
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

A Federated Learning Incentive Mechanism for Dynamic Client Participation: Unbiased Deep Learning Models
1 School of Computer Science and Technology, Wuhan University of Science and Technology, Wuhan, 430065, China
2 College of Computer Science, South-Central Minzu University, Wuhan, 430074, China
3 School of Computer Science and Technology, Zhejiang Normal University, Jinhua, 321004, China
* Corresponding Author: Yuanai Xie. Email:
(This article belongs to the Special Issue: The Next-generation Deep Learning Approaches to Emerging Real-world Applications)
Computers, Materials & Continua 2025, 83(1), 619-634. https://doi.org/10.32604/cmc.2025.060094
Received 23 October 2024; Accepted 03 January 2025; Issue published 26 March 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The proliferation of deep learning (DL) has amplified the demand for processing large and complex datasets for tasks such as modeling, classification, and identification. However, traditional DL methods compromise client privacy by collecting sensitive data, underscoring the necessity for privacy-preserving solutions like Federated Learning (FL). FL effectively addresses escalating privacy concerns by facilitating collaborative model training without necessitating the sharing of raw data. Given that FL clients autonomously manage training data, encouraging client engagement is pivotal for successful model training. To overcome challenges like unreliable communication and budget constraints, we present ENTIRE, a contract-based dynamic participation incentive mechanism for FL. ENTIRE ensures impartial model training by tailoring participation levels and payments to accommodate diverse client preferences. Our approach involves several key steps. Initially, we examine how random client participation impacts FL convergence in non-convex scenarios, establishing the correlation between client participation levels and model performance. Subsequently, we reframe model performance optimization as an optimal contract design challenge to guide the distribution of rewards among clients with varying participation costs. By balancing budget considerations with model effectiveness, we craft optimal contracts for different budgetary constraints, prompting clients to disclose their participation preferences and select suitable contracts for contributing to model training. Finally, we conduct a comprehensive experimental evaluation of ENTIRE using three real datasets. The results demonstrate a significant 12.9% enhancement in model performance, validating its adherence to anticipated economic properties.Keywords
Due to the growing security issues, there is a growing emphasis on developing more secure training methods for deep learning [1,2]. Federated learning (FL), as a successful privacy-preserving paradigm, enables multiple clients to jointly train deep learning models without uploading their own raw data under the coordination of the central server [3]. In FL, training occurs through multiple rounds of global iterations, where clients utilize their local datasets to train local models or gradients, subsequently uploading them to the central server for each training round. The distinct advantages of FL have sparked its adoption in various fields such as healthcare, agriculture, and blockchain applications [4]. Each client retains control over its local data, enabling independent decisions regarding participation in FL training. However, owing to associated participation costs like training and communication expenses, the server must offer appropriate compensation to incentivize self-interested clients to engage in the collaborative training process [5].
However, the FL training process typically involves numerous global iterations, posing challenges in designing efficient incentive mechanisms. First, in large-scale distributed scenarios, clients typically exhibit heterogeneous local resources and independent activity. While assuming unlimited resources and disregarding the straggler effect could enable full client participation, this scenario fails to align with the reality of limited resources. This limitation hampers the execution of many studies that rely on full client participation and constant availability [6–8]. Second, clients may disconnect due to unexpected circumstances during training, i.e., the client’s state may change dynamically [9]. Despite clients’ efforts to minimize disconnections, this incurs additional local costs. Waiting for all clients to respond in dropout situations can seriously impede training efficiency. Although some studies suggest partial client participation to enhance the training process, they presuppose that the server can accurately identify participating clients in each round, which is an ideal assumption [10,11]. Third, client-local datasets are often non-IID [12–14]. Partial local datasets may fail to represent the true data distribution globally, potentially introducing biases during training with dynamic client participation [15].
Despite the clarity of the above considerations, there remain significant challenges in designing an efficient incentive mechanism for unbiased FL. First, how do we effectively incentivize clients to train an unbiased global model under conditions of a limited budget and dynamically changing client status? Encouraging full client participation under a limited budget poses a dilemma for the server. Although existing researchers propose sampling methods to ensure unbiased models, most are applicable only in scenarios where clients are always available [16,17]. Although studies like [18,19] delve into optimization methods for independent client sampling, they assume unconditional client participation in FL. Due to system heterogeneity, clients often face varying local costs during model training, leading to diverse participation preferences [20]. However, without insights into clients’ participation preferences and communication conditions, appropriately rewarding clients becomes challenging. This can result in budget inefficiencies and a decline in client participation levels.
To address the above challenges, we propose a contract-based dynamic participation incentive for unbiased FedeRated LEarning, called ENTIRE. ENTIRE can provide personalized payments to clients with varying participation preferences to compensate for their local costs while ensuring an unbiased deep-learning model. Specifically, we first investigate the impact of randomly independent participation from arbitrary clients on the convergence bounds of FL under non-convex loss functions. Subsequently, we design a set of optimal contracts for clients with heterogeneous participation preferences under different budget constraints and incomplete information models to maximize model performance. Furthermore, we find that when the server’s budget is sufficient, it is adequate to design a single optimal contract to incentivize full participation from all categories of clients. Our main contributions can be summarized as follows:
(1) Methodologically, we propose ENTIRE, a dynamic participation incentive mechanism for unbiased FL aimed at mitigating model bias arising due to dynamic client participation. It encourages all clients to participate in FL by offering independent participation levels and appropriate economic compensation. By customizing personalized participation levels for clients and optimizing reward allocation for contracts, we enhance the model performance under incomplete information.
(2) Theoretically, we establish the FL convergence bound when clients have independent participation levels, which guides the optimization of both model performance and reward allocation. This convergence bound applies to a more general assumption of non-convex loss functions. Furthermore, we derive the optimal contract design under varying budget conditions, enabling ENTIRE to ensure optimal model performance even when the server has an arbitrary budget.
(3) Experimentally, we performed extensive experiments on three real datasets and compared ENTIRE to three state-of-the-art baselines. For the same budget, ENTIRE achieves a 12.9% performance improvement compared to other methods and differs in accuracy by only 0.9% from a model trained with the full participation of all clients. Furthermore, the results show that our approach is equally applicable to the IID scenario.
The remainder of this paper is organized as follows. Section 2 provides a summary of related work. Then, in Section 3, we introduce the system model and define the design goals of ENTIRE through convergence analysis. Section 4 describes the design of optimal contracts under an incomplete information model and varying budget conditions. Subsequently, in Section 5, we provide a comprehensive performance evaluation of ENTIRE through experiments. Finally, we conclude the full paper in Section 6.
The training process in FL entails communication links between a central server and numerous decentralized clients. This large-scale distributed training scenario is prone to client dropout, which seriously hampers the efficiency of model training. Therefore, the classical FedAvg algorithm usually performs multiple local iterations on a randomly selected subset of clients to update the model [21].
Various FL algorithms have been proposed to improve training efficiency. For example, in [22], the model convergence rate was improved by compressing local model updates and designing client scheduling and resource allocation strategies. A stochastic optimization problem linking resource allocation with client scheduling and training loss was presented in [23] and solved using the Lyapunov method. The work in [24] utilized layered computing resources to reduce the end clients’ workload and explored task offloading from edge to end. These approaches focused on the resource allocation issue among clients to optimize the training process from the server’s perspective, neglecting client incentives and assuming clients are consistently available during training. In contrast, our work compensates for heterogeneous clients’ local costs during training and considers the possibility of client dropouts.
To incentivize clients to participate and improve training efficiency, certain approaches have focused on selectively incentivizing specific high-value clients to engage in FL training. The work in [25] designed a Stackelberg-based incentive mechanism, where the server and clients collaboratively determined the participating client set to incentivize maximal data contribution. In [26], a contractual and coalitional game-based incentive mechanism was introduced to motivate the participation of clients with high contributions. A reverse auction-based incentive mechanism to select a more cost-effective set of clients for training was designed in [27]. Although these methods can expedite training efficiency and reduce costs to some extent, selecting only a subset of clients for training with an imbalanced data distribution may introduce bias during the training process, leading to a decline in model performance. Instead, we ensure an unbiased global model while allowing dynamic client participation.
Considering the non-IID data and the independent availability of clients, the work in [28] delved into incentivizing all clients to engage in FL with varying participation probabilities. However, their convergence analysis for unbiased models only was limited to convex functions and applicable solely in scenarios with complete information. Furthermore, their approach still results in clients with negative utility when the server’s budget was insufficient, and failed to motivate all clients to participate. In contrast, our study establishes convergence outcomes under a broader non-convex framework. Moreover, we can incentivize the involvement of all clients and ensure unbiased training models across diverse budget constraints and incomplete information scenarios.
3 System Model and Problem Formulation
In this section, we describe the system model and formulate the optimal participation contract design problem for incomplete information scenarios based on the results of convergence analysis.
We consider an FL scenario with a central server and a set of clients. Each client
Note that we use average rather than weighted average here, due to we consider the weights as part of the local loss function. In large-scale distributed scenarios, FL typically employs the client sampling method for model training [30]. However, each client in FL serves as a decision maker, choosing its own participation level
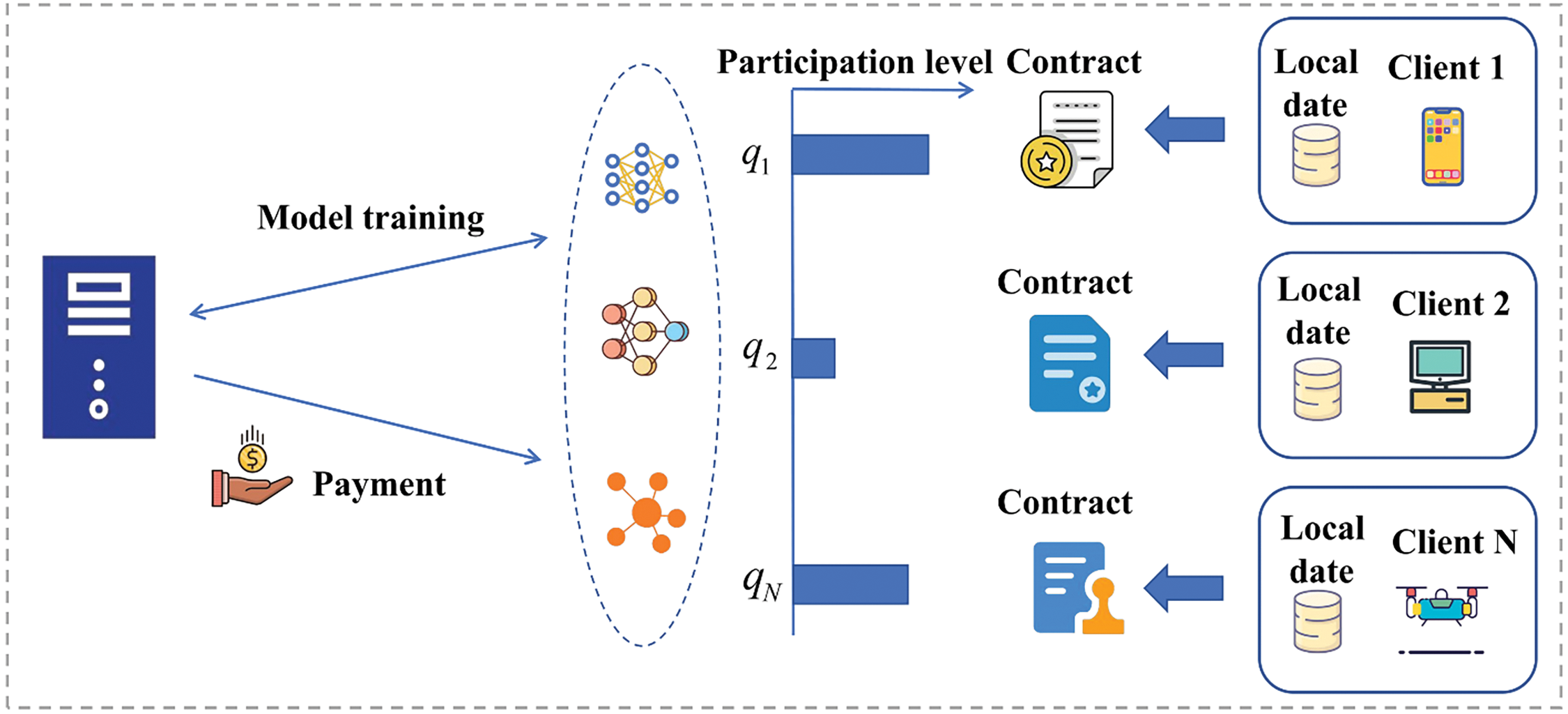
Figure 1: The server and clients sign different participation contracts. Clients and the server conduct training according to the participation levels
The server needs to incentivize clients to join FL at a high participation level to train an efficient global model. In this part, we construct the upper bound on the convergence of Algorithm 1 with non-convex loss functions to relate the global model performance to the client participation level. To establish the theory boundary on convergence, we introduce the following common assumptions from existing work [19,32].

Assumption 1 (β-Lipschitz Continuous Gradient). There exists a constant β, such that the difference between the local gradient
Assumption 2 (Unbiased Stochastic Gradient with Bounded Variance). The stochastic local gradient
Assumption 3 (Bounded Local and Global Variance). The difference between the local gradient
The main convergence result is given in the following theorem:
Theorem 1. The difference between the local gradient
Proof. With the smoothness assumption, taking the expectation of
The term
where
Taking the total expectation collapsing the above in equality, we obtain
Averaging overall t, we can obtain the final result as Eq. (2). This completes the proof. □
The convergence bound in Theorem 1 applies to any varying number of participating clients per round. Furthermore, this upper bound suggests that to guarantee an unbiased global model, all clients need to be incentivized to participate in FL. Because
Without loss of generality, we assume that in incomplete information scenarios, clients can be categorized into
where
In incomplete information scenarios, the type of client’s participation preference is private information and unavailable. The server can only estimate the distribution of
Definition 1 (PC). A participation contract is represented as a 2-tuple
In order to encourage clients to reveal their types truthfully in information asymmetry, we need to introduce the following three fundamental properties, namely budget feasibility (BF), individual rationality (IR), and incentive compatibility (IC).
Definition 2 (BF). A set of PCs satisfies BF if the rewards to be paid to all clients do not exceed the budget
Definition 3 (IR). A set of PCs satisfies IR if they provide non-negative utility to the corresponding type of clients, i.e.,
Definition 4 (IC). A set of PCs satisfies IC if a client can maximize its utility only by honestly choosing the contract that corresponds to its type, i.e.,
The server needs to design a set of optimal PCs that satisfy the above properties to maximize model performance, which can be formalized as
Note that in cases of complete information, the server knows the type to which each client belongs, so only a single contract needs to be sent to each client. However, in the case of incomplete information, where the type of any client is unknown, the server needs to send all the contracts to clients for selection.
4 The Set of Optimal Participation Contracts Design
In this section, we study the optimal PC design problem for different budget levels and provide key insights to distinguish between the different scenarios.
4.1 Optimal Contract Design under Insufficient Budget
When the server lacks the budget to incentivize all clients to fully participate, we assert that the participation level constraint proves more restrictive than the budget-feasibility (BF) constraint. This is because to ensure IC property, the server can only guarantee partial low client types achieve full participation, while it cannot incentivize the others to increase their participation levels with an entire budget. To solve this problem, the key idea of our method is to separate the two constraints by considering varying budget scenarios. We assume the server’s budget cannot support any client type for full participation, allowing us to omit the participation level constraint and allocate the entire budget accordingly. Under the remaining constraints, we outline the essential conditions needed to guarantee an optimal set of PCs in the following proposition:
Proposition 1. A set of feasible PCs must meet the following necessary and sufficient conditions:
Proof. The first two equations are relaxations of the BF and IR constraints, where the latter effectively reduces
Thus, we only need to guarantee
The third and fourth inequalities are about the participation level and reward monotonicity. We use IC constraints to prove the monotonicities of the set of optimal PCs. According to IC property, we have
For the fifth inequality, we show that
Suppose
Note that
Therefore, in order for the optimal contract to satisfy the IC property, we only need to ensure that
According to Proposition 1, we can reduce the complexity of the problem
By solving
Theorem 2. In the incomplete information scenario, the set of optimal PCs is given by
where
Proof. According to the last two constraints of
Following the same procedure, we obtain
where
Let
So far, we have simplified the constraint conditions of
where
Using Eqs. (18) and (22) with some simple transformations, we complete this proof. □
4.2 Optimal Contract Design under Sufficient Budget
Recall that the previous analysis builds on the premise that the budget is inadequate to incentivize full participation by any client type, i.e.,
Theorem 3. In the incomplete information scenario, and when the server’s budget is sufficient, the set of optimal PCs is given as
Proof. According to the monotonicity of the participation level of the set of optimal PCs, we can easily get that when the server’s budget is not enough to incentivize all clients to fully participate, only the clients with the lowest type can satisfy full participation. Thus, we have
Bringing the above results into Eq. (16), we can obtain the optimal set of PCs.
For the case where the server has sufficient budget to incentivize full participation by all clients, we only need to design one PC term. This is because when all clients are fully participated, the clients belonging to the highest type have the largest participation costs, i.e., the optimal PC term only needs to be able to compensate for the
In this section, we perform an extensive experimental evaluation of ENTIRE on three real-world datasets and compare it to three baselines.
FL Setup. Similarly to [28,31], we consider the FL scenario with a central server and
Datasets & Models. We use non-convex deep learning models on two datasets, i.e., a multi-layer perceptron (MLP) on the MNIST dataset and Fashion-MNIST (FMNIST) dataset. We sort and slice the datasets by label to ensure that each client’s local dataset meets non-IID requirements. In this case, most clients will only have data of one class (out of all the 10 classes). Additionally, we train a convolutional neural network (CNN) on the CIFAR-10 dataset to test the performance of our method in IID scenarios. For the training parameters, we use SGD batch size 30 and local epoch 2.
Baselines. (1) CC: A contract-based incentive mechanism under complete information, i.e., the server knows each client’s participation preference. It is unnecessary to consider IC property when designing optimal participation contracts. (2) UC: A contract-based incentive mechanism with a uniform contract, i.e., the server makes the same contract for all client types, and only clients with non-negative utility choose to accept the contract [33]. (3) SG: A Stackerberg game-based incentive mechanism, i.e., the server distributes rewards proportionally based on the participation level selected by the clients, and each client aims to maximize their own utility [28].
We compare the design of optimal PCs for complete and incomplete information scenarios, i.e., CC and ENTIRE. For CC, the server knows the type of each client, and therefore only needs to send one corresponding contract to each client. The optimal set of contracts for the full information scenario is given as
Fig. 2 demonstrates that ENTIRE satisfies monotonicity, IR, and IC simultaneously. In Fig. 2a, the participation levels assigned by CC and ENTIRE for various client types are displayed. Clients with higher types opt for lower participation levels. This decision is driven by the server’s strategy to maximize model performance within a constrained budget by favoring smaller client types in more training rounds due to their lower participation costs. Conversely, under the same budget constraints, ENTIRE designates a reduced participation level for each client type compared to CC. This adjustment is necessary in an environment of incomplete information, where the server lacks specific knowledge about individual client types and must motivate lower client types with positive utility (Fig. 2b).
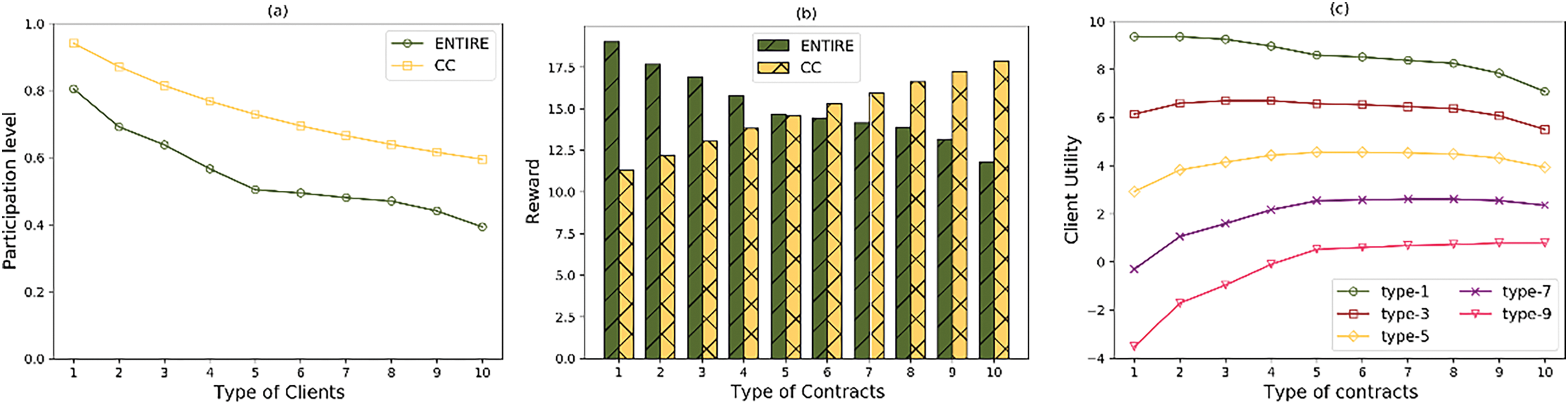
Figure 2: Contract properties: (a) Participation level monotonicity; (b) Reward monotonicity; (c) IR & IC
illustrates the rewards specified by ENTIRE and CC for each contract type. ENTIRE satisfies the monotonicity of rewards in Proposition 1, whereas CC exhibits the opposite behavior. This aligns with the reasoning in Fig. 2a, where the server can guarantee zero utility for all client types in the complete information scenario, but can only ensure that the highest type client achieves zero utility in the incomplete information case. Fig. 2c shows that any client type can only obtain maximum utility by choosing its corresponding type of PC, which satisfies the IC property. In addition, each client has a non-negative utility in choosing its corresponding contract, which satisfies the IR property.
Table 1 illustrates the effect of system parameters on participation levels and rewards specified by ENTIRE. Regarding the reward sensitivity factor

Fig. 3 illustrates the model performance of three methods on different datasets. ENTIRE demonstrates the optimal model performance in Fig. 3a,b, as it ensures that all clients participate in the model training, resulting in an unbiased global model. On the contrary, UC and SG only ensure that a fixed subset of clients joins FL at the same participation level. Although this may lead to a faster convergence rate, due to the lack of training data (especially in extreme non-IID cases), the global model cannot converge to the degree of full client participation.
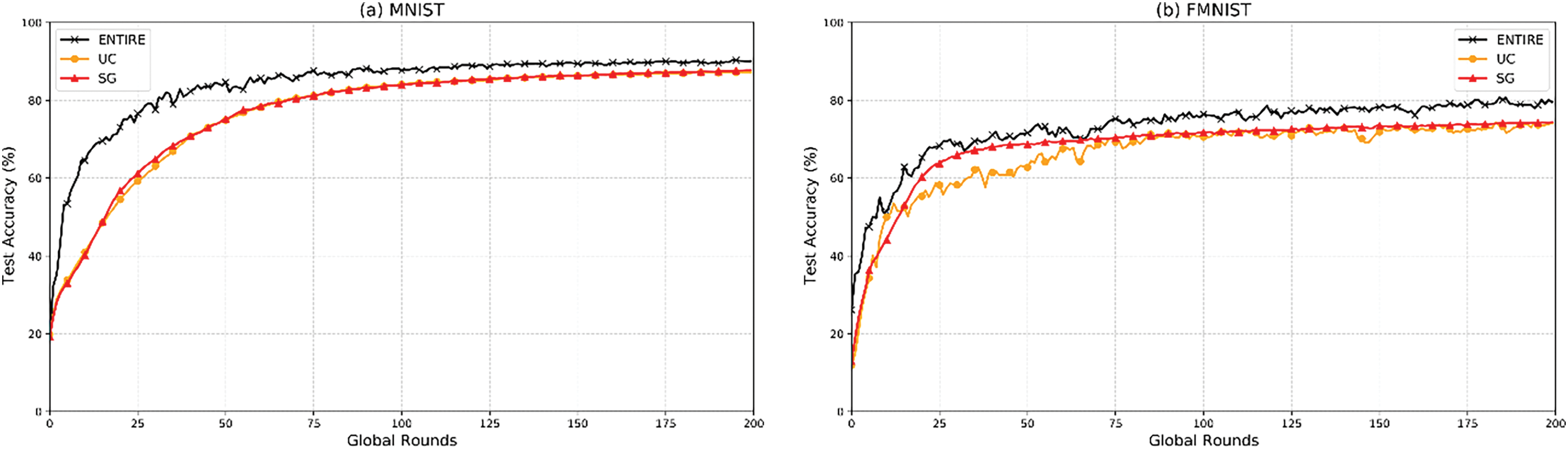
Figure 3: Model performance on different datasets: (a) MNIST dataset with three methods; (b) FMNIST dataset with three methods
Fig. 4 depicts the effect of varying budgets on model performance. In Fig. 4a, both the convergence rate and performance of the global model improve as the budget increases. With
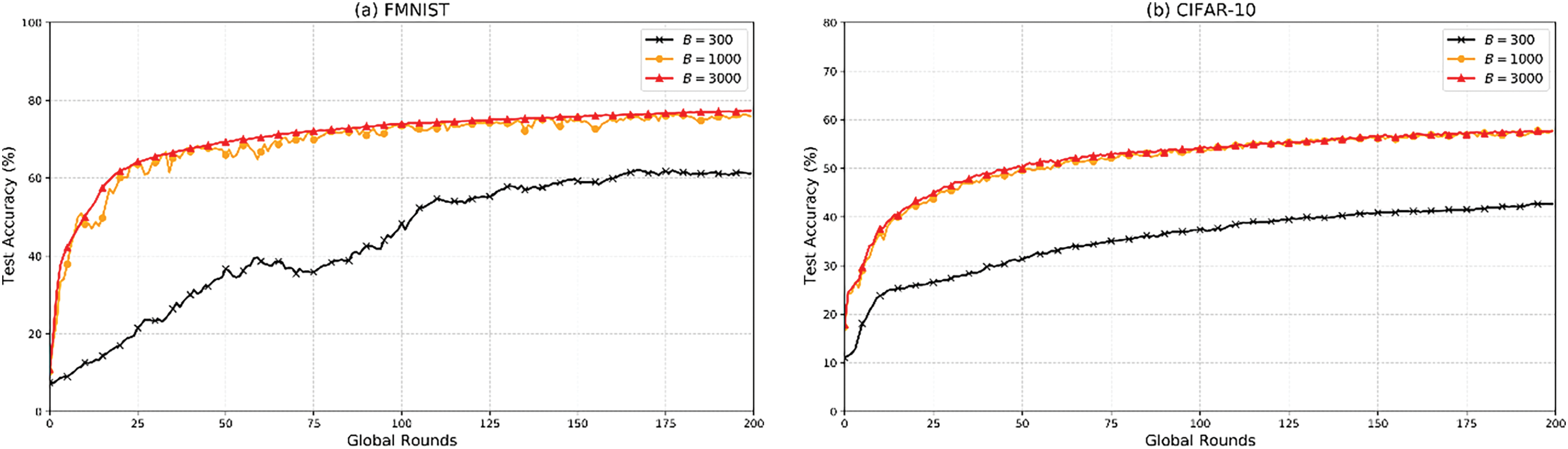
Figure 4: Model performance for different
In this paper, we proposed ENTIRE, a dynamic participation incentive mechanism for unbiased FL, which was able to guarantee an unbiased FL model in scenarios with asymmetric information, and appropriately compensated clients with differing participation costs. First, the impact of clients’ participation levels on the model performance was explored by rigorously deriving a non-convex convergence bound with random client participation. Second, a set of optimal PCs was derived based on the convergence bound to maximize the model performance. Third, the practicality and efficacy of ENTIRE were validated through extensive experiments, showcasing ENTIRE was also applicable to IID scenarios. Note that although ENTIRE uses the FL framework, it still has privacy concerns. Future considerations involve integrating differential privacy to enhance client privacy protection, but this requires sacrificing some model performance. The privacy-utility trade-off under independent client participation is the pivotal direction for future research.
Acknowledgement: We would like to extend our sincere appreciation to the editor and reviewers for their valuable feedback and constructive comments, which greatly improved the quality of this paper.
Funding Statement: This work was supported by the National Natural Science Foundation of China (Nos. 62072411, 62372343, 62402352, 62403500); the Key Research and Development Program of Hubei Province (No. 2023BEB024); the Open Fund of Key Laboratory of Social Computing and Cognitive Intelligence (Dalian University of Technology), Ministry of Education (No. SCCI2024TB02).
Author Contributions: The authors confirm contribution to the paper as follows: study conception and design: Jianfeng Lu, Tao Huang; data collection: Shuqin Cao, Bing Li; analysis and interpretation of results: Yuanai Xie, Shuqin Cao; draft manuscript preparation: Jianfeng Lu and Tao Huang. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data that support the findings of this study are openly available in https://yann.lecun.com/exdb/mnist/ (accessed on 02 January 2025), https://tensorflow.google.cn/datasets/catalog/fashion_mnist (accessed on 02 January 2025), and http://www.cs.toronto.edu/~kriz/cifar.html (accessed on 02 January 2025).
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Tang D, Yan Y, Zhang Z, Chen J, Qin Z. Performance and features: mitigating the low-rate TCP-targeted DoS attack via SDN. IEEE J Sel Areas Commun. 2022;40(1):428–44. doi:10.1109/JSAC.2021.3126053. [Google Scholar] [CrossRef]
2. Tang D, Wang S, Liu B, Jin W, Zhang J. GASF-IPP: detection and mitigation of LDoS attack in SDN. IEEE Trans Serv Comput. 2023;16(5):3373–84. doi:10.1109/TSC.2023.3266757. [Google Scholar] [CrossRef]
3. McMahan B, Moore E, Ramage D, Hampson S, Arcas BAY. Communication-efficient learning of deep networks form decentralized data. Paper presented at: 20th International Conference on Artificial Intelligence and Statistics; 2017 Apr 20–22; Fort Lauderdale, FL, USA. [Google Scholar]
4. Liu H, Lu J, Wang X, Wang C, Jia R, Li M. FedUP: bridging fairness and efficiency in cross-silo federated learning. IEEE Trans Serv Commput. 2024;17(6):3672–84. doi:10.1109/TSC.2024.3489437. [Google Scholar] [CrossRef]
5. Lu J, Liu H, Jia R, Zhang Z, Wang X, Wang J. Incentivizing proportional fairness for multi-task allocation in crowdsensing. IEEE Trans Serv Comput. 2024;17(3):990–1000. doi:10.1109/TSC.2023.3325636. [Google Scholar] [CrossRef]
6. Tang M, Wong VWS. An incentive mechanism for cross-silo federated learning: a public goods perspective. Paper presented at: 40th IEEE Conference on Computer Communications; 2021 May 10–13; Vancouver, BC, Canada. [Google Scholar]
7. Huang C, Zhang H, Liu X. Incentivizing data contribution in cross-silo federated learning. 2022. doi: 10.48550/ARXIV.2203.03885. [Google Scholar] [CrossRef]
8. Lu J, Chen Y, Cao S, Chen L, Wang W, Xin Y. LEAP: optimization hierarchical federated learning on non-IID data with coalition formation game. Paper presented at: 33th International Joint Conference on Artificial Intelligence; 2024 Aug 3–9; Jeju, Republic of Korea. [Google Scholar]
9. Hu M, Wu D, Zhou Y, Chen X, Chen M. Incentive-aware autonomous client participation in federated learning. IEEE Trans Parallel Distrib Syst. 2022;33(10):2612–27. doi:10.1109/TPDS.2022.3148113. [Google Scholar] [CrossRef]
10. Ding N, Fang Z, Huang J. Optimal contract design for efficient federated learning with multi-dimensional private information. IEEE J Sel Areas Commun. 2021;39(1):186–200. doi:10.1109/JSAC.2020.3036944. [Google Scholar] [CrossRef]
11. Huang G, Wu Q, Sun P, Ma Q, Chen X. Collaboration in federated learning with differential privacy: a stackerberg game analysis. IEEE Trans Parallel Distrib Syst. 2024;35(3):455–69. doi:10.1109/TPDS.2024.3354713. [Google Scholar] [CrossRef]
12. Wang H, Jia Y, Zhang M, Hu Q, Ren H, Sun P, et al. FedDSE: distribution-aware sub-model extraction for federated learning over resource-constrained devices. Paper presented at: ACM on Web Conference 2024; 2024 May 13–17; Singapore. [Google Scholar]
13. Wang H, Zheng P, Han X, Xu W, Li R, Zhang T. FedNLR: federated learning with neuron-wise learning rates. Paper presented at: 30th ACM Conference on Knowledge Discovery and Data Mining; 2024 Aug 25–29; Barcelona, Spain. [Google Scholar]
14. Lu J, Liu H, Jia R, Wang J, Sun L, Wan S. Toward personalized federated learning via group collaboration in IIoT. IEEE Trans Ind Inform. 2023;19(8):8923–32. doi:10.1109/TII.2022.3223234. [Google Scholar] [CrossRef]
15. Wang H, Xu H, Li Y, Xu Y, Li R, Zhang T. FedCDA: federated learning with cross-rounds divergence-aware aggregation. Paper presented at: 12th International Conference on Learning Representations; 2024 May 7–11; Vienna, Austria. [Google Scholar]
16. Cho YJ, Wang J, Joshi G. Towards understanding biased client selection in federated learning. Paper presented at: 25th International Conference on Artificial Intelligence and Statistics; 2022 Mar 28–30. [Google Scholar]
17. Luo B, Xiao W, Wang S, Huang J, Tassiulas L. Adaptive heterogeneous client sampling for federated learning over wireless networks. IEEE Trans Mob Comput. 2024;23(10):9663–77. doi:10.1109/TMC.2024.3368473. [Google Scholar] [CrossRef]
18. Chen W, Horváth S, Richtárik P. Optimal client sampling for federated learning. Trans Mach Learn Res. 2022. [Google Scholar]
19. Yang H, Fang M, Liu J. Achieving linear speedup with partial worker participation in non-IID federated learning. Paper presented at: 9th International Conference on Learning Representations; 2021 May 3–7; Virtual Event, Austria. [Google Scholar]
20. Le THT, Tran NH, Tun KY, Nguyen MNH, Pandey SR, Han Z, et al. An incentive mechanism for federated learning in wireless cellular networks: an auction approach. IEEE Trans Wirel Commun. 2021;20(8):4874–87. doi:10.1109/TWC.2021.3062708. [Google Scholar] [CrossRef]
21. Bonawitz KA, Eichner H, Grieskamp W, Huba D, Ingerman A, Ivanov V, et al. Towards federated learning at scale: system design. Paper presented at: 2th Conference on Machine Learning and Systems; 2019 Mar 31–Apr 2; Stanford, CA, USA. [Google Scholar]
22. Amiri MM, Gündüz D, Kulkarni SR, Poor HV. Convergence of update aware device scheduling for federated learning at the wireless edge. Trans Wirel Commun. 2021;20(6):3643–58. doi:10.1109/TWC.2021.3052681. [Google Scholar] [CrossRef]
23. Wadu MM, Samarakoon S, Bennis M. Joint client scheduling and resource allocation under channel uncertainty in federated learning. IEEE Trans Commun. 2021;69(9):5962–74. doi:10.1109/TCOMM.2021.3088528. [Google Scholar] [CrossRef]
24. Guo Y, Liu F, Zhou T, Cai Z, Xiao N. Privacy vs. efficiency: achieving both through adaptive hierarchical federated learning. IEEE Trans Parallel Distrib Syst. 2023;34(4):1331–42. doi:10.1109/TPDS.2023.3244198. [Google Scholar] [CrossRef]
25. Huang G, Chen X, Ouyang T, Ma Q, Chen L, Zhang J. Collaboration in participant-centric federated learning: a game-theoretical perspective. IEEE Trans Mob Comput. 2023;22(11):6311–26. doi:10.1109/TMC.2022.3194198. [Google Scholar] [CrossRef]
26. Lim WYB, Xiong Z, Miao C, Niyato D, Yang Q, Leung C, et al. Hierarchical incentive mechanism design for federated machine learning in mobile networks IEEE. Internet Things J. 2020;7(10):9575–88. doi:10.1109/JIOT.2020.2985694. [Google Scholar] [CrossRef]
27. Sun P, Chen X, Liao G, Huang J. A profit-maximizing model marketplace with differentially private federated learning. Paper presented at: 41th IEEE Conference on Computer Communications; 2022 May 2–5; London, UK. [Google Scholar]
28. Luo B, Feng Y, Wang S, Huang J, Tassiulas L. Incentive mechanism design for unbiased federated learning with randomized client participation. Paper presented at: 43th IEEE International Conference on Distributed Computing Systems; 2023 Jul 18–21; Hong Kong, China. [Google Scholar]
29. Kairous P, McMahan HB, Avent B, Bellet A, Bennis M, Bhagoji AN, et al. Advances and open problems in federated learning. Found Trends Mach Learn. 2021;14(1–2):1–210. doi:10.1561/2200000083. [Google Scholar] [CrossRef]
30. Zhang H, Li Z, Gong Z, Siew M, Wong CJ, Azouze RE. Poster: optimal variance-reduced client sampling for multiple models federated learning. Paper presented at: 44th IEEE International Conference on Distributed Computing Systems; 2024 Jul 23–26; Jersey City, NJ, USA. [Google Scholar]
31. Wang S, Perazzone JB, Ji M, Chan KS. Federated learning with flexible control. Paper presented at: 42th IEEE Conference on Computer Communications; 2023 May 17–20; New York, NY, USA. [Google Scholar]
32. Reddi SJ, Charles Z, Zaheer M, Garrett Z, Rush K, Konečný J, et al. Adaptive federated optimization. Paper presented at: 9th International Conference on Learning Representations; 2021 May 3–7; Austria. [Google Scholar]
33. Jiang L, Chen B, Xie S, Maharjan S, Zhang Y. Incentivizing resource cooperation for blockchain empowered wireless power transfer in UAV networks. IEEE Trans Veh Technol. 2020;69(12):15828–41. doi:10.1109/TVT.2020.3036056. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools