
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

EDU-GAN: Edge Enhancement Generative Adversarial Networks with Dual-Domain Discriminators for Inscription Images Denoising
1 School of Mechanical and Precision Instrument Engineering, Xi’an University of Technology, Xi’an, 710048, China
2 Department of Information Science, Xi’an University of Technology, Xi’an, 710054, China
3 School of Faculty of Painting, Packaging Engineering and Digital Media, Xi’an University of Technology, Xi’an, 710048, China
4 School of Computer Science and Engineering, Xi’an University of Technology, Xi’an, 710048, China
* Corresponding Author: Erhu Zhang. Email:
Computers, Materials & Continua 2024, 80(1), 1633-1653. https://doi.org/10.32604/cmc.2024.052611
Received 08 April 2024; Accepted 12 June 2024; Issue published 18 July 2024
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Recovering high-quality inscription images from unknown and complex inscription noisy images is a challenging research issue. Different from natural images, character images pay more attention to stroke information. However, existing models mainly consider pixel-level information while ignoring structural information of the character, such as its edge and glyph, resulting in reconstructed images with mottled local structure and character damage. To solve these problems, we propose a novel generative adversarial network (GAN) framework based on an edge-guided generator and a discriminator constructed by a dual-domain U-Net framework, i.e., EDU-GAN. Unlike existing frameworks, the generator introduces the edge extraction module, guiding it into the denoising process through the attention mechanism, which maintains the edge detail of the restored inscription image. Moreover, a dual-domain U-Net-based discriminator is proposed to learn the global and local discrepancy between the denoised and the label images in both image and morphological domains, which is helpful to blind denoising tasks. The proposed dual-domain discriminator and generator for adversarial training can reduce local artifacts and keep the denoised character structure intact. Due to the lack of a real-inscription image, we built the real-inscription dataset to provide an effective benchmark for studying inscription image denoising. The experimental results show the superiority of our method both in the synthetic and real-inscription datasets.Keywords
Inscription images have a high value and irreplaceable role, but mess noise commonly exists in real-inscription images, hindering reading and understanding. Cleanly inscribed images are essential for influencing the performance of downstream tasks, such as character recognition [1], font style transfer [2], and other high-level computer vision tasks. Therefore, it is a crucial step to remove the noise from the inscription images.
Edge prior is an essential component of the image feature, which provides more texture and detailed information in the reconstruction tasks of natural images [3,4]. Meanwhile, a fine edge can provide localization information for segmentation and object detection. Both of the mentioned properties of edge prior are helpful to the task of reconstructing high-quality inscription images. Another important prior is skeleton prior, which provides rich topological information for an object [5] and maintains semantic coherence and structural features [6]. As a result, the edge and glyph structure of the character should be preserved correctly in the inscription image denoising task. On the contrary, missing the two glyph information will result in restored images with blurred local and incoherent font structures. Fig. 1 exemplifies the inscription images denoising task, where (a) represents the noisy image. (b and c) represent the results of incorrect denoising, where (b) has severe artifacts and (c) has damaged font structures, and we highlight the inaccurate parts with red boxes. (d) represents the results of correct denoising.
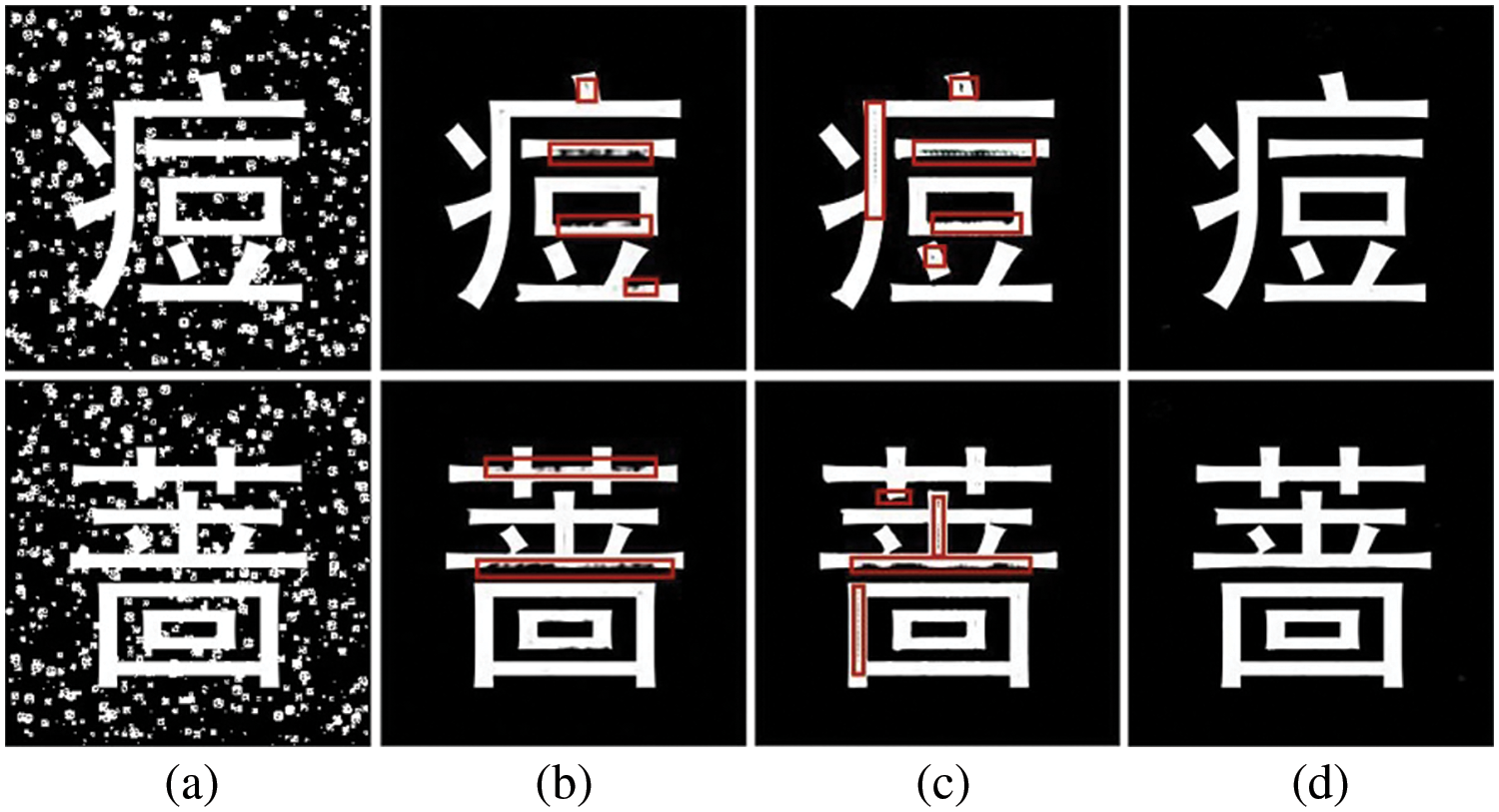
Figure 1: Inscription images denoising examples. (a) Noisy image (b and c) Incorrect denoising results, marking the inaccurate parts of font structure with red boxes, (d) Accurate denoising results
Recently, some inscription image restoration methods have been studied by establishing noise patterns to remove noise. For example, Feng [7] proposed a Gaussian mixture method to simulate noise in document images, but it is unsuitable for complex real-inscription image degradations. Subsequently, Zhang et al. designed a more complex noise model [8,9], where they modeled the noise of documents and inscriptions by adding dots and squares to clean images. Zhang et al. [10] and Wang et al. [11] introduced a GAN to perform blind inscription image denoising, improving image restoration performance. However, inscription images with mottled local and damaged font structures since these works mainly consider pixel-level image restoration and ignore glyph information.
We propose an EDU-GAN framework to address the mentioned issues. The main contributions of our work are summarized as follows:
(1) Unlikely existing denoising architectures, we design edge extraction and edge guidance modules as generator conditions, making the recovered image edge consistent and improving the quality of the restoration image.
(2) We adopt morphological domain training, which boosts the complete semantics of the recovered glyph structure.
(3) Experimental results show that the EDU-GAN model is more suitable for inscription font generation and denoising.
2.1 Inscription Image Restoration
Early research on inscription images mainly focused on physics-based algorithms and filters [12,13]. Recently, deep learning models have been gradually introduced to inscription image restoration. Zhang et al. [9] modeled noises in calligraphic images and then used an adversarial network to restore degraded document images. Miao et al. [8] applied simulated noise methods [9] to the inscription images. Yue et al. [14] introduced a dual adversarial network [10] to perform blind inscription image denoising. A study [15] proposed an improved autoencoder for denoising letter images in scanned invoices. Shi et al. [16] integrated skeleton information into the denoising task and introduced a global-local feature interaction module, thereby improving the denoising performance of the network. Reference [17] input the skeleton and degraded character image into the network and then used the GAN network to reconstruct the character image. However, the above works ignore the structural characteristics of Chinese character images, resulting in unsatisfactory recovery results.
2.2 GAN-Based Image Restoration
Recently, GAN networks have gradually been applied to restore clean images from degraded images. Chen et al. [18] designed the GAN network to generate paired datasets and introduced Convolutional Neural Networks for blind denoising. Yue et al. [14] proposed the simultaneous removal and generation of noise tasks in a unified Bayesian framework. Wang et al. [19] explored a more effective rainy image generation method under the Bayesian framework to improve rain removal performance. However, the above study ignores the consideration of the discriminator. A pioneer work [20] proposed a discriminator based on the U-Net architecture that simultaneously captured global and local information from images, thus encouraging the generator to construct high-quality samples. Subsequently, Huang et al. [21] applied the discriminator of the U-Net structure to medical image denoising. Wei et al. [22] introduced the discriminator of U-Net structure into the super-resolution tasks to generate more high-resolution images with better realistic. The successful application of the above method inspired us to employ based on GAN ideas for restoring inscription images.
Based on the above consideration, we design an EDU-GAN network for inscription image denoising, as shown in Fig. 2, which contains a generator and two based U-Net discriminators. We detail the design of network architecture and modules in this section.
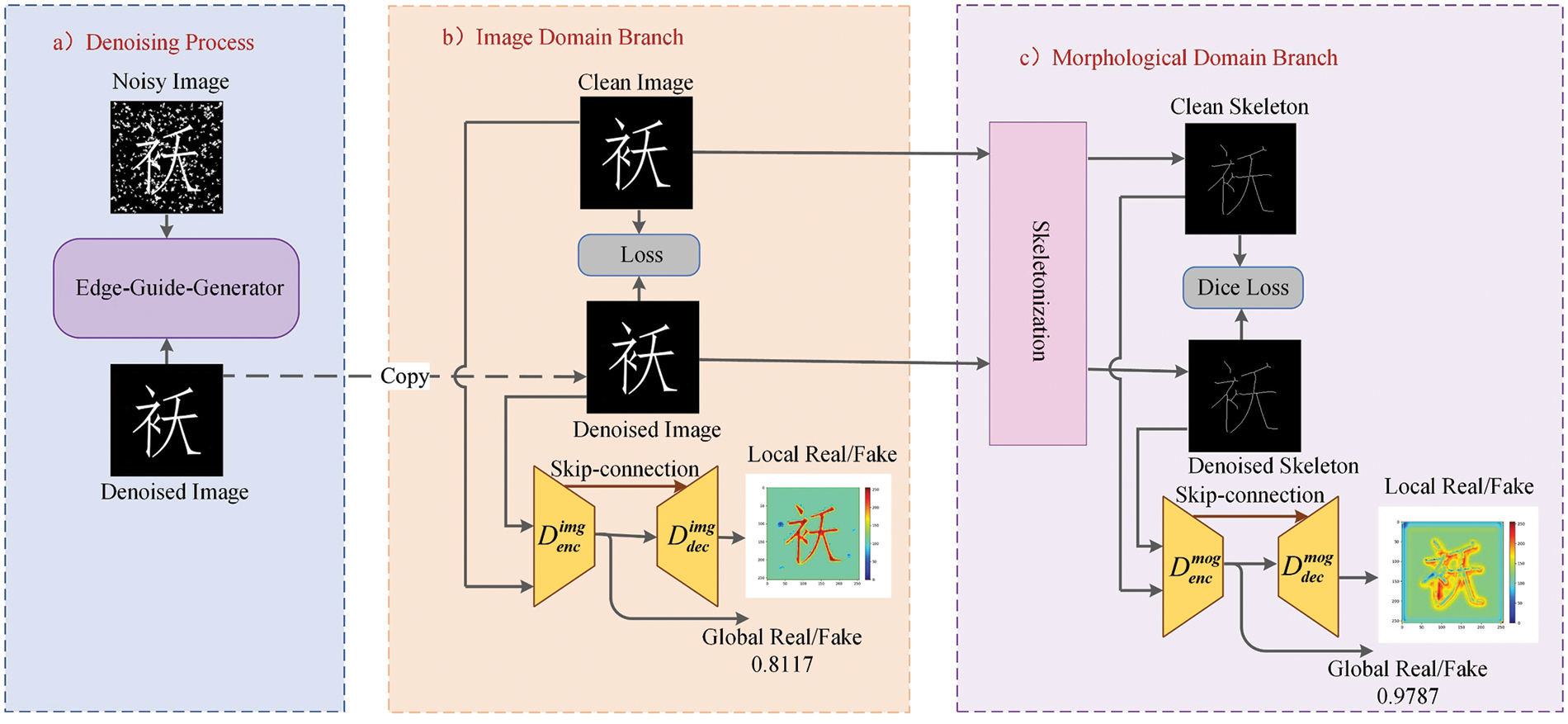
Figure 2: Inscription-denoising network framework
As shown in Fig. 2, the denoising process is to guide an edge-guided generator (EGG) to map the input noisy image
where
The proposed edge-guided generator, as shown in Fig. 3. Firstly, the network performs five stages of feature extraction. Secondly, an edge extraction module (EEM) excavates edge semantics from the lowest scale-ensemble block (SEB1) and highest scale-ensemble block (SEB5). Thirdly, the asymmetric feature fusion module (AFF) is applied to enhance the information flow of different stages. Fourthly, the edge-guide feature module (EFM) integrates the font edge and contextual feature information to improve the restored text edge of consistency. Finally, multiple context prediction modules (CPM) are employed to fuse features in a bottom-up aggregate manner. The CPM1 module outputs the generator prediction results.
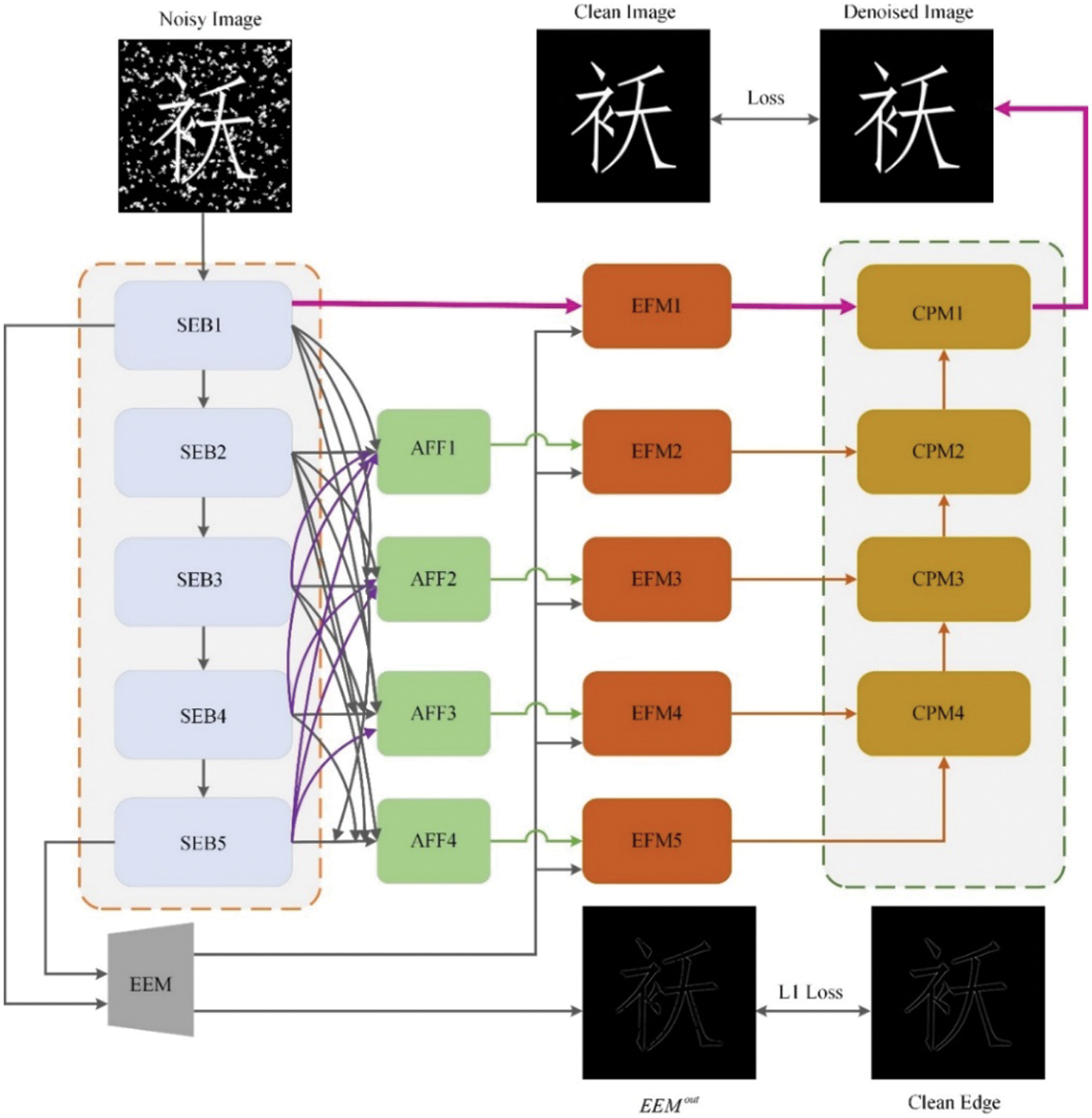
Figure 3: Edge-guide generator framework
3.2.1 Feature Extraction Module
Considering the unknown and complexity of the noise pattern (such as the shape and size of the noise patches) on the inscription images, we design a scale-ensemble block (SEB) as shown in Fig. 4. By utilizing receptive field information of different scales to boost feature extraction capability. Specifically, the feature extraction module contains five SEB modules. SEB1 applies two
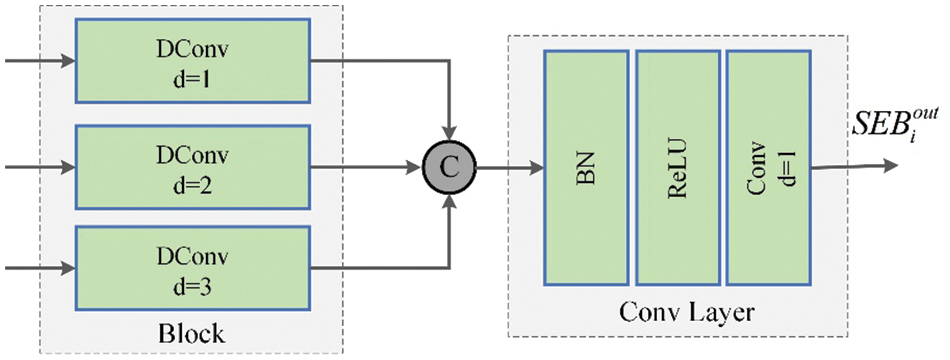
Figure 4: Scale-ensemble block
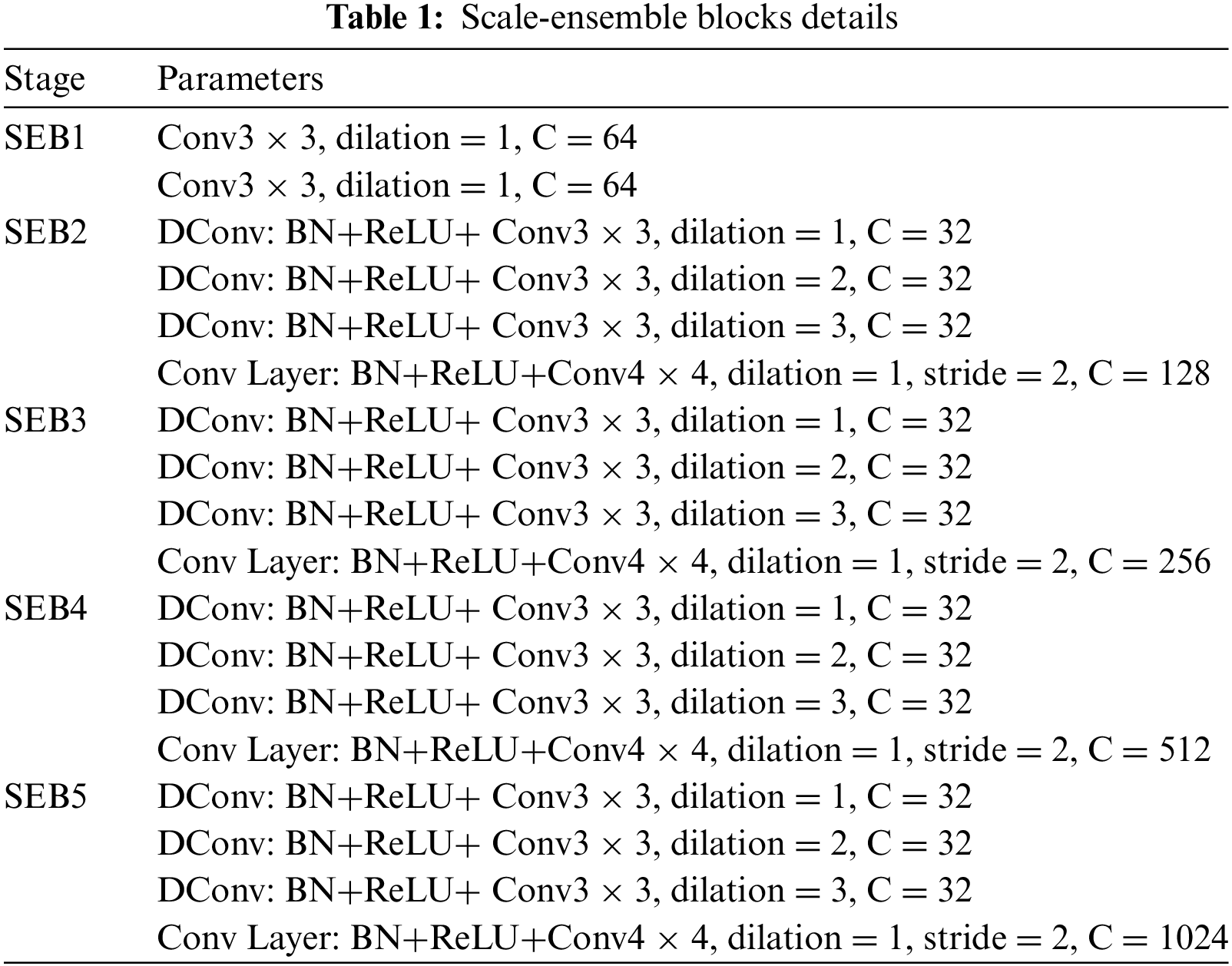
As we discussed, edges are beneficial to image reconstruction tasks, and how to extract clean and accurate text edges from noisy inscription images is crucial. As shown in Fig. 5, we build an edge extraction module (EEM) to excavate edge information from low-level features (
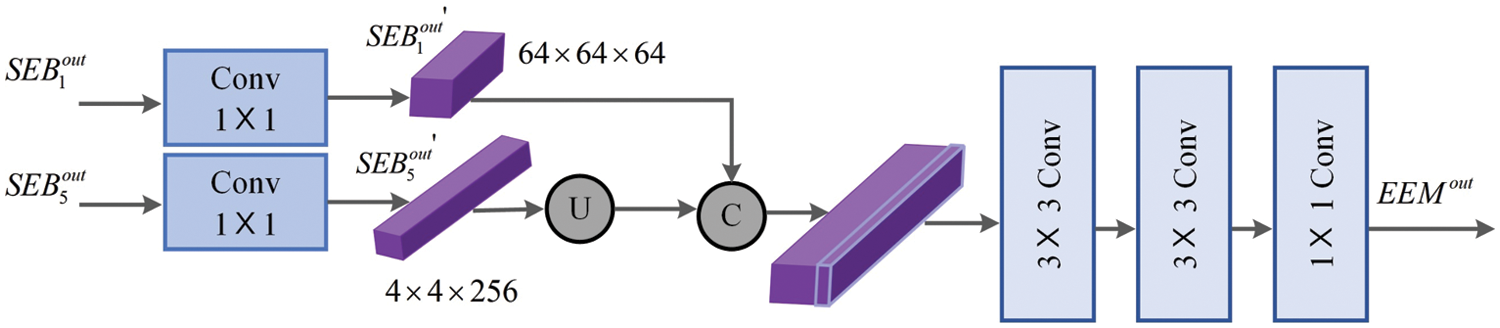
Figure 5: EEM framework
where
Due to the unknown noise level of inscription images, the feature of small noise patches is easy to obtain in the shallower layer, but large noise patches are easy to extract in the deeper layer. To further fully exploit captured shallow and deep features, we design an asymmetric feature fusion module (AFF), inspired by Cho et al. [23], which integrates features at different levels into the original features to enhance the information flow of different levels, refer to Fig. 6.
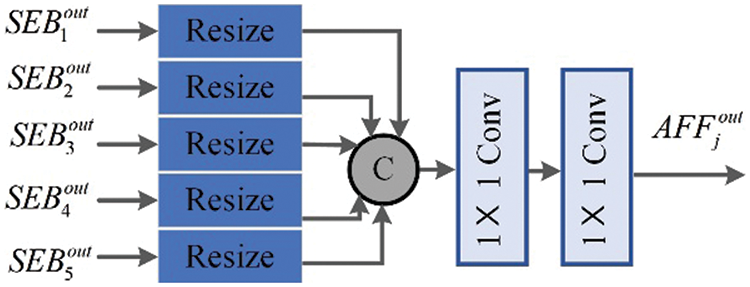
Figure 6: AFF framework
where
Since the high-frequency edge features will gradually disappear with the depth of the network increase, to fully utilize the edge information to reconstruct high-quality images, we design an edge-guide feature module (EFM). The module combines the aggregated information obtained by the AFF module and edge information to supplement the feature representation of structural semantics.
As shown in Fig. 7, given a feature
where
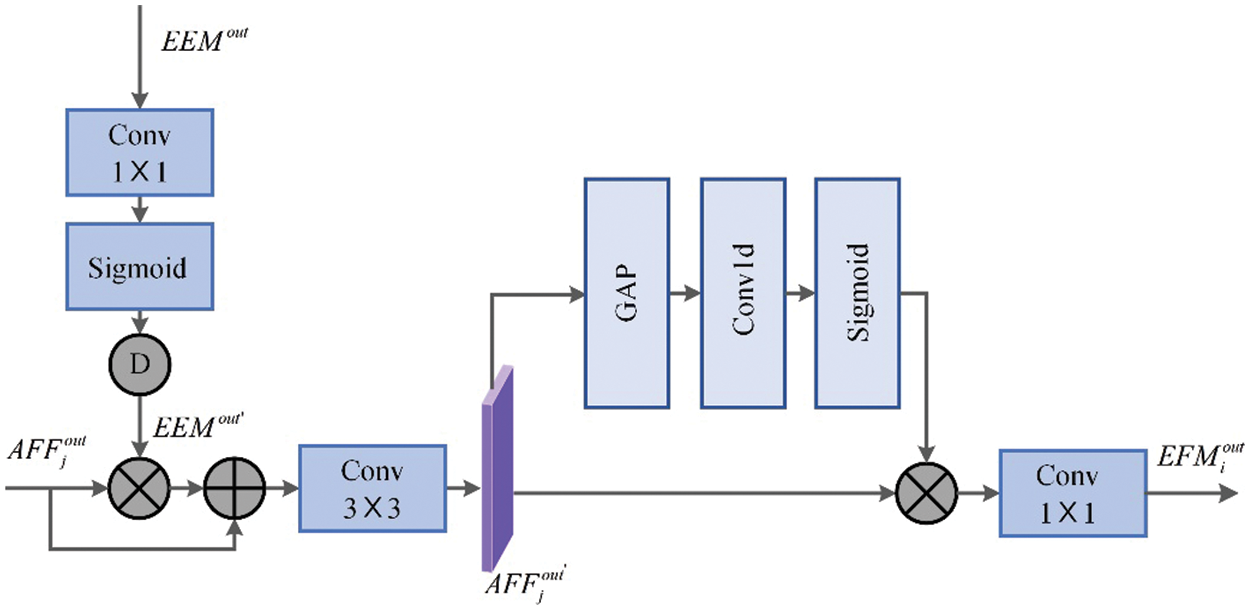
Figure 7: EFM framework
As shown in Fig. 8, we design a bottom-up context prediction module (CPM) to fuse

Figure 8: CPM framework
3.6 Dual-Domain U-Net Discriminator
3.6.1 Image Domain U-Net Discriminator
Inspired by [22], we introduce a U-Net architecture of the discriminator to improve the ability of GAN networks to represent global and local differences. The discriminator consists of an encoder module, a decoder module, and several skip connections attention modules. Encoder
3.6.2 Morphological Domain U-Net Discriminator
The noise may damage the font structure in the inscriptions. To ensure the complete semantics of the font structure, we propose branch of the morphological domain to maintain the skeleton from the inscription image reconstruction. Specifically, the denoised image first inputs the morphological operation of skeleton extraction, i.e.,
The generator adopts compound loss, including content loss, perceptual loss, and adversarial loss, with different perspectives to better constrain and encourage the generator, which produces better realistic images. The detailed losses are as follows:
Adversarial Loss: We employ the Least Squares GAN [25] as discriminator loss. The total adversarial loss can be expressed as:
where
Content Loss: The image reconstruction loss
where
Feature Loss: We also consider the feature-level loss
The discriminator loss
Therefore, the total loss for the discriminator is:
The proposed method of EDU-GAN is implemented by PyTorch in the PyCharm integrated development environment and conducted on NVIDIA GeForce RTX 4070 with 12 GB GPU. During training, the initial learning rates of the discriminators
Algorithm 1 details the EDU-GAN network implementation process. The network inputs the noisy inscription image

In our EDU-GAN, we require noisy Chinese characters images with stains or scratches to train our network, but those kinds of public datasets are lacking. Therefore, we create synthetic inscription and real-inscription datasets to evaluate the performance of the EDU-GAN network. Our synthetic datasets are constructed by adding noise patches on widely used printed Chinese character images1 and handwritten dataset2. And the real-inscription dataset is collected from websites3.
4.2.1 Synthetic Inscription Datasets
Printed Chinese Character Datasets: We generate 41,305 images, including 11 fonts (such as FangSong). Each font contains 3755 commonly used Chinese characters in GB2312. We use Random Walk Modeling (RWM) and the Square Circle Noise Modeling method [9], adding noise to the printed Chinese character images to create synthetic datasets, denoting as
Handwritten Chinese Character Dataset: HWDB1.1 is a handwritten Chinese character dataset containing 1,176,000 images from 300 writers. We select 65,709 images written by 30 people, which are preprocessing and adding noise by RWM methods to create synthetic dataset, denoted as
4.2.2 Real-Inscription Dataset
Due to the lack of a real-inscription image dataset, we collect inscription images from different dynasties. These images are cropped into 1356 images with
There are two commonly used metrics to evaluate the performance in image reconstruction, i.e., peak signal-to-noise ratio (PSNR) and structural similarity (SSIM). However, there is no quantitative index for font structure in inscription denoising, so we propose to evaluate the similarity between skeletons, i.e., SGap.
The main idea of SGap is that the skeleton of the denoised and clean images is the same or similar. Specifically, given a noisy image
Obviously, the larger the value of the first term on the right side of the equation, the
4.4 Experiment Results and Analysis
We compare the performance of the EDU-GAN network with other classic image restoration methods, including calligraphy image denoising CIDGan [9], CharFormer [16], and RCRN [17], considering edge priors denoising methods EdCNN [30] and Mlefng [4] and the well-performing image restoration methods DnCNN [31], Uformer [32], VRGNet [19] and the established and representative methods CBDNet [33] and NBNet [34] for natural image denoising. To fairly evaluate the performance of different methods by setting and providing training environment and data to be the same.
4.4.1 Comparison with Other Methods
Results on Synthetic Datasets: In Table 2, we summarize the performance of our EDU-GAN and other methods on the
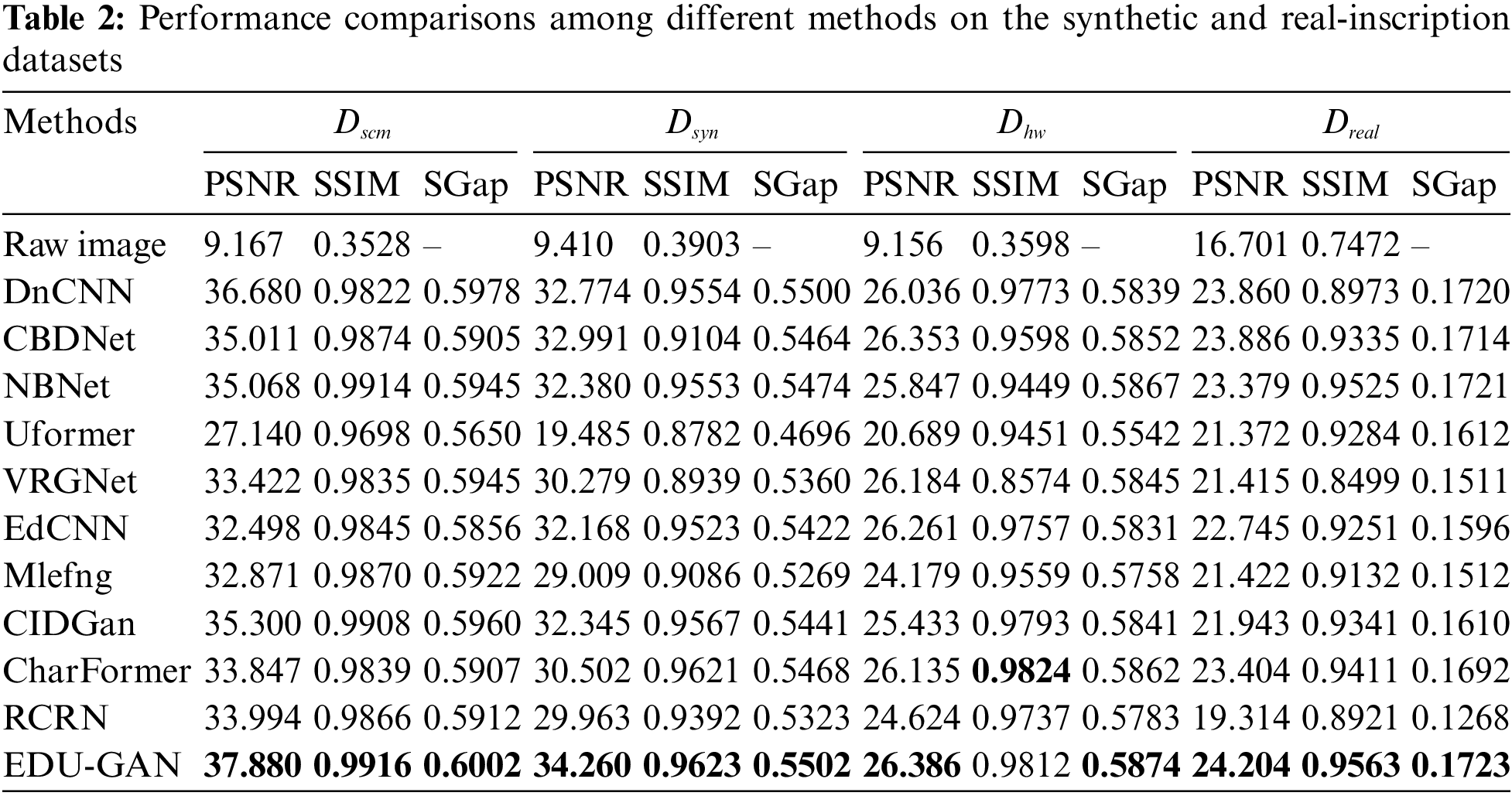

Figure 9: Visualization of denoising results on the
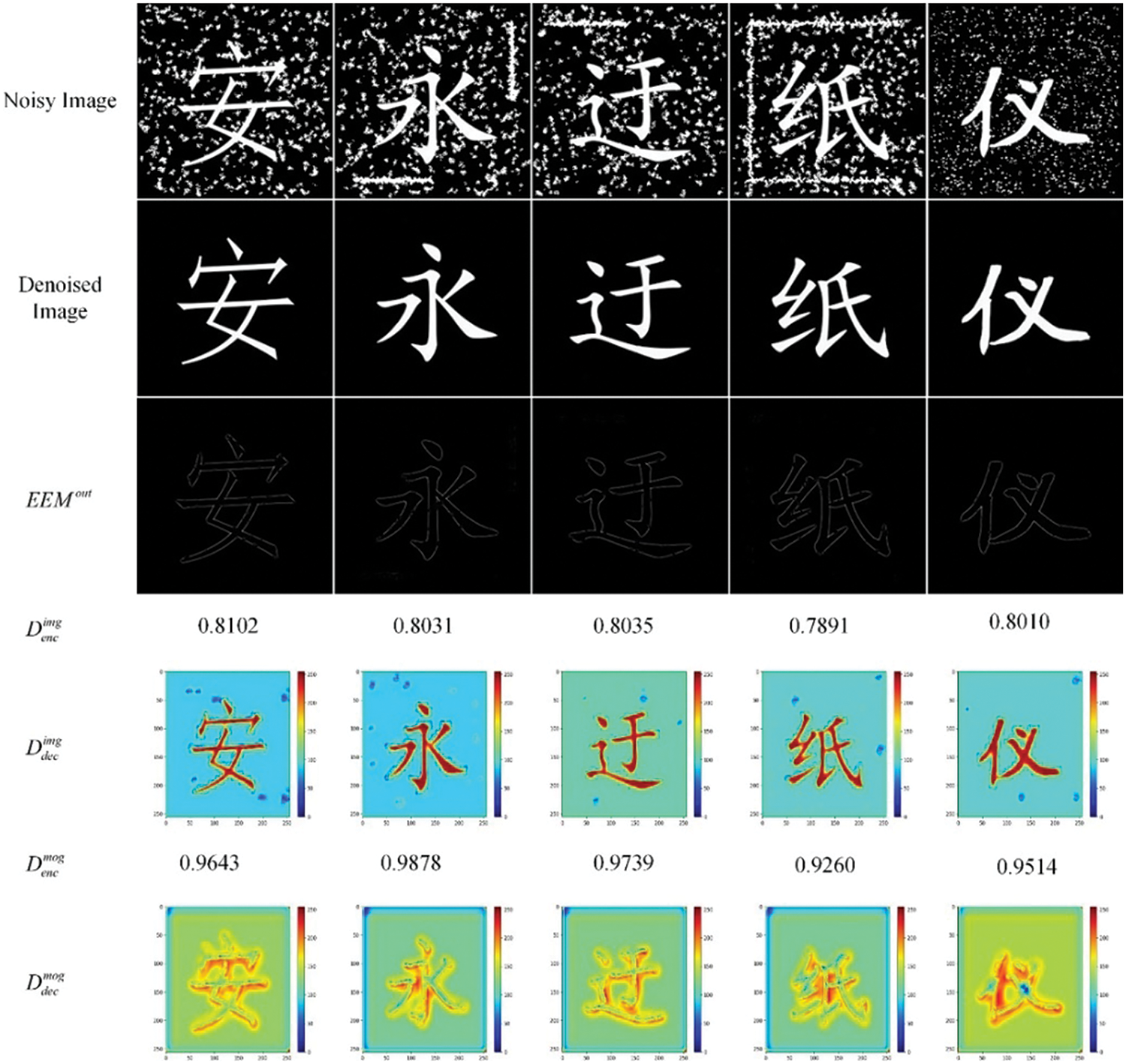
Figure 10: Visualization of different parts of the EDU-GAN trained on the
Results on Real-Inscription Dataset: As shown in Table 2, we also compare EDU-GAN with other methods on the
Figure 11: Visualization of real-inscription denoising results
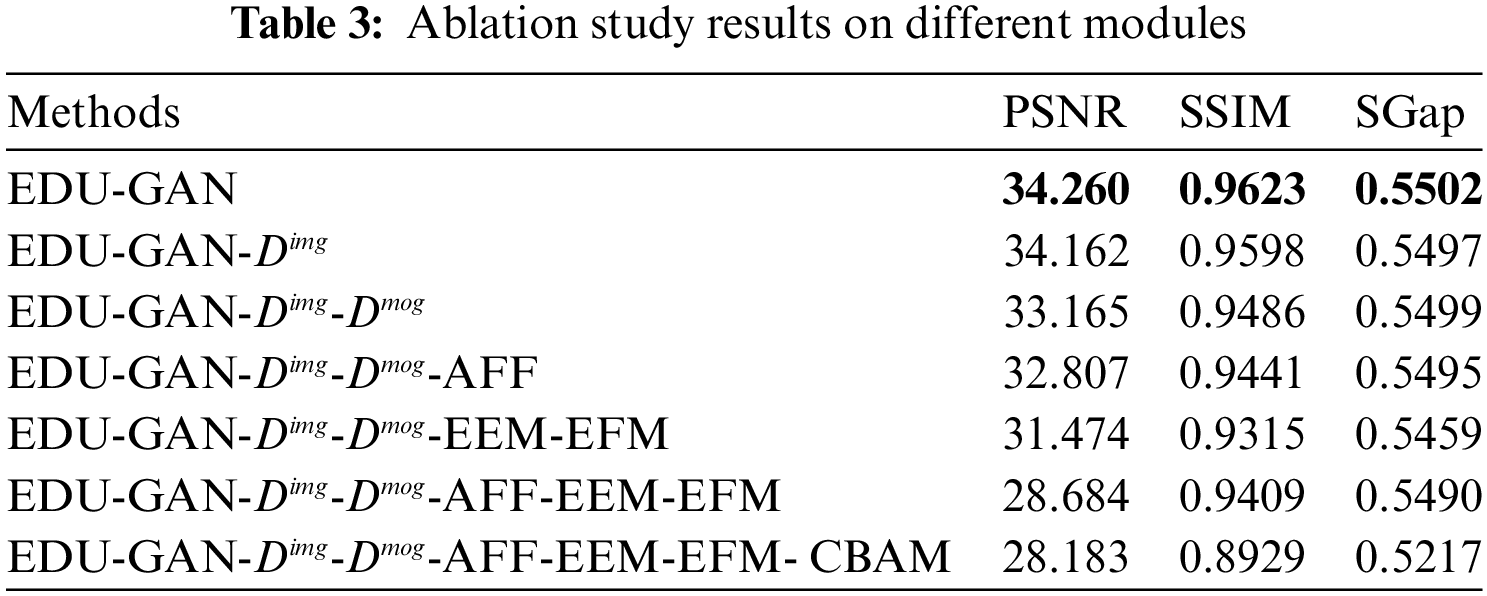
Components Analysis: Table 3 presents the quantitative results of the ablation studies. To verify each design in EDU-GAN is reasonable. First, benefiting from the discriminative architecture that provides global and local information for the generator, EDU-GAN with two U-Net discriminators achieves the highest PSNR and SSIM than EDU-GAN-
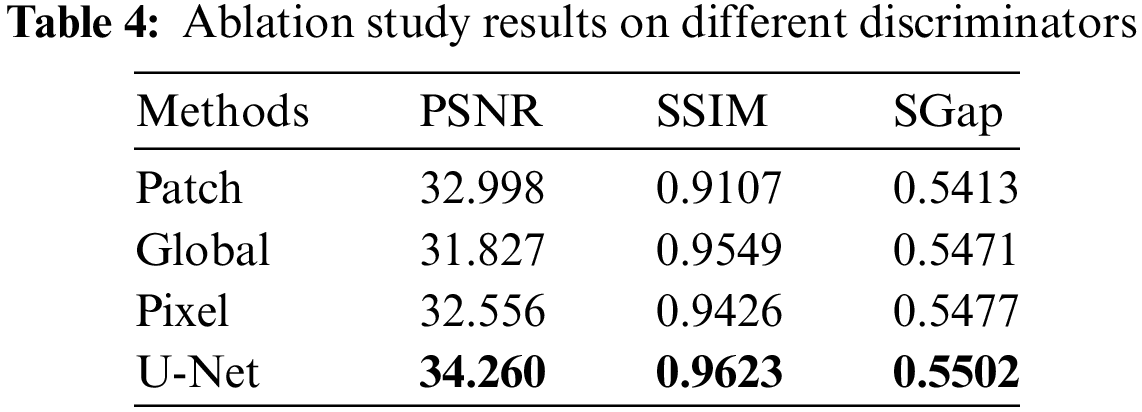
Architectures of Discriminator: Since the discriminator is crucial and cannot be ignored in the GAN network, it is worth exploring the highlights of the U-Net structure discriminator compared with other classic discriminators, such as the patch discriminator [35], global discriminator [36], pixel discriminator [35]. For fair comparisons, using the same overall pipeline, referred to as Fig. 2, the generator uses the EGG network, and the discriminator applies the above three classic discriminators, respectively. Table 4 reports the assembly of global and local information in the discriminator of the U-Net structure achieved the best PSNR and SSIM scores, which denotes our U-Net discriminator outperforms the other three mentioned classical discriminators for inscription image denoising. Because the classic discriminator can only focus on local or global information, it cannot better represent the differences between images. Unlike classical discriminators, the U-Net constructed discriminator can simultaneously capture global and local features in images, thereby guiding the generator towards restoring better images and improving the denoising performance of the network.
Effect of Patch Size: The selection of patch size is also important during the training process, so we randomly cut the training data set into
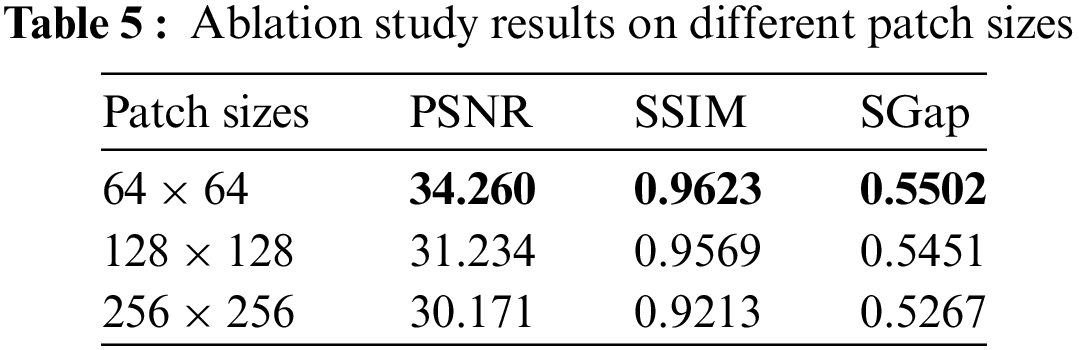

Figure 12: Visualization of denoising results at patch sizes
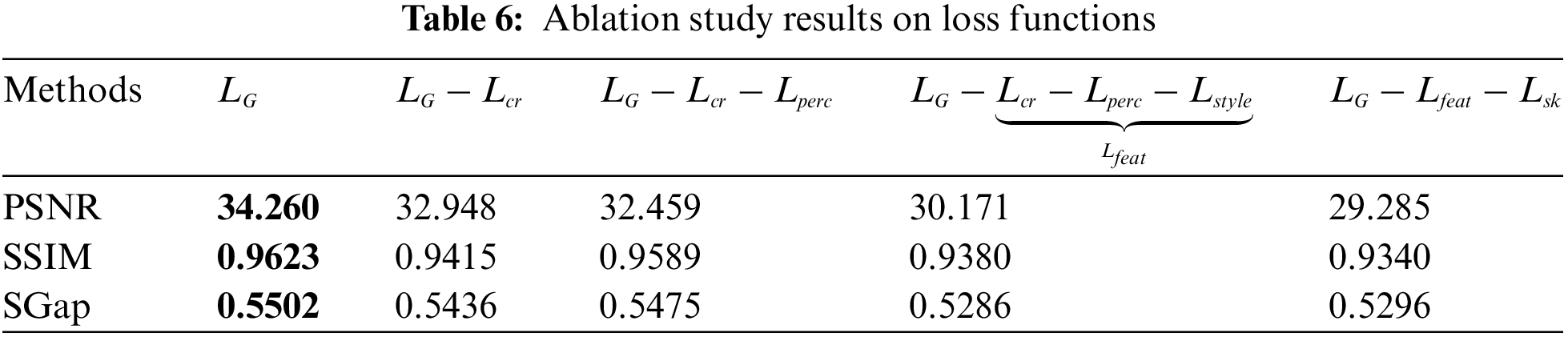
Effect of Loss Functions: The loss of our generator has three parts, which encourages the generator to produce more high-precision denoised images. We compare the impact of denoising with/without these losses, as shown in Table 6. These results on
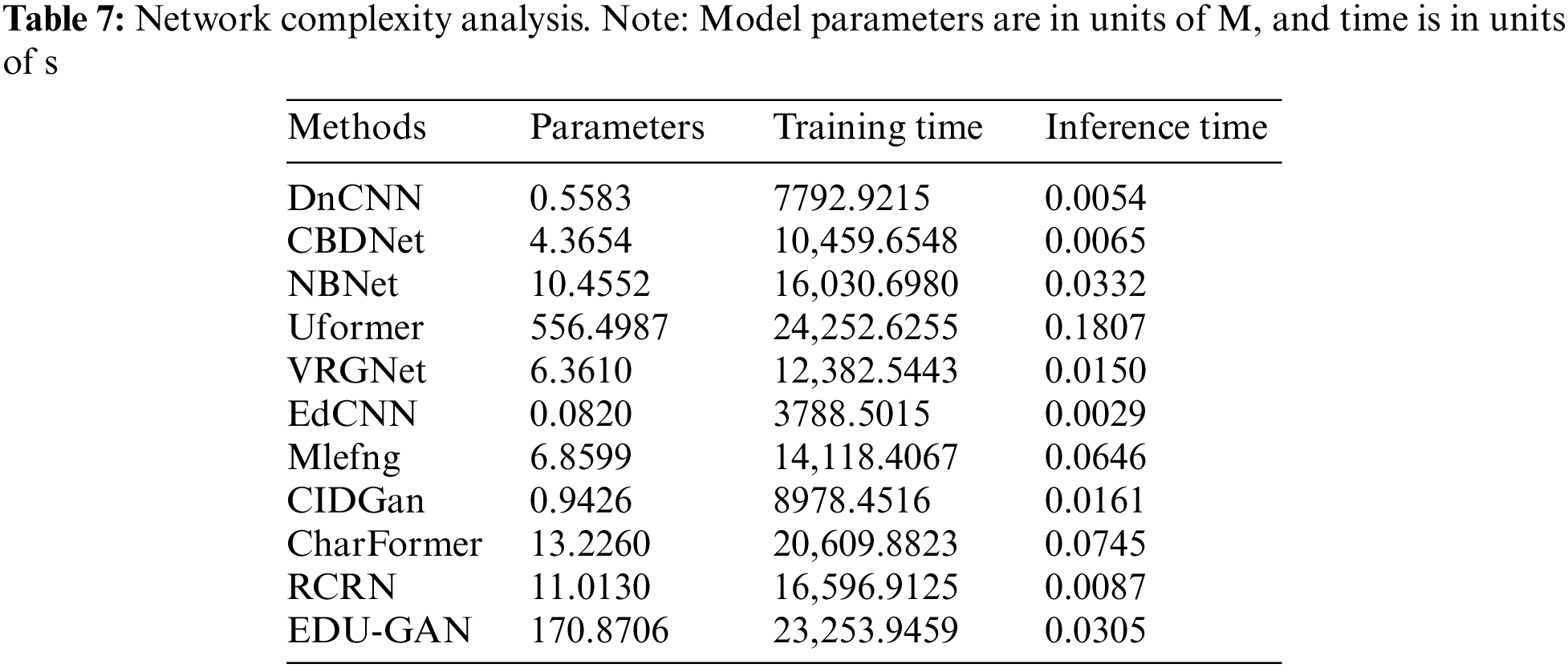
Network Complexity Analysis: Table 7 provides the model parameters, training time, and inference time of different methods. From Table 7, it shows that more complex models require longer training times. Although our model parameters and training time are not advantageous, it achieves the best denoising performance. In particular, our network application scenarios do not require real-time, so we are more tolerant of network training time and inference time. For limited devices, our model needs to be further lightweight.
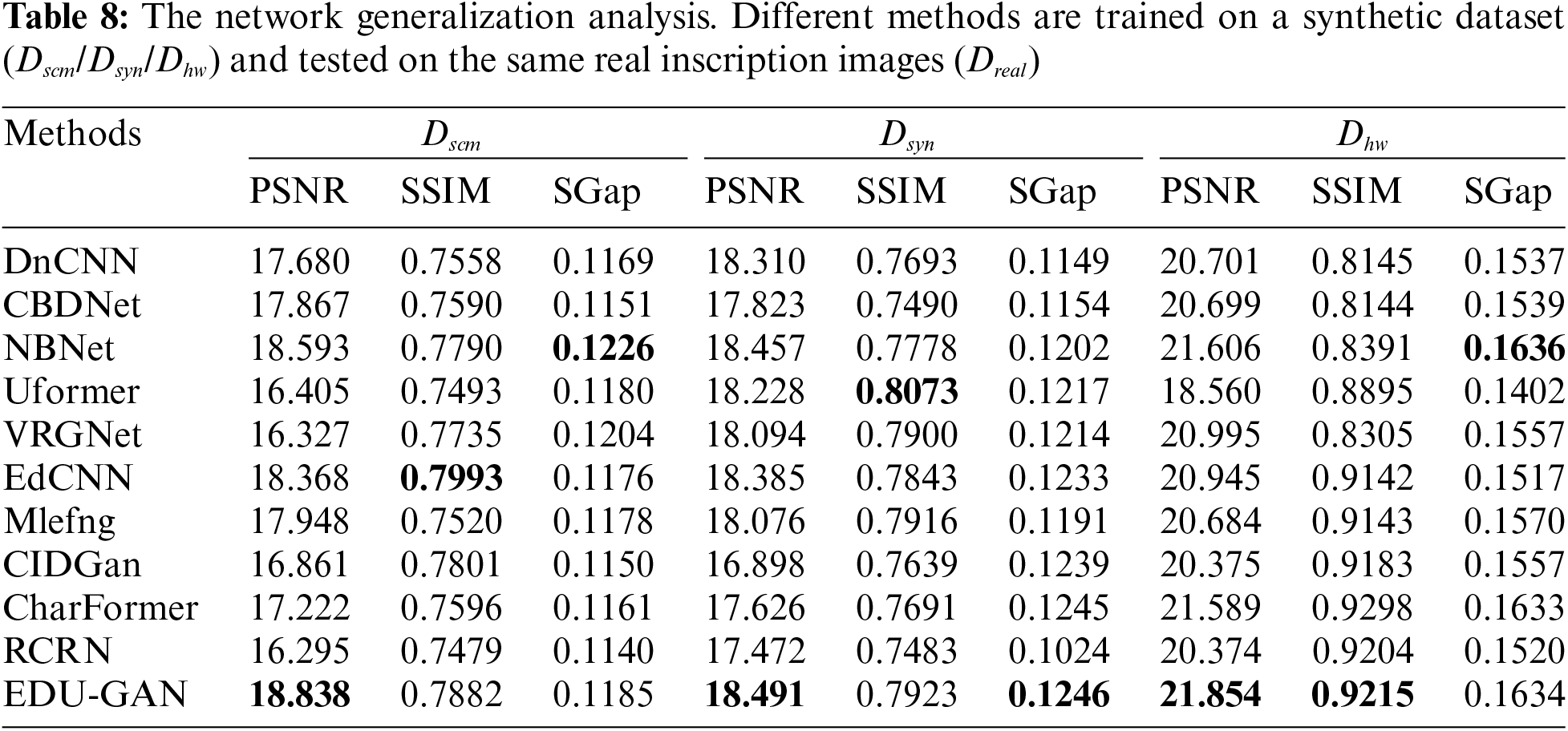
Generalization Analysis: Table 8 shows that different methods are trained on three independent synthetic datasets and then directly used for testing on real-inscription images to verify the robustness ability of the network. Our EDU-GAN achieves better robustness performance than other methods from Table 8. Taking the EDU-GAN network trained on
In the paper, we propose EDU-GAN, a novel framework to remove noise from inscription images. In the generator, the scale-ensemble block (SEB) can model the multi-scale features and improve the ability to detect noise patterns with unknown and complexity. The asymmetric feature fusion module (AFF) is beneficial for obtaining rich multi-level features by effectively aggregating the features of multiple SEB modules. The edge-guide feature module (EFM) is responsible for effectively integrating edge information from the edge extraction module (EEM) and context information to enhance the representation ability of edge information in the deep network. The bottom-up content prediction module (CPM) fuses the features between layers and outputs the prediction results. In the discriminator, we introduce U-Net architecture, providing global and local information for the generator and further applying it to the morphological domain, which enhances the skeleton features and structural integrity of fonts. We comprehensively evaluate the performance of EDU-GAN on synthetic and real-inscription datasets, which demonstrates superior performance gains over other methods.
Although our network can obtain high evaluation indicators, it still has some limitations. Firstly, the successful application of our network is crucial to multiple downstream tasks such as font style recognition and font restoration. However, the size of our network model is relatively large, such as the SEB module. Existing computing resources can afford the proposed network, but our model needs to be further lightweight for devices with limited memory. Secondly, our network is also applicable to non-experts. When the network is trained, the noisy inscription image is input into the network, and the network outputs the denoised image. However, an intuitive user interface may be easier to operate for non-experts, which is a part that needs improvement for future deployment and implementation.
In conclusion, our model performs well in denoising inscription images and has good generalization ability, but the model size is large and needs to be further lightweight in the future.
Acknowledgement: The authors sincerely appreciate the reviewers and the editorial team for their valuable feedback and scientific suggestions.
Funding Statement: This work was supported by the Key R&D Program of Shaanxi Province, China (Grant Nos. 2022GY-274, 2023-YBSF-505); the National Natural Science Foundation of China (Grant No. 62273273).
Author Contributions: Erhu Zhang: Supervision, Project administration, Methodology, Writing–review & editing. Yunjing Liu: Data curation, Methodology, Software, Validation, Writing–original draft. Jingjing Wang: Data curation Guangfeng Lin: Data curation. Jinghong Duan: Data curation. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The authors confirm that the data supporting the findings of this study are available within the article, which can be found at the link below.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1https://www.foundertype.com (accessed on 10/05/2024)
2http://www.nlpr.ia.ac.cn/databases/handwriting/Download.html (accessed on 10/05/2024)
3https://www.9610.com/index.htm (accessed on 10/05/2024)
4https://github.com/liuyunjing0306/EDU-GAN (accessed on 10/05/2024)
References
1. R. Mithe, S. Indalkar, and N. Divekar, “Optical character recognition,” Int. J. Recent Technol. Eng., vol. 2, no. 1, pp. 72–75, 2013. [Google Scholar]
2. Y. Gao and J. Wu, “Gan-based unpaired chinese character image translation via skeleton transformation and stroke rendering,” in Proc. 34th AAAI Conf, New York, NY, USA, 2020, pp. 646–653. doi: 10.1609/aaai.v34i01.5405. [Google Scholar] [CrossRef]
3. S. Chupraphawan and C. A. Ratanamahatana, “Deep convolutional neural network with edge feature for image denoising,” in Proc. Adv. Intell. Sys. Comput., Bangkok, Thailand, 2020, pp. 169–179. doi: 10.1007/978-3-030-19861-9_17. [Google Scholar] [CrossRef]
4. F. Fang, J. Li, Y. Yuan, T. Zeng, and G. Zhang, “Multilevel edge features guided network for image denoising,” IEEE Trans. Neural Networks Learn. Sys., vol. 32, no. 9, pp. 3956–3970, 2020. doi: 10.1109/TNNLS.2020.3016321. [Google Scholar] [PubMed] [CrossRef]
5. C. Liu, Y. Tian, Z. Chen, J. Jiao, and Q. Ye, “Adaptive linear span network for object skeleton detection,” IEEE Trans. Image Process, vol. 30, pp. 5096–5108, 2021. doi: 10.1109/TIP.2021.3078079. [Google Scholar] [PubMed] [CrossRef]
6. J. Cai, L. Peng, Y. Tang, C. Liu, and P. Li, “TH-GAN: Generative adversarial network based transfer learning for historical Chinese character recognition,” in Proc. Int. Conf. Doc. Anal. Recognit., Sydney, NSW, Australia, IEEE, 2019, pp. 178–183. doi: 10.1109/ICDAR.2019.00037. [Google Scholar] [CrossRef]
7. S. Feng, “A novel variational model for noise robust document image binarization,” Neurocomputing, vol. 325, no. 1, pp. 288–302, 2019. doi: 10.1016/j.neucom.2018.09.087. [Google Scholar] [CrossRef]
8. Y. Miao, L. Li, Y. Ji, and G. Li, “Research on denoising method of chinese ancient character image based on chinese character writing standard model,” Sci. Rep., vol. 12, no. 1, pp. 19795, 2022. doi: 10.1038/s41598-022-24388-y. [Google Scholar] [PubMed] [CrossRef]
9. J. Zhang, M. Guo, and J. Fan, “A novel generative adversarial net for calligraphic tablet images denoising,” Multimedia Tools Appl., vol. 79, no. 1–2, pp. 119–140, 2020. doi: 10.1007/s11042-019-08052-8. [Google Scholar] [CrossRef]
10. H. Zhang, Y. Qi, X. Xue, and Y. Nan, “Ancient stone inscription image denoising and inpainting methods based on deep neural networks,” Discret. Dyn. Nat. Soc., vol. 2021, pp. 1–11, 2021. doi: 10.1155/2021/7675611. [Google Scholar] [CrossRef]
11. X. Wang, K. Wu, Y. Zhang, Y. Xiao, and P. Xu, “A gan-based denoising method for chinese stele and rubbing calligraphic image,” Visual Comput., vol. 39, no. 4, pp. 1351–1362, 2023. doi: 10.1007/s00371-022-02410-8. [Google Scholar] [CrossRef]
12. F. Ge and L. He, “A de-noising method based on L0 gradient minimization and guided filter for ancient Chinese calligraphy works on steles,” Eurasip J. Image Video Process., vol. 2019, no. 1, pp. 32, 2019. doi: 10.1186/s13640-019-0423-x. [Google Scholar] [CrossRef]
13. Z. Shi, B. Xu, X. Zheng, and M. Zhao, “An integrated method for ancient Chinese tablet images de-noising based on assemble of multiple image smoothing filters,” Multimedia Tools Appl., vol. 75, no. 19, pp. 12245–12261, 2016. doi: 10.1007/s11042-016-3421-3. [Google Scholar] [CrossRef]
14. Z. Yue, Q. Zhao, L. Zhang, and D. Meng, “Dual adversarial network: Toward real-world noise removal and noise generation,” in ECCV 2020: 16th Euro. Conf., Glasgow, UK, 2020, vol. 12355, pp. 41–58. doi: 10.1007/978-3-030-58607-2_3. [Google Scholar] [CrossRef]
15. S. I. Alshathri, D. J. Vincent, and V. S. Hari, “Denoising letter images from scanned invoices using stacked autoencoders,” Comput. Mater. Contin., vol. 71, no. 1, pp. 1371–1386, 2022. doi: 10.32604/cmc.2022.022458 [Google Scholar] [CrossRef]
16. D. Shi et al., “CharFormer: A glyph fusion based attentive framework for high-precision character image denoising,” in Proc. 30th ACM Int. Conf. Multimed., 2022, pp. 1147–1155. doi: 10.1145/3503161.3548208. [Google Scholar] [CrossRef]
17. D. Shi, X. Diao, H. Tang, X. Li, H. Xing and H. Xu, “RCRN: Real-world character image restoration network via skeleton extraction,” in Proc. 30th ACM Int. Conf. Multimed., 2022, pp. 1177–1185. doi: 10.1145/3503161.3548344. [Google Scholar] [CrossRef]
18. J. Chen, J. Chen, H. Chao, and M. Yang, “Image blind denoising with generative adversarial network based noise modeling,” in 2018 IEEE CVPR, Salt Lake City, UT, USA, 2018, pp. 3155–3164. doi: 10.1109/CVPR.2018.00333. [Google Scholar] [CrossRef]
19. H. Wang, Z. Yue, Q. Xie, Q. Zhao, Y. Zheng and D. Meng, “From rain generation to rain removal,” in 2021 IEEE CVPR, Nashville, TN, USA, 2021, pp. 14786–14796. doi: 10.1109/CVPR46437.2021.01455. [Google Scholar] [CrossRef]
20. E. Schonfeld, B. Schiele, and A. Khoreva, “A U-Net based discriminator for generative adversarial networks,” in 2020 IEEE CVPR, Seattle, WA, USA, 2020, pp. 8207–8216. doi: 10.1109/CVPR42600.2020.00823. [Google Scholar] [CrossRef]
21. Z. Huang, J. Zhang, Y. Zhang, and H. Shan, “DU-GAN: Generative adversarial networks with dual-domain U-Net-based discriminators for low-dose CT denoising,” IEEE Trans. Instrum. Meas., vol. 71, pp. 1–12, 2021. doi: 10.1109/TIM.2021.3128703. [Google Scholar] [CrossRef]
22. Z. Wei, Y. Huang, Y. Chen, C. Zheng, and J. Gao, “A-ESRGAN: Training real-world blind super-resolution with attention U-Net discriminators,” in 20th Pacific Rim Int. Confer. Artif Intell. (PRICAI), Jakarta, Indonesia, 2023, vol. 14327, pp. 16–27. doi: 10.1007/978-981-99-7025-4_2. [Google Scholar] [CrossRef]
23. S. J. Cho, S. W. Ji, J. P. Hong, S. W. Jung, and S. J. Ko, “Rethinking coarse-to-fine approach in single image deblurring,” in Proc. IEEE Int. Conf. Comput. Vision, Montreal, QC, Canada, 2021, pp. 4621–4630. doi: 10.1109/ICCV48922.2021.00460. [Google Scholar] [CrossRef]
24. S. Woo, J. Park, J. Y. Lee, and I. S. Kweon, “CBAM: Convolutional block attention module,” in ECCV 2018: 15th Euro. Conf., Munich, Germany, 2018, vol. 12211, pp. 3–19. doi: 10.1007/978-3-030-01234-2_1. [Google Scholar] [CrossRef]
25. X. Mao, Q. Li, H. Xie, R. Y. Lau, Z. Wang, and S. P. Smolley, “Least squares generative adversarial networks,” in Proc. IEEE Int. Conf. Comput. Vision, Venice, Italy, 2017, pp. 2813–2821. doi: 10.1109/ICCV.2017.304. [Google Scholar] [CrossRef]
26. N. H. Nguyen, “U-Net based skeletonization and bag of tricks,” in Proc. IEEE Int. Conf. Comput. Vision, Montreal, BC, Canada, 2021, pp. 2105–2109. doi: 10.1109/ICCVW54120.2021.00238. [Google Scholar] [CrossRef]
27. K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” in 3rd Int. Conf. Learn. Represent., San Diego, CA, USA, 2015. [Google Scholar]
28. C. Liu, Y. Liu, L. Jin, S. Zhang, C. Luo and Y. Wang, “EraseNet: End-to-end text removal in the wild,” IEEE Trans. Image Process., vol. 29, pp. 8760–8775, 2020. doi: 10.1109/TIP.2020.3018859. [Google Scholar] [PubMed] [CrossRef]
29. H. Wu et al., “Contrastive learning for compact single image dehazing,” in 2021 IEEE CVPR, Nashville, TN, USA, 2021, pp. 10546–10555. doi: 10.1109/CVPR46437.2021.01041. [Google Scholar] [CrossRef]
30. T. Liang, Y. Jin, Y. Li, and T. Wang, “EDCNN: Edge enhancement-based densely connected network with compound loss for low-dose CT denoising,” in 15th IEEE Int. Conf. Signal Process. Proc., Beijing, China, 2020, vol. 2020, pp. 193–198. doi: 10.1109/ICSP48669.2020.9320928. [Google Scholar] [CrossRef]
31. K. Zhang, W. Zuo, Y. Chen, D. Meng, and L. Zhang, “Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising,” IEEE Trans. Image Process., vol. 26, no. 7, pp. 3142–3155, 2017. doi: 10.1109/TIP.2017.2662206. [Google Scholar] [PubMed] [CrossRef]
32. Z. Wang, X. Cun, J. Bao, W. Zhou, J. Liu and H. Li, “Uformer: A general u-shaped transformer for image restoration,” in 2022 IEEE CVPR, New Orleans, LA, USA, 2022, pp. 17662–17672. doi: 10.1109/CVPR52688.2022.01716. [Google Scholar] [CrossRef]
33. S. Guo, Z. Yan, K. Zhang, W. Zuo, and L. Zhang, “Toward convolutional blind denoising of real photographs,” in 2019 IEEE CVPR, Long Beach, CA, USA, 2019, pp. 1712–1722. doi: 10.1109/CVPR.2019.00181. [Google Scholar] [CrossRef]
34. S. Cheng, Y. Wang, H. Huang, D. Liu, H. Fan and S. Liu, “NBNet: Noise basis learning for image denoising with subspace projection,” in 2021 IEEE CVPR, Nashville, TN, USA, 2021, pp. 4894–4904. doi: 10.1109/CVPR46437.2021.00486. [Google Scholar] [CrossRef]
35. J. Zhu, T. Park, P. Isola, and A. A. Efros, “Unpaired image-to-image translation using cycle-consistent adversarial networks,” in Proc. IEEE Int. Conf. Comput. Vision, Venice, Italy, 2017, pp. 2242–2251. doi: 10.1109/ICCV.2017.244. [Google Scholar] [CrossRef]
36. I. Goodfellow et al., “Generative adversarial nets,” in Proc. Int. Conf. Neural Inf. Process. Syst., 2014, pp. 2672–2680. [Google Scholar]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools