
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Enhanced Growth Optimizer and Its Application to Multispectral Image Fusion
1 College of Computer Science and Engineering, Shandong University of Science and Technology, Qingdao, 266590, China
2 Department of Information Management, Chaoyang University of Technology, Taichung, 413310, Taiwan
3 Graduate School of Information, Production and Systems, Waseda University, Kitakyushu, 808-0135, Japan
* Corresponding Author: Shu-Chuan Chu. Email:
Computers, Materials & Continua 2024, 81(2), 3033-3062. https://doi.org/10.32604/cmc.2024.056310
Received 19 July 2024; Accepted 15 October 2024; Issue published 18 November 2024
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The growth optimizer (GO) is an innovative and robust metaheuristic optimization algorithm designed to simulate the learning and reflective processes experienced by individuals as they mature within the social environment. However, the original GO algorithm is constrained by two significant limitations: slow convergence and high memory requirements. This restricts its application to large-scale and complex problems. To address these problems, this paper proposes an innovative enhanced growth optimizer (eGO). In contrast to conventional population-based optimization algorithms, the eGO algorithm utilizes a probabilistic model, designated as the virtual population, which is capable of accurately replicating the behavior of actual populations while simultaneously reducing memory consumption. Furthermore, this paper introduces the Lévy flight mechanism, which enhances the diversity and flexibility of the search process, thus further improving the algorithm’s global search capability and convergence speed. To verify the effectiveness of the eGO algorithm, a series of experiments were conducted using the CEC2014 and CEC2017 test sets. The results demonstrate that the eGO algorithm outperforms the original GO algorithm and other compact algorithms regarding memory usage and convergence speed, thus exhibiting powerful optimization capabilities. Finally, the eGO algorithm was applied to image fusion. Through a comparative analysis with the existing PSO and GO algorithms and other compact algorithms, the eGO algorithm demonstrates superior performance in image fusion.Keywords
As a consequence of the recent advances in computational science, the real-world problems to be solved are becoming increasingly complex [1]. These problems are typically characterized by nonlinearity, large scale, multimodality, and constraints. In response to this, metaheuristic algorithms have emerged as a promising solution to complex optimization challenges.
The growth optimizer (GO) is a population-based meta-heuristic algorithm that models the learning and reflection mechanisms employed by individuals during their social growth. The original GO algorithm was proposed by Zhang et al. [2] in 2023 for solving continuous and discrete global optimization problems. The search process of the original GO algorithm is divided into two phases: the learning phase and the reflection phase. In the learning phase, which is mainly based on the cooperative search mechanism, each individual learns and acquires knowledge from the knowledge gaps that exist between different individuals. In the reflection phase, individuals use different strategies to recognize and overcome their weaknesses. Growth Optimizer (GO) has demonstrated its effectiveness as an optimization algorithm for the resolution of continuous and discrete global optimization problems [2]. Compared to other metaheuristic methods, GO yielded more encouraging outcomes, particularly concerning solution quality and avoiding local optima. Many studies have demonstrated that GO has the capacity for extensive exploration and the ability to accommodate a wide range of applications. For instance, GO has been effectively employed in the identification of parameters associated with solar photovoltaic cells [3], the segmentation of multilevel threshold images and the deployment of wireless sensor network nodes [4], and the enhancement of intrusion detection systems within the context of IoT and cloud environments [5]. However, very recently, Gao et al. [4] proposed an improved GO algorithm (QAGO) and demonstrated its superiority over the original GO algorithm and some other meta-heuristics in a number of numerical and real-world optimization problems. Gao et al. [4] reported that the original GO has challenges in parameter tuning and operator optimization. In particular, since all hyperparameters of the original GO are fixed values, its performance may be significantly degraded if the parameters are not set properly. Conversely, the search operator structure of the original GO constrains the diversity of the search process. In another study, Fatani et al. [5] proposed an enhanced version of GO, designated MGO, and applied it to an intrusion detection system (IDS). In MGO, the operators of the whale optimization algorithm (WOA) are employed to augment the search process of the original GO. Moreover, Kaveh et al. [6] put forth an enhanced hybrid growth optimizer (IHGO) to address discrete structure optimization challenges, where four enhancements are incorporated into the IHGO relative to the initial GO. Firstly, the learning phase of GO is enhanced through the integration of an improved meta-heuristic exploration phase, namely IAOA, which avoids useless search and enhances exploration. Secondly, the replacement strategy of GO is modified to prevent the loss of the current best solution. Thirdly, the hierarchical structure of GO is modified. Fourthly, the reflection phase of GO is adapted to promote the development of promising regions. GO, one of the traditional optimization algorithms, typically necessitates the storage of a considerable number of solutions and the computation of the corresponding values for each solution. This extensive number of computations presents a challenge to the performance of computing devices, as the large number of computations can lead to conflicts and hinder efficiency. In numerous real-world application scenarios, it is unlikely that high-performance computing devices will be utilized consistently for a multitude of reasons. However, a multitude of optimization problems still necessitate resolution.
Compact algorithms provide an efficient solution by retaining some of the advantages of population-based algorithms without the need to store the entire population in memory. In essence, compact evolutionary algorithms optimize the problem in question using only a solution using the population’s statistical features. Consequently, the number of solutions that need to be stored in memory is greatly reduced. As a result, the memory requirements to run these algorithms are greatly reduced compared to population-based algorithms. Compact algorithms fall within the category of Estimation of Distribution Algorithms (EDAs), where the explicit representation of the population is substituted with a probability distribution, as discussed in reference [7]. The initial instantiation of compact algorithms is exemplified by the compact Genetic Algorithm (cGA). The cGA emulates the behavior of a conventional binary-encoded Genetic Algorithm (GA). The findings in Reference [8] reveal that the performance of cGA is nearly comparable to that of GA while significantly demanding less memory space. The convergence analysis of the cGA is established in Reference [9], while an expanded version, known as the extended compact genetic algorithm (ecGA), is detailed in Reference [10]. Research on the scalability of the ecGA is explored in Reference [11], while Reference [12] documents the utilization of the cGA in training neural networks. Additionally, a number of related algorithmic enhancements utilizing the compact strategy have been put forth, such as compact Bat Algorithm(cBA), compact Particle Swarm Optimization (cPSO) [13], compact Sine Cosine Algorithm(cSCA), etc.
Image fusion remains a cutting-edge topic in the fields of image processing and computer vision exploration. Image fusion refers to the fusion of information from multiple images together to generate a new image, thereby ensuring that the new image contains all the key information and features of the original image. Image fusion techniques can effectively combine image information from different sources to improve the quality and information content of the image. Rahmani et al. introduced an adaptive LHS approach to dynamically calculate band coefficients to achieve more precise detail maps. To improve the accuracy of the spectral representation in non-edge regions, they utilized an edge-holding filter on the Pan image to incorporate the detailed map into each MS band. To enhance the effectiveness of pansharpening, Leung et al. concluded that using Pan images to inject detail maps is not sufficient. To address this, they also employed a linear combination of MS images and Pan images with fixed weights. However, there is a limitation in this approach. The utilization of detail maps with fixed weights may also give rise to distortions, like localized artifacts. To mitigate these impacts, we propose an adaptive framework for the computation of the injected detail maps for each low-resolution (LR) MS band. Different algorithms are used to adaptively compute the weights of the detail maps, and the outcomes are examined and compared. The examination of the experimental findings indicates that the detail map weights obtained adaptively by the eGO algorithm are more appropriate for image fusion compared to other algorithms.
In this paper, we present a novel growth optimizer that employs a compact mechanism and Lévy flight [14] to enhance the optimization and convergence capabilities of the algorithm and reduce its memory requirements. Through the CEC2014 and CEC2017 [15] function sets test, the proposed eGO not only takes less memory but also has higher optimization and convergence capabilities. In comparison to other compact algorithms, the proposed eGO algorithm is also capable of demonstrating considerable competitiveness.
The growth optimizer [2] is a robust metaheuristic algorithm that has been designed with inspiration from the learning and reflection mechanisms observed in individuals during their growth processes in society. The process of learning is defined as the acquisition of knowledge from external sources, which enables an individual to grow and develop. Reflection is the process of identifying and addressing the individual’s own shortcomings in order to adjust their learning strategies in a way that facilitates their growth. The individual in GO refers to a problem’s solution. It is employed to solve both continuous and discrete global optimization problems [16]. The GO algorithm comprises the following steps.
The process of identifying and addressing gaps between individuals can significantly contribute to their personal growth. There are four gaps between individuals: The difference between the leader and the elite
where
In order to reflect the aforementioned variability, a learning factor
where
The
Regarding
where
Through assimilating knowledge disparities among various individuals, the
where
After the phase of learning adjustment, the quality of each individual may either improve or deteriorate. Therefore, it’s crucial to verify whether genuine progress has been achieved. If progress is observed, the growth resistance (
where
The processes of learning and reflection are mutually reinforcing. Individuals should develop both learning and reflection skills. Individuals should examine for and correct inadequacies in all areas, and retain information. To make up for deficiencies, they can learn from successful persons while retaining their strengths. If a lesson cannot be repaired, it is recommended to forgo past information and re-learn systematically. Three distinct processing methods exist. The initial approach is to maintain the original dimension; the subsequent way involves selecting an upper-class individual to direct the
In Eq. (8), the upper and lower bounds of the search domain are represented by
It would appear that the extant literature does not endeavor to put forth a mechanism that enhances GO in compact strategy, thereby reducing the algorithm’s memory requirements to a considerable extent. GO may potentially become trapped in local optima and exhibit a slow convergence when attempting to solve high-dimensional, complex optimization problems. In response to the aforementioned questions, this section outlines the methodology for modifying the GO algorithm using the compact strategy, as well as subsequent enhancements to the compact strategy.
The core objective of implementing a compact strategy is to decrease memory consumption while maintaining, or potentially enhancing, the performance of the original algorithm. Enhanced growth optimizer (eGO) is a framework grounded in a growth optimizer which incorporates concepts and designs from GO algorithms. In this section, we will delve into further details regarding the eGO algorithm. The objective of eGO is to emulate the operational characteristics of the underlying GO algorithm while reducing the consumption of memory resources. A virtual population is used to convert the underlying GO individuals into a concise algorithm. The virtual population can be thought of as a probabilistic model of the solution population. It is stored in a data structure called the perturbation vector (
In the Eq. (10),
The process of virtual population initialization is as follows: Each parameter is set such that
It takes a thorough explanation to understand the sampling mechanism of a individual
The
During the iterative process of the compact algorithm, this paper introduces a comparative function based on two parameters to facilitate the identification of superior individuals. The two modifiable parameters, pre-learning and post-learning, correspond to two sample individuals within the
The virtual population size is denoted by
It should be remembered that
The proposed eGO utilizes a perturbation
The Eq. (14) for assimilating the knowledge gap among different individuals is modeled after the GO formula.
What can be observed is that the Eq. (14) for assimilating the knowledge gap among different individuals shares the same structure as the Eq. (6) in GO. However, while index
Similarly, the other two Eqs. (15) and (16) used in the learning and reflection phases are replicated in the same manner.
In eGO, the compact strategy reduces memory usage by employing a probabilistic model representation, which is more memory efficient than the original GO. Traditional algorithms, such as GO, rely on maintaining a complete population, wherein each individual is required to store information such as their position, speed, fitness value, and so forth. For an optimization problem with problem dimension
Lévy flight [14] represents a specific type of stochastic wandering with a probability distribution of step sizes proposed by the French mathematician Levy. The introduction of Lévy flight results in random movements with longer jumps and multiple abrupt changes in direction [19]. This implies that short local searches are interspersed with long jump global searches. In the algorithm space, this kind of flight finds farther-off solutions while improving the neighborhood search close to the ideal answer. This strategy can effectively increase the diversity of individuals and help the algorithm with escaping the local optimal solution [20]. Lévy flights introduce a probability distribution of step lengths, predominantly short steps but with occasional long jumps. This property is well suited for exploring unexplored regions of the search space. Long jumps allow the algorithm to jump out of the local optimal trap and explore more distant regions, increasing the chance of discovering a globally optimal solution. While long jumps make global exploration more efficient, short step sizes are used for local searches near the current optimal solution, which helps to refine the solution and thus speeds up convergence to the optimal solution. Many optimization algorithms are prone to falling into a local optimum, especially for complex multi-peaked functions. Long jumps at Lévy flight reduce this risk. These jumps break the algorithm’s stagnation in a locally optimal solution, allowing it to jump out of the local optimum and continue the global search. Such episodic long jumps disrupt the algorithm’s tendency to converge prematurely on a locally optimal solution, providing new opportunities for further search. In some cases, especially in complex search spaces with multiple local optima, random long jumps in Lévy’s flight can bring the algorithm directly close to the global optimum. This greatly speeds up the convergence process, as the algorithm is able to skip large regions of inefficiency. Once the algorithm has quickly reached the more optimal region, it can switch to fine-grained local search, further increasing the speed of convergence. Therefore, in this thesis, we consider adding Lévy flight to the end of the reflection phase of the algorithm and using a greedy strategy to select the new individuals obtained through Lévy flight and the individuals after the reflection phase.
The flowchart of the enhanced growth optimizer is displayed in Fig. 1.

Figure 1: Flowchart of enhanced growth optimizer
The pseudocode of enhanced growth optimizer is displayed in Algorithm 1.

4 Numerical Experimental Results and Analysis
To evaluate the performance of the proposed algorithm, we tested eGO using 30 test functions from CEC2014 and CEC2017. This paper compares eGO with eGO_l (the ehanced GO algorithm without Lévy flight), GO and other commonly used compact algorithms, including compact Cuckoo Search algorithm (cCS) [21], compact Pigeon-Inspired Optimization (cPIO) [22] and the above three compact algorithms cPSO, cBA and cSCA. CEC2014 and CEC2017 comprise various types of test functions, including single-objective optimization functions, multi-objective optimization functions, and constrained optimization functions, which can address a wide range of optimization problems. The included test functions have been meticulously designed and validated to ensure a fair evaluation of various optimization algorithms.
4.1 Experimental Parameter Settings
This paper uses the maximum number of evaluations (

Tables 2–4 show the means of the eight algorithms on 30, 50, and 100 dimensions of CEC2014, Tables 5–7 show the means of the eight algorithms on 30, 50, and 100 dimensions of CEC2017, respectively, and the metrics of each algorithm at a significance level of






To determine the effectiveness of the algorithm, it is essential to analyze both the optimal value achieved by the algorithm and the convergence of the algorithm. To better illustrate the data changes, we calculated the difference between the average value of the algorithm and the optimal value given by CEC for log. In this paper, a CEC2017-30-dimensional convergence graph is chosen as a representative for convergence analysis. The performance of the eGO algorithm proposed in this paper is compared with that of other algorithms in terms of convergence in Fig. 2. The horizontal axis represents the number of evaluations, while the vertical axis represents the logarithm of the difference between the function value
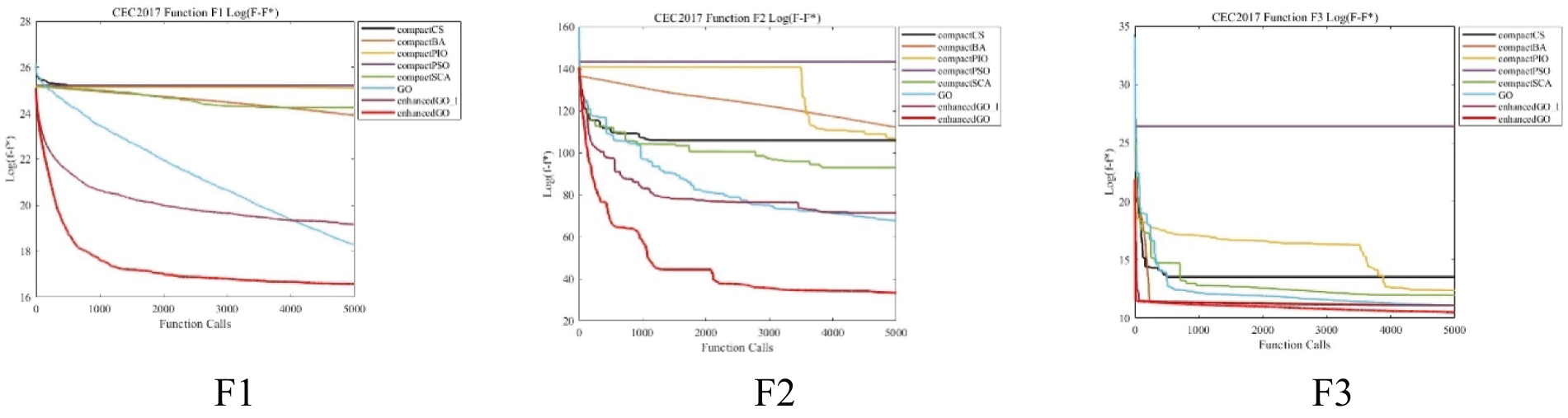
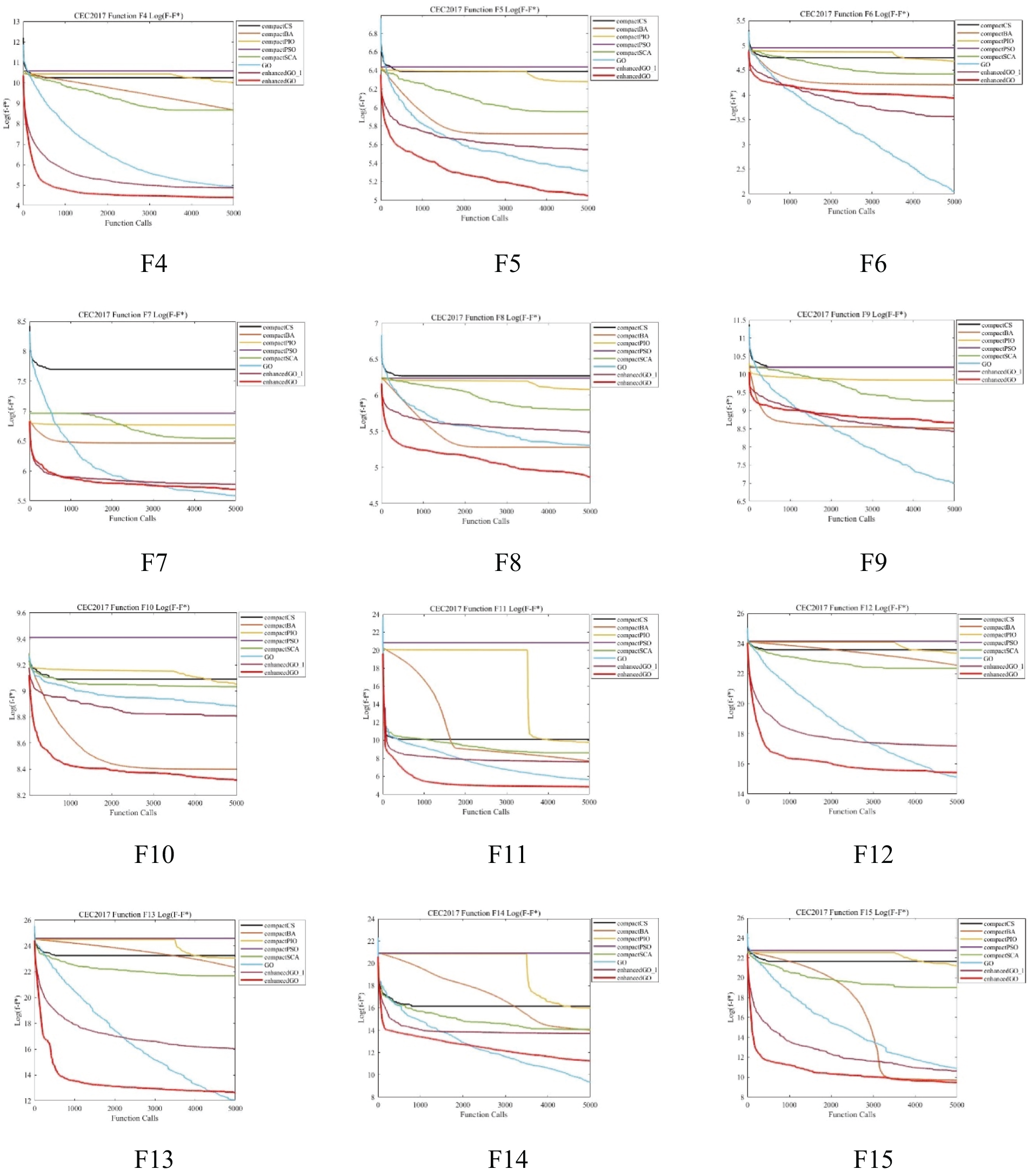

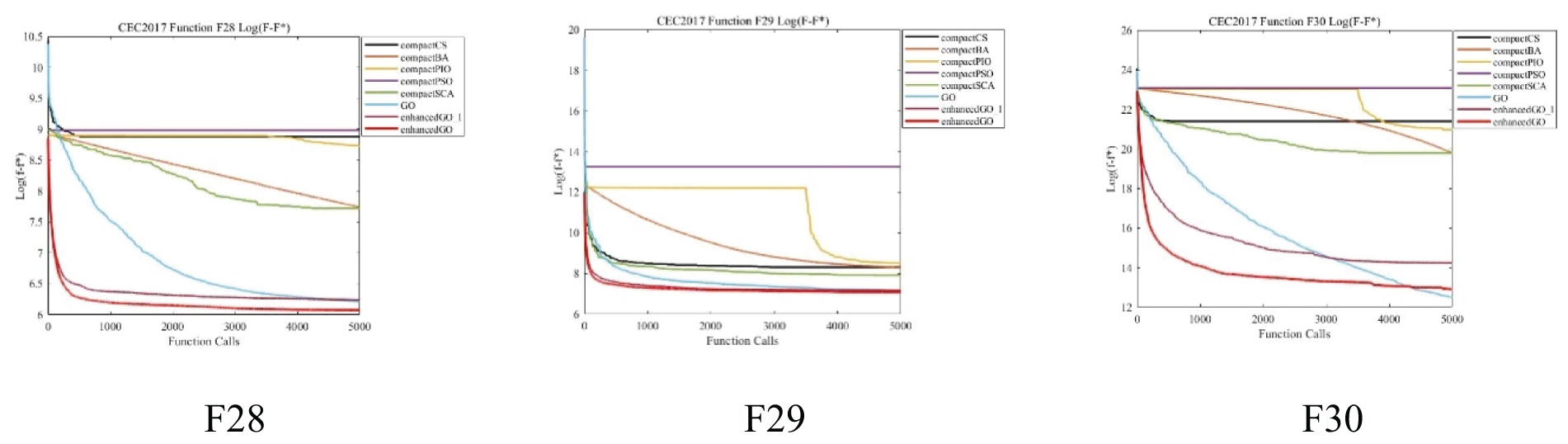
Figure 2: F1–F30 convergence graph of CEC2017 benchmark function on 30-D
5 Case of Study: Enhanced Growth Optimizer for Image Fusion
This section implements image fusion using the eGO algorithm and compares it to traditional methods. Image fusion uses single-band panchromatic (
where
where
where
The optimal value of
The seven algorithms described above are used to adaptively tune the
where
The gradient of the panchromatic map (
where
The high-resolution hybrid image is represented by
The fused image was created by applying Eq. (22) to the refined detail maps. The evaluation results of the image fusion are presented in Table 8. Fig. 3a,b shows the original
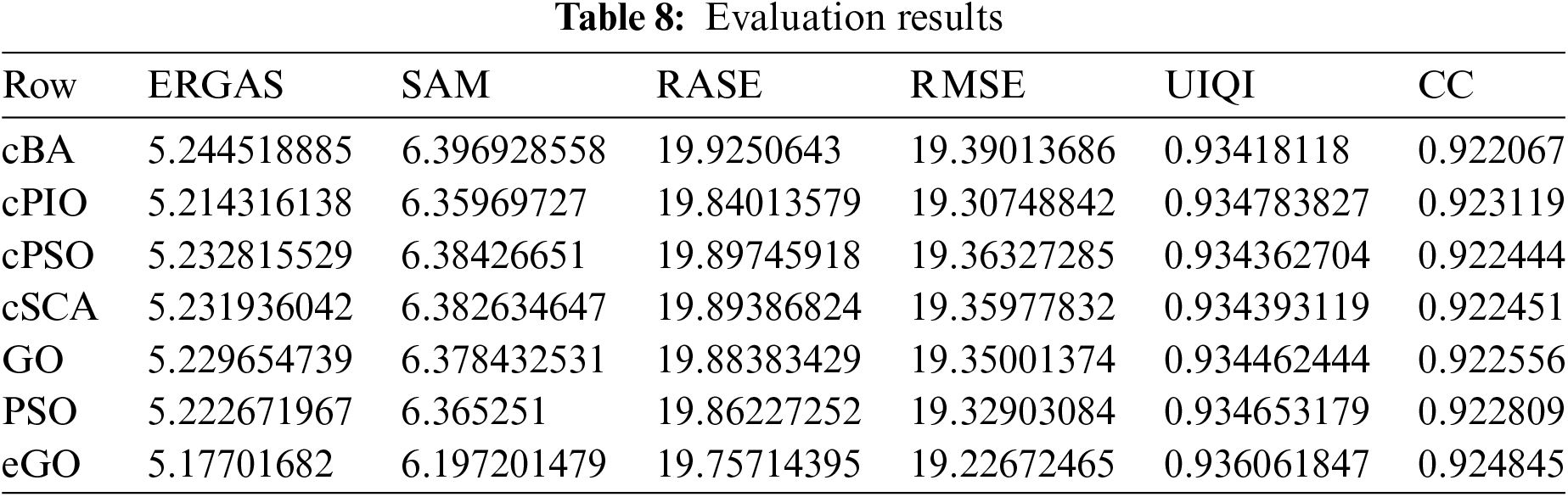


Figure 3: The MS and Pan image of QuickBird and the results of image fusion using various methods
This paper employs the compact strategy to improve the original GO algorithm and introduces Lévy flight to improve the eGO algorithm. The individuals generated in enhanced GO are based on a probabilistic model called perturbation vector (
Acknowledgement: The authors would like to express their gratitude to all the anonymous reviewers and the editorial team for their valuable feedback and suggestions.
Funding Statement: The authors received no specific funding for this study.
Author Contributions: Study conception and design: Jeng-Shyang Pan, Shu-Chuan Chu, Junzo Watada; data collection: Wenda Li, Xiao Sui, Jeng-Shyang Pan; analysis and interpretation of results: Wenda Li, Xiao Sui, Shu-Chuan Chu; draft manuscript preparation: Wenda Li, Xiao Sui, Junzo Watada. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The source code of the GO can be found at https://github.com/tsingke/Growth-Optimizer (accessed on 03 August 2022). The source code for the eGO can be obtained from the corresponding author upon request.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. J. Pierezan and L. Dos Santos Coelho, “Coyote optimization algorithm: A new metaheuristic for global optimization problems,” in 2018 IEEE Congr. Evol. Computat. (CEC), Rio de Janeiro, Brazil, 2018, pp. 1–8. doi: 10.1109/CEC.2018.8477769. [Google Scholar] [CrossRef]
2. Q. Zhang, H. Gao, Z. -H. Zhan, J. Li, and H. Zhang, “Growth optimizer: A powerful metaheuristic algorithm for solving continuous and discrete global optimization problems,” Knowl.-Based Syst., vol. 261, 2023, Art. no. 110206. doi: 10.1016/j.knosys.2022.110206. [Google Scholar] [CrossRef]
3. H. B. Aribia et al., “Growth optimizer for parameter identification of solar photovoltaic cells and modules,” Sustainability, vol. 15, no. 10, 2023, Art. no. 7896. doi: 10.3390/su15107896. [Google Scholar] [CrossRef]
4. H. Gao, Q. Zhang, X. Bu, and H. Zhang, “Quadruple parameter adaptation growth optimizer with integrated distribution, confrontation, and balance features for optimization,” Expert. Syst. Appl., vol. 235, 2024, Art. no. 121218. doi: 10.1016/j.eswa.2023.121218. [Google Scholar] [CrossRef]
5. A. Fatani et al., “Enhancing intrusion detection systems for IoT and cloud environments using a growth optimizer algorithm and conventional neural networks,” Sensors, vol. 23, no. 9, 2023, Art. no. 4430. doi: 10.3390/s23094430. [Google Scholar] [PubMed] [CrossRef]
6. A. Kaveh and K. B. Hamedani, “A hybridization of growth optimizer and improved arithmetic optimization algorithm and its application to discrete structural optimization,” Comput. Struct., vol. 303, 2024, Art. no. 107496. doi: 10.1016/j.compstruc.2024.107496. [Google Scholar] [CrossRef]
7. P. Larrañaga and J. A. Lozano, Estimation of Distribution Algorithms: A New Tool for Evolutionary Computation. Springer Science & Business Media, 2001, vol. 2. Accessed: Jun. 10, 2024. [Online]. Available: https://dl.acm.org/doi/book/10.5555/559621 [Google Scholar]
8. G. R. Harik, F. G. Lobo, and D. E. Goldberg, “The compact genetic algorithm,” IEEE Trans. Evol. Comput., vol. 3, no. 4, pp. 287–297, 1999. doi: 10.1109/4235.797971. [Google Scholar] [CrossRef]
9. R. Rastegar and A. Hariri, “A step forward in studying the compact genetic algorithm,” Evol. Comput., vol. 14, no. 3, pp. 277–289, 2006. doi: 10.1162/evco.2006.14.3.277. [Google Scholar] [PubMed] [CrossRef]
10. G. R. Harik, F. G. Lobo, and K. Sastry, “Linkage learning via probabilistic modeling in the extended compact genetic algorithm (ECGA),” in Scalable Optimization via Probabilistic Modeling. Springer, 2006, pp. 39–61. Accessed: Jun. 10, 2024. [Online]. Available: https://link.springer.com/content/pdf/10.1007/978-3-540-34954-9_3.pdf [Google Scholar]
11. K. Sastry, D. E. Goldberg, and D. Johnson, “Scalability of a hybrid extended compact genetic algorithm for ground state optimization of clusters,” Mater. Manuf. Process., vol. 22, no. 5, pp. 570–576, 2007. doi: 10.1080/10426910701319654. [Google Scholar] [CrossRef]
12. J. C. Gallagher and S. Vigraham, “A modified compact genetic algorithm for the intrinsic evolution of continuous time recurrent neural networks,” in Proc. 4th Ann. Conf. Genet. Evol. Computat., 2002, pp. 163–170. Accessed: Jun. 10, 2024. [Online]. Available: https://gpbib.cs.ucl.ac.uk/gecco2002/EH200.pdf [Google Scholar]
13. F. Neri, E. Mininno, and G. Iacca, “Compact particle swarm optimization,” Inf. Sci., vol. 239, pp. 96–121, 2013. doi: 10.1016/j.ins.2013.03.026. [Google Scholar] [CrossRef]
14. C. T. Brown, L. S. Liebovitch, and R. Glendon, “Lévy flights in Dobe Ju/’hoansi foraging patterns,” Hum. Ecol., vol. 35, pp. 129–138, 2007. doi: 10.1007/s10745-006-9083-4. [Google Scholar] [CrossRef]
15. G. Wu, R. Mallipeddi, and P. N. Suganthan, “Problem definitions and evaluation criteria for the CEC, 2017 competition and special session on constrained single objective real-parameter optimization,” 2017. [Online]. Available: https://www3.ntu.edu.sg/home/epnsugan/index_files/CEC2017/CEC2017.htm [Google Scholar]
16. K. Hussain, M. N. Mohd Salleh, S. Cheng, and Y. Shi, “Metaheuristic research: A comprehensive survey,” Artif. Intell. Rev., vol. 52, no. 4, pp. 2191–2233, 2019. doi: 10.1007/s10462-017-9605-z. [Google Scholar] [CrossRef]
17. R. B. Ash and C. A. Doléans-Dade, Probability and Measure Theory. Academic Press, 2000. Accessed: Jun. 10, 2024. [Online]. Available: https://www.colorado.edu/amath/sites/default/files/attached-files/billingsley.pdf [Google Scholar]
18. W. J. Cody, “Rational Chebyshev approximations for the error function,” Math. Comput., vol. 23, no. 107, pp. 631–637, 1969. doi: 10.1090/S0025-5718-1969-0247736-4. [Google Scholar] [PubMed] [CrossRef]
19. P. Barthelemy, J. Bertolotti, and D. S. Wiersma, “A Lévy flight for light,” Nature, vol. 453, no. 7194, pp. 495–498, 2008. doi: 10.1038/nature06948. [Google Scholar] [PubMed] [CrossRef]
20. A. F. Kamaruzaman, A. M. Zain, S. M. Yusuf, and A. Udin, “Levy flight algorithm for optimization problems-a literature review,” Appl. Mech. Mater., vol. 421, pp. 496–501, 2013. doi: 10.4028/www.scientific.net/AMM.421.496. [Google Scholar] [CrossRef]
21. J. -S. Pan, P. -C. Song, S. -C. Chu, and Y. -J. Peng, “Improved compact cuckoo search algorithm applied to location of drone logistics hub,” Mathematics, vol. 8, no. 3, 2020, Art. no. 333. doi: 10.3390/math8030333. [Google Scholar] [CrossRef]
22. A. -Q. Tian, S. -C. Chu, J. -S. Pan, H. Cui, and W. -M. Zheng, “A compact pigeon-inspired optimization for maximum short-term generation mode in cascade hydroelectric power station,” Sustainability, vol. 12, no. 3, 2020, Art. no. 767. doi: 10.3390/su12030767. [Google Scholar] [CrossRef]
23. L. Liu, M. Chu, R. Gong, L. Liu, and Y. Yang, “Weighted linear loss large margin distribution machine for pattern classification,” Chin. J. Electron., vol. 33, no. 3, pp. 753–765, 2024. doi: 10.23919/cje.2022.00.156; [Google Scholar] [CrossRef]
24. H. Wang et al., “Detecting double mixed compressed images based on quaternion convolutional neural network,” Chin. J. Electron., vol. 33, no. 3, pp. 657–671, 2024. doi: 10.23919/cje.2022.00.179. [Google Scholar] [CrossRef]
25. M. Choi, “A new intensity-hue-saturation fusion approach to image fusion with a tradeoff parameter,” IEEE Trans. Geosci. Remote Sens., vol. 44, no. 6, pp. 1672–1682, 2006. doi: 10.1109/TGRS.2006.869923. [Google Scholar] [CrossRef]
26. H. R. Shahdoosti and H. Ghassemian, “Combining the spectral PCA and spatial PCA fusion methods by an optimal filter,” Inf. Fusion, vol. 27, pp. 150–160, 2016. doi: 10.1016/j.inffus.2015.06.006. [Google Scholar] [CrossRef]
27. Z. Wang and A. C. Bovik, “A universal image quality index,” IEEE Signal Process. Lett., vol. 9, no. 3, pp. 81–84, 2002. doi: 10.1109/97.995823. [Google Scholar] [CrossRef]
Appendix A. Comparison of Standard Deviation and Minimum Value of eGO, eGO_l, GO, and Commonly Used Compact Algorithms






Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools