
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
REVIEW

A Comprehensive Survey of Recent Transformers in Image, Video and Diffusion Models
1 College of Computer Science and Electronic Engineering, Hunan University, Changsha, 410082, China
2 Faculty of Information Technology, Yersin University of Da Lat, Da Lat, 66100, Vietnam
3 Faculty of Information Technology, Ho Chi Minh City Open University, Ho Chi Minh City, 722000, Vietnam
* Corresponding Author: Viet-Tuan Le. Email:
Computers, Materials & Continua 2024, 80(1), 37-60. https://doi.org/10.32604/cmc.2024.050790
Received 17 February 2024; Accepted 17 May 2024; Issue published 18 July 2024
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Transformer models have emerged as dominant networks for various tasks in computer vision compared to Convolutional Neural Networks (CNNs). The transformers demonstrate the ability to model long-range dependencies by utilizing a self-attention mechanism. This study aims to provide a comprehensive survey of recent transformer-based approaches in image and video applications, as well as diffusion models. We begin by discussing existing surveys of vision transformers and comparing them to this work. Then, we review the main components of a vanilla transformer network, including the self-attention mechanism, feed-forward network, position encoding, etc. In the main part of this survey, we review recent transformer-based models in three categories: Transformer for downstream tasks, Vision Transformer for Generation, and Vision Transformer for Segmentation. We also provide a comprehensive overview of recent transformer models for video tasks and diffusion models. We compare the performance of various hierarchical transformer networks for multiple tasks on popular benchmark datasets. Finally, we explore some future research directions to further improve the field.Keywords
Transformer was designed for Natural Language Processing (NLP) tasks. Vaswani et al. [1] marked a milestone in the history of the transformer. Subsequently, BERT [2] achieved state-of-the-art performance across various tasks. The transformer has demonstrated its dominance in the field of NLP. Various versions of Generative Pre-trained Transformers (GPTs) [3,4] have been introduced for numerous NLP tasks. Moreover, articles generated by GPT-3 are often indistinguishable from those written by humans.
For many years, CNNs have been instrumental in solving a wide range of tasks in computer vision. AlexNet [5] is considered at the forefront of the CNNs when it outperformed the traditional handcraft methods on the ImageNet dataset. To further enhance CNN performance, numerous approaches have incorporated self-attention in spatial [6], channel [7,8] or both spatial and channel [9]. However, self-attention is typically integrated as an additional layer within the convolutional network architecture.
The success of transformer-based approaches in NLP has sparked interest in applying similar techniques to computer vision. Many pure transformers have been proposed and utilized to replace the traditional CNNs since the transformers have achieved state-of-the-art performance across various computer vision tasks. In NLP, the original transformer model takes a 1D sequence of words as input. The Vision Transformer (ViT) [10] adapted the transformer architecture to handle 2D images by dividing them into a grid of patches, with each patch being flattened into a single vector. This work is known as the pioneer of using the transformer with visual data.
1.1 Review of Related Survey Articles
Recently, a multitude of transformer variants have been proposed, demonstrating that transformer-based models achieve state-of-the-art results across diverse tasks. To keep pace with the increase of transformer-based approaches, numerous surveys have been introduced to provide comprehensive overviews of the transformer landscape. Table 1 provides a comparison of recent survey works focusing on vision transformer models.
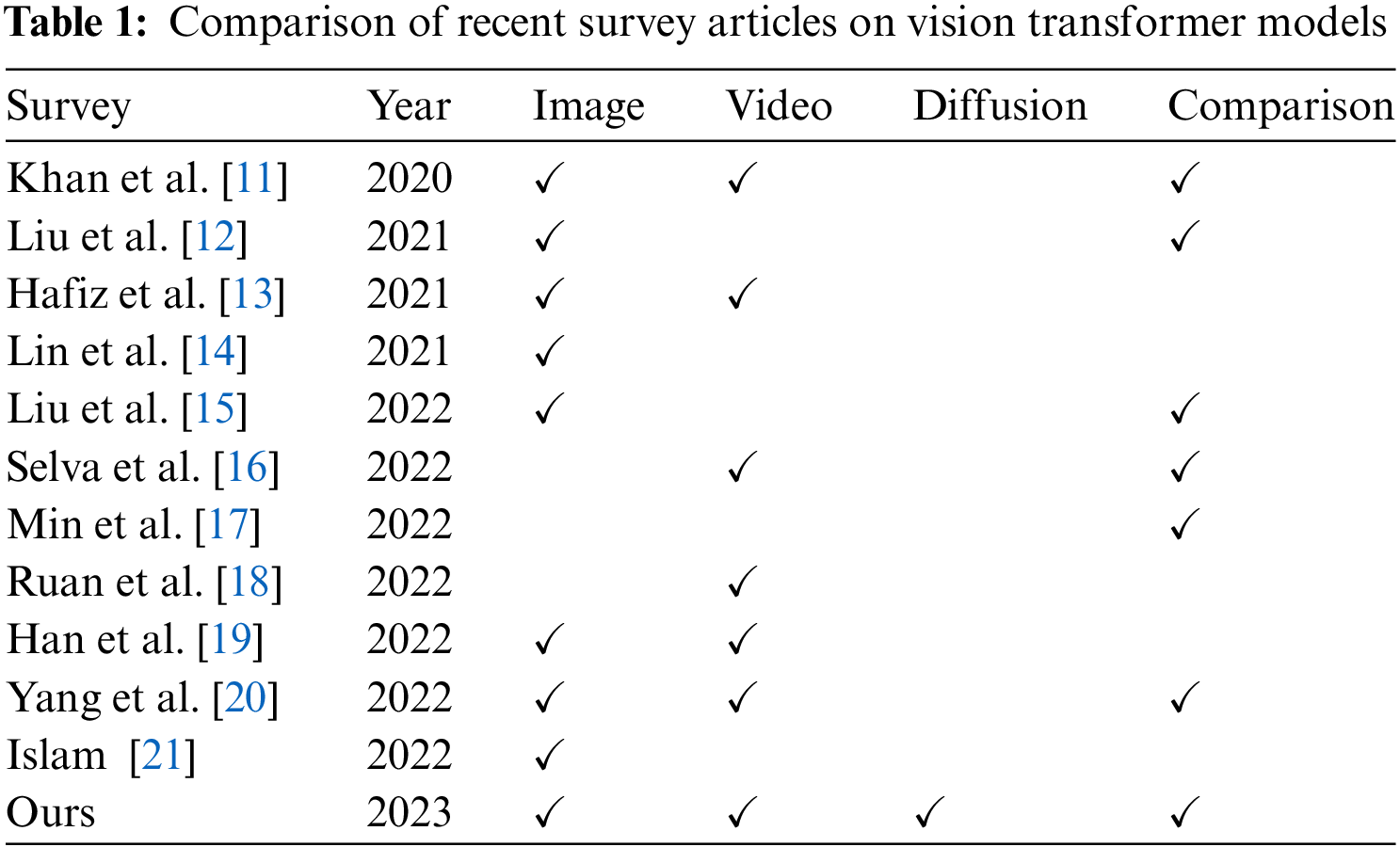
Lin et al. [14] focused on the attention mechanism in their survey. They divided the improvement on attention into six categories including spare attention, linearized attention, prototype and memory compression, low-rank self-attention, attention with prior and improved multi-head mechanism. Then, they discussed position representations, layer normalization and position-wise feed-forward network which are three important parts of the transformer network. They also reviewed the transformer-based approach which modifies from the vanilla transformer to improve the computation of transformer networks.
Khan et al. [11] provided a survey of the transformer approaches in computer vision. Firstly, the methods using single-head self-attention are discussed. These methods are based on convolution operation and add a self-attention layer to exploit the long-range dependencies. In the second part, transformer (multi-head self-attention) methods are reviewed. In addition, the survey also discusses six fields of computer vision that transformer have been applied, including object detection, segmentation, image and scene generation, low-level vision, multi-modal tasks, and video understanding. Han et al. [19] categorized the transformer-based methods into four main parts in their survey, including backbone network, high/mid-level vision, low-level vision, and video processing. In addition, they also discussed multi-modal tasks and the efficient transformer. Two kinds of backbone network were discussed, containing pure transformer and transformer with convolution. Yang et al. [20] reviewed methods using the transformer in image and video applications. In image tasks, the survey first reviews transformer networks as backbones. Then, they provide a detailed discussion about image classification, object detection, and image segmentation tasks in images. In the second part of the survey, the authors provide two aspects of video tasks, including object tracking and video classification.
Hafiz et al. [13] reviewed attention-based deep architectures for machine vision. A detailed discussion of five architectures which are based on attention is provided. Then, they discussed three combinations of CNNs and the transformer. The first kind is a convolutional neural network with extra attention layers [7,9]. CNNs are used to extract features that are input to the transformer. The third kind is the combination of CNN and transformer.
Liu et al. [12] reviewed three popular tasks of computer vision, containing classification, detection, and segmentation. The authors split classification methods into various categories, such as pure transformer, the combination of CNN and transformer, and deep transformer. Islam [21] reviewed recent transformer-based methods for image classification, segmentation, 3D point clouds, and person re-identification. This survey discussed semantic segmentation and medical image segmentation. Xu et al. [22] focused on transformer-based methods in low-level vision and generation in their survey. The authors also reviewed transformer methods for the backbone which are used for classification tasks. In addition, high-level vision and multi-model learning were discussed in this survey.
CNNs have obtained state-of-the-art performance in many fields of computer vision. Transformer has recently introduced and outperformed CNN-based methods in many tasks, such as classification, object detection, and segmentation. Liu et al. [15] reviewed recent deep Multi-layer Perceptron (MLP) approaches. The pioneering MLP methods [23–25] were discussed which obtained comparable performance to CNNs and the transformer. In the main part of the survey, they discuss three categories of MLP block variants. They also provide different architectures of MLP variants, such as single and pyramid architectures. A comparison of MLP, CNN, and transformer-based methods were provided on image classification, object detection, semantic segmentation, low-level vision, video analysis and point cloud.
In contrast, Selva et al. [16] focused on video transformers in their work. In the first main part, the survey discusses some pre-processing methods of video before feeding into the transformer network, such as embedding, tokenization, and positional embedding. Then, two main efficient designs were discussed for long sequences of video. The review provided three different approaches for multi-modality including multi-model fusion, multi-model translation, and multi-model alignment. Training a transformer and the performance of video classification using the transformer were compared in the last section of the survey.
Graphs have been used to represent structural information in many fields. In a graph, objects are represented by nodes/vertices while the relationships between objects are represented by the edges. Min et al. [17] provided an overview of transformers for graphs. The survey discussed three incorporations of transformer and graph, including Graph Neural Networks as auxiliary modules in the transformer, improved positional embedding from graphs, and improved attention matrices from graphs. Moreover, the authors conducted an experiment to compare the effectiveness of methods in the three groups.
On the other hand, Ruan et al. [18] focused on transformer-based methods for video-language learning. A pre-training and fine-tuning strategy for video-language processing is discussed. Then, two types of model structures using the transformer are reviewed, including single-stream and multi-stream structures.
1.2 Contributions of this Survey Article
Recently, numerous methods based on transformers have been proposed for various tasks in computer vision. This review provides a comprehensive discussion of transformer-based approaches across different computer vision tasks. In summary, our main contributions are listed below:
• This paper comprehensively reviews recent visual transformers for image tasks, covering three fundamental areas: downstream, generation and segmentation.
• In addition, we delve into the state-of-the-art transformers for video tasks. Specifically, we comprehensively examine the success of transformers as backbones in a wide range of diffusion models.
• We present a detailed comparison of recent methods that utilize transformers as backbones.
The rest of the survey is organized as follows. Firstly, a discussion of the components of an original transformer network in Section 2. In Section 3, we discuss a wide range of vision transformers for image data. Next, we discuss recent transformers for video data in Section 4. Section 5 discusses recent transformer-based diffusion models. Then, Section 6 compares the performance of the recent methods based on the transformer network. Finally, we discuss some open research problems and give the conclusion of this survey in Sections 7 and 8, respectively.
2 Revisiting the Components of Transformer Network
Transformer was introduced by Vaswani et al. [1] for NLP. The transformer includes an encoder and a decoder which are used to encode the input and generate the output, respectively. Both the encoder and decoder have several transformer blocks. Each block contains a multi-head attention layer, a feed-forward neural network, and layer normalization as illustrated in Fig. 1.
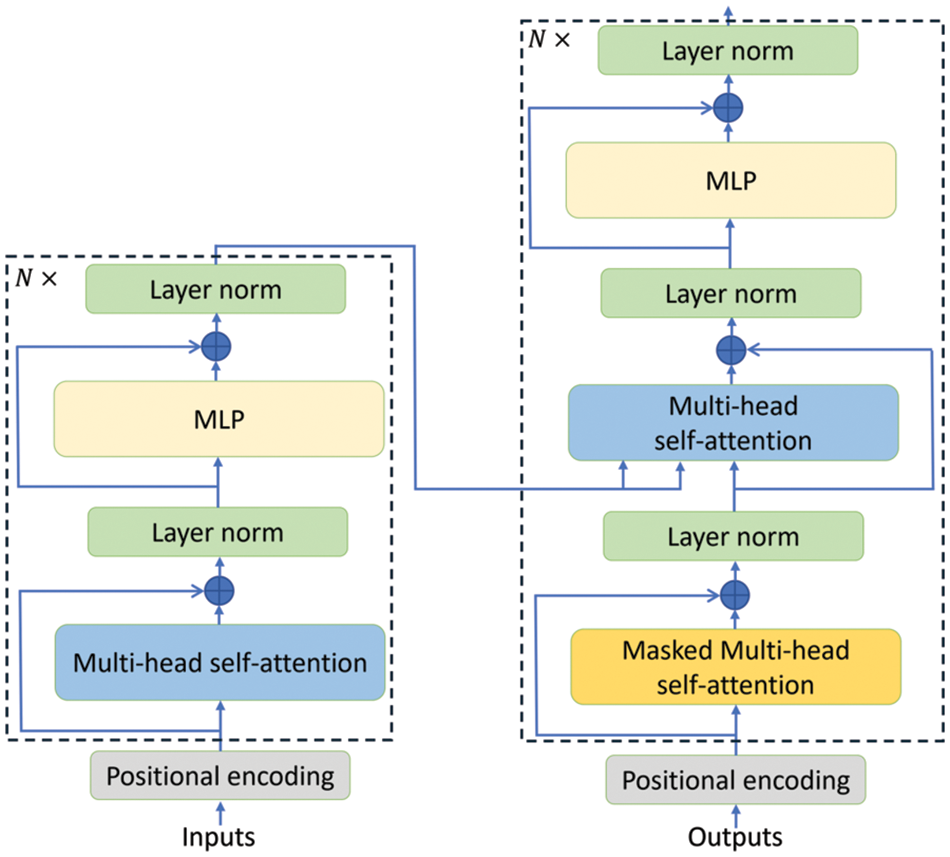
Figure 1: The vanilla transformer block, including an encoder (left) and a decoder (right). The encoder and decoder consist of several layers. Each layer of the encoder and the decoder contains multi-head self-attention mechanism and a multi-layer perceptron. In addition, the decoder has a masked multi-head self-attention
The input vector
where
where the score is calculated by a dot product of the query and the key, and the score is normalized by a softmax operation
Multi-head attention is used to improve the performance of the attention mechanism by projecting the queries, keys and values into multiple subspaces. These projected outputs are processed parallel by attention heads. Then, the output matrices are concatenated and projected to the final output:
where
The second layer of a transformer block is a feed-forward network that contains two linear transformations and a nonlinear activation function in between:
where
2.4 Residual Connection and Layer Normalization
A residual connection [26] is added into each sub-layer, for example, the multi-head attention and the feed-forward network layer. In addition, a layer normalization [27] is followed each residual connection.
The positional information of words in a sentence is not encoded by the self-attention layer. To model the sequential information, the relative or absolute position of the tokens is added to the inputs. Sine and cosine functions are used for positional encoding.
where
3 Vision Transformer for Image Data
3.1 Vision Transformer for Downstream Tasks
DINO [28] is a self-supervised approach, including student and teacher networks. Both student and teacher networks receive two transformations of input. Their outputs are normalized, and a cross-entropy loss is used to measure the similarity of them. To exchange visual information between regions, Fang et al. [29] introduced MSG-Transformer for image classification and object detection. Information in a local window is abstracted by a messenger token and is exchanged with other messenger tokens. Therefore, the information of local regions is exchanged by messenger tokens. To exchange information, groups of channels are obtained by splitting the channels of each messenger token. Then, obtained groups are shuffled with all other messenger tokens to exchange information. However, these transformers produce feature maps limited to a single scale while the CNN can output multi-scale feature maps suitable for various computer vision tasks.
A hierarchical transformer often includes four transformer stages in which different scales of feature maps are generated, as illustrated in Fig. 2. Each stage contains multiple transformer blocks which are composed of a multi-head attention layer and a feed-forward layer. The input is hierarchically reduced spatial size and expanded channel capacity through four stages of the transformer. PVT1 [30] introduced a pure transformer backbone that can be used as backbone for many downstream tasks. The output of the network is multi-scale feature maps which have a resolution of
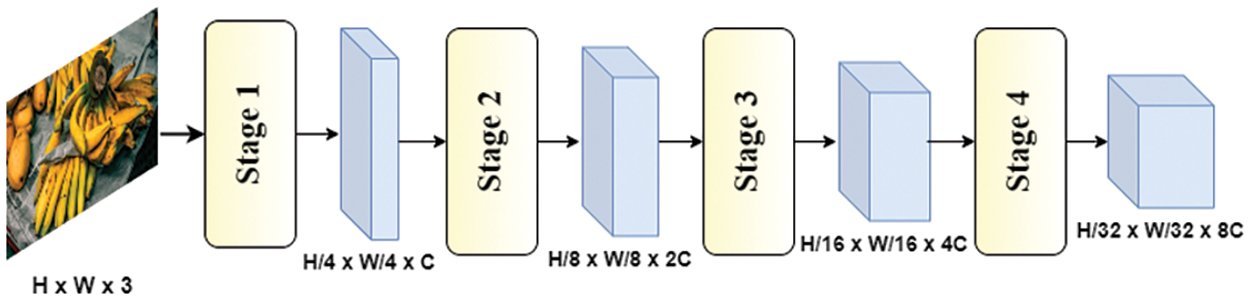
Figure 2: The architecture of a hierarchical transformer includes four stages for generating feature maps of different scales
Uformer [35] is a hierarchical transformer for image restoration. The network contains K encoder stages and K decoder stages. Each encoder stage includes a stack of locally enhanced window transformer blocks and one down-sampling layer. On the opposite stages, each has a stack of locally enhanced window transformer blocks and an up-sampling layer. A
Chu et al. [39] proposed Twins-PCPVT which is based on PVT [30] and Twins-SVT which is based on spatially separable self-attention. In Twins-PCPVT, conditional position encoding is used to replace absolute positional encoding. The spatially separable self-attention contains locally-grouped self-attention which is computed in each sub-window. To exchange the information between local windows, a global self-attention was proposed to communicate between sub-windows. Cswin transformer [40] computes self-attention in two directions by proposing cross-shaped window self-attention. The proposed attention obtains attention of a large area and global attention. In addition, locally-enhanced positional encoding was introduced for the downstream transformer network. Window-based transformers [32] have achieved promising results on multiple tasks of computer vision. Shuffle transformer [41] was proposed to improve the connection between non-overlapping local windows. A shuffle transformer block contains a shuffle multi-head self-attention to enhance the connection between the windows and neighbor-window connection to strengthen the information between windows by inserting a depth-wise convolution before the MLP module. Glance-and-Gaze Transformer [42] proposed Glance attention which computes self-attention with a global reception field. Since the feature maps are split into different dilated partitions, a partition contains information of the whole input feature instead of a local window. To capture the local connection between partitions, a Gaze branch was introduced using the depth-wise convolution.
Hassani et al. [43] introduced a Neighborhood Attention Transformer (NAT) which computes attention using proposed neighborhood attention. This attention has lower computational complexity and local inductive biases. Each point in features attends to its neighboring points. The NAT outputs pyramid features that are used for different downstream tasks in computer vision. DaViT [44] proposed a dual attention vision transformer that computes self-attention using both spatial tokens and channel tokens. Each stage of the transformer has dual attention blocks which include a spatial window attention block, a channel group attention block, and a feed-forward network. To obtain global information, self-attention is computed on the transpose of patch-level tokens instead of patch-level. Moreover, channels are grouped and compute attention to reduce the complexity. Zhang et al. [45] proposed a Multi-Scale Vision Longformer which is used for high-resolution image encoding. An efficient ViT was proposed by modifying the vanilla transformer. Multiple proposed ViT is stacked to construct a multi-scale vision transformer that generates different feature maps. In addition, the attention mechanism of vision longer is used to reduce the complexity. Both global and local tokens are used to access global and local information.
Convolutional Vision Transformer [46] is a hierarchical transformer that leverages convolution to the transformer. The convolution is applied to the Convolutional Token Embedding layer and convolutional transformer block to encode local spatial contexts. In the transformer block, a depth-wise convolution is used instead of the position-wise linear projection in the vanilla transformer. Li et al. [47] proposed a Multiscale Vision Transformer (MViTv2) for image and video classification. Moreover, the proposed method was evaluated with object detection and video recognition tasks. The relative positional embedding is used in the pooled self-attention to model the relative distance across tokens. A residual pooling connection is applied to enhance the representation. The Vitae [48] is a transformer network that contains two main cells, including a reduction cell and a normal cell. Reduction cells use convolutional layers with different dilation rates. The spatial dimension of features is reduced by using stride convolution. The normal cells have the same architecture as the reduction cell. However, the pyramid reduction module extracted multi-scale features are used only in the reduction cell. Chen et al. [49] transited a transformer-based model into a convolution-based model. There are eight steps, including replacing the token, replacing patch embedding, splitting the network into stages, replacing layer-norm, introducing
Tang et al. [50] proposed QuadTree Attention is computed from a rough to fine manner with lower computational complexity. Self-attention is computed with L-level pyramids. At the fine level, attention is calculated from subset tokens that are selected from the coarse level using attention score. Ding et al. [51] proposed a lightweight transformer that consists of a projector to reduce the size of the input feature, an encoder, and a decoder. Moreover, a multi-branch search space was proposed for dense prediction tasks. The search space models features with different scales and global contexts. Inception transformer [52] proposed a transformer-based network that captures both high and low-frequency features. The image tokens are passed through an inception token mixer which is composed of three branches to extract high and low frequency information. To extract high-frequency features, a combination of max-pooling and convolution operation is used while a self-attention is used to extract low-frequency features.
ConvMAE [53] is a hybrid convolution-transformer network that includes an encoder and a decoder. The encoder outputs multi-scale features of the input image. The self-attention of the transformer block is replaced by a
3.2 Vision Transformer for Generation
UNet [57] is a popular convolutional network architecture that was introduced for biomedical image segmentation. The network contains two branches. The left branch is a down-sampling of the feature map while the output features are up-sampled by the other branch. In this section, we discuss transformer networks that have a U-shaped architecture.
TransUNet [58] combines a Transformer and a CNN to extract both local and global context information. CNN is used to extract features of the input. Stacked transformer layers are applied to the extracted features and output the hidden features. A decoder up-samples the output features to the final segmentation mask using a
Swin-Unet [66] proposed a pure transformer that has a shape like UNet for medical image segmentation. Both the encoder and decoder are composed of Swin transformer blocks [32]. Patch merging layer is used to down-sample and increase dimension while the patch expanding layer up-samples and restores the resolution. The extracted features from the encoder are fused with the features from the previous decoder layer via skip connections. Swin UNETR [67] combines Swin transformer [32] and CNN for 3D brain tumor semantic segmentation. A sequence of 3D tokens of the input is generated by a patch partition. The embedding tokens are extracted features by a Swin transformer-based encoder. A decoder is used to predict the final segmentation outputs. VT-UNet [68] proposed a transformer which has U-shaped architecture. The encoder includes three main stages including encoder block and patch merging. The encoder block is composed of two types of windows like a Swin transformer [32]. The decoder contains various decoder blocks, patch expanding and a classifier. Each decoder block has two self-attention encoders as regular and shifted window attentions. These models offer the advantage of proposing a pure transformer network, comprising both a transformer-based encoder and a transformer-based decoder.
3.3 Vision Transformer for Segmentation
Segmenter [69] is a transformer network for semantic segmentation. To exploit the global information, Segmenter is based on the vision transformer which does not use convolutions in the network. The network includes an encoder and decoder. The former is used to exploit the contextualized information while the latter up-samples the output of the encoder to pixel-level scores. In addition, two types of decoder were introduced, including a linear decoder and a mask transformer. In the mask transformer, a set of class embeddings was used to generate a class mask. This work was one of the pioneers in applying transformers to semantic segmentation. By introducing transformers into this domain, the study opened avenues for capturing a global receptive field in segmentation tasks. TopFormer [70] was proposed for semantic segmentation on mobile devices. The network uses stacked MobileNetV2 blocks [71] to create tokens at different scales. Semantic information is extracted by stacked transformer blocks with the generated tokens as input. The transformer block has the same architecture as the original transformer. However, linear layers are replaced by a
4 Vision Transformer for Video
Space-Time Attention Model (STAM) [74] contains a spatial and temporal transformer that is used to extract both spatial and temporal information from video frames. The spatial attention is applied on patches of each frame while the temporal attention is applied on the output of the spatial attention to capture the temporal information of frames. Bain et al. [75] proposed a transformer-based model that includes two encoders for encoding image/video and a sequence of words. To process video input, the divided space-time attention is used with a modification of the residual connection of the temporal self-attention and spatial self-attention blocks. TimeSformer [76] is a transformer-based model for video classification. The model exploits both spatial and temporal information by obtaining temporal attention and spatial attention separately at each block of the transformer. The reduced computational complexity due to the temporal attention and spatial attention are computed once after the other. Zhang et al. [77] proposed a token shift module for modeling temporal information in the transformer. Several shift variants were introduced, including token shift, temporal shift, and patch shift. The token shift module can be inserted into various positions in a transformer-based encoder. Each position of the token shift will determine the degree of motion information. The shift module can be insert before the layer-norm layer, before the multi-head attention and feed-forward network, or post multi-head attention and feed-forward network. VidTr [78] is a video transformer for video classification. To reduce memory consumption, VidTr exploits spatiotemporal features by using spatial and temporal attention separately. In addition, a topK-based pooling was proposed to down-sample temporal since the video contains redundant information. Many works [76–79] have tried to reduce the complexity of the space-time attention. Multiple transformer-based architectures [79] were introduced for video classification. The interactions of all spatiotemporal tokens lead to quadratic complexity while computing multi-head self-attention. Model 2 solves the above limitation using two separate transformer encoders. However, this model increases transformer layers. Model 3 solves this disadvantage by computing temporal self-attention after spatial self-attention in a transformer block as in [76]. In model 4, the keys and values for each query are separated into spatial and temporal dimensions. XViT [80] tries to encode space-time attention which has linear complexity
ConvTransformer [82] was introduced for video frame synthesis. The input frames are extracted features by a feature embedding module. The extracted features with positional maps are used as the input of an encoder-decoder. The generated frames are decoded by a synthesis feed-forward network. Both the encoder and decoder contain a multi-head convolutional self-attention layer and a 2D convolutional feed-forward network. VisTR [83] is an end-to-end transformer-based model for video instance segmentation. The extracted features of a backbone network are passed through an encoder-decoder transformer to output a sequence of object prediction. The instance sequence matching strategy and instance sequence segmentation module are proposed to match the same instance in different images and predict the mask sequence for each instance. TeViT [84] proposed a transformer backbone that exploits temporal features efficiently. To exploit the temporal information, messenger tokens leaned embedding are shifted along the temporal axis. The temporal information is exploited at each stage of the network and the shift mechanism has no extra parameter. In addition, a spatiotemporal query interaction head network is introduced to exploit the temporal information at the instance level. Hwang et al. [85] introduced a transformer-based model for video instance segmentation. The proposed model reduces the cost of the space-time attention by proposing an Inter-Frame Communication transformer (IFC) that solves the heavy computation and memory usage of previous per-frame methods. The information between frames is exchanged when the feature maps of input video are passed through an inter-frame communication encoder. The encoder is composed of transformer-based encoder-receive and gather-communicate.
Yan et al. [86] introduced a multi-view transformer for video recognition. A multi-view transformer contains separate transformer encoders which are used to process tokens of different views. To fuse information from different views, three fusion methods were introduced, including cross-view attention, bottleneck tokens, and MLP fusion. The output is produced by a global encoder. Neimark et al. [87] proposed a video transformer network for video recognition. The entire video is processed using Longformer [88] which has a linear computation complexity. Girdhar et al. [89] proposed an anticipative architecture instead of aggregation of features over the temporal axis. Vision transformer [10] is used as a backbone network to extract features of individual video frames. Then, the extracted features are processed by a causal transformer decoder to predict future features. Fan et al. [90] proposed a multi-scale vision transformer that generates a multi-scale pyramid of features of the input. To generate multi-scale features, a multi-head pooling attention was proposed. The queries Q, keys K, and values V are pooled before computing attention. The network contains multi-stages. At each stage, the channel dimension is increased while the spatiotemporal resolution is reduced. Weng et al. [91] proposed a combination of CNN and transformer network for video reconstruction. A multi-scale feature pyramid is generated by a recurrent convolution backbone including several ConvLSTM layers. The generated features are used as input for token pyramid aggregation which models the internal and intersected dependency of the input features. An up-sampler is used to reconstruct the intensity image.
Zhang et al. [92] proposed a cross-frame transformer for video super-resolution network. The similarity and similarity coefficient matrixes of the input frames are obtained using self-attention computation. The obtained matrixes are used to reconstruct the super resolution frame using a multi-level reconstruction. Geng et al. [93] proposed a transformer network that has UNet architecture for video super resolution tasks. The proposed network contains an encoder to extract features and a decoder to reconstruct output frames. Both the encoder and decoder have four stages that include many Swin transformer blocks [32]. In addition, the extracted features of each stage of the encoder and a single frame query are used as input for the corresponding decoder. Liu et al. [94] proposed a transformer-based network that aims to exploit both object movements and background textures for video in-painting. A sequence of input frames is down-sampled and up-sampled by a CNN encoder and decoder, respectively. In addition, a decoupled spatial-temporal transformer is placed between the encoder and decoder to exploit spatial and temporal information effectively. By disentangling the spatial and temporal attention computation, the computational complexity is reduced significantly. VDTR [95] is a transformer-based model for video de-blurring. The features of the input frames are extracted by a transformer-based auto-encoder. The extracted spatial features are used as the input of a temporal transformer to exploit information from neighboring frames. The attention between the frames is computed by using a temporal cross-attention module which the queries are calculated from the reference feature maps. The output frame is reconstructed by several transformer blocks.
5 Transformer for Diffusion Models
The forward process of the Gaussian diffusion models [96] gradually injects noise into real data:
We can sample
where
The reverse process inverts the forward process:
The reverse process model is trained to optimize the ELBO on the log-likelihood:
Reparameterizing
where
5.2 Transformer-Based Diffusion Models
Diffusion models often leverage a convolutional U-Net to learn the reverse process to construct the output from the noise. DiTs [97] replace the U-Net with a transformer for operating on latent patches and achieve state-of-the-art performance on the class conditional generation tasks. Swinv2-Imagen [98] introduces a diffusion model for text-to-image task, which is based on the Swinv2 transformer and Scene Graph generator. The scene graph generator enhances the text understanding by generating a scene graph and extracting the relational embeddings for generating image. UniDiffuser [99] uses a transformer to process all input types of various modalities, which performs text-to-image, image-to-text, and image-text pair generation. To generate high-quality and realistic outputs from textual descriptions, ET-DM [100] combines the advantages of the diffusion model and transformer model for text-to-image generation. The transformer model exploits the mapping relationship between textual descriptions and image representation. However, the text-to-image (T2I) models require high training costs. PIXART-α [101] solves this issue by introducing three advance designs, including training strategy decomposition, efficient T2I transformer, and high-informative data. PIXART-δ [102] achieves a 7
Diffusion models have been applied to various fields. LayoutDM [103] uses a pure transformer to generate a layout, which captures relationship information between elements effectively. DiffiT [104] proposes a diffusion vision transformer with a hierarchical encoder and decoder, consisting of novel time-dependent self-attention modules. To speed up the learning process of the diffusion probabilistic model, Gao et al. [105] introduced a Masked Diffusion Transformer (MDT), which masks the input image in the latent space and generates images from masked input by an asymmetric masking diffusion transformer. MDT [106] introduces a multimodal diffusion transformer, which encodes the image observation using two vision-language models. In addition, a CLIP model is used to encode the goal images or language annotations. For medical image segmentation, a diffusion transformer U-Net [107] introduces a transformer-based U-Net for extracting various scales of contextual information. Moreover, a cross-attention module fuses the embeddings of the source image and noise map to enhance the relationship from source images. Zhao et al. [108] proposed a spatio-temporal transformer-based diffusion model for realistic precipitation nowcasting. The past observations are used as a condition for the diffusion model to generate the target image sequence from noise. Sora [109] is a large-scale training of generative models, which generates a minute of high-fidelity video or images. A raw input video is compressed into a latent spacetime representation. Then, a sequence of latent spacetime patches is extracted to capture both the appearance and motion information. A diffusion transformer model is used to construct videos from these patches and work tokens.
Table 2 summarizes the popular transformer-based architectures on the ImageNet-1K classification task. This dataset consists of 1.28 M training images and 50 K validation images for 1000 classes. In addition, different configurations are compared to evaluate the efficiency of proposed methods, including model size, number of parameters, FLOPs, and Top-1 accuracy with a single 224
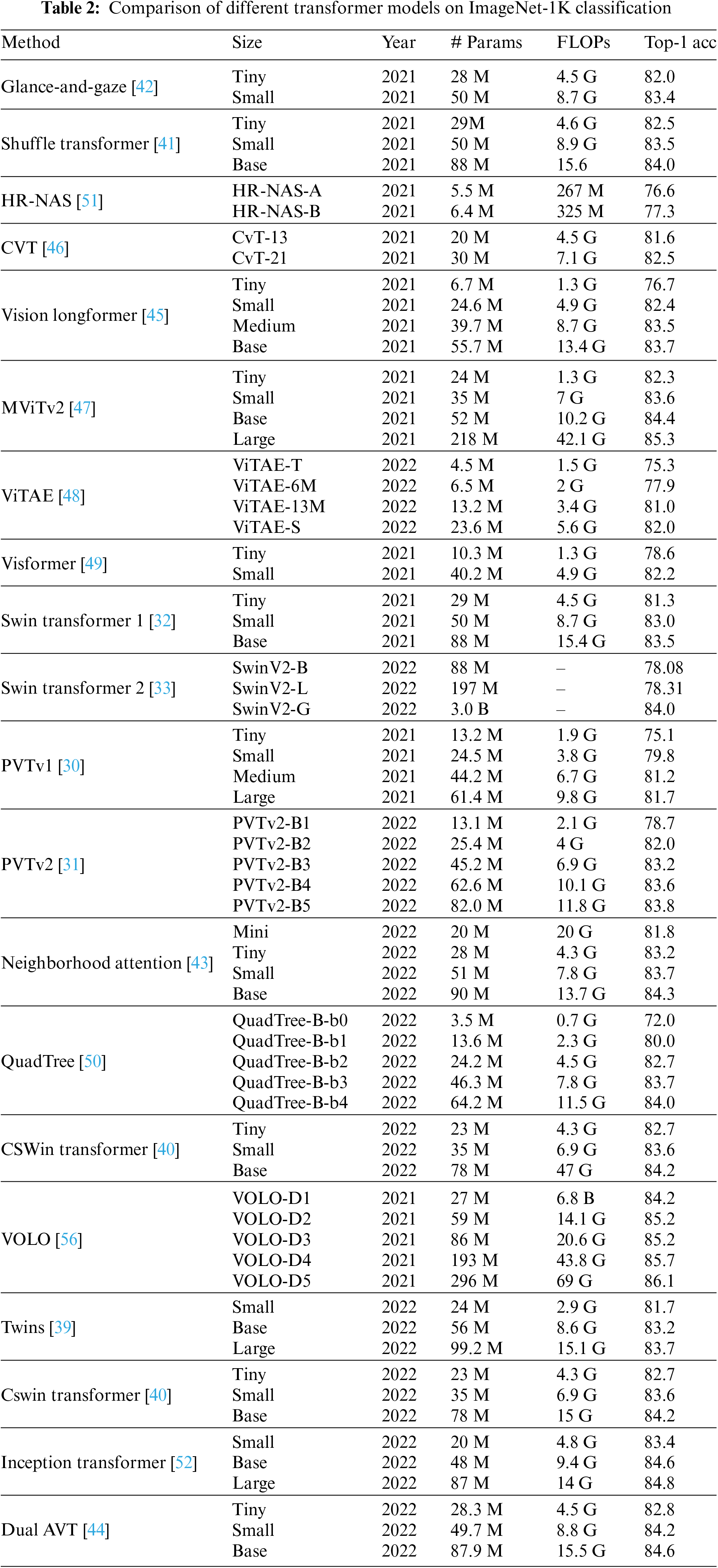
ADE20K is a challenging dataset, including 20 K images for training and 2 K images for validation. Table 3 compares mIoU results on the ADE20K dataset with different transformer models.
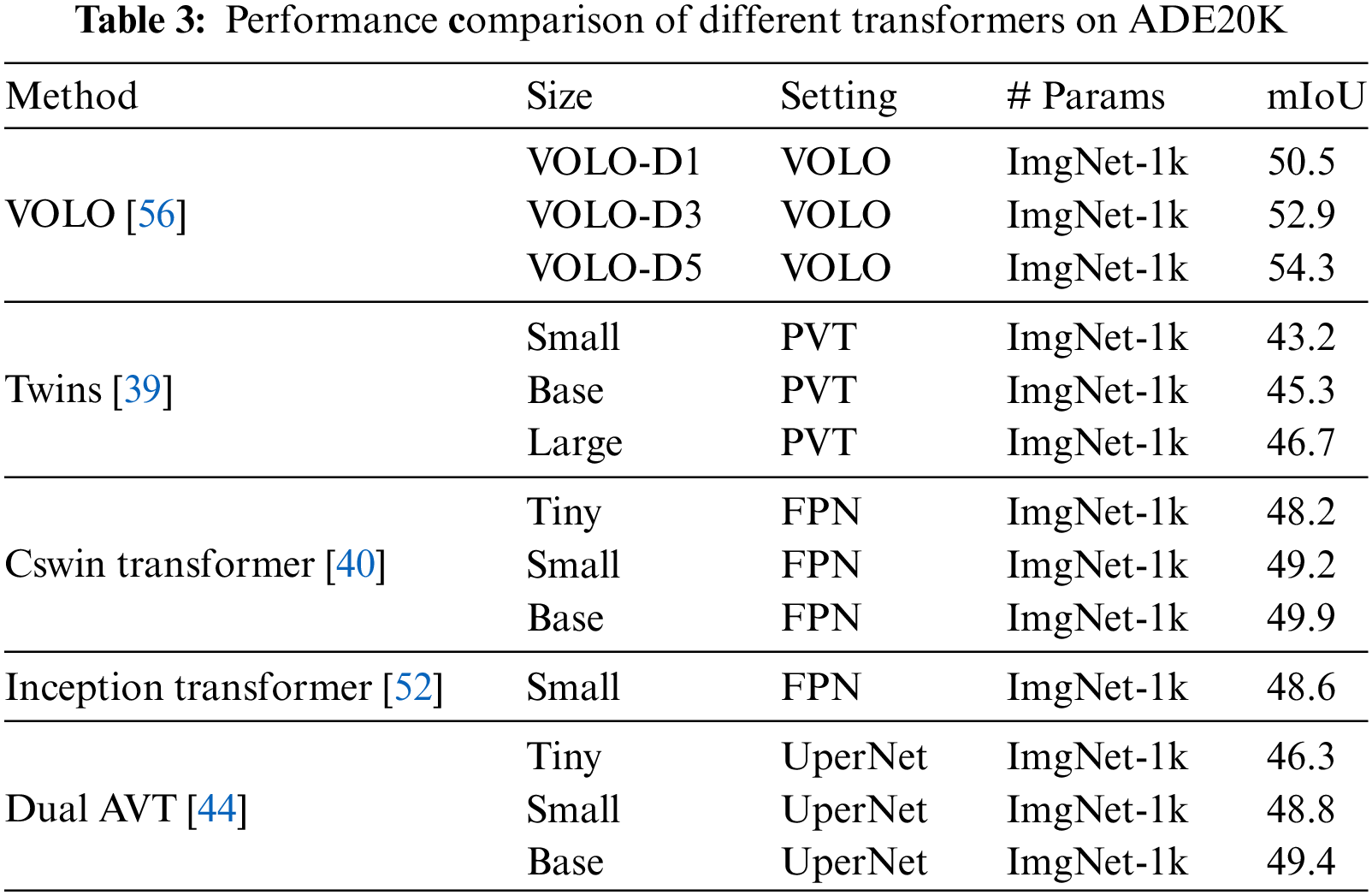
Swin transformer 1 [32] and Swin transformer 2 [33] are two popular window-based transformers. Pyramid Vision Transformer (PVT) 1 [30] and Pyramid Vision Transformer 2 [31] are two transformer architectures that are motion for other hierarchical transformers.
Transformer-based methods have achieved remarkable successes in natural language processing as well as computer vision. Transformers have a strong capability of capturing global context information (long-range dependencies). However, self-attention requires a huge computation cost to compute the attention map. In addition, convolutional neural networks can capture local context that is not modeled well by the transformer.
7.1 Decreasing the Computational Cost
The transformer shows the capability of modeling the long-range dependencies using self-attention mechanism. However, the computation of the full-attention mechanism [10,46–110] is inefficient because the complexity is quadratic to the size of the image. Many proposed methods have been introduced to solve the issues. For example, window-based methods [32,33–40] have linear complexity with the image size. To reduce the computational complexity to linear, many works proposed spatial reduction attention [30,31] by reducing the spatial scale of the key K and value V before the computation of self-attention. To reduce spatial dimension, the key K and value V are applied by a convolution operator or average pooling.
Recently, many studies [43,52] still try to decrease the computational cost of self-attention and compute attention more efficiently. This is an open research direction that many researchers aim to solve.
7.2 Capturing Both Local and Global Contexts
Transformers can capture the global context however it shows limitations in modeling the local context. Many studies try to capture local information by proposing a conv-attention mechanism [111] which introduces convolution in attention mechanism. Reference [46] introduced convolution to token embedding and convolutional projection for attention.
On the other hand, TransUNet [58] extracts local features by using a CNN and a transformer to aggregate global features from extracted local features. TransFuse [65] used two parallel networks including a CNN and a transformer network to capture both local and global features. STransFuse [112] combines transformer and CNN to exploit the benefits of both networks.
Transformer-based models can model global information using the self-attention mechanism. However, recent approaches combine CNN and transformer to exploit local features for the transformer. A pure transformer network that can model both local and global information is an open research direction.
Transformers have demonstrated remarkable performance across various computer vision tasks. In this survey, we have comprehensively reviewed recent transformer-based methods for image, video tasks, and diffusion models. We first categorize the methods for image tasks into three fundamental categories, including downstream, segmentation, and generation tasks. We discuss state-of-the-art transformer-based methods for video tasks and the complexity of these models. Specifically, we provide an overview of the diffusion model and discuss recent diffusion models using a transformer as a backbone network. In addition, we provide a detailed comparison of recent transformer-based models on ImageNet and ADE20K datasets.
Acknowledgement: None.
Funding Statement: This work was supported in part by the National Natural Science Foundation of China under Grants 61502162, 61702175, and 61772184, in part by the Fund of the State Key Laboratory of Geo-information Engineering under Grant SKLGIE2016-M-4-2, in part by the Hunan Natural Science Foundation of China under Grant 2018JJ2059, in part by the Key R&D Project of Hunan Province of China under Grant 2018GK2014, and in part by the Open Fund of the State Key Laboratory of Integrated Services Networks under Grant ISN17-14. Chinese Scholarship Council (CSC) through College of Computer Science and Electronic Engineering, Changsha, 410082, Hunan University with Grant CSC No. 2018GXZ020784.
Author Contributions: The authors confirm contribution to the paper as follows: study conception and design: Dinh Phu Cuong Le, Viet-Tuan Le; analysis and interpretation of results: Dinh Phu Cuong Le, Dong Wang; draft manuscript preparation: Dinh Phu Cuong Le, Dong Wang, Viet-Tuan Le. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: Not applicable.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. A. Vaswani et al., “Attention is all you need,” in 31st Int. Conf. Neural Inf. Process. Syst. (NIPS’17), NY, USA, 2017, vol. 30, pp. 6000–6010. [Google Scholar]
2. J. Devlin, M. W. Chang, K. Lee, and K. Toutanova, “BERT: Pre-training of deep bidirectional transformers for language understanding,” in 2019 Conf. North American Chapter Assoc. Comput. Linguist.: Human Lang. Technol., Minneapolis, Minnesota, 2019, vol. 1, pp. 4171–4186. [Google Scholar]
3. A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever, “Language models are unsupervised multitask learners,” OpenAI Blog, vol. 1, no. 8, pp. 9, 2019. [Google Scholar]
4. T. Brown et al., “Language models are few-shot learners,” in 34th Int. Conf. Neural Inf. Process. Syst., NY, USA, 2020, vol. 33, pp. 1877–1901. [Google Scholar]
5. A. Krizhevsky, I. Sutskever, and E. G. Hinton, “Imagenet classification with deep convolutional neural networks,” in Adv. Neural Inf. Process. Syst., Lake Tahoe, Nevada, USA, 2012, vol. 25, pp. 1097–1105. [Google Scholar]
6. X. Wang, R. Girshick, A. Gupta, and K. He, “Non-local neural networks,” in IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Salt Lake City, UT, USA, 2018, pp. 7794–7803. doi: 10.1109/CVPR.2018.00813. [Google Scholar] [CrossRef]
7. J. Hu, L. Shen, and G. Sun, “Squeeze-and-excitation networks,” in IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Salt Lake City, UT, USA, 2018, pp. 7132–7141. doi: 10.1109/CVPR.2018.00745. [Google Scholar] [CrossRef]
8. J. Wang, Y. Chen, R. Chakraborty, and S. X. Yu, “Orthogonal convolutional neural networks,” in IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Seattle, WA, USA, 2020, pp. 11505–11515. doi: 10.1109/CVPR42600.2020.01152. [Google Scholar] [CrossRef]
9. S. Woo, J. Park, J. Y. Lee, and I. S. Kweon, “CBAM: Convolutional block attention module,” in European Conf. Comput. Vis. (ECCV), Cham, Munich, Germany, Springer, 2018, vol. 11211, pp. 3–19. [Google Scholar]
10. A. Dosovitskiy et al., “An image is worth 16 ×16 words: Transformers for image recognition at scale,” in Int. Conf. Learn. Represent., Austria, 2021. [Google Scholar]
11. S. Khan, M. Naseer, M. Hayat, S. W. Zamir, F. S. Khan, and M. Shah, “Transformers in vision: A survey,” ACM Comput. Surv. (CSUR), vol. 54, no. 10s, pp. 1–41, 2022. doi: 10.1145/3505244. [Google Scholar] [CrossRef]
12. Y. Liu et al., “A survey of visual transformers,” IEEE Trans. Neural Netw. Learn. Syst., pp. 1–21, 2023. doi: 10.1109/TNNLS.2022.3227717. [Google Scholar] [PubMed] [CrossRef]
13. A. M. Hafiz, S. A. Parah, and R. U. A. Bhat, “Attention mechanisms and deep learning for machine vision: A survey of the state of the art,” arXiv preprint arXiv:2106.07550, 2021. [Google Scholar]
14. T. Lin, Y. Wang, X. Liu, and X. Qiu, “A survey of transformers,” AI Open, vol. 3, no. 120, pp. 111–132, 2022. doi: 10.1016/j.aiopen.2022.10.001. [Google Scholar] [CrossRef]
15. R. Liu, Y. Li, L. Tao, D. Liang, and H. T. Zheng, “Are we ready for a new paradigm shift? A survey on visual deep MLP,” Patterns, vol. 3, no. 7, pp. 100520, 2022. doi: 10.1016/j.patter.2022.100520. [Google Scholar] [PubMed] [CrossRef]
16. J. Selva, A. S. Johansen, S. Escalera, K. Nasrollahi, T. B. Moeslund, and A. Clapés, “Video transformers: A survey,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 11, pp. 12922–12943, 2023. doi: 10.1109/TPAMI.2023.3243465. [Google Scholar] [PubMed] [CrossRef]
17. E. Min et al., “Transformer for graphs: An overview from architecture perspective,” arXiv preprint arXiv:2202.08455, 2022. [Google Scholar]
18. L. Ruan and Q. Jin, “Survey: Transformer based video-language pre-training,” AI Open, vol. 3, pp. 1–13, 2022. doi: 10.1016/j.aiopen.2022.01.001. [Google Scholar] [CrossRef]
19. K. Han et al., “A survey on vision transformer,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 1, pp. 87–110, 2022. doi: 10.1109/TPAMI.2022.3152247. [Google Scholar] [PubMed] [CrossRef]
20. Y. Yang et al., “Transformers meet visual learning understanding: A comprehensive review,” arXiv preprint arXiv:2203.12944, 2022. [Google Scholar]
21. K. Islam, “Recent advances in vision transformer: A survey and outlook of recent work,” arXiv preprint arXiv:2203.01536, 2022. [Google Scholar]
22. Y. Xu et al., “Transformers in computational visual media: A survey,” Comput. Vis. Media, vol. 8, no. 1, pp. 33–62, 2022. doi: 10.1007/s41095-021-0247-3. [Google Scholar] [CrossRef]
23. I. Tolstikhin et al., “MLP-Mixer: An all-MLP architecture for vision,” in Adv. Neural Inf. Process. Syst., Virtual, 2021, vol. 34, pp. 24261–24272. [Google Scholar]
24. H. Touvron et al., “ResMLP: Feedforward networks for image classification with data-efficient training,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 4, pp. 5314–5321, 2023. doi: 10.1109/TPAMI.2022.3206148. [Google Scholar] [PubMed] [CrossRef]
25. L. Melas-Kyriazi, “Do you even need attention? A stack of feed-forward layers does surprisingly well on imagenet,” arXiv preprint arXiv:2105.02723, 2021. [Google Scholar]
26. K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Las Vegas, NV, USA, 2016, pp. 770–778. doi: 10.1109/CVPR.2016.90. [Google Scholar] [CrossRef]
27. J. L. Ba, J. R. Kiros, and G. E. Hinton, “Layer normalization,” arXiv preprint arXiv:1607.06450, 2016. [Google Scholar]
28. M. Caron et al., “Emerging properties in self-supervised vision transformers,” in IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Montreal, QC, Canada, 2021, pp. 9650–9660. doi: 10.1109/ICCV48922.2021.00951. [Google Scholar] [CrossRef]
29. J. Fang, L. Xie, X. Wang, X. Zhang, W. Liu, and Q. Tian, “MSG-Transformer: Exchanging local spatial information by manipulating messenger tokens,” in IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), New Orleans, LA, USA, 2022, pp. 12063–12072. doi: 10.1109/CVPR52688.2022.01175. [Google Scholar] [CrossRef]
30. W. Wang et al., “Pyramid Vision Transformer: A versatile backbone for dense prediction without convolutions,” in IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Montreal, QC, Canada, 2021, pp. 568–578. doi: 10.1109/ICCV48922.2021.00061. [Google Scholar] [CrossRef]
31. W. Wang et al., “PVT v2: Improved baselines with pyramid vision transformer,” Comput. Vis. Media, vol. 8, no. 3, pp. 415–418, 2022. doi: 10.1007/s41095-022-0274-8. [Google Scholar] [CrossRef]
32. Z. Liu et al., “Swin transformer: Hierarchical vision transformer using shifted windows,” in IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Montreal, QC, Canada, 2021, pp. 9992–10002. doi: 10.1109/ICCV48922.2021.00986. [Google Scholar] [CrossRef]
33. Z. Liu et al., “Swin Transformer V2: Scaling up capacity and resolution,” in IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), New Orleans, LA, USA, 2022, pp. 11999–12009. doi: 10.1109/CVPR52688.2022.01170. [Google Scholar] [CrossRef]
34. V. T. Le and Y. G. Kim, “Attention-based residual autoencoder for video anomaly detection,” Appl. Intell., vol. 53, no. 3, pp. 3240–3254, 2023. doi: 10.1007/s10489-022-03613-1. [Google Scholar] [CrossRef]
35. Z. Wang, X. Cun, J. Bao, and J. Liu, “Uformer: A general U-shaped transformer for image restoration,” in IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), New Orleans, LA, USA, 2022, pp. 17662– 17672. doi: 10.1109/CVPR52688.2022.01716. [Google Scholar] [CrossRef]
36. Y. Li, K. Zhang, J. Cao, R. Timofte, and L. van Gool, “LocalViT: Bringing locality to vision transformers,” arXiv preprint arXiv:2104.05707, 2021. [Google Scholar]
37. K. Yuan, S. Guo, Z. Liu, A. Zhou, F. Yu and W. Wu, “Incorporating convolution designs into visual transformers,” in IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Montreal, QC, Canada, 2021, pp. 559–568. doi: 10.1109/ICCV48922.2021.00062. [Google Scholar] [CrossRef]
38. S. W. Zamir, A. Arora, S. Khan, M. Hayat, F. S. Khan and M. H. Yang, “Restormer: Efficient transformer for high-resolution image restoration,” in IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), New Orleans, LA, USA, 2022, pp. 5718–5729. doi: 10.1109/CVPR52688.2022.00564. [Google Scholar] [CrossRef]
39. X. Chu et al., “Twins: Revisiting the design of spatial attention in vision transformers,” in Adv. Neural Inf. Process. Syst., Virtual, 2021, vol. 34, pp. 9355–9366. [Google Scholar]
40. X. Dong et al., “Cswin transformer: A general vision transformer backbone with cross-shaped windows,” in IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), New Orleans, LA, USA, 2022, pp. 12114–12124. doi: 10.1109/CVPR52688.2022.01181 [Google Scholar] [CrossRef]
41. Z. Huang, Y. Ben, G. Luo, P. Cheng, G. Yu and B. Fu, “Shuffle transformer: Rethinking spatial shuffle for vision transformer,” arXiv preprint arXiv:2106.03650, 2021. [Google Scholar]
42. Q. Yu, Y. Xia, Y. Bai, Y. Lu, A. L. Yuille and W. Shen, “Glance-and-Gaze vision transformer,” in Adv. Neural Inf. Proce. Syst., Virtual, 2021, vol. 34, pp. 12992–13003. [Google Scholar]
43. A. Hassani, S. Walton, J. Li, S. Li, and H. Shi, “Neighborhood attention transformer,” in IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Vancouver, BC, Canada, 2023, pp. 6185–6194. doi: 10.1109/CVPR52729.2023.00599. [Google Scholar] [CrossRef]
44. M. Ding, B. Xiao, N. Codella, P. Luo, J. Wang and L. Yuan, “DaViT: Dual attention vision transformers,” in Eur. Conf. Comput. Vis. (ECCV), Cham, Springer Nature Switzerland, Tel Aviv, Israel, 2022, pp. 74–92. doi: 10.1007/978-3-031-20053-3_5. [Google Scholar] [CrossRef]
45. P. Zhang et al., “Multi-scale vision longformer: A new vision transformer for high-resolution image encoding,” in IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Montreal, QC, Canada, 2021, pp. 2978–2988. doi: 10.1109/ICCV48922.2021.00299. [Google Scholar] [CrossRef]
46. H. Wu et al., “CvT: Introducing convolutions to vision transformers,” in IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Montreal, QC, Canada, 2021, pp. 22–31. doi: 10.1109/ICCV48922.2021.00009. [Google Scholar] [CrossRef]
47. Y. Li et al., “MViTv2: Improved multiscale vision transformers for classification and detection,” in IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), New Orleans, LA, USA, 2022, pp. 4804–4814. doi: 10.1109/CVPR52688.2022.00476. [Google Scholar] [CrossRef]
48. Y. Xu, Q. Zhang, J. Zhang, and D. Tao, “ViTAE: Vision transformer advanced by exploring intrinsic inductive bias,” in Adv. Neural Inf. Process. Syst., 2021, vol. 34, pp. 28522–28535. [Google Scholar]
49. Z. Chen, L. Xie, J. Niu, X. Liu, L. Wei and Q. Tian, “Visformer: The vision-friendly transformer,” in EEE/CVF Int. Conf. Comput. Vis. (ICCV), Montreal, QC, Canada, 2021, pp. 589–598. doi: 10.1109/ICCV48922.2021.00063. [Google Scholar] [CrossRef]
50. S. Tang, J. Zhang, S. Zhu, and P. Tan, “Quadtree attention for vision transformers,” in Int. Conf. Learn. Represent., 2022. [Google Scholar]
51. M. Ding et al., “HR-NAS: Searching efficient high-resolution neural architectures with lightweight transformers,” in IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Nashville, TN, USA, 2021, pp. 2981–2991. doi: 10.1109/CVPR46437.2021.00300. [Google Scholar] [CrossRef]
52. C. Si, W. Yu, P. Zhou, Y. Zhou, X. Wang and S. Yan, “Inception transformer,” in Adv. Neural Inf. Process. Syst., New Orleans, LA, USA, 2022, vol. 35, pp. 23495–23509. [Google Scholar]
53. P. Gao, T. Ma, H. Li, Z. Lin, J. Dai and Y. Qiao, “MCMAE: Masked convolution meets masked autoencoders,” in Adv. Neural Inf. Process. Syst., New Orleans, LA, USA, 2022, vol. 35, pp. 35632–35644. [Google Scholar]
54. X. Li, W. Wang, L. Yang, and J. Yang, “Uniform masking: Enabling mae pre-training for pyramid-based vision transformers with locality,” arXiv preprint arXiv:2205.10063, 2022. [Google Scholar]
55. Z. Chen et al., “Vision transformer adapter for dense predictions,” in The Eleventh Int. Conf. Learn. Represent. (ICLR), Kigali, Rwanda, 2023. [Google Scholar]
56. L. Yuan, Q. Hou, Z. Jiang, J. Feng, and S. Yan, “VOLO: Vision outlooker for visual recognition,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 45, no. 5, pp. 6575–6586, 2023. doi: 10.1109/TPAMI.2022.3206108. [Google Scholar] [PubMed] [CrossRef]
57. O. Ronneberger, P. Fischer, and T. Brox, “U-Net: Convolutional networks for biomedical image segmentation,” in Medical Image Comput. Computer-Assisted Interven.–MICCAI 2015: 18th Int. Conf., Munich, Germany, Springer International Publishing, 2015, pp. 234–241. doi: 10.1007/978-3-319-24574-4_28. [Google Scholar] [CrossRef]
58. J. Chen et al., “TransUNet: Transformers make strong encoders for medical image segmentation,” arXiv preprint arXiv:2102.04306, 2021. [Google Scholar]
59. A. Hatamizadeh et al., “UNETR: Transformers for 3D medical image segmentation,” in IEEE/CVF Winter Conf. Appl. Comput. Vis. (WACV), Waikoloa, HI, USA, 2022, pp. 1748–1758. doi: 10.1109/WACV51458.2022.00181. [Google Scholar] [CrossRef]
60. O. Petit, N. Thome, C. Rambour, L. Themyr, T. Collins and L. Soler, “U-Net Transformer: Self and cross attention for medical image segmentation,” in Mach. Learn. Med. Imaging: 12th Int. Workshop, Strasbourg, France, Springer, 2021, pp. 267–276. doi: 10.1007/978-3-030-87589-3_28. [Google Scholar] [CrossRef]
61. Y. Gao, M. Zhou, and D. N. Metaxas, “UTNet: A hybrid transformer architecture for medical image segmentation,” in Medical Image Comput. Computer Assisted Interven.–MICCAI 2021: 24th Int. Conf., Strasbourg, France, Springer, 2021, pp. 61–71. doi: 10.1007/978-3-030-87199-4_6. [Google Scholar] [CrossRef]
62. Y. Gao, M. Zhou, D. Liu, and D. Metaxas, “A multi-scale transformer for medical image segmentation: Architectures, model efficiency, and benchmarks,” arXiv preprint arXiv:2203.00131, 2022. [Google Scholar]
63. H. Wang et al., “Mixed transformer U-Net for medical image segmentation,” in ICASSP 2022-2022 IEEE Int. Conf. Acoust., Speech and Signal Process. (ICASSP), Singapore, 2022, pp. 2390–2394. doi: 10.1109/ICASSP43922.2022.9746172. [Google Scholar] [CrossRef]
64. H. Wang, P. Cao, J. Wang, and O. R. Zaiane, “UCTransNet: Rethinking the skip connections in U-Net from a channel-wise perspective with transformer,” in AAAI Conf. Artif. Intell., 2022, vol. 36, pp. 2441–2449. doi: 10.1609/aaai.v36i3.20144. [Google Scholar] [CrossRef]
65. Y. Zhang, H. Liu, and Q. Hu, “TransFuse: Fusing transformers and CNNs for medical image segmentation,” in Medical Image Comput. Comput. Assisted Interven.-MICCAI 2021: 24th Int. Conf., Proc., Part I 24, Strasbourg, France, Springer, 2021, pp. 14–24. doi: 10.1007/978-3-030-87193-2_2. [Google Scholar] [CrossRef]
66. H. Cao et al., “Swin-Unet: Unet-like pure transformer for medical image segmentation,” in Eur. Conf. Comput. Vis. (ECCV), Cham, Springer Nature Switzerland, Tel Aviv, Israel, 2023, pp. 205–218. doi: 10.1007/978-3-031-25066-8_9. [Google Scholar] [CrossRef]
67. A. Hatamizadeh, V. Nath, Y. Tang, D. Yang, H. Roth and D. Xu, “Swin UNETR: Swin transformers for semantic segmentation of brain tumors in MRI images,” in Int. MICCAI Brain. Workshop, Virtual Event, Springer International Publishing, 2022, pp. 272–284. doi: 10.1007/978-3-031-08999-2_22. [Google Scholar] [CrossRef]
68. H. Peiris, M. Hayat, Z. Chen, G. Egan, and M. Harandi, “A robust volumetric transformer for accurate 3D tumor segmentation,” in Medical Image Comput. Computer-Assisted Interven.–MICCAI 2022, Cham, Singapore, Springer Nature Switzerland, 2022, pp. 162–172. doi: 10.1007/978-3-031-16443-9_16. [Google Scholar] [CrossRef]
69. R. Strudel, R. Garcia, I. Laptev, and C. Schmid, “Segmenter: Transformer for semantic segmentation,” in IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Montreal, QC, Canada, 2021, pp. 7242–7252. doi: 10.1109/ICCV48922.2021.00717. [Google Scholar] [CrossRef]
70. W. Zhang et al., “TopFormer: Token pyramid transformer for mobile semantic segmentation,” in IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), New Orleans, LA, USA, 2022, pp. 12073–12083. doi: 10.1109/CVPR52688.2022.01177. [Google Scholar] [CrossRef]
71. M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L. C. Chen, “MobileNetV2: Inverted residuals and linear bottlenecks,” in IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Salt Lake City, UT, USA, 2018, pp. 4510–4520. doi: 10.1109/CVPR.2018.00474. [Google Scholar] [CrossRef]
72. J. Gu et al., “Multi-scale high-resolution vision transformer for semantic segmentation,” in IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), New Orleans, LA, USA, 2022, pp. 12084–12093. doi: 10.1109/CVPR52688.2022.01178. [Google Scholar] [CrossRef]
73. H. Yan, C. Zhang, and M. Wu, “Lawin transformer: Improving semantic segmentation transformer with multi-scale representations via large window attention,” arXiv preprint arXiv:2201.01615, 2022. [Google Scholar]
74. G. Sharir, A. Noy, and L. Zelnik-Manor, “An image is worth 16 × 16 words, what is a video worth?,” arXiv preprint arXiv:2103.13915, 2021. [Google Scholar]
75. M. Bain, A. Nagrani, G. Varol, and A. Zisserman, “Frozen in time: A joint video and image encoder for end-to-end retrieval,” in IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Montreal, QC, Canada, 2021, pp. 1728–1738. doi: 10.1109/ICCV48922.2021.00175. [Google Scholar] [CrossRef]
76. G. Bertasius, H. Wang, and L. Torresani, “Is space-time attention all you need for video understanding?,” in Proc. Int. Conf. Mach. Learn. (ICML), Virtual, 2021, vol. 2. [Google Scholar]
77. H. Zhang, Y. Hao, and C. W. Ngo, “Token shift transformer for video classification,” in 29th ACM Int. Conf. Multimed., China, Virtual Event, 2021, pp. 917–925. doi: 10.1145/3474085.3475272. [Google Scholar] [CrossRef]
78. Y. Zhang et al., “VidTr: Video transformer without convolutions,” in IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Montreal, QC, Canada, 2021, vol. 696, pp. 13557–13567. doi: 10.1109/ICCV48922.2021.01332. [Google Scholar] [PubMed] [CrossRef]
79. A. Arnab, M. Dehghani, G. Heigold, C. Sun, M. Lučić and C. Schmid, “ViViT: A video vision transformer,” in IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Montreal, QC, Canada, 2021, pp. 6816–6826. doi: 10.1109/ICCV48922.2021.00676. [Google Scholar] [CrossRef]
80. A. Bulat, J. M. Perez Rua, S. Sudhakaran, B. Martinez, and G. Tzimiropoulos, “Space-time mixing attention for video transformer,” in Adv. Neural Inf. Process. Syst., 2021, vol. 34, pp. 19594–19607. [Google Scholar]
81. J. Lin, C. Gan, and S. Han, “TSM: Temporal shift module for efficient video understanding,” in IEEE/CVF Int. Conf. Comput. Visi. (ICCV), Seoul, Republic of Korea, 2019, pp. 7082–7092. doi: 10.1109/ICCV.2019.00718. [Google Scholar] [CrossRef]
82. Z. Liu et al., “ConvTransformer: A convolutional transformer network for video frame synthesis,” arXiv preprint arXiv:2011.10185, 2011. [Google Scholar]
83. Y. Wang et al., “End-to-End video instance segmentation with transformers,” in IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Nashville, TN, USA, 2021, pp. 8737–8746. doi: 10.1109/CVPR46437.2021.00863. [Google Scholar] [CrossRef]
84. S. Yang et al., “Temporally efficient vision transformer for video instance segmentation,” in IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), New Orleans, LA, USA, 2022, pp. 2885–2895. doi: 10.1109/CVPR52688.2022.00290. [Google Scholar] [CrossRef]
85. S. Hwang, M. Heo, S. W. Oh, and S. J. Kim, “Video instance segmentation using inter-frame communication transformers,” in Adv. Neural Inf. Process. Syst., 2021, vol. 34, pp. 13352–13363. [Google Scholar]
86. S. Yan et al., “Multiview transformers for video recognition,” in IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), New Orleans, LA, USA, 2022, pp. 3323–3333. doi: 10.1109/CVPR52688.2022.00333. [Google Scholar] [CrossRef]
87. D. Neimark, O. Bar, M. Zohar, and D. Asselmann, “Video transformer network,” in 2021 IEEE/CVF Int. Conf. Comput. Vis. Workshops (ICCVW), Montreal, BC, Canada, 2021, pp. 3156–3165. doi: 10.1109/ICCVW54120.2021.00355. [Google Scholar] [CrossRef]
88. I. Beltagy, M. E. Peters, and A. Cohan, “Longformer: The long-document transformer,” arXiv preprint arXiv:2004.05150, 2004. [Google Scholar]
89. R. Girdhar and K. Grauman, “Anticipative video transformer,” in IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Montreal, QC, Canada, 2021, pp. 13485–13495. doi: 10.1109/ICCV48922.2021.01325. [Google Scholar] [CrossRef]
90. H. Fan et al., “Multiscale vision transformers,” in IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Montreal, QC, Canada, 2021, pp. 6804–6815. doi: 10.1109/ICCV48922.2021.00675. [Google Scholar] [CrossRef]
91. W. Weng, Y. Zhang, and Z. Xiong, “Event-based video reconstruction using transformer,” in IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Montreal, QC, Canada, 2021, pp. 2563–2572. doi: 10.1109/ICCV48922.2021.00256. [Google Scholar] [CrossRef]
92. W. Zhang, M. Zhou, C. Ji, X. Sui, and J. Bai, “Cross-frame transformer-based spatiotemporal video super-resolution,” IEEE Trans. Broadcast., vol. 68, no. 2, pp. 359–369, 2022. doi: 10.1109/TBC.2022.3147145. [Google Scholar] [CrossRef]
93. Z. Geng, L. Liang, T. Ding, and I. Zharkov, “RSTT: Real-time spatial temporal transformer for space-time video super-resolution,” in IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), New Orleans, LA, USA, 2022, pp. 17420–17430. doi: 10.1109/CVPR52688.2022.01692. [Google Scholar] [CrossRef]
94. R. Liu et al., “Decoupled spatial-temporal transformer for video inpainting,” arXiv preprint arXiv:2104.06637, 2021. [Google Scholar]
95. M. Cao, Y. Fan, Y. Zhang, J. Wang, and Y. Yang, “VDTR: Video deblurring with transformer,” IEEE Trans. Circuits Syst. Video Technol., vol. 33, no. 1, pp. 160–171, 2023. doi: 10.1109/TCSVT.2022.3201045. [Google Scholar] [CrossRef]
96. J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” in Adv. Neural Inf Process. Syst., Virtual, 2020, vol. 33, pp. 6840–6851. [Google Scholar]
97. W. Peebles and S. Xie, “Scalable diffusion models with transformers,” in IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Paris, France, 2023, pp. 4172–4182. doi: 10.1109/ICCV51070.2023.00387. [Google Scholar] [CrossRef]
98. R. Li, W. Li, Y. Yang, H. Wei, J. Jiang and Q. Bai, “Swinv2-Imagen: Hierarchical vision transformer diffusion models for text-to-image generation,” Neural Comput. Appl., vol. 8, no. 12, pp. 153113, 2023. doi: 10.1007/s00521-023-09021-x. [Google Scholar] [CrossRef]
99. F. Bao et al., “One transformer fits all distributions in multi-modal diffusion at scale,” in Int. Conf. Mach. Learn., Honolulu, HI, USA, 2023, pp. 1692–1717. [Google Scholar]
100. H. Li, F. Xu, and Z. Lin, “ET-DM: Text to image via diffusion model with efficient Transformer,” Displays, vol. 80, no. 1, pp. 102568, 2023. doi: 10.1016/j.displa.2023.102568. [Google Scholar] [CrossRef]
101. J. Chen et al., “PixArt-α: Fast training of diffusion transformer for photorealistic text-to-image synthesis,” in The twelfth Int. Conf. Learn. Represent., Vienna, Austria, 2024. [Google Scholar]
102. J. Chen et al., “PIXART-δ: Fast and controllable image generation with latent consistency models,” arXiv preprint arXiv:2401.05252, 2024. [Google Scholar]
103. S. Chai, L. Zhuang, and F. Yan, “LayoutDM: Transformer-based diffusion model for layout generation,” in IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Vancouver, BC, Canada, 2023, pp. 18349–18358. doi: 10.1109/CVPR52729.2023.01760. [Google Scholar] [CrossRef]
104. H. Ali, S. Jiaming, L. Guilin, K. Jan, and V. Arash, “DiffiT: Diffusion vision transformers for image generation,” arXiv preprint arXiv:2312.02139, 2023. [Google Scholar]
105. S. Gao, P. Zhou, M. M. Cheng, and S. Yan, “Masked diffusion transformer is a strong image synthesizer,” in IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Paris, France, 2023, pp. 23107–23116. doi: 10.1109/ICCV51070.2023.02117. [Google Scholar] [CrossRef]
106. M. Reuss and R. Lioutikov, “Multimodal diffusion transformer for learning from play,” in 2nd Workshop on Lang. Robot Learn.: Lang. Ground., Atlanta, Georgia, USA, 2023. [Google Scholar]
107. G. J. Chowdary and Z. Yin, “Diffusion transformer U-Net for medical image segmentation,” in Medical Image Comput. Comput. Assisted Interven.–MICCAI 2023, Vancouver, BC, Canada, 2023, pp. 622–631. doi: 10.1007/978-3-031-43901-8_59. [Google Scholar] [CrossRef]
108. Z. Zhao, X. Dong, Y. Wang, and C. Hu, “Advancing realistic precipitation nowcasting with a spatiotemporal transformer-based denoising diffusion model,” IEEE Trans. Geosci. Remote Sens., vol. 62, pp. 1–15, 2024. doi: 10.1109/TGRS.2024.3355755. [Google Scholar] [CrossRef]
109. OpenAI, “Sora: Creating video from text,” 2024. Accessed: Apr. 29, 2024. [Online]. Available: https://openai.com/sora. [Google Scholar]
110. L. Yuan et al., “Tokens-to-Token ViT: Training vision transformers from scratch on imagenet,” in IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Montreal, QC, Canada, 2021, pp. 538–547. doi: 10.1109/ICCV48922.2021.00060. [Google Scholar] [CrossRef]
111. W. Xu, Y. Xu, T. Chang, and Z. Tu, “Co-scale conv-attentional image transformers,” in IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Montreal, QC, Canada, 2021, pp. 9961–9970. doi: 10.1109/ICCV48922.2021.00983. [Google Scholar] [CrossRef]
112. L. Gao et al., “STransFuse: Fusing swin transformer and convolutional neural network for remote sensing image semantic segmentation,” IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens., vol. 14, pp. 10990–11003, 2021. doi: 10.1109/JSTARS.2021.3119654. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools