
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

A Dual Domain Robust Reversible Watermarking Algorithm for Frame Grouping Videos Using Scene Smoothness
1 College of Cryptographic Engineering, Engineering University of the Chinese People’s Armed Police Force, Xi’an, 710086, China
2 Key Laboratory of Information Security of the Chinese People’s Armed Police Force, Engineering University of the Chinese People’s Armed Police Force, Xi’an, 710086, China
* Corresponding Authors: Yucheng Liang. Email: ; Ke Niu. Email:
Computers, Materials & Continua 2024, 79(3), 5143-5174. https://doi.org/10.32604/cmc.2024.051364
Received 04 March 2024; Accepted 14 May 2024; Issue published 20 June 2024
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The proposed robust reversible watermarking algorithm addresses the compatibility challenges between robustness and reversibility in existing video watermarking techniques by leveraging scene smoothness for frame grouping videos. Grounded in the H.264 video coding standard, the algorithm first employs traditional robust watermark stitching technology to embed watermark information in the low-frequency coefficient domain of the U channel. Subsequently, it utilizes histogram migration techniques in the high-frequency coefficient domain of the U channel to embed auxiliary information, enabling successful watermark extraction and lossless recovery of the original video content. Experimental results demonstrate the algorithm’s strong imperceptibility, with each embedded frame in the experimental videos achieving a mean peak signal-to-noise ratio of 49.3830 dB and a mean structural similarity of 0.9996. Compared with the three comparison algorithms, the performance of the two experimental indexes is improved by 7.59% and 0.4% on average. At the same time, the proposed algorithm has strong robustness to both offline and online attacks: In the face of offline attacks, the average normalized correlation coefficient between the extracted watermark and the original watermark is 0.9989, and the average bit error rate is 0.0089. In the face of online attacks, the normalized correlation coefficient between the extracted watermark and the original watermark is 0.8840, and the mean bit error rate is 0.2269. Compared with the three comparison algorithms, the performance of the two experimental indexes is improved by 1.27% and 18.16% on average, highlighting the algorithm’s robustness. Furthermore, the algorithm exhibits low computational complexity, with the mean encoding and the mean decoding time differentials during experimental video processing being 3.934 and 2.273 s, respectively, underscoring its practical utility.Keywords
With the rapid advancement of computer technology, the Internet is witnessing an escalating demand for multimedia watermarking solutions, particularly in safeguarding the ownership and copyright of the vast repository of freely available images and videos online [1]. To address these challenges, the field of information hiding has emerged as a pivotal area of research.
Within the realm of information security, Cryptography [2], Steganography [3], and Watermarking [4] stand out as significant research directions. Cryptography focuses on ensuring the confidentiality and integrity of data by employing encryption algorithms and robust key management practices to prevent unauthorized access, thereby emphasizing data security. In contrast, Steganography is a method that conceals confidential information within a cover medium to maintain its secrecy.
Watermarking technology, on the other hand, involves embedding imperceptible watermark information within digital media to safeguard intellectual property rights and uphold content integrity. Cryptography secures data through encryption techniques like Advanced Encryption Standard (AES) and Rivest-Shamir-Adleman (RSA), safeguarding information from illicit access [5]. Steganography conceals secret data within a carrier medium using techniques such as Least Significant Bit (LSB) replacement and frequency domain manipulation, commonly applied in image, audio, and video domains [6]. Watermarking, meanwhile, utilizes digital watermark embedding in media content to authenticate and preserve intellectual property rights [7].
The collective research efforts in these domains offer diverse solutions for information concealment, catering to varied security requisites and application contexts. Ongoing research endeavors are poised to further enhance these technologies, fortifying information security and fortifying intellectual property rights.
Distinct from cryptographic methods, Digital watermarking technology serves as a vital tool for protecting multimedia data copyrights, traceability, and integrity authentication of digital media, like image [8–10] and video [11–13], by embedding watermark information within digital carriers. Nevertheless, traditional digital watermarking techniques, whether robust or fragile/semi-fragile, often lead to permanent distortion of the embedded image. In some specific applications such as medical and military image processing, even this loss of quality is unacceptable. While embedding information into digital carriers can lead to irreversible distortion, reversible watermarking (RW) techniques [14–17] have been developed to enable non-destructive carrier recovery post-watermark extraction. In algorithm design, the primary objectives typically involve minimizing embedding distortion, ensuring reversibility after information extraction, and maintaining a specified embedding capacity [16]. However, robustness considerations are often secondary, and even minor distortions can result in erroneous extraction of watermark information [17–19]. To enhance this aspect, the concept of robust reversible watermarking (RRW) was introduced [20,21]. In scenarios where there is no attack, the decoder is responsible for both watermark extraction and carrier recovery. However, if the carrier undergoes an attack, the reversibility feature may be compromised, but the robust watermark can still be accurately extracted, indicating potential tampering with the carrier [22–25].
Several RRW algorithms for digital images are introduced in the paper: Coltuc et al. [20,21] introduced the foundational framework for RRW, achieving both robustness and reversibility by sequentially embedding watermark information and auxiliary data. Building upon this work, Wang et al. [22] proposed a two-stage image RRW framework based on the concept of Independent Embedding Domains (IED), an extension of Coltuc’s watermarking algorithm. This innovative approach involves decomposing the original carrier into high and low frequency components using the Haar wavelet transform, enabling independent embedding processes based on two distinct IEDs. By employing this methodology, the framework successfully circumvents issues associated with robust and reversible embedding operations within the same domain, thereby preventing interference between the two types of watermarks. At present, video-oriented RRW algorithms are rare. Most of the video watermarking algorithms are robust watermarking algorithms for digital video: Hazim et al. [26] employed a two-dimensional wavelet transform to partition the image into four sub-bands. Chen et al. [27] organized frames into groups, segmented embedded frames into non-overlapping blocks, decomposed these blocks using singular value analysis, computed Zernike moments, and embedded the watermark accordingly. Fan et al. [28] integrated non-zero quantization coefficients and energy factors to select suitable chrominance subblocks, proposing an optimized modulation technique for embedding watermarks in DCT quantization coefficients to minimize subblock modifications. Takale et al. [29] enhanced watermarking flexibility by combining discrete wavelet transform (DWT) with principal component analysis (PCA). Farri et al. [30] utilized a combination of contourlet transform (CT) and singular value decomposition (SVD) to embed watermarks in low-frequency video sub-bands. The above robust watermarking algorithms for digital video do not have the ability to restore the original video. Although the RRW framework is effective, current applications are focused on protecting digital images.
1.3 Background and Structure Erection
The rapid growth of short video culture has elevated its status as a crucial medium for information dissemination, underscoring the pressing need for effective copyright protection and anti-tampering measures [31,32]. It is of great practical value to develop a video-oriented digital watermarking algorithm with both robustness and reversibility in this context. The H.264/Advanced Video Coding (AVC) video coding standard stands as the predominant video compression standard [33], renowned for its compression efficiency, compatibility, and widespread adoption in short video data transmission [34]. Notably, the coding standard for “TikTok” short videos aligns with AVC (H.264). Leveraging the multiple independent redundant domains inherent in this coding standard, this study refines the RRW framework proposed in [22] and introduces a novel video dual-domain watermarking algorithm centered on hidden frame selection. To facilitate this, video frames are organized into groups using a scene smoothness grouping mechanism, with robust watermarks embedded into the low-frequency quantization Discrete Cosine Transform (QDCT) coefficient domain, i.e., the Direct Current (DC) coefficient domain, through the selection of hidden frames. Concurrently, the high-frequency QDCT coefficient domain, i.e., the Alternating Current (AC) coefficient domain, serves as the embedding domain for reversible watermarking, ensuring both robustness of the watermark and lossless recovery of the original video content. The contributions of the proposed algorithm can be listed as follows:
1. Introducing a scene smoothness grouping mechanism and hidden frame selector for enhanced video fidelity across various sizes with low computational complexity and easy application to existing videos.
2. Optimization of the image-oriented RRW framework for effective copyright protection of MP4 videos, enabling original video restoration while preserving MP4 video copyrights.
3. Integration of robust watermark splicing and Reed-Solomon error correction coding technologies in the algorithm to ensure robust security against malicious attacks, with controlled embedding strength for a balance between invisibility and robustness. Leveraging Histogram Shifting watermark embedding technology allows for lossless extraction of reversible watermarks, facilitating seamless original video recovery.
The relevant contents of this paper and the arrangement of subsequent chapters are as follows: Section 1 outlines the theoretical underpinnings of the algorithm, Section 2 presents the algorithm framework, Section 3 details watermark embedding, extraction, and carrier recovery processes, Section 4 offers a comparative analysis of experimental results against other advanced robust watermarking algorithms, and finally, Section 5 provides a summary of the thesis.
The fundamental concept underpinning the RRW framework, as introduced by Wang et al. [22], revolves around the concept of Independent Embedding Domains (IED). In essence, the original carrier undergoes a transformation into two distinct IEDs, one designated for robust embedding and the other for reversible embedding. Through this independent transformation process, the quality of the intermediate IED resulting from the initial stage remains uncompromised by reversible embedding, thereby preserving the robustness of the watermark.
The original carrier is transformed into two embedding domains (EDs)
The embedding process consists of two stages, as illustrated in the Fig. 1. Initially,
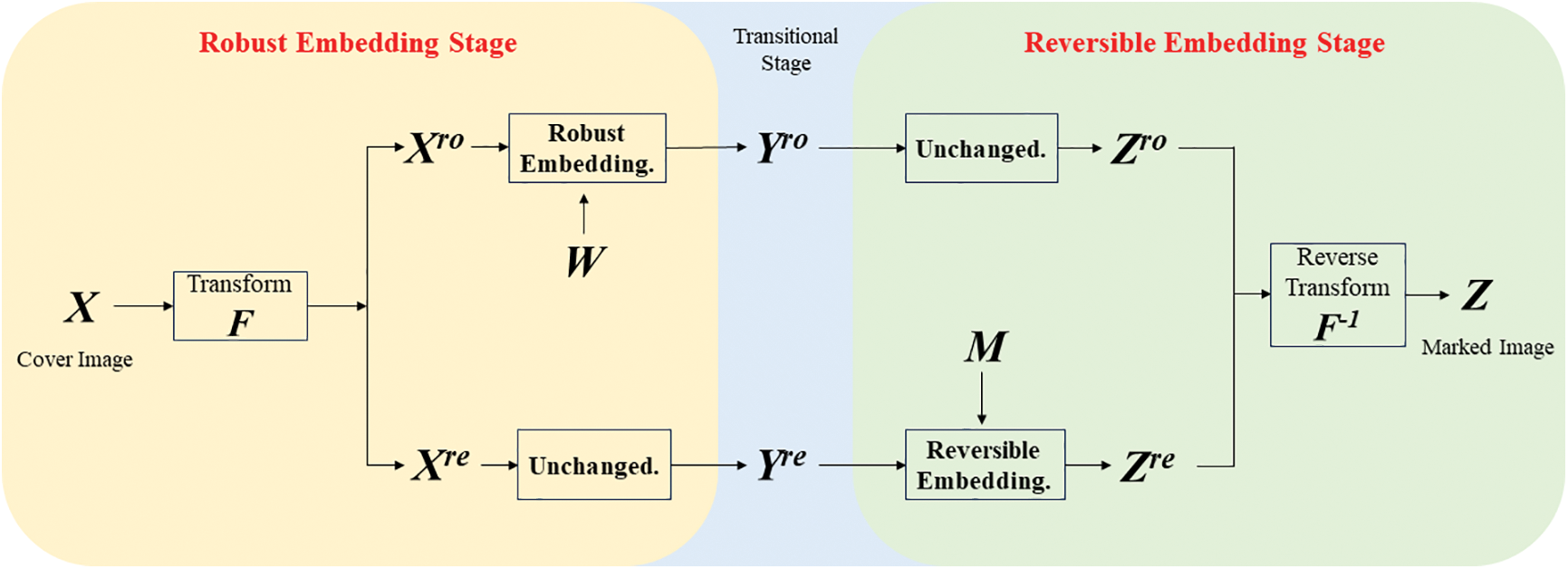
Figure 1: WANG’s RRW framework
In the decoding process, the carrier
If the encoded carrier
2.2 Watermark Error Correction Coding Techniques
Reed-Solomon code (RS) is a class of error-correcting codes proposed by Reed et al. in 1960 [35]. RS code is a linear error correction code known for its powerful error correction ability, which can correct multiple random errors and burst errors at the same time. In order to improve the fault-tolerance of watermarking, the methods outlined in this study include applying lossless RS coding (Reed-Solomon Code) to robust watermarking and reversible watermarking before embedding the watermark. The coding principle of RS code is shown in Eqs. (1) to (4).
In the given scenario,
3 Development and Evaluation of Algorithm Framework
In this section, we present the algorithm framework and introduce a scene smoothness grouping mechanism along with a frame selector. Frame selection plays a crucial role in the algorithm, especially considering the sensitivity of the watermark information. Embedding the watermark in every frame may expose the information to unauthorized users and significantly increase the video’s bit rate. Therefore, it is essential to carefully choose frames with hidden embedding positions. Leveraging the IED framework and recognizing that human eyes are more responsive to brightness than chroma [36], the algorithm groups video frames and selects smooth frames within each group as the hidden frames, determining the embedding positions of the watermark.
The algorithm in this paper is structured into three main stages, as illustrated in Fig. 2. The Hidden Frames Selecting Stage involves hidden frame selection, where frames from the cover video are grouped using a scene detection mechanism. Frames meeting the hidden frame selection criteria form the hidden frame set
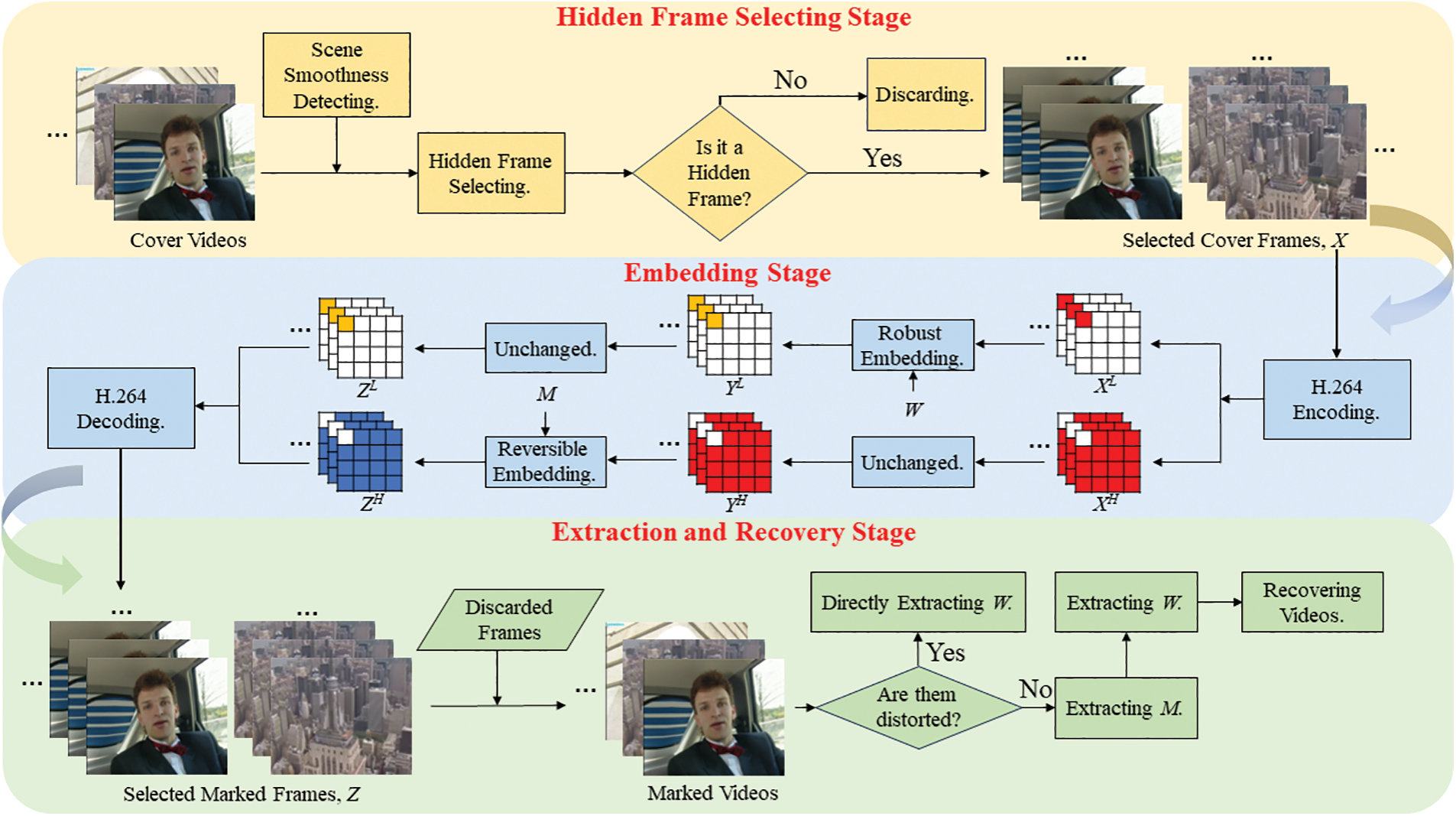
Figure 2: The proposed algorithmic framework overview
The Second Stage, known as the Embedding Stage, begins by obtaining two embedding domains in
In the first sub-stage,
The Extraction and Recovery Stage involves the extraction and recovery process, where
If the marked video is distorted, the robust watermark
In traditional video robust watermarking algorithms within the compressed domain, a common approach involves utilizing a single embedding domain [37–41]. In scenarios where the marked video undergoes distortion from an attack, the resulting distorted marked video can be denoted as
During this process, the noise affecting the transitional video frame
The variance function
In the context of the noise affecting the embedding coefficient
In the context of the H.264 encoding standard, where
3.3 Design of Scene Smoothness Grouping Mechanism and Hidden Frame Selector
Utilizing the Scene Smoothness Grouping Mechanism (SSGM), a Hidden Frame Selector (HFS) is devised to effectively group frames and select appropriate frames for embedding. The distinction between frames plays a crucial role in determining whether they belong to the same group or different groups, as illustrated in Fig. 3.
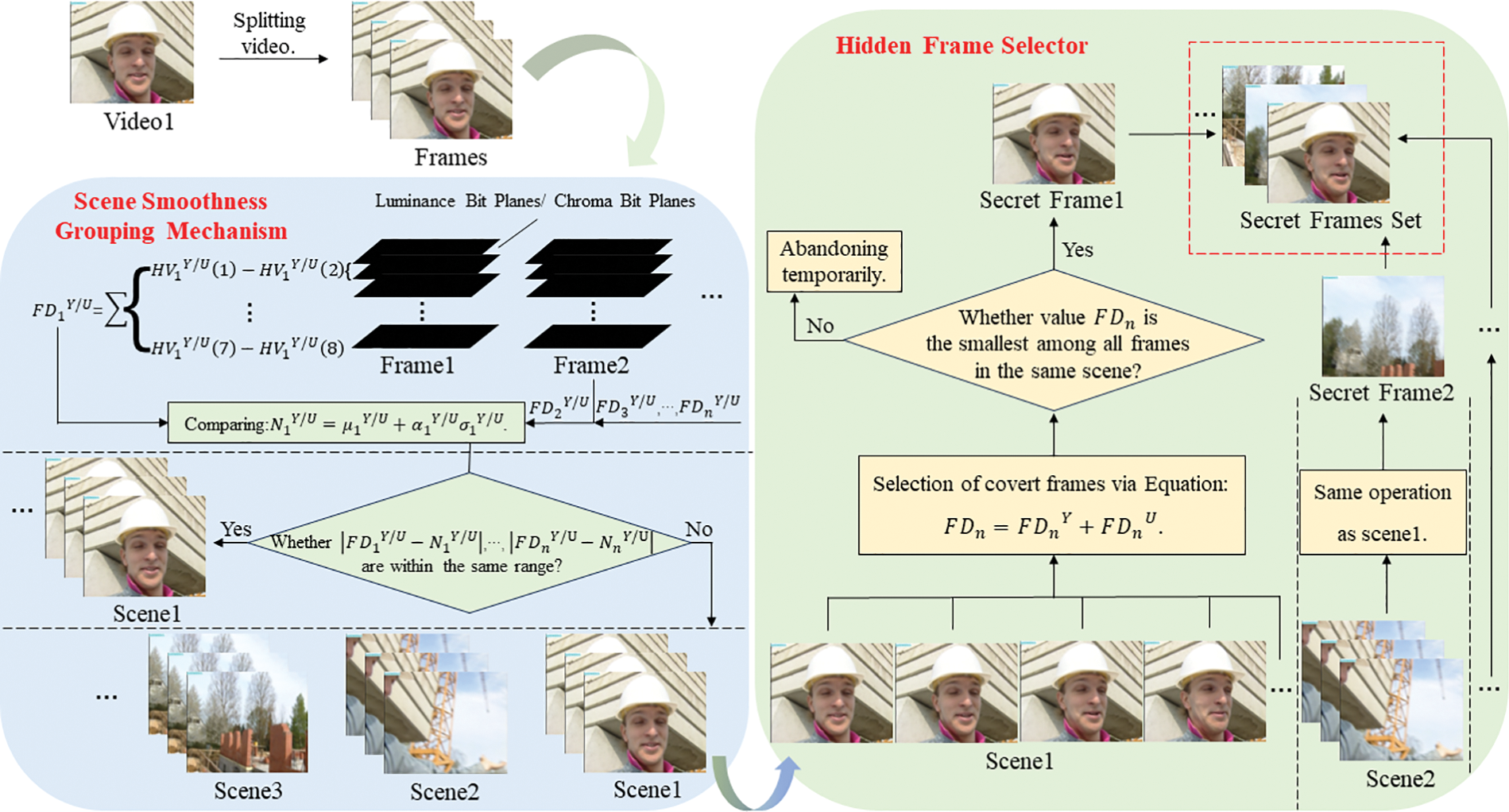
Figure 3: Development of scene smoothness grouping mechanism and hidden frame selector algorithm
Taking the video “Foreman” as a case study, the initial step involves dividing the video into individual frames. Subsequently, the differences between adjacent bits of the eight-bit effective bit plane of the Y channel and U channel within each frame are computed. Simultaneously, a threshold is determined, and the comparison between the difference and the threshold aids in grouping the video “Foreman” based on scene smoothness criteria. These frame variances can be represented in the form of histogram differences. The equation for histogram differences is presented in Eq. (8).
where
where
It is postulated that the
3.4 Principles Analysis Underlying HFS
In each frame group, the HFS chooses the frame with the smallest difference between adjacent bit planes in the Y channel and U channel as the output. The underlying principle guiding HFS will be elucidated below. To begin, considering the Y channel, the Y channel of a frame is depicted as a matrix, where each element of the matrix corresponds to the Y channel value of a pixel, as illustrated below:
where
where
where
where w is the weight vector,
4 Developing Two-Domain RRW Algorithm for Frame Grouping in Compressed Videos via Scene Smoothness Analysis
In this section, we propose a novel approach for embedding and extracting robust and reversible watermarks based on the algorithm framework presented in this paper, as well as the subsequent restoration of the original video. Considering the perceptual impact on the human eye, which is more sensitive to changes in brightness rather than chromaticity, our algorithm leverages the H.264 video encoding framework to efficiently utilize a large number of QDCT coefficients. Through the application of traditional robust watermark splicing techniques (such as those proposed by WANG), the robust watermark is embedded in the low-frequency QDCT domain
4.1 Robust Watermark Embedding: Enhancing Security and Integrity
At this stage, the robust watermark W is embedded in the low-frequency DC QDCT domain
In Fig. 4, exemplified by the video “Foreman,” the hidden frame is divided into m non-overlapping macroblocks following H.264 encoding.

Figure 4: Robust watermark embedding in foreman video using traditional splicing technology
For the macroblocks
If
At the same time the difference
It is important to highlight those adjustments to the threshold
4.2 Reversible Watermark Embedding: Techniques and Considerations
In the reversible embedding phase, the reversible watermark
where
where
4.3 Extraction of Watermark and Carrier Recovery in Two Domains
The algorithm in this study delineates the extraction and recovery stages into two scenarios:
(1) In the event that
According to the inverse translation technique of HS,
According to Eq. (14), the robust watermark extraction operation is as follows:
The distortion introduced by robust watermarking is mitigated through the reversible watermark
When
This subsection provides a detailed overview of the algorithmic steps employed in this study for watermark embedding and extraction. The watermark embedding process is delineated as follows:
Step 1 (Selection of Hidden Frames): The hidden frame set
Step 2 (H.264 Video Encoding): The hidden frame set
Step 3 (Robust Watermark Embedding): The macroblocks in
Step 4 (Reversible Watermark Embedding): A reversible watermark
Step 5 (H.264 Video Decoding):
The critical aspect of the video watermarking algorithm lies in ensuring efficient copyright protection, facilitating successful watermark extraction and video recovery. The process of watermark extraction and video recovery is outlined as follows:
Step 1 (H.264 Video Encoding): The two-domain watermarking video is encoded using H.264, resulting in
Step 2 (Reversible Watermark Extraction and Recovery): The reversible watermark
Step 3 (Robust Watermark Extraction and Recovery): The robust watermark
Step 4 (Original Video Recovery): The original video is recovered by merging
5 Simulation Study and Experimental Findings in Video Watermarking
In this section, the performance evaluation of the proposed algorithm is conducted through a comparative analysis with three existing video watermarking algorithms [28,44,45] in terms of perceptual quality and robustness. Each of the three video watermarking algorithms employs distinct strategies for selecting embedding locations within video frames or blocks.
Fan et al. [28] utilize a combination of non-zero quantization coefficient and energy factor to identify suitable chrominance subblocks for watermark embedding. They further introduce an optimal modulation technique to embed the watermark within the QDCT coefficient of the selected subblocks.
Singh et al. [44] employ a histogram difference method to extract color moving frames and still frames from the original video. A first-level linear wavelet transform is applied to the chroma channel of moving frames, with the low-frequency sub-band LL chosen for watermark embedding.
Sharma et al. [45] propose a frame selection mechanism based on scene change detection. They group video frames according to scene transitions and introduce a hybrid approach involving graph-based transformation, singular value decomposition, and chaotic encryption for watermark embedding.
In the embedding capacity assessment conducted in this study, a 256-bit watermark sequence is utilized. Notably, the algorithm presented in this paper and Fan et al.’s method leverage H.264 video coding, enabling a watermark payload of 256 bits. On the other hand, Singh et al. and Sharma et al. focus on image watermarking. For these methods, the watermark bit string is transformed into a grayscale image following Zig-Zag scanning, serving as the input for watermark embedding.
The experimental setup involves the MatlabR2021a platform running on an i5 processor, connected to x.264 via the MEX interface for simulation execution. The experimental video dataset comprises three segments of 176 × 144 traditional YUV video sequences in QCIF format: “Foreman”, “Carphone”, “Mobile”, “Tennis”, “City”, “Soccer” (https://media.xiph.org/video, accessed: Feb. 20, 2023.) and three short video sequences of 720 × 1080 resolution in MP4 format (“Tree”, “Street”, “Food”). The proposed algorithm’s invisibility and robustness are assessed across these video sequences.
5.1 Evaluation of Invisibility in Video Watermarking Algorithms
In the H.264 video standard, the largest macroblock is 16 × 16 block. Since most of the scenes in the video is smooth scenes, 16 × 16 macroblocks are also the largest number of macroblocks in most videos. In the invisibility analysis, we block the stego-frame of each experimental video into 16 × 16 blocks. According to the embedding method of robust splicing technology, 1 robust watermark bit is embedded in the DC coefficient of each macroblock. Finally, for the experimental video with a resolution of 176 × 144, the robust embedding capacity of a single hidden frame remains at 99 robust watermark bits; for the experimental video with a resolution of 720 × 1080, except for the 16 × 16 block Except for pixels, the remaining pixels are not considered for embedding bits, and the robust embedding capacity of a single hidden frame remains at 3015 robust watermark bits. The size of the reversible watermark bits generated after embedding the robust watermark changes with different experimental videos.
At the subjective evaluation stage, the experimental videos were visually inspected before and after the watermark embedding process by human observers. Fig. 5 illustrates one of the original video frames of each experimental video alongside the corresponding frames post-embedding. Despite conducting comparisons across the experimental population, conclusive determinations regarding the presence of watermarks within the video frames could not be ascertained at the subjective level.

Figure 5: Comparison of original video frames with corresponding post-embedding frames in experimental videos
At the objective evaluation stage, the algorithm proposed in this study is assessed through the computation of the mean peak signal-to-noise ratio (MPSNR) and mean structural similarity (MSSIM) metrics between the original video frame and the concealed video frame, as defined in Eqs. (23) and (24).
where
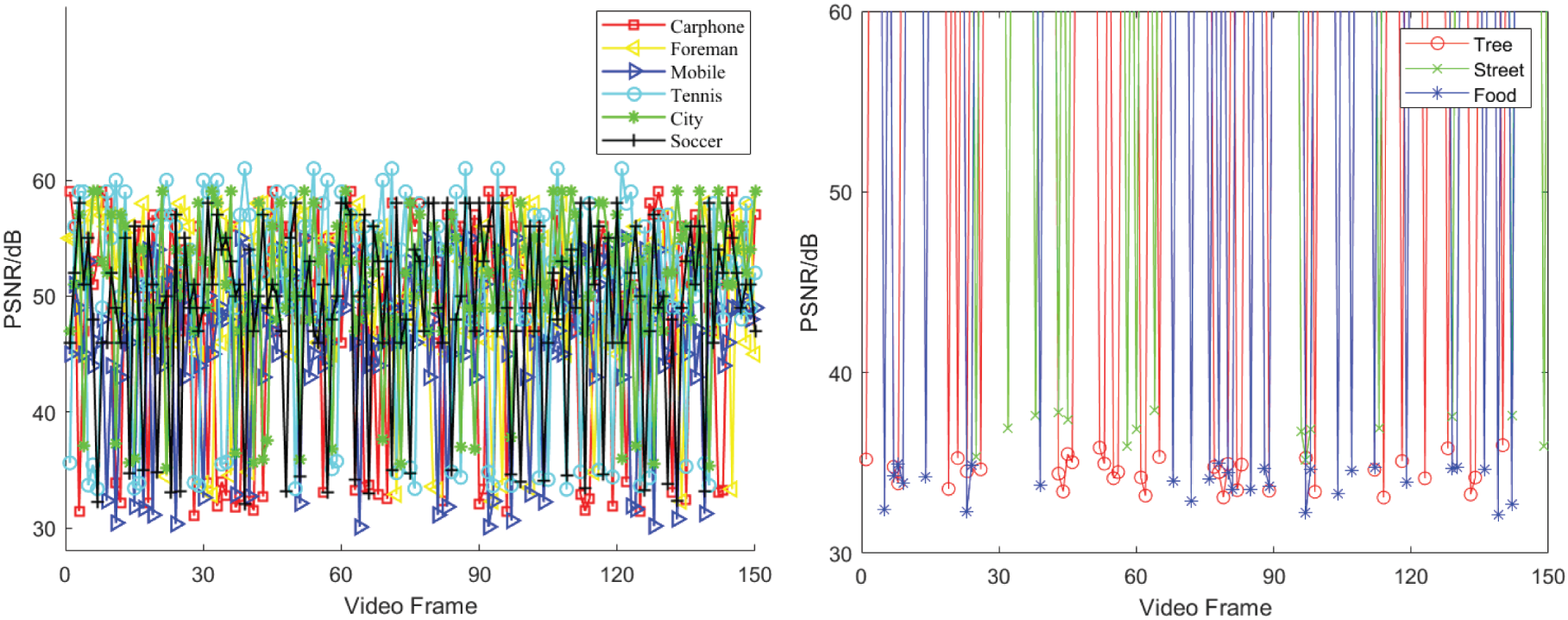
Figure 6: Comparative analysis of PSNR performance for the initial 150 frames in traditional and short videos embedded with watermark
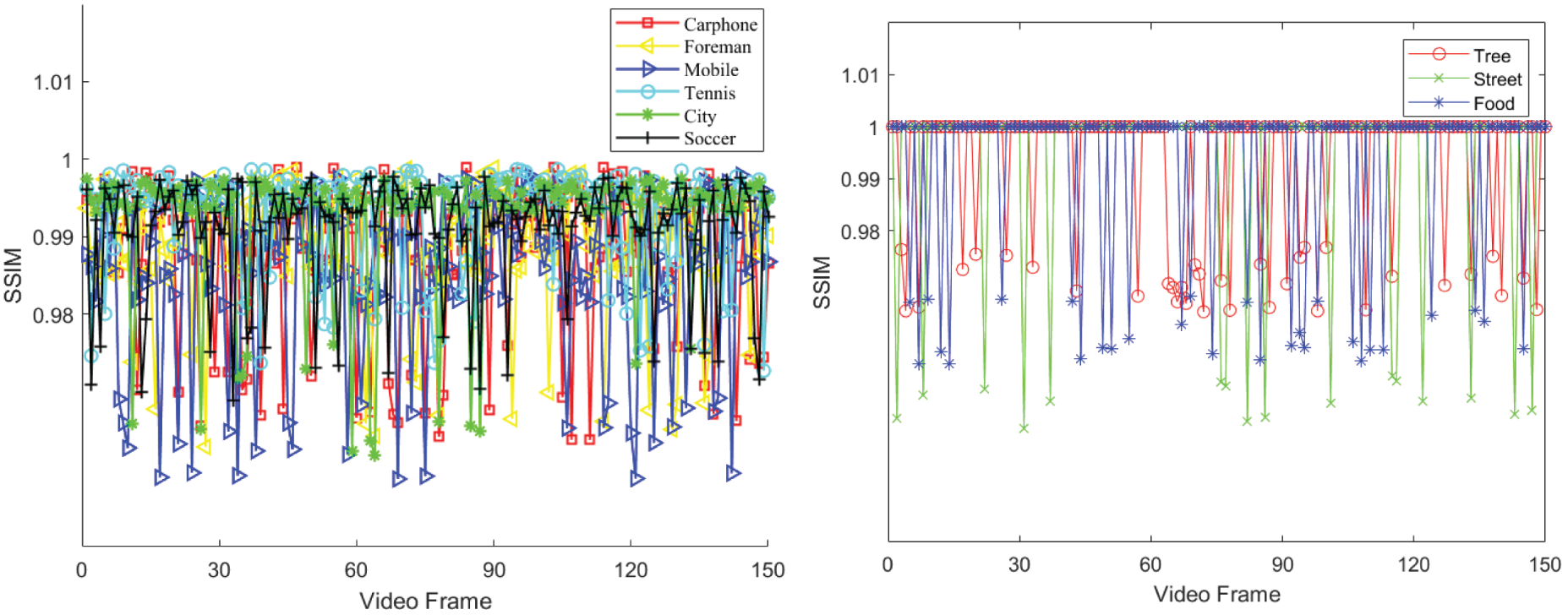
Figure 7: Comparative analysis of SSIM performance for the initial 150 frames in traditional and short videos embedded with watermark


Note that the hidden frame after embedding the watermark in Fig. 5, and all the data in Figs. 6, 7 and Tables 1 and 2 are completed at the same embedding strength. Specifically, we calculate the PSNR and SSIM for the first 150 frames of each experimental video at the threshold T = 1 (Eq. (11)), and the MPSNR and MSSIM corresponding to the two metrics. A large number of watermarking embedded video experiments show that the comprehensive invisibility of experimental video is the best at this time. The X value in Fig. 6 is the video frame number of the experimental video, and the Y value is the PSNR between each original video frame and the video frame embedded with the watermark. The X value in Fig. 7 is the same as that in Fig. 6, and the Y value is the SSIM between each original video frame and the video frame after embedding the watermark. Tables 1 and 2 correspond to the mean values of experimental indicators in Figs. 6 and 7, respectively. The same embedding strength will be used in subsequent residual invisibility comparative analysis experiments and robustness analysis experiments.
Based on the data from Figs. 6, 7, Tables 1, and 2, the Mean Peak PSNR (MPSNR) values for the six traditional videos in QCIF format after embedding watermarks
It is important to note that the algorithm discussed in this study focuses on a watermarking technique specifically designed for H.264 compressed videos. Analysis of the experimental data reveals that the PSNR and SSIM of traditional QCIF videos post-information embedding fall within a specific range. As QCIF videos undergo transformation into MP4 format following compression by the H.264 standard, each frame experiences information loss compared to the original frame. Consequently, frames not designated as hidden frames may exhibit variations compared to the original uncompressed video frames. Nonetheless, the minimum PSNR of the hidden frame post-information embedding remains above 30 dB, with the lowest SSIM exceeding 0.95. Additionally, the PSNR and SSIM values for video frames not selected as hidden frames in short MP4 videos are infinite and 1, indicating the algorithm’s independent embedding process, ensuring that the embedding of hidden frames does not impact other frames. The minimum PSNR and SSIM values for hidden frames after information embedding are maintained above 32 dB and 0.94, respectively. In conclusion, the algorithm demonstrates good invisibility characteristics.
Table 3 presents the MPSNR and MSSIM values for each video in accordance with the comparison scheme. Analysis of the table reveals that the average MPSNR and MSSIM values for the proposed method are 49.3830 dB and 0.9996, respectively. These exceptional metrics serve as evidence of the superiority of the proposed technique over the compared scheme.
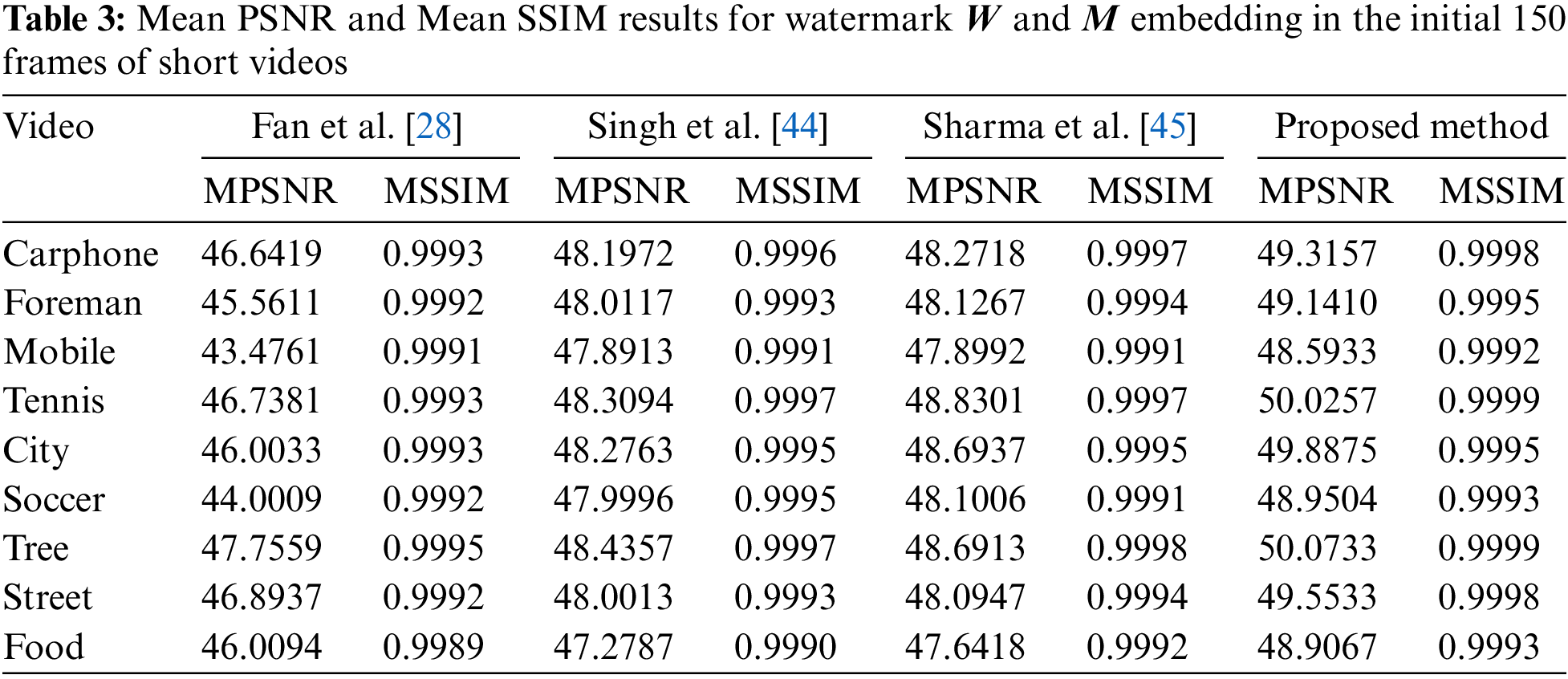
Given the limitations in interpreting invisibility solely based on PSNR and SSIM, we conducted additional experiments to assess the performance of the proposed algorithm in terms of bit-rate expansion. The results of these experiments are summarized in Table 4.
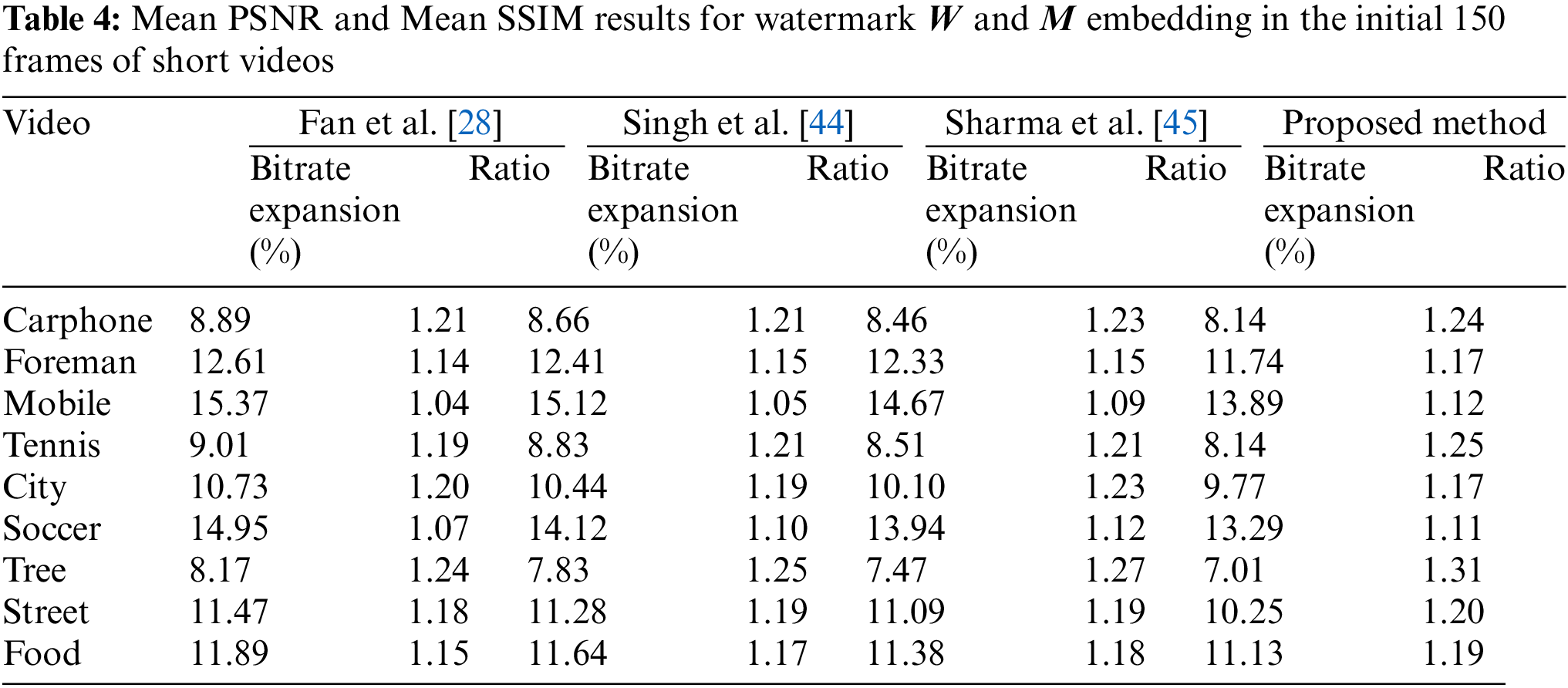
Bitrate expansion involves increasing the video file size to accommodate embedded information. Table 4 displays the bit-rate expansion and the ratio of embedded information to video increment for the proposed algorithm, Fan et al.’s method, Singh et al.’s method, and Sharma et al.’s method. The Ratio represents the amount of embedded information relative to the video size increase, with the embedded information comprising
5.2 Evaluation of Robustness in Video Watermarking Algorithms
In this subsection, we will evaluate the robustness of the proposed algorithm and compare it to the methods of Fan et al., Singh et al., and Sharma et al., under various video attacks. To comprehensively evaluate the robustness of the proposed algorithm, we will choose two types of attacks for experiments.
The first type of attack is offline, including Gaussian noise with an average of 0 and variances of 0.01, 0.05 and 0.1, salt and pepper noise with variances of 0.01, 0.05 and 0.1, Gaussian low-pass filtering with variances of 0.1, 0.05 and 0.1, and 3 × 3 filters with variances of 0.1, 0.2 and 0.3 (fuzzy attacks). Frame Dropping (random 10%~35%), frame average (random 10%~35%), Frame Swapping (random 10%~35%), and then compression (quantization programming QP = 26~28).
The second type of attack is online attack: collusion attack is a kind of attack that needs to be mainly guarded against in online attacks, which refers to the cooperation between the attacker and the information hider to obtain the hidden information or the original carrier. In the field of information hiding, there are two main categories:
Class I collusion: Embedding the same pseudo-watermark in multiple different carriers. This kind of collusion obtains the legitimate watermark by removing or estimating the legitimate watermark embedded in the carrier through a linear average.
Class II collusion: Embedding different pseudo-watermarks in different copies of the same carrier. This kind of collusion obtains an estimated version of the carrier without legitimate watermarks through a linear average, compares the estimated version with the current suspected carrier with legitimate watermarks, and obtains an original carrier without legitimate watermarks.
For video watermarking, attackers aim to illegally infringe the copyright security of videos in order to obtain videos without robust watermarking. Therefore, in the robustness analysis experiment of this paper, Class II collusion is used to attack experimental videos to evaluate the robustness of the proposed algorithm against online attacks. The frames of the same scene in the video are approximately the same. The specific practice of this experiment is to group each frame obtained according to SSGM as the video frame of the same scene, and randomly generate multiple bit strings with the same length as the robust watermark bit string after error correction coding as different pseudo-watermarks.
Finally, we extract watermarks from the hacked hidden frames and evaluate the robustness of the algorithm by calculating and comparing the mean normalized correlation number (MNC) and mean bit error rate (MBER) of the original watermarks. The definitions of MNC and MBER are shown in Eqs. (25) and (26).
where
5.2.1 Robustness Analysis of Offline Attacks
This subsubsection describes the robustness of the proposed algorithm against offline attacks by combining six traditional YUV experiment videos and three MP4 experiment videos. The robust watermark is extracted from the hidden frame after offline attack, and the NC value between the extracted robust watermark in each hidden frame and the corresponding original robust watermark is calculated, and the MNC value is taken to evaluate the robustness of the proposed algorithm. The robustness of the proposed algorithm is compared with three video robust watermarking algorithms. The results are shown in Figs. 8 to 14 below.
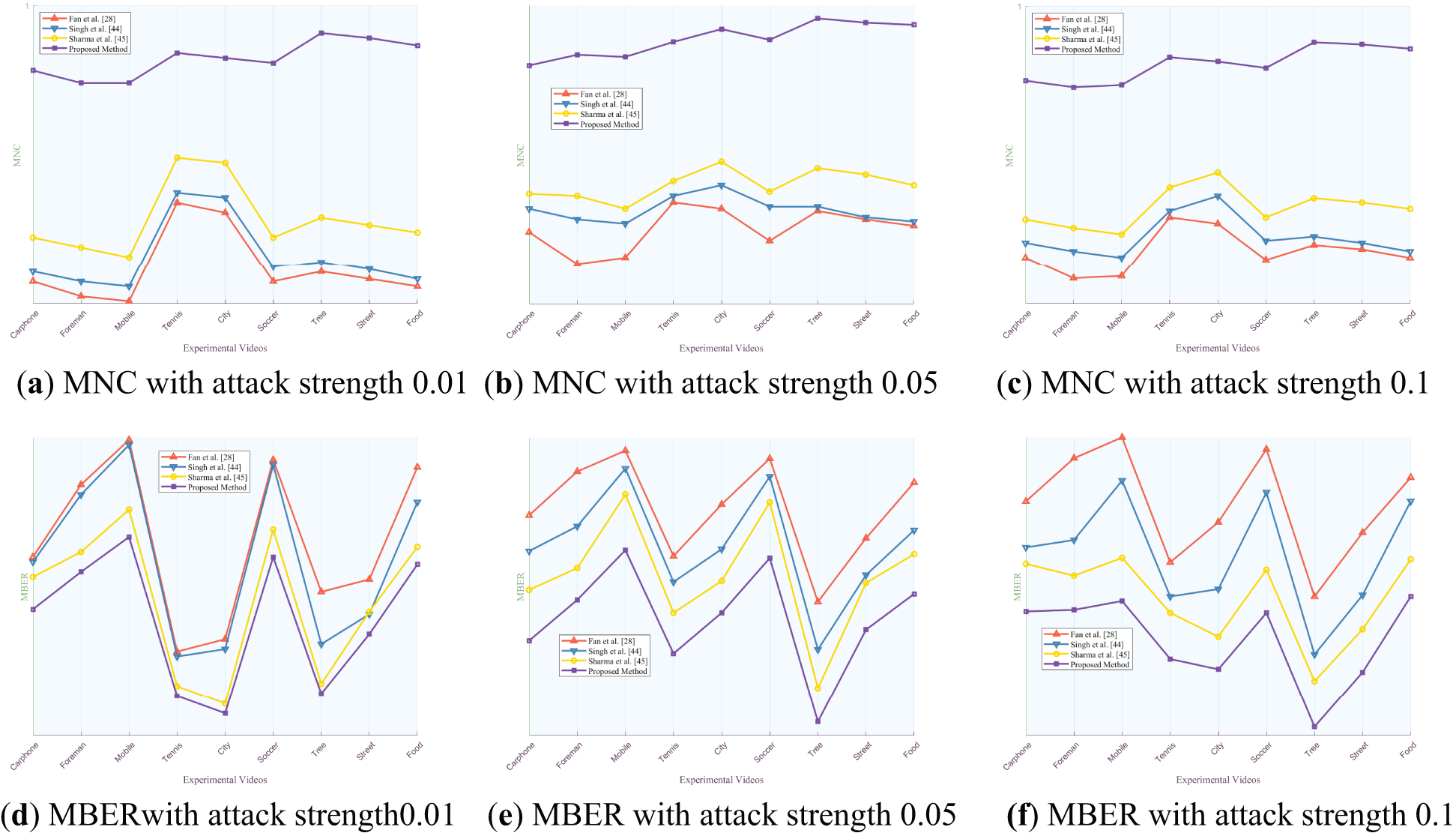
Figure 8: Comparison of MNC and MBER values of the proposed algorithm against three algorithms under various intensities of gaussian noise attack
Figure 9: Comparison of MNC and MBER values of the proposed algorithm against three algorithms under various intensities of salt-and-pepper noise attack
Figure 10: Comparison of MNC and MBER values of the proposed algorithm against three algorithms under various intensities of fuzzy attack
Figure 11: Comparison of MNC and MBER values of the proposed algorithm against three algorithms under various intensities of frame dropping attack
Figure 12: Comparison of MNC and MBER values of the proposed algorithm against three algorithms under various intensities of frame average attack
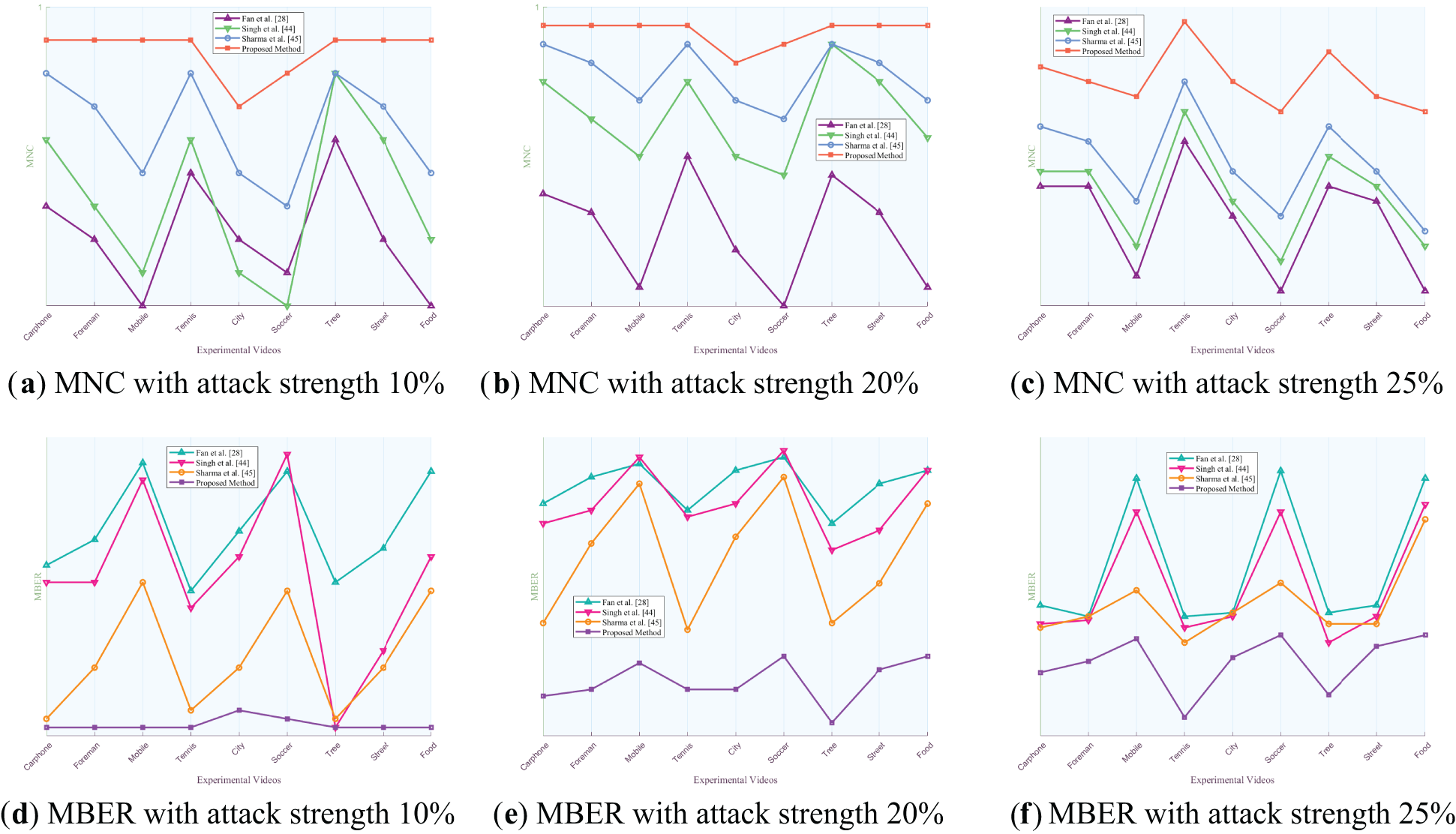
Figure 13: Comparison of MNC and MBER values of the proposed algorithm against three algorithms under various intensities of frame swapping attack
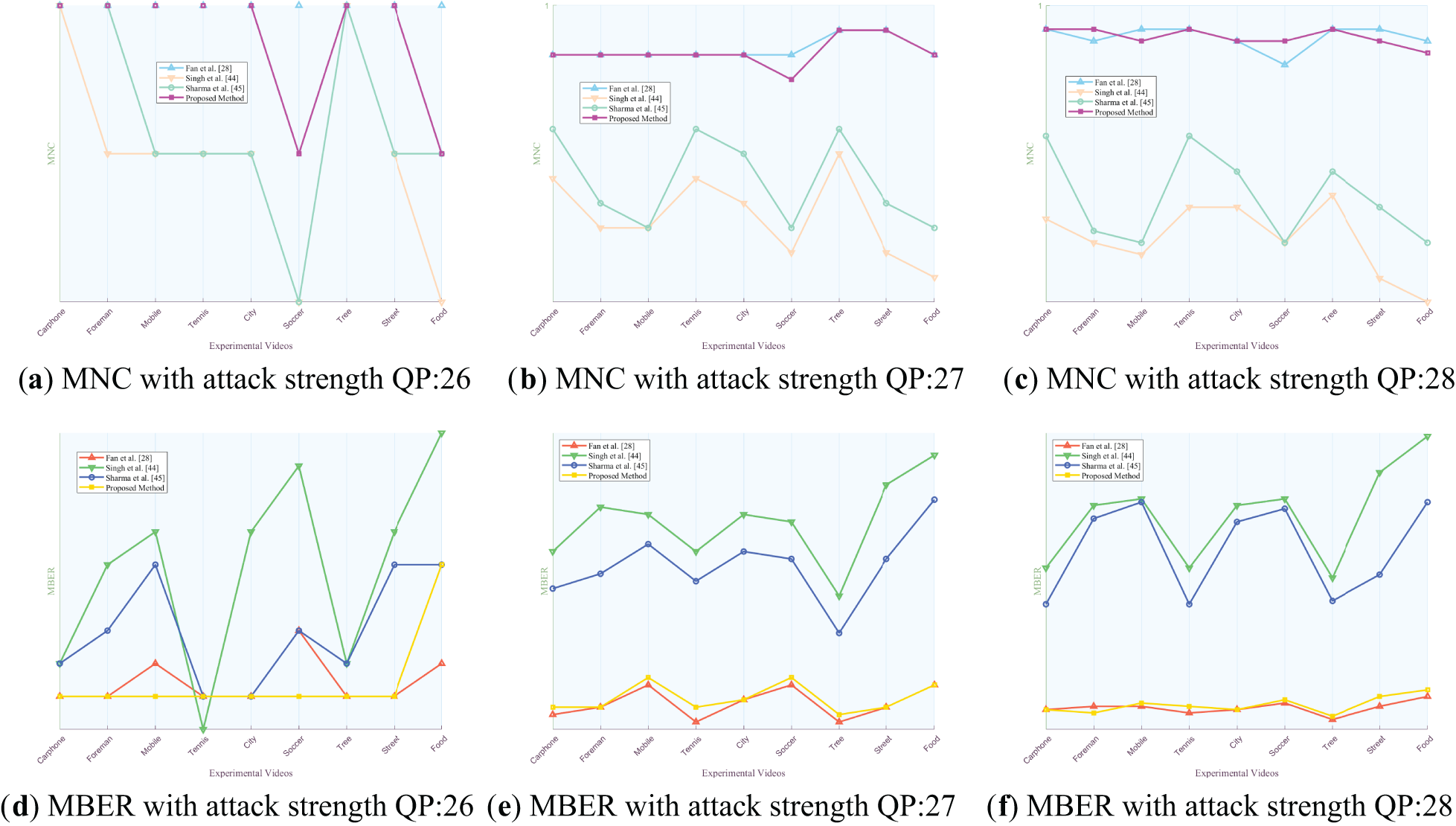
Figure 14: Comparison of MNC and MBER values of the proposed algorithm against three algorithms under various intensities of recompression attack
Figs. 8 to 14 present the MNC and MBER values of the proposed algorithm and three comparative video watermarking algorithms under various attack scenarios, including Gaussian noise, salt and pepper noise, blur, Frame Dropping, Frame Averaging, Frame Swapping, and recompression. The analysis of these tables indicates that the algorithm introduced in this study exhibits superior performance in withstanding attacks on traditional videos such as Carphone, Foreman, Tennis, and the short video Tree, characterized by smoother scenes, slower changes, and less content changes. This superiority is evident in the algorithm’s ability to minimize the decrease in MNC values and limit the increase in MBER values under adverse conditions, showcasing its robustness in preserving watermark integrity.
The algorithm under study demonstrates robustness against traditional noise attacks, particularly Gaussian noise and salt and pepper noise, as evidenced by MNC values consistently exceeding 0.9946 and MBER values remaining below 0.0571. Notably, the algorithm’s resilience diminishes as noise intensity increases, reflected in the decreasing trend of MNC values and the escalating trend of MBER values. In the context of fuzzy attacks, the algorithm excels in robustness, achieving a peak MNC value of 1 and maintaining MBER values below 0.001. This heightened resilience can be attributed to the algorithm’s ability to mitigate the impact of fuzzy attacks on pixel values within experimental video frames through frequency domain transformation, enabling accurate watermark extraction despite alterations in pixel values across different regions.
When confronted with frame attacks in experimental videos, the methods proposed by Fan et al., Singh et al., Sharma et al., and our own method all exhibit enhanced resilience compared to traditional noise attacks. Each of these algorithms serves as a video watermarking technique designed to identify the most appropriate frame within the video for embedding, showcasing robustness against frame-based adversarial scenarios. Specifically, the algorithm introduced in this study excels in countering frame average attacks, achieving MNC values exceeding 0.9994 and MBER values below 0.0016, thereby demonstrating substantial robustness. Despite the pixel averaging process employed in frame average attacks, the influence on the watermark post-frequency domain transformation remains relatively minor, as the errors introduced by the attack fall within the error correction capabilities of the error correcting code. When faced with escalating Frame Dropping attacks, the algorithm presented in this study exhibits a noticeable weaken in both MNC and MBER values. Notably, among the various video types analyzed, the experimental results for traditional videos such as Mobile and short video Food show a more pronounced weakening effect. This can be attributed to the rapid scene transformations, lower image smoothness, and closer proximity of hidden frames within these particular videos. As the number of frames extracted increases, the likelihood of the hidden frame containing the watermark being compromised rises, consequently elevating the risk of losing the marked frame. Such occurrences can result in misalignment during subsequent watermark extraction processes. While errors remain within correctable limits, misalignment can impact extraction accuracy to some extent, leading to a reduction in MNC values and an increase in MBER values. Nonetheless, the minimum MNC value remains above 0.9988, and the maximum MBER value stays below 0.0042. When confronted with varying intensities of Frame Swapping attacks, the algorithm under study also demonstrates a weakening trend, albeit with a smaller magnitude compared to Frame Dropping attacks. Frame Dropping attacks result in the loss of hidden frames within the video, leading to potential misalignment and errors in subsequent watermark extraction processes. Specifically, the loss of a hidden frame can cause subsequent frames to shift forward, disrupting the embedding order before and after the missing frame. As the intensity of Frame Dropping attacks escalates, the misalignment of subsequent hidden frames may occur, impacting the accuracy of watermark extraction. In contrast, when facing Frame Swapping attacks, the total number of frames remains constant, mitigating the risk of losing hidden frames. The algorithm’s robustness against Frame Swapping attacks surpasses that against Frame Dropping attacks, as the consistent number of frames ensures that hidden frames are preserved to a certain extent. This results in MNC values above 0.9989 and MBER values below 0.0037, indicating a higher level of resilience against Frame Swapping attacks.
The experimental results demonstrate the robustness of the video watermarking algorithm against recompression attacks of various QP. Notably, when comparing the recompression effects of QP = 26 and QP = 28, it is observed that the recompression with QP = 26 yields better results due to the lower quantization steps resulting in less distortion. The final MNC value remains above 0.9996, while the MBER value stays below 0.0012, indicating the algorithm’s resilience to QP recompression attacks. Specifically, the original QP of 26 showcases superior performance compared to QP 28, highlighting the importance of quantization parameters in maintaining watermark integrity during recompression processes. These findings underscore the algorithm’s effectiveness in preserving watermark robustness under varying QP settings.
In order to evaluate the performance superiority of the proposed algorithm compared with the current development, the proposed algorithm was compared with three reference video robust watermarking algorithms [28,44,45], and the attack intensity and related parameter Settings were consistent with those in Subsection 5.2. Using the experimental video Carphone as a case study, Figs. 15 and 16 illustrate the comparative summary of average MNC and MBER values for the algorithm proposed in this paper and the three comparison algorithms across various attack intensities. Each numerical column denotes the average MNC and MBER values of the watermarking algorithm under three distinct attack intensities.
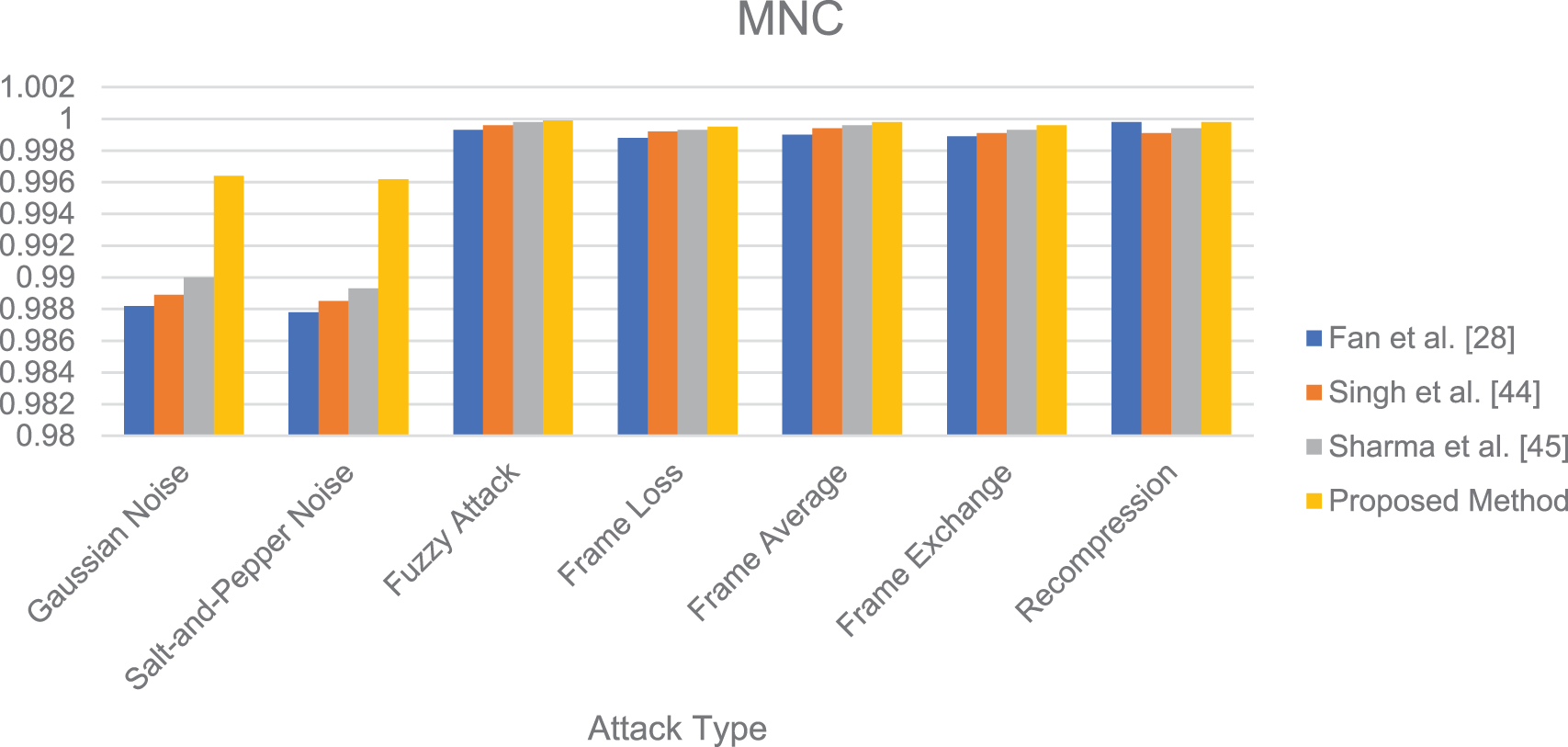
Figure 15: Analysis of average MNC values for the algorithm and three comparison algorithms in response to varied attack intensities using the experimental video “Carphone” as a case study
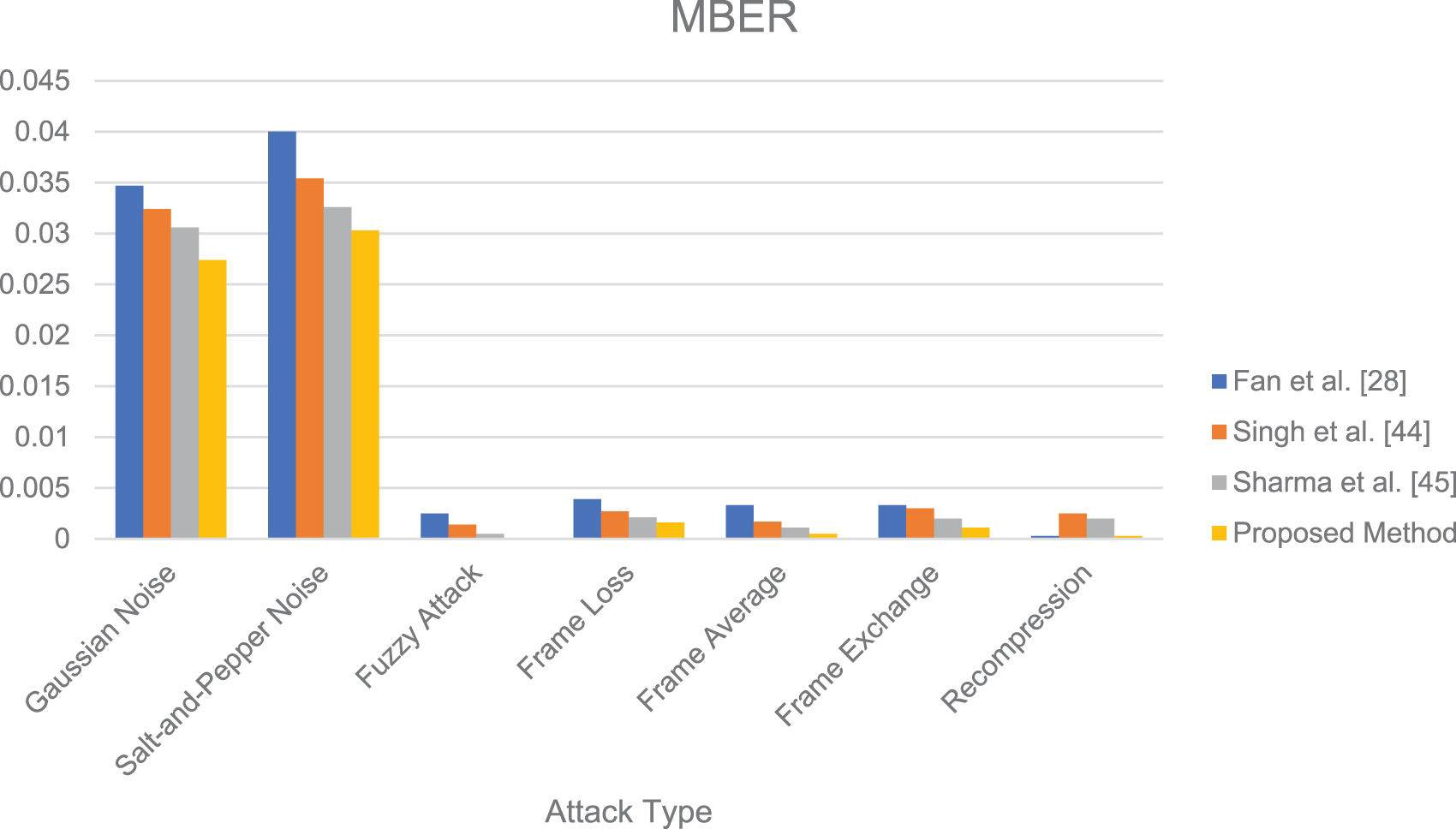
Figure 16: Analysis of average MBER values for the algorithm and three comparison algorithms in response to varied attack intensities using the experimental video “Carphone” as a case study
The results presented in Figs. 8 to 16 indicate that our proposed algorithm outperforms the three comparison algorithms in terms of MNC and MBER values under equivalent attack types and intensities, showcasing superior robustness. Notably, Fan et al.’s method exhibits comparable robustness against re-compression attacks and outperforms other attack types compared to our algorithm. This can be attributed to Fan’s approach of selecting sub-blocks for watermark embedding based on video frequency and watermark characteristics, enhancing robustness, and maintaining invisibility in video watermarking. The key distinction between our algorithm and Fan et al. lies in the sub-block selection criteria: Fan’s method is based on chromaticity and modulation, while our algorithm detects, and groups frame smoothness based on brightness and chromaticity histogram differences. Ultimately, our algorithm selects the frame with the least disparity in brightness and chromaticity histograms within the same group for embedding, achieving heightened robustness and invisibility in video watermarking.
5.2.2 Robustness Analysis of Online Attacks
In order to evaluate the robustness of the proposed algorithm against online attacks, this subsubsection applies Class II collusion attacks in Subsection 5.2 to nine experimental videos based on the proposed algorithm. Specific practices are as follows:
1. First, the video frames in the same frame group of the experimental video obtained through SSGM are obtained and approximate as the carrier and corresponding copy in the Class II collusion attack. Note that the experimental video at this time has been marked with dual-domain watermarks.
2. Use pseudorandom number generator [46]. Generate pseudo-random bit strings as pseudo-watermarks in Class II collusion attacks. Note that the number of pseudo-watermarks generated should be the same as the number of video frames in the experimental video.
3. Embed the generated watermark into each frame of each frame group one by one to obtain the damaged video. Note that the embedding method is the same as the robust splicing technique used in this algorithm.
4. Extract the robust watermark from the distorted video, calculate the NC value and BER between the extracted robust watermark and the original robust watermark in each hidden frame, and finally calculate the average NC value and the average BER value of all hidden frames, MNC and MBER, as standards to evaluate the robustness of the proposed algorithm against Class II collusion attacks.
The experimental results obtained are shown in Table 5.
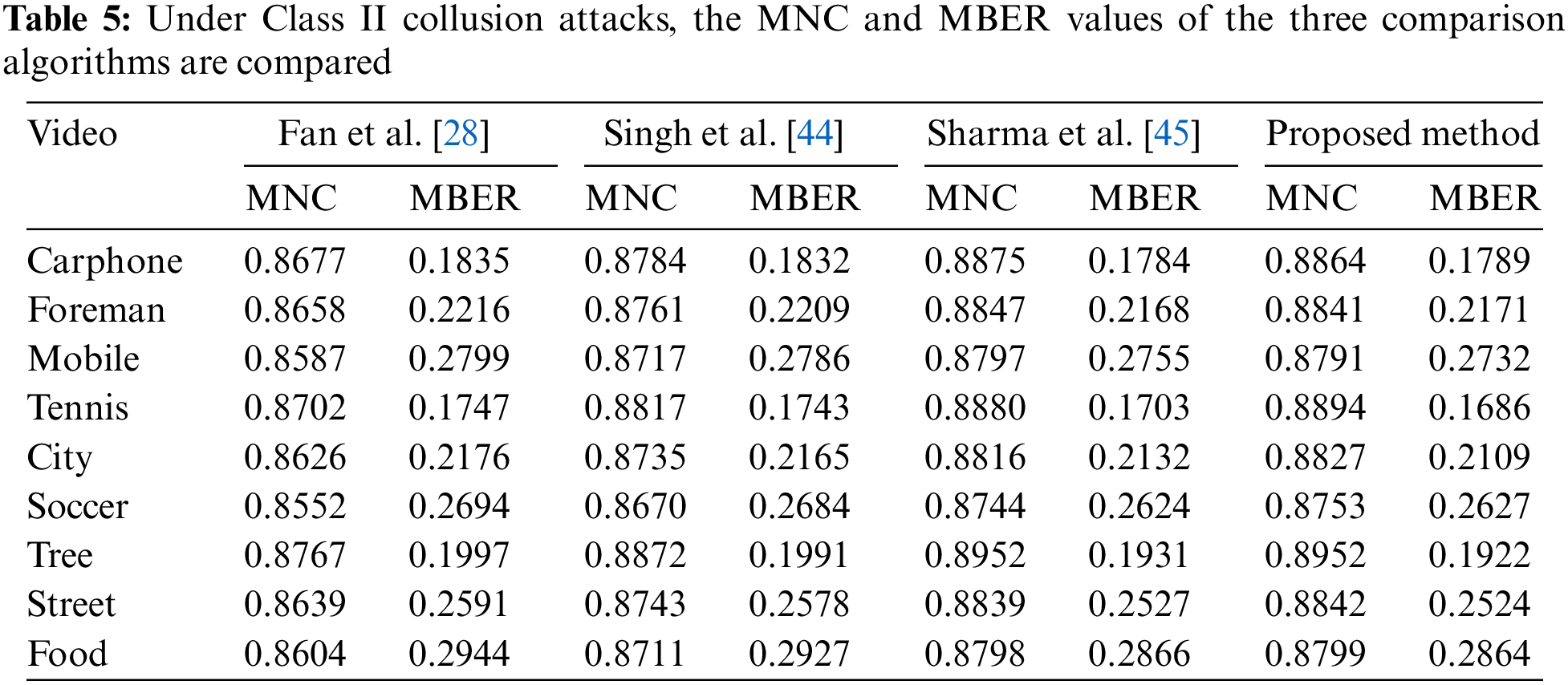
In the face of online attacks, the MNC value between the extracted watermark and the original watermark is 0.8840, and the MBER value is 0.2269. As can be seen from the data in Table 5, the weakening of MNC value and MBER value of the proposed algorithm in the face of Class II collusion attacks is much greater than that of MNC value and MBER value in offline attacks of Subsection 5.2.1, which is because, a Type II collusion attack targets all video frames in an experimental video, affecting all initially embedded legal dual-domain watermark bits. In contrast, offline attacks do not impact all the legal watermarks due to variations in attack strengths. Notably, the embedding method of pseudo-random watermark bits aligns with that of legal dual-domain watermarks, leading to the pseudo-random watermark bits overriding the legal ones. Consequently, Type II collusion attacks prove more effective against legitimate dual-domain watermarks compared to offline attacks. This maximizes the impact of the watermark, significantly reducing the proposed algorithm’s robustness against online attacks compared to offline attacks. However, according to the performance range of NC value and BER value, when NC value is greater than 0.85 and BER value is less than 0.35, it indicates that the extracted watermark still has strong robustness and can be clearly identified [47]. Therefore, the proposed algorithm is still robust against Class II collusion attacks. It is worth noting that the performance of the three compared robust watermarking algorithms is not bad, because the three comparison algorithms, like the proposed algorithms, are all algorithms that select video frames for robust watermark embedding. A prerequisite for the successful attack of Class II collusion attacks is that the attacked algorithm needs to embed a large number of video frames. Therefore, the three algorithms are also robust to collusion attacks to a certain extent.
It is worth mentioning that Class II collusion attacks require the following assumptions:
1. Each hidden frame has the same mean and variance.
2. Robust watermarking follows Gaussian distribution, and the mean value is 0.
3. Hidden frame and robust watermark are independent of each other.
From the idea of the proposed algorithm, the robust watermark bits are embedded in the DC coefficients of all macroblocks in several hidden frames, which will suffer loss after H.264 decoding, so the assumption of Gaussian distribution will not be satisfied. Therefore, the attacker cannot theoretically obtain an estimated version of the video that completely removes the robust watermark, and the premise of “collusion” is lost.
Finally, according to the above analysis, the algorithm proposed in this paper can effectively resist Class II collusion attacks.
5.3 Computational Complexity Assessment
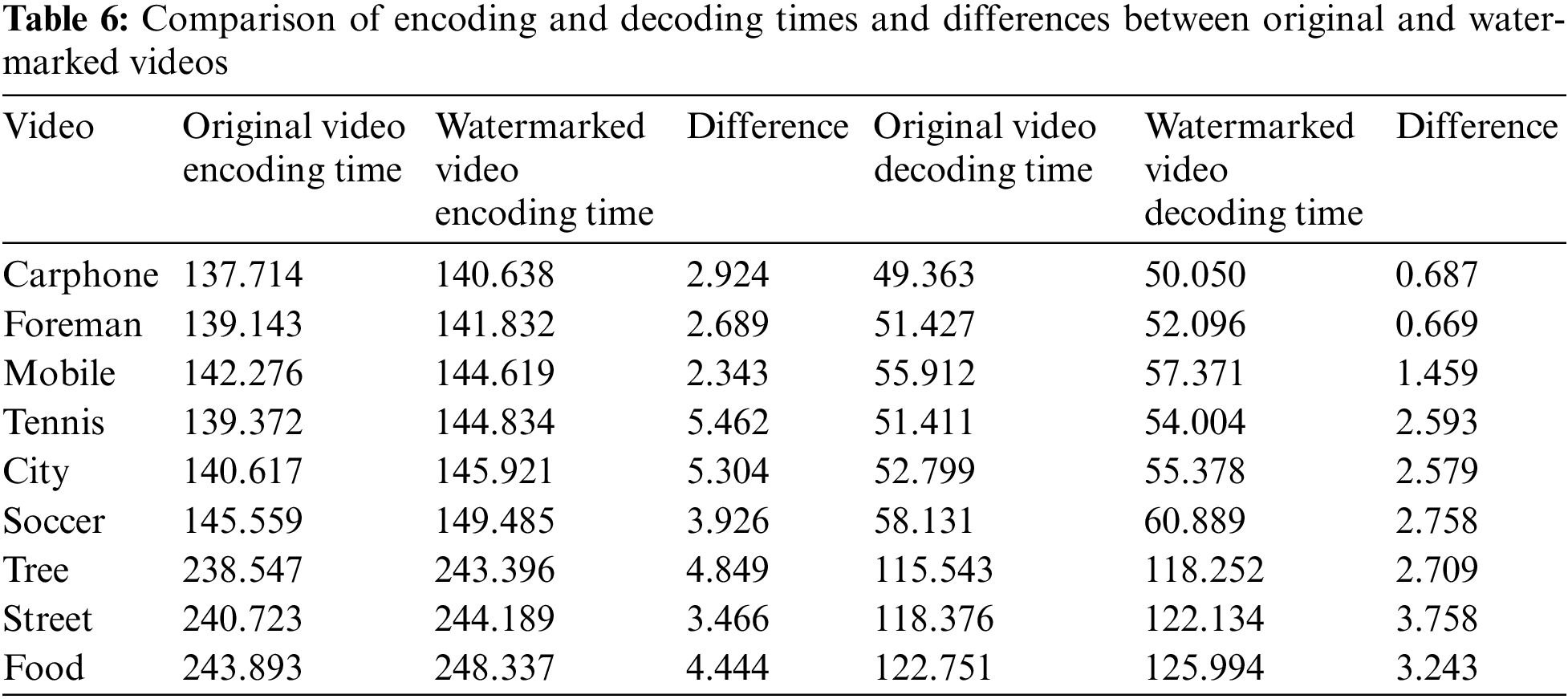
In assessing the practical efficiency of the proposed algorithm for real-world applications, this subsection delves into the computational complexity of the algorithm. The complexity analysis experiment involved measuring the time taken for encoding and decoding both before and after watermark embedding in seconds. Table 6 presents a comparison of the encoding and decoding times for the original video and the watermarked video. The results reveal that the encoding time difference for the experimental video is minimal, at less than 5.462 s, both before and after watermark embedding. Similarly, the decoding time difference does not exceed 3.758 s, indicating a low level of complexity.
This article introduces a robust reversible watermarking algorithm tailored for frame-grouped videos based on scene smoothness. The algorithm preprocesses the watermark and auxiliary information and embeds the high-frequency and low-frequency coefficients of the U channel of the transformation coefficients to achieve robust reversible watermark embedding. By employing separate embedding stages for low and high frequencies, the algorithm ensures high robustness in the initial stage while maintaining low distortion in the subsequent stage. This approach enables high error correction capabilities for watermarks, mitigates the impact of reversible embedding on watermark robustness, and efficient extraction of robust watermarks even in the presence of attacks. Compared with the three comparison algorithms, the performance of PSNR and SSIM is improved by 7.59% and 0.4% on average, while the performance of NC and BER is enhanced by 1.27% and 18.16% on average. The experimental findings demonstrate that the proposed algorithm outperforms several state-of-the-art keyframe embedding video watermarking algorithms, meeting the requirements of practical applications, and offering effective copyright protection for videos. A significant advantage lies in the algorithm’s ability to achieve high fidelity across videos of varying sizes through scene smoothness grouping, coupled with low computational complexity for convenient and rapid application to existing videos. Future research directions may explore the design of more sophisticated mechanisms for frame grouping and embedding selection to enhance robustness further.
In the future work, we will try to design a smoother frame grouping standard and a more reasonable and accurate embedding frame selection mechanism, and the embedding position is accurate to the block, further reducing the amount of modifications to the unit frame, and achieving progress in invisibility. Although robust watermark splicing technology has strong resistance to aggression, it needs threshold to control the embedding strength, and there is a problem that the amount of original frame modification per unit watermark bit is large. Therefore, the subsequent work will also take the improvement of robust watermark embedding technology as another focus of development and propose a watermark embedding technology with a smaller amount of modification per unit watermark bit. At the same time, strengthen its robustness, and better balance the contradiction and balance between invisibility and robustness. At the same time, it is planned to find a frequency domain transformation with less computational complexity, which can better reduce the computational complexity and strengthen the development prospect and status of future work in practical applications.
Acknowledgement: We thank all the members who have contributed to this work with us.
Funding Statement: This work was supported in part by the National Natural Science Foundation of China under Grants 62202496, 62272478 and the Basic Frontier Innovation Project of Engineering university of People Armed Police under Grants WJY202314, WJY202221.
Author Contributions: Conceptualization: Yucheng Liang, Ke Niu; Experimental operation and data proofreading: Yucheng Liang, Yingnan Zhang; Analysis and interpretation of results: Yucheng Liang, Ke Niu, Yingnan Zhang; Draft Manuscript preparation: Yucheng Liang, Yifei Meng; Figure design and drawing: Yucheng Liang, Ke Niu, Yifei Meng. All authors read and approved the final manuscript.
Availability of Data and Materials: Given that the source code and data contain research findings that have not yet been publicly disseminated by our experimental team, we currently face challenges in making them openly available. Moreover, our academic institution is governed by confidentiality protocols that necessitate the disclosure of the source code and data only after the stipulated decryption period has been met.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. B. Ma, K. Li, J. Xu, C. Wang, J. Li and L. W. Zhang, “Enhancing the security of image steganography via multiple adversarial networks and channel attention modules,” Digit. Signal Process., vol. 141, no. 7, pp. 104121, 2023. doi: 10.1016/j.dsp.2023.104121. [Google Scholar] [CrossRef]
2. W. Diffie and M. E. Hellman, “New directions in cryptography,” in Democratizing Cryptography: The Work of Whitfield Diffie and Martin Hellman. New York, NY, USA: Association for Computing Machinery, 2022, pp. 365–390. doi: 10.1145/3549993.3550007. [Google Scholar] [CrossRef]
3. J. Fridrich, Steganography in Digital Media: Principles, Algorithms, and Applications. Cambridge, UK: Cambridge University Press, 2009. doi: 10.1017/CBO9781139192903. [Google Scholar] [CrossRef]
4. I. Cox, M. Miller, and J. Bloom, Digital Watermarking and Steganography. San Francisco, CA, USA: Morgan Kaufmann, 2007. doi: 10.1016/B978-0-12-372585-1.X5001-3. [Google Scholar] [CrossRef]
5. S. Subramani and S. K. Svn, “Review of security methods based on classical cryptography and quantum cryptography,” Cybern. Syst., vol. 2, no. 2, pp. 1–19, 2023. doi: 10.1080/01969722.2023.2166261. [Google Scholar] [CrossRef]
6. S. Rustad, P. N. Andono, and G. F. Shidik, “Digital image steganography survey and investigation (goal, assessment, method, development, and dataset),” Signal Process., vol. 206, no. 3, pp. 108908, 2023. doi: 10.1016/j.sigpro.2022.108908. [Google Scholar] [CrossRef]
7. R. Singh, M. Saraswat, and A. Ashok, “From classical to soft computing based watermarking techniques: A comprehensive review,” Future Gener. Comput. Syst., vol. 141, no. 2, pp. 738–754, 2023. doi: 10.1016/j.future.2022.12.015. [Google Scholar] [CrossRef]
8. E. Gul and A. N. Toprak, “Contourlet and discrete cosine transform based quality guaranteed robust image watermarking method using artificial bee colony algorithm,” Expert Syst. Appl., vol. 212, no. 1, pp. 118730, 2023. doi: 10.1016/j.eswa.2022.118730. [Google Scholar] [CrossRef]
9. A. Soualmi, L. Laouamer, and A. Adel, “A blind watermarking approach based on hybrid imperialistic competitive algorithm and SURF points for color images’ authentication,” Biomed. Signal Process. Control, vol. 84, no. 3, pp. 105007, 2023. doi: 10.1016/j.bspc.2023.105007. [Google Scholar] [CrossRef]
10. A. Soualmi, A. Benhociner, and I. Midoun, “Artificial bee colony-based blind watermarking scheme for color images alter detection using BRISK features and DCT,” Arab. J. Sci. Eng., vol. 49, no. 3, pp. 3253–3266, 2023. doi: 10.1007/s13369-023-07958-8. [Google Scholar] [CrossRef]
11. P. Aberna and L. Agilandeeswari, “Digital image and video watermarking: Methodologies, attacks, applications, and future directions,” Multimed. Tools Appl., vol. 83, no. 2, pp. 5531–5591, 2024. doi: 10.1007/s11042-023-15806-y. [Google Scholar] [CrossRef]
12. X. Yu, C. Wang, and X. Zhou, “A survey on robust video watermarking algorithms for copyright protection,” Appl. Sci., vol. 8, no. 10, pp. 1891, 2018. doi: 10.3390/app8101891. [Google Scholar] [CrossRef]
13. M. Asikuzzaman and M. R. Pickering, “An overview of digital video watermarking,” IEEE Trans. Circuits Syst. Video Technol., vol. 28, no. 9, pp. 2131–2153, 2017. doi: 10.1109/TCSVT.2017.2712162. [Google Scholar] [CrossRef]
14. J. Ouyang, J. Huang, and X. Wen, “A semi-fragile reversible watermarking method based on qdft and tamper ranking,” Multimed. Tools Appl., vol. 83, no. 14, pp. 41555–41578, 2023. doi: 10.1007/s11042-023-16963-w. [Google Scholar] [CrossRef]
15. L. Tanwar and J. Panda, “Hybrid reversible watermarking algorithm using histogram shifting and pairwise prediction error expansion,” Multimed. Tools Appl., vol. 83, no. 8, pp. 22075–22097, 2024. doi: 10.1007/s11042-023-15508-5. [Google Scholar] [CrossRef]
16. R. Ogla, E. S. Mahmood, R. I. Ahmed, and A. M. S. Rahma, “New fragile watermarking technique to identify inserted video objects using H.264 and color features,” Comput. Mater. Contin., vol. 76, no. 3, pp. 1–22, 2023. doi: 10.32604/cmc.2023.039818 [Google Scholar] [CrossRef]
17. Y. Q. Shi, X. Li, X. Zhang, H. T. Wu, and B. Ma, “Reversible data hiding: Advances in the past two decades,” IEEE Access, vol. 4, pp. 3210–3237, 2016. doi: 10.1109/ACCESS.2016.2573308. [Google Scholar] [CrossRef]
18. Y. F. Wang, Y. M. Zhou, Z. X. Qian, S. Li, and X. Zhang, “Review of robust video watermarking,” J. Chin. Image Graphics, vol. 27, no. 1, pp. 27–42, 2022. [Google Scholar]
19. T. S. Nguyen, “Reversible data hiding scheme based on coefficient pair mapping for videos H.264/AVC without distortion drift,” Symmetry, vol. 14, no. 9, pp. 1768, 2022. doi: 10.3390/sym14091768. [Google Scholar] [CrossRef]
20. D. Coltuc, “Towards distortion-free robust image authentication,” J. Phys., vol. 77, no. 1, pp. 012005, 2007. doi: 10.1088/1742-6596/77/1/012005. [Google Scholar] [CrossRef]
21. D. Coltuc and J. M. Chassery, “Distortion-free robust watermarking: A case study,” presented at the Secur., Steganogr., Watermark. Multimed. Contents IX, San Jose, USA, Feb. 27, 2007. [Google Scholar]
22. X. Wang, X. Li, and Q. Pei, “Independent embedding domain based two-stage robust reversible watermarking,” IEEE Trans. Circuits Syst. Video Technol., vol. 30, no. 8, pp. 2406–2417, 2019. doi: 10.1109/TCSVT.2019.2915116. [Google Scholar] [CrossRef]
23. G. Gao, M. Wang, and B. Wu, “Efficient robust reversible watermarking based on ZMs and integer wavelet transform,” IEEE Trans. Ind. Inform., vol. 20, no. 3, pp. 4115–4123, 2023. doi: 10.1109/TII.2023.3321101. [Google Scholar] [CrossRef]
24. Y. Tang, C. Wang, S. Xiang, and Y. Cheung, “A robust reversible watermarking scheme using attack-simulation-based adaptive normalization and embedding,” IEEE Trans. Inf. Forensics Secur., vol. 19, no. 1, pp. 4114–4129, 2024. doi: 10.1109/TIFS.2024.3372811. [Google Scholar] [CrossRef]
25. B. Ma, Z. Tao, R. Ma, C. Wang, J. Li and X. Li, “A high-performance robust reversible data hiding algorithm based on polar harmonic fourier moments,” IEEE Trans. Circuits Syst. Video Technol., vol. 34, no. 4, pp. 2763–2774, 2023. doi: 10.1109/TCSVT.2023.3311483. [Google Scholar] [CrossRef]
26. H. T. Hazim, N. Alseelawi, and H. T. H. ALRikabi, “A novel method of invisible video watermarking based on index mapping and hybrid DWT-DCT,” Int. J. Online Biomed. Eng., vol. 19, no. 4, pp. 155–173, 2023. [Google Scholar]
27. S. Chen, A. Malik, X. Zhang, G. Feng, and H. Wu, “A fast method for robust video watermarking based on Zernike moments,” IEEE Trans. Circuits Syst. Video Technol., vol. 33, no. 12, pp. 7342–7353, 2023. doi: 10.1109/TCSVT.2023.3281618. [Google Scholar] [CrossRef]
28. D. Fan, H. Zhao, C. Zhang, H. Liu, and X. Wang, “Anti-recompression video watermarking algorithm based on H. 264/AVC,” Mathematics, vol. 11, no. 13, pp. 2913, 2023. [Google Scholar]
29. S. Takale and A. Mulani, “DWT-PCA based video watermarking,” J. Electron., Comput. Netw. Appl. Math., vol. 2, no. 6, pp. 1–7, 2022. doi: 10.55529/jecnam. [Google Scholar] [CrossRef]
30. E. Farri and P. Ayubi, “A robust digital video watermarking based on CT-SVD domain and chaotic DNA sequences for copyright protection,” J. Ambient Intell. Humaniz. Comput., vol. 14, no. 10, pp. 13113–13137, 2023. doi: 10.1007/s12652-022-03771-7. [Google Scholar] [CrossRef]
31. X. Y. Tao, L. Z. Xiong, and X. Zhang, “Robust video watermarking scheme based on QDCT global equalization strategy,” Comput. Sci., vol. 50, no. 11, pp. 168–176, 2023. [Google Scholar]
32. Y. Zhou, Q. Ying, Y. Wang, X. Zhang, Z. Qian and X. Zhang, “Robust watermarking for video forgery detection with improved imperceptibility and robustness,” presented at the 2022 IEEE 24th Int. Workshop Multimed. Signal Process (MMSPShanghai, China, Sep. 26–28, 2022. [Google Scholar]
33. X. H. Huang, “The research on digital video watermarking algorithm based on H.264 Bitstream,” M.S. thesis, Overseas Chinese Univ., Quanzhou, China, 2024. [Google Scholar]
34. W. Jin, J. D. Liu, and H. Q. Xu, “H.264/AVC video encryption algorithm based on integer dynamic cross-coupling tent mapping model,” Multimed. Tools Appl., vol. 83, no. 5, pp. 13369–13393, 2023. doi: 10.1007/s11042-023-15448-0. [Google Scholar] [CrossRef]
35. I. S. Reed and G. Solomon, “Polynomial codes over certain finite fields,” J. Soc. Ind. Appl. Math., vol. 8, no. 2, pp. 300–304, 1960. doi: 10.1137/0108018. [Google Scholar] [CrossRef]
36. A. J. Calabria and M. D. Fairchild, “Perceived image contrast and observer preference I. The effects of lightness, chroma, and sharpness manipulations on contrast perception,” J. Imaging Sci. Technol., vol. 47, no. 6, pp. 479–493, 2003. doi: 10.2352/J.ImagingSci.Technol.2003.47.6.art00006. [Google Scholar] [CrossRef]
37. P. Kadian, S. M. Arora, and N. Arora, “Robust digital watermarking techniques for copyright protection of digital data: A survey,” Wirel. Pers. Commun., vol. 118, no. 4, pp. 3225–3249, 2021. doi: 10.1007/s11277-021-08177-w. [Google Scholar] [CrossRef]
38. Q. Wang et al., “An overview on digital content watermarking,” presented at the Signal Inf. Process., Netw. Comput., Shangdong, China, Sep. 13–17, 2021. [Google Scholar]
39. Y. A. Hassan and A. M. S. Rahmah, “An overview of robust video watermarking techniques,” Iraqi J. Sci., vol. 64, no. 7, pp. 4513–4524, 2023. doi: 10.24996/ijs.2023.64.7.38. [Google Scholar] [CrossRef]
40. H. Lakshmi and S. Borra, “Digital video watermarking tools: An overview,” Int. J. Inf. Comput. Secur., vol. 16, no. 1–2, pp. 1–19, 2021. doi: 10.1504/IJICS.2021.117391 [Google Scholar] [CrossRef]
41. P. Garg and R. R. Kishore, “Performance comparison of various watermarking techniques,” Multimed. Tools Appl., vol. 79, no. 35–36, pp. 25921–25967, 2020. doi: 10.1007/s11042-020-09262-1. [Google Scholar] [CrossRef]
42. V. B. Giffen, D. Herhausen, and T. Fahse, “Overcoming the pitfalls and perils of algorithms: A classification of machine learning biases and mitigation methods,” J. Bus. Res., vol. 144, no. 6, pp. 93–106, 2022. doi: 10.1016/j.jbusres.2022.01.076. [Google Scholar] [CrossRef]
43. Y. Hu, H. K. Lee, and J. Li, “DE-based reversible data hiding with improved overflow location map,” IEEE Trans. Circuits Syst. Video Technol., vol. 19, no. 2, pp. 250–260, 2008. [Google Scholar]
44. R. Singh, H. Mittal, and R. Pal, “Optimal keyframe selection-based lossless video-watermarking technique using IGSA in LWT domain for copyright protection,” Complex Intell. Syst., vol. 8, no. 2, pp. 1047–1070, 2022. doi: 10.1007/s40747-021-00569-6. [Google Scholar] [CrossRef]
45. C. Sharma, B. Amandeep, R. Sobti, T. K. Lohani, and M. Shabaz, “A secured frame selection based video watermarking technique to address quality loss of data: Combining graph based transform, singular valued decomposition, and hyperchaotic encryption,” Secur. Commun. Netw., vol. 2021, pp. 5536170, 2021. doi: 10.1155/2021/5536170. [Google Scholar] [CrossRef]
46. B. A. Wichmann and I. D. Hill, “Generating good pseudo-random numbers,” Comput. Stat. Data Anal., vol. 51, no. 3, pp. 1614–1622, 2006. doi: 10.1016/j.csda.2006.05.019. [Google Scholar] [CrossRef]
47. S. Chen, Q. Su, and H. Wang, “An improved blind watermarking method facing dual color images based on Hadamard transform,” Soft Comput., vol. 27, no. 17, pp. 12517–12538, 2023. doi: 10.1007/s00500-023-07898-3. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools