
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

IMTNet: Improved Multi-Task Copy-Move Forgery Detection Network with Feature Decoupling and Multi-Feature Pyramid
1 School of Information, Guizhou University of Finance and Economics, Guiyang, 550025, China
2 College of Big Data Statistics, Guizhou University of Finance and Economics, Guiyang, 550025, China
* Corresponding Author: Zhongyuan Jiang. Email:
(This article belongs to the Special Issue: Multimedia Security in Deep Learning)
Computers, Materials & Continua 2024, 80(3), 4603-4620. https://doi.org/10.32604/cmc.2024.053740
Received 09 May 2024; Accepted 13 August 2024; Issue published 12 September 2024
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Copy-Move Forgery Detection (CMFD) is a technique that is designed to identify image tampering and locate suspicious areas. However, the practicality of the CMFD is impeded by the scarcity of datasets, inadequate quality and quantity, and a narrow range of applicable tasks. These limitations significantly restrict the capacity and applicability of CMFD. To overcome the limitations of existing methods, a novel solution called IMTNet is proposed for CMFD by employing a feature decoupling approach. Firstly, this study formulates the objective task and network relationship as an optimization problem using transfer learning. Furthermore, it thoroughly discusses and analyzes the relationship between CMFD and deep network architecture by employing ResNet-50 during the optimization solving phase. Secondly, a quantitative comparison between fine-tuning and feature decoupling is conducted to evaluate the degree of similarity between the image classification and CMFD domains by the enhanced ResNet-50. Finally, suspicious regions are localized using a feature pyramid network with bottom-up path augmentation. Experimental results demonstrate that IMTNet achieves faster convergence, shorter training times, and favorable generalization performance compared to existing methods. Moreover, it is shown that IMTNet significantly outperforms fine-tuning based approaches in terms of accuracy and F1.Keywords
Malicious image forgeries, including techniques such as copy-move, splicing, and removal, can severely undermine the credibility and integrity of digital images. The copy-move tampering method, being one of the most prevalent image tampering techniques, is highly concealable and presents significant challenges for detection. Moreover, the characteristics (such as the saturation, light source, and noise) of the tampered areas can be adapted easily without affecting the original image properties. Therefore, CMFD methods have attracted the attention of forensic science scholars.
The traditional CMFD methods can be classified into two main categories: block-based methods and keypoint-based methods. In the block-based methods, discrete cosine transform (DCT) technologies are generally used in image processing because of their energy compaction properties. The work in [1] analyzes the exhaustive search algorithms and proposes a block matching detection method based on DCT. This work is one of the landmark methods in CMFD methods. Each block contains 64 (8 × 8) features and any two feature vectors that are within a certain range should be matched to determine the duplicated regions. However, the proposed method cannot detect the small duplicated regions and the detection precision is dissatisfactory because of its lexicographically sorting algorithm. The study in [2] improves the method of [1] by reducing the number of features to a quarter that is located in the low frequency parts. However, the detection accuracy is unsatisfactory since some DCT coefficients that are located in the intermediate frequency parts are truncated. A Discrete Cosine Transformation (DCT) and Singular Value Decomposition (SVD) based technique is proposed to detect the copy-move image forgery in [3], the combination of DCT and SVD makes the proposed scheme robust against compression, geometric transformations, and noise. A hybrid method is reported to classify copy-move and splicing images based on the texture information of images in the spatial domain [4]. The proposed method divides the image into equal blocks to get scale-invariant features. The tampered image regions can be detected by matching the scale-invariant features. The proposed method is robust to most regular signal processing type attacks. However, it is less effective against some geometric transformation-type attacks.
In the keypoint-based methods, the underlying principle is that modifications made to the image, such as copy-move operations, will alter the local features and consequently impact the distribution and characteristics of the detected keypoints. By analyzing the changes in the keypoint-based representations, these techniques aim to identify the presence of tampering in the image. Amerini et al. in [5] propose a novel methodology based on a scale invariant features transform (SIFT) method. The proposed method can be used to determine whether a copy-move attack has occurred in an image. It also can be used to recover the geometric transformation that is used to perform cloning technologies. Furthermore, the proposed method can be used to individuate the altered areas and estimate the geometric transformation parameters with high reliability. The work in [6] reports an improved SIFT structure with inherent scaling invariance that is designed to enhance the capability of extracting effective keypoints in the homogeneous region. Zhong et al. in [7] analyze the structure and excavate the inherent characteristics of local descriptors (SURF) for feature extraction in the coarse and smooth regions. Subsequently, the proposed method utilizes kernel features for coarse feature matching to reduce matching costs. Following this, a smaller set of candidate keypoints is identified, which are then used in conjunction with complete features to conduct fine keypoint matching in order to identify suspicious candidate keypoint pairs. A method is proposed in [8] to find and locate the duplicated and pasted portions of a manipulated image by using the combination of Hessian and Raw patch features. In the proposed method, a parallelism condition is applied together with a random sample consensus method to eliminate mismatches. The proposed method was shown to be effective by obtaining high
Traditional image tampering detection methods have faced growing challenges in keeping pace with the rapidly evolving landscape of image forgery techniques. In response, the increased pervasiveness of deep learning technologies has led to the development of contemporary copy-move forgery detection algorithms that predominantly leverage specialized neural network architectures, which are purposefully designed and trained for the task of image tampering identification. It is proposed in [9] that an end-to-end approach called BusterNet can identify the source and target regions by detecting image similarity through parallel branching. However, this method requires high accuracy on both branches. The work in [10] reports a serial branching network that is used to improve the drawbacks of BusterNet. The reported network consists of a copy-move similarity detection network and a source/target region distinguishment network. The branching network is simpler and more accurate compared with the BusterNet. However, generalization was powerless. The study in [11] proposes the Dense-InceptionNet that combines DenseNet and InceptionNet, by utilizing multiscale information and dense features. The study presented in [12] introduces the Spatial Pyramidal Attention Network which is designed to capture inter-block relationships across multiple scales through a pyramidal structure of locally self-attentive blocks. However, this approach demonstrates diminished effectiveness at lower image resolutions and overlooks the interplay between high-dimensional and low-dimensional features. The research in [13] reports a deep learning method for forgery detection at both image and pixel levels. In this method, authors used a pre-trained deep model with a global average pooling (GAP) layer instead of default fully connected layers to detect forgery. The GAP layer creates a good dependency between the feature maps and the classes. The study in [14] proposes the Laterally Linked Pixel (LLP) algorithm, which utilizes two-dimensional arrays and a single layer derived from a unit-linking pulsed neural network to detect copied regions. The method employs kernel tricks to identify multiple manipulations within a single forged image. The accuracy obtained through the LLP algorithm is about 90% and further forgery detection is improved based on optimized kernel selections in classification algorithm.
While extensive experimental evaluations have demonstrated the satisfactory performance of the aforementioned specialized neural network-based copy-move forgery detection methods, such approaches inherently compromise the broader generalizability of the underlying network architecture. This runs counter to the primary objective of neural networks, which is to learn robust, generalizable representations that can be effectively applied across a diverse range of related tasks and domains. Consequentially, the following problems arise: (1) Deep neural networks (DNNs) require a substantial quantity of high-quality labeled datasets [15]. (2) DNNs need hardware with higher computing capacity. (3) As a data-driven algorithm, DNNs produce individual results based on various types of data. However, collecting an enormous amount of data does not provide a comprehensive representation. (4) DNNs aim to create a general model that could cater to the needs of different users, environments, and devices. Consequently, there remains an urgent need to adapt and refine the general model to address personalized tasks effectively [16].
Transfer learning is concerned with the transfer of knowledge across domains, leveraging prior experience as a bridge to facilitate the adaptation from one scenario to another. Among its various subfields, feature decoupling stands out as a significant subclass, demonstrating a broad spectrum of applications. Feature decoupling is an approach to designing neural network architectures and training processes that aim to make the features learned from the network independent or uncorrelated from each other. The main purpose of feature decoupling is to improve the generalization ability and interpretability of the model. A feature decoupled training pipeline for describe-then-detect is designed for weakly supervised local feature learning [17]. Additionally, an introduced line-to-window search strategy enhances descriptor learning by explicitly utilizing camera pose information, and attained state-of-the-art performance across various tasks. The work in [18] reports a multi-scale single image deraining network, called the feature decoupling and reorganization network, which introduces a dilated pyramid split attention module to decouple input features and reorganize extracted features.
The aforementioned work exemplifies practical applications of feature decoupling, which often entails specific modifications to network architecture, such as the incorporation of regularization techniques or the addition of terms to the loss function to promote feature independence. By employing feature decoupling, the model is anticipated to acquire more robust and distinguishable feature representations, thereby enhancing its performance on novel and previously unseen data.
Image semantic information can be broadly categorized into three layers: the visual, object, and conceptual layers. The visual layer, often referred to as the shallow feature layer, encompasses detailed attributes such as color and shape. The object layer, or mid-level feature, usually contains object attributes. The conceptual layer, known as the high-level feature contains abundant semantic information. ResNet-50 [19] is specifically designed for image classification tasks. However, the tasks of CMFD and image classification have distinct focuses on the image, which necessitate the network to possess diverse feature extraction capabilities and representation capabilities. Meanwhile, quantitative analysis is performed experimentally on the pre-trained ResNet-50 to achieve structural risk minimization. It is worth mentioning that the 3461 model is a variant of the ResNet-50. It indicates that the ConvNet Layer of four modules in ResNet-50 is repeated 3, 4, 6, and 1 times, respectively.
Fig. 1 illustrates the comparison of the ResNet-50 deep module (fourth module) possessing varying numbers of convolutional layers, where the 3 4 6 1, 3 4 6 3 and 3 4 6 6 represent the numbers of stacks of residual blocks within the module, respectively. Multiple classes of models with slight variations were trained while keeping the first three modules frozen. The comparative analysis of visualization outcomes derived from the three distinct models suggests that increasing the depth of the network architecture enhances the ability to extract complex details. Nevertheless, based on the pertinent graphical representation, it can be inferred that integrating more complex structures into the model is inappropriate for tackling the CMFD task.
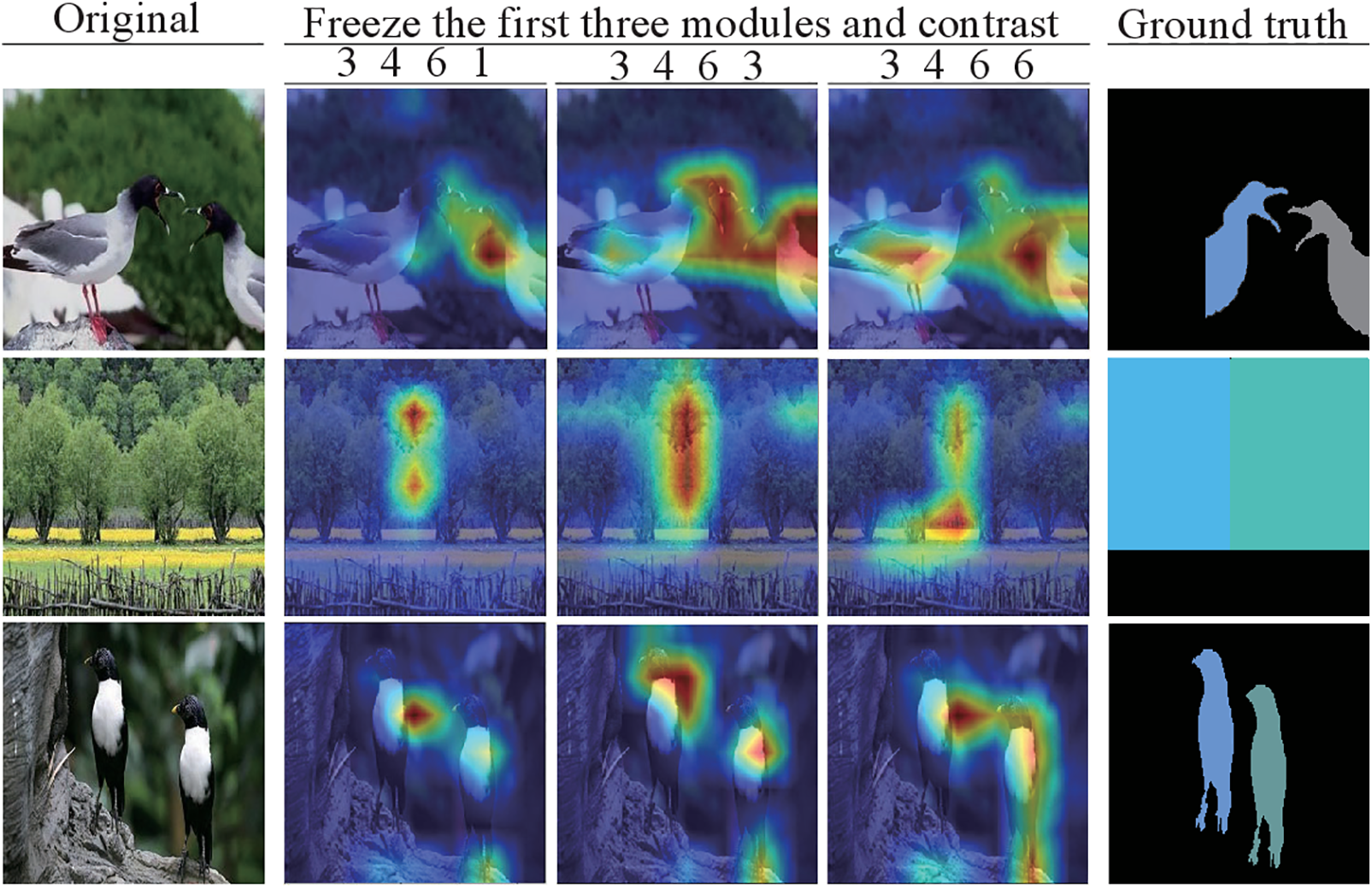
Figure 1: Contrast analysis. The first three module weights are frozen based on a pre-trained ResNet-50. The effect of the model is analyzed while the convolution layer of the fourth module is changed. Source and tampered areas are indicated in blue and gray
To address the aforementioned limitations, this paper introduces a feature decoupling approach within the context of transfer learning, leveraging knowledge migration to enhance model performance. When the source and target domains are similar, the main challenge in feature decoupling is determining which layers of knowledge in the source domain network should be fixed or fine-tuned [20].
In the proposed scheme, the relationship between the CMFD task and the number of deep feature repetition layers in the pre-trained ResNet-50 is explored. ResNet-50 is introduced for several compelling reasons: (1) the incorporation of identity shortcut connections within the residual branching structure (RBS) optimizes the process of backpropagation, thereby rendering ResNet-50, a simple and highly efficient method. (2) ResNet-50 employs a limited number of optimization techniques effectively, thereby minimizing potential interferences. Furthermore, the architecture incorporates two types of RBS. RBS-1 utilizes a step size of 2, which significantly reduces the output size and mitigates the risk of overfitting. On the other hand, RBS-2 serves as the major module in the ResNet network, primarily focused on enhancing the representational capabilities. (3) In addition, in the field of passive forensics, the scarcity of high-quality datasets leads to low model generalization ability and accuracy rates.
The objective of this paper is to streamline the multi-task framework of ResNet-50 to mitigate disaster forgetting and enhance task efficiency. To accomplish this, the multi-task objective is simplified into a single-task objective. Specifically, the focus is on maximizing the utilization of the solution space for the image classification task through pertinent experiments. Our goal is to enhance the model performance on the CMFD task when the image classification task has already reached its optimum. This paper proposes an improved multi-task copy-move forgery detection network by using a multi-feature pyramid module (MFPM) and features decoupling across tasks. The main contributions of this study are as follows:
1. An optimization problem is abstracted to establish a link between image classification and CMFD based on ResNet-50 using feature decoupling, wherein the relationship between the deep structure and task is illustrated during optimization.
2. This paper provides a quantitative demonstration of the similarities between image classification tasks and CMFD. Moreover, it addresses the challenge of limited high-quality data in CMFD through the transfer of frozen weights and retraining of the model.
3. The CMFD field saw the first introduction of the MFPM. It utilizes three matching maps to detect suspicious regions and enhances localization accuracy through the application of Feature Pyramid Networks and an optimized bottom-up pathway.
The rest of this paper is organized as follows. Section 2 describes the stages of the proposed method and briefly explains every step. Section 3 presents databases that are being used for experiments and an experimental setup and results in discussions for the proposed architecture. It offers tables and figures related to results calculated using the proposed architecture. At last, Section 4 provides conclusions for this study.
To address the challenges in dataset building and training due to the difficulty of collecting high-quality annotated collections of tampered images in CMFD, IMTNet is proposed in this paper, the diagram is shown in Fig. 2. It comprises two components: copy-move forgery detection algorithm based on feature decoupling and tampered image localization algorithm named MFPN, which effectively leverages both high and low-dimensional image information.
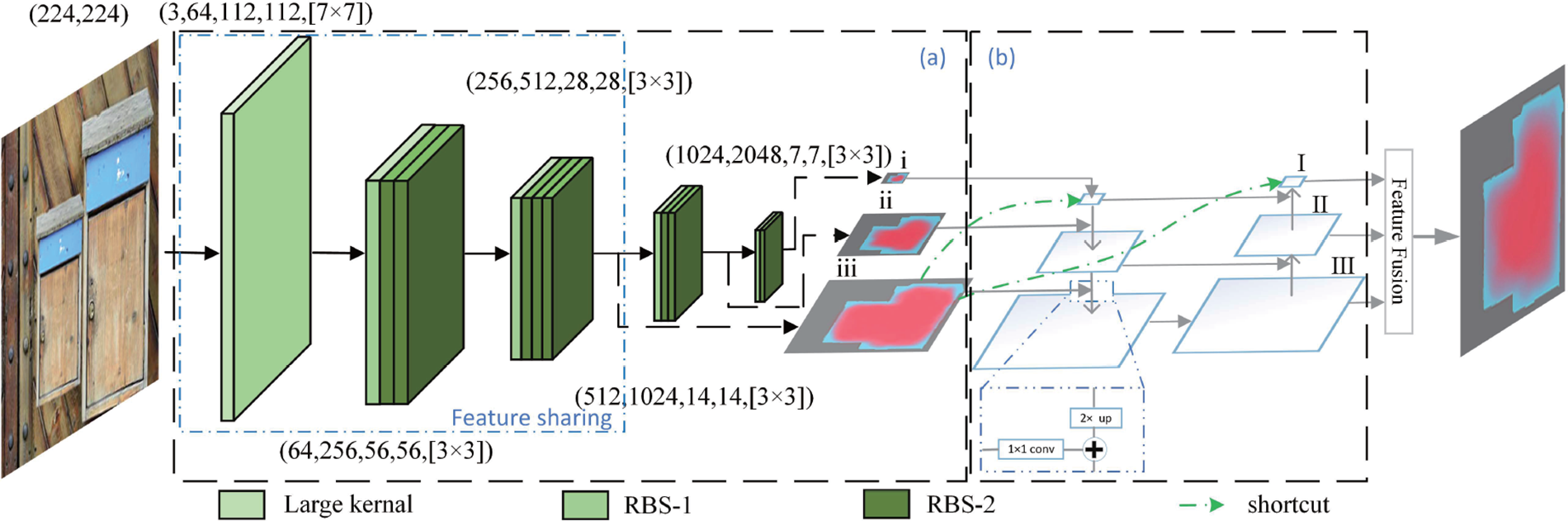
Figure 2: The diagram of IMTNet for copy-move forgery detection and localization. (a) Improved ResNet-50 backbone. (b) MFPN
2.1 Copy-Move Forgery Detection Algorithm Based on Feature Decoupling
ResNet-50 based on transfer learning. Due to the difficulty of collecting datasets in CMFD, the current number of datasets available is limited. Furthermore, the varying shallow weights obtained during different training epochs can potentially disrupt correlation ablation experiments. To tackle the aforementioned challenges, our proposal involves the adoption of a feature decoupling approach and enhancements to the network structure of the pre-trained ResNet-50. The primary objective is to maximize the leverage of the source domain as a feature extraction network for the target domain.
The pre-trained ResNet-50 combined with the feature decoupling approach empowers the IMTNet to acquire highly relevant implicit expression features. Furthermore, feature decoupling is employed as a regularization technique to mitigate dissimilarities between the source and target marginal distributions. This mathematical description can be formulated as
where
in which
in which
Optimization problem solution for multi-task based on ResNet-50. A ConvNet Layer
where
where
The multi-task optimization problem described above is transformed into a single optimization problem, where
Initially, we assume that the model is the most optimal image classification solution. According to the steps above, this optimal solution can be adapted to the specifics of image copy-move tampering. In the deep model, the number of iterations between layers is scaled by
2.2 Tampered Image Positioning Algorithm
The MFPN incorporates top-down and bottom-up bidirectional fusion branches, which combine low-level features information and high-level semantic information to improve the accuracy of semantic representation [21]. Therefore, IMTNet leverages the inherent multi-scale and hierarchical characteristics of the network to construct MFPN, which greatly enhances its representational capabilities and localization quality. Moreover, it reduces the cost of building MFPN. The output results of the three matching maps and their combination are shown in Fig. 3a,b show the forgery image and the ground truth mask, and Fig. 3c–f shows the results of the three up-sampled matching maps I, II and III and the final suspicious area location results.
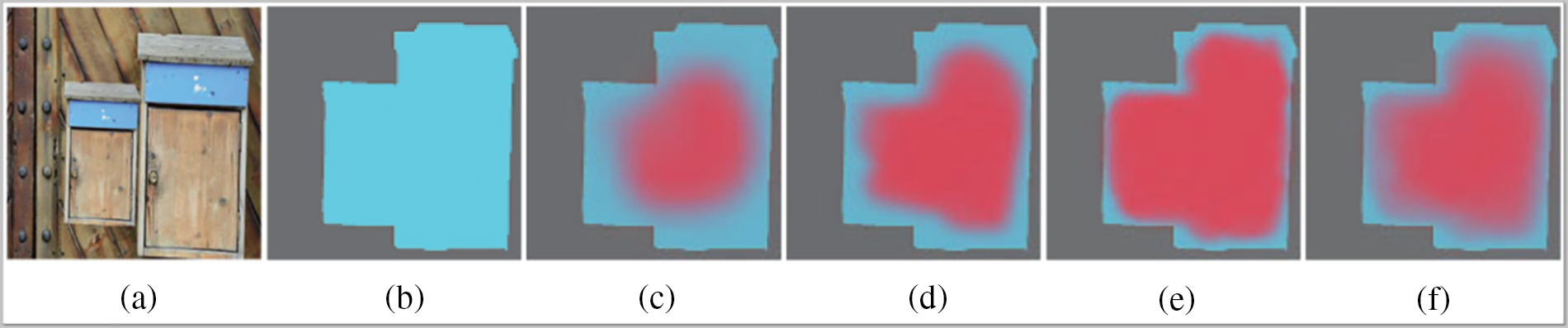
Figure 3: The output results of the three matching maps and their combination
The numerous untrained forgery classes or objects result in difficulty in applying a classic DNNs model to address those data. Therefore, an auxiliary image tampering localization model is proposed to learn the correlations between the rich hierarchical features. In the proposed scheme,
where the parameter
where the subscript
In the IMTNet, the 2NN matching algorithm [22] is used to reduce the matching errors. Assume
The relevant features can be filtered according to Eq. (10) while
In Eq. (9), set
where
Finally, the feature matching coefficient
where
where 32, 48, and 64 represent the number of channels in MFPM for locks
Task relevance can be trained based on the premise that similar tasks share the same model weights, and these tasks can be transformed or low-rank regularized to obtain richer representations. The feature decoupling approach used in this paper aims to capture multiple aspects of task relevance properties, such as sparsely and low-ranking of tasks. This is achieved by decomposing the model partial weights into the sum or product of different convolution operator components that capture information in addition to specific task information that is beneficial to each task. The flexibility of the feature decoupling technique provides a deeper understanding of the nature of multi-task, enabling feature sharing of model weights for both image classification and image tampering detection tasks [23].
IMTNet is trained on two benchmark datasets: the CASIA2.0 [24] and CoMoFod_small [25] dataset. Meanwhile, the mentioned datasets are mixed as the target domain datasets. The blended dataset contains many manipulated images that have been attacked, which could enhance the “quality” of the dataset and improve its robustness. Moreover, MICC-F2000 [5], MICC-F600 [26], COVERAGE [27], and DEFACTO [28] are used to conduct generalization tests. Original and tampered images from the Ardizzone [29] dataset and the MICC-F2000 dataset are used. In addition, there are 140 images in the dataset for the attack resistance experiments, where 35 identical images come from the Ardizzone dataset that have undergone different tampering attacks, and in order to enlarge the size of the dataset, 35 images in the MICC-F2000 dataset are extracted that have also undergone different tampering attacks, totaling 70 tampered images. Thus, the interference due to different images is reduced and the model is realized for the anti-attack experiments.
Anchor points are used in the experiment to divide the semantic information of images, such as the visual layer, object layer, and concept layer. These points are chosen because each downsampling greatly enhances the representation of semantic information. Additionally, the shallow features of the images are generic, which is the reason that the shallow weights of the model are frozen.
The ablation study is divided into two phases. The first phase assessed the similarity between the source and target domains to identify the appropriate number of layers to freeze. The second phase explored the correlation between the deep architecture of ResNet-50 and its performance on the CMFD task.
Similarity between the image classification domain and CMFD domain. The deep architecture of ResNet-50 is analyzed at various scales. An experimental comparison is conducted to evaluate the representational capabilities of ResNet-50 when trained directly or with specific modules frozen. Table 1 and Fig. 4 present the experimental results from alternative perspectives, respectively. The data in Table 1 are the value of

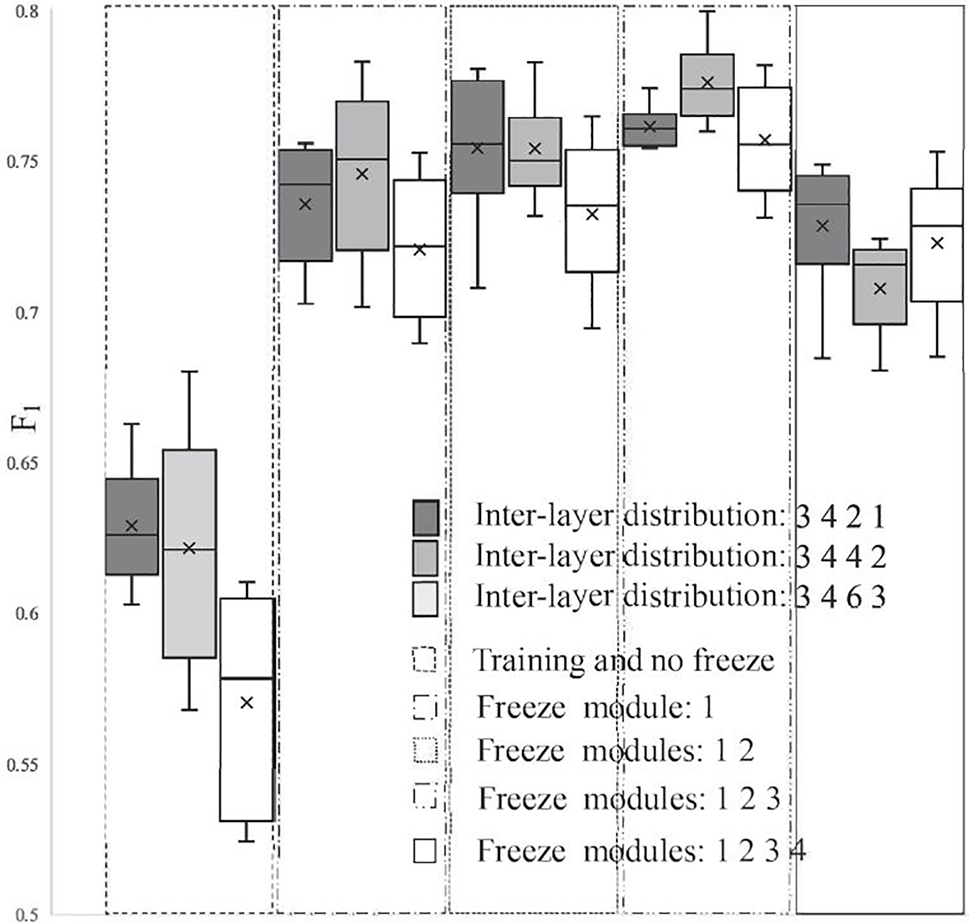
Figure 4: Interlayer relationships
In Fig. 4, the inter-layer relationship refers to freezing the pre-trained parameters of different modules within the same model, obtained after training on the image classification task. And then the weight parameters of the unfrozen modules are initialized and trained in the image copy-move tampering detection task, while the generalization ability of the model in image copy-move tampering detection is later measured to achieve the comparison of results in Fig. 4.
Fig. 4 shows that the model trained directly is more stochastic and less stable compared to the pre-trained ResNet-50. It can be seen that the
The experimental results in Fig. 4 indicate that the proposed IMTNet model achieves better performance in the CMFD task by applying the feature decoupling method, while freezing the first three module weights of ResNet-50.
The relationship between the deep structure of ResNet-50 and CMFD. In Fig. 5, the experimental result of accuracy is weighted and summed in proportions. The experimental datasets are the mixture of generalized experimental data based on MICC-F2000 and MICC-F600 datasets. The comparison experiment is repeated 35 times for each group that is a series of values derived from the same model after 35 experiments under the same conditions. Removing the two highest and the three worst results, the first three modules are frozen to avoid disruptions of the parameter change. The relationship between model depth and the image tampering detection task is revealed by the change in the probability distribution of
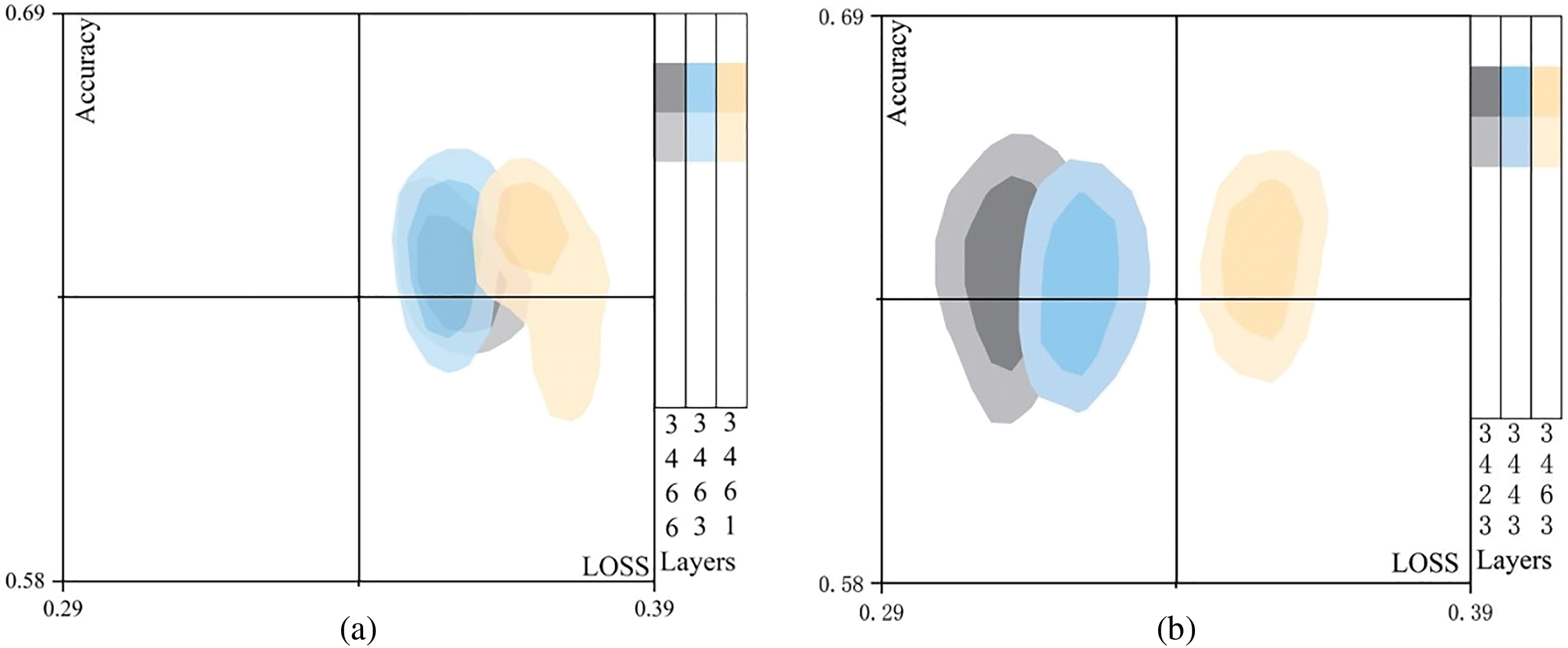
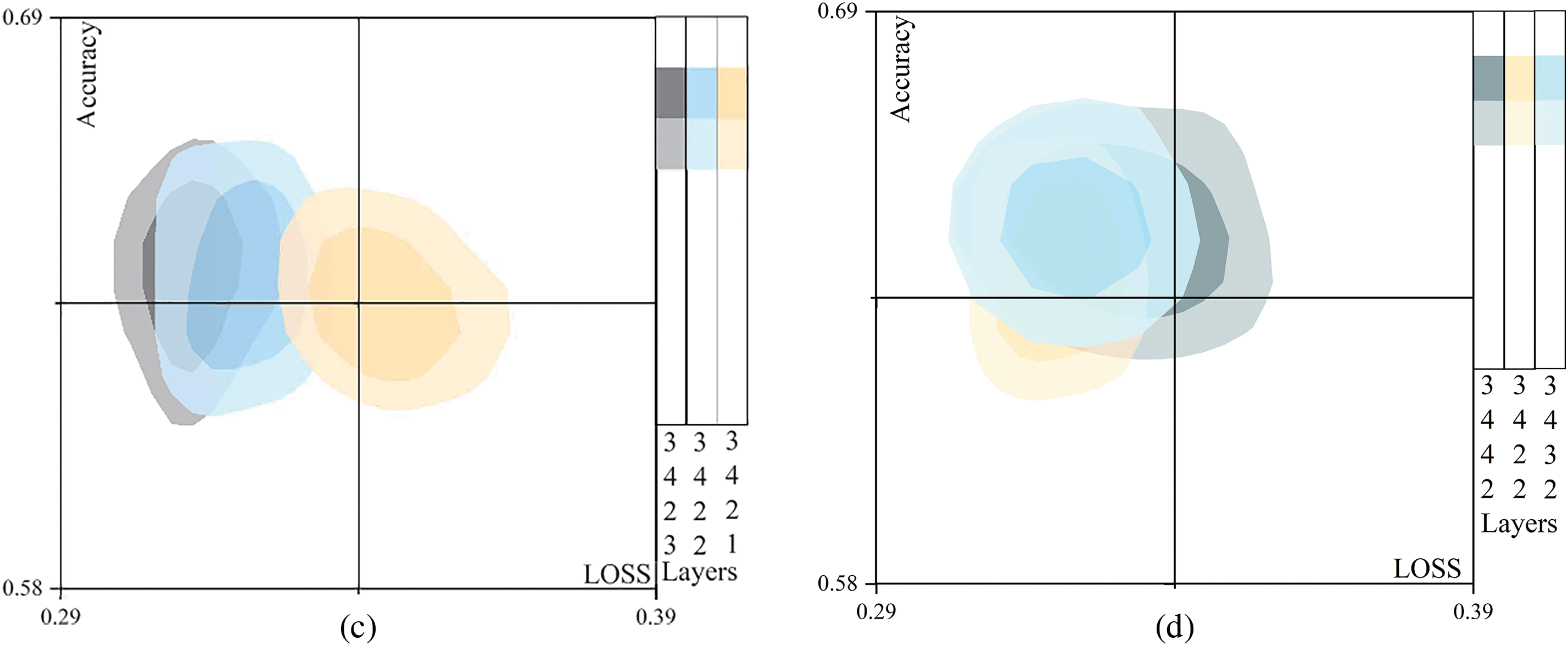
Figure 5: Ablation experiment of model deep layers. (a) Last module comparison. (b) Penultimate module comparison. (c) Refined comparison. (d) Final detail comparison
Fig. 5a characterizes the relationship between the model generalization ability and the model loss function. It can be seen from the distribution of model layers that model structure 3,4,6,6 does not perform as well as expected while consuming more hardware resources. In addition, the generalizability of the model is also reduced. The problem is mainly due to the model using concrete concepts to represent targets rather than abstract regions in tampered images. Furthermore, model structures 3,4,6,1 have insufficient characterization ability and the upper bound of the generalization error and the loss function error is large, which highlights the weakness of the model characterization ability and the instability of the characterization.
Fig. 5b illustrates the training of the last layer while keeping the first three modules frozen, and it also involves reducing the number of convolutional layers in the third module. Experimental evidence reveals that the abundance of highly specific semantic features extracted from the middle and deep layers hinders the detection of tampered images.
As demonstrated in Fig. 5c, the comparison of the generalization performance of the model structures 3,4,2,3 and 3,4,2,2 reveals that they are comparable. Fig. 5a,c shows that the deep parameter reduction of the model has little effect on the model’s ability in image tampering detection. This leads to the conclusion that lightweighting the model without compromising its representational capabilities can significantly reduce operational resource consumption and enhance computing speed. At present, the preference is given to the model with larger loss as it is believed to possess better generalization ability. Additionally, this model is more compact and consumes fewer resources.
Based on the results depicted in Fig. 5d, the stable and well-generalized model structure 3432 has been selected as the optimal structure. By modifying the parameters of the last two layers of the model, the network can better characterize the problem of “whether the image has been tampered with” with an abstract entity description.
An exploration of the relevant properties of IMTNet. The mean values from multiple experiments by using MICC-F2000 and MICC-F600 datasets are presented in Table 2. The pre-training datasets we used are ImageNet-1K and ImageNet-21K. The ImageNet dataset is indeed a very common and important source of pre-trained models in the field of transfer learning. The ImageNet-1K is the most commonly used subset of the ImageNet dataset, containing 1000 classes and approximately 1.3 million images. The ImageNet-21K is the full ImageNet dataset, containing 21,841 classes and approximately 14 million images.
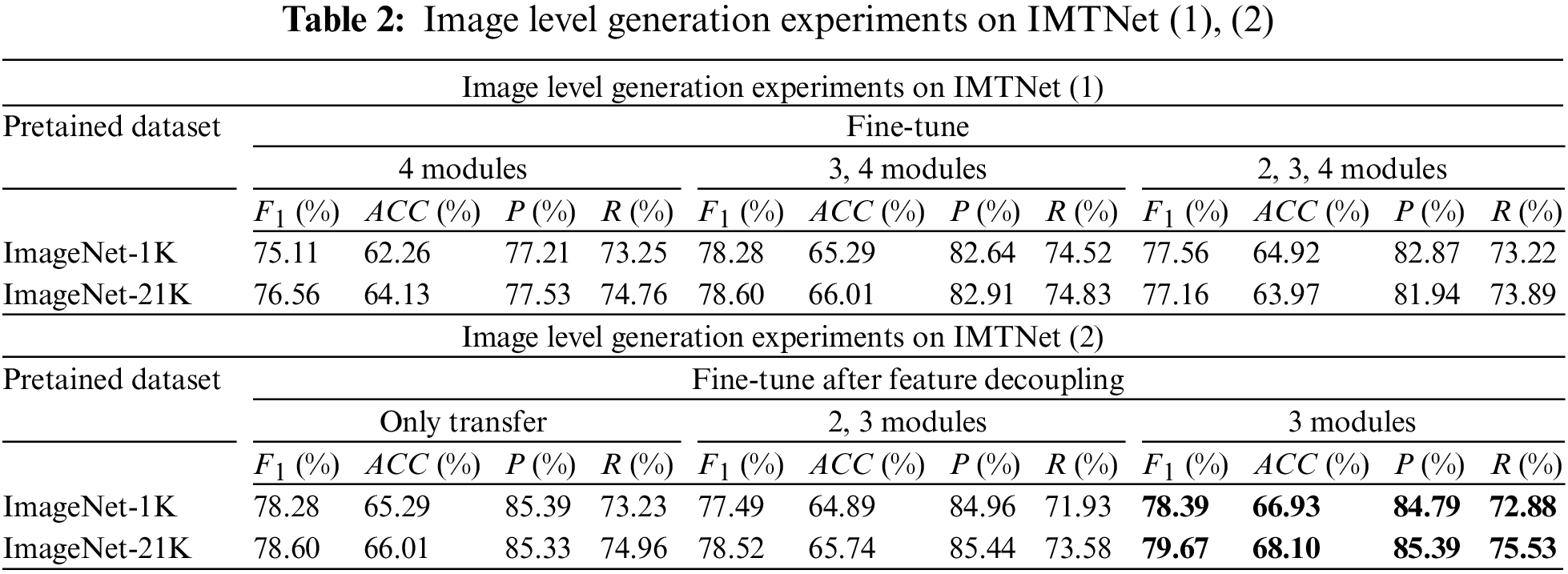
From the perspective of the generalization dataset, feature decoupling and fine-tuning are compared in the CMFD task quantitatively. The experimental data is utilized to measure the similarity between the image classification domain and the CMFD domain. Then, the comparison of the number of frozen layers vs. the number of fine-tuned layers is made. The experimental results have led to the determination that the most optimal approach involves fine-tuning the third module subsequent to the feature decoupling process.
Fig. 6 depicts the correlation between the number of training parameters in a model and its representation capabilities. The trainable parameters are derived by subtracting the model’s frozen parameters from the model’s full parameters, while the model detection accuracy is derived from the model’s performance in the generation experiments. This reveals that IMTNet exhibits outstanding generalization performance by employing a trace of parameters.
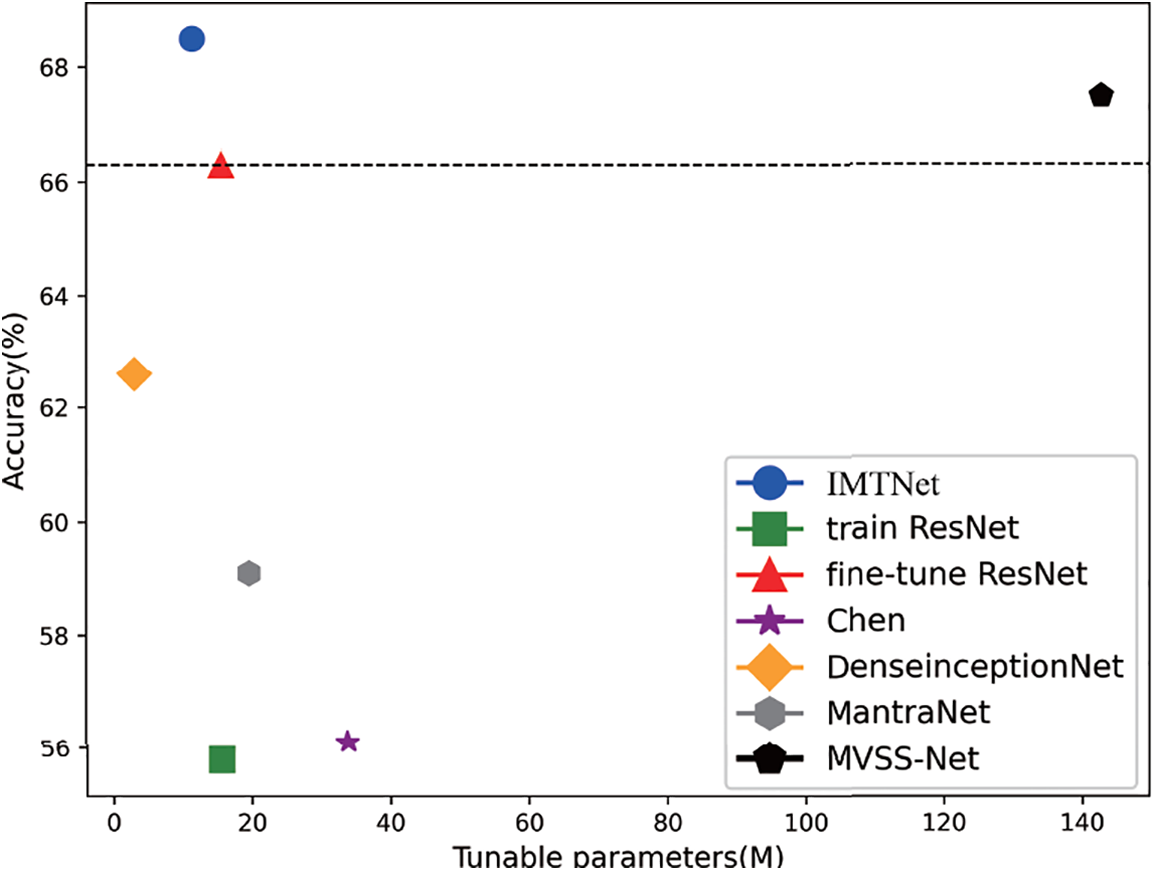
Figure 6: Generalization accuracy-training parameter
Additionally, Fig. 7 presents the comparison between feature decoupling and fine-tuning across five distinct dataset sizes: 166, 766, 2046, 4171, and 5337. These datasets are part of the training dataset. After subtracting 5337 images from the training dataset, the test dataset is uniformly the remaining 15,328 images. The highest value is taken in 25 runs. The results of the experiment indicate that, for datasets with less than 1000 samples, fine-tuning is generally a more effective approach compared to feature decoupling followed by fine-tuning. Fig. 7a,b portrays the relationship from different perspectives.
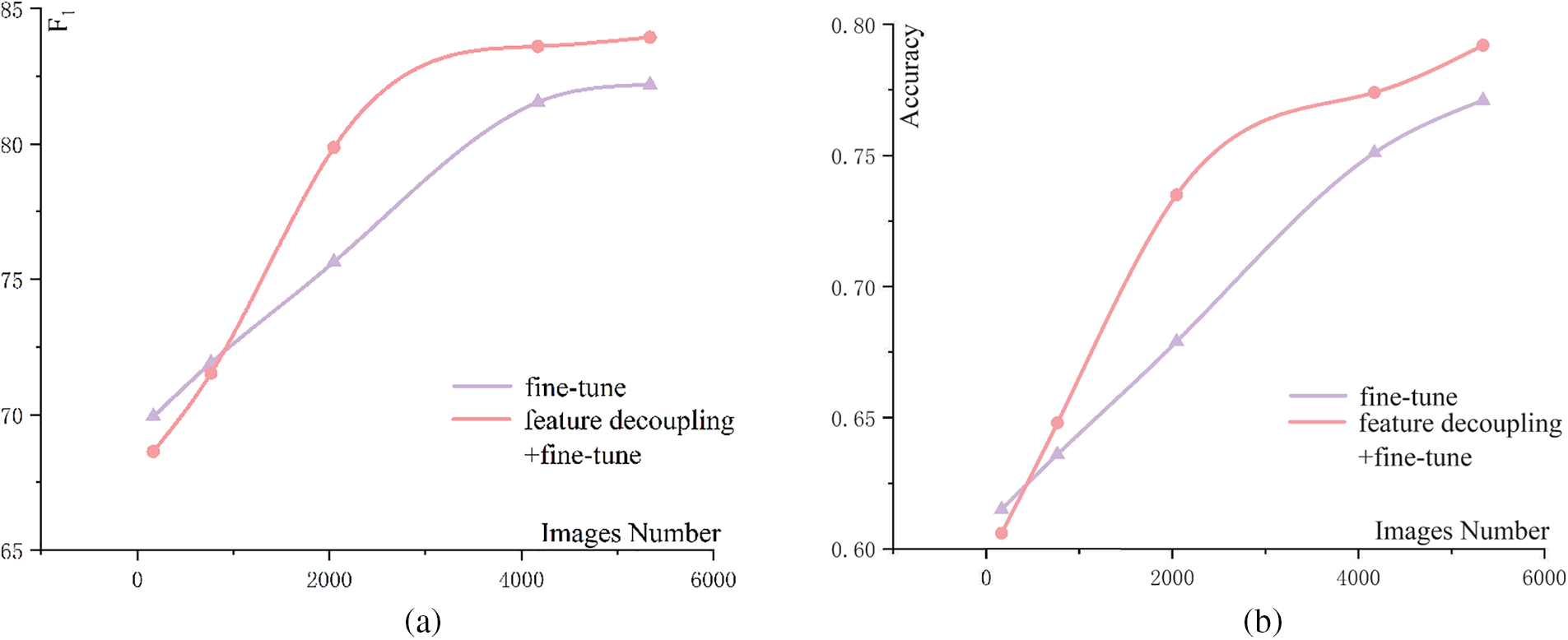
Figure 7: Comparative analysis of fine-tuning and feature decoupling. (a) F1-images number. (b) Accuracy-images number
The following observations, derived from the comparison of the results obtained from these experiments, have been listed below: (1) The findings from the quantitative analysis experiments indicate that the CMFD task necessitates shallower layers for the ResNet-50 model as compared to the image classification task. (2) Fine-tuning achieves superior performance compared to feature decoupling when the dataset is limited in size. (3) For the ResNet-50 model, the CMFD task achieves better performance when reducing the number of convolutional layers in the third module, compared to reducing the number of convolutional layers in the last module.
The anti-attack experiments of various algorithms are described below to evaluate the robustness of the pre-trained network. 1: Rotation attack. 2: Gaussian noise attack. 3: JPEG image compression attack. 4: Blurring attack. 5: Scaling attack.
As shown in Fig. 8, the value is used as an indicator to evaluate the detection capabilities of various methods in different tampering environments. The curve depicted is obtained through the quadratic interpolation of the relevant data points. In which, Fig. 8a–e show the result comparisons under various attacks. In anti-attack experiments, the following observations are presented: (1) under a variety of attacks, IMTNet exhibits excellent robustness compared to other methods. (2) IMTNet possesses the property conferred by feature decoupling as seen in the comparison of ResNet-50.
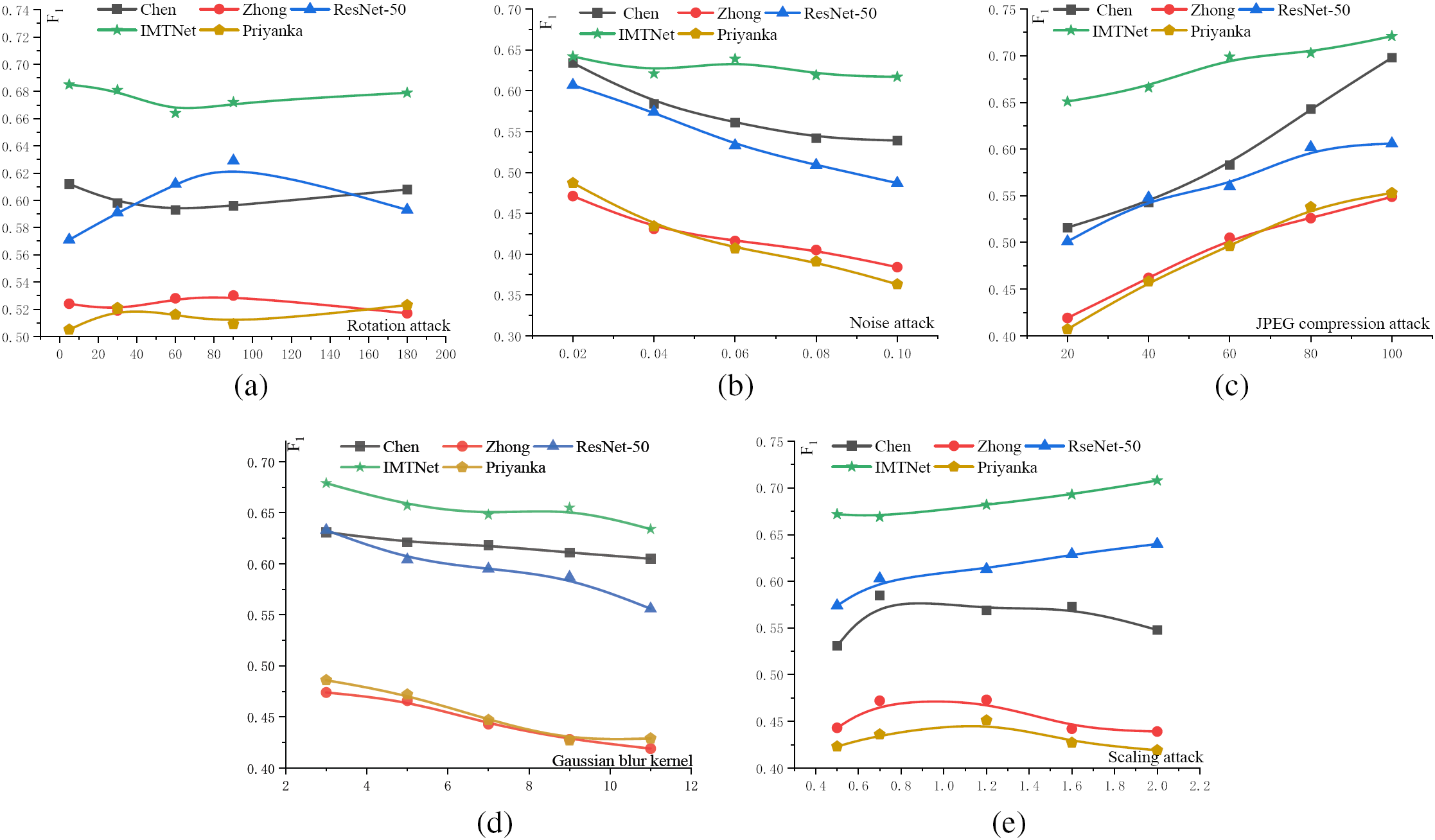
Figure 8: Resistance to attack performance. (a) Rotation attack. (b) Noise attack. (c) JPEG compression attack. (d) Blur attack. (e) Scaling attack
To test the performance of IMTNet, MICC-F2000, MICC-F600 and COVERAGE datasets are used to conduct generalization tests. Table 3 shows the value of
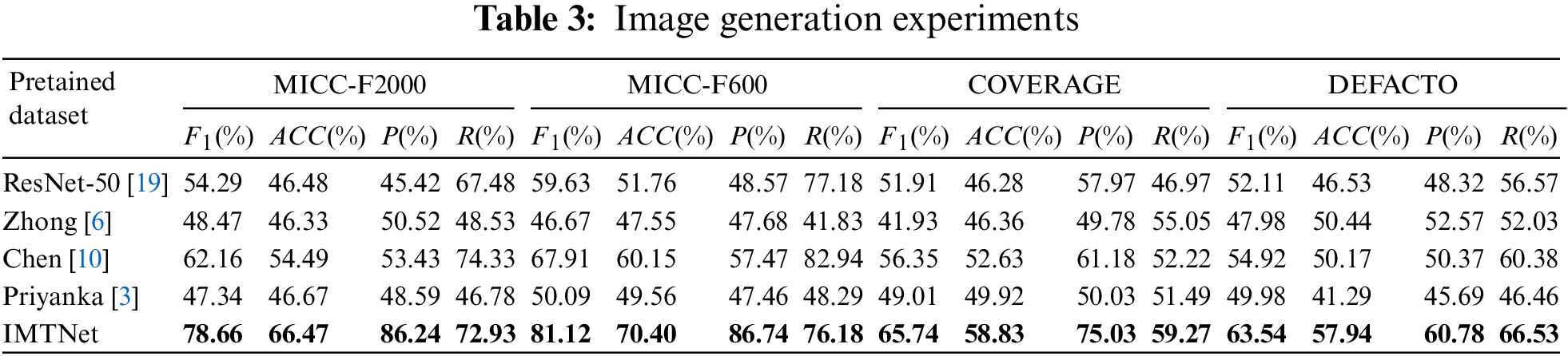
The algorithm in [19] introduces a classification task based on ResNet-50, the first row in Table 3 is the result of CMFD task by training directly on ResNet-50, it can be seen that applying the classification task model directly to the CMFD task does not work well. However, the accuracy and

Figure 9: The CMFD results of IMTNet. a(1)~e(1) The forgery images. a(2)~e(2) Corresponding detection results
In the proposed scheme, the relationship between ResNet-50 and CMFD is thoroughly demonstrated through quantitative experiments. IMTNet is proposed by leveraging the image classification feature domains and reducing the deep architecture of ResNet-50. Firstly, the relationship between CMFD and deep network architecture is formulated as an optimization problem. In the CMFD task, IMTNet exhibits outstanding performance compared to ResNet-50 and other CMFD algorithms by reducing the deep structure of ResNet-50 and utilizing the feature decoupling method. Secondly, experiments demonstrate that the IMTNet reduced the number of ResNet-50 parameters while enhancing the generalization capability of the model. Furthermore, the integration of MFPN improved the capability of the proposed method in detecting suspicious areas in tampered images.
Acknowledgement: None.
Funding Statement: This work was supported and founded by the Guizhou Provincial Science and Technology Project under the Grant No. QKH-Basic-ZK[2021]YB311, the Youth Science and Technology Talent Growth Project of Guizhou Provincial Education Department under Grant No. QJH-KY-ZK[2021]132, the Guizhou Provincial Science and Technology Project under the Grant No. QKH-Basic-ZK[2021]YB319, the National Natural Science Foundation of China (NSFC) under Grant 61902085, and the Key Laboratory Program of Blockchain and Fintech of Department of Education of Guizhou Province (2023-014).
Author Contributions: The authors confirm contribution to the paper as follows: study conception and design: Huan Wang, Zhongyuan Jiang; data collection: Huan Wang, Qing Qian and Yong Long; analysis and interpretation of results: Huan Wang, Zhongyuan Jiang and Qing Qian; draft manuscript preparation: Huan Wang, Zhongyuan Jiang and Yong Long. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data that support the findings of this study are available from the corresponding author, jiangzydj@163.com, upon reasonable request.
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. J. Fridrich, B. D. Soukal, and A. J. Lukas, “Detection of copy-move forgery in digital images,” in Proc. Digit. Forensic Res. Workshop, Cleveland, OH, USA, 2003, pp. 19–23. [Google Scholar]
2. Y. P. Huang, L. Wei, S. Wei, and D. Long, “Improved DCT-based detection of copy-move forgery in images,” Forensic Sci. Int., vol. 206, no. 3, pp. 178–184, 2011. doi: 10.1016/j.forsciint.2010.08.001. [Google Scholar] [PubMed] [CrossRef]
3. Priyanka, G. Singh, K. Singh, “An improved block based copy-move forgery detection technique,” Multimed. Tools Appl., vol. 79, no. 19, pp. 13011–13035, 2020. doi: 10.1007/s11042-019-08354-x. [Google Scholar] [CrossRef]
4. A. Akram, J. Rashid, A. Jaffar, F. Hajjej, W. Iqbal and N. Sarwar, “Weber law based approach for multi-class image forgery detection,” Comput. Mater. Contin., vol. 78, pp. 145–166, 2024. doi: 10.32604/cmc.2023.041074. [Google Scholar] [CrossRef]
5. I. Amerini, L. Ballan, R. Caldelli, A. BDel Bimbo, and G. Serra, “A SIFT-based forensic method for copy-move attack detection and transformation recovery,” IEEE Trans. Inf. Forensics Secur., vol. 6, no. 3, pp. 1099–1110, 2011. doi: 10.1109/TIFS.2011.2129512. [Google Scholar] [CrossRef]
6. Y. Gan, J. Zhong, and C. Vong, “A novel copy-move forgery detection algorithm via feature label matching and hierarchical segmentation filtering,” Inf. Process. Manage., vol. 59, no. 1, pp. 167–178, 2022. doi: 10.1016/j.ipm.2021.102783. [Google Scholar] [CrossRef]
7. J. L. Zhong, J. X. Yang, H. Zeng, and Y. Q. Zhao, “A novel image copy-move forgery detection algorithm using the characteristics of local descriptors,” Int. J. Pattern Recognit. Artif. Intell., vol. 36, no. 15, pp. 1–16, 2022. doi: 10.1142/S0218001422540192. [Google Scholar] [CrossRef]
8. Y. Aydın, “Automated identification of copy-move forgery using Hessian and patch feature extraction techniques,” J. Forensic Sci., vol. 69, no. 1, pp. 131–138, 2024. doi: 10.1111/1556-4029.15415. [Google Scholar] [PubMed] [CrossRef]
9. W. Yue, W. Abd-Almageed, and P. Natarajan, “Busternet: Detecting copy-move image forgery with source/target localization,” in Proc. Eur. Conf. on Comput. Vis. (ECCV), Munich, Germany, 2018, pp. 170–186. doi: 10.1007/978-3-030-01231-1_11. [Google Scholar] [CrossRef]
10. B. Chen, W. Tan, G. Coatrieux, Y. Zheng, and A. Shafique, “A serial image copy-move forgery localization scheme with source/target distinguishment,” IEEE Trans. Multimedia, vol. 23, pp. 3506–3517, 2020. doi: 10.1109/TMM.2020.3026868. [Google Scholar] [CrossRef]
11. J. L. Zhong and C. M. Pun, “An end-to-end dense-inceptionnet for image copy-move forgery detection,” IEEE Trans. Inf. Forensics Secur., vol. 15, pp. 2134–2146, 2019. doi: 10.1109/TIFS.2019.2957693. [Google Scholar] [CrossRef]
12. X. Hu, Z. Zhang, Z. Jiang, S. Chaudhuri, Z. Yang and R. Nevatia, “SPAN: Spatial pyramid attention network for image manipulation localization,” 2020, arXiv:2009.00726. [Google Scholar]
13. F. Z. Mehrjardi, A. M. Latif, and M. S. Zarchi, “Copy-move forgery detection and localization using deep learning,” Int. J. Pattern Recognit. Artif. Intell., vol. 37, no. 9, pp. 1–21, 2023. doi: 10.1142/S0218001423520122. [Google Scholar] [CrossRef]
14. K. K. Thyagharajan and G. Nirmala, “Image manipulation detection through laterally linked pixels and kernel algorithms,” Comput. Syst. Sci. Eng., vol. 41, no. 1, pp. 357–371, 2022. doi: 10.32604/csse.2022.020258. [Google Scholar] [CrossRef]
15. F. Z. Zhuang et al., “A comprehensive survey on transfer learning,” Proc. IEEE, vol. 109, no. 1, pp. 43–76, 2020. doi: 10.1109/JPROC.2020.3004555. [Google Scholar] [CrossRef]
16. S. Dong, P. Wang, and K. Abbas, “A survey on deep learning and its applications,” Comput. Sci. Rev., vol. 40, no. 5, 2021, Art. no. 100379. doi: 10.1016/j.cosrev.2021.100379. [Google Scholar] [CrossRef]
17. K. Li, L. Wang, L. Liu, Q. Ran, K. Xu, and Y. Guo, “Decoupling makes weakly supervised local feature better,” 2022, arXiv:2201.02861. [Google Scholar]
18. K. Li, J. Huang, H. Ren, W. Ran, and H. Lu, “Feature decoupling and reorganization network for single image deraining,” Multimed. Syst., vol. 30, 2024, Art. no. 154. doi: 10.1007/s00530-024-01348-2. [Google Scholar] [CrossRef]
19. K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proc. of the IEEE Conf. on Comput. Vis. Pattern Recognit., Las Vegas, NV, USA, 2016, pp. 770–778. doi: 10.1109/CVPR.2016.90. [Google Scholar] [CrossRef]
20. K. Wang, J. H. Liew, Y. Zou, D. Zhou, and J. Feng, “PANet: Few-shot image semantic segmentation with prototype alignment,” in Proc. IEEE/CVF Conf. on Comput. Vis. Pattern Recognit., COEX Convention Center, Seoul, Republic of Korea, 2019, pp. 9197–9206. doi: 10.1109/ICCV.2019.00929. [Google Scholar] [CrossRef]
21. K. Zhou, Y. X. Yang, Y. Qiao, and T. Xiang, “Domain adaptive ensemble learning,” IEEE Trans. Image Process., vol. 30, pp. 8008–8018, 2021. doi: 10.1109/TIP.2021.3112012. [Google Scholar] [PubMed] [CrossRef]
22. J. S. Beis and G. D. Lowe, “Shape indexing using approximate nearest-neighbor search in high-dimensional spaces,” in Proc. IEEE Comput. Soc. Conf. Comput. Vis. Pattern Recognit., San Juan, PR, USA, 1997, pp. 1000–1006. doi: 10.1109/CVPR.1997.609451. [Google Scholar] [CrossRef]
23. J. Yu et al., “Unleashing the power of multi-task learning: A comprehensive survey spanning traditional, deep, and pretrained foundation model Eras,” 2024, arXiv:2404.18961. [Google Scholar]
24. J. Dong, W. Wang, and T. N. Tan, “CASIA image tampering detection evaluation database,” in Proc. IEEE China Summit & Int. Conf. on Signal and Inf. Process., Beijing, China, 2013. doi: 10.1109/ChinaSIP.2013.6625374. [Google Scholar] [CrossRef]
25. D. Tralic, I. Zupancic, S. Grgic, and M. Grgic, “CoMoFoD-new database for copy-move forgery detection,” in Proc. Int. Symp. on Electron. in Mar. (ELMAR), Zadar, Croatia, 2013, pp. 49–54. [Google Scholar]
26. I. Amerini, L. Ballan, R. Caldelli, A. Del Bimbo, L. Del Tongo and G. Serra, “Copy-move forgery detection and localization by means of robust clustering with J-Linkage,” Signal Process.: Image Commun., vol. 28, no. 6, pp. 659–669, 2013. doi: 10.1016/j.image.2013.03.006. [Google Scholar] [CrossRef]
27. B. Wen, Z. Ye, R. Subramanian, T. T. Ng, X. Shen and S. Winkler, “COVERAGE—A novel database for copy-move forgery detection,” in Proc. Int. Conf. on Inf. Photonics(ICIP), Phoenix, AZ, USA, 2016. doi: 10.1109/ICIP.2016.7532339. [Google Scholar] [CrossRef]
28. G. Mahfoudi, B. Tajini, F. Retraint, F. Morain-Nicolier, J. Dugelay and M. Pic, “DEFACTO: Image and face manipulation dataset,” in Proc. 27Th Eur. Sig. Process. Conf. (EUSIPCO), Coruna, Spain, 2019, pp. 1–5. doi: 10.23919/EUSIPCO.2019.8903181. [Google Scholar] [CrossRef]
29. E. Ardizzone, A. Bruno, and G. Mazzola, “Copy-move forgery detection by matching triangles of keypoints,” IEEE Trans. Inf. Forensics Secur., vol. 10, no. 10, pp. 2084– 2094, 2021. doi: 10.1109/TIFS.2015.2445742. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools