
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

From Detection to Explanation: Integrating Temporal and Spatial Features for Rumor Detection and Explaining Results Using LLMs
College of Information and Network Security, Zhejiang Police College, Hangzhou, 310053, China
* Corresponding Author: Nanjiang Zhong. Email:
(This article belongs to the Special Issue: The Latest Deep Learning Architectures for Artificial Intelligence Applications)
Computers, Materials & Continua 2025, 82(3), 4741-4757. https://doi.org/10.32604/cmc.2025.059536
Received 10 October 2024; Accepted 18 December 2024; Issue published 06 March 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The proliferation of rumors on social media has caused serious harm to society. Although previous research has attempted to use deep learning methods for rumor detection, they did not simultaneously consider the two key features of temporal and spatial domains. More importantly, these methods struggle to automatically generate convincing explanations for the detection results, which is crucial for preventing the further spread of rumors. To address these limitations, this paper proposes a novel method that integrates both temporal and spatial features while leveraging Large Language Models (LLMs) to automatically generate explanations for the detection results. Our method constructs a dynamic graph model to represent the evolving, tree-like propagation structure of rumors across different time periods. Spatial features are extracted using a Graph Convolutional Network, which captures the interactions and relationships between entities within the rumor network. Temporal features are extracted using a Recurrent Neural Network, which accounts for the dynamics of rumor spread over time. To automatically generate explanations, we utilize Llama-3-8B, a large language model, to provide clear and contextually relevant rationales for the detected rumors. We evaluate our method on two real-world datasets and demonstrate that it outperforms current state-of-the-art techniques, achieving superior detection accuracy while also offering the added capability of automatically generating interpretable and convincing explanations. Our results highlight the effectiveness of combining temporal and spatial features, along with LLMs, for improving rumor detection and understanding.Keywords
The development of social media has greatly improved the communication efficiency, but it has also inadvertently contributed to the rapid spread of rumors and caused serious social impact. During key events such as the US presidential election [1] and the COVID-19 epidemic [2], rumors flooded social media, causing social chaos. For example, Islam et al. [2] found that during the COVID-19 pandemic, 82% of the news information between 31 December 2019, and 05 April 2020, consisted of rumors. These rumors included false information about government control measures, incorrect treatments, and the origins of the disease, causing severe negative impacts on both individuals and the government. This highlights the urgent need for effective strategies to detect rumors and block the spread of rumors through reasonable explanations.
The initial approaches to rumor detection primarily relied on analyzing the text of the rumors. Early methods evolved from traditional machine learning [3–5] to deep learning [6–9] and achieved some degree of success. However, since rumor texts are often brief and can be easily disguised as normal content, detection methods based solely on text analysis have certain limitations in terms of accuracy.
As a result, more and more methods [10] have started to focus on rumor detection based on propagation structures, as these are more difficult to falsify. These methods generally fall into two categories when constructing propagation structure models: temporal-domain-based methods and spatial-domain-based methods. Temporal-domain-based methods [11–13] build a temporal propagation structure based on the chronological order of reposts or comments, as shown in Fig. 1b. On the other hand, spatial-domain-based methods [14–16] construct a tree-like propagation network based on the interaction relationships between reposts or comments, as shown in Fig. 1c.
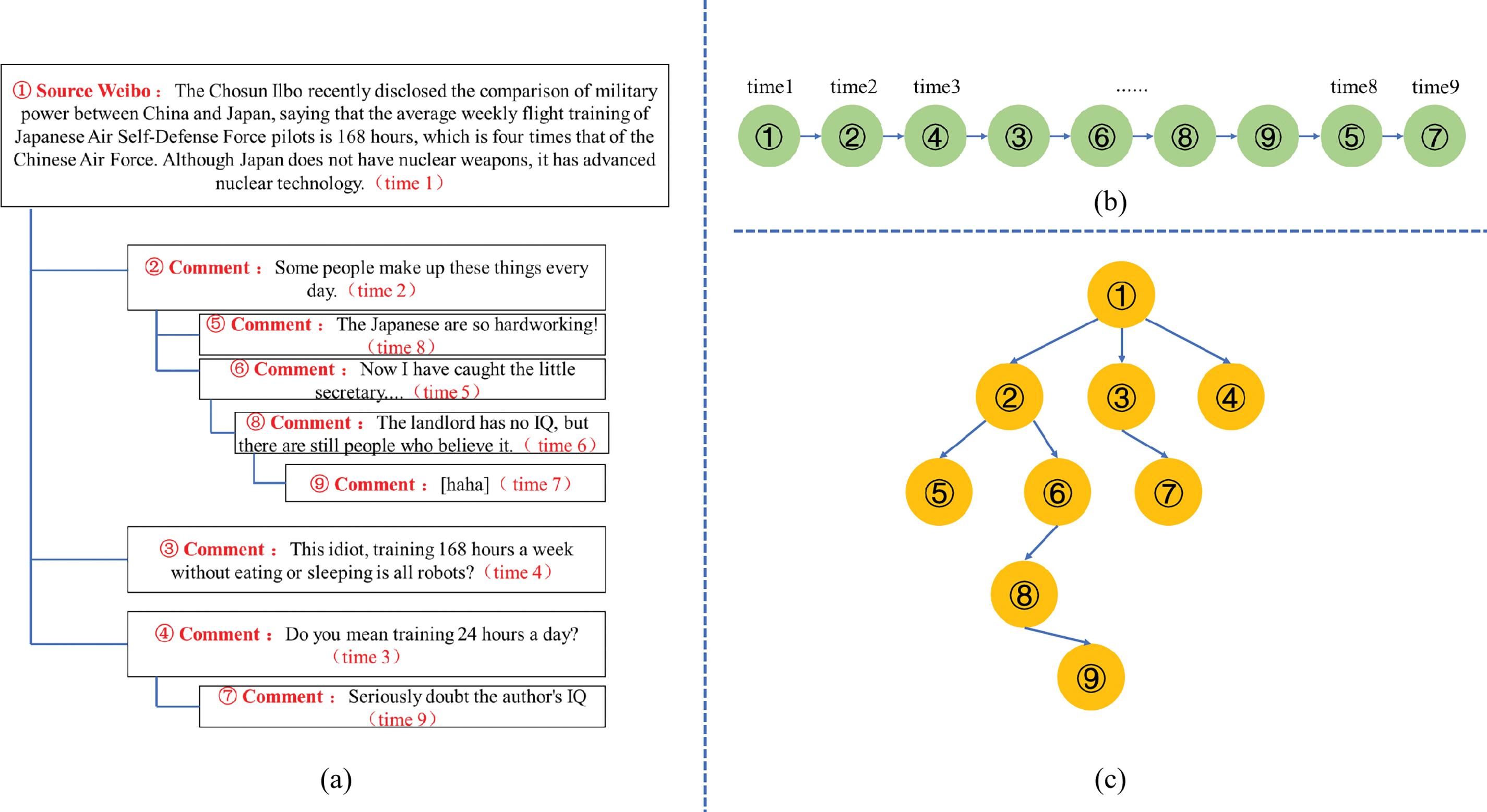
Figure 1: Traditional rumor propagation modeling approaches. (a) Hierarchical structure of rumor comments: ① represents the original tweet of the event, and the lower-level text is a comment on the upper-level text. For example, ② is a comment on ①, and ⑤ is a comment on ②. The “time n” at the end of the text indicates the time when the comment was posted, with n increasing from smallest to largest to represent the chronological order of comment postings. (b) Modeling method based on temporal features: The sequence structure is constructed based on the chronological order of comment postings. (c) Modeling method based on spatial features: A propagation network is constructed based on the relationships between comments, and rumors are detected by extracting the spatial features of the propagation network
However, the existing methods have the following main issues: 1) They fail to effectively integrate the temporal and spatial features of rumor propagation. Some methods merely combine temporal and spatial features by concatenating them, without capturing the dynamic changes in the propagation structure over time. 2) They lack reasonable explanations for the detection results. Deep learning methods are notably deficient in interpretability, yet providing a clear and reasonable explanation for the detection results is crucial for effectively curbing the spread of rumors.
To address the aforementioned issues, this paper proposes a rumor detection method that integrates both temporal and spatial features, and provides reasonable explanations for detection results using a LLM. For rumor detection, we first construct a dynamic propagation graph model by generating multiple propagation graphs based on repost and comment relationships at different time points. Then, we employ a Graph Convolutional Network (GCN) to extract spatial features from the propagation graph at each discrete time point. Finally, we capture the temporal features of the propagation network by feeding the features from different time points into a Gated Recurrent Unit (GRU) model. In this process, we are able to effectively capture the temporal evolution of the rumor spatial propagation network.
We selected LLM as the interpreter, using carefully crafted prompts to input the detection results, rumor text, and propagation information, thereby generating a reasonable explanation for the detection results. In this process, we divided the propagation information into a propagation chain, allowing the LLM to perform step-by-step reasoning in the order of comment timestamps, enabling more effective analysis and interpretation of the rumor propagation process.
To evaluate the effectiveness of our method, we conducted experiments on the Weibo and PHEME datasets. Even without applying any data filtering, the experimental results still showed that our method significantly outperforms existing approaches. In terms of explaining the detection results, multiple case studies demonstrated that our method can provide clear and convincing explanations for the detection outcomes.
Our main contributions are as follows:
• We propose a novel rumor detection method that constructs a dynamic propagation graph model and utilizes GCN and GRU models to extract rumor features, significantly improving detection accuracy.
• We introduce a LLM to provide convincing explanations for the rumor detection results, which is crucial for effectively curbing the spread of rumors.
• We conducted extensive experiments comparing various state-of-the-art rumor detection methods, and the results indicate that our method performs better.
2.1 Temporal-Domain-Based Methods
As social media spreads globally, the challenge of detecting misinformation and rumors has intensified. Temporal-domain-based methods, particularly those using time series analysis, have gained significant attention for identifying rumors by analyzing the propagation patterns of information.
For instance, one approach [17] uses Recurrent Neural Networks (RNNs) to capture the erratic, burst-like patterns typical of rumor spread, contrasting with the steady progression of truthful information. This innovation lies in applying RNNs to model the specific temporal dynamics of rumor propagation, offering an adaptive detection mechanism.
Another method [18] combines time series data with user behavior analysis, examining reposting rates and the speed of information spread. Rumors tend to have faster, more volatile lifespans in early propagation stages, which serves as a key indicator. The novelty of this approach is integrating both temporal data and user behavior to improve detection robustness.
Additionally, integrating social network features with time series analysis has proven effective for early-stage rumor detection [19]. This approach analyzes both temporal behavior and social interactions, offering a more nuanced understanding of rumor propagation. Its contribution lies in combining these two dimensions to enhance early detection accuracy.
Furthermore, multi-modal models, such as the Capture, Score, and Integrate (CSI) framework [7], combine content, social context, and temporal features for comprehensive detection. By incorporating emotional tone, user behavior, and timing, these models provide more robust mechanisms for rumor identification. The novelty here is the multi-dimensional approach, leveraging a wide range of features for enhanced detection.
Overall, temporal-domain-based methods offer a powerful tool for identifying rumors by analyzing the dynamic patterns of information propagation within social networks.
2.2 Spatial-Domain-Based Methods
Spatial-domain-based rumor detection methods focus on analyzing the structural features of information dissemination networks. These methods use graph theory and network topology to examine the relationships between nodes (users) and identify potential rumors.
One approach [20] constructs a graph of information propagation and applies graph embedding techniques to capture the network’s topological features. By analyzing node connectivity and subgraph structures, this method can distinguish between rumors and truthful information. Research shows that rumors often form densely connected subgraphs, which are key indicators of misinformation. The novelty lies in focusing on these subgraphs to track rumor spread.
Another approach [21] uses social network graph models to analyze node interactions, particularly the role of influential nodes (e.g., opinion leaders) in rumor spread. Studies show that rumors tend to spread rapidly among these key nodes, with concentrated dissemination paths. The novelty of this method is its focus on influential node dynamics, which helps predict and control rumor spread more effectively.
Additionally, Graph Convolutional Networks (GCNs) have been used [14] to analyze spatial features of social networks. GCNs examine the relationships between neighboring nodes to detect rumors by analyzing information flow and interaction patterns. This method is particularly effective in detecting subtle signals of rumor spread in complex networks. The novelty of GCNs lies in their ability to handle large, intricate networks, making them highly effective for real-time rumor detection.
Overall, spatial-domain-based methods use graph theory and network structures to identify rumors by analyzing how information propagates and how key nodes interact, offering a powerful tool for detecting misinformation.
Large language models (LLMs), such as GPT-3 and its successors, have revolutionized applications in natural language processing and conversational AI. However, their ability to generate highly realistic, human-like text poses significant challenges for misinformation detection [22]. As LLMs produce content that closely mimics human writing, traditional detection methods, which rely on linguistic features like structure and syntax, often fail to distinguish between machine-generated and human-written misinformation [23,24].
Several studies have explored using LLMs in misinformation detection. Yang et al. [25] utilize GPT-3.5 to extract entities and build relational graphs, enhancing the identification of false information. While effective, it still faces challenges in accuracy and scope. Hu et al. [26] highlight a key limitation: fine-tuned, task-specific models for fake news detection outperform general-purpose LLMs, suggesting that LLMs’ versatility may hinder their efficiency in detecting misinformation.
The growing sophistication of LLMs has spurred interest in hybrid models that combine their capabilities with specialized detection mechanisms. These models aim to improve detection at scale, but LLMs still struggle with capturing nuanced context, addressing adversarial manipulation, and adapting to new domains without fine-tuning. As LLMs continue to evolve, further research is needed to enhance their effectiveness in misinformation detection.
In conclusion, while LLMs offer advances in natural language generation, their use in misinformation detection remains complex. Current efforts leverage LLMs alongside other models, but overcoming their limitations will require further innovation.
Let
For a clearer expression, we will omit the event number
The overall structure of the method in this paper is shown in Fig. 2. The proposed rumor detection model consists of five main components, dynamic graph construction, encoding text contents, spatial feature extraction, temporal feature extraction and classification with MLP.
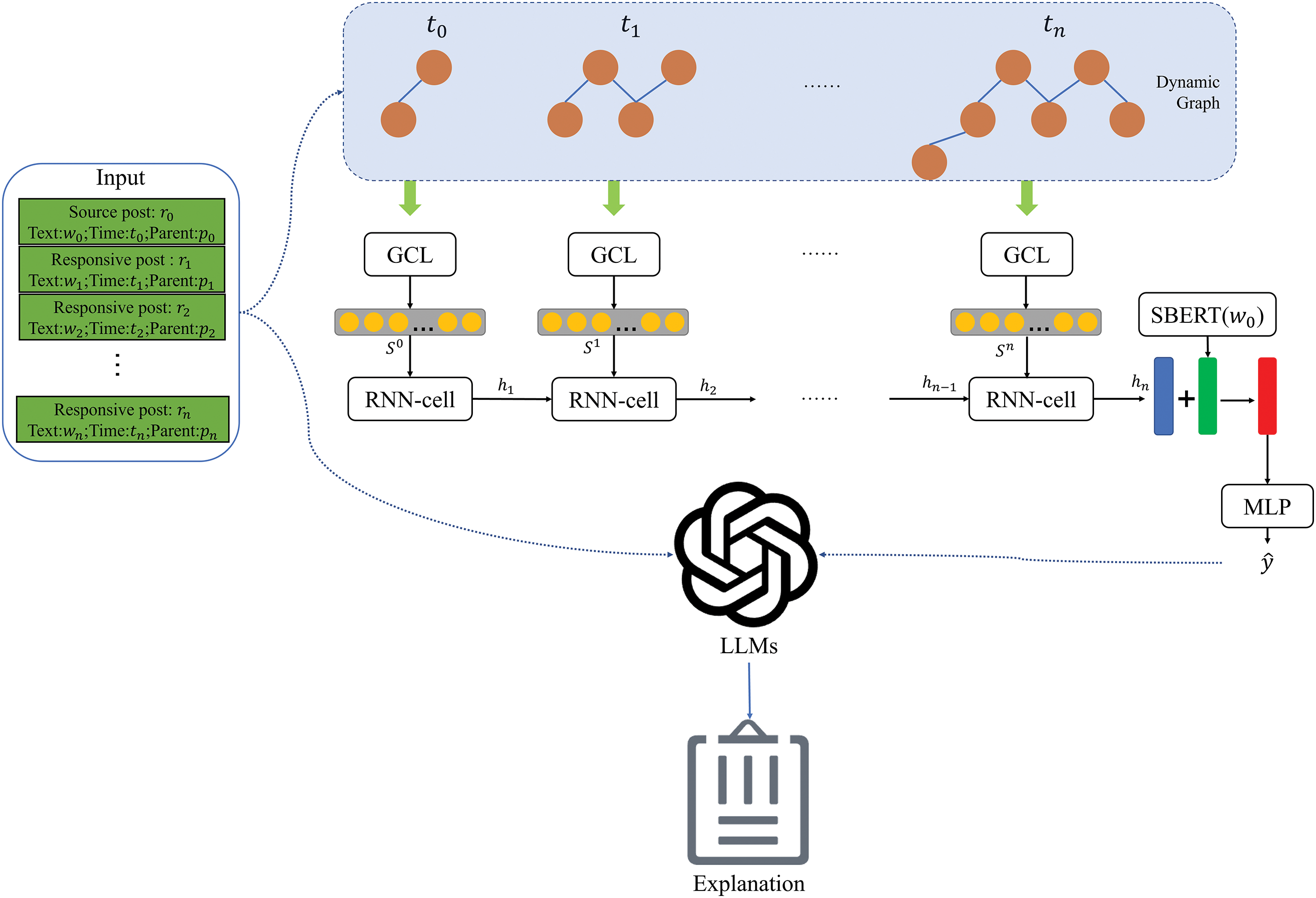
Figure 2: The framework of our approach
First, we construct a dynamic propagation structure graph of events, and then use graph convolutional neural networks to extract spatial features of propagation structure. Then we use the spatial domain features as input and use the recurrent neural network to extract the temporal domain features. At this time, we get a representation of the fusion of spatial domain and temporal domain features. Then, we integrate the text features of the source microblog to enhance the final feature representation. Finally, MLP is used to classify microblog events.
4.2 Dynamic Graph Construction
In this subsection, we construct a dynamic propagation structure graph of events. Unlike ordinary propagation structure graph models, which only build a single complete propagation structure graph, we construct multiple propagation graphs based on time series.
The choice of dynamic graph construction is motivated by the need to capture the evolving nature of rumor propagation over time. Rumors spread through social networks are not static; they evolve as new comments, reposts, and interactions occur. By modeling this progression dynamically, we can better understand how rumors unfold in real-time, allowing us to capture more nuanced patterns of rumor spread.
As shown in Fig. 3, the nodes represent the source microblog and its comments in the event, and the edges between the nodes represent their comment relationships. For example,
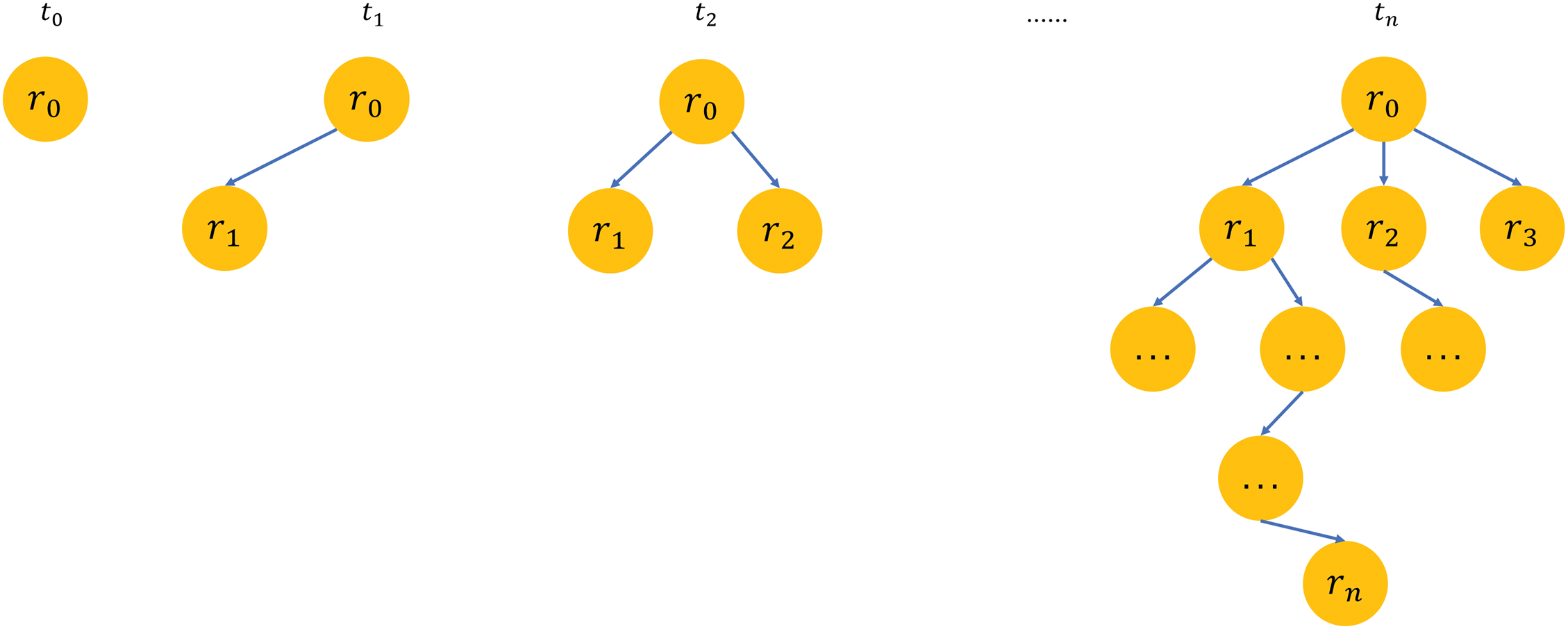
Figure 3: Schematic diagram of dynamic graph construction
In this view, we model each event as a set of directed graphs
The element
That is, when
We use text content features as initialization features of nodes in G, so in this section we will describe the method of text content encoding. We adopt Sentence-BERT (SBERT) [27] to encode the text content feature. SBERT is a pre-trained model for encoding text content features. This method is fine-tuned on Bidirectional Encoder Representations from Transformers (BERT) using Siamese and three-level network structure, which improves the traditional sentence embedding method and achieves very good results in multiple application scenarios.
SBERT adds a pooling operation to the output of BERT to derive a fixed sized sentence embedding. The pooling strategy in this paper is MEAN pooling.
The propagation structure graph at time
4.4 Spatial Feature Extraction
We employ a two-layer graph convolutional network to extract spatial feature from the dynamic graphs. Graph Convolutional Network (GCN) is an extension of CNN on graph data, which can effectively capture graph features by aggregating the neighborhood information of nodes in the graph.
For each graph in different time period
where
Finally, through average pooling, as shown in Eq. (13), we get the final spatial features.
4.5 Temporal Feature Extraction
In this part, we use a recurrent neural network to extract the temporal features of rumor propagation. We take the spatial features {
This article compares three different RNN units: basic RNN, LSTM, and GRU through experiments, and finally finds that GRU has the best effect. Its calculation formula is as follows:
where
The output
4.6 Classification and Training
The predicted label
where
We train all parameters in the model by minimizing the cross-entropy between the predicted result and the ground truth
where
Although our rumor detection module can accurately identify rumors, effective curbing of their spread is difficult without providing reasonable explanations. To address this, we utilize a LLM to offer coherent explanations for the rumors. However, in real social scenarios, the number of comments can be quite large, while LLMs have limitations on input length. Furthermore, LLMs often struggle to handle excessively long or redundant information [28,29].
In recent research on LLMs [30–32], complex tasks are typically decomposed into a series of simpler tasks, which significantly enhances the ability of LLMs to handle complexity. Accordingly, we delineate the prompts into a Chain-of-Propagation (CoP), facilitating easier reasoning for the LLMs. Given that comments within a certain timeframe often share similar sentiments, we construct the CoP based on the chronological order of comment timestamps, as illustrated in Fig. 4.
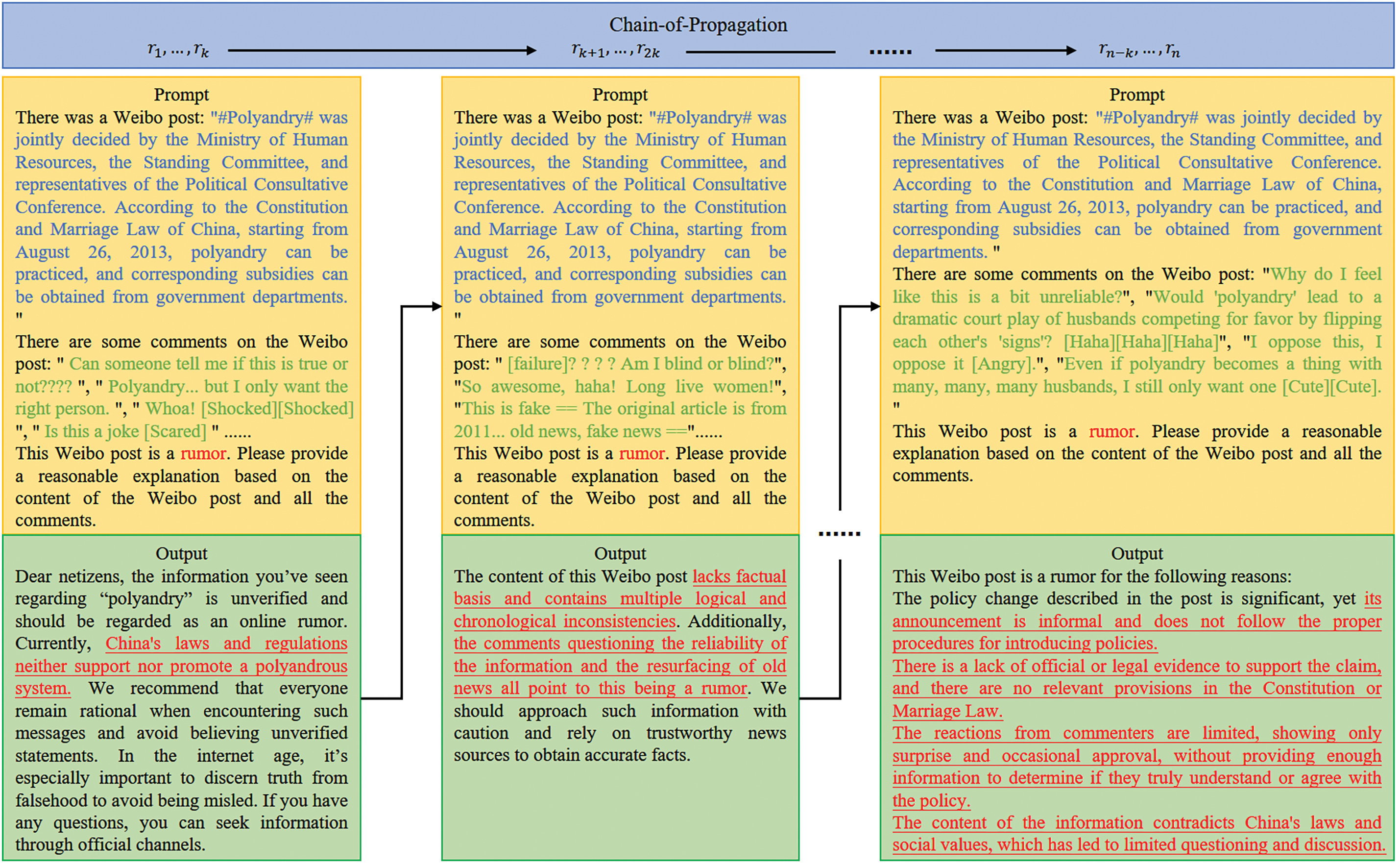
Figure 4: Schematic diagram of CoP
We divide all the comments
We benchmark our proposed method against state-of-the-art baselines using two public datasets: WEIBO [33] and PHEME [34]. The WEIBO dataset, compiled from Xinhua News Agency and Weibo, comprises a rich collection of data. Similarly, the PHEME dataset is an aggregation of content centered around five distinct breaking news stories, with each story featuring a collection of associated posts. Adhering to the methodology outlined in [35], both the WEIBO and PHEME datasets are segmented into training and testing subsets with an 8:2 ratio. Table 1 shows the statistics of the datasets.

Our hardware environment is configured with a Hygon C86 3285 8-core processor, 128 GB of memory, and an NVIDIA RTX A6000 graphics card. We implemented our rumor detection method using the PyTorch framework, with parameter optimization using the Adam algorithm. In our model, we utilized the pre-trained SBERT: all-MiniLM-L6-v2 and selected the Llama-3-8B [36] large language model as the rumor result interpreter.
In terms of model parameter settings, the output feature dimension of SBERT is 512. The GCL layer uses two layers of GCN, with the first layer having an input feature dimension of 512 and an output feature dimension of 256, while the second layer has an output feature dimension of 50. In the RNN layer, we select a single GRU layer as the temporal feature extraction model, with a hidden layer feature dimension of 100. The classifier has an input feature dimension of 100 and an output dimension corresponding to the number of classes, which is 2.
We frequently employ Accuracy as the primary evaluation metric for binary classification tasks, including the detection of fake news. Nonetheless, the reliability of Accuracy is significantly undermined when dealing with datasets that exhibit class imbalance. To address this limitation, our experimental framework incorporates a suite of complementary metrics alongside Accuracy. Specifically, we introduce Precision, Recall, and the F1 score to provide a more nuanced and comprehensive assessment of our model’s performance in the context of rumor detection.
We compare the following baseline models with our model:
• SVM-TS [37]: SVM-TS detects fake news using heuristic rules and a linear SVM classifier.
• CNN [9]: This CNN-based method learns feature representations for early misinformation detection by analyzing posts in fixed-length sequences.
• GRU [12]: The GRU model, an RNN variant, excels at capturing contextual information from related posts over time.
• TextGCN [38]: TextGCN uses graph convolutional networks to improve word and document embedding, viewing the corpus as a heterogeneous graph.
• EANN [39]: EANN, a GAN-based model, extracts event-invariant features for new event detection.
• RumorGAN [11]: RumorGAN generates conflicting or uncertain signals to strengthen the discriminator (GRU), enabling it to learn more robust representations of rumors.
• GACL [16]: A GNN-based model using adversarial and contrastive learning to encode global propagation, resist noise and adversarial samples, and capture event-invariant features.
• BiGCN [14]: BiGCN is a model based on GCN, which can embed propagation structure and diffusion structure at the same time.
5.4 Comparative Experimental Results and Analysis
Table 2 presents the experimental outcomes for our approach and the baseline methods. Key observations include:

(1) Across all datasets, SVM-TS underperforms, suggesting that manually engineered features may be inadequate for fake news detection.
(2) Deep learning models (CNN, GRU, RumorGAN, GACL) surpass SVM-TS, highlighting their advantages over conventional techniques.
(3) Our method is superior to other methods in both data sets, which proves the effectiveness of feature fusion in temporal domain and spatial domain.
We did an ablation study to see whether each module contributes to the model and which modules contribute more. Our model’s main components include SBERT, GCN, and GRU. Based on the complete model, we systematically remove the module and compare their changes in accuracy, precision, recall, F1 value. Fig. 5 shows the experiment results.
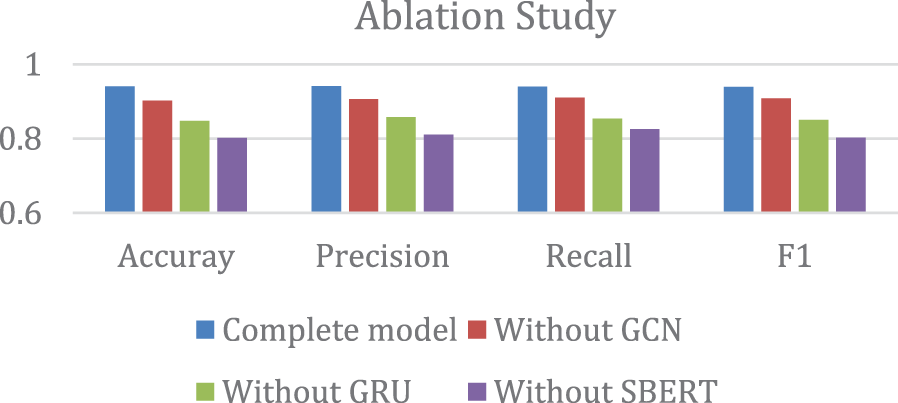
Figure 5: Ablation study results
The ablation study reveals that the performance of the model is significantly reduced when any of the components (SBERT, GCN, or GRU) are removed. This confirms that each module makes a meaningful contribution to the model’s overall ability to detect rumors accurately.
• Full Model. The complete model, which integrates SBERT, GCN, and GRU, achieved the highest performance across all metrics. This demonstrates that combining textual, spatial, and temporal features results in a robust and accurate rumor detection system.
• Without SBERT. Removing the SBERT module resulted in the greatest performance drop, underscoring the importance of textual information in detecting rumors. Without SBERT, the model struggled to differentiate between rumor and non-rumor text effectively.
• Without GRU. When the GRU module, responsible for extracting temporal features, was removed, the model’s ability to capture the dynamic evolution of rumors over time was significantly hindered. This resulted in reduced recall and F1 scores, demonstrating that the temporal dimension is crucial for effective rumor detection, especially in understanding how rumors evolve over time.
• Without GCN. The removal of the GCN module also led to a noticeable decline in performance, particularly in accuracy and recall. This suggests that the GCN’s ability to capture spatial features in the propagation structure of rumors is essential for improving the model’s ability to identify and track the spread of rumors in the network.
Next, we evaluated the impact of several key parameters in our method, with validation results shown in Fig. 6. We selected three parameters for validation: RNN type, learning rate, and number of iterations.

Figure 6: Impact of RNN types, learning rate and epoch
The choice of these hyperparameters was guided by several considerations. First, the RNN type (such as LSTM, GRU, or Simple-RNN) was chosen based on its ability to capture the temporal dynamics of rumor propagation, with LSTM and GRU generally offering better performance in handling long-term dependencies in time series data. Second, the learning rate was selected as a crucial factor influencing the convergence speed and stability of the model. Lastly, the number of iterations was determined by balancing model training time and accuracy. Too few iterations may result in underfitting, while too many could lead to overfitting or unnecessary computational overhead.
For these three parameters, we used cross-validation to assess performance on the Weibo dataset, which served as a case study in our experiments. To ensure the robustness of the results, we kept the other parameters fixed at their optimal values while adjusting one parameter at a time. This allowed us to isolate the effects of each parameter and find the best configuration for the task at hand. The final hyperparameter values were selected based on the validation performance, ensuring the model achieved the best possible balance between accuracy and computational efficiency.
In Fig. 6, the x-axis represents different types of RNNs, learning rates, and iteration epochs, while the y-axis displays the values of accuracy, precision, recall, and F1 score. The curves in different colors represent the variation trends of different evaluation metrics.
After obtaining the model’s classification results, we used a LLM to explain these results, particularly for events classified as rumors by the model. We chose Llama-3-8B as the interpreter and selected a real tweet from the Weibo dataset as an example. The tweet’s main content discussed China’s supposed plan to implement a “polyandry” system. Table 3 shows the prompts and the outputs.

We employed CoP method, where multiple steps of prompts were used to obtain the final output. The selected example contained 143 reposts or comments, with 113 remaining after removing empty entries. We set the number of comments included in each reasoning step to K = 5, resulting in a total of 23 reasoning steps. Table 3 includes the first two reasoning steps’ prompts and outputs, as well as the final model output.
In Table 3, the sentences highlighted in blue represent the tweet, the green sentences represent comments, and the red sentences provide evidence that the event is a rumor. From the red text, we can observe that as the reasoning steps progressed, the amount of evidence in the output increased, while irrelevant sentences decreased.
In the first reasoning step, only one sentence was able to explain why the tweet was a rumor, and it didn’t consider the comment information. However, in the second reasoning step, there were two sentences serving as evidence for the tweet being a rumor, and the model began to take comments into account, using them to explain why the tweet was classified as a rumor. After 23 reasoning steps, the final output provided a comprehensive explanation of the rumor, covering four key points: 1) It did not follow proper policy-making procedures; 2) It lacked legal basis; 3) There was limited reaction in the comments; 4) It contradicted China’s social values.
The advantage of this method lies in its ability to automatically generate highly persuasive explanatory text for rumors, without requiring manual refinement of language. Additionally, it is simple to use, requiring only carefully designed prompts. However, its limitation is that it cannot reveal the internal mechanisms of the model’s prediction algorithm.
This paper proposes a novel rumor detection method that integrates temporal and spatial features, and builds upon this by introducing Llama-3-8B to explain the detection results. Different from the existing methods, our method can detect rumors more accurately and automatically generate text to explain the detection results. Through experiments on the Weibo and PHEME datasets, we demonstrate that this method outperforms existing models. Ablation studies confirm the importance of each model component, particularly the SBERT module, highlighting the critical role of textual information in rumor detection. Case studies show that our approach effectively explains the detection results. Although our model performs well, we recognize the importance of continuous improvement to address the issue of social media rumors. Future research will focus on expanding the model’s adaptability and exploring its application across various data sources and emerging platforms. Our work represents a significant step forward in the fight against online rumors, laying a solid foundation for the development of more complex detection systems.
Acknowledgement: Thanks to the project financial support provided by Zhejiang Provincial Department of Education and the experimental environment provided by Zhejiang Police College.
Funding Statement: This work was supported by General Scientific Research Project of Zhejiang Provincial Department of Education (Y202353247).
Author Contributions: The authors confirm contribution to the paper as follows: study conception and design: Nanjiang Zhong; data collection: Nanjiang Zhong; analysis and interpretation of results: Nanjiang Zhong, Xinchen Jiang, Yuan Yao; draft manuscript preparation: Nanjiang Zhong. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data that support the findings of this study are available from the corresponding author, Nanjiang Zhong, upon reasonable request.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. Allcott H, Gentzkow M. Social media and fake news in the 2016 election. J Econ Perspect. 2017;31(2):211–36. doi:10.1257/jep.31.2.211. [Google Scholar] [CrossRef]
2. Islam MS, Sarkar T, Khan SH, Kamal A-HM, Hasan SM, Kabir A, et al. COVID-19-related infodemic and its impact on public health: a global social media analysis. Am J Trop Med Hyg. 2020;103(4):1621. doi:10.4269/ajtmh.20-0812. [Google Scholar] [PubMed] [CrossRef]
3. Liu X, Nourbakhsh A, Li Q, Fang R, Shah S. Realtime rumor debunking on twitter. In: Proceedings of the 24th ACM International on Conference on Information and Knowledge Management; 2015; New York, NY, USA: Association for Computing Machinery. p. 1867–70. [Google Scholar]
4. Zhao Z, Resnick P, Mei Q. Enquiring minds: early detection of rumors in social media from enquiry posts. In: Proceedings of the 24th International Conference on World Wide; 2015; Republic and Canton of Geneva, Switzerland: International World Wide Web Conferences Steering Committee. p. 1395–405. [Google Scholar]
5. Castillo C, Mendoza M, Poblete B. Information credibility on Twitter. In: Proceedings of the 20th International Conference on World Wide Web; 2011; New York, NY, USA: Association for Computing Machinery. p. 675–84. [Google Scholar]
6. Cheng M, Nazarian S, Bogdan P. VRoC: variational autoencoder-aided multi-task rumor classifier based on text. In: Proceedings of the Web Conference 2020; 2020; New York, NY, USA: Association for Computing Machinery. [Google Scholar]
7. Ruchansky N, Seo S, Liu Y. CSI: a hybrid deep model for fake news detection. In: Proceedings of the 2017 ACM on Conference on Information and Knowledge Management; 2017; New York, NY, USA: Association for Computing Machinery. p. 797–806. [Google Scholar]
8. Yu F, Liu Q, Wu S, Wang L, Tan T. A convolutional approach for misinformation identification. In: Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence; 2017 August 19–25; Melbourne, Australia. p. 3901–3907. [Google Scholar]
9. Ma J, Gao W, Wong KF. Detect rumor and stance jointly by neural multi-task learning. In: Companion Proceedings of the the Web Conference 2018; 2018; Republic and Canton of Geneva, Switzerland: International World Wide Web Conferences Steering Committee. p. 585–93. [Google Scholar]
10. Pattanaik B, Mandal S, Tripathy RM. A survey on rumor detection and prevention in social media using deep learning. Knowl Inf Syst. 2023;65. 10:3839–80. [Google Scholar]
11. Ma J, Gao W, Wong KF. Detect rumors on twitter by promoting information campaigns with generative adversarial learning. In: The World Wide Web Conference; 2019; New York, NY, USA: Association for Computing Machinery. [Google Scholar]
12. Ma J, Gao W, Mitra P, Kwon S, Jansen BJ, Wong K-F, et al. Detecting rumors from microblogs with recurrent neural networks. In: Proceedings of the Twenty-Fifth International Joint Conference on Artificial Intelligence, IJCAI’16; 2016; New York, NY, USA: AAAI Press. p. 3818–24. [Google Scholar]
13. Li R, Jiang Z, Gao S, Yang W. Incorporating neural point process-based temporal feature for rumor detection. In: International Conference on Combinatorial Optimization and Applications; 2023; Cham, Switzerland: Springer Nature. p. 419–30. [Google Scholar]
14. Bian T, Xiao X, Xu T, Zhao P. Rumor detection on social media with bi-directional graph convolutional networks. Proc AAAI Conf Artif Intell. 2020;34:549–56. [Google Scholar]
15. Naumzik C, Feuerriegel S. Detecting false rumors from retweet dynamics on social media. In: Proceedings of the ACM Web Conference 2022; 2022; New York, NY, USA: Association for Computing Machinery. p. 2798–809. [Google Scholar]
16. Sun T, Qian Z, Dong S, Li P, Zhu Q. Rumor detection on social media with graph adversarial contrastive learning. In: Proceedings of the ACM Web Conference 2022; 2022; New York, NY, USA: Association for Computing Machinery. p. 2789–97. [Google Scholar]
17. Ma J, Gao W, Wong KF. Detect rumors in microblog posts using propagation structure via kernel learning. In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (ACL 2017); 2017 Jul 30–Aug 4; Vancouver, BC, Canada: Association for Computational Linguistics; p. 708–17. [Google Scholar]
18. Kwon S, Cha M, Jung K. Rumor detection over varying time windows. PLoS One. 2017;12(1):e0168344. doi:10.1371/journal.pone.0168344. [Google Scholar] [PubMed] [CrossRef]
19. Wu K, Yang S, Zhu KQ. False rumors detection on Sina Weibo by propagation structures. In: 2015 IEEE 31st International Conference on Data Engineering; 2015. p. 651–62. [Google Scholar]
20. Kumar S, Hamilton WL, Leskovec J, Jurafsky D. Community interaction and conflict on the web. In: Proceedings of the 2018 World Wide Web Conference; 2018; Republic and Canton of Geneva, Switzerland: International World Wide Web Conferences Steering Committee. p. 933–43. [Google Scholar]
21. Vosoughi S, Roy D, Aral S. The spread of true and false news online. Science. 2018;359(6380):1146–51. doi:10.1126/science.aap9559. [Google Scholar] [PubMed] [CrossRef]
22. Chen C, Shu K. Combating misinformation in the age of LLMs: opportunities and challenges. arXiv preprint arXiv:2311.05656. 2023. [Google Scholar]
23. Ivan V, Matúš P, Ivan S, Robert M, Dominik M, Maria B. Disinformation capabilities of large language models. arXiv preprint arXiv:2311.08838. 2023. [Google Scholar]
24. Chen C, Shu K. Can LLM-generated misinformation be detected? arXiv preprint arXiv:2309.13788. 2024. [Google Scholar]
25. Yang C, Zhang P, Qiao W, Gao H, Zhao J. Rumor detection on social media with crowd intelligence and ChatGPT-assisted networks. In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing; 2023; Singapore. p. 5705–17. [Google Scholar]
26. Hu B, Sheng Q, Cao J, Shi Y, Li Y, Wang D, et al. Bad actor, good advisor: exploring the role of large language models in fake news detection. Proc AAAI Conf Artif Intell. 2024;38(20):22105–13. [Google Scholar]
27. Reimers N. Sentence-BERT: sentence embeddings using siamese BERT-networks. arXiv preprint arXiv:1908.10084. 2019. [Google Scholar]
28. Huang Y, Xu J, Jiang Z, Lai J, Li Z, Yao Y, et al. Advancing transformer architecture in long-context large language models: a comprehensive survey. arXiv preprint arXiv:2311.12351. 2023. [Google Scholar]
29. Xie W. Analysis of the reasoning with redundant information provided ability of large language models. arXiv preprint arXiv:2310.04039. 2023. [Google Scholar]
30. Besta M, Blach N, Kubicek A, Gerstenberger R, Gianinazzi L, Gajda J, et al. Graph of thoughts: solving elaborate problems with large language models. AAAI Tech Track Nat Lang Process I. 2024;38(16):17682–90. [Google Scholar]
31. Yao S, Yu D, Zhao J, Shafran I, Griffiths TL, Cao Y, et al. Tree of thoughts: deliberate problem solving with large language models. In: Advances in Neural Information Processing Systems (NeurIPS 2023); 2023 Dec 10–16; New Orleans, LA, USA. [Google Scholar]
32. Liu Q, Tao X, Wu J, Wu S, Wang L. Can large language models detect rumors on social media? arXiv preprint arXiv:2402.03916. 2024. [Google Scholar]
33. Jin Z, Cao J, Guo H, Zhang Y, Luo J. Multimodal fusion with recurrent neural networks for rumor detection on microblogs. In: Proceedings of the 25th ACM International Conference on Multimedia; 2017; New York, NY, USA: Association for Computing Machinery. p. 795–816. [Google Scholar]
34. Zubiaga A, Liakata M, Procter R. Exploiting context for rumour detection in social media. In: International Conference on Social Informatics; 2017; Berlin/Heidelberg, Germany: Springer. p. 109–23. [Google Scholar]
35. Qian S, Wang J, Hu J, Fang Q, Xu C. Hierarchical multi-modal contextual attention network for fake news detection. In: Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval; 2021 Jul; New York, NY, USA: Association for Computing Machinery. p. 153–62. [Google Scholar]
36. Grattafiori A, Dubey A, Jauhri A, Pandey A, Kadian A, Al-Dahle A, et al. The Llama 3 herd of models. arXiv preprint arXiv:2407.21783. 2024. [Google Scholar]
37. Ma J, Gao W, Wei Z, Lu Y, Wong K-F. Detect rumors using time series of social context information on microblogging websites. In: Proceedings of the 24th ACM International on Conference on Information and Knowledge Management; 2015; New York, NY, USA: Association for Computing Machinery. p. 1751–4. [Google Scholar]
38. Yao L, Mao C, Luo Y. Graph convolutional networks for text classification. Proc AAAI Con Arti Intell. 2019;33(1):7370–7. [Google Scholar]
39. Wang Y, Ma F, Jin Z, Yuan Y, Xun G, Jha K, et al. EANN: event adversarial neural networks for multi-modal fake news detection. In: Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining; 2018; New York, NY, USA: Association for Computing Machinery. p. 849–57. [Google Scholar]
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools