
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
E-SWAN: Efficient Sliding Window Analysis Network for Real-Time Speech Steganography Detection
1 School of Engineering and Technology, Jiyang College of Zhejiang A&F University, Zhuji, 311800, China
2 College of Mathematics and Computer Science, Zhejiang A&F University, Hangzhou, 311300, China
* Corresponding Author: Jie Yang. Email:
# Kening Wang and Feipeng Gao contributed equally to this work
Computers, Materials & Continua 2025, 82(3), 4797-4820. https://doi.org/10.32604/cmc.2025.060042
Received 22 October 2024; Accepted 20 December 2024; Issue published 06 March 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
With the rapid advancement of Voice over Internet Protocol (VoIP) technology, speech steganography techniques such as Quantization Index Modulation (QIM) and Pitch Modulation Steganography (PMS) have emerged as significant challenges to information security. These techniques embed hidden information into speech streams, making detection increasingly difficult, particularly under conditions of low embedding rates and short speech durations. Existing steganalysis methods often struggle to balance detection accuracy and computational efficiency due to their limited ability to effectively capture both temporal and spatial features of speech signals. To address these challenges, this paper proposes an Efficient Sliding Window Analysis Network (E-SWAN), a novel deep learning model specifically designed for real-time speech steganalysis. E-SWAN integrates two core modules: the LSTM Temporal Feature Miner (LTFM) and the Convolutional Key Feature Miner (CKFM). LTFM captures long-range temporal dependencies using Long Short-Term Memory networks, while CKFM identifies local spatial variations caused by steganographic embedding through convolutional operations. These modules operate within a sliding window framework, enabling efficient extraction of temporal and spatial features. Experimental results on the Chinese CNV and PMS datasets demonstrate the superior performance of E-SWAN. Under conditions of a ten-second sample duration and an embedding rate of 10%, E-SWAN achieves a detection accuracy of 62.09% on the PMS dataset, surpassing existing methods by 4.57%, and an accuracy of 82.28% on the CNV dataset, outperforming state-of-the-art methods by 7.29%. These findings validate the robustness and efficiency of E-SWAN under low embedding rates and short durations, offering a promising solution for real-time VoIP steganalysis. This work provides significant contributions to enhancing information security in digital communications.Keywords
With the proliferation of Internet technology and the reduction in communication costs, Voice over Internet Protocol (VoIP) has gained widespread application. However, this has also brought new security challenges, particularly the misuse of voice steganography techniques, which are increasingly being used as potential means for covert information transmission and illegal activities [1–3]. Faced with increasing detection and monitoring pressures, malicious actors are turning to more advanced and covert information hiding techniques. Steganography allows secret information to be cleverly embedded into seemingly ordinary VoIP speech stream data without drawing attention [4]. For example, common steganography techniques such as least significant bit replacement [5] and Quantization Index Modulation (QIM) [6] can embed significant amounts of hidden information with minimal impact on audio quality. Therefore, as steganography techniques advance, developing more efficient steganalysis techniques becomes increasingly important.
In response to the development of steganography techniques, steganalysis technologies have also been continuously progressing. Current steganalysis methods can be broadly categorized into two types: traditional machine learning methods relying on manual feature extraction, and modern methods based on deep learning.
Traditional methods typically use manually designed features, such as spectral analysis [7] and entropy measurements [8], combined with algorithms like Support Vector Machines (SVM) [9–11], extreme gradient boosting (XGBoost) [12] or Random Forests [13] for steganalysis, suitable for small-scale data analysis. However, these methods often show insufficient detection accuracy and limited generalization ability when facing low embedding rates or new steganography techniques. Consequently, in recent years, deep learning methods based on neural networks have gradually become a research hotspot in the field of VoIP speech steganalysis, with representative works including methods based on Convolutional Neural Networks (CNN) [14–17] and Recurrent Neural Networks (RNN) or Long Short-Term Memory (LSTM) [18–20]. These methods can automatically learn complex features, improving the detection capability for low embedding rate steganographic content and demonstrating stronger generalization ability. However, there is still room for improvement in accuracy under low embedding rates and short duration scenarios, and real-time performance needs further enhancement. To address these issues, this paper proposes a new Efficient Sliding Window Analysis Network (E-SWAN), aiming to balance detection accuracy and computational efficiency.
Existing steganalysis methods typically need to make trade-offs between detection accuracy and computational complexity when facing complex environments. These methods can be broadly categorized into traditional machine learning methods that rely on handcrafted features and modern deep learning-based methods. Traditional methods often struggle with generalization, especially when dealing with diverse data types such as image, video, and audio. Recent advances in deep learning have provided more effective approaches for steganalysis, as they can automatically learn complex features without the need for manual feature engineering. In particular, deep learning for steganalysis has shown significant improvements in the analysis of diverse data types, such as images, video, and audio, by leveraging deep architectures like CNNs and RNNs [21]. The sliding window technique, as a fundamental method in signal processing, can extract local features by moving a fixed-size window over the signal, effectively reducing computational complexity in the process. Therefore, sliding windows are particularly suitable for handling large-scale data tasks with high real-time requirements. Sliding windows not only preserve the overall structure of the signal but also finely capture subtle changes in the data, making them an important tool in steganalysis. Based on sliding window technology, the Convolutional Sliding Window (CSW) method [22] has achieved significant success in VoIP speech steganalysis, especially in low embedding rate scenarios, but there is still room for improvement. In light of this, this paper proposes a new E-SWAN. To optimize network architecture design to significantly improve computational efficiency while ensuring detection accuracy, providing an efficient solution for real-time VoIP speech steganalysis.
The proposed E-SWAN integrates two key modules, LTFM and CKFM, to address the challenges of VoIP speech steganalysis. The LTFM (LSTM Temporal Feature Miner) leverages LSTM networks to capture long-range temporal dependencies, which are essential for analyzing the temporal variations inherent in speech signals. This allows the model to effectively detect temporal patterns related to steganographic embedding. The CKFM (Convolutional Key Feature Miner), on the other hand, focuses on extracting crucial spatial features using convolutional operations. These spatial features help identify localized changes in the speech signal that are indicative of hidden information. By combining LTFM and CKFM, the proposed method benefits from both temporal and spatial feature extraction, significantly enhancing detection accuracy and robustness, especially under low embedding rates.
The core innovations of the E-SWAN are specifically reflected in the following aspects:
• Two-Module Deep Learning Architecture: This study proposes a novel deep learning model architecture based on an Efficient Sliding Window Analysis Network (E-SWAN), which integrates two core modules: the LSTM Temporal Feature Miner (LTFM) and the Convolutional Key Feature Miner (CKFM), based on a sliding window approach. The LTFM module utilizes LSTM networks to deeply mine long-term temporal features of speech signals, capturing intricate temporal dependencies introduced by steganographic embedding. This capability is crucial for detecting subtle variations in compressed speech streams. On the other hand, the CKFM module employs convolutional operations to extract key spatial features that help identify local and fine-grained modifications indicative of steganographic content. By combining LTFM and CKFM, the proposed method efficiently captures both temporal and spatial information, enhancing detection performance across a wide range of embedding rates.
• Improved Detection Accuracy and Robustness: Our experimental results demonstrate that the proposed model achieves a significant balance between detection accuracy and computational efficiency across various embedding rates and speech durations. Notably, the combination of LTFM and CKFM not only helps capture complementary feature aspects (temporal and spatial) but also results in superior detection accuracy, particularly in challenging scenarios with low embedding rates and short speech samples. This dual-module design ensures robust performance even under adverse conditions.
• Comprehensive Evaluation and Comparison: We compared E-SWAN against existing state-of-the-art methods using multiple datasets and across different embedding rates. Experimental results consistently indicate that E-SWAN outperforms other models in both detection accuracy and adaptability, demonstrating stronger robustness across different speech durations, embedding rates, and steganographic methods.
The remainder of this paper is organized as follows. Section 2 reviews related work in VoIP speech steganalysis, covering both traditional and deep learning-based methods. Section 3 presents a detailed explanation of the proposed E-SWAN, including its design concept, network structure, and key components. Section 4 describes the experimental setup, presents comprehensive evaluation results, and provides in-depth discussion of the model’s performance under various scenarios. Finally, Section 5 concludes the paper with a summary of contributions, limitations, and future research directions.
The process of hiding secret information in compressed speech involves embedding the data during the speech encoding phase to ensure the embedded message remains imperceptible. Typically, secret data is embedded by modifying certain codec parameters, such as Linear Predictive Coding (LPC) coefficients or pitch delay parameters, to incorporate the hidden payload without degrading speech quality. Fig. 1 illustrates the main stages at which embedding can occur during compression: within the pitch synthesis filter and the LPC synthesis filter.
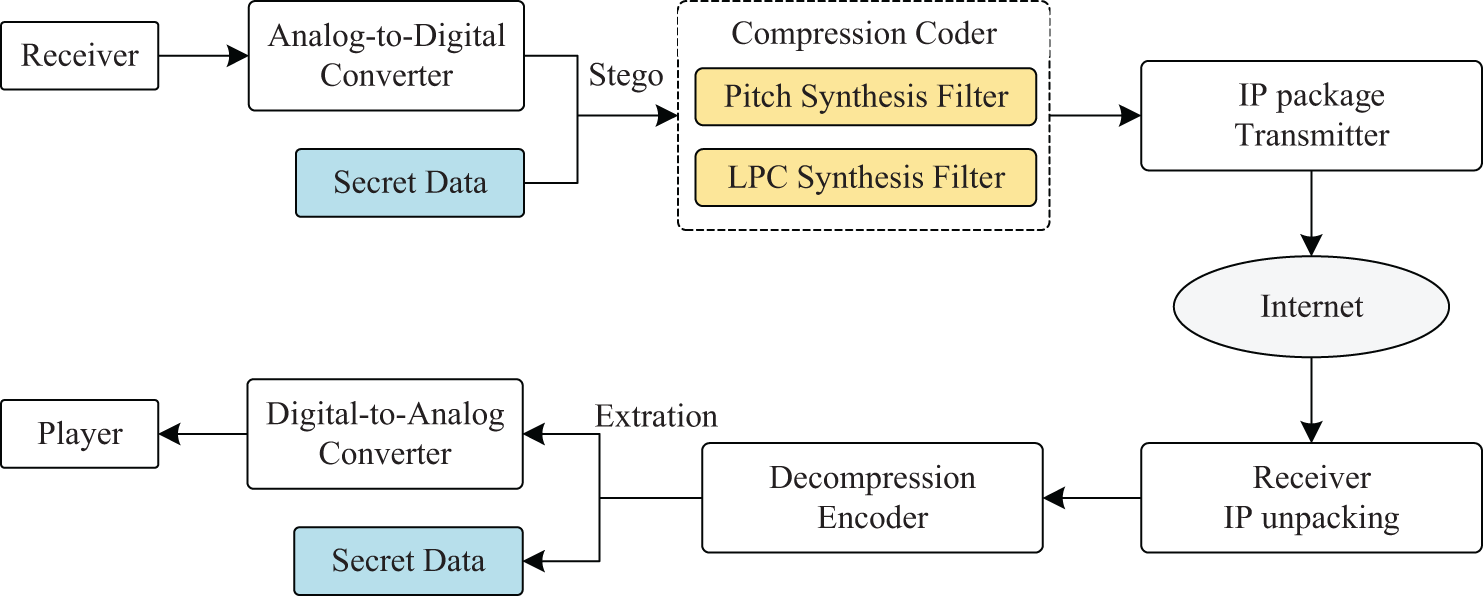
Figure 1: Process flow of information hiding and extraction in VoIP transmission
The extraction process, conversely, involves recovering this hidden information during decompression by analyzing and extracting the modified parameters. This process is crucial in the context of information hiding as it ensures the hidden message can be successfully retrieved at the receiving end.
Steganography involves the embedding of secret information into audio signals by modifying certain properties of the speech signal, such as quantization indices in QIM or pitch delay parameters in PMS. These modifications are carefully designed to be imperceptible to the listener while maximizing the capacity for hidden data embedding and ensuring minimal distortion of the original audio quality.
Speech Voice steganography techniques have continuously evolved with the rapid development of digital communication in VoIP, where Quantization Index Modulation (QIM) steganography and Pitch Modulation Steganography (PMS) steganography are two common and effective methods.
QIM steganography embeds secret data during the Linear Predictive Coding (LPC) vector quantization process. For example, Xiao et al. [23] proposed Complementary Neighbor Vertex (CNV) QIM steganography, which embeds data by partitioning QIM codebook information to improve embedding efficiency and concealment. Subsequently, Tian et al. [24] proposed SEC-QIM, combining matrix encoding to enhance resistance against steganalysis while improving embedding efficiency. Liu et al. [25] treated LPC quantization indices as points in three-dimensional space, using a QIM-based nearest neighbor projection point replacement technique to embed information into quantization indices, enhancing steganographic concealment, and proposed the NPP-QIM steganography method.
PMS achieves secret information embedding by modifying adaptive codebook delay codewords. Huang et al. [26] proposed the pitch search range steganography algorithm, synchronously embedding data during low bit-rate speech encoding, allowing speech coding and steganography to occur simultaneously. Ren et al. [27] proposed an AMR adaptive steganography scheme based on unvoiced speech, embedding information by modifying pitch delay parameters while maintaining short-term stability of pitch delay. Liu et al. [28] further optimized this method, proposing a new steganography scheme based on pitch delay search, embedding information through fractional pitch delay while keeping integer pitch delay unchanged to enhance steganographic concealment.
Steganalysis, on the other hand, is the process of detecting the presence of hidden information within audio signals. This process involves analyzing speech features that may reveal subtle traces of data embedding. Conventional steganalysis techniques have relied on handcrafted features combined with machine learning classifiers, while recent approaches have increasingly employed deep learning models to automatically learn and detect complex steganographic patterns.
Early steganalysis methods predominantly relied on handcrafted statistical features and used machine learning algorithms for classification. For instance, Kraetzer et al. [29] analyzed Mel-frequency features of audio signals and used SVM for classification to detect steganographic information in audio. This method leveraged SVM’s strong generalization ability to effectively detect audio steganography. However, the manual feature extraction process is complex and susceptible to noise and feature selection issues. For QIM steganography, Liu et al. [30] achieved certain detection accuracy by extracting statistical features generated during the vector quantization process and modeling them using Markov chains. Similarly, for PMS, Ren et al. [31] analyzed statistical features of pitch delay and detected hidden information using machine learning methods. However, these methods depend heavily on expert knowledge in feature selection, making them difficult to adapt to rapidly evolving steganography techniques. Moreover, manually extracted features often fail to comprehensively capture complex steganographic traces, especially in low embedding rate scenarios. Additionally, these methods often require redesigning features when facing new steganographic algorithms, lacking universality and scalability.
In recent years, deep learning based steganalysis methods have made significant progress in the field of VoIP speech steganalysis. Wu et al. [19] proposed a two-layer LSTM recurrent neural network steganalysis model (RNN-SM). This model effectively captures long and short-term dependencies in speech stream signals, greatly improving steganalysis accuracy. Subsequently, Hu et al. [15] developed the Steganalysis Feature Fusion Network (SFFN) model, further expanding the application of LSTM in processing low bit-rate VoIP speech streams, demonstrating the powerful performance of deep learning methods in complex data environments.
Recent advancements in the field of speech steganalysis have led to the development of several novel methods, particularly leveraging deep learning models and multi-domain information fusion techniques. Li et al. [32] proposed SANet, a steganography algorithm-independent steganalysis model for low-bit-rate compressed speech, utilizing an uncompressed domain intermediate representation to enhance detection accuracy. Zhang et al. [33] introduced TENet, a transformer encoder-based steganalysis model that effectively detects QIM-based steganography in VoIP speech streams, leveraging transformer encoders for high detection efficiency. Guo et al. [34] proposed MDoIF, a method based on multi-domain information fusion for AMR speech streams, which combines Bayesian network modeling with feature selection to achieve robust performance, particularly at low embedding rates. These references provide valuable insights into recent innovations in steganalysis techniques and underscore the growing trend of employing advanced deep learning frameworks to improve detection robustness and accuracy.
The sliding window technique, as a powerful data processing method, has shown excellent results in multiple fields. In image processing, sliding windows are widely used for object detection and image segmentation tasks [35]. In natural language processing, sliding window techniques are applied to text classification and named entity recognition [36]. In time series analysis, sliding window methods are used for stock price prediction and anomaly detection [37]. The widespread application of this technique stems from its ability to effectively capture local features and analyze data at different scales.
In the field of speech signal processing, sliding window techniques have also shown tremendous potential. For example, in speech recognition, sliding windows are used to extract short-time spectral features [38]. In speaker recognition tasks, sliding window techniques help capture dynamic features of speech [39]. These successful applications provide a solid theoretical and practical foundation for introducing sliding window techniques into the field of speech steganalysis.
Based on the widespread application and success of sliding window technology, Yang et al. [22] proposed the innovative CSW method, cleverly combining CNN with sliding window techniques. The CSW method uses CNN to extract spatial features while capturing time series information through sliding windows, effectively improving the accuracy of steganalysis. This method can not only handle variable-length VoIP speech stream signals but also capture subtle steganographic traces in speech while maintaining relatively low computational complexity.
However, although deep learning algorithms excel in many aspects, there is still room for improvement in handling global features and adapting to complex steganography methods. Furthermore, how to further improve the real-time performance and adaptability of models while maintaining high detection accuracy remains an important challenge facing current research.
To address the shortcomings of the aforementioned steganalysis methods, this study proposes a new network model for real-time detection of steganographic information in compressed speech streams. This model is specifically designed to detect QIM and PMS algorithms, significantly improving detection performance under different embedding rates and speech duration conditions. Our method aims to overcome the limitations of existing approaches and provide a more efficient and accurate steganalysis solution through innovative network design and feature fusion techniques.
The proposed model is designed to analyze two distinct categories of compressed speech inputs, CNV and PMS, each requiring a specific input representation derived from the underlying compression algorithms.
For CNV inputs, our focus is on the Line Spectral Pair (LSP) coefficients. In LPC based codecs, each frame is typically encoded using three 8-bit vector quantization codewords. These codewords, which encode the LSP coefficients, effectively capture the spectral envelope of the speech signal, resulting in a three-parameter representation per frame. In contrast, PMS inputs necessitate the extraction of pitch-delay-related parameters, yielding a four-parameter representation for each frame.
To facilitate efficient detection, we abstract the audio input as a matrix. Let T denote the total number of frames in an audio segment. The input can then be represented as a matrix
The elements of matrix S, denoted as
The architecture of E-SWAN is composed of two primary subnetworks: LTFM and CKFM. These subnetworks are strategically designed to capture distinct aspects of speech signals. The LTFM is responsible for extracting global sequence-related features, while the CKFM focuses on mining local features. This dual-pronged approach allows for a comprehensive analysis of the speech signal, leveraging both temporal and spatial characteristics. The synergy between these subnetworks enables E-SWAN to effectively process and analyze speech data for steganalysis purposes. The structural composition of E-SWAN, including the detailed arrangement of its subnetworks, is illustrated in Fig. 2.
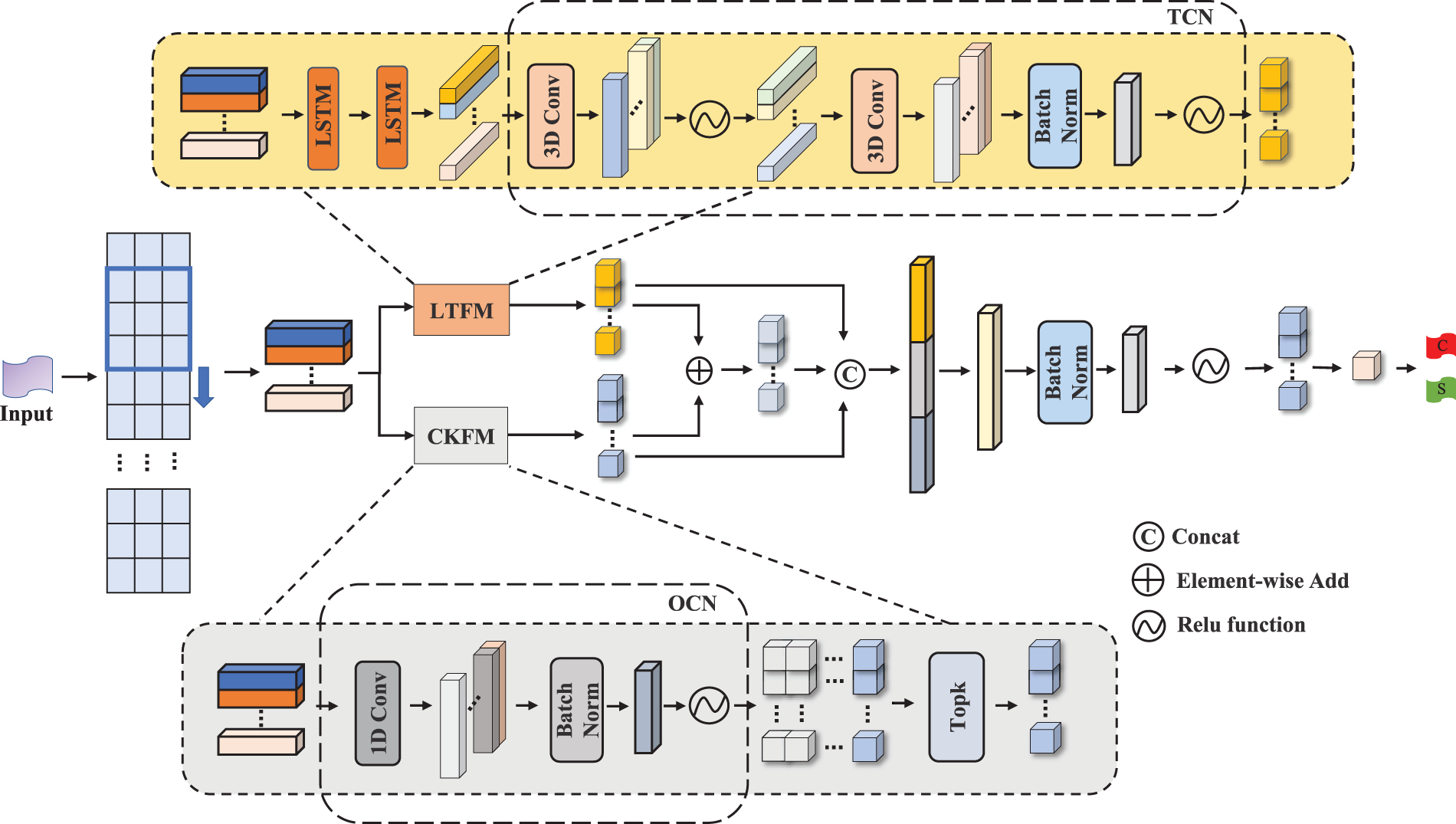
Figure 2: E-SWAN network architecture
The LTFM comprises two LSTM layers and a Temporal Convolutional Network (TCN). LSTM layers are employed to detect long-term dependencies in time series data, providing an optimal mechanism for extracting global sequence-related features. TCN essentially captures temporal dependencies through dilated convolutions. By constructing different convolutional kernels, the TCN architecture introduced in this paper can utilize convolutional kernels of varying sizes to perform feature extraction in different subspaces, thereby enhancing the expressive ability of the obtaining features.
The CKFM integrates the One-Dimensional Convolutional Network (OCN) as a key component. The OCN employs one-dimensional convolutional layers to extract features from the input data, followed by batch normalization and ReLU activation functions. This structure enhances the model’s ability to capture local features, thus improving training stability and convergence speed.
Feature sets from LTFM and CKFM are aggregated to form a new feature collection, which is then concatenated with the remaining feature information. This concatenated feature set undergoes a series of operations through a fully connected layer, including Linear layer, Batch Normalization layer, ReLU (Rectified Linear Unit) activation functions, and Dropout layer. Finally, the output is obtained through a Sigmoid activation function.
During the training process, an Adam optimizer is utilized to optimize model parameters, and cross-entropy loss is calculated between predicted results and true labels. Throughout the training phase, the model’s performance is continuously evaluated by monitoring loss and accuracy metrics.
Sliding window techniques play a crucial role in signal processing. The theoretical foundation of thistechnique derives from time-frequency analysis, allowing for local analysis of audio signals while main-taining temporal continuity. Consequently, this study introduces a sliding window-based steganography analysis algorithm. An example of the sliding window used in this study is shown in Fig. 3.
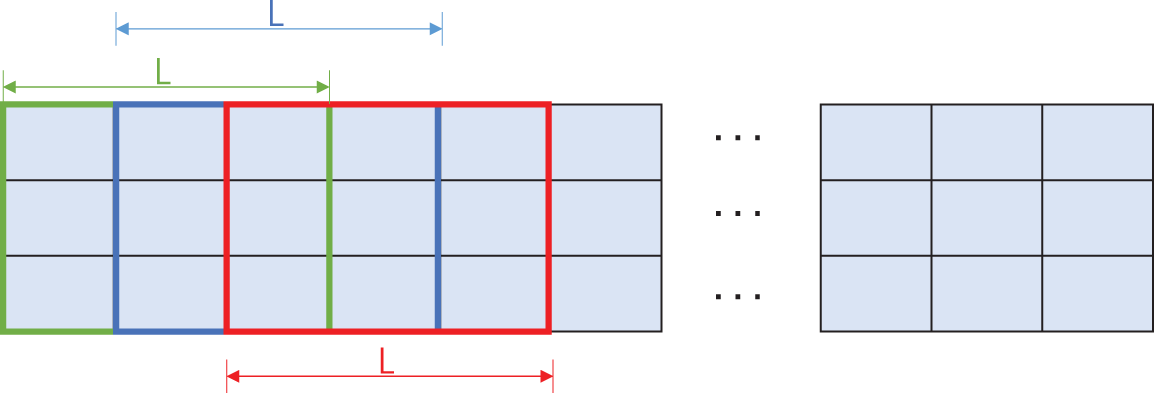
Figure 3: Sliding window example
The sliding window technique is used to segment the input into overlapping chunks, each consisting of multiple feature dimensions over a time segment. While these segments are illustrated in a 2D manner to indicate capturing multiple features at once, the data is then flattened into a 1D sequence for processing by the LSTM, which handles the temporal dependencies across these segments. This representation allows us to visually convey how spatial relationships within the features are retained during the initial extraction phase before LSTM processes the temporal dependencies.
Let the detection window length L represent the number of frames contained in the detection window. Given a stream S, the last received frame is designated as
When the next frame
The algorithm introduced in this study, based on sliding window technology, reduces computational overhead while maintaining the integrity and stability of feature extraction, avoiding unnecessary parameter calculations. Within the scope of this study, the sliding window length is consistently L = 3, which facilitates the extraction of relational features between each frame and its adjacent frames in speech streams.
In the field of deep learning, effective extraction of multi-level feature information is crucial for parsing complex data structures. For data with temporal characteristics, LSTM networks have demonstrated the ability to capture long-term dependencies, as shown in Fig. 4.
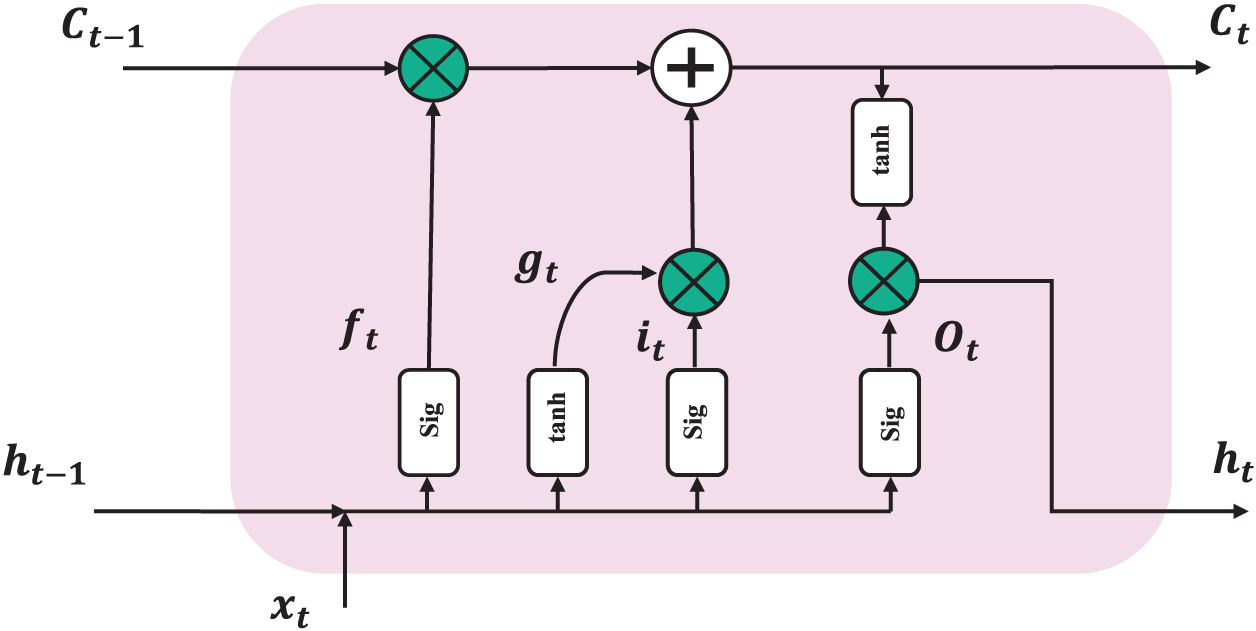
Figure 4: LSTM model introduction
This study designs a residual module architecture for processing input data with three-dimensional features. These data are presented in the form of three-dimensional tensors, with dimensions corresponding to batch size, time series length, and three feature channels. The framework uses two cascaded LSTM units to extract temporal features from the input data, as shown in Fig. 5.

Figure 5: LTFM module network structure
To optimize the computational process, VoIP speech stream inputs are encoded and represented as
At the beginning of the network, the input tensor is processed through two LSTM layers. The first LSTM layer captures the relationships between time steps in the input data while reducing the feature dimension to 50. This transformation emphasizes the inherent temporal features in the sequence while reducing data complexity. The subsequent LSTM layer maintains the 50-dimensional feature dimension, aiming to further mine deeper temporal features and capture long-term dependencies in the data.
Feature extraction from local regions of the input matrix is accomplished through convolution operations. Specifically, assuming the
When the convolution kernel overlaps with elements, features are extracted from the input, as shown in Eq. (7).
where the weights represent the contribution of the
To extract more comprehensive features of speech signals within the sliding window, multiple convolution kernels are used simultaneously for feature extraction. Assuming the number of convolution kernels in the first layer is
The ReLU activation function is defined as shown in Eq. (10).
The ReLU function introduces non-linearity, enhancing the network’s ability to model complex relationships. After introducing the ReLU function, it can be represented by Eq. (11).
Increasing the number of convolutional layers within a certain range is beneficial for extracting higher-level signal features and subsequent feature analysis. However, excessive layers may lead to overfitting and reduce detection efficiency. Therefore, another convolutional layer is added after the first one. The operation of the second convolutional layer is essentially the same as the first, also containing multiple convolution kernels, each with a width equal to
where
After applying three-dimensional convolution, the output undergoes batch normalization. This layer normalizes the input from the previous layer. This step reduces internal covariate shift, improving convergence speed and enhancing model stability during training. The batch normalization operation is denoted by
The output then passes through a ReLU activation function, resulting in the output shown in Eq. (15).
After processing through two layers of convolutional networks, the output is obtained. The tensor dimension is then reduced by removing unit-length dimensions and taking the average along the second and third dimensions, resulting in a three-dimensional feature representation. This operation effectively reduces the risk of model overfitting while maintaining the overall feature distribution by reducing the number of network parameters. This not only alleviates the computational burden of subsequent processing but may also enhance the robustness of feature mapping and remove redundant information.
The averaging operation can be formally represented by
After reducing the feature dimension, the resulting features are flattened into a one-dimensional tensor
The CKFM achieves efficient feature processing of input data through a tight integration of OCN, Batch Normalization layer, and ReLU activation functions, as illustrated in Fig. 6.
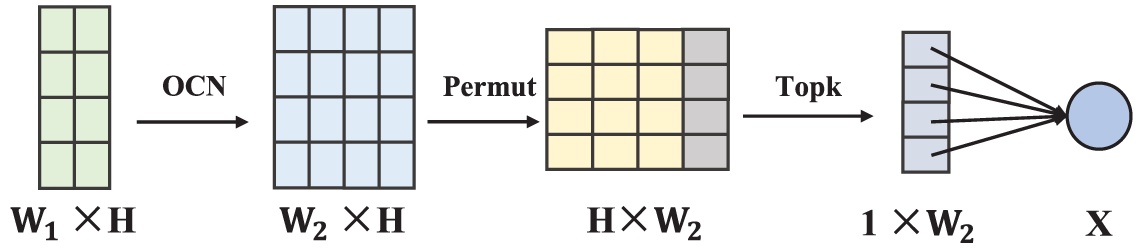
Figure 6: CKFM module network structure
In the initial stage of the module, the input data is a one-dimensional tensor with three channels. This dimension is first processed through a one-dimensional convolutional layer, aimed at expanding the data’s depth without increasing the number of parameters. Here, the number of input channels is set to 3, while the output corresponds to the depth of the convolutional tensor. Through this processing, each convolution operation involves only a single element, effectively extracting features from the original data. The one-dimensional convolution operation is represented by
Immediately following, one-dimensional batch normalization layer is applied, as shown in Eq. (18).
The batch-normalized data then passes through a ReLU activation function. The ReLU function introduces non-linearity to the network, enhancing the model’s ability to capture complex relationships between inputs and outputs, thereby accelerating the neural network training process and improving model performance, as shown in Eq. (19).
As
In this way, the CKFM module effectively processes and compresses the input data, extracting key features while maintaining computational efficiency. This design not only reduces the number of model parameters but also helps prevent overfitting, improving the model’s performance across various tasks.
In the process of constructing deep learning models to solve complex classification tasks, the quality and representation of feature information play a decisive role in improving model performance. This study integrates the output features of the LTFM module and CKFM module, enabling the model to capture and interpret data information from different levels and perspectives. Based on this feature fusion, the model effectively enhances the non-linear expressive ability of features by stacking a series of linear layers, thereby improving classification effects, as shown in Eqs. (20) and (21).
The
The residual module employs the LSTM model to capture deep information, while the fully convolutional module effectively extracts local features. By adding the results of these two modules, a new feature representation
The concatenated feature tensor W is then input into two linear processing layers. The first linear layer consists of a fully connected layer, batch normalization, ReLU activation, and Dropout operation. The fully connected layer transforms the input dimension from 2400 to 2048, providing the model with a high-density feature representation. This is followed by batch normalization, which standardizes features and accelerates model training while improving stability. The ReLU activation function endows the model with the ability to capture complex non-linear relationships between inputs and outputs, while the Dropout operation serves as a regularization technique to mitigate overfitting and enhance the model’s generalization ability. The Dropout operation can be simplified as Dropout(
The second linear layer consists of another fully connected layer and a Sigmoid activation function. This layer is primarily used to fuse diverse feature information and optimize the classifier’s performance. Finally, the Sigmoid function compresses the model’s output to the range [0, 1], representing the predicted binary classification probability F. This probability value is used to determine whether the detected audio data stream contains steganographic information, providing a basis for the final decision, as shown in Eq. (24).
where Stego represents steganographic sample files, and Cover represents carrier sample files.
We perform experiments on the speech dataset proposed in [18]. The experimental dataset comprises English and Chinese speech samples, consisting of 72 h of English speech and 41 h of Chinese speech. These original speech samples were initially stored in pulse code modulation format.
To construct the dataset required for the experiments, all speech samples were first encoded using the G.729 encoder. G.729 is a low bit-rate (8 kbit/s) speech codec widely used in VoIP communications. The steganographic technique proposed in [23] was employed to randomly embed 01 bit streams into the encoded speech data, generating a steganographic speech dataset in CNV format. Additionally, the method described in [26] was used to hide secret information in speech files, constructing the PMS dataset.
In this paper, the embedding rate is defined as the ratio of embedded bits to the total embedding capacity. To comprehensively evaluate the model’s performance under different embedding rates, we constructed training datasets with durations of 10s and embedding rates ranging from 10% to 100%. We also created additional datasets with embedding rates from 1% to 9% for comparative analysis.
The steganographic speech dataset and carrier speech dataset were divided into training, testing, and validation sets using a 6:2:2 ratio. This resulted in 9240 training speech files, 3080 testing speech files, and 3080 validation files for each dataset group.
All comparative experimental data were derived from the test set. Accuracy was primarily used as the evaluation metric, calculated as follows:
where True Positive (TP) represents the number of correctly predicted positive samples, False Positive (FP) represents the number of negative samples incorrectly predicted as positive, False Negative (FN) represents the number of positive samples incorrectly predicted as negative, and True Negative (TN) represents the number of correctly predicted negative samples.
Furthermore, to assess the model’s real-time performance, we introduced the average detection time per speech stream as a detection time indicator. If the detection time for any steganographic technique is significantly less than the speech stream length, it indicates that the model possesses real-time detection capability.
Experiments were conducted on a GeForce GTX 3090 GPU with 24 GB of video memory. The implementation of models and algorithms utilized the PyTorch framework. During the neural network training process, Adam was selected as the optimizer, with a learning rate of 0.001, and cross-entropy was used as the loss function. The maximum number of iterations was set to 200, with a training batch size of 128.
This section primarily explores the selection of model hyperparameters and their impact on performance, while also comparing the effectiveness of different model structures. The proposed model requires the determination of certain key hyperparameters, such as the number of channels and convolutional layers. Generally, increasing these hyperparameters can enhance the network’s representational capacity. However, this may also increase the risk of overfitting, potentially reducing detection performance. Therefore, we conducted experiments to determine the optimal hyperparameter configuration. To evaluate the impact of different model substructures on performance, we conducted experiments using the CNV dataset with a speech duration of 10s and an embedding rate of 10%. Table 1 presents the experimental results.
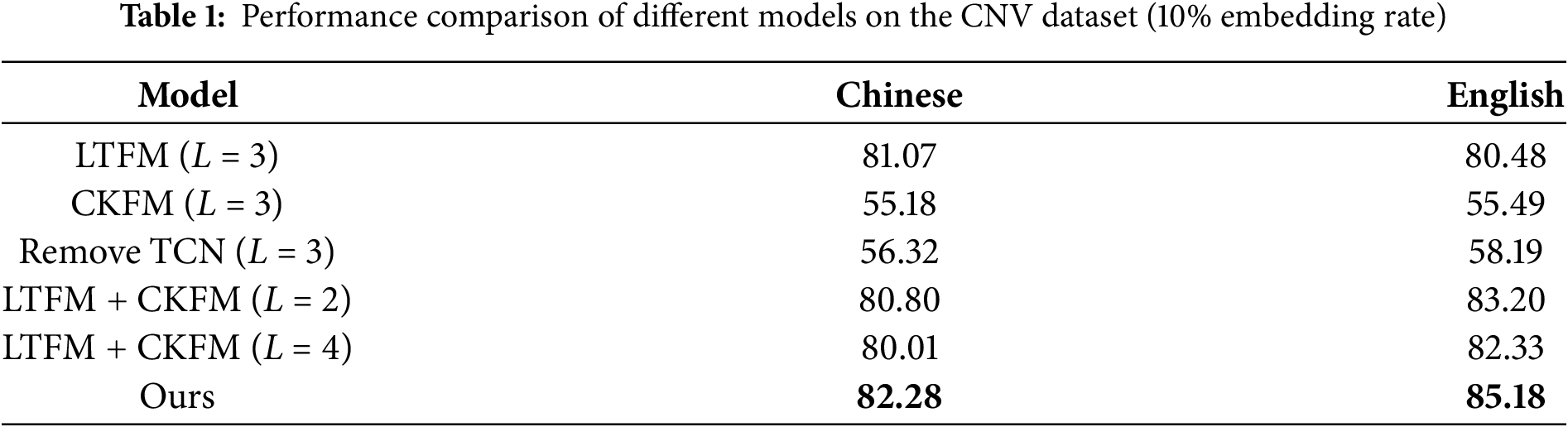
From Table 1, it is evident that the removal of the TCN component led to a significant drop in accuracy, with results of 56.32% for Chinese and 58.19% for English, compared to the original accuracy of 82.28% and 85.18%, respectively. This represents a drop of approximately 26% for Chinese and 27% for English. This highlights the critical role played by TCN in capturing temporal dependencies and ensuring model robustness. The combination of LTFM and CKFM modules alone was not sufficient to achieve the same level of performance, emphasizing the importance of temporal convolution in feature extraction. By integrating TCN with LTFM and CKFM, the proposed model effectively leverages both temporal and spatial feature representations, resulting in significantly improved detection accuracy, especially under challenging conditions such as low embedding rates.
We also conducted experiments with different sliding window sizes. When processing Chinese and English CNV datasets, results showed that a sliding window size of 3 achieved higher accuracy compared to window sizes of 2 or 4.
4.3 Performance Analysis at Different Embedding Rates
This experiment utilized two distinct speech datasets (CNV and PMS), each comprising Chinese and English speech samples. We employed five different detection methods (RNN_SM, SFFN, CSW, SANet, and Ours) for the analysis. The embedding rates ranged from 10% to 100%, with 10 different embedding rates cases. The experimental results for both datasets are presented in Tables 2 and 3.
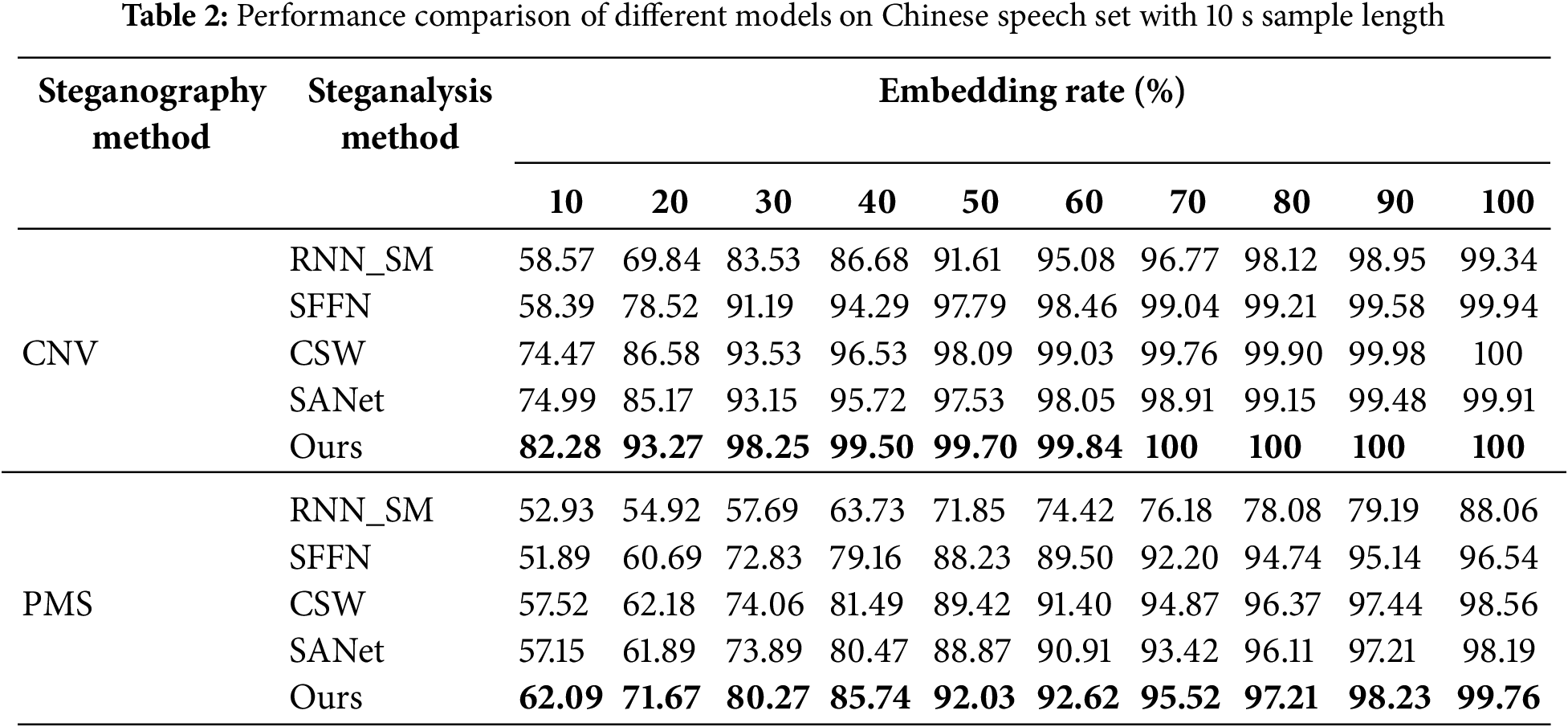
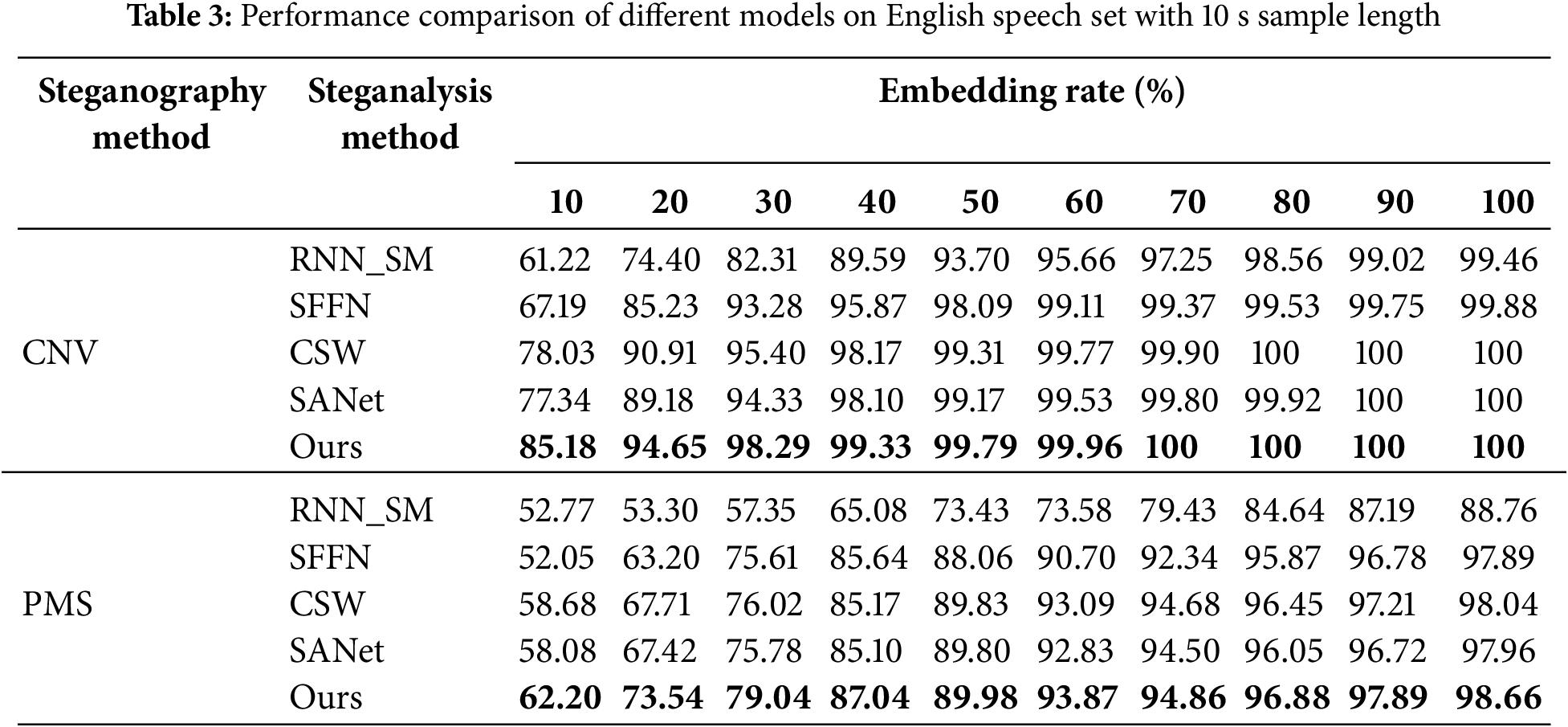
As evidenced in Table 2, our proposed model demonstrated superior performance on the PMS Chinese dataset, achieving an accuracy of 62.09% at a 10% embedding rate. The model’s accuracy consistently improved as the embedding rate increased, reaching 99.76% at a 100% embedding rate. In comparison, while the RNN_SM, SFFN, CSW, and SANet methods also showed improvement with increasing embedding rates, their performance was consistently lower than our model across all conditions. Notably, compared to SANet, our model achieved up to 7.1% higher accuracy at lower embedding rates on the CNV dataset, while for the PMS dataset, the improvement ranged from 2% to 5%, particularly for embedding rates between 30% to 70%.
Table 3 presents similar trends for the English speech set. Our model maintained high accuracy across various embedding rates, with its performance advantage becoming more pronounced as the embedding rate increased. At a 10% embedding rate, our model achieved a 62.20% success rate, which steadily improved to 98.66% at a 100% embedding rate.
For the CNV dataset, our model’s performance was particularly impressive. In the Chinese speech set, our model achieved an 82.28% success rate at a 10% embedding rate, significantly outperforming other analytical methods which had accuracy rates below 75% under the same conditions. At a 70% embedding rate, our model reached 100% accuracy, whereas RNN_SM, SFFN, CSW, and SANet achieved accuracies of 96.77%, 99.04%, 99.76%, and 98.91%, respectively.
The performance on the CNV English dataset was equally remarkable, with our model achieving an 85.18% success rate at a 10% embedding rate. The accuracy continuously improved as the embedding rate increased, stabilizing at 100% after a 70% embedding rate, consistently outperforming the comparison methods.
These results comprehensively demonstrate the significant advantages and practical application value of our proposed model in handling steganalysis tasks across a wide range of embedding rates. The model exhibits excellent performance in both low and high embedding rate scenarios, showcasing its strong adaptability and robustness. This performance advantage is not limited to a single language or dataset but is consistently verified across Chinese and English speech and different steganographic methods, further confirming the universality and practicality of our approach.
4.4 Performance Comparison at Low Embedding Rates
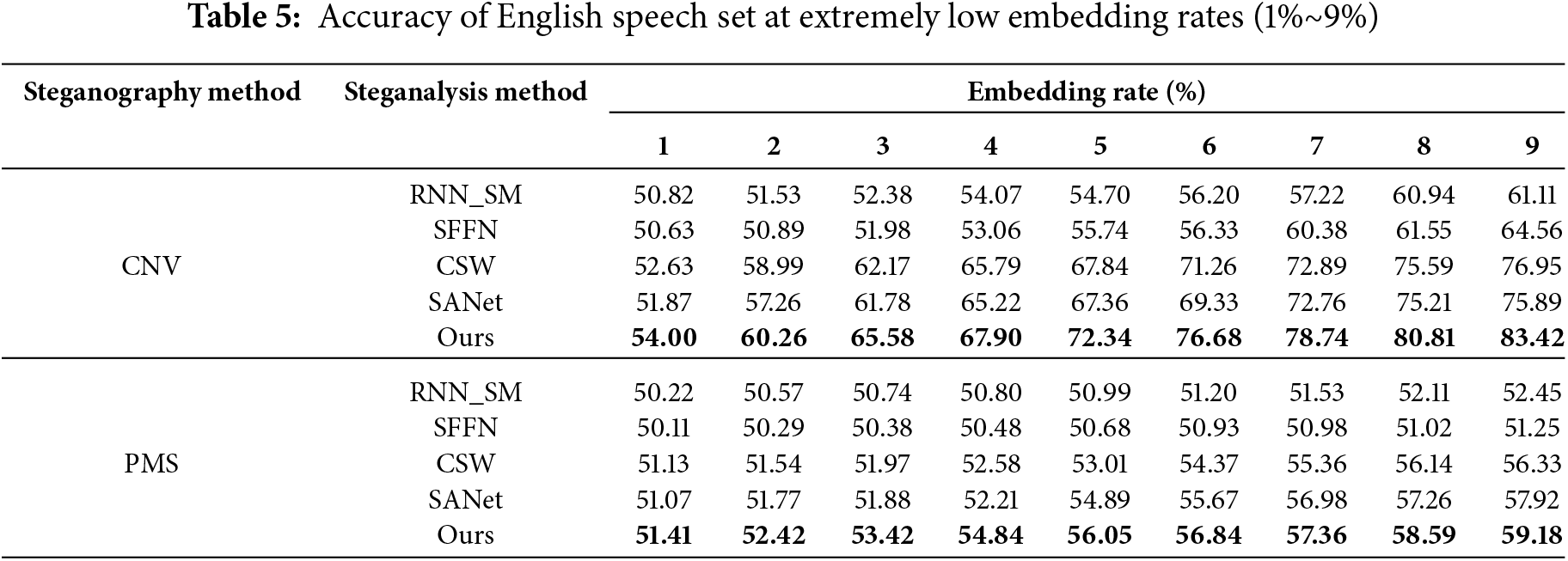
This experiment aims to conduct a comparative study of steganalysis under extremely low embed-ding rate conditions. Tables 4 and 5 present the experimental results for detecting Chinese and English speech using CNV and PMS datasets, with embedding rates ranging from 1% to 9%.
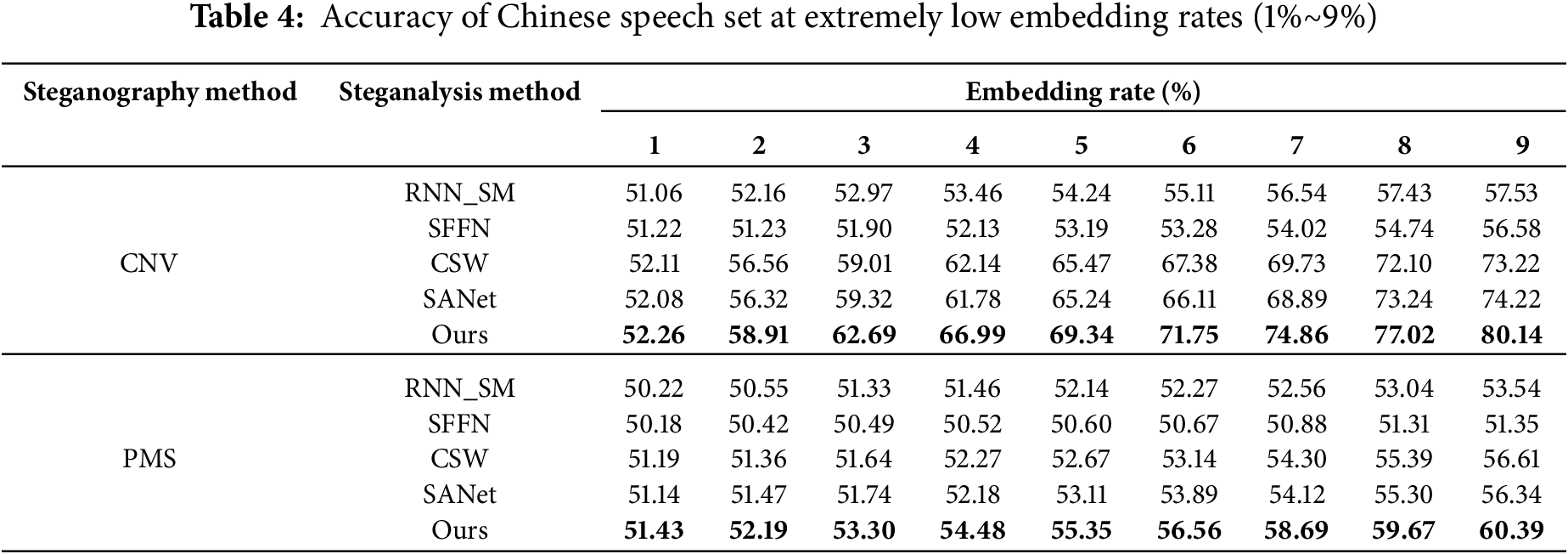
As shown in Tables 4 and 5, on the CNV Chinese dataset, the proposed model demonstrates excellent performance. At an extremely low embedding rate of 1%, the model achieves a detection success rate of 52.26%, slightly higher than RNN_SM, SFFN, CSW, and SANet. As the embedding rate increases, the performance steadily improves, reaching an accuracy of 80.14% at 9% embedding rate, surpassing RNN_SM by 22.61%, SFFN by 23.56%, CSW by 6.92%, and SANet by 5.92%. Notably, at 5% embedding rate, our model achieves 69.34% accuracy, while other models generally remain below 66%, with RNN_SM at 54.24%, SFFN at 53.19%, CSW at 65.47%, and SANet at 65.24%.
For the CNV English dataset, the proposed model shows more prominent performance at higher embedding rates. Although comparable to other models at low embedding rates, at 9% embedding rate, the detection success rate reaches 83.42%. This performance significantly exceeds RNN_SM by 22.31%, SFFN by 18.86%, CSW by 6.47%, and SANet by 7.53%. These results suggest that the proposed model has distinct advantages in handling English speech steganalysis tasks.
On the PMS dataset, the proposed model also demonstrates advantages. For the Chinese PMS dataset, the model achieves an accuracy of 60.39% at 9% embedding rate, notably higher than RNN_SM at 53.54%, SFFN at 51.35%, CSW at 56.61%, and SANet at 56.34%. Similar results are observed for the English PMS dataset, with the proposed model reaching 59.18% at 9% embedding rate, outperforming RNN_SM at 52.45%, SFFN at 51.25%, CSW at 56.33%, and SANet at 57.92%.
In some experimental scenarios, particularly with very low embedding rates or datasets containing high levels of variability and noise, the steganalysis results approached random guessing. This challenge is not unique to our model but is common across steganalysis approaches when detecting subtle perturbations. The minimal signal introduced by low-rate steganography can be easily masked by background noise or variability in the cover data, highlighting current methodological limitations in handling such subtle scenarios.
4.5 Performance Analysis at Short-Time Low Embedding Rate
Considering the impact of speech stream length on detection accuracy, we divided the dataset into non-overlapping consecutive segments with speech stream lengths ranging from 0.1 to 1 s. This experiment aims to evaluate the performance of the proposed model under different speech lengths and embedding rates. Five embedding rates (10%, 30%, 50%, 70%, and 90%) and four speech lengths (0.1, 0.3, 0.5, and 1 s) were considered in the experiment. The experimental results for the Chinese speech datasets are presented in Figs. 7 and 8, illustrating the performance of various models on CNV and PMS datasets, respectively.
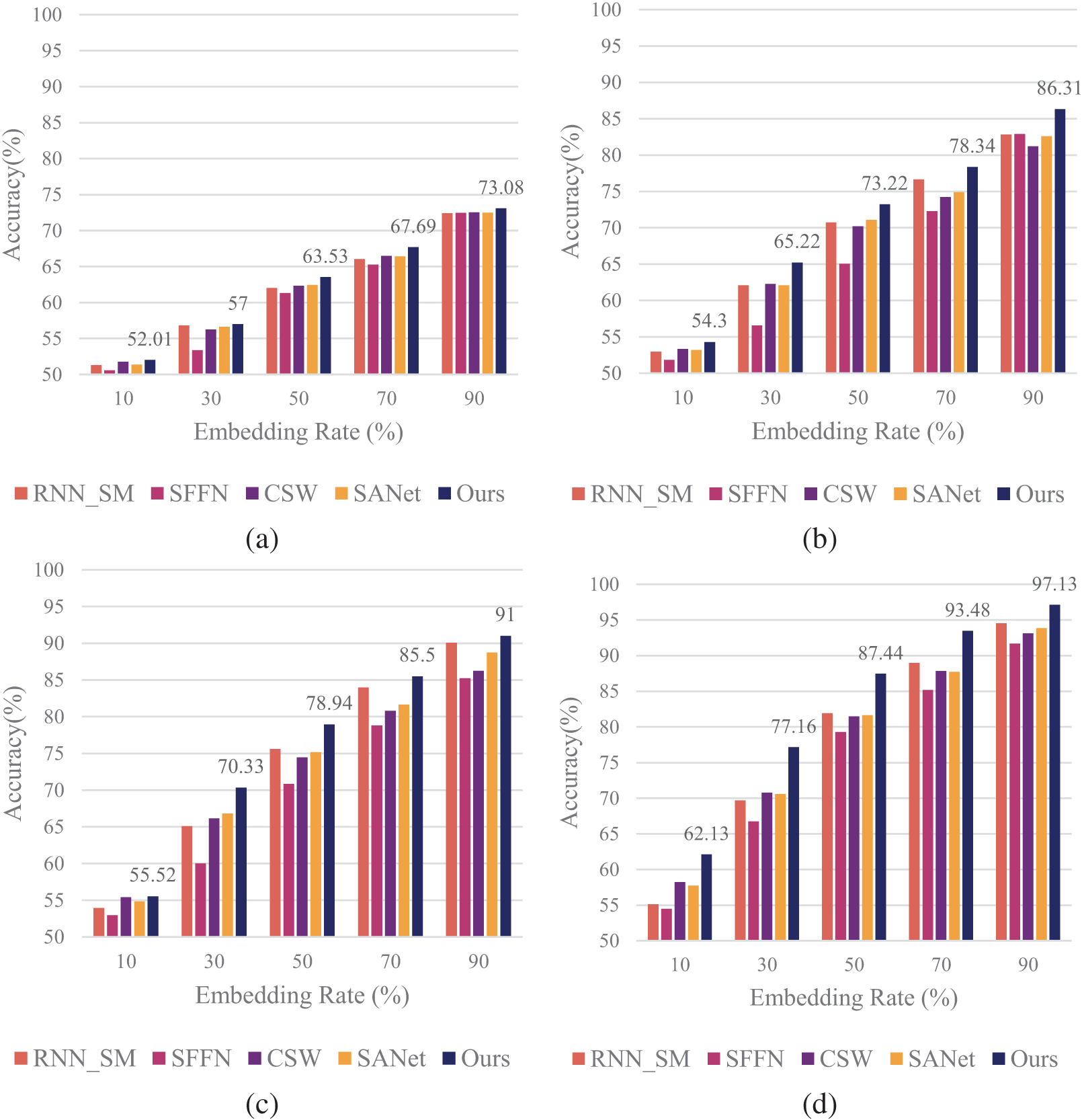
Figure 7: Performance comparison of steganalysis methods on Chinese CNV speech at various embedding rates and durations. (a) 0.1 s; (b) 0.3 s; (c) 0.5 s; (d) 1.0 s
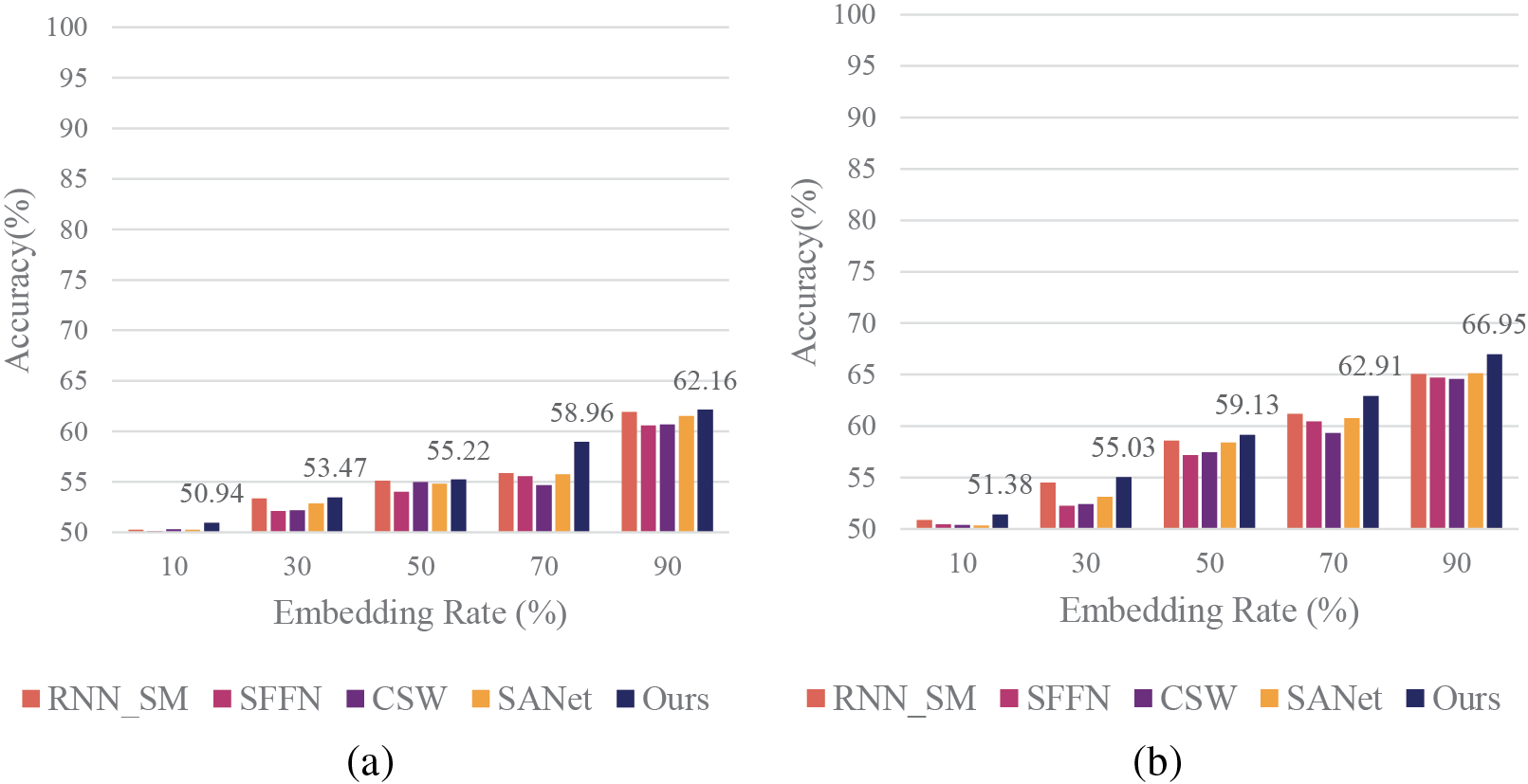
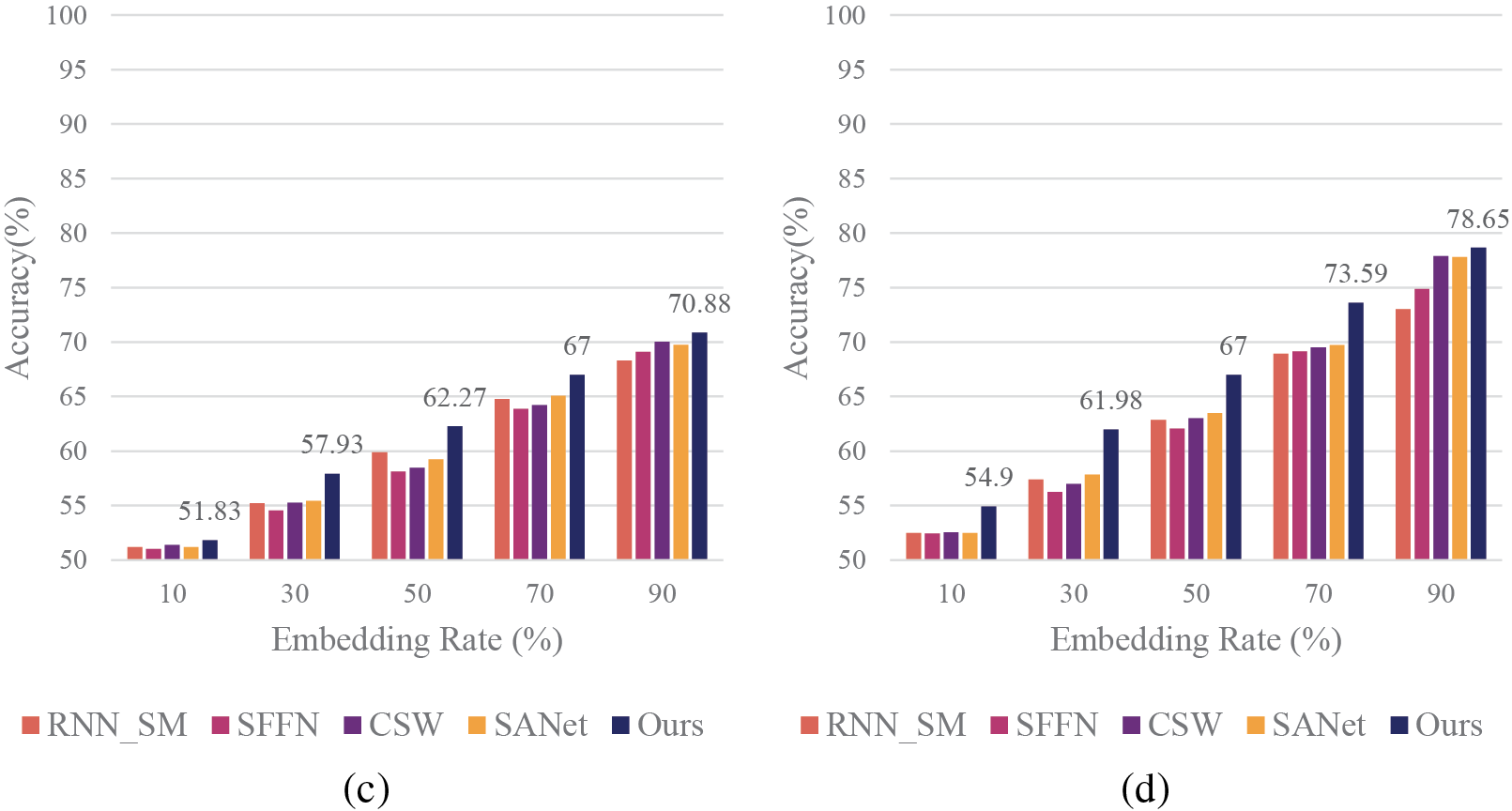
Figure 8: Performance comparison of steganalysis methods on Chinese PMS speech at various embedding rates and durations. (a) 0.1 s; (b) 0.3 s; (c) 0.5 s; (d) 1.0 s
For the Chinese CNV speech dataset (Fig. 7), the proposed model demonstrates superior performance across different speech lengths and embedding rates. As both parameters increase, all models show improved detection accuracy, with our model consistently outperforming others. At 1 s speech length and 90% embedding rate, our model achieves 97.13% accuracy, significantly surpassing comparative models.
It’s noteworthy that for shorter speech lengths (0.1 and 0.3 s) and lower embedding rates (10% and 30%), the advantage of our model is less pronounced. This may be attributed to the limited steganographic information available under these conditions, posing challenges for effective detection. However, as speech length and embedding rate increase, the superiority of our model becomes increasingly evident.
Similar trends are observed in the Chinese PMS speech dataset results (Fig. 8). Our model outperforms comparative models in most scenarios, particularly at higher embedding rates and longer speech lengths. At 1 s speech length and 90% embedding rate, our model achieves 78.65% accuracy, an improvement of 0.96% over the CSW model and 1.12% over SANet.
Turning to the English speech datasets, Figs. 9 and 10 present results for CNV and PMS datasets, respectively. As can be seen from Fig. 9, the performance trends largely mirror those observed in the Chinese datasets. For the English CNV dataset, our model maintains its leading position across various conditions. At 1 s speech length and 90% embedding rate, it achieves 98.20% accuracy, showcasing significant improvement over RNN_SM, SFFN, CSW, and SANet.
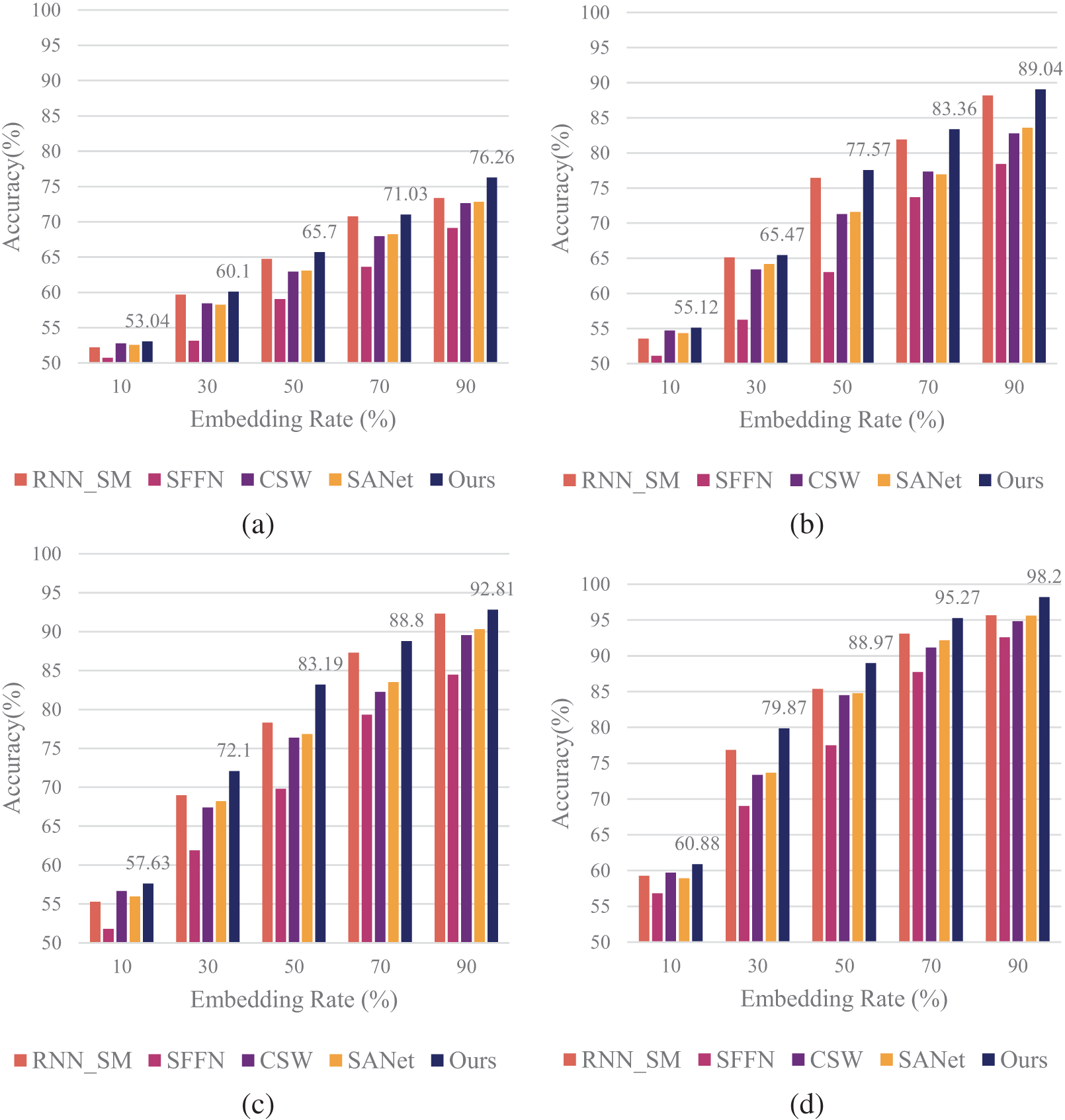
Figure 9: Performance comparison of steganalysis methods on English CNV speech at various embedding rates and durations. (a) 0.1 s; (b) 0.3 s; (c) 0.5 s; (d) 1.0 s
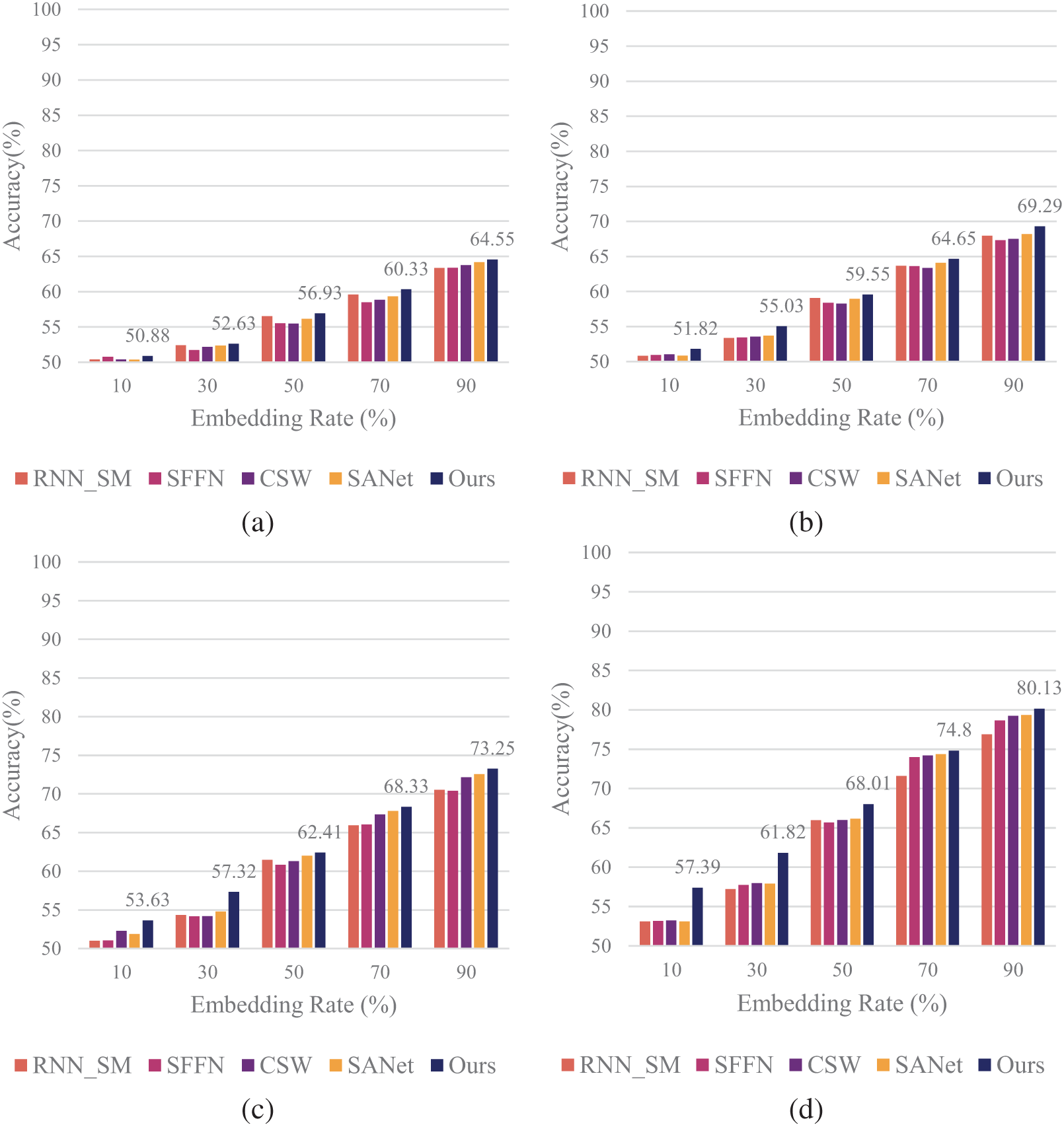
Figure 10: Performance comparison of steganalysis methods on English PMS speech at various embedding rates and durations. (a) 0.1 s; (b) 0.3 s; (c) 0.5 s; (d) 1.0 s
In Fig. 10, the English PMS dataset results further corroborate the model’s effectiveness. At 1 s speech length and 90% embedding rate, our model attains 80.13% accuracy, surpassing the RNN_SM model by 4.25%, SFFN by 3.86%, CSW by 1.15%, and SANet by 1.32%.
In this experiment considering short-time speech segments, our model demonstrated clear advantages over existing approaches. The performance at lower embedding rates and shorter speech lengths was consistently higher. For example, at 0.5 s speech length and 30% embedding rate, our model achieved 3.2% higher detection accuracy compared to RNN_SM, while improvements over SFFN, CSW, and SANet ranged from 1% to 3% depending on the embedding rate.
These comprehensive results demonstrate the proposed model’s strong adaptability and stability in handling speech steganalysis tasks across different languages, speech lengths, and embedding rates. The model’s performance notably improves with increasing speech length and embedding rate, likely due to the availability of more feature information, enabling more accurate detection.
In VoIP communication, real-time transmission of speech signals requires steganalysis models to be efficient enough to meet real-time processing demands. All models employ GPU (Graphics Processing Unit) acceleration to ensure consistency and fairness of test conditions. Table 6 shows the detection time required by various models to process a 1s speech stream.

The experimental results show that the proposed method requires an average of only 2.21 ms to process a 1 s speech stream, which is 0.67, 0.56 and 0.36 ms faster than the SFFN, CSW, and SANet methods, respectively. This result amply demonstrates the real-time processing capability of our algorithm. In terms of computational efficiency, compared to SANet’s 2.57 ms per 1 s speech stream, our model represents an approximately 14% reduction in processing time, highlighting the potential of E-SWAN for real-time applications in VoIP environments where computational efficiency is critical.
It is worth noting that although (
Further analysis indicates that the proposed method achieves a good balance between real-time performance and detection accuracy. The time advantage of this method over SFFN, CSW, and SANet will have a significant impact when processing large amounts of speech stream data.
This paper introduces the E-SWAN, a novel deep learning model for speech steganalysis that effectively balances detection accuracy and real-time performance. By integrating residual and fully convolutional networks, E-SWAN demonstrates superior feature extraction capabilities, particularly for low em-bedding rates. Experimental results on CNV and PMS datasets show significant improvements over existing methods, achieving up to 98.20% accuracy for 1 s speech samples with 90% embedding rates, while processing a 0.1 s stream in just 2.21 ms. These findings underscore E-SWAN’s potential for real-time VoIP steganalysis. However, challenges remain for extremely short speech and very low embedding rates, suggesting directions for future research. This work contributes to advancing speech steganalysis technology and enhancing information security in digital communications.
Future work will focus on overcoming the limitations observed in low embedding rate scenarios where detection accuracy is close to random guessing. This includes exploring more robust feature extraction methods, ensemble learning, and domain adaptation to improve model performance under noisy conditions. We also plan to enhance real-time processing capabilities and explore transformer-based architectures for capturing global features more effectively.
Acknowledgement: We thank the journal’s editors and anonymous reviewers for many helpful comments and Yang Labs for hardware support.
Funding Statement: This work was supported in part by the Zhejiang Provincial Natural Science Foundation of China under Grant LQ20F020004, and in part by the National College Student Innovation and Research Training Program under Grant 202313283002.
Author Contributions: The authors confirm contribution to the paper as follows: study conception and design: Kening Wang, Feipeng Gao; data collection: Jie Yang, Hao Zhang; analysis and interpretation of results: Jie Yang, Hao Zhang; draft manuscript preparation: Kening Wang, Feipeng Gao; Kening Wang and Feipeng Gao contributed equally to this work. Jie Yang served as the corresponding author and oversaw data collection and analysis. All authors reviewed the results and approved the final manuscript.
Availability of Data and Materials: The data will be made available by the corresponding author upon reasonable request.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Pekerti AA, Sasongko A, Indrayanto A. Secure end-to-end voice communication: a comprehensive review of steganography, modem-based cryptography, and chaotic cryptography techniques. IEEE Access. 2024 Jun;12(1):75146–68. doi:10.1109/ACCESS.2024.3405317. [Google Scholar] [CrossRef]
2. Saenger J, Mazurczyk W, Keller J, Thorpe C. VoIP network covert channels to enhance privacy and information sharing. Future Gener Comput Syst. 2020 Oct;111(1):96–106. doi:10.1016/j.future.2020.04.032. [Google Scholar] [CrossRef]
3. Peng J, Tang S. Covert communication over VoIP streaming media with dynamic key distribution and authentication. IEEE Trans Ind Electron. 2020 Apr;68(4):3619–28. doi:10.1109/TIE.2020.2979567. [Google Scholar] [CrossRef]
4. Wu Z, Guo J, Zhang C, Wang J. Steganography and steganalysis in voice over IP: a review. Sensors. 2021 Feb;21(4):1032. doi:10.3390/s21041032. [Google Scholar] [PubMed] [CrossRef]
5. Mahmoud MM, Elshoush HT. Enhancing LSB using binary message size encoding for high capacity, transparent and secure audio steganography—an innovative approach. IEEE Access. 2022 Mar;10(3):29954–71. doi:10.1109/ACCESS.2022.3155146. [Google Scholar] [CrossRef]
6. Laskar B, Bouzid M. Enhancing secure communication: a QIM-based steganography approach for G. 722.2 speech streams with Stable Roommate Index Division. Multimed Tools Appl. 2024 Jun;81(28):1–19. doi:10.1007/s11042-024-19496-y. [Google Scholar] [CrossRef]
7. Carvajal-Gámez BE, Castillo-Martínez MA, Castañeda-Briones LA, García-Lamont F, Hernández-Pérez J. Audio steganalysis estimation with the Goertzel algorithm. Appl Sci. 2024 Jul;14(14):6000. doi:10.3390/app14146000. [Google Scholar] [CrossRef]
8. Djebbar F, Ayad B. Energy and entropy based features for WAV audio steganalysis. J Inf Hiding Multim Signal Process. 2017 Jan;8(1):168–81. [Google Scholar]
9. Yazdanpanah S, Kheyrandish M, Mosleh M. Lsbr speech steganalysis based on percent of equal adjacent samples. J Circ, Syst Comput. 2022 Apr;31(6):2250118. doi:10.1142/S0218126622501183. [Google Scholar] [CrossRef]
10. Wu Z, Li R, Yin P, Wang J. Steganalysis of quantization index modulation steganography in G.723.1 codec. Future Internet. 2020 Dec;12(1):17. doi:10.3390/fi12010017. [Google Scholar] [CrossRef]
11. Ren Y, Liu D, Liu C, Zhao H, Yan Z. A universal audio steganalysis scheme based on multiscale spectrograms and DeepResNet. IEEE Trans Dependable Secure Comput. 2023 Jan;20(1):665–79. doi:10.1109/TDSC.2022.3141121. [Google Scholar] [CrossRef]
12. Sun C, Tian H, Chang CC, Wang S, Lin IC. Steganalysis of adaptive multi-rate speech based on extreme gradient boosting. Electronics. 2020 Mar;9(3):522. doi:10.3390/electronics9030522. [Google Scholar] [CrossRef]
13. Mawalim CO, Unoki M. Speech watermarking method using McAdams coefficient based on random forest learning. Entropy. 2021 Oct;23(10):1246. doi:10.3390/e23101246. [Google Scholar] [PubMed] [CrossRef]
14. Kheddar H, Megías D. High capacity speech steganography for the G723.1 coder based on quantised line spectral pairs interpolation and CNN auto-encoding. Appl Intell. 2022 Jun;52(8):9441–59. doi:10.1007/s10489-021-02938-7. [Google Scholar] [CrossRef]
15. Hu Y, Huang Y, Yang Z, Xiao J, Yang H. Detection of heterogeneous parallel steganography for low bit-rate VoIP speech streams. Neurocomputing. 2021 Jan;419(4):70–9. doi:10.1016/j.neucom.2020.08.002. [Google Scholar] [CrossRef]
16. Zhang C, Jiang S. Detection of QIM-based steganography in VoIP streams: a MobileViT-inspired model. IEEE Signal Process Lett. 2024 Jul;31:1735–9. doi:10.1109/LSP.2024.3419691. [Google Scholar] [CrossRef]
17. Qiu Y, Tian H, Li H, Li W, Liu X, Liu J. Separable convolution network with dual-stream pyramid enhanced strategy for speech steganalysis. IEEE Trans Inf Forensics Secur. 2023 May;18:2737–50. doi:10.1109/TIFS.2023.3269640. [Google Scholar] [CrossRef]
18. Lin Z, Huang Y, Wang J. RNN-SM: fast steganalysis of VoIP streams using recurrent neural network. IEEE Trans Inf Forensics Secur. 2018 Jul;13(7):1854–68. doi:10.1109/TIFS.2018.2806741. [Google Scholar] [CrossRef]
19. Wu Z, Guo J. MFPD-LSTM: a steganalysis method based on multiple features of pitch delay using RNN-LSTM. J Inf Secur Appl. 2023 May;74(6):103469. doi:10.1016/j.jisa.2023.103469. [Google Scholar] [CrossRef]
20. Yang W, Li M, Zhou B, Ren Y, Yang K, Yu X. Steganalysis of low embedding rate CNV-QIM in speech. Comput Model Eng Sci. 2021 Aug;128(2):623–37. doi:10.32604/cmes.2021.015629. [Google Scholar] [CrossRef]
21. Kheddar H, Hemis M, Himeur Y, Megías D, Amira A. Deep learning for steganalysis of diverse data types: a review of methods, taxonomy, challenges and future directions. Neurocomputing. 2024 May;581(7):127528. doi:10.1016/j.neucom.2024.127528. [Google Scholar] [CrossRef]
22. Yang Z, Yang H, Chang CC, Sun J, Li X. Real-time steganalysis for streaming media based on multi-channel convolutional sliding windows. Knowl Based Syst. 2022 Feb;237(5955):107561. doi:10.1016/j.knosys.2021.107561. [Google Scholar] [CrossRef]
23. Xiao B, Huang Y, Tang S. An approach to information hiding in low bit-rate speech stream. Paper presented at: IEEE GLOBECOM 2008-2008 IEEE Global Telecommunications Conference; 2008. p. 1–5. doi:10.1109/GLOCOM.2008.ECP.375. [Google Scholar] [CrossRef]
24. Tian H, Liu J, Li S. Improving security of quantization-index-modulation steganography in low bit-rate speech streams. Multimed Syst. 2014 Mar;20(2):143–54. doi:10.1007/s00530-013-0302-8. [Google Scholar] [CrossRef]
25. Liu P, Li S, Wang H. Steganography in vector quantization process of linear predictive coding for low-bit-rate speech codec. Multimed Syst. 2017 Jul;23(4):485–97. doi:10.1007/s00530-015-0500-7. [Google Scholar] [CrossRef]
26. Huang Y, Liu C, Tang S, Bai S. Steganography integration into a low-bit rate speech codec. IEEE Trans Inf Forensics Secur. 2012 Dec;7(6):1865–75. doi:10.1109/TIFS.2012.2218599. [Google Scholar] [CrossRef]
27. Ren Y, Liu D, Yang J, Li S, Liu J, Wang S. An AMR adaptive steganographic scheme based on the pitch delay of unvoiced speech. Multimed Tools Appl. 2019 Apr;78(7):8091–111. doi:10.1007/s11042-018-6600-6. [Google Scholar] [CrossRef]
28. Liu X, Tian H, Huang Y, Wang S, Lu W. A novel steganographic method for algebraic-code-excited-linear-prediction speech streams based on fractional pitch delay search. Multimed Tools Appl. 2019 Apr;78(7):8447–61. doi:10.1007/s11042-018-6867-7. [Google Scholar] [CrossRef]
29. Kraetzer C, Dittmann J. Pros and cons of mel-cepstrum based audio steganalysis using SVM classification. Paper presented at: International Workshop on Information Hiding; 2007; Saint Malo, France; p. 359–77. doi:10.1007/978-3-540-77370-2_24. [Google Scholar] [CrossRef]
30. Liu X, Tian H, Liu J, Li S, Wang S. Steganalysis of adaptive multiple-rate speech using parity of pitch-delay value. Paper presented at: Security and privacy in new computing environments: Second EAI International Conference, SPNCE 2019; 2019 Apr; Tianjin, China. p. 282–97. doi:10.1007/978-3-030-21373-2_21. [Google Scholar] [CrossRef]
31. Ren Y, Yang J, Wang J, Wang L. AMR steganalysis based on second-order difference of pitch delay. IEEE Trans Inf Forensics Secur. 2017 Jun;12(6):1345–57. doi:10.1109/TIFS.2016.2636087. [Google Scholar] [CrossRef]
32. Li S, Wang J, Liu P, Shi K. SANet: a compressed speech encoder and steganography algorithm independent steganalysis deep neural network. IEEE/ACM Transact Audio, Speech, Lang Process. 2023 Nov;32(10):680–90. doi:10.1109/TASLP.2023.3337667. [Google Scholar] [CrossRef]
33. Zhang C, Jiang S, Chen Z. TENet: leveraging transformer encoders for steganalysis of QIM steganography in VoIP speech streams. Multimed Tools Appl. 2024 Dec;83(19):57107–38. doi:10.1007/s11042-023-17802-8. [Google Scholar] [CrossRef]
34. Guo C, Yang W, Huang L. Steganalysis of AMR speech stream based on multi-domain information fusion. IEEE/ACM Transact Audio Speech Lang Process. 2024 May;32(3):4077–90. doi:10.1109/TASLP.2024.3408033. [Google Scholar] [CrossRef]
35. Zeng Z, Cui L, Qian M, Zhang Z, Wei K. A survey on sliding window sketch for network measurement. Comput Netw. 2023 May;226(3):109696. doi:10.1016/j.comnet.2023.109696. [Google Scholar] [CrossRef]
36. Zhang L, Holmes JM, Liu Z, Vora SA, Sio TT, Vargas CE, et al. Beam mask and sliding window-facilitated deep learning-based accurate and efficient dose prediction for pencil beam scanning proton therapy. Med Phys. 2024 Sep;51(2):1484–98. doi:10.1002/mp.16758. [Google Scholar] [PubMed] [CrossRef]
37. Park S, Jung S, Jung S, Lee W, Chung T. Sliding window-based LightGBM model for electric load forecasting using anomaly repair. J Supercomput. 2021 Nov;77(11):12857–78. doi:10.1007/s11227-021-03787-4. [Google Scholar] [CrossRef]
38. Xie J, Hu K, Zhu M, Yu J, Zhu Q. Bioacoustic signal classification in continuous recordings: syllable-segmentation vs sliding-window. Expert Syst Appl. 2020 Aug;152(6):113390. doi:10.1016/j.eswa.2020.113390. [Google Scholar] [CrossRef]
39. Peng Z, Li X, Zhu Z, Chu J, Luo X, Zhao G. Speech emotion recognition using 3D convolutions and attention-based sliding recurrent networks with auditory front-ends. IEEE Access. 2020 Apr;8:16560–72. doi:10.1109/ACCESS.2020.2967791. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools