
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Optimizing AES S-Box Implementation: A SAT-Based Approach with Tower Field Representations
1 School of Computer Science and Information Security, Guilin University of Electronic Technology, Guilin, 541004, China
2 School of Computing and Information Systems, The University of Melbourne, Melbourne, 3010, Australia
3 Guangxi Wangxin Information Technology Co., Ltd., Nanning, 530000, China
* Corresponding Authors: Ying Zhao. Email: ; Wei Feng. Email:
Computers, Materials & Continua 2025, 83(1), 1491-1507. https://doi.org/10.32604/cmc.2025.059882
Received 18 October 2024; Accepted 02 February 2025; Issue published 26 March 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The efficient implementation of the Advanced Encryption Standard (AES) is crucial for network data security. This paper presents novel hardware implementations of the AES S-box, a core component, using tower field representations and Boolean Satisfiability (SAT) solvers. Our research makes several significant contributions to the field. Firstly, we have optimized the GF() inversion, achieving a remarkable 31.35% area reduction (15.33 GE) compared to the best known implementations. Secondly, we have enhanced multiplication implementations for transformation matrices using a SAT-method based on local solutions. This approach has yielded notable improvements, such as a 22.22% reduction in area (42.00 GE) for the top transformation matrix in GF(()2)-type S-box implementation. Furthermore, we have proposed new implementations of GF((()2)2)-type and GF(()2)-type S-boxes, with the GF((()2)2)-type demonstrating superior performance. This implementation offers two variants: a small area variant that sets new area records, and a fast variant that establishes new benchmarks in Area-Execution-Time (AET) and energy consumption. Our approach significantly improves upon existing S-box implementations, offering advancements in area, speed, and energy consumption. These optimizations contribute to more efficient and secure AES implementations, potentially enhancing various cryptographic applications in the field of network security.Keywords
Information security is crucial in the Internet of Things (IoT) [1,2], particularly in healthcare, transportation, and smart cities. Cryptography plays a key role in protecting the security of IoT data. However, IoT devices have limitations in computational, storage, and energy. Improving the efficiency of cryptographic implementations in terms of area, delay, and power consumption has become a critical challenge. As a dominant encryption, the performance requirements (such as low area and low delay) for AES [3] implementation have become increasingly urgent. The AES consists of four subfunctions: SubBytes (S-box), ShiftRows, MixColumns, and AddRoundKey. As a core component, the implementation of the S-box directly affects the circuit area and delay of the AES implementations [4–6]. Therefore, the goal of this paper is to improve the area and delay of the S-box implementation, thereby enhancing the performance of the AES implementation.
The AES S-box involves the inversion over
Nowadays, the methods for optimizing combinational logic mainly include heuristic [22,23] and SAT-based methods [24,25]. The above AES S-box implementations are mainly based on heuristics. Heuristics provide satisfactory results, but they may not necessarily achieve the optimal results. Specifically, these heuristics primarily rely on 2-input logic gates. In fact, 3-input and 4-input logic gates (such as NOR3, OA21, MOAI) can also be used to optimize AES S-box. SAT-based methods includes more logic gate types than heuristics. Using more logic gate types can improve the performance of AES S-box. Although SAT-based methods cannot directly optimize the entire circuit of AES S-box, they can provide better optimization results in certain criticals (e.g., the inversion over
Therefore, to enhance the performance of AES S-box, we combine SAT-based methods with field-tower approachs using a greater variety of logic gate types. This combination optimizes the implementations of
(1) A novel SAT-based method (GEC model with more logic gate types) is proposed to optimize the inversion over
(2) Novel SAT-based methods using local solutions (LocalBGC and LocalGEC models) are introduced to optimize the implementations of TL/BL and Mul(-Sum). For
(3) A comprehensive strategy (i.e., creating modules of different logic gate types using Verilog or setting comprehensive constraints) is proposed to avoid the automatic optimization of Synopsys Design Compiler. This automatic optimization may alter the logic gate types and structures of the original AES S-box designs. Additionally, the implementations and evaluations of
The performed synthesized experiments demonstrate that, when the area is considered, the area of the proposed
Summarizing the above experimental results, compared to the most efficient implementations [18,19], the proposed
2 Theoretical Background and SAT-based Optimization Methods
2.1 A Tower Field Representation of AES S-Box
Fig. 1 shows the implementation process of the AES S-box based on a tower field representation. The main idea is that an element U in
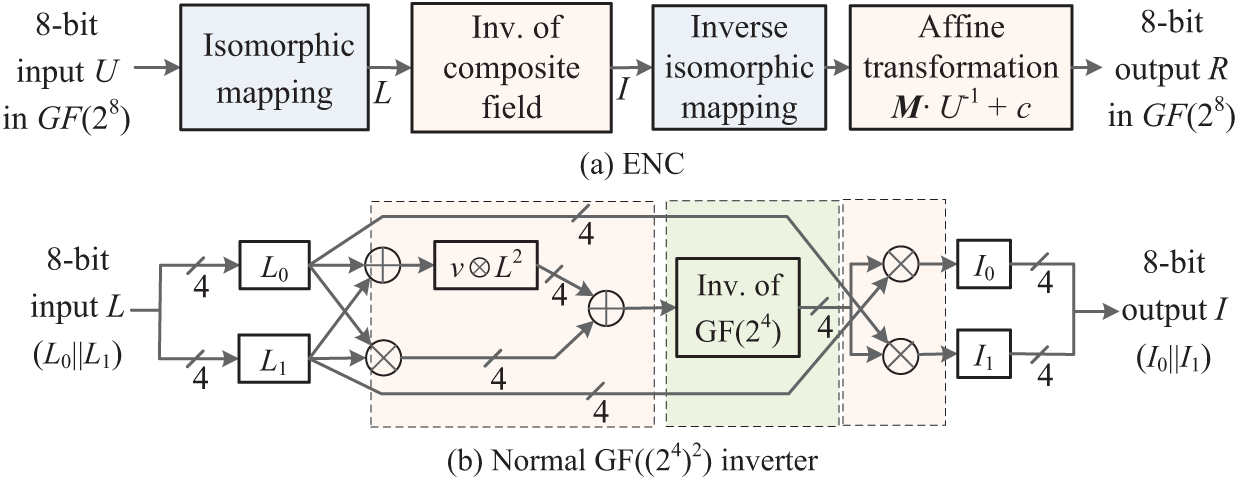
Figure 1: The computing process of the S-box using a tower of fields
Fig. 1 depicts quite a standard implementation. In recent works, the isomorphic mapping matrix representations of the S-boxes of
2.2 Boolean Satisfiability (SAT)
The main idea behind SAT-based methods is to establish a series of Boolean expressions between the inputs/outputs of the logic circuits, and use SAT solvers to search for optimal implementations. To optimize the implementation of logic circuits, Feng et al. [25] proposed three models: Bit-Slice Gate Complexity (BGC), Gate Equivalent Complexity (GEC), and local solutions models (LocalBGC and LocalGEC), for different design goals in moderately complex circuits. For instance, the GEC model is employed when searching for those implementations that use K logic gates, G gate equivalents (GE) or/and depth level D, for a circuit with
First, define the
Then, the encoding between the inputs and outputs of the circuit is established through the inputs and outputs, denoted by Q and T respectively of K logic gates.
Encoding gate inputs Q: For the
Encoding outputs T and Y: The GEC model includes NOT and 2-, 3-, 4-input logic gates, and the encoding of the
The outputs
Finally, the area
where
Take a circuit with 2 inputs (

The encoding of BGC is similar to that of GEC. The only difference lies in the encoding of the inputs/outputs of logic gates. BGC only includes XOR, OR, AND, and NOT, imposing constraints on the number of logic gate types. The encoding of a search model based on local solutions (LocalBGC/LocalGEC) is similar to the encoding of BGC/GEC models, except that it first finds a solution of partial outputs and then searches for a solution of the remaining outputs based on the found partial solution.
3 SAT-Based Optimization of AES S-Box Implementations
The implementation method of
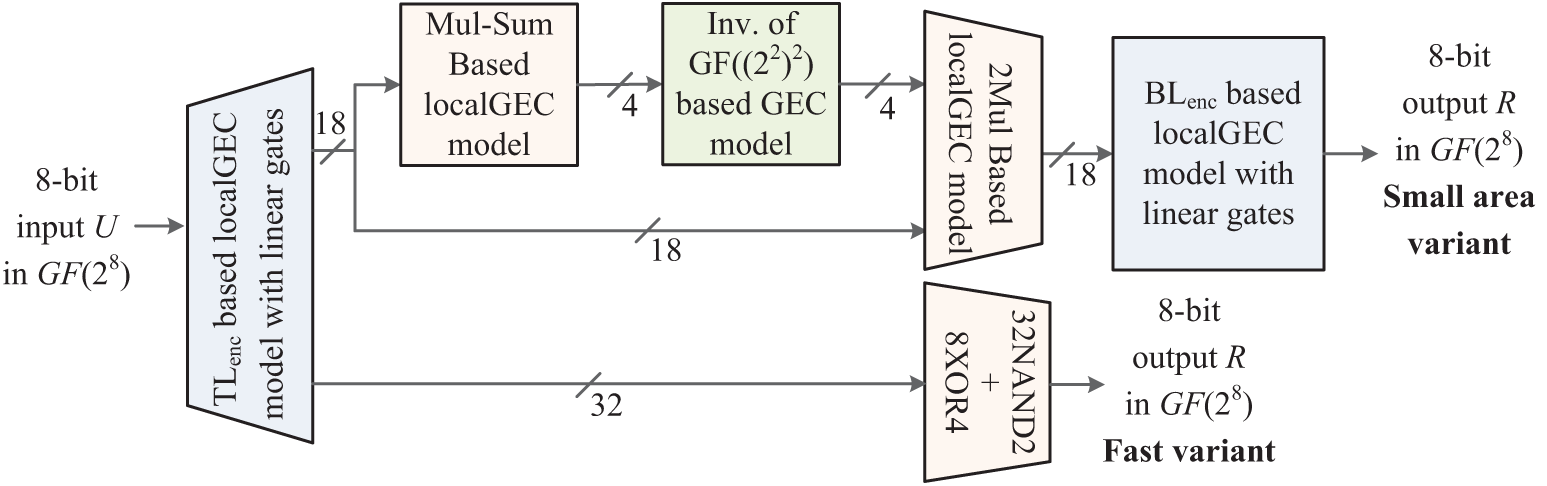
Figure 2: Optimized method for

Meanwhile, the SAT-based method was also applied on the circuit structure of
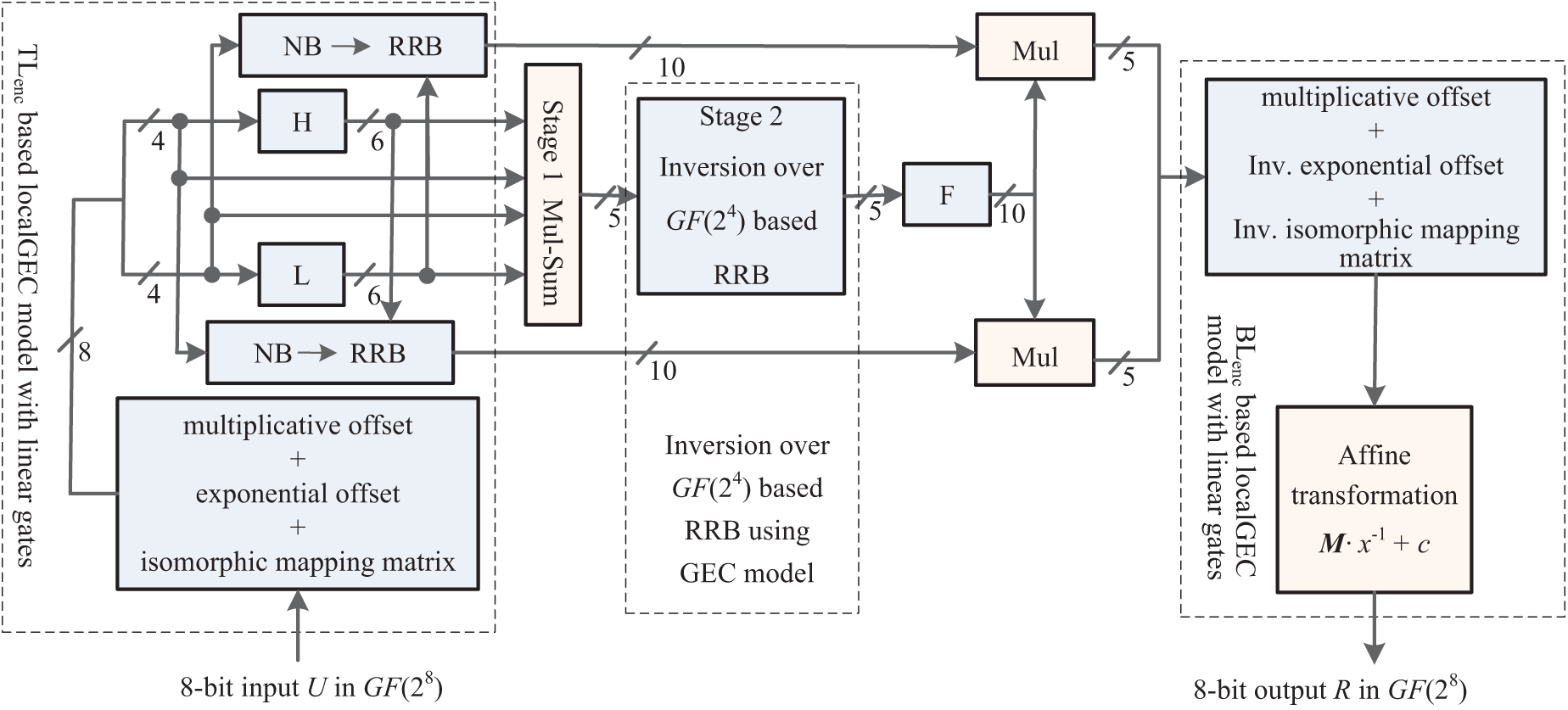
Figure 3: Optimized method for

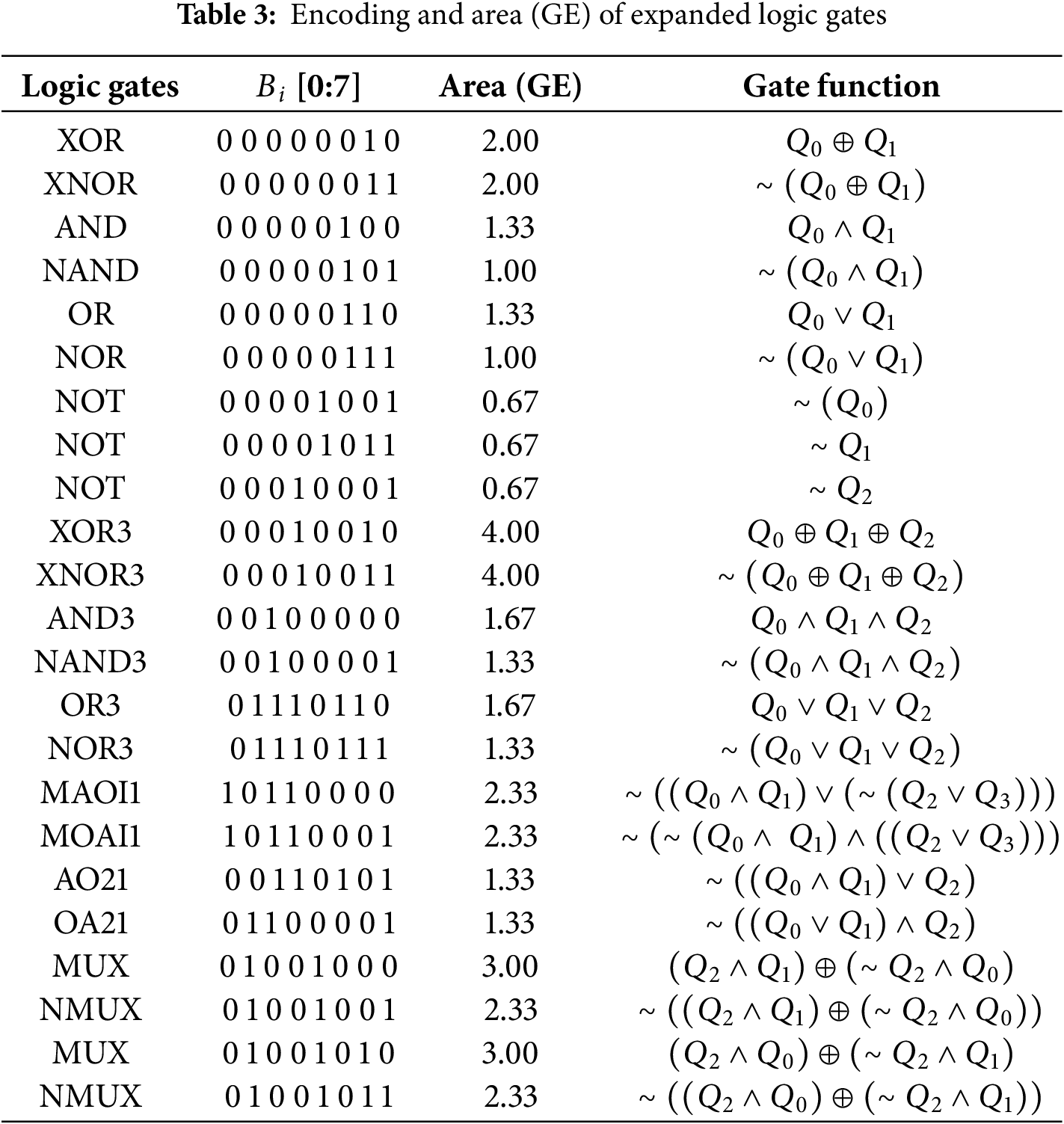
Furthermore, to optimize the implementation of the above functions based on more logic gates, the logic gate types used in the GEC/LocalGEC model have been further extended, as shown in Table 3. And for a fair comparison, the (sub) optimal solutions of each function have been searched based on Nangate 45 nm Open Cell Library. Moreover, to ensure the optimization implementation adopts the logic gate types in Table 3, a constraint has been added to the new GEC/LocalGEC model, as shown in Eq. (7). The specific search processes for different operations are described as below:
For instance, minimizing the implementation area, the specific process of using the GEC model to search for (sub)optimal implementations of the inversion is described as follows:
(1) Defining inputs/outputs: The inversion over
(2) Design goal: The inverse circuit (minimizing the area) with a depth of 3 and an area G of 22 GE was proposed by Maximov et al. [18]. So our goal is to search for solutions of the inversion that have an area smaller than G, according to Eq. (4).
(3) Encoding inputs and outputs of logic gates: Constrain the number of logic gates as
(4) Using SAT to search for solutions: If the solution exists, obtain the area of the current solution and assign it to G. Go to step 2) and continue searching for a smaller area implementation. Otherwise, the minimum area of the inversion over
Employing our method, for

Furthermore, the inversion over

3.2 Optimizing TL/BL/Mul(-Sum) Using Local Solutions
Although the GEC and BGC models can search for optimized implementations for some logic circuits, including the TL/BL/Mul(-Sum) in our approach, their efficiency still depends on the complexity of the considered circuits. However, finding optimized/improved implementations for circuits with high computational complexity may become infeasible. Therefore, a method for optimizing the implementation of (complex) circuits using local solutions is proposed, as shown in Fig. 4. For a circuit with

Figure 4: Optimized implementation of circuit based on local solution
For the
(1) (Obtaining local outputs): Obtain a local output set
(Partial encoding): Encode
Obtain other local outputs
Therefore, the minimum area and fast implementations of the matrix M0 require 13 (with depth 3) and 14 XORs (with depth 2), respectively. Compared to the implementations in [15], a reduction by 2 and 1 XORs has been achieved, respectively.
Based on the above method, for the
Furthermore, LocalGEC models are employed in the search for efficient implementations of Mul(-Sum). In difference to the results in [18,19], our implementations replace some AND/OR gates with smaller area NAND/NOR gates. As a consequence, the implementation of Mul(-Sum) in [19] requires 25 ANDs and 10 ORs, while our approach, utilizing 25 NANDs and 10 NORs, achieves an area reduction of 11.55 GE.
The implementations of
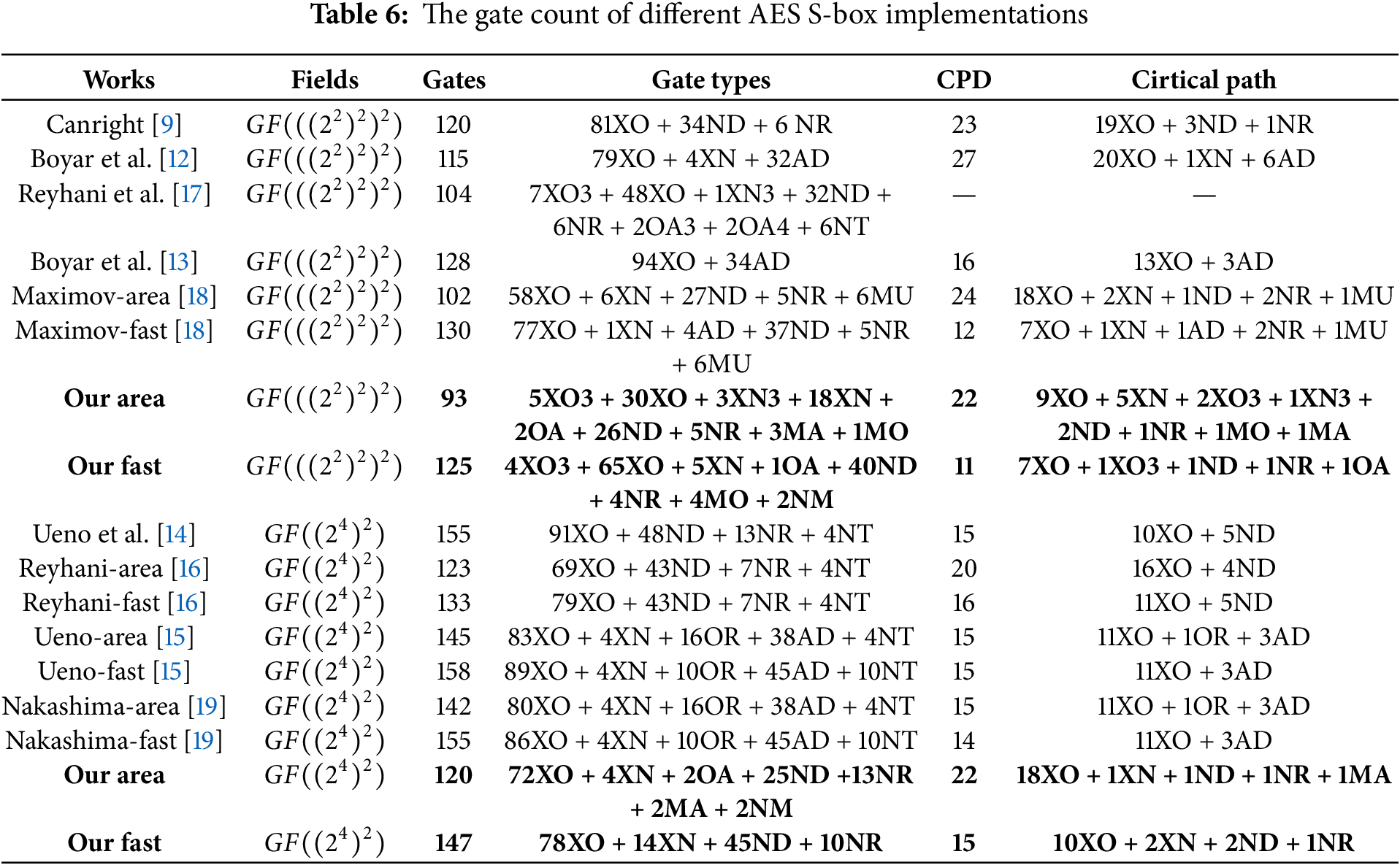
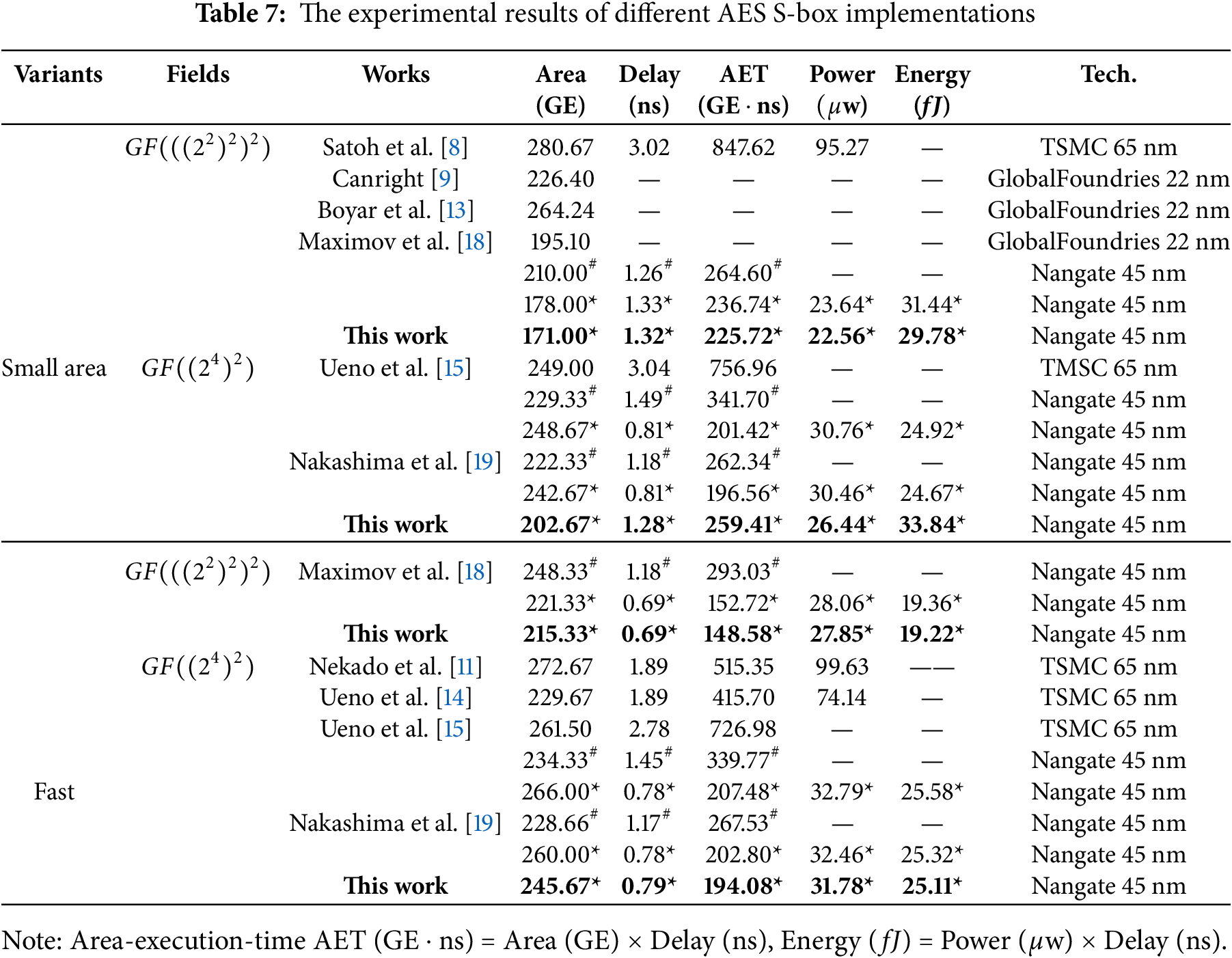
To verify the efficiency and performance of the above approach, the new AES S-box circuit structures are implemented using Verilog language and synthesized using Synopsys Design Compiler software with Nangate 45 nm Open Cell Library. The implementation performance have been evaluated, more precisely specifying the number of 2-input NAND gate equivalents (Area), the circuit delay for the critical path (Delay), the area-execution-time product (AET), power and energy. Table 7 presents the implementation results of different AES S-box structures on different standard cell libraries, where ‘#’ indicates the results from [19], and ‘*’ indicates the results implemented by the comprehensive strategy proposed by us.
The synthesis strategy covers the encapsulation technology of modules and logic gates. Its specific implementation includes using Verilog language to build modules with certain functions or specific logic gates. An example of a module using encapsulation techniques is presented, as shown in Eq. (9). It shows that an implementation module of the inverse over
Meanwhile, some strategies and constraints have been set up to prevent automatic optimization from changing the logic gate types and structure of the proposed S-box circuits. For example, the “set_dont_touch” command is used to protect specific modules, logic units, and signals, preventing their structures from being modified by the Synopsys Design Compiler. Furthermore, the timing, area, and power consumption evaluations provided by Design Compiler are based on actual comprehensive results. However, it is worth noting that it performs a logical synthesis rather than a physical implementation. Therefore, if the design constraints, tool settings, and verification process are consistent during logic synthesis, the performance indicators of the same circuit implementation will remain consistent. To ensure the stability of the circuit implementation, the specific comprehensive commands are described as Command 1.

Fig. 5 shows the comparison between the implementation results of the proposed structure and the implementation results in [19]. “M”, “U”, “N”, and “T” represent the works of [15,18,19] and this work, respectively. “A” and “F” represent the small area variant and the fast variant, respectively. “0” and “1” represent
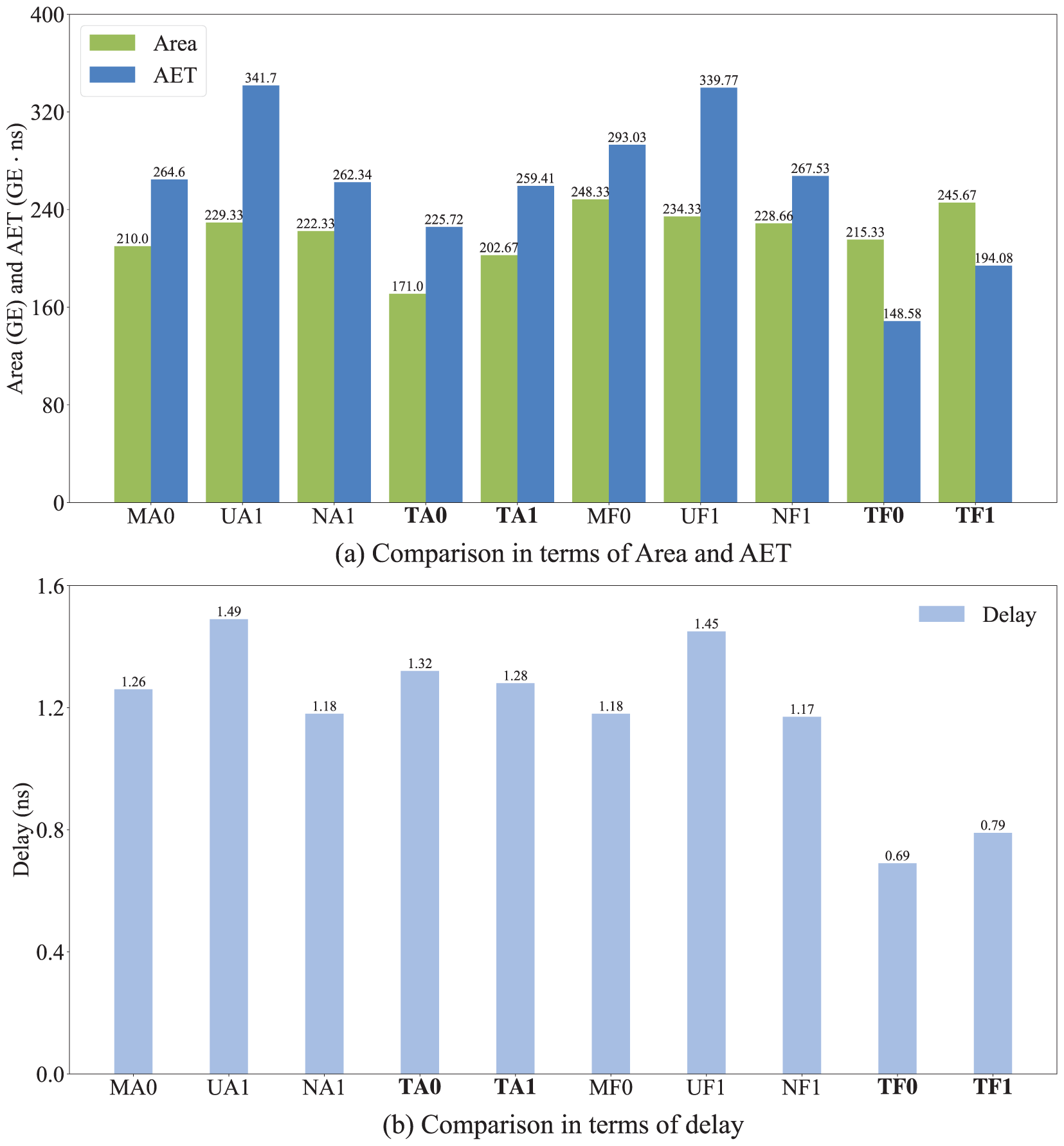
Figure 5: Comparison of implementation results between our structures (TA0, TA1, TF0 and TF1) and the structures in [19]
It is worth noting that Table 7 shows that MA0 in [18] requires 210.00 GE (reported in [19]). In contrast, MA0 requires 58 XORs, 6 XNORs, 27 NANDs, 5 NORs, and 6 MUXs, with an estimated area of
From the above comparison, it can be concluded that the proposed
This paper presented a novel hardware implementation strategy for AES S-boxes. It combines composite field arithmetic with SAT solvers. We decomposed the AES S-box implementation into five optimization tasks. These tasks include inversion over
Acknowledgement: The authors also gratefully acknowledge the helpful comments and suggestions of the reviewers and editors, which have improved the presentation.
Funding Statement: This work was supported in part by the National Natural Science Foundation of China (No. 62162016), and in part by the Innovation Project of Guangxi Graduate Education (Nos. YCBZ2023132 and YCSW2023304).
Author Contributions: Study conception and design: Jingya Feng, Ying Zhao; data collection: Jingya Feng, Tao Ye; analysis and interpretation of results: Jingya Feng, Ying Zhao, Wei Feng; draft manuscript preparation: Jingya Feng; supervision: Ying Zhao, Wei Feng. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: Not applicable.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
1https://github.com/fjyxzm/AESSbox (accessed on 01 February 2025).
2One of the file based input formats that STP reads, https://stp.readthedocs.io/en/stable/cvc-input-language.html (accessed on 01 February 2025).
References
1. Tangade S, Manvi SS, Lorenz P. Trust management scheme based on hybrid cryptography for secure communications in VANETs. IEEE Trans Vehicular Technol. 2020;69(5):5232–43. doi:10.1109/TVT.2020.2981127. [Google Scholar] [CrossRef]
2. Aydın H, Aydın GZG, Sertbaş A, Aydın MA. Internet of things security: a multi-agent-based defense system design. Comput Electr Eng. 2023;111(3):108961. doi:10.1016/j.compeleceng.2023.108961. [Google Scholar] [CrossRef]
3. National Institute of Standards and Technology. Advanced Encryption Standard (AES). Federal Information Processing Standards Publication (FIPS PUB 197). U.S. Department of Commerce; 2021 [cited 2024 Dec 10]. Available from: https://csrc.nist.gov/files/pubs/fips/197/final/docs/fips-197.pdf. [Google Scholar]
4. Cheng PY, Su YC, Chao PCP. Novel high throughput-to-area efficiency and strong-resilience datapath of AES for lightweight implementation in IoT devices. IEEE Internet Things J. 2024;11(10):17678–87. doi:10.1109/JIOT.2024.3359714. [Google Scholar] [CrossRef]
5. Lin MB, Chuang JH. The design of a high-throughput hardware architecture for the AES-GCM algorithm. IEEE Trans Consum Electron. 2024;70(1):425–32. doi:10.1109/TCE.2023.3332872. [Google Scholar] [CrossRef]
6. Zhang M, Shi T, Wu W, Sui H. Optimized quantum circuit of AES with interlacing-uncompute structure. IEEE Trans Comput. 2024;73(11):2563–75. doi:10.1109/TC.2024.3449094. [Google Scholar] [CrossRef]
7. Rudra A, Dubey PK, Jutla CS, amd Josyula Rao VK, Rohatgi P, et al. Efficient Rijndael encryption implementation with composite field arithmetic. In:Cryptographic Hardware and Embedded Systems–CHES 2001; 2001; Berlin/ Heidelberg: Springer. p. 171–84. [Google Scholar]
8. Satoh A, Morioka S, Takano K, Munetoh S. A compact Rijndael hardware architecture with S-box optimization. In: Advances in Cryptology–ASIACRYPT 2001; 2001; Berlin/Heidelberg: Springer. p. 239–54. [Google Scholar]
9. Canright D. A very compact S-box for AES. In: Cryptographic Hardware and Embedded Systems–CHES 2005; 2005; Berlin/Heidelberg: Springer. p. 441–55. [Google Scholar]
10. Nogami Y, Nekado K, Toyota T, Hongo N, Morikawa Y. Mixed bases for efficient inversion in F((22)2)2 and conversion matrices of subbytes of AES. In: Cryptographic Hardware and Embedded Systems–CHES 2010; 2010; Berlin/Heidelberg: Springer. p. 234–47. [Google Scholar]
11. Nekado K, Nogami Y, Iokibe K. Very short critical path implementation of AES with direct logic gates. In: Advances in information and computer security. Berlin/Heidelberg: Springer; 2012; p. 51–68. [Google Scholar]
12. Boyar J, Peralta R. A new combinational logic minimization technique with applications to cryptology. In: Experimental Algorithms, 9th International Symposium, SEA 2010; 2010; Berlin/Heidelberg: Springer. p. 178–89. [Google Scholar]
13. Boyar J, Peralta R. A small depth-16 circuit for the AES S-box. In: Information security and privacy research. Berlin/Heidelberg: Springer; 2012; p. 287–98. [Google Scholar]
14. Ueno R, Homma N, Sugawara Y, Nogami Y, Aoki T. Highly efficient GF(28) inversion circuit based on redundant GF arithmetic and its application to AES design. In: Cryptographic Hardware and Embedded Systems–CHES 2015. Berlin/Heidelberg: Springer; 2015; p. 63–80. [Google Scholar]
15. Ueno R, Homma N, Nogami Y, Aoki T. Highly efficient GF(28) inversion circuit based on hybrid GF representations. J Cryptographic Eng. 2019;9:101–13. doi:10.1007/s13389-018-0187-8. [Google Scholar] [CrossRef]
16. Reyhani-Masoleh A, Taha M, Ashmawy D. Smashing the implementation records of AES S-box. IACR Trans Cryptograp Hardw Embedded Syst. 2018;2018(2):298–336. doi:10.13154/tches.v2018.i2.298-336. [Google Scholar] [CrossRef]
17. Reyhani-Masoleh A, Taha M, Ashmawy D. New low-area designs for the AES forward, inverse and combined S-boxes. IEEE Trans Comput. 2020;69(12):1757–73. doi:10.1109/TC.2019.2922601. [Google Scholar] [CrossRef]
18. Maximov A, Ekdahl P. New circuit minimization techniques for smaller and faster AES S-boxes. IACR Trans Cryptograp Hardw Embedded Syst. 2019;2019(4):91–125. doi:10.13154/tches.v2019.i4.91-125. [Google Scholar] [CrossRef]
19. Nakashima A, Ueno R, Homma N. AES S-box hardware with efficiency improvement based on linear mapping optimization. IEEE Transact Circ Syst II: Express Briefs. 2022;69:3978–82. doi:10.1109/TCSII.2022.3185632. [Google Scholar] [CrossRef]
20. Song J, Lee K, Park J. Low area and low power threshold implementation design technique for AES S-box. IEEE Transact Circ Syst II: Express Briefs. 2023;70(3):1169–73. doi:10.1109/TCSII.2022.3217150. [Google Scholar] [CrossRef]
21. Singha TB, Palathinkal RP, Ahamed SR. Analysis of S-box hardware resources to improve AES intrinsic security against power attacks. IEEE Embed Syst Letters. 2024;16(4):525–8. doi:10.1109/LES.2024.3478070. [Google Scholar] [CrossRef]
22. Bao Z, Guo J, Ling S, Sasaki Y. PEIGEN-A platform for evaluation, implementation, and generation of S-boxes. IACR Transact Symmet Cryptol. 2019;2019:330–94. doi:10.46586/tosc.v2019.i1.330-394. [Google Scholar] [CrossRef]
23. Liu Q, Wang W, Fan Y, Wu L, Sun L, Wang M. Towards low-latency implementation of linear layers. IACR Transact Symmet Cryptol. 2022;2022:158–82. doi:10.46586/tosc.v2022.i1.158-182. [Google Scholar] [CrossRef]
24. Lu Z, Wang W, Hu K, Fan Y, Wu L, Wang M. Pushing the limits: searching for implementations with the smallest area for lightweight S-boxes. In: International Conference on Cryptology in India-INDOCRYPT; 2021; Cham: Springer. p. 159–78. [Google Scholar]
25. Feng J, Wei Y, Zhang F, Pasalic E, Zhou Y. Novel optimized implementations of lightweight cryptographic S-boxes via SAT solvers. IEEE Transact Circ Syst I: Regular Papers. 2024;71(1):334–47. doi:10.1109/TCSI.2023.3325559. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools