
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

LQTTrack: Multi-Object Tracking by Focusing on Low-Quality Targets Association
1 Henan Key Laboratory of Big Data Analysis and Processing, School of Computer and Information Engineering, Henan University, Kaifeng, 475001, China
2 College of Information Science and Technology & Artificial Intelligence, Nanjing Forestry University, Nanjing, 210037, China
3 School of Computer, Nanjing University of Posts and Telecommunications, Nanjing, 210023, China
* Corresponding Author: Ying Cao. Email:
(This article belongs to the Special Issue: Machine Vision Detection and Intelligent Recognition, 2nd Edition)
Computers, Materials & Continua 2024, 81(1), 1449-1470. https://doi.org/10.32604/cmc.2024.056824
Received 31 July 2024; Accepted 18 September 2024; Issue published 15 October 2024
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Multi-object tracking (MOT) has seen rapid improvements in recent years. However, frequent occlusion remains a significant challenge in MOT, as it can cause targets to become smaller or disappear entirely, resulting in low-quality targets, leading to trajectory interruptions and reduced tracking performance. Different from some existing methods, which discarded the low-quality targets or ignored low-quality target attributes. LQTTrack, with a low-quality association strategy (LQA), is proposed to pay more attention to low-quality targets. In the association scheme of LQTTrack, firstly, multi-scale feature fusion of FPN (MSFF-FPN) is utilized to enrich the feature information and assist in subsequent data association. Secondly, the normalized Wasserstein distance (NWD) is integrated to replace the original Inter over Union (IoU), thus overcoming the limitations of the traditional IoU-based methods that are sensitive to low-quality targets with small sizes and enhancing the robustness of low-quality target tracking. Moreover, the third association stage is proposed to improve the matching between the current frame’s low-quality targets and previously interrupted trajectories from earlier frames to reduce the problem of track fragmentation or error tracking, thereby increasing the association success rate and improving overall multi-object tracking performance. Extensive experimental results demonstrate the competitive performance of LQTTrack on benchmark datasets (MOT17, MOT20, and DanceTrack).Keywords
Glossary/Nomenclature/Abbreviations
| MOT | Multi-object tracking |
| TBD | Tracking-by-Detectio |
| LQA | Low-quality targets association strategy |
| FPN | Feature Pyramid Networks |
| MSF F-FPN | Multi-scale feature fusion of Fpn |
| NWD | Normalized Wasserstein distance |
| IoU | Intersection over Union |
| GIoU | Generalized Intersection over Union |
| LRFS | Labeled Random Finite Sets |
| Re-ID | Re-identification |
Multi-object tracking (MOT) is a task that forms the tracks of objects by detecting and tracking objects in a video across space and time while maintaining consistent identities [1,2]. It has been utilized in several applications, such as autonomous driving and video surveillance. In real-time related research [3–5], Tracking-by-Detection (TBD) has emerged as one of the mainstream paradigms for target tracking. TBD is a two-stage method involving detection and data association steps. Initially, a detector is employed to identify individual objects in each frame. Subsequently, the detection results are temporally associated using a data association scheme to create continuous tracks for each object. Recently, the rapid advancements in detection and association techniques have led to significant performance improvements in MOT [5–8]. However, occlusion continues to be a significant challenge in MOT, as it can cause objects to become low-quality or even disappear, like the target located by the red boxes shown in Fig. 1. Then the targets with low-quality would cause trajectory interruption and fragmentation, thereby reducing tracking performance. In our paper, the low-quality target is defined by the confidence score of the target where its confidence score lies in

Figure 1: Examples of low-quality targets. (a) shows all the detection boxes with their scores. (b) shows that low score detection is associated because of attention to low-quality targets (0.1 < score < 0.6). Red Dashed box represents associated detection, solid wire frame represents associations. The same box color represents the same identity
Several methods have been proposed to address this. For instance, ByteTrack [5] improves tracking by associating each detection box considering both high and low-score detection. BoT-SORT [9] uses a simple yet effective method for Intersection over Union (IoU) and Re-identification’s (Re-ID) cosine-distance fusion for more robust associations between detections and tracklets. While these recent methods enhance the performance of MOT, issues still remain with the association of low-quality targets caused by occlusion. Firstly, the traditional IoU based measurement is susceptible to positional deviations of low-quality targets. However, occlusion often reduces targets to smaller sizes, leading to a lack of overlap between the bounding boxes of these targets. Consequently, the traditional IoU method fails to accurately reflect the relative similarity between the bounding boxes, resulting in incorrect matching of targets. Secondly, recent methods [7–10] lack the effective consideration for matching the current frame’s detection with previously interrupted trajectories from earlier frames
Therefore, we construct the LQTTrack with a Low-quality targets association strategy (LQA) to pay more attention to low-quality targets in MOT. In our association design, during the first stage, visual features and motion information of the previous frame’s tracklets
1) Different from the existing methods, which discard low-quality targets directly, LQTTrack is designed to pay attention to low-quality target association to enhance the overall accuracy of multi-object tracking.
2) In LQA of LQTTrack, besides the employment of multi-scale feature fusion of FPN (MSFF-FPN) in visual features enrichment during the first stage. In subsequent stages, Normalized Wasserstein Distance (NWD) is integrated to address the sensitivity of traditional IoU to low-quality targets with small size and positional deviations, thus improving the robustness of multi-target tracking.
3) In LQA of LQTTrack, the third association stage is integrated to enhance the matching between the current frame’s low-quality targets and previously interrupted trajectories from earlier frames to reduce the trajectory interruption phenomena.
With the continuous advancement of deep learning technology, multi-object tracking techniques have seen rapid improvements in recent years [5,9,20,21]. In the following discussion, we elaborate on two aspects of multi-object tracking: feature extraction, and data association.
Motion information and appearance cues are the main dependent features of current multi-target tracking [22–24]. On the one hand, some researchers opt to forgo appearance information [5,25], relying solely on high-performance detectors and motion information to achieve high operational speed and state-of-the-art performance. For instance, ByteTrack [5] utilizes only motion information, matching tracking through high and low-score detection boxes. Uniform Camera Motion Compensation Track (UCMCTrack) [26] has designed a new motion model-based tracker robust to camera motion, introducing an innovative non-IoU distance metric driven by motion cues alone. On the other hand, numerous researches [6,27] still support the idea that additional appearance cues can enhance multi-object tracking. BoT-SORT [9] proposes camera motion compensation and a more accurate Kalman filter state vector for better bounding box localization, along with a novel fusion method based on IoU and re-id cosine distance. Quasi-Dense Tracking (QDTrack) [28] suggests that position-motion matching is only suitable for simple scenes, as positional information can easily mislead in crowded and occluded scenarios. Choosing to discard position and motion information proposes a matching method based on dense ground truth for extracting appearance features and uses Bi-directional softmax (Bi-softmax) for bidirectional matching, achieving good tracking results using only appearance information. Our method opts to use appearance cues to assist multi-object tracking and embed multi-scale feature fusion to enhance features.
Data association is an important module in the MOT and has also attracted widespread attention and research. Multi-target Tracking using Joint Detection and Tracking (MTTJDT) [29] proposes a multi-loss function that consists of a combination of classifications using the focal loss function and localization loss employing the Complete Intersection Over Union (CIoU) loss function, with a loss-scale parameter used to balance the two functions. This approach enables the prioritization of specific factors, such as object type or position, while also accounting for imbalances in challenging classes and samples. It also employs a dual-regression bounding box to associate objects between adjacent frames by considering the distance between their centers. Transformer-based Assignment Decision Network (TADN) [30] transforms information related to detections and known targets in each frame to directly compute optimal assignments for each detection. Sparse Graph Tracker (SGT) [31] improves tracking of low-score detection by utilizing higher-order relational features, which are more discriminative by aggregating the features of neighboring detection and their relations. ByteTrack [5] makes full use of low-score detection boxes by incorporating them into the process, which improves the accuracy of data association compared to other approaches that only associate high-score detection boxes. However, these methods lack effective consideration for matching the current frame’s detection and previously interrupted trajectories, thus limiting the further improvement of tracking performance. To solve this problem, algorithms like [11,12] consider the matching of previously interrupted trajectories through multi-hypothesis data association methods. For instance, Multiple Hypotheses Tracking (MHT) [11] uses a track tree that encapsulates multiple hypotheses starting from a single observation and delays data association decisions by keeping multiple hypotheses active until data association ambiguities are resolved. Tracklet-level Multiple Hypothesis Tracking (TLMHT) [12] incorporates a tracklet-level association pruning method into MHT and proposes a novel iterative Maximum Weighted Independent Set (MWIS) algorithm to avoid solving the MWIS problem from scratch. Though the effective consideration of interrupted trajectories, the employment of non-differentiate matching schemes ignores the attributes of low-quality targets, and this oversight still forbids further improvement in resolving interrupted trajectories. Therefore, in our paper, the target is firstly divided into high and low-quality ones according to the confidence scores. Then, in our association scheme, the MSFF-FPN is integrated into the first association stage to improve the success rate of high-quality targets. For low-quality targets, the NWD is utilized to assess motion consistency between targets and trajectories, including interrupted ones. This approach ensures that the small size of low-quality targets does not affect the measurement, facilitating the formation of accurate target tracks.
Additionally, to address issues related to data association uncertainty, methods based on Labeled Random Finite Sets (LRFS) model the states and measurements of targets as random finite sets. For instance, Vo et al. [32] introduced the concept of LRFS and proposed a multi-target tracking filter fully described by multi-object prediction and update equations, which is the first theoretical approach capable of trajectory estimation. Additionally, Xue et al. [33] introduced a Bayesian recursive filter tracking method that combines the Density-based spatial clustering of applications with noise (DBSCAN) clustering algorithm with the
Moreover, compared to traditional IoU or distance-based association methods, SimpleTrack [21] adopts Generalized Intersection over Union (GIoU) [35] for association while still utilizing Hungarian or greedy algorithms to match trajectories and detection. However, GIoU degrades to IoU when the predicted and ground truth boxes are completely overlapping, thus failing to capture the relative positional relationship between them. Additionally, GIoU requires the computation of the minimum enclosing rectangle for each predicted and ground truth box, which increases computational complexity and limits convergence speed. In our paper, different from GIoU, NWD is adapted in our paper to measure the motion consistency of trajectories and targets by paying attention to low-quality targets.
Different from the existing methods [8,36,37], which discards low-quality targets directly, in this work, LQTTrack with low-quality association strategy (LQA) is constructed to further improve the performance of MOT by paying attention to low-quality targets. The overview of LQTTrack is shown in Fig. 2.
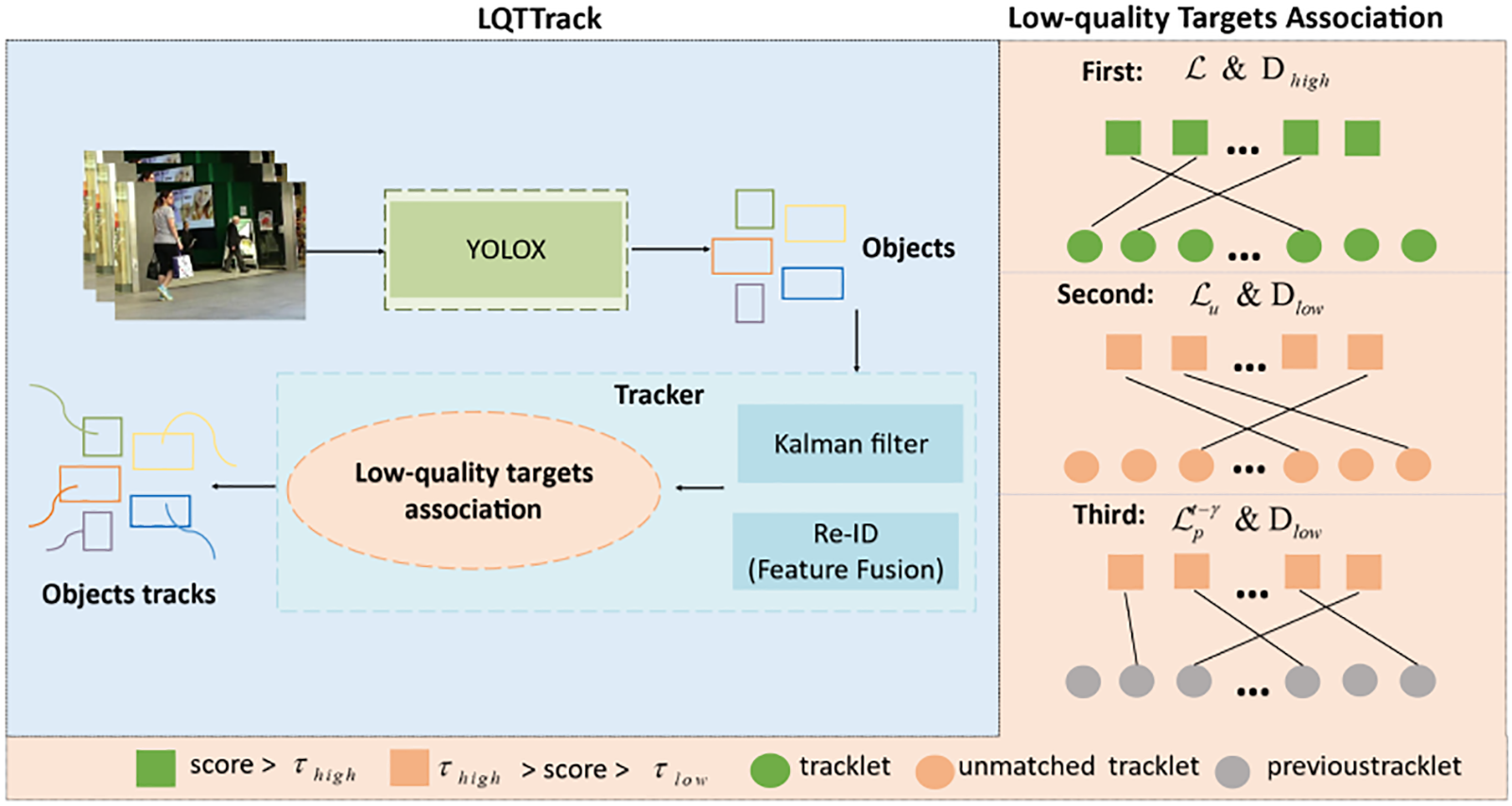
Figure 2: The overview of LQTTrack
In our LQTTrack, for each frame
First-stage association: In this stage, visual features of the previous frame’s tracklets
Specifically, the multi-scale feature fusion of LQTTrack is shown in Fig. 3. The last three layers of backbone [38] are utilized to output the multi-level visual clues
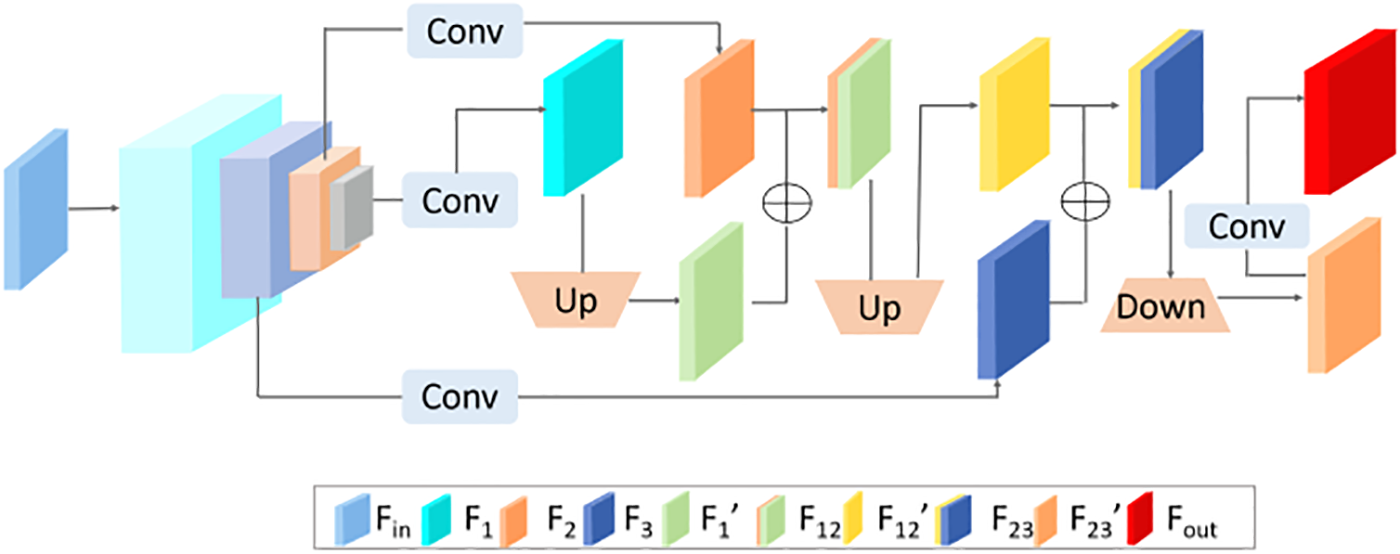
Figure 3: The multi-scale feature fusion of LQTTrack
In Eq. (1),
Finally, as shown in Eq. (2), downsampling operation
Then, based on the enhanced features, as shown in Eq. (3), the Exponential Moving Average (EMA) is first utilized to form the feature embedding of tracklet
In Eq. (3),
After that, the appearance cost matrix between the current frame high-quality target
Besides the visual similarity, utilising motion information for tracklets prediction through KF, as shown in Eq. (6), motion similarity between prediction box
Then, appearance and motion similarity matrices are integrated according to Eq. (7). Here,
Second Stage Association: In this stage, considering the limited visual information of low-quality target
Specifically, we first model the bounding boxes as two-dimensional gaussian distribution and then use NWD to compute the similarity. Due to the elliptical shape of the density contour of the two-dimensional gaussian distribution, the distribution situation of the gaussian distribution can be represented by the inscribed ellipse of the bounding box. Therefore, the bounding boxes can be modeled as a two-dimensional gaussian distribution, where the center pixel of the bounding box has the highest weight, and the importance of the pixel gradually decreases from the center to the boundary [39]. The bounding box
Then, the similarity between bounding box A and box B can be converted to the distribution distance between two-dimensional gaussian distributions. According to Wasserstein distance comes from the Optimal Transport theory [14], for two-dimensional gaussian distributions
Furthermore, for gaussian distributions
Finally, we use NWD to associate prediction box
Third Stage Association: For the current frame’s low-quality target
Then, based on the cost matrix
The pseudo-code is demonstrated in Algorithm 1, in the designed algorithm, for the input video sequence V, along with an object detector Det and Kalman Filter KF, two thresholds

We conducted a fair evaluation of several publicly available datasets, including MOT17 [17], MOT20 [18], and DanceTrack [19]. MOT17 and MOT20 are both pedestrian tracking datasets with predominantly linear motion. Notably, MOT20 has a significantly higher density of pedestrians, and the crowded scene means more occlusion, making it a challenging dataset to track. The main task of DanceTrack is to track actors on stage with complex patterns of target movement and large amplitude of movement while multiple targets are dressed in the same costume with similar appearances. For ablation studies, we follow by using the first half of each video in the training set of MOT17 for training and the last half for validation.
In this section, ByteTrack [5], TLMHT [12], GLMB [34], TADN [30], SGT [31], StrongSORT++ [6], Observation-Centric SORT (OC-SORT) [16], FairMOT [8], RelationTrack [40], Correlation Tracker (CorrTracker) [41], and Transformer for MOT (TransMOT) [42] are compared with the proposed LQTTrack. Among these, TADN [30] introduces a transformer-based assignment detection network as an alternative to traditional data association methods for MOT. SGT [31] and ByteTrack [5] focus on improving the tracking of low-score detections. TLMHT [12] addresses trajectory interruption issues through multiple hypotheses data association. GLMB [34] develops a multi-target tracker using the LRFS framework. Based on this analysis, the experimental section specifically analyzed and compared with ByteTrack, TLMHT, GLMB, TADN, and SGT.
This experiment employs CLEAR metrics [43], including Multiple object tracking accuracy (MOTA), Higher order tracking accuracy (HOTA) [44], Identification F1 (IDF1), Identity switches (IDSW) [45], etc., to evaluate the tracking performance comprehensively in various aspects. MOTA emphasizes the tracker’s performance, while IDF1 measures the tracker’s ability to maintain consistent IDs (Identity documents). We also emphasize the use of Association accuracy score (AssA) to evaluate the association performance. On the other hand, HOTA achieves a balance between detection accuracy, association accuracy, and localization accuracy, making it an increasingly important metric for evaluating trackers. False positives (FP) represents the number of false positives in the entire video sequence, while False negatives (FN) represents the number of false negatives. IDSW denotes the number of identity swaps among tracked targets. Additionally, Frames processed per second (FPS) is utilized to evaluate our tracker’s speed (FPS).
Inspired by ByteTrack’s high and low score matching framework and considering the effective use of appearance features, we revised Deep OC-SORT using ByteTrack’s matching strategy. We used the revised version as the baseline. To ensure a fair comparison of tracking performance, we employed the same yolox detector as in recent works [5,6,9]. For Re-ID, we used fast-reid [46] with the SBS-50 model, trained with its default training strategy on MOT17, MOT20, and DanceTrack for 60 epochs. For experiments on MOT17 and MOT20, we set
In this section, we present benchmark results for multiple datasets. We conduct experiments on MOT17 [17], MOT20 [18], and DanceTrack [19]. The best results for each indicator are displayed in bold.
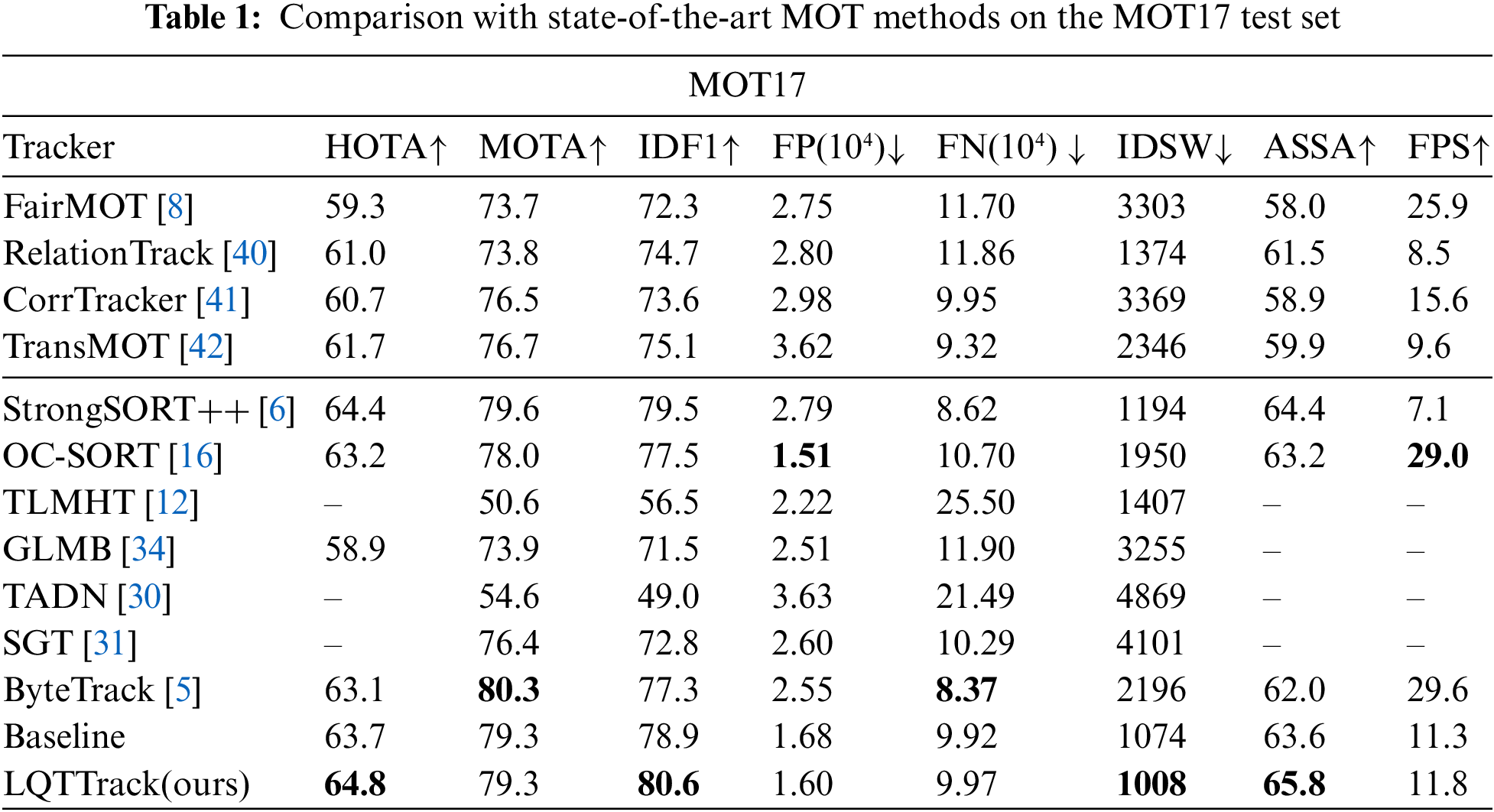
In this part, MOT17 is first used to verify the performance of LQTTrack. For the experiments on the MOT17-test, we employed a proprietary detector to generate detection and aligned them with ByteTrack [5] to ensure fairness. Experimental results and comparisons of MOT17 are shown in Table 1. Through the analysis, it is easy to find that LQTTrack achieves the best performance in 64.8, 80.6, 65.8, and 1008 in HOTA, IDF1, AssA, and IDSW. Compared to TLMHT [12], which addresses tracklet interruption but does not distinguish between high and low-quality targets, LQTTrack places a greater emphasis on low-quality targets. Our method improves upon TLMHT by 28.7, 24.1, and 399 in MOTA, IDF1, and IDSW, respectively. These improvements further demonstrate the superior performance of our approach relative to TLMHT. Compared to GLMB [34], which uses the LRFS framework, our method surpasses GLMB by 5.9, 5.4, 9.1, and 2247 in HOTA, MOTA, IDF1, and IDSW. Compared to TADN [30], which also addresses occlusion issues, our method surpasses TADN by 24.7, 31.6, and 3861 in MOTA, IDF1, and IDSW. Compared to SGT [31] and ByteTrack [5], which also focus on low-quality targets, our method exceeds SGT by 2.9, 7.8, and 3098 in MOTA, IDF1, and IDSW. Additionally, our method outperforms ByteTrack by 1.7, 3.3, 3.8, and 1188 in HOTA, IDF1, AssA, and IDSW. Moreover, compared to the baseline, LQTTrack improved the method by 1.1, 1.7, and 2.2 in HOTA, IDF1, and AssA. The superior performance demonstrates that the proposed LQTTrack has the ability to improve the association success rate for low-quality targets and optimize the accuracy of MOT by leveraging a more reasonable low-quality targets association strategy.
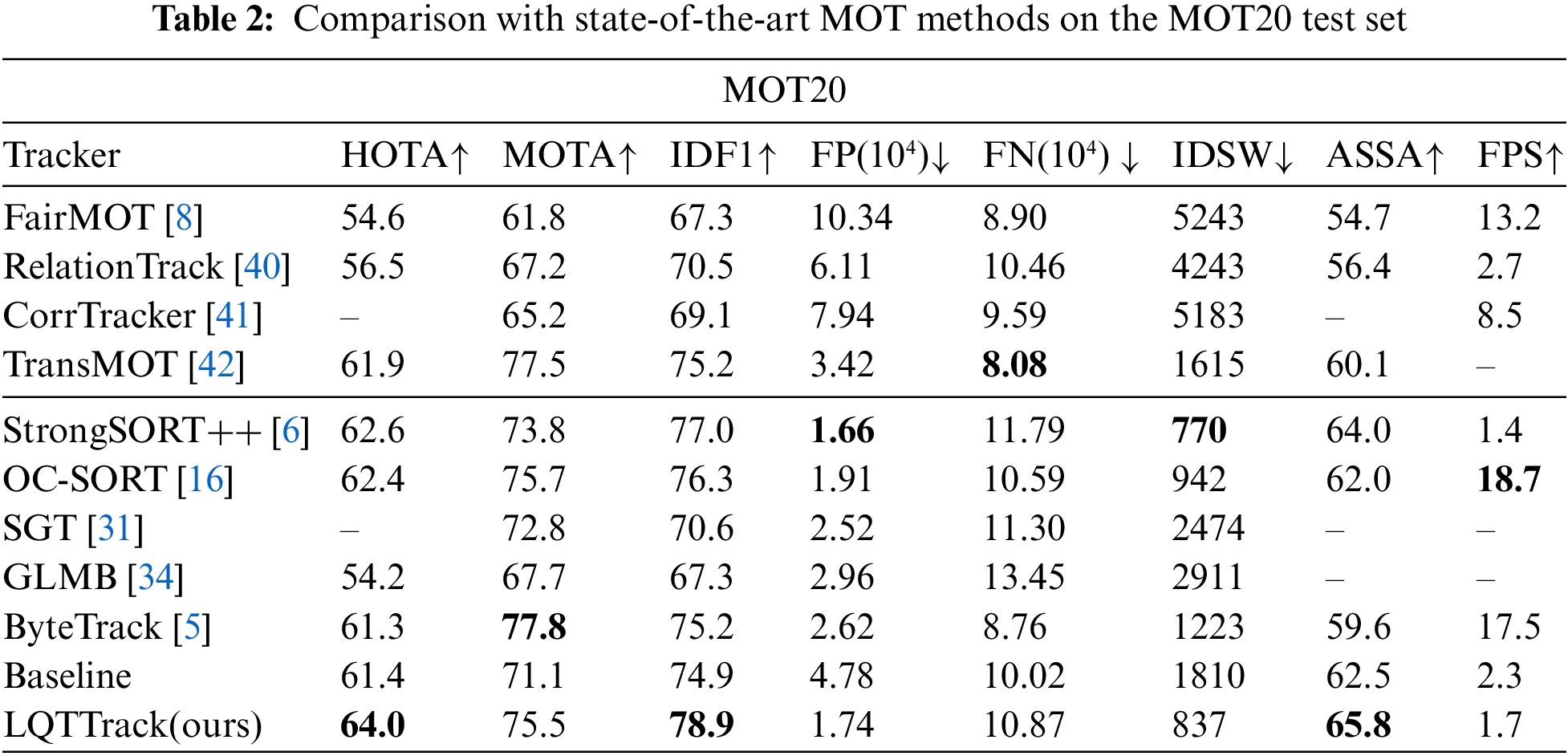
In this section, MOT20 is employed to further evaluate the performance of the proposed. Unlike MOT17, MOT20 contains more crowded scenes where higher occlusion implies more low-quality targets and higher chances of unmatched targets. The experimental results presented in Table 2, LQTTrack still surpasses the current SOTA (State-of-the-art) algorithms and achieves 64.0, 78.9, and 65.8 in HOTA, IDF1, and AssA. Compared with ByteTrack [5], our method outperforms 2.7, 3.7, 6.2, and 386 in HOTA, IDF1, AssA, and IDSW. Additionally, compared to SGT [31], our method outperforms 2.7, 8.3, and 1637 in MOTA, IDF1, and IDSW. Compared to GLMB [34], our method surpasses GLMB by 9.8, 7.8, 11.6, and 2074 in HOTA, MOTA, IDF1, and IDSW. Moreover, compared to the baseline, LQTTrack improved the method by 2.6, 4.4, 4.0, 3.3, and 973 in HOTA, MOTA, IDF1, AssA, and IDSW. When facing scenarios with many low-quality targets, our processing of low-quality targets significantly improves the accuracy of multi-target tracking. All of these indicate the effectiveness of the proposal.
In this part, DanceTrack is utilized to validate the performance of the proposed. DanceTrack is a dataset with the challenges of complex object motion patterns and similar appearances. The validated results and comparisons are exhibited in Table 3. From this presentation, we can see that the proposed achieves better results of 92.0 and 82.1 in MOTA and Detection accuracy (DetA) when compared with the majority of trackers. The better performance demonstrates the effectiveness of our proposed method. However, LQTTrack did not show a significant improvement in HOTA and AssA compared to the baseline. The analysis indicates that using the same parameters (specifically,
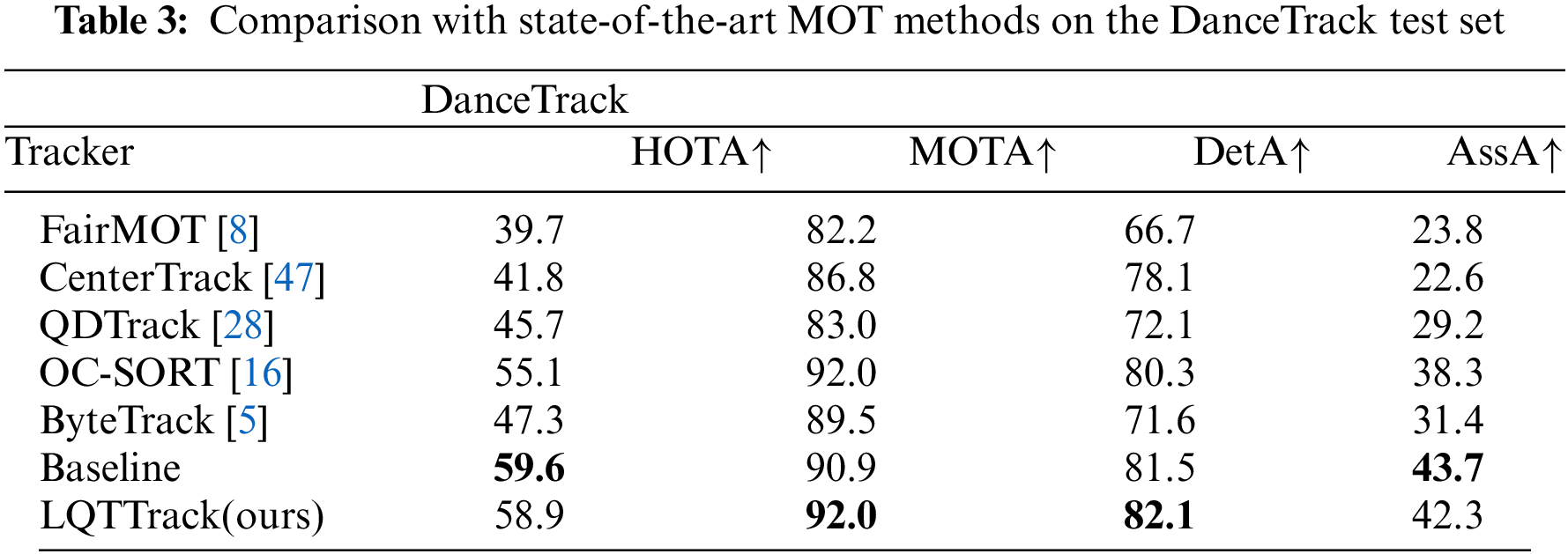
Furthermore, with the IDF1-MOTA-HOTA comparisons displayed in Fig. 4, the superior performance, especially in MOT20, indicates the robust performance in handling numerous low-quality targets.
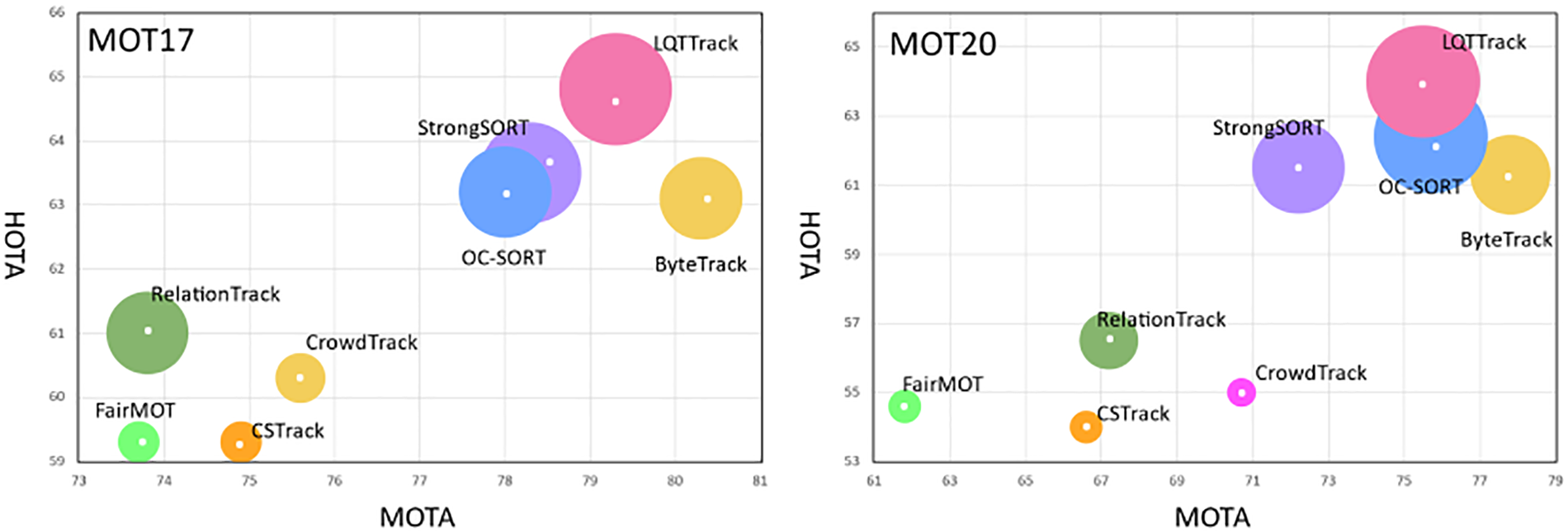
Figure 4: IDF1-MOTA-HOTA comparisons of state-of-the-art trackers with our proposed LQTTrack on the MOT17 and MOT20 test sets. The x-axis is MOTA, the y-axis is HOTA, and the radius of the circle is AssA. There is still excellent performance on MOT20 test sets with many low-quality targets
In this section, ablation studies are conducted to verify the contributions of the designed Low-quality targets association strategy (LQA), Multi-Scale Feature Fusion of FPN (MSFF-FPN) and Normalized Wasserstein distance (NWD) which are the main modules in LQTTrack. Additionally, to avoid potential detector bias, we uniformly employed bytetrack’s yolox-x ablation study weights, which were trained on the first half of sequences from CrowdHuman and MOT17.
(1) The effect of LQA.
i) LQA with NWD without MSFF-FPN. We used LQA as a universal tool into the Baseline, Deep OC-SORT, and OC-SORT methods to verify the effectiveness of LQA. The validation results based on the MOT17 dataset are shown in Table 4. Compared to the baseline, the using of LQA improved the method baseline by 1.39, 0.45, 0.54, and 0.95 in HOTA, MOTA, IDF1, and AssA. Compared to Deep OC-SORT, the method of Deep OC-SORT was improved by 0.2, 1.91, 0.57, and 1.51 in HOTA, MOTA, IDF1, and AssA. Similarly, compared to OC-SORT, using LQA improved the OC-SORT method by 0.83, 0.65, 1.64, 1.81, and 68 in HOTA, MOTA, IDF1, AssA, and IDSW. The above performance improvements indicate that LQA is superior in handling low-quality targets.
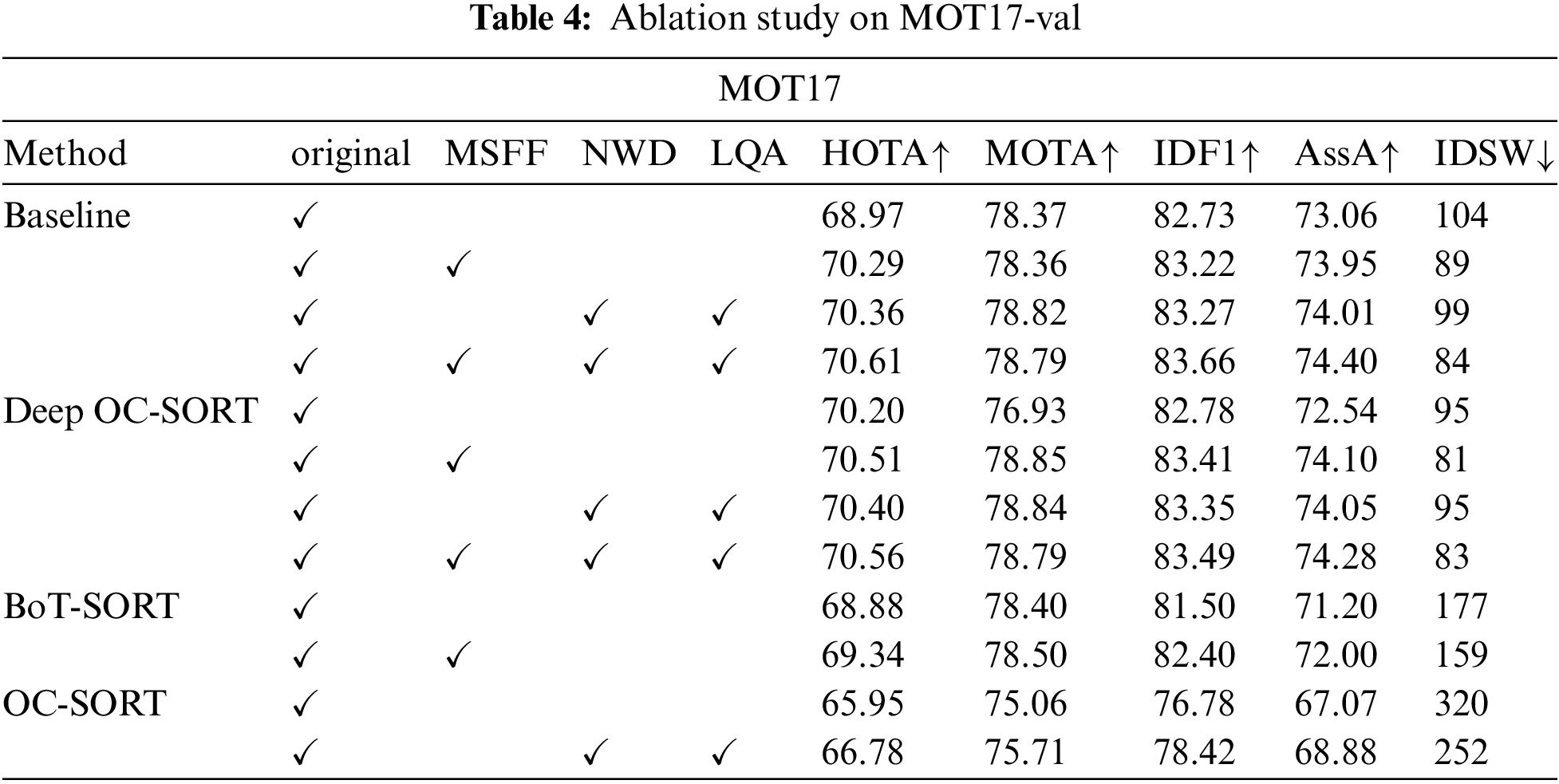
Furthermore, video MOT20-03 is selected to further verify the effectiveness of our module on low-quality targets for its dense scenes and many low-quality targets. In this part, we set the detection of
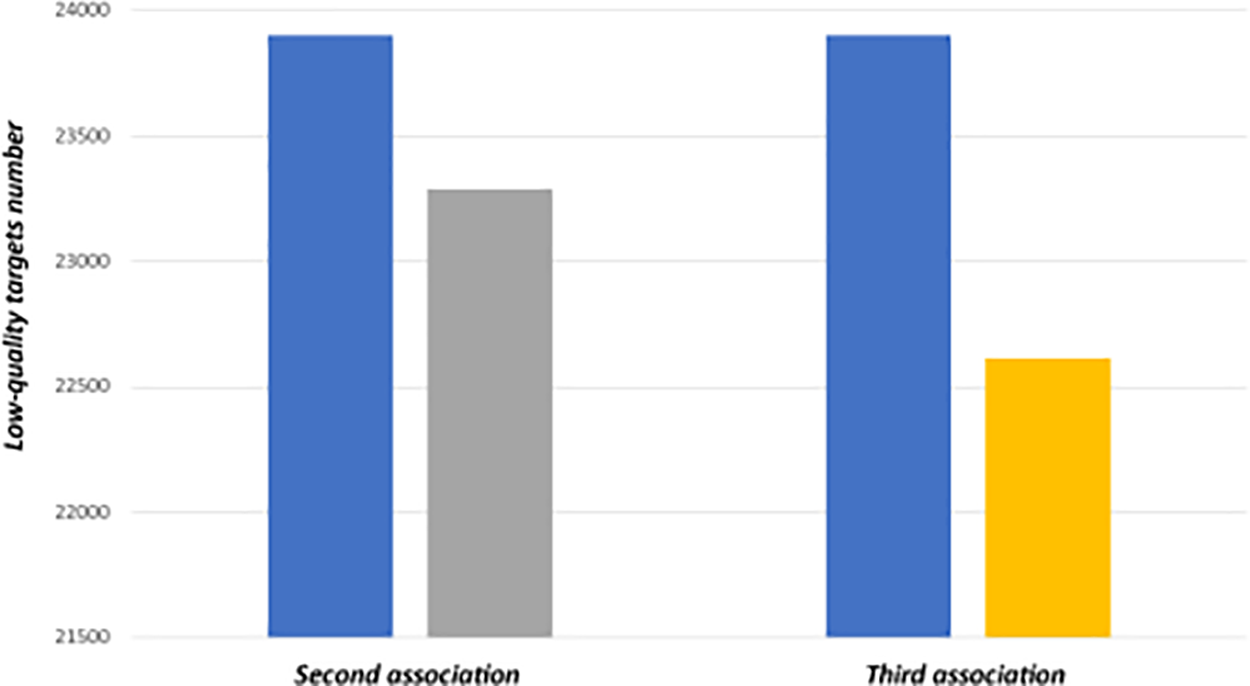
Figure 5: Example of the advantage of LQTTrack. In the second and third associations, we processed low-quality targets separately. LQTTrack effectively reduces the number of low-quality targets on MOT20-03
ii) LQA without NWD and MSFF-FPN. Furthermore, we embed LQA without NWD into the Deep OC-SORT and OC-SORT methods to verify the effect of LQA without NWD. The validation results based on the MOT17 dataset are shown in Table 5. Compared to Deep OC-SORT, the utilizing of LQA improves the method Deep OC-SORT by 0.14, 2.15, 0.39, and 1.19 in HOTA, MOTA, IDF1, and AssA. Similarly, compared to OC-SORT, the method OC-SORT has been improved by 0.6, 1.53, 2.23, and 109 in HOTA, IDF1, AssA, and IDSW. The above performance improvements indicate that LQA without NWD and MSFF-FPN can significantly improve the original performance, which validates the effectiveness of the proposed third-stage association.
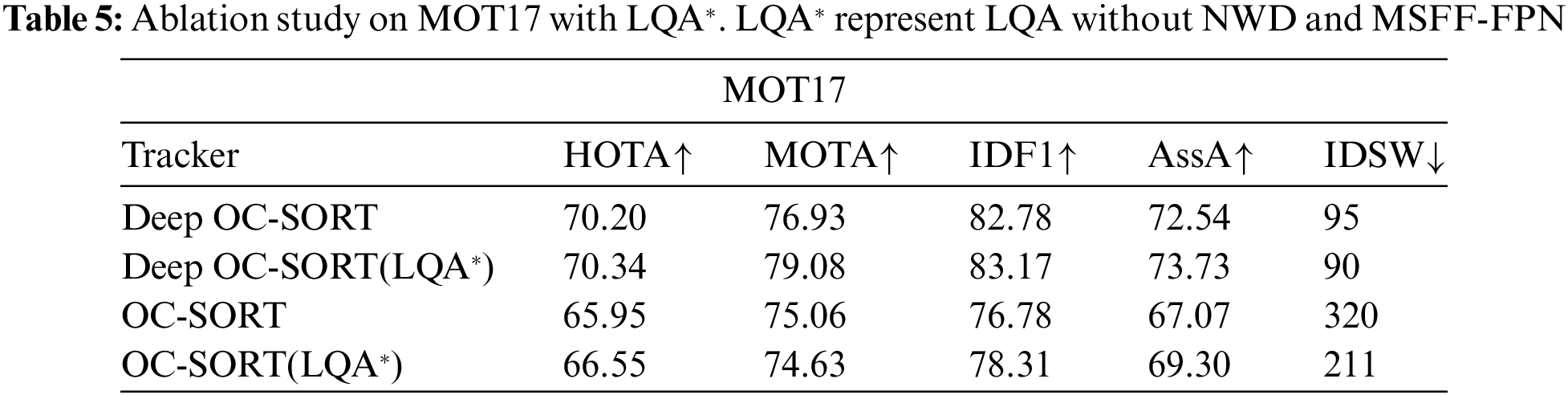
iii) The effect of LQA with both NWD and MSFF-FPN. Moreover, the proposed association is completely integrated into Baseline and Deep OC-SORT. From the results described in Table 4 for Baseline and Deep OC-SORT, the integration of the proposed has improved the performance of baseline by 1.64, 0.42, 0.93, 1.34, and 20 in HOTA, MOTA, IDF1, AssA, and IDSW, the same optimization of Deep OC-SORT by 0.36, 1.86, 0.71, and 1.74 in HOTA, MOTA, IDF1, and AssA. This further validates the effectiveness and superiority of LQTTrack.
The optimization performance of LQA, both with and without NWD and MSFF-FPN, demonstrates LQTracker’s superiority in reducing track fragmentation and tracking errors.
(2) The effect of MSFF-FPN. This work utilizes the multi-scale feature fusion strategy of FPN (MSFF-FPN) to achieve rich feature information. Therefore, MSFF-FPN is embedded in Baseline, Deep OC-SORT, and BOT-SORT. The experimental results are shown in Table 4. Compared to the baseline, the using of MSFF-FPN improves the method baseline on MOT17 datasets by 1.32, 0.49, and 0.89 in HOTA, IDF1, and AssA. Compared to the Deep OC-SORT method, the method of Deep OC-SORT on MOT17 datasets has been improved by 0.31, 1.92, 0.63, and 1.56 in HOTA, MOTA, IDF1, and AssA. Similarly, compared to the Deep OC-SORT, using MSFF-FPN improves the BoT-SORT method on MOT17 by 0.46, 0.9, and 0.8 in HOTA, IDF1, and AssA. These results demonstrate the effectiveness of MSFF-FPN.
(3) The effect of NWD. To address the incomplete consideration of low-quality targets in IoU measurement methods, NWD is adopted to handle low-quality targets with small sizes. Therefore, to measure the contribution of NWD, this section integrates GIoU and NWD into the Deep OC-SORT and OC-SORT methods with high-low-scores mechanism and verifies its effectiveness using the MOT20 dataset, which contains more low-quality targets with small sizes. The validation results are presented in Table 6. Compared to Deep OC-SORT, which utilized IoU originally, the employment of GIoU has achieved the improvement of 0.8, 3.56, 2.87, 2.05, and 316 in HOTA, MOTA, IDF1, AssA, and IDSW, but the employment of NWD has a more substantial enhancement 0.23, 0.31, 0.63, 0.45, and 83 in HOTA, MOTA, IDF1, AssA, and IDSW compared with GIoU. Similarly, for OC-SORT, compared to the original IoU, the use of GIoU leads to the increment of metrics, but NWD shows the best performance.
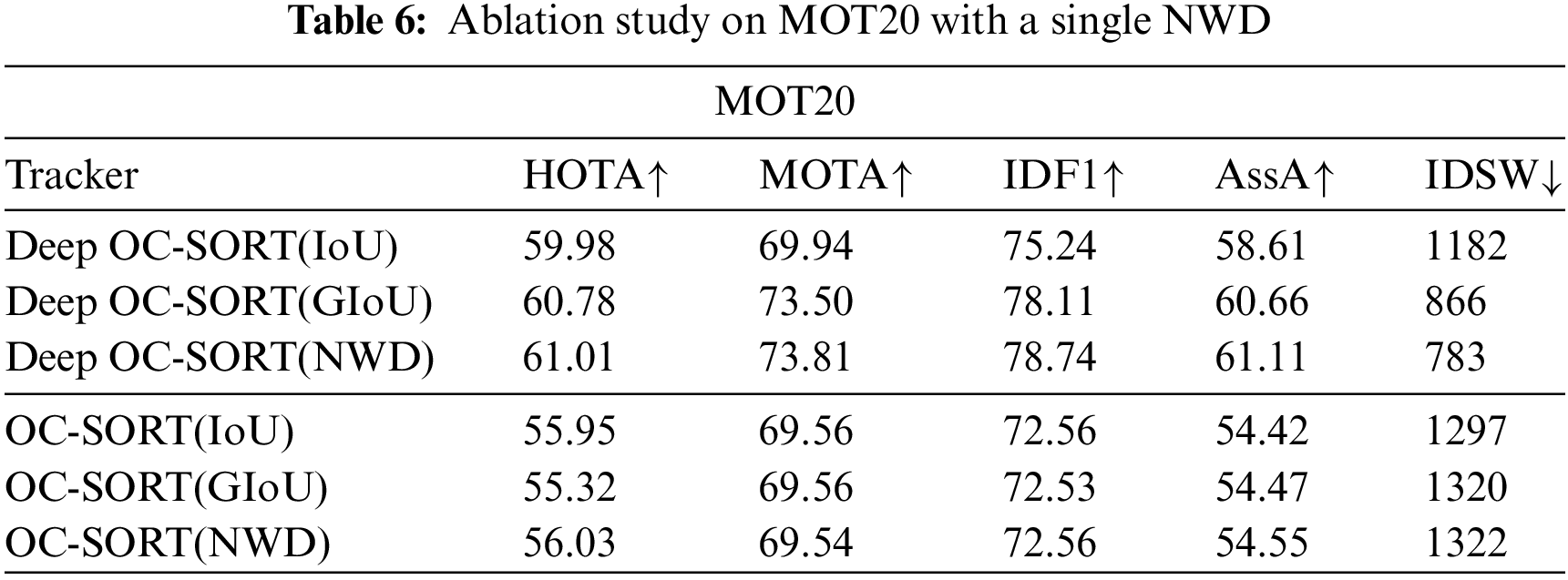
From the experimental results and analysis, it is easy to find that IoU is sensitive to positional deviations of the target. GIoU can the IoU by introducing a minimum bounding rectangle to represent the distance between two boxes, addressing the positional relationship when the bounding boxes do not overlap. However, GIoU remains reliant on IoU and defaults to IoU when the bounding boxes contain overlapping information. In contrast, NWD leverages Gaussian distribution to account for the overall distribution characteristics of the target area, and this approach can effectively measure the similarity even when there is limited overlap or mutual containment between bounding boxes, and it is less sensitive to scale. Consequently, NWD is more suitable for low-quality targets and demonstrates greater robustness in target association.
4.4 Parameter Sensitivity Study
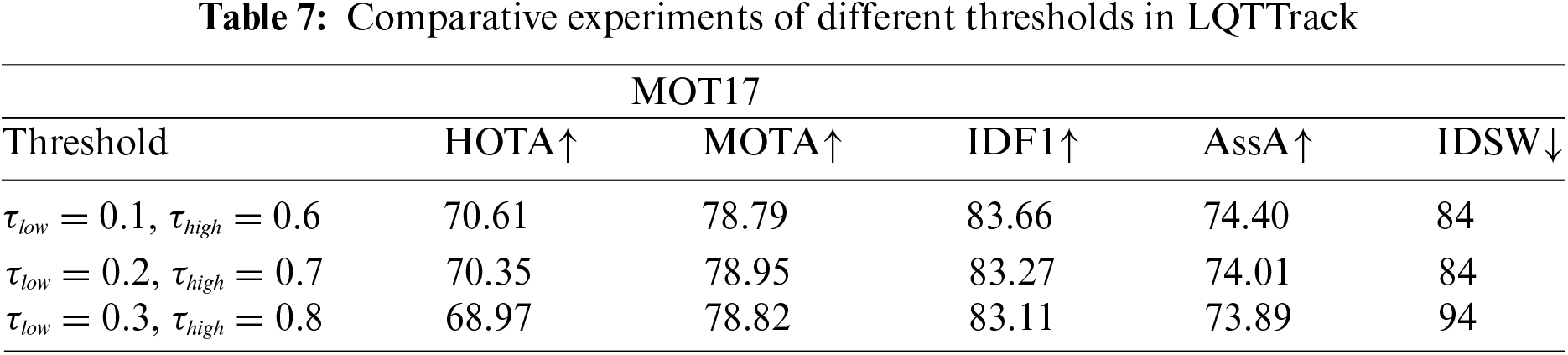
(1) Threshold for high and low-quality targets selection.
In order to verify the influence of high and low score thresholds on data association, we only change the score thresholds
(2) Parameter for similarity computation.
The parameter adaptive weight
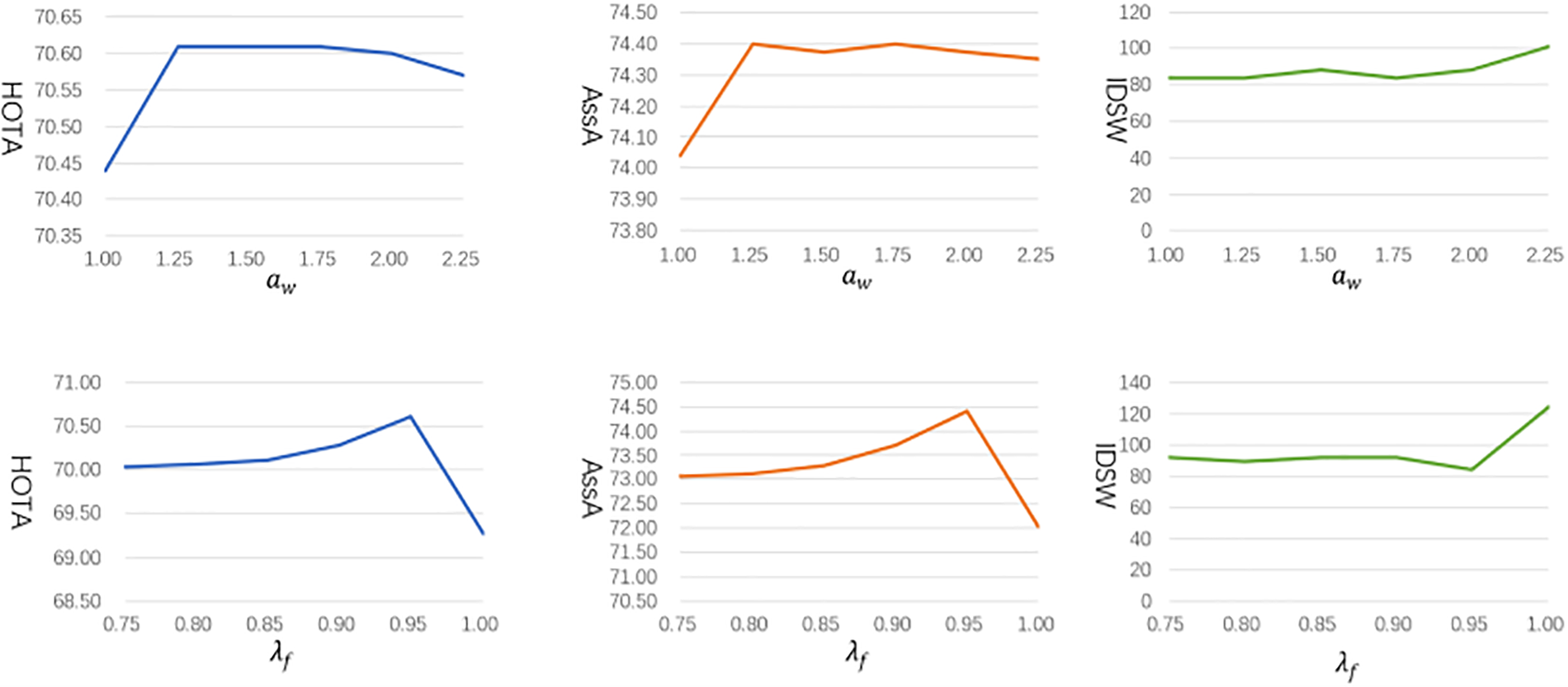
Figure 6: Study for the parameter of the adaptive weight
The FPS is measured with NVIDIA GeForce RTX 3080Ti GPU. The FPS of the proposed is analyzed on the test set of MOT17 and MOT20, and the results are represented in Fig. 7. MSFF-FPN represents a multi-scale feature fusion module combined with the baseline, whereas LQA denotes a low-quality target association strategy without the MSFF-FPN, also combined with the baseline. For MOT17, from Fig. 7a, MSFF-FPN exhibits relatively lower operational efficiency, but LQA demonstrates a comparative advantage in operational efficiency, achieving increased FPS. Overall, LQTTrack enhances performance without imposing additional computational burdens. For MOT20, from Fig. 7b, the effect of MSFF-FPN and LQA on FPS is similar to the MOT17 sets. However, LQTTrack exhibits relatively lower operational efficiency. Substantially, MSFF-FPN exhibits relatively lower operational efficiency, but LQA demonstrates a comparative advantage in operational efficiency, achieving increased FPS. This is primarily due to the increased computational complexity resulting from feature fusion while enhancing model performance and reducing processing speed. We will also focus on optimizing the efficiency of LQTTrack in our next phase of work.
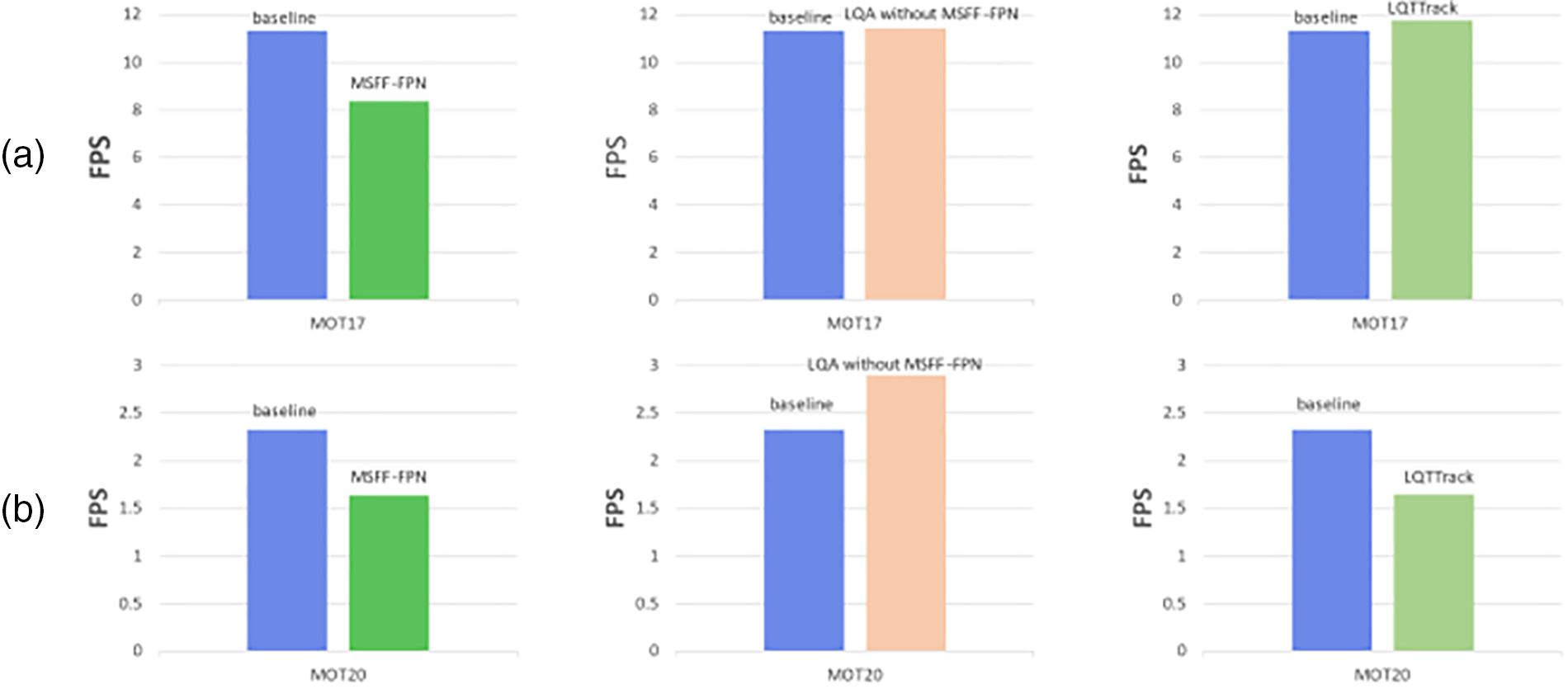
Figure 7: FPS of the method on the test sets of MOT17 and MOT20. (a) represents the FPS performance comparison of each module on the MOT17 dataset, (b) represents the FPS performance comparison of each module on the MOT20 dataset
In this work, we present an effective method LQTTrack for multi-object tracking with low-quality. LQTTrack is very effective in occlusion with the help of low-quality association schemes and NWD and feature fusion, enhancing the accuracy and robustness of multi-object tracking. We have verified the effectiveness of our method on MOT17, MOT20, and DanceTrack benchmarks. In the future, we will perform additional research on feature extraction and data association techniques to enhance the outcomes of multi-object tracking.
Acknowledgement: The authors would like to express our sincere gratitude and appreciation to each other for our combined efforts and contributions throughout the course of this research paper.
Funding Statement: This research was supported by the National Natural Science Foundation of China (No. 62202143) and Key Research and Promotion Projects of Henan Province (Nos. 232102240023, 232102210063, 222102210040).
Author Contributions: The authors confirm contribution to the paper as follows: study conception and design: Suya Li, Ying Cao; data collection: Xin Xie; analysis and interpretation of results: Hengyi Ren, Dongsheng Zhu; draft manuscript preparation: Suya Li, Ying Cao. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data will be available from the corresponding author upon reasonable request.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare that they have no conflicts of interest.
References
1. L. Jiao, D. Wang, Y. Bai, P. Chen, and F. Liu, “Deep learning in visual tracking: A review,” IEEE Trans. Neural Netw. Learn. Syst., vol. 34, no. 9, pp. 5497–5516, 2023. doi: 10.1109/TNNLS.2021.3136907. [Google Scholar] [CrossRef]
2. S. Hassan, G. Mujtaba, A. Rajput, and N. Fatima, “Multi-object tracking: A systematic literature review,” Multimed. Tools Appl., vol. 83, no. 14, pp. 43439–43492, 2024. doi: 10.1007/s11042-023-17297-3. [Google Scholar] [CrossRef]
3. A. Bewley, Z. Ge, L. Ott, F. Ramos, and B. Upcroft, “Simple online and realtime tracking,” in 2016 IEEE Int. Conf. Image Process., Phoenix, AZ, USA, 2016, pp. 3464–3468. [Google Scholar]
4. N. Wojke, A. Bewley, and D. Paulus, “Simple online and realtime tracking with a deep association metric,” in 2017 IEEE Int. Conf. Image Process., Beijing, China, 2017, pp. 3645–3649. [Google Scholar]
5. Y. Zhang et al., “ByteTrack: Multi object tracking by associating every detection box,” in Comput. Vis.– European Conf. Comput. Vis. (ECCV) 2022, Israel, 2022, pp. 1–21. [Google Scholar]
6. Y. Du et al., “StrongSORT: Make deepsort great again,” IEEE Trans. Multimed., vol. 25, pp. 8725–8737, 2023. [Google Scholar]
7. J. Peng et al., “Chained-tracker: Chaining paired attentive regression results for end-to-end joint multiple-object detection and tracking,” in Eur. Conf. Comput. Vis. 2020, Glasgow, UK, 2020, pp. 145–161. [Google Scholar]
8. Y. Zhang, C. Wang, X. Wang, W. Zeng, and W. Liu, “FairMOT: On the fairness of detection and re-identification in multiple object tracking,” Int. J. Comput. Vision., vol. 129, no. 11, pp. 3069–3087, 2021. doi: 10.1007/s11263-021-01513-4. [Google Scholar] [CrossRef]
9. N. Aharon, R. Orfaig, and B. -Z. Bobrovsky, “BoT-SORT: Robust associations multi-pedestrian tracking,” 2022, arXiv:2206.14651. [Google Scholar]
10. G. Maggiolino, A. Ahmad, J. Cao, and K. Kitani, “Deep OC-SORT: Multi-pedestrian tracking by adaptive re-identification,” in 2023 IEEE Int. Conf. Image Process. (ICIP), Kuala Lumpur, Malaysia, 2023, pp. 3025–3029. [Google Scholar]
11. C. Kim, F. Li, A. Ciptadi, and J. M. Rehg, “Multiple hypothesis tracking revisited,” in Proc. IEEE Int. Conf. Comput. Vis., Santiago, Chile, 2015, pp. 4696–4704. [Google Scholar]
12. H. Sheng, J. Chen, Y. Zhang, W. Ke, Z. Xiong and J. Yu, “Iterative multiple hypothesis tracking with tracklet-level association,” IEEE Trans. Circuits Syst. Video Technol., vol. 29, no. 12, pp. 3660–3672, 2019. doi: 10.1109/TCSVT.2018.2881123. [Google Scholar] [CrossRef]
13. T. -Y. Lin, P. Dollár, R. Girshick, K. He, B. Hariharan and S. Belongie, “Feature pyramid networks for object detection,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., Honolulu, HI, USA, 2017, pp. 2117–2125. [Google Scholar]
14. J. Wang, C. Xu, W. Yang, and L. Yu, “A normalized gaussian wasserstein distance for tiny object detection,” 2021, arXiv:2110.13389. [Google Scholar]
15. Y. Xu, Y. Ban, G. Delorme, C. Gan, D. Rus and X. Alameda-Pineda, “TransCenter: Transformers with dense queries for multiple-object tracking,” 2021, arXiv:2103.15145. [Google Scholar]
16. J. Cao, J. Pang, X. Weng, R. Khirodkar, and K. Kitani, “Observation-centric SORT: Rethinking sort for robust multi-object tracking,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit, Vancouver, BC, Canada, 2023, pp. 9686–9696. [Google Scholar]
17. A. Milan, L. Leal-Taixé, I. Reid, S. Roth, and K. Schindler, “MOT16: A benchmark for multi-object tracking,” 2016, arXiv:1603.00831. [Google Scholar]
18. P. Dendorfer et al., “MOT20: A benchmark for multi object tracking in crowded scenes,” 2020, arXiv:2003.09003. [Google Scholar]
19. P. Sun et al., “DanceTrack: Multi-object tracking in uniform appearance and diverse motion,” in 2022 IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), New Orleans, LA, USA, 2022, pp. 20961–20970. [Google Scholar]
20. Y. Dai, Z. Hu, S. Zhang, and L. Liu, “A survey of detection-based video multi-object tracking,” Displays, vol. 75, no. 5, 2022, Art. no. 102317. doi: 10.1016/j.displa.2022.102317. [Google Scholar] [CrossRef]
21. Z. Pang, Z. Li, and N. Wang, “SimpleTrack: Understanding and rethinking 3D multi-object tracking,” in Comput. Vis.–ECCV 2022 Workshops, Tel Aviv, Israel, 2022, pp. 680–696. [Google Scholar]
22. H. Luo, Y. Gu, X. Liao, S. Lai, and W. Jiang, “Bag of tricks and a strong baseline for deep person re-identification,” in 2019 IEEE/CVF Conf. Comput. Vis. Pattern Recognit. Workshops (CVPRW), Long Beach, CA, USA, 2019, pp. 1487–1495. [Google Scholar]
23. K. Zhou, Y. Yang, A. Cavallaro, and T. Xiang, “Omni-scale feature learning for person re-identification,” in 2019 IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Seoul, Republic of Korea, 2019, pp. 3701–3711. [Google Scholar]
24. J. Seidenschwarz, G. Brasó, V. C. Serrano, I. Elezi, and L. Leal-Taixé, “Simple cues lead to a strong multi-object tracker,” in 2023 IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Vancouver, BC, Canada, 2023, pp. 13813–13823. [Google Scholar]
25. D. Stadler and J. Beyerer, “Modelling ambiguous assignments for multi-person tracking in crowds,” in 2022 IEEE/CVF Winter Conf. Appl. Comput. Vis. (WACV), Waikoloa, HI, USA, 2022, pp. 133–142. [Google Scholar]
26. K. Yi et al., “UCMCTrack: Multi-object tracking with uniform camera motion compensation,” in Proc. AAAI Conf. Artif. Intell., Vancouver, BC, Canada, 2024, pp. 6702–6710. [Google Scholar]
27. H. -N. Hu, Y. -H. Yang, T. Fischer, T. Darrell, F. Yu and M. Sun, “Monocular quasi-dense 3D object tracking,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 2, pp. 1992–2008, 2023. doi: 10.1109/TPAMI.2022.3168781. [Google Scholar] [CrossRef]
28. T. Fischer et al., “QDTrack: Quasi-dense similarity learning for appearance-only multiple object tracking,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 12, pp. 15380–15393, 2023. doi: 10.1109/TPAMI.2023.3301975. [Google Scholar] [CrossRef]
29. T. Keawboontan and M. Thammawichai, “Toward real-time UAV multi-target tracking using joint detection and tracking,” IEEE Access, vol. 11, pp. 65238–65254, 2023. doi: 10.1109/ACCESS.2023.3283411. [Google Scholar] [CrossRef]
30. A. Psalta, V. Tsironis, and K. Karantzalos, “Transformer-based assignment decision network for multiple object tracking,” Comput. Vis. Image Understanding, vol. 241, 2024, Art. no. 103957. doi: 10.1016/j.cviu.2024.103957. [Google Scholar] [CrossRef]
31. J. Hyun, M. Kang, D. Wee, and D. -Y. Yeung, “Detection recovery in online multi-object tracking with sparse graph tracker,” in 2023 IEEE/CVF Winter Conf. Appl. Comput. Vis. (WACV), Waikoloa, HI, USA, 2023, pp. 4839–4848. [Google Scholar]
32. B. -T. Vo and B. -N. Vo, “Labeled random finite sets and multi-object conjugate priors,” IEEE Trans. Signal Process, vol. 61, no. 13, pp. 3460–3475, 2013. doi: 10.1109/TSP.2013.2259822. [Google Scholar] [CrossRef]
33. X. Xue, S. Huang, J. Xie, J. Ma, and N. Li, “Resolvable cluster target tracking based on the DBSCAN clustering algorithm and labeled RFS,” IEEE Access, vol. 9, pp. 43364–43377, 2021. doi: 10.1109/ACCESS.2021.3066629. [Google Scholar] [CrossRef]
34. L. Van Ma, T. T. D. Nguyen, C. Shim, D. Y. Kim, N. Ha and M. Jeon, “Visual multi-object tracking with re-identification and occlusion handling using labeled random finite sets,” Pattern Recognit., vol. 156, no. 13, 2024, Art. no. 110785. doi: 10.1016/j.patcog.2024.110785. [Google Scholar] [CrossRef]
35. H. Rezatofighi, N. Tsoi, J. Gwak, A. Sadeghian, I. Reid and S. Savarese, “Generalized intersection over union: A metric and a loss for bounding box regression,” in 2019 IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Long Beach, CA, USA, 2019, pp. 658–666. [Google Scholar]
36. J. Kong, E. Mo, M. Jiang, and T. Liu, “MOTFR: Multiple object tracking based on feature recoding,” IEEE Trans. Circuits Syst. Video Technol., vol. 32, no. 11, pp. 7746–7757, 2022. doi: 10.1109/TCSVT.2022.3182709. [Google Scholar] [CrossRef]
37. W. Feng, L. Lan, Y. Luo, Y. Yu, X. Zhang and Z. Luo, “Near-online multi-pedestrian tracking via combining multiple consistent appearance cues,” IEEE Trans. Circuits Syst. Video Technol., vol. 31, no. 4, pp. 1540–1554, 2021. doi: 10.1109/TCSVT.2020.3005662. [Google Scholar] [CrossRef]
38. H. Zhang et al., “ResNeSt: Split-attention networks,” in 2022 IEEE/CVF Conf. Comput. Vis. Pattern Recognit. Workshops (CVPRW), New Orleans, LA, USA, 2022, pp. 2735–2745. [Google Scholar]
39. C. Xu, J. Wang, W. Yang, H. Yu, L. Yu and G. -S. Xia, “Detecting tiny objects in aerial images: A normalized wasserstein distance and a new benchmark,” ISPRS J. Photogramm. Remote Sens., vol. 190, no. 9, pp. 79–93, 2022. doi: 10.1016/j.isprsjprs.2022.06.002. [Google Scholar] [CrossRef]
40. E. Yu, Z. Li, S. Han, and H. Wang, “RelationTrack: Relation-aware multiple object tracking with decoupled representation,” in IEEE Trans. Multimed., 2023, vol. 25, pp. 2686–2697. [Google Scholar]
41. Q. Wang, Y. Zheng, P. Pan, and Y. Xu, “Multiple object tracking with correlation learning,” in 2021 IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Nashville, TN, USA, 2021, pp. 3875–3885. [Google Scholar]
42. P. Chu, J. Wang, Q. You, H. Ling, and Z. Liu, “TransMOT: Spatial-temporal graph transformer for multiple object tracking,” in 2023 IEEE/CVF Winter Conf. Appl. Comput. Vis. (WACV), Waikoloa, HI, USA, 2023, pp. 4859–4869. [Google Scholar]
43. K. Bernardin and R. Stiefelhagen, “Evaluating multiple object tracking performance: The clear mot metrics,” EURASIP J. Image Video Process, vol. 2008, pp. 1–10, 2008. doi: 10.1155/2008/246309. [Google Scholar] [CrossRef]
44. J. Luiten et al., “HOTA: A higher order metric for evaluating multi-object tracking,” Int. J. Comput. Vision., vol. 129, no. 2, pp. 548–578, 2021. doi: 10.1007/s11263-020-01375-2. [Google Scholar] [CrossRef]
45. E. Ristani, F. Solera, R. Zou, R. Cucchiara, and C. Tomasi, “Performance measures and a data set for multi-target, multi-camera tracking,” in Comput. Vis.–ECCV 2016 Workshops, Amsterdam, The Netherlands, 2016, pp. 17–35. [Google Scholar]
46. L. He, X. Liao, W. Liu, X. Liu, P. Cheng and T. Mei, “FastReID: A pytorch toolbox for general instance re-identification,” 2020, arXiv:2006.02631. [Google Scholar]
47. X. Zhou, V. Koltun, and P. Krähenbühl, “Tracking objects as points,” in Comput. Vis.–ECCV 2020, Glasgow, UK, 2020, pp. 474–490. [Google Scholar]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools