
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

CPEWS: Contextual Prototype-Based End-to-End Weakly Supervised Semantic Segmentation
1 School of Computer Science, Zhengzhou University of Aeronautics, Zhengzhou, 450046, China
2 National Key Laboratory of Air-Based Information Perception and Fusion, Luoyang, 471000, China
3 Chongqing Research Institute of Harbin Institute of Technology, Chongqing, 401151, China
4 Aerospace Electronic Information Technology Henan Collaborative Innovation Center, Zhengzhou, 401151, China
* Corresponding Authors: Jiaqi Han. Email: ; Lingling Li. Email:
(This article belongs to the Special Issue: Novel Methods for Image Classification, Object Detection, and Segmentation)
Computers, Materials & Continua 2025, 83(1), 595-617. https://doi.org/10.32604/cmc.2025.060295
Received 29 October 2024; Accepted 02 January 2025; Issue published 26 March 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The primary challenge in weakly supervised semantic segmentation is effectively leveraging weak annotations while minimizing the performance gap compared to fully supervised methods. End-to-end model designs have gained significant attention for improving training efficiency. Most current algorithms rely on Convolutional Neural Networks (CNNs) for feature extraction. Although CNNs are proficient at capturing local features, they often struggle with global context, leading to incomplete and false Class Activation Mapping (CAM). To address these limitations, this work proposes a Contextual Prototype-Based End-to-End Weakly Supervised Semantic Segmentation (CPEWS) model, which improves feature extraction by utilizing the Vision Transformer (ViT). By incorporating its intermediate feature layers to preserve semantic information, this work introduces the Intermediate Supervised Module (ISM) to supervise the final layer’s output, reducing boundary ambiguity and mitigating issues related to incomplete activation. Additionally, the Contextual Prototype Module (CPM) generates class-specific prototypes, while the proposed Prototype Discrimination Loss and Superclass Suppression Loss guide the network’s training, effectively addressing false activation without the need for extra supervision. The CPEWS model proposed in this paper achieves state-of-the-art performance in end-to-end weakly supervised semantic segmentation without additional supervision. The validation set and test set Mean Intersection over Union (MIoU) of PASCAL VOC 2012 dataset achieved 69.8% and 72.6%, respectively. Compared with ToCo (pre trained weight ImageNet-1k), MIoU on the test set is 2.1% higher. In addition, MIoU reached 41.4% on the validation set of the MS COCO 2014 dataset.Keywords
Nomenclature
| CAM | Class Activation Mapping |
| CLIP | Contrastive Language-Image Pre-Training |
| CNNs | Convolutional Neural Networks |
| CPM | Contextual Prototype Module |
| CRF | Conditional Random Field |
| DeiT | Data-efficient Image Transformers |
| ISM | Intermediate Supervised Module |
| MAP | Mask Average Pooling |
| MIoU | Mean Intersection over Union |
| MLP | Multilayer Perceptron |
| PAR | Pixel-Adaptive Refinement |
| PDL | Prototype Discrimination Loss |
| SSL | Superclass Suppression Loss |
| ViT | Vision Transformer |
Weakly supervised semantic segmentation aims to train neural networks using weak labels to generate reliable pixel-level pseudo labels. Researcher only need to perform simple annotation on the dataset samples to obtain weak labels, which can greatly reduce annotation costs. The common types of weak labels include image-level labels [1], points [2], bounding boxes [3], and scribbles [4]. Image-level labels are particularly easy to obtain. Most studies use image-level labels for weakly supervised semantic segmentation, and the paper also uses image level labels to train the network. Most existing weakly supervised semantic segmentation methods follow two stages [5]. The first stage generates relatively accurate pixel-level pseudo labels, while the second stage uses these labels for model training. However, this two-stage process requires separate training for each stage, making the overall training complex and inefficient. Therefore, the paper employs an end-to-end [6] training method, where a single model is established and trained throughout the entire process. This approach allows for simultaneous model optimization and refinement of pixel-level pseudo labels, leading to improved segmentation results.
CAM [7] is a heat map generated by neural networks, which can convert image-level labels into pixel-level activation maps, assigning an activation value to each pixel to represent the activation intensity of the class in the image. Most weakly supervised semantic segmentation methods based on image-level labels first generate the CAM as the initial pseudo-label and subsequently refined [8] to produce a more reliable pseudo-label for model training. However, CAM has inherent limitations in semantic localization. It typically only activates the most recognizable semantic regions, leading to problems with incomplete activation and false activation of unknown classes. As illustrated in Fig. 1a, CAM activates only the most recognizable regions, such as the cats’, sheep’s, and dogs’ main body areas, while failing to fully activate the legs, resulting in incomplete activation. In Fig. 1b, the first row shows that CAM false associates branches with the bird’s tail due to their similarity, highlighting a problem of false activation. Similar issues are observed with the aircraft and runway in the second row, and with seawater and ships in the third row. These problems significantly impair the performance of weakly supervised semantic segmentation models.

Figure 1: (a) Incomplete activation. CAM fails to fully activate all relevant regions, leading to incomplete coverage of some target regions. (b) False activation. CAM mistakenly activates regions unrelated to the target
Recent studies have shown that incomplete activation often arises because most methods use CNNs to generate CAM. CNNs rely on smaller convolution kernels for local feature extraction, which makes it challenging to capture global information. For instance, Fatima et al. [9] present a solution to enhance CNN performance by incorporating U-Net for saliency estimation and adding residual connections, which help capture richer feature information and improves segmentation accuracy. Unlike traditional methods, the ViT employs a self-attention mechanism, enabling global feature extraction across the entire sequence. Additionally, position encoding in ViT preserves the sequence’s order and structural information, which enhances its ability to handle global information. For example, Ullah et al. [10] show that the self-attention mechanism in a lightweight ViT effectively captures global contextual information, enhancing the accuracy of recognition and classification for apple leaf diseases, while also demonstrating ViT’s advantage in processing global features. In contrast, traditional CNN-based methods are limited to local feature extraction. However, during feature extraction, object boundaries often become ambiguous, and adjacent patch tokens tend to exhibit increasing similarity. To address this, the paper improves feature extraction with ViT by utilizing an intermediate layer that preserves more semantic information and introducing an ISM. Specifically, ISM module inputs the intermediate layer features into a classifier to generate CAM, which then obtains cosine similarity relationships to supervise the high-level features. This helps generate more accurate pseudo labels, reducing boundary ambiguity and mitigating issues related to incomplete activation.
The problem of false activation has been investigated by some scholars [11] (detailed in relevant work). However, these methods heavily rely on additional supervision or human prior knowledge to identify categories with co-occurrence problems. This paper introduces a method based on class prototypes, adapted from the field of few-shot semantic segmentation, to achieve accurate segmentation without additional supervision (such as saliency maps, text information, additional supplementary data). In few-shot semantic segmentation, a single class representation prototype is typically used, but this often results in the activation of only a small number of pixels due to incomplete feature information extraction. In contrast, our integrated CPM method captures more accurate category features. By generating category-specific positive prototypes to represent the foreground and negative prototypes to represent the background using image-level labels, the paper address the issue of false activation. Furthermore, the paper propose
This method achieved state-of-the-art results on the PASCAL VOC 2012 [12] and MS COCO 2014 [13] datasets. The key contributions of this work are as follows:
• This work proposes a novel end-to-end network model for weakly supervised semantic segmentation, named Contextual Prototype-Based End-to-End Weakly Supervised Semantic Segmentation (CPEWS), which stores contextual prototypes in a fixed pool of positive and negative prototypes to preserve their stability throughout the training process.
• By employing ViT as the backbone, this approach effectively captures global contextual information and models long-range dependencies across different regions of the image. The introduction of the ISM leverages the cosine similarity of intermediate layer features to supervise high-level features, reducing boundary ambiguity and mitigating incomplete activation.
• By employing the CPM, class-specific prototypes are generated using k-means clustering and class probability predictions. Based on these prototypes, the paper introduces two novel loss functions
• Extensive experiments on the PASCAL VOC 2012 and MS COCO 2014 datasets show that CPEWS achieves state-of-the-art performance in end-to-end weakly supervised semantic segmentation without additional supervision.
The rest of the paper is organized as follows. Section 2 primarily introduces the key techniques and advancements in the field of weakly supervised semantic segmentation, including end-to-end methods, incomplete activation, prototype learning, and false activations. Section 3 presents an overview of the proposed network framework, including the ISM and CPM modules. Section 4 primarily analyzes the experimental details. Section 5 summarizes the methods proposed in the paper, discusses potential future developments, and highlights the limitations of the proposed model.
End-to-end weakly supervised semantic segmentation. Training a well-performing end-to-end weakly supervised semantic segmentation network is challenging due to the reliance on weak labels for supervision. Chen et al. [14] introduce a multi-granularity denoising module that addresses saliency maps noise and reduces the disparity between simple and complex data through a bidirectional alignment mechanism. Yang et al. [15] spatially separate co-occurring objects by subdividing the image into smaller blocks. In the feature space, semantic representation is enhanced through multi-granularity knowledge comparison, which effectively addresses the issue of false activations. Yang et al. [16] introduce uncertainty estimation to reduce bias and propose an affinity diversification module to foster greater semantic diversity. These methods excel in local feature extraction by leveraging CNN architectures, enabling them to efficiently capture fine-grained local information. However, the inherent limitation of CNNs lies in their constrained receptive fields, especially for tasks that require modeling long-range dependencies. To address this challenge in weakly supervised semantic segmentation, this paper introduces the ViT, which offers superior global feature modeling and effectively captures the relationships between different regions in the image.
Incomplete activation. ViT has shown strong performance in image processing tasks and has achieved significant breakthroughs in recent years. Recent research has begun integrating ViT into weakly supervised semantic segmentation tasks. Ru et al. [17] learn semantic affinity from Transformer’s multi-head self-attention and design a Pixel-Adaptive Refinement module (PAR) combined with low-level visual information to further ensure local consistency of pseudo-labels. Sun et al. [18] capture class label attention by extracting gradients from attention maps and mapping other labels to their corresponding classes. Xu et al. [19] embed multiple class labels to enable the model to learn activation maps for different classes individually. Wu et al. [20] employ a dual-student framework with reliable progressive learning, leveraging discrepancy loss to generate multiple CAMs. These CAMs provide mutual supervision, helping to reduce incomplete activation caused by the learning of incorrect pseudo labels. These methods demonstrate the potential of ViT in weakly supervised semantic segmentation, where the attention mechanism and class labeling information can be effectively utilized to improve segmentation performance. However, these methods do not address the issue of boundary ambiguity that arises with ViT. In this paper, intermediate layer knowledge is used to supervise the features output by the last layer to improve boundary ambiguity and solve the problem of incomplete activation.
Prototype learning. Prototype learning has been extensively studied in few-shot semantic segmentation. The theory of prototype learning [21] demonstrates that prototypes can represent local features, global features, or specific properties of objects. Example prototypes [22] can dynamically represent the discriminant features of specific images, effectively handling intra-class variations in object features. Contextually integrated prototypes [23] can capture more specific and accurate categorical semantic patterns. Lang et al. [24] employ a two-stage training strategy. In the first stage, semantic segmentation is used to train extractors, and prototypes are generated through Mask Average Pooling (MAP). In the second stage, meta-learning is applied to integrate base classes with new classes. Kayaba et al. [25] build on this approach by adding multi-scale fusion, effectively addressing the issue of spatial inconsistency. Tang et al. [26] capture feature differences through contextual awareness and enhance model representation by aligning feature distributions. While these methods all leverage prototype learning and context-aware strategies to strengthen the expressive power of semantic segmentation, they incorporate prototypes as dynamic components of the learning model. In contrast, this paper stores prototypes in a fixed pool prior to training to ensure their stability. Additionally, loss functions are designed to optimize network parameters and enhance the model’s ability to extract instance information.
False activation, also known as overactivation, refers to the false activation of the CAM in non-target regions. This problem has garnered significant attention in recent years. Chen et al. [27] optimize CAM to generate high quality pixel-level pseudo-labels by removing the co-occurrence relationship between categories in the image. Lee et al. [28] use saliency maps as pseudo pixel feedback to distinguish foreground objects from co-occurring backgrounds. Xie et al. [29] suppress background objects by inputting a series of preset background descriptions into the text encoder of the Contrastive Language-Image Pre-Training (CLIP) network and leveraging a pre-trained model. Lee et al. [30] enhance the network’s ability to distinguish between targets and backgrounds by manually collecting additional training images containing co-occurring background objects. Zhang et al. [31] build on the CLIP model by using CLIP as a frozen backbone network for semantic feature extraction, while introducing a new decoder to interpret these features for prediction. These methods effectively address the challenge of separating foreground and background in weakly supervised semantic segmentation through innovative techniques. However, they heavily depend on additional supervision or human prior knowledge to identify categories with co-occurrence issues, which can result in false activations. In contrast, this paper’s solution avoids the use of extra supervisory information or human knowledge. Instead, it addresses the foreground-background separation issue by incorporating contextual prototypes.
The paper propose the CPEWS model for weakly supervised semantic segmentation, as illustrated in Fig. 2. This model employs ViT as the backbone to extract high-level features
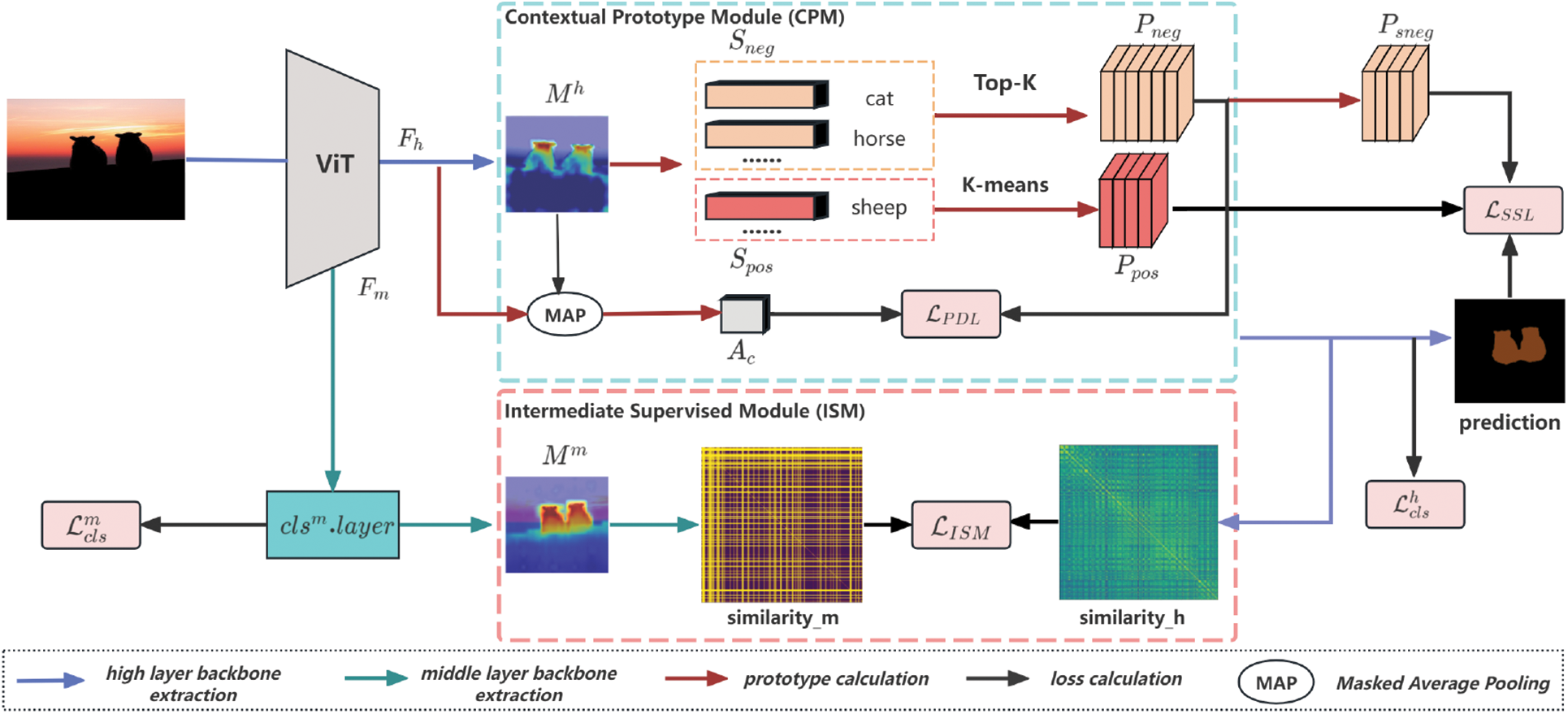
Figure 2: Overall framework of CPEWS. ISM introduces cosine similarity of intermediate layer features as an auxiliary supervision signal; CPM is used to generate positive and negative prototypes of a specific class, and to calculate the loss using the generated prototypes
3.1 Intermediate Supervised Module
The ViT is employed to effectively model global contextual information, capture long-range dependencies across different regions of the image, and leverage intermediate layer knowledge to reduce boundary ambiguity, thereby addressing the issue of incomplete activation. As shown in Fig. 2, the training data is fed into the ViT as an input sequence. The image X is flattened and linearly projected into tokens. In each Transformer block, multi-head self-attention is used to capture global feature dependencies. Specifically, for the
where, X represents the image sequence,
where, h represents the number of attention heads.
Simultaneously, ISM is introduced. In the feature extraction process of the ViT backbone network, this method introduces a linear classification layer in the intermediate layer. Experiments indicate that, among the 12 blocks in ViT, the later layers retain more semantic information, while the earlier layers lack advanced feature capture. This linear classification layer generates an auxiliary class activation map
where, c denotes the category, d represents the dimensionality of the feature map,
Subsequently, Using thresholds
where,

3.2 Contextual Prototype Module
This module uses CPM to capture more accurate prototypes of specific classes. Specifically, it enhances the expressive power of category features by exploring the relationships between specific instances and other instances, constructing contextual prototypes. The high-level features
where i is the pixel on the class localization map
To store positive and negative samples, the paper establish the positive sample pool
The production processes for prototypes

3.3 Prototypical Discrimination Loss and Superclass Suppression Loss
To train the network with positive sample prototypes
where, the prototype
where, the parameter
The
where,
Although this loss effectively suppresses co-occurrence background, some foreground information is also suppressed. For example, the front of a bus may be collected as false information from the front of a train, which can lead to the network suppressing the information from the front of the train. To solve this problem, a superclass information is proposed, which leverages the information provided by a known dataset to filter out shared negative prototypes and reconstruct class relationships. Specifically, when calculating
By jointly optimizing
As illustrated in Fig. 2, the CPEWS model is comprised of five optimization loss functions: classification loss (
where,
Dataset. This paper utilizes widely used datasets, PASCAL VOC 2012 and MS COCO 2014, in the field of weakly supervised semantic segmentation. PASCAL VOC 2012 features 21 semantic categories (including background) and is often extended with the SBD dataset. The expanded dataset includes 10,582 training images, 1449 validation images, and 1464 test images, covering 20 common categories such as humans, animals, vehicles, and daily necessities. MS COCO 2014, a more challenging and large-scale dataset, encompasses 81 categories (including background) across people, animals, transportation, and electronic products. This dataset consists of 83 K images for training, 40 K images for validation, and 41 K images for testing.
Evaluation indicators. Effective evaluation metrics are essential for assessing the performance of weakly supervised semantic segmentation models. Commonly used indicators include execution time and Mean Intersection over Union (MIoU). Execution time is an important metric, but hardware configuration can influence this factor. As a result, many weakly supervised semantic segmentation studies do not provide detailed results. MIoU is commonly used for the accuracy of weakly supervised semantic segmentation models, and the specific calculation formula is:
where, G denotes the ground truth, P denotes the predicted result, C represents the total number of categories.
Experimental conditions. The experimental conditions in this study includes 48 GB of RAM, an NVIDIA GeForce RTX 4090 with 24 GB. The software environment consists of Python 3.9, PyTorch 1.12.1+cu116, torchaudio 0.12.1+cu116, and torchvision 0.13.1+cu116.
Parameter settings. The experiment employs the ViT-base (ViT-B) [32] as the backbone network, initialized with ImageNet pre-trained weights [33]. The PolyWarmupAdamW optimizer is used for training, with the following parameter settings: momentum set to
The hyperparameter settings in Table 1 were optimized using various strategies. The momentum reference was set according to [34]. The weight decay factor and warm-up learning rate were optimized via cross-validation. Initially, common values (e.g., 0.01, 0.001, 0.0001) were chosen, followed by K-fold cross-validation to evaluate different hyperparameter combinations. Ultimately, the best-performing set of parameters was selected. The number of network iterations was determined based on prior literature [35]. Experimental results indicate that the MIoU value achieves optimal performance when the batch size is set to 4. The parameters for the number of prototypes K and
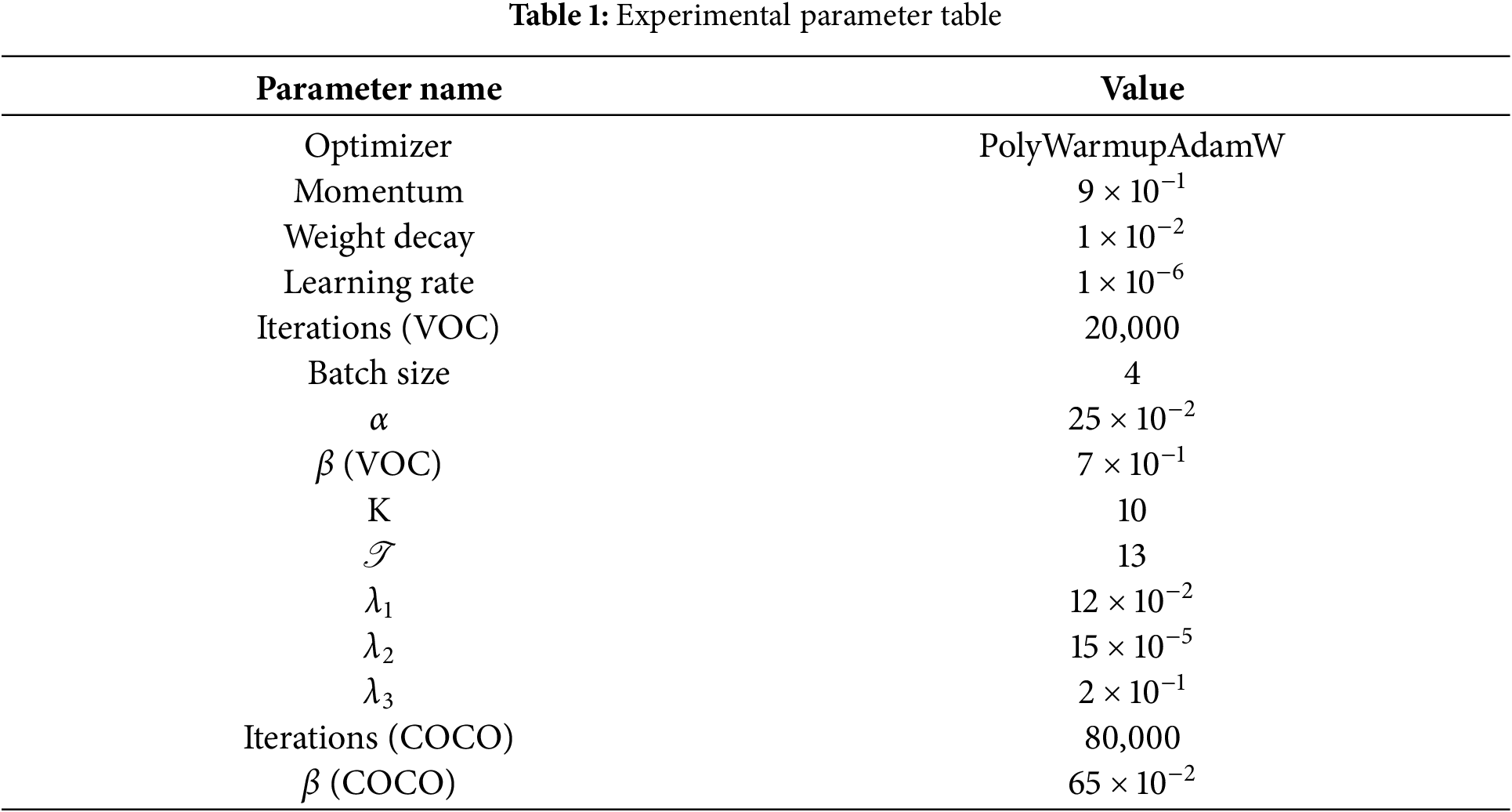
Table 2 presents the comparison of MIoU performance of the CPEWS model on the PASCAL VOC 2012 and MS COCO 2014 datasets. The CPEWS model achieved MIoU reached of 69.8% on the validation set and 72.6% on the test set of the PASCAL VOC 2012 dataset, and 41.4% on the validation set of the MS COCO 2014 dataset. These results surpass those of state-of-the-art single-stage methods, demonstrating the significant performance advantages of CPEWS in processing these datasets.
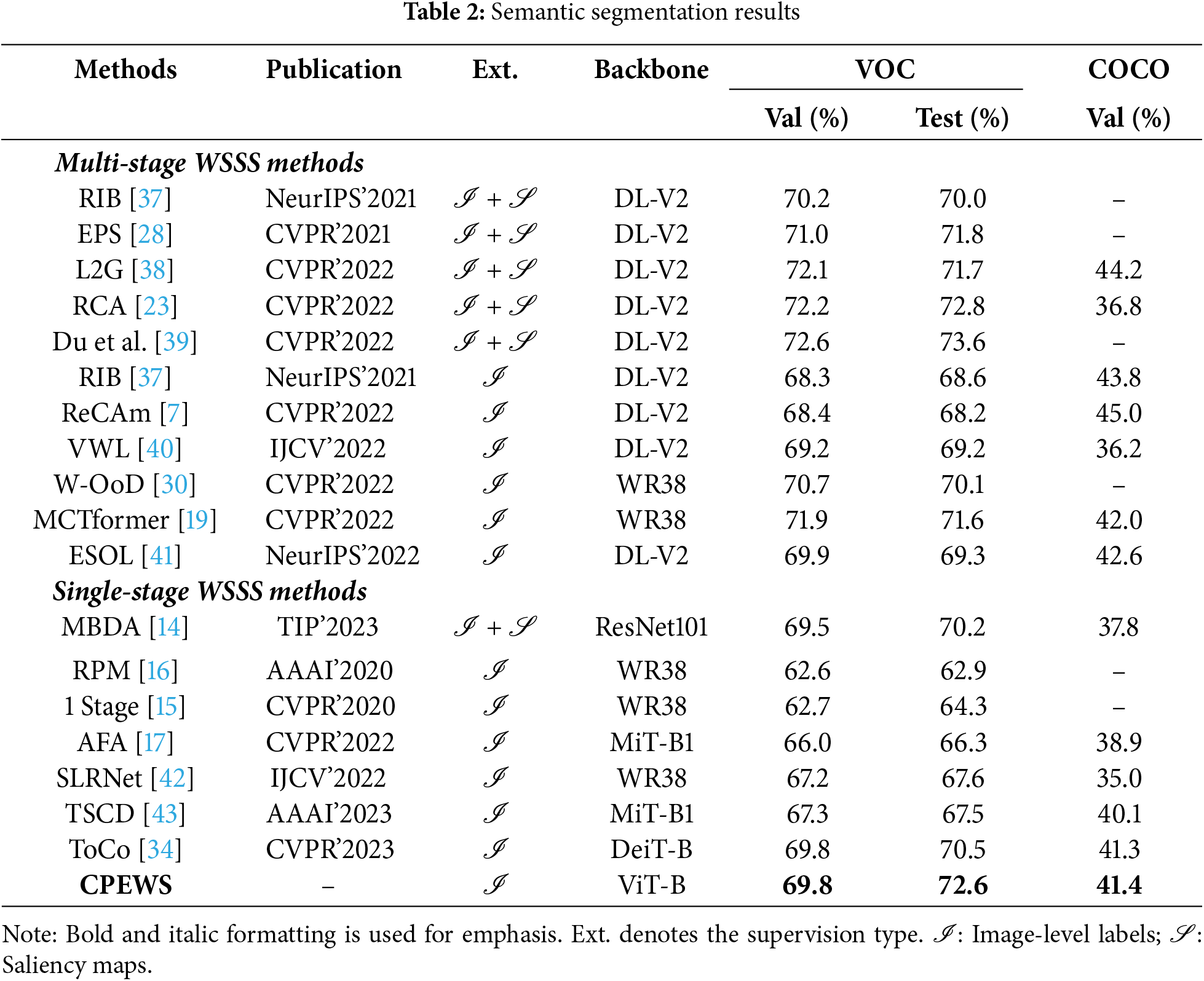
Performance on VOC validation set. The CPEWS model achieved an MIoU of 69.8%, outperforming advanced single-stage methods by a significant margin—3.8% higher than AFA [17] and 2.6% higher than SLRNet [42]. This result demonstrates that CPEWS significantly enhances the performance of weakly supervised semantic segmentation by effectively integrating contextual information and utilizing intermediate layer-supervised boundary features.
Performance on the VOC test set. The MIoU after CRF post-processing is 72.6%, which is 2.1% higher than the state-of-the-art ToCo [34] method (pre-trained with ImageNet-1k weights). This indicates that the CPEWS model excels in refining segmentation boundaries and handling complex scenes. Notably, even without CRF post-processing, the CPEWS model achieved an MIoU of 71.4%, 1.2% higher than ToCo. This demonstrates that CPEWS not only performs well after post-processing, but also demonstrates strong performance without additional optimization.
Performance on COCO validation set. The CPEWS model achieved an MIoU of 41.4%, outperforming advanced single-stage methods by 2.5% over AFA [17], 6.4% over SLRNet [42], and 0.1% over ToCo [34]. Additionally, the MBDA [14] is 3.6% higher than that of recent single-stage methods utilizing additional supervision. These results demonstrate that the CPEWS model significantly enhances the performance of weakly supervised semantic segmentation, setting a new state-of-the-art for single-stage methods.
To investigate the impact of key modules on the model, extensive ablation studies were conducted on the PASCAL VOC 2012 dataset to validate their effectiveness. Specifically, each key module was gradually removed from the model to observe the resulting changes in performance. This approach clarifies the role and contribution of each module within the overall model. Additionally, t-tests were conducted on two models, Data-efficient Image Transformers (DeiT) [44] and ViT-B, to validate the effectiveness of the models.
The experimental results in Table 3 indicate that the number of prototype updates significantly impacts model performance. The experiments involved 0, 1, 2, and 5 prototype updates. Without prototype updates, the MIoU achieves 35.6%. With five updates, the MIoU reached 45.5%. However, due to the high resource consumption required for prototype computation, the number of updates was gradually reduced. With two updates, the MIoU increased to 61.5%. As the number of updates decreased, the MIoU showed a gradual upward trend. When the prototype was calculated before training and not updated during the training process, the MIoU reached 64.5%.

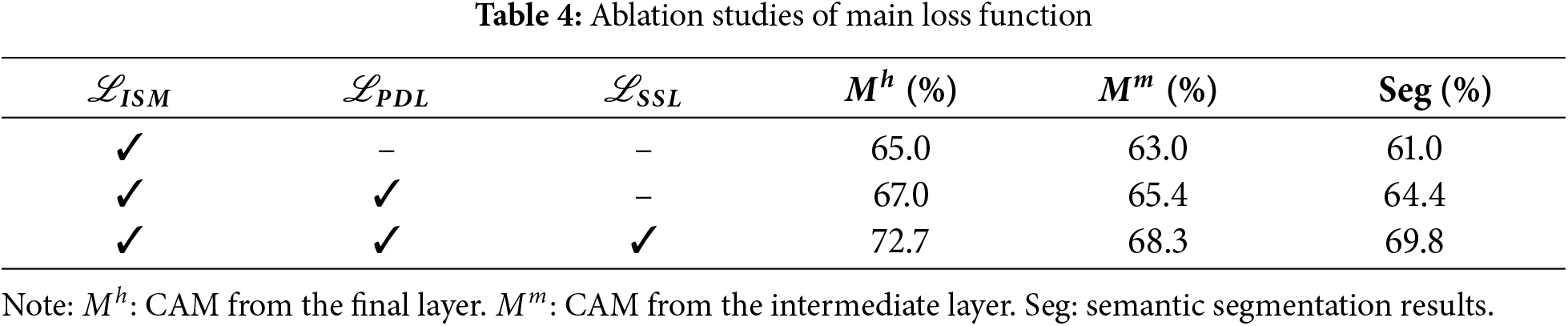
The experimental results presented in Table 4 highlight the significant impact of the loss function on the model’s segmentation performance. When using only
The experimental results in Table 5 demonstrate the impact of the number of Transformer blocks on the model’s segmentation performance. Shallow blocks in ViT fail to capture high-level semantic information, while deeper blocks can introduce boundary ambiguity. Experiments were conducted with 8, 10, and 12 blocks. The results show that with 8 blocks,

Fig. 3 illustrates the variation in MIoU for the DeiT and ViT-B models. A t-test is conducted to compare the MIoU values between the two models, assessing whether the differences are statistically significant and providing a basis for model selection. The analysis shows that while both DeiT and ViT-B exhibit a similar upward trend in MIoU during the initial training stages, DeiT demonstrates significantly lower MIoU in the later stages compared to ViT-B. This suggests that, for complex tasks or large-scale datasets, DeiT’s lighter design and computational constraints may result in slower feature extraction and training speeds. The t-test results further confirm this significant difference in MIoU, supporting the conclusion that ViT-B outperforms DeiT overall. Based on these findings, ViT-B emerges as the more suitable backbone network, due to its faster training speed and superior accuracy.
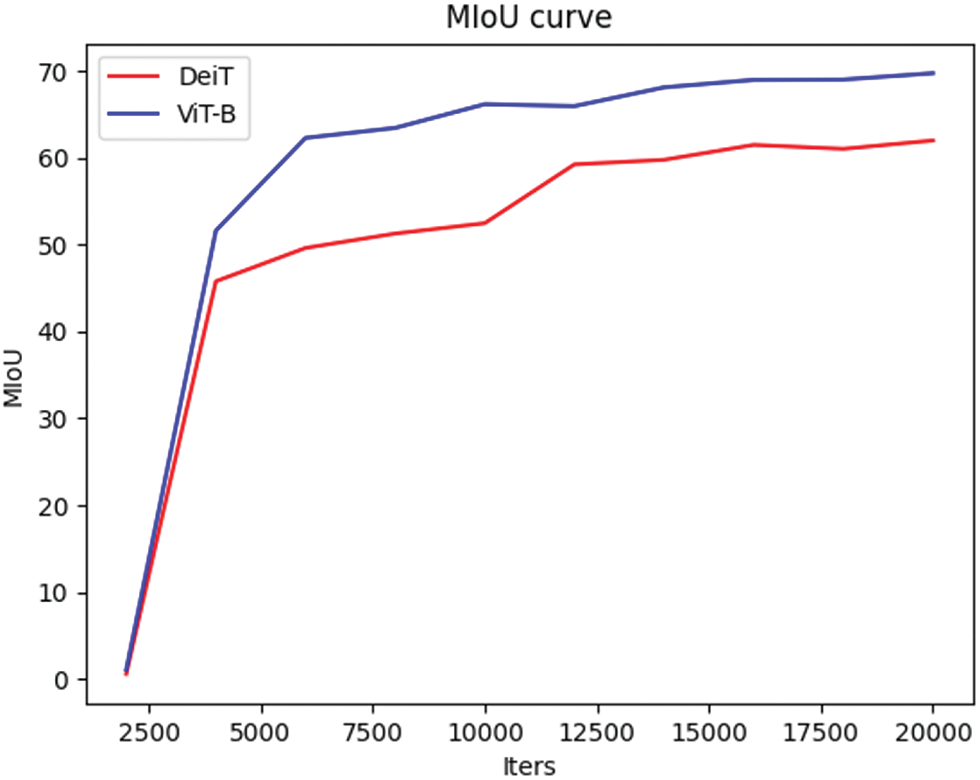
Figure 3: Comparison of the MIoU curves between the DeiT and ViT-B models
This section presents and analyzes the visualizations of the CPEWS model on the widely used semantic segmentation datasets PASCAL VOC 2012 and MS COCO 2014. These visualizations not only validate the effectiveness of the CPEWS model but also highlight its advantages in addressing weakly supervised semantic segmentation tasks. The experimental results demonstrate that the CPEWS model excels in resolving issues such as incomplete activation, false activation. By observing the visual results of CAM, pseudo-labels, and semantic segmentation, the paper can clearly illustrate the network’s superior performance in tackling these challenges. Additionally, the model’s performance during training was monitored and evaluated using loss function and MIoU curves. These figures demonstrate the model’s gradual optimization throughout the training process, highlighting how the CPEWS model converges more effectively and enhances overall performance through ongoing refinement and adjustment.
Fig. 4 presents the visualization results of the CAM generated by the CPEWS model. Specifically, Fig. 4a highlights the CPEWS model’s significant effectiveness in addressing the problem of incomplete activation. By employing ViT as the backbone network and leveraging the intermediate layer to supervise the final layer features, the network can more effectively activate the target category regions comprehensively. Fig. 4b illustrates the model’s effectiveness in mitigating false activation. By learning from contextual prototypes and incorporating

Figure 4: The CPEWS model addresses problems of incomplete activation (a) and false activation (b) in CAM by introducing CPM,
Fig. 5 illustrates the effectiveness of the proposed method, which utilizes ViT as the backbone network to capture global information and enhance pseudo label quality. By adding an additional linear classification layer to the network’s intermediate features and incorporating

Figure 5: Second column implements an improved ViT with
Figs. 6 and 7 respectively demonstrate the exceptional performance of the CPEWS model in weakly supervised semantic segmentation tasks on the PASCAL VOC 2012 and MS COCO 2014 datasets. Fig. 6 showcases the semantic segmentation performance of the CPEWS model on the VOC dataset, alongside a comparison with the AFA [17], ToCo [34] methods, and the Ground Truth (GT). Demonstrating the segmentation effects for various categories, such as people, cars, and birds, clearly shows that the CPEWS model generates more accurate segmentation masks for different objects. Fig. 7 presents the semantic segmentation performance of the CPEWS model on the COCO dataset, along with visualizations of CAM and Pseudo Labels. The results demonstrate that the model maintains strong performance even on large-scale datasets.

Figure 6: The visualization results of semantic segmentation on the VOC dataset are compared with two mainstream methods. The second column shows AFA, and the third column shows ToCo

Figure 7: The visualization results of semantic segmentation on the COCO dataset. CAM (second column) and Pseudo Labels (third column)
Fig. 8 shows the loss function variation curve over 20,000 iterations. The graph reveals a steady decrease in the loss function value as training progresses, indicating effective optimization at each iteration and gradual convergence toward the optimal solution. The curve exhibits a smooth decline with a consistent rate of decrease, without any abrupt changes, demonstrating the stability and efficiency of the training process. In the final stages, the loss function stabilized at a low value with no signs of reaching a local minimum, suggesting that the model did not fall into a local optimal solution. This consistent optimization throughout the training process highlights the model’s robust performance and successful convergence.
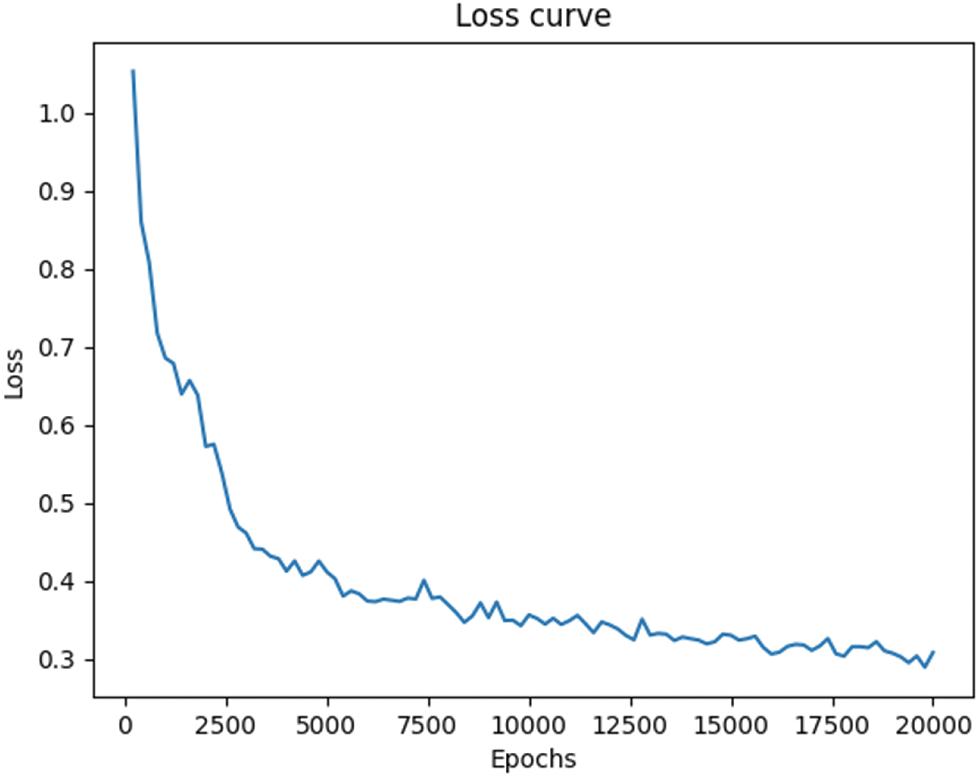
Figure 8: The loss curve indicates that as the number of training iterations increases, the loss function value steadily decreases, following a consistent downward trend
Fig. 9 shows the progression of MIoU as the number of iterations increases. As training advances, the MIoU value steadily rises, indicating that the model is continuously optimizing with each iteration, leading to consistent improvements in segmentation performance. This reflects the model’s active learning and adaptation, gradually enhancing its segmentation capability. Moreover, the sustained increase in MIoU suggests that the training process remains stable, with no signs of stagnation or overfitting. The improvement across all categories, rather than just a few, further confirms that the model is effectively learning. The consistent rise in MIoU further validates the effectiveness of the loss function and optimization strategy, as the model successfully learns and enhances its ability to recognize target categories at each stage of training.
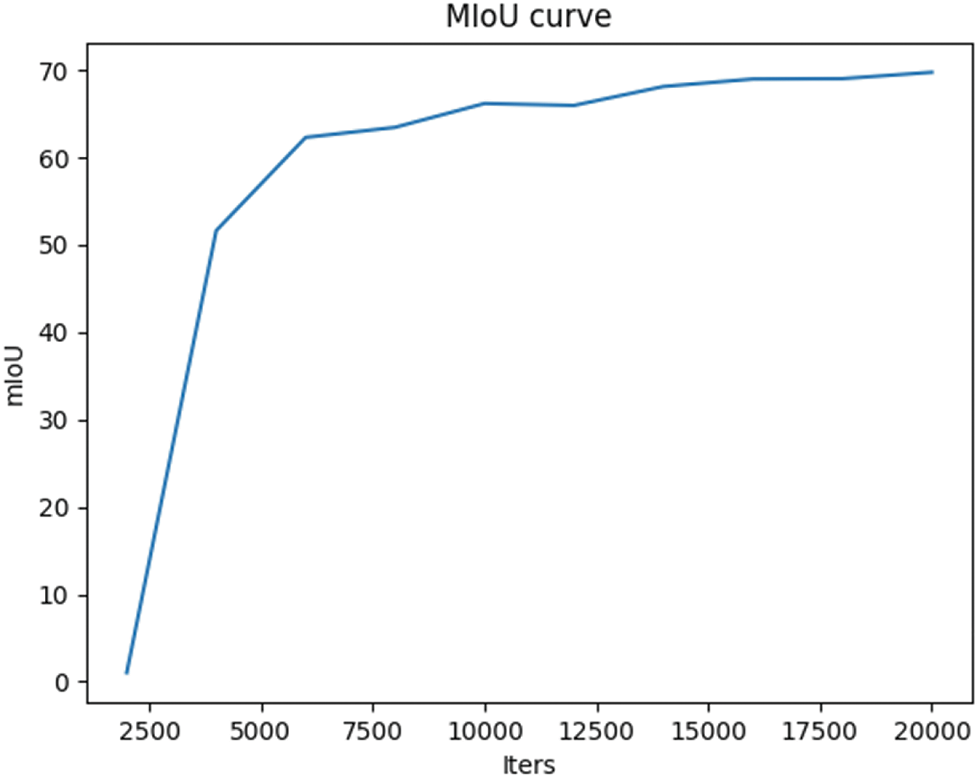
Figure 9: The trend of MIoU as the number of iterations increases
This paper introduces a novel end-to-end weakly supervised semantic segmentation model called CPEWS, which leverages ViT as the backbone network for feature extraction and global information capture. Specifically, by utilizing the intermediate feature layers of ViT, which retain rich semantic information, the ISM module is employed to supervise the patch tokens of the final layer. Aligning the semantic regions of the intermediate and final layer features using
Acknowledgement: I would like to express my heartfelt gratitude to everyone who contributed to this paper. Their efforts and insights have been invaluable to the success of this work.
Funding Statement: The study has been supported by funding from the following sources: National Natural Science Foundation of China (U1904119); Research Programs of Henan Science and Technology Department (232102210054); Chongqing Natural Science Foundation (CSTB2023NSCQ-MSX0070); Henan Province Key Research and Development Project (231111212000); Aviation Science Foundation (20230001055002); supported by Henan Center for Outstanding Overseas Scientists (GZS2022011).
Author Contributions: The authors contributed to the paper as follows: Led the research efforts and managed the project timeline: Xiaoyan Shao; Designed the research algorithms and drafted the manuscript: Jiaqi Han; Reviewed and revised the manuscript, overseeing the entire project: Lingling Li; Provided algorithmic support: Xuezhuan Zhao; Assisted in manuscript editing: Jingjing Yan. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data presented in this study are available upon request from the corresponding author.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conficts of interest to report regarding the present study.
: Table A1 presents all the formulas used in this paper. These formulas are crucial for understanding the core concepts and technical details, and they serve as a reference for the derivations and calculations underpinning the proposed model.

References
1. Lee J, Kim E, Yoon S. Anti-adversarially manipulated attributions for weakly and semi-supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2021. p. 4071–80. [Google Scholar]
2. Akiva P, Dana K. Towards single stage weakly supervised semantic segmentation. arXiv:2106.10309. 2021. [Google Scholar]
3. Lee J, Yi J, Shin C, Yoon S. BBAM: bounding box attribution map for weakly supervised semantic and instance segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2021. p. 2643–52. [Google Scholar]
4. Zhang B, Xiao J, Zhao Y. Dynamic feature regularized loss for weakly supervised semantic segmentation. arXiv:2108.01296. 2021. [Google Scholar]
5. Ru L, Du B, Wu C. Learning visual words for weakly-supervised semantic segmentation. In: Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence (IJCAI-21); 2021. p. 982–8. [Google Scholar]
6. Zhang B, Xiao J, Jiao J, Wei Y, Zhao Y. Affinity attention graph neural network for weakly supervised semantic segmentation. IEEE Trans Pattern Anal Mach Intell. 2021;44(11):8082–96. [Google Scholar]
7. Chen Z, Wang T, Wu X, Hua X-S, Zhang H, Sun Q. Class re-activation maps for weakly-supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2022. p. 969–78. [Google Scholar]
8. Yoon S-H, Kwon H, Kim H, Yoon K-J. Class tokens infusion for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2024. p. 3595–605. [Google Scholar]
9. Fatima M, Attique Khan M, Shaheen S, Albarakati HM, Wang S, Jilani SF, et al. Breast lesion segmentation and classification using u-net saliency estimation and explainable residual convolutional neural network. Fractals. 2024. doi:10.1142/s0218348x24400607. [Google Scholar] [CrossRef]
10. Ullah W, Javed K, Khan MA, Alghayadh FY, Bhatt MW, Naimi ISAl, et al. Efficient identification and classification of apple leaf diseases using lightweight vision transformer (ViT). Discov Sustain. 2024;5(1):116. doi:10.1007/s43621-024-00307-1. [Google Scholar] [CrossRef]
11. Shao F, Luo Y, Chen L, Liu P, Yang Y, Xiao J. Mitigating biased activation in weakly-supervised object localization via counterfactual learning. arXiv:2305.15354. 2023. [Google Scholar]
12. Everingham M, Eslami SMA, Van Gool L, Williams CKI, Winn J, Zisserman A. The pascal visual object classes challenge: a retrospective. Int J Comput Vis. 2015;111(1):98–136. doi:10.1007/s11263-014-0733-5. [Google Scholar] [CrossRef]
13. Lin T-Y, Maire M, Belongie S, Hays J, Perona P, Ramanan D, et al. Microsoft COCO: common objects in context. In: Computer Vision-ECCV 2014: 13th European Conference; 2014 Sep 6–12; Zurich, Switzerland: Springer. p. 740–55. [Google Scholar]
14. Chen T, Yao Y, Tang J. Multi-granularity denoising and bidirectional alignment for weakly supervised semantic segmentation. IEEE Trans Image Process. 2023;32:2960–71. doi:10.1109/TIP.2023.3275913. [Google Scholar] [PubMed] [CrossRef]
15. Yang Z, Fu K, Duan M, Qu L, Wang S, Song Z. Separate and conquer: decoupling co-occurrence via decomposition and representation for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2024. p. 3606–15. [Google Scholar]
16. Yang Z, Meng Y, Fu K, Wang S, Song Z. Tackling ambiguity from perspective of uncertainty inference and affinity diversification for weakly supervised semantic segmentation. arXiv:2404.08195. 2024. [Google Scholar]
17. Ru L, Zhan Y, Yu B, Du B. Learning affinity from attention: end-to-end weakly-supervised semantic segmentation with transformers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2022. p. 16846–55. [Google Scholar]
18. Sun W, Zhang J, Liu Z, Zhong Y, Barnes N. GETAM: gradient-weighted element-wise transformer attention map for weakly-supervised semantic segmentation. arXiv:2112.02841. 2021. [Google Scholar]
19. Xu L, Ouyang W, Bennamoun M, Boussaid F, Xu D. Multi-class token transformer for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2022. p. 4310–9. [Google Scholar]
20. Wu Y, Ye X, Yang K, Li J, Li X. DuPL: dual student with trustworthy progressive learning for robust weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2024. p. 3534–43. [Google Scholar]
21. Zhou T, Wang W, Konukoglu E, Van Gool L. Rethinking semantic segmentation: a prototype view. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2022. p. 2582–93. [Google Scholar]
22. Chen Q, Yang L, Lai J-H, Xie X. Self-supervised image-specific prototype exploration for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2022. p. 4288–98. [Google Scholar]
23. Zhou T, Zhang M, Zhao F, Li J. Regional semantic contrast and aggregation for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2022. p. 4299–309. [Google Scholar]
24. Lang C, Cheng G, Tu B, Han J. Learning what not to segment: a new perspective on few-shot segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2022. p. 8057–67. [Google Scholar]
25. Kayabaşı A, Tüfekci G, Ulusoy İ. Elimination of non-novel segments at multi-scale for few-shot segmentation. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV); 2023. p. 2559–67. [Google Scholar]
26. Tang F, Xu Z, Qu Z, Feng W, Jiang X, Ge Z. Hunting attributes: context prototype-aware learning for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2024. p. 3324–34. [Google Scholar]
27. Chen Z, Tian Z, Zhu J, Li C, Du S. C-CAM: causal CAM for weakly supervised semantic segmentation on medical image. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2022. p. 11676–85. [Google Scholar]
28. Lee S, Lee M, Lee J, Shim H. Railroad is not a train: saliency as pseudo-pixel supervision for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2021. p. 5495–505. [Google Scholar]
29. Xie J, Hou X, Ye K, Shen L. CLIMS: cross language image matching for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2022. p. 4483–92. [Google Scholar]
30. Lee J, Oh SJ, Yun S, Choe J, Kim E, Yoon S. Weakly supervised semantic segmentation using out-of-distribution data. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2022. p. 16897–906. [Google Scholar]
31. Zhang B, Yu S, Wei Y, Zhao Y, Xiao J. Frozen clip: a strong backbone for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2024. p. 3796–806. [Google Scholar]
32. Jang S, Yun J, Kwon J, Lee E, Kim Y. DIAL: dense image-text alignment for weakly supervised semantic segmentation. arXiv:2409.15801. 2024. [Google Scholar]
33. Ridnik T, Ben-Baruch E, Noy A, Zelnik-Manor L. ImageNet-21k pretraining for the masses. arXiv:2104.10972. 2021. [Google Scholar]
34. Ru L, Zheng H, Zhan Y, Du B. Token contrast for weakly-supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2023. p. 3093–102. [Google Scholar]
35. Wu F, He J, Yin Y, Hao Y, Huang G, Cheng L. Masked collaborative contrast for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV); 2024. p. 862–71. [Google Scholar]
36. Chen L, Lei C, Li R, Li S, Zhang Z, Zhang L. FPR: false positive rectification for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV); 2023. p. 1108–18. [Google Scholar]
37. Lee J, Choi J, Mok J, Yoon S. Reducing information bottleneck for weakly supervised semantic segmentation. Adv Neural Inform Process Syst. 2021;34:27408–21. [Google Scholar]
38. Jiang P-T, Yang Y, Hou Q, Wei Y. L2G: a simple local-to-global knowledge transfer framework for weakly supervised semantic segmentation. In: Proceedings of the IEEE/CVF Conference On Computer Vision and Pattern Recognition (CVPR); 2022. p. 16886–96. [Google Scholar]
39. Du Y, Fu Z, Liu Q, Wang Y. Weakly supervised semantic segmentation by pixel-to-prototype contrast. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); 2022. p. 4320–9. [Google Scholar]
40. Ru L, Du B, Zhan Y, Wu C. Weakly-supervised semantic segmentation with visual words learning and hybrid pooling. Int J Comput Vis. 2022;130(4):1127–44. doi:10.1007/s11263-022-01586-9. [Google Scholar] [CrossRef]
41. Li J, Jie Z, Wang X, Wei X, Ma L. Expansion and shrinkage of localization for weakly-supervised semantic segmentation. Adv Neural Inform Process Syst. 2022;35:16 037–51. [Google Scholar]
42. Pan J, Zhu P, Zhang K, Cao B, Wang Y, Zhang D, et al. Learning self-supervised low-rank network for single-stage weakly and semi-supervised semantic segmentation. Int J Comput Vis. 2022;130(5):1181–95. doi:10.1007/s11263-022-01590-z. [Google Scholar] [CrossRef]
43. Xu R, Wang C, Sun J, Xu S, Meng W, Zhang X. Self correspondence distillation for end-to-end weakly-supervised semantic segmentation. Proc AAAI Conf Artif Intell. 2023;37(3):3045–53. doi:10.1609/aaai.v37i3.25408. [Google Scholar] [CrossRef]
44. Touvron H, Cord M, Douze M, Massa F, Sablayrolles A, Jégou H. Training data-efficient image transformers & distillation through attention. In: International Conference on Machine Learning (ICML); 2021; PMLR. pp. 10347–57. [Google Scholar]
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools