
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Phishing Attacks Detection Using Ensemble Machine Learning Algorithms
1 Department of Computer Science and Information Systems, College of Applied Sciences, Almaarefa University, Diriyah, Riyadh, 13713, Saudi Arabia
2 Applied College, King Faisal University, Al-Ahsa, 31982, Saudi Arabia
3 Department of Management Information Systems, College of Business Administration, King Faisal University, Al-Ahsa, 31982, Saudi Arabia
4 Department of Computer Science, Faculty of Computer Science and Information Technology, Jerash University, Jerash, 26110, Jordan
5 Department of Business Intelligence and Data Analysis, Faculty of Financial Sciences and Business, Irbid National University, Irbid, 21110, Jordan
6 Faculty of Information Technology, Ajloun National University, Ajloun, 26767, Jordan
* Corresponding Author: Marwan Abu-Zanona. Email:
Computers, Materials & Continua 2024, 80(1), 1325-1345. https://doi.org/10.32604/cmc.2024.051778
Received 15 March 2024; Accepted 03 June 2024; Issue published 18 July 2024
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Phishing, an Internet fraud where individuals are deceived into revealing critical personal and account information, poses a significant risk to both consumers and web-based institutions. Data indicates a persistent rise in phishing attacks. Moreover, these fraudulent schemes are progressively becoming more intricate, thereby rendering them more challenging to identify. Hence, it is imperative to utilize sophisticated algorithms to address this issue. Machine learning is a highly effective approach for identifying and uncovering these harmful behaviors. Machine learning (ML) approaches can identify common characteristics in most phishing assaults. In this paper, we propose an ensemble approach and compare it with six machine learning techniques to determine the type of website and whether it is normal or not based on two phishing datasets. After that, we used the normalization technique on the dataset to transform the range of all the features into the same range. The findings of this paper for all algorithms are as follows in the first dataset based on accuracy, precision, recall, and F1-score, respectively: Decision Tree (DT) (0.964, 0.961, 0.976, 0.968), Random Forest (RF) (0.970, 0.964, 0.984, 0.974), Gradient Boosting (GB) (0.960, 0.959, 0.971, 0.965), XGBoost (XGB) (0.973, 0.976, 0.976, 0.976), AdaBoost (0.934, 0.934, 0.950, 0.942), Multi Layer Perceptron (MLP) (0.970, 0.971, 0.976, 0.974) and Voting (0.978, 0.975, 0.987, 0.981). So, the Voting classifier gave the best results. While in the second dataset, all the algorithms gave the same results in four evaluation metrics, which indicates that each of them can effectively accomplish the prediction process. Also, this approach outperformed the previous work in detecting phishing websites with high accuracy, a lower false negative rate, a shorter prediction time, and a lower false positive rate.Keywords
The Internet has become a vital tool for individuals. In 2014, over 40% of the global population utilized the Internet, with industrialized countries experiencing a higher adoption rate of 78%. The North Atlantic Treaty Organization or NATO recognizes the Internet as a crucial asset for governments, an essential component of national infrastructures, and a significant catalyst for socio-economic progress and advancement [1]. The proliferation of Internet usage has led to the emergence of malicious code and malware that aim to infiltrate computer systems by attacking and destroying the information stored within them. These attacks are specifically crafted to collect users’ information, including credit card numbers and passwords, as well as to distribute information without the user’s consent. Malware is software that possesses the ability to do harm to data and systems [2,3]. The threat extends beyond individuals to encompass organizations, enterprises, and even governments, encompassing both civil and military infrastructures. These entities face the risk of losing vital information and damaging their reputation. Several instances have occurred in recent years when credit and debit cards have been unlawfully obtained from online payment systems, Google’s intellectual property has been unlawfully taken, and users’ personal information has been exposed, among other examples [4,5].
Various definitions exist for cybersecurity, one of which is provided by Kaspersky Lab: Cybersecurity refers to the act of safeguarding computers, servers, mobile devices, electronic systems, networks, and data from harmful attacks [6,7]. It is alternatively referred to as information technology security or electronic information security. The word encompasses a wide range of topics, including computer security, disaster recovery, and end-user education. Cybersecurity aims to safeguard personal, governmental, and business data from unauthorized access or alteration. It primarily involves three key tasks: (a) implementing measures to protect hardware, software, and the information they store, (b) ensuring the state or quality of protection against various threats, and (c) implementing and enhancing these activities [8,9].
In the dynamic realm of cybersecurity, characterized by more complex and varied threats, the use of machine learning (ML) has emerged as a crucial factor in strengthening digital security measures. ML enables cybersecurity experts to examine large information, identify irregularities, and forecast potential risks in real time. This innovative technology not only improves the efficiency and precision of identifying potential threats but also allows for proactive measures to be taken in response to developing cyber hazards [10,11]. Conventional security solutions frequently face difficulties in keeping up with the ever-changing nature of cyber threats. Given the vast amount and intricate nature of data produced by networks, systems, and users, conducting manual analysis becomes unfeasible. Machine learning algorithms are particularly adept at handling large datasets, detecting trends, and adjusting to changing attack methods. The flexibility of ML to adapt makes it a significant resource for addressing the always-evolving threat scenario [12].
Machine learning is utilized in multiple areas of cybersecurity, encompassing tasks such as recognizing harmful malware, identifying abnormal user actions, forecasting potential weaknesses, and automating incident response. Through the utilization of sophisticated algorithms, cybersecurity experts may maintain an advantageous position over cyber adversaries, thereby acquiring a proactive advantage in protecting vital digital resources. Nevertheless, this integration is not devoid of its difficulties. ML models necessitate meticulous training and validation to guarantee precision and mitigate the risk of erroneous positive or negative outcomes. Furthermore, the ethical considerations surrounding the use of automated systems in security settings and the possibility of adversarial assaults on machine learning models contribute to the intricacy of their implementation [13,14].
Phishing attacks continue to be a substantial menace to cybersecurity, presenting dangers to both individuals and companies. Phishers utilize diverse strategies to trick users into revealing sensitive information, such as login passwords, financial data, or personal information. Conventional rule-based techniques used to identify phishing assaults may have difficulties in keeping up with the ever-changing tactics used by malevolent individuals. Also, the nature of these attacks makes it difficult for humans to distinguish between legitimate and phishing attacks.
The objective of this research is to create a proficient system for detecting phishing attacks by utilizing a combination of machine learning techniques under an ensemble classifier. Ensemble method utilizes a combination of numerous base learners to enhance the accuracy of predictions and improve overall performance in generalization. Fig. 1 shows the problem statement formation of this research.
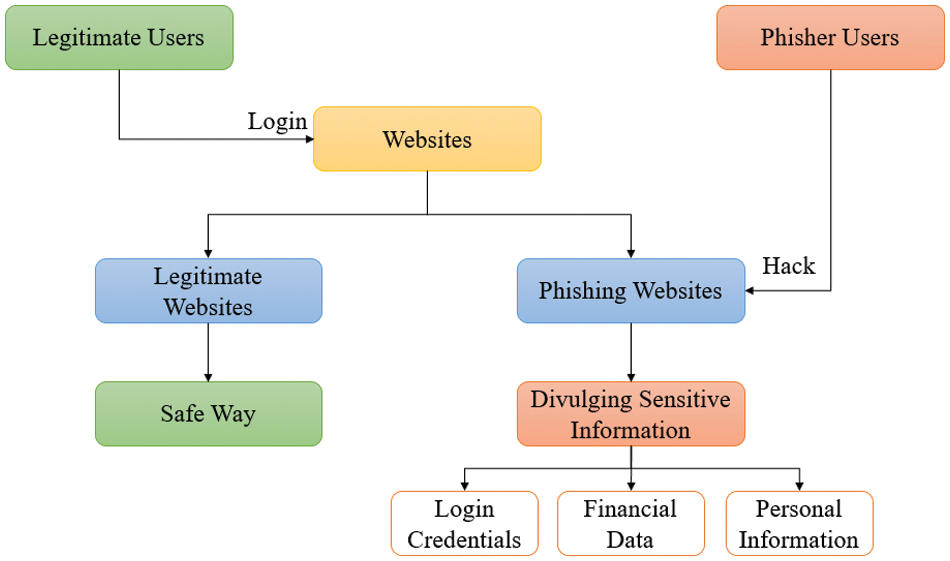
Figure 1: Problem statement formation
The reminder for this paper is organized as following sections: Section 2 presents the literature review. Section 3 describes the methodology used in terms of dataset, machine learning algorithm, and performance metrics. Section 4 describes the proposed ensemble learning approach. Section 5 explains and illustrates the experimental results for the two datasets. Section 6 discusses the findings. Finally, the conclusion of this paper and future work.
Table 1 shows the summary of the previous articles that are related to this study in terms of the machine learning algorithms used, the phishing dataset, preprocessing steps, evaluation metrics, and the performance results. Abutaha et al. [12] employed four machine learning methods: Gradient Boosting, Random Forest, Neural Network, and Support Vector Machine to detect a URL phishing. The dataset consisted of 1,056,937 URLs that were labelled as either phishing or legal. The dataset was processed to create 22 distinct features, which were subsequently reduced to a smaller set using several feature reduction approaches. They applied data preprocessing to the dataset, such as remove 14,786 duplicate records and handle missing values. To assess the algorithms performance, they used five evaluation metrics: precision, recall, F1-score, false positive rate, and accuracy. The findings demonstrated that Support Vector Machine attained the highest level of accuracy in identifying the examined URLs, with an accuracy value of 97.3%. The method can be integrated with add-on/middleware functionalities in Internet browsers to notify online users whenever they attempt to enter a phishing website only based on its URL. Abu-Nimeh et al. [13] utilized ML methods: support vector machines (SVM), classification and regression trees (CART), logistic regression (LR), Bayesian additive regression trees (BART), random forests (RF), and neural networks (NNet), to forecast phishing websites. The dataset utilized consisted of 2889 websites, comprising both phishing and legitimate websites. This dataset was employed in the training and testing processes, utilizing a total of 43 characteristics. Four assessment criteria were employed to analyze the performance of the algorithms: area under the ROC curve (AUC), precision, F1-score, and recall, they have shown that the RF algorithm achieved the highest performance in predicting phishing websites, with an AUC of 0.9442.
Samad et al. [14] introduced a multi-layer strategy to reduce the consequences of spear-phishing attacks, which are highly successful phishing attacks because of the social and psychological obstacles they provide. The proposed methodology utilized both the textual content and accompanying files of an email in order to combat phishing campaigns. They utilized sentiment analysis techniques, specifically SVM and RF classifiers, to categorize websites as either spam or non-spam. This approach yielded impressive accuracy rates. They utilized a dataset sourced from the Kaggle platform, comprising 3000 websites that were categorized as either spam or non-spam. In addition, they utilized Latent Dirichlet Allocation (LDA) for topic modeling in order to identify the prevailing topics within the dataset. They have demonstrated that the RF algorithm achieved the highest accuracy of 97% in comparison to the other algorithms during the detecting procedure. In their study, Yadav et al. [15] examined the application of machine learning algorithms for the identification of phishing websites. Their concentration was on feature selection, a process that entails analyzing and reducing a complicated data set to a smaller dimension by considering several attributes. They utilized a dataset consisting of 1500 data tuples obtained from the SPAMASSASIAN corpus, along with a separate validation dataset comprised of websites sourced from Gmail users. The data was preprocessed by techniques such as HTML parsing, data cleansing, stemming, stop word deletion, and tokenization. The study utilized three machine learning classification techniques, including J48, random forest, and logistic regression, to forecast the occurrence of phishing and non-phishing websites. The random forest method demonstrated superior performance in the prediction process, achieving a precision rate of 99% and an accuracy rate of 97.4%.
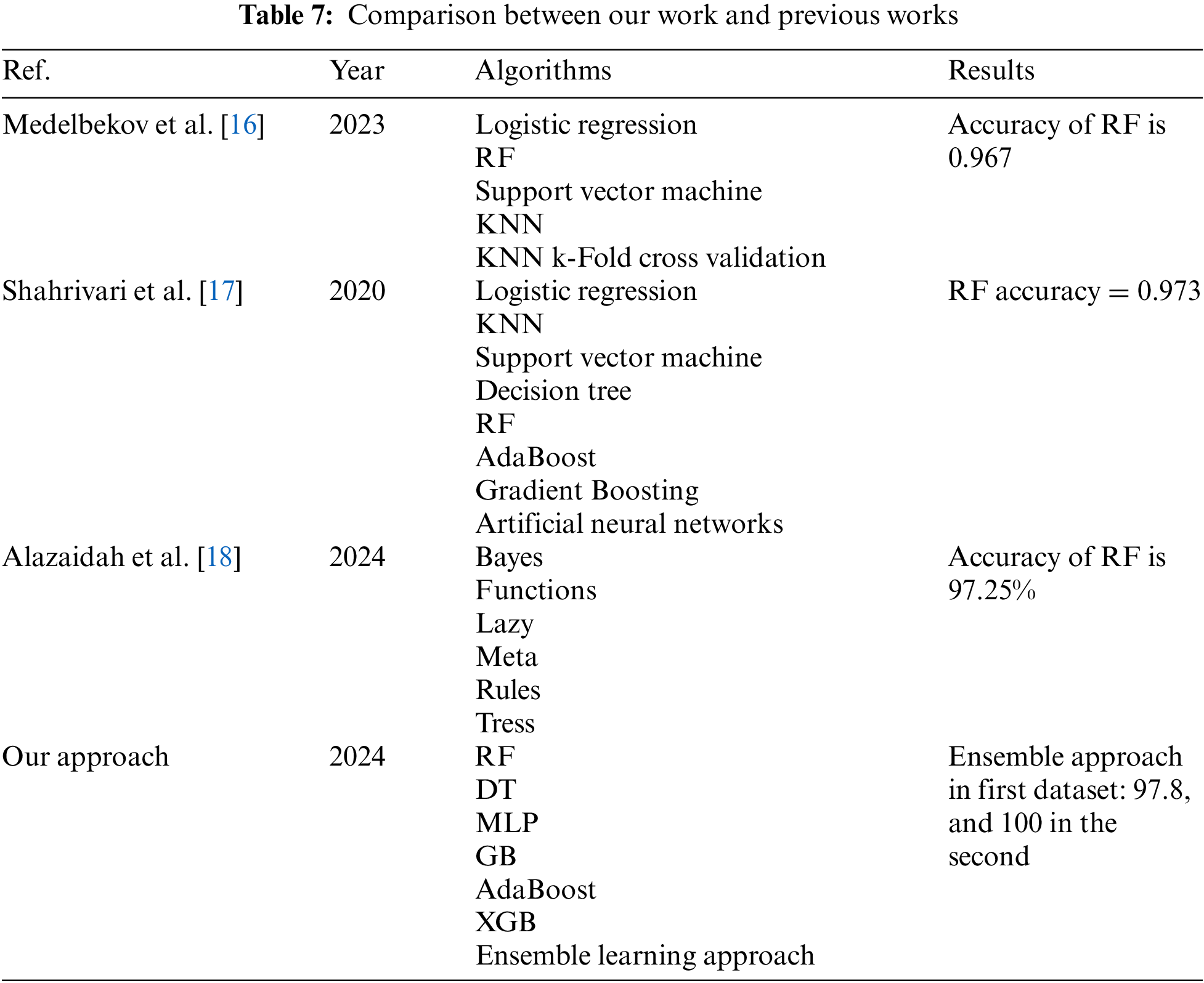
Medelbekov et al. [16] conducted an independent analysis and created a model to identify phishing sites. The researchers utilized a phishing dataset comprising 30 distinct characteristics and a total of 11,055 instances. These instances were categorized into three classes: 0 denoting suspicious, −1 denoting legitimate, and 1 denoting phishing. The model was trained using five algorithms: LR, SVM, RF, K-nearest neighbors, and KNN k-Fold Cross Validation. Four assessment measures were employed to analyze the performance of the algorithms: accuracy, recall, F1-score, and precision. The Random Forest algorithm demonstrated superior performance in the detection process when compared to other methods. Specifically, it achieved an accuracy of 0.967, precision of 0.90, recall of 0.946, and a F1-score of 0.963. Shahrivari et al. [17] used machine learning algorithms (LR, KNN, SVM, Decision Tree, RF, AdaBoost, Gradient Boosting, and Artificial Neural Networks) to predict the phishing websites based on a phishing dataset. They used the phishing website dataset that contains 11,055 websites with 32 attributes divided into legitimate, and phishing. Then, they used four classification metrics to evaluate the performance of these algorithms in prediction process: accuracy, recall, F1-score, and precision. They have shown that the RF gave the best performance results in the prediction phishing websites as a follow: 0.972682 of accuracy, 0.981484 of precision, 0.969852 of recall, and 0.975622 of F1-score.
Alazaidah et al. [18] determined the most effective classifier for detecting phishing out of twenty-four different classifiers representing six learning methodologies in machine learning. They are utilizing two datasets pertaining to Phishing with distinct properties. The initial dataset is a binary classification dataset. The dataset has 30 integer features, with the majority of them being binary. There are 11,055 instances in this collection. The second dataset is a multiclass dataset with three class labels. It has 9 integer-type features and 1353 instances. The classifiers are divided into six groups: Bayes (Bayes Net, Naïve Bayes, Naïve Bayes Updateable), Functions (Logistic Regression, Multilayer Perceptron, Simple Logistic, SMO-C), Lazy (IBk, K-Star, LWL), Meta (AdaBoostM1, Filtered Classifier, LogitBoost, MultiClass Classifier, Random Committee), Rules (Decision Table, JRip, PART, Zero), and Trees (Decision Stump, J48, LMT, Random Forest, and Random Tree). They assessed the performance of these classifiers using eight evaluation metrics: Accuracy, True Positive, False Positive, Precision, Recall, F1-score, MCC, and ROC Area. They showed that Random Forest, Filtered Classifier, and J48 classifiers were the most effective in identifying phishing websites.
This section presents the methodology used in this paper, which contains three steps: the datasets used, the machine learning algorithms used to build the models, and the performance metrics applied to assess the algorithms performance. In the first step, we describe the datasets in terms of the number of features with brief information, the number of instances, and the frequency of websites divided into two groups: legitimate and phishing. In the second step, the building models are explained, and the performance metrics that are used are presented in the third step: accuracy, F1-score, recall, and precision.
We used two phishing websites datasets that contain many characteristics related to the websites. Each dataset has different features and number of instances.
1) First Dataset1: This dataset contains 11,055 instances with 32 features that is related to the website’s information divided into two groups: legitimate, and phishing, as shown in Table 2.
Fig. 2 shows the frequency of the websites divided into two groups: legitimate, and phishing. Fig. 3 shows the snapshots of the first dataset.
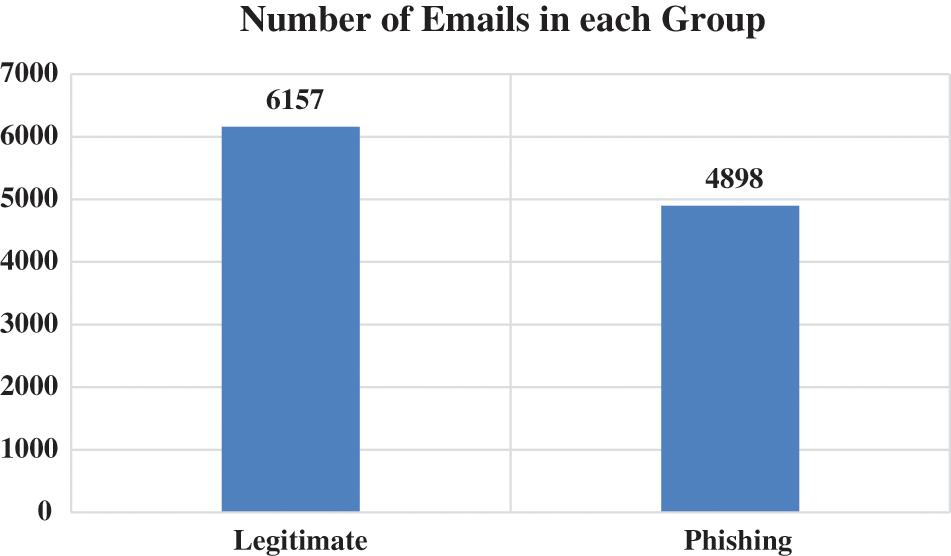
Figure 2: Dataset frequency–first dataset
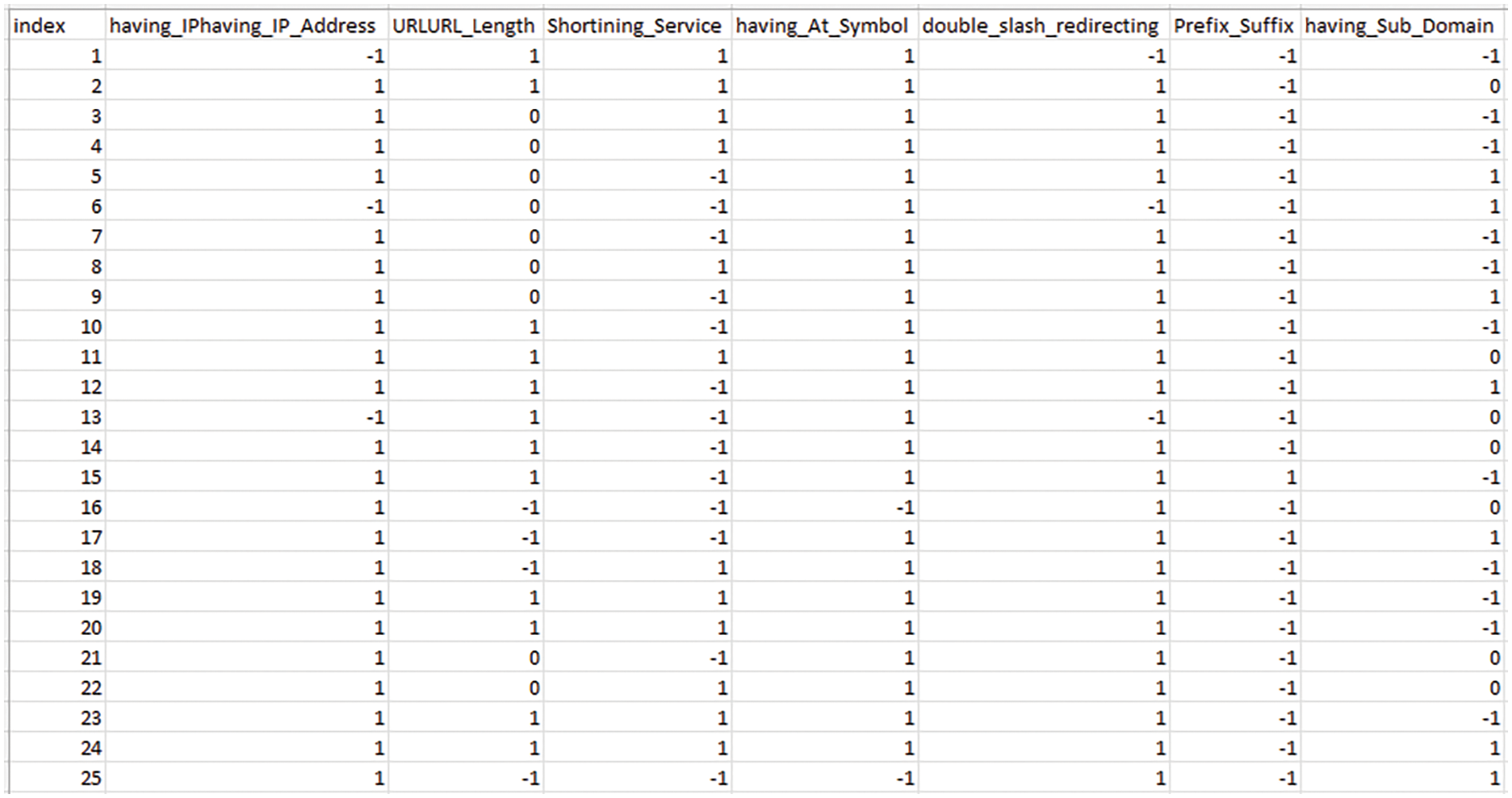
Figure 3: First dataset snapshot
2) Second Dataset2: This dataset contains 10,000 instances with 50 features hat is related to the website’s information divided into two groups: legitimate, and phishing, as shown in Table 3.
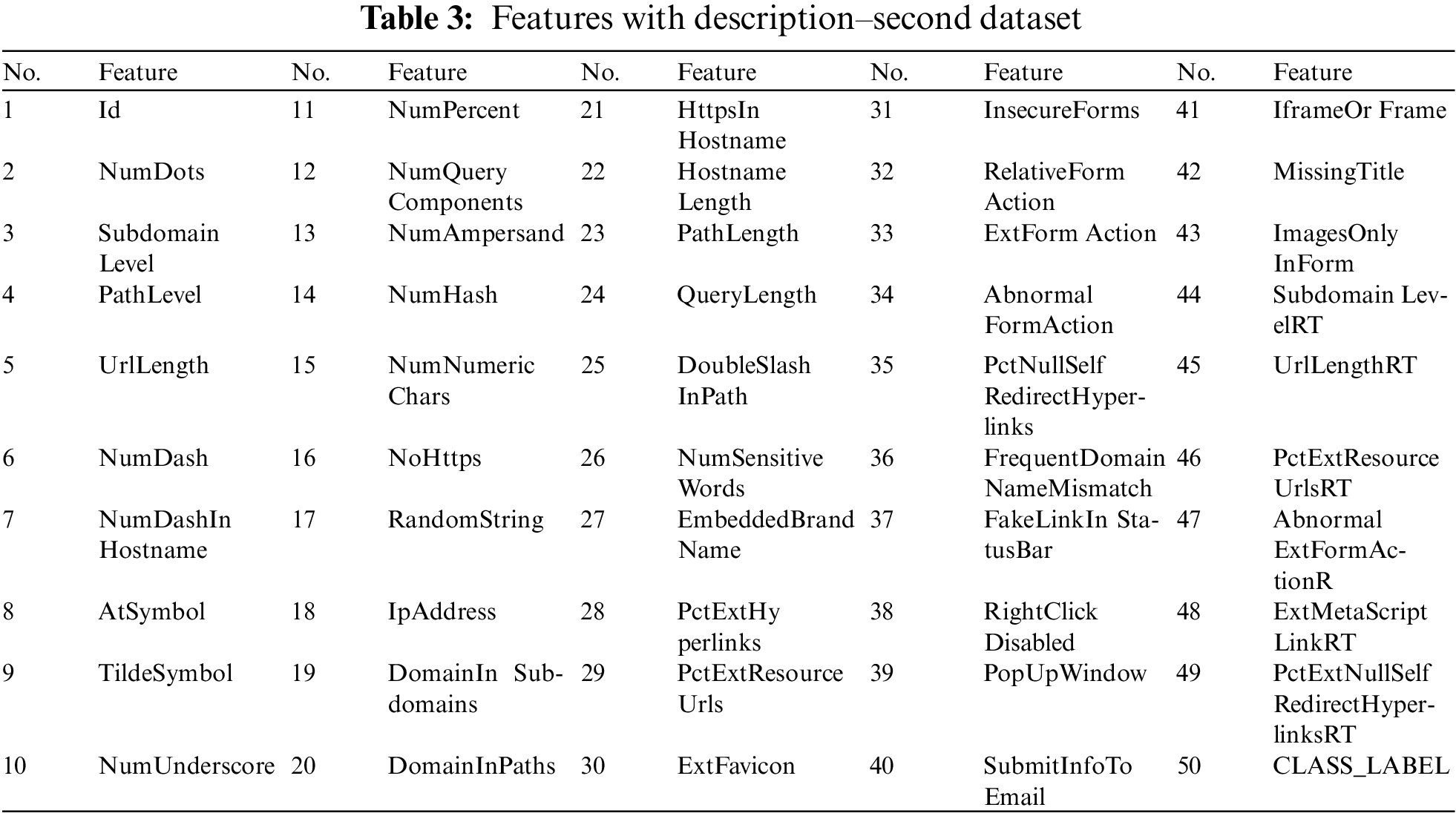
Fig. 4 shows the frequency of the websites of two class labels for the second dataset and Fig. 5 shows the snapshot of this dataset.
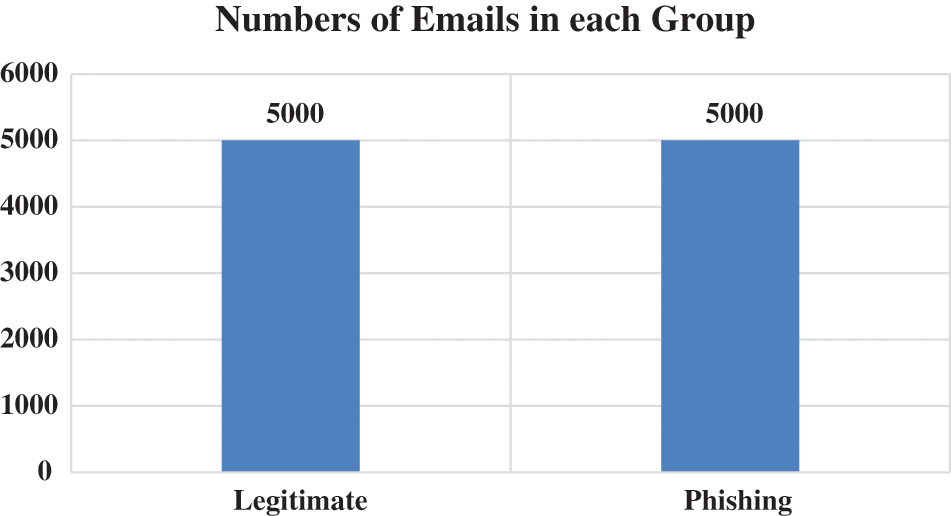
Figure 4: Dataset frequency–second dataset
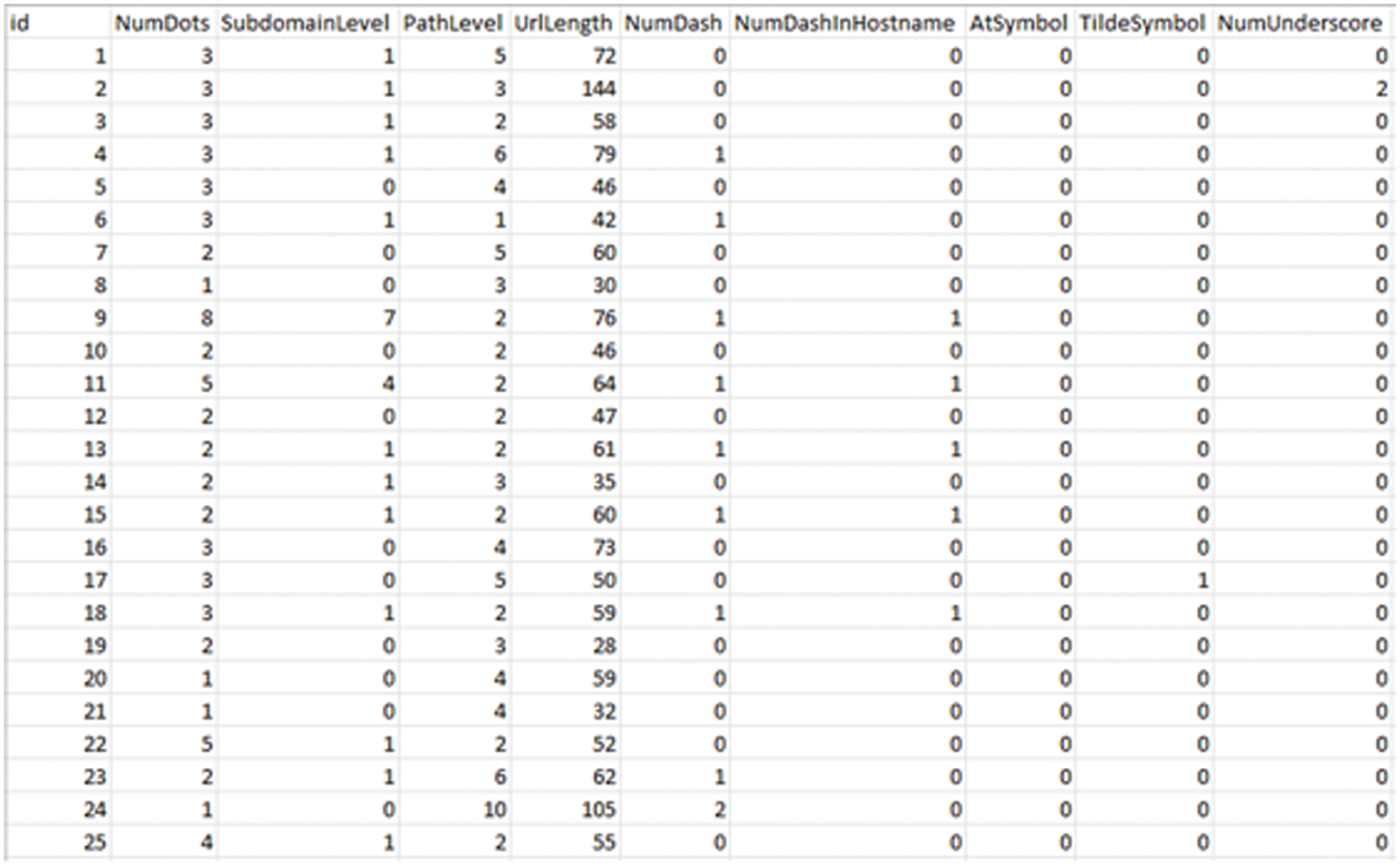
Figure 5: Second dataset snapshot
We applied seven classification machine learning algorithms on each dataset to predict the type of website whether legitimate or phishing. Machine learning algorithms are computational models that enable computers to discern patterns and make predictions or decisions based on data, without requiring explicit programming. These algorithms are fundamental to contemporary artificial intelligence and are applied in several domains such as image and audio recognition, natural language processing, recommendation systems, fraud detection, phishing websites and autonomous vehicles.
3.2.1 Random Forest (RF) Algorithm
Random forests utilize ensemble learning, a technique that mixes many decision trees to generate predictions for both classification and regression tasks. Ensemble learning has various advantages in machine learning, such as enhanced performance, resilience, and the capability to tackle intricate issues. Random forests employ ensemble learning methodologies to augment their prediction capability. In the classification task, the RF calculate the prediction average for all trees, while it is computing the mean for the regression task [19]. Decision trees are the essential building elements that form the core of random forests. Decision trees are hierarchical models that use binary splits on features to produce predictions. Every division partitions the data into smaller subsets according to specific criteria, ultimately resulting in the prediction of a target variable [20].
Random forests can enhance accuracy, mitigate overfitting, and effectively address intricate problems by amalgamating the predictions of many decision trees. By utilizing an aggregation of decision trees, random forests are able to effectively capture many facets of the data, resulting in more resilient predictions. In the Eq. (1), the RF compute the final prediction denoted by y, hi(x) is the prediction for each decisions tree, and the N refers to the number of trees.
3.2.2 Decision Tree Algorithm (DT)
Decision trees are utilized for the purpose of classifying and regressing jobs, offering models that are straightforward and comprehensible. Decision tree is a hierarchical model utilized in decision support systems to illustrate actions and their possible outcomes, taking into account chance events, resource expenditures, and utility. The tree structure consists of a central root node, which is connected to other nodes through branches [21]. These nodes might be internal nodes or leaf nodes, creating a hierarchical and tree-like arrangement. The idea of this algorithm in the prediction process is it splitting the data into groups and sub groups. These groups have a root node that it selected based on many methods like entropy, information gain, gain ratio, and gini index, in this paper, we select the entropy as a main method in splitting process. The formula of this method is shown in Eq. (2) [22]:
where, H(S) is the entropy of the dataset S, p+ is the proportion of positive instances (samples belonging to the positive class) in the dataset S, and p− is the proportion of negative instances (samples belonging to the negative class) in the dataset S.
3.2.3 Multilayer Perceptron Algorithm (MLP)
A nodes, commonly referred to as neurons or perceptrons. The neural network architecture is a feedforward design, indicating that information is transmitted in a unidirectional manner from the input layer, to the hidden layers, and finally to the output layer. MLPs are extensively employed for diverse tasks such as pattern recognition, classification, regression, and other applications. The MLP contains three layers: input, hidden and output [23,24]. 1) Input Layer: The first layer of the network, where the input features are fed into the network. Each node in this layer represents a feature of the input data. 2) Hidden Layers: Intermediate layers between the input and output layers. These layers are responsible for learning complex patterns and representations from the input data. 3) Output Layer: The final layer of the network, which produces the output or prediction. The number of nodes in this layer depends on the type of task (e.g., binary classification, multiclass classification, regression).
The formula of this method is shown in Eq. (3):
where, aj is the output of neuron j in a particular layer, f() is the activation function applied to the weighted sum of inputs, wij is the weight of the connection between the ith neuron in the previous layer and the jth neuron in the current layer, xi is the output of the ith neuron in the previous layer, and bj is the bias associated with neuron j.
3.2.4 eXtreme Gradient Boosting Algorithm (XGB)
XGBoost, also known as eXtreme Gradient Boosting, is a machine learning technique that falls under the category of ensemble learning. Supervised learning tasks, such as regression and classification, are now fashionable. XGBoost constructs a prognostic model by amalgamating the prognostications of numerous independent models, frequently decision trees, in an iterative fashion. The method operates by progressively including weak learners into the ensemble, with each subsequent learner specifically targeting the rectification of faults produced by the preceding ones. The system employs a gradient descent optimization method to minimize a predetermined loss function while undergoing training. The XGBoost algorithm possesses several notable characteristics [25]. It excels at handling intricate relationships within data, use regularization approaches to mitigate overfitting, and incorporates parallel processing for enhanced computational efficiency. XGBoost is extensively utilized in several fields owing to its exceptional predicted accuracy and adaptability over a wide range of datasets. The formula of this method is shown in Eq. (4) [26]:
where, n is the number of training instances, K is the number of trees in the model, fk represents the kth tree, and Ω(fk) is the regularization term which penalizes complexity of the model to prevent overfitting.
Within the realm of machine learning models, there are a variety of possibilities to select from, and AdaBoost is among them. It belongs to the family of advanced ensemble learning models that trains a sequence of weak classifiers on distinct subsets of the training data in an iterative manner. In each iteration, the algorithm increases the weights of the samples that were categorized incorrectly in the previous iteration. This allows the system to priorities the more difficult examples. This approach enables the succeeding weak classifiers to allocate greater focus to the previously misclassified examples, hence enhancing their performance. Adaptive boosting is a technique used to minimize the error of a machine-learning algorithm. It achieves this by combining multiple weak machine-learning models into a single, more powerful model. The formula of this method is shown in Eq. (5) [27,28]:
where, H(x) is the strong learner, h(x) is the weak learner, and sign (⋅) is the sign function which returns −1 for negative values and 1 for non-negative values.
3.2.6 Gradient Boosting (GB) Algorithm
Gradient Boosting is a robust machine learning method employed for solving regression and classification tasks. It is a member of the ensemble learning methods category, in which numerous weak learners (models that perform somewhat better than random guessing) are integrated to form a powerful learner. Gradient Boosting constructs models in a progressive manner, where each subsequent model is designed to specifically address the faults generated by the preceding models, The formula of this method is shown in Eq. (6) [29]:
where, F(X) is the strong learner, h(x) is the weak learner, and om is the optimal step size(learning rate).
The experimental results for the aforementioned machine learning are based on four evaluation metrics: precision, recall, F1-score, and accuracy. The formula for each metric and shallow explanation are shown below, where FN refers to False Negative, TP refers to True Positive, TN refers to True Negative and FP refers to False Positive [30]:
• Accuracy is computed by divided the ratio of samples that are correctly predicted to the total number of samples.
• Precision is computed by divided the ratio of positive samples that are correctly predicted to the total number of expected positive samples.
• The ratio of true positive samples in the dataset to the total number of predicted positive samples is referred to as the Recall.
• F1-score is the average of Recall and Precision.
4 Proposed Ensemble Learning Approach
4.1 Proposed Approach Overview
The proposed approach used in this paper is a Voting classifier that combined the best three machine leaning algorithms: RF, XGB and MLP. This classifier is applied on thew two phishing datasets to predict the type of the website if it normal or malicious.
Data preprocessing is an essential stage in machine learning and data analysis. Data preprocessing include the tasks of cleansing, converting, and structuring unprocessed data into a usable format for model training or analysis. In this paper, we applied a normalization method as a preprocessing step. We relied on a Python library to apply this step, which is called MinMaxScaler. MinMaxScaler is a preprocessing method employed to rescale numerical characteristics to a predetermined range, typically ranging from 0 to 1, as shown in Eq. (1), where x is the required sample to be normalized, and i is the index in the dataset [31].
This is accomplished by converting the data using the lowest and highest values of each characteristic. The MinMaxScaler class from the sklearn.preprocessing module in the scikit-learn library can be utilized in Python. Figs. 6 and 7 illustrate the examples from two dataset after applied this step.
Figure 6: First dataset–applied MinMaxScalar
Figure 7: Second dataset–applied MinMaxScalar
4.3 Training Machine Learning Classifiers
The training data contained labels indicating whether a specific output corresponded to an expected class. The primary objective is to train the learning model to accurately identify the location of unfamiliar data by comparing it to the reference data. Nevertheless, we discovered that in several instances, a solitary learning model may have yielded the optimal outcomes or the least number of errors. Consequently, we implemented an ensemble learning approach that entailed creating many hypotheses based on the training data and integrating them to accurately identify the position of the sample. By amalgamating the decisions from many models, this strategy significantly improved the overall efficiency of the model, leading to heightened accuracy in the outputs. Furthermore, this method resulted in a stable and more resilient model compared to separate models. In order to construct our ensemble model, we methodically carry out the training process for each machine learning classifier that comprises our ensemble. The classifiers mentioned in Section 3.2 encompass the Random Forest, XGBoost, Gradient Boosting, DT, MLP, and AdaBoost Classifiers. The varied structures, hyperparameters, and distinct capabilities of each classifier play a crucial role in facilitating a comprehensive learning process. These trained classifiers are subsequently used as the foundation for the ensemble approach. This strategy enhances the ensemble’s ability to detect malicious actions in loT situations by using Weighted Voting.
4.4 Ensemble Voting Classifier
A Voting classifier is a machine learning model that is trained on an ensemble of many models and makes predictions by selecting the class with the highest probability among the models. The Voting classifier combines the results of multiple classifiers and predicts the output class based on the majority vote, as shown in Fig. 8. The concept involves consolidating individual specialized models and determining their accuracy. Instead of constructing separate models and evaluating their correctness individually, we develop a unified model that trains on these models and predicts the output by considering the majority vote from each model for each output class. Eq. (12) shows the formula of Voting classifier that combined three machine learning algorithms: RF, XGB, and MLP, where: Pi is the prediction for each classifier, and the Wi denotes the wight assigned to the prediction for the classifier [32,33]. The reason behind the selection process of these classifiers was they gave the best performance results individually compared with the others. The strategy of combining these classifiers is each classifier gives a prediction value and the prediction class is determined by considering the majority vote.
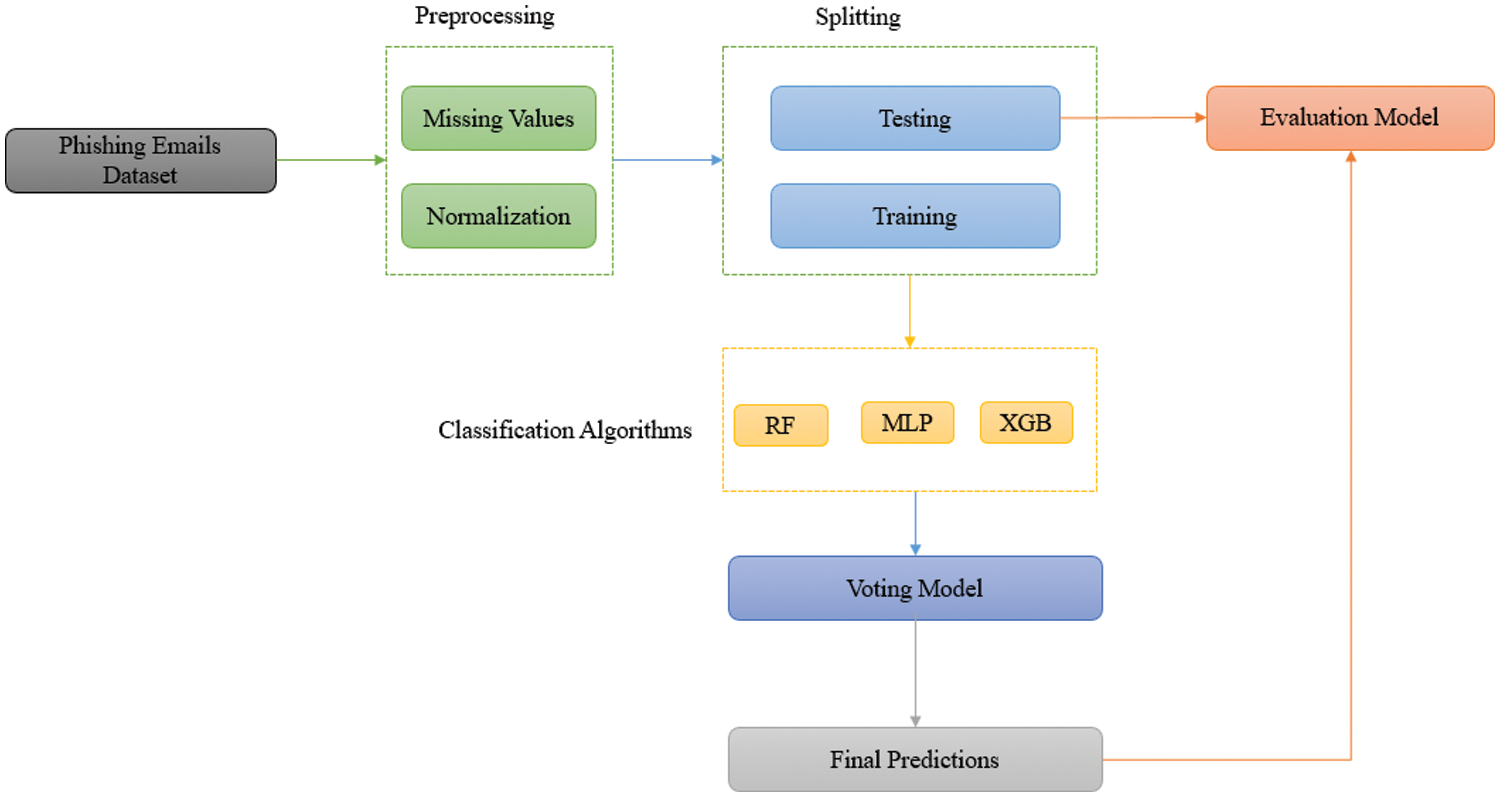
Figure 8: Flow chart of Voting algorithm
This section explained our findings by applied seven machine learning techniques on two datasets based on the above evaluation metrics: recall, accuracy, F1-score, and precision. Then, we analysis the experiments setup for each algorithm that include the parameters used with their values.
This section presents experimental setup, as shown in Table 4, for the machine learning algorithms used in this paper in order to detect the phishing attacks in phishing websites datasets.
Before the dataset fed to machine learning algorithms, it must be divided into two groups: testing and training. The training dataset is used to build the models based on these algorithms, while the testing dataset is used to assess the models’ performance that are built. In this paper, the ratio of the training and testing is as follows: 0.90 of whole dataset is used in training process and the remainder is used in testing process.
This section presents the results that obtained in this paper after applied the six machine leaning algorithms: RF, DT, MLP, XGB, AdaBoost, and GB in two phishing datasets. We conducted these experiments on Anaconda environment for binary classification task. Then, we compared the results with Voting classifier based on four evaluation metrics: accuracy, recall, F1-score, and precision.
Fig. 9 and Table 5 show the findings for each algorithm in each dataset. The Voting has the best performance results in prediction process compared with the rest of algorithms as follows: accuracy = 0.978, precision = 0.975, recall = 0.987, and F1-score = 0.981.
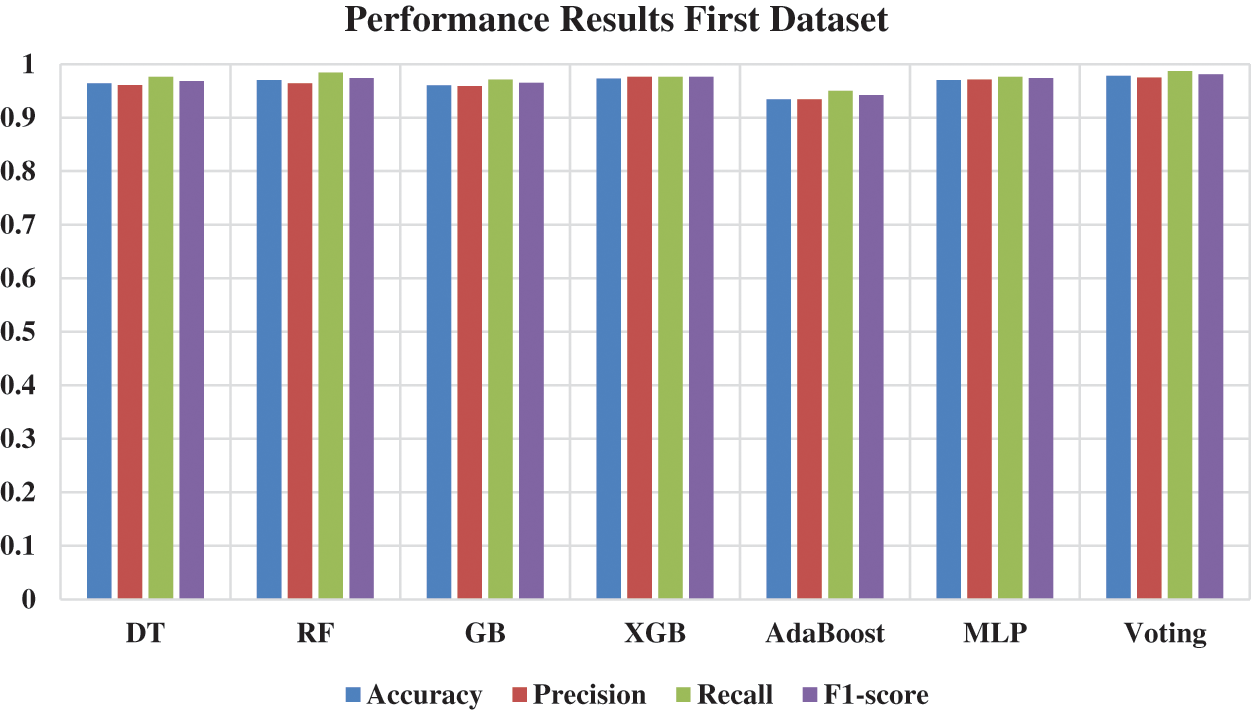
Figure 9: Performance results–first dataset
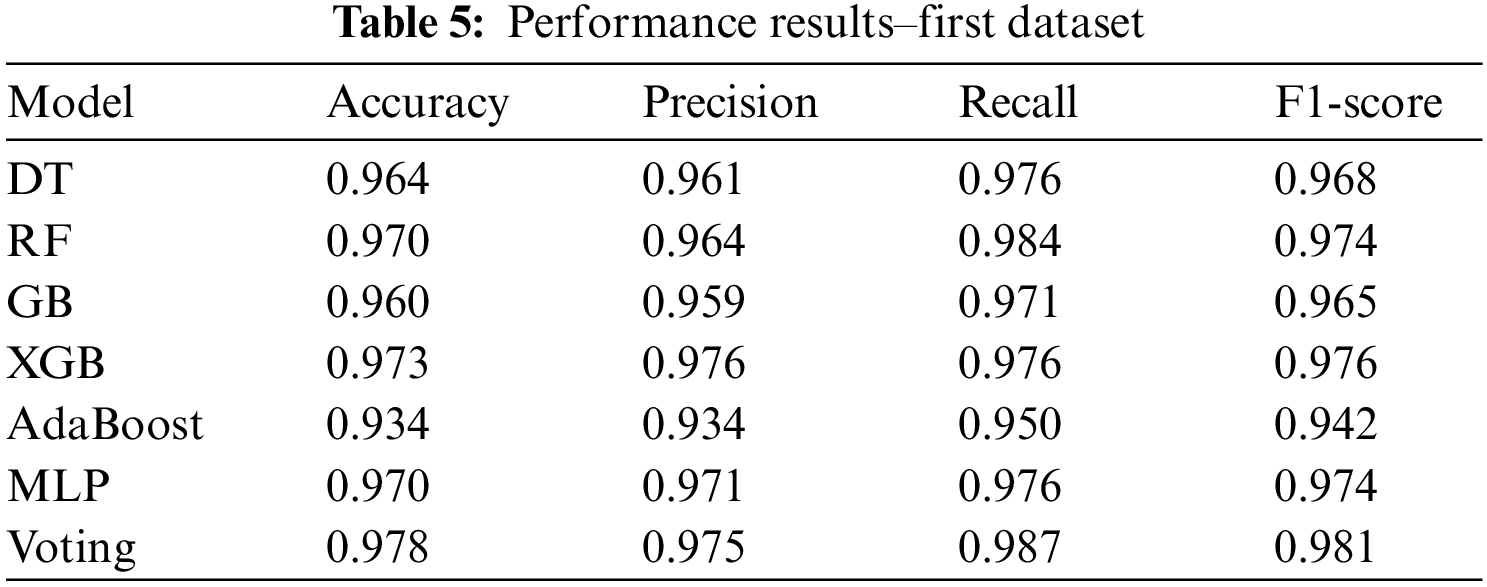
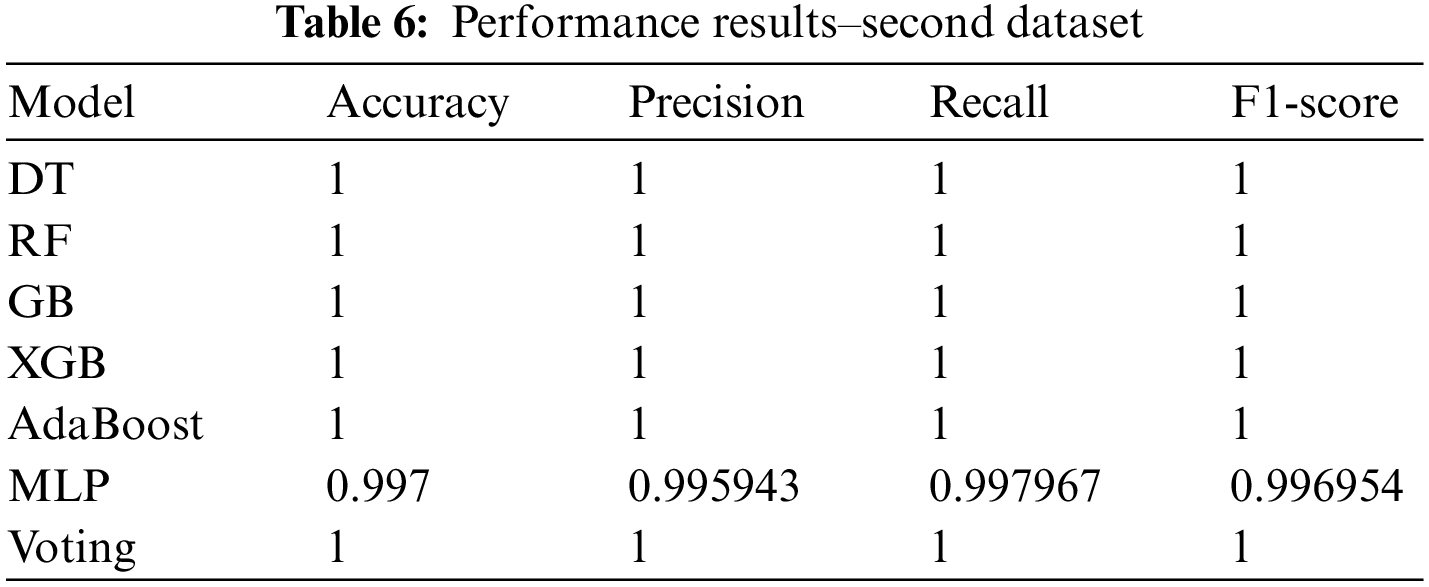
Fig. 10 and Table 6 show the findings for each algorithm in each dataset. All the algorithms gave the same results in four evaluation metrics, which indicates the each of them can effectively accomplish the prediction process.
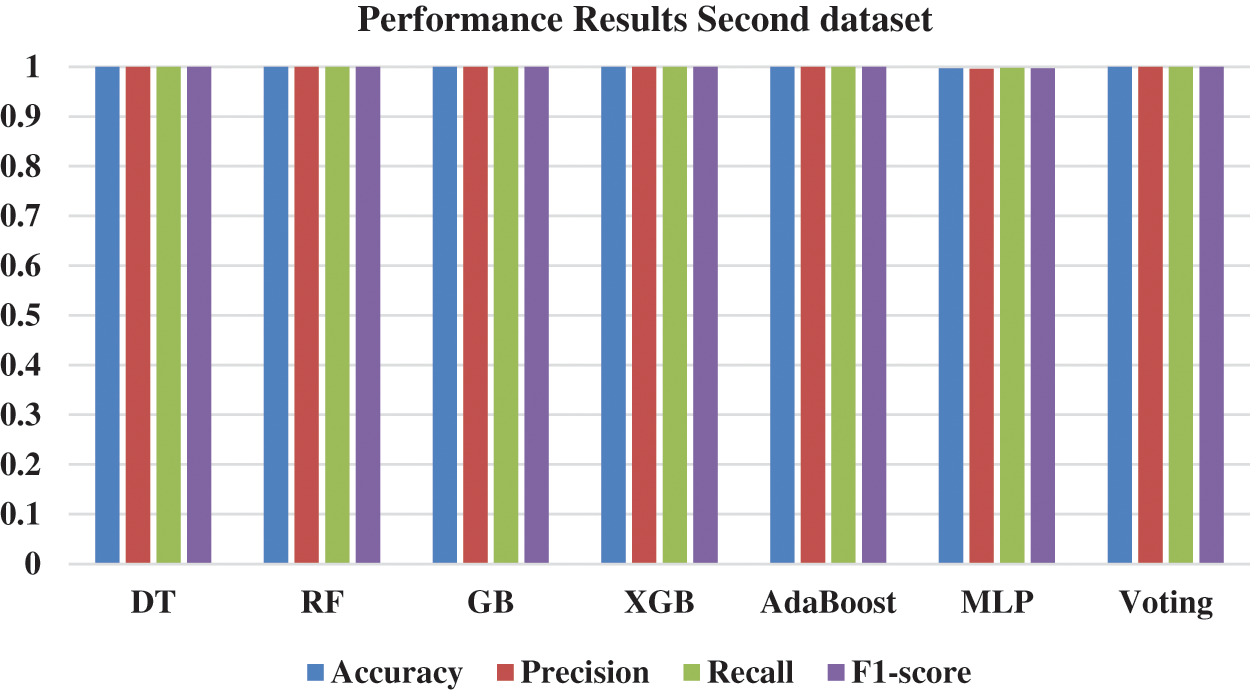
Figure 10: Performance results–second dataset
This section discusses and explains the findings obtained from the two experiments to detect phishing attacks in two phishing datasets. These findings are obtained based on seven machine learning algorithms: RF, DT, MLP, XGB, AdaBoost, GB, and a Voting classifier. The Voting classifier outperformed the other machine learning algorithms in this study and the previous studies in terms of accuracy, recall, F1-score, and precision in the first dataset. As shown in Table 7, Sindhu et al. [19] applied five machine algorithms to the first dataset, and the RF gave the best results with an accuracy of 0.967. Other papers, like Pandey et al. [20] used 8 algorithms, and Zhu et al. [21] used 24 classifiers, and the results were 97.26 and 97.25, respectively. In this study, we obtained a higher accuracy in the same dataset with 97.8. In the second dataset, to our knowledge, we did not find any study applying machine learning or deep learning to it. We gave higher results in the second dataset for all seven algorithms based on four evaluation metrics.
Based on our findings, we achieved the following goals:
1.1 We built a robust ensemble learning approach based on three algorithms (RF, XGB, and MLP) that gave the best detection accuracy in both datasets compared with the other algorithms in this study or in previous works.
1.2 In the detection process, we took less time compared with previous work, and we used the same computer settings.
1.3 The false negative and false positive rates are decreased by obtaining a higher accuracy value based on the robust approach that was built into both datasets.
The contributions of this paper are summarized in the below points:
1.1 Developing an ensemble learning methodology utilizing resilient machine learning algorithms to differentiate between authentic and phishing websites within a larger phishing dataset.
1.2 Achieving a high level of precision in distinguishing between genuine and phishing websites in order to minimize both incorrect identifications and missed detections. The goal is to ensure that the detection system effectively recognizes phishing attacks while minimizing the likelihood of erroneously labeling legitimate websites.
1.3 To minimize the occurrence of false positives in phishing detection, hence avoiding the incorrect identification of legitimate websites as phishing websites, which can lead to user annoyance and undermine confidence in the detection system. The objective is to find a balance between sensitivity and specificity, maximizing the accuracy of detection while decreasing the occurrence of false positives.
1.4 Improved Detection Accuracy: Machine learning algorithms have the ability to analyze large amounts of data to identify subtle patterns and characteristics that indicate phishing attacks. This leads to enhanced detection accuracy in comparison to traditional rule-based or heuristic methods.
Phishing, an online scam in which individuals are tricked into divulging important personal and financial details, presents a substantial threat to both consumers and Internet-based institutions. Evidence suggests a continuous increase in phishing attacks. Furthermore, these deceptive techniques are also growing more complex, making them more difficult to detect. Therefore, it is crucial to employ advanced algorithms to tackle this problem. Machine learning is an exceptionally efficient method for detecting and revealing these detrimental behaviors. Machine learning algorithms can detect shared attributes in the majority of phishing attacks. This paper utilizes seven machine learning methods to analyze two phishing datasets, aiming to classify the type of websites and establish its normality. Subsequently, we will employ the normalization procedure on the dataset to standardize the range of all the features to a uniform scale. The results indicated that the XGB algorithm demonstrates superior performance in the prediction process, achieving an accuracy of 0.978, precision of 0.975, recall of 0.987, and F1-score of 0.981 in the initial dataset. In the second dataset, all the algorithms yielded identical results across four evaluation measures, suggesting their same effectiveness in performing the prediction procedure. As a future work, we plan to: 1) Apply the deep learningalgorithms on the aforementioned dataset and another machine learning. 2) Apply feature selection methods, 3) the ensemble model will be generalized, and 4) study the impact of another data preprocessing techniques.
Acknowledgement: Nisreen Innab would like to express sincere gratitude to AlMaarefa University, Riyadh, Saudi Arabia, for supporting this research. Ahmed, Mohamed and Marwan extend sincere thanks and appreciation to the administration of King Faisal University in the Kingdom of Saudi Arabia for providing all forms of support to the university’s faculty members, especially in the field of scientific research.
Funding Statement: This article is funding from Deanship of Scientific Research in King Faisal University with Grant Number KFU 241085.
Author Contributions: Conceptualization: Ahmed Abdelgader Fadol Osman; methodology: Nisreen Innab; formal analysis: Mohammed Awad Mohammed Ataelfadiel and Marwan Abu-Zanona; original draft preparation: Farah H. Zawaideh, Mouiad Fadeil Alawneh; review and editing: Bassam Mohammad Elzaghmouri; visualization: Bassam Mohammad Elzaghmouri and Ahmed Abdelgader Fadol Osman; project administration: Nisreen Innab and Marwan Abu-Zanona . All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: Data is openly available in a public repository in section datasets.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
1https://www.kaggle.com/code/akashkr/phishing-url-eda-and-modelling/input (accessed on 01/05/2024).
2https://www.kaggle.com/datasets/amj464/phishing (accessed on 01/05/2024).
References
1. S. Villamil, C. Hernández, and G. Tarazona, “An overview of Internet of Things,” Telkomnika (Telecommunication Computing Electronics and Control), vol. 18, no. 5, pp. 2320–2327, 2020. doi: 10.12928/telkomnika.v18i5.15911. [Google Scholar] [CrossRef]
2. B. B. Gupta and M. Quamara, “An overview of Internet of Things (IoTArchitectural aspects, challenges, and protocols,” Concurr. Comput., vol. 32, no. 21, pp. e4946, 2020. doi: 10.1002/cpe.4946. [Google Scholar] [CrossRef]
3. Y. Li and Q. Liu, “A comprehensive review study of cyber-attacks and cyber security; Emerging trends and recent developments,” Energy Rep., vol. 7, no. 8, pp. 8176–8186, 2021. doi: 10.1016/j.egyr.2021.08.126. [Google Scholar] [CrossRef]
4. K. T. Smith, L. M. Smith, M. Burger, and E. S. Boyle, “Cyber terrorism cases and stock market valuation effects,” Inf. Comput. Secur., vol. 31, no. 4, pp. 385–403, 2023. doi: 10.1108/ICS-09-2022-0147. [Google Scholar] [CrossRef]
5. I. H. Sarker, “Deep cybersecurity: A comprehensive overview from neural network and deep learning perspective,” SN Comput. Sci., vol. 2, no. 3, pp. 154, 2021. doi: 10.1007/s42979-021-00535-6. [Google Scholar] [CrossRef]
6. D. Bhamare, M. Zolanvari, A. Erbad, R. Jain, K. Khan and N. Meskin, “Cybersecurity for industrial control systems: A survey,” Comput. Secur., vol. 89, pp. 101677, 2020. doi: 10.1016/j.cose.2019.101677. [Google Scholar] [CrossRef]
7. H. Kavak, J. J. Padilla, D. Vernon-Bido, S. Y. Diallo, R. Gore and S. Shetty, “Simulation for cybersecurity: State of the art and future directions,” J. Cybersecur., vol. 7, no. 1, pp. tyab005, 2021. doi: 10.1093/cybsec/tyab005. [Google Scholar] [CrossRef]
8. D. Dasgupta, Z. Akhtar, and S. Sen, “Machine learning in cybersecurity: A comprehensive survey,” The J. Def. Model. Simul., vol. 19, no. 1, pp. 57–106, 2022. doi: 10.1177/1548512920951275. [Google Scholar] [CrossRef]
9. K. Shaukat et al., “Performance comparison and current challenges of using machine learning techniques in cybersecurity,” Energies, vol. 13, no. 10, pp. 2509, 2020. doi: 10.3390/en13102509. [Google Scholar] [CrossRef]
10. T. Berghout, M. Benbouzid, and S. M. Muyeen, “Machine learning for cybersecurity in smart grids: A comprehensive review-based study on methods, solutions, and prospects,” Int. J. Crit. Infrastruct. Prot., vol. 38, no. 19, pp. 100547, 2022. doi: 10.1016/j.ijcip.2022.100547. [Google Scholar] [CrossRef]
11. I. D. Aiyanyo, H. Samuel, and H. Lim, “A systematic review of defensive and offensive cybersecurity with machine learning,” Appl. Sci., vol. 10, no. 17, pp. 5811, 2020. doi: 10.3390/app10175811. [Google Scholar] [CrossRef]
12. M. Abutaha, M. Ababneh, K. Mahmoud, and S. A. H. Baddar, “URL phishing detection using machine learning techniques based on URLs lexical analysis,” in 2021 12th Int. Conf. Inf. Commun. Syst. (ICICS), Valencia, Spain, IEEE, May 2021, pp. 147–152. [Google Scholar]
13. S. Abu-Nimeh, D. Nappa, X. Wang, and S. Nair, “A comparison of machine learning techniques for phishing detection,” in Proc. Anti-Phish. Work. Groups 2nd Annual eCrime Res. Summit, Oct. 2007, pp. 60–69. [Google Scholar]
14. D. Samad and G. A. Gani, “Analyzing and predicting spear-phishing using machine learning methods,” Multidiszciplináris Tudományok, vol. 10, no. 4, pp. 262–273, 2020. doi: 10.35925/j.multi.2020.4.30. [Google Scholar] [CrossRef]
15. N. Yadav and S. P. Panda, “Feature selection for email phishing detection using machine learning,” in Int. Conf. Innov. Comput. Commun.: Proc. ICICC 2021, Springer Singapore, 2022, vol. 2, pp. 365–378. doi: 10.1007/978-981-16-2597-8. [Google Scholar] [CrossRef]
16. M. Medelbekov, M. Nurtas, and A. Altaibek, “Machine learning methods for phishing attacks,” J. Problems Comput. Sci. Inf. Technol., vol. 1, no. 2, 2023. doi: 10.26577/JPCSIT.2023.v1.i2.02. [Google Scholar] [CrossRef]
17. V. Shahrivari, M. M. Darabi, and M. Izadi, “Phishing detection using machine learning techniques,” arXiv preprint arXiv:2009.11116, 2020. [Google Scholar]
18. R. Alazaidah et al., “Website phishing detection using machine learning techniques,” J. Stat. Appl. Probab., vol. 13, no. 1, pp. 119–129, 2024. doi: 10.18576/jsap/130108. [Google Scholar] [CrossRef]
19. S. Sindhu, S. P. Patil, A. Sreevalsan, F. Rahman, and M. S. AN, “Phishing detection using random forest, SVM and neural network with backpropagation,” in Int. Conf. Smart Technol. Comput., Electr. Electron. (ICSTCEE), IEEE, 2020, pp. 391–394. [Google Scholar]
20. A. Pandey, N. Gill, K. Sai Prasad Nadendla, and I. S. Thaseen, “Identification of phishing attack in websites using random forest-SVM hybrid model,” in Intell. Syst. Des. Appl.: 18th Int. Conf. Intell. Syst. Des. Appl. (ISDA 2018), Vellore, India, Springer International Publishing, 2020, vol. 941, pp. 120–128. [Google Scholar]
21. E. Zhu, Y. Ju, Z. Chen, F. Liu, and X. Fang, “DTOF-ANN: An artificial neural network phishing detection model based on decision tree and optimal features,” Appl. Soft Comput., vol. 95, no. 13, pp. 106505, 2020. doi: 10.1016/j.asoc.2020.106505. [Google Scholar] [CrossRef]
22. O. Kayode-Ajala, “Applying machine learning algorithms for detecting phishing websites: Applications of SVM, KNN, decision trees, and random forests,” Int. J. Inf. Cybersecur., vol. 6, no. 1, pp. 43–61, 2022. [Google Scholar]
23. S. Al-Ahmadi, “PDMLP: Phishing detection using multilayer perceptron,” Int. J. Netw. Secur. Appl. (IJNSA), vol. 12, pp. 59–72, 2020. [Google Scholar]
24. A. Odeh, I. Keshta, and E. Abdelfattah, “Efficient prediction of phishing websites using multilayer perceptron (MLP),” J. Theor. Appl. Inf. Technol., vol. 98, no. 16, pp. 3353–3363, 2020. [Google Scholar]
25. N. N. Naik, “Modelling enhanced phishing detection using XGBoost,” Doctoral dissertation, National College of Ireland, Dublin, 2021. [Google Scholar]
26. K. Joshi et al., “Machine-learning techniques for predicting phishing attacks in blockchain networks: A comparative study,” Algorithms, vol. 16, no. 8, pp. 366, 2023. doi: 10.3390/a16080366. [Google Scholar] [CrossRef]
27. B. Sharma and P. Singh, “An improved anti-phishing model utilizing TF-IDF and AdaBoost,” Concurr. Comput., vol. 34, no. 26, pp. e7287, 2022. [Google Scholar]
28. F. Nthurima, A. Mutua, and W. S. Titus, “Detecting phishing emails using random forest and AdaBoost classifier model,” 2023. doi: 10.32591/coas.ojit.0602.03123n. [Google Scholar] [CrossRef]
29. K. Omari, “Phishing detection using gradient boosting classifier,” Proc. Comput. Sci., vol. 230, no. 5, pp. 120–127, 2023. doi: 10.1016/j.procs.2023.12.067. [Google Scholar] [CrossRef]
30. P. Flach, “Performance evaluation in machine learning: The good, the bad, the ugly, and the way forward,” in Proc. AAAI Conf. Artif. Intell., vol. 33, no. 1, pp. 9808–9814, Jul. 2019. doi: 10.1609/aaai.v33i01.33019808. [Google Scholar] [CrossRef]
31. H. Shaheen, S. Agarwal, and P. Ranjan, “MinMaxScaler binary PSO for feature selection,” in First Int. Conf. Sustainable Technol. Comput. Intell.: Proc. ICTSCI 2019, Springer Singapore, 2020, pp. 705–716. [Google Scholar]
32. A. Dogan and D. Birant, “A weighted majority voting ensemble approach for classification,” in 2019 4th Int. Conf. Comput. Sci. Eng. (UBMK), IEEE, Sep. 2019, pp. 1–6. [Google Scholar]
33. T. N. Rincy and R. Gupta, “Ensemble learning techniques and its efficiency in machine learning: A survey,” in 2nd Int. Conf. Data, Eng. Appli. (IDEA), IEEE, Feb. 2020, pp. 1–6. [Google Scholar]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools