
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Cross-Target Stance Detection with Sentiments-Aware Hierarchical Attention Network
College of Cryptographic Engineering, Engineering University of PAP, Xi’an, 710086, China
* Corresponding Author: Mingshu Zhang. Email:
Computers, Materials & Continua 2024, 81(1), 789-807. https://doi.org/10.32604/cmc.2024.055624
Received 02 July 2024; Accepted 20 August 2024; Issue published 15 October 2024
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The task of cross-target stance detection faces significant challenges due to the lack of additional background information in emerging knowledge domains and the colloquial nature of language patterns. Traditional stance detection methods often struggle with understanding limited context and have insufficient generalization across diverse sentiments and semantic structures. This paper focuses on effectively mining and utilizing sentiment-semantics knowledge for stance knowledge transfer and proposes a sentiment-aware hierarchical attention network (SentiHAN) for cross-target stance detection. SentiHAN introduces an improved hierarchical attention network designed to maximize the use of high-level representations of targets and texts at various fine-grain levels. This model integrates phrase-level combinatorial sentiment knowledge to effectively bridge the knowledge gap between known and unknown targets. By doing so, it enables a comprehensive understanding of stance representations for unknown targets across different sentiments and semantic structures. The model’s ability to leverage sentiment-semantics knowledge enhances its performance in detecting stances that may not be directly observable from the immediate context. Extensive experimental results indicate that SentiHAN significantly outperforms existing benchmark methods in terms of both accuracy and robustness. Moreover, the paper employs ablation studies and visualization techniques to explore the intricate relationship between sentiment and stance. These analyses further confirm the effectiveness of sentence-level combinatorial sentiment knowledge in improving stance detection capabilities.Graphic Abstract
Keywords
Unlike target-specific stance detection, cross-target stance detection requires models with the ability to apply learned knowledge to unseen targets. In recent years, technologies such as graph neural networks, knowledge graphs, and attention mechanisms have been proposed for stance prediction [1–3], which identify social, linguistic, and political factors reflecting stance, and design new knowledge transfer architectures to efficiently capture the identified factors across targets. While these models show higher accuracy empirically compared to existing language models through selecting more representative data samples using domain knowledge, enhanced data augmentation, and transfer learning methods, the reasons for their effectiveness in cross-target stance prediction have not been fully proven.
With the rise of pre-trained language models, such as Bidirectional Encoder Representations from Transformers (BERT), which have been extensively pre-trained on large corpora of text [4–6], the effectiveness of these models in processing short texts and social media data has been demonstrated. For instance, Bello et al. [7] utilized BERT for sentiment analysis of tweets, showcasing its effectiveness in handling short and informal texts. He et al. [8] demonstrated the robustness of BERT in handling noisy external knowledge through pre-training and fine-tuning methods, showing that it can infer the correct stance even in the presence of noisy external information. However, these models still fall short in addressing the challenges of cross-target stance detection, particularly when the stance inclination towards a target heavily relies on specific contextual and emotional nuances [9,10], and their generalization ability weakens when faced with new domains.
Early methods for cross-target stance detection bridged the knowledge gap between targets by leveraging shared common words or conceptual-level knowledge [1,11,12]. Nevertheless, these methods face challenges when dealing with short, informal texts from social media and distinguishing implied stances from users, resulting in limited effectiveness. Zhang et al. [4] addressed this issue by utilizing semantic and sentiment dictionaries to facilitate knowledge transfer. Their model constructed a semantic-sentiment heterogeneous graph and learned multi-hop semantic connections through graph convolutional networks, integrating this as prior knowledge into a Bi-directional Long Short-term Memory (Bi-LSTM) stance classifier. However, sentiment in text is expressed through interactions among multiple words, and word-level analysis fails to capture these interactions effectively. Consequently, word-level sentiment knowledge is limited in judging the sentiment and stance of sentences that contain implicit opinions or require deep understanding.
In light of this, the paper proposes a new approach for cross-target stance detection, termed the Sentiment-based Hierarchical Attention Model (SentiHAN). SentiHAN introduces hierarchical attention networks and sentiment analysis modules to account for stance at the phrase level, particularly in cases where there are significant sentimental expression differences across targets. By leveraging the sentiment analysis module, SentiHAN better perceives the emotional diversity in text. This hierarchical model not only captures emotional nuances more effectively but also helps mitigate some challenging linguistic phenomena, such as irony and nuanced expressions, that are difficult to understand semantically. Additionally, the model addresses the weak transferability issues of traditional multi-layer attention networks, maintaining a high level of generalization capability when encountering new targets. Moreover, sentiment analysis provides additional interpretability, aiding in understanding how the model non-linearly determines stances based on emotional cues.
Among the existing methods for cross-target stance detection, researchers focus on improving the transferability of stance detection models by utilizing external knowledge sources such as Wikipedia and common sense, given the multidimensional characteristics of stance [4,8,13] which is especially more observed in tasks involving few-shot and zero-shot stance detection [10,14]. However, the selection and introduction of external knowledge are largely based on subjective judgment, leading to data redundancy or even the introduction of incorrect external knowledge, while models typically lack the ability to assess the validity of data. Consequently, these methods suffer from poor interpretability and inefficient training, creating challenges in enhancing model training accuracy under such approaches. Some studies have integrated sentiment analysis into stance detection to increase the accuracy and applicability of the model [13,15,16]. These models are capable of learning rich sentimental context information from text, but they may face limitations in cross-target stance detection because they are not specifically designed for this purpose. Meanwhile, the interaction between stance and sentiment is still controversial, with some studies arguing that using sentiment as a feature is inefficient [17]. However, these studies often determine sentiment relevance based on the correlation between stance and sentiment or utilize sentiment dictionaries for sentiment analysis, which may not fully capture the complex relationship between sentiment and position.
A common sentiment feature model used for stance analysis is Sent2Vec [18], which learns word embeddings based on the sentiment similarity between words, better reflecting the sentiment nuances in the text. Although this model is effective in capturing local sentiment contexts of words, it may not fully reveal the complex sentiment attitudes of the entire text. A Transferable Transformer-Based Architecture for Compositional Sentiment Semantics (SentiBERT) [19] not only considers sentiment connections between words but also integrates global sentiment information at the text level. It uses a pre-trained Bi-LSTM model to understand the sentimental diversity dependent on the document context. Furthermore, a BERT variant for sentiment prediction, a language model pre-trained on a large amount of data, can be fine-tuned on specific domain data to adapt to the problem of cross-target stance detection in comment texts. The core idea of incorporating sentiment for hierarchical perception in cross-target stance detection is to utilize the combined sentiment between short sentiment, explicitly modeling the complex underlying relationships between short sentence sentiment, short sentence semantics, and text stances towards targets, refining the information that reflects the target sentimental tendency in cross-target stance detection tasks. Accordingly, through explicit modeling at the sentiment level, the model can not only enhance its deep understanding of text granularity but also promote its adaptability and generalizability in cross-target contexts, moving closer to an efficient way for humans to handle and understand stances.
To transcend the limitations of pure textual information, researchers have begun to shift their focus to approaches that consider both textual and additional information (e.g., sentiment, semantics, and target relationships) [20]. Research on few-shot and zero-shot stance detection provides valuable insights for cross-target stance detection. For example, Luo et al. [10] explored how sentiment and common sense can be utilized to improve zero-shot stance detection, demonstrating that integrating sentiment analysis and common sense reasoning can significantly enhance stance detection performance in the absence of explicit targets. Fu et al. [21] proposed enhancing stance detection accuracy by identifying the opinion within texts, helping models better understand and handle stance relationships across different targets. Wang et al.’s [14] research showed that combining adversarial networks with external knowledge can improve the generalization ability of models on unseen targets, which is particularly important in addressing the frequent emergence of new targets in cross-target detection. Stance detection methods based on transfer learning aim to transfer the knowledge from pre-trained models and datasets to new scenarios, thereby reducing the reliance on labeled data in new contexts. This approach primarily addresses cross-target stance detection and zero/low-shot stance detection tasks. By using sentiment knowledge as an auxiliary feature for stance representation in cross-target stance detection, the models can identify sentiment polarity (positive, negative, or neutral) in text, bridging the gap between different targets. This transfer of knowledge is particularly beneficial for the following reasons:
Firstly, sentiment knowledge serves as a universally applicable semantic feature, enriching the representation learning of both the text and the target. It can act as a bridge for cross-target knowledge transfer, even across different themes [4]. For instance, whether the stance concerns political events or product reviews, the sentiment features often exhibit similar forms. These shared sentiment features enable the model to accurately capture the stance of new targets.
Secondly, the transfer of sentiment knowledge helps alleviate the issue of data scarcity for specific targets. In cross-target tasks, certain targets may have limited data. By leveraging the sentiment knowledge from existing targets, the model can still perform well even with insufficient data. This effectiveness is due to the highly generalized nature of sentiment features extracted through sentiment analysis, which can be effectively transferred across different targets.
Finally, from an information theory perspective, the transfer of sentiment features enhances the efficiency of model in utilizing information. By integrating sentiment knowledge, the model can more accurately comprehend the underlying meaning of the text instance detection, thereby reducing information uncertainty and improving detection accuracy and robustness.
2.3 Cross-Target Stance Detection
Stance detection is often regarded as a special kind of text classification task. In this field, converting words into embedding vectors is a routine task, thus general language models can be applied [22]. The complexity of cross-target stance detection requires models that provide a deep understanding of the semantics and model the dependencies between multiple targets. Cross-target stance detection is more demanding due to the nature of social media texts [23]. For example, texts are short, informal, may contain abbreviations, and are more fragmented resulting in a lack of contextual information [24]. In recent research, Ding et al. [25] proposed a Multi-Perspective Prompt Tuning (MPPT), which uses instruction-based perspectives from Pre-trained Language Models as a bridge for knowledge transfer. However, MPPT tends to exhibit potential biases inherent in large language models when applied to short texts.
Existing studies have investigated joint learning for stance and sentiment detection [13]. Sun et al. [26] proposed an LSTM-based model to capture both the stance and sentiment information of posts; however, their model did not include an attention mechanism. The lack of attentional mechanisms in text classification models hinders their ability to capture contextual relationships, focus on important information, deal with ambiguity and provide interpretability, leading to sub-optimal performance and reduced transparency. To address these limitations, Li et al. [27] enhanced their models by introducing attention mechanisms along with sentiment and stance features, which significantly improved the performance of the SemEval-16 dataset. The attention mechanism demonstrated significant results in understanding crucial parts of the text and integrating information in a hierarchical structure [15]. Especially in short texts, it can assist the model in focusing on the information that is most crucial for stance. Further research has demonstrated the effectiveness of hierarchical attention mechanisms in processing complex textual structures. Ratmele et al. [28] combined Hierarchical Attention Network (HAN) with hierarchical networks that simulate the structure of documents, validating its effectiveness through the analysis of 29,604 discussion posts. Similarly, Chanaa [29] highlighted the effectiveness of HAN in extracting opinions from unstructured reviews, particularly in capturing multi-layered information within texts.
Given these insights, this paper introduces a hierarchical perceptual mechanism that meticulously examines and integrates various levels of textual information to enhance the recognition of stances in short texts. This approach not only alleviates the reliance of the model on external knowledge and adapts to the diversity and complexity of short texts but also improves the ability of the model to recognize both implicit and explicit stance signals. Additionally, the high-level features extracted through sentiment analysis are generalizable, and by utilizing the weighted processing capabilities of attention mechanisms, the model can better adapt to new target domains, thereby enhancing its cross-target generalization capabilities.
Inspired by the Knowledge-aware Hierarchical Attention Networks (KHAN) [15], this paper proposes the SentiHAN model, which makes several improvements by fully considering the informal nature and information sparsity of short text structures:
1) External Knowledge. Instead of injecting external knowledge through knowledge graphs, the model incorporates structural sentiment, an inherent attribute of text. This approach mitigates the issue of noise while supplementing shared features.
2) Injection Method. The simple combination of inputs is expanded to complementary learning of combined semantics and combined sentiment within the multi-head attention mechanism (text-level attention layer). This enhances the ability of the model to learn transferable stance knowledge across different text structures, semantic environments, and sentiment backgrounds.
3) Cross-Target Paradigm. The hierarchical structure is retained, particularly replacing the title-level attention layer with the target-level attention layer. This emphasizes the target-driven role in cross-target stance detection tasks, ensuring the applicability of model across different target pairs.
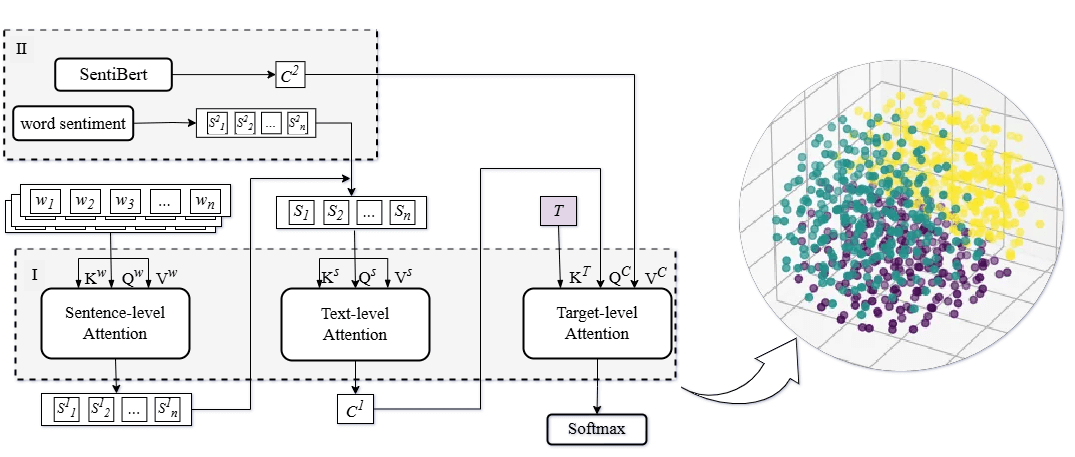
The hierarchical perception model structure proposed in this paper is illustrated in Fig. 1, encompassing: at the word level, key information is captured through word embeddings and attention mechanisms; at the sentence level, sentiment analysis and dependency relationship are combined to understand the syntactic and sentimental structure; at the target level, the focus is on identifying arguments relevant to the target. Through such multidimensional analysis, we aim to offer a comprehensive perspective for understanding and analyzing cross-target stances in short texts, significantly enhancing accuracy and reliability in practical applications.
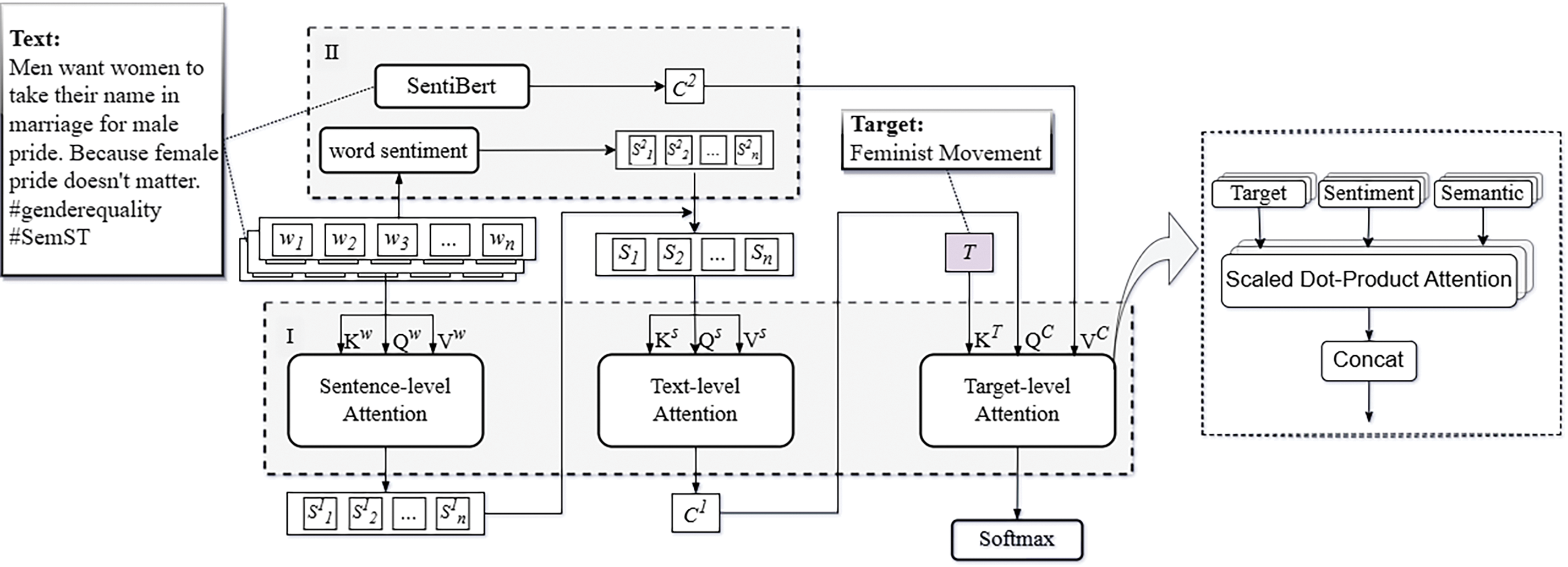
Figure 1: Structure of the SentiHAN: hierarchical attention network (I), sentiment analysis (II)
Short texts often come as unstructured data, merely represented as sequences of words (or symbols). We preprocess the input texts to represent them in a structured form. Initially, the input text is converted into a set of sentences, each sentence is represented as
3.1 Sentence-Level Attention Layer
In the sentence-level attention layer, our goal is to learn the “relationships between words” within the sentence to better capture the local context of each word. Specifically, we break down short texts into phrases and apply a multi-head self-attention block to the collection of word embedding vectors in each phrase, determining the contribution of each word to the stance. This step identifies the words with the greatest semantic significance in the text:
Here
It is worth noting that the core advantage of the multi-head attention mechanism lies in its ability to learn different features from different subspaces. A small number of heads cannot achieve the desired effect, while a large number of heads can lead to model instability, especially when training data is limited, and significantly increases computational costs and memory consumption. Through our experiments, we found that the model performs best when the number of heads is set to four, which is consistent with the findings in the literature [15].
3.2 Text-Level Attention Layer
In this layer, the model uses text-level attention mechanisms to integrate “relationships between sentences” and capture the global semantics of the text. This enables the model to understand the text at a higher level of abstraction, providing foundational support for the final stance assessment. Initially, the word embedding vectors from the previous layer are averaged sentence by sentence to create sentence embedding vectors. Thus, the d-dimensional word embedding vectors of the j-th sentence are averaged to produce a d-dimensional embedding vector
In this definition,
Sentiment Analysis. SentiBERT’s training in sentiment analysis allows cross-target stance detection to require a model that learns in one domain and transfers to another, which captures generic sentiment indications as well as flexibly adapts to new, unseen targets and text types. This layer uses SentiBERT for combined sentiment analysis in short texts, converting word-level feature embeddings into sentiment embeddings that are responsible for extracting the sentiment features associated with individual words.
These affective embeddings complement semantic features as additional knowledge.
3.3 Target-Level Attention Layer
This layer is particularly crucial for cross-target detection. A target, as the reference for expressed opinions or stands, utilizes the attention mechanism to calculate the influence of different sentences on different targets. This ensures that the model generates accurate, personalized stance assessments for each target during cross-target analysis. In complex contexts, the stance impact of a specific sentence on a target may depend on its context within the entire text. The attention mechanism helps the model dynamically capture this dependency, assigning higher weights to sentences more relevant to a particular stance target. This ensures that the model, when detecting stances, considers the most crucial information instead of treating all information equally. Inspired by the significance of targeting, we apply a headline-level attention layer to sentence embedding. The goals of this headline attention layer are: (1) to reinforce the key ideas contained in the headline; (2) to capture fine-grained information; (3) to map sentiment relevancy. Set as the text's headline embedding vector as
where
However, using the target attention layer in the final stage of SentiHAN might cause the globally semantic-aware sentence embedding vectors to be overly biased towards target perception, resulting in poor robustness. To prevent this issue, we added a residual connection to the output of the target attention layer to preserve the two-dimensional semantic features previously learned from the sentence-level attention layer:
Wherein,
The model is trained by minimizing the multi-class cross-entropy loss in order to effectively predict the stance of the text.
Here, N denotes the size of the training set, C represents the total number of stance categories, Θ denotes all trainable parameters of the model, and λ is the coefficient for the L2 regularization term.
The experiments selected two datasets: SemEval16 [3] and P-Stance [23]. The statistical details of the datasets are shown in Table 1. Sem16 covers two topics and four targets: Donald Trump (DT), Hillary Clinton (HC), legalization of abortion (LA), and the feminist movement (FM), with instances categorized as support, against, or neutral. Four cross-target stance detection tasks were constructed on Sem16 (FM→LA, LA→FM, HC→DT, DT→HC). Meanwhile, the P-Stance dataset is an order of magnitude larger than other publicly available datasets and offers multiple targets under the same theme: “Donald Trump,” “Joe Biden,” and “Bernie Sanders,” with instances divided into support and oppose. Six cross-target pairs were constructed in the P-Stance datasets: Trump→Sanders, Sanders→Trump, Sanders→Biden, Biden→Sanders, Trump→Biden, and Biden→Trump.
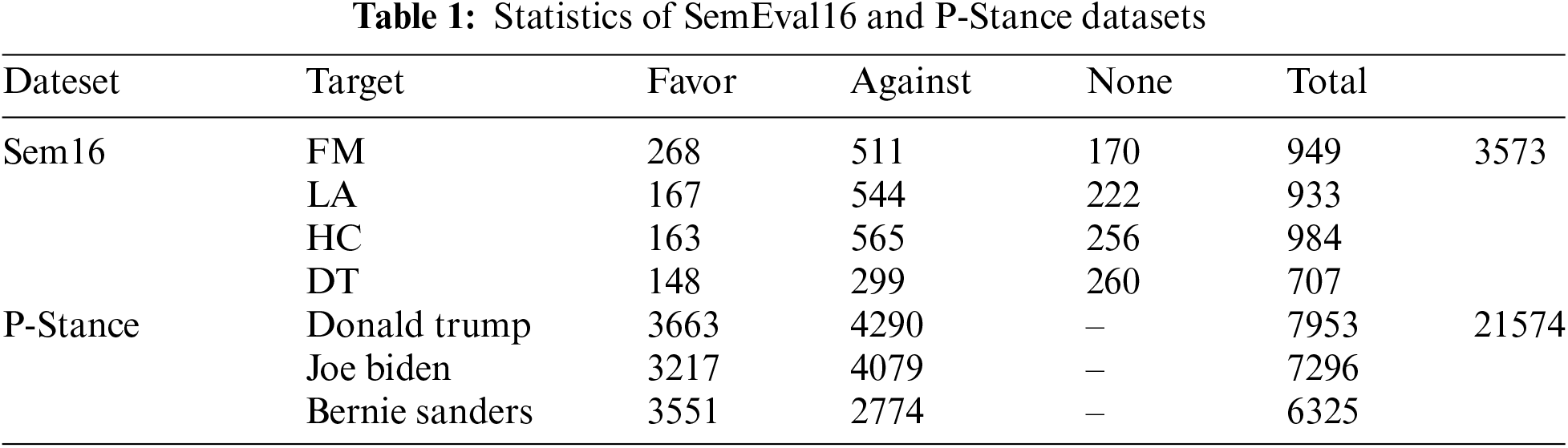
This paper uses Macro-F1 (the macro-average F1 of “support” and “against”) and F1avg (the average of micro-average F1 and macro-average F1) as the evaluation metrics to measure the classification performance of the model.
Benchmark Methods. This paper evaluates and compares the following reliable baseline methods against its model:
BiCond [11]: Utilizes bidirectional conditional encoding to simultaneously learn representations of sentences and targets for stance detection. This method emphasizes the importance of considering the target in understanding textual attitudes.
CrossNet [1]: Uses self-attention layers to extract important context words related to the target, learning specific target stance features. This approach highlights the role of self-attention mechanisms in extracting target-relevant information.
SEKT [4]: A knowledge-based Graph Convolutional Network (GCN) model that incorporates semantic-emotional knowledge into heterogeneous graph construction to bridge the gap between source and target objectives, achieving cross-target stance detection.
BERT [5]: Employs the pre-trained BERT-base model, using “[CLS] target [SEP] sentence [SEP]” as input for each instance. This reflects the strong capabilities of pre-trained models in various natural language processing tasks, while also emphasizing the importance of directly combining target and sentence information in the input.
JointCL [30]: A joint contrastive learning framework consisting of stance contrastive learning and target-aware prototype graph contrastive learning.
TarBK [31]: Combines background knowledge for cross-target stance detection.
TPDG [3]: Combines target information and sentence structure, proposing a model of target-adaptive pragmatic dependency graphs through the construction of dependency graphs to understand textual stances.
PT-HCL [32]: A stance detection method for unknown targets based on a hierarchical contrastive learning strategy.
KEprompt [33]: Expands the prompt tuning capabilities of language models by utilizing external semantic knowledge and injecting background knowledge.
TGA-Net [34]: Implicitly captures relationships between topics using generalized topic representations.
The SentiHAN method was implemented on Ubuntu 18.04 OS (Operating System) using PyTorch 1.1.0. Experiments ran on a machine equipped with an Intel Xeon Platinum 8255C CPU (Central Processing Unit), 72 GB of memory, and an NVIDIA RTX 2080 Ti(11 GB), with CUDA 10.0 and cuDNN v7.6.5 installed. The batch size was set to 64, using the Adam optimizer, with a learning rate of 1e-3, and a weight decay factor of 5e-2 for all datasets.
To ensure a fair and consistent comparison, we re-implemented and evaluated the results of certain benchmark models within the same experimental environment. Additionally, to assess the performance of our proposed method, we selected benchmark model results reported in related literature. The experimental settings and datasets in these studies are highly relevant to our research and are widely recognized as standard benchmarks in the field. While we have made every effort to ensure a fair comparison of all results, there may be uncontrollable factors due to differences in experimental setups in the cited literature. Our experimental results take these potential differences into account. The hyperparameters of the KHAN model were referenced [15], fine-tuned, and experimented with in our model using the following settings to achieve optimal performance: batch_size = 64, learning_rate = 0.001, embed_size = 256, dropout = 0.4, num_layer = 2, num_head = 4.
Table 2 reports the experimental results of models on SemEval16. CrossNet, as an extension of BiCond, incorporates attention mechanisms, highlighting the role of self-attention in extracting target-related information. The model performs slightly better than its predecessor, demonstrating the feasibility of attention mechanisms in perceiving stance representations for specific entities. However, this word-level information-based knowledge transfer scheme still shows overall poor performance. BERT utilizes contextual semantic information of different targets to achieve good results in FM-LA and HC-DT, but due to the lack of any knowledge transfer strategy, its performance in other tasks is unsatisfactory, indicating instability. SEKT and TPDG improve the generalization ability of model through transfer learning methods, achieving better and more balanced results across all labels. JointCL, TarBK, and PT-HCL show similar results, indicating comparable performance in cross-target stance detection. KEprompt performs poorly in FM-LA, LA-FM, and HC-DT but significantly outperforms other models in DT-HC (60.9%), demonstrating strong performance in this specific setting. SentiBERT performs well in all four tasks, with an average Macro-F1 of 62.05%, improving by 6.32% over the fine-tuning-based method PT-HCL and by 6.8% over the leading knowledge-infused model TarBK. From the perspective of external knowledge, SEKT incorporates sentiment knowledge of words, TarBK introduces target background knowledge based on Wikipedia, KEprompt integrates prompt tuning with ConceptGraph background knowledge, and SentiHAN learns memory links of combined sentiment knowledge and semantic features. The F1avg scores of multiple target pairs, as shown in Fig. 2, indicate that SentiHAN outperforms other models. However, models based on sentiment knowledge (SEKT, SentiHAN) show less stability compared to those based on commonsense knowledge (TarBK, KEprompt). This may be influenced by the distribution of semantic knowledge in the dataset, as discussed in the case analysis.
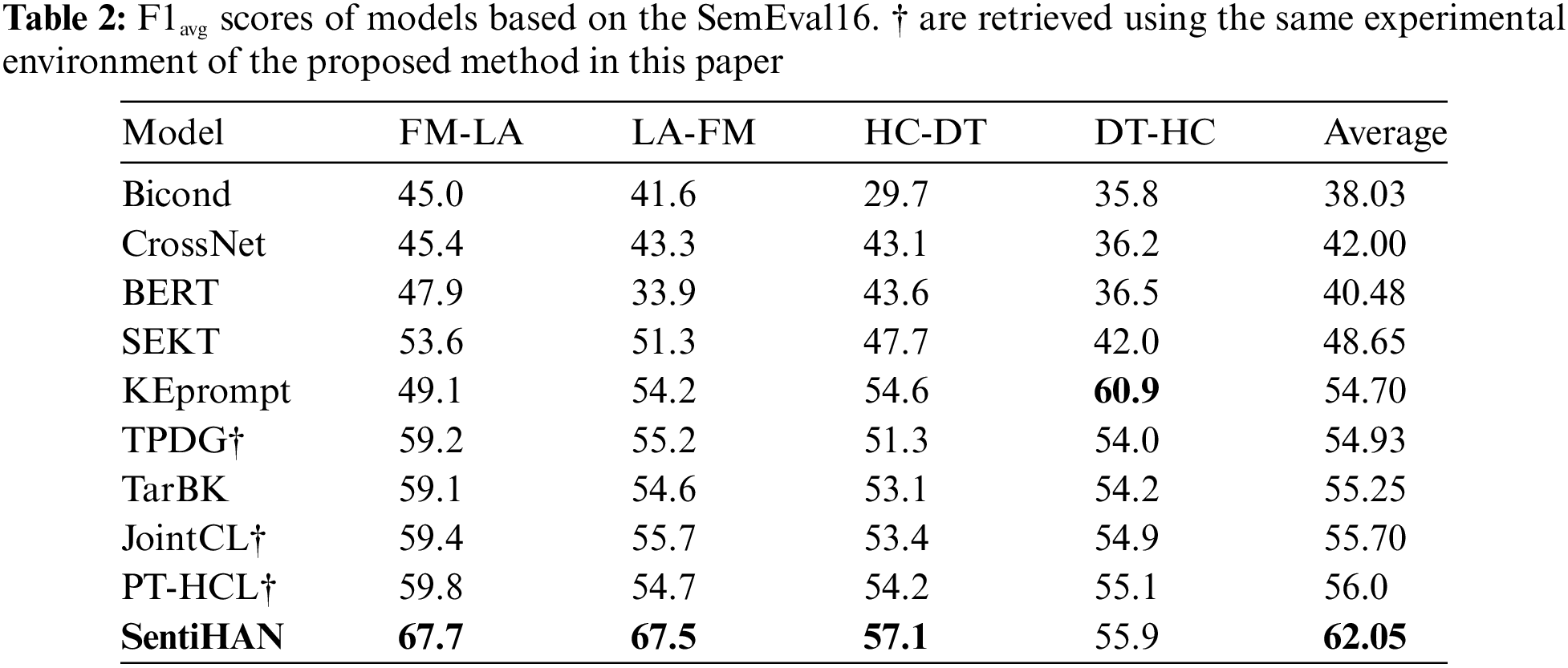
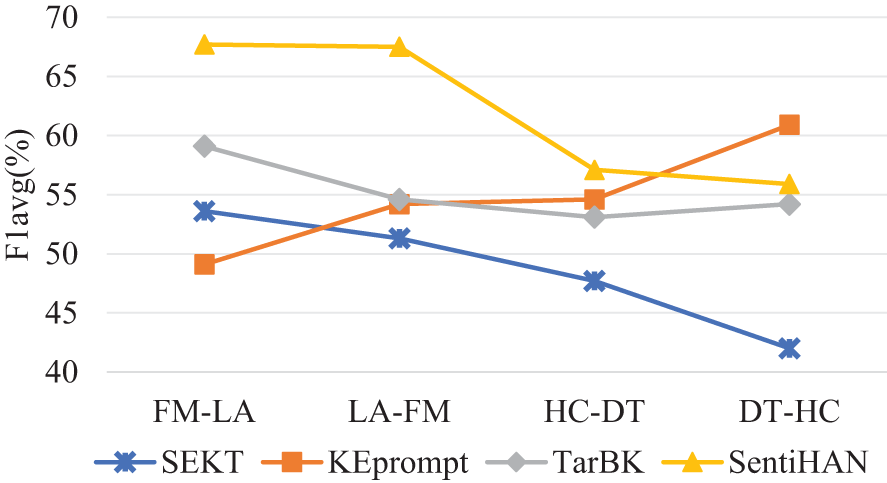
Figure 2: Comparison of external knowledge models
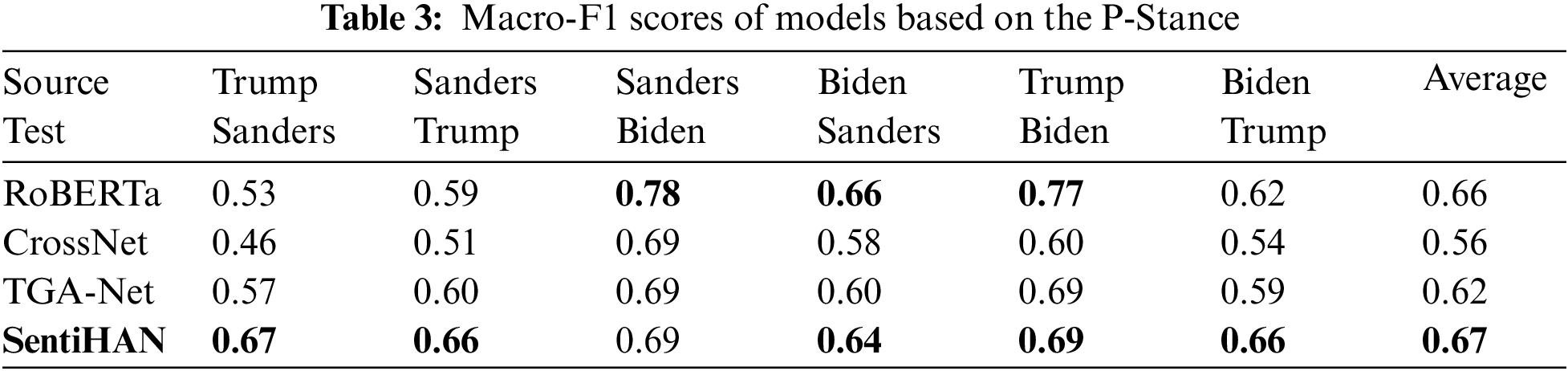
Table 3 reports the experimental results of models on P-Stance. Compared to RoBERTa, CrossNet, and TGA-Net, SentiHAN shows more balanced performance across all targets and achieves the best average Macro-F1 score without obvious weaknesses. SentiHAN’s consistently high scores and balanced performance indicate strong generalization ability across different targets. This means the model can effectively learn and adapt to the data characteristics of different targets, performing well in various test scenarios.
The results of the ablation experiments are summarised in Table 4. In this experiment, we verify the effectiveness of sentiment knowledge (SEN), semantic knowledge (SEM), and target knowledge (TG). Experiment compare the three versions of SentiHAN:
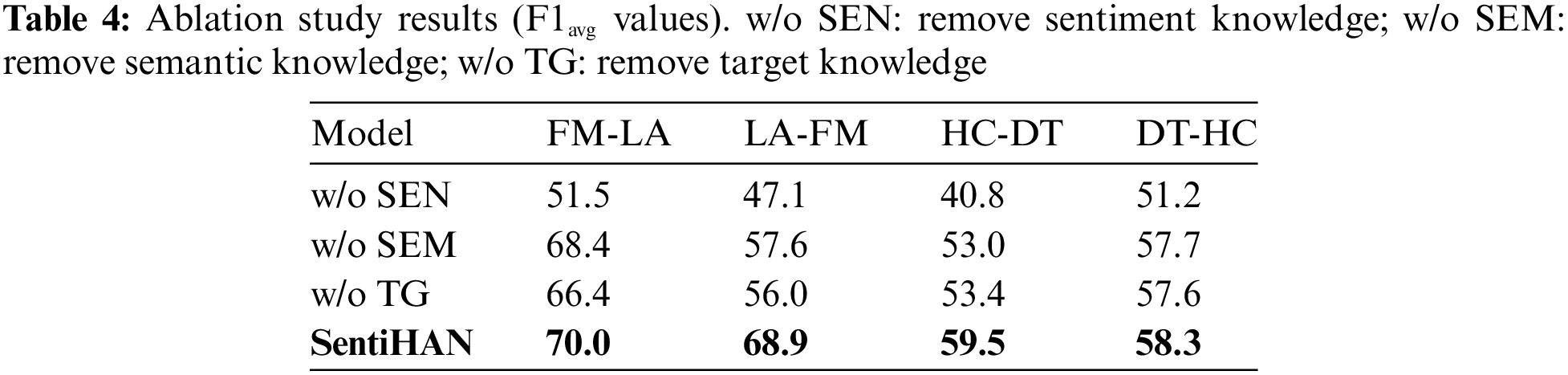
w/o SEN: The performance significantly declined, particularly in the FM-LA task where the F1avg value dropped from 70.0 to 51.5. This decline may be attributed to the lack of sentiment knowledge, which prevents the model from accurately identifying and interpreting sentiment features in the text, thus affecting stance detection. The absence of sentiment knowledge leaves the model without the necessary contextual information support when dealing with expressions laden with strong sentiment nuances.
w/o SEM: There was a notable negative impact on capturing deep semantic relationships within the text. For instance, the F1avg value in the HC-DT task decreased from 59.5 to 53.0. This decline can be attributed to the crucial role of semantic knowledge in understanding the overall text and capturing complex semantic connections. The lack of semantic knowledge prevents the model from fully understanding the semantic relationships between sentences and paragraphs, thereby affecting the judgment of emotions and stance. This issue is particularly pronounced when dealing with long texts or sentences with complex structures, where SEM fails to effectively establish semantic associations between words.
w/o TG: The overall performance was poor, possibly due to the critical role of target knowledge in accurately conveying sentiment features across different targets and improving stance detection accuracy. The absence of target knowledge means the model cannot distinguish and associate sentiment information across multiple targets in sentiment analysis tasks.
In summary, sentiment knowledge, semantic knowledge, and target knowledge all play significant roles in enhancing the performance of the SentiBERT method. The integration of target knowledge and sentiment knowledge, along with a deep understanding of semantics, enables the SentiHAN model to exhibit superior performance in capturing complex semantic links between words, emotions, and stance labels. This further confirms the necessity and superiority of combining hierarchical perception and sentiment analysis strategies. It also enhances the adaptability and generalization ability of model in cross-target contexts, thereby more closely approximating the efficient manner in which humans process and understand stances.
Fig. 3 displays the distribution of three types of stance labels and three types of sentiment labels within the datasets for DT, HC, FM, and LA, where the sum of “negative” and “positive” dominates, indicating the prevalence of sentimental tone in texts. Additionally, the proportion of negative sentiments generally exceeds that of positive sentiments, aligning with the rough ratio of support to opposition, which coincides with the customary alignment of sentimental expression and stance tendencies.
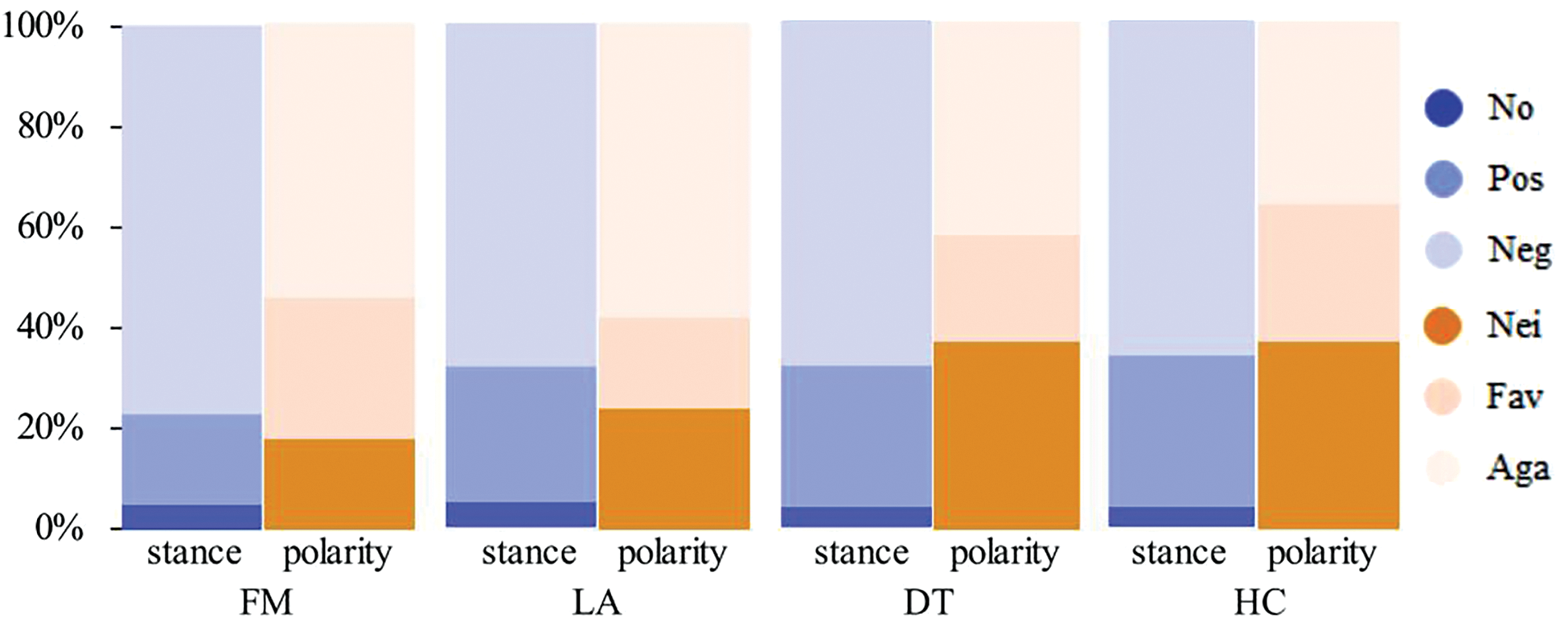
Figure 3: Sentiment and stance label distribution in the SemEval16. Stance: favor, against, and neither; sentiment: negative, positive, and neither (denoted as no). The vertical axis represents proportions
However, Table 5 presents the orthogonal relationship between stance and sentiment for DT, HC, FM, and LA, under which the alignment between sentiment and stance exhibits variability. Typically, positive sentiments are the main means of expressing support, while negative sentiments predominantly convey opposition. Nevertheless, in the “support” stance of FM and LA, the proportion of positive sentiment is noticeably lower than that of combined sentiments. This is contrary to the expected relationship between sentiment and stance, and the discrepancies arise mainly from three aspects: (1) supporters might also hold critical views on certain aspects of the issues or solutions; (2) cultural and social contexts, which may relate to the nature of the issue or the background of the discussion; and (3) implications, irony, or other forms of subtle expression techniques. This phenomenon reveals that, even in seemingly straightforward expressions of support or opposition, the usage and expression of sentiments are far more complex than they appear, underscoring the importance of considering sentimental complexity when studying stance expressions.
Fig. 4 further intuitively reflects the differences in the aforementioned results and the superiority of our model. In the FM and DT instance visualizations, the stark color contrast widely demonstrates the presence of emotionalized contexts in texts. When dealing with texts that contain rich sentimental expressions and clear sentimental tendencies, the model utilizes SentiBERT effectively to capture combined sentiments, managing to grasp both evident sentimental signals and structured information in the texts. Particularly by observing instance 7 in FM and instances 1 and 13 in DT, we notice that although the sentimental tendencies at the word level generally tilt positive, the overall sentimental polarity of the texts appears negative, explaining the unconventional distributions shown in Table 5. In these cases, the SentiHAN model still exhibits superior performance compared to other models, suggesting its advantages in handling texts with complex sentiments or implicit expressions, demonstrating its flexibility and robustness.
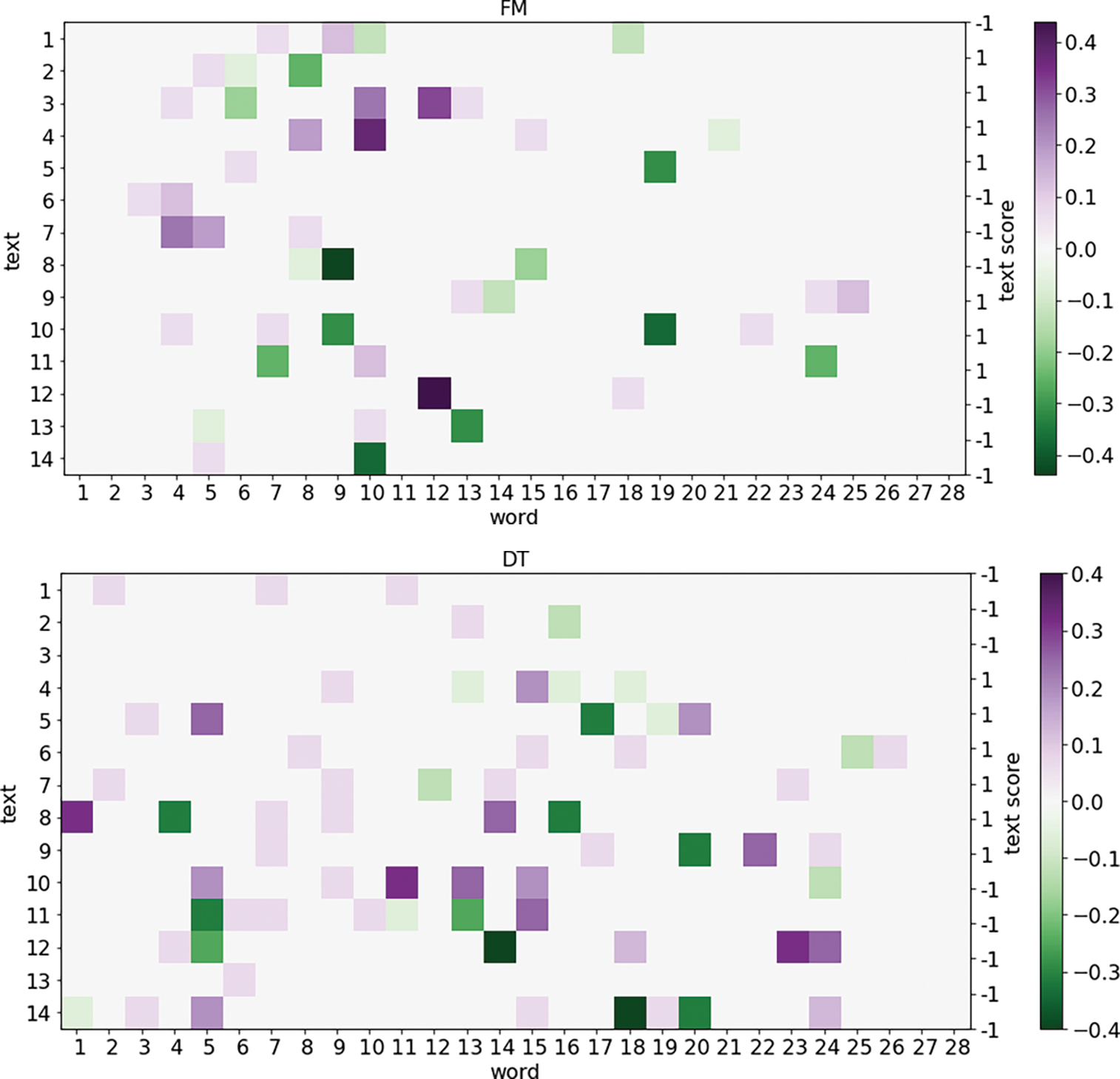
Figure 4: Visualisation of sentimental polarity. Randomly selected ten text instances targeted towards FM and DT (6 supporting, 6 opposing, and 2 neutral) for a visual analysis. The left vertical axis represents the instances, the horizontal axis indicates the position of words in sentences, and colors represent the sentimental polarity of words (learned from a sentiment lexicon) while the right vertical axis shows the sentence’s sentimental polarity
To illustrate the inner workings of SentiHAN and to provide a deeper understanding of how sentiment knowledge contributes to stance detection, Fig. 5 presents a case study on the interpretability of compositional sentiment and stance. It is crucial to understand how SentiHAN simultaneously captures both sentiment and stance. In the sentence, “If feminists spent half the time reading papers instead of reading tumblr, they would not be ignorant sexist bigots," words like “ignorant" and “bigots" are highlighted in strong negative colors, indicating a pronounced negative sentiment. The hierarchical structure of SentiHAN facilitates a better understanding of how sentiment words are utilized across multiple layers, revealing the complexity of the interplay between stance and sentiment. The phrase “not be ignorant sexist bigots” clearly conveys a critical stance towards the behavior of those labeled as “feminists." By analyzing sentiment knowledge, we can uncover the emotional inclinations conveyed by different words and phrases in the text, thus gaining a clearer understanding of how these emotions influence the expression of a stance. SentiHAN proves to be a powerful tool for elucidating this relationship, making the stance detection process more comprehensible.
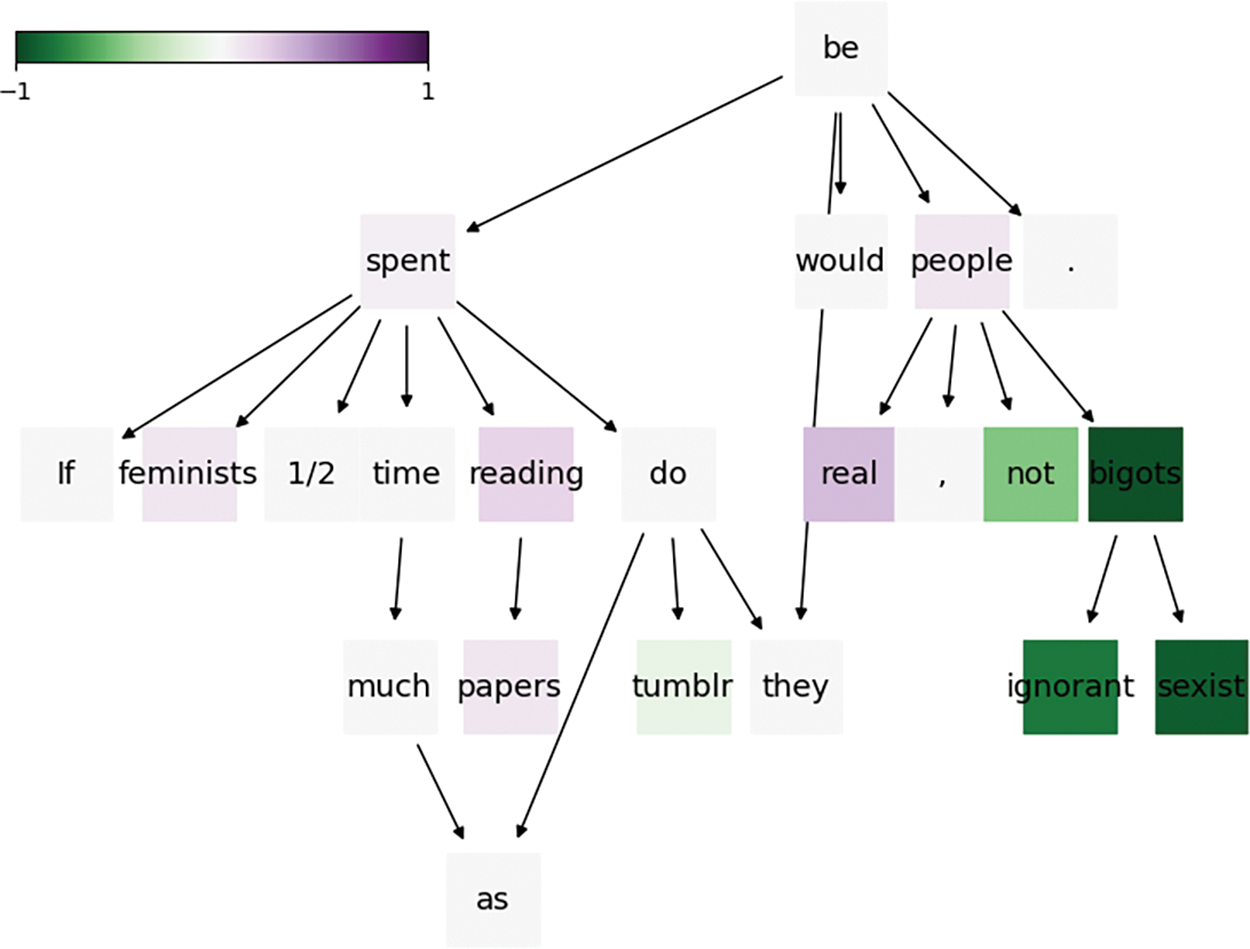
Figure 5: Case for interpretability of compositional sentiment stance
We conducted a detailed analysis of the error predictions made by the SentiHAN model on the SemEval-2016 dataset and discussed the findings with reference to specific examples from the dataset. The main sources of errors identified are as follows:
Impact of Text Noise: The informal nature of social media and short texts can introduce noise into the text, such as spelling errors, abbreviations, and non-standard language expressions. Although SentiHAN mitigates noise effects through structural sentiment information, such noise can still lead to misclassification in certain cases. For example, in the tweet “Where is the childcare program @joanburton which you said would be in place? #loneparents #7istooyoung #SemST," the presence of multiple hashtags may cause the model to incorrectly handle the influence of these tags, resulting in an erroneous prediction.
Insufficient External Knowledge: While SentiHAN reduces noise by substituting knowledge graphs with structural sentiment injection, the model may still lack sufficient external knowledge to accurately understand the context in texts requiring extensive background knowledge. For instance, in the tweet “I get several requests with petitions to save whales but never to stop the slaughter of babies in the wombs of mothers. #abortion. #SemST," the statement involves specific cultural and historical contexts. Petitions to save whales generally concern animal protection and environmental issues, which are focal points for many global environmental organizations. This statement expresses dissatisfaction or confusion about the imbalance in societal concerns. Due to the lack of relevant background knowledge, the model misinterprets the stance of the comment. This indicates that future research should focus on finding effective methods to leverage topic tags and external knowledge while minimizing the noise they introduce.
In addition, the SentiHAN model uses SentiBERT for sentiment analysis, which effectively integrates emotion knowledge for stance detection. However, SentiBERT, being a variant of the BERT architecture, has relatively high computational complexity. This can affect inference speed, particularly in real-time applications like social media monitoring, where large volumes of data are processed. Inference speed can vary depending on factors such as hardware setup (CPU vs. GPU (Graphic Processing Unit) /TPU (Tensor Processing Unit)), the length of input data, and the overall complexity of the model. While SentiHAN provides accurate stance detection, managing and optimizing its real-time inference speed is crucial for maintaining responsiveness in high-demand environments.
This paper proposes a novel sentiment-aware multi-granularity feature fusion cross-target stance detection model (SentiHAN). The model reveals that in cross-target stance detection, text, sentiment knowledge, and target information can be utilized from the perspective of different granularity features, a facet often neglected by most existing methods. Unlike previous cross-target stance detection methods, SentiHAN begins with key semantic analysis at the lexical level and then shifts focus to sentences and phrases with dense stance expressions at the intermediate level. Finally, it synthesizes this data at the highest level to obtain a comprehensive understanding of the entire document or cross-target stances. By incorporating sentiment knowledge, the model's understanding of text semantics is enhanced, enabling more effective learning of contextual semantic backgrounds. In SentiHAN, different parameter sets are used for different levels of the network, effectively increasing complementarity among different granularities, and thereby enhancing the cross-target stance analysis capability of the model. The application of the multi-head attention mechanism plays a crucial role in capturing complex dependencies among semantics, sentiment, and targets, contributing to the improved transferability of stance knowledge across targets.
Extensive experimental results on real-world public datasets not only demonstrate the superiority of SentiHAN but also showcase the advancement of multi-level feature fusion and the incorporation of sentiment knowledge methods in cross-target stance detection tasks. The experimental results confirm the efficiency and robustness of models, improving stance prediction in complex thematic and sentiment contexts, particularly in sentiment-driven expressions prevalent in social media and reviews.
However, there are still many areas worthy of exploration in this work. Firstly, the framework structure and learning strategies can be further optimized to enhance the framework's adaptability to different sentiment types. Secondly, various pre-trained models can be explored to enhance the ability framework to handle multi-source external knowledge. Finally, the research needs to find a balance between model performance and interpretability, with more focus on consistent performance evaluation across different datasets. In future work, we will continue to explore and research these issues.
Acknowledgement: Thank all the people who contributed to this paper.
Funding Statement: This document was supported by the National Social Science Fund of China (20BXW101).
Author Contributions: The authors confirm contribution to the paper as follows: study conception and design: Mingshu Zhang, Kelan Ren; data collection: Facheng Yan and Honghua Chen; analysis and interpretation of results: Bin Wei, Wen Jiang; draft manuscript preparation: Kelan Ren. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: No new data were created during this study. The study brought together existing data obtained upon request and subject to licence restrictions from a number of different sources.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. C. Xu, C. Paris, S. Nepal, and R. Sparks, “Cross-target stance classification with self-attention networks,” in ACL-Annu. Meet. Assoc. Comput. Linguist, Proc. Stud. Res. Workshop, Australia, 2018, pp. 778–783. [Google Scholar]
2. J. Devlin, M. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” in NAACL HLT-Conf. N. Am. Chapter Assoc. Comput. Linguistics: Hum. Lang. Technol.-Proc. Demonstr. Sess., Minneapolis, 2019, pp. 4171–4186. [Google Scholar]
3. B. Liang et al., “Target-adaptive graph for cross-target stance detection,” in Web Conf. -Proc. World Wide Web Conf., Ljubljana Slovenia, Apr. 19–23, 2021, pp. 3453–3464. [Google Scholar]
4. B. Zhang, M. Yang, X. Li, Y. Ye, X. Xu and K. Dai, “Enhancing cross-target stance detection with transferable semantic-emotion knowledge,” in Proc. Annu. Meet. Assoc. Comput. Linguist., Jul. 2020, pp. 3188–3197. [Google Scholar]
5. Y. Zhang et al., “Stance-level sarcasm detection with BERT and stance-centered graph attention networks,” ACM Trans. Internet Technol., vol. 23, no. 2, pp. 1–21, Jul. 2023. doi: 10.1145/3617123. [Google Scholar] [CrossRef]
6. Y. Sun and Y. Li, “Stance detection with knowledge enhanced BERT,” in Lect. Notes Comput., Jun. 2021, vol. 13070, pp. 239–250. doi: 10.1007/978-3-030-93049-3_20. [Google Scholar] [CrossRef]
7. A. Bello, S. -C. Ng, and M. -F. Leung, “A BERT framework to sentiment analysis of tweets,” Sensors, vol. 23, no. 1, Jan. 2023, Art. no. 506. doi: 10.3390/s23010506. [Google Scholar] [PubMed] [CrossRef]
8. Z. He, N. R. Mokhberian, and K. Lerman, “Infusing knowledge from wikipedia to enhance stance detection,” in WASSA-Workshop Comput. Approaches Subj., Sentim. Soc. Media Anal., Proc. Workshop, Dublin, Ireland, May 2022, pp. 71–77. [Google Scholar]
9. A. Upadhyaya, M. Fisichella, and W. Nejdl, “A multi-task model for sentiment aided stance detection of climate change tweets,” 2022, arXiv:2211.03533. [Google Scholar]
10. Y. Luo, Z. Liu, and Y. Shi, “Exploiting sentiment and common sense for zero-shot stance detection,” in Proc. Main Conf. Int. Conf. Comput. Linguist., Coling, Gyeongju, Republic of Korea, Oct. 2022, pp. 7112–7123. [Google Scholar]
11. I. Augenstein, T. Rocktäschel, A. Vlachos, and K. Bontcheva, “Stance detection with bidirectional conditional encoding,” in EMNLP-Conf. Empir. Methods Nat. Lang. Process., Austin, Texas, Nov. 2016, pp. 876–885. [Google Scholar]
12. P. Wei and W. Mao, “Modeling transferable topics for cross-target stance detection,” in SIGIR-Proc. Int. ACM SIGIR Conf. Res. Dev. Inf. Retr., Paris, France, Jul. 2019, pp. 1173–1176. [Google Scholar]
13. M. Hardalov, A. Arora, N. Nakov, and I. Augenstein, “Few-shot cross-lingual stance detection with sentiment-based pre-training,” in Proc. AAAI Conf. Artif. Intell., AAAI, Jun. 2022, vol. 36, pp. 10729–10737. doi: 10.1609/aaai.v36i10.21318. [Google Scholar] [CrossRef]
14. C. Wang et al., “Adversarial network with external knowledge for zero-shot stance detection,” in Lect. Notes Comput. Sci., Harbin, China, Sep. 2023, vol. 14232, pp. 824–835. doi: 10.1007/978-981-99-6207-5_26. [Google Scholar] [CrossRef]
15. Y. Ko et al., “KHAN: Knowledge-aware hierarchical attention networks for political stance prediction,” in ACM Web Conf. -Proc. World Wide Web Conf., WWW, Austin, TX, USA, Apr. 2023, pp. 1572–1583. [Google Scholar]
16. M. Hosseinia, E. Dragut, and A. Mukherjee, “Stance prediction for contemporary issues: Data and experiments,” in Proc. Eighth Int. Workshop Nat. Lang. Process. Soc. Med., Jul. 2020, pp. 32–40. doi: 10.18653/v1/2020.socialnlp-1.5. [Google Scholar] [CrossRef]
17. A. Aldayel and W. Magdy, “Assessing sentiment of the expressed stance on social media,” in Lect. Notes Comput. Sci., Doha, Qatar, Nov. 2019, pp. 277– 286. doi: 10.1007/978-3-030-34971-4_19. [Google Scholar] [CrossRef]
18. M. N. Moghadasi and Y. Zhuang, “Sent2Vec: A new sentence embedding representation with sentimental semantic,” in Proc. -IEEE Int. Conf. Big Data, Big Data, Atlanta, GA, USA, Dec. 2020, pp. 4672–4680. doi: 10.1109/BigData50022.2020.9378337. [Google Scholar] [CrossRef]
19. D. Yin, T. Meng, and K. W. Chang, “SentiBERT: A transferable transformer-based architecture for compositional sentiment semantics,” in Proc. Annu. Meet. Assoc. Comput Linguist, USA, Jul. 2020, pp. 3695– 3706. [Google Scholar]
20. C. Li and D. Goldwasser, “Using social and linguistic information to adapt pretrained representations for political perspective identification,” in Find. Assoc. Comput. Linguist.: ACL-IJCNLP, Aug. 2021, pp. 4569–4579. doi: 10.18653/v1/2021.findings-acl.401. [Google Scholar] [CrossRef]
21. Y. Fu et al., “Incorporate opinion-towards for stance detection,” Know.-Based Syst., vol. 246, Jun. 2022, Art. no. 108657. doi: 10.1016/j.knosys.2022.108657. [Google Scholar] [CrossRef]
22. C. Li et al., “MEAN: Multi-head entity aware attention network for political perspective detection in news media,” in Proc. Fourth Workshop NLP Internet Freedom: Censorship, Disinform., Propaganda, Jun. 2021, pp. 66–75. doi: 10.18653/v1/2021.nlp4if-1.10. [Google Scholar] [CrossRef]
23. N. Alturayeif, H. Luqman, and M. Ahmed, “A systematic review of machine learning techniques for stance detection and its applications,” Neural Comput. Appl., vol. 35, pp. 5113–5144, Jan. 2023. doi: 10.1007/s00521-023-08285-7. [Google Scholar] [PubMed] [CrossRef]
24. K. Cortis and B. Davis, “Over a decade of social opinion mining: A systematic review,” Artif. Intell. Rev., vol. 54, pp. 4873–4965, Oct. 2021. doi: 10.1007/s10462-021-10030-2. [Google Scholar] [PubMed] [CrossRef]
25. D. Ding et al., “Cross-target stance detection by exploiting target analytical perspectives,” in ICASSP IEEE Int. Conf. Acoust. Speech Signal Process Proc., Seoul, Republic of Korea, Apr. 2024, pp. 10651–10655. [Google Scholar]
26. Q. Sun, Z. Wang, S. Li, Q. Zhu, and G. Zhou, “Stance detection via sentiment information and neural network model,” Front Comput. Sci., vol. 13, pp. 127–138, Feb. 2019. [Google Scholar]
27. Y. Li and C. Caragea, “Multi-task stance detection with sentiment and stance lexicons,” in EEMNLP-IJCNLP-Conf. Empir. Methods Nat. Lang. Process. Int. Jt. Conf. Nat. Lang. Process., Proc. Conf., Hong Kong, China, 2019, pp. 6299–6305. [Google Scholar]
28. A. Ratmele and R. Thakur, “OpExHAN: Opinion extraction using hierarchical attention network from unstructured reviews,” Soc. Netw. Anal. Min., vol. 12, no. 1, Dec. 2022, Art. no. 148. [Google Scholar]
29. A. Chanaa, “E-learning text sentiment classification using hierarchical attention network (HAN),” Int. J. Emerg. Technol. Learn., vol. 16, no. 13, pp. 157– 167, Jul. 2021. [Google Scholar]
30. B. Liang et al., “JointCL: A joint contrastive learning framework for zero-shot stance detection,” in Proc. Annu. Meet. Assoc. Comput. Linguist, Dublin, Ireland, May 2020, vol. 1, pp. 81–91. [Google Scholar]
31. Q. Zhu et al., “Enhancing zero-shot stance detection via targeted background knowledge,” in SIGIR-Proc. Int. ACM SIGIR Conf. Res. Dev. Inf. Retr., New York, NY, USA, Jul. 2022, pp. 2070–2075. doi: 10.1145/3477495.3531807. [Google Scholar] [CrossRef]
32. B. Liang et al., “Zero-shot stance detection via contrastive learning,” in WWW-Proc. ACM Web Conf., Apr. 2022, pp. 2738–2747. doi: 10.1145/3485447.3511994. [Google Scholar] [CrossRef]
33. H. Huang et al., “Knowledge-enhanced prompt-tuning for stance detection,” ACM Trans. Asian Low-Resour. Lang. Inf. Process, vol. 22, no. 159, pp. 1–20, Jun. 2023. doi: 10.1145/3588767. [Google Scholar] [CrossRef]
34. P. J. Khiabani and A. Zubiaga, “Few-shot learning for cross-target stance detection by aggregating multimodal embeddings,” IEEE Trans. Computat. Soc. Syst., vol. 11, no. 2, pp. 2081–2090, Apr. 2024. doi: 10.1109/TCSS.2023.3264114. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools