
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

An Efficient and Secure Data Audit Scheme for Cloud-Based EHRs with Recoverable and Batch Auditing
1 College of Cryptography Engineering, Engineering University of People’s Armed Police, Xi’an, 710086, China
2 Key Laboratory of Network and Information Security, Engineering University of People’s Armed Police, Xi’an, 710086, China
3 School of Information and Communication Engineering, Beijing University of Posts and Telecommunications, Beijing, 100876, China
* Corresponding Author: Xu An Wang. Email:
Computers, Materials & Continua 2025, 83(1), 1533-1553. https://doi.org/10.32604/cmc.2025.062910
Received 30 December 2024; Accepted 27 February 2025; Issue published 26 March 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Cloud storage, a core component of cloud computing, plays a vital role in the storage and management of data. Electronic Health Records (EHRs), which document users’ health information, are typically stored on cloud servers. However, users’ sensitive data would then become unregulated. In the event of data loss, cloud storage providers might conceal the fact that data has been compromised to protect their reputation and mitigate losses. Ensuring the integrity of data stored in the cloud remains a pressing issue that urgently needs to be addressed. In this paper, we propose a data auditing scheme for cloud-based EHRs that incorporates recoverability and batch auditing, alongside a thorough security and performance evaluation. Our scheme builds upon the indistinguishability-based privacy-preserving auditing approach proposed by Zhou et al. We identify that this scheme is insecure and vulnerable to forgery attacks on data storage proofs. To address these vulnerabilities, we enhanced the auditing process using masking techniques and designed new algorithms to strengthen security. We also provide formal proof of the security of the signature algorithm and the auditing scheme. Furthermore, our results show that our scheme effectively protects user privacy and is resilient against malicious attacks. Experimental results indicate that our scheme is not only secure and efficient but also supports batch auditing of cloud data. Specifically, when auditing 10,000 users, batch auditing reduces computational overhead by 101 s compared to normal auditing.Keywords
In the era of big data, a vast amount of sensitive information is being stored on cloud servers, and the associated data security issues in cloud storage have become increasingly prominent. In the cloud storage environment, the security measures provided by a single service provider are insufficient. Although cloud storage services are provided by major internet companies, absolute security cannot be guaranteed. Furthermore, in the event of data loss or corruption, companies may try to conceal the issue in order to protect their reputation and minimize potential losses. This highlights a critical issue: once users upload their data, they lose control over the original data, leading to a lack of trust in cloud storage. In electronic healthcare systems, Electronic Health Records (EHRs) are used to document users’ health data and identify their health status. Due to the large number of patients, some medical institutions store EHRs on cloud servers to reduce the pressure on local storage. However, since EHRs contain sensitive patient information, users must verify the integrity of their EHRs while ensuring their privacy is protected. Data integrity auditing can verify users’ data.
Generally, a cloud storage auditing protocol involves three entities: the user, the auditor, and the cloud server. Based on the security parameters, the user initializes the system and generates the system parameters. Subsequently, the user signs each block with a private key to obtain the block’s tags. The cloud server stores the data and the corresponding tags, while the user deletes all locally stored data and the generated tags. The auditor sends an audit request to the cloud server. The cloud server must return valid proof to the auditor. The auditor then verifies the proof.
A practical data audit scheme has garnered significant interest from researchers because of its broad practical utility. Recently, Zhou et al. [1] proposed a practical data audit scheme with retrievability. Their solution can achieve many excellent features, such as retrievability, indistinguishable privacy preservation, and dynamic updates. Nevertheless, it has come to our attention that a malicious cloud server has the capability to fabricate the labels of data blocks. Thus, even if a malicious cloud server were to remove all externally stored data, it could still present falsified evidence of having outsourced the data. Based on the scheme of Zhou et al., we provide data owners with a data audit scheme for cloud-based EHRs with recoverable and batch auditing. Our scheme can resist forgery attacks.
Specifically, we observed that during the auditing phase, a malicious cloud server, using public information, outsourced data, and auxiliary information related to the data at its disposal, can forge proof. This means that when the auditor verifies the validity of the proof, the forged proof provided by the malicious cloud server can still satisfy the verification equation. To address this, we redesigned the auditing phase by incorporating random masking techniques and hash functions. Moreover, the evidence provided by the cloud server must undergo stricter verification equations by the auditor. By combining random masking techniques and hash functions, our algorithm can resist both proof forgery attacks and replay audit attacks. Additionally, our scheme supports batch auditing, enabling the auditor to audit more data in the same amount of time. For users, this means they can monitor data dynamics in real time and quickly detect any data corruption.
In Section 2, we present recent work on cloud auditing protocols. In Section 3, we review Zhou et al.’s practical data audit scheme and introduce attacks against their algorithm. We introduce the system model, threat model, design goals, and preliminary knowledge in Section 4. In Section 5, we present a data audit scheme for cloud-based EHRs with recoverable and batch auditing. In Section 6, we provide formal proof of the security of the signature algorithm and the auditing scheme. Additionally, we demonstrate the privacy protection of the scheme and its ability to resist malicious attackers. In Section 7, we conduct a comparative analysis with other schemes. In Section 8, we present the conclusion of our paper.
In 2007, Ateniese et al. [2] introduced the Provable Data Possession (PDP) scheme, enabling users to securely store data on untrusted servers. Users have the capability to verify the integrity of the original data. However, this scheme only supports static auditing. During that same year, Juels et al. [3] presented the “Proofs of Retrievability” (POR) scheme, which utilizes sampling and erasure code techniques in cloud servers to ensure the retrievability and possession of data files. The scheme is capable of validating the integrity of stored data files and restoring data in the presence of sporadic errors. However, this scheme supports only a limited number of verifications. Both schemes verify data integrity, but the POR scheme incorporates erasure code techniques for data recovery. As the amount of stored data grows, users’ auditing tasks become increasingly burdensome. To solve this challenge, Wang et al. [4] proposed a publicly verifiable dynamic auditing scheme, which leverages Third Party Auditors (TPAs) to validate the integrity of dynamically stored data in the cloud. Cui et al. [5] improved the efficiency of auditing and user revocation by leveraging TPA, reducing many time-consuming operations. Wang et al. [6] also proposed a PDP protocol that supports third-party verification, implementing blind auditing and leveraging homomorphic signatures to aggregate data labels for batch auditing. For batch auditing, Huang et al. [7] implemented batch auditing for multiple files to reduce computational overhead. However, this scheme is vulnerable to malicious TPAs. Li et al. [8] designed a certificateless public auditing scheme that supports batch auditing, in which only designated auditors can verify the data.
To support dynamic updates of cloud data, Erway et al. [9] were the first to propose an integrity auditing scheme for dynamic data. To address the significant computational overhead generated during updates, Tian et al. [10] introduced the Dynamic Hash Table (DHT) for updating cloud data; however, their approach raises concerns about data confidentiality. Yuan et al. [11] designed a novel framework to support provable data possession schemes for dynamic multi-replica data. Bai et al. [12] and Zhou et al. [13] leveraged blockchain technology to enable dynamic updates on cloud data. However, their efficiency is constrained by the blockchain consensus protocol. Recently, Zhou et al. [14] implemented a dynamic multi-replica cloud auditing scheme using the Leaves Merkle Hash Tree (LMHT), which demonstrates improved performance in data deletion. Yu et al. [15] found that a malicious TPA could obtain sensitive information through replay audit attacks, posing significant privacy concerns. Shah et al. [16] proposed a public auditing scheme capable of resisting malicious TPA attacks. However, this scheme limits the number of audits and is restricted to encrypted files.
Numerous public auditing schemes [17,18–21], built upon Public Key Infrastructure (PKI), face the key limitation of expensive certificate management. Wang et al.’s identity-based PDP scheme [22] eliminates the need for certificate management. In the literature, an identity-based auditing scheme [23] has also been proposed. In their work, Wang et al. [23] tasked the auditor with creating tags and encrypting the file. Both PKI-based and identity-based auditing schemes face several challenges. Wang et al. [24] introduced a certificate-driven auditing approach that leverages bilinear pairings for verification in both private and public validation processes. The scheme supports both private and public verification, with private verification incurring lower computational costs than public verification. Shen et al. [25] proposed a certificateless PDP scheme for cloud-based electronic health records, enabling the restoration of corrupted data. In 2023, Zhou et al. [1] introduced a practical data auditing scheme. The auditing process is fast and efficient. However, Zhou et al.’s scheme [1] is vulnerable to evidence fabrication by adversaries. Our scheme retains the advantages of the original scheme while enhancing security. Importantly, our scheme addresses security flaws, offering improved security and resistance against forged evidence attacks.
3 Analysis Zhou et al.’s Scheme
Zhou et al. proposed an auditing scheme that ensures retrievability and privacy preservation [1]. In this section, we first review Zhou et al.’s scheme. Then, we identify the security weaknesses in its construction.
3.1 Review of Zhou et al.’s Scheme
Leveraging the Invertible Bloom Filter (IBF), Zhou et al. proposed a data auditing scheme. Due to the properties of the IBF, in the event of data corruption, users can utilize the remaining blocks to recover the damaged data blocks. Additionally, the scheme achieves indistinguishable privacy protection, even in the face of replay audit attacks.
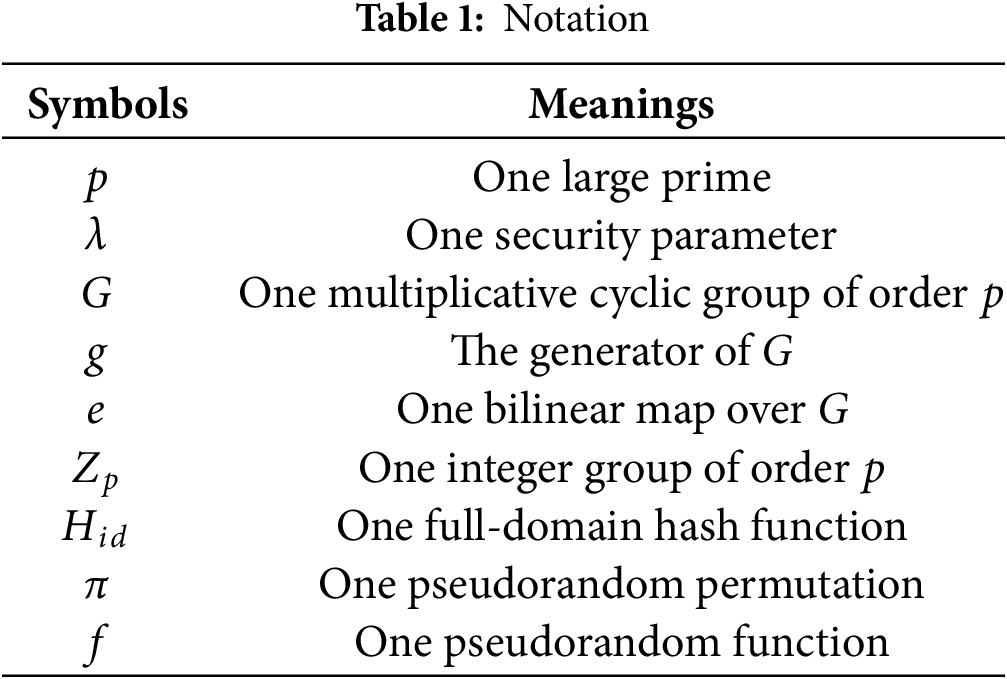
The scheme proposed by Zhou et al. employs the notation summarized in Table 1.
The user modifies a block after the
For the modify request
If the verification Eq. (1) holds true, the CS modifies the M and the HVL
If the Eq. (2) holds, it outputs 1; otherwise, it outputs 0. The TPA returns the result to the user.
We observe that when the CS executes the polynomial time algorithm
In this way, when the TPA executes the algorithm
The malicious CS does not need to store the data M and HVLs
Finally, the malicious CS is able to successfully attack Zhou et al.’s scheme by only storing the sequence
We propose a data auditing scheme with recoverability and batch auditing capabilities for EHRs. Our scheme is designed for patients and healthcare institutions, enabling patients to outsource their electronic health records to cloud services. If the data is found to be corrupted or lost, patients can recover it, ensuring the integrity and availability of the electronic health records. The TPA can perform batch audits on the patients’ EHRs. Our scheme’s system comprises five entities: data owners, sensors, data users, a third-party auditor, and a cloud server. The system model of our scheme is illustrated in Fig. 1.
• Sensors: Comprising wearable devices, embedded sensors, and body area sensors, they collect real-time health data from patients, such as heart rate, blood glucose levels, and physical activity status. As a result, sensors are considered trusted entities.
• Data Owner (DO): The data owner, who is always a patient, generates EHRs using sensors and other data collection devices. Once the data is collected, the patient encrypts and transmits it to the cloud server. The patient can dynamically update the data stored on the cloud server and recover it if the data is found to be corrupted or lost. The data owner is regarded as a trusted entity.
• Cloud Server (CS): The CS provides storage and computational resources for the medical data of data owners. When the third-party auditor issues an audit request, the CS generates a proof in response. However, due to unforeseen circumstances, the stored data may become corrupted, and in an effort to protect its reputation, the CS may forge a proof. As a result, the CS is regarded as a semi-trusted entity.
• Third Party Auditor (TPA): The TPA is authorized by the data owner to periodically audit the medical data stored in the cloud. However, the TPA may exhibit curiosity, such as by conducting repeated audits on the same data to gain additional insights. As a result, the TPA is regarded as a semi-trusted entity.
• Data User (DU): The DU is a user authorized by the DO to access the relevant EHR. Typically, the DU is the patient’s attending physician. During medical visits, the DO can grant key authorization to the DU, enabling them to download the encrypted EHR from the CS and decrypt it. The DU is regarded as a trusted entity.
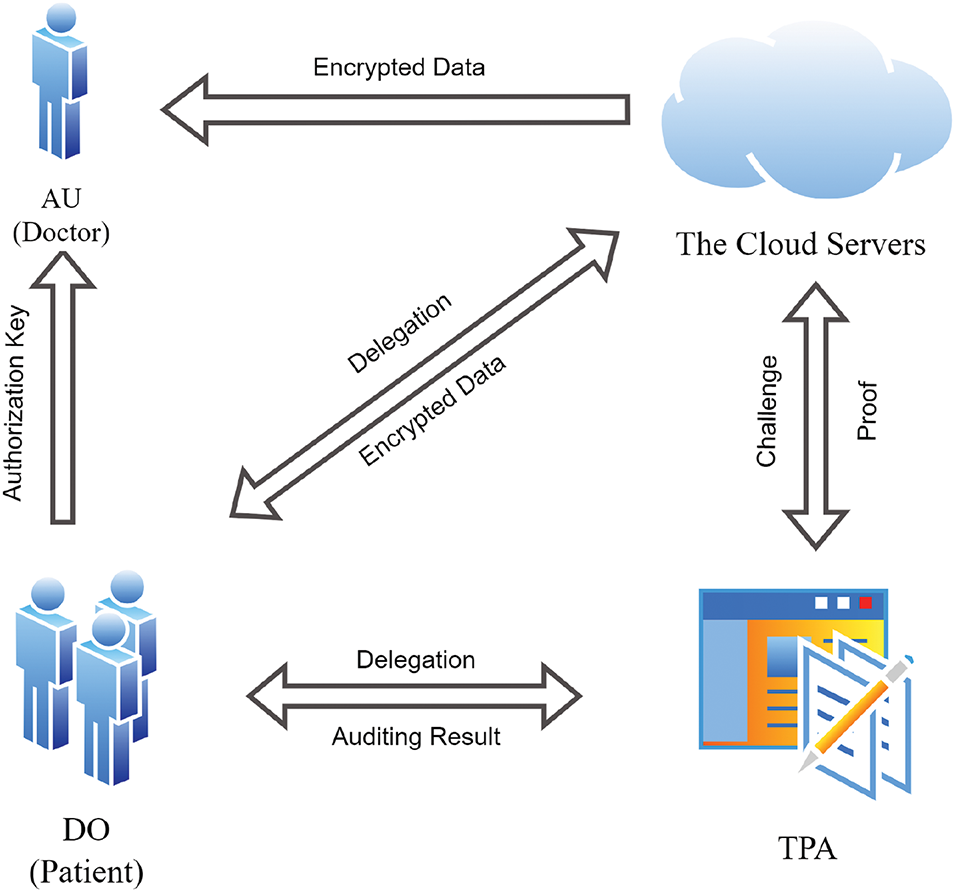
Figure 1: System model
The system leverages wearable devices, embedded sensors, and body-area sensors to collect real-time health data from patients, such as heart rate, blood sugar levels, and exercise status. This data is used to generate EHRs for the patients. Due to limitations in storage and computational resources, patients encrypt the data and transmit it to the cloud server, where dynamic update algorithms ensure timely updates to the health data. The CS stores the patients’ EHRs and generates data possession proofs in response to audit requests from the TPA. When doctors request access, the CS provides the relevant electronic health records. Authorized by the data owner, the TPA periodically sends audit requests to verify the integrity, accuracy, and privacy of the EHRs stored in the cloud. If the auditing algorithm fails, the TPA promptly notifies the patient of data corruption or loss. In such cases, the patient can utilize a data recovery algorithm to restore the damaged data. When seeking medical treatment, the patient provides the doctor with the decryption key. The doctor then downloads and decrypts the EHR from the CS to facilitate accurate diagnosis and treatment.
This system model integrates medical IoT, cloud computing, and privacy protection technologies to deliver an efficient, transparent, and secure collaborative framework for patients, doctors, and data auditors in complex healthcare environments.
In our threat model, the cloud server is considered untrustworthy and may behave maliciously. The cloud server may attempt to forge valid proofs to conceal data loss and preserve its reputation. The TPA is assumed to be curious. While it performs public verification of outsourced data integrity under user authorization and honestly participates in the auditing protocol, it may attempt to infer sensitive data information. We assume that the DO and DU will not compromise the scheme.
We classify potential adversaries into two categories:
Type I Adversary (
Type II Adversary (
It is important to note that both the CS and the auditor are considered ’semi-trusted,’ and their behavior may not always align with real-world scenarios. A malicious cloud server, having access to the data and tags, can generate forged proofs. A malicious auditor may exploit mathematical techniques to launch replay audit attacks and infer the content of the data. As a result, we treat both the CS and the TPA as untrusted entities. To address the issue of untrusted entities, we enhance the security of the signature algorithm to mitigate malicious cloud servers and strengthen the auditing algorithm to counteract malicious auditors. This ensures the integrity and privacy of the data while enhancing the reliability of the auditing process.
We aim to design a data auditing scheme with recoverability and batch auditing capabilities for EHR systems. The scheme not only enables data recovery but also facilitates batch auditing. Additionally, the scheme ensures correctness, privacy protection, and resistance to forgery attacks.
To ensure effective integrity auditing of outsourced data within the threat model, our scheme must fulfill the following objectives:
Functionality: Support for Dynamic Updates: Since the EHR of the DO may be updated dynamically, the data auditing scheme must support dynamic auditing. Data Recoverability: To enhance data availability, the scheme should enable the DO to recover corrupted data through data recovery operations, thereby improving data security. Batch Auditing: The auditor should deliver audit results to multiple data owners simultaneously. This ensures that the DO can promptly monitor the status of their EHR. In the event of a batch audit failure, a normal audit identifies the specific data owner’s EHR that is compromised and recovery algorithms can be applied to restore the corrupted data.
Security: Privacy Protection: The DO should encrypt their EHR data to safeguard the privacy of their medical information. During the auditing process, the auditor should neither require access to nor be able to retrieve the user’s stored data. Furthermore, the auditor must not infer any sensitive information about the user from the response messages.
Efficiency: Lightweight: To ensure the scheme is suitable for resource-constrained devices, the design should minimize communication overhead and computational costs during data auditing.
We use an IBF to compute data differences and improve IBF for recovering data blocks in cases of corruption. We first initialize the IBF as an empty table with
1. Encoding: Given a data
2. Decoding: Given two data
4.5
To recover corrupted data, we set


In this section, we propose a secure cloud-based EHR data auditing scheme designed to prevent data leakage. The scheme also incorporates an improved IBF to facilitate the recovery of corrupted data. In large-scale EHR systems, the DO collects real-time health data through sensors and uploads it to the CS. Our scheme comprises two components: Normal Audit and Batch Audit.
5.1 Construction of Our Scheme
In this section, we propose a more secure and privacy-preserving cloud auditing scheme. We adopt the same notation as Zhou et al.’s scheme [1]. The procedures of our scheme are illustrated in Fig. 2.
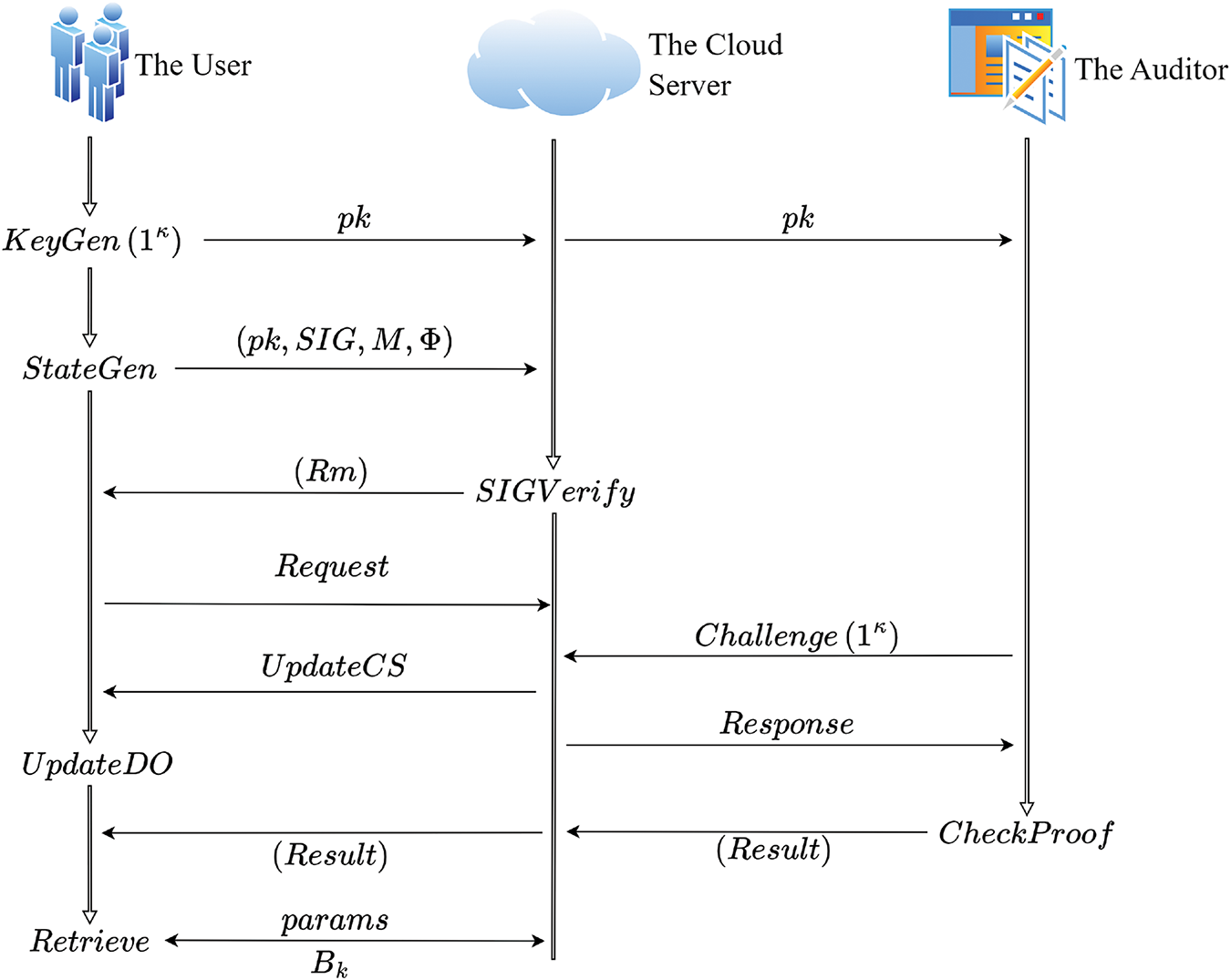
Figure 2: Procedures of our scheme
If Eq. (3) holds true, the CS updates the data M and the corresponding HVL
If Eq. (4) holds, it outputs 1; otherwise, it outputs 0. TPA returns the result.
Batch Audit:
To deliver timely audit results for multiple users, we introduce the batch auditing feature. In the event of a batch audit error, the normal audit is employed to identify the specific user and the problematic data block. Subsequently, the data recovery algorithm is applied to restore the corrupted data. If an error is detected during the batch audit, the need for separate audits for each user is minimized by isolating the issue to the specific user and data block, enabling faster response and recovery. The scheme facilitates batch auditing of cloud data for multiple data owners.
Let
The TPA selects two random numbers
If Eq. (5) holds, it confirms that the user’s data is intact. In this case, the TPA proceeds to perform batch auditing. Otherwise, the TPA conducts a standard audit to identify the specific DO and the data block that is compromised. The damaged data is then recovered using the recovery algorithm described in the following section.
The correctness of Eq. (4) is derived as follows:
The correctness of Eq. (5) is derived as follows:
In this section, we present the security proof of our scheme from two aspects: (1) the unforgeability of the auditing scheme and (2) the resistance to type I adversary
Theorem 1. Our signature algorithm is existentially unforgeable under adaptive chosen-message attacks (EUF-CMA).
Specifically, assume there exists an EUF-CMA adversary
Proof. The following proves that the signature algorithm can be reduced to the CDH problem. The adversary
The reduction process is as follows:
(1)
(2) Hash Query (up to
(1) If the list
(2) Otherwise,
(3) Tag Query (up to
(4) Output: The adversary
Theorem 2. Assume the hash function H is a random oracle. If the CDH assumption holds, then our scheme is existentially unforgeable under an adaptive chosen message attack.
Proof. Assume there is a challenger
Setup. The
Query. The
Hash query. The
Signature query. The
Forgery. Finally, under the challenge
Moreover, the challenger
Based on Eqs. (6) and (7), the challenger
In this way,
Theorem 3. Our scheme is resistant to malicious TPA attacks, thereby ensuring privacy protection. A malicious TPA cannot obtain the actual data from the proof provided by the CS.
Proof. We use random masking techniques to ensure data privacy and security. The CS introduces random numbers to protect data security. In our scheme,
Theorem 4. Our scheme is resistant to forgery attacks as described in Section 3.
Proof. In
□
We compared our scheme with schemes [5,7,8], and [1] in terms of functionality. As shown in Table 2, our scheme supports features such as dynamic updates, privacy protection, data recovery, and batch auditing. In contrast, none of the schemes [7,5,8], or [1] simultaneously satisfy all these functional requirements. Scheme [7] only supports batch auditing, while scheme [5] only supports privacy protection. Scheme [8] does not support data recovery for corrupted data, and scheme [1] does not support batch auditing. Our scheme overcomes these limitations and provides comprehensive functionality.

We compare the computational costs of each phase with schemes [5,7,8], and [1]. The notations in our scheme are described in Table 3. In our scheme, the data owner generates homomorphic verification labels before outsourcing the data. In Table 4, the computational cost for generating labels is

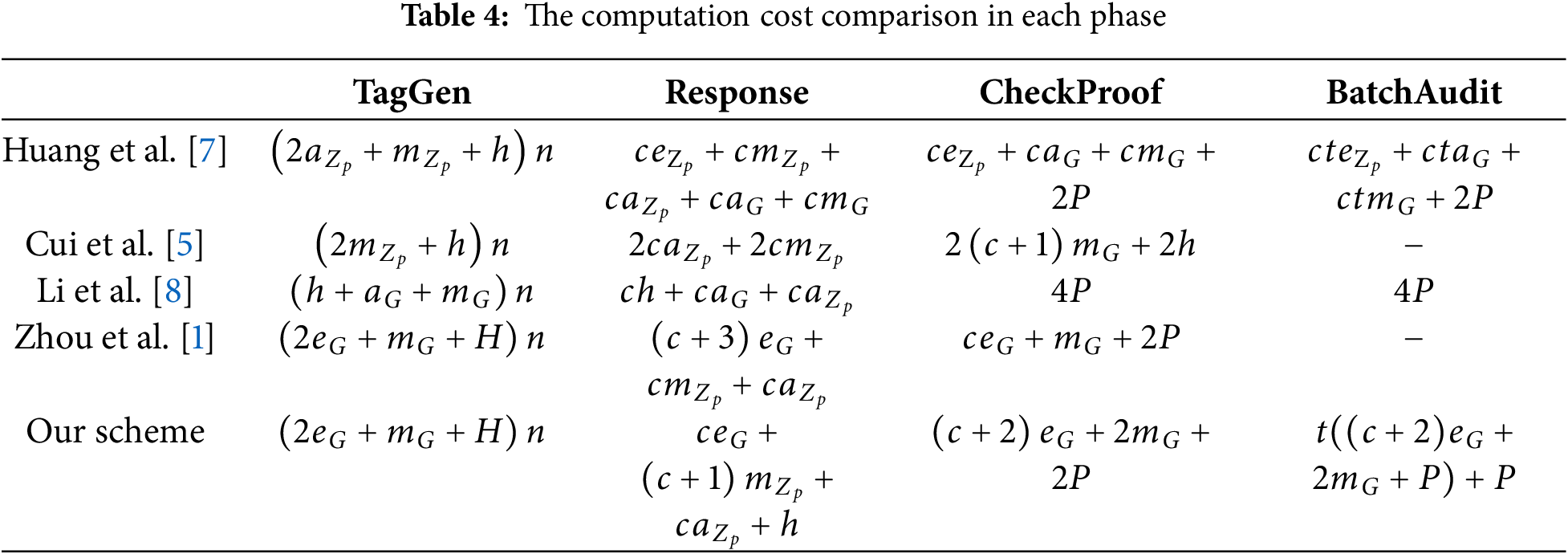
Table 4 shows that our scheme has the same computational cost as scheme [1] for generating homomorphic verification labels. For the
Compared to scheme [7], our scheme requires roughly the same computational cost in the
In this section, we analyze our scheme in terms of communication overhead and computational cost. Our experiments were conducted on a computer equipped with I7-9750H 2.60 GHz processor and 8 GB of memory. We implemented our scheme using the JAVA programming language and the JPBC cryptographic library. In the experiments, we selected a 512-bit base field size and a 160-bit size element in
Here,
We perform a simulation of our scheme on the computer. In Fig. 3a, we can see the runtime of each phase for scheme [1], and in Fig. 3b, we can observe the runtime of each phase for our scheme. Since we only modifies the
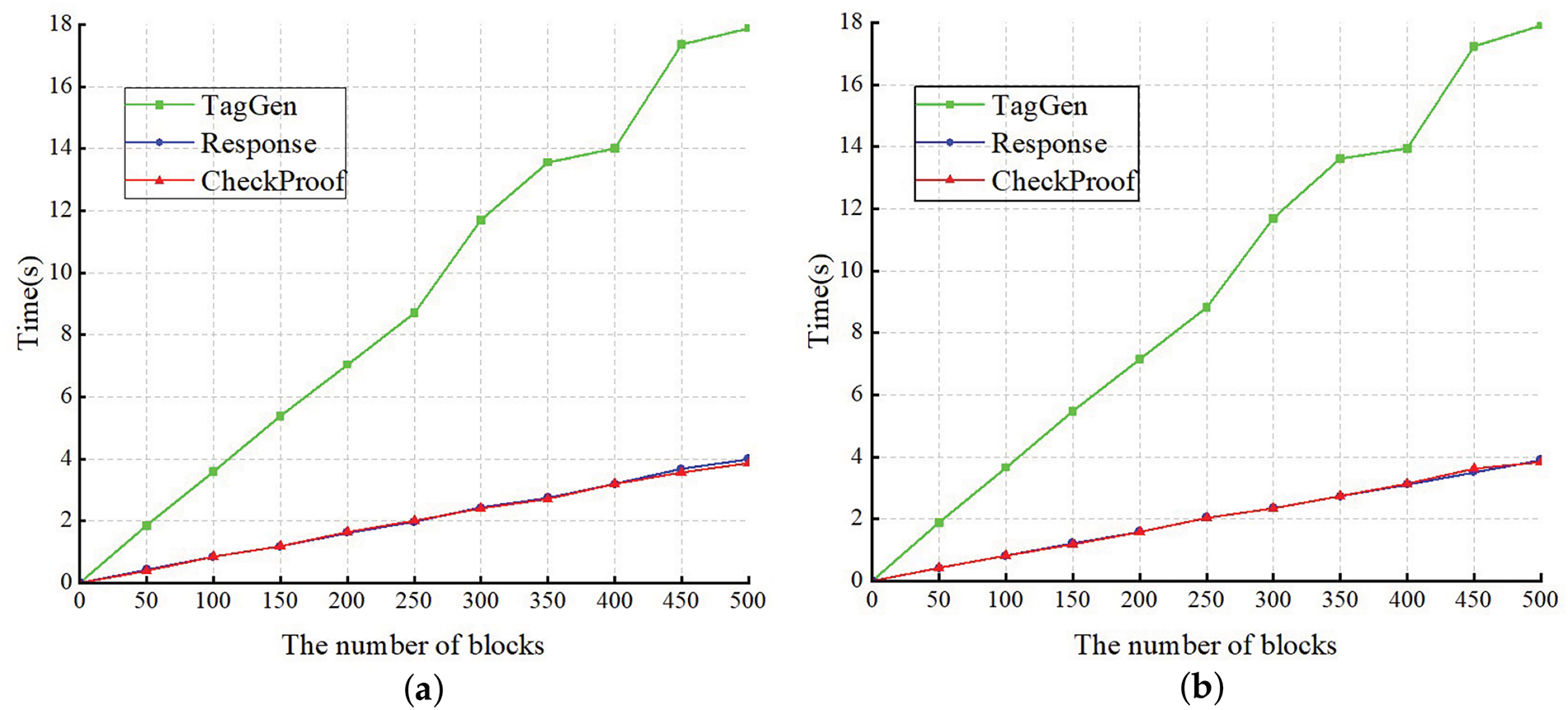
Figure 3: (a) Computation cost of the original scheme; (b) Computation cost of our scheme
In Fig. 4a, we compare the runtime of the
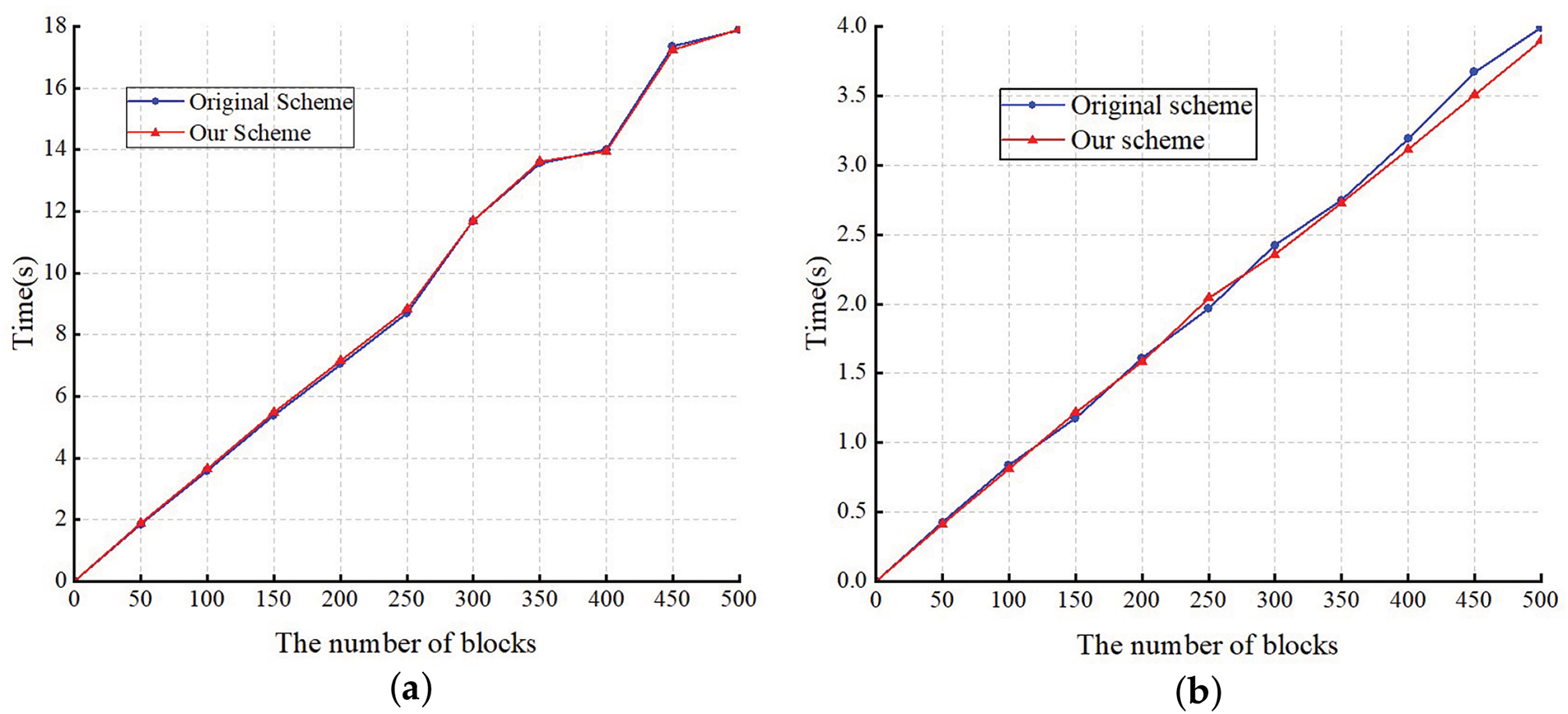
Figure 4: (a) Computational cost comparison in the TagGen phase; (b) Computational cost comparison in the Response phase
In Fig. 4b, we compare the runtime of the
In Fig. 5a, we compare the runtime of the
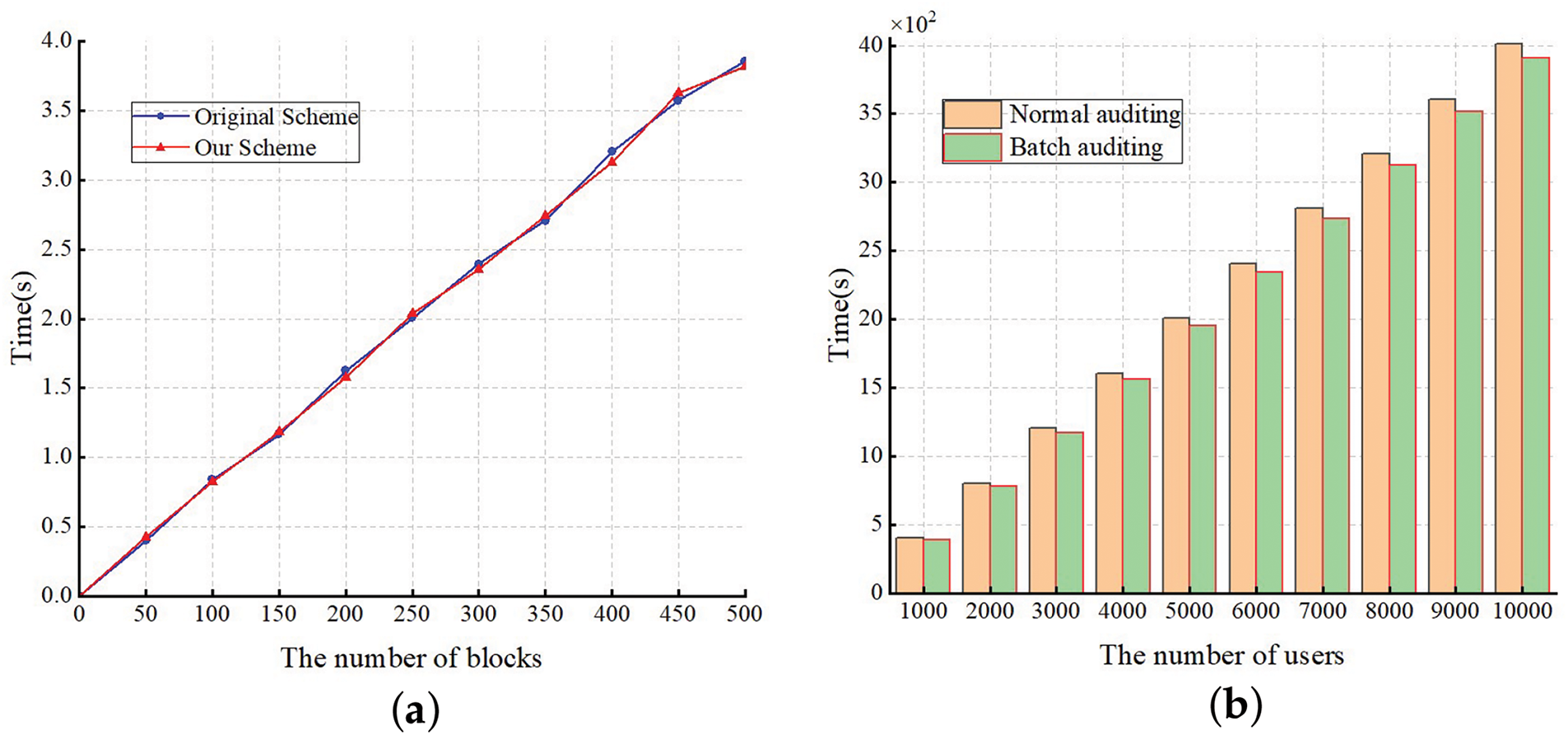
Figure 5: (a) Computational cost comparison in the CheckProof phase; (b) Comparison of normal auditing and batch auditing
In Fig. 5b, we evaluate the computational cost of auditing 0 to 10,000 different users simultaneously. The results in Fig. 5b demonstrate that the computational cost increases with the number of users. As the number of users increases, the advantages of batch auditing become more pronounced. Specifically, for 10,000 users, batch auditing reduces the computational cost by 101 s compared to normal auditing. Our scheme supports batch auditing, allowing the TPA to audit a larger volume of data in the same timeframe. For users, this enables timely monitoring of data status and rapid detection of data corruption.
For larger datasets, we implemented our auditing scheme across varying file sizes. As shown in Fig. 6, the signature time increases proportionally with the file size. It is worth noting that the proof generation and verification times exhibit minimal variation, as c is set to 460. Comparing Fig. 6a and b, we observe that although our scheme introduces additional computations during the auditing phase, the computational overhead remains minimal. Simultaneously, the scheme ensures enhanced security.
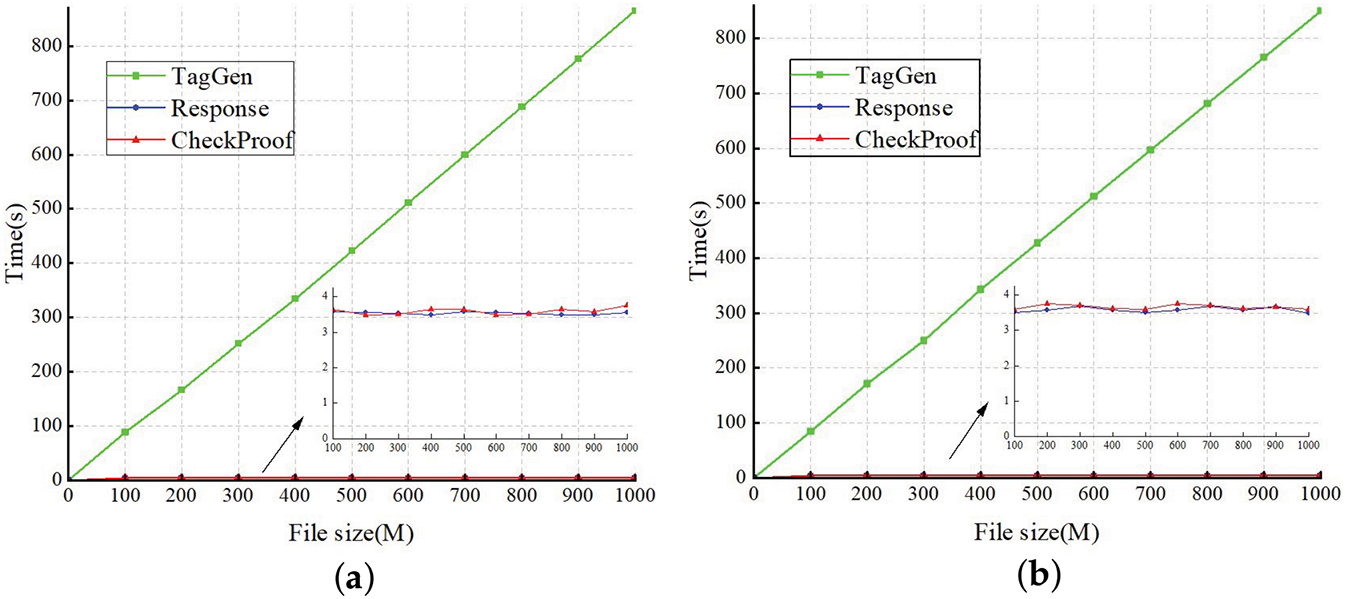
Figure 6: (a) Computation cost of the original scheme with different file sizes; (b) Computation cost of our scheme with different file sizes
To ensure the security of users’ data, Zhou et al. proposed a practical data auditing scheme. However, certain security issues have been identified during the auditing process. After identifying the issues in the original scheme, we propose an auditing scheme with recoverability and batch auditing capabilities to address these challenges. Our scheme incorporates masking techniques to enhance the auditing phase, ensuring secure data storage at a reduced cost. Additionally, we utilize an improved IBF to efficiently recover damaged data in the event of corruption. The security analysis demonstrates enhanced security, while the performance analysis reveals only a marginal increase in computational overhead. Most importantly, our scheme supports batch auditing, enabling the TPA to audit a larger volume of data within the same timeframe and allowing users to monitor data dynamics and rapidly detect data corruption.
Acknowledgement: The authors are grateful to all the editors and anonymous reviewers for their comments and suggestions.
Funding Statement: This work is supported by National Natural Science Foundation of China (No. 62172436). Additionally, it is supported by Natural Science Foundation of Shaanxi Province (No. 2023-JC-YB-584) and Engineering University of PAP’s Funding for Scientific Research Innovation Team and Key Researcher (No. KYGG202011).
Author Contributions: The authors confirm contribution to the paper as follows: Conceptualization, Yuanhang Zhang and Xu An Wang; methodology, Xu An Wang and Weiwei Jiang; validation, Mingyu Zhou; resources, Xiaoxuan Xu; data curation, Hao Liu; writing—original draft preparation, Yuanhang Zhang. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data that support the findings of this study are available from the corresponding author, Xu An Wang, upon reasonable request.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Zhou Z, Luo X, Wang Y, Mao J, Luo F, Bai Y, et al. A practical data audit scheme with retrievability and indistinguishable privacy-preserving for vehicular cloud computing. IEEE Transact Vehic Technol. 2023;72(12):16592–606. doi:10.1109/TVT.2023.3295953. [Google Scholar] [CrossRef]
2. Ateniese G, Burns R, Curtmola R, Herring J, Kissner L, Peterson Z, et al. Provable data possession at untrusted stores. In: Proceedings of the 14th ACM Conference on Computer and Communications Security; 2007; New York, NY, USA. p. 598–609. doi:10.1145/1315245.1315318. [Google Scholar] [CrossRef]
3. Juels A, Kaliski BS. Pors: proofs of retrievability for large files. In: CCS ’07. New York, NY, USA: Association for Computing Machinery; 2007. p. 584–97. doi:10.1145/1315245.1315317. [Google Scholar] [CrossRef]
4. Wang Q, Wang C, Li J, Ren K, Lou W. Enabling public verifiability and data dynamics for storage security in cloud computing. Vol. 5789. In: Computer security–ESORICS 2009. Lecture notes in computer science. Berlin/Heidelberg; Germany: Springer; 2009. p. 355–70. [Google Scholar]
5. Cui M, Han D, Wang J, Li K-C, Chang C-C. ARFV: an efficient shared data auditing scheme supporting revocation for fog-assisted vehicular ad-hoc networks. IEEE Transact Vehic Technol. 2020;69(12):15815–27. doi:10.1109/TVT.2020.3036631. [Google Scholar] [CrossRef]
6. Wang C, Chow SSM, Wang Q, Ren K, Lou W. Privacy-preserving public auditing for secure cloud storage. IEEE Transact Comput. 2013;62(2):362–75. doi:10.1109/TC.2011.245. [Google Scholar] [CrossRef]
7. Huang L, Zhou J, Zhang G, Zhang M. Certificateless public verification for data storage and sharing in the cloud. Chinese J Elect. 2020;29(4):639–47. doi:10.1049/cje.2020.05.007. [Google Scholar] [CrossRef]
8. Li R, Wang XA, Yang H, Niu K, Tang D, Yang X. Efficient certificateless public integrity auditing of cloud data with designated verifier for batch audit. J King Saud Univ-Comput Inf Sci. 2022;34(10, Part A):8079–89. doi:10.1016/j.jksuci.2022.07.020. [Google Scholar] [CrossRef]
9. Erway C, Küpçü A, Papamanthou C, Tamassia R. Dynamic provable data possession. ACM Trans Inf Syst Secur. 2015 Apr;17(4):1–29. doi:10.1145/2699909. [Google Scholar] [CrossRef]
10. Tian H, Chen Y, Chang CC, Jiang H, Huang Y, Chen Y, et al. Dynamic-hash-table based public auditing for secure cloud storage. IEEE Transact Serv Comput. 2017;10(5):701–14. doi:10.1109/TSC.2015.2512589. [Google Scholar] [CrossRef]
11. Yuan Y, Zhang J, Xu W. Dynamic multiple-replica provable data possession in cloud storage system. IEEE Access. 2020;8:120778–84. doi:10.1109/ACCESS.2020.3006278. [Google Scholar] [CrossRef]
12. Bai Y, Zhou Z, Luo X, Wang X, Liu F, Xu Y. A cloud data integrity verification scheme based on blockchain. In: 2021 IEEE SmartWorld, Ubiquitous Intelligence & Computing, Advanced & Trusted Computing, Scalable Computing & Communications, Internet of People and Smart City Innovation (SmartWorld/SCALCOM/UIC/ATC/IOP/SCI); Atlanta, GA, USA; 2021. p. 357–63. doi:10.1109/SWC50871.2021.00055. [Google Scholar] [CrossRef]
13. Zhou Z, Luo X, Bai Y, Wang X, Liu F, Liu G, et al. A scalable blockchain-based integrity verification scheme. Wirel Commun Mob Comput. 2022;2022(1):7830508. doi:10.1155/2022/7830508. [Google Scholar] [CrossRef]
14. Zhou H, Shen W, Liu J. Certificate-based multi-copy cloud storage auditing supporting data dynamics. Comput Secur. 2025;148(3):104096. doi:10.1016/j.cose.2024.104096. [Google Scholar] [CrossRef]
15. Yu Y, Au MH, Ateniese G, Huang X, Susilo W, Dai Y, et al. Identity-based remote data integrity checking with perfect data privacy preserving for cloud storage. IEEE Transact Inform Foren Secur. 2017;12(4):767–78. doi:10.1109/TIFS.2016.2615853. [Google Scholar] [CrossRef]
16. Shah MA, Swaminathan R, Baker M. Privacy-preserving audit and extraction of digital contents. Cryptology ePrint Archive. 2008; [cited 2025 Jan 20]. Available from: https://eprint.iacr.org/2008/186. [Google Scholar]
17. Shacham H, Waters B. Compact proofs of retrievability. J Cryptol. 2013;26(3):442–83. doi:10.1007/s00145-012-9129-2. [Google Scholar] [CrossRef]
18. Yan H, Li J, Zhang Y. Remote data checking with a designated verifier in cloud storage. IEEE Syst J. 2020;14(2):1788–97. doi:10.1109/JSYST.2019.2918022. [Google Scholar] [CrossRef]
19. Yu J, Ren K, Wang C, Varadharajan V. Enabling cloud storage auditing with key-exposure resistance. IEEE Transact Inform Foren Secur. 2015;10(6):1167–79. doi:10.1109/TIFS.2015.2400425. [Google Scholar] [CrossRef]
20. Yang K, Jia X. An efficient and secure dynamic auditing protocol for data storage in cloud computing. IEEE Transact Paral Distrib Syst. 2013;24(9):1717–26. doi:10.1109/TPDS.2012.278. [Google Scholar] [CrossRef]
21. Shen J, Shen J, Chen X, Huang X, Susilo W. An efficient public auditing protocol with novel dynamic structure for cloud data. IEEE Transact Inform Forens Secur. 2017;12(10):2402–15. doi:10.1109/TIFS.2017.2705620. [Google Scholar] [CrossRef]
22. Wang H, Wu Q, Qin B, Domingo-Ferrer J. Identity-based remote data possession checking in public clouds. IET Information Security. 2014;8(2):114–21. doi:10.1049/iet-ifs.2012.0271. [Google Scholar] [CrossRef]
23. Wang H, He D, Tang S. Identity-based proxy-oriented data uploading and remote data integrity checking in public cloud. IEEE Transact Inform Forens Secur. 2016;11(6):1165–76. doi:10.1109/TIFS.2016.2520886. [Google Scholar] [CrossRef]
24. Wang F, Xu L, Choo KKR, Zhang Y, Wang H, Li J. Lightweight certificate-based public/private auditing scheme based on bilinear pairing for cloud storage. IEEE Access. 2020;8:2258–71. doi:10.1109/ACCESS.2019.2960853. [Google Scholar] [CrossRef]
25. Shen J, Zeng P, Choo KKR, Li C. A certificateless provable data possession scheme for cloud-based EHRs. IEEE Transact Inform Forens Secur. 2023;18:1156–68. doi:10.1109/TIFS.2023.3236451. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools