
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

MarkNeRF: Watermarking for Neural Radiance Field
1 Cryptographic Engineering Department, Institute of Cryptographic Engineering, Engineering University of PAP, Xi’an, 710086, China
2 Key Laboratory of Network and Information Security of PAP, Xi’an, 710086, China
* Corresponding Author: Jia Liu. Email:
(This article belongs to the Special Issue: Multimedia Security in Deep Learning)
Computers, Materials & Continua 2024, 80(1), 1235-1250. https://doi.org/10.32604/cmc.2024.051608
Received 10 March 2024; Accepted 01 June 2024; Issue published 18 July 2024
 View Full Text
View Full Text Download PDF
Download PDFAbstract
This paper presents a novel watermarking scheme designed to address the copyright protection challenges encountered with Neural radiation field (NeRF) models. We employ an embedding network to integrate the watermark into the images within the training set. Then, the NeRF model is utilized for 3D modeling. For copyright verification, a secret image is generated by inputting a confidential viewpoint into NeRF. On this basis, design an extraction network to extract embedded watermark images from confidential viewpoints. In the event of suspicion regarding the unauthorized usage of NeRF in a black-box scenario, the verifier can extract the watermark from the confidential viewpoint to authenticate the model’s copyright. The experimental results demonstrate not only the production of visually appealing watermarks but also robust resistance against various types of noise attacks, thereby substantiating the effectiveness of our approach in safeguarding NeRF.Keywords
Neural radiance field (NeRF) [1] is a technique employed for generating high-quality 3D reconstruction models. It utilizes neural networks to learn a continuous function mapping spatial coordinates to density and color, enabling the synthesis of novel viewpoints. NeRF has garnered significant attention in computer vision research [2–5]. It is foreseeable that, similar to the sharing of 2D images and videos, future trends will involve the online sharing of 3D content. Research on copyright protection for NeRF is currently limited, and training on NeRF has consistently posed a significant challenge. Consequently, safeguarding the copyright of NeRF models has emerged as an important and pressing issue.
Common copyright protection technologies include data encryption [6,7], digital watermarking [8–10], digital signatures [11], etc. However, since NeRF models need to be displayed to users and require a certain degree of robustness, data encryption and digital signature technologies are not applicable. Therefore, we have focused our discussion on digital watermarking. Digital watermarking embeds a copyright identifier into digital media through embedding algorithms. When a copyright dispute arises, the copyright owner can extract the watermark information from the media through the inverse operation of the embedding algorithm to confirm copyright ownership. Traditional watermarking algorithms [12] mainly rely on specific mathematical functions to modify the media for embedding watermarks. However, traditional algorithms often fail to achieve a good balance between imperceptibility, robustness, and watermark capacity. With the application of deep learning technology in the field of watermarking, the embedding and extraction methods of watermarks no longer require manually designing complex mathematical functions and demonstrate good performance. In deep learning watermarking [13], copyright owners embed watermark information into carrier images through encoders and extract watermark information from images containing watermarks processed through noise layers through decoders. The embedding and extraction process is close to a black box. However, although existing deep learning-based watermarking algorithms exhibit strong robustness, excellent imperceptibility, and large embedding capacity, most watermark algorithms are designed for multimedia data such as images, sound, and video, lacking research on watermark algorithms for implicit data like NeRF. One intuitive solution is to directly embed watermarks into samples rendered by NeRF models using existing watermark methods. However, this method only protects the copyright of rendered samples, not the NeRF model itself. If the NeRF model is stolen, malicious users may generate new samples using new rendering methods, making this method unsuitable for protecting 3D model copyrights. Traditional 3D data are primarily represented in the form of point clouds [14], voxels [15], or triangular meshes [16]. Copyright protection strategies for these types of 3D data generally fall into three categories: directly embedding watermarks by translating, rotating, or scaling 3D shapes [17]; modifying 3D model parameters to embed watermarks [18]; and employing deep learning techniques for watermark embedding [19]. However, NeRF models do not have specific structural information, so these methods cannot protect the copyright of NeRF.
Li et al. [20] established a connection between information hiding and NeRF, proposing the StegaNeRF scheme for information embedding. This approach involves training a standard NeRF model, which is subsequently utilized as a generator for generating new viewpoints. During the training process of the message extraction network, the NeRF network is trained twice to ensure accurate message extraction from the 2D images rendered from the StegaNeRF network. Additionally, Luo et al. [21] introduced the CopyRNeRF scheme, which employs watermark colors as a substitute for the original colors in NeRF to protect the model’s copyright. Furthermore, a distortion-resistant rendering scheme was designed to ensure robust information extraction in the 2D rendering of NeRF. This method directly safeguards the copyright of NeRF models while maintaining high rendering quality and bit precision. However, both of the aforementioned methods involve secondary training of NeRF, incurring substantial training costs.
To address the issue of needing to retrain the NeRF model for copyright protection purposes, in this paper we propose a novel watermarking algorithm tailored for NeRF. We employ a conventional approach, utilizing an embedding network to embed the watermark into the images within the training set. Then, we utilized the NeRF model for 3D modeling. Copyright validation is achieved by the generation of a secret image from a confidential viewpoint using the NeRF model, followed by the design of a watermark extractor using neural network overperparameterization techniques to extract the embedded watermark from this image. In a black-box scenario [22], when suspicion arises regarding the unauthorized use of 3D models, the verifier can extract the watermark from the confidential viewpoint to authenticate the model’s copyright. In order to fortify the model’s robustness, a noise layer was incorporated during the optimization process to achieve anti-distortion rendering. In the event of a malicious theft of the model, even when attackers employ diverse rendering methods or process the rendered image, the copyright verifier retains the capability to extract watermark information from the model. This paper makes the following contributions:
1. Our proposal presents a novel watermarking scheme for NeRF, taking advantage of its ability to generate new perspective images and utilize perspective information as the key. The security of the watermark algorithm is ensured by the continuity of perspective synthesis and the large key space.
2. To implement the watermarking scheme, we rely on traditional watermarking techniques and eliminate the requirement for secondary NeRF training. By training a simple extraction network, we extract watermarks from a specific perspective of the model.
3. To achieve robustness, we introduced a noise layer during the training process of the NeRF model, achieving anti distortion rendering.
This section describes the application scenarios of our algorithm and the specific details of algorithm implementation. Existing watermarking schemes for neural radiance fields require secondary training of the model, and the quality of watermark extraction is not high. Therefore, this paper proposes a black-box watermarking scheme for neural radiance fields, where we directly embed watermark information into the NeRF model without the need for secondary training of the model. By leveraging the ability of the NeRF model to synthesize new viewpoints, we use viewpoint information as a key and train an extractor to extract watermark information from secret viewpoint images. In real-world scenarios, when our model is stolen, we can prove the model’s copyright by extracting the watermark information using the key.

The specific process of the application scenario is shown in Fig. 1.
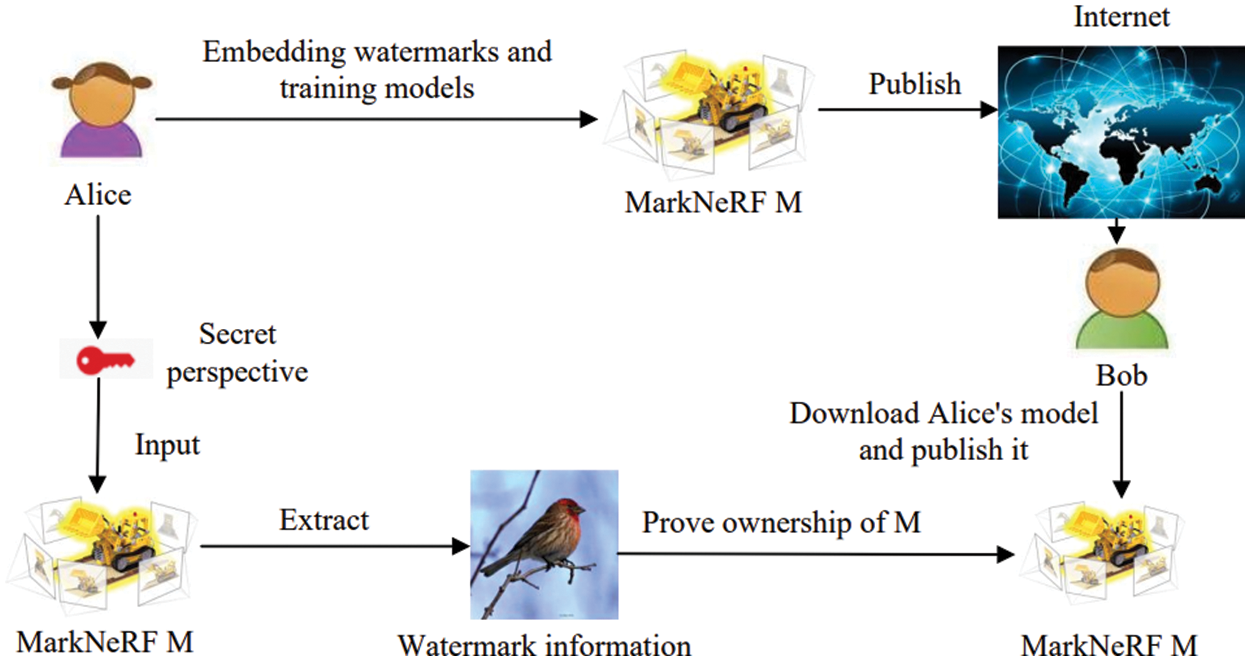
Figure 1: Application scenario process. The copyright owner embeds watermark information into the MarkNeRF model before publishing it on the Internet. In the event of malicious model theft, the copyright owner can extract the watermark from the model using the designated key
This approach comprises five key stages: watermark embedding, MarkNeRF training, noise layer processing, watermark extraction, and copyright verification. Fig. 2 shows the process of our scheme. The process begins with the embedding of the watermark W into the original image set
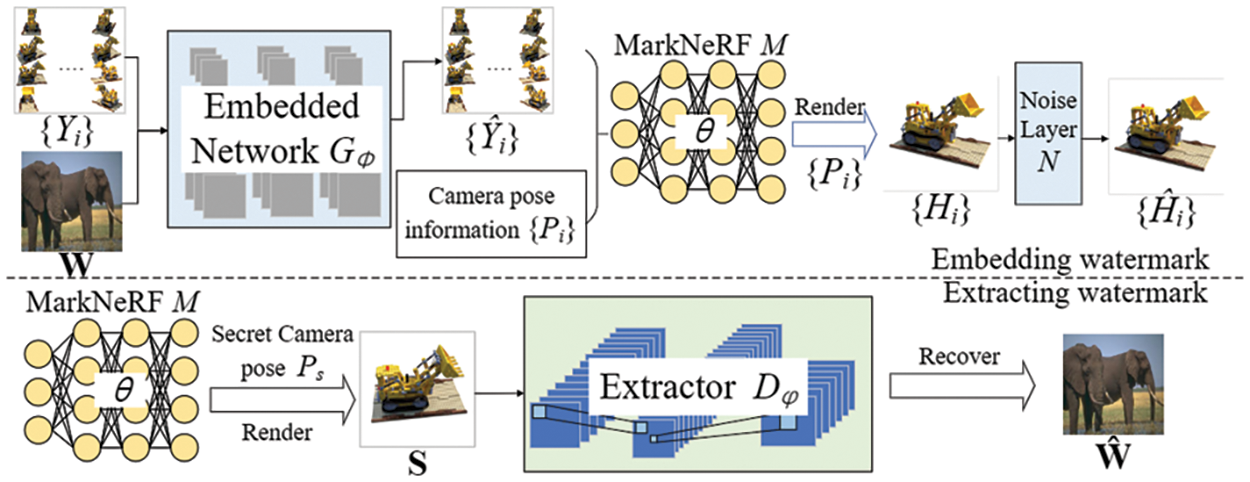
Figure 2: Algorithm process of MarkNeRF. The network is embedded to generate a set of watermarked images, after which the MarkNeRF model and extractor are trained. The attack layer is designed to simulate various types of noise attacks, while the extractor is responsible for extracting watermark information from a concealed perspective
Modeling. We treat embedding and extraction as two separate tasks, and define the processes for embedding and extraction as follows:
Furthermore, the embedding and extraction procedures, we conducted training for MarkNeRF M and applied a noise layer to the rendered image. The overall process can be described as follows:
subject to
We utilized a joint learning approach for the embedding and extraction of watermarks, with the aim of achieving copyright protection for NeRF. A noise layer has been employed to mimic the behavior of potential attackers in the implementation of N. Even if the attacker obtains the model through secondary training without changing the perspective, we can still extract watermarks from the model, making the method proposed in this paper robust.
Embedding. Drawing upon the remarkable capacity and superior image quality of the encoding-decoding network proposed in [23], we developed an embedding network denoted as
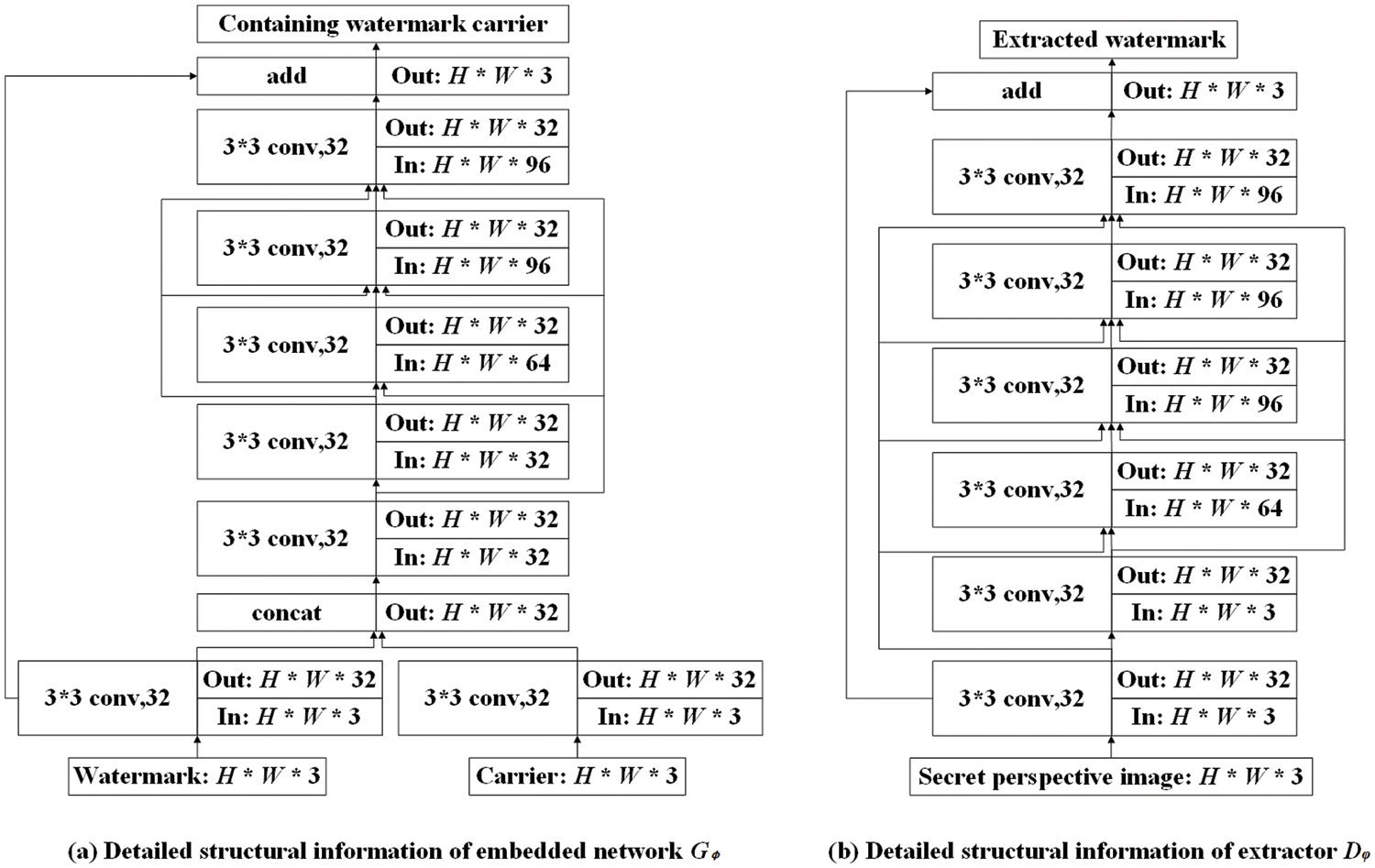
Figure 3: Detailed network structure of embedded networks and extractors. Both
MarkNeRF. The neural radiation field is trained using an MLP network, which inputs the three-dimensional coordinate position x= (x, y, z) and direction d= (θ, φ) of spatial points, outputs the color c= (r, g, b) of spatial points, and the density σ of corresponding positions (voxels). In the specific implementation, the position information of x and d is encoded first, then x is input into the MLP network and outputted with σ and a 256 dimensional intermediate feature. The intermediate feature and d are then input together into the fully connected layer to predict colors, and finally a two-dimensional image is generated through volume rendering. The network structure of NeRF is shown in Fig. 4.
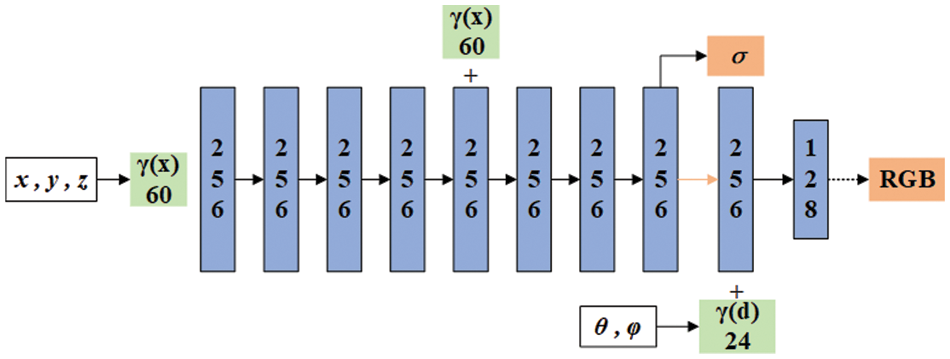
Figure 4: Detailed network structure of MarkNeRF. Similar to NeRF [1], we trained the model using an 8-layer MLP network
In the training process of MarkNeRF, we used the same network structure as NeRF and an 8-layer MLP network. The rendered image
Extractor. Extractor
Loss function. We employed an iterative approach to optimize the embedding network, MarkNeRF network, and extractor network. To achieve this, we simultaneously optimized three losses for
The second part of the loss
where
The third component of the loss
where α is a hyperparameter used to balance the loss functions. Therefore, the overall loss to train the copyright-protected neural radiance fields can be obtained as follows:
where
This section delineates the experimental settings and analyzes the performance of our algorithm under different experimental conditions. The performance of watermark algorithms is typically assessed based on two main criteria: invisibility and robustness. We evaluated the invisibility and robustness of our algorithm by comparing it with other algorithms. Subsequently, to analyze the impact of different modules within the algorithm on the overall framework, we conducted ablation experiments by selectively removing certain modules.
Dataset. We evaluated our algorithm using the NeRF Semantic and Layered Light Field Flow (LLFF) datasets from the NeRF dataset. Among them, LLFF’s forward scenes include {flower}, {room}, {leaves…} and NeRF Synthetic’s 360 degree scenes include {lego}, {drums}, {chair}, {hotdog}, {ship…}. To evaluate the effectiveness of our method, in the NeRF Semantic dataset, our training process involved inputting 100 views per scene. To evaluate the visual quality of our method, we selected 20 images from the test dataset associated with each scenario. Additionally, we conducted renderings of 200 views per scene to examine the accuracy of watermark extraction under different camera perspectives. Furthermore, we randomly selected images from the ImageNet dataset to serve as watermark images. Throughout the experiment, we present all the results as average outcomes.
Training. Our method was implemented using PyTorch. The images were resized to a dimension of 256 × 256. The hyperparameters were set as follows:
Baselines. To Baselines our knowledge, there is currently limited research on watermarking for NeRF. As a result, we compared four strategies to ensure a fair comparison: (1) LSB [24]+NeRF [1]: Utilizing the classic LSB algorithm to embed watermark information into the dataset images before training the NeRF model; (2) DeepStega [25]+NeRF [1]: Employing the two-dimensional watermarking method DeepStega to process the image prior to training the NeRF model; (3) HiDDeN [26]+NeRF [1]: Processing the image using the HiDDeN scheme before training the NeRF model; (4) StegaNeRF [20]; (5) CopyRNeRF [21].
Evaluation. We assessed the efficacy of our proposed method relative to other approaches based on the invisibility and robustness of digital watermarking. For invisibility, we utilized the Peak Signal-to-Noise Ratio (PSNR), Structural Similarity (SSIM), and Learned Perceptual Image Patch Similarity (LPIPS) [27] to compare the visual quality of the output results watermark image embedding. For robustness, we investigated the efficiency of extracting watermark images by evaluating the quality of the rendered images under various distortions. Furthermore, we conducted a study on the ability to extract watermark images from a secret camera perspective.
Quality of embedded images. In Fig. 5, we randomly select images from various scenes as the original images and embed them into the same watermark image W Generally, the details of the watermark are nearly imperceptible within the image. Although enlarged differences may be discernible, the visibility of these differences is not crucial, as long as the labeled image is perceived to be closely aligned with the original image. We conducted additional embedding experiments involving more than 500 images in the dataset, resulting in an average PSNR of 36.41 dB and an average SSIM of 0.975 between the embedded images and the original images.
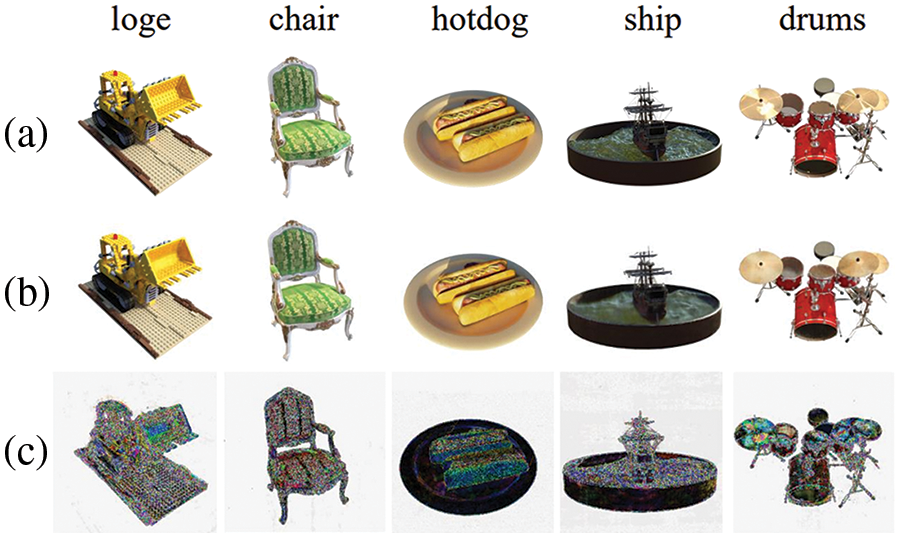
Figure 5: Results of watermark embedding. (a) Original image; (b) Embedded image; (c) Residual (×10)
Quality of rendering effects and watermark extraction. We conducted a quantitative assessment of the reconstruction quality using various baseline methods, and the experimental results for the lego and trex datasets are presented in Tables 1 and 2. It is worth noting that all watermarking algorithms have a relatively small impact on the quality of NeRF rendering, achieving a high level of reconstruction quality. The qualitative results of different baseline methods are shown in Figs. 6 and 7. Specifically, while LSB [24]+NeRF [1], DeepStega [25]+NeRF [1], and HiDDeN [26]+NeRF [1] demonstrated favorable outcomes in terms of steganography or watermarking for two-dimensional images, they were unable to effectively extract information from rendered images due to the alterations caused by NeRF-based view synthesis. In contrast, MarkNeRF demonstrated accurate recovery of watermark images through the incorporation of an additional extractor
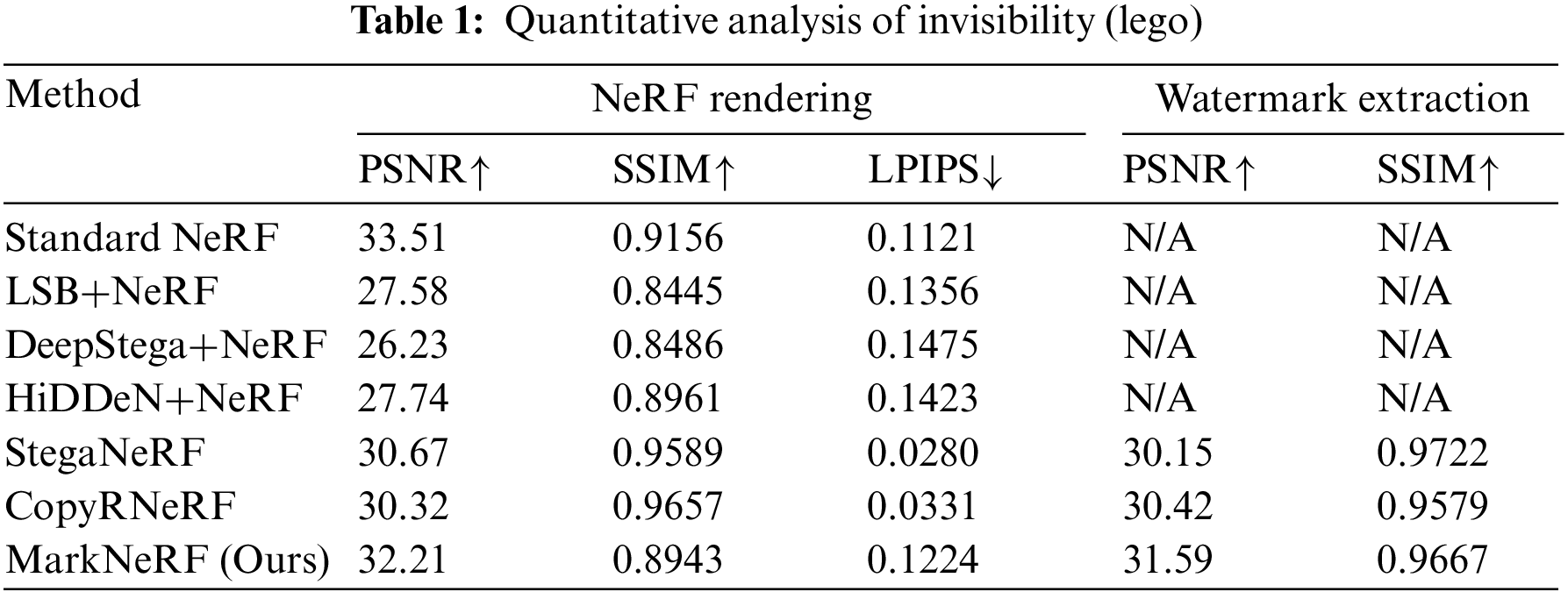
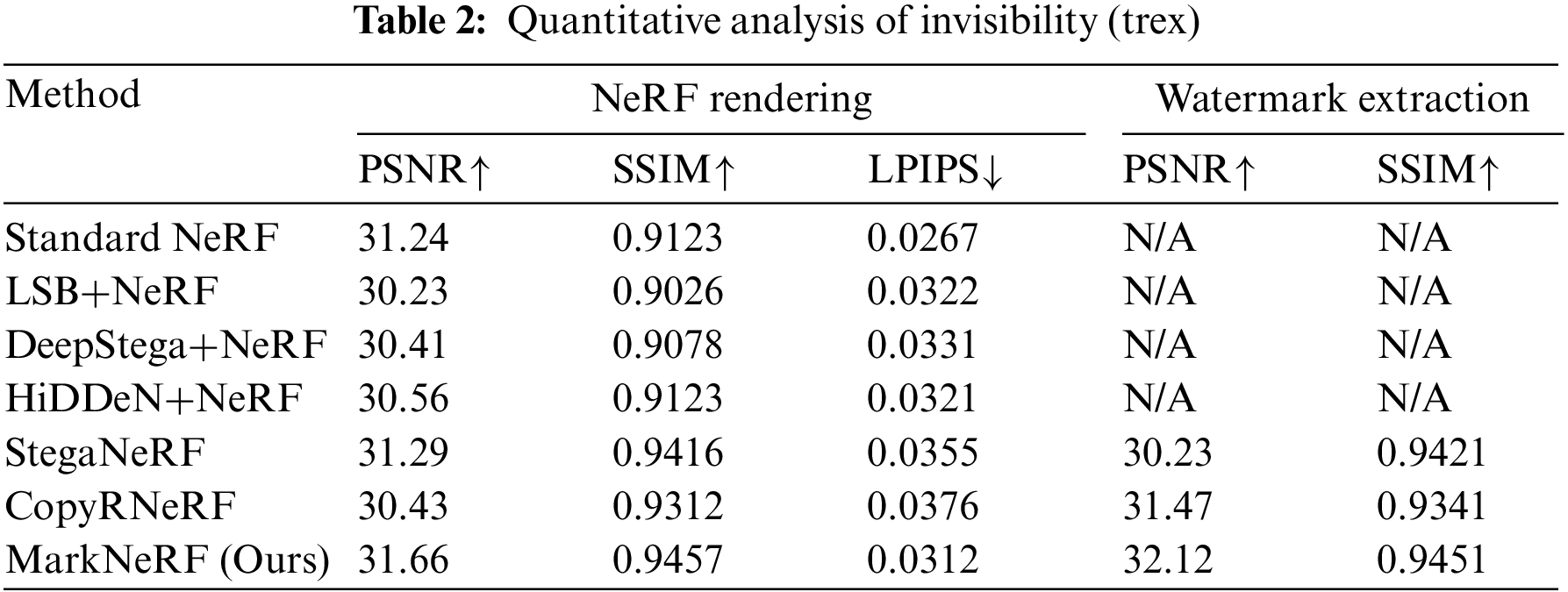

Figure 6: The rendering effect of NeRF model (lego) under different baselines. We demonstrated the residuals (×10) between images rendered with different schemes and ground truth values

Figure 7: The rendering effect of NeRF model (trex) under different baselines. We demonstrated the residuals (×10) between images rendered with different schemes and ground truth values

Figure 8: Extracting watermark image effects. (a) Original watermark image; (b) Extracted watermark image; (c) Residual (×10)
Model robustness on 2D noise. We assess the robustness of our method by subjecting it to various traditional noise attacks. Comparing the SSIM values of images rendered by different methods after passing through noise layers with the original image, the experimental results are detailed in Table 3. We examine several common types of noise, such as Gaussian noise, Poisson noise, Speckle noise and Pepper noise. It is evident from the results that our method demonstrates strong resilience against various two-dimensional noises. Specifically, our approach delivers comparable performance in image rendering to alternative methods in the absence of noise. However, when confronted with different distortions, the superior rendering quality highlights the efficacy of our antidistortion rendering during the training process.

Effectiveness of a secret perspective. To assess the efficacy of the secret perspective in MarkNeRF, images rendered from various perspectives are subjected to testing using an extractor. The experimental results are depicted in Fig. 9. From the obtained results, it is evident that as the rotation angle increases, the extracted watermark image progressively becomes more blurred, eventually becoming unextractable. However, when the rotation angle is small, adjacent views of the secret perspective can still extract some watermark information. In the following work, we will optimize the extractor network structure so that watermark information can only be extracted from the secret perspective.

Figure 9: Comparison of watermark extraction effects on different visual images. We test the images rendered from different perspectives in our extractor, and as the rotation angle increases, the extracted watermark information gradually becomes blurred
To quantitatively analyze the influence of different perspectives on the effectiveness of watermark extraction, this study also provides the PSNR and SSIM values between the extracted watermark images and the original watermark images when inputting images from different perspectives. These experimental results are illustrated in Fig. 10. The angle variation φ in the figure represents the angle of counterclockwise rotation around the central z-axis.
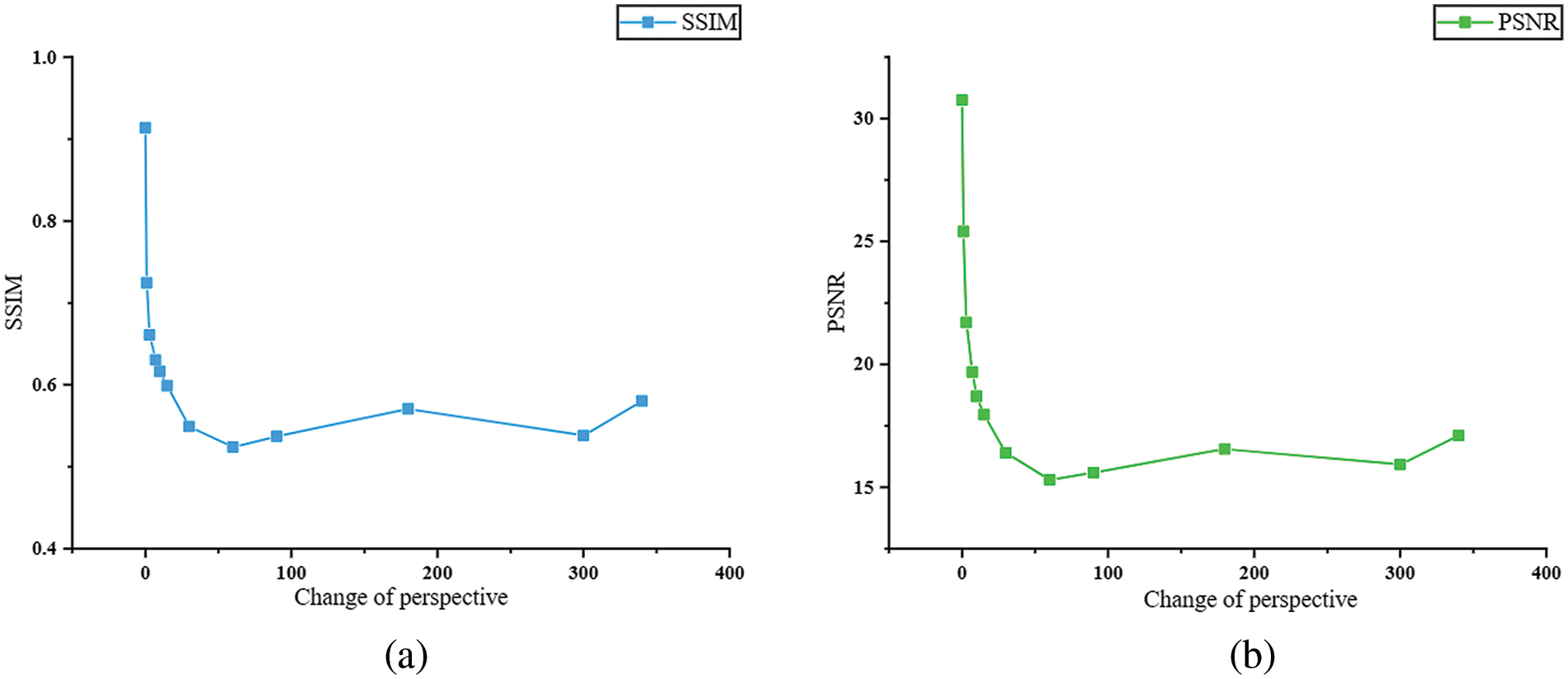
Figure 10: Quantitative analysis of the watermark extraction effect. (a) The influence of the angle φ on the SSIM value between the extracted watermark image and the original watermark image; (b) The influence of the angle φ on the PSNR between the extracted watermark image and the original watermark image
Impact of noise adding modules. To evaluate the impact of the noise processing module in our watermarking algorithm, we removed the noise module and retrained our model. We compared the performance of models without the noise module and our noise-resistant model in extracting watermarks under noise attacks. Fig. 11 illustrates the visual results of watermark extraction under different noise attacks for both models. We conducted tests under Poisson noise, speckle noise, pepper noise, and Gaussian noise, respectively. Experimental results demonstrate that compared to the NeRF model without the noise module, our model exhibits less distortion and demonstrates certain robustness against noise influence.

Figure 11: Comparison of experimental results between models without the noise module and our model. The first column illustrates the watermark extraction performance of the model without the noise module under different noise attacks, while the second column depicts the watermark extraction performance of our model under the same noise attacks. We also displayed the PSNR values between each image and ground truth values
Influence of hyperparameters and watermark size. For the hyperparameter settings, we conducted control experiments with different values of
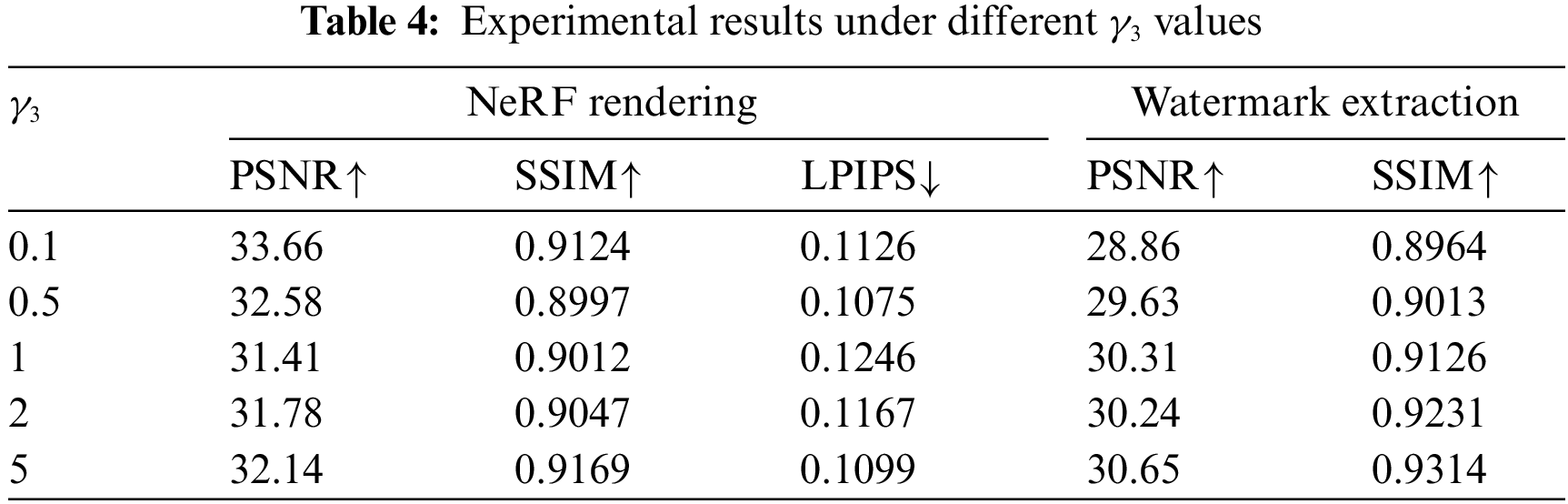
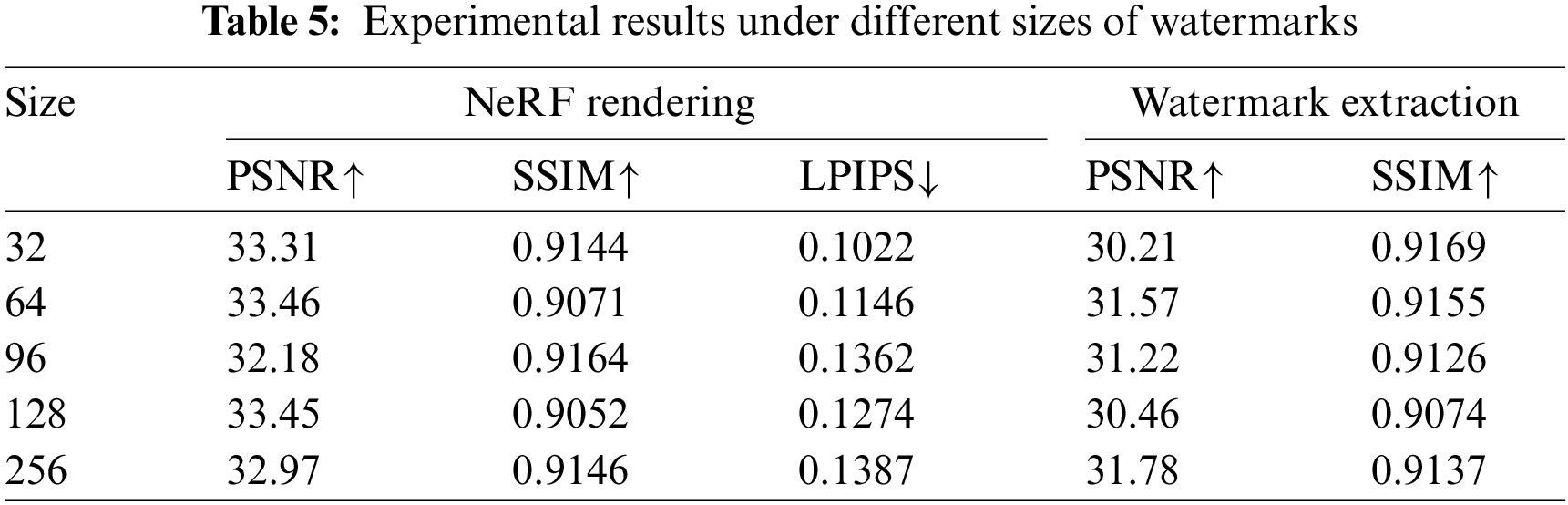
Impact of embedding networks. To test the effectiveness of embedding watermark information into the NeRF dataset images, we trained two NeRF models using the original dataset images without embedded watermark information and the dataset images with embedded watermark information, respectively, and compared their rendering results. We conducted experiments on multiple datasets, and the results are shown in Fig. 12. From the experimental results, it can be observed that there is no significant visual difference between the images rendered by the NeRF model trained with embedded watermark information and the NeRF model trained without embedded watermark information. This suggests that during the NeRF model training process, our watermark information was optimally lost, resulting in ineffective transmission of the embedded watermark information to the NeRF model. In future work, we will consider adopting more effective methods to embed watermark information into the NeRF model.

Figure 12: Extracting watermark image effects. (a) Groundtruth; (b) The images rendered by the NeRF model trained with embedded watermark information; (c) The images rendered by the NeRF model trained without embedded watermark information; (d) Residual (×10) image between (b) and (c)
With the proposal of Neural Radiation Field (NeRF), NeRF technology has developed rapidly in 3D content generation and editing, street view maps, and robot positioning and navigation in recent years. However, training NeRF models requires a large amount of resources, and there is currently limited research on NeRF copyright protection. How to effectively protect NeRF has become an important issue. This article introduces a new method of NeRF copyright protection, namely MarkNeRF. We propose a framework that embeds watermark information into the NeRF model through an embedding network. The copyright owner can use the secret perspective information as a key, and then extract the watermark from the image rendered from the secret perspective through an extractor, achieving copyright protection of the NeRF model. In addition, we have also designed anti distortion rendering to enhance the robustness of the model. The experimental results show that our method not only exhibits high visual quality in watermark extraction, but also has a certain degree of robustness, thus verifying the effectiveness of our method in NeRF copyright protection.
Limitations: Although we considered the robustness of the model in the design process, when malicious users attack the weight of the model, the model may be compromised, affecting rendering quality and watermark extraction performance. In addition, the extractor we designed can still extract some watermark information if the secret perspectives are relatively close, and there is still room for optimization in the network structure of the extractor. In future work, we will actively consider how to solve these problems.
Acknowledgement: None.
Funding Statement: This study is supported by the National Natural Science Foundation of China, with Fund Number 62272478.
Author Contributions: The authors confirm the following contributions to this article: Research concept and design: Lifeng Chen and Weina Dong; Experimental, analytical, and interpretive results: Lifeng Chen and Wenquan Sun; Drafted by Lifeng Chen. Jia Liu and Xiaozhong Pan reviewed the results and approved the final version of the manuscript. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: If readers need data, they can contact my email: 3011745933@qq.com.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi and R. Ng, “NeRF: Representing scenes as neural radiance fields for view synthesis,” Commun. ACM, vol. 65, no. 1, pp. 99–106, Jan. 2022. doi: 10.1145/3503250. [Google Scholar] [CrossRef]
2. K. Liu et al., “StyleRF: Zero-shot 3D style transfer of neural radiance fields,” Mar. 24, 2023. Accessed: Jan. 15, 2024. [Online]. Available: http://arxiv.org/abs/2303.10598 [Google Scholar]
3. Y. J. Yuan, Y. T. Sun, Y. K. Lai, Y. Ma, R. Jia and L. Gao, “NeRF-editing: Geometry editing of neural radiance fields,” in 2022 IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), New Orleans, USA, IEEE, 2022, pp. 18332–18343. [Google Scholar]
4. A. Pumarola, E. Corona, G. Pons-Moll, and F. Moreno-Noguer, “D-NeRF: Neural radiance fields for dynamic scenes,” in 2021 IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Nashville, USA, IEEE, 2021, pp. 10313–10322. [Google Scholar]
5. W. Xian, J. B. Huang, J. Kopf, and C. Kim, “Space-time neural irradiance fields for free-viewpoint video,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Nashville, USA, 2021, pp. 9421–9431. [Google Scholar]
6. C. L. Chowdhary, P. V. Patel, K. J. Kathrotia, M. Attique, K. Perumal and M. F. Ijaz, “Analytical study of hybrid techniques for image encryption and decryption,” Sensors, vol. 20, no. 18, pp. 5162, 2020. doi: 10.3390/s20185162. [Google Scholar] [PubMed] [CrossRef]
7. C. M. L. Etoundi et al., “A novel compound-coupled hyperchaotic map for image encryption,” Symmetry, vol. 14, no. 3, pp. 493, Feb. 2022. doi: 10.3390/sym14030493. [Google Scholar] [CrossRef]
8. J. Park, J. Kim, J. Seo, S. Kim, and J. H. Lee, “Illegal 3D content distribution tracking system based on DNN forensic watermarking,” in 2023 Int. Conf. Artif. Intell. Inform. Commun. (ICAIIC), Kumamoto, Japan, 2023, pp. 777–781. [Google Scholar]
9. L. Y ariv et al., “Multiview neural surface reconstruction by disentangling geometry and appearance,” in Advances in Neural Information Processing Systems, 2020, vol. 3, pp. 2492–2502. [Google Scholar]
10. I. Yoo et al., “Deep 3D-to-2D watermarking: Embedding messages in 3D meshes and extracting them from 2D renderings,” in 2022 IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), New Orleans, LA, USA, IEEE, 2022, pp. 10021–10030. [Google Scholar]
11. B. D. Rouhani, H. Chen, and F. Koushanfar, “DeepSigns: A generic watermarking framework for IP protection of deep learning models,” May 31, 2018. Accessed: Apr. 14, 2024. [Online]. Available: http://arxiv.org/abs/1804.00750 [Google Scholar]
12. W. Chen, C. Zhu, N. Ren, T. Seppänen, and A. Keskinarkaus, “Screen-cam robust and blind watermarking for tile satellite images,” IEEE Access, vol. 8, pp. 125274–125294, 2020. doi: 10.1109/ACCESS.2020.3007689. [Google Scholar] [CrossRef]
13. C. Zhang, A. Karjauv, P. Benz, and I. S. Kweon, “Towards robust deep hiding under non-differentiable distortions for practical blind watermarking,” in Proc. 29th ACM Int. Conf. Multimed., Chengdu, China, 2021, pp. 5158–5166. [Google Scholar]
14. G. Y. Zhang, J. H. Liu, and J. Mi, “Research on watermarking algorithms for 3D color point cloud models,” (in ChineseComput. Technol. Dev., vol. 33, no. 5, pp. 62–68, 2023. [Google Scholar]
15. M. Hamidi, A. Chetouani, M. El Haziti, M. El Hassouni, and H. Cherifi, “Blind robust 3D mesh watermarking based on mesh saliency and wavelet transform for copyright protection,” Information, vol. 10, no. 2, pp. 67, 2019. doi: 10.3390/info10020067. [Google Scholar] [CrossRef]
16. G. Y. Zhang and J. Cui, “Anti simplified blind watermarking algorithm based on vertex norm 3D mesh model,” (in ChineseComput. Eng. Design, vol. 44, no. 3, pp. 692–698, 2023. [Google Scholar]
17. G. N. Pham, S. H. Lee, O. H. Kwon, and K. R. Kwon, “A 3D printing model watermarking algorithm based on 3D slicing and feature points,” Electronics, vol. 7, no. 2, pp. 23, 2018. doi: 10.3390/electronics7020023. [Google Scholar] [CrossRef]
18. X. G Xiong, L. Wei, and G. Xie, “A robust color image watermarking algorithm based on 3D-DCT and SVD,” (in ChineseComput. Eng. Sci., vol. 37, no. 6, 2015. [Google Scholar]
19. F. Wang, H. Zhou, H. Fang, W. Zhang, and N. Yu, “Deep 3D mesh watermarking with self-adaptive robustness,” Cybersecurity, vol. 5, no. 1, pp. 24, 2022. doi: 10.1186/s42400-022-00125-w. [Google Scholar] [CrossRef]
20. C. Li, B. Y. Feng, Z. Fan, P. Pan, and Z. Wang, “StegaNeRF: Embedding invisible information within neural radiance fields,” Dec. 03, 2022. Accessed: Jan. 15, 2024. [Online]. Available: http://arxiv.org/abs/2212.01602 [Google Scholar]
21. Z. Luo, Q. Guo, K. C. Cheung, S. See, and R. Wan, “CopyRNeRF: Protecting the copyright of neural radiance fields,” Jul. 29, 2023. Accessed: Jan. 15, 2024. [Online]. Available: http://arxiv.org/abs/2307.11526 [Google Scholar]
22. Y. Adi, C. Baum, M. Cisse, B. Pinkas, and J. Keshet, “Turning your weakness into a strength: Watermarking deep neural networks by backdooring,” in 27th USENIX Secur. Symp., Baltimore, MD, USA, 2018, pp.1615–1631. [Google Scholar]
23. K. A. Zhang, A. Cuesta-Infante, L. Xu, and K. Veeramachaneni, “SteganoGAN: High capacity image steganography with GANs,” Jan. 29, 2019. Accessed: Jan. 15, 2024. [Online]. Available: http://arxiv.org/abs/1901.03892 [Google Scholar]
24. S. D. Muyco and A. A. Hernandez, “Least significant bit hash algorithm for digital image watermarking authentication,” in Proc. 2019 5th Int. Conf. Comput. Artif. Intell., New York, USA, 2019, pp. 150–154. [Google Scholar]
25. S. Baluja, “Hiding images in plain sight: Deep steganography,” in Advances in Neural Information Processing Systems, Barcelona, Spain, 2017, vol. 30. [Google Scholar]
26. J. Zhu, R. Kaplan, J. Johnson, and L. Fei-Fei, “HiDDeN: Hiding data with deep networks,” Jul. 25, 2018. Accessed: Jan. 15, 2024. [Online]. Available: http://arxiv.org/abs/1807.09937 [Google Scholar]
27. R. Zhang et al., “The unreasonable effectiveness of deep features as a perceptual metric,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., Salt Lake City, USA, 2018, pp. 586–595. [Google Scholar]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools