
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Joint Feature Encoding and Task Alignment Mechanism for Emotion-Cause Pair Extraction
College of Computer and Control Engineering, Northeast Forestry University, Harbin, 150040, China
* Corresponding Author: Didi Sun. Email:
Computers, Materials & Continua 2025, 82(1), 1069-1086. https://doi.org/10.32604/cmc.2024.057349
Received 15 August 2024; Accepted 30 October 2024; Issue published 03 January 2025
 View Full Text
View Full Text Download PDF
Download PDFAbstract
With the rapid expansion of social media, analyzing emotions and their causes in texts has gained significant importance. Emotion-cause pair extraction enables the identification of causal relationships between emotions and their triggers within a text, facilitating a deeper understanding of expressed sentiments and their underlying reasons. This comprehension is crucial for making informed strategic decisions in various business and societal contexts. However, recent research approaches employing multi-task learning frameworks for modeling often face challenges such as the inability to simultaneously model extracted features and their interactions, or inconsistencies in label prediction between emotion-cause pair extraction and independent assistant tasks like emotion and cause extraction. To address these issues, this study proposes an emotion-cause pair extraction methodology that incorporates joint feature encoding and task alignment mechanisms. The model consists of two primary components: First, joint feature encoding simultaneously generates features for emotion-cause pairs and clauses, enhancing feature interactions between emotion clauses, cause clauses, and emotion-cause pairs. Second, the task alignment technique is applied to reduce the labeling distance between emotion-cause pair extraction and the two assistant tasks, capturing deep semantic information interactions among tasks. The proposed method is evaluated on a Chinese benchmark corpus using 10-fold cross-validation, assessing key performance metrics such as precision, recall, and F1 score. Experimental results demonstrate that the model achieves an F1 score of 76.05%, surpassing the state-of-the-art by 1.03%. The proposed model exhibits significant improvements in emotion-cause pair extraction (ECPE) and cause extraction (CE) compared to existing methods, validating its effectiveness. This research introduces a novel approach based on joint feature encoding and task alignment mechanisms, contributing to advancements in emotion-cause pair extraction. However, the study’s limitation lies in the data sources, potentially restricting the generalizability of the findings.Keywords
Emotion-Cause Pair Extraction (ECPE) is a field of study that extracts emotion-cause pairs with causal relationships from diverse data sources [1]. With the rapid growth of social networks, users increasingly post comments online, and the emotions and corresponding causes expressed in these comments provide valuable information for various applications, such as opinion monitoring and comment mining [2]. Due to its significance, emotion-cause pair extraction has gained popularity as a research area in recent years. Previous research on ECPE has emphasized the internal relations within emotion-cause pairs or clauses, as they offer semantic and contextual information about the sentence during the extraction process. The extraction of inaccurate emotion clauses and emotion-cause pairs, however, results from this research’s disregard for the causal information between emotion-cause pairs and clauses. Additionally, previous studies have concentrated on the individual predictions of the assistant and emotion-cause pair extraction tasks, ignoring the informational interactions across the tasks. This has led to difficulties in preserving predictive consistency between tasks. To overcome these problems, emotion-cause pair extraction using joint feature encoding and task alignment mechanisms improves the accuracy of emotion-cause pair extraction, strengthens information interaction between tasks, and allows for a deeper comprehension of the contextual semantics and causal information within sentences.
Traditional emotion-cause pair extraction techniques primarily employ sequential coding to learn internal relationships within emotion-cause pairs or clauses through a predefined order [1]. However, for the emotion-cause pair extraction task, the causal relationship between emotion clauses and cause clauses is crucial for identifying potential emotion-cause pairs. Sequential coding, unfortunately, disregards information about the interrelationships between clauses [2]. In this context, extracting and efficiently analyzing the causal relationships within clause contexts can reveal more detailed information about the categorization of clause pairs. Furthermore, the emotion-cause relationship is essential for extraction and information interaction between the two assistant tasks. Analyzing this relationship can provide valuable clues. Despite this, most prior research on emotion-cause pair extraction considers ECPE and the assistant tasks (CE: extracting cause clauses from documents, and Emotion Extraction (EE): extracting emotion clauses from documents) as two distinct extraction tasks that cannot share relevant information, resulting in inconsistent sentence prediction.
For instance, in Table 1, sentence (c7) is identified as an emotion clause in emotion-cause pairs during the ECPE process. However, it is not labeled as an emotion clause in the context of EE [3]. Consequently, the labeling consistency between emotion-cause pair extraction and the assistant task cannot be assured [4–8]. To address this issue, the labeling consistency can be further enhanced by facilitating information exchange between the emotion-cause pair extraction and the assistant tasks.

This paper proposes an emotion-cause pair extraction method based on a Joint Feature Encoding and Task Alignment (JFTA) mechanism to address the limitations of existing studies. Traditional methods either lack the ability to simultaneously model extracted features and feature interaction information or suffer from inconsistent label predictions between emotion-cause pair extraction and independent assistant tasks, such as emotion extraction and cause extraction. The JFTA approach leverages feature information obtained from emotion-cause pairs and clauses to capture causality through feature interaction. Additionally, it utilizes the sharing of interrelated information to reduce the labeling distance between emotion-cause pair extraction and assistant tasks, thereby improving prediction accuracy. This novel approach contributes to the advancement of emotion-cause pair extraction research by overcoming the shortcomings of conventional methods. To achieve this objective, the proposed methodology employs a Bidirectional Encoder Representation from Transformers (BERT) as a document encoder to generate clause representations. Subsequently, a heterogeneous undirected graph and a relational graph convolutional network are used to model the multiple relationships between emotion-cause pairs and clauses. Finally, task alignment is achieved by minimizing the bi-directional Kullback-Leibler (KL) divergence between the emotion-cause pair extraction and the product of emotion extraction and cause extraction output distributions, ensuring uniformity of the label space across all tasks.
The experimental results, evaluated on a public Chinese benchmark corpus [1], demonstrate the effectiveness of the technique proposed in this study. The main contributions of this paper are as follows:
1) Heterogeneous undirected graphs and Relational Graph Convolutional Networks (RGCN) are employed to modelling the diverse relationships among emotion-cause pairs and clauses, facilitating the learning of causal connections between sentences during the encoding process.
2) This paper introduces a task alignment mechanism that effectively captures the information interactions between tasks, obtains deep semantic information, and further narrows the labeling distance between ECPE and the combination of EE and CE. This ensures labeling consistency across these related tasks.
3) This study validates the approach’s performance through a comprehensive series of ablation experiments, hyper-parameter tuning, and additional tests. The benchmark dataset’s experimental results demonstrate the effectiveness and superiority of the proposed method in comparison to prior techniques.
The remaining content of this article is organized as follows: Section 2 provides an overview of relevant work on the topic. Section 3 introduces the proposed model and provides a detailed definition of the task. Section 4 describes the comprehensive experiments conducted and analyzes the results, discussing the implications of the findings. The article is concluded in Section 5, which summarizes the main insights and contributions of the study.
The identification of sentiment polarity [9–12] and emotion categories [1,13] is part of the well-established field of sentiment and opinion analysis in natural language processing [13–15]. A more recent advancement in emotion detection techniques is Emotion cause analysis (ECA). Based on the emotion and cause extraction elements, several subordinate tasks revolve around the ECA theme, including emotion-cause extraction (ECE) [1–2,16–17] and ECPE [3,9,11].
The ECE task, originally presented by Xia et al. [1], is a word-level cause labeling task that has been the subject of numerous investigations using rule-based approaches [16,18–19] and machine learning methods [20]. Chen et al. [18] redefined the ECE problem as a sentence-level extraction task, suggesting that clauses may be the optimal information unit for identifying reasons. Subsequently, a related study [2] created a benchmark dataset for the ECE task using Sina News to develop a Chinese emotional causes dataset. Following the completion of this task, various studies have proposed conventional machine learning techniques [21–23]. Recently, deep neural networks have been employed in several studies to accomplish this task [24–28]. Despite its significant research value [21,22], the ECE task has two distinct limitations. First, the process of manually annotating emotions prior to cause extraction constrains its practical applicability. Second, this approach fails to consider the interaction among emotions and causes.
To overcome these limitations, Xia et al. [1] established a pioneering task in emotion cause analysis called ECPE. This endeavor aims to extract from a target document a set of phrase pairs containing emotions and their corresponding causes. The ECPE task presents a greater challenge than the ECE task, as it necessitates a comprehensive understanding of the text’s content and structure to extract emotions, causes, and emotion-cause pairs. The two-step strategy employed to address the ECPE challenge [1] utilizes a binary classifier to pair the emotion and cause clauses extracted in the initial steps. While this pipeline design offers simplicity and intuition, it suffers from two significant drawbacks: error propagation from step one to step two and the substantial computational requirements of the two-step technique [28–30]. To mitigate these shortcomings, recent work predominantly solves the ECPE problem using an end-to-end deep learning framework. This structure consists of three primary segments: emotion-cause pairings and sentence prediction, word-level encoders, and clause-level encoders. The word-level encoder typically employs a shared bi-directional LSTM [11–15], while the clause-level encoder utilizes a Transformer encoder [11], a convolutional neural network (CNN) [19], or a bi-directional LSTM [11–15]. During the final prediction phase, the majority of current approaches employ softmax classifiers [11–15] to determine whether a potential emotion-cause pair constitutes the correct emotion-cause pair. Existing approaches tackle the ECPE task from various perspectives, including ranking [16], sequence labeling [17,18], link prediction [19], multi-label learning [13], multi-task learning [12,20], directed graph construction [25], symmetric local search [18], event context [23], and graph neural networks [24]. However, most end-to-end methods employ sequential coding, whereby the task-specific attributes are acquired in a predetermined order. Sequential coding exposes the paired encoder and the clause encoder to different quantities of information, as information only moves unidirectionally from the emotion/cause clause encoder to the paired encoder [7,8]. Consequently, if the emotion/cause clause encoder produces an inaccurate forecast, it substantially distorts the pair’s prediction.
In contrast, the joint encoding strategy has gained increasing attention in multi-task learning [31–34]. This approach solves the sequential coding problem described above by balancing the flow of information between emotion-cause clauses, cause clauses, and emotion-cause pairings. It also effectively extracts the causal relationships between sentences in ECPE tasks [35]. The efficacy of joint coding stems from its facilitation of communication between the paired encoder and the emotion/cause clause encoder. As causality plays a crucial role in determining the compatibility of emotion and cause, the clause encoder, during the encoding process, may prioritize the assessment of clause pairing suitability over the mere extraction of emotion or cause information.
Moreover, as the two assistant task modules in the task flow and the ECPE module should intuitively concur on phrase recognition, adjusting the labeling distance between the tasks is crucial for the overall performance of the ECPE. Specifically, the CE module should predict a sentence as a non-causal clause when the ECPE module has identified it as such. However, this labeling consistency cannot be assured because most of the previous ECPE research (e.g., Yan et al. [7], Ding et al. [4], Wang et al. [8], Bing et al. [9]) was conducted in a mutually independent manner.
While prior multi-task learning frameworks effectively learn features for individual tasks, they face limitations in simultaneously modeling extracted features and their interactions or ensuring consistent label predictions across emotion-cause pair extraction and independent assistant tasks, such as emotion extraction and cause extraction. To address these challenges, this paper has proposed a novel approach that leverages a joint feature encoding and task alignment mechanism. This method efficiently captures the complex interactions between clauses and balances the information flow between tasks, ultimately enhancing the overall performance of emotion-cause pair extraction.
This section provides a comprehensive description of our approach, which encodes both pairs and clauses while modeling the causal relationships between clauses through a RGCN. The bi-directional alignment of ECPE with EE and CE is achieved through a task alignment mechanism. The structure of the proposed approach is illustrated in Fig. 1.
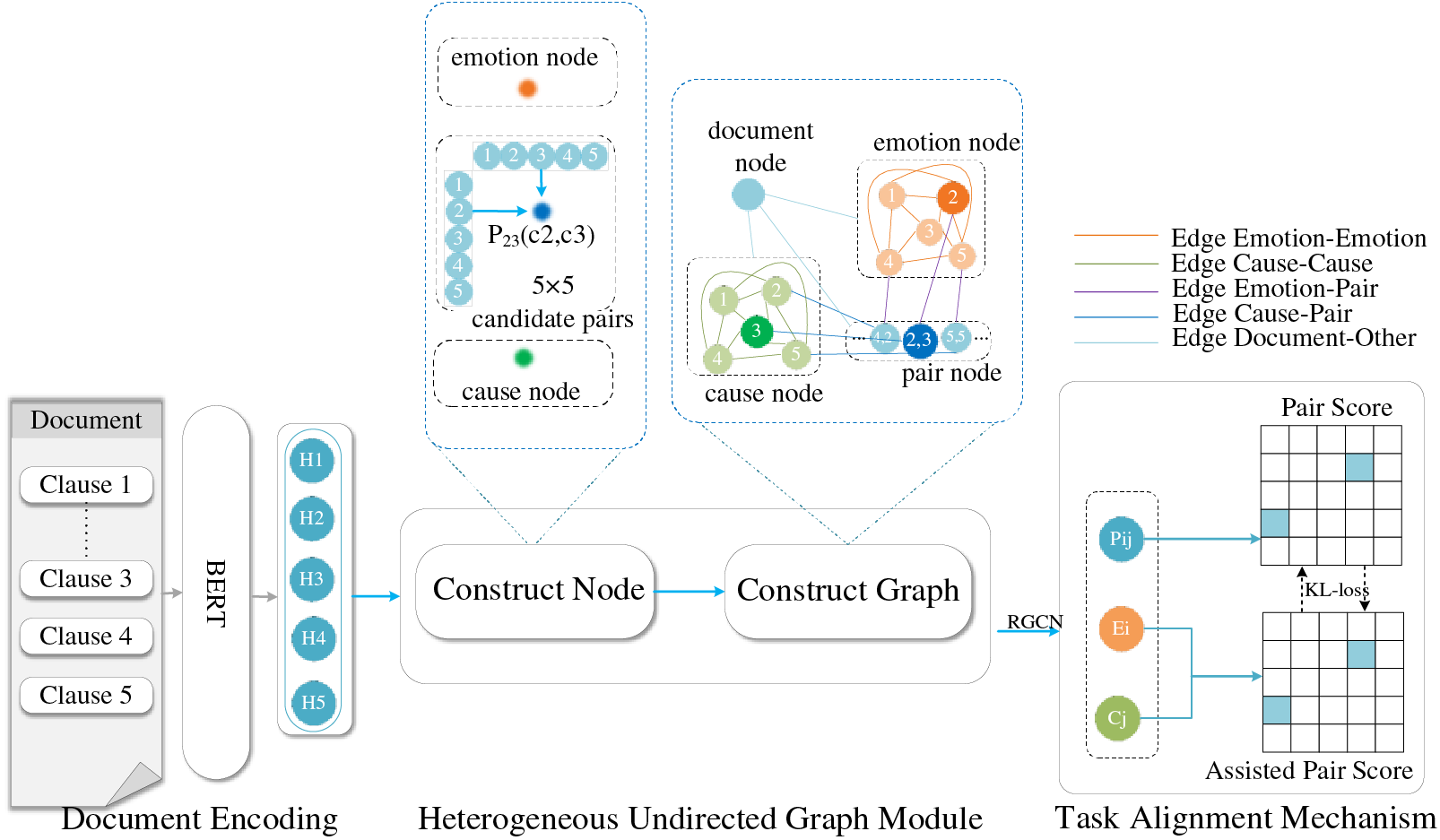
Figure 1: The architecture of the proposed JFTA model. The model incorporates an encoder, a heterogeneous graph for concurrent modeling of specific features and inter-feature interaction data, a classifier, and a task alignment mechanism to ensure label prediction consistency between ECPE and assistant tasks
Given a document
where
The ECPE task consists of two assistant tasks: CE and EE. If any pair
where
Given a document
where
The representation of pairs is obtained through expression (4). This process involves constructing a matrix of candidate pairs M, connecting the relevant two clauses in the matrix, and projecting them with a learnable relative position embedding. The candidate pairing matrix
where
3.2 Heterogeneous Undirected Graph Module
To address the issue of information interaction between pairs and clauses, as well as to capture the causal relationships between them, we construct a heterogeneous undirected graph model. This graph effectively manages the relationships both within and between clauses and pairs. The graph consists of four distinct types of nodes: emotion, cause, pair, and document. We employ separate nodes for emotion clauses and cause clauses, as the information about emotion and causation is typically conveyed using different phrases within clauses. Moreover, we incorporate pair nodes in the graph to represent the causal relationship among emotion clauses and cause clauses. This design ensures a balanced flow of information between clauses and pair nodes. To provide global information, such as topics, we also include document nodes in the graph to serve as hubs for other nodes. Furthermore, we establish five types of edges in the graph to more precisely represent the relationships between nodes:
1) Edges between Clauses (Edge Emotion-Emotion and Edge Cause-Cause): The proposed graph structure incorporates two distinct types of edges between clauses: emotion-emotion and cause-cause [24]. These interconnections guarantee that all emotion and cause nodes are comprehensively linked, enabling each node to exchange contextual information with other pertinent nodes. This design facilitates effective communication and context sharing among the relevant components of the graph.
2) Edges Between Clauses and Pairs (Edge Emotion-Pair and Edge Cause-Pair): This study also defines two types of edges between clauses and pairs: emotion clause-pair and cause clause-pair [24]. These connections enable all pair nodes to directly connect to the corresponding emotion and cause nodes. They serve as the primary mechanism for pair nodes to interact with clause nodes, facilitating the transmission of causal information from emotion and cause nodes to pair nodes. Furthermore, pair nodes and these linkages can be utilized by emotion and cause nodes for communication.
3) Edges between Document and Other Nodes (Document-Other Edges): The document node forms connections with all other nodes, enabling the transmission of global information about the entire document to these nodes [24]. This mechanism serves a dual purpose: it facilitates the dissemination of pertinent information while effectively filtering out noise from disconnected nodes.
Furthermore, each node class incorporates self-loop edges, which contribute to the preservation of the node’s features during interactions. Subsequently, the features of each node’s neighbors are integrated using an RGCN [29] on a heterogeneous undirected graph. The initialization of the emotion nodes and cause nodes is set using clause representations as follows:
where
Additionally, the document nodes are initialized by the average the representations of all clauses within the pooled document:
Following graph construction, we apply the RGCN to the generated graph. Each node u is characterized by the following equation:
where
As the final step, the last hierarchical representation of all nodes, obtained after
To mitigate the label prediction inconsistency between the emotion-cause pair extraction task and the assistant tasks, this study employs a task alignment mechanism. This approach learns the label distance between emotion-cause pair extraction and the combination of emotion extraction and cause extraction during the training phase. By increasing the information interaction between tasks, the model achieves improved label prediction consistency.
After obtaining the representations of all nodes, we apply a multilayer perceptual machine (MLP) to predict emotion-cause pairs.
where the
To evaluate the performance of ECPE, we employ a binary cross-entropy loss function to calculate the loss:
where
To enhance the efficacy of clause nodes in learning emotion and cause information, we introduce two assistant tasks [26]: CE and EE. These tasks are designed to assist clause nodes in capturing essential contextual information within clauses. The probabilities for these tasks are computed as follows:
where
Two ancillary tasks experience corresponding losses:
where
As previously mentioned, the predictions from EE and CE may not align with those from ECPE. This discrepancy can lead to emotions identified by ECPE not being recognized by EE, hindering model optimization. To address this problem, we introduce an alignment mechanism that synchronize the prediction scores of ECPE with those of the assistant tasks during training. The process of generating the assisted pair score is shown in Fig. 2. Initially, we utilize emotion score
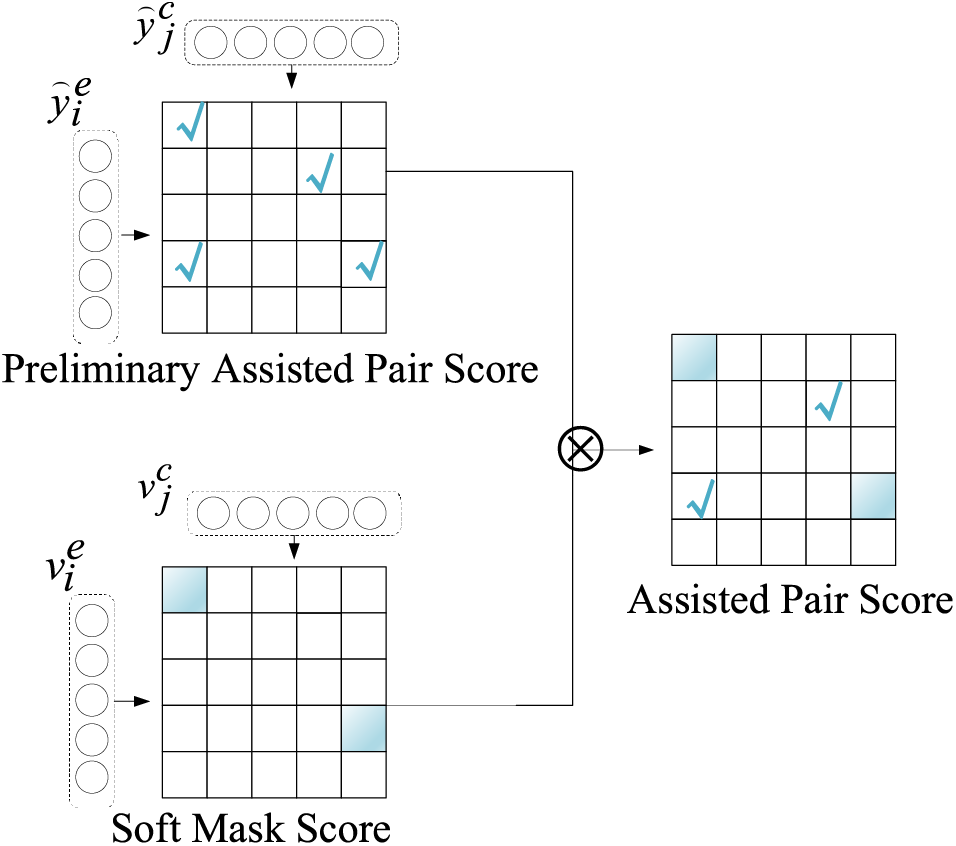
Figure 2: Generation of assisted pair score in the task alignment mechanism. The “√” indicates candidate emotion-cause pairs. The blue grid indicates blocked pairs
where
where
The difference among the assisted emotion-cause pair score
The model is trained using a cross-entropy loss function. The final loss function comprises ECPE and a weighted sum of EE, CE, and task alignment mechanisms. The total loss of in model is represented by the sum of the weights of
where
4 Experimental Results and Analysis
This section employs publicly available datasets to evaluate the efficacy of the proposed JFTA model for ECPE using Relational Graph Convolutional Networks (RGCNs) and task alignment mechanisms. The following subsections present the experimental methodology, results, and an ablation study to assess the model’s performance and key components.
We evaluated the proposed model using the ECPE corpus described by Xia et al. [1], which is derived from the Chinese Affective Causes Corpus [8]. Table 2 presents the key details of this benchmark dataset. The corpus consists of 1945 Chinese documents sourced from Sina Metropolis Newspaper, including 1746 documents with one emotion-cause pair, 177 documents with two emotion-cause pairs, and 22 documents with more than two emotion-cause pairs. For the evaluation, we randomly selected 90% of the data for training and 10% for testing, employing 10-fold cross-validation. The primary task is ECPE, with two subtasks: EE and CE, consistent with prior research [3–7]. We assessed the model’s performance using precision (P), recall (R), and F1 score (F1) metrics.

The pre-trained BERT model was employed as the embedding layer, with the hidden layer size set to 768. The default parameter settings for BERT-base-Chinese were utilized. The hyperparameters
Baseline Models
The efficacy of the proposed model is assessed by comparing it to the following baseline approach:
1) ECPE-2Steps [1] (2019) employs a two-step strategy for extracting emotion-cause pairs. It involves three distinct models with varied learning configurations: Indep, Inter-CE, and Inter-EC.
2) ECPE-2D [4] (2020) introduces a novel method that seamlessly integrates the representation, linking, and prediction of emotion-cause pairings using an end-to-end approach based on a window-constrained 2D converter. However, the effectiveness of this integration relies significantly on the manually selected window size.
3) ECPE-MLL [25] (2020) employs a sliding window mechanism to simplify the ECPE task. To enhance the robustness of the extraction process, this technique simultaneously performs cause-centered emotion extraction and emotion-centered cause extraction by integrating two joint frameworks.
4) RankCP [26] (2020) addresses the ECPE problem from a ranking perspective, employing kernel-based relative position embedding and graph attention networks to enhance the representation and ranking of emotion-cause pairs.
5) PTN [27] (2023) is characterized by the application of a pairwise labeling framework, facilitating the exhaustive and uniform extraction of emotion-cause pairs.
6) MGSAG [28] (2022) is a graph-based model that uses fine-grained semantic-aware graphs to investigate the dependencies between clauses and keywords. Additionally, it models the relationships between clauses by employing coarse-grained semantic-aware graphs.
7) MMN [37] (2023) proposes the Modularized Mutuality Network (MMN) to capture reciprocity in relationships. The MMN architecture consists of three key components: Interposition-aware Encoders, a Mutual Refinement Module, and a Bi-regularized Pairwise Predictor. The Interposition-aware Encoders account for the relative positioning of elements, while the Mutual Refinement Module facilitates the reciprocal refinement of representations. Finally, the Bi-regularized Pairwise Predictor leverages bidirectional regularization to predict reciprocal relationships accurately. This modularized approach effectively addresses the challenges associated with modeling reciprocity in complex systems.
8) GANU [38] (2023) proposes a model that utilizes multi-granularity information, including word-, clause-, and document-level data. The architecture consisted of a foundational encoder, followed by a multi-head attention module designed to process affective and causal cues. Additionally, it incorporates a graph attention network featuring a cross-graph co-attention mechanism. The final component is a neural classifier that makes predictions based on the processed data.
9) GAT-ECPE [39] (2024) introduces a knowledge-guided graph attention network to facilitate interactions across various activities. The model’s guiding principle is inter-sentence dependency graphs, which enable the aggregation of features between pairs of phrases. This approach leverages the relational information encoded in the dependency graphs to enhance the extraction of emotion-cause pairs.
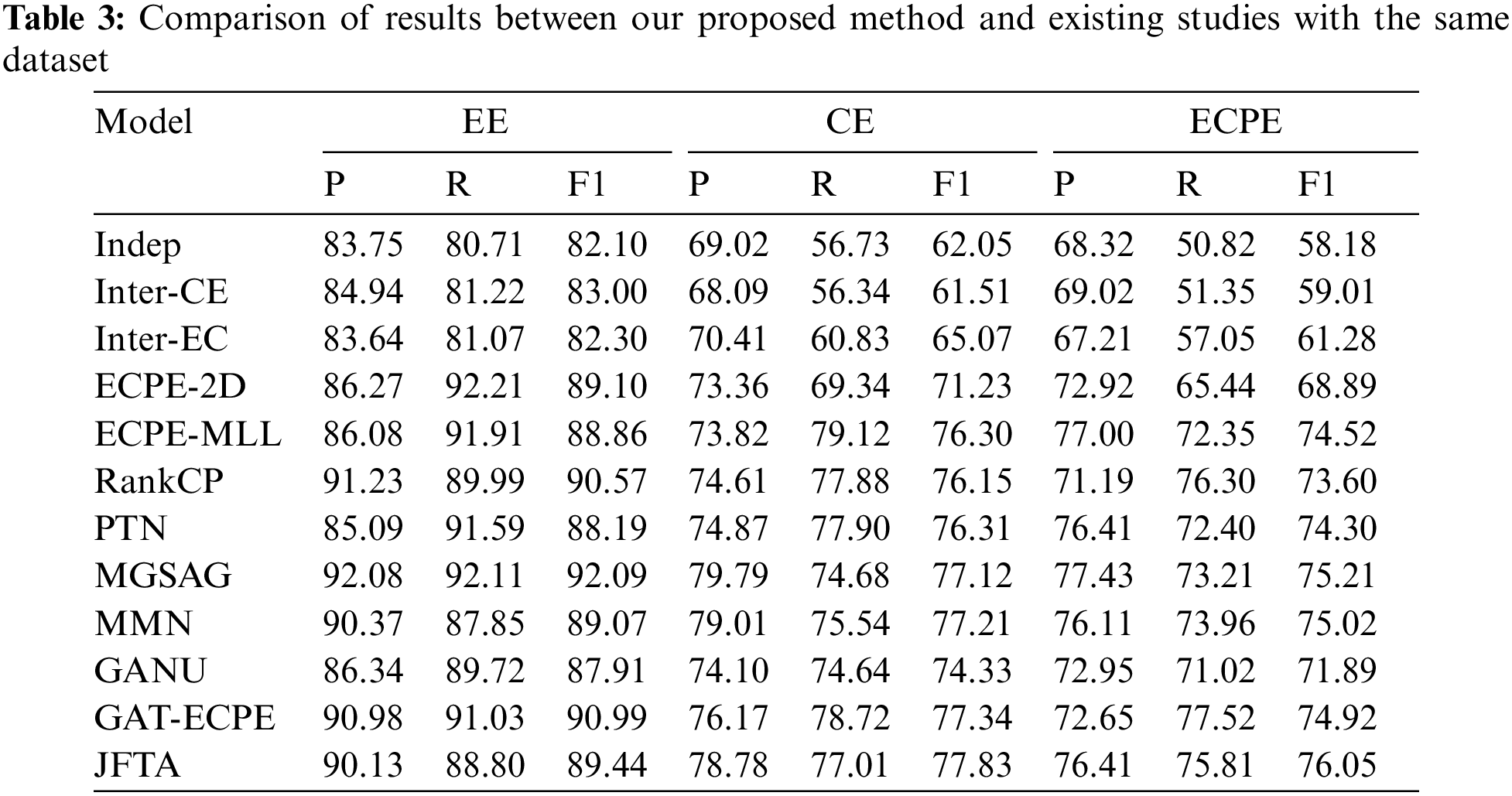
Table 3 presents the results of the ECPE task and its two subtasks, EE and CE, after 130 h of model training. Performance is evaluated using precision (P), recall (R), and F1 score (F1). JFTA demonstrates significant advantages over previous approaches, particularly in the primary ECPE task and the secondary CE task. We attribute the key role in information interaction to JFTA’s joint encoding approach and alignment mechanism, which enable bidirectional information flow and balance between pairs, clauses, and tasks. Our approach achieves a 1.03% F1 improvement on the dataset compared to MMN, the best-performing baseline. While MGSAG excels in EE by utilizing an emotion lexicon, its poor CE performance leads to a decrease in overall ECPE performance, revealing an imbalance between the tasks. CE is generally more challenging, as sentiment expressions often contain a single keyword, whereas cause expressions involve multiple words and require deeper textual understanding. For CE, our method achieves a 0.62% F1 improvement. The enhancements in CE and ECPE are primarily attributed to our joint feature encoding approach and task alignment mechanism, which effectively model specific feature information, capture interaction information between features, and balance label prediction information among the EE, CE, and ECPE tasks. The performance on the ECPE task is improved overall as a result of this balance.
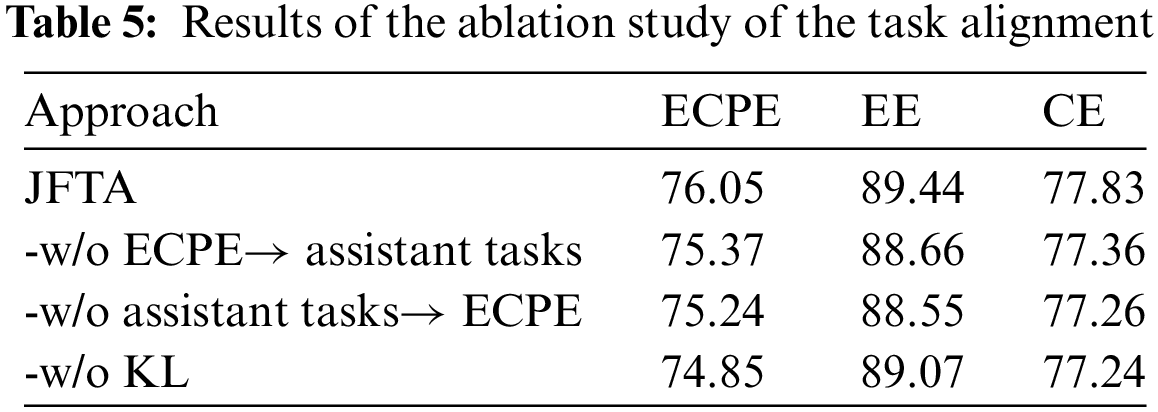
This ablation study aimed to validate the efficacy of the task alignment mechanism and the significance of edges and nodes in heterogeneous graphs with diverse relationships. Table 4 presents the results of the ablation analysis for edges and nodes in heterogeneous networks with various relations, while Table 5 demonstrates the outcomes of the task alignment mechanism.
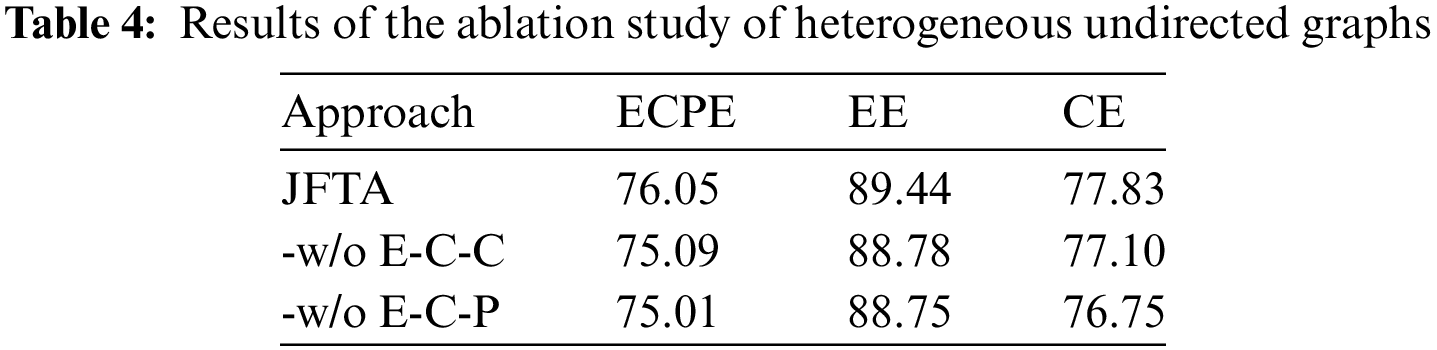
4.4.1 Effects of Heterogeneous Undirected Graphs
-w/o E-C-C: To replace the cause-cause and emotion-emotion clauses (-w/o E-C-C), we utilize an edge type. The removal of these two types of edges significantly diminishes our model’s performance on the CE and EE tasks. Consequently, this deterioration leads to a decline in the overall performance of the ECPE task. This alteration disrupts the equilibrium between EE and CE, causing the framework to prioritize EE while neglecting CE, which is the primary objective among the three goals. Our analysis of the experimental results in Table 4 reveals that the elimination of E-C-C results in a 0.96% decrease in the F1 score of ECPE. Moreover, a substantial performance decline occurs in both emotion extraction and cause extraction, underscoring the importance of emotions or causes nodes to exchange contextual information with other associated nodes.
-w/o E-C-P: We remove the edges of the emotion clause-pair and the cause clause-pair (-w/o E-C-P) and replace them with another edge. Table 4 demonstrates that this modification leads to a more significant performance deterioration in the ECPE task compared to the removal of clause-clause-edges (-w/o E-C-C), with a 1.04% decrease in the F1 score for ECPE. The elimination of E-C-P edges renders emotion and cause extraction more independent, complicating the extraction of emotion information from emotion clauses and cause information from cause clauses. This lack of distinction hinders the model’s ability to effectively extract and utilize causal information, emphasizing the importance of pair node and clause node interactions in transferring causal information from emotion and cause nodes to pair nodes.
4.4.2 Effects of Task Alignment Mechanisms
This study commenced by examining the influence of the directionality of the task alignment mechanism on performance. The initial approach involved utilizing unidirectional alignment to modify the predictions for the ECPE task and its two assistant tasks: emotion extraction and cause extraction. The results revealed a decline in performance across all three tasks when employing unidirectional alignment. Specifically, the F1 scores, which serve as a measure of a test’s accuracy, were found to be lower for each task under these conditions.
Moreover, we investigated a scenario in which the task alignment mechanism was completely eliminated, corresponding to a bidirectional alignment setting. In this context, the F1 scores for all three tasks—ECPE, EE, and CE—underwent a considerable decline. Remarkably, the ECPE task demonstrated the most profound decrease in F1 scores, highlighting the critical role of task alignment in achieving optimal performance in emotion-cause pair extraction.
These findings emphasize the paramount significance of inter-task label space alignment within our model. The marked decrease in performance, especially in the ECPE task, when the alignment mechanism is modified or eliminated, corroborates the imperative of preserving a resilient bidirectional alignment. This bidirectional alignment plays a pivotal role in guaranteeing the efficacious integration and coordination of predictions across tasks, consequently elevating the overall model performance.
This section examines the influence of the hyperparameter values
4.5.1 Effects of the Value of
We analyze the effect of different
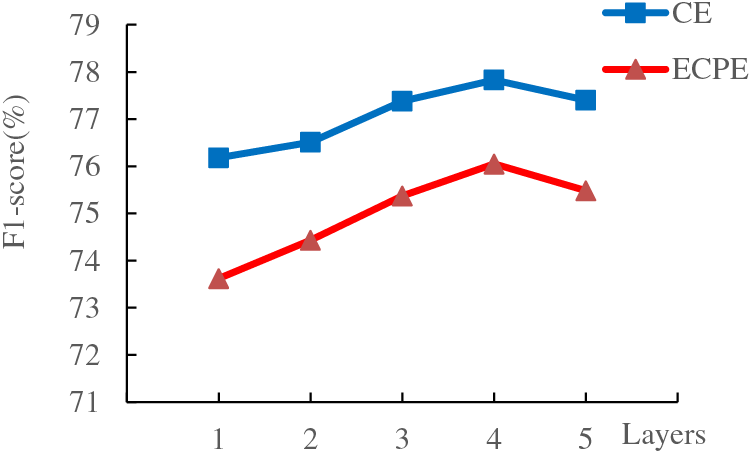
Figure 3: The influence of different
4.5.2 Effects of the Value of
The final loss function employed in training the model is a compound of multiple loss functions, including emotion-cause pair extraction loss, emotion extraction loss, causes extraction loss, and task alignment loss, each assigned a corresponding weight. Consequently, determining the optimal weights for maximum model performance presents a challenge. To address this, we conducted hyperparametric experiments to exploring the effects of different loss weights by setting the value of
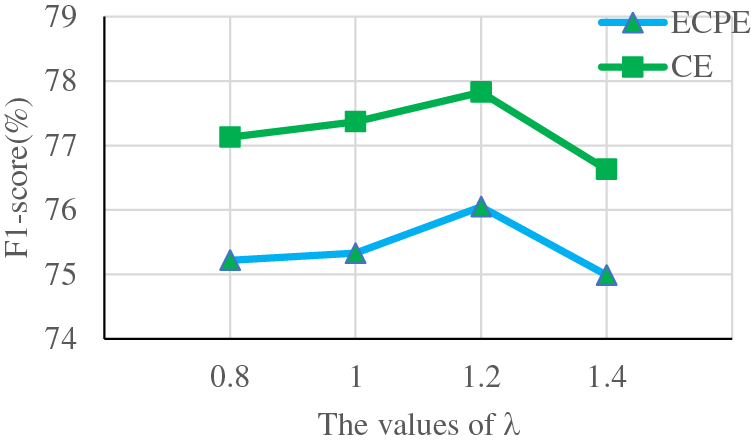
Figure 4: The influence of different λ
Table 6 presents a comparative case study analysis of the prediction outcomes generated by the MGSAG model and our proposed model. The objective is to elucidate the advantages of the JFTA model through a direct comparison of the results obtained from both approaches.

The first example’s document comprises two emotion-cause pairings: one pair with identical emotion and cause clauses, and another pair consisting of (c5, c4). The MGSAG model identifies two pairs: (c5, c4) and (c5, c6), with the latter being an erroneous identification. However, our model accurately detects both genuine emotion-cause pairs, indicating its superior performance in capturing the causality between emotions and their corresponding causes.
In the second example, a pair of emotion-cause (c4, c3) exists within the document. However, the MGSAG model inaccurately identifies (c9, c8) as an emotion-cause pair. This error may stem from the MGSAG model’s imprecise selection of context window clauses, resulting in an incorrect extraction of the emotion-cause pair. Conversely, our approach demonstrates superior accuracy in causal and contextual reasoning by successfully identifying the correct emotion-cause pair.
This publication examines the work on ECPE. We propose a model that simultaneously encodes features of emotion-cause pairs and clauses to obtain causal information. This approach addresses two key issues in ECPE research: the imbalance of feature interactions between pair and clause encoders, and the lack of shared interrelated information between the ECPE task and assistant tasks. To capture deeper semantic information and enhance ECPE performance, we employ a task alignment technique that minimizes the labeling discrepancy between the ECPE task and assistant tasks. Experiments conducted on the ECPE benchmark data confirm the effectiveness of our method, with results showing an F1 score of 76.05% for ECPE, a 1.03% improvement over the state-of-the-art method, and an F1 score of 77.83% for CE, a 0.49% improvement over the state-of-the-art method. To avoid introducing noise, future research will concentrate on adapting the model to different languages and domains and dynamically incorporating contextual information depending on the causal requirements of emotion-cause pairs.
Acknowledgement: The authors would like to express their gratitude to Northeast Forestry University for providing administrative and technical support as well as to all the anonymous reviewers and the editorial team for their valuable feedback and suggestions.
Funding Statement: The authors received no specific funding for this study.
Author Contributions: The authors confirm contribution to the paper as follows: study conception and design: Shi Li, Didi Sun; data collection: Shi Li, Didi Sun; analysis and interpretation of results: Shi Li, Didi Sun; draft manuscript preparation: Shi Li, Didi Sun. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The codes and data are available under request from the authors.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare no conflicts of interest to report regarding the present study.
References
1. R. Xia and Z. Ding, “Emotion-cause pair extraction: A new task to emotion analysis in texts,” 2019, arxiv:1906.01267. [Google Scholar]
2. D. Cavaliere, G. Fenza, V. Loia, and F. Nota, “Emotion-aware monitoring of users’ reaction with a multi-perspective analysis of long- and short-term topics on twitter,” Int. J. Interact. Multimed. Artif. Intell., vol. 8, no. 4, pp. 166–175, 2023. doi: 10.9781/ijimai.2023.02.003. [Google Scholar] [CrossRef]
3. S. Y. M. Lee, Y. Chen, and C. R. Huang, “A text-driven rule-based system for emotion cause detection,” in Proc. NAACL HLT 2010 Workshop Comput. Approaches Anal. Gener. Emot. Text, 2010, pp. 45–53. [Google Scholar]
4. Z. Ding, R. Xia, and J. Yu, “ECPE-2D: Emotion-cause pair extraction based on joint two-dimensional representation, interaction and prediction,” in Proc. 58th Annu. Meet. Assoc. Comput. Linguis., 2020, pp. 3161–3170. doi: 10.18653/v1/2020.acl-main.288. [Google Scholar] [CrossRef]
5. Z. Cheng, Z. Jiang, Y. Yin, H. Yu, and Q. Gu, “A symmetric local search network for emotion-cause pair extraction,” in Proc. 28th Int. Conf. Comput. Linguist., 2020, pp. 139–149. doi: 10.18653/v1/2020.coling-main.12. [Google Scholar] [CrossRef]
6. A. Singh, S. Hingane, S. Wani, and A. Modi, “An end-to-end network for emotion-cause pair extraction,” 2021, arXiv:2103.01544. [Google Scholar]
7. Z. Yan, C. Zhang, J. Fu, Q. Zhang, and Z. Wei, “A partition filter network for joint entity and relation extraction,” 2021, arXiv:2108.12202. [Google Scholar]
8. A. Wang, A. Liu, H. H. Le, and H. Yokota, “Towards effective multi-task interaction for entity-relation extraction: A unified framework with selection recurrent network,” 2022, arXiv:2202.07281. [Google Scholar]
9. L. Bing, “Sentiment analysis and opinion mining (synthesis lectures on human language technologies),” Comput. Linguist., vol. 40, no. 2, pp. 511–513, 2012. doi: 10.1162/coli_r_00186. [Google Scholar] [CrossRef]
10. J. Li, H. Fei, and D. Ji, “Modeling local contexts for joint dialogue act recognition and sentiment classification with bi-channel dynamic convolutions,” in Proc. 28th Int. Conf. Comput. Linguist., 2020, pp. 616–626. doi: 10.18653/v1/2020.coling-main.53. [Google Scholar] [CrossRef]
11. S. Wu, H. Fei, Y. Ren, D. Ji, and J. Li, “Learn from syntax: Improving pair-wise aspect and opinion terms extraction with rich syntactic knowledge,” 2021, arXiv:2105.02520. [Google Scholar]
12. H. Fei, C. Li, D. Ji, and F. Li, “Mutual disentanglement learning for joint fine-grained sentiment classification and controllable text generation,” in Proc. 45th Int. ACM SIGIR Conf. Res. Develop. Inform. Retri., 2022, pp. 1555–1565. doi: 10.1145/3477495.3532029. [Google Scholar] [CrossRef]
13. D. Tang, B. Qin, and T. Liu, “Aspect level sentiment classification with deep memory network,” 2016, arXiv:1605.08900. [Google Scholar]
14. H. Fei, F. Li, C. Li, S. Wu, J. Li and D. Ji, “Inheriting the wisdom of predecessors: A multiplex cascade framework for unified aspect-based sentiment analysis,” in Proc. Thirty-First Int. Joint Conf. Artif. Intell. (IJCAI-22), 2022, pp. 4121–4128. [Google Scholar]
15. W. Shi, F. Li, J. Li, H. Fei, and D. Ji, “Effective token graph modeling using a novel labeling strategy for structured sentiment analysis,” 2022, arXiv:2203.0796. [Google Scholar]
16. A. Neviarouskaya and M. Aono, “Extracting causes of emotions from text,” in Proc. Sixth Int. Joint Conf. Nat. Lang. Process., 2013, pp. 932–936. [Google Scholar]
17. X. Li, K. Song, S. Feng, D. Wang, and Y. Zhang, “A co-attention neural network model for emotion cause analysis with emotional context awareness,” in Proc. 2018 Conf. Empir. Methods Nat. Lang. Process., 2018, pp. 4752–4757. doi: 10.18653/v1/D18-1506. [Google Scholar] [CrossRef]
18. Y. Chen, S. Y. M. Lee, S. Li, and C. R. Huang, “Emotion cause detection with linguistic constructions,” in Proc. 23rd Int. Conf. Comput. Linguis. (Coling 2010), 2010, pp. 179–187. [Google Scholar]
19. K. Gao, H. Xu, and J. Wang, “Emotion cause detection for Chinese micro-blogs based on ECOCC model,” in Adv. Know. Discov. Data Min.: 19th Pacific-Asia Conf., PAKDD 2015, Ho Chi Minh City, Vietnam, Springer International Publishing, May 19–22, 2015, pp. 3–14. doi: 10.1007/978-3-319-18032-8_1. [Google Scholar] [CrossRef]
20. D. Ghazi, D. Inkpen, and S. Szpakowicz, “Detecting emotion stimuli in emotion-bearing sentences,” in Comput. Linguist. Intell. Text Process. 16th Int. Conf. CICLing 2015, Cairo, Egypt, Springer International Publishing, Apr. 14–20, 2015, pp. 152–165. doi: 10.1007/978-3-319-18117-2_12. [Google Scholar] [CrossRef]
21. Y. Chen, W. Hou, X. Cheng, and S. Li, “Joint learning for emotion classification and emotion cause detection,” in Proc. 2018 Conf. Empir. Methods Nat. Lang. Process., 2018, pp. 646–651. doi: 10.18653/v1/D18-1066. [Google Scholar] [CrossRef]
22. Z. Ding, H. He, M. Zhang, and R. Xia, “From independent prediction to reordered prediction: Integrating relative position and global label information to emotion cause identification,” Proc. AAAI Conf. Artif. Intell., vol. 33, no. 1, pp. 6343–6350, 2019. doi: 10.1609/aaai.v33i01.33016343. [Google Scholar] [CrossRef]
23. C. Fan et al., “A knowledge regularized hierarchical approach for emotion cause analysis,” in Proc. 2019 Conf. Empir. Methods Nat. Lang. Process. 9th Int. Joint Conf. Nat. Lang. Process. (EMNLP-IJCNLP), Association for Computational Linguistics, 2019, pp. 5618–5628. doi: 10.18653/v1/D19-1563. [Google Scholar] [CrossRef]
24. J. Liu, X. Shang, and Q. Ma, “Pair-based joint encoding with relational graph convolutional networks for emotion-cause pair extraction,” 2022, arXiv:2212.01844. [Google Scholar]
25. Z. Ding, R. Xia, and J. Yu, “End-to-end emotion-cause pair extraction based on sliding window multi-label learning,” in Proc. 2020 Conf. Empir. Methods Nat. Lang. Process. (EMNLP), 2020, pp. 3574–3583. doi: 10.18653/v1/2020.emnlp-main.290. [Google Scholar] [CrossRef]
26. P. Wei, J. Zhao, and W. Mao, “Effective inter-clause modeling for end-to-end emotion-cause pair extraction,” in Proc. 58th Annu. Meet. Assoc. Comput. Linguist., 2020, pp. 3171–3181. doi: 10.18653/v1/2020.acl-main.289. [Google Scholar] [CrossRef]
27. Z. Wu, X. Dai, and R. Xia, “Pairwise tagging framework for end-to-end emotion-cause pair extraction,” Front Comput. Sci., vol. 17, no. 2, 2023, Art. no. 172314. doi: 10.1007/s11704-022-1409-x. [Google Scholar] [CrossRef]
28. Y. Bao, Q. Ma, L. Wei, W. Zhou, and S. Hu, “Multi-granularity semantic aware graph model for reducing position bias in emotion-cause pair extraction,” 2022, arXiv:2205.02132. [Google Scholar]
29. M. Schlichtkrull, T. N. Kipf, P. Bloem, R. Van Den Berg, I. Titov and M. Welling, “Modeling relational data with graph convolutional networks,” in The Semant. Web. ESWC 2018, Springer International Publishing, 2018, pp. 593–607. doi: 10.1007/978-3-319-93417-4_38. [Google Scholar] [CrossRef]
30. G. Hu, Y. Zhao, and G. Lu, “Emotion prediction oriented method with multiple supervisions for emotion-cause pair extraction,” IEEE-ACM Trans. Audio Speech Lang., vol. 31, pp. 1141–1152, 2023. doi: 10.1109/TASLP.2023.3250833. [Google Scholar] [CrossRef]
31. T. Lai, H. Ji, C. X. Zhai, and Q. H. Tran, “Joint biomedical entity and relation extraction with knowledge-enhanced collective inference,” 2021, arXiv:2105.13456. [Google Scholar]
32. Y. Wang, B. Yu, Y. Zhang, T. Liu, H. Zhu and L. Sun, “TPLinker: Single-stage joint extraction of entities and relations through token pair linking,” 2020, arXiv:2010.13415. [Google Scholar]
33. T. J. Fu, P. H. Li, and W. Y. Ma, “GraphRel: Modeling text as relational graphs for joint entity and relation extraction,” in Proc. 57th Annu. Meet. Assoc. Comput. Linguist., 2019, pp. 1409–1418. doi: 10.18653/v1/P19-1136. [Google Scholar] [CrossRef]
34. J. Wang and W. Lu, “Two are better than one: Joint entity and relation extraction with table-sequence encoders,” 2020, arXiv:2010.03851. [Google Scholar]
35. X. Chen, Q. Li, and J. Wang, “Conditional causal relationships between emotions and causes in texts,” in Proc. 2020 Conf. Empir. Methods Nat. Lang. Process. (EMNLP), 2020, pp. 3111–3121. doi: 10.18653/v1/2020.emnlp-main.252. [Google Scholar] [CrossRef]
36. I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” 2017, arXiv:1711.05101. [Google Scholar]
37. X. Shang, C. Chen, Z. Chen, and Q. Ma, “Modularized mutuality network for emotion-cause pair extraction,” IEEE-ACM Trans. Audio Speech Lang., vol. 31, pp. 539–549, 2023. doi: 10.1109/TASLP.2022.3228129. [Google Scholar] [CrossRef]
38. S. Chen and K. Mao, “A graph attention network utilizing multi-granular information for emotion-cause pair extraction,” Neurocomputing, vol. 543, 2023, Art. no. 126252. doi: 10.1016/j.neucom.2023.126252. [Google Scholar] [CrossRef]
39. P. Zhu, B. Wang, K. Tang, H. Zhang, X. Cui and Z. Wang, “A knowledge-guided graph attention network for emotion-cause pair extraction,” Knowl.-Based Syst., vol. 286, no. 3, 2024, Art. no. 111342. doi: 10.1016/j.knosys.2023.111342. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2025 The Author(s). Published by Tech Science Press.
Copyright © 2025 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools