
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Cloud-Edge Collaborative Federated GAN Based Data Processing for IoT-Empowered Multi-Flow Integrated Energy Aggregation Dispatch
Electric Power Dispatching Control Center, Guangdong Power Grid Co., Ltd., Guangzhou, 510030, China
* Corresponding Author: Zhan Shi. Email:
Computers, Materials & Continua 2024, 80(1), 973-994. https://doi.org/10.32604/cmc.2024.051530
Received 07 March 2024; Accepted 27 May 2024; Issue published 18 July 2024
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The convergence of Internet of Things (IoT), 5G, and cloud collaboration offers tailored solutions to the rigorous demands of multi-flow integrated energy aggregation dispatch data processing. While generative adversarial networks (GANs) are instrumental in resource scheduling, their application in this domain is impeded by challenges such as convergence speed, inferior optimality searching capability, and the inability to learn from failed decision making feedbacks. Therefore, a cloud-edge collaborative federated GAN-based communication and computing resource scheduling algorithm with long-term constraint violation sensitiveness is proposed to address these challenges. The proposed algorithm facilitates real-time, energy-efficient data processing by optimizing transmission power control, data migration, and computing resource allocation. It employs federated learning for global parameter aggregation to enhance GAN parameter updating and dynamically adjusts GAN learning rates and global aggregation weights based on energy consumption constraint violations. Simulation results indicate that the proposed algorithm effectively reduces data processing latency, energy consumption, and convergence time.Keywords
The rapid growth of renewable energy sources such as distributed photovoltaics (PVs) and wind power brings new challenges to the energy demand-supply balance due to their volatile, random, and intermittent characteristics [1,2]. This spurs the development of novel energy dispatch services where distributed PVs, electric vehicles, and adjustable loads are intelligently aggregated and dispatched based on real-time processing of grid state data gathered by Internet of Things (IoT) devices [3,4]. Therefore, the influx of massive state data, the increasing randomness and volatility of energy sources, as well as the rising complexity of energy dispatch services, present an urgent requirement to integrate information flow, energy flow, and service flow [5]. However, the traditional cloud-based paradigm is no longer suitable to meet the exponentially growing data processing demands of multi-flow integration [6,7]. How to realize real-time and energy-efficient data processing for multi-flow integrated energy aggregation dispatch remains an open issue.
Edge computing can provide proximate data processing. It can be combined with cloud computing in a complementary fashion to realize cloud-edge collaboration and support complex data processing [8,9]. In addition, with the advancement of communication technologies such as power line communication (PLC) and 5G, cloud-edge collaboration can further improve workload balance via edge-edge migration and cloud-edge migration [10,11]. For example, data can be intelligently migrated from a heavy-loaded edge server to a light-loaded edge server to reduce processing delay and improve computing resource utilization efficiency [12,13]. The core of edge-cloud collaboration for multi-flow integrated energy aggregation dispatch lies in resource scheduling optimization. Service data migration, computing resource allocation, and transmission power control should be adaptively optimized with time-varying channel states, electromagnetic interference, server workload, and service requirements.
Generative adversarial network (GAN) is a deep learning model, which can enhance the training process by min-max zero-sum game of generator and discriminator networks to achieve Nash equilibrium. In [14], Ali et al. employed GAN to obtain the resource scheduling strategy for high-reliable low-delay communication in wireless networks. In [15], Rohit et al. adopted a GAN-assisted network slicing resource orchestration algorithm in industrial IoT applications. In [16], Hua et al. presented a GAN-assisted distributed deep learning to solve the resource scheduling problem among multiple network slices. In [17], Naeem et al. leveraged GAN-based deep distributional Q-network for learning the action-value distribution for intelligent transmission scheduling to achieve ultra-reliable low latency communication. The application of GAN in resource scheduling helps improve model robustness, optimize scheduling strategies, and reduce experimental costs, thereby facilitating the effective operation and management of power systems. However, when applying GAN to multi-flow integrated energy aggregation dispatch, several technical challenges remain to be addressed.
First, the realization of multi-flow integrated energy aggregation dispatch is indispensable from real-time and energy-efficient data processing. However, low processing energy consumption and delay are paradoxical goals. Increasing transmission power can reduce transmission delay and the total data processing delay, but reduces the future energy budget and increases the probability of energy consumption constraint violation [5]. Second, traditional GAN suffers from slow convergence speed and inferior optimality searching capability due to the lack of global foresight of workload distribution. It is intuitive to explore cloud-edge collaboration to provide a priori knowledge of the entire network for improving GAN without significantly increasing communication overheads. Last but not least, traditional GAN cannot learn from failed decision making feedbacks such as the violation occurrences of energy consumption constraint. How to augment GAN with failure occurrence sensitiveness to further improve convergence and optimality searching performances is a key challenge.
Federated learning adopts a semi-distributed learning framework. Compared to traditional centralized learning, it reduces communication costs, enhances global performance, and speeds up the model convergence. By integrating federated learning, IoT, and cloud-edge collaboration, part of the model training can be done on edge servers, reducing communication overhead between cloud and edge servers, and thus improving real-time performance [18]. Furthermore, federated learning improves the global network insight performance of GAN in a distributed environment, boosting the convergence rate. In [19], Xu et al. proposed a federated generative adversarial network (FGAN)-based decentralized data synthesizing and data processing integration method, which is able to improve the traffic classification performance. In [20], Eisuke et al. proposed an FGAN-based image generation model training method in wireless ad hoc collaboration, which achieves better performance in cross-node data learning and image generation. In [21], Sui et al. augmented the training dataset by leveraging the FGAN method and addressed the unlabeled data by means of an active learning method. In [22], Li et al. proposed an alternative approach which learns a globally shared GAN model by aggregating locally trained generators’ updates with maximum mean discrepancy to achieve the highest inception score and produce high-quality instances. However, there are still some unresolved issues in the literature mentioned above. Firstly, these works did not take into account the multi-flow integration based on IoT and cloud-edge collaboration, and did not enable joint optimization of energy consumption and delay. Secondly, edge-edge as well as edge-cloud migration are not considered, making it difficult to achieve load balancing and reduce processing delay. Lastly, the insights provided by failure events have not been effectively utilized, resulting in poor accuracy and convergence speed.
To deal with the aforementioned challenges, a cloud-edge collaborative FGAN-based data processing algorithm is proposed for multi-flow integrated energy aggregation dispatch, with the optimization objective of minimizing the long-term average weighted sum of total energy consumption and total delay under long-term energy consumption constraint. First, we develop the system models of cloud-edge collaborative migration, data processing, and total energy consumption and delay for multi-flow integrated energy aggregation dispatch. Second, we formulate a communication and computing resource scheduling optimization problem. Then, we utilize Lyapunov optimization to perform problem decomposition. Finally, a cloud-edge collaborative FGAN-based communication and computing resource scheduling algorithm with long-term constraint violation sensitiveness is presented, which effectively exploits global environment information to optimize the cloud-edge resource scheduling strategy, and achieves a joint guarantee of transmission delay and energy consumption.
The main innovations are introduced as follows:
• Real-time and energy-efficient data processing for multi-flow integrated energy aggregation dispatch: We formulate a weighted sum of total energy consumption and delay minimization problem for real-time and energy-efficient data processing, where the weight factor is utilized to balance the energy consumption and delay. In addition, the energy deficit virtual queue is incorporated into the optimization objective through problem decomposition, which enforces low-energy consumption resource scheduling optimization.
• Cloud-edge collaborative FGAN-based resource scheduling algorithm: A cloud-edge collaboration FGAN-based communication and computing resource scheduling algorithm is proposed. The edge-edge and edge-cloud data migration are considered to reduce processing delay. In addition, the cloud and edge servers cooperate to perform network training and parameter interaction to jointly optimize communication resource scheduling, such as transmission power, as well as computing resource scheduling, including data migration and computing resource allocation.
• Improved convergence and optimality for FGAN with constraint violation sensitiveness: We integrate federated learning with GAN to leverage global insight for improving convergence and optimality performance of resource scheduling in multi-flow integrated energy aggregation dispatch data processing. In addition, the number of constraint violation occurrences is utilized for dynamic adjustment of the learning rate and network parameter weight to achieve constraint violation sensitiveness and improve accuracy and convergence speed.
The remaining part is arranged as shown below. Section 2 presents the system model. Section 3 expatiates problem formulation and decomposition. The cloud-edge collaborative FGAN-based resource scheduling algorithm is proposed in Section 4. Sections 5 and 6 give the simulation results and conclusion.
The multi-flow integrated energy aggregation dispatch framework based on cloud-edge collaboration is illustrated in Fig. 1, including four layers of device, edge, cloud, and application. There is various electrical equipment in the device layer, including distributed PV, electric vehicle, charging pile, and adjustable load. Numerous IoT devices are arranged to gather key equipment state data, which are uploaded to the edge layer based on PLC. The edge layer deploys several edge servers that process the data uploaded from devices within their coverage. To reduce data processing delay and improve load balance, an edge server can also migrate its data to other neighbor servers or the cloud server for processing via edge-edge migration or edge-cloud migration. The cloud layer consists of a cloud server with large computing capacity but located far away from the device layer. Thus, edge-cloud migration reduces processing delay at the cost of increased transmission delay. The application layer operates novel services of PV dispatch, electric vehicle dispatch, load dispatch, and virtual power plant dispatch based on the data processed by edge and cloud servers.
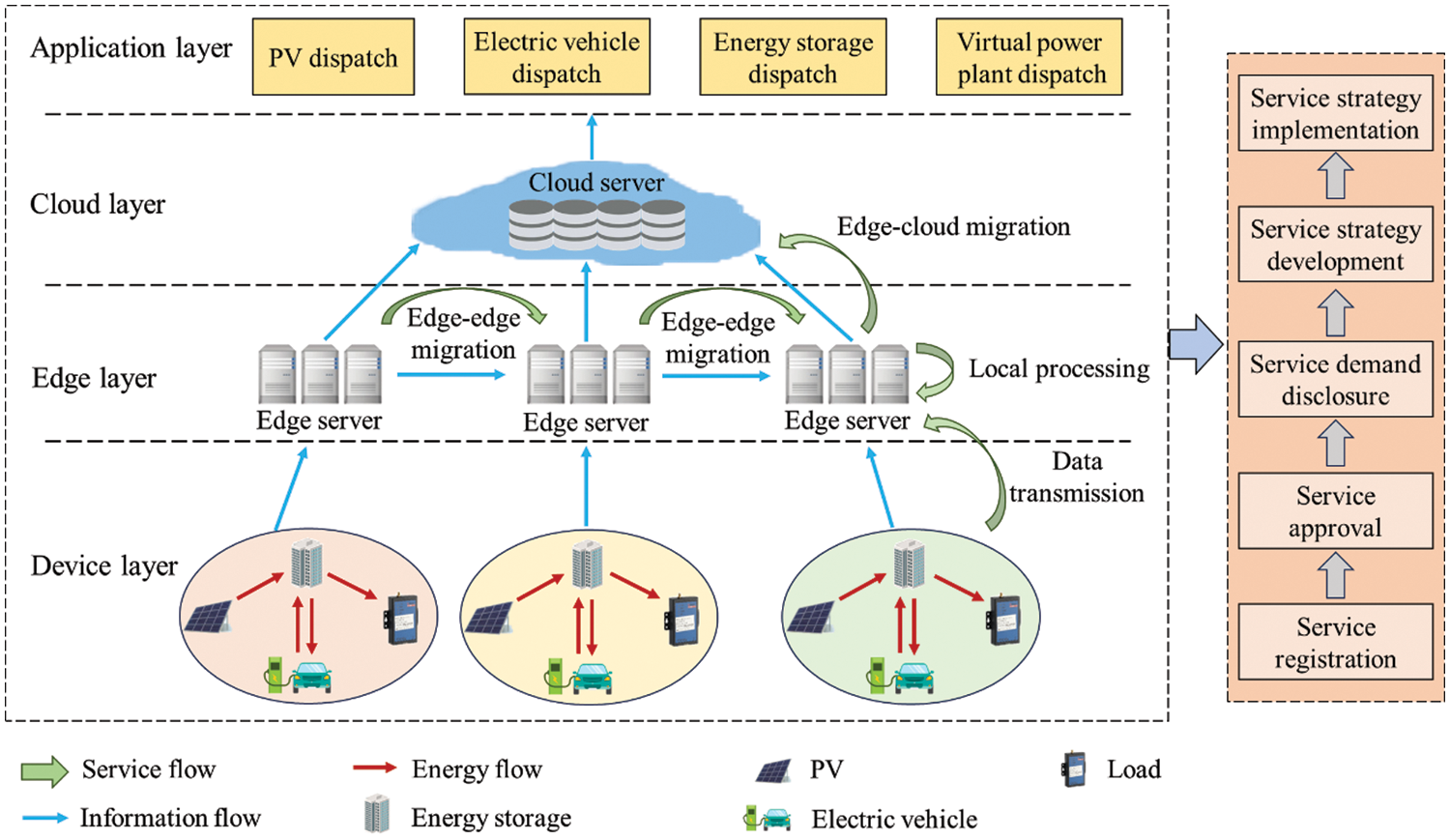
Figure 1: Multi-flow integrated energy aggregation dispatch framework based on cloud-edge collaboration
There exist information, energy and service flows based on the interaction among device, edge, cloud and application layers. Information flow contains the entire lifecycle of data collection, transmission, processing. Energy flow represents the whole process of energy generation, transmission, conversion, and utilization in energy aggregation dispatch of low-voltage distribution gird. Particularly, distributed PV generators, electric vehicles, loads, and energy storage units are intelligently aggregated and scheduled to meet the demand-supply balance. Both information flow and energy flow serve are the key pillars to realize the service flow of various applications including service registration, approval, demand disclosure, service strategy development, and implementation.
Define the set of
Due to the time varying computing resources and workloads, edge servers are categorized into two types, i.e., heavy-loaded servers and light-loaded servers. A heavy-loaded edge server with little computing resources and overwhelming workloads will result in large processing delay. Therefore, it is intuitive to avoid heavy-loaded edge servers by optimizing edge-edge and edge-cloud migrations. Define
2.1 Cloud-Edge Collaborative Migration Model
2.1.1 Device-Edge Data Transmission Model
At each time slot, IoT device uploads the collected data to edge layer through PLC. In slot
where
where
To intuitively illustrate the effect of EMI on PLC, the alpha-stable distribution is employed to describe the EMI with distinct impulse characteristics [23]. Define
where
The transmission energy consumption of
2.1.2 Edge-Edge and Edge-Cloud Data Migration Models
The data packet is migrated to the edge server or cloud server based on 5G communications. The edge-edge and edge-cloud data migration delays are calculated as
where
The energy consumptions of edge-edge and edge-cloud data migration are calculated as
The edge data processing delay of data from device
where
The edge data processing energy consumption is given by
where
If edge-cloud migration is implemented, the cloud data processing delay is given by
where
The cloud data processing energy consumption is calculated as
where
2.3 Total Energy Consumption and Delay Model
The total delay of the cloud-edge collaborative processing is calculated by summing transmission delay, edge-edge migration delay, edge processing delay, edge-cloud migration delay, and cloud processing delay, i.e.,
The total energy consumption is calculated by summing transmission energy consumption, edge-edge migration energy consumption, edge processing energy consumption, edge-cloud migration energy consumption, and cloud processing energy consumption, i.e.,
3 Problem Formulation and Decomposition
To promote low-latency and energy-efficient data processing for multi-flow integrated energy aggregation dispatch, the objective is minimizing the long-term average weighted sum of total energy consumption and delay of data processing of all the devices over
It is hard to settle
Adopting Lyapunov optimization [25],
where
4 Cloud-Edge Collaborative FGAN-Based Communication and Computing Resource Scheduling Algorithm for Multi-Flow Integrated Energy Aggregation Dispatch
To address the decomposed problem
Firstly, we model the formulated problem as MDPs in the following:
State: In slot t, the state space of edge server
Action: In slot
where
Reward function: The reward function is designed as the negative optimization objective of problem
4.2 Coud-Edge Collaborative FGAN with Long-Term Constraint Violation Sensitiveness
Traditional GAN algorithms show slow convergence and inferior optimality without global knowledge. To address this issue, we augment traditional GAN with the federated learning framework and develop a novel cloud-edge collaborative FGAN algorithm with long-term constraint violation sensitiveness, the framework of which is shown in Fig. 2. The proposed algorithm provides edge servers with insights of entire network based on cloud-empowered global aggregation. This significantly improves the global optimality searching capability of traditional GAN and avoids falling into local optimal dilemmas. Each edge server maintains an actor-critic based GAN generator and a GAN discriminator. In the GAN generator, the actor network is used to observe states and learn scheduling policies with policy gradients, and the critic network learns the state value function to assist in policy update. The training purpose of GAN generator is to improve its capability of generating the resource scheduling strategy and to confuse GAN discriminator in a best-effort way. The GAN discriminator outputs the evaluation results and guides the update of the GAN generator according to the state-action pairs of the GAN generator. The training purpose of GAN discriminator is to improve its ability to distinguish the expert policy from the resource scheduling strategy generated by GAN generator. Thus, the edge server continuously optimizes the relationship between GAN generator and GAN discriminator through mutual gaming. At the end of each slot, each server transmits the GAN model parameters to the cloud server, which aggregates the parameters and distributes them to edge servers to guide the learning of the optimal scheduling decision under global information. The proposed algorithm improves the accuracy of the traditional reinforcement learning actor-critic structure for policy generation by employing a GAN network. Compared to deep Q-network (DQN), deep actor-critic (DAC) and deep deterministic policy gradient (DDPG), the proposed algorithm combines federated learning, which not only provides the necessary global information for GAN to accelerate its convergence, but also enables model training on various distributed endpoints, thus greatly reducing the cost of data transmission in data centers. Meanwhile, the proposed algorithm solves the problem that DQN, DAC and DDPG are not applicable to distributed scenarios, such as low-voltage distribution networks, and proves its effectiveness in dealing with distributed training scenarios.
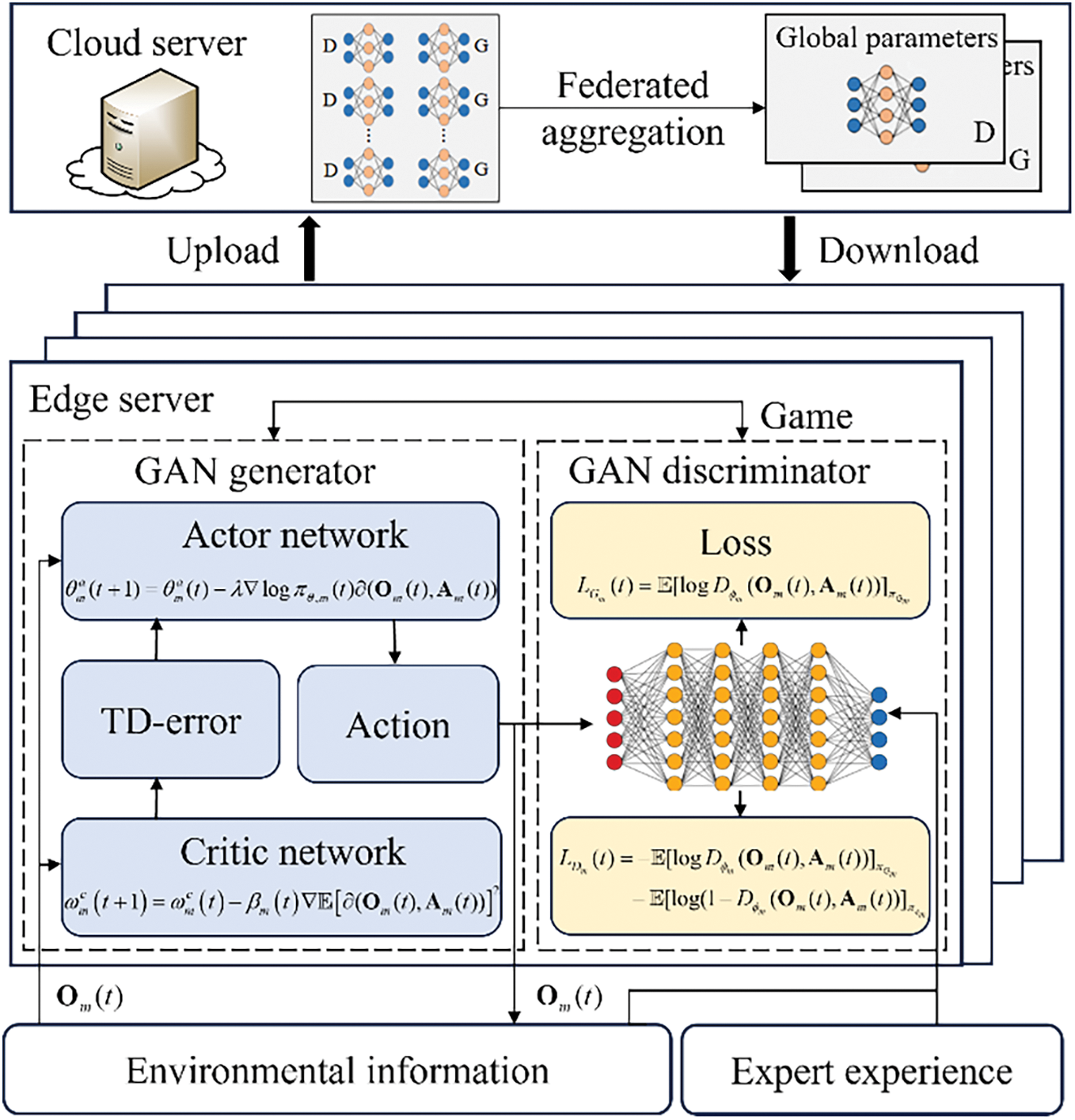
Figure 2: Framework of cloud-edge collaborative FGAN with long-term constraint violation sensitiveness
4.2.1 Actor-Critic Based GAN Generator
For the GAN generator of each edge server, the input and output of the actor network are the state space
The policies generated by the actor network are evaluated by the critic network, the input of which is the states
where
where
GAN discriminator takes the set of states
The GAN discriminator updates the GAN generator parameters and its own network parameters based on the discrimination results. For the generator, its objective is to produce a policy that the discriminator recognizes as an expert strategy, i.e.,
For the GAN discriminator, its objective is to distinguish between expert strategies and generated strategies from the generator, i.e.,
Traditional GAN algorithm adopts Jenson’s Shannon (JS) divergence as the discriminator loss function. When there is no overlap between the GAN generator policy distribution and the expert policy distribution, JS divergence will be constant, resulting in gradient disappearance and making the training difficult in the parameter update process. Thus, this paper builds upon traditional GAN by incorporating the Wasserstein distance to evaluate the deviation between generated and expert strategies. The Wasserstein distance is defined as
where
4.2.3 Federated Learning Enabled GAN Parameter Updating
Federated learning is a distributed learning method that trains global parameters by sharing trained parameters among various edge servers instead of original dataset, which is introduced into GAN in this paper. Define

Step 1: Each edge server uses the distributed global parameters
Step 2: After edge-side updating, each edge server uploads GAN parameters
where
where
Step 3: Repeat steps 1 and 2 until the GAN generator policy for each edge server is close to the same as the expert policy, i.e.,
The proposed algorithm is divided into GAN and federated learning enabled GAN parameters updating. The computation complexity of the GAN generator is
The effectiveness of the cloud-edge collaborative FGAN algorithm with long-term constraint violation sensitiveness is verified through simulations. We consider a multi-flow integrated energy aggregation dispatch scenario based on IEEE 33 bus [26], which is shown in Fig. 3. The scenario consists of 25 devices, 5 edge servers and 1 cloud server. Other relevant parameters are specified in Table 1 [22,27]. Three comparison algorithms are utilized. The federated deep actor-critic (DAC) based cloud-edge collaborative resource scheduling algorithm (FDAC) [28], the GAN based cloud-edge collaborative resource scheduling algorithm (GAN) [29], and the DDPG based cloud-edge collaborative resource scheduling algorithm (DDPGRS) [30] are adopted as comparison algorithms. In FDAC, the edge server uses the traditional DAC algorithm to generate communication and computing resource scheduling decisions, and the cloud server performs model aggregation and parameter dissemination. In GAN, each edge server establishes an independent GAN to learn communication and computing resource scheduling decisions, and the cloud only performs data processing rather than global aggregation. Both FDAC and GAN do not take into account the long-term constraint of energy consumption. In DDPGRS, each edge server connected to the central cloud server via a fiber connection utilizes the actor part of DDPG to search the optimal data offloading strategy and energy consumption control of the device. However, DDPGRS does not take into account the edge-edge migration.
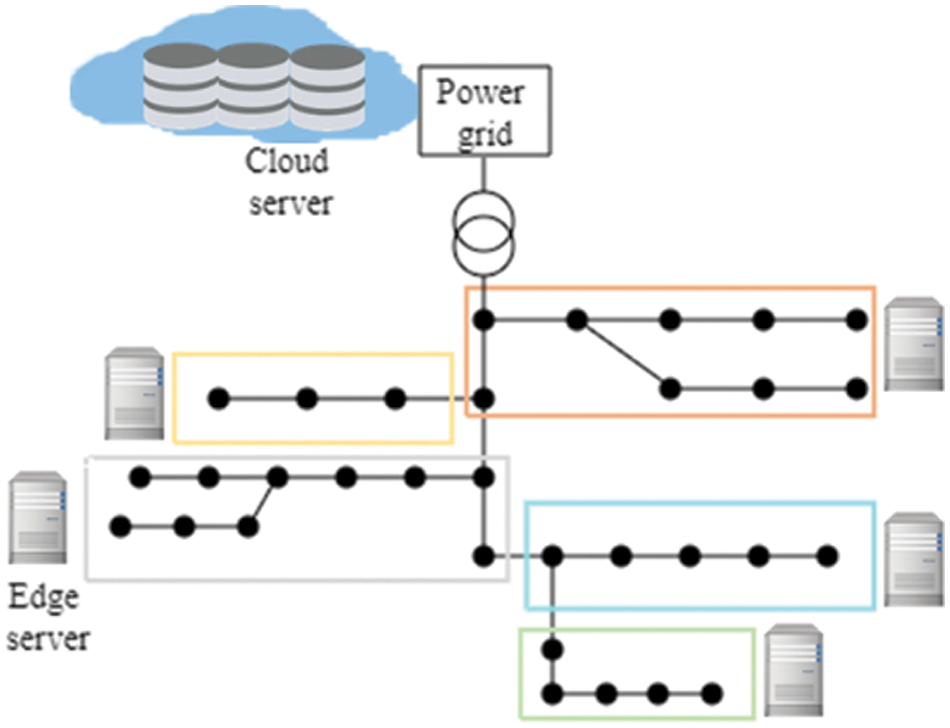
Figure 3: IEEE 33 bus model based on simulation scenario
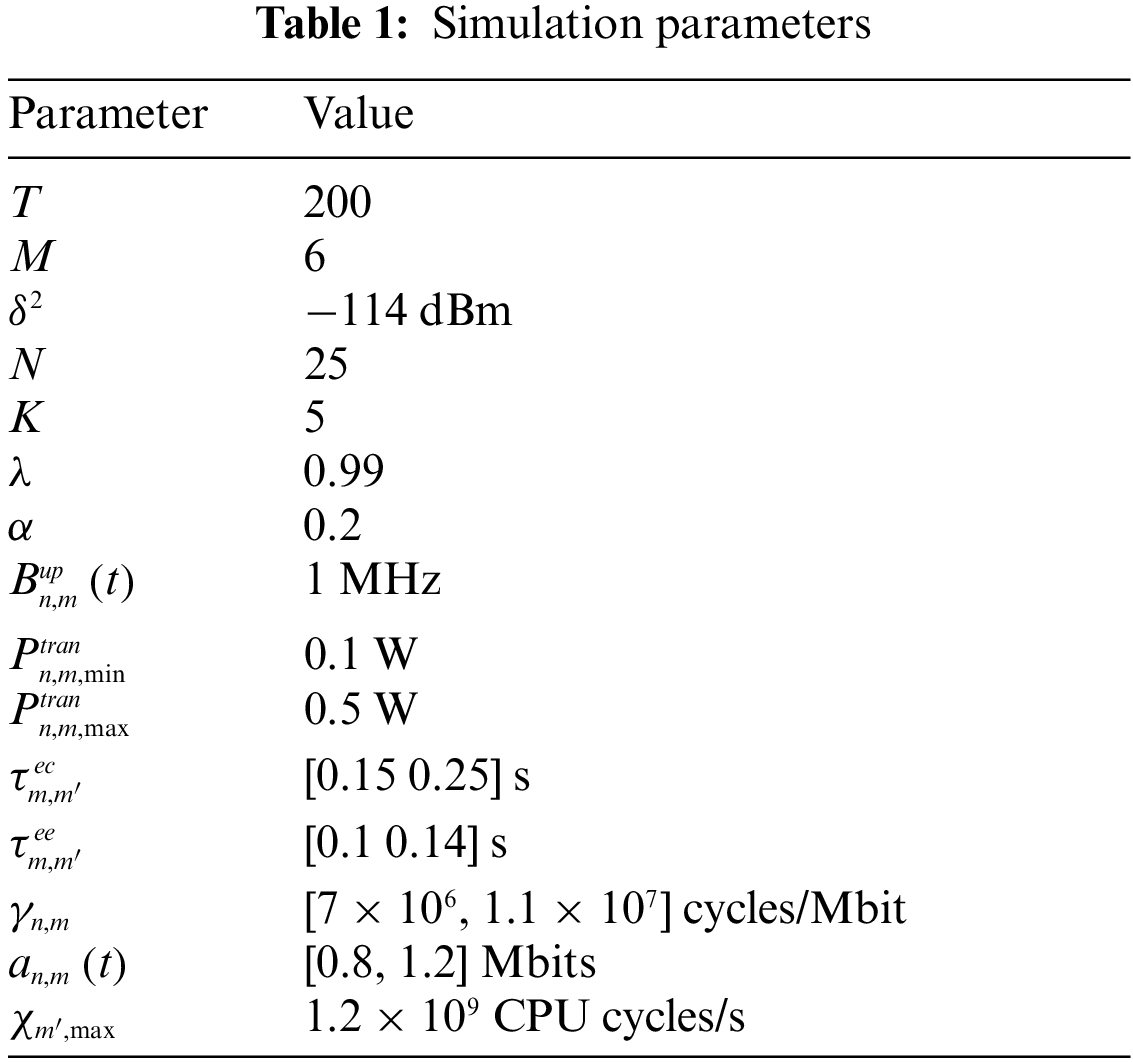
Fig. 4 demonstrates the average weighted sum of total energy consumption and delay vs. time slot. The proposed algorithm has the minimum weighted sum value and smaller fluctuations. When
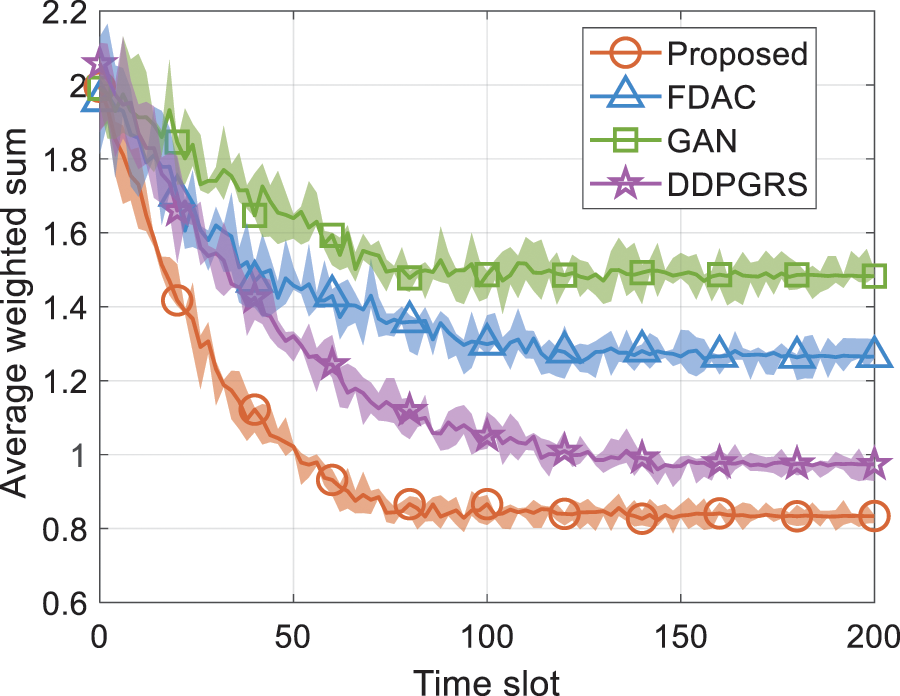
Figure 4: Average weighted sum of total energy consumption and delay vs. time slot
Fig. 5 demonstrates the average weighted sum of total energy consumption and delay for 50 simulations. Compared to the FDAC, GAN and DDPGRS, the proposed algorithm reduces the median of the average weighted sum of total energy consumption and delay by 35.71%, 42.65% and 26.95%, respectively. Meanwhile, the proposed algorithm has the smallest mean and variance of the average weighted sum of total energy consumption and delay, indicating the reliability and generalizability of the findings.
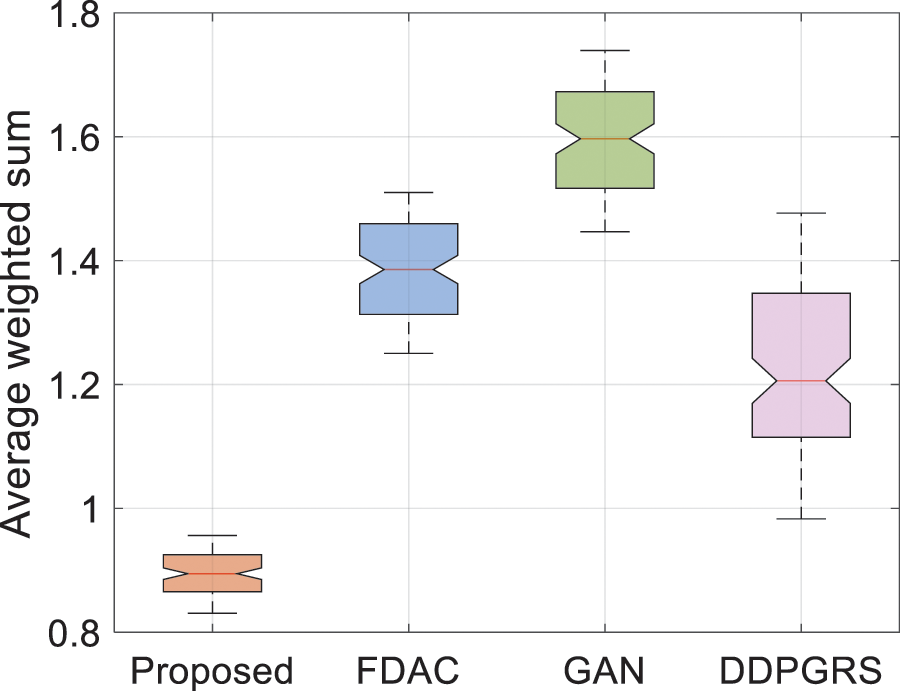
Figure 5: Average weighted sum of total energy consumption and delay for 50 simulations
Fig. 6 shows the loss functions vs. time slot, respectively. The proposed algorithm has the fastest convergence, the lowest loss function of generator, and the highest loss function of discriminator. Compared to FDAC, GAN and DDPGRS, the loss function of generator achieved by the proposed algorithm is decreased by 9.66%, 33.10%, and 12.37%. The rationale behind this is that the proposed algorithm adopts the Wasserstein distance rather than the traditional JS divergence to calculate loss function. During model training, the Wasserstein distance significantly improves the accuracy of the model in capturing the details of the data distribution, which in turn effectively contributes to the generalization performance of the model. When the Wasserstein distance is adopted as a loss function, it motivates the generative model to produce outputs that are closer to the real data distribution.
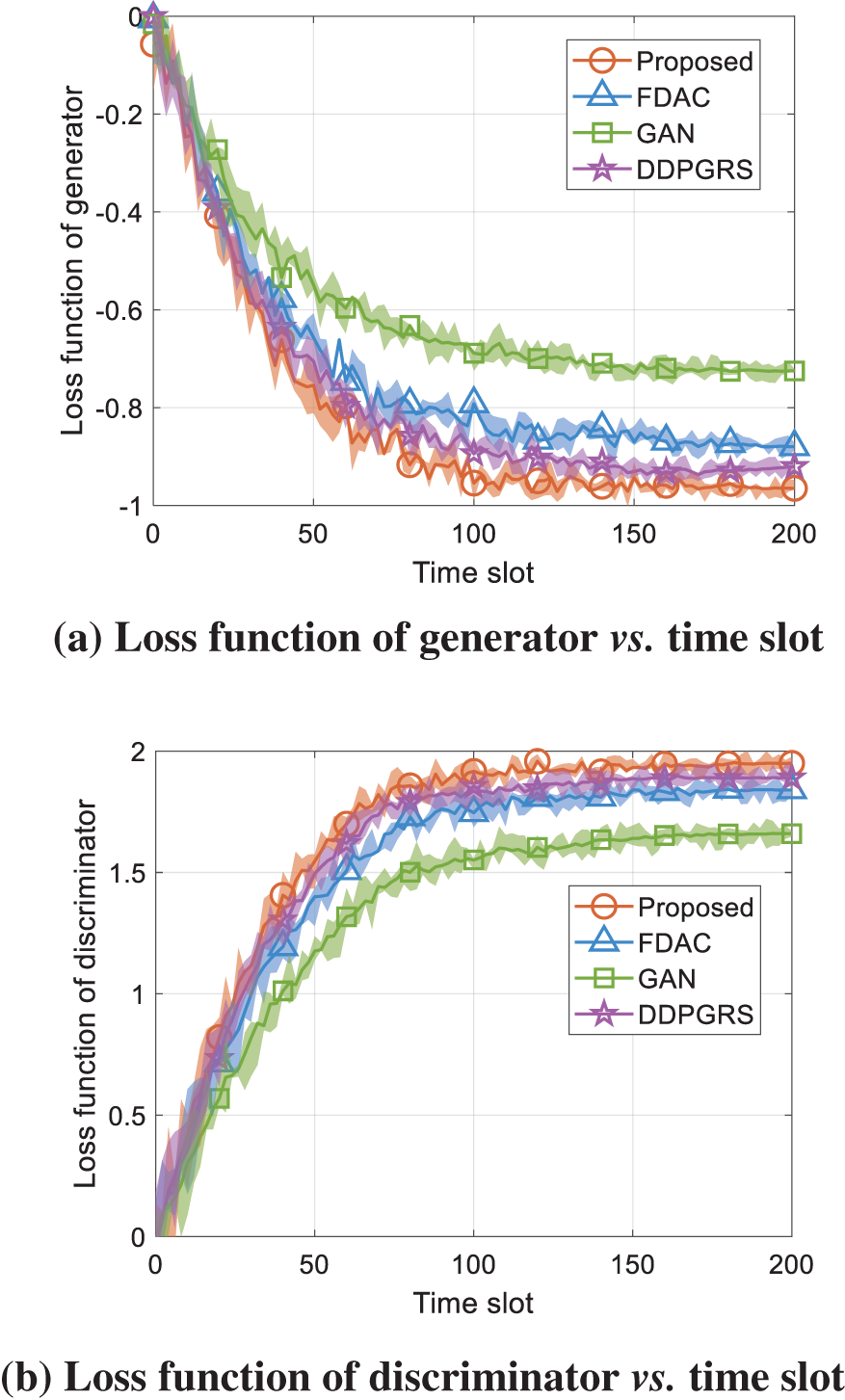
Figure 6: Loss functions vs. time slot
Fig. 7 shows the energy consumption virtual queue backlogs of different algorithms. The red line denotes the median. Compared to the FDAC, GAN and DDPGRS, the proposed algorithm reduces the median of the energy consumption virtual deficit queue backlog by 49.90%, 62.55% and 34.64%, respectively. Moreover, the proposed algorithm decreases the virtual deficit queue backlog deviation by 75.69%, 68.23% and 35.86%. The reason is that the proposed algorithm considers energy consumption virtual deficit queues and applies them in the optimization objective, so as to optimize the scheduling policy according to the urgency of tasks and real-time availability of resources, which effectively reduces the service delay as well as the system energy consumption. In addition, the algorithm considers the sensitivity to constraint violations when dynamically adjusting the learning rate and global aggregation weights to minimize the occurrence of constraint violations.
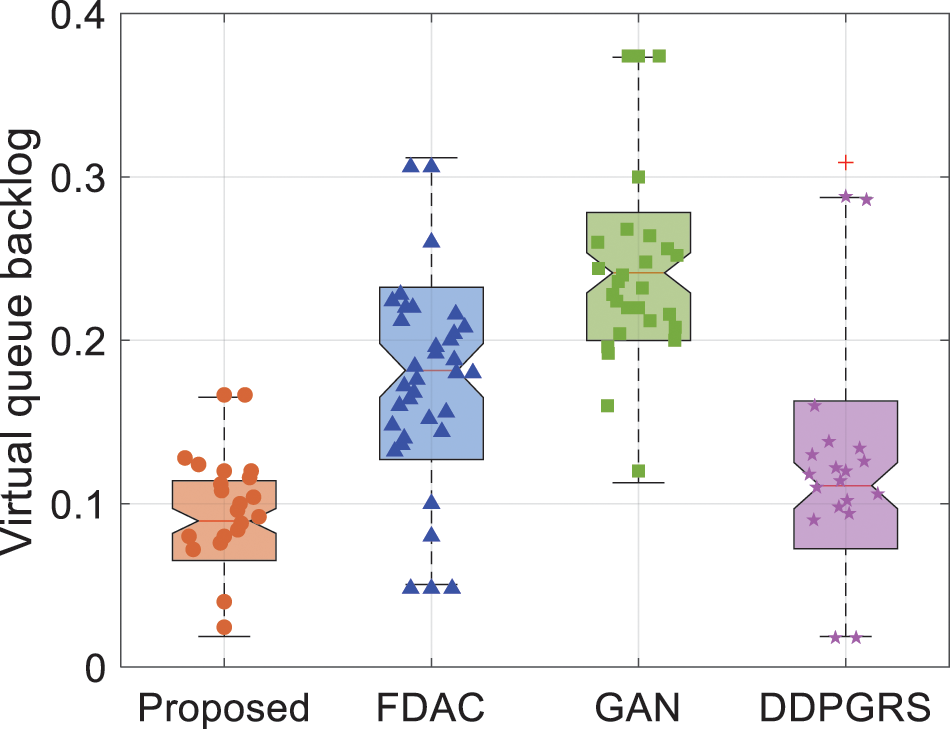
Figure 7: Energy consumption virtual queue backlogs of different algorithms
Fig. 8 demonstrates the trade-off between the total energy consumption and the total delay under different weight values of
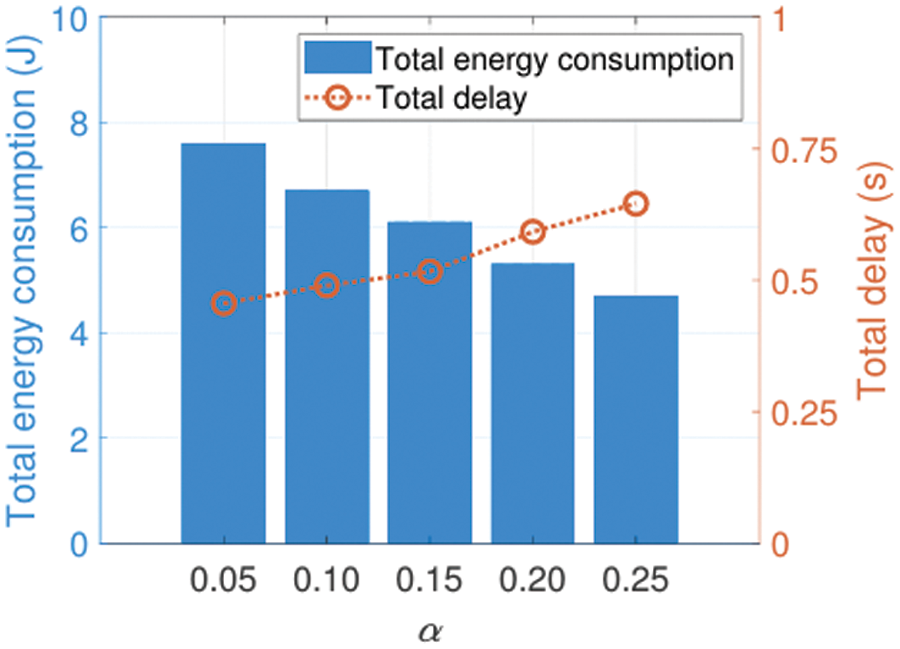
Figure 8: Total energy consumption and total delay vs. the weight
Fig. 9 shows delay composition and migration composition vs. edge server computing resources. As the edge server computing resources increase from 3
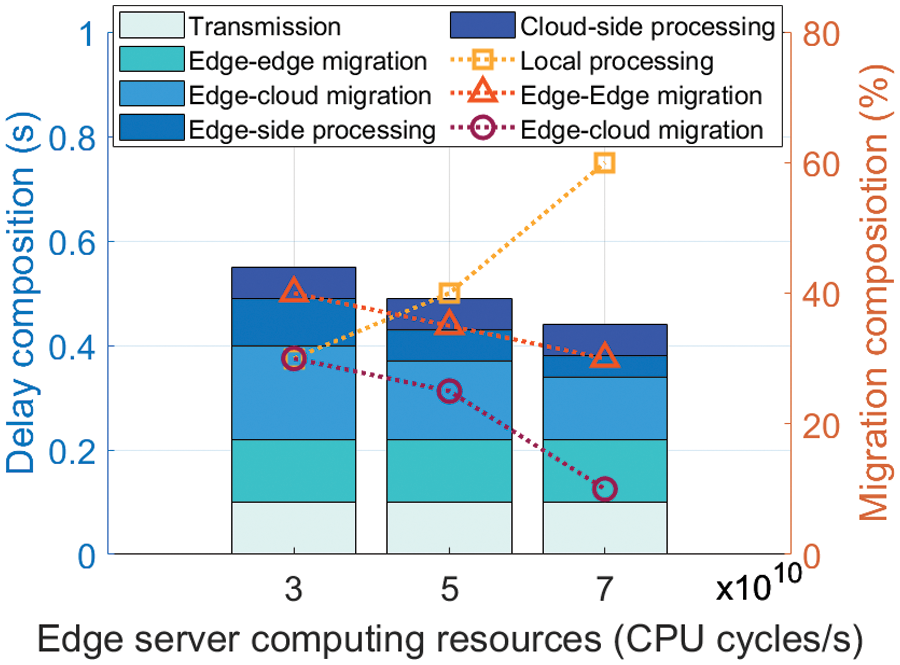
Figure 9: Delay composition and migration composition vs. edge server computing resources
Fig. 10 shows the delay composition and migration composition vs. data computation complexity. As the data computation complexity increases from 7
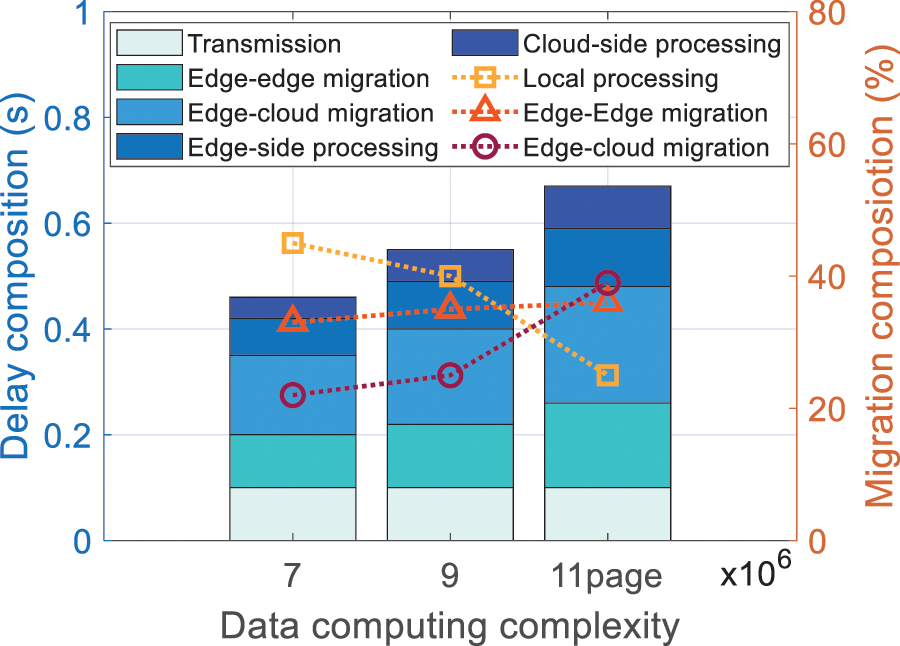
Figure 10: Delay composition and migration composition vs. data computation complexity
Table 2 shows the computation complexity of different algorithms. Although federated learning introduces additional communication overhead, the computation complexity of the proposed algorithm is still in the same order of magnitude as FDAC, GAN. The computation complexity of the proposed algorithm is slightly higher than FDAC, GAN, and DDPGRS, but the weighted sum of the proposed algorithms is reduced by 33.24%, 46.74%, and 23.47% compared to FDAC, GAN, and DDPGRS, respectively.

This paper addresses the joint optimization challenge of communication and computing resource scheduling for multi-flow integrated energy aggregation dispatch. The study introduces a cloud-edge collaborative FGAN algorithm that is sensitive to long-term constraint violations to facilitate energy-efficient data processing with reduced latency, even under stringent energy consumption constraints. This method significantly enhances energy efficiency and response times, offering a robust solution for the real-world implementation of multi-flow integrated energy aggregation dispatch systems. It also presents innovative strategies for adapting to diverse computational resources and data complexities. When benchmarked against FDAC, GAN and DDPGRS, the proposed FGAN algorithm achieves a 33.24%, 46.74% and 34.64% reduction in the average weighted sum of energy consumption and latency, respectively, and lowers the average energy consumption virtual queue deficit backlogs by 49.90% and 62.55% and 35.86%. Simulation results further reveal its capability to dynamically adjust migrations between edge devices and from edge to cloud, in response to fluctuations in available computing resources and data processing complexities, thereby ensuring workload balance.
However, the proposed algorithm still has some potential limitations. For instance, it does not account for certain unexpected situations and possible attacks, posing risks of privacy breaches, which may result in low scheduling accuracy. Smart contracts and blockchain technology enable data and transactions to occur on decentralized networks, reducing the risk of single points of failure and enhancing the reliability and security of the system. Future research efforts could combine smart contracts with blockchain to improve security.
Acknowledgement: The author would like to thank the Electric Power Dispatching Control Center of Guangdong Power Grid Co., Ltd. for supporting this work.
Funding Statement: This work was supported by China Southern Power Grid Technology Project under Grant 03600KK52220019 (GDKJXM20220253).
Availability of Data and Materials: The data that support the findings of this study are available from the corresponding author upon reasonable request.
Conflicts of Interest: The author declares that they have no conflicts of interest to report regarding the present study.
References
1. Y. Wu, V. K. N. Lau, D. H. K. Tsang, L. P. Qian, and L. Meng, “Optimal energy scheduling for residential smart grid with centralized renewable energy source,” IEEE Syst. J., vol. 8, no. 2, pp. 562–576, Jun. 2014. doi: 10.1109/JSYST.2013.2261001. [Google Scholar] [CrossRef]
2. Y. Liu, S. Xie, Q. Yang, and Y. Zhang, “Joint computation offloading and demand response management in mobile edge network with renewable energy sources,” IEEE Trans. Vehicular Technol., vol. 69, no. 12, pp. 15720–15730, Dec. 2020. doi: 10.1109/TVT.2020.3033160. [Google Scholar] [CrossRef]
3. L. Lei, Y. Tan, G. Dahlenburg, W. Xiang, and K. Zheng, “Dynamic energy dispatch based on deep reinforcement learning in IoT-driven smart isolated microgrids,” IEEE Internet Things J., vol. 8, no. 10, pp. 7938–7953, May 2021. doi: 10.1109/JIOT.2020.3042007. [Google Scholar] [CrossRef]
4. J. Zhang, Q. Yan, X. Zhu, and K. Yu, “Smart industrial IoT empowered crowd sensing for safety monitoring in coal mine,” Digit. Commun. Netw., vol. 9, no. 2, pp. 296–305, Apr. 2023. doi: 10.1016/j.dcan.2022.08.002. [Google Scholar] [CrossRef]
5. P. Srikantha and D. Kundur, “Intelligent signal processing and coordination for the adaptive smart grid: An overview of data-driven grid management,” IEEE Signal Process. Mag., vol. 36, no. 3, pp. 82–102, May 2019. doi: 10.1109/MSP.2018.2877001. [Google Scholar] [CrossRef]
6. D. Gan, X. Ge, and Q. Li, “An optimal transport-based federated reinforcement learning approach for resource allocation in cloud-edge collaborative IoT,” IEEE Internet Things J., vol. 11, no. 2, pp. 2407–2419, Jan. 15, 2024. doi: 10.1109/JIOT.2023.3292368. [Google Scholar] [CrossRef]
7. Z. Zhou et al., “Blockchain-based secure and efficient secret image sharing with outsourcing computation in wireless networks,” IEEE Trans. Wirel. Commun., vol. 23, no. 1, pp. 423–435, 2024. doi: 10.1109/TWC.2023.3278108. [Google Scholar] [CrossRef]
8. H. Liao et al., “Cloud-edge-device collaborative reliable and communication-efficient digital twin for low-carbon electrical equipment management,” IEEE Trans. Ind. Inform., vol. 19, no. 2, pp. 1715–1724, Feb. 2023. doi: 10.1109/TII.2022.3194840. [Google Scholar] [CrossRef]
9. J. H. Syu, J. C. W. Lin, G. Srivastava, and K. Yu, “A comprehensive survey on artificial intelligence empowered edge computing on consumer electronics,” IEEE Trans. Consum. Electron., vol. 69, no. 4, pp. 1023–1034, 2023. doi: 10.1109/TCE.2023.3318150. [Google Scholar] [CrossRef]
10. F. Fang and X. Wu, “A win-win mode: The complementary and coexistence of 5G networks and edge computing,” IEEE Internet Things J., vol. 8, no. 6, pp. 3983–4003, Mar. 15, 2021. doi: 10.1109/JIOT.2020.3009821. [Google Scholar] [CrossRef]
11. Z. Yang et al., “Differentially private federated tensor completion for cloud-edge collaborative AIoT data prediction,” IEEE Internet Things J., vol. 11, no. 1, pp. 256–267, Jan. 1, 2024. doi: 10.1109/JIOT.2023.3314460. [Google Scholar] [CrossRef]
12. F. Zeng, K. Zhang, L. Wu, and J. Wu, “Efficient caching in vehicular edge computing based on edge-cloud collaboration,” IEEE Trans. Vehicular Technol., vol. 72, no. 2, pp. 2468–2481, Feb. 2023. doi: 10.1109/TVT.2022.3213130. [Google Scholar] [CrossRef]
13. A. T. Z. Kasgari, W. Saad, M. Mozaffari, and H. V. Poor, “Experienced deep reinforcement learning with generative adversarial networks (GANs) for model-free ultra reliable low latency communication,” IEEE Trans. Commun., vol. 69, no. 2, pp. 884–899, Feb. 2021. doi: 10.1109/TCOMM.2020.3031930. [Google Scholar] [CrossRef]
14. R. K. Gupta, S. Mahajan, and R. Misra, “Resource orchestration in network slicing using GAN-based distributional deep Q-network for industrial applications,” J. Supercomput., vol. 79, no. 5, pp. 5109–5138, Oct. 2022. doi: 10.1007/s11227-022-04867-9. [Google Scholar] [CrossRef]
15. Y. Hua, R. Li, Z. Zhao, H. Zhang, and X. Chen, “GAN-based deep distributional reinforcement learning for resource management in network slicing,” in 2019 IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 2019, pp. 1–6. doi: 10.1109/GLOBECOM38437.2019.9014217. [Google Scholar] [CrossRef]
16. F. Naeem, S. Seifollahi, Z. Zhou, and M. Tariq, “A generative adversarial network enabled deep distributional reinforcement learning for transmission scheduling in internet of vehicles,” IEEE Trans. Intell. Transp. Syst., vol. 22, no. 7, pp. 4550–4559, Jul. 2021. doi: 10.1109/TITS.2020.3033577. [Google Scholar] [CrossRef]
17. S. Zhang, Z. Yao, H. Liao, Z. Zhou, Y. Chen and Z. You, “Endogenous security-aware resource management for digital twin and 6G edge intelligence integrated smart park,” China Commun., vol. 20, no. 2, pp. 46–60, Feb. 2023. doi: 10.23919/JCC.2023.02.004. [Google Scholar] [CrossRef]
18. C. Xu, R. Xia, Y. Xiao, Y. Li, G. Shi and K. C. Chen, “Federated traffic synthesizing and classification using generative adversarial networks,” in ICC 2021-IEEE Int. Conf. Commun., Montreal, QC, Canada, 2021, pp. 1–6. doi: 10.1109/ICC42927.2021.9500866. [Google Scholar] [CrossRef]
19. E. Tomiyama, H. Esaki, and H. Ochiai, “WAFL-GAN: Wireless ad hoc federated learning for distributed generative adversarial networks,” in 2023 15th Int. Conf. Knowl. Smart Technol. (KST), Phuket, Thailand, 2023, pp. 1–6. doi: 10.1109/KST57286.2023.10086811. [Google Scholar] [CrossRef]
20. H. Sui, X. Sun, J. Zhang, B. Chen, and W. Li, “Multi-level membership inference attacks in federated learning based on active GAN,” Neural Comput. Appl., vol. 35, no. 23, pp. 17013–17027, Apr. 2023. doi: 10.1007/s00521-023-08593-y. [Google Scholar] [CrossRef]
21. W. Li, J. Chen, Z. Wang, Z. Shen, C. Ma and X. Cui, “IFL-GAN: Improved federated learning generative adversarial network with maximum mean discrepancy model aggregation,” IEEE Trans. Neural Netw. Learn. Syst., vol. 34, no. 12, pp. 10502–10515, Dec. 2023. doi: 10.1109/TNNLS.2022.3167482. [Google Scholar] [PubMed] [CrossRef]
22. G. Laguna-Sanchez and M. Lopez-Guerrero, “On the use of alpha-stable distributions in noise modeling for PLC,” IEEE Trans. Power Deliv., vol. 30, no. 4, pp. 1863–1870, Aug. 2015. doi: 10.1109/TPWRD.2015.2390134. [Google Scholar] [CrossRef]
23. Z. Zhou, Y. Guo, Y. He, X. Zhao, and W. M. Bazzi, “Access control and resource allocation for M2M communications in industrial automation,” IEEE Trans. Ind. Inform., vol. 15, no. 5, pp. 3093–3103, May 2019. doi: 10.1109/TII.2019.2903100. [Google Scholar] [CrossRef]
24. M. Wasim and D. S. Naidu, “Lyapunov function construction using constrained least square optimization,” in IECON, 2022–48th Annual Conference of the IEEE Industrial Electronics Society, Brussels, Belgium, 2022, pp. 1–5. doi: 10.1109/IECON49645.2022.9968442. [Google Scholar] [CrossRef]
25. J. Zhang, S. Guo, J. Guo, D. Zeng, J. Zhou and A. Y. Zomaya, “Towards data-independent knowledge transfer in model-heterogeneous federated learning,” IEEE Trans. Comput., vol. 72, no. 10, pp. 2888–2901, Oct. 2023. doi: 10.1109/TC.2023.3272801. [Google Scholar] [CrossRef]
26. J. Liu, P. Li, G. Wang, Y. Zha, J. Peng and G. Xu, “A multitasking electric power dispatch approach with multi-objective multifactorial optimization algorithm,” IEEE Access, vol. 8, pp. 155902–155911, 2020. doi: 10.1109/ACCESS.2020.3018484. [Google Scholar] [CrossRef]
27. B. Kar, W. Yahya, Y. D. Lin, and A. Ali, “Offloading using traditional optimization and machine learning in federated cloud-edge–fog systems: A survey,” IEEE Commun. Surv. Tut., vol. 25, no. 2, pp. 1199–1226, Secondquarter 2023. doi: 10.1109/COMST.2023.3239579. [Google Scholar] [CrossRef]
28. Z. Su et al., “Secure and efficient federated learning for smart grid with edge-cloud collaboration,” IEEE Trans. Ind. Inform., vol. 18, no. 2, pp. 1333–1344, Feb. 2022. doi: 10.1109/TII.2021.3095506. [Google Scholar] [CrossRef]
29. R. Yan, Y. Yuan, Z. Wang, G. Geng, and Q. Jiang, “Active distribution system synthesis via unbalanced graph generative adversarial network,” IEEE Trans. Power Syst., vol. 38, no. 5, pp. 4293–4307, Sep. 2023. doi: 10.1109/TPWRS.2022.3212029. [Google Scholar] [CrossRef]
30. H. Hu, D. Wu, F. Zhou, X. Zhu, R. Q. Hu and H. Zhu, “Intelligent resource allocation for edge-cloud collaborative networks: A hybrid DDPG-D3QN approach,” IEEE Trans. Vehicular Technol., vol. 72, no. 8, pp. 10696–10709, Aug. 2023. doi: 10.1109/TVT.2023.3253905. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools