DOI:10.32604/csse.2021.017362
| Computer Systems Science & Engineering DOI:10.32604/csse.2021.017362 | |
| Article |
Inverse Length Biased Maxwell Distribution: Statistical Inference with an Application
1Department of Mathematics, Faculty of Science, Al al-Bayt University, Mafraq, Jordan
2Department of Mathematics, College of Science and Human Studies at Hotat Sudair, Majmaah University, Majmaah 11952, Saudi Arabia
*Corresponding Author: Ayed R. A. Alanzi. Email: a.alanzi@mu.edu.sa
Received: 28 January 2021; Accepted: 14 March 2021
Abstract: In this paper, we suggested and studied the inverse length biased Maxell distribution (ILBMD) as a new continuous distribution of one parameter. The ILBMD is obtained by considering the inverse transformation technique of the Maxwell length biased distribution. Statistical characteristics of the ILBMD such as the moments, moment generating function, mode, quantile function, the coefficient of variation, coefficient of skewness, Moors and Bowley measures of kurtosis and skewness , stochastic ordering, stress-strength reliability, and mean deviations are obtained. In addition, the Bonferroni and Lorenz curves, Gini index, the reliability function, the hazard rate function, the reverse hazard rate function, the odds function, and the distributions of order statistics for the ILBMD, are presented. The ILBMD parameter is estimated using the maximum likelihood method, the method of moments, the maximum product of spacing technique, the ordinary and weight least square procedures, and the Cramer-Von-Mises methods. The Fishers information, as well as the Rényi and q-entropies, are derived. To investigate the usefulness of the proposed lifetime distribution and to illustrate the purpose of the study, a real dataset of the relief times of 20 patients receiving an analgesic is used.
Keywords: Maxell distribution; inverse length biased Maxwell distribution; Fisher’s information; methods of estimation; goodness of fit tests
A random variable W follows a Maxwell distribution with scale parameter
where
and a cumulative distribution function defined as
The mode and median of the LBMD are
The rest of this paper is organized as follows: In Section 2, we present the derivation of the suggested distribution. Section 3 deals with the main statistical properties of the ILBMD. Different methods of estimation for the distribution parameter are given in Section 4. In Section 5, a simulation study is conducted to investigate the distribution. An application of real data is presented in Section 6 and the paper is concluded in Section 7.
2 Derivation of the Suggested Model
If a random variable W has a LBMD with pdf given in (3), then the random variable
and
Plots of the pdf and cdf of the ILBMD are presented in Fig. 1 for various distribution parameter. Fig. 1, revealed that the pdf of the suggested distribution is skewed to the right and be more flatting as
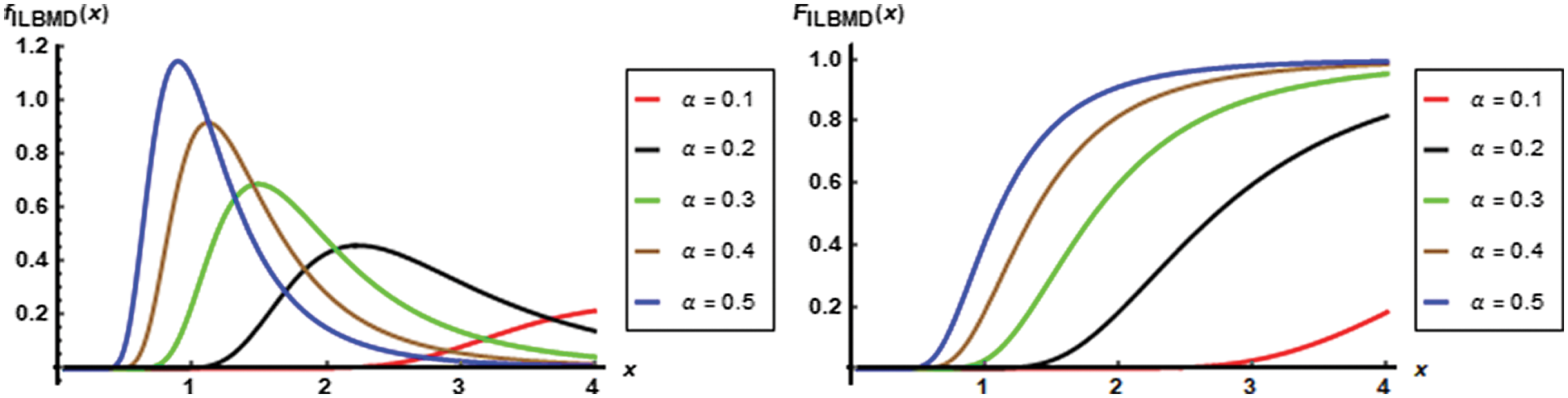
Figure 1: The ILBMD pdf and cdf plots for
In this section, the main properties if the proposed model are presented.
The reliability is a well-known in engineering where it gives the probability for surviving at least time t of a product operate, while the hazard function shows the nature of failure rate related to the product. Generally, the reliability and hazard functions are fundamental to study the characteristics of the time to event data. Figs. 2 and 3 are the plots of the hazard, reliability reversed hazard, and the odds functions of the ILBMD for
• Hazard rate function: The hazard rate (HR) function is a very important property in characterizing any lifetime distribution. The HR of the ILBMD is given by
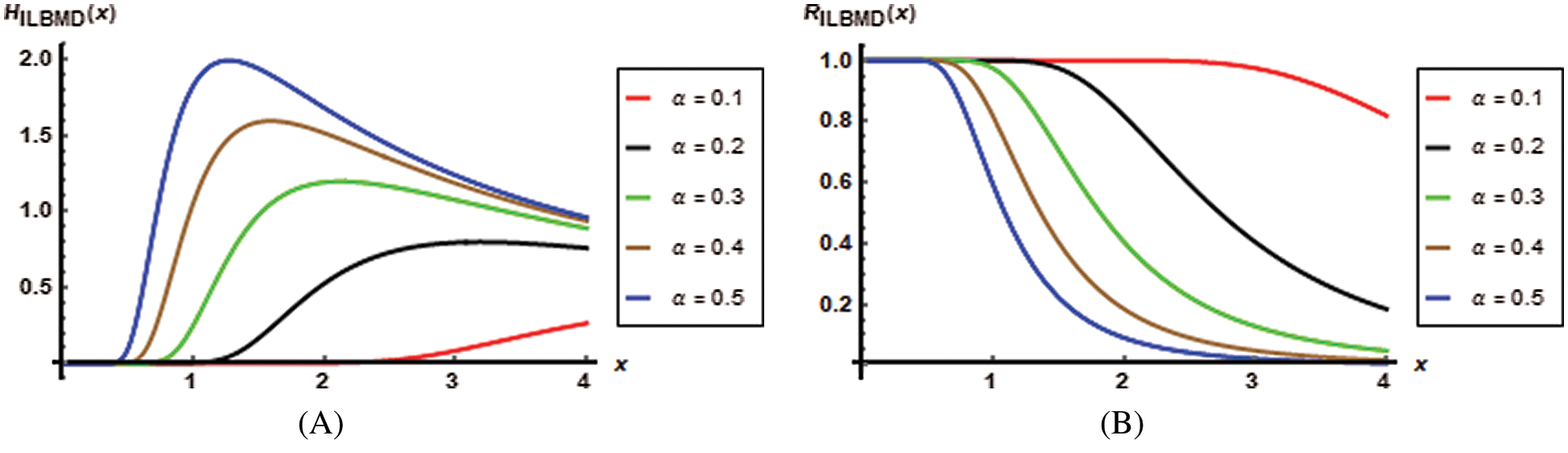
Figure 2: The hazard (A) and reliability (B) functions of the ILBMD plots for
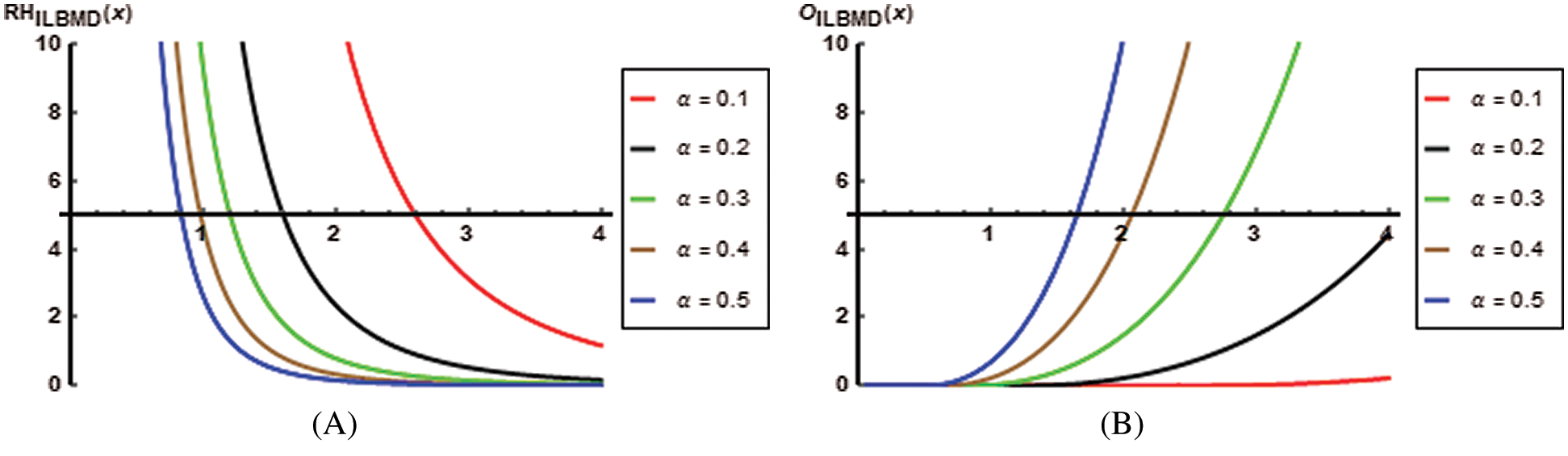
Figure 3: The reverse hazard (A) and odds (B) functions of the ILBMD plots for
To determine the shape of the HR function we followed the technique of [17] which is defined as
• Reliability function: The reliability function of the ILBMD distribution is
Fig. 2B shows that the reliability plots of the ILBMD intersect at the point
• Reversed hazard function: The reversed hazard function of the ILBMD is defined as
• Odds function: The odds function of the ILBMD is given by
Based on Fig. 3 it can be noted that the reversed hazard decreases with negative J-shaped distribution, while the odds function increases taking the J-shaped with more flatting for small amounts of the parameter
In this section, the mode of the ILBMD is derived. Since the pdf
The derivative of
3.3 Moments and Quantile Function
In this section, we derived the various moments of the suggested ILBMD as
• Let
• If
where
From Eq. (11), the first and second moments of the ILBMD, respectively, are given as
• The variance of the ILBMD is
• The degree of long-tail is measured by skewness (Sk) and for the ILBMD it is given by
• The coefficient of variation of the ILBMD is
which is a very small value.
• Let
Based on Eq. (6), the harmonic mean of the ILBMD distribution can be obtained for
If
The Moors and Bowley measures of kurtosis and skewness, respectively, are given by
Theorem: Let
Proof: To find the Fisher’s information of the ILBMD, we have
The first derivative of this function with respect to
Again differentiate the last equation with respect to
Now, take the expectation of
This information is very helpful in determining the variance of estimator or lower bound of an estimator.
Let
and the corresponding cdf is defined as
The stochastic ordering can be considered to compare the behavior of two random variables. Let X and Y be two random variables, then X is said to be smaller than in
1) Mean residual life order
2) Likelihood ratio order
3) Hazard rate order
4) Stochastic order
Based on these relations, we have
Theorem 2: Let
Proof: Based on the concept of the likelihood ratio order, we have
where its logarithm is
The first derivative of this equation with respect to x is
Now, if
3.7 Mean and Median Deviations
This section, introduced the mean and median deviations of the ILBMD,
where
Theorem: Let
where Erfc is the complementary function of the error function erfc, and
Since the median of the ILBMD is
The qth quantile xq of the ILBMD can be found by solving the equation
3.8 Gini Index and Some Curves
Let X be a non-negative random variable with a continuous twice differentiable cumulative distribution function
The Gini index for the ILBMD is given by
It is clear that the Gini index value is small and it is about 0.24. The Bonferroni curve for the ILBMD is defined as
The Lorenz curve for the ILBMD is defined as
3.9 Stress-Strength Reliability
Let X and Y be independent random variables observed from the pdf
Theorem: Let the random variables X and Y be independent selected from the ILBMD. The stress-strength reliability is given by
The Rényi entropy is defined as
• Let
• The q-entropy, say
4 Different Methods of Estimation
In this section, we discuss different estimation procedures for estimating the unknown suggested model parameter.
Let
The log likelihood function is given by
The derivative of
The mean of the ILBMD random variable is
4.3 Cramèr–von-Mises Estimation
Let
For the proposed ILBMD, the Cv estimator,
with respect to
4.4 Ordinary and Weighted Least Squares Methods
Let
For the ILBMD, the LS estimator,
with respect to
with respect to
with respect to
4.5 Method of Maximum Product of Spacing
The maximum product of spacing (MPS) method as suggested by Cheng et al. [20,21] is a powerful alternative to the MLE method for estimating the parameters of continuous distributions. Reference Shanker et al. [22] showed that the MPS method possess similar properties as the MLE method.
Let uniform spacing’s of a random sample of size n uniform spacing’s is given as be
where
Or, equivalently, by maximizing the function
Now, the MPS estimate of the ILBMD parameter
In this section, we compared the various suggested estimators of the model parameters. We selected the values of the parameters
Table 1: Estimates and MSEs with MLE, CV, and MOM methods for the ILBMD with
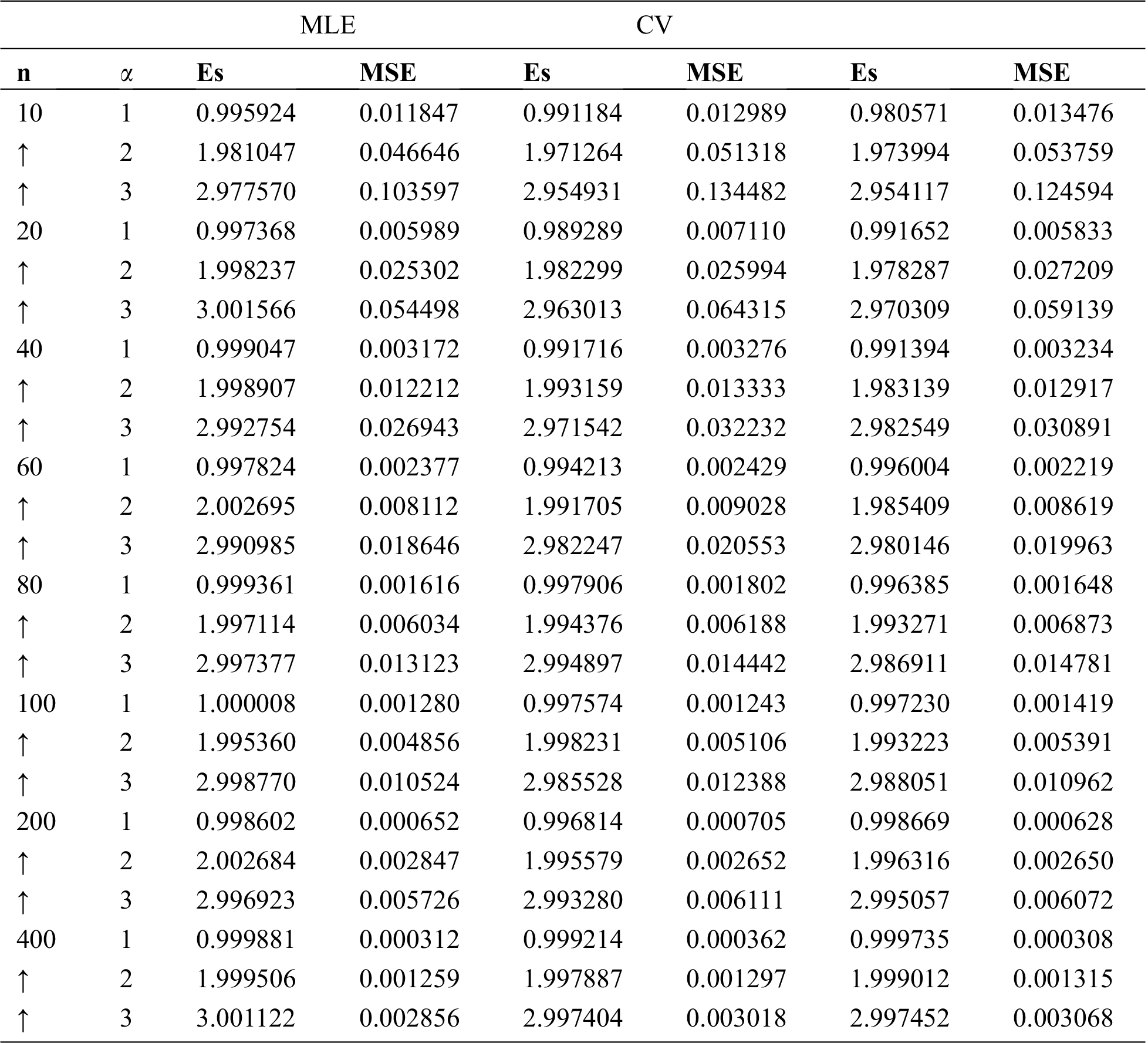
Table 2: Estimates and MSEs with LS, WLS, and MPS methods for the ILBMD with
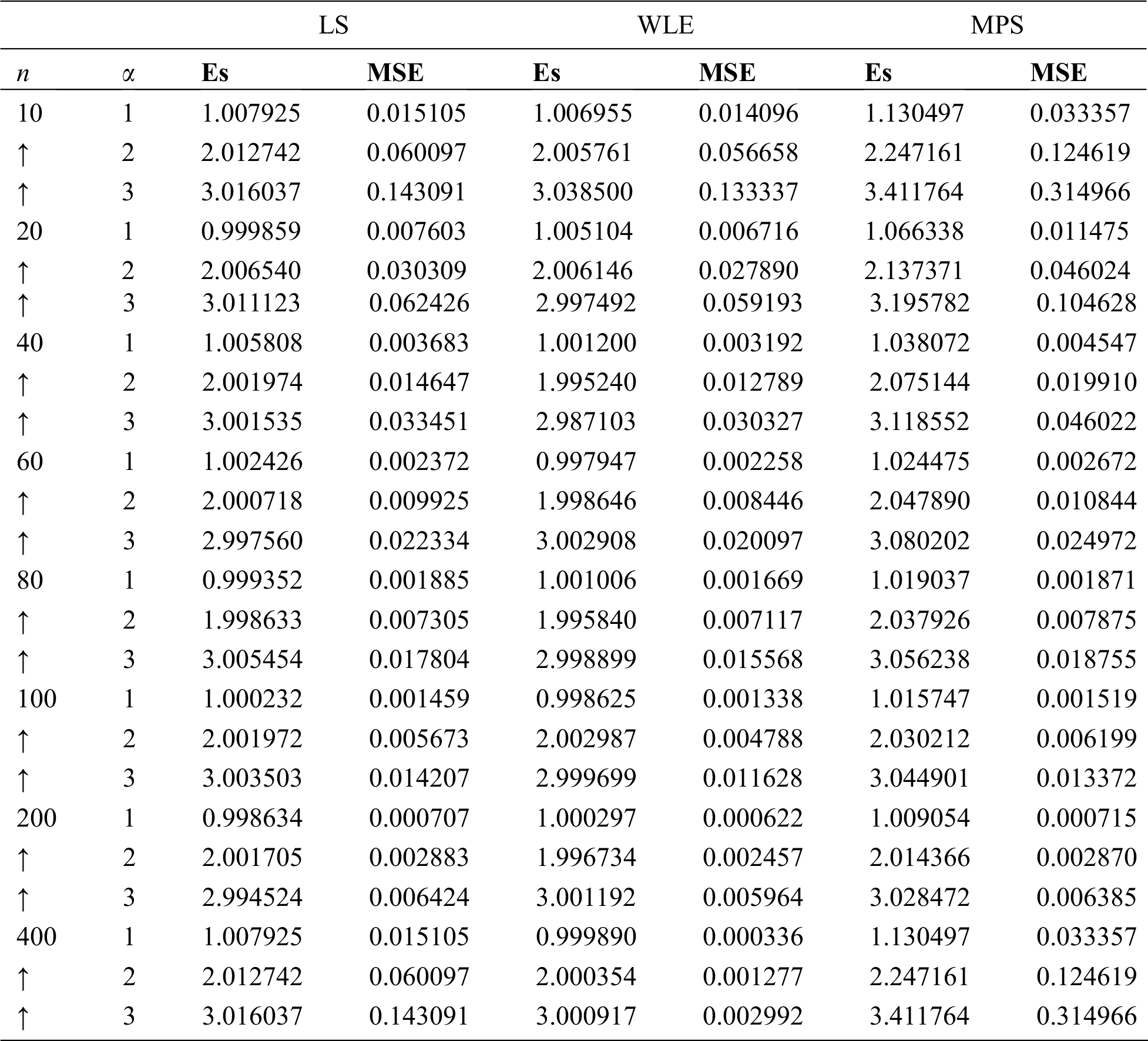
The bias of the suggested estimators is very small and goes to zero for all cases considered in this study. Also, as the samples sizes increase the MSE of all proposed estimators decreases.
In this section, we use lifetime data set to compare the fit of the suggested ILBMD distribution with four competitors distributions: Rani, length-biased Maxwell distribution, Rama, and exponential defined as
1) Rani distribution (Rn) suggested by Shanker et al. [23] with pdf given by
2) Length-biased Maxwell distribution (LBM),
3) Rama distribution (Rm) suggested by Gross et al. [24] with pdf given by
4) Exponential distribution (Exp),
The data set given in this section represents the relief times of 20 patients receiving an analgesic. This data set was taken from [25] and it is: 1.1, 1.4, 1.3, 1.7, 1.9, 1.8, 1.6, 2.2, 1.7, 2.7, 4.1, 1.8 ,1.5, 1.2, 1.4, 3.0, 1.7, 2.3, 1.6, 2.0.
In order to compare the two models, we consider the Akaike Information Criterion (AIC), Consistent Akaike Information Criterion (CAIC), Hannan-Quinn Information Criterion (HQIC), and Bayesian Information Criterion (BIC). The generic formulas for finding AIC, CAIC, HQIC, and BIC are respectively, given as
Table 3: Model comparison using AIC, CAIC, BIC, HQIC, -2logL, and the KS test criterion for the 20 patients data
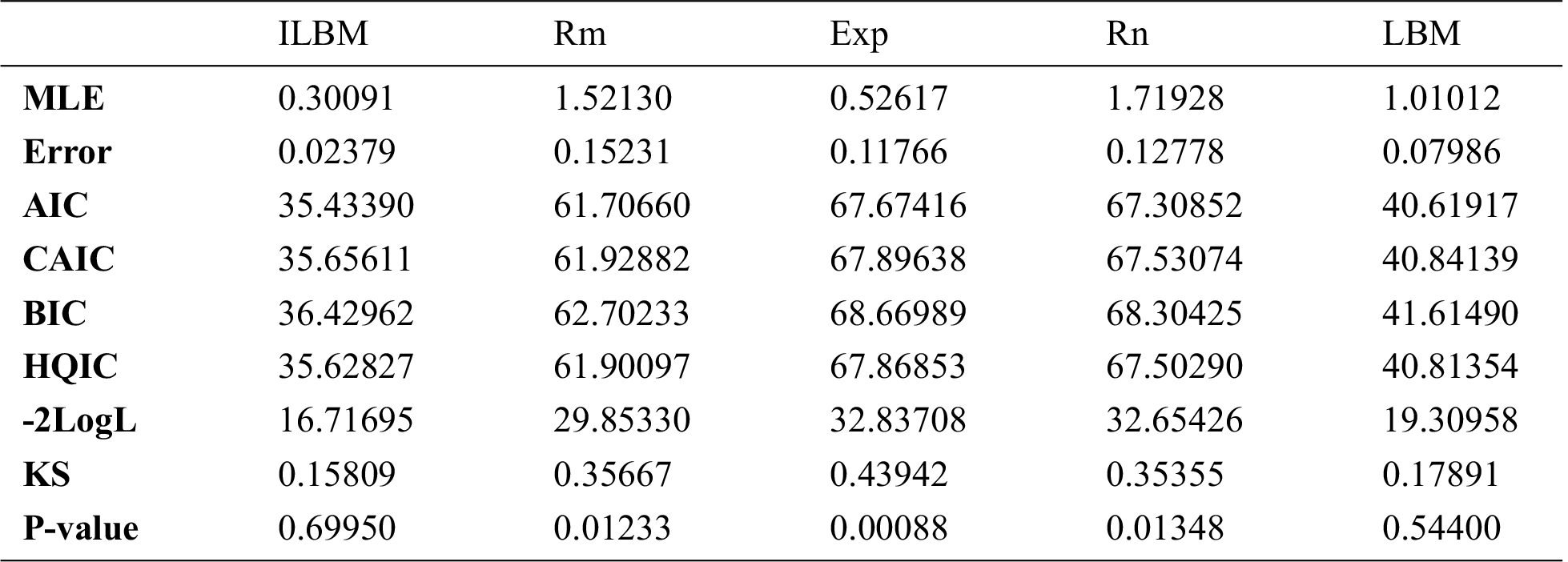
Hence, we can deduce that the inverse length biased Maxwell distribution leads to a better fit than the Rama, Rani, length biased Maxwell and exponential distribution. The Kolmogorov Smirnov p-value suggests that inverse length biased Maxwell distribution fits statistically better than other distributions considered in this example to the 20 patients data set. Plots of the fitted densities and the histogram are given in Fig. 4.
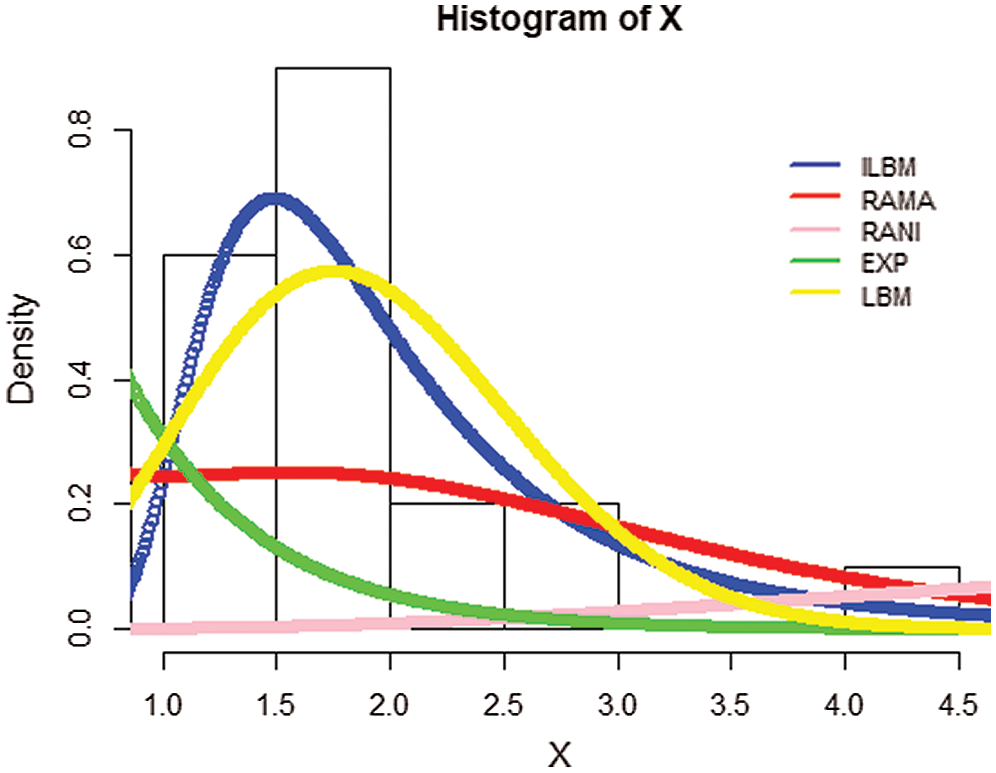
Figure 4: The fitted pdfs of the Rama, Rani, LBM, Exp and ILBM models
In this article, we introduced and studied the ILBMD. Some statistical properties of the ILBMD are derived and discussed. The reliability and hazard functions of the distribution are analyzed. Also, the distribution of order statistics, mode, harmonic mean, Fisher's information, the stochastic ordering and the mean deviations about the mean and median are presented. The distribution parameter is estimated using different estimation methods includes the maximum likelihood estimation, method of moments, maximum product of spacing, ordinary and weight least square procedures, and the Cramer-Von-Mises methods. The q and Rényi entropies are derived as well as the stress strength reliability is obtained. A real data sets is considered to support the paper objectives. It is revealed that the ILBMD is more power than its competitors used in this study. As a future works the distribution parameter can be estimated based on ranked set sampling method, see [26–32].
Acknowledgement: The authors are grateful to the Editor and anonymous reviewers for their valuable comments and suggestions.
Funding Statement: A.R.A. Alanzi would like to thank the Deanship of Scientific Research at Majmaah University for financial support and encouragement.
Conflicts of Interest: The authors declare that they have no conflicts of interest.
1. Y. A. Iriarte, J. M. Astorga, H. Bolfarine, H. W. Gómez et al., “Gamma-Maxwell distribution,” Communications in Statistics - Theory and Methods, vol. 46, no. 9, pp. 4264–4274, 2016. [Google Scholar]
2. J. Huang and S. Chen, “Tail behavior of the generalized Maxwell distribution,” Communications in Statistics-Theory and Methods, vol. 45, no. 14, pp. 4230–4236, 2016. [Google Scholar]
3. A. Saghir, A. Khadim and Z. Lin, “The Maxwell length-biased distribution: Properties and estimation,” Journal of Statistical Theory and Practice, vol. 11, no. 1, pp. 26–40, 2016. [Google Scholar]
4. C. R. Rao, J. Mathew and C. Chesneau, “On discrete distributions arising out of methods of ascertainment,” Sankhya: The Indian Journal Statististical Series A, vol. 27, pp. 311–324, 1965. [Google Scholar]
5. J. Mathew and C. Chesneau, “On discrete distributions arising out of methods of ascertainment,” Mathematical and Computational Applications, vol. 25, no. 4, pp. 1–21, 2020. [Google Scholar]
6. K. Modi and V. Gill, “Length-biased weighted Maxwell distribution,” Pakistan Journal of Statistics and Operation Research, vol. 11, no. 4, pp. 465–472, 2015. [Google Scholar]
7. K. L. Singh and K. L. Srivastava, “Estimation of the parameter in the size-biased inverse Maxwell distribution,” International Journal of Statistika and Mathematika, vol. 10, no. 3, pp. 52–55, 2014. [Google Scholar]
8. A. I. Al-Omari, A. D. Al-Nasser and E. Ciavolino, “A size-biased Ishita distribution and application to real data,” Quality & Quantity, vol. 53, no. 1, pp. 493–512, 2019. [Google Scholar]
9. M. Garaibah and A. I. Al-Omari, “Transmuted Ishita distribution and its applications,” Journal of Statistics Applications & Probability, vol. 8, no. 2, pp. 67–81, 2019. [Google Scholar]
10. R. M. Usman, M. A. Haq, S. Hashmi and A. I. Al-Omari, “The Marshall-Olkin length-biased exponential distribution and its applications,” Journal of King Saud University - Science, vol. 31, no. 2, pp. 246–251, 2019. [Google Scholar]
11. D. H. Shraa and A. I. Al-Omari, “Darna distribution: Properties and applications,” Electronic Journal of Applied Statistical Analysis, vol. 12, no. , pp. 520–541, 2019. [Google Scholar]
12. A. I. Al-Omari and I. K. Alsmairan, “Length-biased Suja distribution: Properties and application,” Journal of Applied Probability and Statistics, vol. 14, no. 3, pp. 95–116, 2019. [Google Scholar]
13. K. M. Alhyasat, K. Ibrahim, A. I. Al-Omari and M. A. Abu Baker, “Power size biased two-parameter Akash distribution,” Statistics in Transition New Series, vol. 21, no. 3, pp. 73–91, 2020. [Google Scholar]
14. V. K. Sharma, S. Dey, S. K. Singh and U. Manzoor, “On length and area biased Maxwell distributions,” Communications in Statistics - Simulation and Computation, vol. 47, no. 5, pp. 1506–1528, 2018. [Google Scholar]
15. A. I. Al-Omari and M. Gharaibeh, “Topp-Leone Mukherjee-Islam distribution: Properties and applications,” Pakistan Journal of Statistics, vol. 34, no. 6, pp. 479–494, 2018. [Google Scholar]
16. M. Gharaibeh, “Transmuted Aradhana distribution: Properties and applications,” Jordan Journal of Mathematics and Statistics, vol. 13, no. 2, pp. 287–304, 2020. [Google Scholar]
17. R. E. Glaser, “Bathtub and related failure rate characterizations,” Journal of the American Statistical Association, vol. 75, no. 371, pp. 667–672, 1980. [Google Scholar]
18. P. D. M. Macdonald, “Comment on an estimation procedure for mixtures of distributions by Choi and Bulgrem,” Journal of Royal Statistical Society, B, vol. 33, pp. 326–329, 1971. [Google Scholar]
19. J. Swain, S. Venkatraman and J. Wilson, “Least squares estimation of distribution functions in Johnson's translation system,” Journal of Statistical Computation and Simulation, vol. 29, no. 4, pp. 271–297, 1988. [Google Scholar]
20. R. C. H. Cheng and N. A. K. Amin, “Maximum product-of-spacings estimation with applications to the lognormal distribution, University of Wales IST, Math Report 79-1, 1983. [Google Scholar]
21. R. C. H. Cheng and N. A. K. Amin, “Estimating parameters in continuous univariate distributions with a shifted origin,” Journal of the Royal Statistical Society: Series B (Methodological), vol. 45, no. 3, pp. 394–403, 1983. [Google Scholar]
22. F. P. A. Coolen and M. J. Newby, “A note on the use of the product of spacings in Bayesian inference,” Technische Universiteit Eindhoven, 1990, (Memorandum COSOR; Vol. 9035). [Google Scholar]
23. R. Shanker, “Rani distribution and its application,” Biometrics & Biostatistics International Journal, vol. 6, no. 1, pp. 1–10, 2017. [Google Scholar]
24. R. Shanker, “Rama distribution and its application,” International Journal of Statistics and Applications, vol. 7, no. 1, pp. 26–35, 2017. [Google Scholar]
25. A. J. Gross and V. A. Clark, Survival distributions: Reliability applications in the biomedical sciences. New York: John Wiley and Sons, 1975. [Google Scholar]
26. A. Haq, J. Brown, E. Moltchanova and A. I. Al-Omari, “Ordered double ranked set samples and applications to inference,” American Journal of Mathematical and Management Sciences, vol. 33, no. 4, pp. 239–260, 2014. [Google Scholar]
27. A. Haq, J. Brown, E. Moltchanova and A. I. Al-Omari, “Varied L ranked set sampling scheme,” Journal of Statistical Theory and Practice, vol. 9, no. 4, pp. 741–767, 2015. [Google Scholar]
28. E. Zamanzade and A. I. Al-Omari, “New ranked set sampling for estimating the population mean and variance,” Hacettepe Journal of Mathematics and Statistics, vol. 45, no. 6, pp. 1891–1905, 2016. [Google Scholar]
29. A. Santiago, C. Bouza, J. M. Sautto and A. I. Al-Omari, “Randomized response procedure in estimating the population ratio using ranked set sampling,” Journal of Mathematics and Statistics, vol. 12, no. 2, pp. 107–114, 2016. [Google Scholar]
30. A. I. Al-Omari, “Estimation of mean based on modified robust extreme ranked set sampling,” Journal of Statistical Computation and Simulation, vol. 81, no. 8, pp. 1055–1066, 2011. [Google Scholar]
31. A. I. Al-Omari, “Ratio estimation of population mean using auxiliary information in simple random sampling and median ranked set sampling,” Statistics and Probability Letters, vol. 82, no. 11, pp. 1883–1890, 2012. [Google Scholar]
32. M. Syam, K. Ibrahim and A. I. Al-Omari, “The efficiency of stratified quartile ranked set sample in estimating the population mean,” Tamsui Oxford Journal of Information and Mathematical Sciences, vol. 28, no. 2, pp. 175–190, 2012. [Google Scholar]
 | This work is licensed under a Creative Commons Attribution 4.0 International License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. |