
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Efficient User Identity Linkage Based on Aligned Multimodal Features and Temporal Correlation
1 School of Cyberspace Security, Beijing University of Posts and Telecommunications, Beijing, 100876, China
2 Faculty of Information Technology, Beijing University of Technology, Beijing, 100124, China
* Corresponding Author: Kangfeng Zheng. Email:
Computers, Materials & Continua 2024, 81(1), 251-270. https://doi.org/10.32604/cmc.2024.055560
Received 01 July 2024; Accepted 13 August 2024; Issue published 15 October 2024
 View Full Text
View Full Text Download PDF
Download PDFAbstract
User identity linkage (UIL) refers to identifying user accounts belonging to the same identity across different social media platforms. Most of the current research is based on text analysis, which fails to fully explore the rich image resources generated by users, and the existing attempts touch on the multimodal domain, but still face the challenge of semantic differences between text and images. Given this, we investigate the UIL task across different social media platforms based on multimodal user-generated contents (UGCs). We innovatively introduce the efficient user identity linkage via aligned multi-modal features and temporal correlation (EUIL) approach. The method first generates captions for user-posted images with the BLIP model, alleviating the problem of missing textual information. Subsequently, we extract aligned text and image features with the CLIP model, which closely aligns the two modalities and significantly reduces the semantic gap. Accordingly, we construct a set of adapter modules to integrate the multimodal features. Furthermore, we design a temporal weight assignment mechanism to incorporate the temporal dimension of user behavior. We evaluate the proposed scheme on the real-world social dataset TWIN, and the results show that our method reaches 86.39% accuracy, which demonstrates the excellence in handling multimodal data, and provides strong algorithmic support for UIL.Keywords
In recent years, with the development of mobile Internet technology and the increase in user demand, there are more and more virtual accounts in cyberspace, and the same user owns multiple accounts in different applications or even on the same platform. UIL refers to identifying user accounts belonging to the same identity across different platforms. UIL is essential for downstream tasks such as information diffusion prediction [1] and cross-platform recommendation [2].
Users frequently generate content with concurrent intrinsic relevance across diverse social media platforms, marked by temporal stamps and predominantly manifested as textual or visual content, as shown in Fig. 1. UIL research is bifurcated into approaches leveraging: (i) unimodal data, focusing on text-based elements such as user IDs and posts [3–7]; and (ii) multimodal data, integrating textual and visual information to holistically profile user identities and behaviors through data complementarity [8–12]. Acknowledging the temporal clustering of contextually related user posts, recent studies [6,12] have incorporated temporal dimensions, enhancing the precision of behavioral pattern recognition, rendering user profiles more nuanced, and augmenting cross-platform user identification accuracy and efficacy.

Figure 1: UIL based on multimodal UGCs
In response to the current state of research, this study focuses on two key points: (1) Exploring an innovative method that utilizes multimodal UGCs. (2) Analyzing the effect of the time factor on user behavior, incorporating the timestamps of UGCs into the model design. For the first point, current UIL methods based on multimodal UGCs generally adopt textual or visual models trained on unimodal data to extract features from heterogeneous data such as text and images, and then directly train feature extraction or modal fusion models based on anchor user pairs to build up an interaction and fusion mechanism between heterogeneous modalities. However, these approaches exist the following problems: (1) Due to the natural semantic gap between text and image modalities, the desired synergistic effect is hard to achieve by integrating multimodal features based on a limited number of anchor pairs across social platforms. (2) The current method needs to train both textual and visual models, and the number of parameters is large, which makes the training inefficient. (3) Different service providers focus on different features, e.g., the content posted on Instagram is mainly images with short text, while the posts posted on Twitter are mainly text supplemented by images, and the text of the posts on Instagram is shorter than Twitter. Coping with the variability of data modality and the imbalance of data volume is another problem to be faced by UIL. For the second point, existing methods usually use a simplified function to summarize the effect of time on user behavior, ignoring the changes that may exist within the period.
To solve the above problems, we propose EUIL. As shown in Fig. 2, the method includes the BLIP-based text enhancement module, the aligned feature extraction module, the multimodal adapter module, and the temporal correlation-based cross-modal similarity calculation module. Specifically, the BLIP-based text enhancement module first utilizes the powerful multimodal model BLIP [13] to generate captions for images in graphic posts, which not only compensates for the problem of missing textual data but also further explores the deep semantic information of images; then, the alignment feature extraction module unifies the features of texts and images with the pre-trained cross-modal comparative learning model CLIP [14]. Then, the alignment feature extraction module unifies the texts and images with the pre-trained cross-modal contrast learning model CLIP, which can maintain cross-modal semantic consistency while capturing the unique features of the texts and images, effectively bridging the semantic gap between the texts and the images. Furthermore, we design a multimodal adapter module optimized for UIL based on the multi-head self-attention mechanism to generate highly customized user feature representations by fine-tuning limited parameters without changing the underlying model. Finally, the cross-modal similarity computation module based on temporal linkage constructs the inter-user similarity matrix based on the generated multimodal features and dynamically adjusts the importance of the information within each time window in the UIL process by introducing a time factor assignment mechanism. We conduct a series of exhaustive experiments on real datasets to confirm the efficient UIL capability of the proposed method in coping with heterogeneous modal data imbalance.

Figure 2: Illustration of the proposed scheme for UIL
The main contributions of this paper are as follows:
• Presents an efficient UIL method for multimodal data. Based on the pre-trained multimodal large model CLIP to extract text and image features on social media platforms, the unique features of each text and image are captured while maintaining cross-modal semantic consistency, effectively bridging the semantic gap between text and image, and providing excellent feature initialization for subsequent fine-tuning.
• Innovatively employs the BLIP text generation model to enhance short text on social media platforms. Generating image captions compensates for the problem of insufficient text information and deeply integrates the semantic information of images.
• Presents a multimodal adapter module for UIL tasks. The module effectively fuses text and image features from CLIP based on a multi-head self-attention mechanism. The training of the lightweight multimodal adapter module makes it possible to generate comprehensive feature representations suitable for user identity association without changing the parameters of the pre-trained multimodal model, making the training efficient.
• Innovatively designs a segmented time decay function that distinguishes and meticulously models the differential effects over different periods. This approach not only better fits the complex characteristics of real-world user behavior dynamically changing over time, but also strengthens the model’s sensitivity and adaptability to UIL matching under different time windows, thus improving the accuracy of UIL and the practicality of the model.
• Evaluates the proposed method on real social datasets, and the experimental results demonstrate the superiority of the proposed model over state-of-the-art models.
Existing UIL studies can be categorized into unimodal data-based methods and multimodal data-based methods based on the data modality utilized.
2.1.1 Unimodal Data-Based Methods
Current unimodal UIL methodologies predominantly harness users’ textual data, encompassing attributes and published content. Based on the fact that people prefer to choose similar usernames across social platforms, EEUPL [3] utilizes usernames and profiles for linkage, assigns similar data to the same bucket via the minHashLSH algorithm, and generates similarity graphs by calculating only the similarity of user pairs within the buckets, which reduces the number of user pairs to be compared. MAUIL [7] categorizes the social media texts into character-, word-, and topic-level attributes, extracting features via unsupervised methodologies tailored to each category. Gao et al. [6] link entities in the texts to a knowledge graph through entity recognition and entity linking techniques, subsequently constructing word similarity matrices and entity similarity matrices using GloVE [15] and TransE [16], respectively. AsyLink [4] first introduces external text location pairs by associating words with locations using the topic modeling technique, reducing the bias caused by sparse link labels. Then it constructs the user-user interaction tensor as the basis for linking and captures the matching patterns in the user interaction tensor with a 3D convolutional neural network. Huang et al. [5] incorporate user attributes, generated content, and check-ins, mitigating local semantic noise via semantic feature extraction and enhancing noise resilience through multi-view graph data augmentation. In addition, graph neural networks are also used for UIL, where the social relationship graph is constructed by considering users as nodes and the relationships between users as edges. To model the influence of the neighbors, MEgo2Vec [17] designs three mechanisms for representing different attributes, distinguishing different neighbors and capturing structural information of the social network, which addresses the problem of error propagation and the presence of noise in social networks. Long et al. [18] propose a degree-aware graph neural network model DegUIL, which effectively solves the challenges brought by tail nodes and super head nodes in the UIL task. By supplementing and correcting the neighborhood information of nodes, DegUIL improves the quality of node representation and thus improves the accuracy of user identity links across social networks.
Unimodal data-based UIL methods rely only on textual modal data for UIL, ignoring the rich semantic information embedded in images, and failing to comprehensively capture and understand users’ multifaceted behavioral characteristics and personalized preferences.
2.1.2 Multimodal Data-Based Methods
Multimodal data-based methods utilize both textual modal data and visual modal data of users. LinkSocial [8] extracts username features based on bi-grams, crops images to extract faces using OpenFace, an open-source image similarity framework, and uses deep learning to represent the face features on a 128-dimensional unit hypersphere. AHGNet [11] combines several deep learning techniques for extracting user features from multimodal social data, where textual information is captured using (Bidirectional Encoder Representations from Transformers, BERT) [19] and TextCNN [20] fusion models deep semantic features, image information is encoded using ResNet [21] to extract high-dimensional image features, check-in data is represented by constructing spatio-temporal co-occurrence matrix and applying GRU [22] model to form spatio-temporal sequences and social relationships are transformed into feature vectors revealing the structure of the social network using DeepWalk [23] algorithm. UserNet [12] is used to analyze the user's textual information using BiLSTM [24] to encode users’ text posts to capture contextual information as well as potential emotional and semantic features in the posts, and uses a pre-trained ResNet model to extract the depth features of the images uploaded by users, and then constructs the similarity matrices based on textual features and the similarity matrices based on image features, respectively, and predicts whether the users from the two platforms are the same person by fusing the similarity matrices of the two modalities whether they are the same person or not. AMSA [9] uses the BLIP model to generate textual descriptions for the images and extracts the subject of the text using the Latent Dirichlet Allocation (LDA) [25] model. In addition, AMSA extracts the textual features from the textual collection using BERT and extracts the image features of the user using ConvNeXT [26]. GRU-based model extracts the user’s check-in features and fuses them into a user representation vector. MFlink [10] utilizes usernames and user-generated multimodal data to represent the user. Specifically, the method employs the bag-of-words model to extract the username features and extracts the user’s posting text and image content information based on the BERT and ResNet models, respectively, and finally integrates the three modalities with the help of graph neural network and attention mechanism to integrate the three modalities. The current research extracts the features of each modal data based on the corresponding unimodal model and then trains the model based on the anchor user data for inter-modal interaction and fusion, however, there is a semantic gap between text and image, and due to the lack of multimodal social data and the difficulty in acquiring the anchor user pairs, it is more difficult to train the feature extraction model and the multimodal fusion model based on text and image features extracted from unimodal models, making the UIL unsatisfactory.
Given that visual and linguistic modalities often convey complementary insights, the synergy achieved through joint multimodal representation learning has demonstrated remarkable efficacy across various tasks, including visual question answering, image captioning, and quotation interpretation.
The CLIP (Contrastive Language-Image Pre-training) model is a multimodal pre-training model proposed by OpenAI, designed to bridge the semantic gap between text and images through contrastive learning. The innovation of CLIP lies in its use of unsupervised learning methods, training on large-scale data pairs of image and text scraped from the Internet, thereby learning cross-modal representations. The CLIP model comprises two main components: an image encoder and a text encoder. The image encoder can be any pre-trained convolutional neural network (CNN), such as ResNet, while the text encoder is typically based on the Transformer architecture. These two encoders map input images and text into the same vector space, allowing for a direct comparison of their similarities.
During training, CLIP utilizes a contrastive loss function, which aims to maximize the similarity of positive pairs while minimizing the similarity of negative pairs. Suppose we have a set of images I and corresponding textual descriptions T, where each image
Here,
Building upon CLIP, the BLIP Series Models [13,27] represent an advanced multimodal pre-training architecture, incorporating refined training paradigms and architectural enhancements. Beyond joint representation learning, BLIP emphasizes improvements in text generation rooted in visual understanding, thus achieving a harmonious integration of visual analysis and linguistic expression, marking a significant advance toward comprehensive multimodal intelligence. BLIP2 is an upgraded version of BLIP, further enhancing the model's performance and efficiency while retaining its original strengths. BLIP2 achieves higher cross-modal matching accuracy and faster inference speed through improvements in model architecture and optimized training strategies.
To clearly articulate our research problem and its underlying components, we first introduce the necessary notation and then define the research problem itself.
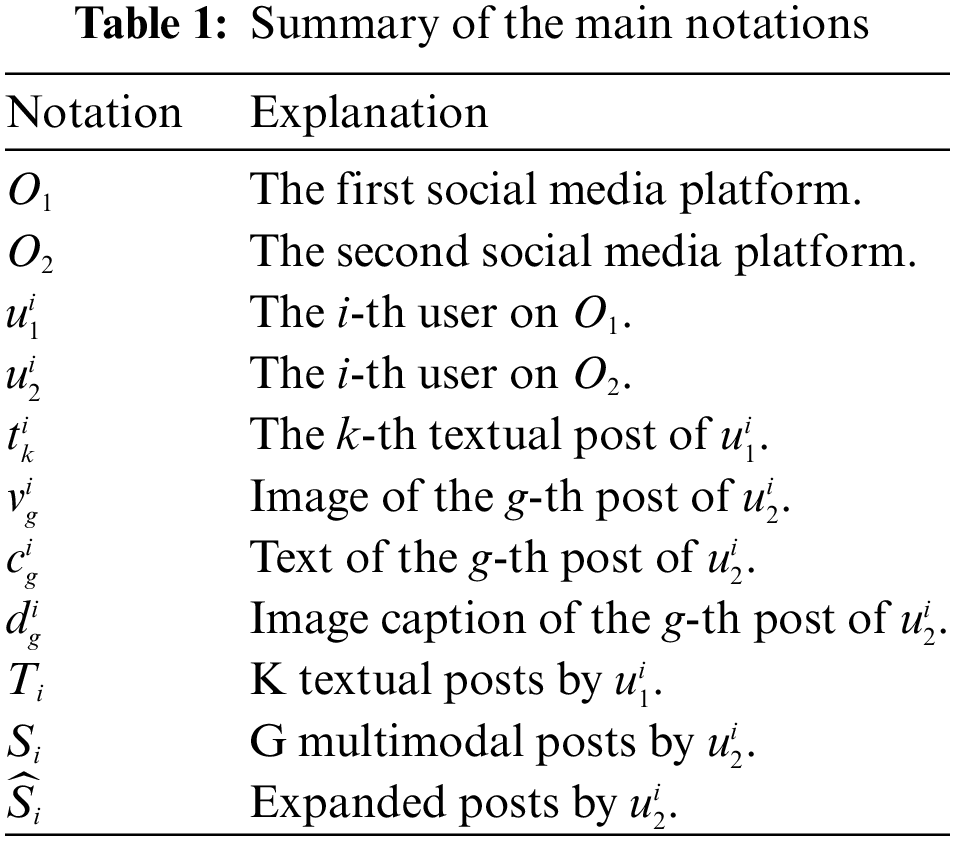
We establish a set of symbols that will be used throughout our discussion to ensure clarity and consistency. Table 1 summarizes the main notations used in this paper.
In this work, we aim to address the problem of UIL based on multimodal UGCs across different social media platforms. Without loss of generality, we focus on UIL between
Suppose we have a set of training user account pairs
Facing the task of UIL in multimodal UGCs scenarios, we propose an efficient UIL method based on aligned multimodal features and temporal correlation, including the BLIP-based text enhancement module, the aligned feature extraction module, the multimodal adapter module, and the temporal correlation-based cross-modal similarity calculation module. To address the problem of data modality variability and data volume imbalance in the content posted by users on different social media, the BLIP-based text enhancement module first utilizes the BLIP model to generate a detailed description for the image content as a supplement to the text modality data. Then, to address the semantic gap between image and text, the aligned feature extraction module extracts the representation of text and image under a unified feature space with the CLIP model. Then, we design and train the multimodal adapter module to generate feature representations suitable for UIL. Finally, the temporal correlation-based cross-modal similarity computation module constructs the multimodal user similarity matrix, and we introduce a time factor to reweight the similarity matrix. We input the multimodal similarity matrix into the classification network to classify the input user pairs. The specific implementation of each module is described in detail below.
4.1 BLIP-Based Text Enhancement
Diverse social media platforms are characterized by distinct functionalities; for instance, Instagram prioritizes visual content, with user-generated multimodal posts predominantly featuring images accompanied by brief or even absent textual accompaniments. To bolster textual content on such platforms and leverage the copious semantic information embedded in images, we introduce a text augmentation strategy grounded in the BLIP model. This approach taps into the decoder component of a pre-trained BLIP model to generate descriptive captions for individual images within posts. BLIP, a robust bidirectional text-image pre-training model, boasts a decoder capable of translating image substance into coherent natural language narratives. By doing so, it effectively transforms non-verbal image data into textual representations, thereby enabling the interpretation of image content through the lens of linguistic semantics and enriching the overall semantic context.
Specifically, for the G multimodal posts
By transforming image information into text, the semantic gap between two different modalities, image and text, can be narrowed, which facilitates the comparison and fusion of data from the two modalities in a unified semantic space, and is conducive to improving the accuracy of cross-modal UIL. Especially on social media platforms, image posts posted by users are often accompanied by short or even no textual descriptions. BLIP-generated captions can effectively supplement this lack of information and provide more valuable information clues for UIL. In addition, image-based caption generation can be viewed as a kind of data augmentation of text, which increases the diversity of data and helps to improve the generalization ability of the subsequent model and the ability to cope with unseen complex situations.
4.2 Aligned Feature Extraction
Traditional work tends to use targeted image models and language models to extract image and text features respectively, e.g., extracting 2048-D image feature vectors using the ResNet model and 768-D or 1024-D text features using the BERT model, and then training modal fusion networks or classification networks based on these two features. However, due to the semantic gap between text and images, high quality as well as a high quantity of multimodal data from anchor users is required to achieve the desired training results. Since social data tends to have a lot of noise and anchor users are expensive to acquire, the current results of training fused multimodal features based on unimodal models are not satisfactory.
To address the above problem, we design the alignment feature extraction module to provide a unified feature representation of text and images on social media with the help of a pre-trained cross-modal comparative learning model, CLIP. CLIP employs a comparative learning strategy, the basic idea of which is to maximize the similarity between positive sample pairs (an image and the text that describes it correctly), while minimizing the similarity between negative sample pairs (an image and an irrelevant text description). This approach motivates the model to learn representations that efficiently map images and text into a shared semantic space. The process of extracting features based on the CLLP model can be formalized as Eqs. (2) and (3):
where
The contents posted on different social media platforms by users are often different, and for the UIL task, some of the posts are extremely similar in content, which possesses a positive impact on the UIL effect, while some of the posts are equivalent to noise, which harms the UIL effect. Considering the different degrees of contribution of each post to end-UIL, we design a lightweight Adapter module to personalize and optimize the features extracted from the CLIP model to further enhance the performance of these features in the UIL task. The Adapter module is typically a pre-trained model that is supplemented by one or more layers of a small network structure, allowing for the targeting of the UIL without changing the parameters of the original model. Adapter modules typically add one or more layers of small network structures to a pre-trained model, allowing fine-tuning of the model's performance for a specific task without changing the original model parameters. In the multimodal UIL scenario, we design the multimodal Adapter module as a four-terminal, multi-headed self-attention module, with each end as shown in Eq. (4):
where
Specifically, we set up the Adapter module for the text end of the
The MLP consists of two fully connected layers, where
The feature
where
The Adapter module utilizes a multi-head self-attention mechanism to assign dynamic weights to the features of each modality of each post so that those post features that are more representative and distinguishable in determining the identity of a user will receive higher attention and weighting. The multi-head self-attention mechanism processes the input features in parallel from multiple different perspectives, and each head outputs a weighted subset of feature vectors, and then stitches together the results from the individual heads to ultimately generate a new representation of the features that reflect the importance of each post.
The multimodal Adapter module makes full use of the powerful cross-modal features provided by CLIP and fine-tunes the differentiation of the importance of image features based on the actual application scenarios, which improves the accuracy of UIL, and does not require fine-tuning of the large multimodal model during training, but only needs to train the lightweight Adapter module, which improves the performance of UIL.
4.4 Temporal Correlation-Based Cross-Modal Similarity
In response to the behavioral patterns of users posting content on different social media platforms, it is found that users tend to post content with some kind of intrinsic relevance within the same period. Based on this observation, we construct a multimodal similarity computation framework incorporating a time factor for measuring users' content consistency across platforms.
First, we construct a user similarity matrix based on text posts on the
where
However, considerations based solely on content similarity are not sufficient to fully capture the temporal nature of user behavior. Given that content posted by users within the same period is more relevant, we introduce a time factor r to adjust the similarity weights. This time factor r is defined as shown in Eq. (9):
where

Figure 3: Image of the time decay function. The horizontal coordinate is the time interval and the vertical coordinate is the time factor value
According to Eq. (7), we calculate the time factor matrix R between K textual posts and G multimodal posts, and finally, we combine the time factor-adjusted cross-modal similarity defined as a list of content similarities weighted by the time factor as shown in Eq. (10) as follows:
where
The cross-modal similarity calculation method based on the time factor not only effectively addresses the limitations of single-modal similarity calculations but also successfully leverages temporal information to enhance the accuracy and effectiveness of the UIL task. By incorporating the time factor into the similarity calculation, this method provides a more nuanced understanding of the relationship between different modalities, particularly when dealing with unaligned image-text pairs. Algorithm 1 outlines the complete process of the EUIL algorithm.

To demonstrate the effectiveness of the proposed method, we conducted experiments on real-world datasets to prove the effectiveness of the proposed method. All experiments were conducted on servers with Intel (R) Xeon (R) Gold 6330 CPUs and three Nvidia A800 GPUs.
Dataset. We validate our approach on the TWIN dataset [12] collected by Chen et al. The TWIN dataset collects information about users on two popular heterogeneous social media platforms, Twitter and Instagram. After filtering out some low-quality data, 5765 user pairs were obtained on Twitter and Instagram, along with 1,729,500 UGCs and corresponding timestamps.
Training settings. We divided the user account pairs into three parts: 80% for training, 10% for validation, and 10% for testing. These are considered as positive samples, while negative samples are randomly generated with the same number of positive and negative samples. We converted the UIL into a binary classification task, using accuracy as the evaluation metric. For optimization, we used the Adam optimizer with a learning rate of 0.0001.
Due to the limited research done on the issue of linking user identities in UGCs, we compare our scheme with the following baseline:
• WSF-GBDT: This baseline is derived from the method in [28], which introduced four writing-style features, including lexical, syntactic, structural, and content-specific features, to characterize users and employed the support vector machine [29] for the UIL.
• WHOLE: This baseline also characterizes each user account’s textual/visual modality by considering all UGCs as a whole. WHOLE employs BiLSTM to derive the textual representation, conducts the text-text similarity and the text-image similarity separately by MLP, and obtains the final user similarity by fusing the text-text similarity and the text-image similarity.
• UserNet: This baseline utilizes two bidirectional long and short-term memory networks to encode text posts from users of the
Table 2 shows the performance comparison of the different methods. Based on this table, we obtain the following observations: (1) Our proposed method and UserNet are significantly better than WSF-GBDT. this may be attributed to the fact that the former two methods integrate multimodal user representations, not just writing style features. (2) Our proposed method outperforms WHOLE, demonstrating the advantages of fine-grained similarity modeling in the context of user identity correlation, and can further incorporate temporal correlation. (3) Our proposed method significantly outperforms the optimal baseline UserNet. This may be attributed to the fact that UserNet extracts text features using the text-specific unimodal model BiLSTM and image features using the visual unimodal model ResNet, respectively, and computes the similarity matrices directly on top of the two unimodal features, ignoring the semantic gaps between the text and image. semantic gap between text and image. In contrast, our proposed method, which uses the text encoder and image encoder of the multimodal model CLIP to extract features, allows the features of different modalities to be in the same embedding space that can be compared and is more capable of capturing the similarity relationship between image and text. To visually demonstrate the effectiveness of the multimodal model in extracting aligned features on social media, we use a similarity matrix to show the similarity of the image-text features extracted by CLIP, where the lighter the color of the block of elements in the matrix, the higher the image similarity. Where image-text pairs come from heterogeneous multimodal posts made by users on social media, there is often a potential correlation between images and text. As shown in the Fig. 4 below, the features extracted by the CLIP model better capture this correlation.
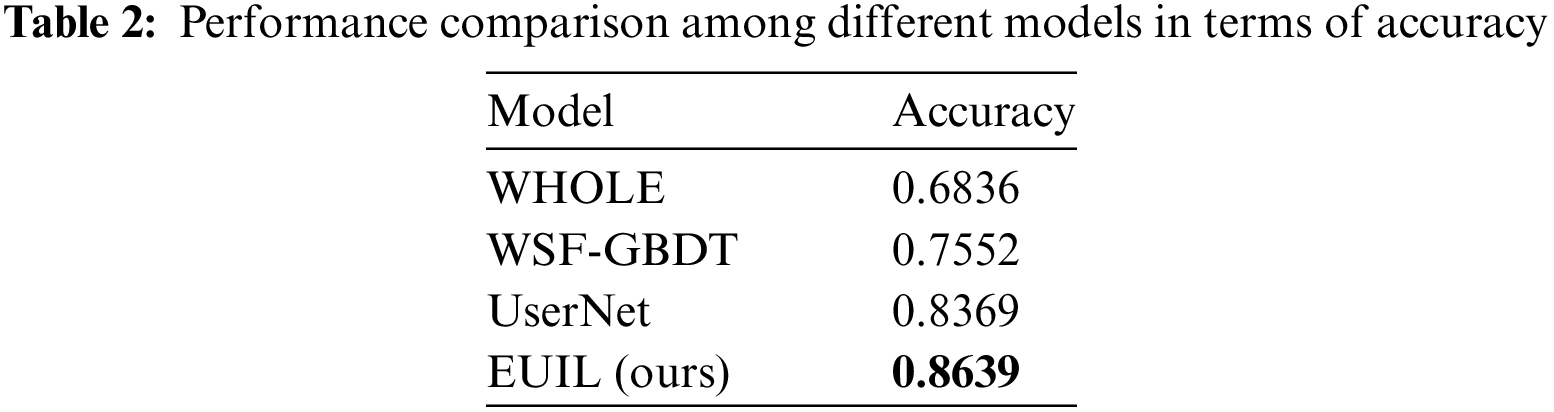
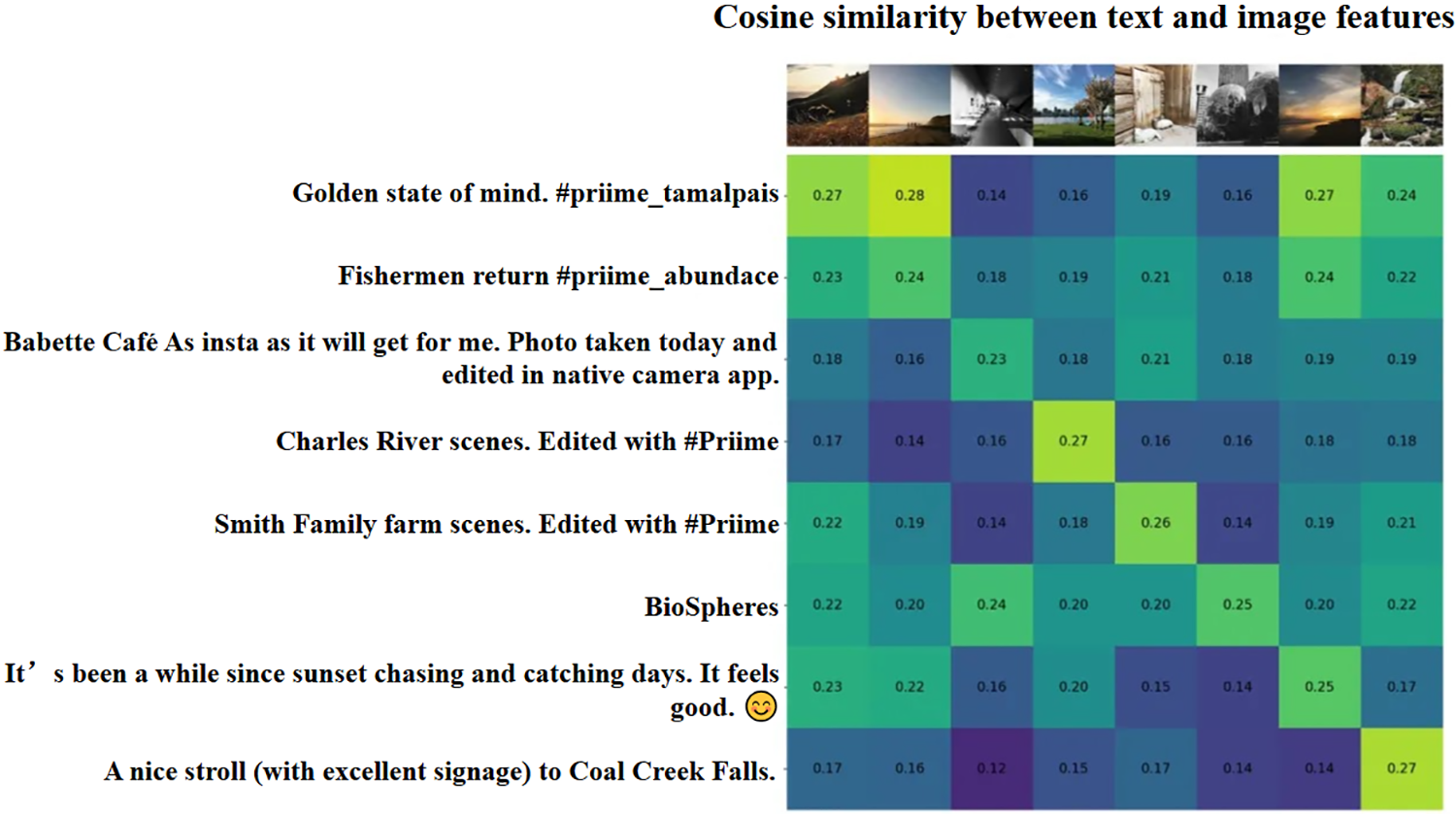
Figure 4: Similarity matrix of multimodal posts based on features extracted from CLIP model
To gain a deeper understanding of our proposed model, we compare our proposed method EUIL with several derived methods. Specifically, we explore the effects of modal diversity, text enhancement, multimodal Adapter, and time factor on UIL performance.
•
•
• EUILtext&img: Only the raw data posted by the users of the
•
•
•
To explore the contribution of each modality to UIL, we compared the results between EUIL,
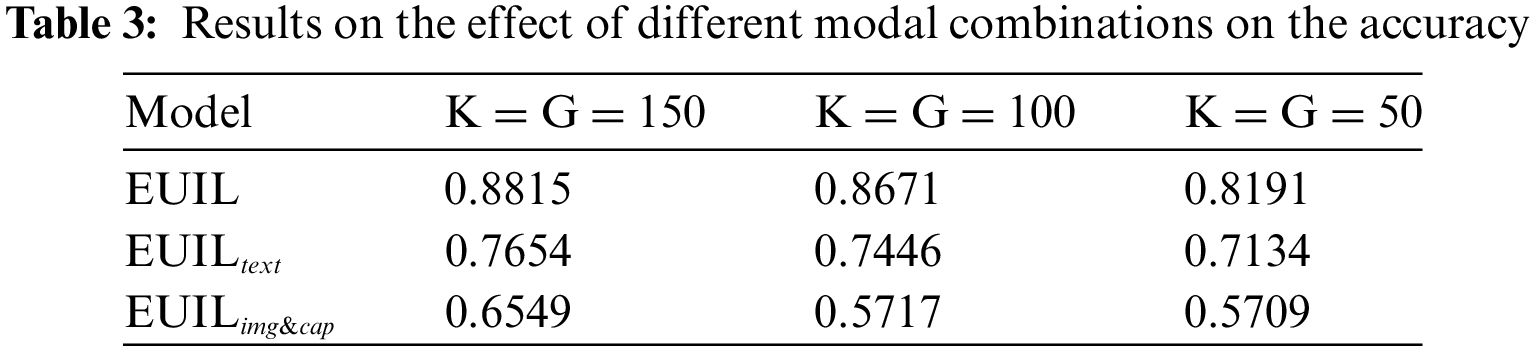
The primary observation that the accuracy of the EUIL model is higher than that of
To validate the contribution of the BLIP-based text enhancement module to UIL, we compare the results of EUIL,
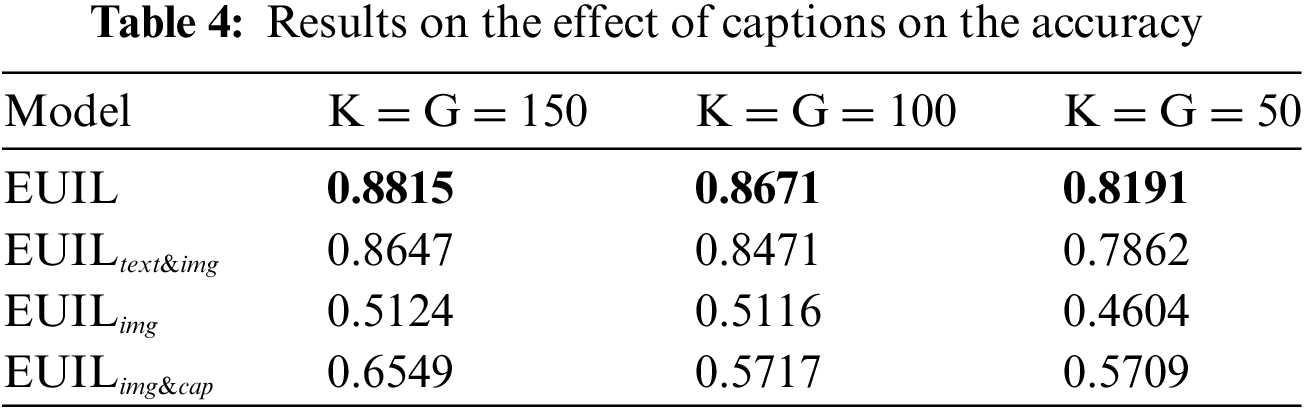
Preliminary observations show that the accuracy of EUIL model outperforms
To validate the contribution of the multimodal Adapter module to UIL, we compared the results of EUIL and

Observations show that the EUIL model exhibits a significant advantage in accuracy over its variant
To validate the contribution of introducing the time factor to UIL, we compared the results of EUIL with

Observations show that the accuracy of the EUIL model outperforms that of the
Our approach leverages aligned multimodal features and temporal correlation to enhance the performance of the UIL task. By utilizing aligned multimodal features and incorporating temporal information, we have achieved significant improvements. However, despite these advancements, there remain some limitations and areas for potential improvement:
(1) Integration of Multi-Dimensional User Features: EUIL primarily focuses on studying the contribution of multi-modal user-generated content to user alignment. However, different social media platforms emphasize various types of content, which poses significant challenges to the proposed methods, potentially affecting their generalization and robustness. Beyond user-generated content, other user features on social media platforms, such as user profiles and social network structures, may provide crucial clues for enhancing the accuracy of UIL. To build more universally applicable models, future work should consider incorporating a wider range of user features into the model.
(2) Construction of Datasets with Multi-Dimensional User Features: Training and evaluating models using more diverse datasets ensures their generality and robustness. However, due to user privacy protection, publicly available datasets that meet the requirements are limited. Therefore, constructing datasets that include comprehensive features is necessary for future work, including collecting data from multiple social media platforms, and covering information from diverse user groups, thereby enhancing the representativeness and breadth of research. In this way, we can more comprehensively evaluate the model's performance in real-world scenarios, ensuring its adaptability to real-world environments and improving its recognition capabilities in complex situations.
(3) The dynamic nature of social media user behavior and preferences poses significant challenges for UIL. Capturing long-term trends and short-term changes is crucial for maintaining the accuracy and relevance of these systems. In future work, we can pursue research along the following three directions: (1) Longitudinal Tracking Mechanism: We plan to develop a mechanism capable of tracking user behavior over extended periods. This will involve collecting and analyzing historical data to identify patterns and trends in user activities. By doing so, the system can adapt to long-term changes in user behavior. (2) Dynamic Learning Algorithms: We aim to design algorithms that can continuously update user models based on incoming data. This dynamic learning capability will enable the system to quickly adapt to short-term changes in user behavior, such as shifts in interests or sudden changes in activity patterns. (3) Feedback Loop for Model Refinement: We propose implementing a feedback loop to refine user models based on real-time feedback. This could involve engaging users with the system, such as through corrections or verifications of linked identities, to improve the accuracy of the models. We believe that these enhancements will significantly improve the robustness and adaptability of our UIL system. They will enable the system to maintain its performance even as user behavior evolves.
The performance of EUIL on the TWIN dataset indicates that UIL relying solely on UGC across Twitter and Instagram platforms is feasible. Unlike user profiles, which can be disclosed or contain false information, UGC often represents genuine user behavior and is publicly available on social platforms, which makes UGC-based UIL techniques susceptible to malicious exploitation for consolidating sensitive personal information across social media platforms. Therefore, it is necessary to take measures to ensure privacy security. Research on data privacy protection in other fields is relatively advanced [30], but research on user social data privacy protection is relatively insufficient. There are specific UIL adversarial attack methods targeting user attributes, such as the DeLink [31] framework, which draws from adversarial text generation ideas to help users modify their social media usernames, thus defending against UIL. Additionally, there are adversarial attack methods targeting the structure of social networks, such as the TOAK [32] strategy, which leverages the topological structure information of networks by carefully perturbing network structures to reduce the matching accuracy of UIL models. However, there are currently adversarial methods specifically targeting UGC. To prevent UGC from being maliciously utilized, our next steps will explore how to generate adversarial UGC by introducing imperceptible perturbations without disrupting the intended expression of the user, thereby reducing the effectiveness of UGC-based UIL strategies and further protecting user data privacy.
In this paper, we propose an efficient UIL scheme based on aligned multimodal features and temporal correlation to address the challenges of multimodal UIL in social media platforms. The method utilizes the BLIP model for image-generated captions, which compensates for the lack of textual information in social media platforms and significantly improves the expressive power of image modality in UIL tasks. Moreover, the method makes full use of the pre-trained multimodal large model CLIP to realize the representation of data in both text and image modalities under a unified feature space, achieving an effective fusion of cross-modal features. The subsequently designed multimodal adapter module, by its lightweight and flexible features, can extract a comprehensive feature representation that is highly correlated and suitable for user identity association from the multimodal features extracted by CLIP by training with a small number of additional parameters. In addition, we introduce a time factor assignment mechanism to construct a user similarity prediction model that can dynamically reflect the temporal dynamics of user interest evolution and social behavior, thus enhancing the timeliness and accuracy of the UIL method. Experiments demonstrate that this method performs well on large-scale real-world social media datasets, not only overcoming the problem of data modal differences and imbalance but also surpassing the existing state-of-the-art methods in terms of accuracy and efficiency.
Acknowledgement: Not applicable.
Funding Statement: The authors received no specific funding for this study.
Author Contributions: The authors confirm contribution to the paper as follows: Conceptualization and methodology, Jiaqi Gao; software, Jiaqi Gao and Bin Wu; validation, Xiujuan Wang, Kangfeng Zheng and Chunhua Wu; writing—original draft preparation, Jiaqi Gao; writing—review and editing, Xiujuan Wang and Chunhua Wu; supervision, Kangfeng Zheng. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data that support the findings of this study are available from the corresponding author, Kangfeng Zheng, upon reasonable request.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. X. Chen, F. Zhou, K. Zhang, G. Trajcevski, T. Zhong and F. Zhang, “Information diffusion prediction via recurrent cascades convolution,” presented at the 2019 IEEE 35th Int. Conf. Data Eng. (ICDE), Macao, China, Apr. 8–11, 2019, pp. 770–781. [Google Scholar]
2. T. H. Lin, C. Gao, and Y. Li, “CROSS: Cross-platform recommendation for social E-commerce,” presented at the Proc. 42nd Int. ACM SIGIR (Special Interest Group Inf. Retr.) Conf. Res. Develop. Inf. Retr., Paris, France, Jul. 21–25, 2019, pp. 515–524. [Google Scholar]
3. M. Wang, W. Wang, W. Chen, and L. Zhao, “EEUPL: Towards effective and efficient user profile linkage across multiple social platforms,” World Wide Web, vol. 24, no. 5, pp. 1731–1748, Jun. 2021. doi: 10.1007/s11280-021-00882-7. [Google Scholar] [CrossRef]
4. J. Shao, Y. Wang, H. Gao, B. Shi, H. Shen and X. Cheng, “AsyLink: User identity linkage from text to geo-location via sparse labeled data,” Neurocomputing, vol. 515, no. 6, pp. 174–184, Jan. 2023. doi: 10.1016/j.neucom.2022.10.027. [Google Scholar] [CrossRef]
5. Y. Huang, P. Zhao, Q. Zhang, L. Xing, H. Wu and H. Ma, “A Semantic-enhancement-based social network user-alignment algorithm,” Entropy, vol. 25, no. 1, Jan. 2023, Art. no. 172. doi: 10.3390/e25010172. [Google Scholar] [PubMed] [CrossRef]
6. H. Gao, Y. Wang, J. Shao, H. Shen, and X. Cheng, “User identity linkage across social networks with the enhancement of knowledge graph and time decay function,” Entropy, vol. 24, no. 11, Nov. 2022, Art. no. 1603. doi: 10.3390/e24111603. [Google Scholar] [PubMed] [CrossRef]
7. B. Chen and X. Chen, “MAUIL: Multilevel attribute embedding for semisupervised user identity linkage,” Inf. Sci., vol. 593, pp. 527–545, May 2022. doi: 10.1016/j.ins.2022.02.023. [Google Scholar] [CrossRef]
8. V. Sharma and C. Dyreson, “LINKSOCIAL: Linking user profiles across multiple social media platforms,” presented at the 2018 IEEE Int. Conf. Big Knowl. (ICBK), Singapore, Nov. 17–18, 2018, pp. 260–267. [Google Scholar]
9. Y. Li, G. Gou, G. Xiong, Z. Li, and M. Cui, “The potential utility of image descriptions: User identity linkage across social networks based on MultiModal self-attention fusion,” presented at the 2023 IEEE Int. Perform., Comput., Commun. Conf. (IPCCC), Anaheim, CA, USA, Nov. 17–19, 2023, pp. 265–273. [Google Scholar]
10. S. Li, D. Lu, Q. Li, X. Wu, S. Li and Z. Wang, “MFLink: User identity linkage across online social networks via multimodal fusion and adversarial learning,” IEEE Trans. Emerg. Top. Comput. Intell., pp. 1–10, Mar. 2024. doi: 10.1109/TETCI.2024.3440057. [Google Scholar] [CrossRef]
11. X. Chen, X. Song, G. Peng, S. Feng, and L. Nie, “Adversarial-enhanced hybrid graph network for user identity linkage,” presented at the Proc. 44th Int. ACM SIGIR Conf. Res. Develop. Inf. Retr., Jul. 11–15, 2021, pp. 1084–1093. [Google Scholar]
12. X. Chen, X. Song, S. Cui, T. Gan, Z. Cheng and L. Nie, “User identity linkage across social media via attentive time-aware user modeling,” IEEE Trans. Multimedia, vol. 23, pp. 3957–3967, Nov. 2020. doi: 10.1109/TMM.2020.3034540. [Google Scholar] [CrossRef]
13. J. Li, D. Li, C. Xiong, and S. Hoi, “ BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation,” presented at the Proc. 39th Int. Conf. Mach. Learn. (PMLR), Baltimore, MD, USA, Jul. 17–23, 2022, pp. 12888–12900. [Google Scholar]
14. A. Radford et al., “Learning transferable visual models from natural language supervision,” presented at the Proc. 38th Int. Conf. Mach. Learn. (ICML), Jul. 18–24, 2021, pp. 8748–8763. [Google Scholar]
15. J. Pennington, R. Socher, and C. D. Manning, “GloVe: Global vectors for word representation,” presented at the Proc. 2014 Conf. Empir. Methods Nat. Lang. Process. (EMNLP), Doha, Qatar, Oct. 25–29, 2014, pp. 1532–1543. [Google Scholar]
16. A. Bordes, N. Usunier, A. Garcia-Duran, J. Weston, and O. Yakhnenko, “Translating embeddings for modeling multi-relational data,” presented at the Proc. 26th Int. Conf. Neural Inf. Proc. Syst., Lake Tahoe, NV, USA, Dec. 05–10, 2013, pp. 2787–2795. [Google Scholar]
17. J. Zhang et al., “MEgo2Vec: Embedding matched ego networks for UIL across social networks,” presented at the Proc. 27th ACM Int. Conf. Inf. Knowl. Manag., Torino, Italy, Oct. 22–26, 2018, pp. 327–336. [Google Scholar]
18. M. Long et al., “ DegUIL: Degree-aware graph neural networks for long-tailed user identity linkage,” presented at the Proc. Eur. Conf. Mach. Learn. Princ. Pract. Knowl. Discov. Databases, Turin, Italy, Sep. 18–22, 2023, pp. 122–138. [Google Scholar]
19. J. Devlin, M. W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” 2018, arXiv:1810.04805. [Google Scholar]
20. Y. Kim, “Convolutional neural network for sentence classification,” 2015, arXiv:1408.5882. [Google Scholar]
21. K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” presented at the Proc. 2016 IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Las Vegas, NV, USA, Jun. 27–30, 2016, pp. 770–778. [Google Scholar]
22. J. Chung et al., “Empirical evaluation of gated recurrent neural networks on sequence modeling,” 2014, arXiv:1412.3555. [Google Scholar]
23. B. Perozzi, R. Al-Rfou, and S. Skiena, “DeepWalk: Online learning of social representations,” presented at the Proc. 20th ACM SIGKDD Int. Conf. Knowl. Discov. Data Min., NY, USA, Aug. 24–27, 2014, pp. 701–710. [Google Scholar]
24. S. Hochreiter and J. Schmidhuber, “Long short-term memory,” Neural Comput., vol. 9, no. 8, pp. 1735–1780, Nov. 1997. doi: 10.1162/neco.1997.9.8.1735. [Google Scholar] [PubMed] [CrossRef]
25. D. M. Blei, A. Y. Ng, and M. I. Jordan, “Latent dirichlet allocation,” J. Mach. Learn. Res., vol. 3, pp. 993–1022, Mar. 2003. [Google Scholar]
26. Z. Liu, H. Mao, C. Y. Wu, C. Feichtenhofer, T. Darrell and S. Xie, “A convnet for the 2020s,” presented at the Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), New Orleans, LA, USA, Jun. 18–24, 2022, pp. 11976–11986. [Google Scholar]
27. J. Li et al., “BLIP-2: Bootstrapping language-image pre-training with frozen image encoders and large language models,” presented at the Proc. Int. Conf. Mach. Learn. (ICML), Honolulu, HI, USA, Jul. 23–29, 2023, pp. 19730–19742. [Google Scholar]
28. R. Zheng, J. Li, H. Chen, and Z. Huang, “A framework for authorship identification of online messages: Writing style features and classification techniques,” J. Am. Soc. Inf. Sci. Technol., vol. 57, no. 3, pp. 378–393, Dec. 2005. doi: 10.1002/asi.20316. [Google Scholar] [CrossRef]
29. C. Cortes and V. Vapnik, “Support-vector networks,” Mach. Learn., vol. 20, no. 3, pp. 273–297, Sep. 1995. doi: 10.1007/BF00994018. [Google Scholar] [CrossRef]
30. F. Buccafurri, V. De Angelis, and S. Lazzaro, “MQTT-A: A broker-bridging P2P architecture to achieve anonymity in MQTT,” IEEE Internet Things J., vol. 10, no. 17, pp. 15443–15463, Sep. 2023. doi: 10.1109/JIOT.2023.3264019. [Google Scholar] [CrossRef]
31. P. Zhang et al., “DeLink: An adversarial framework for defending against cross-site user identity linkage,” ACM Trans. Web, vol. 18, no. 2, pp. 1–34, Mar. 2024. doi: 10.1145/3643828. [Google Scholar] [CrossRef]
32. J. Shao et al., “TOAK: A topology-oriented attack strategy for degrading user identity linkage in cross-network learning,” presented at the Proc. 32nd ACM Int. Conf. Inf. Knowl. Manag. (CIKM), Birmingham, UK, Oct. 21–25, 2023, pp. 2208–2218. [Google Scholar]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools