
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
An Iterated Greedy Algorithm with Memory and Learning Mechanisms for the Distributed Permutation Flow Shop Scheduling Problem
College of Information Science and Engineering, Northeastern University, Shenyang, 110819, China
* Corresponding Author: Hongfeng Wang. Email:
(This article belongs to the Special Issue: Recent Advances in Ensemble Framework of Meta-heuristics and Machine Learning: Methods and Applications)
Computers, Materials & Continua 2025, 82(1), 371-388. https://doi.org/10.32604/cmc.2024.058885
Received 23 September 2024; Accepted 25 November 2024; Issue published 03 January 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The distributed permutation flow shop scheduling problem (DPFSP) has received increasing attention in recent years. The iterated greedy algorithm (IGA) serves as a powerful optimizer for addressing such a problem because of its straightforward, single-solution evolution framework. However, a potential draw-back of IGA is the lack of utilization of historical information, which could lead to an imbalance between exploration and exploitation, especially in large-scale DPFSPs. As a consequence, this paper develops an IGA with memory and learning mechanisms (MLIGA) to efficiently solve the DPFSP targeted at the mini-mal makespan. In MLIGA, we incorporate a memory mechanism to make a more informed selection of the initial solution at each stage of the search, by extending, reconstructing, and reinforcing the information from previous solutions. In addition, we design a two-layer cooperative reinforcement learning approach to intelligently determine the key parameters of IGA and the operations of the memory mechanism. Meanwhile, to ensure that the experience generated by each perturbation operator is fully learned and to reduce the prior parameters of MLIGA, a probability curve-based acceptance criterion is proposed by combining a cube root function with custom rules. At last, a discrete adaptive learning rate is employed to enhance the stability of the memory and learning mechanisms. Complete ablation experiments are utilized to verify the effectiveness of the memory mechanism, and the results show that this mechanism is capable of improving the performance of IGA to a large extent. Furthermore, through comparative experiments involving MLIGA and five state-of-the-art algorithms on 720 benchmarks, we have discovered that MLI-GA demonstrates significant potential for solving large-scale DPFSPs. This indicates that MLIGA is well-suited for real-world distributed flow shop scheduling.Keywords
Supplementary Material
Supplementary Material FileDistributed manufacturing is emerging as a dominant model in various industrial scenarios such as steelmaking-continuous casting and furniture assembly. It has numerous advantages over traditional manufacturing, such as reducing transportation costs, accelerating response to demand, mitigating production risks, and enhancing resilience [1]. In recent years, distributed permutation flow shop scheduling problem (DPFSP) has been one of the fastest growing topics toward distributed manufacturing [2,3]. Compared to the permutation flow shop scheduling problem (PFSP), DPFSP requires additional consideration of jobs’ allocation across different factories. Once the assignment is determined, there is a PFSP within each factory.
Since the DPFSP is more complex than the PFSP, some effective designs on the PFSP may not be applicable to directly solve the DPFSP. For this reason, a number of meta-heuristic algorithms have been customized based on the characteristics of the DPFSP, e.g., iterated greedy algorithm (IGA) [4–6], scatter search [7], memetic algorithm [8,9], and artificial bee colony [10]. It can be found that IGA is a common optimizer to tackle the DPFSP. The main reason is that the single-solution evolution framework of IGA is more simple and effective than population-based evolutionary algorithms in solving DPFSPs. Meanwhile, IGA also has some limitations because it focuses more on the current best or better solutions, while it ignores useful historical information.
Furthermore, the combination of reinforcement learning (RL) and meta-heuristics is also a hot research topic [7]. Depending on the characteristics of scheduling problems, some model-free RL approaches, such as Q-learning and Sarsa, can be used to help meta-heuristics choose operators [11,12], local search strategies [13–15], heuristics [16] or other decisions [17] without increasing the algorithm’s complexity. To further improve the performance of IGA and approximate the solution’s optimality of the DPFSP, this paper develops an IGA with memory and learning mechanisms (MLIGA). The specific contributions are summarized below:
(1) A memory mechanism is introduced for IGA to make full use of the information from historical solutions. By mimicking human memory patterns, this mechanism not only collects and expands historical solutions, but also reconstructs and reinforces them to provide more appropriate initial solutions for each iteration of the IGA according to the historical information.
(2) A two-layer cooperative RL mechanism is designed to adaptively determine the critical parameters of the IGA and the operations of the memory mechanism.
(3) A probability curve based acceptance criterion is employed to ensure that the experience generated by each perturbation operator is fully learned and reduce the prior parameters of the algorithm. This criterion, which combines a cube root function with custom rules, provides a dynamic balance between exploration and exploitation in our algorithm.
(4) Inspired by linear warm-up techniques, a discrete adaptive learning rate is proposed to enhance the stability of the memory and learning mechanisms.
The rest of this paper is organized below. Section 2 reviews the related literature and summarizes some research gaps, followed by the developed MLIGA in Section 3. To evaluate the performance of MLIGA and the effectiveness of some internal designs, Section 4 conducts a series of comparative experiments and Section 5 analyzes the results in detail. Finally, Section 6 presents conclusions and future research directions.
In this section, we investigate the related works to emphasize the research gap between previous studies and this paper. A detailed and intuitive comparison can be found in Table S1 in the Supplementary Document. Since DPFSP is a classic standard problem, we will no longer provide a mathematical model here, but the model is available in [2].
Since DPFSP was first proposed by [2], the related literature has been progressively enriched, leading to the proposal of a variety of meta-heuristic algorithms in succession. For example, Lin et al. [18] proposed a modified IGA. Naderi et al. [19] employed a scatter search algorithm with some advanced techniques. Zhao et al. designed a Q-learning enhanced fruit fly optimization algorithm [20].
Apart from those mentioned above, most of the research has focused on variants of the DPFSP. Lin et al. [21] proposed a backtracking search hyper-heuristic algorithm to solve the distributed assembly permutation flow shop scheduling problem. Lu et al. [22] addressed an energy-efficient scheduling of distributed flow shop with heterogenous factories and designed a hybrid multiobjective optimization algorithm to optimize both makespan and total energy consumption. Fernandez-Viagas et al. [23] dealt with the DPFSP for minimizing the total flowtime. Lu et al. [24] proposed a knowledge-based multiobjective memetic optimization algorithm to investigate a sustainable DPFSP with a non-identical factory with objectives of minimizing makespan, negative social impact, and total energy consumption. Guo et al. [25] employed an effective fruit fly optimization algorithm for the DPFSP with the optimization goal of minimizing the total flowtime. Lu et al. [26] designed a Pareto-based collaborative multiobjective optimization algorithm to study an energy-efficient scheduling of DPFSP with limited buffers with the optimization of makespan and total energy consumption. There has been scant literature on the standard DPFSP in the past five years. In this paper, we propose a more efficient algorithm for the standard DPFSP to explore better solutions on the benchmarks, which can also be easily extended to deal with variants of the DPFSP.
IGA has been widely used in addressing DPFSPs due to its simple and effective single-solution evolution framework [4–6]. Despite previous efforts, it also has some limitations. On the one hand, it usually fails to utilize valuable information from historical solutions (i.e., memories), which may cause an imbalance between exploration and exploitation. Therefore, we design a memory mechanism to deal with the limitation. By mimicking human memory patterns, this mechanism not only collects and expands historical solutions, but also reconstructs and reinforces them to provide more appropriate initial solutions for each iteration of the IGA according to the historical information. This comprehensive approach to leveraging historical solutions is not commonly found in previous studies.
On the other hand, the majority of relevant literature uses the simulated annealing based acceptance criterion in the proposed IGA [27]. A potential drawback of this acceptance criterion is to introduce an extra parameter that needs to be tuned beforehand [4–6]. To improve such a deficiency, we propose a probability curve based acceptance criterion by combining the cube root function with customized rules for IGA, which does not introduce an additional parameter.
2.3 Application of RL in DPFSPs
Due to the superior performance of RL on decision-making problems [28], combining meta-heuristic algorithms with RL has become a hot topic in the field of scheduling, in which the widely used RL approach is Q-learning. For instance, Zhao et al. [11] utilized the Q-learning algorithm to choose the appropriate perturbation operators during iterations. Chen et al. [29] dynamically selected the scheme of task splitting as action by employing Q-learning algorithm. Zhao et al. [16] employed the Q-learning algorithm to choose an appropriate low-level heuristic. Jia et al. [17] adaptively adjusted the size of each subpopulation in the memetic algorithm via Q-learning. Yu et al. [30] embedded Q-learning algorithm into meta-heuristics to select the premium local search strategy during iterations.
Different from the above studies, Zhao et al. [14] employed two independent Q-learning algorithms to control two subpopulations in parallel. A major disadvantage is the lack of communication and cooperation between learning agents. In our work, we propose a two-layer cooperative reinforcement learning mechanism that intelligently determines key parameters of the IGA and controls operations of the memory mechanism. The learning mechanism, which features direct communication and cooperation between layers, is a novel concept not yet explored in the literature. Furthermore, inspired by linear warm-up techniques, we incorporate a discrete adaptive learning rate to enhance the stability of the learning mechanisms, which is another innovative aspect of our work.
As discussed above, we propose a novel algorithm named MLIGA to solve the DPFSP aimed at minimizing makespan. Later in this work,
As shown in Fig. 1, MLIGA starts with an initial solution using
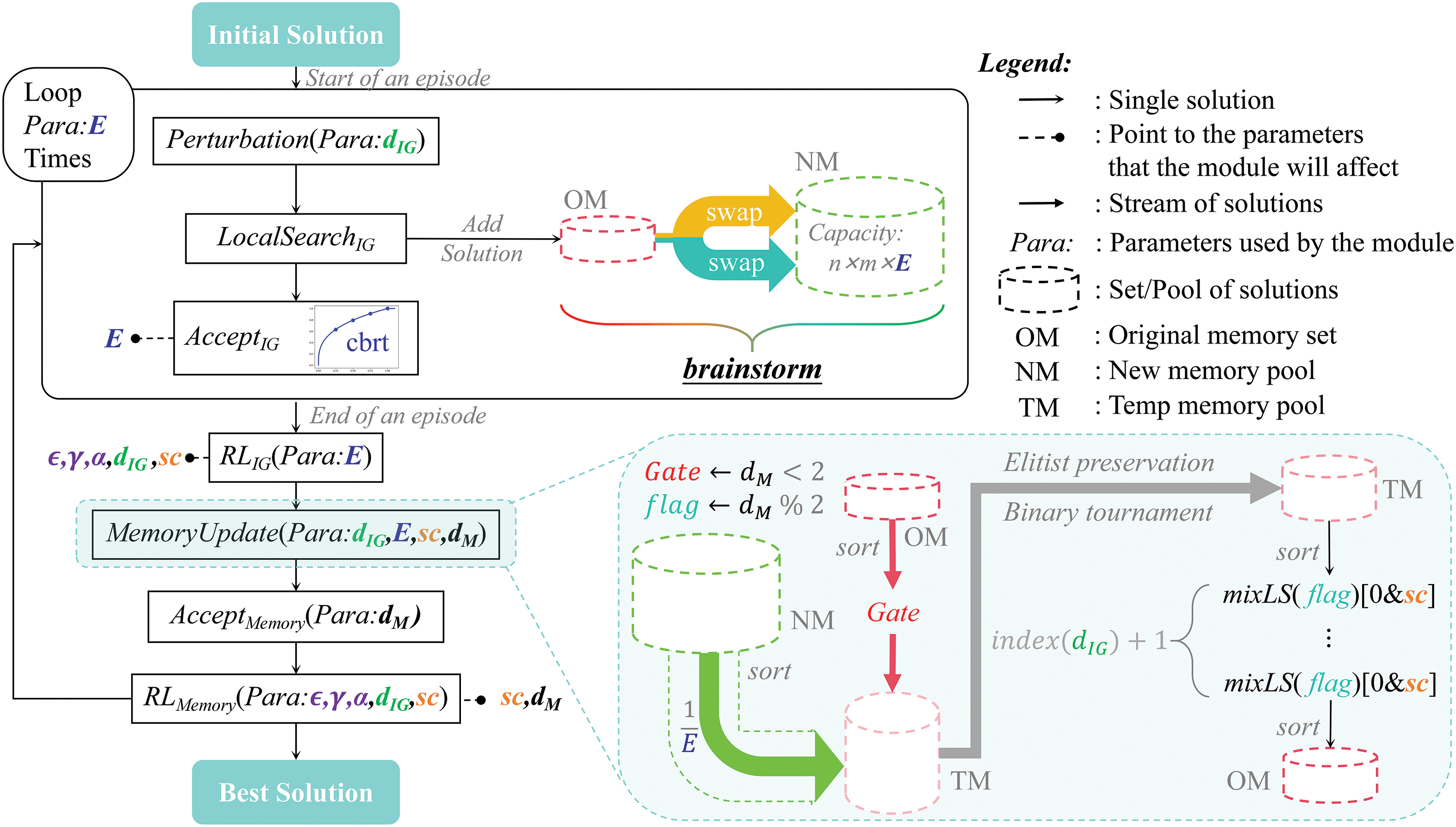
Figure 1: The framework of the proposed MLIGA

Apart from the acceptance, other elements of IGA have not been specifically designed and the details can be found in the Supplementary Document or related literature. First, for DPFSP, we adopt a widely-used solution representation proposed by [2], consisting of a set of
As illustrated in Fig. 1, each perturbation operator
Following the above analysis, we design a probability curve based acceptance criterion, i.e.,
when
Additionally, the design of
The detailed procedure of
The memory mechanism includes three main elements:
As shown in Fig. 1, in each episode, every solution obtained after

3.3.2 Reconstruction and Reinforcement of Memories
Following

The aforementioned treatments are insufficient for the memory mechanism—not only should memories be collected, extended, and reconstructed, but they should also be reinforced. Therefore, considering the limited computational resources and the balance between exploration and exploitation, only two solutions

3.3.3 Update of Solutions in the Memory Mechanism
After
Inspired by [31], we design a two-layer cooperative RL mechanism to hierarchically and synergistically control the pivotal parameters of IGA and the memory mechanism. In accordance with the algorithm structure depicted in Fig. 1, the first layer of RL is denoted as
In

According to the design of
In

Comparing to
In order to investigate the performance of MLIGA and the effectiveness of some internal designs, we conducted comprehensive experiments. This section presents a detailed description of the experimental design as well as all relevant information.
For standard benchmarks, we utilized the Large test instances and Calibration instances employed by [5]. Further details about them can be found in the Supplementary Document. In addition, given the stochastic nature of the algorithms, each algorithm was independently repeated 10 times on each instance, and the results were subsequently averaged. The average relative percentage deviation (ARPD) [5] was chosen as the performance comparison metric. The relative percentage deviation (RPD) is first calculated as Equation (S3) in the Supplementary Document. As for the termination criterion, we adopted the maximum number of fitness evaluations utilized by [32]. To determine the maximum number of fitness evaluations, we employed the method proposed by [12], which is detailed in the Supplementary Document. Finally, all algorithms were coded by Python, and run on the PC: Intel(R) Core(TM) i9-13900K @ 3000 MHz with 64.0 GB RAM in the 64bit Windows 10 operation system.
4.2 Settings of Key Parameters
To avoid duplication of labor, the parameters in the learning mechanism were directly adopted from the combination of parameter values used by [12], i.e.,
The
4.3 Settings of Comparison Algorithms
To verify the effectiveness of MLIGA, we compared it with five state-of-the-art comparison algorithms, which are shown in Table 2.

4.4 Settings of Ablation Experiments
We also designed ablation experiments to examine specific designs and critical components in MLIGA. The first experiment was conducted to investigate the effect of different initialization procedures on MLIGA. In addition to the
5 Numerical and Statistical Results
In this section, we implemented all the experiments designed in Section 4, and subsequently analyzed the results using the Analysis of Variance (ANOVA) technique [34] and the Tukey’s Honest Significant Difference (HSD) with 95% confidence intervals [35]. More detailed analysis results are provided in Supplementary Document.
The analysis of the results shows that there is no significant difference among these values, as the
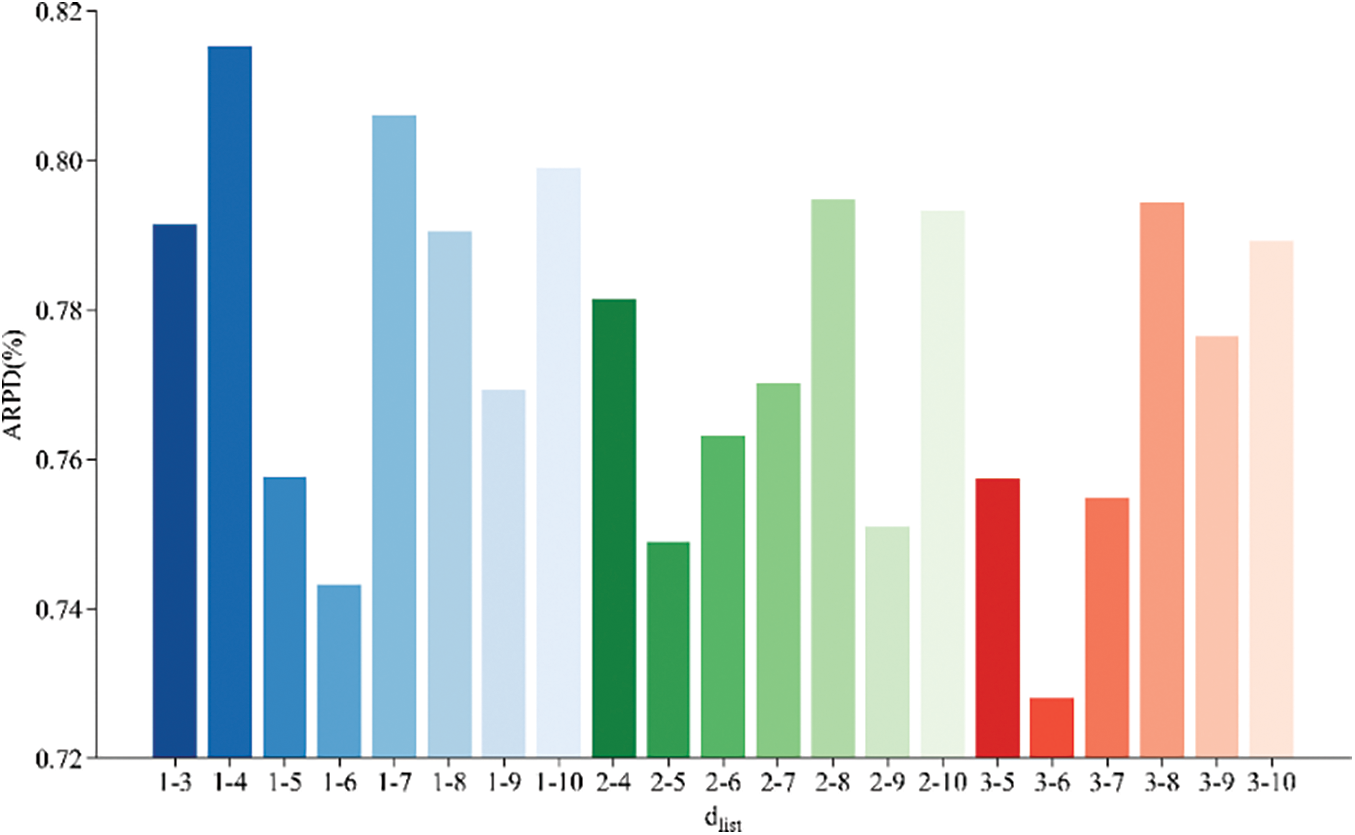
Figure 2: Means plots for all
As designed in Section 4.3, we conducted the comparison experiment. Fig. 3 shows the analysis of the results, and the smallest mean ARPD value is highlighted in bold. According to Fig. 3, MLIGA demonstrates superior overall performance compared to DABC, DFFO, QFOA, and QIGA. Moreover, given that QIGA utilizes a single-layer RL framework, the results can also indicate that the learning mechanism proposed in this paper is superior to the single-layer RL framework.
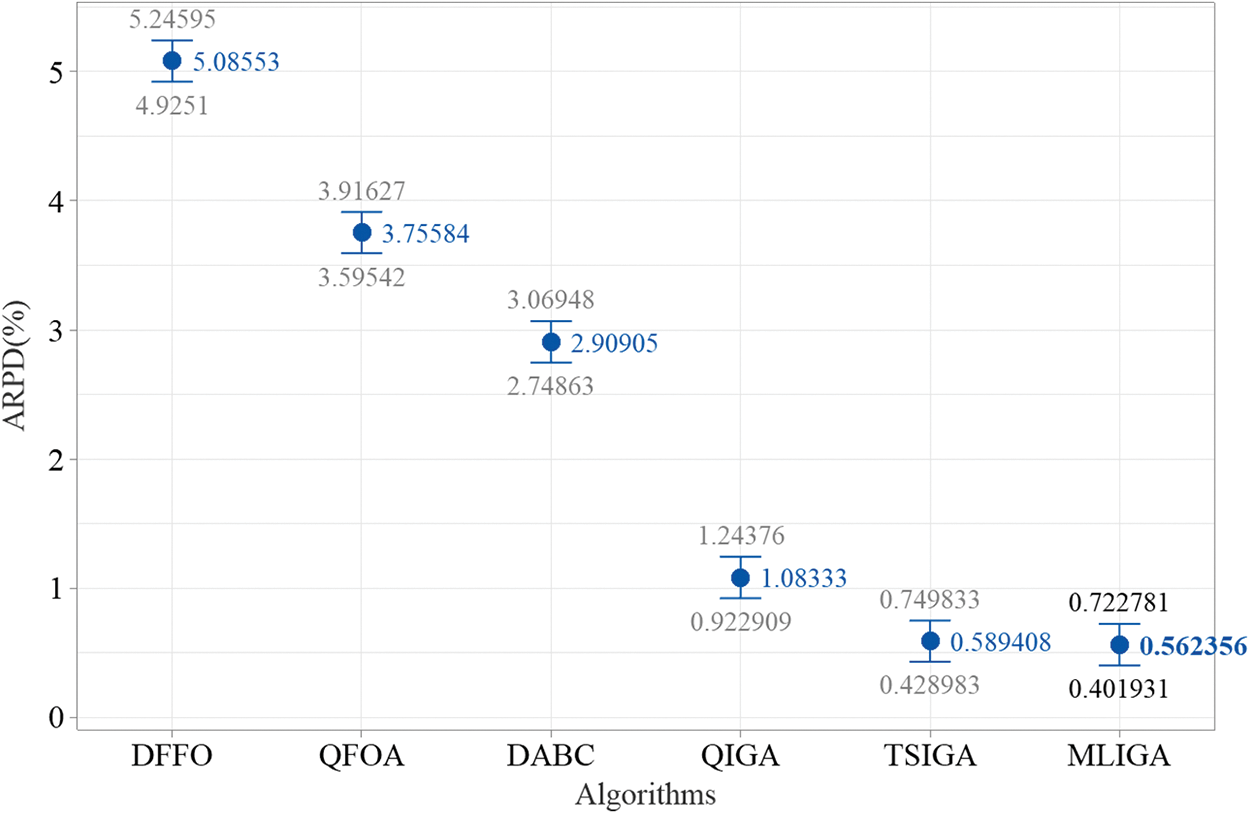
Figure 3: Means plots for all algorithms. All means have HSD 95% confidence intervals
However, the mean ARPD value of MLIGA is slightly lower than that of TSIGA, with no significant difference observed. Therefore, we need to further analyze MLIGA and TSIGA. The Large test instances used are not all large-scale instances, e.g., for an instance with 7 factories and 20 jobs in Large test instances, each factory contains fewer than 3 jobs on average. Small-scale instances are easily solved by most existing meta-heuristics for the DPFSP [5] and large-scale instances are more common in real-world distributed flow shop scheduling. Consequently, more attention should be paid to solving large-scale instances. Nevertheless, the definition of large-scale instances in DPFSP remains unclear, with much literature preferring to define instance scale based solely on the number of factories (
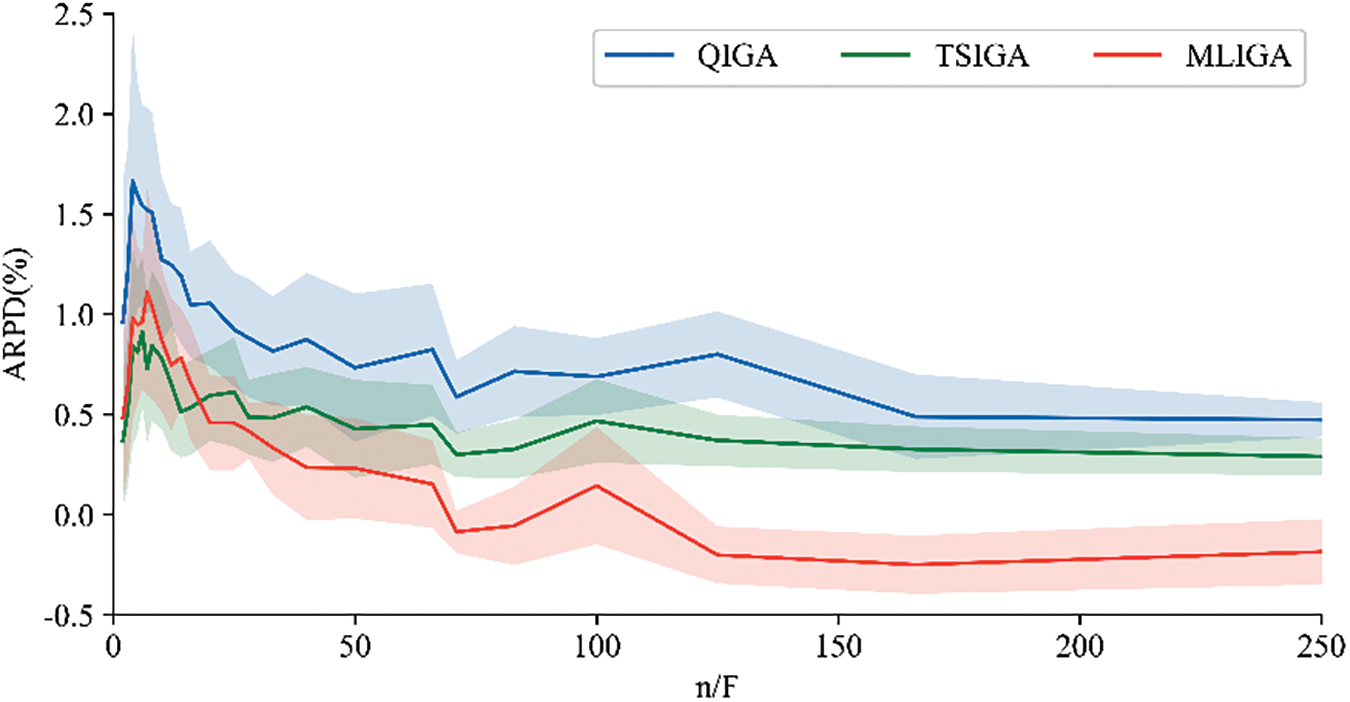
Figure 4: Line graph of ARPD of the three algorithms following the increase in the scale of instances
According to Fig. 4, MLIGA exhibits slightly inferior performance compared to TSIGA when
The analytical results of ablation experiments on initialization are shown in Table 3. It can be found that: 1) Compared to

Table 4 lists the analytical results of ablation experiments on probability curves. From Table 4, it can be found that the

The impact of the probability curves is not only manifested in the result, but also more directly evident in the
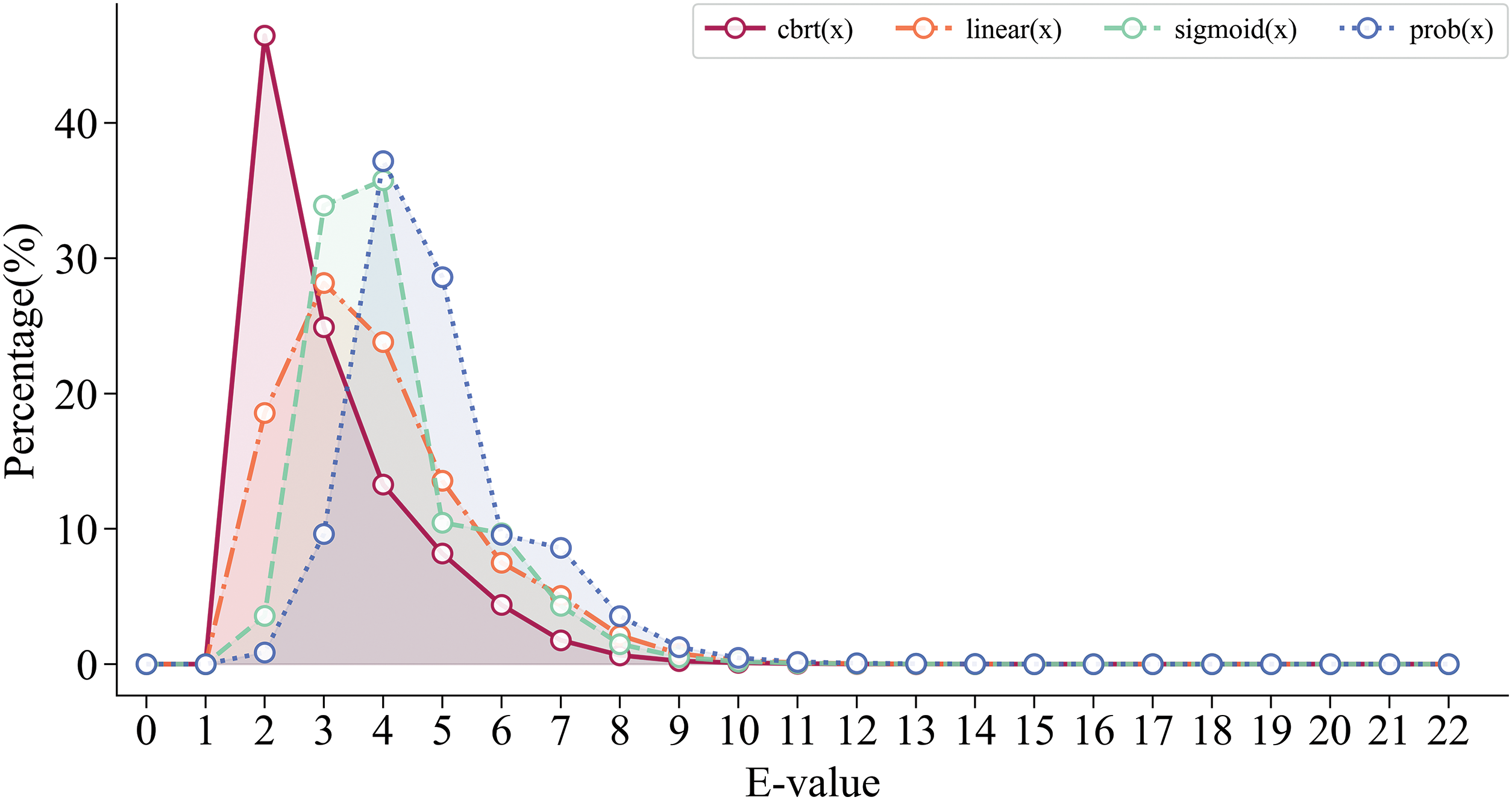
Figure 5: Line graph of percentage of each
At last, the analytical results for MLIGA and Memoryless MLIGA are listed in Table 5. The results suggest that the memory mechanism can significantly improve the overall performance of the algorithm, with a significant difference observed between MLIGA and Memoryless MLIGA. This phenomenon effectively demonstrates the pivotal role of the memory mechanism in MLIGA’s performance.

In this paper, we developed a novel algorithm named MLIGA to solve the DPFSP with the objective of minimizing the makespan. One of main contribution is to incorporate a memory mechanism in IGA, which can help the algorithm escape from the local optima by collecting, extending, reconstructing (including forgetting), and reinforcing memories, with providing more appropriate starting solutions for IGA during iterations. In addition, we proposed a two-layer cooperative RL mechanism to determine the crucial parameters of IGA and the memory mechanism. Through a series of comprehensive experiments, it is clear that MLIGA exhibits excellent performance on large-scale DPFSP instances, indicating its potential applicability in real-world distributed flow shop scheduling.
However, there are also some limitations, including the performance is not as good as TSIGA in small-scale benchmarks, and there are some sorting operations in the memory mechanism. In the future, we will explore the feasibility of implementing switchable acceptance criteria based on the scale of instances to improve the performance of MLIGA on small-scale benchmarks, design more suitable acceptance strategies according to the structure of algorithm, or refine the framework of MLIGA to avoid some sorting operations. Furthermore, we will extend the application of MLIGA to tackle more variants of DPFSPs. More investigations on multi-objective evolutionary algorithms are also crucial for solving DPFSPs with multiple optimization objectives.
Acknowledgement: None.
Funding Statement: This work was supported in part by the National Key Research and Development Program of China under Grant No. 2021YFF0901300, in part by the National Natural Science Foundation of China under Grant Nos. 62173076 and 72271048.
Author Contributions: Study conception and design: Binhui Wang; data collection: Binhui Wang; analysis and interpretation of results: Binhui Wang; draft manuscript preparation: Binhui Wang; review and editing: Hongfeng Wang; funding acquisition: Hongfeng Wang. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: Not applicable.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
Supplementary Materials: The supplementary material is available online at https://doi.org/10.32604/cmc.2024.058885.
References
1. C. E. Okwudire and H. V. Madhyastha, “Distributed manufacturing for and by the masses,” Science, vol. 372, no. 6540, pp. 341–342, Apr. 2021. doi: 10.1126/science.abg4924. [Google Scholar] [PubMed] [CrossRef]
2. B. Naderi and R. Ruiz, “The distributed permutation flowshop scheduling problem,” Comput. Oper. Res., vol. 37, no. 4, pp. 754–768, 2010. doi: 10.1016/j.cor.2009.06.019. [Google Scholar] [CrossRef]
3. P. Perez-Gonzalez and J. M. Framinan, “A review and classification on distributed permutation flowshop scheduling problems,” Eur. J. Oper. Res., vol. 312, no. 1, pp. 1–21, Jan. 2024. doi: 10.1016/j.ejor.2023.02.001. [Google Scholar] [CrossRef]
4. V. Fernandez-Viagas and J. M. Framinan, “A bounded-search iterated greedy algorithm for the distributed permutation flowshop scheduling problem,” Int. J. Prod. Res., vol. 53, no. 4, pp. 1111–1123, Feb. 2015. doi: 10.1080/00207543.2014.948578. [Google Scholar] [CrossRef]
5. R. Ruiz, Q. -K. Pan, and B. Naderi, “Iterated Greedy methods for the distributed permutation flowshop scheduling problem,” Omega, vol. 83, no. 1, pp. 213–222, Mar. 2019. doi: 10.1016/j.omega.2018.03.004. [Google Scholar] [CrossRef]
6. Z. Shao, W. Shao, and D. Pi, “Effective heuristics and metaheuristics for the distributed fuzzy blocking flow-shop scheduling problem,” Swarm Evol. Comput., vol. 59, Dec. 2020, Art. no. 100747. doi: 10.1016/j.swevo.2020.100747. [Google Scholar] [CrossRef]
7. Q. -Y. Han, H. -Y. Sang, Q. -K. Pan, B. Zhang, and H. -W. Guo, “An efficient collaborative multi-swap iterated greedy algorithm for the distributed permutation flowshop scheduling problem with preventive maintenance,” Swarm Evol. Comput., vol. 86, Apr. 2024, Art. no. 101537. doi: 10.1016/j.swevo.2024.101537. [Google Scholar] [CrossRef]
8. S. -Y. Wang and L. Wang, “An estimation of distribution algorithm-based memetic algorithm for the distributed assembly permutation flow-shop scheduling problem,” IEEE Trans. Syst. Man Cybern. Syst., vol. 46, no. 1, pp. 139–149, Jan. 2016. doi: 10.1109/TSMC.2015.2416127. [Google Scholar] [CrossRef]
9. J. Deng and L. Wang, “A competitive memetic algorithm for multi-objective distributed permutation flow shop scheduling problem,” Swarm Evol. Comput., vol. 32, no. 6, pp. 121–131, Feb. 2017. doi: 10.1016/j.swevo.2016.06.002. [Google Scholar] [CrossRef]
10. J. Mao, Q. Pan, Z. Miao, and L. Gao, “An effective multi-start iterated greedy algorithm to minimize makespan for the distributed permutation flowshop scheduling problem with preventive maintenance,” Expert. Syst. Appl., vol. 169, May 2021, Art. no. 114495. doi: 10.1016/j.eswa.2020.114495. [Google Scholar] [CrossRef]
11. F. Zhao, G. Zhou, T. Xu, N. Zhu, and Jonrinaldi, “A knowledge-driven cooperative scatter search algorithm with reinforcement learning for the distributed blocking flow shop scheduling problem,” Expert Syst. Appl., vol. 230, Nov. 2023, Art. no. 120571. doi: 10.1016/j.eswa.2023.120571. [Google Scholar] [CrossRef]
12. M. Karimi-Mamaghan, M. Mohammadi, B. Pasdeloup, and P. Meyer, “Learning to select operators in meta-heuristics: An integration of Q-learning into the iterated greedy algorithm for the permutation flowshop scheduling problem,” Eur. J. Oper. Res., vol. 304, no. 3, pp. 1296–1330, Feb. 2023. doi: 10.1016/j.ejor.2022.03.054. [Google Scholar] [CrossRef]
13. F. Zhao, Z. Wang, and L. Wang, “A reinforcement learning driven artificial bee colony algorithm for distributed heterogeneous no-wait flowshop scheduling problem with sequence-dependent setup times,” IEEE Trans. Autom. Sci. Eng., vol. 20, no. 4, pp. 2305–2320, Oct. 2023. doi: 10.1109/TASE.2022.3212786. [Google Scholar] [CrossRef]
14. F. Zhao, T. Jiang, and L. Wang, “A reinforcement learning driven cooperative meta-heuristic algorithm for energy-efficient distributed no-wait flow-shop scheduling with sequence-dependent setup time,” IEEE Trans. Ind. Inform., vol. 19, no. 7, pp. 8427–8440, Jul. 2023. doi: 10.1109/TII.2022.3218645. [Google Scholar] [CrossRef]
15. F. Zhao, G. Zhou, and L. Wang, “A cooperative scatter search with reinforcement learning mechanism for the distributed permutation flowshop scheduling problem with sequence-dependent setup times,” IEEE Trans. Syst. Man Cybern. Syst., vol. 53, no. 8, pp. 4899–4911, 2023. doi: 10.1109/TSMC.2023.3256484. [Google Scholar] [CrossRef]
16. F. Zhao, S. Di, and L. Wang, “A hyperheuristic with Q-learning for the multiobjective energy-efficient distributed blocking flow shop scheduling problem,” IEEE Trans. Cybern., vol. 53, no. 5, pp. 3337–3350, May 2023. doi: 10.1109/TCYB.2022.3192112. [Google Scholar] [PubMed] [CrossRef]
17. Y. Jia, Q. Yan, and H. Wang, “Q-learning driven multi-population memetic algorithm for distributed three-stage assembly hybrid flow shop scheduling with flexible preventive maintenance,” Expert Syst. Appl., vol. 232, Dec. 2023, Art. no. 120837. doi: 10.1016/j.eswa.2023.120837. [Google Scholar] [CrossRef]
18. S. -W. Lin, K. -C. Ying, and C. -Y. Huang, “Minimising makespan in distributed permutation flowshops using a modified iterated greedy algorithm,” Int. J. Prod. Res., vol. 51, no. 16, pp. 5029–5038, Aug. 2013. doi: 10.1080/00207543.2013.790571. [Google Scholar] [CrossRef]
19. B. Naderi and R. Ruiz, “A scatter search algorithm for the distributed permutation flowshop scheduling problem,” Eur. J. Oper. Res., vol. 239, no. 2, pp. 323–334, Dec. 2014. doi: 10.1016/j.ejor.2014.05.024. [Google Scholar] [CrossRef]
20. C. Zhao, L. Wu, C. Zuo, and H. Zhang, “An improved fruit fly optimization algorithm with Q-learning for solving distributed permutation flow shop scheduling problems,” Complex Intell. Syst., vol. 10, no. 5, pp. 5965–5988, Oct. 2024. doi: 10.1007/s40747-024-01482-4. [Google Scholar] [CrossRef]
21. J. Lin, Z. -J. Wang, and X. Li, “A backtracking search hyper-heuristic for the distributed assembly flow-shop scheduling problem,” Swarm Evol. Comput., vol. 36, pp. 124–135, Oct. 2017. doi: 10.1016/j.swevo.2017.04.007. [Google Scholar] [CrossRef]
22. C. Lu, L. Gao, J. Yi, and X. Li, “Energy-efficient scheduling of distributed flow shop with heterogeneous factories: A real-world case from automobile industry in China,” IEEE Trans. Ind. Inform., vol. 17, no. 10, pp. 6687–6696, Oct. 2021. doi: 10.1109/TII.2020.3043734. [Google Scholar] [CrossRef]
23. V. Fernandez-Viagas, P. Perez-Gonzalez, and J. M. Framinan, “The distributed permutation flow shop to minimise the total flowtime,” Comput. Ind. Eng., vol. 118, pp. 464–477, Apr. 2018. doi: 10.1016/j.cie.2018.03.014. [Google Scholar] [CrossRef]
24. C. Lu, L. Gao, W. Gong, C. Hu, X. Yan and X. Li, “Sustainable scheduling of distributed permutation flow-shop with non-identical factory using a knowledge-based multi-objective memetic optimization algorithm,” Swarm Evol. Comput., vol. 60, Feb. 2021, Art. no. 100803. doi: 10.1016/j.swevo.2020.100803. [Google Scholar] [CrossRef]
25. H. -W. Guo, H. -Y. Sang, X. -J. Zhang, P. Duan, J. -Q. Li and Y. -Y. Han, “An effective fruit fly optimization algorithm for the distributed permutation flowshop scheduling problem with total flowtime,” Eng. Appl. Artif. Intell., vol. 123, Aug. 2023, Art. no. 106347. doi: 10.1016/j.engappai.2023.106347. [Google Scholar] [CrossRef]
26. C. Lu, Y. Huang, L. Meng, L. Gao, B. Zhang and J. Zhou, “A Pareto-based collaborative multi-objective optimization algorithm for energy-efficient scheduling of distributed permutation flow-shop with limited buffers,” Robot Comput.-Integr. Manuf., vol. 74, Apr. 2022, Art. no. 102277. doi: 10.1016/j.rcim.2021.102277. [Google Scholar] [CrossRef]
27. Z. Zhao, M. Zhou, and S. Liu, “Iterated greedy algorithms for flow-shop scheduling problems: A tutorial,” IEEE Trans. Autom. Sci. Eng., vol. 19, no. 3, pp. 1941–1959, 2021. doi: 10.1109/TASE.2021.3062994. [Google Scholar] [CrossRef]
28. J. Wang, H. Zheng, S. Zhao, and Q. Zhang, “Energy-aware remanufacturing process planning and scheduling problem using reinforcement learning-based particle swarm optimization algorithm,” J. Clean. Prod., vol. 476, Oct. 2024, Art. no. 143771. doi: 10.1016/j.jclepro.2024.143771. [Google Scholar] [CrossRef]
29. X. Chen et al., “Reinforcement learning for distributed hybrid flowshop scheduling problem with variable task splitting towards mass personalized manufacturing,” J. Manuf. Syst., vol. 76, no. 4, pp. 188–206, Oct. 2024. doi: 10.1016/j.jmsy.2024.07.011. [Google Scholar] [CrossRef]
30. H. Yu, K. -Z. Gao, Z. -F. Ma, and Y. -X. Pan, “Improved meta-heuristics with Q-learning for solving distributed assembly permutation flowshop scheduling problems,” Swarm Evol. Comput., vol. 80, Jul. 2023, Art. no. 101335. doi: 10.1016/j.swevo.2023.101335. [Google Scholar] [CrossRef]
31. Q. Yan, H. Wang, and F. Wu, “Digital twin-enabled dynamic scheduling with preventive maintenance using a double-layer Q-learning algorithm,” Comput. Oper. Res., vol. 144, Aug. 2022, Art. no. 105823. doi: 10.1016/j.cor.2022.105823. [Google Scholar] [CrossRef]
32. Q. Yan, H. Wang, and S. Yang, “A learning-assisted bi-population evolutionary algorithm for distributed flexible job-shop scheduling with maintenance decisions,” IEEE Trans. Evol. Comput., 2024. doi: 10.1109/TEVC.2024.3400043. [Google Scholar] [CrossRef]
33. Y. Yu, F. -Q. Zhang, G. -D. Yang, Y. Wang, J. -P. Huang and Y. -Y. Han, “A discrete artificial bee colony method based on variable neighborhood structures for the distributed permutation flowshop problem with sequence-dependent setup times,” Swarm Evol. Comput., vol. 75, Dec. 2022, Art. no. 101179. doi: 10.1016/j.swevo.2022.101179. [Google Scholar] [CrossRef]
34. M. G. Larson, “Analysis of Variance,” Circulation, vol. 117, no. 1, pp. 115–121, 2008. doi: 10.1161/CIRCULATIONAHA.107.654335. [Google Scholar] [CrossRef]
35. H. Abdi and L. J. Williams, “Tukey’s honestly significant difference (HSD) test,” in Encyclopedia of Research Design. SAGE Publications, Inc., 2010. [Google Scholar]
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools