
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Predicting Users’ Latent Suicidal Risk in Social Media: An Ensemble Model Based on Social Network Relationships
1 School of Information Science and Technology, Beijing Forestry University, Beijing, 100083, China
2 Engineering Research Center for Forestry-Oriented Intelligent Information Processing of National Forestry and Grassland Administration, Beijing, 100083, China
* Corresponding Author: Chunling Wang. Email:
Computers, Materials & Continua 2024, 79(3), 4259-4281. https://doi.org/10.32604/cmc.2024.050325
Received 02 February 2024; Accepted 17 April 2024; Issue published 20 June 2024
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Suicide has become a critical concern, necessitating the development of effective preventative strategies. Social media platforms offer a valuable resource for identifying signs of suicidal ideation. Despite progress in detecting suicidal ideation on social media, accurately identifying individuals who express suicidal thoughts less openly or infrequently poses a significant challenge. To tackle this, we have developed a dataset focused on Chinese suicide narratives from Weibo’s Tree Hole feature and introduced an ensemble model named Text Convolutional Neural Network based on Social Network relationships (TCNN-SN). This model enhances predictive performance by leveraging social network relationship features and applying correction factors within a weighted linear fusion framework. It is specifically designed to identify key individuals who can help uncover hidden suicidal users and clusters. Our model, assessed using the bespoke dataset and benchmarked against alternative classification approaches, demonstrates superior accuracy, F1-score and AUC metrics, achieving 88.57%, 88.75% and 94.25%, respectively, outperforming traditional TextCNN models by 12.18%, 10.84% and 10.85%. We assert that our methodology offers a significant advancement in the predictive identification of individuals at risk, thereby contributing to the prevention and reduction of suicide incidences.Keywords
Suicide is a significant contributor to global mortality, accounting for over 700,000 deaths annually [1,2]. Early detection of individuals at risk is crucial for effective suicide prevention [3]. Social media platforms, where individuals often express their thoughts openly during periods of suicidal ideation, have emerged as critical tools for assessing mental well-being [3,4]. The detection of suicide risk through social media offers the advantages of wide reach, cost-effectiveness, and access to real-time information, distinguishing it from traditional methods like clinical diagnosis and questionnaire assessments [5–7]. Thus, it is imperative to provide effective risk assessment and crisis intervention for users at risk of suicide on these platforms.
Previous research has demonstrated the efficacy of artificial intelligence (AI), especially in natural language processing (NLP) and machine learning, for online suicide risk assessment through text analysis [8–11]. However, these text-based assessments might not identify individuals who do not openly express their suicidal thoughts online [12–14]. Moreover, the authenticity of the posts must be verified. Without considering additional features, interpreting certain posts could be challenging. Integrating non-textual features, such as social network relationships, could enhance the accuracy of suicide risk predictions. This feature is crucial for identifying at-risk users online, as most suicidal users have bidirectional connections with others who are either suicidal or have public profiles, with few non-suicidal connections [15]. Another study revealed that suicidal ideation could spread through social network relationships on social media, showing an infectious effect that intensifies through user interaction [16]. Our research, therefore, prioritizes the extraction of features related to social network relationships to advance the prediction of suicide risk.
Several challenges hinder progress in this field. Initially, the existing body of research on this subject is somewhat limited, with most studies focusing on the following relationships to measure their influence within social networks [17]. It is important to recognize that the social network structure of suicidal individuals is typically narrow and sparse, offering limited identifiable features. Nevertheless, users exhibit a range of valuable social behavioral factors, such as network activity, frequency of nocturnal blog posts, and network confidence [18]. To our knowledge, there has been no progress in integrating these factors into the analysis of social network relationships. This study aims to incorporate these elements as corrective factors, enhancing our predictive accuracy regarding suicide risk.
Furthermore, there is a notable lack of publicly available, authoritative Chinese datasets focusing on social network relationships, with the majority being in English and consisting primarily of textual data [19,20]. Cultural differences may impede the effectiveness of these datasets when applied to other social media platforms, such as China’s Sina Weibo (Weibo) [21]. In China, research predominantly utilizes Weibo. Huang et al. [22] identified virtual communities on Weibo, known as Weibo Tree Hole, where users frequently post comments that explicitly indicate suicidal ideation, making it an essential resource for identifying individuals at risk of suicide. The Zoufan Tree Hole on Weibo, the largest of its kind, contained over three million comments by March 2023, and continues to grow.
To tackle the identified challenges, this paper introduces a novel Chinese suicide dataset derived from the Zoufan Tree Hole and outlines a new model named Text Convolutional Neural Network based on social network relationships (TCNN-SN). This model proficiently extracts the social network relationships feature on Weibo and predicts key users to uncover additional at-risk individuals and groups. The contributions of this paper are multifaceted:
• We develop a comprehensive Chinese dataset for predicting latent suicidal risk among Weibo users. This dataset, comprising accurately labeled suicidal and non-suicidal users along with their relationships, addresses the notable absence of Chinese-centric datasets in this research area.
• Diverging from most existing studies that focus on individual risk assessment, our TCNN-SN model emphasizes the prediction of groups. It adeptly identifies pivotal users within social networks, thereby facilitating the detection of hidden suicidal individuals and clusters.
• The study highlights several critical behavioral factors on Weibo, designated as correction factors, which enhance the extraction of social network relationship features.
• In this paper, we use scaling coefficients and the weighted linear fusion approach to further improve the forecasting performance. Experiments show that our model has significant improvements compared with the baseline model.
The structure of the paper is as follows: Section 2 reviews related work in suicide risk detection on social media. Section 3 introduces the TCNN-SN model. Section 4 details the creation of the dataset. Section 5 outlines the experimental design, including baseline models and metrics for evaluation. Section 6 presents a comprehensive analysis of the experimental outcomes. The implications of the findings are discussed in Section 7. The paper concludes with a summary and reflections on its limitations, alongside suggestions for future research directions in Section 8.
Recent studies have increasingly highlighted the significant impact of social media on suicidal ideation [5]. Rabani’s study [23] discovered that analyzing Twitter data can assist in identifying young internet users who may be at risk of suicide. Coppersmith et al. [24] noted a noticeable rise in expressions of sadness in tweets posted prior to a user’s suicide attempt. Ma et al. [25] illustrated that examining linguistic patterns and online activities on Weibo, utilizing a Chinese suicide lexicon, can efficiently identify suicide risk indicators on social media.
The recent advancements in technology have made suicide prediction methods increasingly popular, leveraging advanced techniques like NLP, machine learning, deep learning, and sentiment analysis. Machine learning involves constructing models, extracting features and patterns from data, and using them to make accurate predictions. For instance, Lin et al. [26] employed support vector machines, decision trees, and logistic regression to estimate psychological stress levels and suicidal thoughts among male and female military personnel. Similarly, Hiraga [27] utilized multinomial logistic regression, Naive Bayes, and linear Support Vector Machines (SVMs) to categorize users with mental disorders on a Japanese blogging platform. Some studies also utilize dictionary features with SVM, random forest, and Term Frequency-Inverse Document Frequency (TF-IDF) models for training [28,29]. Tadesse et al. [30] assessed the predictive power of N-grams, Lexicon and Latent Dirichlet Allocation (LDA), and Linguistic Inquiry and Word Count (LIWC) techniques individually and in combination for identifying depression in classification tasks.
Deep learning models like CNNs, RNNs, and LSTMs have recently been used to detect suicide risk in social media users [31–33]. Compared to traditional machine learning methods, deep learning offers a more objective, accurate, and comprehensive assessment of suicide risk by leveraging extensive data and deep neural networks. Shen et al. [21] demonstrated the superiority of the LSTM classifier over five other machine learning models. The introduction of the TextCNN model in 2014 [34] has opened up new opportunities for text recognition research. Zhao et al. [35,36] utilized TextCNN to analyze microblogs and identify depressed users, while Li et al. [11] developed the TCNN-MF-LA model based on TextCNN to effectively identify Weibo users at risk of suicide.
Moreover, cutting-edge methods have significantly enhanced the precision of suicide prediction. A framework for quantitatively evaluating the ChatGPT model’s ability to assess suicide risk on social media has been introduced [37]. Yang et al. [38] developed Tree Hole Intelligent Agents technology using Knowledge Graphs, effectively spotting individuals at risk of suicide in the Zoufan Tree Hole with outstanding preventive results. The trend of combining various models is also on the rise. Renjith et al. [39] combined LSTM and CNN models to scrutinize social media posts for potential suicidal intentions. Research has shown that an integrated neural network employing word embedding techniques with a combined LSTM-CNN model can yield promising classification performance [30,40].
Despite the focus on text-level prediction in the studies mentioned, this approach has its limitations, leading to an interest in analyzing social media relationship networks as a novel research frontier. Ji et al. [41] introduced a relationship network using the LSTM model, but the network features were not distinct enough for satisfactory classification. The PageRank model is widely used for extracting features from social networks [17]. Lahoti et al. [42] developed a query-dependent PageRank-based algorithm on Twitter for finding experts, applicable across social networks with endorsement features. Priyanta et al. [43] explored user ranking with personalized PageRank to identify topic initiators on Twitter. Yet, most of these studies center on English-language social networks, with scant research in Chinese contexts. Liu et al. [44] created the TSRank algorithm for accurately gauging user influence on Weibo. The Ptr-Rank model, created by Miao [36], effectively identifies depressed users. According to their research, the node iteration values derived from the PageRank model can be compared to user influence on the Weibo social network. Nevertheless, these studies often overlook additional behavioral factors such as network confidence and blog posting frequency at night, which can impact social network features and the model’s effectiveness.
This section initiates with an overview of constructing Weibo social network relations, followed by a discussion on the extraction and augmentation of features. It also delves into assessing the logical coherence of our extracted features and outlines the proposed methodological approach.
3.1 Feature Extraction of Weibo Social Network Relationships
The process of extracting proposed features begins with these steps: (1) Constructing a social network relationships graph to depict the core structure and diffusion paths within the user’s social network. (2) Evaluating their influence to identify key users and influential groups, thereby determining various vectors of transmission.
3.1.1 Construction of Weibo Social Network Relationships
Predicated on the principle of homophily, nodes exhibiting analogous labels or attributes exhibit a propensity to affiliate or connect with other nodes of similar characteristics [45]. Henceforth, as delineated in Fig. 1, Weibo users can be conceptualized as nodes, enabling the formation of a directed network predicated on their interrelations [46]. Leveraging this conceptual framework allows for the application of information dissemination theory [47] to dissect the architecture of Weibo social networks and prognosticate the pivotal users propagating suicide ideation, alongside their respective channels of transmission.

Figure 1: Weibo social network relationships and their corresponding probability matrix are constructed in the form of a directed graph. The circle symbolizes the user, while the arrow represents the following relationships
3.1.2 User Influence in Weibo Social Network
User influence, employed as an index to ascertain the significance and impact of users within the network, emerges as a pivotal attribute of the Weibo social networks [48]. An augmentation in user influence correlates with expedited dissemination of content among peers, culminating in an expanded outreach via social network connections. The PageRank algorithm is utilized to quantify user influence within the Weibo social network [17]. Specifically, the interconnections among Weibo users, analogous to webpage links in the PageRank model, facilitate the computation of user influence through the employment of a transition probability matrix [44]. Fig. 1 illustrates the Weibo social network alongside its corresponding probability matrix. This matrix delineates the likelihood of a user following another within the Weibo social network. Utilizing this matrix allows for the iterative computation of user influence, serving as a foundation for subsequent predictive endeavors.
As highlighted in the introduction, social media users exhibit a range of critical social behavioral factors. This is particularly evident in Weibo, where each user presents a complex array of data including network activity, nocturnal blog frequency, and network confidence, which are instrumental in refining the evaluation of user influence within the network. These aspects are identified as correction factors in our study.
• Network activity [44] measures a user’s engagement level on the Weibo social network, with indicators such as frequent microblogging, active engagement with peers, and participation in popular discussions signifying high user engagement.
• Nocturnal blog frequency [11] accounts for the number of user posts during late-night hours, specifically from 11 PM to 3 AM. A clear distinction is observed in the nocturnal posting patterns between individuals linked to suicide and those who are not. Users not associated with suicide tend to post more during daytime, while those with suicide tendencies show a higher frequency of nocturnal posts, often related to depression, insomnia, and anxiety. This distinction provides additional insights for identifying users at risk of suicide.
• Network confidence [44,48] assesses a user’s capacity to exert influence upon others through their postings on the Weibo social network. Individuals commanding higher esteem within the Weibo ecosystem wield more substantial influence, accumulate larger followings, and are often distinguished by the platform as certified ‘Big V’ users, denoting their elevated status.
In this paper, we present a deep learning classification framework, TCNN-SN, aimed at enhancing the ability to detect and categorize suicidal ideation among Weibo users at risk. This improvement is achieved by extracting and refining relational features from the Weibo social network.
Fig. 2 delineates the structure of our proposed framework. The model encompasses the following integral components: (1) User Suicide Risk Evaluation Model: This involves the analysis and processing of microblogs authored by users, from which textual, semantic, and contextual attributes are extracted. Consequently, the text-level probability of a user’s suicide risk

Figure 2: The architecture of the proposed model. Our aim is primarily to predict Weibo users at risk of suicide, thereby enabling the model to process input in the form of a sequence of Chinese texts
3.2.1 User Suicide Risk Evaluation Model
Firstly, the preprocessed microblogs are transformed into word vectors using Word2Vec technology, which serves as the input layer for the TextCNN model. By executing convolution operations and pooling classifications, determining the suicide probability
Thus, the user suicidal risk evaluation model is established.
3.2.2 Social Network Suicide Risk Calculation Model
The relationships listed below can be used to determine each user’s PageRank value:
where
It is worth noting that the practical application of Eq. (2) necessitates its transformation into a calculable model. This can be achieved by using the transition probability matrix method described in Section 3.1.2 for calculation purposes as
where
Typically,
where
The formula for calculating
where
Comprehensive authentication, the quantity of fans, the ability to identify highly reputable individuals, and the importance of social engagement and information sharing can all be used to assess
where
The comprehensive correction factor
By substituting
Notably,
By normalizing
Through calculation, the propagation influence of various neighboring nodes on user nodes is comprehensively taken into consideration. We can ascertain the user’s influence-level probability of suicide risk within the social network and establish the social network suicidal risk evaluation model.
The accuracy of Eq. (10) in predicting suicide risk is directly proportional to the integrity of network relationships, but finding a suitable network in Weibo is often challenging, resulting in low accuracy. We propose a weighted linear fusion approach to merge the aforementioned models, introducing a scaling parameter
The classifier uses the value of
Due to privacy and security concerns, obtaining relevant data poses a significant challenge for detecting suicidal ideation. The lack of a comprehensive public dataset tailored for Chinese users further complicates this issue. To overcome these challenges, we have created a new Chinese suicide dataset based on Weibo. This dataset has undergone thorough cleaning and de-identification procedures to enable the prediction of users at risk.
4.1 Data Collection and Annotation
Our goal is to gather data from the Zoufan Tree Hole. Initially, we collect 81,762 unprocessed microblog comments from which we identify 22,380 unique users. We then conduct an initial screening of these comments using the Chinese suicide dictionary [50], resulting in 9,901 instances showing clear signs of suicidal tendencies and another 10,000 instances without such indications. To ensure dataset balance, we select 8,000 microblog samples from each category as the basis for constructing the dataset. Subsequently, we identify 3,797 users who mutually follow each other from the acquired user pool, with 1,147 of them appearing in the initial screening of 16,000 microblogs. Using unique user IDs, we crawl all original microblogs posted within the past year, totaling 79,369 unprocessed microblogs. Focusing on the latest 50 original microblogs per user to account for changing suicidal tendencies, we compile a dataset containing 16,296 microblogs.
To ensure accurate user annotations, four psychology experts independently conduct manual assessments. Any discrepancies in the results are resolved through discussion to reach a final decision. Users are categorized individually using the criteria outlined in Table 1.

Table 2 shows some examples of Weibo posts with and without suicidal ideation.

Microblog language is informal, often diverging from standard linguistic norms. The presence of emojis and Weibo-specific characters, irrelevant to detection tasks, may potentially impact the final results. To guarantee uniform data collection, we execute the following preprocessing steps:
• Remove ‘#’ symbols before and after ‘Topic’ and ‘SuperTopic’ using regular expressions.
• Eliminate emoticons from Weibo text and replace emojis with corresponding words like “smile”, “tears”, etc.
• Delete other users’ names mentioned with the ‘@’ symbol.
• Exclude URLs from the text as they are not relevant for our detection task.
• Remove data containing garbled code, which can affect model checking, especially in Chinese text.
• Eliminate irrelevant data related to microblog behavior, such as instances where users share pictures, as it lacks significance for model detection.
• Exclude text data with a length of less than 5 characters to ensure adequate emotional expression.
• Utilize regular expressions to match Chinese and English characters, punctuation marks, numbers, spaces, etc., while removing other characters, ensuring the removal of emojis, Japanese characters, or any other unwanted content.
After the preprocessing steps, we obtain a dataset consisting of 1,147 users and 16,296 microblogs. To protect user privacy, our paper utilizes desensitization techniques by replacing personal information with unique IDs.
For co-occurrence network analysis, the social network graph of the dataset can be created using Gephi software [58] (as depicted in Fig. 3).

Figure 3: The social network graph of microblog users is constructed based on the dataset in this paper. Different colors are employed to indicate varying degrees of suicide risk, with red representing a higher risk and green indicating no suicidal tendency. The intensity of suicidal or non-suicidal tendencies increases with the darkness of the color
The experimental investigation employs the Chinese data set described in Section 4. The dataset is divided into two sets: A training set and a test set. 80% of the data is used for model training, while the remaining 20% is used to evaluate model performance. We preprocess the microblogs before to starting the experiment. After that, we segment the text and remove stop words and special characters using jieba, a Chinese word segmentation program. Subsequently, we use Word2Vec to convert the text into a word vector representation, which we then feed into our model. The PyTorch 2.0 framework is utilized in the execution of the experiments. During training, we use the Adam optimizer in conjunction with the cross-entropy loss function to reduce the possibility of our model overfitting.
To verify the effectiveness of our proposed features and models, we carry out text classification tests using the same dataset and choose three machine learning and three deep learning techniques that are frequently employed in NLP.
5.2.1 Machine Learning Methods
We extract features from Weibo users’ microblogs, then feed them into the appropriate machine learning models and conduct comparative experiments. Among our training models are:
• Support Vector Machines (SVM): The features extracted from Weibo posts are fed into a support vector machine with an RBF kernel. We select a regularization value C = 0.1 and set the kernel function’s parameter γ to the reciprocal of the feature dimension.
• Naive Bayes (NB): The polynomial Naive Bayes model is employed with a smoothing parameter alpha of 0.001.
• Random Forest (RF): The RF contains 50 decision trees. Bootstrap sampling is employed for each tree in the random forest ensemble. The Gini index is used when selecting division attributes.
In our comparative experiment, we utilize TextCNN, TextRNN, and TextRCNN. Following text segmentation, the users’ Weibo text serves as the model’s input. The prediction result indicates if the user is suicidally inclined.
• TextCNN [34]: A fully connected layer is employed for classification after local characteristics are extracted from text at various window sizes using convolution and pooling procedures. With 128 convolution kernels and three kernel sizes, the input word vector dimension is set to 100 (2, 3, and 4). The model’s ultimate prediction result is obtained after the convolution, max-pooling, and linear layers.
• TextRNN [59]: It is an RNN-based approach that effectively handles text sequences of varying lengths and captures contextual information by recursively propagating hidden states. These states are subsequently classified using fully connected layers. Three layers and a size of 100 are assigned to the word vector input of the model.
• TextRCNN [60]: Using CNN to extract local features from text sequences, it is an RNN-NN combination that efficiently collects contextual information, pools the features, and classifies using a fully connected layer. This model uses three layers of RNN and has an input word vector dimension of 100.
To assess the baseline using our proposed model, we employ evaluation metrics such as accuracy
We have additionally utilized the Receiver Operating Characteristic Curve (ROC curve) and AUC (area under the ROC curve) as commonly used metrics of predictive quality that take into account the probability of the predicted class [10]. The true positive rate (TPR) is plotted against the false positive rate (FPR) on the ROC curve. They are calculated as follows:
This section discusses the various approaches employed on the dataset we constructed, as well as the results produced. The social network relationships feature is added to the three machine learning techniques mentioned in Section 5.2.1. The experimental results, as illustrated in Fig. 4, demonstrate that our proposed features yield notable outcomes even when utilizing naive machine learning techniques. Among these models, the NB-SN model outperforms the others, reaching maximum values on all assessment metrics. Specifically, the accuracy reaches 73.93% and the F1-score climbs to 81.9%. Therefore, we compare the NB-SN model with other deep learning approaches.

Figure 4: Classification results of machine learning methods. ‘model-SN’ signifies the utilization of social network relationships feature in the method
Fig. 5 illustrates a comparison of our proposed model to existing deep learning methods. Deep learning techniques perform better than conventional machine learning techniques when text is the only input. Moreover, we find performance disparities amongst the different deep learning techniques: TextCNN attains the maximum accuracy of 76.39%, whilst TextRNN and TextRCNN have marginally reduced accuracies of 74.80% and 74.43%, respectively. It is probable that users are posting more and longer microblogs, which could explain why the RNN-based algorithm suffers with extended sequences.
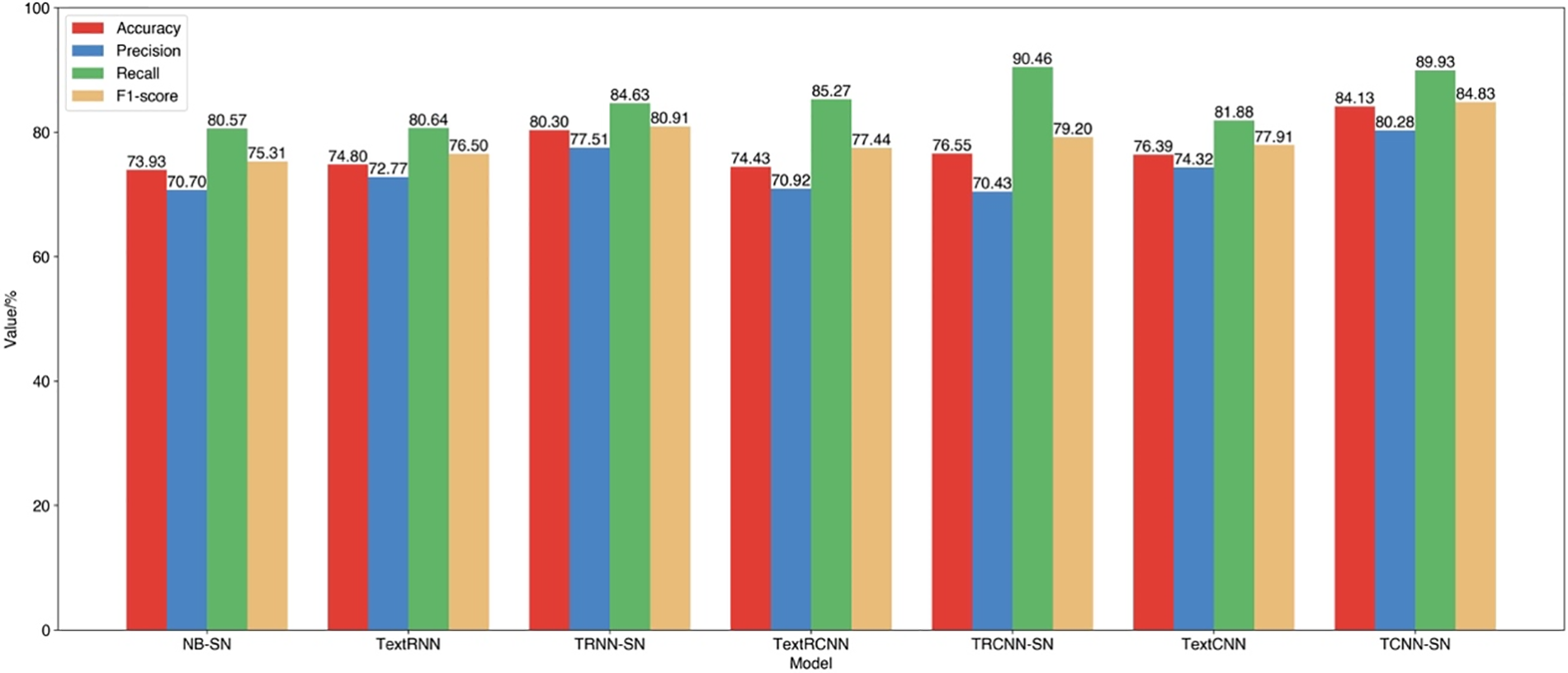
Figure 5: Classification results of different methods. ‘model-SN’ signifies the utilization of social network relationships feature in the method
We incorporate Weibo social network relationships feature into three deep learning models. As seen in Fig. 5, our proposed TCNN-SN model beats all previous models with an accuracy of 83.96% and an F1-score of 85.41%. This is a notable improvement of 7.1% and 9.88%, respectively, over the original TextCNN model. Furthermore, every evaluation metric of TextRNN-SN and TextRCNN-SN show significant improvement over their respective original models, proving the efficacy of incorporating extracted social network relationships feature into deep learning models.
To further understand model performance, the AUC-ROC curve is used to compare the models in Fig. 6. The AUC values from the different classifiers are displayed in the legend of each figure, demonstrating that the outcomes above 80% when the different models were combined with our recommended feature. In particular, our proposed TCNN-SN model has an impressive AUC value of 92.40%, which is 9% higher than the original TextCNN model, demonstrating that our proposed model does an excellent job of distinguishing between the two target categories.

Figure 6: The AUC-ROC curves for different models. (a) Machine learning group; (b) deep learning group. ‘model-SN’ signifies the utilization of social network relationships feature in the method
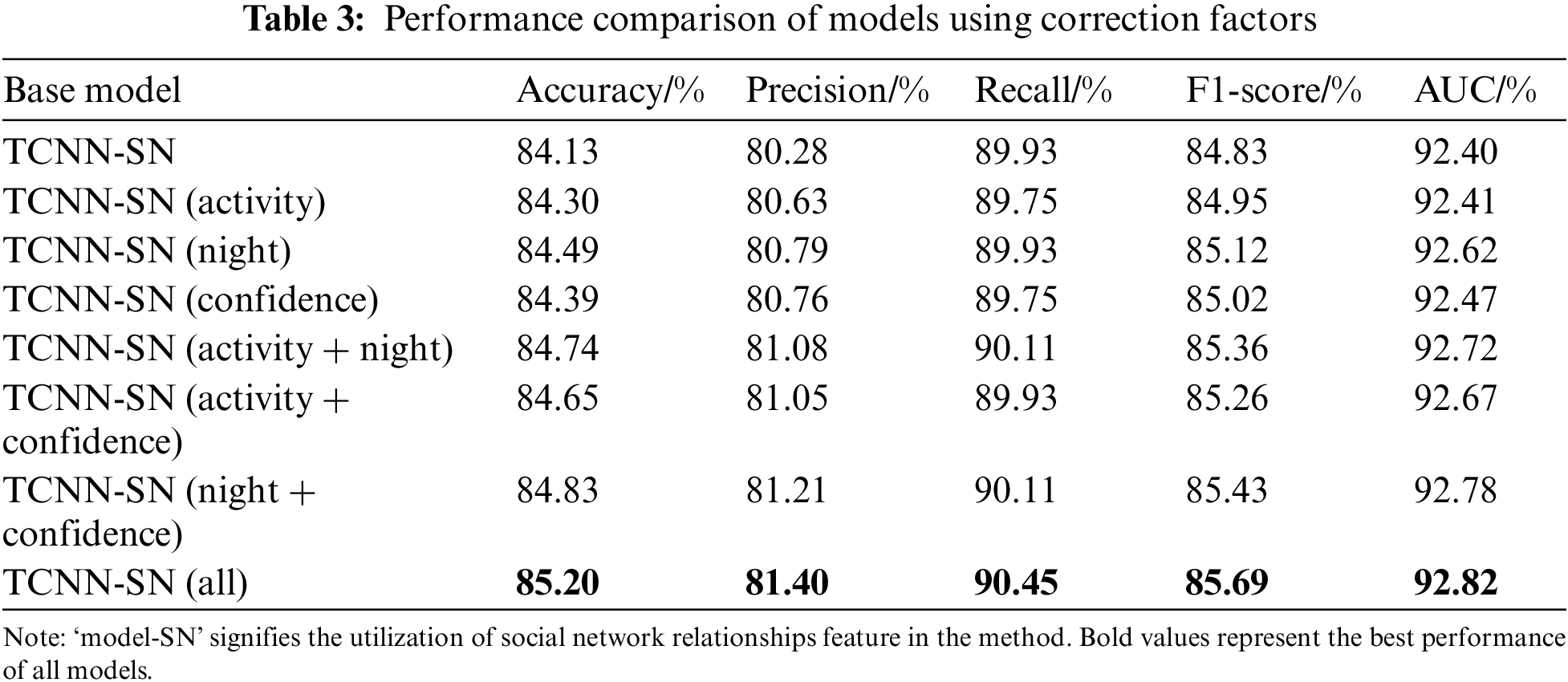
We further evaluate the contributions of the three correction factors indicated in Section 3, namely
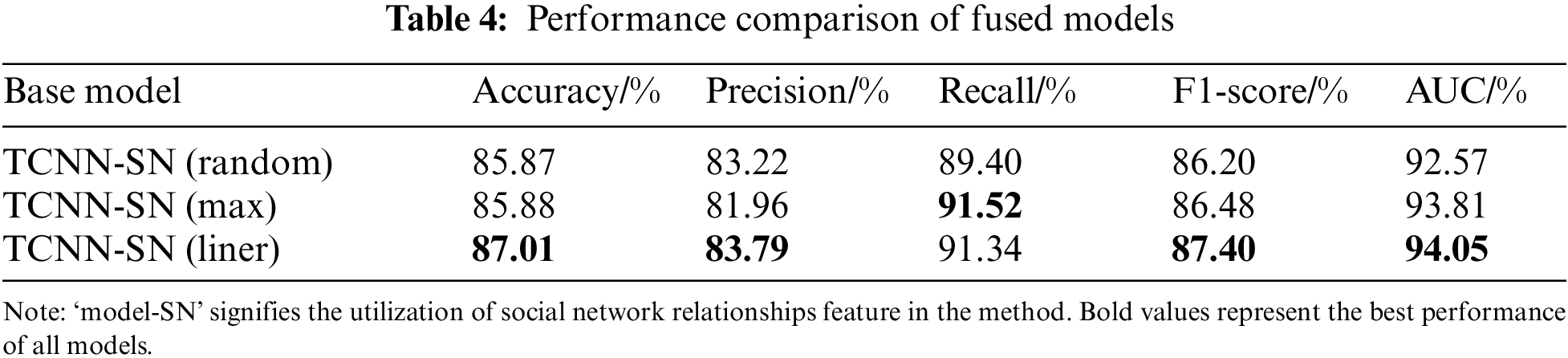
Based on the aforementioned model (Table 3, Line 8), we compare our suggested linear weighted fusion model to random fusion and maximum value fusion. Table 4 depicts that all the fused model’s evaluation metrics, such as accuracy, F1-score, and AUC, have increased overall. Notably, our linear weighted fusion model exhibits superior accuracy, precision, F1-score, and AUC, i.e., 87.01%, 83.79%, 87.4%, and 94.05% respectively as compared to the other two models. This can be explained by the fact that it combines extracted data and prediction outputs to accurately forecast suicide risk by utilizing the advantages of each unique model through a sensible weight allocation. In contrast, the other two approaches lack this potential.
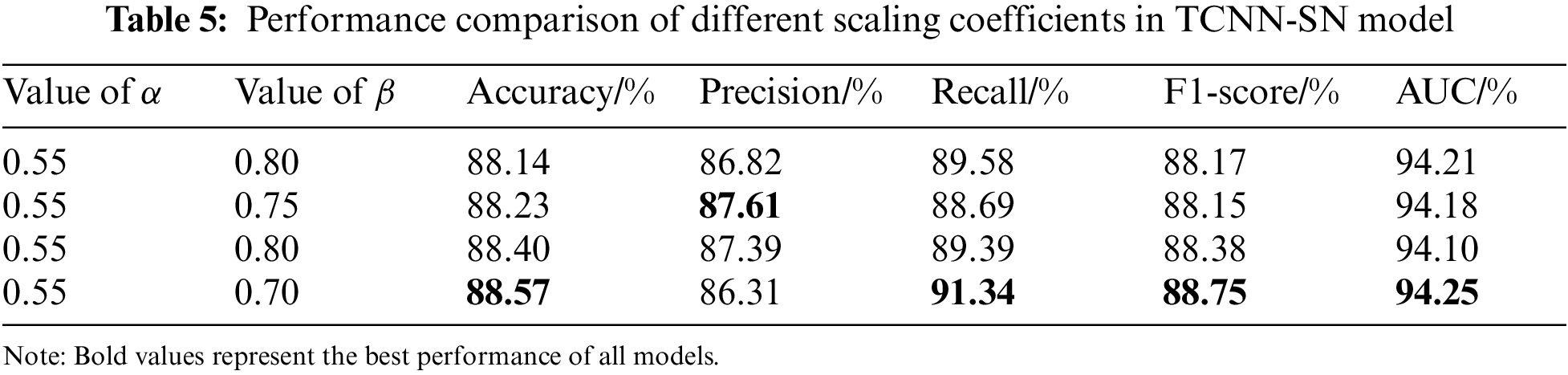
We aim to further enhance the suggested model’s performance after linear weighted fusion. Optimizing our suggested model requires careful consideration of the scaling constants α and β, as discussed in Section 3. We conduct group-by-team testing utilizing the order relation analysis method (G1-method) [61] and achieve four optimal findings, as shown in Table 5. When
We analyze the model’s performance across varying data scales, as depicted in Fig. 7. Evidently, our model achieves optimal performance when trained on 100% of the available data and consistently performs well across different dataset proportions. These results highlight the advantages of utilizing larger training sets.

Figure 7: Influence of our constructed data scale in training, measured in accuracy and F1-score
Suicide remains a leading cause of death worldwide, highlighting the urgent need for early detection and intervention strategies to reduce suicide risk. Our study emphasizes the critical role of social media in identifying signs of suicidal behavior among its users. Unlike other approaches, our analysis focuses on the importance of social network relationships feature alongside user-generated content. Our model adeptly navigates the complexities of social network connections to spot potential signs of suicide risk and predicts individuals and groups at increased risk in an automated and discreet manner.
7.1 Effectiveness Analysis of the Proposed Feature
The empirical assessment in our research indicates a notable improvement in the performance of all six baseline models after integrating our suggested features, as depicted in Figs. 4 and 5. This finding validates the effectiveness of our features, supporting the results of prior studies [15,18].
Several aspects contribute to this success. First, incorporating social network relationships into our model enhances the analysis of user interactions, such as likes and follows, their influence, and the critical latent information embedded within these interactions.
Moreover, our approach accounts for the impact of neighboring nodes on adjacent users. Due to the interconnectedness of social media users and their tendency to share information, especially those in more vulnerable states at higher suicide risk, are significantly influenced by their peers [62].
Finally, our method offers a holistic evaluation of these individuals at high risk, acknowledging their likelihood to form groups or communities [15]. Our model excels at identifying users based on social network behaviors, even without explicit suicide-related content, enabling analysis on both individual and group levels. This capability significantly extends beyond the limitations of traditional methods that rely solely on textual content analysis.
7.2 Contributions and Interactions of Correction Factors
Our hypothesis, which posited that users exhibit various significant correction factors that markedly improve the effectiveness of the extracted features, is corroborated by the experimental data shown in Table 3. The results conclusively demonstrate that all three correction factors critically enhance the model’s performance.
Among these,
Further investigation into the interplay among the correction factors reveals that the combined use of two factors yields superior categorization outcomes compared to employing a single factor alone. This assertion is substantiated by the findings detailed in Lines 5–7 of Table 3. Intriguingly, the model that integrates
7.3 Theoretical Contributions to Research
This study introduces novel insights and perspectives by examining the role of social network relationships characteristics in suicide prevention. First, unlike conventional social network theory, which predominantly concentrates on network structure and the dissemination of influence [63], this paper melds individual mental health considerations with social network theory to scrutinize the influence of social network relationships on users’ suicidal propensities. Traditional theories of suicide prevention largely emphasize individual psychological factors [64]. Conversely, our methodology embraces a collective perspective, facilitating the identification of additional groups and communities at risk through the analysis of social network relationships.
Second, our proposed feature possesses the capability to discern potential social information about users without necessitating the evaluation of textual content for accuracy or authenticity. Algorithms that depend exclusively on explicit expressions of suicidal ideation or a predefined lexicon might yield imprecise outcomes, as users often refrain from disclosing such content [13,65]. Our model is adept at detecting subtle indicators of mental health issues, particularly through social network relationships, thereby acting as a proactive and remedial strategy for potential suicides, especially in contexts where access to medical resources is constrained and there is a lack of nocturnal suicide monitoring.
Third, the dearth of comprehensive datasets, especially those that encapsulate social network relationships among users, is attributed to ethical and privacy considerations in research methodologies [66]. Despite these challenges, we have successfully constructed such a dataset. This dataset bridges a significant void in contemporary research by providing a precious resource of Chinese data.
Fourth, to our knowledge, there exists a limited body of research that employs social network relationships to forecast suicide risk on social media platforms. This investigation stands as the most current within the preceding five years. Our work augments traditional text-based approaches and enables a multi-layered psychosocial examination of individuals, both suicidal and non-suicidal. This approach encourages cross-disciplinary collaboration among computer science, mental health, and social network studies.
7.4 Practicall Contributions to Research
The findings from this and related investigations provide a foundation for developing practical online suicide monitoring systems [38]. These systems facilitate automated and unobtrusive surveillance and analysis of potential signs of communication and behavior indicative of suicidal ideation on social media platforms. Given the critical importance of prompt intervention in suicide prevention, it is imperative to establish crisis intervention protocols for individuals at risk of suicide on social media and to deploy efficacious intervention strategies upon their identification. Such an approach can bolster the efforts of offline rescue organizations, such as the Tree Hole Rescue Group [67], in addressing suicidal crises.
Moreover, inspired by the work of Liang et al. [68], this study could be integrated with the computer and information science community to develop a TD-Crime-like framework for suicide prediction on social media platforms. This approach is particularly pertinent considering that the likelihood of suicide is affected by spatiotemporal factors and the occurrence of missing data.
While the results affirm the notable efficacy of our proposed methodology, several limitations remain. One primary challenge is the integration of data augmentation and multimodal analysis, given the rich diversity of information present in microblogs, such as user-generated images, videos, and geolocation data [69]. Furthermore, the issue of temporal dynamics cannot be overlooked. Our model predominantly concentrates on static network relationships and user behavioral traits, yet the prediction of suicide risk necessitates an analysis of changes in users’ behaviors and moods across various time frames. Additionally, the current paucity of publicly accessible datasets that are compatible with our proposed model, a consequence of ethical and legal considerations, calls for a more thorough assessment of the model’s generalizability and applicability, especially its efficacy across different datasets or scenarios [1,21].
In this study, we introduce a cutting-edge ensemble model based on social network relationships to autonomously predict users’ latent suicidal risk in social media. Our proposed model, named TCNN-SN, transcends mere analysis of textual content by delving into user interactions, thereby facilitating the extraction of social network relationships feature. It adeptly identifies users wielding considerable influence and exhibiting a high risk of suicide, in addition to pinpointing related groups within social networks. Moreover, we integrate three correction factors to enhance the robustness of the feature extraction process. To address the limitations inherent in individual models, particularly their propensity for misclassifying specific samples, we apply a weighted linear fusion technique. This approach also compensates for the model’s reliance on textual data for prediction. Additionally, a novel Chinese suicide dataset, derived from Weibo’s Zoufan Tree Hole and encompassing 1147 users along with their relationships, is meticulously constructed. This dataset emerges as a crucial resource for scholars in psychology and computer science dedicated to suicide risk analysis. Comprehensive experiments conducted on this dataset affirm the superior performance of TCNN-SN over existing baseline models, underscoring its promising utility in suicide risk prediction endeavors.
In future research, we intend to explore the integration of cutting-edge technologies from computing and information science to broaden the model’s utility. Our objective is to refine its predictive capabilities for various related challenges, including the prognosis of depression, anxiety, and anorexia.
Acknowledgement: The authors thank the anonymous reviewers for their valuable comments.
Funding Statement: This research was funded by Outstanding Youth Team Project of Central Universities (QNTD202308).
Author Contributions: The authors confirm contribution to the paper as follows: Study conception and design: X. M., C. W.; data collection: J. Y., M. L., Y. Z., L. W.; analysis and interpretation of results: X. M., C. W.; draft manuscript preparation: X. M. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: Not applicable.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. A. Mbarek, S. Jamoussi, and A. B. Hamadou, “An across online social networks profile building approach: Application to suicidal ideation detection,” Future Gener. Comput. Syst., vol. 133, pp. 171–183, 2022. doi: 10.1016/j.future.2022.03.017. [Google Scholar] [CrossRef]
2. World Health Organization, World Health Statistics 2023: Monitoring Health for the SDGs, Sustainable Development Goals, 2023. Geneva, Switzerland: World Health Organization, Global Report, pp. 121–126. 2023. [Google Scholar]
3. T. H. Aldhyani, S. N. Alsubari, A. S. Alshebami, H. Alkahtani, and Z. A. Ahmed, “Detecting and analyzing suicidal ideation on social media using deep learning and machine learning models,” Int. J. Environ. Res. Public Health, vol. 19, no. 19, pp. 12635, 2022. doi: 10.3390/ijerph191912635. [Google Scholar] [PubMed] [CrossRef]
4. S. K. S. Shah, S. Pandhare, A. Ambapkar, and S. H. Bhandari, “Suicidal thoughts prediction from social media posts using machine learning and deep learning,” Quest J. Electron. Commun. Eng. Res., vol. 8, no. 5, pp. 64–71, 2022. [Google Scholar]
5. Y. Xue, Q. Li, T. Wu, L. Feng, L. Zhao and F. Yu, “Incorporating stress status in suicide detection through microblog,” Comput. Syst. Sci. Eng., vol. 34, no. 2, pp. 65–78, 2019. doi: 10.32604/csse.2019.34.065. [Google Scholar] [CrossRef]
6. Å.U. Lindh et al., “Predicting suicide: A comparison between clinical suicide risk assessment and the suicide intent scale,” J. Affect. Disord., vol. 263, pp. 445–449, 2020. doi: 10.1016/j.jad.2019.11.131. [Google Scholar] [PubMed] [CrossRef]
7. A. L. Calear and P. J. Batterham, “Suicidal ideation disclosure: Patterns, correlates and outcome,” Psychiatry Res., vol. 278, no. 2, pp. 1–6, 2019. doi: 10.1016/j.psychres.2019.05.024. [Google Scholar] [PubMed] [CrossRef]
8. R. Sawhney, H. Joshi, L. Flek, and R. Shah, “Phase: Learning emotional phase-aware representations for suicide ideation detection on social media,” in Proc. 16th Conf. Eur. Chapter Assoc. Comput. Linguist.: Main Volume, Bangkok, Thailand, Apr. 19–23, 2021, pp. 2415–2428. [Google Scholar]
9. D. Dewangan, S. Selot, and S. Panicker, “The accuracy analysis of different machine learning classifiers for detecting suicidal ideation and content,” Asian J. Elect. Sci., vol. 12, no. 1, pp. 46–56, 2023. doi: 10.51983/ajes-2023.12.1.3694. [Google Scholar] [CrossRef]
10. H. Kour and M. K. Gupta, “An hybrid deep learning approach for depression prediction from user tweets using feature-rich CNN and bi-directional LSTM,” Multimed. Tools Appl., vol. 81, no. 17, pp. 23649–23685, 2022. doi: 10.1007/s11042-022-12648-y. [Google Scholar] [PubMed] [CrossRef]
11. Z. Li, W. Cheng, J. Zhou, Z. An, and B. Hu, “Deep learning model with multi-feature fusion and label association for suicide detection,” Multimed. Syst., vol. 29, no. 4, pp. 1–11, 2023. doi: 10.1007/s00530-023-01090-1. [Google Scholar] [CrossRef]
12. N. A. Baghdadi, A. Malki, H. M. Balaha, Y. AbdulAzeem, M. Badawy and M. Elhosseini, “An optimized deep learning approach for suicide detection through Arabic tweets,” PeerJ. Comput. Sci., vol. 8, no. 1, pp. e1070, 2022. doi: 10.7717/peerj-cs.1070. [Google Scholar] [PubMed] [CrossRef]
13. Y. Ophir, R. Tikochinski, C. S. Asterhan, I. Sisso, and R. Reichart, “Deep neural networks detect suicide risk from textual Facebook posts,” Sci. Rep., vol. 10, no. 1, pp. 16685, 2020. doi: 10.1038/s41598-020-73917-0. [Google Scholar] [PubMed] [CrossRef]
14. D. Liu et al., “Suicidal ideation cause extraction from social texts,” IEEE Access, vol. 8, pp. 169333–169351, 2020. doi: 10.1109/ACCESS.2020.3019491. [Google Scholar] [CrossRef]
15. X. Wang, C. Zhang, and L. Sun, “An improved model for depression detection in micro-blog social network,” in 2013 IEEE 13th Int. Conf. Data Min. Workshops, Dallas, TX, USA, Dec. 07–10, 2013, pp. 80–87. [Google Scholar]
16. C. Wang, X. Song, S. Zhu, Z. Zhang, and T. Liu, “An analysis of the theme of a suicide blogger’s comment,” in Chin. Ment. Health J., Beijing, China, vol. 35, no. 2, pp. 121–126, 2021. [Google Scholar]
17. L. Hong, Y. Qian, C. Gong, Y. Zhang, and X. Zhou, “Improved key node recognition method of social network based on pagerank algorithm,” Comput. Mater. Contin., vol. 74, no. 1, pp. 1887–1903, 2023. doi: 10.32604/cmc.2023.029180. [Google Scholar] [CrossRef]
18. G. Shen et al., “Depression detection via harvesting social media: A multimodal dictionary learning solution,” in 26th Int. Joint Conf. Artif. Intell., Melbourne, Australia, 2017, pp. 3838–3844. [Google Scholar]
19. K. Valeriano, A. Condori-Larico, and J. Sulla-Torres, “Detection of suicidal intent in Spanish language social networks using machine learning,” Int. J. Adv. Comput. Sci. Appl., vol. 11, no. 4, pp. 688–695, 2020. doi: 10.14569/issn.2156-5570. [Google Scholar] [CrossRef]
20. F. M. Shah, F. Haque, R. U. Nur, S. Al Jahan, and Z. Mamud, “A hybridized feature extraction approach to suicidal ideation detection from social media post,” in 2020 IEEE Region 10 Symp. (TENSYMP), Dhaka, Bangladesh, Jun. 05–07, 2020, pp. 985–988. [Google Scholar]
21. T. Shen et al., “Cross-domain depression detection via harvesting social media,” in 27th Int. Joint Conf. Artif. Intell., Stockholm, Sweden, 2018, pp. 1611–1617. [Google Scholar]
22. Z. Huang, Y. Min, F. Lin, and D. Xie, “Time characteristics of suicide information in social media,” China Digital Med., vol. 14, pp. 7–10, 2019. [Google Scholar]
23. S. T. Rabani, Q. R. Khan, and A. M. U. D. Khanday, “Detection of suicidal ideation on Twitter using machine learning & ensemble approaches,” Baghdad Sci. J., vol. 17, no. 4, pp. 1328, 2020. doi: 10.21123/bsj.2020.17.4.1328. [Google Scholar] [CrossRef]
24. G. Coppersmith, K. Ngo, R. Leary, and A. Wood, “Exploratory analysis of social media prior to a suicide attempt,” in Proc. Third Workshop Comput. Linguist. Clin. Psychol., San Diego, CA, USA, Jun. 16, 2016, pp. 106–117. [Google Scholar]
25. Y. Ma and Y. Cao, “Dual attention based suicide risk detection on social media,” in 2020 IEEE Int. Conf. Artif. Intell. Comput. Appl. (ICAICA), Dalian, China, IEEE, Jun. 27–29, 2020, pp. 637–640. [Google Scholar]
26. G. M. Lin, M. Nagamine, S. N. Yang, Y. M. Tai, C. Lin, and H. Sato, “Machine learning based suicide ideation prediction for military personnel,” IEEE J. Biomed. Health Inform., vol. 24, no. 7, pp. 1907–1916, 2020. doi: 10.1109/JBHI.2020.2988393. [Google Scholar] [PubMed] [CrossRef]
27. M. Hiraga, “Predicting depression for Japanese blog text,” in Proc. ACL 2017, Stud. Res. Workshop, Vancouver, Canada, 2017, pp. 107–113. [Google Scholar]
28. W. Santos, A. Funabashi, and I. Paraboni, “Searching Brazilian Twitter for signs of mental health issues,” in Proc. 12th Lang. Resour. Eval. Conf., Marseille, France, May 11–16, 2020, pp. 6111–6117. [Google Scholar]
29. H. Moradian, M. A. Lau, A. Miki, E. D. Klonsky, and A. L. Chapman, “Identifying suicide ideation in mental health application posts: A random forest algorithm,” Death Stud., vol. 47, no. 9, pp. 1044–1052, 2023. doi: 10.1080/07481187.2022.2160519. [Google Scholar] [PubMed] [CrossRef]
30. M. M. Tadesse, H. Lin, B. Xu, and L. Yang, “Detection of suicide ideation in social media forums using deep learning,” Algorithms, vol. 13, no. 1, pp. 7, 2019. doi: 10.3390/a13010007. [Google Scholar] [CrossRef]
31. R. Punithavathi, S. Thenmozhi, R. Jothilakshmi, V. Ellappan, and I. M. T. Ul, “Suicide ideation detection of covid patients using machine learning algorithm,” Comput. Syst. Sci. Eng., vol. 45, no. 1, pp. 247–261, 2023. doi: 10.32604/csse.2023.025972. [Google Scholar] [CrossRef]
32. A. M. Almars, “Attention-based Bi-LSTM model for arabic depression classification,” Comput. Mater. Contin., vol. 71, no. 2, pp. 3091–3106, 2022. doi: 10.32604/cmc.2022.022609. [Google Scholar] [CrossRef]
33. H. Zogan, I. Razzak, S. Jameel, and G. Xu, “DepressionNet: A novel summarization boosted deep framework for depression detection on social media,” arXiv preprint arXiv:2105.10878, 2021. [Google Scholar]
34. Y. Kim, “Convolutional neural networks for sentence classification,” arXiv preprint arXiv:1408.5882, 2014. [Google Scholar]
35. X. Zhao, “Research of depression recognition based on micro-blog text and deep learning,” M.S. thesis, Beijing Univ. Technol., China, 2019. [Google Scholar]
36. H. Miao, “Research of depression recognition method based on micro-blog,” M.S. thesis, Beijing Univ. Technol., China, 2020. [Google Scholar]
37. H. Ghanadian, I. Nejadgholi, and H. A. Osman, “ChatGPT for suicide risk assessment on social media: Quantitative evaluation of model performance,” arXiv preprint arXiv:2306.09390, 2023. [Google Scholar]
38. B. X. Yang et al., “A suicide monitoring and crisis intervention strategy based on knowledge graph technology for “tree hole microblog users in China,” Front. Psychol., vol. 12, pp. 674481, 2021. doi: 10.3389/fpsyg.2021.674481. [Google Scholar] [CrossRef]
39. S. Renjith, A. Abraham, S. B. Jyothi, L. Chandran, and J. Thomson, “An ensemble deep learning technique for detecting suicidal ideation from posts in social media platforms,” J. King Saud Univ.-Comput. Inf. Sci., vol. 34, no. 10, pp. 9564–9575, 2022. doi: 10.1016/j.jksuci.2021.11.010. [Google Scholar] [CrossRef]
40. B. Priyamvada et al., “Stacked CNN-LSTM approach for prediction of suicidal ideation on social media,” Multimed. Tools Appl., vol. 82, no. 18, pp. 1–22, 2023. doi: 10.1007/s11042-023-14431-z. [Google Scholar] [CrossRef]
41. S. Ji, X. Li, Z. Huang, and E. Cambria, “Suicidal ideation and mental disorder detection with attentive relation networks,” Neural Comput. Appl., vol. 34, no. 13, pp. 10309–10319, 2022. doi: 10.1007/s00521-021-06208-y. [Google Scholar] [CrossRef]
42. P. Lahoti, G. de Francisci Morales, and A. Gionis, “Finding topical experts in Twitter via query-dependent personalized PageRank,” in Proc. 2017 IEEE/ACM Int. Conf. Adv. Social Netw. Anal. Min., Sydney, Australia, 2017, pp. 155–162. [Google Scholar]
43. S. Priyanta, I. N. P. Trisna, and N. Prayana, “Social network analysis of Twitter to identify issuer of topic using pagerank,” Int. J. Adv. Comput. Sci. Appl., vol. 10, no. 1, pp. 107–111, 2019. doi: 10.14569/issn.2156-5570. [Google Scholar] [CrossRef]
44. W. Liu, M. Zhang, and D. Zhang, “User influence analysis algorithm for Weibo topics,” J. Comput. Appl., vol. 39, no. 1, pp. 213, 2019. [Google Scholar]
45. Y. Jiang, S. Deng, H. Li, and Y. Liu, “Predicting user personality with social interactions in Weibo,” Aslib J. Inf. Manag., vol. 73, no. 6, pp. 839–864, 2021. doi: 10.1108/AJIM-02-2021-0048. [Google Scholar] [CrossRef]
46. W. Ye, Z. Liu, and L. Pan, “Who are the celebrities? Identifying vital users on Sina Weibo microblogging network,” Knowl.-Based Syst., vol. 231, pp. 107438, 2021. [Google Scholar]
47. X. Wei, Y. Zhang, Y. Fan, and G. Nie, “Online social network information dissemination integrating overconfidence and evolutionary game theory,” IEEE Access, vol. 9, pp. 90061–90074, 2021. [Google Scholar]
48. S. Al-Yazidi, J. Berri, M. Al-Qurishi, and M. Al-Alrubaian, “Measuring reputation and influence in online social networks: A systematic literature review,” IEEE Access, vol. 8, pp. 105824–105851, 2020. [Google Scholar]
49. X. Wang and G. Sukthankar, “Multi-label relational neighbor classification using social context features,” in Proc. 19th ACM SIGKDD Int. Conf. Knowl. Discov. Data Min., New York, NY, USA, Aug. 2013, pp. 464–472. [Google Scholar]
50. M. Lv, A. Li, T. Liu, and T. Zhu, “Creating a Chinese suicide dictionary for identifying suicide risk on social media,” PeerJ, vol. 3, pp. e1455, 2015. [Google Scholar] [PubMed]
51. J. A. Fulcher, S. Dunbar, E. Orlando, S. J. Woodruff, and S. Santarossa, “#selfharn on Instagram: Understanding online communities surrounding non-suicidal self-injury through conversations and common properties among authors,” Digit. Health, vol. 6, 2020. doi: 10.1177/2055207620922389. [Google Scholar] [PubMed] [CrossRef]
52. O. V. Prikhodko et al., “Ways of expressing emotions in social networks: Essential features, problems and features of manifestation in internet communication,” Online J. Commun. Media Technol., vol. 10, no. 2, pp. e202010, 2020. doi: 10.29333/ojcmt/7931. [Google Scholar] [CrossRef]
53. Y. Zhang, Y. Lu, Y. Jin, and Y. Wang, “Individualizing mental health responsibilities on Sina Weibo: A content analysis of depression framing by media organizations and mental health institutions,” J. Commun. Healthc., vol. 14, no. 2, pp. 163–175, 2021. doi: 10.1080/17538068.2020.1858220. [Google Scholar] [CrossRef]
54. X. Liu et al., “Proactive suicide prevention online (PSPOMachine identification and crisis management for Chinese social media users with suicidal thoughts and behaviors,” J. Med. Internet Res., vol. 21, no. 5, pp. e11705, 2019. doi: 10.2196/11705. [Google Scholar] [PubMed] [CrossRef]
55. A. M. Memon, S. G. Sharma, S. S. Mohite, and S. Jain, “The role of online social networking on deliberate self-harm and suicidality in adolescents: A systematized review of literature,” Indian J. Psychiatry, vol. 60, no. 4, pp. 384, 2018. doi: 10.4103/psychiatry.IndianJPsychiatry_414_17. [Google Scholar] [PubMed] [CrossRef]
56. P. Li and Q. Zhuo, “Emotional straying: Flux and management of women’s emotions in social media,” PLoS One, vol. 18, no. 12, pp. e0295835, 2023. doi: 10.1371/journal.pone.0295835. [Google Scholar] [PubMed] [CrossRef]
57. Q. Liu, Z. Shao, J. Tang, and W. Fan, “Examining the influential factors for continued social media use: A comparison of social networking and microblogging,” Ind. Manag. Data Syst., vol. 119, no. 5, pp. 1104–1127, 2019. doi: 10.1108/IMDS-05-2018-0221. [Google Scholar] [CrossRef]
58. S. Majeed, M. Uzair, U. Qamar, and A. Farooq, “Social network analysis visualization tools: A comparative review,” in 2020 IEEE 23rd Int. Multitopic Conf. (INMIC), Bahawalpur, Pakistan, IEEE, Nov. 05–07, 2020, pp. 1–6. [Google Scholar]
59. Z. Yang, D. Yang, C. Dyer, X. He, A. Smola and E. Hovy, “Hierarchical attention networks for document classification,” in Proc. 2016 Conf. N. Am. Chapter Assoc. Comput. Linguist.: Hum. Lang. Technol., San Diego, California, USA, Jun. 12–17, 2016, pp. 1480–1489. [Google Scholar]
60. S. Lyu and J. Liu, “Convolutional recurrent neural networks for text classification,” J. Database Manag. (JDM), vol. 32, no. 4, pp. 65–82, 2021. doi: 10.4018/JDM.2021100105. [Google Scholar] [CrossRef]
61. J. Y. Tong and G. Srivastava, “A decision-making method of intelligent distance online education based on cloud computing,” Mob. Netw. Appl., vol. 27, no. 3, pp. 1151–1161, 2022. doi: 10.1007/s11036-022-01945-3. [Google Scholar] [CrossRef]
62. I. Himelboim, X. Xiao, D. K. L. Lee, M. Y. Wang, and P. Borah, “A social networks approach to understanding vaccine conversations on Twitter: Network clusters, sentiment, and certainty in HPV social networks,” Health Commun., vol. 35, no. 5, pp. 607–615, 2020. doi: 10.1080/10410236.2019.1573446. [Google Scholar] [PubMed] [CrossRef]
63. W. Chen, C. Castillo, and L. V. Lakshmanan, Information and Influence Propagation in Social Networks. Springer Nature, 2022. [Google Scholar]
64. N. Kapur and R. D. Goldney, Suicide Prevention. Oxford University Press, Glasgow, Great Britain, 2019. [Google Scholar]
65. Y. Ophir, C. S. Asterhan, and B. B. Schwarz, “The digital footprints of adolescent depression, social rejection and victimization of bullying on Facebook,” Comput. Human Behav., vol. 91, no. 2, pp. 62–71, 2019. doi: 10.1016/j.chb.2018.09.025. [Google Scholar] [CrossRef]
66. J. S. L. Figuerêdo, A. L. L. Maia, and R. T. Calumby, “Early depression detection in social media based on deep learning and underlying emotions,” Online Soc. Netw. Media, vol. 31, no. 1, pp. 100225, 2022. doi: 10.1016/j.osnem.2022.100225. [Google Scholar] [CrossRef]
67. F. Wang and Y. Li, “An auto question answering system for tree hole rescue,” in Health Inform. Sci.: 9th Int. Conf., Amsterdam, The Netherlands, Oct. 20–23, 2020, pp. 15–24. [Google Scholar]
68. W. Liang et al., “Crime prediction with missing data via spatiotemporal regularized tensor decomposition,” IEEE Trans. Big Data, vol. 9, no. 5, pp. 1392–1407, 2023. doi: 10.1109/TBDATA.2023.3283098. [Google Scholar] [CrossRef]
69. T. Gui et al., “Cooperative multimodal approach to depression detection in Twitter,” in Proc. AAAI Conf. Artif. Intell., Honolulu, Hawaii, USA, Jan. 27–Feb. 01, 2019, vol. 33, no. 1, pp. 110–117. doi: 10.1609/aaai.v33i01.3301110. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools