
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

EfficientNetB1 Deep Learning Model for Microscopic Lung Cancer Lesion Detection and Classification Using Histopathological Images
1 Department of Computer Science, Lahore College for Women University, Lahore, 54000, Pakistan
2 Artificial Intelligence & Data Analytics Lab., CCIS Prince Sultan University, Riyadh, 11586, Saudi Arabia
3 Department of Information Systems, College of Computer and Information Sciences, Princess Nourah bint Abdulrahman University, P.O. Box 84428, Riyadh, 11671, Saudi Arabia
4 Department of Computer Science, College of Computer and Information Sciences, King Saud University, Riyadh, 145111, Saudi Arabia
* Corresponding Author: Tahani Jaser Alahmadi. Email:
(This article belongs to the Special Issue: Medical Imaging Based Disease Diagnosis Using AI)
Computers, Materials & Continua 2024, 81(1), 809-825. https://doi.org/10.32604/cmc.2024.052755
Received 14 April 2024; Accepted 23 August 2024; Issue published 15 October 2024
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Cancer poses a significant threat due to its aggressive nature, potential for widespread metastasis, and inherent heterogeneity, which often leads to resistance to chemotherapy. Lung cancer ranks among the most prevalent forms of cancer worldwide, affecting individuals of all genders. Timely and accurate lung cancer detection is critical for improving cancer patients’ treatment outcomes and survival rates. Screening examinations for lung cancer detection, however, frequently fall short of detecting small polyps and cancers. To address these limitations, computer-aided techniques for lung cancer detection prove to be invaluable resources for both healthcare practitioners and patients alike. This research implements an enhanced EfficientNetB1 deep learning model for accurate detection and classification using histopathological images. The proposed technique accurately classifies the histopathological images into three distinct classes: (1) no cancer (benign), (2) adenocarcinomas, and (3) squamous cell carcinomas. We evaluated the performance of the proposed technique using the histopathological (LC25000) lung dataset. The preprocessing steps, such as image resizing and augmentation, are followed by loading a pretrained model and applying transfer learning. The dataset is then split into training and validation sets, with fine-tuning and retraining performed on the training dataset. The model’s performance is evaluated on the validation dataset, and the results of lung cancer detection and classification into three classes are obtained. The study’s findings show that an enhanced model achieves exceptional classification accuracy of 99.8%.Keywords
Lung and colorectal cancer are specific diseases that may show that cells in the colon and rectum are not functioning properly. Globally, lung cancer is the primary cause of cancer-related mortality. However, genetics, exposure to environmental risk factors, and different tobacco smoking patterns contribute to significant regional variations in lung cancer incidence and mortality rates. Lung cancer begins when irregular cells proliferate uncontrollably within the lungs. It may lead to the extensive growth of these cells, which is an output of the extension of cancer cell growth. Lung cancer continued to be the most common cause of cancer-related deaths, accounting for nearly 1.8 million deaths, or 18% of all cancer-related deaths, according to the statistics [1]. According to the study, lung cancer detection will increase, and it may cause deaths in the future. Another review [2] analyses that the global cancer death rate is approximately 23% per 100,000 people.
The x-axis, or horizontal axis, is marked with different cancer types, such as lung, colorectum, liver, stomach, breast, oesophagus, pancreas, prostate, cervixuteri, and leukaemia cancer. The prevalence of each type of cancer, expressed as a percentage, was indicated on the vertical axis (y-axis). This shows that at the global level, a huge percentage of people are dying due to lung cancer, as shown in Fig. 1.
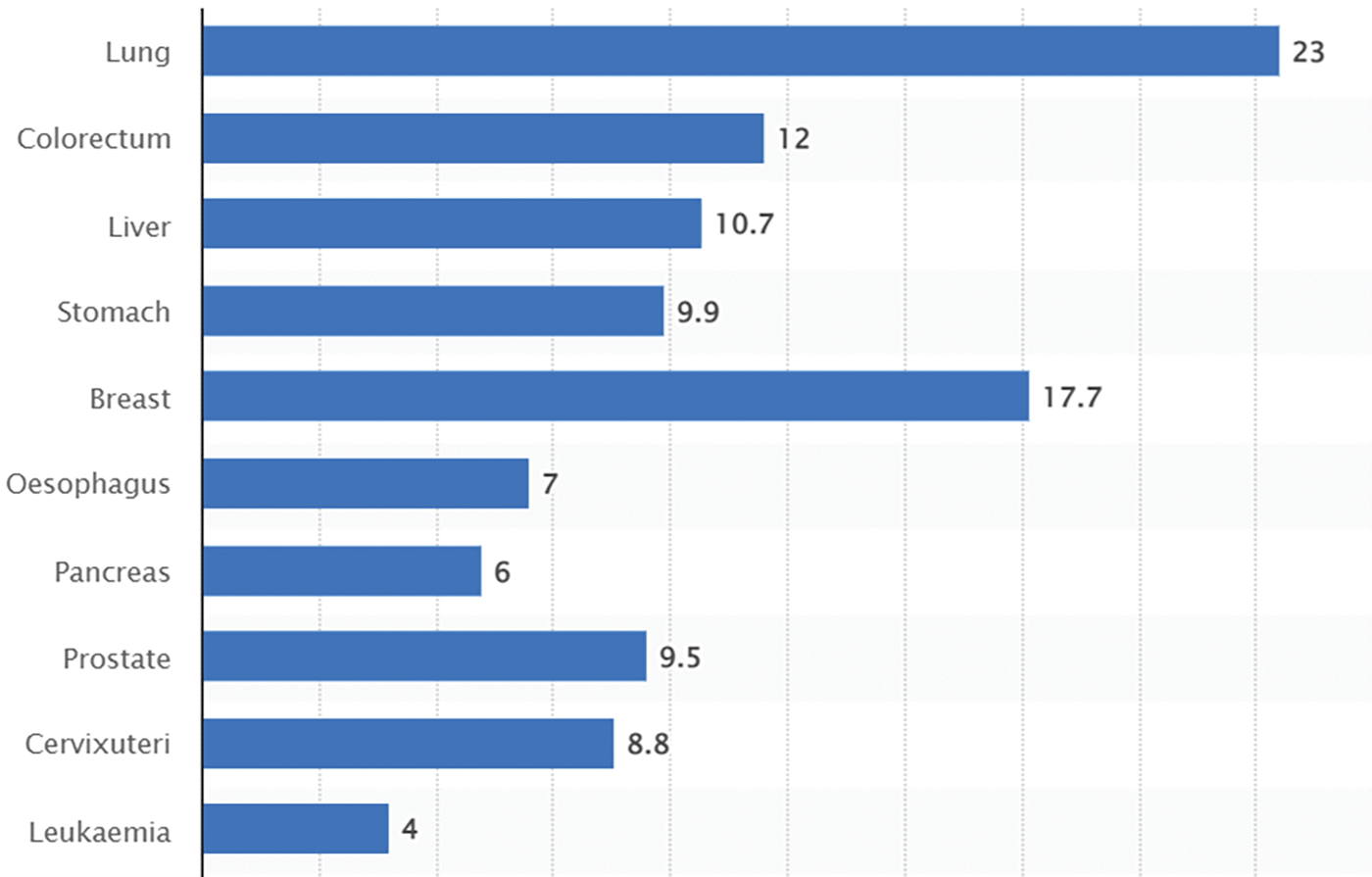
Figure 1: Death statistical rate for lung cancer
The data in this context confirms the findings of a previous study. The cancer’s uncontrollable nature and unpredictability in its early stages contribute to the rise in the number of patients with the disease. This may lead to the patient’s death, as the last stage of treatment is very critical and may cause the patient’s death earlier than expected. Comparing the twenty years from 2020 to 2040 to see what is forecasted for the future of this cancer. As indicated in Table 1, the review analyses the lung as the primary site.
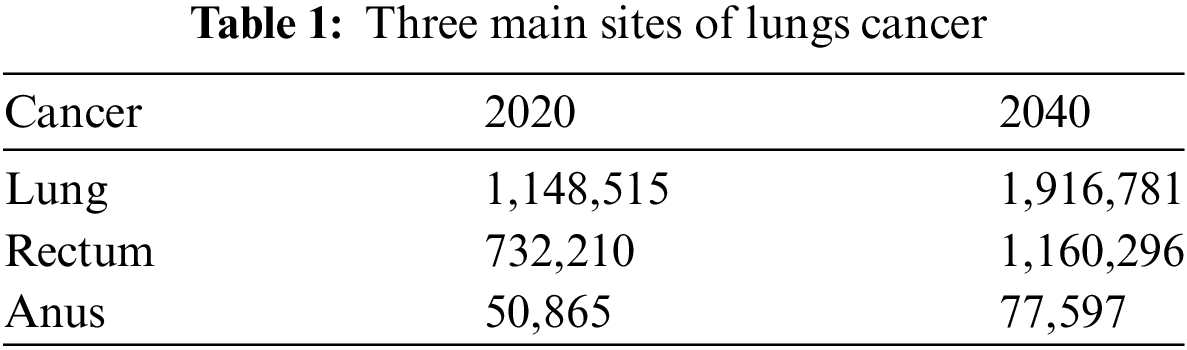
It is evidence that lung cancer needs to be addressed at the early stages because if the stage is increasing, then it is sure that the treatment is also becoming more difficult with time [3]. The use of modern technology and the positive role of artificial intelligence in this regard can be productive. The support of the evidence from the literature indicates that the imagery technique and other histopathological techniques are helpful in reaching the facts [4]. This is why they should be employed in the early stages. In addition, the table shows that the role of the cancer sites is also essential. It is analyzed by the World Health Organization (WHO) of 2023 that colorectal cancer is dominant in the lungs, rectum, and anus areas. This is why when addressing the technique applications, it is important to value the three sites and ensure analysis of the three with respect to the technique for diagnosis.
This research aims to contribute to the field by demonstrating the efficacy of deep learning in histopathological image analysis for lung cancer diagnosis. By elucidating the complexities of lung cancer classification. We endeavor to pave the way for more accurate and efficient clinical decision support systems in oncology with the following main contributions:
i) Investigated the potential of histopathological images as a diagnostic tool for lungs cancer.
ii) Collected and analyzed a diverse dataset of histopathological images to assess their diagnostic value.
iii) Proposed data-driven recommendations and strategies for improving lung cancer detection based on proposed model.
The remainder of this research paper is structured as follows: Section 2 provides an overview of prior studies that bear resemblance to this research. In Section 3, the proposed research technique is implemented and discussed in detail. Section 4 presents results and their deep analysis, comparisons in Sections 4, 5, respectively. Finally, the paper concludes with a summary of the results, encapsulating the key takeaways and contributions of this study in Section 7.
Lung cancer is diagnosed in the early stages with the help of high-quality laboratory tests and imaging techniques, including biopsies, x-rays, PET scans, and CT scans These methods are popular and helpful in identifying treatment for the patients, but these methods have human error and time consuming [5]. The use of artificial intelligence techniques is also helpful as it utilizes data based on medical images which are supportive of studying minor issues. The use of a research hotspot is helpful because it is an effective auxiliary method for the detection rate of adenomas in the body.
Classification techniques, including Support Vector Machine (SVM), Decision Trees, Naive Bayes and Logistic Regression were used to assess lung cancer lesion detection. The developed classifier leverages Artificial Intelligence methodologies to automatically classify histopathological images of lung tissue into three categories: healthy, adenocarcinoma, and squamous cell carcinoma. Additionally, the system incorporates a reporting module that utilizes explainable deep learning techniques. This module provides the pathologist with insights into the specific areas of the image utilized for classification and the confidence levels associated with each class assignment [6]. In related studies, a proposed methodology showcases notable advancements across multiple performance metrics through the utilization of six distinct deep learning algorithms, namely Convolution Neural Network (CNN), CNN Gradient Descent (CNN GD), VGG-16, VGG-19, Inception V3, and Resnet-50 [7]. The assessment, based on both CT scan and histopathological images, reveals superior detection accuracy particularly when analyzing histopathological tissues, suggesting promising avenues for enhanced diagnostic capabilities in lung cancer detection.
In another study [8], an extreme learning machine method was proposed for the classification of the LC25000 dataset. A hybrid approach is proposed for classifying histopathological images, utilizing a combination of deep learning (DL) and machine learning techniques [9]. A deep learning network tailored for segmenting H&E-stained histology images from the colon cancer dataset was introduced with the goal of facilitating early diagnosis. The network attained a 94.8% accuracy rate when analyzing images of tumor tissue. Moreover, the authors developed the DeepRePath network, leveraging Convolutional Neural Networks (CNNs) to predict the stages of lung adenocarcinoma. This model was trained on the Genome Atlas dataset and validated using images from patients at various stages of the disease. DeepRePath demonstrated an AUC of 77% [10]. In another method, Convolutional Neural Networks (CNNs) is used in regions of interest (ROI) based on feature learning from nodules for the diagnosis of lung cancer. Utilizing generative adversarial networks (GANs) to enhance the dataset, they obtained CT scan images from the databases of the Infectious Disease Research Institute (IDRI) and the Lung Image Database Consortium (LIDC). Using CNN based algorithms. Using CNN-based algorithms, they were able to achieve a maximum classification accuracy of 93.9% [11]. A lightweight CNN architecture was used by the authors to present a method for identifying pulmonary nodules on computed tomography (CT) scan images [12]. Their model distinguished between normal, benign, and malignant cases with a classification accuracy of 97.9% when tested on the LIDC dataset. Using CT scan images, the authors suggested an alternative method for detecting lung cancer. Following image denoising, they used a variety of Ensemble Methods (EM) for image classification and an Improved Deep Neural Network (IDNN) for image segmentation [13].
3 Proposed Research Methodology
The proposed methodology establishes preprocessing steps, including image resizing and augmentation, as described in Fig. 2. This ensures that the images are appropriately prepared for further analysis. After the preprocessing stage, a pretrained model is loaded. Transfer learning is applied to leverage the knowledge from the pretrained model. This involves utilizing the existing weights and architecture of the pretrained model. The model can benefit from the learned features and patterns captured by the pretrained model. The dataset is divided into training and validation sets. The training set is used to fine-tune and retrain the model. During this stage, the model learns to adapt to the specific characteristics of the dataset and optimize its performance. After training, we evaluate the model on the validation dataset. This evaluation helps assess the model’s performance and generalization ability, giving insights into how well it can classify and detect lung-related features. The results of lung detection are obtained, and the dataset is classified into three classes: (1) no cancer (benign), (2) adenocarcinomas, and (3) squamous cell carcinomas. These classes may represent different categories or characteristics of the lungs. To present the results effectively, a combination of visual and statistical approaches is employed. Additionally, various performance measures are employed to quantitatively assess the model’s accuracy, precision, recall, or other relevant metrics.
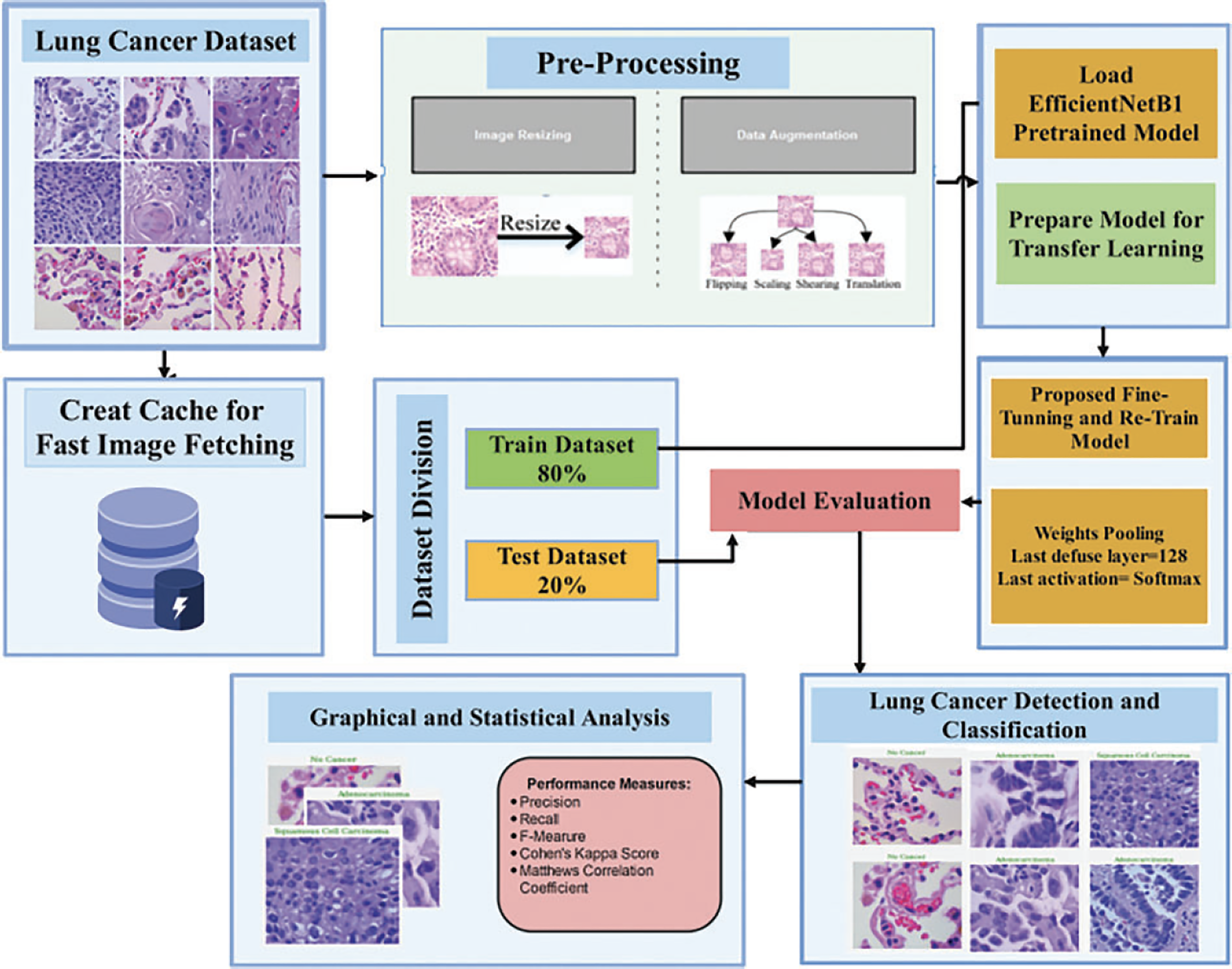
Figure 2: Proposed methodology

The LC25000 dataset was chosen for several reasons: it offers a wide range of images across multiple categories, ensuring comprehensive training and evaluation in diverse visual contexts. Its large size provides sufficient data for training robust deep learning models. The dataset’s precise labelling facilitates accurate supervision during model training and validation. Additionally, its widespread use in research allows for meaningful comparison with other studies.
The LC25000 dataset includes 15,000 histopathological images, divided into three classes (benign, adenocarcinomas, and squamous cell carcinomas), each with 5000 images (768 × 768 pixels, JPEG format) as exhibited in Fig. 3. The dataset was split into 12,000 training images and 3000 validation images. This division supports supervised learning and allows the model to improve its classification accuracy iteratively. The validation set provides an independent benchmark to assess the model’s generalization and effectiveness on new data, ensuring balanced evaluation and sufficient training data for accurate lung lesion detection. All images have a size of 768 × 768 pixels and are in JPEG file format. The dataset consists of three distinct classes: (1) No cancer (benign), (2) Adenocarcinomas, and (3) Squamous cell carcinomas.
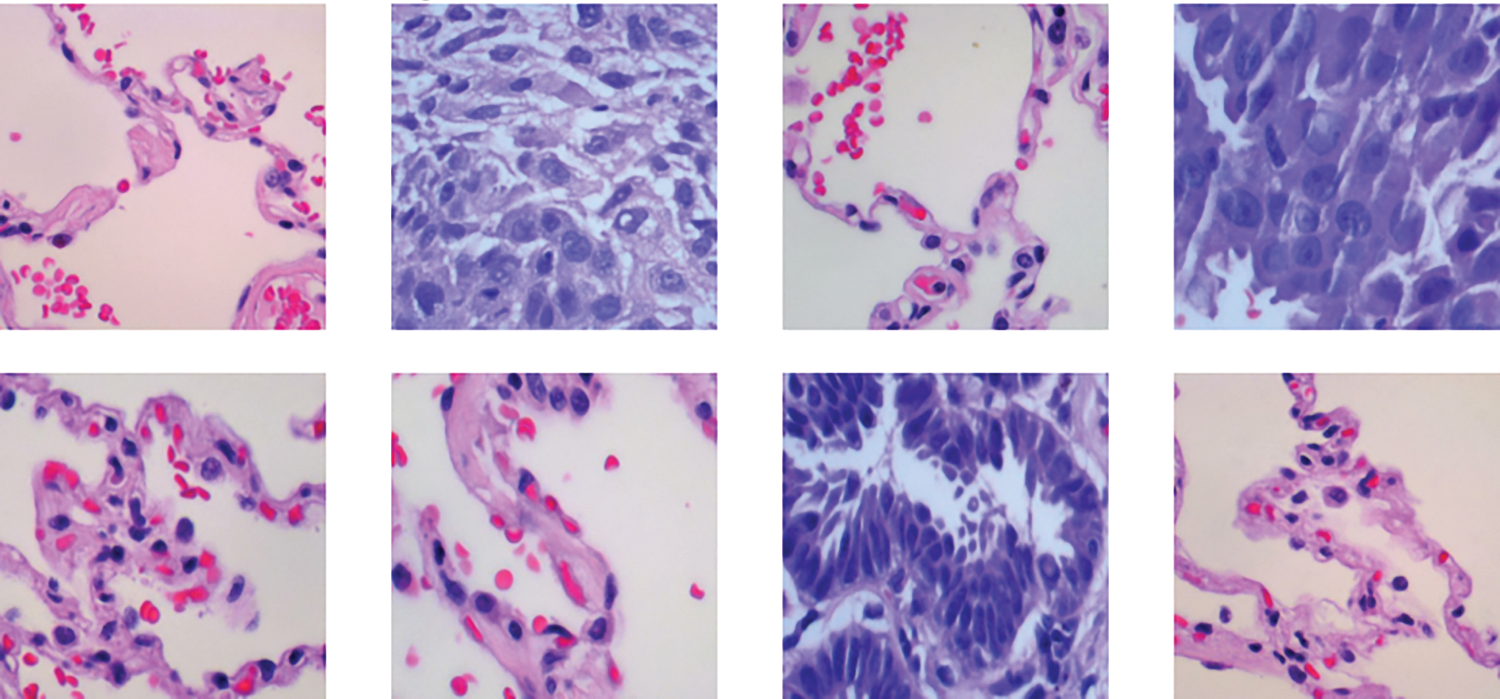
Figure 3: Example of histopathological images from the LC25000 dataset
Image augmentation methods increase the model’s robustness and generalization by artificially expanding the training dataset with modified images. The model can recognize objects regardless of their orientation, position, or size by simulating various real-world variations with techniques like rotation, translation, scaling, and flipping. While color jittering and noise addition help the model become invariant to noise and lighting, normalization ensures consistent input data. The model is encouraged to focus on the overall context by using cropping and cutout/erasing to simulate partial visibility and occlusions. Elastic distortion imitates geometric transformations, increasing the model’s robustness. Together, these augmentations reduce overfitting, improve the model’s ability to handle various image conditions, and ultimately result in more accurate and consistent results in real-world applications.
The CNNs’ input layers are designed to accept images of specific sizes for the training process. Consequently, the dimensions of lung histopathological images are initially adjusted to match the input layer sizes of three deep learning models. EfficientNetB1 has an input layer size of 224 × 224 × 33. To enhance the training performance of the deep learning models and prevent overfitting, augmentation techniques are employed, as shown in Fig. 4. Augmentation involves increasing the number of training images in the dataset, thereby enabling more effective learning by the models. The proposed method utilizes various augmentation methods, including scaling in the x and y dimensions within the range of [0.5, 2], flipping in both horizontal and vertical orientations, translation in both horizontal and vertical directions with an angle range of [−20, 20], and shearing in both x and y directions within a specified range.
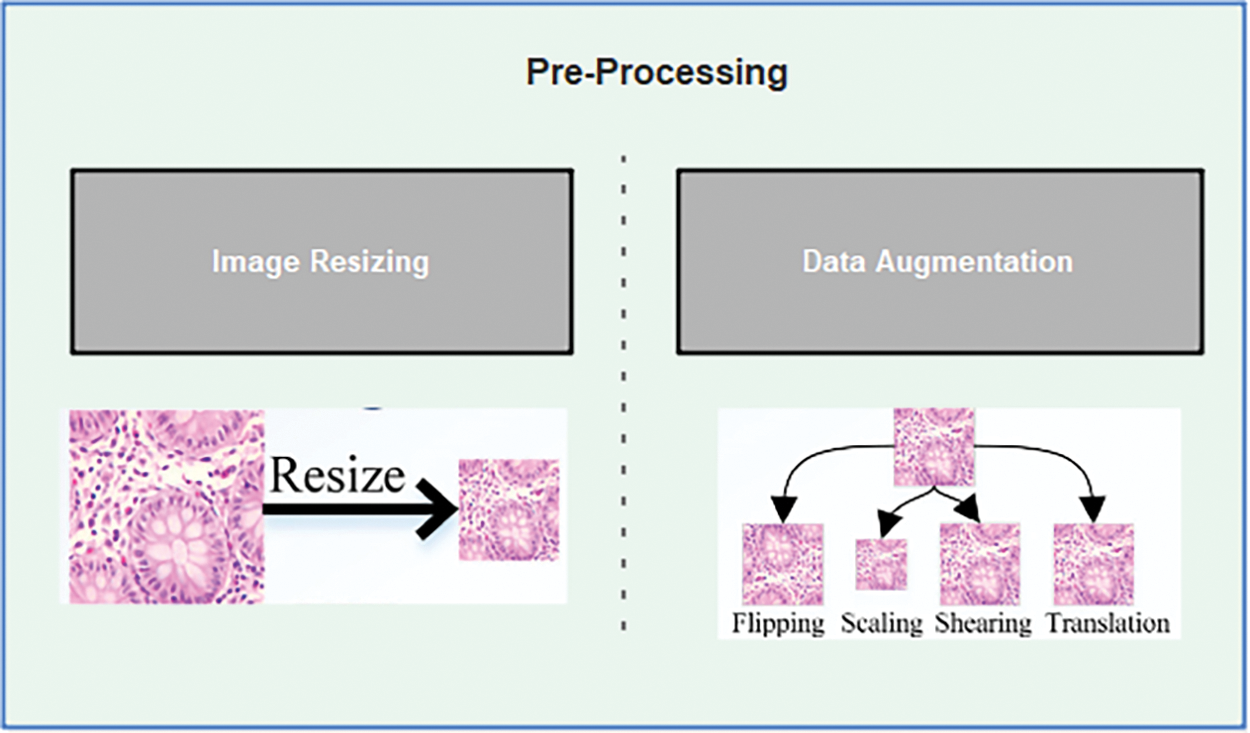
Figure 4: Pre-processing for lungs dataset
Loading a pretrained model is an essential step in the proposed methodology. The pre-trained model refers to a model that has already been trained on a large dataset for a specific task, such as image classification or object detection. The utilization of a pretrained model allows for the extraction of knowledge and features acquired through extensive training on a vast dataset. The process of loading a pretrained model typically encompasses retrieving or accessing the model’s weights and architecture, usually stored in a file format such as TensorFlow’s Saved_Model or PyTorch’s state_dict. These files contain the parameters and learn representations of the pretrained model. Once the pretrained model is obtained, it can be loaded into the deep learning being used for the project. This process varies depending on the framework, but generally, there are functions or methods provided to load the model from the saved files.
Once the pretrained model is successfully loaded, it serves as a starting point for our specific task. The weights and architecture of the pretrained model capture general features and patterns from the initial training, which can be leveraged to expedite training and improve performance on our specific dataset. In some cases, only the backbone or convolutional layers of the pretrained model are utilized, while the final layers or classifiers are replaced or fine-tuned to adapt to the new task. This allows us to retain the valuable feature extraction capabilities of the pretrained model while tailoring the output layers to our specific classification or detection needs. Loading a pretrained model is a crucial step in transfer learning, as it enables us to benefit from the expertise and representations learned by state-of-the-art models. By starting with a pretrained model, we can save computational resources and achieve better results by building upon the existing knowledge captured in the model’s parameters.
Transfer learning leverages pretrained models to address new tasks or datasets by freezing certain layers during training. Freezing layers means keeping the weights and parameters of specific layers fixed, preventing updates. This allows exclusive training of the higher layers, which capture task-specific features, while the lower layers retain general features like edges or textures that are transferable across tasks. By freezing these layers, we utilize the pretrained model’s knowledge efficiently, saving computational resources and training time while adapting to the new task, as shown in Fig. 5.
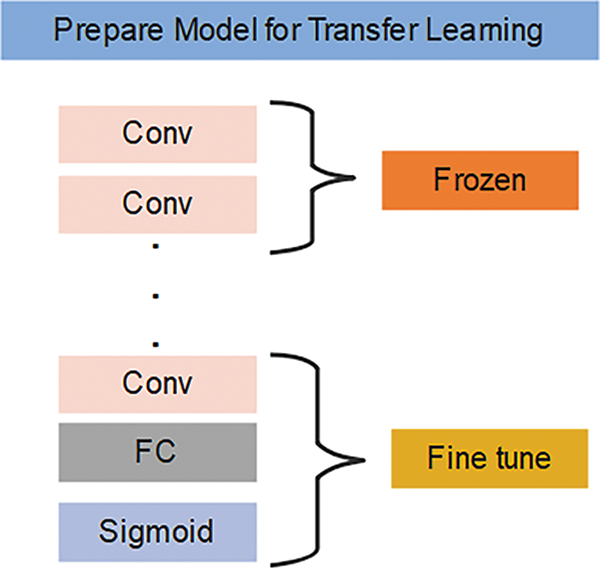
Figure 5: Transfer learning steps
The step-in fine-tuning is to choose a pre-trained model to take advantage of its learned features and lower computational demands, such as EfficientNetB1 trained on ImageNet. The model architecture is then modified by adding custom layers for feature extraction or by modifying the final layers to conform to the output requirements of the new task. The modified layers are trained to adapt to task specific data, while the initial layers are usually frozen to preserve generic features learning during pre-training. The model can gradually improve learned features by unfreezing layers. To maintain stability and avoid making abrupt changes to pre-trained weights, a lower learning rate is used during fine tuning. To maximize model performance, hyperparameters are changed based on performance metrics. This is verified by a thorough assessment on different validation or test datasets, which verifies the model’s generalizability and suitability for practical uses.
To fine-tune the model with the specified improvements, we can follow these steps:
1) Initialize the pretrained model with the weights from ImageNet: Load the pretrained model, including its architecture and weights, obtained from training on the ImageNet dataset. This initialization ensures that the model starts with learned features that are applicable to a wide range of visual tasks.
2) Adjust the final pooling layer: Modify the last pooling layer of the model to accommodate the specific requirements of the new task. Since we have three classes, we can set the pooling layer to have an output size of 128. This adjustment allows the model to learn more discriminative features relevant to the classification of our target classes.
3) Update the activation function: The final activation function should be set to softmax, which is suitable for multi-class classification problems. Softmax produces a probability distribution over the classes, allowing us to interpret the model’s outputs as confidence scores for each class.
4) Retrain the model: After making the necessary modifications, we can proceed to retrain the model using the training dataset. During this process, the updated layers, including the modified pooling layer and the final activation function, are fine-tuned to adapt to the specific classification task at hand. The earlier layers, which are frozen, continue to serve as feature extractors.
4 Lung Cancer Detection and Classification Model Evaluation
Once the model is retrained, it is crucial to evaluate its performance using the validation dataset. This evaluation provides insights into the model’s ability to generalize and make accurate predictions on unseen data. By implementing these improvements, including adjusting the pooling layer size to 128, applying SoftMax as the final activation function, and retraining the model, we can optimize its performance for the classification of the three target classes. The proposed improved technique, combined with fine-tuning parameters, has significantly enhanced the accuracy of lung detection and classification. Through careful adjustments and optimizations, we have achieved impressive results in accurately identifying and categorizing lung cancer related features. The fine-tuning process, which involves leveraging a pretrained model and updating specific layers, has allowed the proposed model to adapt to the nuances of lung cancer lesion detection and classification. By initializing the model with weights obtained from ImageNet, we have provided it with a solid foundation of learned features applicable to various visual tasks.
Additionally, we have fine-tuned the model by modifying the last pooling layer to output a size of 128, which enables it to capture more discriminative features relevant to our specific task. The incorporation of softmax as the final activation function facilitates effective multi-class classification, producing confidence scores for each of the three target classes. The results of the proposed methodology demonstrate a significant improvement in accuracy compared to previous techniques. The proposed method exhibits enhanced precision and recall in detecting lung cancer related features, ensuring that abnormalities are correctly identified. Moreover, the classification performance of the model has been greatly enhanced, accurately assigning the input images to their respective classes.
These advancements in accuracy have been achieved through meticulous fine-tuning and parameter optimization, allowing the model to learn intricate patterns and characteristics associated with lung cancer lesion detection and classification. The effectiveness of our improved technique can be observed through both quantitative measures and visual representations, showcasing the model’s remarkable performance and its ability to precisely classify colon-related data.
Experiments were conducted on a Windows 10 Pro machine with an Intel Core i3 6006U CPU (2.00 GHz, 2 cores, 4 logical processors), 16 GB RAM, and a 120 GB SSD with 1TB HDD. The system ran a Jupyter notebook environment via Anaconda Navigator. Python 3.7.5 was used, along with libraries like NumPy (1.18.5), Pandas (1.3.5), TensorFlow (2.3.0), and Scikit-learn (1.0.2). A high-spec laptop with GPU acceleration was employed for lung cancer image classification, improving deep learning model performance and reducing training time.
For the evaluation of lung cancer lesion detection models, several performance metrics were utilized to assess the accuracy and effectiveness of the models. These evaluation metrics collectively provide insights into different aspects of model performance, including accuracy, precision, recall, F-measure, Cohen’s Kappa Score (CKC), Matthews Correlation Coefficient (MCC) and training time. These performance measure results are shown in Table 2.

The EfficientNetB1 model used for lung cancer lesion detection had a total parameter count of 6,739,594. These parameters represent the learnable components of the model that are adjusted during the training process to optimize its performance. Out of the total parameters, 164,355 were trainable. These trainable parameters are updated through the backpropagation algorithm during the training phase. They enable the model to learn and adapt to the specific characteristics.
The EfficientNetB1 model had 6,575,239 non-trainable parameters, which are fixed and not updated during training. These parameters, often linked to pre-trained weights, contribute to the model’s ability to classify lung cancer features. The combination of trainable and non-trainable parameters enables the model to learn from the data while utilizing existing knowledge. Training the efficientnet_model took 3765.04 s, which includes all processes such as forward and backward passes, gradient computations, and weight updates. Training time can vary based on model complexity, dataset size, and hardware, and is important for assessing the computational efficiency and planning resources, as shown in Fig. 6
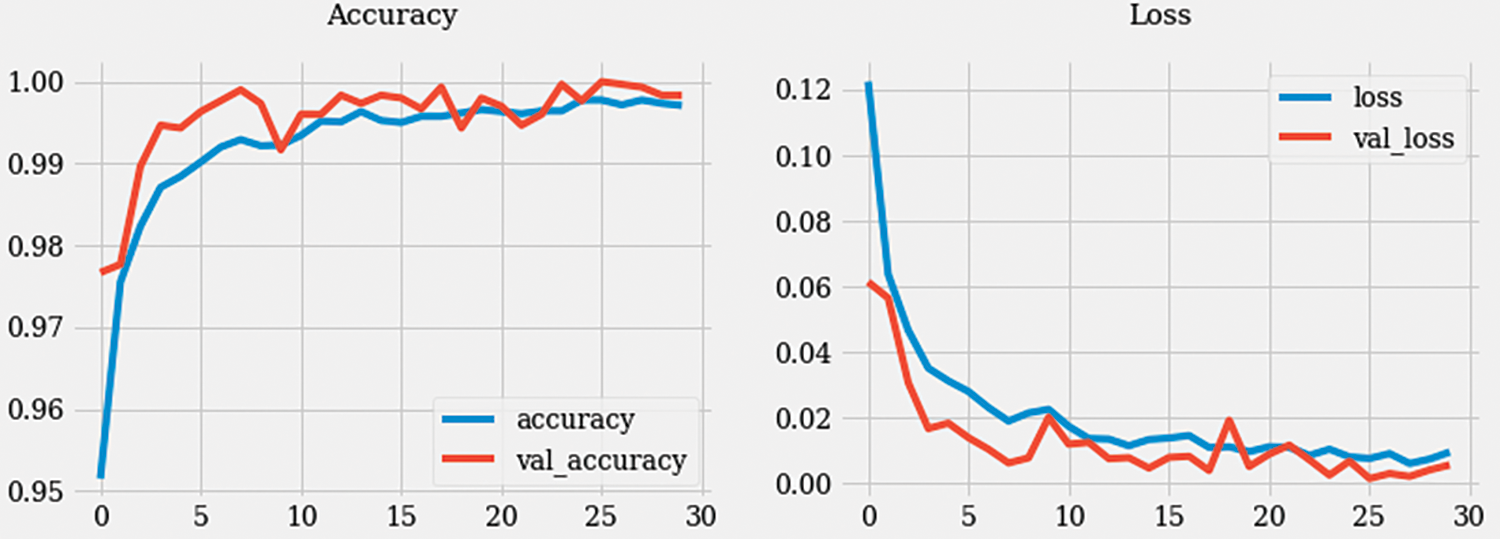
Figure 6: Accuracy and loss graph
During the training process, the model underwent 480 iterations with an average duration of 215 milliseconds per step. The loss achieved during training was 0.0021, indicating a low error rate, while accuracy reached 0.9993, signifying a high level of correct predictions. In the validation phase, the model went through 120 steps, each taking approximately 127 ms. The validation loss, which measures the error rate on the validation dataset, was 0.0054, indicating a slightly higher error rate compared to the training phase. The validation accuracy achieved was 0.9983, indicating a high level of accuracy in predicting the validation dataset samples.
The training loss of 0.00207 and the training accuracy of 0.9993 suggest that the model successfully learned the patterns and features in the training dataset. The validation loss of 0.00538 and the validation accuracy of 0.9983 demonstrate that the model generalized well and performed accurately on unseen validation data as presented in Fig. 7. These metrics provide insights into the model’s performance, indicating its ability to effectively learn and classify colon detection samples. The low loss values and high accuracy suggest that the model is robust and capable of accurately identifying colon-related features in the given dataset.
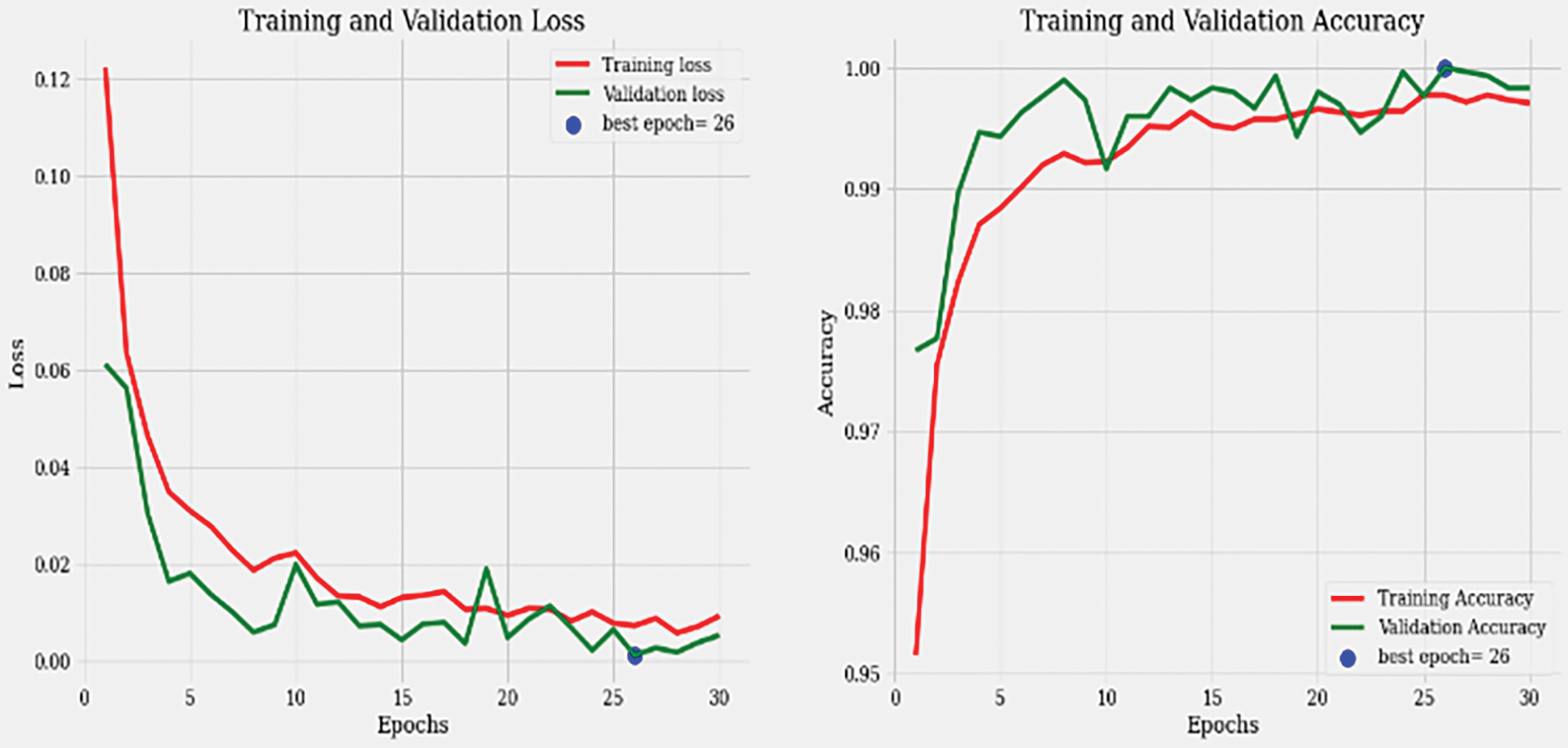
Figure 7: Training and validation loss graph
The precision value of 0.998408 indicates that the model achieved a high percentage of correctly predicted positive instances in relation to the total number of positive predictions. Similarly, the recall value of 0.998301 indicates that the model effectively identified a large portion of the actual positive instances. The F-measure, or F1-score, is a measure that combines precision and recall, providing an overall assessment of the model’s performance. With an F-measure of 0.998351, the EfficientNetB1 model achieved an excellent balance between precision and recall.
Cohen’s Kappa Score measures the agreement between predicted and actual labels, considering the possibility of agreement occurring by chance. A score of 0.997499 suggests an extremely high level of agreement beyond what would be expected by chance alone. The Matthews Correlation Coefficient (MCC) is another metric that evaluates the quality of binary classifications, considering true positives, true negatives, false positives, and false negatives. A value of 0.997503 indicates a very strong correlation between predicted and actual labels as described in Fig. 8.
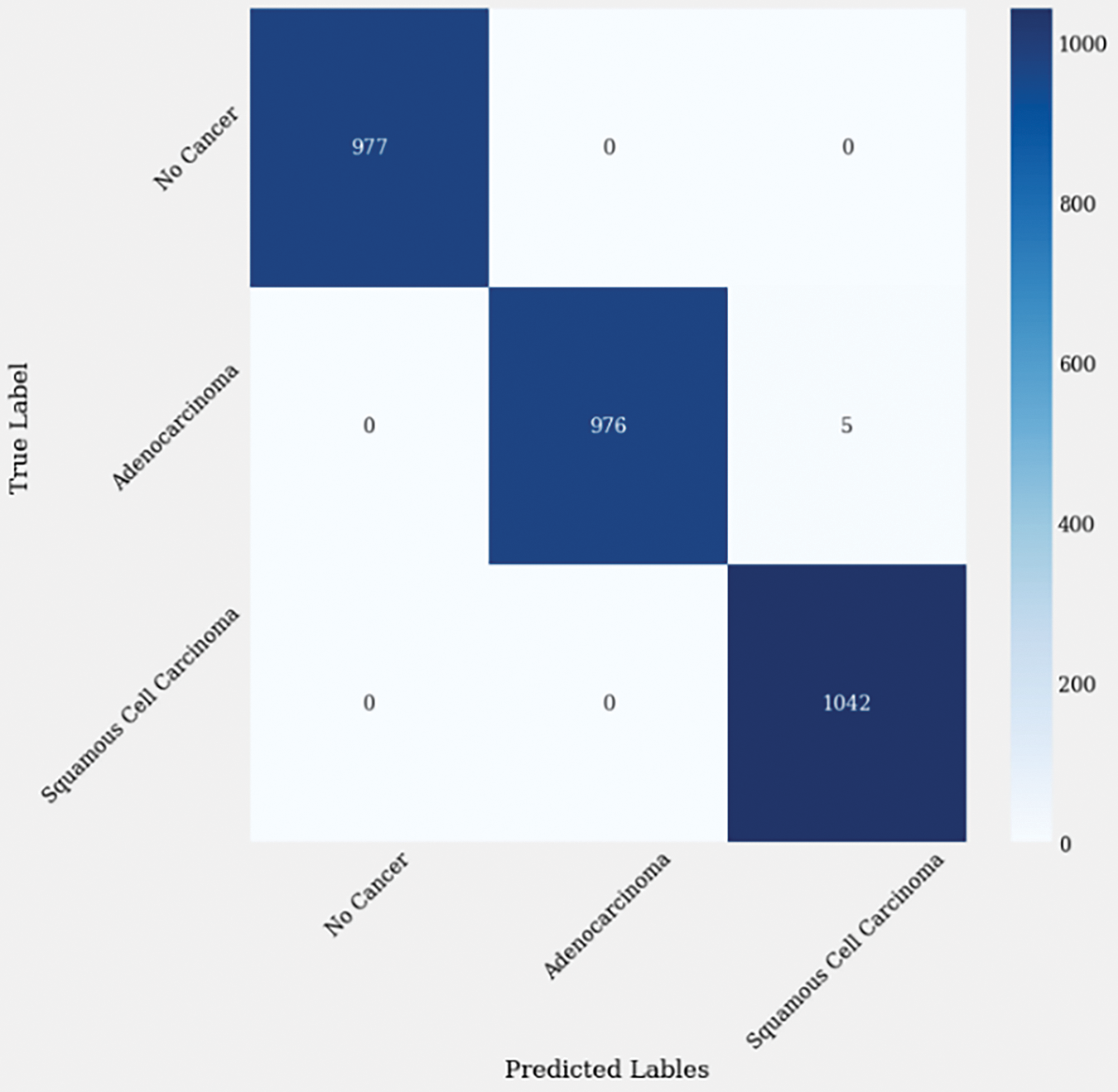
Figure 8: Confusion matrix of enhanced EffiicientNetB1
5.3 Graphical Representation of Classified Images
Overall, the EfficientNetB1 model demonstrated exceptional precision, recall, F-measure, Cohen’s Kappa Score, and Matthews Correlation Coefficient. These results indicate the model’s ability to accurately classify instances in the context of the evaluated lung cancer analysis task. The graphical representation of lung lesion detection using histopathological images are shown below in Fig. 9.
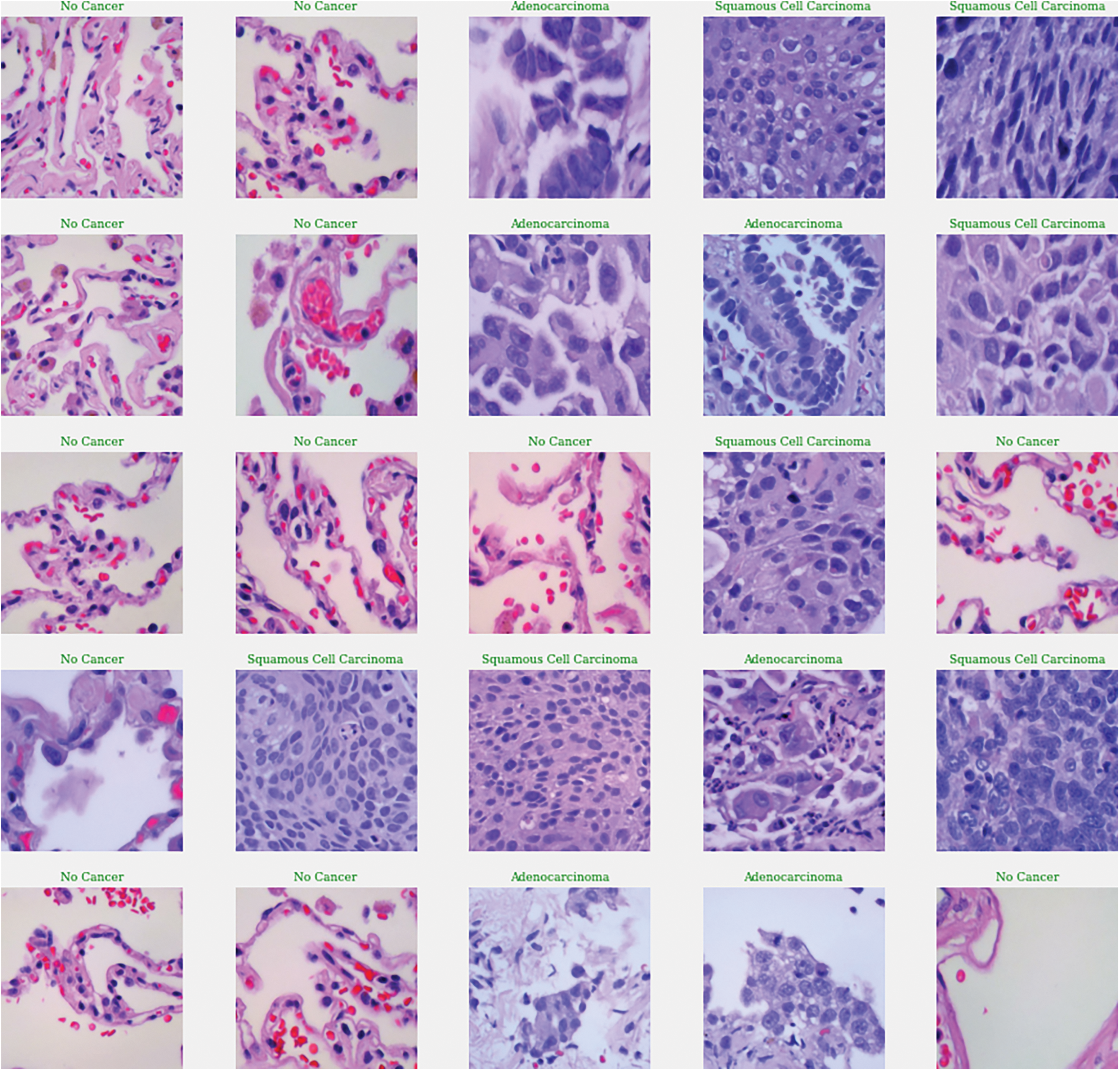
Figure 9: Graphical representation of lung cancer classification
6 Comparison with State of Art Methods
The proposed method, however, outperformed all these existing methods. The enhanced EfficientNetB1 model achieves 99.8% classification accuracy, a significant improvement over many current approaches. This high degree of precision suggests a more accurate and dependable categorization of histopathological images. By transfer learning and a pretrained EfficientNetB1 model, the suggested approach gains access to sophisticated features from a sizable dataset, improving its performance on histopathological images with fewer training examples. As a result, the model becomes less reliant on large amounts of domain-specific data and is more efficient.
EfficientNetB1’s compound scaling strategy and specialized architectural components allow it to operate on image datasets with remarkably high efficiency. The model first applies initial convolution layers to input images on image datasets to capture fundamental spatial features. After that, it makes use of several Mobile Inverted Bottleneck Convolution (MBConv) blocks, which combine depth wise separable convolutions with an inverted residual structure to improve feature extraction. This design preserves important image features while lowering computational complexity. By adaptively recalibrating channel-wise feature responses, the Squeeze-and-Excitation (SE) blocks in MBConv enhance the model’s ability to highlight important details in the images. The Swish activation function enhances the model’s ability to recognize intricate patterns even more. As evidenced by its top-1 accuracy of 79.1% on ImageNet, EfficientNetB1 achieves high accuracy with fewer parameters and lower computational costs through these processes. Due to its efficiency, EfficientNetB1 performs much better than traditional models when it comes to image classification tasks. It can handle complex datasets and high-resolution images with less memory usage and faster inference times.
This represents a significant improvement compared to the best-performing existing method, which achieved an accuracy of 98.66%. The proposed method’s higher accuracy indicates its effectiveness in accurately classifying the images, potentially leading to more reliable results in medical diagnostics or other applications where image classification is essential. The comparison with the current state-of-the-art methods is presented in Table 3.
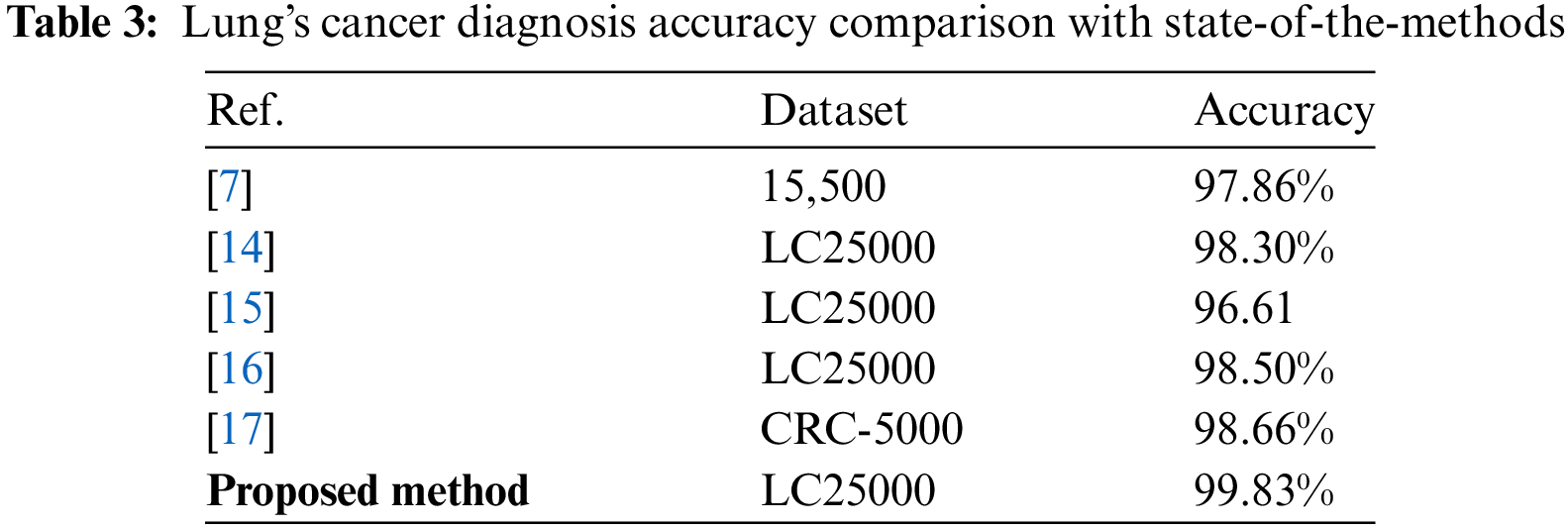
However, many of the existing methods often show lower accuracy, fewer categories for classification, inefficient transfer learning, and uneven validation and preprocessing steps. The proposed method, which uses an enhanced EfficientNetB1 model with transfer learning, significantly outperforms state-of-the-art methods with a high classification accuracy 99.8%. By classifying histopathological images into three distinct groups: benign, adenocarcinoma, and squamous cell carcinomas it offers more accurate diagnostic information. The method benefits from robust preprocessing steps like image augmentation and resizing. High reliability and applicability are guaranteed by its validation on the LC25000 lung dataset.
In this research, an enhanced EfficientNetB1 deep learning technique is implemented to accurately detect and classification of lung cancer using histopathological images. The proposed technique effectively detects the lung cancer lesion and classifies the histopathological images into three distinct categories: (1) No cancer (benign), (2) adenocarcinomas, and (3) squamous cell carcinomas. To evaluate the performance of the proposed method, the histopathological (LC25000) lung cancer dataset is utilized.
Overall, the proposed approach includes the utilization of the fine-tuning process along with the specific improvements and parameter adjustments that have been implemented. It demonstrates a notable advancement in the field of lung cancer lesion detection and classification, offering reliable and accurate analysis that can contribute to improved medical diagnoses and treatments. Using publicly available datasets, the proposed algorithm’s ability to recognize and classify microscopic lung cancer lesions in histopathological images was evaluated. The extremely encouraging accuracy proved the algorithm’s efficacy which is 99.83%. However, the study was limited to data on histopathology. In subsequent research, the dataset will be expanded to include colon cancer cases. This larger and more varied dataset will help the model generalize better and handle a wider range of cancer abnormalities. Future research using multi-modal datasets will also look into lesion detection and classification.
Acknowledgement: We thank Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2024R513), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia. Authors are also thankful to Prince Sultan University, Riyadh Saudi Arabia for support of Article Processing Charges (APC) for this publication.
Funding Statement: The Funding of research is provided by Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2024R513), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Author Contributions: Conceptualization: Rabia Javed, Amjad Rehman, Tanzila Saba; methodology: Amjad Rehman, Tahani Jaser Alahmadi, Rabia Javed; software: Rabia Javed, Amjad Rehman, Bayan AlGhofaily, Sarah Al-Otaibi; validation: Amjad Rehman, Tanzila Saba, Tahani Jaser Alahmadi; writing—original draft preparation, Rabia Javed, Amjad Rehman, Tanzila Saba; writing—review and editing, Tahani Jaser Alahmadi, Sarah Al-Otaibi, Tanzila Saba, Amjad Rehman; visualization, Bayan AlGhofaily, Sarah Al-Otaibi, Rabia Javed,; supervision: Amjad Rehman, Tanzila Saba, Tahani Jaser Alahmadi; project administration, Tanzila Saba, Tahani Jaser Alahmadi, Amjad Rehman; funding: Bayan AlGhofaily, Tahani Jaser Alahmadi. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data that support the findings of this study are openly available in [LC25000] at https://paperswithcode.com/dataset/lc25000 (accessed on 04 June 2024), reference number [18].
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. H. Sung et al., “Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries,” CA Cancer J. Clin., vol. 71, no. 3, pp. 209–249, May 2021. doi: 10.3322/CAAC.21660. [Google Scholar] [PubMed] [CrossRef]
2. U. Subramaniam, M. M. Subashini, D. Almakhles, A. Karthick, and S. Manoharan, “An expert system for COVID-19 infection tracking in lungs using image processing and deep learning techniques,” Biomed. Res. Int., vol. 2021, no. 5, pp. 1–17, 2021. doi: 10.1155/2021/1896762. [Google Scholar] [PubMed] [CrossRef]
3. M. A. Alkhonaini et al., “Detection of lung tumor using ASPP-Unet with whale optimization algorithm,” Comput. Mater. Contin., vol. 72, no. 2, pp. 3511–3527, Mar. 2022. doi: 10.32604/CMC.2022.024583. [Google Scholar] [CrossRef]
4. J. Omar Bappi, M. A. T. Rony, M. Shariful Islam, S. Alshathri, and W. El-Shafai, “A novel deep learning approach for accurate cancer type and subtype identification,” IEEE Access, vol. 12, pp. 94116–94134, 2024. doi: 10.1109/ACCESS.2024.3422313. [Google Scholar] [CrossRef]
5. S. Luan et al., “Deep learning for fast super-resolution ultrasound microvessel imaging,” Phys. Med. Biol., vol. 68, no. 24, 2023, Art. no. 245023. doi: 10.1088/1361-6560/ad0a5a. [Google Scholar] [PubMed] [CrossRef]
6. X. Xie et al., “Evaluating cancer-related biomarkers based on pathological images: A systematic review,” Front. Oncol., vol. 11, 2021. doi: 10.3389/fonc.2021.763527. [Google Scholar] [PubMed] [CrossRef]
7. M. S. Naga Raju and B. Srinivasa Rao, “Lung and colon cancer classification using hybrid principle component analysis network-extreme learning machine,” Concurr. Comput., vol. 35, no. 1, Jan. 2023, Art. no. e7361. doi: 10.1002/cpe.7361. [Google Scholar] [CrossRef]
8. R. Kadirappa, S. Deivalakshmi, R. Pandeeswari, and S. B. Ko, “DeepHistoNet: A robust deep-learning model for the classification of hepatocellular, lung, and colon carcinoma,” Microsc. Res. Tech., vol. 87, no. 2, pp. 229–256, Feb. 2024. doi: 10.1002/jemt.24426. [Google Scholar] [PubMed] [CrossRef]
9. W. S. Shim et al., “Identifying the prognostic features of early-stage lung adenocarcinoma using multi-scale pathology images and deep convolutional neural networks,” Cancers, vol. 13, no. 13, Jul. 2021, Art. no. 3308. doi: 10.3390/CANCERS13133308/S1. [Google Scholar] [CrossRef]
10. S. Suresh and S. Mohan, “ROI-based feature learning for efficient true positive prediction using convolutional neural network for lung cancer diagnosis,” Neural Comput. Appl., vol. 32, no. 20, pp. 15989–16009, Oct. 2020. doi: 10.1007/S00521-020-04787-W/FIGURES/14. [Google Scholar] [CrossRef]
11. J. Xia, Z. Cai, A. A. Heidari, Y. Ye, H. Chen and Z. Pan, “Enhanced moth-flame optimizer with quasi-reflection and refraction learning with application to image segmentation and medical diagnosis,” Curr. Bioinform., vol. 18, no. 2, pp. 109–142, 2023. doi: 10.2174/1574893617666220920102401. [Google Scholar] [CrossRef]
12. P. M. Shakeel, M. A. Burhanuddin, and M. I. Desa, “Automatic lung cancer detection from CT image using improved deep neural network and ensemble classifier,” Neural Comput. Appl., vol. 34, no. 12, pp. 9579–9592, Jun. 2022. doi: 10.1007/S00521-020-04842-6/FIGURES/5. [Google Scholar] [CrossRef]
13. M. A. Talukder, M. M. Islam, M. A. Uddin, A. Akhter, K. F. Hasan and M. A. Moni, “Machine learning-based lung and colon cancer detection using deep feature extraction and ensemble learning,” Expert. Syst. Appl., vol. 205, Nov. 2022, Art. no. 117695. doi: 10.1016/J.ESWA.2022.117695. [Google Scholar] [CrossRef]
14. M. Masud, N. Sikder, A. Al Nahid, A. K. Bairagi, and M. A. Alzain, “A machine learning approach to diagnosing lung and colon cancer using a deep learning-based classification framework,” Sensors, vol. 21, no. 3, Jan. 2021, Art. no. 748. doi: 10.3390/S21030748. [Google Scholar] [PubMed] [CrossRef]
15. M. Tharwat, N. A. Sakr, S. El-Sappagh, H. Soliman, K. S. Kwak and M. Elmogy, “Colon cancer diagnosis based on machine learning and deep learning: Modalities and analysis techniques,” Sensors, vol. 22, no. 23, Dec. 2022. doi: 10.3390/S22239250. [Google Scholar] [PubMed] [CrossRef]
16. A. Ben Hamida et al., “Deep learning for colon cancer histopathological images analysis,” Comput. Biol. Med., vol. 136, no. 7, Sep. 2021. doi: 10.1016/J.COMPBIOMED.2021.104730. [Google Scholar] [PubMed] [CrossRef]
17. M. J. Tsai and Y. H. Tao, “Deep learning techniques for colorectal cancer tissue classification,” in 2020 14th Int. Conf. Sig. Process. Commun. Syst., ICSPCS, Adelaide, Australia, Dec. 2020. doi: 10.1109/ICSPCS50536.2020.9310053. [Google Scholar] [CrossRef]
18. A. A. Borkowski, M. M. Bui, L. B. Thomas, C. P. Wilson, L. A. DeLand and S. M. Mastorides, “Lung and Colon cancer histopathological image dataset (LC25000),” Dec. 2019, Accessed: Jun. 4, 2024. [Online]. Available: https://www.kaggle.com/datasets/javaidahmadwani/lc25000 [Google Scholar]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools