
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Leveraging Uncertainty for Depth-Aware Hierarchical Text Classification
1 Chongqing Key Laboratory of Computational Intelligence, Chongqing University of Posts and Telecommunications, Chongqing, 400000, China
2 Division of Emerging Interdisciplinary Areas, Hong Kong University of Science and Technology, Hong Kong, 999077, China
* Corresponding Authors: Ye Wang. Email: ; Hong Yu. Email:
(This article belongs to the Special Issue: Advancements in Natural Language Processing (NLP) and Fuzzy Logic)
Computers, Materials & Continua 2024, 80(3), 4111-4127. https://doi.org/10.32604/cmc.2024.054581
Received 01 June 2024; Accepted 04 August 2024; Issue published 12 September 2024
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Hierarchical Text Classification (HTC) aims to match text to hierarchical labels. Existing methods overlook two critical issues: first, some texts cannot be fully matched to leaf node labels and need to be classified to the correct parent node instead of treating leaf nodes as the final classification target. Second, error propagation occurs when a misclassification at a parent node propagates down the hierarchy, ultimately leading to inaccurate predictions at the leaf nodes. To address these limitations, we propose an uncertainty-guided HTC depth-aware model called DepthMatch. Specifically, we design an early stopping strategy with uncertainty to identify incomplete matching between text and labels, classifying them into the corresponding parent node labels. This approach allows us to dynamically determine the classification depth by leveraging evidence to quantify and accumulate uncertainty. Experimental results show that the proposed DepthMatch outperforms recent strong baselines on four commonly used public datasets: WOS (Web of Science), RCV1-V2 (Reuters Corpus Volume I), AAPD (Arxiv Academic Paper Dataset), and BGC. Notably, on the BGC dataset, it improves Micro-F1 and Macro-F1 scores by at least 1.09% and 1.74%, respectively.Keywords
Hierarchical Text Classification (HTC) is a classic multi-label text classification problem, where labels exhibit a hierarchical structure represented by a tree or directed acyclic graph [1]. Many related tasks represent hierarchy, such as international patent classification [2], product annotation [3], web page categorization [4], and news classification [5]. Accurate HTC helps the system to organize and retrieve information more effectively, provide personalized recommendation services, and improve user experience and operational efficiency. In the real world, one text sample may have multiple labels. As shown in Fig. 1, taking news classification as an example, the text corresponds to labels such as ‘News’, ‘Business’, ‘Sports’ and ‘Stock’, which usually contain hierarchical dependencies. However, in practical scenarios, some texts cannot be matched to appropriate leaf node labels. The text is matched with the hierarchical labels “News”, “Business”, “Sports” and “Stock”. While, regarding the leaf node labels “Football” and “Tennis”, the text cannot be assigned to appropriate labels, resulting in the classification stopping at the parent node label “Sports”. In practical applications, existing label hierarchies might not comprehensively cover all possible text topics. This means that some texts may not have corresponding leaf node labels and can only be matched to higher-level parent node labels. Therefore, for texts that cannot be assigned to appropriate leaf node labels, the model should only predict the correct parent node labels. Due to the incomplete match between text data and the hierarchical structure, directly predicting the leaf node labels becomes challenging [6].

Figure 1: Samples that cannot be assigned to leaf nodes
Global approaches are the mainstream methods in current HTC, regarding the label structure as flattened, which leads to the issue of “incomplete text-label matching” in classification results [7]. The Seq2Seq-based approaches can solve this problem by generating label sequences from the root node to the leaf node along the hierarchical structure [8]. The current Seq2Seq procedures focus on classifying leaf node labels as the end goal, concentrating on improving classification performance [9] and reducing parameter size [10]. However, existing ways overlook certain issues where some texts cannot be perfectly matched to leaf node labels, and not all samples should be classified as leaf nodes. One solution is to introduce multiple nodes within the hierarchical structure, capturing semantic information of texts at different levels, balancing specificity and correctness [11]. Further, other methods leverage probability to provide better classification by normalizing the output of Softmax into probability distributions for each category [7]. Currently, these hierarchical text classification (HTC) methods focus on extracting label features to achieve better hierarchical representations. They flatten the hierarchical structure for label prediction, which may result in inconsistent predicted labels due to ignoring the hierarchy. Moreover, errors can affect subsequent label predictions because errors in parent node labels propagate step-by-step to leaf node labels. Accumulated errors can significantly impact the model’s performance.
To address the aforementioned issue, we propose a model (DepthMatch1) leveraging uncertainty for dynamic depth matching. Further, to prevent incomplete text-label matching, we propose to classify texts into appropriate parent node labels instead of leaf node labels. Inspired by the Dempster-Shafer evidence theory (DST), we leverage evidence to describe the uncertainty of the classifier’s prediction on label sequences. Meanwhile, we design an adaptive depth-aware method integrated with the hierarchical structure, dynamically determining whether to stop or proceed with classification. During the prediction process, we proactively stop classification to prevent error propagation and ensure credible and robust predictions. The DeepMatch model addresses the issue of improperly matched texts by introducing uncertainty measures and a dynamic adaptive classification approach. Additionally, DeepMatch employs a depth-aware strategy based on uncertainty to mitigate error propagation. The contributions of this paper are as follows:
1. We propose an uncertainty model based on a sequence-to-sequence structure, leveraging the Dempster-Shafer evidence theory to obtain uncertainty sharing among hierarchical sequences. Further, text and local label sequences are cross-fused, enhancing comprehensive representations with uncertainty from parent node labels to classify leaf nodes.
2. To address the problem of error propagation in classification, we propose a dynamic early stopping strategy. Specifically, for texts with incomplete text-label matching, it is necessary to adaptively determine the depth of classification to prevent error propagation.
3. We conduct comprehensive experiments on four public datasets to validate our proposed model, representing its superior performance over the current state-of-the-art (SOTA) models. Furthermore, we analyze the performance without leaf node labels in the ground truth, demonstrating the necessity of the proposed strategy.
2.1 Hierarchical Classification
In hierarchical multi-label classification, a text corresponds to multiple class labels, and these labels have natural hierarchical dependencies, such as parent-child relationships. Effectively utilizing the hierarchical structure is crucial for HTC. Various studies have focused on representing hierarchical information. The hierarchical-aware global model HiAGM [12] represents the hierarchy as a directed graph and then aggregates node information using the prior probabilities of label dependencies. Based on HiAGM, the HTCInfoMax model [13] was proposed, which is based on maximizing mutual information between text and labels. Additionally, some techniques utilize both local and global hierarchical information and unify them. The HARNN model [14] uses attention mechanisms in local classifiers to extract label features, while the global classifier concatenates features extracted from each level for prediction. The LA-HCN model [15] uses common factors to establish connections among sibling categories, propagating text representations from parent to child layers to determine the most compatible category in the child layer and giving it more attention. The hierarchical-guided contrastive learning HGCLR model [16] embeds the hierarchy into the text encoder rather than modeling it separately. Although these hierarchical classification methods focus on extracting label features to obtain better hierarchical representations, they often flatten the hierarchy to predict labels. This can lead to incomplete text-label matching due to the limited size of the label hierarchy.
2.2 Sequence-to-Sequence Learning
Sequence to Sequence (Seq2Seq) learning [17] is widely used in machine translation tasks and text generation tasks. Researchers use the Seq2Seq ways for multi-label classification, encoding each text into contextual representations. Then they integrate historical information into the attention mechanism to assist in label decoding [18]. The Seq2Image means [19] converts genome sequences into images and uses Convolutional Neural Networks (CNNs) for classification. In multi-label sentiment classification, the application of Seq2Seq performs better than other approaches by implicitly modeling emotion relevance [20].
In the application of Seq2Seq to hierarchical classification, the Seq2Tree [7] framework introduces a sequence-to-tree approach. It addresses the “incomplete text-label matching” problem in HTC, where each predicted leaf node within a path should not conflict with its parent node. They combine the tree structure with the Depth-First Search (DFS) algorithm, ensuring that nodes within the same path can be predicted in a top-down order. Initially, they use DFS to convert hierarchical labels into label sequences, and then map the text and label sequences in a Seq2Seq manner. Additionally, they design a Constrained Decoding (CD) strategy, which guides the generation process using label dependencies. The candidate labels generated by the CD strategy are constrained to the child nodes of the generated parent node. Specifically, after encoding the input sequence, the decoder predicts the DFS label sequence. The
where Decoder represents the decoder,
In summary, the DepthMatch (Ours) model is compared with the Seq2Tree model as shown in Fig. 2. The Seq2Tree model adopts the DFS strategy and uses the Softmax output of category probability distribution as the classification basis. However, errors occurring at parent nodes during the decoding process can affect the classification of child nodes, leading to error accumulation over time. Our DepthMatch model quantifies the prediction uncertainty of each layer label in a top-down manner using evidence theory, combining uncertainty with parent-child dependencies during decoding. During decoding, we can quantify the model’s confidence in classification. When uncertainty is high, we early stop classification at parent nodes to ensure robust predictions and avoid error propagation.

Figure 2: Seq2Tree vs. the proposed DepthMatch model
The overall framework of the model is illustrated in Fig. 3. The training process consists of three parts: constructing local label sequences, measuring the evidence uncertainty of hierarchy, and performing label encoding-decoding under a depth-aware strategy. We first flatten the labels in each layer and construct label sequences based on dependencies. Then, we measure the uncertainty of the label sequences using the Dempster-Shafer evidence theory (DST). Finally, we share text and label embeddings to generate text representations with local label information, and then decode label sequences guided by uncertainty.

Figure 3: The overall framework of the proposed DepthMatch, an uncertainty-guided depth-aware model for hierarchical text classification
Hierarchical Text Classification (HTC) aims to predict corresponding labels from input text. Given input text
3.2 Local Label Sequence Construction
We represent a local label hierarchy as a subgraph of the global label structure, flattening a local label hierarchy into a label sequence.
Here,
To combine local hierarchical sequences with textual features, we propose a top-down sequence-to-sequence approach:
3.3 Hierarchical Evidence Uncertainty Quantification
The Dempster-Shafer evidence theory (DST) is a way for uncertain reasoning, where different textual features are utilized to obtain classification evidence. It quantifies the uncertainty of assigning a text to labels, thus providing uncertainty estimates for each label in the label sequence. For a classification problem, the set of all possible labels is represented by the identification framework
The basic trust assignment function
where
We adopted the text encoder component of the pre-trained BERT model, which consists of a stack of 12 layers of Transformer Encoder structure. We transform the given input text
Here,
The advantage of evidence uncertainty lies in its modeling based on the Dirichlet distribution, which directly parameterizes the belief mass from the neural network outputs. Through the Dirichlet distribution, it is possible to flexibly control the allocation of belief mass, hence better reflecting the uncertainty of the model at different hierarchical sequences during decoding.
3.4 Uncertainty-Based Depth-Aware Hierarchical Classification
By leveraging DST, we can better handle classification uncertainty and flexibly perform inference and decision-making under label sequence decoding. In DST, we can derive more accurate conclusions by combining evidence from multiple different sequences of preceding layers. The uncertainty from multiple sequences is combined incrementally, formalizing the pairwise Dempster combination rule:
where
Utilizing the combination rule, labels are sequentially combined from the front to the back of the sequence:
where
Next is evidence combination, defining the accumulation of uncertainty for each layer as:
The uncertainty accumulation
3.5.1 Encoding of Hierarchical Label Structure
To obtain the comprehensive feature representation, we utilize Graphormer to model the hierarchical structure of labels. Then, we map category indices to corresponding embedding vectors
In the given context,
To achieve effective training and accelerate convergence, we apply softmax to the attention weights
We obtain the label feature representation
3.5.2 Decoding of Label Sequences
During the training phase, our DepthMatch model employs local hierarchical sequences to classify each layer’s label in a top-down manner. To achieve shared text and label embedding weights, we extend and perform element-wise multiplication between the attention mask of the input text and the label attention mask, resulting in a cross attention mask:
This mask is used to control the multiplication matrix between Query and Key in the cross-attention mechanism. Here,
where
where
In multi-label classification, for the h-th layer, we use a binary cross-entropy loss function for the label
where J represents the number of sub-labels,
The final loss function integrated with the depth-aware strategy is:
where
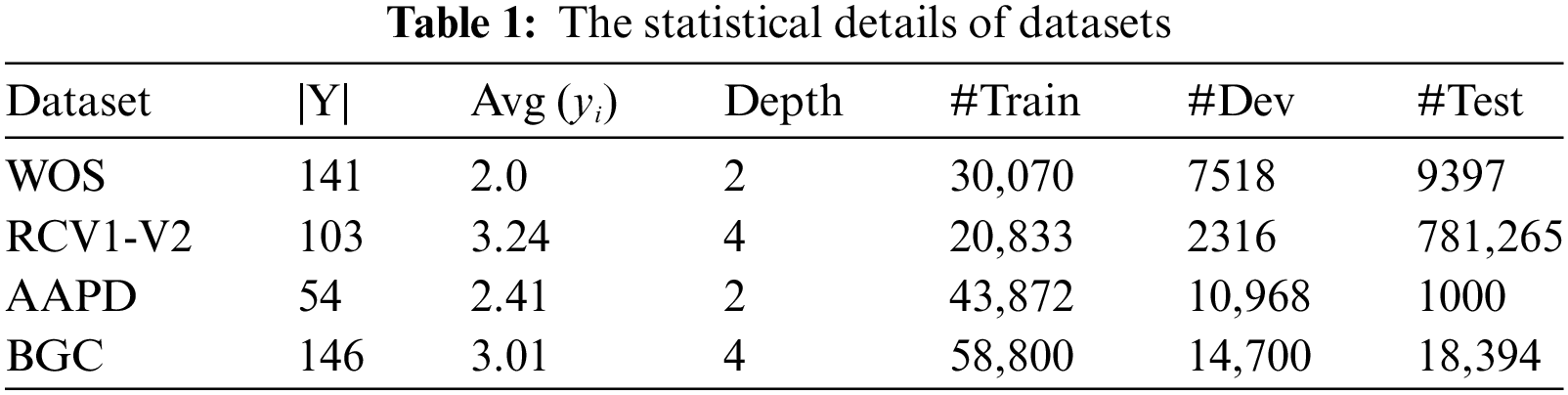
We conduct our experiments on four datasets: WOS (Web of Science) [21], RCV1-V2 (Reuters Corpus Volume I) [22], AAPD (Arxiv Academic Paper Dataset) [23], and BGC. The BGC dataset is available at: www.inf.uni-hamburg.de/en/inst/ab/lt/resources/data/blurb-genre-collection.html (accessed on 1 August, 2024). We evaluate our experimental results using multiple metrics. WOS covers abstracts of academic papers published in the Web of Science database, AAPD collects abstracts of Arxiv academic papers along with corresponding subject category information, RCV1-V2 is a news classification corpus, and BGC dataset consists of blurbs (short texts) of books and metadata such as authors, publication dates, and page numbers. WOS is used for single-path HTC, while RCV1-V2, AAPD, and BGC contain multi-path classification labels. The labels in all four datasets form hierarchical tree-like structures. Detailed statistics are shown in Table 1.
4.2 Baseline Models and Evaluation Metrics
We selected several baseline methods for comparison, including FastText [24], TextVDCNN [25], HTCInfoMax [13], TextRCNN [26], HiAGM [12], HBGL [27], HiMatch [28], HGCLR [16], HiTIN [29] and Seq2Tree [7] models.
We follow the evaluation metrics of baseline models such as [12,13,27,28], using Micro-F1 and Macro-F1. The specific formulas are as follows:
where
For the text encoder, we use the BERT model, with the transformer’s bert-base-uncased as the base architecture. For Graphormer, we set the adaptive graph attention heads to 8 and feature size to 768. The model is trained on the training set, and after each epoch, evaluation is performed on the validation set. The detailed hyperparameter information is shown in Table 2.

The proposed model is experimentally compared with baseline models on the WOS, RCV1-V2, AAPD, and BGC datasets. The specific experimental results are shown in Table 3. On the four public datasets, compared to previous mainstream models, our proposed model achieves better performance. The model’s Micro-F1 values on the WOS, RCV1-V2, AAPD, and BGC datasets are 87.59%, 86.90%, 78.81%, and 80.46%, respectively, all reaching state-of-the-art (SOTA) performance. The Macro-F1 values are 81.54%, 69.32%, 63.37%, and 66.55%, respectively, achieving optimal results on WOS and BGC as well. The performance is significantly improved.

4.5.1 Performance Analysis of Text with Incomplete Text-Label Matching
We first extract all texts from the ground-truth labels in the RCV1-V2 dataset that have parent node labels but no corresponding leaf node labels. In Table 4, we present statistics on the number of texts corresponding to each parent node label and their proportion in the dataset. By summarizing, we observe that texts with incomplete matching leaf node labels account for 23.47% of the entire test set, indicating that approximately one-fourth of the texts should not be assigned corresponding leaf node labels. Therefore, we test the performance of the Seq2SESeq and HGCLR models on these texts, as shown in Fig. 4. The horizontal axis represents the performance of different parent node labels corresponding to the texts, all of which should terminate classification at the current parent node label. We use lines to indicate the Micro-F1 and Macro-F1 scores of the two models on these classes, and use bar charts to reflect the performance gain compared to the SOTA model. It can be seen that we outperform the SOTA model in the majority of classes, with a 33% improvement in Micro-F1 score for class E41 and over 120% increase in Macro-F1 score for Class C18.


Figure 4: The Micro-F1 and Macro-F1 scores and their performance gain between DepthMatch and HGCLR under incomplete text-label matching
4.5.2 Mean and Standard Deviation
We analyze two types of F1 scores and their standard deviations for the model under different random seeds during the training process, as shown in Fig. 5. Two dashed lines represent two types of F1 scores, and the shaded area indicates the standard deviation across multiple experiments. It is commonly observed across the four datasets that during the early stages of training, the model’s performance varies significantly, and there is also a considerable difference across multiple experiments. As the number of epochs increases, the model gradually stabilizes.

Figure 5: Mean and standard deviation of F1 score
4.5.3 Model Parameter Analysis
We analyze the parameter count of our model and compare it with other mainstream models, as shown in Fig. 6. Our model’s parameter count is slightly smaller than HGCLR but significantly smaller than other types of models. One important reason is that, apart from our text encoder and local hierarchical structure encoder, no additional parameters are required. In contrast, models like HiAGM and HiMatch consume additional space to project text feature parameters onto labels, while HTCInforMax introduces additional auxiliary neural networks.

Figure 6: Comparison of model parameters between DepthMatch and current mainstream models
4.5.4 Analysis of Uncertainty and Accuracy
We visualize the data uncertainty of difficult samples with low accuracy and the model uncertainty one layer above the leaf nodes, as shown in Fig. 6. We utilize the semantic vectors extracted directly from the extensively pre-trained BERT model to measure the evidence uncertainty of the samples, indicating the difficulty of the samples themselves. As seen from Fig. 7a, this uncertainty typically ranges between 0.6 and 0.9. Directly using such texts for classification poses significant risks. The model uncertainty one layer above the leaf nodes accumulates based on the uncertainty of predictions from higher-level models, typically exceeding 0.75. Such high uncertainty indicates challenges in robustly classifying leaf nodes. Fig. 7b demonstrates the impact of using an early stopping strategy on difficult samples. It can be observed that the error rate in classification significantly decreases for multiple difficult classes, with a reduction of 15.1% for Class E31 and an average reduction of around 10%. The bar chart results confirm the effectiveness of the depth-aware strategy, enabling more accurate classification results for samples with high uncertainty.

Figure 7: The uncertainty of difficult samples and the comparison of classification error rates on challenging samples with and without depth matching. (a) Epistemic and aleatoric uncertainty. (b) Error rates for classification
We replace the components in DepthMatch with a standard self-attention model and a standard attention masking model, as shown in Table 5. After the replacement, the model performance declined. Firstly, compared to the standard self-attention model, we introduced edge encoding and spatial encoding. These components learn the information between two edges and the connectivity between two nodes, respectively, enhancing the representation capability of the label hierarchy. Secondly, compared to the standard attention masking model, we extended and performed a product operation on the label attention mask. Then, we generated a cross-attention mask to measure the relevance between the current text and the labels. Our model improves performance through the representation of the hierarchy and the interaction between the text and labels.

We conduct experiments on the WOS and RCV1-V2 dataset, and the results are shown in Table 6, the model’s classification performance is superior to previous results, with improvements of 1.48% and 1.39% in Micro-F1 and Macro-F1, respectively. A good hierarchical representation is crucial for HTC tasks. Similarly, under the depth-aware strategy, the model also shows significant improvement, with increases of 1.17% and 1.2% in Micro-F1 and Macro-F1, respectively. The model can produce more reliable classification results.

In Table 7, we repeated the experiments for the proposed method and the baseline Seq2Tree five times (using different random seeds). We conducted experiments on the WOS and RCV1-V2 datasets. It can be seen that these improvements are statistically significant based on the paired t-test at the 95% significance level.

Hierarchical Text Classification (HTC) aims to match text with labels in a structured manner. To address the issues of incomplete text-label matching and error propagation, this paper proposes an uncertainty-guided HTC deep awareness model called DepthMatch. The model employs Dempster-Shafer Evidence Theory to enable uncertainty sharing between hierarchical sequences. Additionally, a dynamic stopping strategy is introduced, using uncertainty to determine the depth of text classification and prevent error propagation. In real-world datasets, most labels have relatively few data, especially at the leaf nodes of the hierarchy. This situation poses challenges for model learning and can lead to unpredictable problems. Therefore, addressing the long-tail problem in hierarchical multi-label text classification is an important research direction for the future.
Acknowledgement: This work was partly supported by the National Natural Science Foundation of China (62136002 and 62306056), the National Natural Science Foundation of Chongqing (cstc2022ycjh-bgzxm0004), and the Science and Technology Commission of Chongqing Municipality (CSTB2023NSCQ-LZX0006), respectively.
Funding Statement: This work was sponsored by the National Key Research and Development Program of China (No. 2021YFF0704100), the National Natural Science Foundation of China (No. 62136002), and the Chongqing Natural Science Foundation (No. cstc2022ycjh-bgzxm0004).
Author Contributions: The authors confirm contribution to the paper as follows: study conception and design: Zixuan Wu, Ye Wang; data collection: Zixuan Wu; analysis and interpretation of results: Zixuan Wu, Ye Wang, Lifeng Shen; draft manuscript preparation: Zixuan Wu, Ye Wang, Lifeng Shen, Feng Hu, Hong Yu. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: Publicly available datasets were analyzed in this study. The Web of Science Dataset is available at https://data.mendeley.com/datasets/9rw3vkcfy4/6 (accessed on 1 August 2024), the Reuters Corpus Volume I Dataset is available at https://trec.nist.gov/data/reuters/reuters.html (accessed on 1 August 2024), the Arxiv Academic Paper Dataset is available at https://drive.google.com/file/d/1QoqcJkZBHsDporttTxaYWOM_ExSn7-Dz/view (accessed on 1 August 2024), the BGC dataset is available at https://www.inf.uni-hamburg.de/en/inst/ab/lt/resources/data/blurb-genre-collection.html. (accessed on 1 August 2024).
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1Our code is available at https://anonymous.4open.science/r/DepthMatch-157E/ (accessed on 1 August, 2024).
References
1. Y. K. Cao, Z. Y. Wei, Y. J. Tang, and C. K. Jin, “Hierarchical label text classification method with deep-level label-assisted classification,” in 2023 IEEE 12th Data Driven Control Learn. Syst. Conf. (DDCLS), Xiangtan, China, IEEE, 2023, pp. 1467–1474. doi: 10.1109/DDCLS58216.2023.10166293. [Google Scholar] [CrossRef]
2. J. C. Gomez and M. Moens, “A survey of automated hierarchical classification of patents,” in Professional Search Modern World, 2014, pp. 215–249. doi: 10.1007/978-3-319-12511-4_11. [Google Scholar] [CrossRef]
3. R. Aly, S. Remus, and C. Biemann, “Hierarchical multi-label classification of text with capsule networks,” in Proc. 57th Annu. Meeting Assoc. Comput. Linguistics: Student Res. Workshop, Florence, Italy, 2019, pp. 323–330. doi: 10.18653/v1/P19-2045. [Google Scholar] [CrossRef]
4. X. Song, Y. Zhu, X. M. Zeng, and X. S. Chen, “Hierarchical contaminated web page classification based on meta tag denoising disposal,” Secur. Commun. Netw., vol. 2021, pp. 1–11, 2021. doi: 10.1155/2021/2470897. [Google Scholar] [CrossRef]
5. J. H. Wang and L. Zhang, “News text classification based on deep learning and TRBert model,” in 2023 IEEE 3rd Int. Conf. Electron. Technol. Commun. Inf. (ICETCI), Changchun, China, IEEE, 2023, pp. 1244–1248. doi: 10.1109/ICETCI57876.2023.10176604. [Google Scholar] [CrossRef]
6. Y. Wang, Q. H. Hu, H. Chen, and Y. H. Qian, “Uncertainty instructed multi-granularity decision for large-scale hierarchical classification,” Inf. Sci., vol. 586, pp. 644–661, 2022. doi: 10.1016/j.ins.2021.12.009. [Google Scholar] [CrossRef]
7. C. Yu, Y. Shen, and Y. Mao, “Constrained sequence-to-tree generation for hierarchical text classification,” in Proc. 45th Int. ACM SIGIR Conf. Res. Dev. Inf. Retrieval, Madrid, Spain, 2022, pp. 1865–1869. doi: 10.48550/arXiv.2204.00811. [Google Scholar] [CrossRef]
8. J. H. Wang, Y. Cheng, J. T. Chen, T. T. Chen, D. Chen and J. Wu, “Ord2Seq: Regarding ordinal regression as label sequence prediction,” in Proc. IEEE/CVF Int. Conf. Comput. Vis., Paris, France, 2023, pp. 5865–5875. doi: 10.48550/arXiv.2307.09004. [Google Scholar] [CrossRef]
9. B. L. Wang, I. Titov, J. Andreas, and Y. Kim, “Hierarchical phrase-based sequence-to-sequence learning,” in Proc. 2022 Conf. Empirical Methods Nat. Lang. Process., Abu Dhabi, United Arab Emirates, 2022, pp. 8211–8229. doi: 10.48550/arXiv.2211.07906. [Google Scholar] [CrossRef]
10. S. H. Im, G. B. Kim, H. Oh, S. Jo, and D. H. Kim, “Hierarchical text classification as sub-hierarchy sequence generation,” in Proc. AAAI Conf. Artificial Intell., Washington, DC, USA, 2023, vol. 37, pp. 12933–12941. doi: 10.48550/arXiv.2111.11104 [Google Scholar] [CrossRef]
11. J. Valmadre, “Hierarchical classification at multiple operating points,” in Proc. 36th Int. Conf. Neural Inf. Process. Syst., New Orleans, LA, USA, 2022, pp. 18034–18045. doi: 10.48550/arXiv.2210.10929. [Google Scholar] [CrossRef]
12. J. Zhou et al., “Hierarchy-aware global model for hierarchical text classification,” in Proc. 58th Annu. Meeting Assoc. Comput. Linguist., Washington, DC, USA, 2020, pp. 1106–1117. doi: 10.18653/v1/2020.acl-main.104. [Google Scholar] [CrossRef]
13. Z. F. Deng, H. Peng, D. X. He, J. X. Li, and S. Y. Philip, “HTCInfoMax: A global model for hierarchical text classification via information maximization,” in Proc. 2021 Conf. North Am. Chapter Assoc. Comput. Linguist.: Hum. Lang. Technol., 2021, pp. 3259–3265. doi: 10.18653/v1/2021.naacl-main.260. [Google Scholar] [CrossRef]
14. W. Huang et al., “Hierarchical multi-label text classification: An attention-based recurrent network approach,” in Proc. 28th ACM Int. Conf. Inf. Knowl. Manage., New York, NY, USA, 2019, pp. 1051–1060. doi: 10.1145/3357384.3357885. [Google Scholar] [CrossRef]
15. X. Y. Zhang, J. H. Xu, C. Soh, and L. H. Chen, “LA-HCN: Label-based attention for hierarchical multi-label text classification neural network,” Expert Syst. Appl., vol. 187, 2022, Art. no. 115922. doi: 10.1016/j.eswa.2021.115922. [Google Scholar] [CrossRef]
16. Z. H. Wang, P. Y. Wang, L. Z. Huang, X. Sun, and H. F. Wang, “Incorporating hierarchy into text encoder: A contrastive learning approach for hierarchical text classification,” in Proc. 60th Annu. Meeting Assoc. Computat. Linguist., Dublin, Ireland, 2022, pp. 7109–7119. doi: 10.48550/arXiv.2203.03825. [Google Scholar] [CrossRef]
17. I. Sutskever, O. Vinyals, and Q. V. Le, “Sequence to sequence learning with neural networks,” in Proc. 27th Int. Conf. Neural Inf. Process. Syst., Montreal, QC, Canada, 2014, vol. 2, pp. 3104–3112. doi: 10.48550/arXiv.1409.3215. [Google Scholar] [CrossRef]
18. Y. Q. Xiao, Y. Li, J. Yuan, S. R. Guo, Y. Xiao and Z. Y. Li, “History-based attention in seq2seq model for multi-label text classification,” Knowl.-Based Syst., vol. 224, 2021, Art. no. 107094. doi: 10.1016/j.knosys.2021.107094. [Google Scholar] [CrossRef]
19. N. Tavakoli, “Seq2Image: Sequence analysis using visualization and deep convolutional neural network,” in 2020 IEEE 44th Annu. Comput. Softw. Appl. Conf. (COMPSAC), Madrid, Spain, IEEE, 2020, pp. 1332–1337. doi: 10.1109/COMPSAC48688.2020.00-71. [Google Scholar] [CrossRef]
20. Q. Q. Guo, Z. F. Zhu, Q. Lu, D. Y. Zhang, and W. Q. Wu, “A dynamic emotional session generation model based on seq2seq and a dictionary-based attention mechanism,” Appl. Sci., vol. 10, no. 6, 2020, Art. no. 1967. doi: 10.3390/app10061967. [Google Scholar] [CrossRef]
21. K. Kowsari, D. E. Brown, M. Heidarysafa, K. J. Meimandi, M. S. Gerber and L. E. Barnes, “HDLTex: Hierarchical deep learning for text classification,” in 2017 16th IEEE Int. Conf. Mach. Learn. Appl. (ICMLA), Cancun, Mexico, IEEE, 2017, pp. 364–371. doi: 10.48550/arXiv.1709.08267. [Google Scholar] [CrossRef]
22. D. D. Lewis, Y. Yang, T. Russell-Rose, and F. Li, “RCV1: A new benchmark collection for text categorization research,” J. Mach. Learn. Res., vol. 5, pp. 361–397, 2004. [Google Scholar]
23. P. C. Yang, X. Sun, W. Li, S. M. Ma, W. Wu and H. F. Wang, “SGM: Sequence generation model for multi-label classification,” in Proc. 27th Int. Conf. Comput. Linguist., Santa Fe, NM, USA, 2018, pp. 3915–3926. doi: 10.48550/arXiv.1806.04822. [Google Scholar] [CrossRef]
24. A. Joulin, É. Grave, P. Bojanowski, and T. Mikolov, “Bag of tricks for efficient text classification,” in Proc. 15th Conf. Eur. Chapter Assoc. Comput. Linguist., Valencia, Spain, 2017, pp. 427–431. doi: 10.48550/arXiv.1607.01759. [Google Scholar] [CrossRef]
25. A. Conneau, H. Schwenk, Y. L. Cun, and L. Barrault, “Very deep convolutional networks for text classification,” in 15th Conf. Eur. Chapter Assoc. Comput. Linguist., Valencia, Spain, 2017, pp. 1107–1116. doi: 10.48550/arXiv.1606.01781. [Google Scholar] [CrossRef]
26. S. W. Lai, L. H. Xu, K. Liu, and J. Zhao, “Recurrent convolutional neural networks for text classification,” in Proc. Twenty-Ninth AAAI Conf. Artificial Intell., Austin, TX, USA, 2015, pp. 2267–2273. doi: 10.1609/aaai.v29i1.9513. [Google Scholar] [CrossRef]
27. T. Jiang, D. Q. Wang, L. L. Sun, Z. Z. Chen, F. Z. Zhuang and Q. H. Yang, “Exploiting global and local hierarchies for hierarchical text classification,” in Proc. 2022 Conf. Empirical Methods Nat. Lang. Process., Abu Dhabi, United Arab Emirates, 2022, pp. 4030–4039. doi: 10.48550/arXiv.2205.02613. [Google Scholar] [CrossRef]
28. H. B. Chen, Q. L. Ma, Z. X. Lin, and J. Y. Yan, “Hierarchy-aware label semantics matching network for hierarchical text classification,” in Proc. 59th Annu. Meeting Assoc. Comput. Linguist. 11th Int. Joint Conf. Nat. Lang. Process., 2021, pp. 4370–4379. doi: 10.18653/v1/2021.acl-long.337. [Google Scholar] [CrossRef]
29. H. Zhu, C. Zhang, J. J. Huang, J. R. Wu, and K. Xu, “HiTIN: Hierarchy-aware tree isomorphism network for hierarchical text classification,” in Proc. 58th Annu. Meeting Assoc. Comput. Linguist., 2023, pp. 7809–7821. doi: 10.48550/arXiv.2305.15182. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools