
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE
Improving Diversity with Multi-Loss Adversarial Training in Personalized News Recommendation
1 School of Computer and Cyber Sciences, Communication University of China, Beijing, 100024, China
2 State Key Laboratory of Media Convergence and Communication, Communication University of China, Beijing, 100024, China
* Corresponding Author: Shuang Feng. Email:
Computers, Materials & Continua 2024, 80(2), 3107-3122. https://doi.org/10.32604/cmc.2024.052600
Received 08 April 2024; Accepted 18 July 2024; Issue published 15 August 2024
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Users’ interests are often diverse and multi-grained, with their underlying intents even more so. Effectively capturing users’ interests and uncovering the relationships between diverse interests are key to news recommendation. Meanwhile, diversity is an important metric for evaluating news recommendation algorithms, as users tend to reject excessive homogeneous information in their recommendation lists. However, recommendation models themselves lack diversity awareness, making it challenging to achieve a good balance between the accuracy and diversity of news recommendations. In this paper, we propose a news recommendation algorithm that achieves good performance in both accuracy and diversity. Unlike most existing works that solely optimize accuracy or employ more features to meet diversity, the proposed algorithm leverages the diversity-aware capability of the model. First, we introduce an augmented user model to fully capture user intent and the behavioral guidance they might undergo as a result. Specifically, we focus on the relationship between the original clicked news and the augmented clicked news. Moreover, we propose an effective adversarial training method for diversity (AT4D), which is a pluggable component that can enhance both the accuracy and diversity of news recommendation results. Extensive experiments on real-world datasets confirm the efficacy of the proposed algorithm in improving both the accuracy and diversity of news recommendations.Keywords
In recent years, significant advancements have been made in content recommendation technologies used by online news platforms such as Microsoft News and applications like “Toutiao”. These developments have substantially enhanced the browsing experience for readers and attracted a large user base to digital news content [1,2]. Despite these advancements, the overwhelming volume of daily news articles presents a significant challenge for users trying to find content that matches their interests [3]. Excessive information can dilute user attention. The filtering and distribution mechanisms of news recommendation (NR) systems can alleviate information overload, helping users navigate through the vast array of articles to discover those most relevant to their interests [4].
Most existing news recommendation methods prioritize accuracy as their primary optimization goal [5]. They rank candidate news by computing the similarity between user interests and candidate news to generate the final recommendation list [6–9]. For example, Okura et al. [6] use gate recurrent unit (GRU) networks to learn user representations from historical news browsed by users and denoising autoencoders to learn news representations. Wu et al. [7] apply multi-head self-attention networks to learn user and news representations, ranking candidate news based on their correlation. An et al. [8] utilize user ID embeddings for long-term user representations and GRU networks for short-term user representations. Zhang et al. [9] employ the pre-trained model to improve news textual representations. However, these methods often neglect recommendation diversity in favor of optimizing recommendation accuracy, resulting in a failure to comprehensively cover different user interests. Additionally, the lack of diversity awareness in news recommendation models can lead to low levels of recommendation diversity. Therefore, enhancing recommendation diversity is crucial to improving user experience and engagement [10]. Users are dissatisfied with the homogeneous news presented in the recommendation list. Accuracy-based news recommendation algorithms are prone to inducing individuals into filter bubbles [11] and echo chambers [12].
In this paper, we propose a news recommendation algorithm that can effectively improve both news recommendation diversity and accuracy. First, we introduce an augmented user model that focuses on user intent. It infers potential behavioral guidance rather than merely considering the relevance between user-clicked news and candidate news. Specifically, we apply data augmentation techniques on user-clicked news. Then, we incorporate both original and augmented instances within different attention heads to capture user intent, infer potential behavioral guidance, and learn diverse representations for users with similar interests. Furthermore, we introduce an effective adversarial training method for diversity (AT4D) to incentivize the model to avoid selecting homogeneous news information. AT4D is a pluggable component that can enhance both accuracy and diversity in news recommendations. Extensive experiments on real-world news recommendation datasets show that the proposed algorithm outperforms baseline methods in accuracy and diversity, as evidenced by metrics including AUC, MRR, nDCG@5, nDCG@10, and ILAD@10 values.
The contributions of this paper are as follows:
• We propose an augmented user model to capture user intent and potential behavioral guidance comprehensively.
• We introduce an effective adversarial training method for diversity (AT4D), a pluggable component that enhances both accuracy and diversity in news recommendations.
• Extensive experiments conducted on real-world news recommendation datasets demonstrate that the proposed algorithm achieves better performance in terms of both accuracy and diversity of recommendation compared to seven baseline methods.
Numerous scholars have researched news recommendations in detail. A core task of news recommendation is to compute the relevance between candidate news and user interests to generate a recommendation list. For instance, Okura et al. [6] use GRU networks to learn user representations from historical news browsed by users and denoising autoencoders to learn news representations. Wu et al. [7] apply multi-head self-attention networks to learn user and news representations, ranking candidate news based on their representations. An et al. [8] learn long-term user representations using user ID embeddings and short-term user representations through GRU networks. Wang et al. [13] propose a fine-grained interest-matching method that models the correlation between candidate news and clicked news to compute ranking scores. Wang et al. [14] introduce knowledge graphs into news recommendation, integrating semantic and knowledge-level representations of news. The effectiveness of using knowledge is demonstrated through a content-based deep recommendation framework for click-through rate prediction. These news recommendation methods primarily focus on matching users’ personalized interests by optimizing recommendation accuracy, often neglecting recommendation diversity. However, a lack of recommendation diversity can negatively impact users’ long-term experience and engagement. Some news recommendation methods explicitly consider recommendation diversity. For example, Qi et al. [11] employ a hierarchical user interest matching framework that matches candidate news with user interests at various levels to enhance the modeling capability of personalized news recommendation. Gharahighehi et al. [15] use a neighborhood-based session recommendation system in anonymous sessions to improve the diversity issue in news recommendation, which demonstrates effective diversity improvements across four datasets. Qi et al. [16] merge news popularity information to address the cold start and diversity problems in tailored news recommendation. These works aim to improve the diversity of recommendation results by more comprehensively mining users’ historical interaction information and addressing diverse user interests. In contrast, our proposed algorithm incorporates diversity awareness, thereby enhancing both the accuracy and diversity of news recommendations.
In this section, we introduce our proposed news recommendation algorithm, which aims to enhance both accuracy and diversity. We begin by elucidating the problem formulation addressed in this study. Then, we present the model architecture for the augmented user model and news model separately. Finally, we describe our pluggable component, AT4D. The structures of these components are illustrated in Fig. 1.
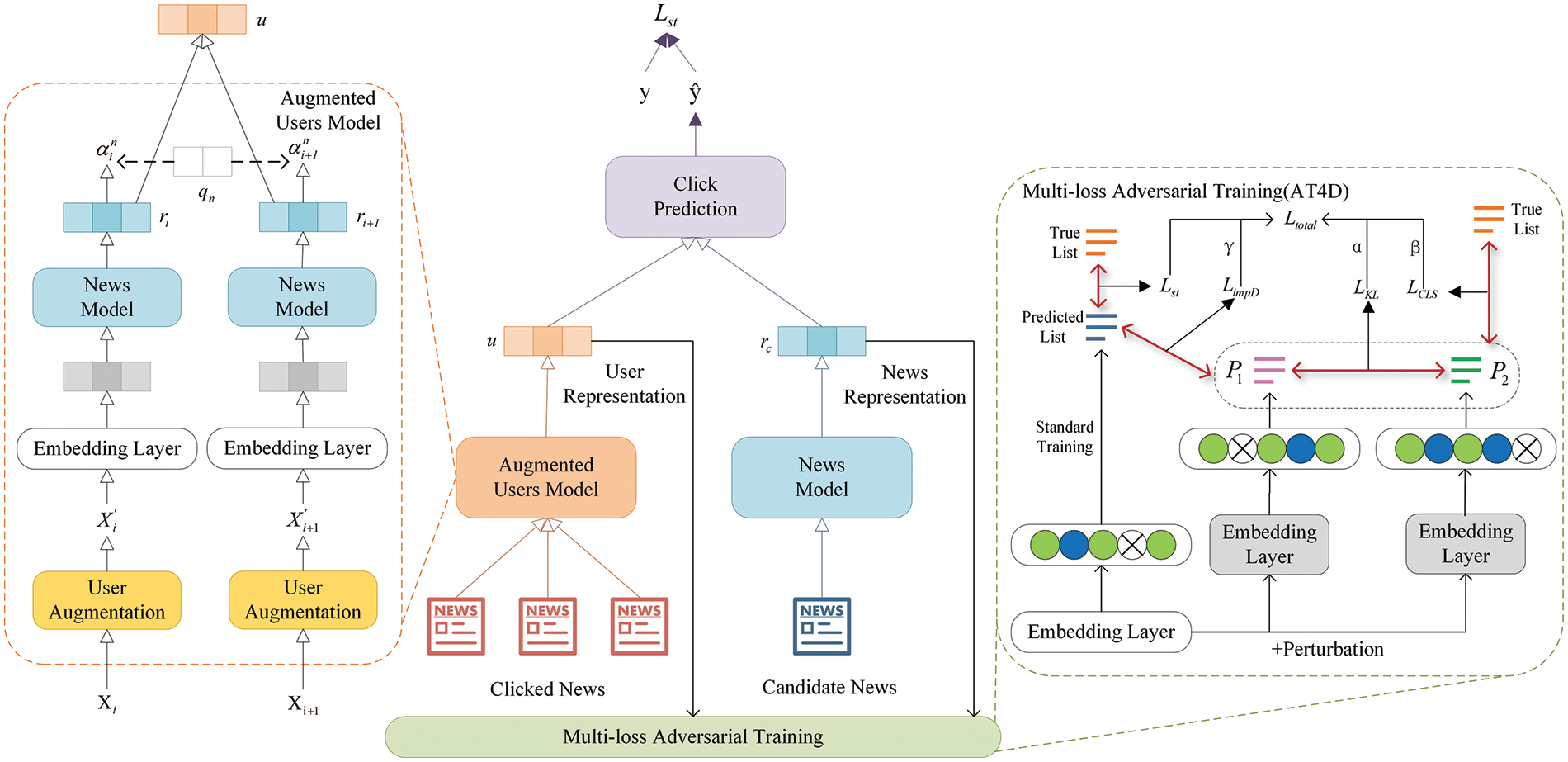
Figure 1: Architecture of the proposed algorithm
Given a user
The augmented user model of the proposed algorithm, as illustrated in Fig. 1, aims to extract user intent from both the original clicked news and the augmented clicked news, inferring potential behavioral guidance to enhance recommendation performance. Data augmentation is initially widely applied in the field of computer vision [17], typically involving random operations such as cropping and rotation to enhance data efficiency. Following this intuition, we apply data augmentation strategies to news text in the proposed algorithm. Firstly, we denote the original text as
where
where
where
The news model is used to learn representations of news across varying semantic scales from textual data. In the proposed algorithm, the news model is employed to learn representations of historical news including those users have clicked and news that users have not clicked, and candidate news from the recommended list. We utilize the news information in the dataset, including the title, abstract, category, and subcategory. Typically, the title provides a succinct summary of the news content, and the abstract delivers a concise overview of the event [19]. Categories and subcategories help readers quickly locate news and inform them about the news’s attributes. Given that news information varies in semantic scale and characteristic level, we propose a multi-level attention learning framework. It treats news information at distinct levels of granularity as separate features. Instead of simply concatenating these features into a single continuous text for representation, our approach aims to achieve a unified representation of news. The news model consists of three major components: text encoder, element encoder, and attention-based pooling layer.
The text encoder is employed to learn representations of news text. The text encoder consists of three layers. The first layer is the word embedding layer, which uses GloVe [20] to convert the text into low-dimensional word vectors. Note the word sequence of the text as
where
where
The second component of the news model is the element encoder, which is utilized to learn representations of news from the categories and subcategories. Many users, when using online news services, first select a category such as “politics” before engaging in extended reading sessions. Clearly, the categories and subcategories are crucial for modeling news. They enable us to obtain the information conveyed by the news more accurately. Therefore, we simultaneously consider category and subcategory information in learning news representations. The input of the element encoder comprises the category ID denoted as
where
The third component of the news model is the attention-based pooling layer. Different types of news texts contain varying levels of semantic information, leading to differences in the quality of learned news representations. Some news texts are ambiguous and brief, which is detrimental to learning news representations. On the other hand, some news texts have clear perspectives and detailed content. In these cases, there are many news expressing different attitudes towards the same event. We aim to take note of these aspects in the implementation of news recommendation algorithms to prevent users from being confined within information bubbles. Therefore, words with explicit attitudes when representing the news carry high weight. For short and ambiguous news, categories are weighted more heavily than the text in representing such news. Inspired by these observations, we use an attention-based pooling layer to capture semantic information of news with varying qualities. The attention weights for the title, abstract, category, and subcategory are denoted as
where
The unified news representation learned by the news model is obtained as in Eq. (15).
In this section, we explain how to calculate click prediction scores for candidate news to obtain the recommended list. The click predictor is utilized to forecast the probability of users clicking on candidate news. The representation of candidate news is denoted as
3.5 Multi-Loss Adversarial Training
In this section, we introduce our pluggable component, AT4D. During the training process, most news recommendation methods are for accuracy [5]. An enormous amount of news is generated worldwide every day, containing rich semantics. However, it is undeniable that a considerable amount of homogeneous information is also produced, which is common in news recommendation. Inspired by Wu et al. [22], we recognize that adversarial training can enhance the precision and fairness of news recommendation, yet its capability to improve both accuracy and diversity remains unexplored. To address this issue, we propose multi-loss adversarial training, which effectively facilitates learning on hard samples. Adversarial training is a training technique that enhances model robustness by incorporating adversarial samples during the training process. It mitigates the effect of redundant information from past user click activities on the model’s performance and improves the model’s generalization capacity. Additionally, we aim to prevent a decrease in model accuracy due to inconsistencies between the training and testing phases. We adopt a variant of the regularization training method R-AT proposed by Ni et al. [23]. Specifically, through the perturbation method of FreeLB [24], we dynamically perturb the input news embedding vectors in multiple steps and minimize adversarial risks in different regions around input samples. The output samples are passed through two sub-modules of dropout, where neural units are randomly discarded to generate two adversarial samples with other distributions. Next, by lowering the bidirectional Kullback-Leibler (KL) divergence between two distinct output probability distributions, we regularize the model prediction, which is denoted as
where
where
where
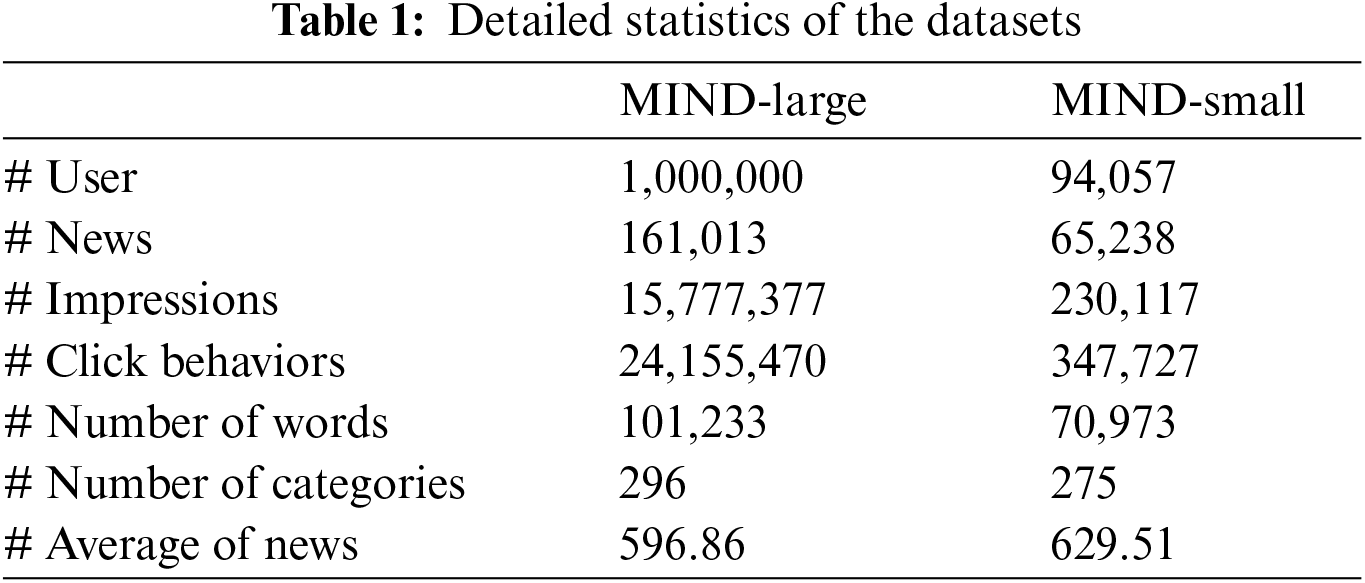
We conduct experiments on the real-world news recommendation dataset MIND [1], which was collected from MSN News logs. The MIND dataset is available in two versions: MIND-large and MIND-small. MIND-large is constructed from Microsoft News user behavior data spanning six weeks, from 12 October 2019, to 22 November 2019. The user data from the first four weeks is utilized for building user reading histories, data from the second-to-last week is used for model training, and data from the final week is reserved for evaluation. A uniformly random sample of MIND-large’s daily behavioral records was used to create MIND-small, a scaled-down version of MIND-large. Detailed statistics of the dataset are presented in Table 1.
We tune parameters in our work on the MIND-small dataset, followed by training and evaluation on both MIND-large and MIND-small datasets. We initialize the word embedding using pre-trained 300-dimensional GloVe [20]. For consistency with other baselines and training efficiency, we treated each news article clicked by the user as a positive sample and randomly selected four articles from the recommendation list that were not clicked as negative samples. In the multi-loss adversarial training, hyperparameters
We employ seven comparative models as baseline models for this task, including:
• NAML [7], using attention networks and CNN to obtain news and user modeling;
• LSTUR [8], utilizing user ID embeddings to model long-term user interests and GRU networks to model short-term user interests;
• UNBERT [9], using the pre-trained model BERT to get multi-grained user-news interactions at news-level and word-level;
• DKN [14], using knowledge-aware convolutional neural networks for news modeling and candidate-aware attention for user modeling;
• TANR [27], a neural news recommendation method with an auxiliary topic classification task to get topic-aware news representation;
• NRMS [28], employing multi-head self-attention mechanisms to learn user and news representations;
• MINS [29], embedding topics and textual features to encode news and using a parallel interest network to encode users.
In this section, we evaluate the performance of our proposed algorithm on the MIND-large and MIND-small datasets, focusing on both accuracy and diversity in news recommendation. Specifically, we pose the following four research questions to guide the experiments:
RQ1: Does our proposed algorithm effectively improve diversity while enhancing the accuracy of recommendation results?
RQ2: Is AT4D effective in our proposed algorithm?
RQ3: How does each module of our proposed algorithm effectively enhance its performance?
RQ4: Can the pluggable component AT4D boost the performance of other methods in terms of accuracy and diversity?
5.1 Performance Comparison (RQ1)
In the preceding chapters, we introduce the proposed news recommendation algorithm, two open-source news recommendation datasets, and four accuracy-based evaluation metrics, along with one diversity-based evaluation metric. To tackle RQ1, we carry out extensive experiments on the MIND-small and MIND-large datasets. We evaluated the performance of our method by comparing it with the baseline models. The average results and the variance of these methods on the two datasets are summarized in Tables 2 and 3, as well as Fig. 2. Considering the size of the page, we have shifted the decimal point of the result to the right by two places in Tables 2 and 3. Improv. refers to the improvement of the best performance over the next best performance.
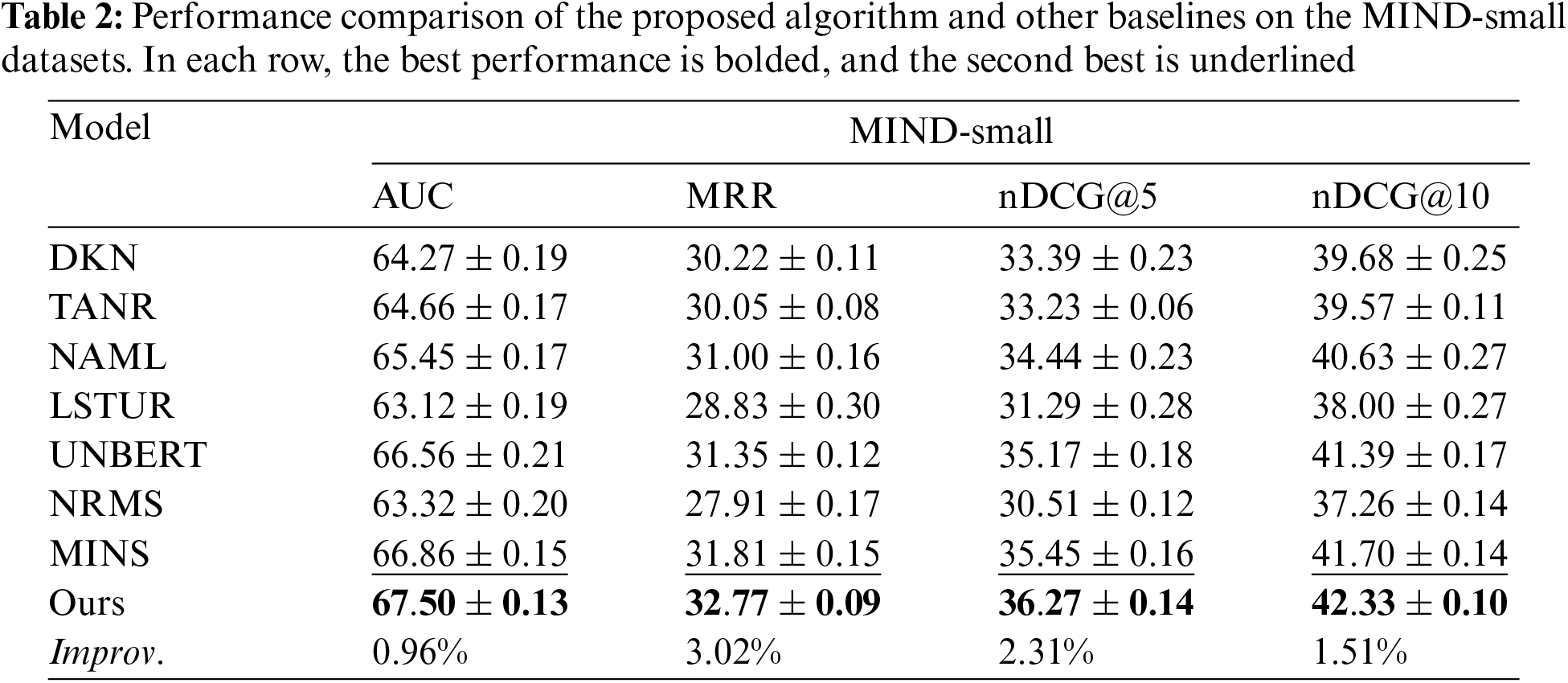
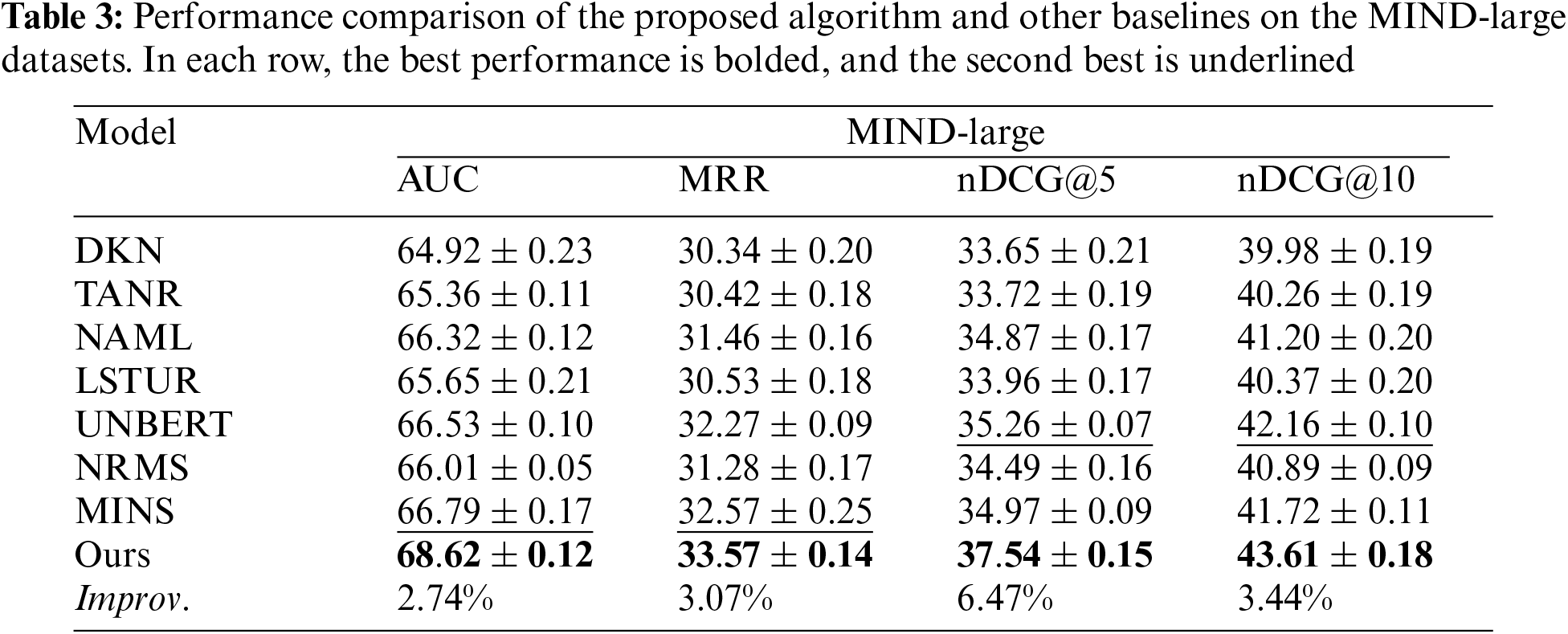
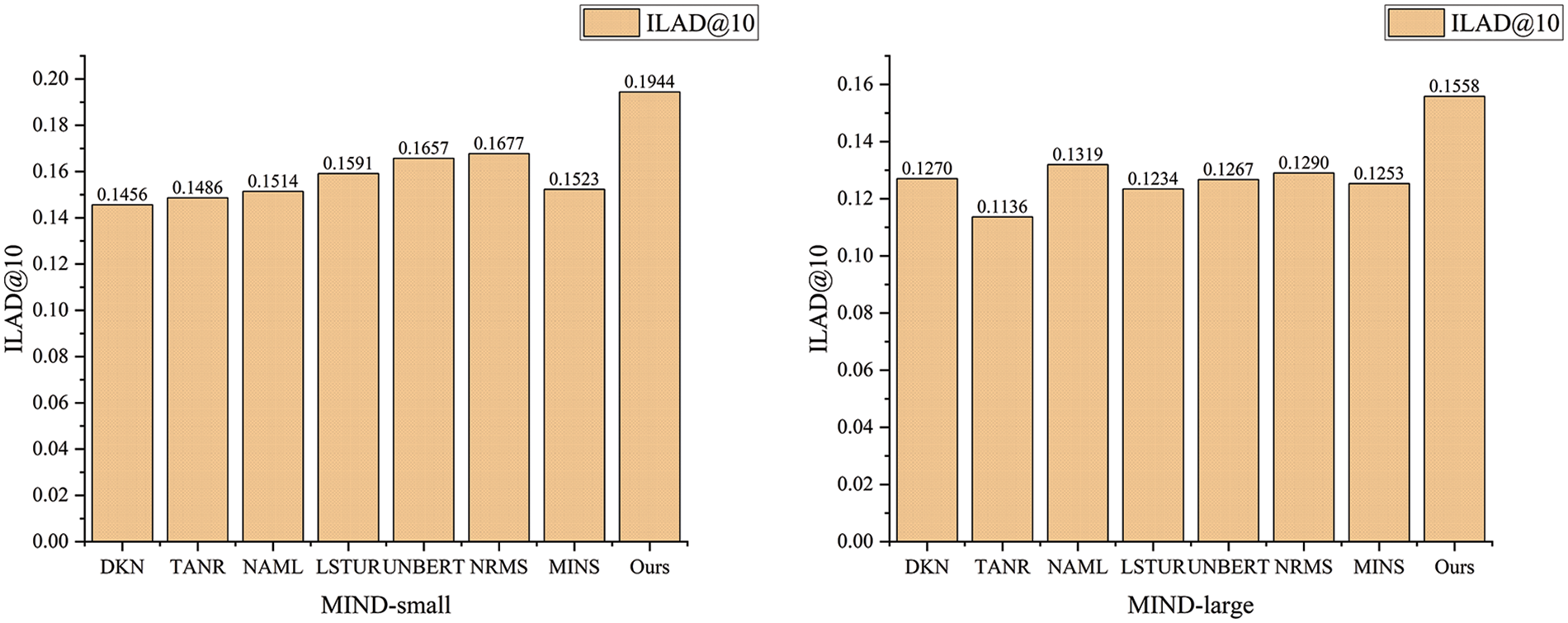
Figure 2: Performance of different methods on recommendation diversity on the MIND-small datasets and the MIND-large datasets, respectively
We obtain several observations from Tables 2 and 3. Firstly, on the publicly available datasets MIND-large and MIND-small, the proposed algorithm outperforms the current baseline models, DKN, TANR, NAML, LSTUR, UNBERT, NRMS, and MINS, in terms of four accuracy-based metrics. This indicates the effectiveness of the proposed algorithm. The proposed algorithm can improve the accuracy of user interest matching, so as to attract more users’ attention to the online news platforms.
Secondly, methods using attention mechanisms (TANR, NAML, LSTUR, UNBERT, NRMS, and MINS) for learning news representations outperform DKN. This is because attention mechanisms can model deep interactions between words, enabling more accurate learning of news representations by capturing the relative importance of these interactions. Particularly, in terms of accuracy-based metrics, MINS outperforms other attention-based methods on MIND-small datasets as it additionally considers the inter-news dependencies. UNBERT outperforms other attention-based methods on MIND-large datasets in terms of the nDCG@5 and nDCG@10, as it additionally leverages the pre-trained model to improve textual understanding.
From Fig. 2, it can be observed that when considering the diversity of recommendation results, previous accuracy-driven works often exhibit mediocre performance in diversity evaluation. This results in low diversity of the final candidate news. It is shown that the experimental results of the same method on the MIND-large dataset are consistently lower than those on the MIND-small dataset. Moreover, the baseline model shows no significant trend in terms of diversity performance on both datasets. The proposed algorithm shows significant improvements in diversity evaluation metrics ILAD@10 over the best-performing baseline models on the MIND-small and MIND-large datasets, with enhancements of 15.92% and 18.12%, respectively. The advancement indicates that the proposed algorithm not only enhances accuracy but also further improves diversity.
5.2 Effectiveness in Adversarial Training (RQ2)
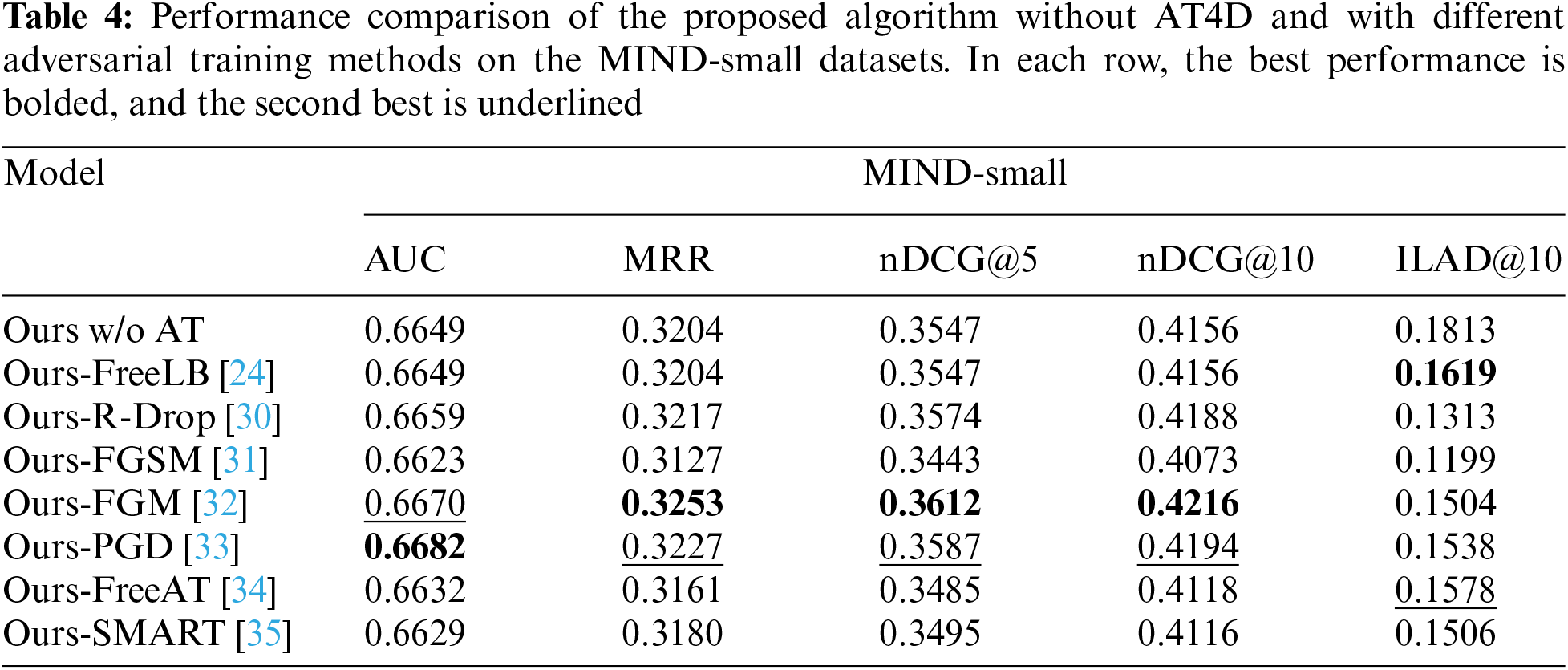
As mentioned in Section 3.5, a large amount of homogeneous news information can lead to insufficient or ambiguous semantic information, rendering news recommendation results unsatisfactory. Additionally, adversarial training proves effective for the news recommendation task, although its effectiveness in learning from hard samples is limited. In this section, we experiment with seven adversarial training methods to assess their positive impact on the news recommendation task.
We derive some observational results from Table 4. Using adversarial training strategies not only serves to prevent overfitting and effectively enhance the model’s generalization capability but also, to some extent, can improve the accuracy and diversity of news recommendation. From the experimental results in Table 4, it is evident that employing FGM and PGD adversarial training methods yields good recommendation performance under accuracy-based evaluation metrics. In contrast, the performance under diversity-based evaluation metrics is moderate. However, using the FreeLB adversarial training method does not significantly compromise recommendation performance under accuracy-based evaluation metrics while yielding optimal performance under diversity-based evaluation metrics. Furthermore, FreeAT performs less favorably than FreeLB in terms of diversity metrics for news recommendation tasks, and it does not outperform FGM and PGD in terms of accuracy metrics. Based on this promising preliminary experimentation, we propose AT4D, which adopts the perturbation manner of FreeLB. This choice is informed by AT4D’s aim to balance the accuracy and diversity of news recommendation results.
In this section, we conduct ablation studies to assess how each module of the proposed algorithm effectively enhances its performance. We validate the effectiveness of the augmented user representation and the AT4D by removing them from the proposed algorithm and evaluating their impact on news recommendation using the MIND-small dataset.
From Fig. 3, we find that the absence of any module can lead to a decrease in the performance of the model. The AT4D contributes the most to the model, primarily because it is a multi-loss adversarial training that can significantly improve both the accuracy and diversity of recommendation results. Following AT4D, the augmented user representation shows the next highest contribution. In summary, each module in the news recommendation process contributes significantly to the model’s performance.
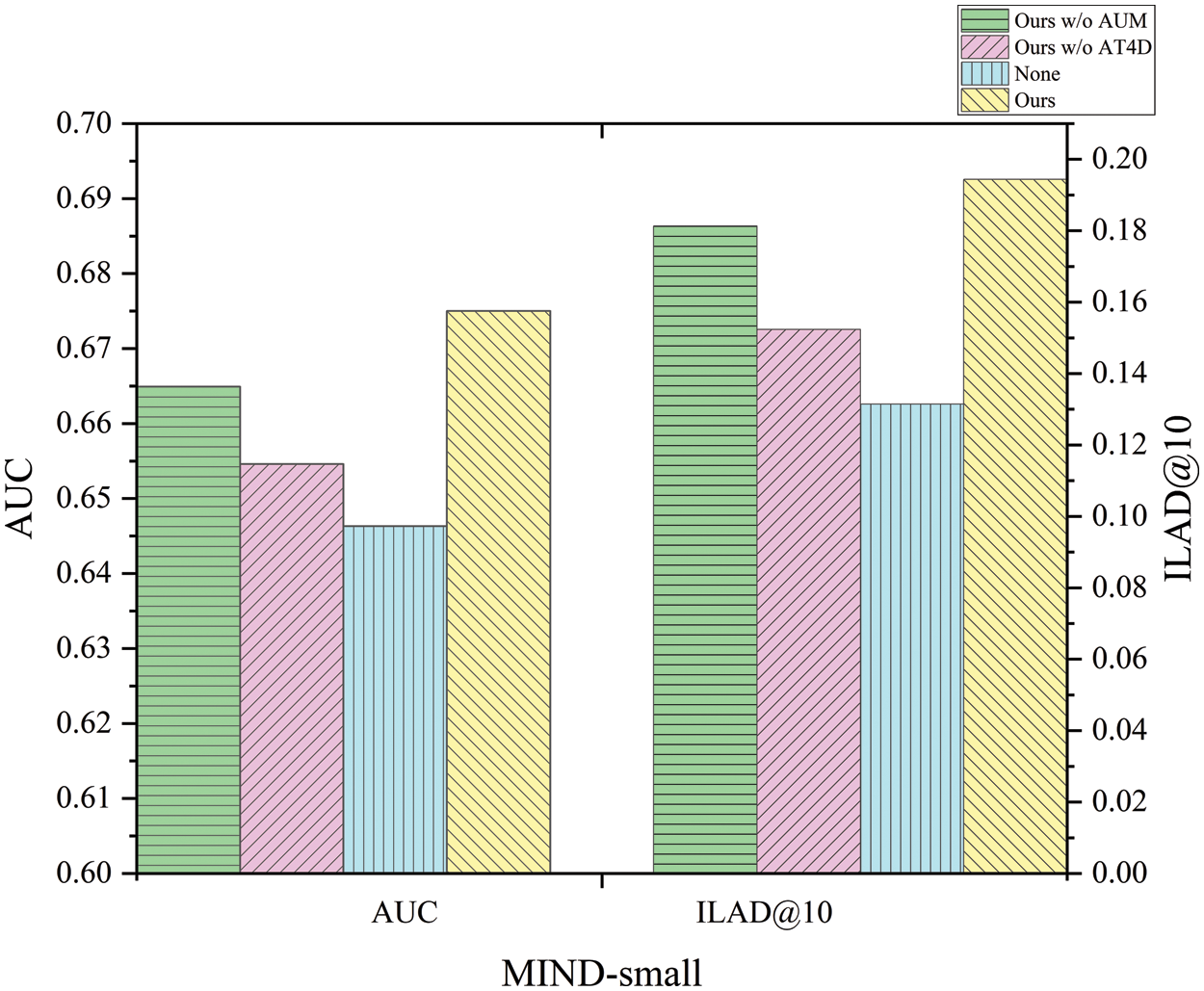
Figure 3: Effectiveness of several core model components on the NIND-small dataset
5.4 Compatibility with Other NR Models (RQ4)
As previously mentioned, AT4D is a pluggable component, allowing us to integrate it with existing news recommendation methods to enhance their performance. Therefore, to validate AT4D’s compatibility with other news recommendation methods, we apply it to several news recommendation models listed in Table 2, namely NAML, DKN, TANR, NRMS, LSTUR, and MINS. Besides adding AT4D, we do not modify their original training settings. We evaluate their accuracy and diversity on the MIND-small dataset. The results of their performance in terms of recommendation are summarized in Table 5 and Fig. 4. Green font indicates an increase in results, while red font indicates a decrease.
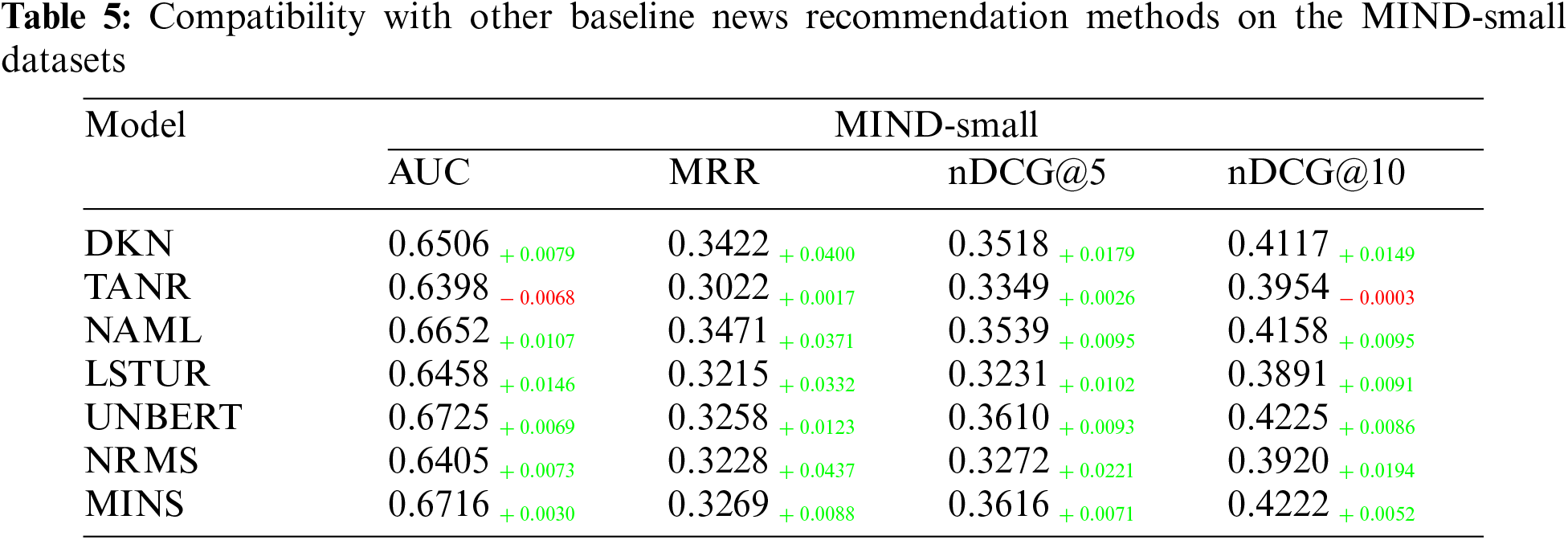
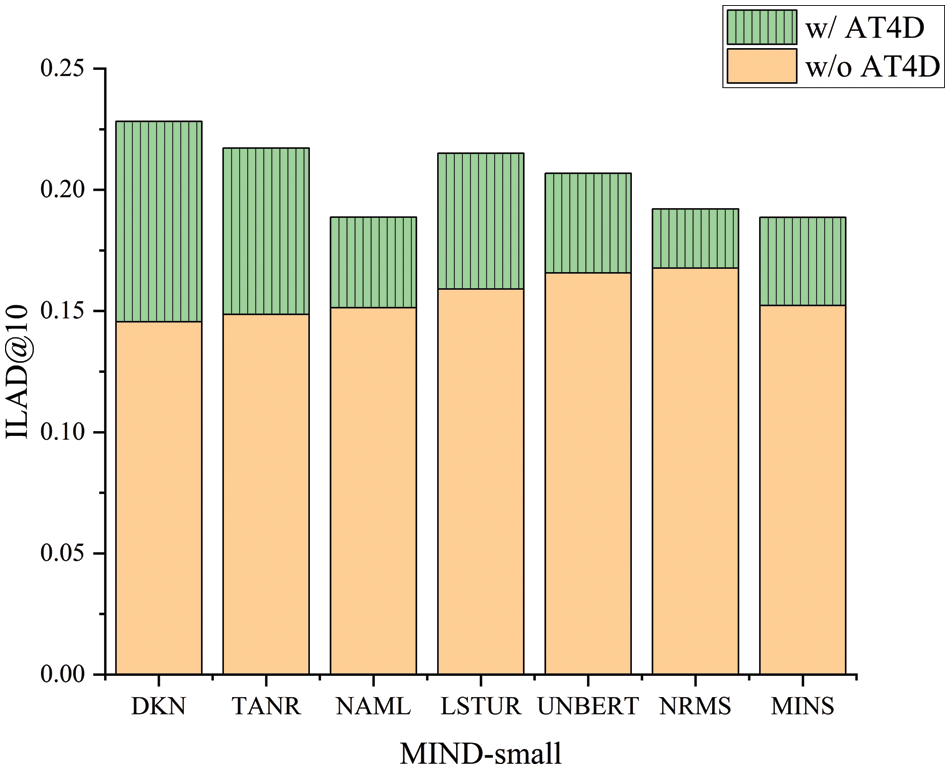
Figure 4: Effectiveness of AT4D under ILAD@10 metric on the MIND-small dataset
We find that our AT4D consistently and effectively improves the accuracy of existing news recommendation models, except for the TANR model. We think TANR first learns important words as topics, which can bring some inevitable errors. Since AT4D acts directly on the model, this error is magnified. Additionally, AT4D efficiently enhances the diversity of these methods, significantly increasing the diversity level of previously accuracy-based recommendation approaches without sacrificing much accuracy. The AT4D performs best in improving diversity for the DKN method, which may be attributed to the additional incorporation of entity information in DKN, enabling AT4D to implement across multiple semantic dimensions effectively.
In this paper, we propose a news recommendation algorithm that achieves high performance in both accuracy and diversity. Unlike most existing approaches that solely optimize accuracy or incorporate more features into the model to enhance diversity, our proposed algorithm attains high performance in both accuracy and diversity through the model’s capacity. In the proposed algorithm, we introduce an augmented user model to fully capture user intent and the consequent behavior guidance. Additionally, we propose an effective multi-loss adversarial training method for diversity (AT4D), a pluggable component that improves both the accuracy and diversity of news recommendation results.
However, our proposed algorithm has certain limitations. Due to constraints within the dataset, we only have access to limited news and user information. In future work, we aim to explore the integration of semantic understanding and text generation capabilities powered by large language models to expand datasets and enhance the performance of our news recommendation algorithm.
Acknowledgement: The authors extend their appreciation to the anonymous reviewers for their constructive comments.
Funding Statement: This research was funded by Beijing Municipal Social Science Foundation (23YTB031) and the Fundamental Research Funds for the Central Universities (CUC23ZDTJ005).
Author Contributions: The authors confirm contribution to the paper as follows: study conception and design: Shuang Feng, Ruijin Xue; data collection: Ruijin Xue; analysis and interpretation of results: Ruijin Xue; draft manuscript preparation: Ruijin Xue, Shuang Feng, Qi Wang. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The data that support the findings of this study are openly available at https://msnews.github.io/ (accessed on 18 May 2024).
Ethics Approval: Not applicable.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. F. Wu et al., “MIND: A largescale dataset for news recommendation,” in Proc. 58th Annu. Meet. Assoc. Comput. Linguist., Jul. 2020, pp. 3597–3606. [Google Scholar]
2. K. Yang, S. Long, W. Zhang, J. Yao, and J. Liu, “Personalized news recommendation based on the text and image integration,” Comput. Mater. Contin., vol. 64, no. 1, pp. 557–570, 2020. doi: 10.32604/cmc.2020.09907. [Google Scholar] [CrossRef]
3. S. Raza and C. Ding, “News recommender system: A review of recent progress, challenges, and opportunities,” Artif. Intell. Review., vol. 55, no. 1, pp. 749–800, Jan. 2022. doi: 10.1007/s10462-021-10043-x. [Google Scholar] [PubMed] [CrossRef]
4. C. Wu, F. Wu, M. An, J. Huang, Y. Huang and X. Xie, “NPA: Neural news recommendation with personalized attention,” in Proc. 25th ACM SIGKDD Int. Conf. Knowl. Discov. & Data Mining, Anchorage, AK, USA, Jul. 2019, pp. 2576–2584. [Google Scholar]
5. C. Wu, F. Wu, T. Qi, and Y. Huang, “End-to-end learnable diversity-aware news recommendation,” arXiv:2204.00539, 2022. doi: 10.48550/arXiv.2204.00539. [Google Scholar] [CrossRef]
6. S. Okura, Y. Tagami, S. Ono, and A. Tajima, “Embedding-based news recommendation for millions of users,” in Proc. 23rd ACM SIGKDD Int. Conf. Knowl. Discov. & Data Mining, Halifax, NS, Canada, 2017, pp. 1933–1942. [Google Scholar]
7. C. Wu, F. Wu, M. An, J. Huang, Y. Huang and X. Xie, “Neural news recommendation with attentive multi-view learning,” in Proc. Twenty-Eighth Int. Joint Conf. on Artif. Intell., Macao, China, 2019, pp. 3863–3869. [Google Scholar]
8. M. An, F. Wu, C. Wu, K. Zhang, Z. Liu and X. Xie, “Neural news recommendation with long-and short-term user representations,” in Proc. 57th Annu. Meet. Assoc. Comput. Linguist., Florence, Italy, Jul. 2019, pp. 336–345. [Google Scholar]
9. Q. Zhang et al., “UNBERT: User-news matching BERT for news recommendation,” in Proc. Thirtieth Int. Joint Conf. Artif. Intell., Montreal, QC, Canada, 2021, pp. 3356–3362. [Google Scholar]
10. C. Wu, F. Wu, Y. Huang, and X. Xie, “Personalized news recommendation: Methods and challenges,” ACM Trans. Inf. Syst., vol. 41, no. 1, pp. 1–50, Jan. 2023. doi: 10.1145/3530257. [Google Scholar] [CrossRef]
11. T. Qi et al., “HieRec: Hierarchical user interest modeling for personalized news recommendation,” in Proc. 59th Annu. Meet. Assoc. Comput. Linguist. 11th Int. Joint Conf. Nat. Lang. Process., 2021, pp. 5446–5456. [Google Scholar]
12. K. Shivaram, P. Liu, M. Shapiro, M. Bilgic, and A. Culotta, “Reducing cross-topic political homogenization in content-based news recommendation,” in Proc. 16th ACM Conf. Recommender Syst., New York, NY, USA, 2022, pp. 220–228. [Google Scholar]
13. H. Wang, F. Wu, Z. Liu, and X. Xie, “Fine-grained interest matching for neural news recommendation,” in Proc. 58th Annu. Meet. Assoc. Comput. Linguist., Jul. 2020, pp. 836–845. [Google Scholar]
14. H. Wang, F. Zhang, X. Xie, and M. Guo, “DKN: Deep knowledge-aware network for news recommendation,” in Proc. 2018 World Wide Web Conf., Lyon, France, 2018, pp. 1835–1844. [Google Scholar]
15. A. Gharahighehi and C. Vens, “Diversification in session-based news recommender systems,” Pers. Ubiquitous Comput., vol. 27, no. 1, pp. 5–15, 2023. doi: 10.1007/s00779-021-01606-4. [Google Scholar] [CrossRef]
16. T. Qi, F. Z. Wu, C. H. Wu, and Y. F. Huang, “PP-Rec: News recommendation with personalized user interest and time-aware news popularity,” in Proc. 59th Annu. Meet. Assoc. Comput. Linguist., 2021, pp. 5457–5467. [Google Scholar]
17. L. Zhang, P. Liu, and J. A. Gulla, “A deep joint network for sessionbased news recommendations with contextual augmentation,” in Proc. 29th Hypertext Soc. Media, Baltimore, MD, USA, 2018, pp. 201–209. [Google Scholar]
18. J. Wei and K. Zou, “EDA: Easy data augmentation techniques for boosting performance on text classification tasks,” in Proc. 2019 Conf. Empir. Methods Nat. Lang. Process. 9th Int. Joint Conf. Nat. Lang. Process., Hong Kong, China, 2019, pp. 6383–6389. [Google Scholar]
19. W. Fan, Y. Wang, and H. Hu, “Mimicking human verification behavior for news media credibility evaluation,” Appl. Sci., vol. 13, no. 17, pp. 9553, 2023. doi: 10.3390/app13179553. [Google Scholar] [CrossRef]
20. J. Pennington, R. Socher, and C. Manning, “GloVe: Global vectors for word representation,” in Proc. 2014 Conf. Empir. Methods Nat. Lang. Process., Doha, Qatar, 2014, pp. 1532–1543. [Google Scholar]
21. X. Glorot, A. Bordes, and Y. Bengio, “Deep sparse rectifier neural networks,” in Proc. Fourteenth Int. Conf. Artif. Intell. Stat., Fort Lauderdale, FL, USA, 2011, pp. 315–323. [Google Scholar]
22. C. Wu, F. Wu, X. Wang, Y. Huang, and X. Xie, “Fairness-aware news recommendation with decomposed adversarial learning,” in Proc. AAAI Conf. Artif. Intell., 2021, vol. 35, no. 5, pp. 4462–4469. doi: 10.1609/aaai.v35i5.16573. [Google Scholar] [CrossRef]
23. S. Ni, J. Li, and H. Kao, “R-AT: Regularized adversarial training for natural language understanding,” in Findings Assoc. Comput. Linguist.: EMNLP 2022; Assoc. Comput. Linguist., Abu Dhabi, United Arab Emirates, 2022, pp. 6427–6440. [Google Scholar]
24. C. Zhu, Y. Cheng, Z. Gan, S. Sun, T. Goldstein and J. Liu, “FreeLB: Enhanced adversarial training for natural language understanding,” 2019. doi: 10.48550/arXiv.1909.11764. [Google Scholar] [CrossRef]
25. D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” 2014. doi: 10.48550/arXiv.1412.6980. [Google Scholar] [CrossRef]
26. T. Qi et al., “ProFairRec: Provider fairness-aware news recommendation,” in Proc. 45th Int. ACM SIGIR Conf. Res Dev. Inf. Retr., Madrid, Spain, 2022, pp. 1164–1173. [Google Scholar]
27. C. Wu, F. Wu, M. An, Y. Huang, and X. Xie, “Neural news recommendation with topic-aware news representation,” in Proc. 57th Annu. Meet. Assoc. Comput. Linguist., Florence, Italy, 2019, pp. 1154–1159. [Google Scholar]
28. C. Wu, F. Wu, S. Ge, T. Qi, Y. Huang and X. Xie, “Neural news recommendation with multi-head self-attention,” in Proc. 2019 Conf. Empir. Methods Nat. Lang. Process. 9th Int. Joint Conf. Nat. Lang. Process., Hong Kong, China, 2019, pp. 6389–6394. [Google Scholar]
29. R. Wang, S. Wang, W. Lu, and X. Peng, “News recommendation via multi-interest news sequence modelling,” in ICASSP 2022-2022 IEEE Int. Conf. Acoust., Speech Signal Process., Singapore, 2022, pp. 7942–7946. [Google Scholar]
30. L. Wu et al., “R-Drop: Regularized dropout for neural networks,” Adv. Neural Inf. Process. Syst., vol. 34, pp. 10890–10905, 2021. [Google Scholar]
31. I. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and harnessing adversarial examples,” 2014. doi: 10.48550/arXiv.1412.6572. [Google Scholar] [CrossRef]
32. T. Miyato, A. Dai, and I. Goodfellow, “Adversarial training methods for semi-supervised text classification,” 2016. doi: 10.48550/arXiv.1605.07725. [Google Scholar] [CrossRef]
33. A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu, “Towards deep learning models resistant to adversarial attacks,” 2017. doi: 10.48550/arXiv.1706.06083. [Google Scholar] [CrossRef]
34. A. Shafahi et al., “Adversarial training for free!” in Proc. 33rd Int. Conf. Neural Inf. Process. Syst., Vancouver, Canada, 2019. [Google Scholar]
35. H. Jiang, P. He, W. Chen, X. Liu, J. Gao and T. Zhao, “SMART: Robust and efficient fine-tuning for pre-trained natural language models through principled regularized optimization,” in The 58th Annu. Meet. Assoc. Comput. Linguist., 2020. [Google Scholar]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools