
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Integrating Ontology-Based Approaches with Deep Learning Models for Fine-Grained Sentiment Analysis
1 The Knowledge-Intensive Software Engineering (NiSE) Research Group, Department of Artificial Intelligence, Ajou University, Suwon City, 16499, Republic of Korea
2 Department of Software and Computer Engineering, Ajou University, Suwon City, 16499, Republic of Korea
* Corresponding Author: Seok-Won Lee. Email:
Computers, Materials & Continua 2024, 81(1), 1855-1877. https://doi.org/10.32604/cmc.2024.056215
Received 17 July 2024; Accepted 20 September 2024; Issue published 15 October 2024
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Although sentiment analysis is pivotal to understanding user preferences, existing models face significant challenges in handling context-dependent sentiments, sarcasm, and nuanced emotions. This study addresses these challenges by integrating ontology-based methods with deep learning models, thereby enhancing sentiment analysis accuracy in complex domains such as film reviews and restaurant feedback. The framework comprises explicit topic recognition, followed by implicit topic identification to mitigate topic interference in subsequent sentiment analysis. In the context of sentiment analysis, we develop an expanded sentiment lexicon based on domain-specific corpora by leveraging techniques such as word-frequency analysis and word embedding. Furthermore, we introduce a sentiment recognition method based on both ontology-derived sentiment features and sentiment lexicons. We evaluate the performance of our system using a dataset of 10,500 restaurant reviews, focusing on sentiment classification accuracy. The incorporation of specialized lexicons and ontology structures enables the framework to discern subtle sentiment variations and context-specific expressions, thereby improving the overall sentiment-analysis performance. Experimental results demonstrate that the integration of ontology-based methods and deep learning models significantly improves sentiment analysis accuracy.Keywords
Abbreviations
| NLP | Natural language processing |
| Bi-LSTM | Bidirectional long short-term memory |
| CNN | Convolutional neural network |
| TF-IDF | The word-frequency inverse document frequency features |
| LDA | Latent dirichlet allocation |
| LSA | Latent semantic analysis |
| doc2vec | Document to vector |
| LinearSVC | Linear support vector classifier |
Sentiment analysis, also known as opinion mining, has emerged as a critical research area in natural language processing (NLP) and computational linguistics [1]. It involves identifying, extracting, and analyzing subjective information expressed in text to discern the sentiments, opinions, attitudes, or emotions of individuals toward specific entities, topics, or events [2]. Understanding sentiment polarity and intensity is invaluable for businesses, organizations, policymakers, and researchers to gauge public opinion, assess customer satisfaction, and make informed decisions [3]. Hence, sentiment analysis spans various domains, including product reviews, social media posts, movie reviews, and restaurant feedback.
Driven by advancements in machine learning, deep learning, and semantic analysis, sentiment-analysis techniques have evolved significantly in recent years. Traditional sentiment-analysis methods often rely on lexicon-based approaches in which sentiment lexicons containing sentiment-bearing words and phrases are used to classify text into positive, negative, or neutral categories. However, lexicon-based methods face challenges in handling context-dependent sentiment expressions, sarcasm, ambiguity, and language nuances, particularly in informal text settings, such as social media and online reviews [4]. To address these challenges, researchers have explored sophisticated techniques that leverage domain-specific knowledge, semantic understanding, and contextual information [5]. Hence, ontology-based approaches are being integrated with deep learning models to enhance sentiment-analysis accuracy and robustness across diverse domains.
Although significant advances have been made in sentiment analysis, existing models often struggle with context-dependent sentiments, ambiguity, and the accurate recognition of nuanced emotions. Motivated by these challenges, this study proposes a novel framework that combines ontology-based methods with deep learning models to improve the accuracy of sentiment analysis. Unlike traditional models, our approach leverages structured domain knowledge and semantic understanding to capture complex patterns and relationships in unstructured text data. Thus, a more robust solution can be offered for fine-grained sentiment analysis in domains such as film reviews and restaurant feedback, where sentiment analysis has substantial relevance. Film reviews offer insights into audience perceptions, preferences, and critiques of movies, actors, directors, and specific aspects of filmmaking, such as cinematography, plot, acting, and soundtrack [6–9]. Similarly, restaurant feedback reflects customers’ opinions, experiences, and sentiments regarding the quality of food, services, ambience, pricing, and overall dining experience.
In this context, our research endeavors to develop and validate an integrated framework for fine-grained sentiment analysis of film reviews and restaurant feedback. This study differs from existing deep learning models because it integrates ontology-based methods that utilize structured domain knowledge with advanced deep learning techniques. Unlike traditional models that rely primarily on unstructured data, our approach systematically incorporates explicit topic recognition and domain-specific sentiment lexicons. This combination allows the model to better handle context-dependent sentiments, implicit meanings, and nuanced emotions, leading to a more accurate and robust sentiment analysis. By bridging the gap between structured knowledge and deep learning capabilities, our framework offers a novel solution that outperforms conventional methods in tasks such as fine-grained sentiment classification.
The contribution of this article is as follows:
This study constructed a detailed domain ontology model for user review data from the catering industry. This model divides the evaluation objects into coarse-and fine-grained evaluation items and systematizes six coarse-grained and 20 fine-grained evaluation objects using a tree structure. Therefore, this study proposes an explicit topic-recognition algorithm that can effectively extract explicit topics from comments.
More specifically, an emotion recognition method based on an emotion dictionary is proposed and a bidirectional long short-term memory (Bi-LSTM) network and attention mechanism are introduced to address the difficulty of recognizing complex emotional expressions. The combination of word position information, part-of-speech information, and topic information significantly improves the accuracy of emotion recognition through the optimized Bi-LSTM model.
In this study, an experimental verification using a movie review dataset was conducted, and multiple experimental comparison methods were designed. The experimental results show that ontology-based fine-grained sentiment classification achieved excellent performance in movie review sentiment analysis, particularly in feature-level sentiment analysis, in which the fusion method significantly improves the accuracy of sentiment classification.
The remainder of this paper is organized as follows. Section 2 provides a comprehensive review of related work on sentiment analysis, ontology-based methods, and deep learning models. Section 3 presents the proposed methodology and framework. Section 4 details the experimental setup, datasets, and evaluation metrics. Section 5 presents the results and analysis of the experiments. Finally, Sections 6 and 7 conclude with a summary of the findings, implications, and directions for future research.
As an important part of NLP, text sentiment analysis is of great significance in both practical applications and theoretical fields. Compared with general sentiment tendency analysis, fine-grained sentiment analysis has a finer granularity in the analysis of the evaluation object; instead of simply judging the sentiment tendency of the text, it needs to identify the specific object or attribute that the author evaluates. Compared with the general sentiment polarity judgment, in addition to the identification of sentiment polarity, another core point of fine-grained sentiment analysis is identifying the object or object attributes of the author’s expression of sentiment [10].
Topic identification plays a significant role in enhancing the accuracy and relevance of fine-grained sentiment recognition by ensuring that sentiments are appropriately contextualized. There are four primary methods for topic identification: word-frequency statistics, syntax-based methods, machine-learning methods, and ontology-based methods. Because they are less discussed and have fewer topic terms, some specific domains require specific auxiliary rules for different scenarios when employing word-frequency statistic-based approaches. Park et al. [11] took a more representative approach. In their study, nouns and noun phrases (nouns that appear in the same sentence) were used as topics. They also specified two rules to minimize false recall and chose low-frequency topics as nouns or noun phrases that were close to sentiment terms. Dependency-based syntactic analysis was employed in [12] in their investigation to enhance the process of recognizing low-frequency themes and increase the precision of topic identification. Belguith et al. [13] employed association rules to identify and recognize implicit themes. They defined particular sentiment words as the antecedents of the rule and topic words as the results of the rule, and implicit themes were found based on the association rules. A semi-supervised learning method based on a mutual self-expansion pattern was proposed by Guo [14] to identify implicit themes. This method involves mining frequent itemsets using the FP-Growth algorithm to obtain seed attribute words and then discovering new attribute words through incremental iterations. The algorithmic accuracy and avoidance of theme bias are ensured by utilizing the confidence level of the extracted words and patterns in each iteration round.
According to the current state of research, the primary issue with the existing method of topic recognition based on word-frequency data is that many nouns or noun phrases are mistakenly recognized as topic terms. This is because the method is primarily based on rules. Therefore, to reduce false recall and obtain a better recognition impact, word-frequency statistic-based topic-recognition methods must carefully create filtering rules, especially for implicit topic recognition, which has a more serious false recall problem [15].
Ontology-based approaches increase the accuracy of theme detection by identifying the evaluation object and its attributes [16], as well as determining the link between the attributes of the evaluation object. Three layers of fine-grained sentiment analysis of products were achieved by Attri et al. [17] using the product domain ontology to extract attributes and hierarchical relationships between attributes in the product ontology: overall product, attribute class, and individual attributes. An ontological approach to identify implicit themes was proposed by Wang et al. [18]. This involves building a domain ontology to classify themes and determining the collocation relationship between themes and sentiment words by mapping implicit features. However, the accuracy of using collocation relationships to identify implicit themes needs to be improved further, and the users of Chinese comments are not standardized.
Although ontologies are more difficult to solve and require more material and human resources to develop, ontology-based theme recognition techniques can help uncover themes and the relationships between them. The theme text is implied in the semantic text of a situation that is not expressed. For instance, in the review’s text, “The restaurant service is very good, but after getting off the bus, you still need to walk 108,000 miles,” the phrase “walk 108,000 miles” conveys a negative emotion related to the theme. Consequently, the semantic analysis identifies “location” as contributing to this negative sentiment.
Emotion dictionaries and machine learning are the two primary categories of emotion recognition techniques. According to the emotion dictionary-based emotion detection approach, users express their emotional inclinations using words that contain emotions [19]. For example, positive feelings can be expressed with words such as “like,” “good-looking,” and “delicious,” while negative emotions can be expressed with phrases such as “bad” and “hate.” As a result, some academics use an emotion dictionary to find the emotion words in a text, and then use that dictionary to compute the emotional tendency of individual words or phrases in the document, as well as the emotional tendency of the entire document. For instance, Jaradeh et al. [20] determined the emotion polarity by building an emotion lexicon that considers how the lexical nature of emotion words affects emotion polarity, levels the intensity of adverbial modification up or down based on the intensity of the emotion expression, and determines emotion polarity using a specific calculation rule. Some academics also contended that emotion words vary across domains and that natural language is complex. Consequently, they suggested creating emotion dictionaries automatically, even though creating comprehensive word lists for each domain requires substantial investment in both time and resources [21]. For instance, the English corpus uses the literature [2] to determine the emotional-polarity relationship between words based on conjunctions in the text. This information is then combined with word morphological characteristics such as negative form to create an emotional-polarity constraint matrix. Finally, an emotional lexicon is constructed by computing the emotional polarity of words based on mutual information. It is difficult to create distinct sentiment dictionaries for various domains. The accuracy rate of manually constructed sentiment dictionaries is high; however, the coverage of sentiment words is not sufficiently comprehensive, and the accuracy rate of automatically constructed sentiment dictionaries is not guaranteed to be high. The sentiment dictionary method yields better results for simple structures and semantic single-sentence sentiment recognition. However, even with the syntactic and grammatical structure of a document, the effect on complex text structures with multilayer semantic relationships, including multiple negations and other complex text structures, needs to be improved. It is not possible to guarantee the accuracy of automatically generated sentiment dictionaries.
The model architecture of the proposed fine-grained sentiment-analysis method for online reviews, which combines deep learning and ontology, is depicted in Fig. 1.
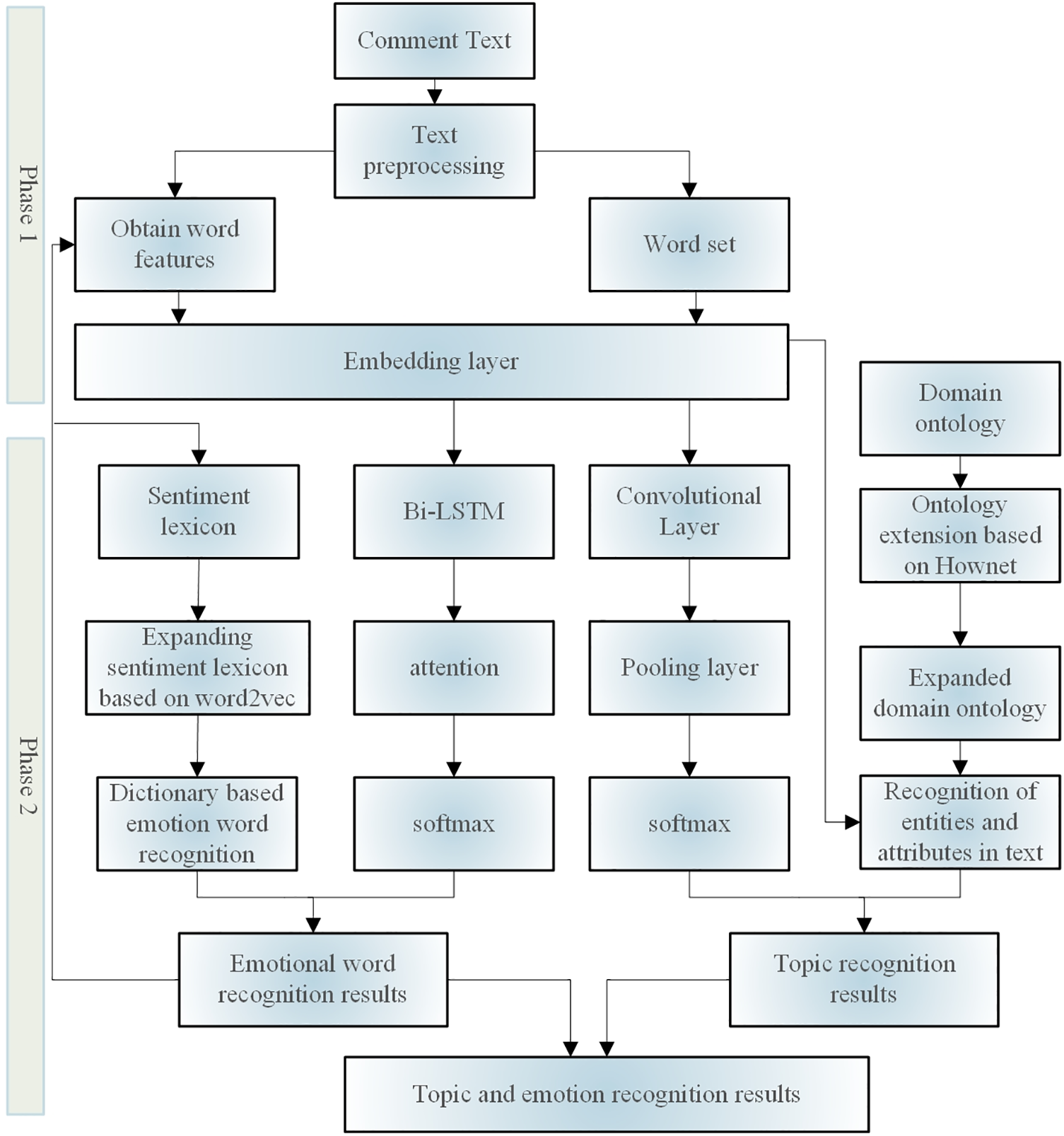
Figure 1: Framework of fine-grained sentiment-analysis model for online comments
Phase 1 involves fusion with the domain ontology to determine the topic information of the comment. We input the comment text data and then perform data preprocessing (e.g., segmentation, cleaning, and normalization), obtain vocabulary features and vocabulary sets (words with similar features) separately, and input the preprocessed data into the embedding layer. The textual content of a broad comment encompasses several themes: topics with distinct topic words are referred to as explicit topics, and topics without specific topic words but still containing semantic information about the topic are referred to as implicit topics. The writer creates a domain ontology and expands it semantically to identify explicit subjects in the written content. Simultaneously, a convolutional neural network (CNN) was employed to extract the local characteristics of the text to pinpoint its implicit themes and precisely locate both explicit and implicit themes.
Phase 2 involves determining a topic’s explicit sentiment using a sentiment lexicon and sentiment judging guidelines. The deep learning model incorporates the sentiment lexicon to recognize textual sentiment words, degree words, negative words, and non-sentiment words, as well as to extract word features. To learn information about sentiment words, degree words, and negative words surrounding the topic words in the neural network, a word-embedding model is built based on the type of words and position function for the topic information. The text is processed using a Bi-LSTM network to extract semantic information from the entire text. Simultaneously, the attention mechanism enhances the extraction of important information and resolves long-term dependency issues in lengthy texts. During the experiment, we found that the Bi-LSTM+attention had very little effect compared to the pure Bi-LSTM+Softmax. This is because the pre-trained model can learn discriminative features after fine-tuning, resulting in an increase in the attention layer, which has almost no effect on the entity recognition results.
However, a good attention transition matrix is helpful for prediction and can add constraints to the final predicted labels to ensure the rationality of the prediction results. After further experiments, it was found that by adjusting the learning rates of Bi-LSTM and the attention layer, such as using a smaller learning rate for Bi-LSTM and a learning rate 100 times higher for the attention layer than for Bi-LSTM, the effect of Bi-LSTM+attention was significantly improved compared with that of Bi-LSTM+Softmax. In addition, based on the traditional Named entity recognition model LSTM+attention, we also tried Bi-LSTM+attention, but the effect slightly decreased and the prediction time increased; therefore, we did not introduce the LSTM layer in the end. The viewpoint extraction task, also known as target-oriented opinion word extraction in the industry, aims to extract viewpoint words corresponding to a given target from comment sentences. Viewpoint extraction can also be seen as a Named entity recognition task, but if a comment involves multiple entities and viewpoints, accurately extracting all “entity viewpoint” relationships is a technical challenge. Drawing on the ideas of machine reading comprehension tasks, a reasonable query was constructed to introduce prior knowledge and assist with viewpoint extraction.
3.1 Explicit Topic Identification Based on Domain Ontology
3.1.1 Domain Ontology Construction
Fig. 2 illustrates the construction of an ontology model for the catering domain based on Meituan consumer review dataset. The assessment items are split into two tiers based on varying amounts of detail: (1) coarse-grained evaluation objects, such as dishes, services, locations, and other review text elements; (2) fine-grained evaluation objects, such as “service” attributes, “waiting time in the queue,” “attitude of service staff,” and other fine-grained elements. With the evaluation object serving as the root node and comprising six coarse-grained and twenty fine-grained evaluation objects, the evaluation object system follows a tree structure. The last leaf node represents the sentiment polarity of the subject, whereas the null node is a virtual node, as shown in Fig. 2.
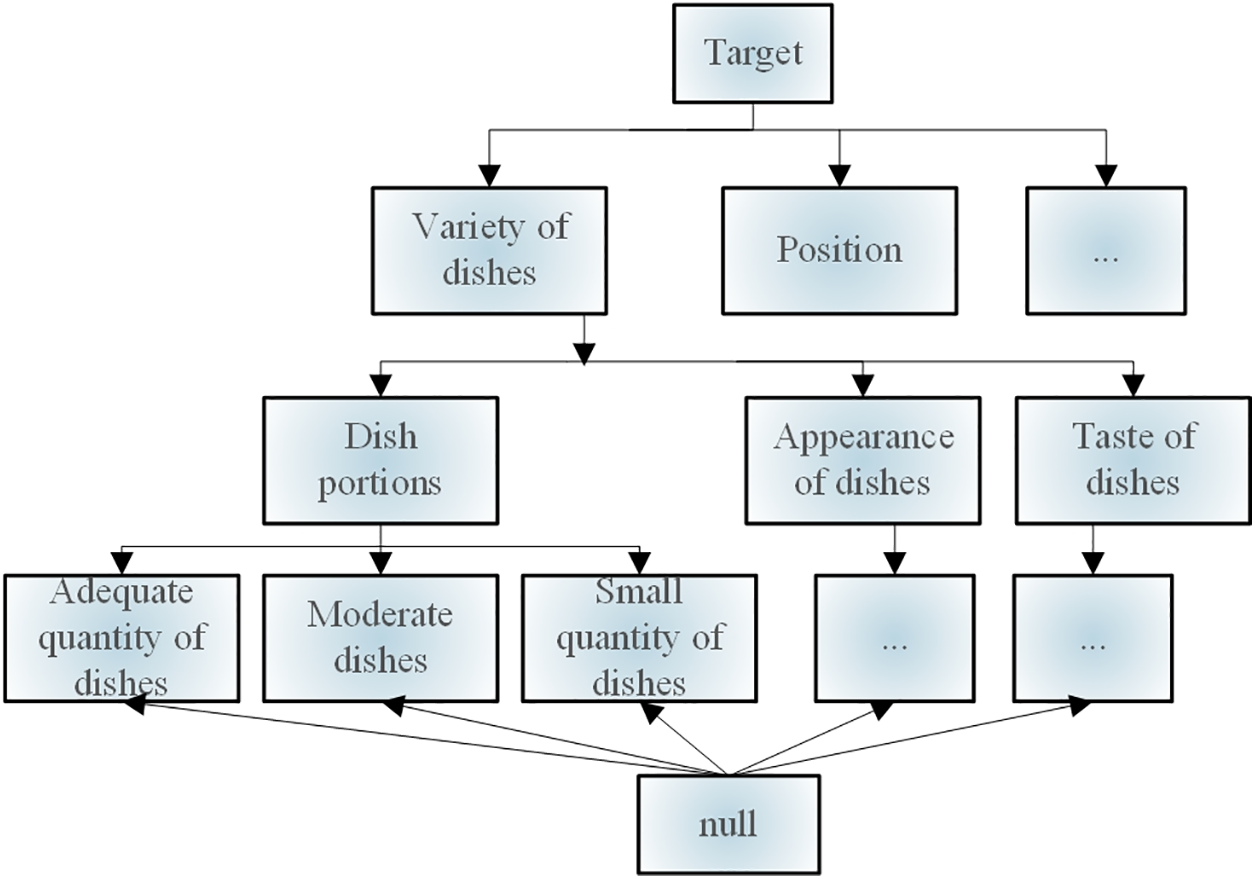
Figure 2: Ontology model in the catering industry
3.1.2 Explicit Subject Recognition Algorithms
The following ontology-based explicit topic-recognition algorithm was created based on the ontology model of the catering domain:

The primary function of the algorithm is to determine whether a comment sentence contains a subject feature word. It is presumed that a topic is stated if it contains a topic feature term; otherwise, it is assumed that the related topic is not involved. The viability of the method depends on how well the words are separated and how comprehensive the feature word collection is. The author has made two changes to improve the accuracy of identifying explicit topics: first, a custom dictionary is created for the comment data; second, the matching requirement of the feature word set is loosened, eliminating the need for two words to match. The training corpus is segmented before creating the user-feature word set. Next, 2- and 3-gram feature word sequences are created. Next, the sequences are counted and filtered using the number of occurrences greater than the threshold N as alternatives. Finally, the user-defined feature word set is created manually through filtering. The judgment operation for the feature words
where
Algorithm 1 identifies explicit topics in comments based on the ontology files created. Nevertheless, not all themes are fully covered by the feature word set because of the intricacy of the comment data. In addition to the issue of coverage, another concern with review data is implicit expression. For instance, the comment “The chef of this restaurant is too stingy; the dishes do not cover the plates” implies that there are not as many dishes as there are plates, even though this is not made clear. An implicit theme recognition technique based on convolutional networks is presented to discover implicit expressions when explicit theme recognition is unable to address them.
3.2 Explicit–Implicit Theme Identification Fusion
An explicit–implicit theme recognition algorithm was built using the explicit theme recognition algorithm and implicit theme recognition algorithm. Fig. 3 illustrates the algorithm flow.
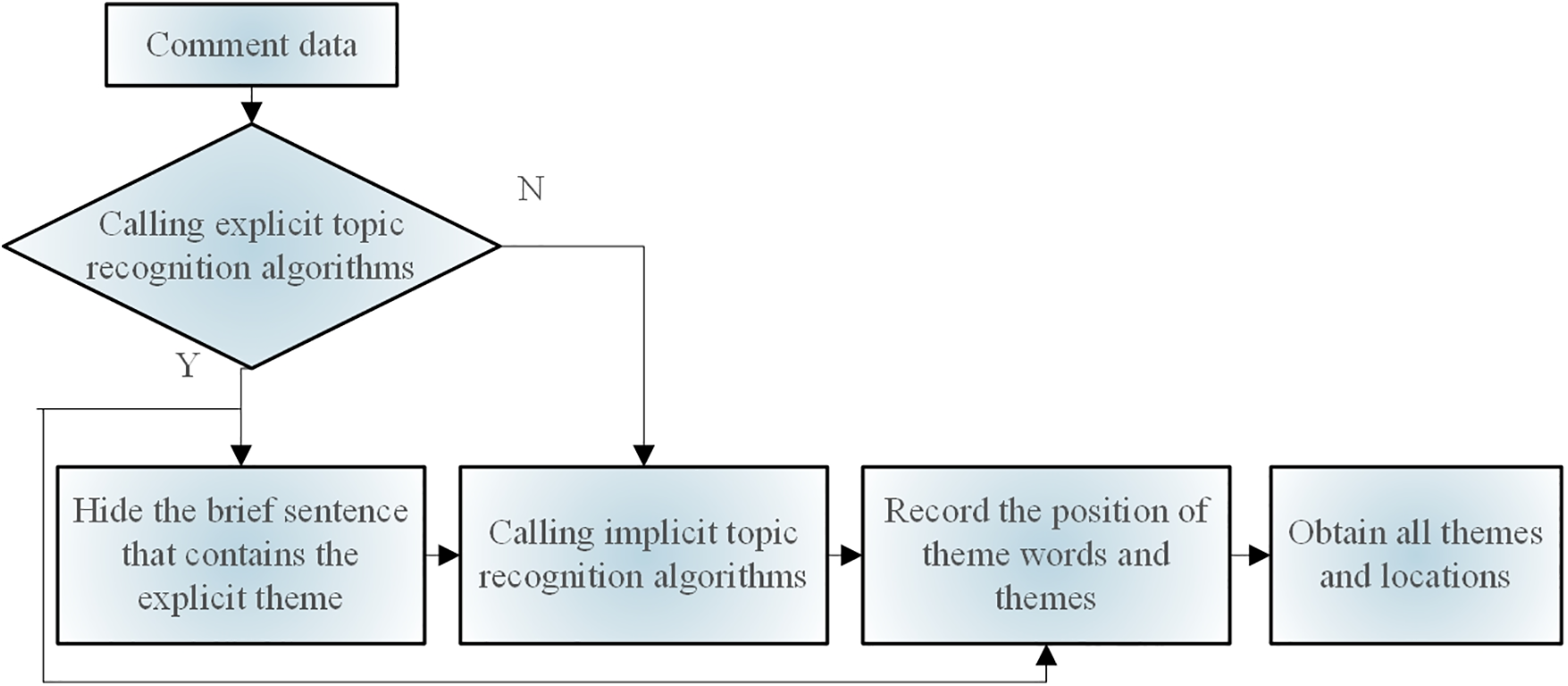
Figure 3: Explicit–implicit recognition algorithm process
First, an explicit topic identification is conducted. If the explicit topic is successfully identified, the sentence in the remark must be eliminated to prevent the explicit topic from interfering with the subsequent topic recognition. The implicit topic-recognition algorithm is typically used for topic recognition in the event that an explicit topic cannot be identified. The following two benefits belong to the algorithm that combines the CNN model and ontology method:
1. The model’s subject recognition is improved by combining ontology techniques with deep learning techniques, adding ontology-based factual knowledge to the model, and using ontology knowledge to facilitate model training.
2. Although deep learning techniques can address the issue of limited ontology feature word coverage, fusion techniques also contribute to high ontology recognition rates. This improves the model’s capacity for generalization while preserving the topic-recognition accuracy.
4.1 Construction of an Emotion Word List
The word list has been expanded to comprise the following six steps:
1) Segmentation of text on a particular topic, with sentiment words added to the lexicon as a user dictionary.
2) Construct a 2-gram word set, arrange them in reverse order of word frequency, and filter out the word sets with word frequency greater than the threshold R as alternatives.
3) Manually screen new emotion words and add synonyms and near-synonyms of emotion words as a new emotion word set.
4) Add the new emotion words to the user dictionary and repeat Steps 1)–3) until there are no new emotion words.
5) Based on the constructed word set, use word2vec to train the corpus with word vectors, and based on the sentiment words appearing in the training text, perform expansion to obtain the expanded word set K. The algorithm used to expand the sentiment word list is as follows:

6) Manually review the extended word set W to obtain the final sentiment word set.
4.2 Emotion Recognition Based on an Emotion Lexicon
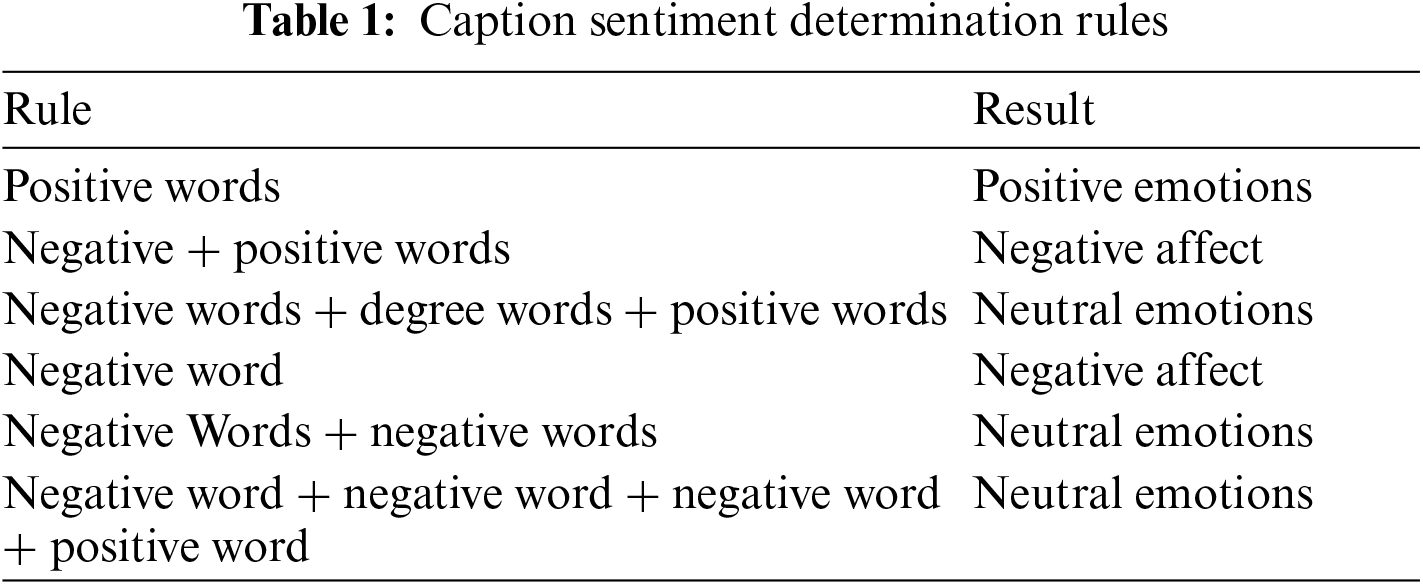
Sentiment words can be used for subject-sentiment recognition based on a created sentiment lexicon. The technique of emotion recognition based on emotion words is more straightforward and precise than more intricate ones. Based on the emotion lexicon, the author suggests a technique for recognizing emotions. Emotional polarity is determined in Stage 1 using the created assessment object ontology. A subject’s emotional tendency can be ascertained directly if the text hits the emotion feature word of the subject node in the domain ontology. In Phase 2, the emotion lexicon is employed for identification in the event that the emotion feature words in the ontology cannot be located. The topic’s emotion is first determined using emotion word determination rules, after which the topic fragment’s emotion, degree, and negative words are identified. The rules for determining emotions are displayed in Table 1.
4.3 CNN-Based Implicit Topic Recognition
4.3.1 Implicit Theme Identification
The implicit topic-recognition challenge is modeled using a CNN because of the following benefits: first, it can more accurately represent the text’s local semantics; second, it can integrate phrases at various levels of detail for contextual correlation; and third, it can be described at the character level without requiring word splitting. The comment data subjects are typically dispersed throughout the entire remark with strong local coherence, which aligns with the potent local feature extraction capability of the CNN model. One of the best methods for applying CNN to the text domain is TextCNN. An implicit topic model is created based on the TextCNN model. To enhance the model’s ability to identify an implicit topic, even in the absence of explicit feature words, special characters are first used to randomly mask the explicit feature words in the topic while entering the comment text. This allows the model to identify topics based on semantic information within the context. Second, the size and step size of the CNN convolutional kernel are increased in the design to capture local topic description information during the convolutional operation, given that descriptive language is typically employed to represent implicit topics instead of explicit feature words. Convolution kernel sizes of two or three with a step size of one are typically used. The step size is set to 3 and 4, and convolution kernels of sizes 4, 5, and 6 are introduced into the suggested structure.
4.3.2 Implicit Thematic Text Division
To prevent topic overlap and prepare for the training of emotion recognition models, a topic fragment localization approach is proposed to identify text segments related to a given topic. As illustrated in Fig. 3, the algorithm is divided into two phases: prediction and training. Initially, an explicit topic-recognition algorithm is used in the training phase. If the topic is successfully identified, the training text is the fragment containing the topic; otherwise, the training text is chosen based on the length of the comments. The topic segment is found in the model prediction stage using a sliding window with a 200 character size and a 100 character sliding step. There are 200 characters in the window size and 100 characters in the sliding step. There can be no more than five windows, owing to computational constraints and the real distribution of comment lengths. The primary function of the algorithm is to identify text-topic segments in the first four windows by applying the conventional sliding window method. Text fragments are carried forward from the conclusion of the text to the final window to maximize the coverage of the complete comment text. Every text snippet is subjected to model predictions, and the snippet with the highest score is designated as the topic snippet, as shown in Fig. 4.
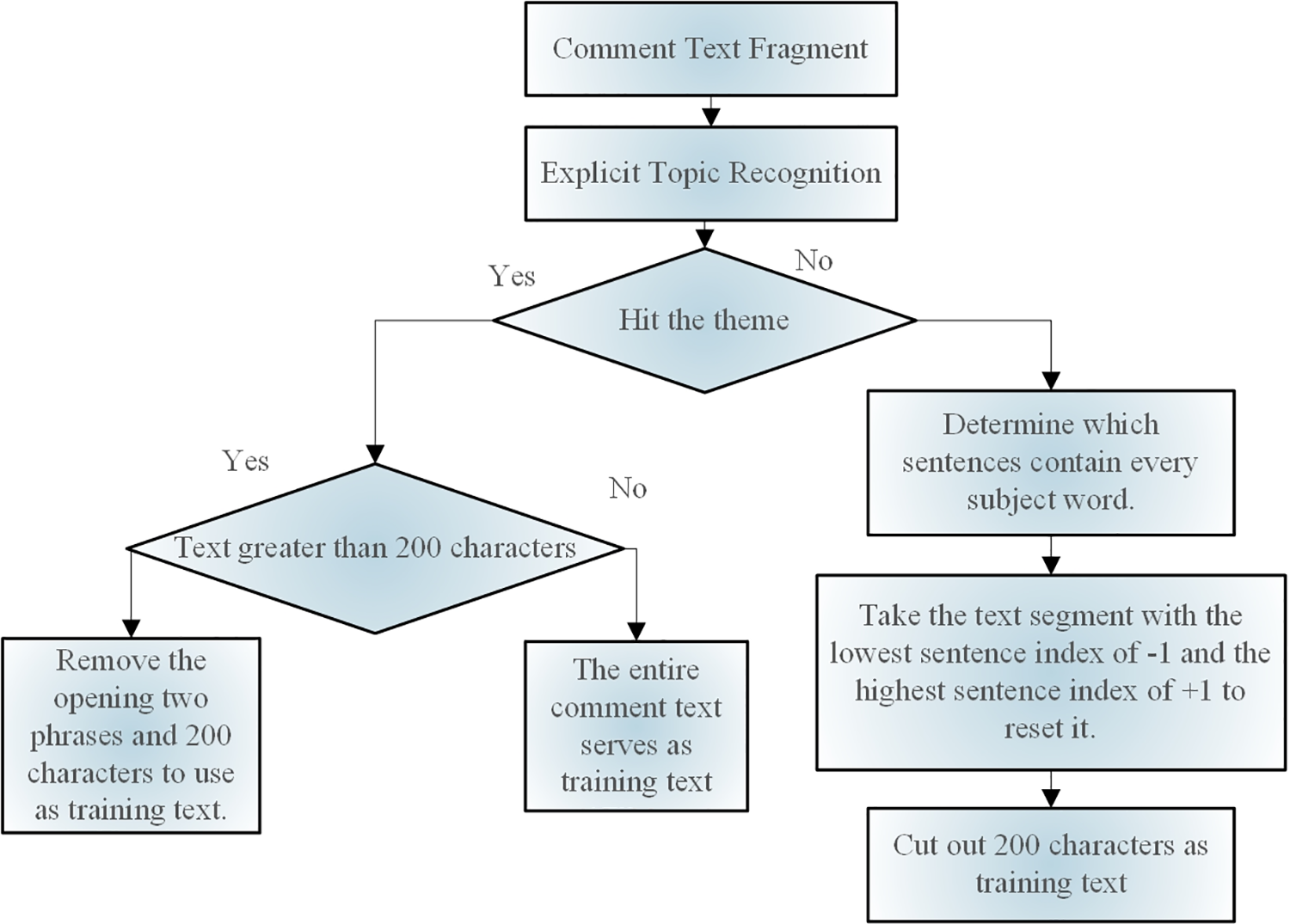
Figure 4: Theme text division process during training stage
4.4 Emotion Recognition Based on Bi-LSTM and Attention Mechanism
Messages with overt emotional content can be recognized by emotion detection algorithms, whereas writings with more subtle emotional content may be difficult to detect or even misinterpreted by these systems. For instance, “The food in this house is not as good as the one I made myself; I have never eaten that that is so delicious.” Although this line conveys a negative opinion, the algorithm mentioned above can mistakenly interpret the comment as neutral or favorable. By themselves, sentiment dictionaries are insufficient for determining a comment’s sentiment tendency; therefore, deep learning models can be used to make targeted enhancements that increase the accuracy of sentiment recognition.
The following four extra pieces of information must be considered in a sentiment-analysis task, in addition to sentiment words, to assess the sentiment tendency of a sentence:
1) Word placement. The placement of a word affects semantic statements. For instance, there is a huge difference in meaning between “this restaurant is far away” and “this restaurant is not far away.” Although the sequence model can be modeled using the LSTM model, better outcomes are frequently obtained when location information is included in word vectors using location coding.
2) Lexicality. Textual emotions are easier to recognize when lexical information is explicitly indicated. Sentences containing adverbs and adjectives are judged more strongly than sentences containing other words owing to their emotional inclinations.
3) Word category in terms of recognizing feelings, some words play a stronger role than others. These terms include sentiment words, negative words, and degree adverbs. Consequently, the input text contains word category information.
4) Theme information. Emotional tendency needs to be dependent on a specific object, and different themes have different concerns; therefore, theme information is important background information for commenting on emotion recognition.
When data are lacking, actively feeding this information into the model can help it learn more and enhance its ability to recognize emotions. In light of this, the Bi-LSTM model is suitably optimized, and Fig. 5 displays the model structure.
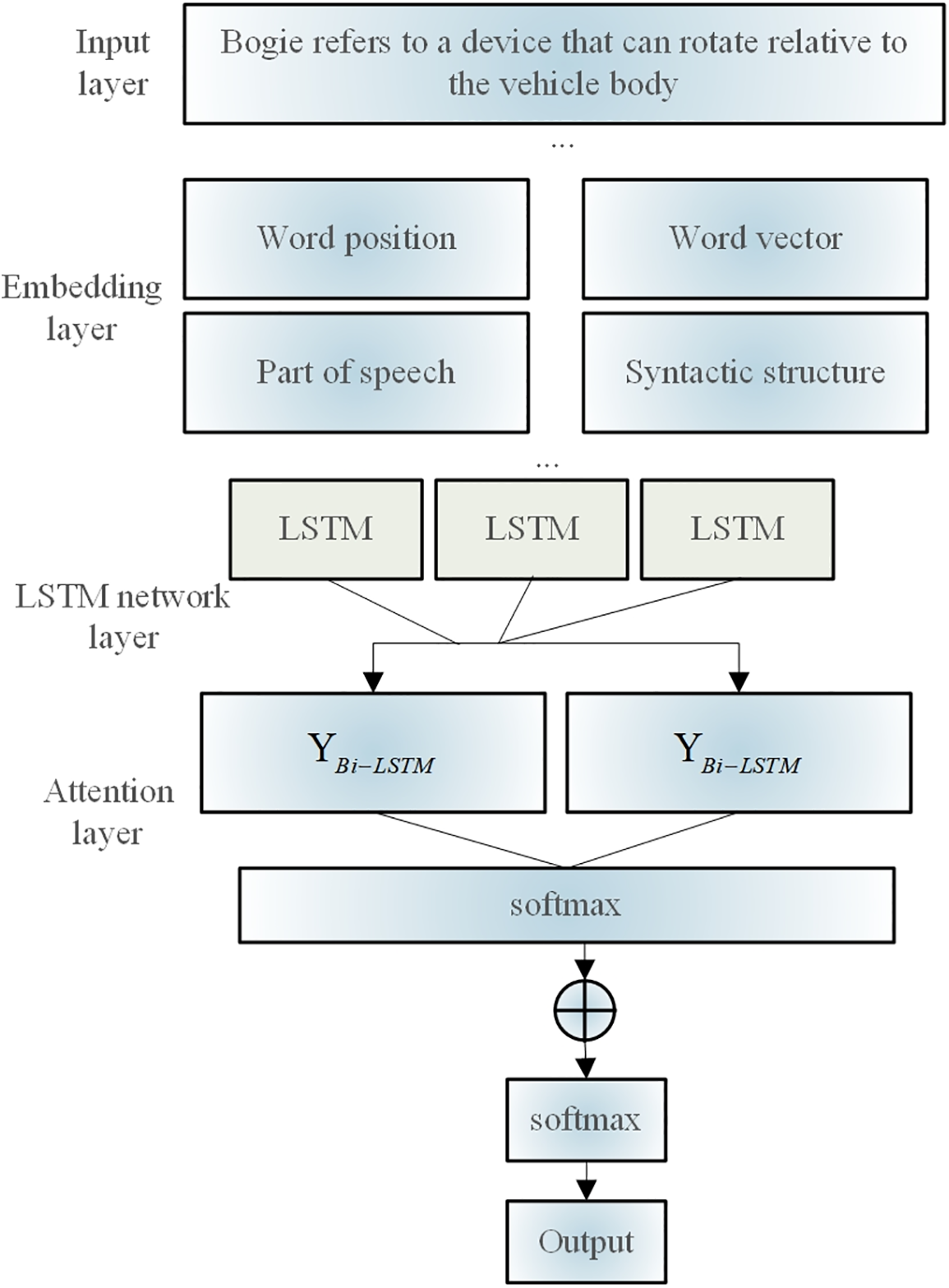
Figure 5: Affective polarity recognition model framework
First, in the input stage, word position, word characteristics, word categories, and subject information are included to compensate for any flaws that could cause inadequate feature extraction in the LSTM networks in the event of insufficient data. Second, an attention layer is added after the LSTM network layer, which helps the model capture important textual information and enhance the sentiment recognition effect of the model. Among these, topic information is obtained by the topic-recognition algorithm and incorporated into the model because different topics may have different sentiment polarities in the comment text.
4.5 Ontology-Based Features for Fine-Grained Sentiment Classification of Film Reviews
Building a movie ontological quaternion or

The word-frequency inverse document frequency features (TF-IDF) and TextRank algorithms are used to extract keywords from the preprocessed text. The intersection of keywords is considered the potential feature word to increase the representativeness of the features. A conceptual model for cinema ontology is subsequently constructed by manually screening additional keywords associated with the features. Table 3 displays the feature description of the conceptual cinema ontology model.

A conceptual model of film ontology was employed to examine the features of the films in which viewers were most interested. As it was impossible to discern preferences from neutral sentiment remarks, they were removed from the analysis.
4.5.1 Experimental Data and Preprocessing
1) Data acquisition: Recent popular films were chosen as the experimental subjects by Douban Movie, a Chinese film website with significant influence. In total, 32,762 brief online reviews were retrieved after 201 movie reviews were crawled using a web crawler. Comments containing fewer than two phrases were excluded.
2) Label annotation: Star ratings were used as the annotation information, which were classified into three sentiment intensities: 1 and 2 stars were labeled as −1, 4, 5 stars were labeled as +1, and 3 stars were labeled as 0. Randomly, 6070 of the comments were manually labeled, and the annotation was based on the ontology model constructed in the previous section for scoring the sentiments (negative: −1, positive: 1, and neutral: 0), and the linear sum of the attribute values was used as the overall sentiment tendency of the comment. A consistency test of the Kappa statistic was used to illustrate the unbiasedness of the labeled information. Statistics on the proportion of annotations show that neutral sentiments account for 34.78%, positive sentiments account for 44.12%, and negative sentiments account for 21.10%, indicating that the categories of annotations are balanced.
3) Preprocessing process: participle (jieba, stuttering participle) → de-deactivation (using own constructed deactivation lists) → lexical annotation.
4) Experimental environment: Python 3.6, PyCharm.
4.5.2 Experimental Methods and Results
In the trials, the data were divided into two sets, a 75% training set and a 25% validation set, using the F1 value as the model assessment metric. The accuracies given below correspond to the model’s F1 values on the validation set after ten-fold cross-validation.
First Experiment (dic): Making use of the sentiment dictionary method, the tagged data was used as labels and the preprocessed reviews were compared with the BosonNLP sentiment lexicon to determine the overall sentiment tendency of the movie reviews.
Second Experiment (ml): Feature engineering is a machine learning technique used to extract film features from preprocessed texts. The following are the specific concepts: The word-frequency features (TF) are extracted and then downsized to latent dirichlet allocation (LDA) features using the LDA topic model. TF-IDF are extracted and then downsized to latent semantic analysis (LSA) features using the truncated singular value decomposition method. The original data is digitalized into document to vector (doc2vec) features using the doc2vec algorithm. The doc2vec algorithm digitizes source data into doc2vec features.
The feature combination is completed by fusing the LDA, LSA, and doc2vec features, converting the resultant features into a sparse matrix, and merging them with the TF-IDF features. Finally, classification is performed using the linear support vector classifier (LinearSVC) technique.
Third Experiment (n): A technique based on neural networks was used. Daily word vectors that had already been trained were introduced, and the data were trained using the Bi-LSTM model, which was built on the open-source Kashgari framework.
Analysis of the experimental data showed that Experiment 1 (dic) had an accuracy rate of 48.7%. Overall, a coarse-grained analysis of movie reviews using simple sentiment dictionaries yielded disappointing results. The accuracy rate (ml) in Experiment 2 was 55.1%. The accuracy of the model classification improved by six. Four percentage points compared with Experiment 1 (dic). This suggests that the machine-learning-based approach can learn more characteristics from the data, but the model accuracy remained unsatisfactory.
Experiment 3 (nn) had an accuracy rate of 93.7%, representing a 38.6 percentage point improvement in the model classification accuracy rate compared to Experiment 2 (ml). Although the experimental results are more satisfactory, the current market analysis cannot be achieved by analyzing movie reviews based on the overall hierarchy.
Because of the need to label feature attribute sentiment values, the following experiments used manually labeled datasets as experimental data.
The fourth experiment (dic + tz) used the emotion lexicon method. The film ontology conceptual model was applied to match feature viewpoint pairings and calculate feature-level emotional inclinations based on Experiment 1 (dic).
Trial No. 5 (nn + tz): Neural network model with an emotional lexicon integrated. To perform feature-level sentiment analysis, the feature viewpoint pairs matched in Experiment 4 (dic + tz) were combined based on the model that performed the best overall hierarchical classification (i.e., Experiment 3 (nn)). Sentiment intensity was set as positive, negative, or neutral.
Experiment 6: Segmenting emotional intensity (nn + tz + ei). Emotion intensity segmentation was performed using the original emotion word scores in accordance with Plutchik’s multidimensional emotion model based on the Bi-LSTM model built in Experiment 5 (nn + tz). The emotions represented by the scores were categorized according to the descriptions in Section 2.2, with emotion intensity ranging from −4 to 4, and investigated at the emotion intensity level.
Analysis of the experimental findings: The average accuracy of Experiment 4 is 78.5%. It can be observed that the accuracy of sentiment classification based on the feature level is 29.8 percentage points greater than that based on the overall level when compared with Experiment 1 (dic), which also uses the sentiment dictionary technique. This demonstrates that fine-grained emotion categorization based on the feature level is more likely to recognize the emotional disposition of comments and validates the correctness of the conceptual ontology model built in this study. The average accuracy of Experiment 5 (nn + tz) is 90.2%, which is marginally below the overall hierarchy’s optimal result. However, it is 11.7 percentage points higher than that of Experiment 4’s (dic + tz) feature-level sentiment lexicon method, and the classification effect is more satisfactory. Understanding customers’ emotional preferences at each feature level of the film is made easier using feature-level sentiment analysis, which is particularly useful for market analysis. The average accuracy in Experiment 6 (nn + tz + ei) is 93.0%. Experiment 5 (nn + tz) revealed that the accuracy of the fusion algorithm with the three categories of emotion intensity was 2.8 percentage points lower than that of the recognition of emotion words with high emotion intensity. This indicates that there is still room for improvement in the classification accuracy of emotion intensity refinement; that is, multidimensional emotion intensity is conducive to achieving more accurate emotion classification.
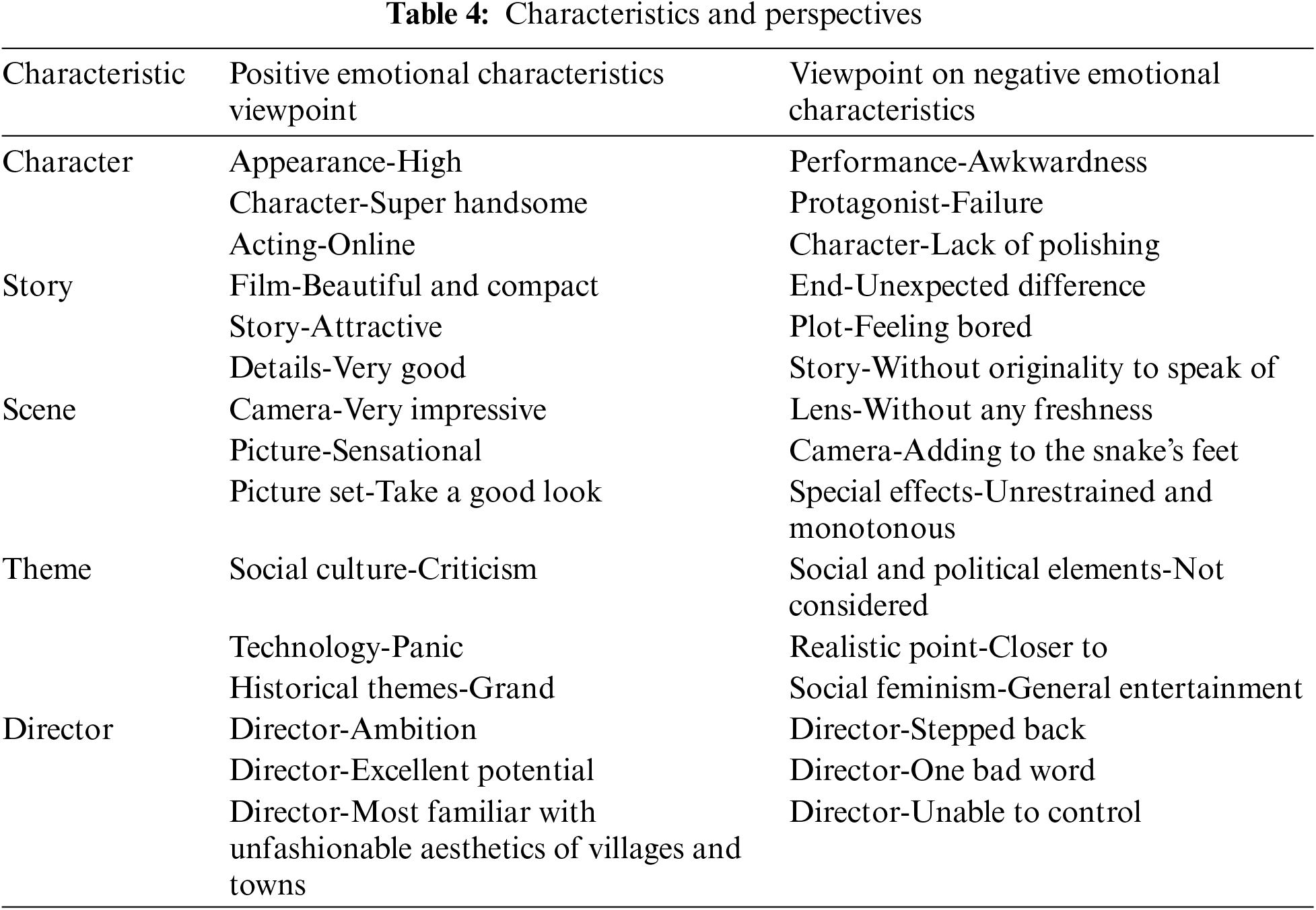
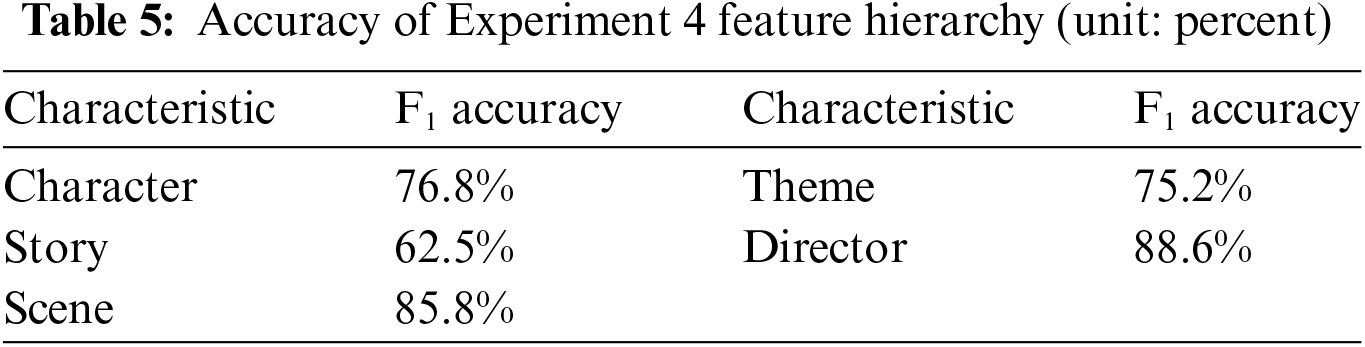
Examples of feature viewpoint pairs matched in Experiment 4 (dic + tz) are shown in Table 4, with slight adjustments to the word order for ease of reading. The accuracy of Experiment 4 at the feature level is shown in Table 5.
The experimental results are shown in Table 6.
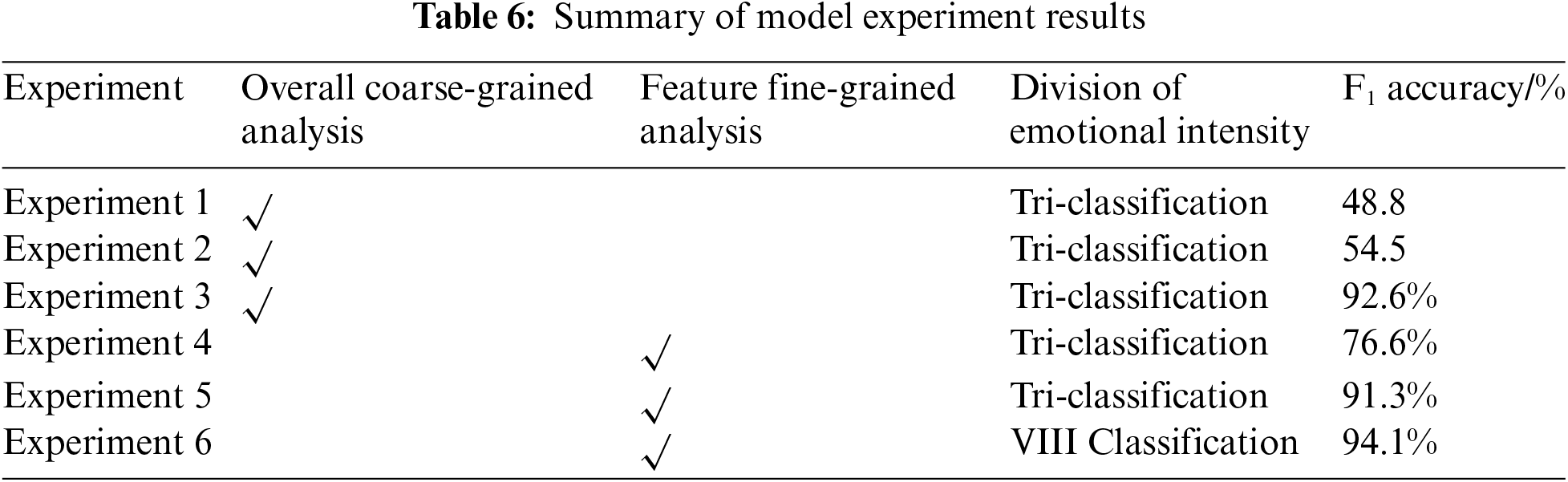
1) In terms of classifying the emotion of the overall hierarchy of film reviews, Experiment 3 (nn) performed best for the neural network-based model; nevertheless, it fails to differentiate between the emotional inclination of the film feature level. The study’s theoretical validity and practical importance are confirmed by Experiment 6 (nn + tz + ei), which produces improved classification results and accomplishes a fine-grained classification of emotions based on emotional intensity and film-review elements.
2) The comparison of the model classification results of Experiments 1 (dic), 2 (ml), and 3 (nn), as well as the comparison of the model classification results of Experiments 4 (dic + tz) and 5 (nn + tz), demonstrates how the classification accuracy based on the sentiment lexicon, machine learning, and neural network algorithms gradually increases at the same level of text granularity and sentiment intensity. This demonstrates that the more data features learned, the more complicated the model and the more accurate the categorization.
3) At different text granularity and sentiment intensity levels, even if the same algorithm is used for processing, the classification accuracy will be improved with granularity refinement. For example, in the comparison of Experiments 1 (dic) and 4 (dic + tz), the results of analyzing different text granularities with the same sentiment lexicon improved from 48. 8% to 78.5%, an increase of 29.7 percentage points in the accuracy rate. The comparison of Experiments 5 (nn + tz) and 6 (nn + tz + ei), using the same algorithm of fusing the lexicon and neural network to analyze different levels of sentiment intensity, shows an increase from 91.3% to 94.1%, with an increase of 2.8 percentage points in accuracy. The above two points illustrate the scientific validity of the sentiment-analysis task in refining text from the perspectives of text granularity and sentiment intensity.
5 Experimental Results and Analyses
5.1 MMT Catering Emotional Classification
The data processing, ontology parsing, and model training modules comprised the three primary components of the experimental system. The preprocessing of the neural network input data, including word segmentation, lexical annotation, positional annotation, denoising, and emotion word recognition, was mostly completed in the data processing module. The sentiment dictionary and catering domain ontologies are included in the ontology parsing module. The catering domain ontology was utilized for explicit subject recognition, and the sentiment dictionary ontology was employed for sentiment recognition. The topic and emotion recognition sections comprise the two sections of the model training module. CNN-based and ontology rule-based techniques have been used for topic recognition. To accomplish topic-specific emotion recognition, the topic-recognition results were loaded into an emotion recognition model. The field of emotion recognition encompasses techniques that rely on LSTM networks and ontological rules. To enhance theme emotion recognition, LSTM networks were combined with the theme recognition outcomes.
The experimental dataset comprised Meituan consumer review dataset, which was split into two subsets: the test set, which contains 2.5 million reviews, and the training set, which contains 100,000 reviews. The evaluation indices were accuracy (P), recall (R), and F1 value, and the experimental object was the dish part in order to minimize the impact of computational resources and time. Ten thousand objects constituted the experimental test set, and Table 7 displays the evaluation findings for subject recognition.
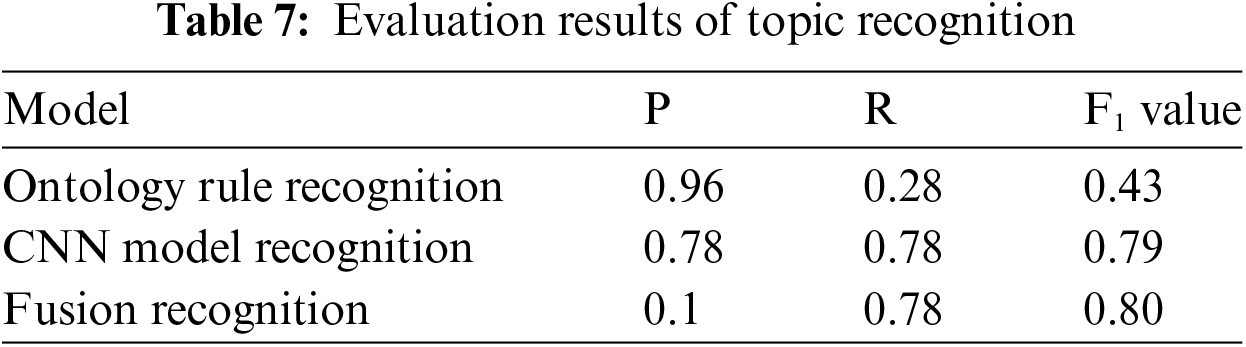
Owing to its manual creation and small number of rules, the rule-based approach requires strong matching, as shown in Table 7, which can result in high accuracy and low recall. This confirms the hypothesis that the high accuracy of rule-based approaches is beneficial. However, topic identification techniques based on neural network models have comparatively high recall and low accuracy. To achieve higher recall and better generalization, neural networks can learn independently and undertake specific semantic evaluations of the text to identify implicit themes. High rule-based accuracy can fulfill certain requirements for particular jobs. However, from the perspective of F1 value, the neural-network-based method clearly outperformed the rule-based approach. By combining the benefits of neural networks with an ontology, the fusion technique enhances the recognition results. Table 8 displays the evaluation indices for recognizing emotions.

The experimental results demonstrated that the ability of a neural network to recognize emotions can be enhanced by including topic location information, word type, lexical nature, and other data. The effect of rule-based emotion recognition is much smaller than that of rule-based theme recognition. The primary reason is that theme recognition serves as the foundation for emotion recognition; if theme recognition is flawed, emotion recognition is certain to be flawed. Chinese comment text expressions, however, are nuanced, varied, and nonstandardized. Take the example, “The picture looks like a small portion, but in fact it’s quite a lot.” The word “portion” conveys theme information; however, the sentiment and emotion of the phrase are directed toward the picture. The sentiment “very little” is aimed at the image, and it could be interpreted negatively by a rule-based recognition method. However, this line also conveys a positive attitude. It is important to consider the tone and general sentiments of text, particularly for sentiment recognition. For example, “quite a few portions” could be classified as either a positive or neutral sentiment. Consequently, text sentiment identification requires a combination of criteria, and rule-based approaches alone are not as effective.
Three separate models—Transformer [3], AdvLSTM [14], and NewsRNN [15]—are the subjects of the experiments described in this study. Each model depicts a distinct architectural solution to a given issue. The Transformer is well-known for its attention mechanism, which works well in identifying word dependencies in long sequences. An improved version of LSTM, known as AdvLSTM, may include additional gating mechanisms or attention processes to improve memory retention. NewsRNN is primarily concerned with processing sequential data such as news items, perhaps using recurrent connections designed for this type of input.
The loss function was determined during the model compilation to evaluate the difference between the probability distribution created from the current training and the actual distribution. The convergence findings are schematically represented in Fig. 6, which also provides a comparison between the reference algorithm and the approach proposed in this study. The selected metric is accuracy, and the optimizer parameter is set at 1e−5. The convergence rate is a crucial indicator of the effectiveness of an algorithm in terms of visual design. Faster convergence suggests greater effectiveness in achieving the ideal values. It is clear from the comparison results that when applied to the Meituan consumer review dataset, the proposed model shows comparatively small losses. However, there is still room for improvement in terms of convergence speed.
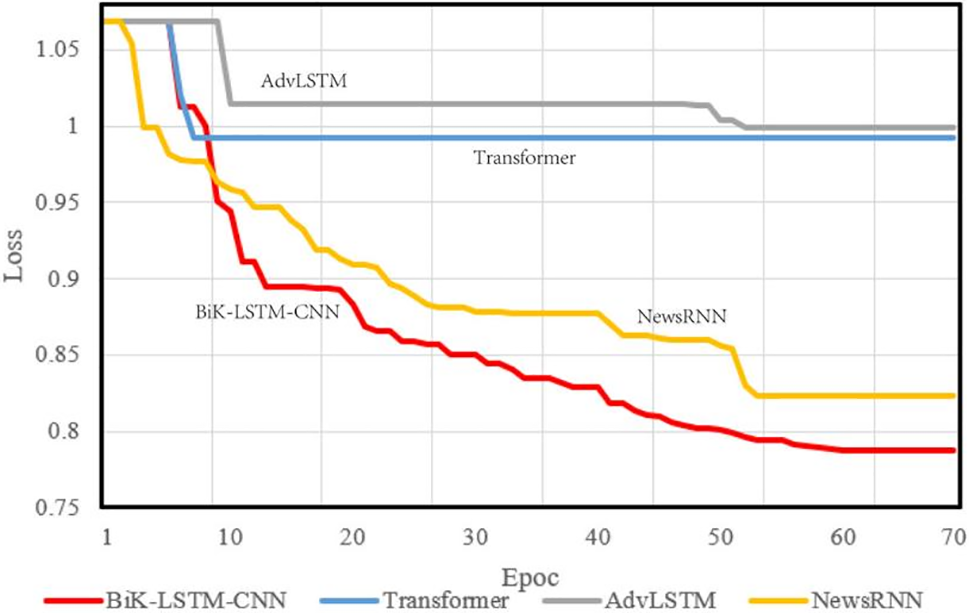
Figure 6: Training loss on the Meituan consumer review dataset
Fig. 7 shows the significant improvements over the Transformer, AdvLSTM, and NewsRNN models on the Meituan customer review dataset that the suggested model could achieve. In particular, there is an increase of 0.46% and 0.69% in the macro recall rate and increases of 0.44% and 0.57% in the macro precision rate. Additionally, the Macro F1 shows gains of 1.23%, 1.92%, and 0.52%, respectively. The Meituan consumer review dataset’s noticeable improvement is ascribed to its unbalanced sample distribution across all categories. Furthermore, the test accuracy of the NewsRNN, AdvLSTM, and Transformer models on the Meituan consumer review dataset is 81.70%, 77.55%, and 78.84%, respectively. There may be an ideal number of training iterations for each of these four models, as evidenced by the fact that their test set performance is marginally worse than their training set performance [8].
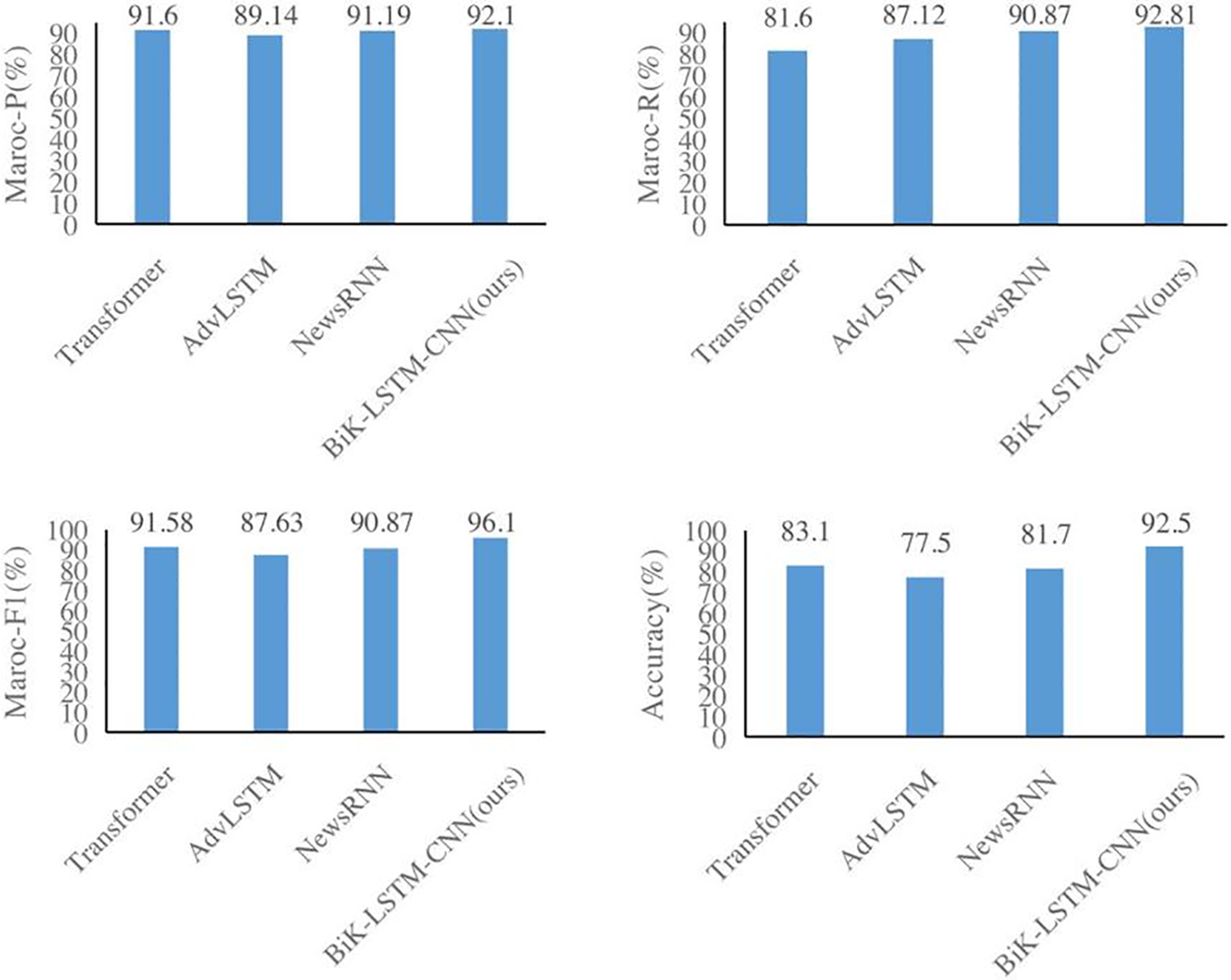
Figure 7: Experimental comparison results of the Meituan consumer review dataset
With 200 samples, the response time for the BiK-LSTM-CNN news hotspot prediction is 17 ms, as shown in Fig. 8. The Transformer has a system response time of 15 ms and requires 20 ms to anticipate the hotspot. The response time for the news hotspot prediction of the Transformer system extends to 23 ms, with a sample size of 300. The news hotspot prediction reaction time for NewsRNN was 27 ms, but the news hotspot prediction response time for the entire system remains at 20 ms. Interestingly, the RNN has the longest reaction time, which can be attributed to the model’s excessive number of parameters that caused long deduction times [9].
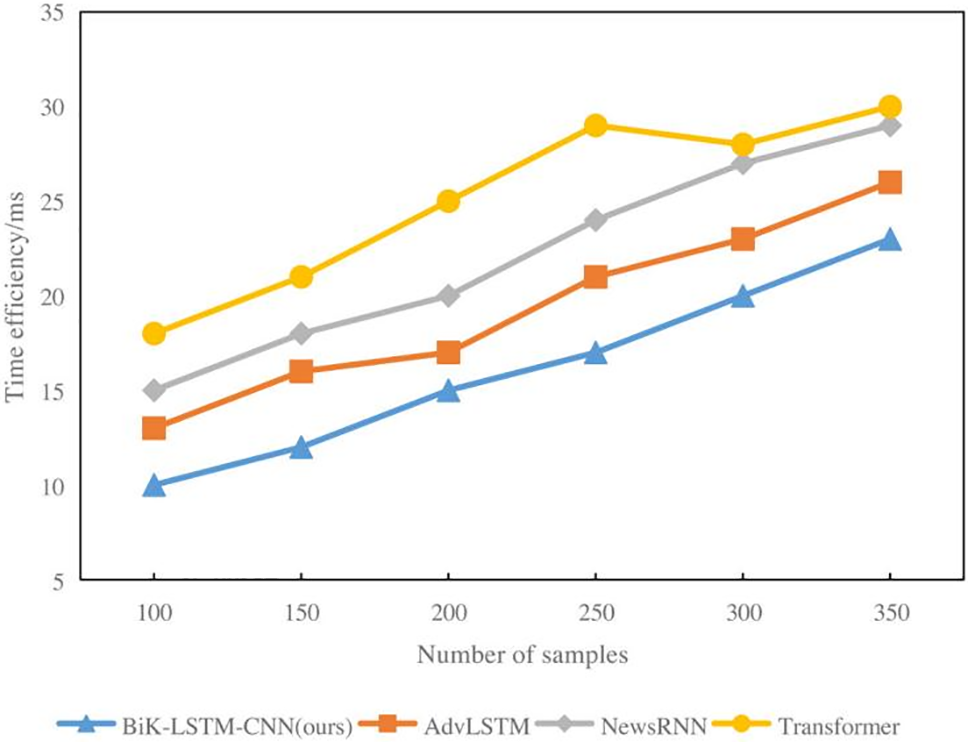
Figure 8: Time efficiency (ms) of the comparison algorithms
One of the key strengths of our approach is the integration of ontology-based methods with deep learning models. By leveraging domain-specific ontologies, the framework can identify both explicit and implicit topics more accurately, ensuring that the sentiment analysis is contextually grounded. This hybrid approach mitigates the limitations of purely statistical or machine-learning-based methods that often struggle with context-dependent sentiment expressions and nuanced languages [12].
The proposed framework is tailored to specific domains, such as film reviews and restaurant feedback. By developing domain-specific sentiment lexicons and ontologies, the framework can handle the unique vocabulary and sentiment expressions that are prevalent in these areas. This customization enhances the relevance and precision of the sentiment classification, making it applicable to real-world scenarios [18].
The use of ontology-based methods helps in systematically organizing and interpreting complex texts that can vary greatly in structure and language use. This contributes to the robustness of the model, allowing it to perform well across diverse datasets with different linguistic and thematic characteristics [3].
Although ontology-based methods offer significant benefits, the development and maintenance of domain-specific ontologies require substantial time, expertise, and resources. This limits the scalability of the approach to other domains or languages where such ontologies are not readily available or easy to construct. Despite these improvements, the identification of implicit sentiments using ontology-based methods remains a challenge. The accuracy of detecting sentiments that are not explicitly stated in the text can vary, especially in cases where implicit sentiments are highly context-dependent or culturally specific. This limitation can affect the overall performance of the framework in real-world applications where implicit sentiments play a significant role [5].
This study presents an integrated framework for fine-grained sentiment analysis of film reviews and restaurant feedback by combining ontology-based methods with deep learning models. Several key insights and conclusions have emerged from the experiments and analyses. First, the integration of ontology-based techniques with deep learning models significantly enhances the accuracy and granularity of sentiment analysis in diverse domains. By leveraging structured domain knowledge from ontologies and capturing complex patterns using deep learning models, our framework achieves robust sentiment classification across various contexts and expressions. Second, the development of domain-specific sentiment lexicons and ontology models tailored to film reviews and restaurant feedback proved crucial for effectively capturing domain-specific sentiments and nuances. The incorporation of specialized lexicons and ontology structures enables the framework to discern subtle sentiment variations and context-specific expressions, thereby improving the overall sentiment-analysis performance.
Furthermore, our experimental results demonstrate the effectiveness of the proposed framework in real-world scenarios, as evidenced by the high accuracy and performance metrics achieved across film reviews and restaurant feedback datasets. The ability of the framework to adapt to different domains and capture sentiment variations underscores its practical applicability and relevance in practical applications.
Acknowledgement: None.
Funding Statement: This work was supported by the BK21 FOUR Program of the National Research Foundation of Korea funded by the Ministry of Education (NRF5199991014091). Seok-Won Lee’s work was supported by Institute of Information & Communications Technology Planning & Evaluation (IITP) under the Artificial Intelligence Convergence Innovation Human Resources Development (IITP-2024-RS-2023-00255968) grant funded by the Korea government (MSIT).
Author Contributions: The authors confirm contribution to the paper as follows: study conception and design: Longgang Zhao, Seok-Won Lee; data collection: Longgang Zhao; analysis and interpretation of results: Longgang Zhao, Seok-Won Lee; draft manuscript preparation: Longgang Zhao, Seok-Won Lee. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: Data available on request from the authors. The data that support the findings of this study are available from the corresponding author, Seok-Won Lee, upon reasonable request.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. S. Zhu, J. Qi, J. Hu, and H. Huang, “Intelligent product redesign strategy with ontology-based fine-grained sentiment analysis,” AI EDAM, vol. 35, no. 3, pp. 295–315, 2021. doi: 10.1017/S0890060421000147. [Google Scholar] [CrossRef]
2. J. A. García, M. Cánovas, and R. Valencia, “Ontology-driven as-pect-based sentiment analysis classification: An infodemiological case study regarding infectious diseases in Latin America,” Future Gener. Comput. Syst., vol. 112, pp. 641–657, 2020. doi: 10.1016/j.future.2020.06.019. [Google Scholar] [PubMed] [CrossRef]
3. E. M. Aboelela, W. Gad, and R. Ismail, “Ontology-based approach for feature level sentiment analysis,” Int. J. Intell. Comput. Inform. Sci., vol. 21, no. 3, pp. 1–12, 2021. doi: 10.21608/ijicis.2021.77345.1094. [Google Scholar] [CrossRef]
4. A. H. Sweidan, N. El-Bendary, and H. Al-Feel, “Sentence-level aspect-based sentiment analysis for classifying adverse drug reactions (ADRs) using hybrid ontology-XLNet transfer learning,” IEEE Access, vol. 9, pp. 90828–90846, 2021. doi: 10.1109/ACCESS.2021.3091394. [Google Scholar] [CrossRef]
5. Y. Zhao, L. Zhang, C. Zeng, W. Lu, Y. Chen and T. Fan, “Construction of an aspect-level sentiment analysis model for online medical reviews,” Inform. Process. Manage., vol. 60, no. 6, 2023, Art. no. 103513. doi: 10.1016/j.ipm.2023.103513. [Google Scholar] [CrossRef]
6. A. Vijayvergia and K. Kumar, “Selective shallow models strength integration for emotion de-tection using GloVe and LSTM,” Multimed. Tools Appl., vol. 80, no. 18, pp. 28349–28363, 2021. [Google Scholar]
7. D. S. Angel, T. T. Mirnalinee, and S. M. Rajendram, “Emotion analysis on text using multiple kernel gaussian,” Neural Process. Lett., vol. 53, pp. 1187–1203, 2021. [Google Scholar]
8. R. Alatrash and R. Priyadarshini, “Fine-grained sentiment-enhanced collaborative filter-ing-based hybrid recommender system,” J. Web Eng., vol. 22, no. 7, pp. 983–1035, 2023. [Google Scholar]
9. V. C. Storey and E. H. Park, “An ontology of emotion process to support sentiment analysis,” J. Assoc. Inform. Syst., vol. 23, no. 4, pp. 999–1036, 2022. doi: 10.17705/1jais.00749. [Google Scholar] [CrossRef]
10. A. Ghorbanali and M. K. Sohrabi, “A comprehensive survey on deep learning-based ap-proaches for multimodal sentiment analysis,” Artif. Intell. Rev., vol. 56, no. Suppl 1, pp. 1479–1512, 2023. [Google Scholar]
11. E. H. Park and V. C. Storey, “Emotion ontology studies: A framework for expressing feel-ings digitally and its application to sentiment analysis,” ACM Comput. Surv., vol. 55, no. 9, pp. 1–38, 2023. doi: 10.1145/3555719. [Google Scholar] [CrossRef]
12. C. Zhang, M. Li, and D. Wu, “Federated multidomain learning with graph ensemble autoen-coder GMM for emotion recognition,” IEEE Trans. Intell. Transp. Syst., vol. 24, no. 7, pp. 7631–7641, 2022. [Google Scholar]
13. M. Belguith, C. Aloulou, and B. Gargouri, “Aspect level sentiment analysis based on deep learning and ontologies,” SN Comput. Sci., vol. 5, no. 1, 2023, Art. no. 58. doi: 10.1007/s42979-023-02362-3. [Google Scholar] [CrossRef]
14. Q. Guo, “Minimizing emotional labor through artificial intelligence for effective labor manage-ment of English teachers,” J. Comb. Math. Comb. Comput., vol. 117, pp. 37–46, 2020. doi: 10.61091/jcmcc117-04. [Google Scholar] [CrossRef]
15. A. Sharma and S. Kumar, “Machine learning and ontology-based novel semantic document indexing for information retrieval,” Comput. Ind. Eng., vol. 176, 2023, Art. no. 108940. doi: 10.1016/j.cie.2022.108940. [Google Scholar] [CrossRef]
16. S. K. Anand and S. Kumar, “Uncertainty analysis in ontology-based knowledge representation,” New Gener. Comput., vol. 40, no. 1, pp. 339–376, 2022. doi: 10.1007/s00354-022-00162-6. [Google Scholar] [CrossRef]
17. V. Attri, I. Batra, and A. Malik, “Enhancement of fake reviews classification using deep learning hybrid models,” J. Surv. Fish. Sci., vol. 10, no. 4S, pp. 3254–3272, 2023. [Google Scholar]
18. J. Wang, S. Wang, M. Lin, Z. Xu, and W. Guo, “Learning speaker-independent multimodal representation for sentiment analysis,” Inf. Sci., vol. 628, pp. 208–225, 2023. doi: 10.1016/j.ins.2023.01.116. [Google Scholar] [CrossRef]
19. J. Liu, S. Zheng, G. Xu, and M. Lin, “Cross-domain sentiment aware word embeddings for review sentiment analysis,” Int. J. Mach. Learn. Cybern., vol. 12, pp. 343–354, 2021. doi: 10.1007/s13042-020-01175-7. [Google Scholar] [CrossRef]
20. A. Jaradeh and M. B. Kurdy, “Aremotive bridging the gap: Automatic ontology augmentation using zero-shot classification for fine-grained sentiment analysis of Arabic text,” IEEE Access, vol. 11, pp. 81318–81330, 2023. doi: 10.1109/ACCESS.2023.3300737. [Google Scholar] [CrossRef]
21. T. Shaik et al., “A review of the trends and challenges in adopting natural language processing methods for education feedback analysis,” IEEE Access, vol. 10, pp. 56720–56739, 2022. doi: 10.1109/ACCESS.2022.3177752. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools