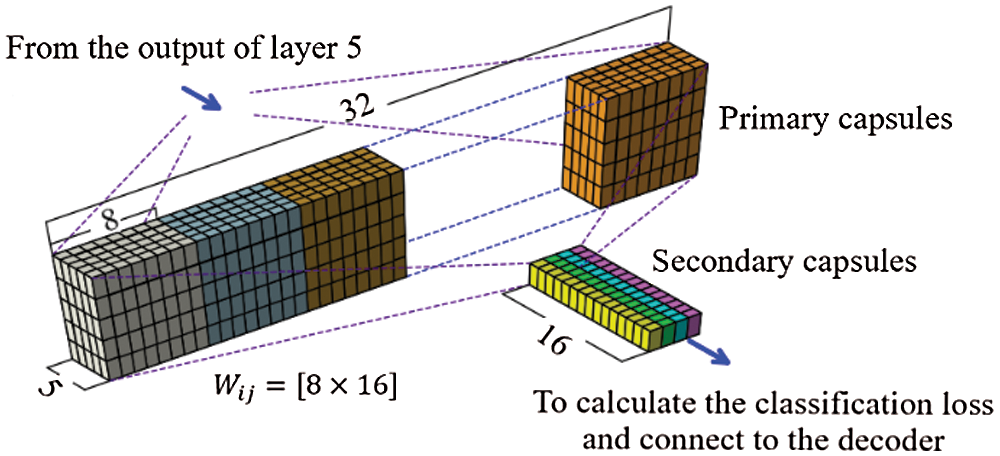
Figure 6: Illustration of primary capsules and secondary capsules
The above configuration does not change for the remaining 2 cases (260 and 268 feature parameters). Of course, the number of corresponding parameters to be calculated varies depending on 260 and 268 feature parameters.
Emotion hypothesis is determined as following:
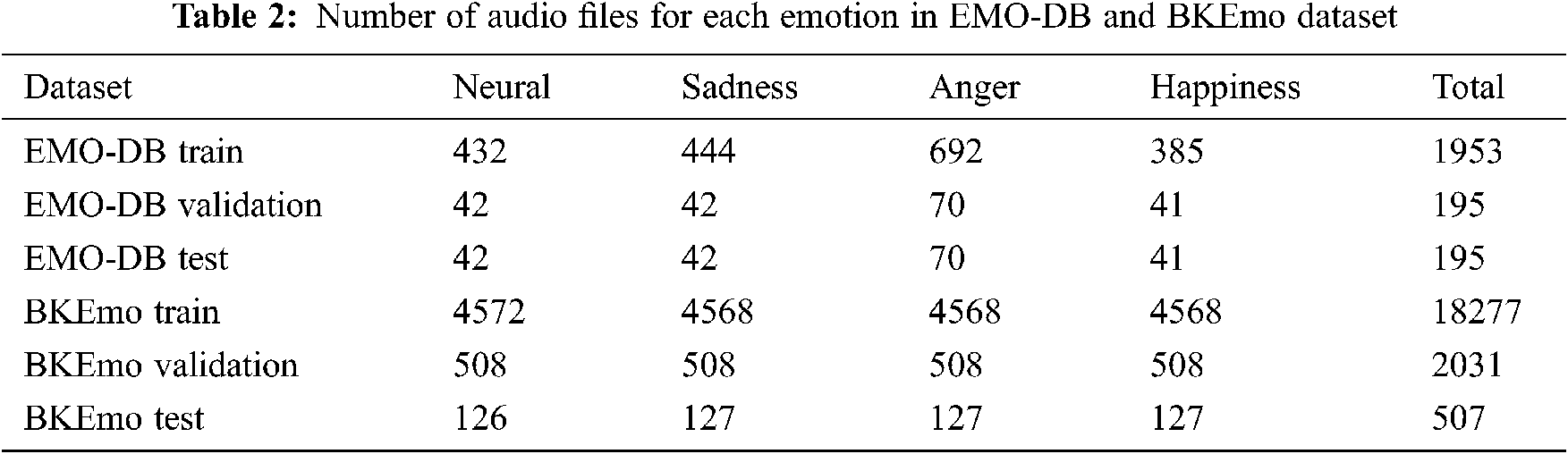
EMO-DB is a German emotional corpus [54]. The corpus was built using a simulation method with 10 professional artists (5 male artists and 5 female artists) and includes 7 emotions: neutral, anger, fear, happiness, sadness, disgust and boredom. There are 10 sentences for the artists to express different emotions. Each emotion is expressed 1 to 6 times. Along with EMO-DB, a Vietnamese emotional corpus BKEmo is also used in this paper. The Vietnamese emotional corpus used for recognition is extracted from the BKEmo corpus developed at Hanoi University of Science and Technology. BKEmo is built according to the simulation method for four emotions: neutral, sadness, anger and happiness. EMO-DB’s emotions, neutral, boredom, anger and happiness, are chosen because these are emotions with the largest number of files. The number of emotions in BK-Emo is also equal to four, and thus, the architecture of the emotion recognition system remains the same for both languages. The total number of files for these 4 emotions of EMO-DB is 358, of which anger has 127 files, neutral has 79 files, happiness has 71 files and boredom has 81 files.
Using data augmentation, we obtained 2,148 files from 358 files. Of the 2,148 files, the subset has 195 files used for testing. This subset of 195 files includes 42 files for neutral, 42 files for boredom, 41 files for happiness, and 70 files for anger. After taking 195 files for testing, the remaining files are split into 10 subsets (these 10 subsets have slightly different file numbers for each subset) for 10-fold cross-validation.
From the BKEmo corpus, the authors of the paper listened and selected 5,584 files for 4 emotions with 22 sentences, 8 male and 8 female voices, and these 5,584 files were used for emotion recognition. More details about the corpus can be found in [45,46]. The 5,584 files are divided into 11 parts, and 1/11 parts (507 files) are data used for testing, the remaining 5,077 files are used for training and validation. By using data augmentation, these 5077 files were augmented into 20,308 files. The set of files for the test, in any case, does not contain the files used for training and validation. The augmented corpus is split into 10 subsets for 10-fold cross-validation, and these 10 subsets have slightly different file numbers for each subset. Data distribution for each emotion is depicted in Tab. 2.
The experiments were performed on a machine with the configuration as following:
• CPU: an Intel Core i7-7700 CPU @ 3.60 GHz
• RAM: 32 GB
• GPU: GeForce GTX 1080 Ti/PCIe/SSE2 with 11 GB of RAM
• Hard-disk: SSD 512 GB
For EMO-DB, the average training time for one fold is approximately 3.3 min, while for BKEmo, this time is approximately 30 min. The accuracy score (%) for each emotion for EMO-DB and BKEmo are given in Tab. 3. The results in this table are the average accuracy of 10 experiments corresponding with 10-folds.
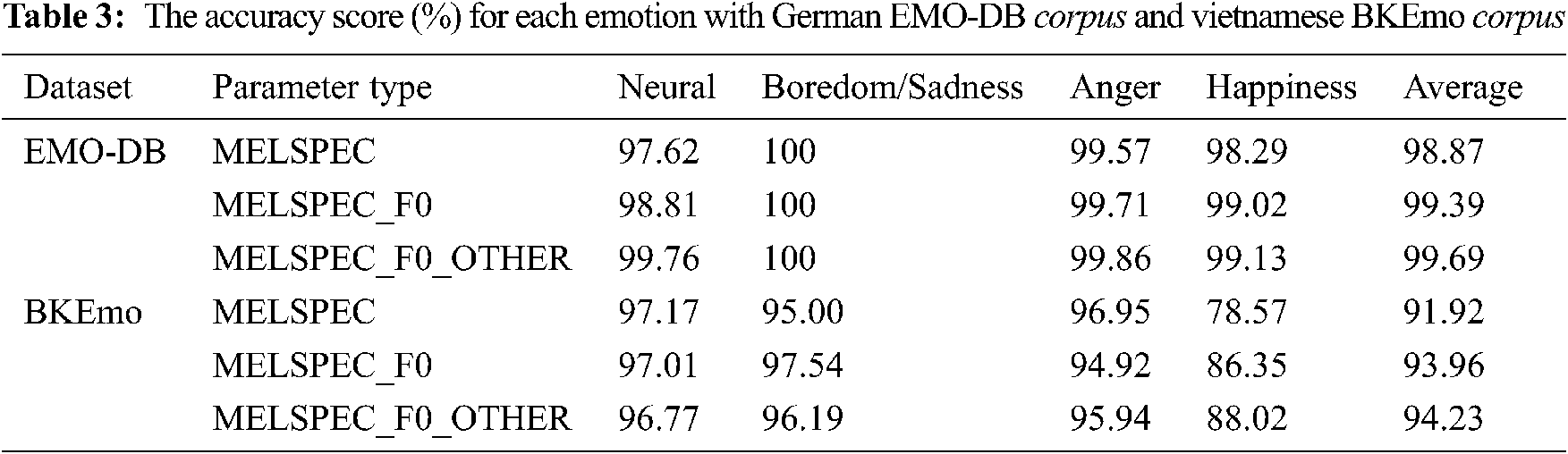
At first, for both corpora EMO-DB and BKEmo, the average accuracy score increased when the number of parameters increased from 260 to 268 and 296, respectively. So beside mel spectrum, the parameters related to
If only comparing the accuracy scores for the EMO-DB corpus of the studies listed in Tab. 4, in general, the average accuracy score in our case is superior to the accuracy score of the vast majority of available studies (except for [55], 99.8% vs. 99.69%). German is not a tonal language. The addition of parameters directly related to
Vietnamese is a tonal language. There are 6 tones of Vietnamese. For Vietnamese, changing the tone of a syllable changes the meaning of the syllable. The variable rule of fundamental frequency
In [45,46], the GMM and DCNN models were used to recognize Vietnamese emotions with the same corpus BKEmo containing only 5,584 original files, which means that there was no data augmentation for the corpus. The maximal number of parameters in [45] was 87. Therefore, the corpus of these two models (GMM and CapsNet) is not exactly the same, and the number of parameters of the two models is also different. The average accuracy score for [45] is 93.12% vs. 94.23% for this CapsNet model. Also with the same set of 296 parameters without data augmentation, the DCNN showed the average recognition accuracy of the 4 emotions was 88.01% vs. 94.23% for this CapsNet model. The common point of the two models is that the recognition score increases significantly when adding parameters related to
In summary, our experiments of emotion recognition using a capsule neural network with parameters related to mel spectrum,
Funding Statement: The authors received no specific funding for this study.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. G. E. Hinton, A. Krizhevsky and S. D. Wang, “Transforming auto-encoders,” in Proc. ICANN, Espoo, Finland, pp. 44–51, 2011. [Google Scholar]
2. S. Sabour, N. Frosst and G. E. Hinton, “Dynamic routing between capsules,” in Proc. NIPS, Long Beach, CA, USA, pp. 3859–3869, 2017. [Google Scholar]
3. G. E. Hinton, S. Sabour and N. Frosst, “Matrix capsules with EM routing,” in Proc. ICLR, Vancouver, Canada, pp. 1–15, 2018. [Google Scholar]
4. J. Bae and D. S. Kim, “End-to-end speech command recognition with capsule network,” in Proc. Interspeech, Hyderabad, India, pp. 776–780, 2018. [Google Scholar]
5. J. Poncelet and V. Renkens, “Low resource end-to-end spoken language understanding with capsule networks,” Computer Speech & Language, vol. 66, no. 101142, pp. 1–21, 2021. [Google Scholar]
6. S. G. Koolagudi and K. S. Rao, “Emotion recognition from speech: A review,” International Journal of Speech Technology, vol. 15, no. 2, pp. 99–117, 2012. [Google Scholar]
7. M. E. Ayadi, M. S. Kamel and F. Karray, “Survey on speech emotion recognition: Features, classification schemes, and databases,” Pattern Recognition, vol. 44, no. 3, pp. 572–587, 2011. [Google Scholar]
8. T. Thanapattheerakul, K. Mao, J. Amoranto and J. H. Chan, “Emotion in a century: A review of emotion recognition,” in Proc. IAIT, Bangkok, Thailand, pp. 17–24, 2018. [Google Scholar]
9. B. Basharirad and M. Moradhaseli, “Speech emotion recognition methods: A literature review,” AIP Conference Proceedings, vol. 1891, no. 020105, pp. 1–7, 2017. [Google Scholar]
10. I. Shahin, “Emotion recognition based on third-order circular suprasegmental hidden Markov model,” in Proc. JEEIT, Amman, Jordan, pp. 800–805, 2019. [Google Scholar]
11. M. Jain, S. Narayan, P. Balaji, A. Bhowmick and M. R. Gurdaspur, “Speech emotion recognition using support vector machine,” in Proc. ICICES, India, pp. 1–6, 2018. [Google Scholar]
12. J. Han, Z. Zhang, G. Keren and B. Schuller, “Emotion recognition in speech with latent discriminative representations learning,” Acta Acustica United with Acustica, vol. 104, no. 5, pp. 737–740, 2018. [Google Scholar]
13. M. Abdelwahab and C. Busso, “Supervised domain adaptation for emotion recognition from speech,” in Proc. ICASSP, Queensland, Australia, pp. 5058–5062, 2015. [Google Scholar]
14. J. Deng, Z. Zhang, F. Eyben and B. Schuller, “Autoencoder-based unsupervised domain adaptation for speech emotion recognition,” IEEE Signal Processing Letters, vol. 21, no. 9, pp. 1068–1072, 2014. [Google Scholar]
15. C. Huang, R. Liang, Q. Wang, J. Xi, C. Zha et al., “Practical speech emotion recognition based on online learning: from acted data to elicited data,” Mathematical Problems in Engineering, vol. 2013, no. 265819, pp. 1–9, 2013. [Google Scholar]
16. H. Hu, M. X. Xu and W. Wu, “Gmm supervector based svm with spectral features for speech emotion recognition,” in Proc. ICASSP, Honolulu, USA, pp. 413–416, 2007. [Google Scholar]
17. W. Zehra, A. R. Javed, Z. Jalil, H. U. Khan and T. R. Gadekallu, “Cross corpus multi-lingual speech emotion recognition using ensemble learning,” Complex & Intelligent Systems, vol. 7, pp. 1845–1854, 2021. [Google Scholar]
18. I. Shahin, A. B. Nassif and S. Hamsa, “Emotion recognition using hybrid gaussian mixture model and deep neural network,” IEEE Access, vol. 7, pp. 26777–26787, 2019. [Google Scholar]
19. I. Shahin, A. B. Nassif and S. Hamsa, “Novel cascaded Gaussian mixture model-deep neural network classifier for speaker identification in emotional talking environments,” Neural Computing and Applications, vol. 32, no. 7, pp. 2575–2587, 2020. [Google Scholar]
20. A. S. Utane and S. L. Nalbalwar, “Emotion recognition through speech using Gaussian mixture model and support vector machine,” International Journal of Scientific & Engineering Research, vol. 4, no. 5, pp. 1439–1443, 2013. [Google Scholar]
21. J. Bang, T. Hur, D. Kim, J. Lee, Y. Han et al., “Adaptive data boosting technique for robust personalized speech emotion in emotionally-imbalanced small-sample environments,” Sensors, vol. 18, no. 11, pp. 1–21, 2018. [Google Scholar]
22. D. Czerwinski and P. Powroznik, “Human emotions recognition with the use of speech signal of polish language,” in Proc. EPMCCS, Kielce, Poland, pp. 1–6, 2018. [Google Scholar]
23. W. Han, H. Ruan, X. Chen, Z. Wang, H. Li et al., “Towards temporal modelling of categorical speech emotion recognition,” in Proc. Interspeech, Hyderabad, India, pp. 932–936, 2018. [Google Scholar]
24. J. Gideon, S. Khorram, Z. Aldeneh, D. Dimitriadis and E. M. Provost, “Progressive neural networks for transfer learning in emotion recognition,” in Proc. Interspeech, Stockholm, Sweden, pp. 1098–1102, 2017. [Google Scholar]
25. E. Tzinis and A. Potamianos, “Segment-based speech emotion recognition using recurrent neural networks,” in Proc. ACII, San Antonio, TX, USA, pp. 190–195, 2017. [Google Scholar]
26. A. J. Kayal and J. Nirmal, “Multilingual vocal emotion recognition and classification using back propagation neural network,” AIP Conference Proceedings, vol. 1715, no. 20054, pp. 1–7, 2016. [Google Scholar]
27. G. Trigeorgis, F. Ringeval, R. Brueckner, E. Marchi, M. A. Nicolaou et al., “Adieu features? end-to-end speech emotion recognition using a deep convolutional recurrent network,” in Proc. ICASSP, Shanghai, China, pp. 5200–5204, 2016. [Google Scholar]
28. O. E. Nii Noi, M. Qirong, G. Xu and Y. Xue, “Coupled unsupervised deep convolutional domain adaptation for speech emotion recognition,” in Proc. BigMM, Xi’an, China, pp. 1–5, 2018. [Google Scholar]
29. E. M. Schmidt and Y. E. Kim, “Learning emotion-based acoustic features with deep belief networks,” in Proc. WASPAA, NY, USA, 65–68, 2011. [Google Scholar]
30. B. Schuller, G. Rigoll and M. Lang, “Speech emotion recognition combining acoustic features and linguistic information in a hybrid support vector machine-belief network architecture,” in Proc. ICASSP, Montreal, Canada, pp. 577–580, 2004. [Google Scholar]
31. J. Liu, W. Han, H. Ruan, X. Chen, D. Jiang et al., “Learning salient features for speech emotion recognition using cnn,” in Proc. ACII Asia, Beijing, China, pp. 1–5, 2018. [Google Scholar]
32. D. Luo, Y. Zou and D. Huang, “Investigation on joint representation learning for robust feature extraction in speech emotion recognition,” in Proc. Interspeech, Hyderabad, India, pp. 152–156, 2018. [Google Scholar]
33. H. M. Fayek, M. Lech and L. Cavedon, “Evaluating deep learning architectures for speech emotion recognition,” Neural Networks, vol. 92, pp. 60–68, 2017. [Google Scholar]
34. C. P. Latha and M. Priya, “A review on deep learning algorithms for speech and facial emotion recognition,” APTIKOM Journal on Computer Science and Information Technologies, vol. 1, no. 3, pp. 92–108, 2016. [Google Scholar]
35. S. Wermter, C. Weber, S. Magg and E. Lakomkin, “Reusing neural speech representations for auditory emotion recognition,” in Proc. IJCNLP, Taipei, Taiwan, pp. 423–430, 2017. [Google Scholar]
36. S. Latif, R. Rana, J. Qadir and J. Epps, “Variational autoencoders for learning latent representations of speech emotion: A preliminary study,” in Proc. Interspeech, Hyderabad, India, pp. 3107–3111, 2018. [Google Scholar]
37. S. Latif, R. Rana, S. Younis, J. Qadir and J. Epps, “Transfer learning for improving speech emotion classification accuracy,” in Proc. Interspeech, Hyderabad, India, pp. 257–261, 2018. [Google Scholar]
38. J. Deng, Z. Zhang, E. Marchi and B. Schuller, “Sparse autoencoder-based feature transfer learning for speech emotion recognition,” in Proc. ACII, Geneva, Switzerland, pp. 511–516, 2013. [Google Scholar]
39. P. Song, “Transfer linear subspace learning for cross-corpus speech emotion recognition,” IEEE Transactions on Affective Computing, vol. 10, no. 2, pp. 265–275, 2017. [Google Scholar]
40. S. Latif, J. Qadir and M. Bilal, “Unsupervised adversarial domain adaptation for cross-lingual speech emotion recognition,” in Proc. ACII, Cambridge, United Kingdom, pp. 732–737, 2019. [Google Scholar]
41. M. Abdelwahab and C. Busso, “Domain adversarial for acoustic emotion recognition,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 26, no. 12, pp. 2423–2435, 2018. [Google Scholar]
42. V. A. Hoang, V. M. Ngo, H. B. Ban and Q. T. Huynh, “A real-time model-based support vector machine for emotion recognition through eeg,” in Proc. ICCAIS, HoChiMinh city, Vietnam, pp. 191–196, 2012. [Google Scholar]
43. L. Vutuan, H. Chengwei, Z. Cheng and Z. Li, “Emotional feature analysis and recognition from Vietnamese speech,” Journal of Signal Processing, vol. 20, no. 10, pp. 1423–1432, 2013. [Google Scholar]
44. J. Zhipeng and H. Chengwei, “High-order Markov random fields and their applications in cross-language speech recognition,” Cybernetics and Information Technologies, vol. 15, no. 4, pp. 50–57, 2015. [Google Scholar]
45. T. L. T. Dao, V. L. Trinh and H. Q. Nguyen, “GMM for emotion recognition of Vietnamese,” Journal of Computer Science and Cybernetics, vol. 33, no. 3, pp. 229–246, 2017. [Google Scholar]
46. T. L. T. Dao, V. L. Trinh and H. Q. Nguyen, “Deep convolutional neural networks for emotion recognition of Vietnamese,” International Journal of Machine Learning and Computing, vol. 10, no. 5, pp. 692–699, 2020. [Google Scholar]
47. Z. Xiao, D. Wu, X. Zhang and Z. Tao, “A cross-corpus recognition of emotional speech,” in Proc. ISCID, Hangzhou, China, pp. 42–46, 2016. [Google Scholar]
48. E. N. N. Ocquaye, Q. Mao, H. Song, G. Xu and Y. Xue, “Dual exclusive attentive transfer for unsupervised deep convolutional domain adaptation in speech emotion recognition,” IEEE Access, vol. 7, pp. 93847–93857, 2019. [Google Scholar]
49. M. Papakostas, E. Spyrou, T. Giannakopoulos, G. Siantikos, D. Sgouropoulos et al., “Deep visual attributes vs. hand-crafted audio features on multidomain speech emotion recognition,” Computation, vol. 5, no. 2, pp. 1–15, 2017. [Google Scholar]
50. P. Boersma, “Praat, a system for doing phonetics by computer,” Glot International, vol. 5, no. 9/10, pp. 341–345, 2001. [Google Scholar]
51. L. R. Rabiner and R. W. Schafer, Theory and Applications of Digital Speech Processing. Hoboken, NJ: Prentice Hall Press, 2010. [Google Scholar]
52. T. L. T. Dao, V. L. Trinh, H. Q. Nguyen and X. T. Le, “Influence of the spectral characteristics of the signal speech to emotion recognition of Vietnamese,” in Proc. FAIR, Danang, Vietnam, pp. 36–43, 2017. [Google Scholar]
53. J. L. Devore, Probability and Statistics for Engineering and the Sciences, 8th ed, California, USA: Brooks/Cole, 2010. [Google Scholar]
54. B. Felix, A. Paeschke, M. Rolfes, W. F. Sendlmeier and B. Weiss, “A database of German emotional speech,” in Proc. EUROSPEECH, Lisbon, Portugal, pp. 1517–1520, 2005. [Google Scholar]
55. A. Revathi, N. Sasikaladevi, R. Nagakrishnan and C. Jeyalakshmi, “Robust emotion recognition from speech: Gamma tone features and models,” International Journal of Speech Technology, vol. 21, no. 3, pp. 723–739, 2018. [Google Scholar]
56. H. K. Mishra and C. C. Sekhar, “Variational Gaussian mixture models for speech emotion recognition,” in Proc. ICAPR, Kolkata, India, pp. 183–186, 2009. [Google Scholar]
57. I. Luengo, E. Navas and I. Hernáez, “Feature analysis and evaluation for automatic emotion identification in speech,” IEEE Transactions on Multimedia, vol. 12, no. 6, pp. 490–501, 2010. [Google Scholar]
58. S. Amarakeerthi, T. L. Nwe, L. C. D. Silva and M. Cohen, “Emotion classification using inter-and intra-subband energy variation,” in Proc. INTERSPEECH, Florence, Italy, pp. 1569–1572, 2011. [Google Scholar]
59. P. Shen, Z. Changjun and X. Chen, “Automatic speech emotion recognition using support vector machine,” in Proc. EMEIT, Heilongjiang, China, pp. 621–625, 2011. [Google Scholar]
60. A. Stuhlsatz, C. Meyer, F. Eyben, T. Zielke, G. Meier et al., “Deep neural networks for acoustic emotion recognition: Raising the benchmarks,” in Proc. ICASSP, Prague, Czech Republic, pp. 5688–5691, 2011. [Google Scholar]
61. Y. Pan, P. Shen and L. Shen, “Speech emotion recognition using support vector machine,” International Journal of Smart Home, vol. 6, no. 2, pp. 101–108, 2012. [Google Scholar]
62. Y. Jin, P. Song, W. Zheng and L. Zhao, “A feature selection and feature fusion combination method for speaker-independent speech emotion recognition,” in Proc. ICASSP, Florence, Italy, pp. 4808–4812, 2014. [Google Scholar]
63. M. Gjoreski, H. Gjoreski and A. Kulakov, “Machine learning approach for emotion recognition in speech,” Informatica, vol. 38, no. 4, pp. 377–384, 2014. [Google Scholar]
64. S. Mao, D. Tao, G. Zhang, P. C. Ching and T. Lee, “Revisiting hidden Markov models for speech emotion recognition,” in Proc. ICASSP, Brighton, UK, pp. 6715–6719, 2019. [Google Scholar]
65. M. Seo and M. Kim, “Fusing visual attention cnn and bag of visual words for cross-corpus speech emotion recognition,” Sensors, vol. 20, no. 19, pp. 1–21, 2020. [Google Scholar]
66. M. Lech, M. Stolar, C. Best and R. Bolia, “Real-time speech emotion recognition using a pre-trained image classification network: Effects of bandwidth reduction and companding,” Frontiers in Computer Science, vol. 2, no. 14, pp. 1–14, 2020. [Google Scholar]
67. F. Haider, S. Pollak, P. Albert and S. Luz, “Emotion recognition in low-resource settings: An evaluation of automatic feature selection methods,” Computer Speech & Language, vol. 65, no. 101119, pp. 1–10, 2021. [Google Scholar]
68. K. Chauhan, K. K. Sharma and T. Varma, “Speech emotion recognition using convolution neural networks,” in Proc. ICAIS, Coimbatore, India, pp. 1176–1181, 2021. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |