DOI:10.32604/csse.2022.020590
| Computer Systems Science & Engineering DOI:10.32604/csse.2022.020590 | |
| Article |
Adaptive Scheme for Crowd Counting Using off-the-Shelf Wireless Routers
1School of Computer and Software, Nanjing University of Information Science & Technology, Nanjing, 210044, China
2Engineering Research Center of Digital Forensics, Ministry of Education, Nanjing University of Information Science and Technology, Nanjing, 210044, China
3School of Engineering & Technology, University of Washington, Tacoma, WA 98402, USA
4China General Nuclear Power Group, Nanjing, 210028, China
5Jiangsu Province Hospital of Chinese Medicine, Affiliated Hospital of Nanjing University of Chinese Medicine, Nanjing, 210029, China
*Corresponding Author: Fei Qian. Email: seujaguar@163.com
Received: 29 May 2021; Accepted: 30 June 2021
Abstract: Since the outbreak of the world-wide novel coronavirus pandemic, crowd counting in public areas, such as in shopping centers and in commercial streets, has gained popularity among public health administrations for preventing the crowds from gathering. In this paper, we propose a novel adaptive method for crowd counting based on Wi-Fi channel state information (CSI) by using common commercial wireless routers. Compared with previous researches on device-free crowd counting, our proposed method is more adaptive to the change of environment and can achieve high accuracy of crowd count estimation. Because the distance between access point (AP) and monitor point (MP) is typically non-fixed in real-world applications, the strength of received signals varies and makes the traditional amplitude-related models to perform poorly in different environments. In order to achieve adaptivity of the crowd count estimation model, we used convolutional neural network (ConvNet) to extract features from correlation coefficient matrix of subcarriers which are insensitive to the change of received signal strength. We conducted experiments in university classroom settings and our model achieved an overall accuracy of 97.79% in estimating a variable number of participants.
Keywords: CSI; device-free; deep learning; crowd counting; Wi-Fi; wireless sensing
Wi-Fi has gained an increasing interest in research due to the implementation of orthogonal frequency-division multiplexing (OFDM) and multiple-input multiple-output (MIMO) technology. In telecommunication with high throughput and multiantenna, the channel state information (CSI) can make the transmissions adapt to current channel condition, which is of great significance. CSI characterizes how wireless signals propagate from the transmitter to the receiver at certain carrier frequency of certain communication link. Each CSI entry represents the channel frequency response (CFR), which is shown in Eq. (1).
where,
Wireless sensing based on Wi-Fi signals has caught tremendous attentions due to its ubiquity and privacy-preserving features [2–8]. Many researchers have paid much attention on human crowd counting based on the widely deployed wireless routers in public areas. Human crowd count estimation has also attracted increasing attention in many potential applications, such as intelligent surveillance, crowd management, urban security and business decision-making etc. For example, the accurate human population distribution information of one city can bring benefit for the government management personnel to make population-related decisions more efficiently. Since the outbreak of the world-wide novel coronavirus pandemic, crowd counting in public areas, such as in shopping centers and in commercial streets, has gained popularity among public health administrations for preventing the crowds from gathering. Traditionally, image-based methods are most often used to estimate the human crowd count, but they are limited to the illumination intensity of environment, line-of-sight propagation property of light, and the public consideration of privacy [9–18]. In this paper, we introduce an adaptive model for human crowd count estimation by exploiting rich CSI data embedded in 802.11n Wi-Fi networks. To test the robustness of the proposed model, we evaluated its performance in four different scenarios, which are shown in Tab. 1.

The CSI data is collected from the AR9344 NIC which is embedded in TP-LINK WDR4310 wireless router based on the Atheros CSI Tool.
After collecting the raw CSI data, Kalman filter with Mahalanobis Distance is used to detect abnormality and smooth out the signal [19–20]. Then, the correlation coefficient matrix of subcarriers is calculated for each data link to generate images. In order to extract fine features of the images, convolutional neural network (ConvNet) is used and the trained classification model achieves a satisfying result on the evaluation dataset in the four scenarios [21].
The remainder of the paper is structured as follows. The Section 2 presents the background and related works of crowd counting and Wi-Fi based wireless sensing. The Section 3 presents the system procedure of human crowd counting system, including data collection and analysis, data preprocessing, feature extraction, and construction of classification model. The Section 4 presents the implementation and evaluation of crowd counting system. The Section 5 presents the conclusion.
2 Background and Related Works
In 2015, Gong et al. [22] designed a Wi-Fi-based real-time calibration-free passive human motion detection system based on the physical layer information using two schemes: short-term averaged variance ration (SVR) and long-term averaged variance ration (LVR). According to the experiment result, a high detection rate and low false positive rate are achieved. In 2016, Domenico et al. [23] proposed one trained-once device-free crowd counting and occupancy estimation using Wi-Fi based on a Doppler spectrum approach in WiMob. The proposed approach analyzes the linear correlation relationship between the shape of the Doppler spectrum and the received signal. In 2017, Zhu et al. [24] proposed an abnormal activity detection system NotiFi which achieved satisfactory performance in accuracy, robustness, and stability. It is based on the fact that the amplitude and phase information of CSI change sensitively whenever the human body occludes the wireless signal from the access point (AP) to the monitor point (MP). Yen-Kai et al. extends crowd counting technique to people-centric Internet of Things (IoT) applications, e.g., security monitoring and energy management for smart homes based on fine-grained physical-layer wireless signatures. They achieved an average correct classification rate of 88% in estimating the exact number of the crowd of size up to nine people in general indoor scenarios. In 2014, Xi et al. [25] proposed the Percentage of nonzero Elements (PEM), in the dilated CSI Matrix, and then the monotonic relationship was explicitly formulated by the Grey Verhulst Model. In 2019, Ibrahim et al. [26] proposed CROSS-COUNT, which uses a single Wi-Fi link to estimate the human crowd count based on the temporal link-blockage pattern and achieves a high accuracy with non-labor-intensive data.
3 System Procedure of Human Crowd Count Estimation
3.1 Data Collection and Analysis
Each CSI measurement contains several fields, which are shown in Tab. 2.
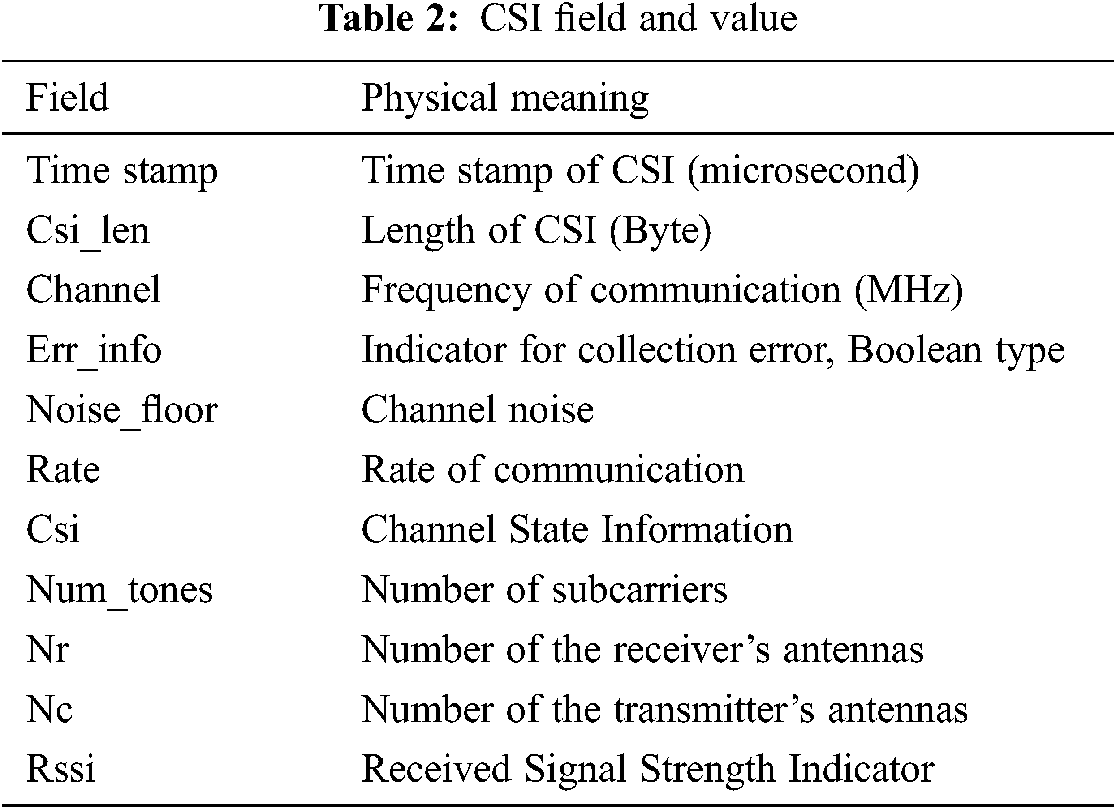
Each CSI measurement is a

Figure 1: Amplitude of 56 subcarriers of 300 CSI packets in empty room
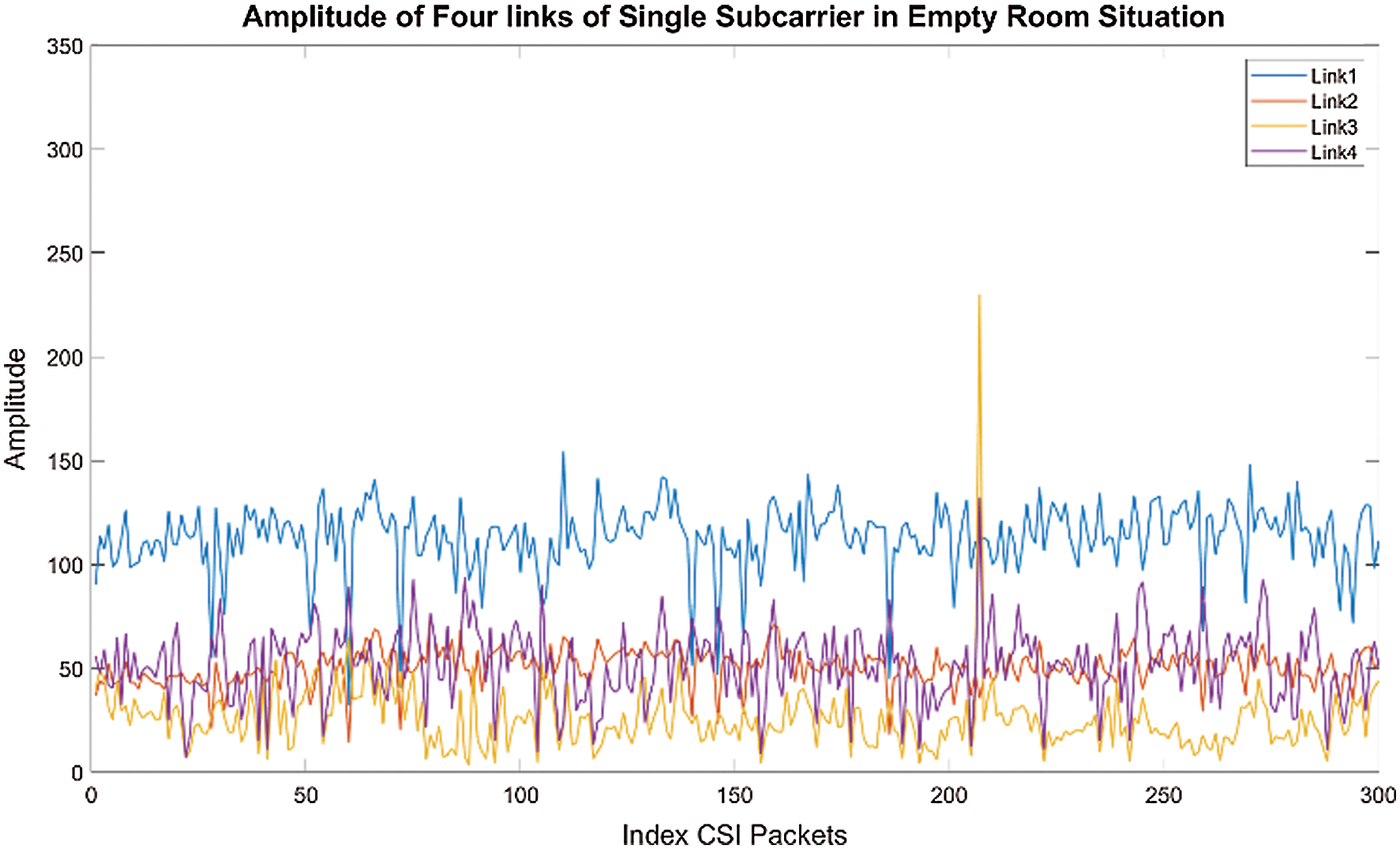
Figure 2: Amplitude of four links of single subcarrier in empty room
Generally, the collected CSI is an estimate of the wireless channel and contains random noise and other inaccuracies. In order to have a better estimate of the wireless channel based on the collected CSI, in this paper, Kalman Filter is used to filter noise and remove outliers. It can be seen in Eqs. (2) and (3).
where,
The Kalman filter can be divided into two procedures: “Prediction” and “Update”.
Prediction procedure using Eqs. (4) and (5):
where,
Update procedure Eqs. (6)–(10):
where,
Since only the current measurement and the estimated state from the previous time are required to compute the estimate for the current state, Kalman filter is a computationally efficient algorithm for real-time and light-weight applications.
In order to detect and remove outliers, Weighted Mahalanobis Distance
where,
The
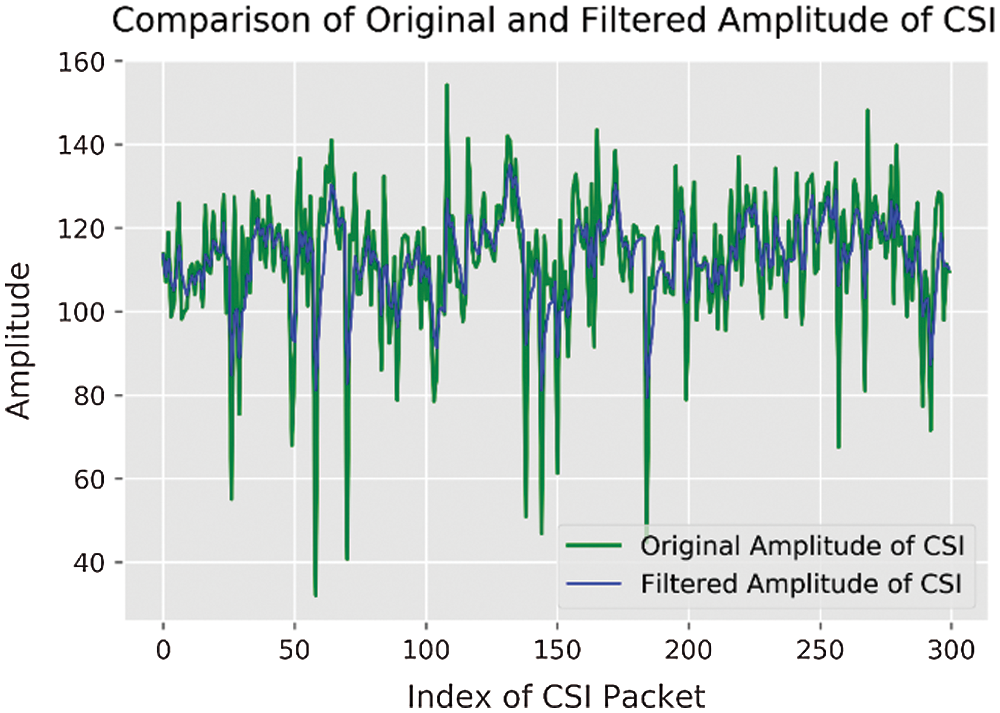
Figure 3: Comparison of original and filtered amplitude of CSI
The amplitudes before and after Kalman filtering of the first subcarrier of link 1 in the empty room situation are shown in Fig. 3.
The correlation coefficient matrix is calculated using Eq. (13).
where,
where,
Considering the tasks of recognizing the number of people in a room, the window size
In this paper, only the amplitude information of CSI is used, as the amplitude correlation of subcarriers is sensitive to the number change of people in a closed room based on the experiment. The data shape of single window is
Generate gray level image with

Figure 4: Image of correlation coefficient matrix of four different classes
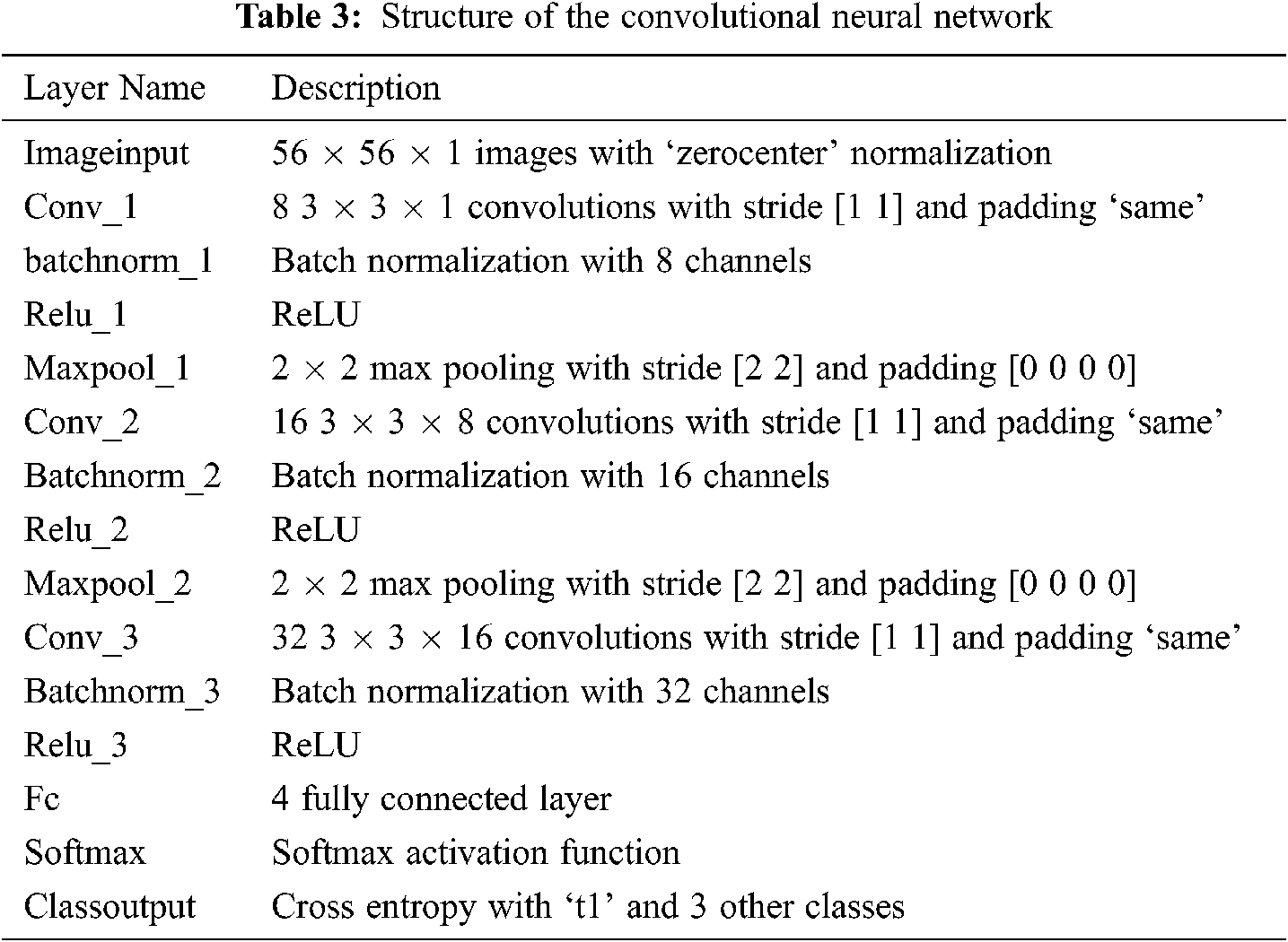
3.4 Construction of ConvNet Classification Model
The structure of ConvNet constructed in this paper is shown in Tab. 3.
3.5 Description of Convnet’s Layers and Parameters
The input is a tensor with shape
Pooling is a form of non-linear down-sampling, which partitions the input image into a set of non-overlapping sub-regions. The max pooling unit uses the function
The rectifier is an activation function defined as Eq. (15).
It maps negative values to zero and keeps the non-negative values unchanged. The rectified linear unit increases the nonlinear properties of the decision function.
Learning rate is a hyperparameter in an optimization algorithm, which determines the step size at each iteration while moving towards a minimum of the cost function. A high learning rate will probably make the learning jump over the minima. On the opposite, a low learning rate generally takes too much time to converge and even makes the learning progress stuck in the local minimum. Therefore, there should be a trade-off when selecting the learning rate for a specific problem. In this paper, a common value 0.01 of learning rate was selected when training the ConvNet.
Batch normalization is a method which uses re-centering and re-scaling to accelerate the training progress and make the neural network more stable. The batch normalization improves the performance by smoothing the objective function.
Batch normalization fixes the means and variances of the inputs of each layer.
where
SoftMax function is a generalized multiple dimensions version of logistic function which is a common S-shape curve. The equation of logistic function is
4 Implementation and Evaluation
4.1 Layout of Experiment Classroom
The experiment was conducted in a university classroom and the layout is shown in Fig. 5. The MP was set in the front of the classroom and the AP was set in the back. The distance between AP and MP is 10 m. Students of certain number walked with normal speed in the aisle. The AP is controlled remotely from outside of the classroom to collect CSI data.
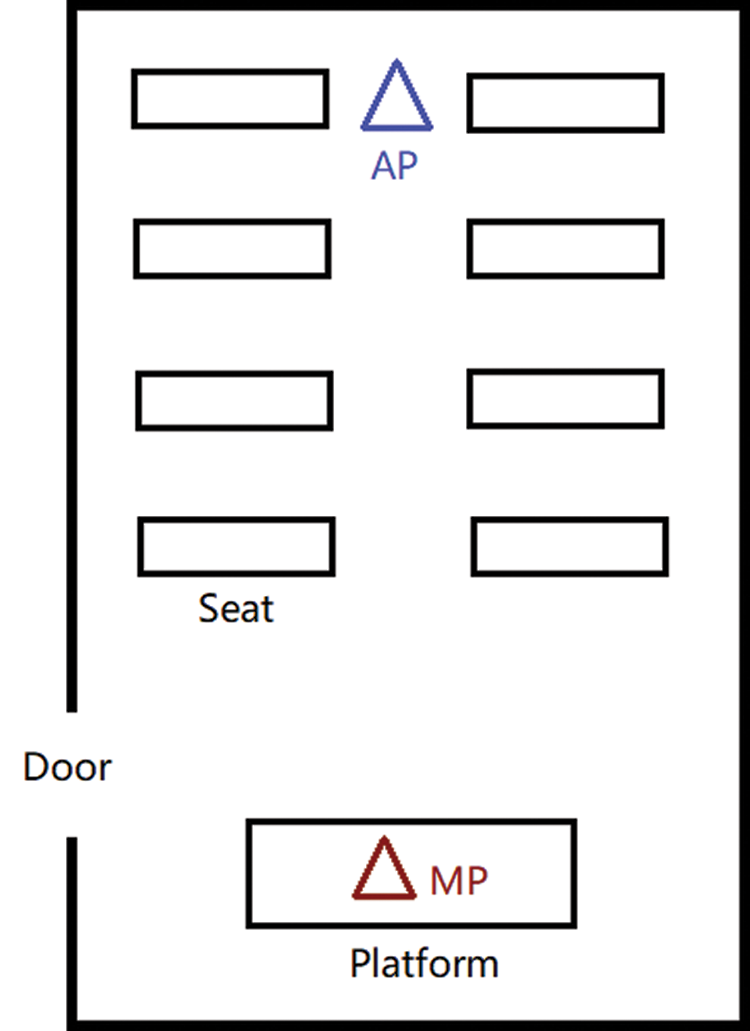
Figure 5: Layout of the experiment environment
4.2 Specification of the Experiment Device
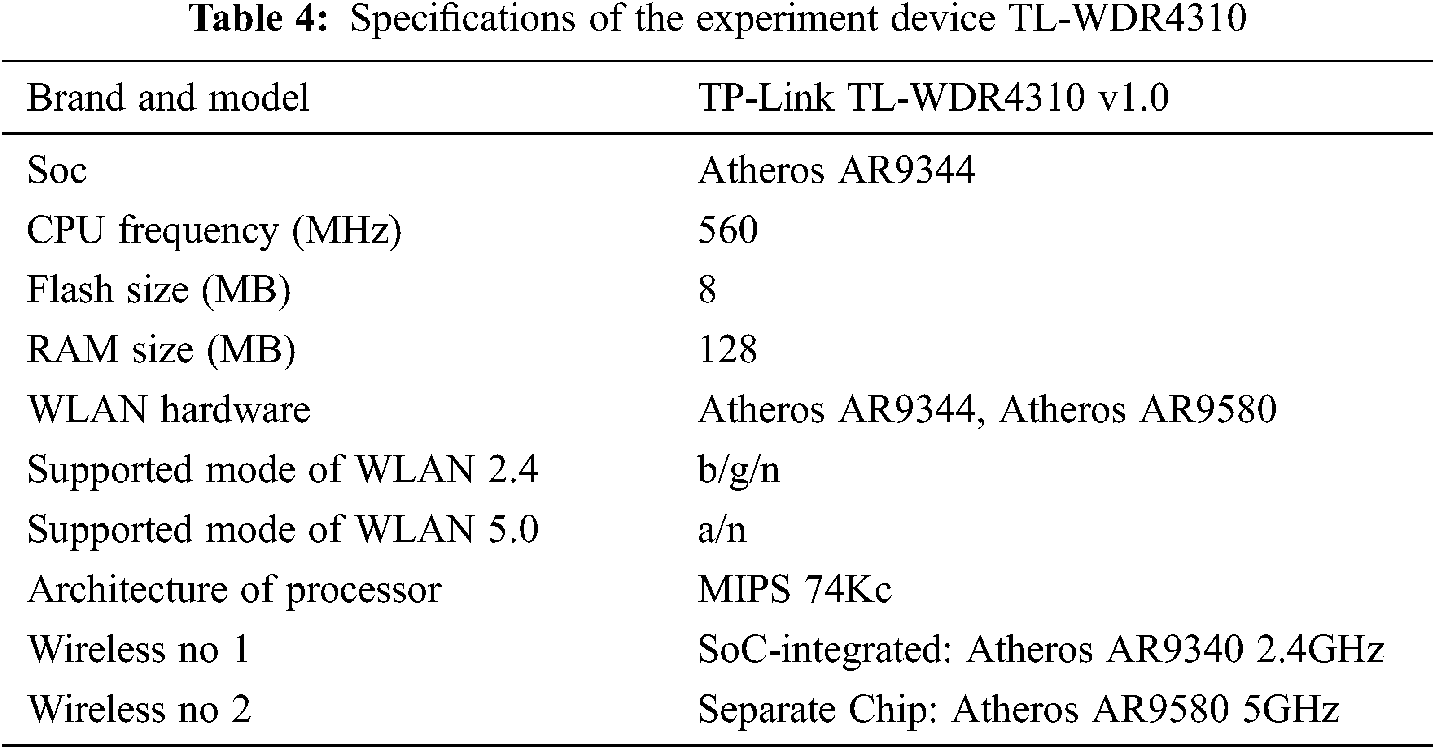
In this experiment, one TL-WDR4310 wireless router flashed with customized OpenWRT firmware was used to collect CSI data. Tab. 4 displays the specifications of the experiment device.
The CSI data was collected using the Atheros-CSI-Tool which is an open source 802.11n measurement and experimentation tool. Based on this tool, detailed PHY wireless communication information was extracted from the Atheros Wi-Fi NICs, including CSI, data rate, the received packet payload, RSSI, etc. All functionalities of Atheros-CSI-Tool are implemented in software without any modification of the firmware. In this experiment, Atheros-CSI-Tool was implemented in the Wi-Fi router with customized OpenWRT firmware.
4.4 Training the ConvNet Classification Model
The ConvNet is implemented using MATLAB Deep Learning Toolbox. Fig. 6 is the graph of training progress.
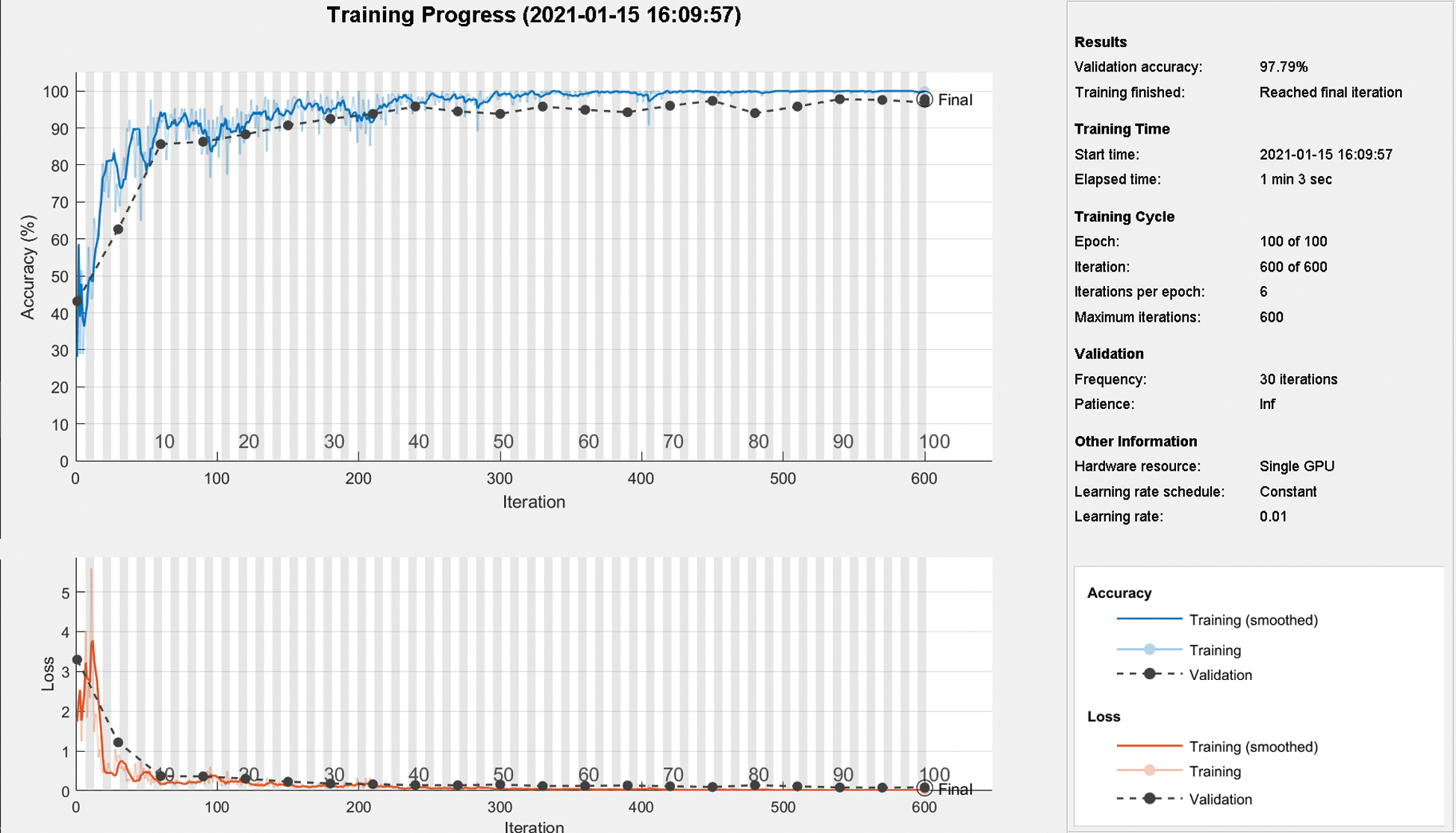
Figure 6: Training progress of the ConvNet with 100 epochs
Fig. 7 is the algorithm for estimating crowd count.

Figure 7: Algorithm: main procedure of evaluating crowd count using the trained model
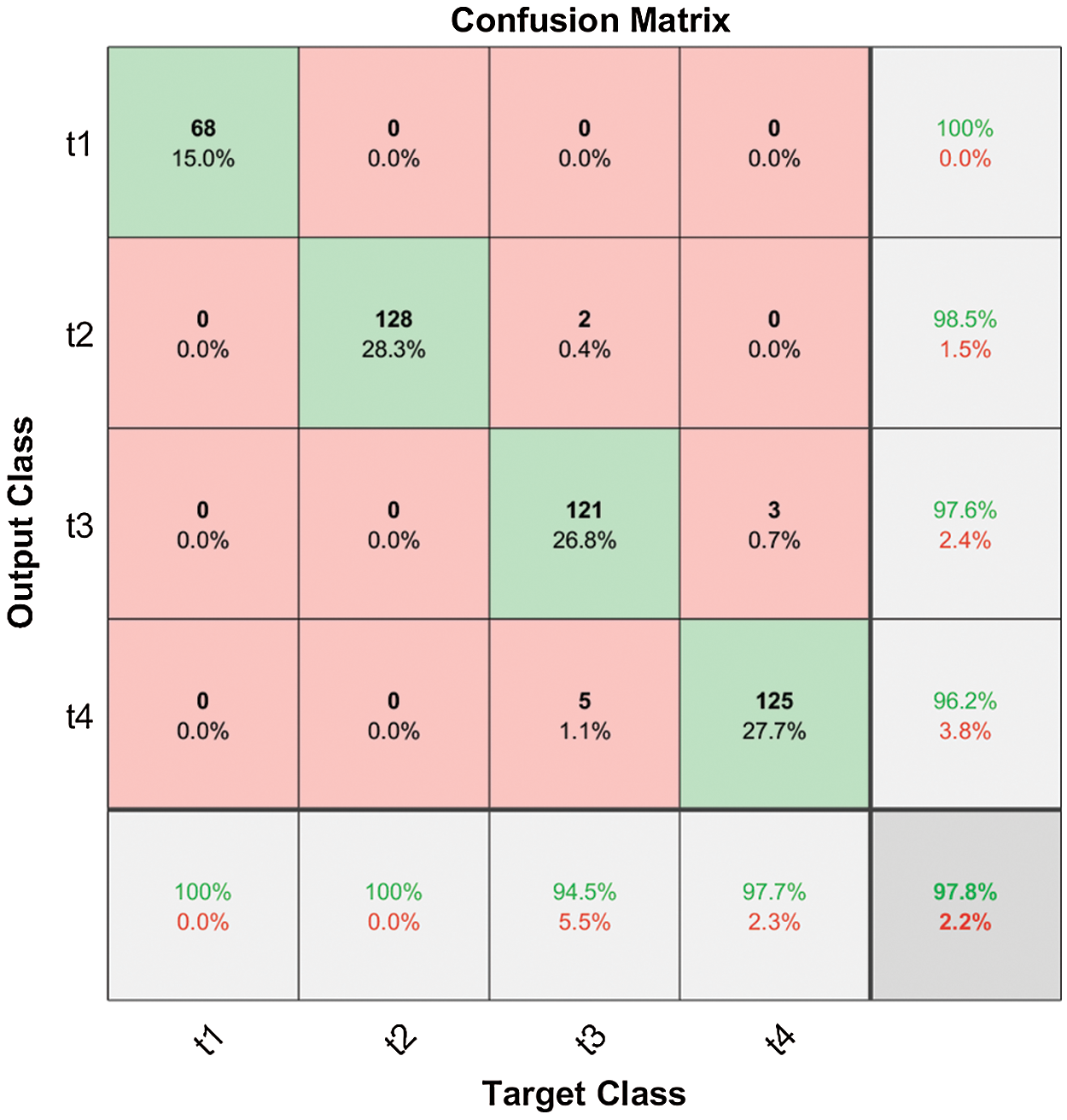
Figure 8: Confusion matrix of the prediction accuracy
The confusion matrix of the evaluation is shown in Fig. 8. It can be seen that the model shows a perfect accuracy when recognizing in Classes 1 and 2 and makes minimal mistakes when distinguishing Class 3 with Class 4. The overall accuracy in all four classes is 97.8%, while the accuracy of recognizing in Classes 1 and 2 is 100% and the accuracy of recognizing in Classes 3 and 4 is 94.5% and 97.7% respectively.
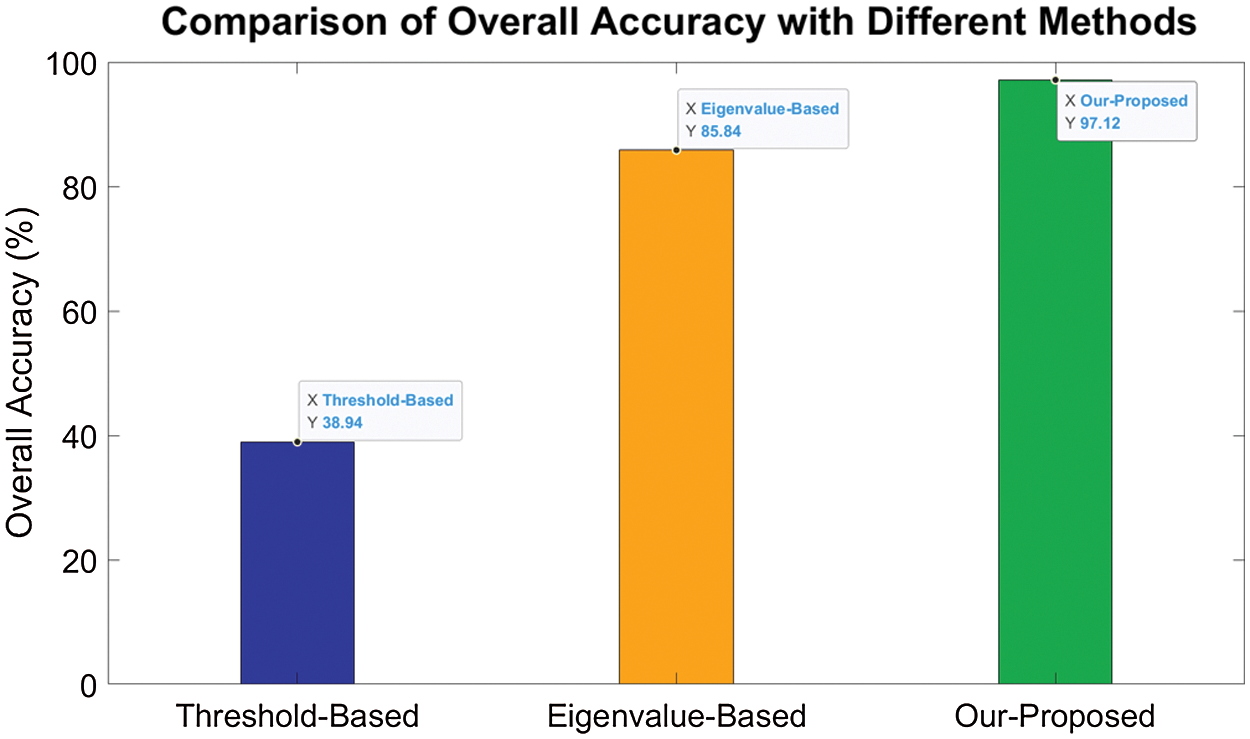
Figure 9: Comparison of overall accuracy with different methods
Two different methods are compared with our proposed method. The comparison bar graph of overall accuracy is shown in Fig. 9. The Threshold-based methods utilize statistical property of the amplitude of CSI, such as variance and mean to recognize the number of people. The Eigenvalue-based methods extract the first several maximum eigenvalues of the correlation matrix of subcarriers. Support Vector Machine implemented with LIBSVM is used to train and evaluate the two methods above [27].
Fig. 10 shows the accuracy of recognizing each class with different methods. It is observed that Threshold-based method almost fails when deployed into different environments except for Scenario 3. The Eigenvalue-based method still shows relatively high performance but the accuracy of recognizing each scenario is lower than our proposed method.
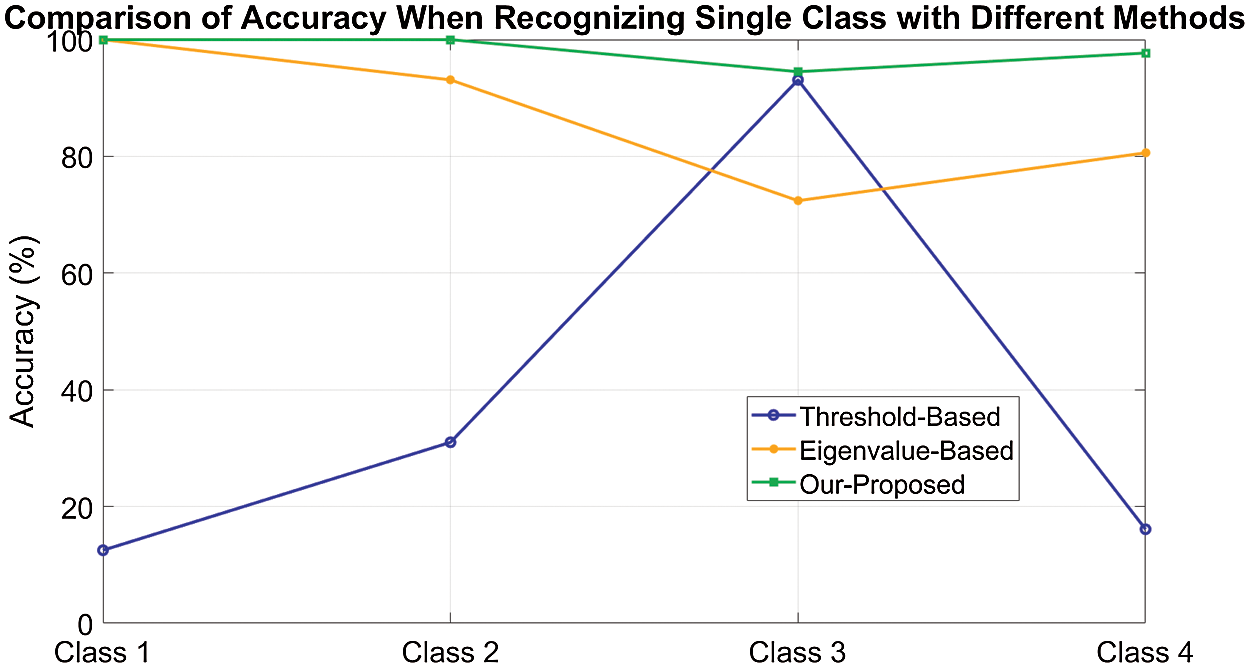
Figure 10: Comparison of accuracy when recognizing single class with different methods
In this paper, we presented the design, implementation, and evaluation of a novel lightweight and adaptive passive crowd counting method based on ConvNet. The system addresses the challenges found in the literature such as lack of robustness, low generalization ability, and high computational cost. The main idea is to generate images with fairly low resolution from the correlation coefficient matrix and classify the small images with a relative shallow ConvNet. With only one pair of AP and MP deployed, an overall accuracy of 97.79% is achieved when experimenting with the number of people into four levels.
Currently, we are extending the method to estimate the number of people up to 20 with multiple APs and MPs deployed in public areas.
Funding Statement: This work was supported by the National Natural Science Foundation of China (Grant No. 61802196, url: http://www.nsfc.gov.cn/); Jiangsu Provincial Government Scholarship for Studying Abroad; The Priority Academic Program Development of Jiangsu Higher Education Institutions (PAPD); NUIST Students’ Platform for Innovation and Entrepreneurship Training Program (Grant No. 202010300080Y, url: http://sjjx.nuist.edu.cn:81/CXCY/NUIST/).
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1. Y. Xie, Z. Li and M. Li, “Precise power delay profiling with commodity WiFi,” in Proc. of the 21st Annual Int. Conf. on Mobile Computing and Networking, New York, NY, USA, pp. 53–64, 2015. [Google Scholar]
2. Y. Cheng and R. Y. Chang, “Device-free indoor people counting using Wi-Fi channel state information for internet of things,” in 2017 IEEE Global Communications Conf., Marina Bay Sands, MBS, Singapore, pp. 1–6, 2017. [Google Scholar]
3. P. Wang, B. Guo, T. Xin, Z. Wang and Z. Yu, “TinySense: Multi-user respiration detection using Wi-Fi CSI signals,” in 2017 IEEE 19th Int. Conf. on e-Health Networking, Applications and Services, Dalian, China, pp. 1–6, 2017. [Google Scholar]
4. L. Gong, W. Yang, Z. Zhou, D. Man, H. Cai et al., “An adaptive wireless passive human detection via fine-grained physical layer information,” Ad Hoc Networks, vol. 38, no. 8, pp. 38–50, 2016. [Google Scholar]
5. S. Palipana, P. Agrawal and D. Pesch, “Channel state information based human presence detection using non-linear techniques,” in Proc. of the 3rd ACM Int. Conf. on Systems for Energy-Efficient Built Environments, New York, NY, USA, pp. 177–186, 2016. [Google Scholar]
6. S. Palipana, D. Rojas, P. Agrawal and D. Pesch, “FallDeFi: Ubiquitous fall detection using commodity Wi-Fi devices,” Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, vol. 1, no. 4, pp. 1–25, 2018. [Google Scholar]
7. K. Qian, C. Wu, Z. Yang, Y. Liu and Z. Zhou, “PADS: Passive detection of moving targets with dynamic speed using PHY layer information,” in 2014 20th IEEE Int. Conf. on Parallel and Distributed Systems, Hsinchu, Taiwan, pp. 1–8, 2014. [Google Scholar]
8. X. Wang, C. Yang and S. Mao, “ResBeat: Resilient breathing beats monitoring with realtime bimodal CSI data,” in 2017 IEEE Global Communications Conf., Marina Bay Sands, Singapore, pp. 1–6, 2017. [Google Scholar]
9. R. Chen, L. Pan, C. Li, Y. Zhou, A. Chen et al., “An improved deep fusion CNN for image recognition,” Computers, Materials & Continua, vol. 65, no. 2, pp. 1691–1706, 2020. [Google Scholar]
10. D. T. Nguyen, W. Li and P. O. Ogunbona, “Human detection from images and videos: A survey,” Pattern Recognition, vol. 51, no. 3, pp. 148–175, 2016. [Google Scholar]
11. S. Li, J. Xue and Y. Han, “No-reference stereoscopic image quality assessment based on local to global feature regression,” in 2019 IEEE Int. Conf. on Multimedia and Expo, Shanghai, China, pp. 448–453, 2019. [Google Scholar]
12. H. Kyu Shin, Y. Han Ahn, S. Hyo Lee and H. Young Kim, “Digital vision based concrete compressive strength evaluating model using deep convolutional neural network,” Computers, Materials & Continua, vol. 61, no. 3, pp. 911–928, 2019. [Google Scholar]
13. V. Sheng and J. Zhang, “Machine learning with crowdsourcing: A brief summary of the past research and future directions,” in Proc. of the AAAI Conf. on Artificial Intelligence, San Francisco, USA, vol. 33, pp. 9837–9843, 2019. [Google Scholar]
14. Z. Xiao, B. Yang and D. Tjahjadi, “An efficient crossing-line crowd counting algorithm with two-stage detection,” Computers, Materials & Continua, vol. 58, no. 3, pp. 1141–1154, 2019. [Google Scholar]
15. R. Chen, G. Zeng, K. Wang, L. Luo and Z. Cai, “A real time vision-based smoking detection framework on DDGE,” Journal on Internet of Things, vol. 2, no. 2, pp. 55–64, 2020. [Google Scholar]
16. Z. Pan, X. Yi, Y. Zhang, B. Jeon and S. Kwong, “Efficient in-loop filtering based on enhanced deep convolutional neural networks for HEVC,” IEEE Transactions on Image Processing, vol. 29, pp. 5352–5366, 2020. [Google Scholar]
17. Z. Pan, X. Yi, Y. Zhang, H. Yuan, F. L. Wang et al., “Frame-level bit allocation optimization based on video content characteristics for HEVC,” ACM Transactions on Multimedia Computing, Communications, and Applications, vol. 16, no. 1, pp. 1–20, 2020. [Google Scholar]
18. L. Shen, X. Chen, Z. Pan, K. Fan, F. Li et al., “No-reference stereoscopic image quality assessment based on global and local content characteristics,” Neurocomputing, vol. 424, no. 5, pp. 132–142, 2021. [Google Scholar]
19. R. E. Kalman, “A new approach to linear filtering and prediction problems,” Journal of Basic Engineering, vol. 82, no. 1, pp. 35–45, 1960. [Google Scholar]
20. R. Kalman, “On the general theory of control systems,” IRE Transactions on Automatic Control, vol. 4, no. 3, pp. 110, 1959. [Google Scholar]
21. S. Albawi, T. A. Mohammed and S. Al-Zawi, “Understanding of a convolutional neural network,” in 2017 Int. Conf. on Engineering and Technology, Antalya, Turkey, pp. 1–6, 2017. [Google Scholar]
22. L. Gong, W. Yang, D. Man, G. Dong, M. Yu et al., “WiFi-based real-time calibration-free passive human motion detection,” Sensors (Basel), vol. 15, no. 12, pp. 32213–32229, 2015. [Google Scholar]
23. S. D. Domenico, G. Pecoraro, E. Cianca and M. D. Sanctis, “Trained-once device-free crowd counting and occupancy estimation using WiFi: A doppler spectrum based approach,” in 2016 IEEE 12th Int. Conf. on Wireless and Mobile Computing, Networking and Communications, New York, NY, USA, pp. 1–8, 2016. [Google Scholar]
24. H. Zhu, F. Xiao, L. Sun, R. Wang and P. Yang, “R-TTWD: Robust device-free through-the-wall detection of moving human with WiFi,” IEEE Journal on Selected Areas in Communications, vol. 35, no. 5, pp. 1090–1103, 2017. [Google Scholar]
25. W. Xi, J. Zhao, X. Li, K. Zhao, S. Tang et al., “Electronic frog eye: Counting crowd using WiFi,” in 2014 IEEE INFOCOM, Toronto, Canada, pp. 361–369, 2014. [Google Scholar]
26. O. T. Ibrahim, W. Gomaa and M. Youssef, “CrossCount: A deep learning system for device-free human counting using WiFi,” IEEE Sensors Journal, vol. 19, no. 21, pp. 9921–9928, 2019. [Google Scholar]
27. C.-C. Chang and C.-J. Lin, “LIBSVM: A library for support vector machines,” ACM Transactions on Intelligent Systems and Technology, vol. 2, no. 3, pp. 1–27, 2011. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |