
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Image Fusion Using Wavelet Transformation and XGboost Algorithm
1 Department of Information Sciences, Division of S & T, University of Education, Lahore, 54770, Pakistan
2 Artificial Intelligence and Data Analytics (AIDA) Lab, CCIS Prince Sultan University, Riyadh, 11586, Saudi Arabia
3 Faculty of Information Sciences, University of Education, Vehari Campus, Vehari, 61100, Pakistan
4 Department of Computer Science, University of Engineering and Technology, Taxila, 47050, Pakistan
5 Department of Mathematical Sciences, College of Science, Princess Nourah Bint Abdulrahman University, Riyadh, 84428, Saudi Arabia
* Corresponding Author: Faten S. Alamri. Email:
(This article belongs to the Special Issue: Advanced Artificial Intelligence and Machine Learning Frameworks for Signal and Image Processing Applications)
Computers, Materials & Continua 2024, 79(1), 801-817. https://doi.org/10.32604/cmc.2024.047623
Received 11 November 2023; Accepted 19 February 2024; Issue published 25 April 2024
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Recently, there have been several uses for digital image processing. Image fusion has become a prominent application in the domain of imaging processing. To create one final image that proves more informative and helpful compared to the original input images, image fusion merges two or more initial images of the same item. Image fusion aims to produce, enhance, and transform significant elements of the source images into combined images for the sake of human visual perception. Image fusion is commonly employed for feature extraction in smart robots, clinical imaging, audiovisual camera integration, manufacturing process monitoring, electronic circuit design, advanced device diagnostics, and intelligent assembly line robots, with image quality varying depending on application. The research paper presents various methods for merging images in spatial and frequency domains, including a blend of stable and curvelet transformations, everage Max-Min, weighted principal component analysis (PCA), HIS (Hue, Intensity, Saturation), wavelet transform, discrete cosine transform (DCT), dual-tree Complex Wavelet Transform (CWT), and multiple wavelet transform. Image fusion methods integrate data from several source images of an identical target, thereby enhancing information in an extremely efficient manner. More precisely, in imaging techniques, the depth of field constraint precludes images from focusing on every object, leading to the exclusion of certain characteristics. To tackle thess challanges, a very efficient multi-focus wavelet decomposition and recomposition method is proposed. The use of these wavelet decomposition and recomposition techniques enables this method to make use of existing optimized wavelet code and filter choice. The simulated outcomes provide evidence that the suggested approach initially extracts particular characteristics from images in order to accurately reflect the level of clarity portrayed in the original images. This study enhances the performance of the eXtreme Gradient Boosting (XGBoost) algorithm in detecting brain malignancies with greater precision through the integration of computational image analysis and feature selection. The performance of images is improved by segmenting them employing the K-Means algorithm. The segmentation method aids in identifying specific regions of interest, using Particle Swarm Optimization (PCA) for trait selection and XGBoost for data classification. Extensive trials confirm the model’s exceptional visual performance, achieving an accuracy of up to 97.067% and providing good objective indicators.Keywords
Image fusion is a new field that uses multiple sensors to create an educational image for medical diagnosis and decision-making [1]. Image Fusion reads several remotely sensed images of the identical scenario, some with rich spectral information and others with high geometric resolution. Image Fusion then extracts the most important information from these two types of images or protests to create one image [2,3]. This method of image fusion consistently yields more data than any information image, improving knowledge quality and materiality. The latest image-capturing technology lets us extract a lot of information from an image. “Image fusion” can combine this data for a more informative image. Recent advances in image-capturing technology allow us to extract many data points from an image. Use “image fusion” to combine all this data for a more insightful image [4,5]. Image fusion uses improved image processing to combine multiple source images. No single fusion method works for all applications. Image fusion algorithms are categorized into multi-view, multi-temporal, multi-focus, and multimodal based on input data and purpose. Table 1 shows the image fusion methods’ pros and cons [4].

This study proposed a wavelet transform-based image fusion approach to increase image geometric resolution. Two input images are first divided into smaller images with similar tenacity at similar stages and different tenacities at different stages. High-frequency sub-images are then used for information fusion, and a highly detailed result image is created by reconstructing these sub-mages. Since high-frequency information determines image symmetrical resolution, this image fusion algorithm can produce good results [6,7]. Usually, an eyewitness sets the fused image’s quality. This article evaluates image fusion using brain image spatial and spectral datasets from Computed Tomography (CT) and Magnetic Resonance Imaging (MRI). CT is utilized to obtain high-resolution, detailed images of bone structures, while MRI is used to visualize components of the brain and soft tissue. These methods improve accuracy and medical applicability with image fusion. After that, image fusion quality is usually assessed visually. Early image fusion research seemed to benefit from the knowledge of the human visual system (HVS) [8]. Digital visual media is a smarter and more efficient way to model, analyze, process, and transmit visual information, but it cannot handle complex scene analysis, processing, and abstraction like HVS Enhancing, segmenting, and coding images using human visual perception is common. Image quality assessment is used to evaluate visual information processing techniques. The HVS’s () edge detection mechanism in color perception is exploited in isotropic diffusion-based visual perception techniques. Images are processed at a perceptually uninformed color pace [6]. An image quality measure related to how the visible social structure surveys image attachment could be found. Many attempts have been made to determine reasonable distortion estimates based on human visual framework models, resulting in a massive cluster of applicant image quality proportions. Despite these studies, a precise visual model and twisting measure have not been found because visual observation is still unknown [9]. Image fusion combines two or more symbolisms or images into a performance image with the unique structures and geologies of each [10].
Image fusion reduces irrelevant data in digital images and creates images that are more understandable for humans and machines. Image fusion evaluates information at each pixel location in digital images and retrains it to best represent the scene content or improve the fused image’s utility. Image fusion is employed in smart robots, medical imaging, industrial process monitoring, electrical circuit architecture, and testing. Medical imaging relies on image fusion to integrate data from CT, MRI, Single Photon Emission Computed Tomography (SPECT), and Positron Emission Tomography (PET) modalities, resulting in enhanced images that aid in diagnosis and treatment. Intelligent robots control motion using image fusion and sensor feedback [9]. Image fusion is commonly used in clinical settings. Clinical images from similar methods or modalities like CT, MRI, SPECT, and PET can be combined to create a more useful image for diagnosis and treatment [11,12]. Remote detection, clinical imaging, military, and space science use image fusion. Image fusion enhances data by combining at least two images. By integrating satellite, aerial, and ground-based imagery with different informational indexes, image fusion policies improve item support framework presentation [13,14]. Fig. 1 depicts image fusion manufacturing. Medical imaging’s gold standard is precise clinical recognition employing segmentation to unveil intricate patterns. Radiologists can assess tumor increase interpretation risk with the proposed algorithm. This method can accurately predict material ablation, preserve critical structures, and mitigate the temperature beyond the harm threshold. Successful cancer treatment requires early detection and localization. This method is generalizable because brain tumor images require little preparation. This study shows how feature selection and image segmentation can improve XGBoost for brain tumor diagnosis [12].

Figure 1: Image fusion manufacturing process
Fig. 1 shows the process of extracting images from different sources and in the pre-process stage, it decomposes each image and extracts relevant image edges, it converts the image edges into fused images using the wavelet transformation technique and combining the fused edges. Image Fusion examines work that began with spatial area image combination systems, for example, writing audits on various spatial and recurrence spaces. Image combination blend techniques, for example, Simple ordinary, Max-Min, Weighted, PCA, HIS, wavelet transform, DCT double tree Discrete wavelet change (DWT), numerous wavelet change DWT, and combination of curvelet and stationary change. The Fusion of the Image is frequently required to mix photographs that are fixed from the tool. Perceptually important highlights have been joined using sophisticated Wavelet-based combining techniques. The complicated doubletree wavelet change-based narrative image combining system is currently being introduced. DWT and Doubletree CWT are extensions of each other, etc. [15,16]. Some Image Fusion Technique views in this paper as depicted in Fig. 2.
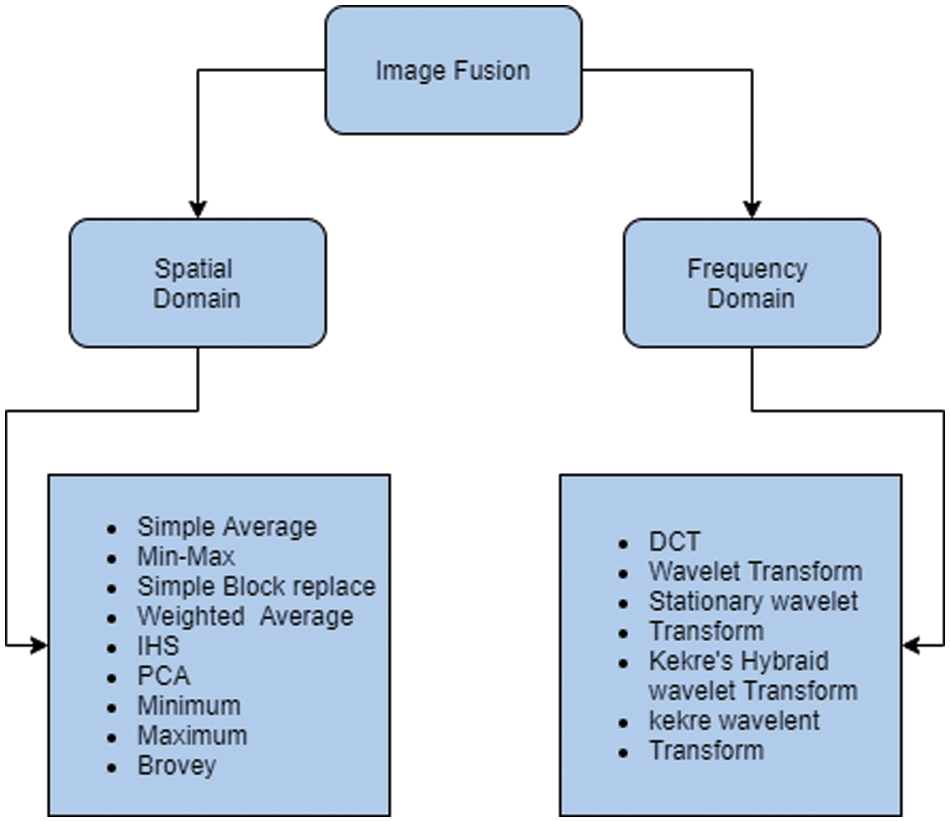
Figure 2: Stepwise representation of the image fusion process
When all is said in done, Fusion systems can be required into various levels. They are signal level, pixel/information level, Featured level, and decision level [17].
Signals from numerous sensors are combined in the signal-based mix approach to generate a novel signal characterized by an improved signal-to-noise ratio compared to the original signals.
Combination is the process of combining unprocessed data from numerous sources to create single informational objectives that are thought to be more designed and helpful than either the information or the progressions between informational indexes acquired at various times.
Combinations extract multiple information sources’ highlights, such as edges, corners, lines, surface attributes, and so on. Thereafter, they combine them into at least one component map that could be used for extra handling rather than the initial data. It served as a contribution to the preparation for image division or location modification.
Combination combines the outcomes of diverse computations to get a conclusive, entangled decision. Soft Fusion is the practice of communicating the results of numerous calculations as confidences rather than options [18].
Jadhav has worked on Image fusion assumes a significant job. Using only the most salient details from each image, image fusion combines at least two photographs into a single image. Each time images are obtained from the machine; an image fusion is frequently necessary to combine the images. To combine perceptually important highlights, complex wavelet-based combination algorithms have been used. A story Image fusion strategy dependent on doubletree complex wavelet change is introduced right now. Doubletree CWT is an increase in DWT. The suggested combination approach capitalizes on the limitations of the Discrete Wavelet Transform by implementing the Q-move DT-CWT. Additionally, it eliminates the distracting artifacts seen in the Fusion Image by assigning adequate weighting schemes to high-pass wavelet coefficients and low-pass coefficients separately [19–22]. Image fusion is employed to retrive vital information from several input images and combine it into a single output image, enhancing its utility and efficacy compared to any of the input images. It enhances the level and practicality of information. The application defines the visual appearance of the integrated view. Image fusion is extensively used in several fields such as intelligent robotics, audiovisual systems, medical imaging, quality control in manufacturing, analysis of electrical circuitry, diagnostics of complex machinery and devices, and automation in assembly line robots. This paper provides a written assessment of many spatial and image-combining techniques, including averaging, min-max, square replacement, HIS, PCA, bravery, pyramid-based, and change-based methods. To undertake a quantitative correlation of these methodologies, various quality metrics have been discussed [23,24]. In quantitative analysis, the output image is examined in terms of spatial and spectral details. The quantitative analysis approach evaluates the quality of the combined output image by using established quality factors to analyze both spatial and spectral similarity between the combined output image and the source input images. In Table 2, different metrics used for quantitative analysis and their description is shown [18].

Image fusion on the whole with its classification dependent on its modal frameworks and calculations. The study explained that extensive work had been done in the space of image combination, yet, there is a vast potential for novel and innovative research at present. The study has also shown that each calculation currently has its distinct attributes and limitations. An analyst might see that there is no superior image-combining strategy compared to others. The effectiveness and suitability of a particular technique depend on how it is used. As per the search view, it very well may be reasoned that PCA-based image combination methods bring about a superior upgraded image without changing the spatial and spectral subtleties of the image. Applications that need separate RGB segment estimations may use wavelet-based methods. Wavelet-based methods reduce visual distortion. With initial tone changes, the image was more defined. Lighter portions were brighter and darkish areas were less apparent in the final image.
Clinical findings and treatment and the image require a progressively correct model with much more elegance and data for the right clinical determination. Radiological imaging modalities, utilization, applications, and watched focal points and challenges of every methodology are introduced to give a far-reaching perspective on clinical imaging modalities. This leads to the suggestion of half-breed imaging mixtures for improved image representation of diverse human organs [25,26]. The fusion process in contemporary image fusion methods involves analyzing the issues and future trends that develop in sectors such as surveillance, photography, medical diagnostics, and remote sensing. Besides that, various challenges, and shortcomings of image fusion techniques like [21]:
• In the case of computing efficiency, an effective algorithm might combine the information of novel images to generate the final resulting image.
• In imperfect environmental conditions, the main challenge is acquiring images that may have issues like under-exposure and noise due to weather and lighting conditions.
In the future, it will be possible to effectively analyze and comprehend images by using Machine Learning (ML) techniques. The advancement in neural networks has facilitated the ability to identify objects, recognize patterns, and perform complex analyses on images with a surprising degree of accuracy. Seeking to achieve increasing precision is essential in domains such as medicine, where accurate diagnosis may profoundly affect the lives of patients. By using machine learning approaches and algorithms in image processing, it becomes possible to automate tasks that were previously done by hand. Machine learning techniques provide efficient and accurate identification of defects, eliminating the need for manual examination. As a result, there is an improvement in process efficiency, a decrease in errors caused by human factors, and a reduction in expenses [22].
Medical images integrate both precise spatial and detailed anatomical information into a single image. The integration of many clinical image modalities results in a significant enhancement in the quality of the fused image. Image fusion is the process of combining several information images to generate a single output image that provides the most accurate depiction of the scene compared to any of the individual information images. High-level panchromatic and multispectral image fusion objectives are required. To improve vision, use the model or authentic world image. Various methodologies exist for image fusion, including IHS, PCA, DWT, Laplacian pyramids, Gradient Pyramids, DCT, and SF. Image fusion merges informational images while excluding valuable data to get the final image. The Fuzzy Interference framework is used by the Fuzzy Pet Fusion Algorithm to combine images. This paradigm combines the advantages of both SWT and fuzzy reasoning, resulting in exceptional outcomes. In addition, it offers a high PSNR rating and a low RMSE. These qualities are preferable to those that arise from the uncontrolled use of SWT and Fuzzy bases. Consequently, it may be used in many applications within the field of image processing [27,28].
To best achieve the objective purpose of the paper, a Systematic Literature Review (SLR) was made, keeping the principles set up by Kitchenham et al. [29]. This unique duplicate worked through the methods, which included arranging the review, driving the assessment, and uncovering the examination. The ways appear which show the sub-assignments done in the organizing, coordinating, and revealing of the stage shown in Fig. 3.
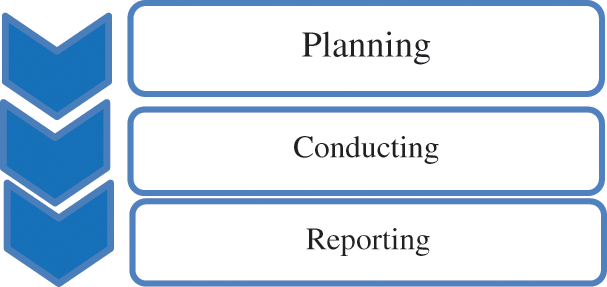
Figure 3: Steps of creating SLR
The Planning stage focused on choosing the purpose that delayed the review. Likewise, it expressly examined why such an examination is vital. What questions need to be replied to? Additionally, which databases would be given to vast past considers? This examination expects to find the different image fusion procedures, the calculations used, and the classifiers acquired. The accompanying inquiries are prepared to reply right now.
As the review focused on getting the fundamental essence of the field, an investigation was done in the chosen past papers. In the main stage, we carefully accumulated wellsprings of information to be used by going them through a predefined measure. These are done in the following steps as shown in Fig. 4.
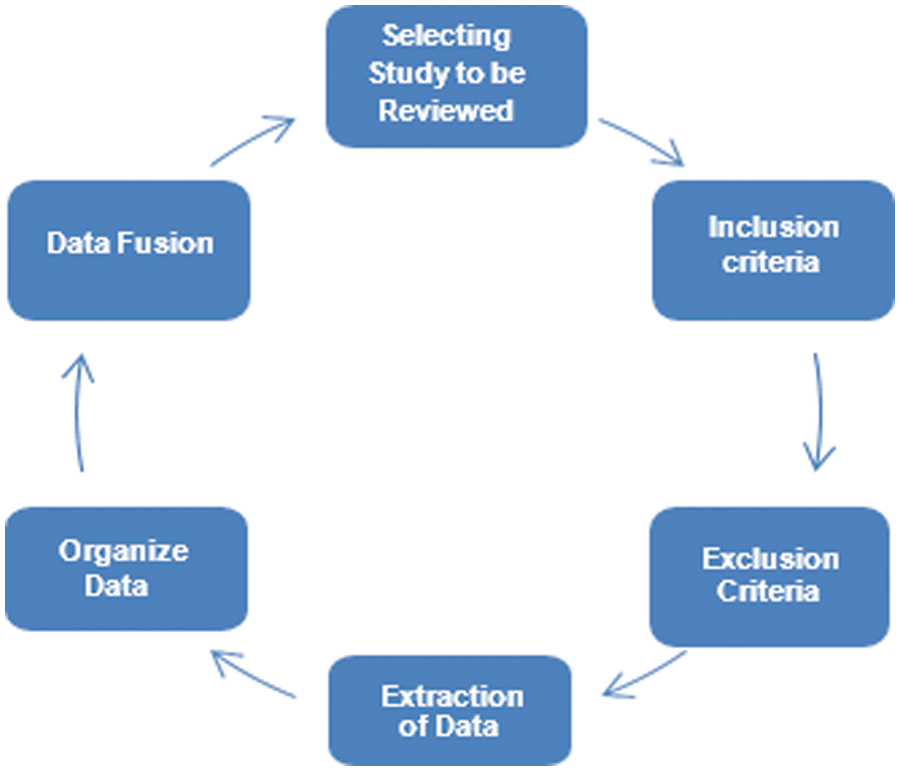
Figure 4: Predefined measures
The report is created of the removed data as displayed by the gained reactions to the examination questions; different strategies were separated and inspected. From this time forward, the accounting procedure is used to explain the information. Moreover, tables, plots, and proper graphs included imagining the findings. The papers were circulated according to their substance and significance with each question to gain fitting reactions. The suitable responses are gathered and figured as a report. All in all, the report studied for any slips or damage.
Image fusion is the amalgam of multiple images to create a single image that captures the most essential features from each of the original images shown in Fig. 5. The combination is required to intertwine images caught from the various instruments, which might be multi-sensor, multi-center, and multi-modular images. Combination strategies incorporate from the least complicated strategy for pixel averaging to progressively confounded techniques, for example, head part investigation and wavelet change combination. There are numerous strategies to intertwine images and can be grouped, contingent upon whether the image to combined in the spatial space or the recurrence area. The evaluation of the fused images’ quality often relies on the specific field of application. The issue of spatial enhancement is crucial in remote sensing. Its objective is to combine image data with varying spatial resolutions by creating synthetic images at a higher spatial resolution from lower-quality data. Specifically, the DWT has lately been used to merge remote sensing data. To prevent the occurrence of ringing artifacts, it is advisable to use brief decomposition/reconstruction filters in a wavelet-based fusion scheme. However, it is important to consider the issues that arise from inadequate frequency selectivity caused by very short filters. The critically-sampled multi-resolution analysis fails to maintain translation invariance.
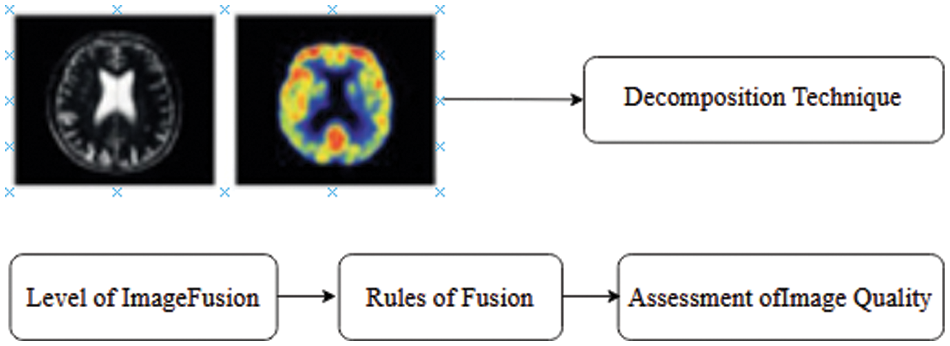
Figure 5: Stages of image fusion
To defeat defects of DWT, Kingsbury presented the DTCWT comprising two trees of specific esteemed wavelet channels that work equally, with the channels intended to deliver the genuine and fanciful pieces of the complex-esteemed coefficients [30]. This study extends it to higher measurements. The image-preparing innovation has become massively both as far as applications and prerequisites it needs. The image combination conspires to confront the issue of intertwining images obtained from various modalities, to meld shading images, to meld images of multiple goals, sizes, and photographs of different organizations, to make strange (un-genuine) images. To support contours in the images that must be remembered for the intertwined calculation to limit the impact of protest. One of the most supportive wavelets change to conquer every one of these issues is the DT-CWT. DT-CWT strategy can hold edge data without massive ringing relics. It is additionally acceptable to keep surfaces from the information images. Every one of these highlights adds to the expanded move invariance and direction selectivity of the DT-CWT [31].
Fused images are collected through various modalities, continuous or higher quality images shown in Fig. 6. The essential thought is to decay every image into sub-images utilizing complex wavelet change. Data combination is computed dependent on nitty-gritty coefficients of sub-images and coming about the images obtained using reverse double tree wavelet change. The proposed conspire depends on the ‘slope’ foundation [32].
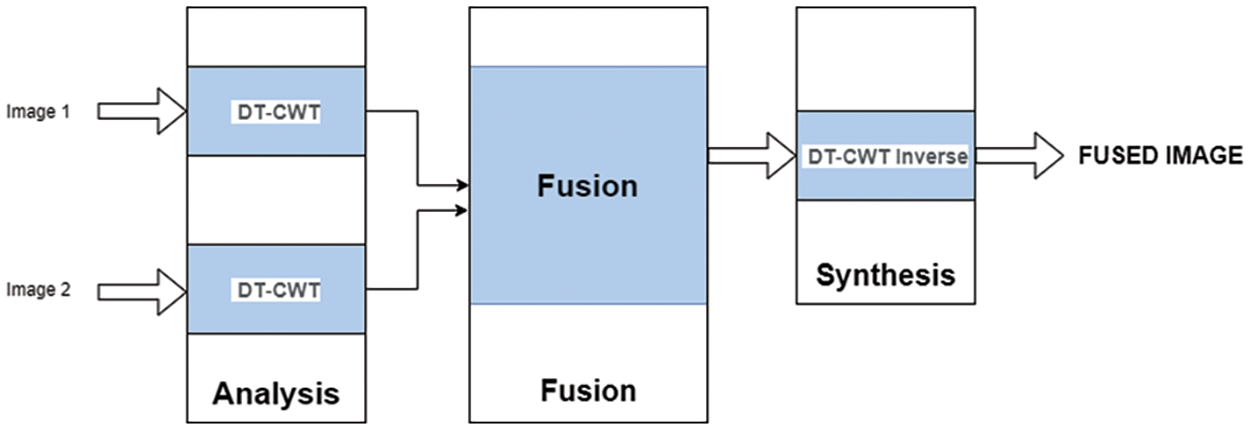
Figure 6: Image fusion algorithm

5.3 Image Fusion Using Wavelet Transformation
Due to the considerable differences in neighboring pixel power values, bio-orthogonal wavelets are frequently used in image processing to identify and channel white Gaussian noise. On the two-dimensional image, a wavelet alteration was made [33,34]. The steps to perform Image fusion are as follows:
• Step through Examination Images.
• Perform Dual-Tree CWT to every one-off test.
• Establish the degree of degradation (This study proposes a 6-level scale of disintegration).
• Join the mind-boggling wavelet coefficients (Magnitudes).
• Implementing converse Dual-Tree CWT (Reconstruction).
• Producing Final intertwined images.
• A crisp image with well-defined edges is obtained by the slope method.
5.4 Experimental Results Obtained Using Wavelet Transformation
After learning the idea of DT-CWT, the following stage was to execute it. To achieve this task, this study employs the C language. The implementation of this function was done using MATLAB. The rule-based inclination combination in the Dual-Tree Complex Wavelet area has been conducted utilizing different images from a benchmark database or static images. The heartiness of the suggested combination procedure is confirmed conclusively with specific images shown in Fig. 7a, for example, multi-sensor images, multispectral remote detecting images, and clinical images, CT, MR images, Surreal images [34] using the algorithm given below:
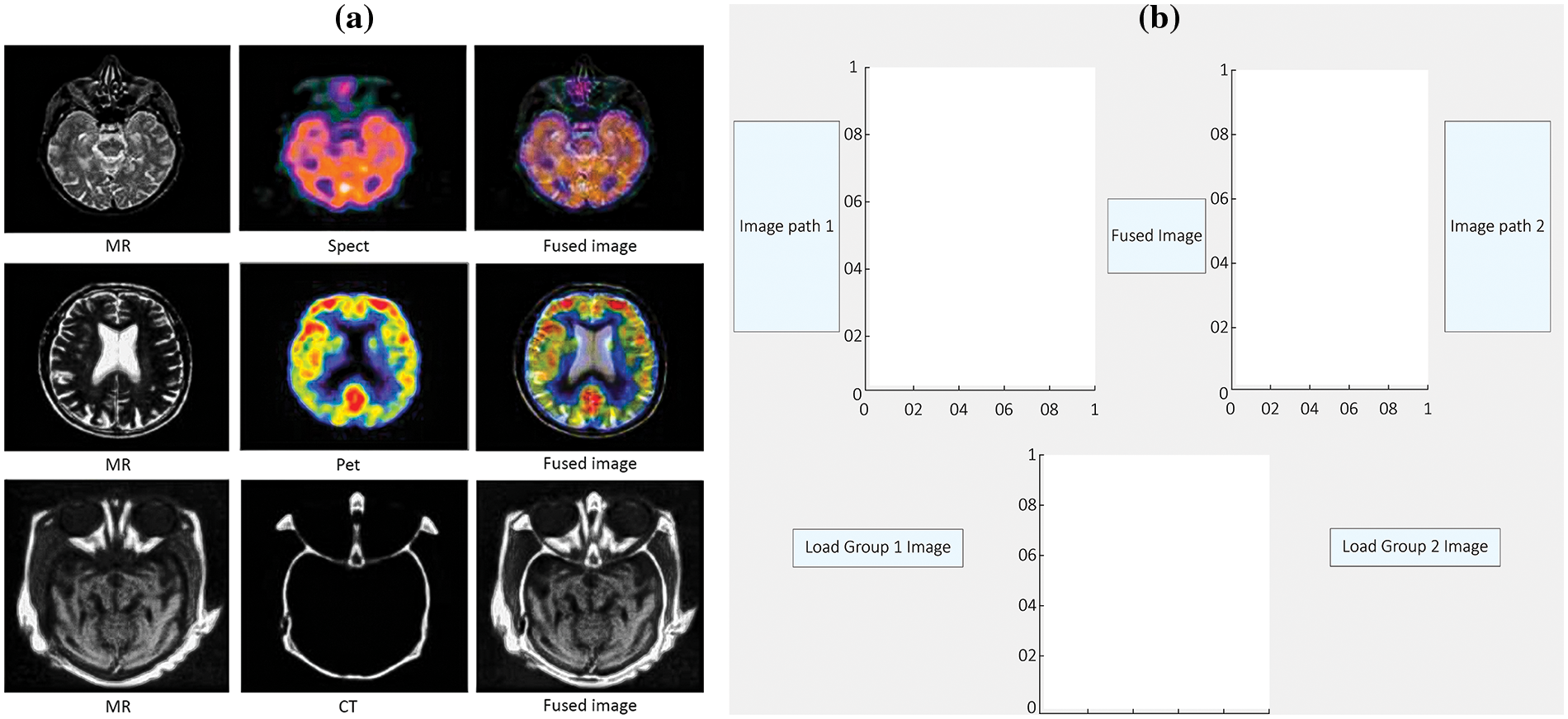
Figure 7: The efficacy of the proposed fusion technique is definitively validated using particular images, namely: (a) Spatial gradients obtained by smoothing the average of two input images and, (b) A graphical user interface designed for image fusion

We can likewise mix ongoing images. Steps to combine the images are as follows [32]:
• We have made a graphical user interface (GUI) as appeared shown in Fig. 7b.
• We have made two textboxes to store the chosen image.
• We upload the photographs to the hub that we need to integrate. In the third Box, the combined image is shown.
• The spatial level angles of image one and image two have appeared.
• The spatial gradient is computed by applying a smoothing operation to the average vector of two merged images. Fig. 8a illustrates the fusion of the two images, while Fig. 8b the resulting combination on the third axis.
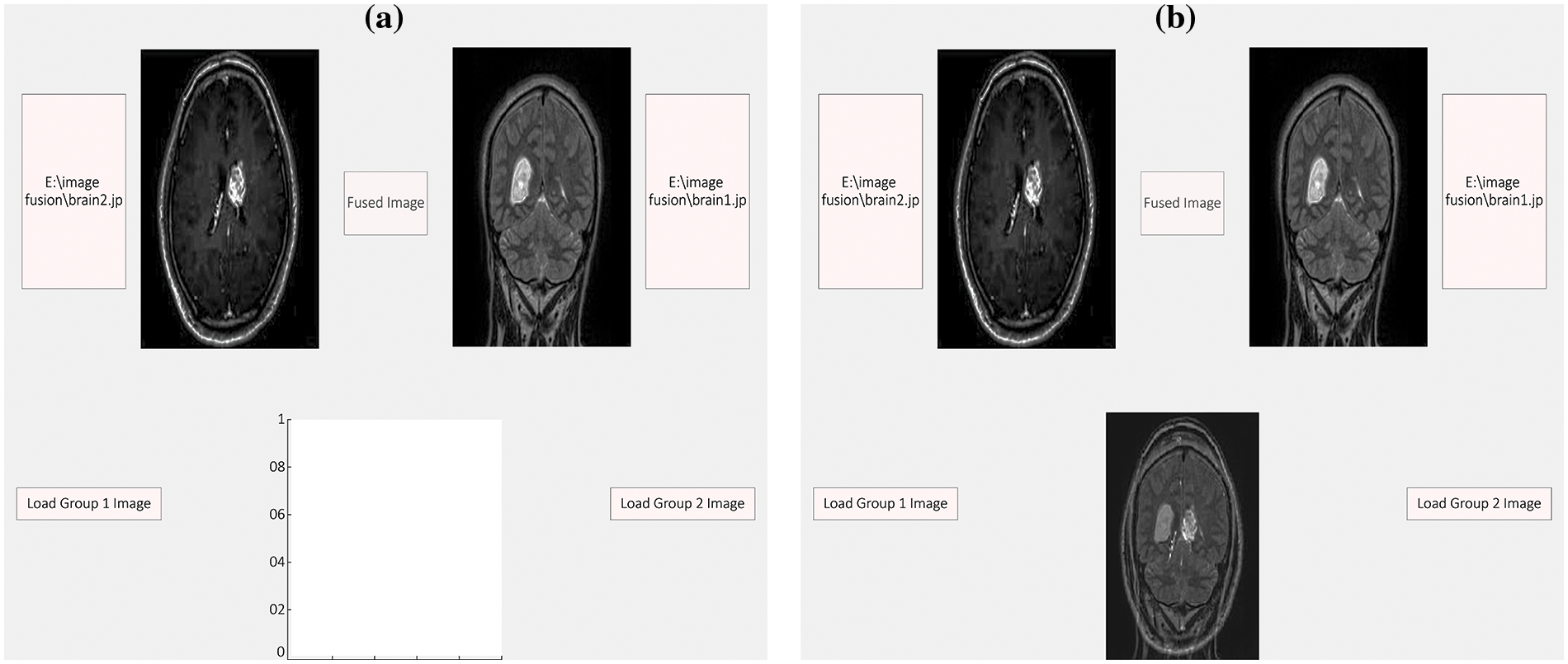
Figure 8: The figure illustrates the process of smoothing the spatial slope by manipulating the normal of two fused images, (a) represents the two images that are to be fused, (b) depicts the resulting fused image on the third axis
Wavelet transformation is a precision-based algorithm that accurately represents image edges and smoothness areas, preserving time and frequency details. The system utilizes genuine localization segments and computer vision techniques to enhance the efficiency of image fusion processing. The approach entails conducting repeated trials using wavelet basis functions and wavelet decomposition levels to get high-quality fused image data. The accuracy of wavelet transformation is the ratio of accurate edge predictions to the total number of edge predictions in the image instances being represented. Precision = TP/TP + FP, where TP: Correct Prediction, FP: False Prediction.
The recall of image fusion algorithms is the proportion of accurately predicted image edges to the total number of images, which includes overlapping images. The recall is mathematically defined as the ratio of TP to the sum of true positives and FN, expressed as Recall = TP/(TP + FN).
The F-measure quantifies the average performance of classifiers by considering both accuracy and recall. It is calculated using ground truth data for all frames in the image. Static quality measures include recall, precision, and F-measure. A higher F-measure value indicates superior performance of the classifier. F-Measure = Precision × Recall/Precision + Recall.
6.4 Balanced Classification Rate
The combination of wavelet processing and XGBoost algorithms produces fused images that effectively preserve both anatomical and functional information from grayscale and pseudo-color images, respectively. The wavelet processing effectively captures detailed anatomical information from gray-scale photographs, but it does not accurately represent the functional color components. XGBoost produces the highest value of fused images, as shown in Fig. 9a.
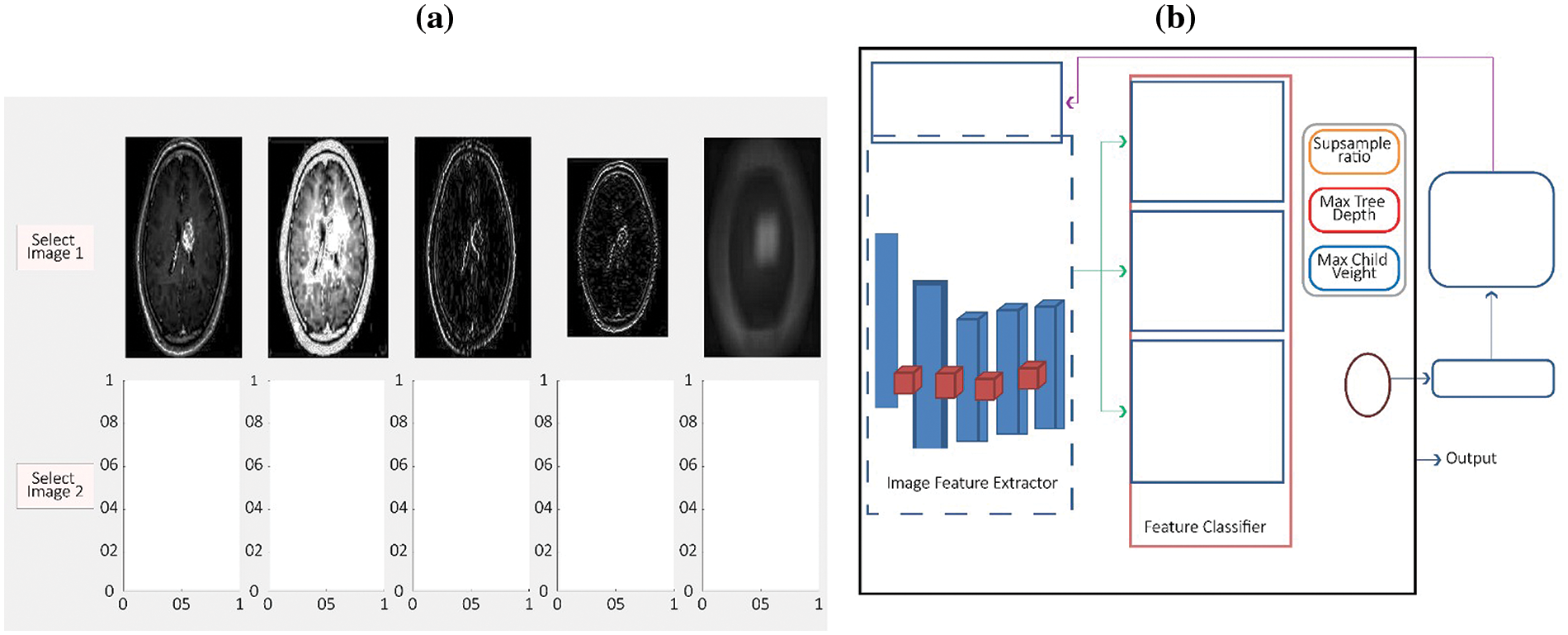
Figure 9: Represents the XGBoost’s gradient boosting process for image fusion, (a) Spatial grey level gradients of image 1 and image 2, (b) XGBoost structure of image fusion
It is always better to use a negative rate matrix for the evaluation of image fusion techniques. It gives very simple, yet efficient performance measures for the proposed model. Here are the two most common negative rate matrices for performance measures from the confusion matrix.
The negative rate matrix comprises two negative rates, namely True Negative and False Negative. A true negative is a prediction made by the wavelet transformation classifier that accurately identifies the absence of edges in several images. False negative is the term used to describe the amount of predictions made by the classifier when it wrongly identifies overlapping images as positive.
7 Extreme Gradient Boost (XGBoost)
Image classification and regression algorithm XGBoost. Fig. 9b shows how the gradient boosting framework based on XGBoost continuously incorporates new decision trees to fit a value with residuals for several rounds, improving image fusion. XGBoost ensures the system fully extracts and uses distinguished features to classify images accurately. Optimizing XGBoost matches the model structure to extracted features to better understand image features [31]. The ensemble model XGBoost classifies image features in the wavelet decomposition and recomposition problem when a single classifier fails. The Ensemble model uses the XGBoost algorithm on extracted image features to classify features fusion-based state of the art and represent salient features at different scales than the original images. XGBoost ensures the system fully extracts and uses distinguished features to classify images accurately. Optimizing XGBoost matches the model structure to extracted features to better understand image features. Fused image quality assessment depends on the application domain. Remote sensing employs spatial augmentation techniques to integrate image data with varying spatial resolutions, creating synthetic images of greater resolution from lower-resolution data. Remote sensing data fusion has recently used the utilization of the DWT. Avoid ringing artifacts with short decomposition/reconstruction filters in wavelet-based fusion. However, very short filters can cause selective frequency problems. Critically-sampled multi-resolution analysis loses variance translation. The study presented here introduces XGBoost, a scalable end-to-end tree-boosting system that has gained widespread adoption among data scientists due to its ability to consistently attain state-of-the-art performance on many machine learning tasks. We provide an innovative technique that takes into account sparsity in data and a weighted quantile sketch to facilitate approximation tree learning. We provide valuable information on cache access patterns, data compression, and sharing to construct tree-boosting systems that can be scaled effectively. By integrating these observations, XGBoost can handle datasets with billions of samples by using much fewer computational steps compared to current methods [35]. The XGBoost approach enables the automated detection of brain cancers. This algorithm is dependable. This approach employs numerous extraction procedures to accurately detect the presence of a brain tumor. By using this technique, the level of ambient noise in magnetic resonance images of the brain has been reduced. The brain tumors were categorized via Wavelet Transformation.
To guarantee high accuracy in image classification as a whole, XGBoost makes sure the algorithm extracts image features entirely and efficiently uses distinguishing features. To better grasp the image features, XGBoost optimization makes the model’s structure fit the retrieved features [36]. In this section, the XGBoost-based image classification structure is shown in Fig. 9b given below. The model is split into two sections: A feature classifier and an extractor of features. The feature extractor first pulls out several image features from the image data set that were acquired using sensors. The features are then used by XGBoost to train and categorize. The data is then trained to optimize the overall Wavelet Transformation and XGBoost framework based on the fitness value returned by the model. Finally, after the termination conditions are fulfilled, the optimal hyperparameter value obtained from XGBoost is used to generate the image classification model [37]. The following is a description of the process:
• Set up the framework’s parameters.
• Following transformation, feature data gathered from each activation layer and pooling layer.
• The feature is processed by a fully linked layer as a one-dimensional vector.
• Vectors that are initialized into a fresh training data set are utilized by the following classifier to make predictions.
The purpose of SLR was to identify the current state of research on methods of Image fusion, specifically focusing on the algorithms used and the classifiers extracted in the publications. The suggested combination technique addresses all the shortcomings of the DWT via the implementation of the Q-move DT-CWT. It also removes the unwanted artifacts in the overlapped image by assigning suitable weighting schemes to high-pass wavelet coefficients and low-pass coefficients separately. The use of the standardized most significant inclination-based sharpness model for low recurrence coefficients enhances the accuracy of the background surface information and enhances the quality of the obscured regions in the fusion process. There are several choices for the suggested computation. We have used a sophisticated wavelet that has estimated immunity to movement, exceptional ability to pick certain directions, PR (peak-to-ratio) functionality, limited redundancy, and realistic estimation capabilities. At that juncture, we use image amalgamation using CWT instead of conventional DWT. A unique XGBoost-based wavelet transformation approach is employed to significantly enhance the model’s comprehension of image information and thus boost the accuracy of image classification. The XGBoost feature extractor and feature classifier make up the majority of the model. The proposed credit scoring model might be modified in the future by using the XGBoost algorithm to optimize deeper models.
Acknowledgement: This research was supported by Princess Nourah bint Abdulrahman University and Researchers Supporting Project Number (PNURSP2024R346), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia. The author would also like to thank Prince Sultan University, Riyadh Saudi Arabia for support for APC.
Funding Statement: This research was funded by Princess Nourah bint Abdulrahman University and Researchers Supporting Project Number (PNURSP2024R346), Princess Nourah bint Abdulrahman University, Riyadh, Saudi Arabia.
Author Contributions: Naseem, Mahmood, and Saba conceived the study and experimented. Naseem, and Mahmood designed the methodology. Saba, Rehman, Umer, Nawazish, and Alamri, reviewed, drafted, and revised the study. Naseem, Rehman, Umer and Alamri provided essential research resources. Naseem, Mahmood, Umer, and Alamri contributed to the design and analyzed data. Nawazish, Rehman, and Saba conducted the proofreading of the study. All authors have read and agreed to the published version of the manuscript.
Availability of Data and Materials: Not applicable.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. J. Ma, Y. Ma, and C. Li, “Infrared and visible image fusion methods and applications: A survey,” Inform Fusion, vol. 45, no. 1, pp. 153–178, 2019. doi: 10.1016/j.inffus.2018.02.004. [Google Scholar] [CrossRef]
2. S. Klonus and M. Ehlers, “Image fusion using the Ehlers spectral characteristics preservation algorithm,” GISci. Remote Sens., vol. 44, no. 2, pp. 93–116, 2007. doi: 10.2747/1548-1603.44.2.93. [Google Scholar] [CrossRef]
3. W. El-Shafai, R. Aly, T. E. Taha, and F. E. A. El-Samie, “CNN framework for optical image super-resolution and fusion,” J. Opt., vol. 1, no. 1, pp. 1–20, 2023. [Google Scholar]
4. D. Mishra and B. Palkar, “Image fusion techniques: A review,” Int. J. Comput. Appl., vol. 130, no. 9, pp. 7–13, 2015. doi: 10.5120/ijca2015907084. [Google Scholar] [CrossRef]
5. C. Ghandour, W. El-Shafai, E. S. M. El-Rabaie, and E. A. Elshazly, “Applying medical image fusion based on a simple deep learning principal component analysis network,” Multimed. Tools Appl., vol. 1, no. 1, pp. 1–33, 2023. [Google Scholar]
6. Aghamaleki, J. Abbasi, and A. Ghorbani, “Image fusion using dual tree discrete wavelet transform and weights optimization,” The Visual Compu., vol. 39, no. 3, pp. 1181–1191, 2023. [Google Scholar]
7. W. El-Shafai, C. Ghandour, and S. El-Rabaie, “Improving traditional method used for medical image fusion by deep learning approach-based convolution neural network,” J. Opt., vol. 1, no. 1, pp. 1–11, 2023. doi: 10.1007/s12596-023-01123-y. [Google Scholar] [CrossRef]
8. R. Aly, N. A. El-Hag, W. El-Shafai, T. E. Taha, F. E. A. El-Samie and F. G. Hashad, “Efficient implementation of image fusion and interpolation for brain tumor diagnosis,” J. Opt., vol. 53, no. 1, pp. 30–48, 2023. [Google Scholar]
9. C. Ghandour, S. E. Walid El-Shafai, and N. Abdelsalam, “Comprehensive performance analysis of different medical image fusion techniques for accurate healthcare diagnosis applications,” Multimed. Tools and Appl., vol. 83, no. 1, pp. 24217–24276, 2023. [Google Scholar]
10. S. Masood, M. Sharif, M. Yasmin, M. A. Shahid, and A. Rehman, “Image fusion methods: A survey,” J. Eng. Sci. Technol. Rev., vol. 10, no. 6, pp. 186–194, 2017. doi: 10.25103/jestr.106.24. [Google Scholar] [CrossRef]
11. P. Kavita, D. R. Alli, and A. B. Rao, “Study of image fusion optimization techniques for medical applications,” Int. J. Cognit. Comput. Eng., vol. 3, no. 1, pp. 136–143, 2022. doi: 10.1016/j.ijcce.2022.05.002. [Google Scholar] [CrossRef]
12. B. Atitallah, M. D. Safa, W. Boulila, A. Koubaa, and H. B. Ghezala, “Fusion of convolutional neural networks based on Dempster-Shafer theory for automatic pneumonia detection from chest X-ray images,” Int. J. Imag. Syst. Tech, vol. 32, no. 2, pp. 658–672, 2022. doi: 10.1002/ima.22653. [Google Scholar] [CrossRef]
13. A. T. Azar, Z. I. Khan, S. U. Amin, and K. M. Fouad, “Hybrid global optimization algorithm for feature selection,” Comput. Mater. Contin., vol. 74, no. 1, pp. 2021–2037, 2023. [Google Scholar]
14. W. Tang, F. He, Y. Liu, and Y. Duan, “MATR: Multimodal medical image fusion via multiscale adaptive transformer,” IEEE Trans. Image Process., vol. 31, no. 1, pp. 5134–5149, 2022. doi: 10.1109/TIP.2022.3193288 [Google Scholar] [PubMed] [CrossRef]
15. P. Student, “Study of image fusion-techniques method and applications,” Int. J. Comput. Sci. Mobile Comput., vol. 3, no. 11, pp. 469–476, 2014. [Google Scholar]
16. A. Jabbar, S. Naseem, T. Mahmood, T. Saba, F. Alamri and A. Rehman, “Brain tumor detection and multi-grade segmentation through hybrid caps-VGGnet model,” IEEE Access, vol. 11, no. 1, pp. 72518–72536, 2023. doi: 10.1109/ACCESS.2023.3289224. [Google Scholar] [CrossRef]
17. A. K. Raz, C. R. Kenley, and D. A. DeLaurentis, “A system-of-systems perspective for information fusion system design and evaluation,” Inform. Fusion, vol. 35, no. 1, pp. 148–165, 2017. doi: 10.1016/j.inffus.2016.10.002. [Google Scholar] [CrossRef]
18. M. Heba, E. S. M. E. Rabaieb, W. A. Elrahmana, O. S. Faragallahc, and F. E. A. El-Samieb, “Medical image fusion: A literature review present solutions and future directions,” Menoufia J. Electron. Eng. Res., vol. 26, no. 2, pp. 321–350, 2017. doi: 10.21608/mjeer.2017.63510. [Google Scholar] [CrossRef]
19. S. Jadhav, “Image fusion based on wavelet transform,” Int. J. Eng. Res., vol. 3, no. 7, pp. 442–445, 2014. doi: 10.17950/ijer/v3s7/707. [Google Scholar] [CrossRef]
20. B. Rajalingam, B. Fadi Al-Turjman, R. Santhoshkumar, and M. Rajesh, “Intelligent multimodal medical image fusion with deep guided filtering,” Multimed. Syst. 28, vol. 1, no. 4, pp. 1449–1463, 2022. doi: 10.1007/s00530-020-00706-0. [Google Scholar] [CrossRef]
21. K. Meethongjan, M. Dzulkifli, A. Rehman, A. Altameem, and T. Saba, “An intelligent fused approach for face recognition,” J. Intell. Syst., vol. 22, no. 2, pp. 197–212, 2013. doi: 10.1515/jisys-2013-0010. [Google Scholar] [CrossRef]
22. N. Abbas, D. Mohamad, A. S. Almazyad, and J. S. Al-Ghamdi, “Machine aided malaria parasitemia detection in Giemsa-stained thin blood smears,” Neural Comput. Appl., vol. 29, no. 1, pp. 803–818, 2018. doi: 10.1007/s00521-016-2474-6. [Google Scholar] [CrossRef]
23. Z. Bai and X. L. Zhang, “Speaker recognition based on deep learning: An overview,” Neural Networks, vol. 140, no. 1, pp. 1–39, 2021. doi: 10.1016/j.neunet.2021.03.004 [Google Scholar] [PubMed] [CrossRef]
24. P. H. Dinh, “A novel approach using structure tensor for medical image fusion,” Multidimens. Syst. Signal Process., vol. 33, no. 3, pp. 1001–1021, 2022. doi: 10.1007/s11045-022-00829-9. [Google Scholar] [CrossRef]
25. S. P. Singh, W. Lipo, G. Sukrit, G. Haveesh, P. Parasuraman and G. Balázs, “3D deep learning on medical images: A review,” Sens., vol. 18, no. 5097, pp. 1–25, 2020. doi: 10.3390/s20185097 [Google Scholar] [PubMed] [CrossRef]
26. P. H. Dinh, “An improved medical image synthesis approach based on marine predators algorithm and maximum gabor energy,” Neural Comput. Appl., vol. 34, no. 6, pp. 4367–4385, 2022. doi: 10.1007/s00521-021-06577-4. [Google Scholar] [CrossRef]
27. L. Ji, F. Yang, and X. Guo, “Image fusion algorithm selection based on fusion validity distribution combination of difference features,” Electron., vol. 10, no. 15, pp. 1–10, 2021. doi: 10.3390/electronics10151752. [Google Scholar] [CrossRef]
28. I. Abunadi, “Deep and hybrid learning of MRI diagnosis for early detection of the progression stages in Alzheimer’s disease,” Connect Sci., vol. 34, no. 1, pp. 2395–2430, 2022. doi: 10.1080/09540091.2022.2123450. [Google Scholar] [CrossRef]
29. B. Kitchenham, O. P. Brereton, D. Budgen, M. Turner, J. Bailey and S. Linkman, “Systematic literature reviews in software engineering–a systematic literature review,” Inf. Softw. Technol., vol. 51, no. 1, pp. 7–15, 2009. doi: 10.1016/j.infsof.2008.09.009. [Google Scholar] [CrossRef]
30. N. Alseelawi, H. T. Hazim, and H. T. H. S. ALRikabi, “A novel method of multimodal medical image fusion based on hybrid approach of NSCT and DTCWT,” Int. J. Online Biomed. Eng., vol. 18, no. 3, pp. 114–133, 2022. doi: 10.3991/ijoe.v18i03.28011. [Google Scholar] [CrossRef]
31. F. Yin, W. Gao, and Z. X. Song, “Medical image fusion based on feature extraction and sparse representation,” Int. J. Biomed. Imag., vol. 11, no. 1, pp. 1–11, 2017. doi: 10.1155/2017/3020461 [Google Scholar] [PubMed] [CrossRef]
32. K. Xu, Q. Wang, H. Xiao, and K. Liu, “Multi-exposure image fusion algorithm based on improved weight function,” Neurorobot., vol. 16, no. 1, pp. 1–8, 2022. doi: 10.3389/fnbot.2022.846580 [Google Scholar] [PubMed] [CrossRef]
33. T. B. Steena, P. Perumal, C. Suganthi, R. Asokan, S. Sreeji and P. Preethi, “Optimizing image fusion using wavelet transform based alternative direction multiplier method,” in 2nd Int. Conf. Adv. Comput. Innovat. Technol. Eng. (ICACITE), Greater Noida, India, IEEE, 2022, vol. 1, pp. 2021–2024. [Google Scholar]
34. W. El-Shafai et al., “An efficient medical image deep fusion model based on convolutional neural networks,” Comput. Mater. Contin., vol. 74, no. 2, pp. 2905–2925, 2023. doi: 10.32604/cmc.2023.031936. [Google Scholar] [CrossRef]
35. W. Jiao, X. Hao, and C. Qin, “The image classification method with CNN-XGBoost model based on adaptive particle swarm optimization,” Inf., vol. 12, no. 4, pp. 1–22, 2021. doi: 10.3390/info12040156. [Google Scholar] [CrossRef]
36. T. Chen and C. Guestrin, “XGBoost: A scalable tree boosting system,” in Proc. 22nd ACM SIGKDD Int. Conf. Knowl. Discov. Data Min., 2016, vol. 1, no. 1, pp. 785–794. doi: 10.1145/2939672. [Google Scholar] [CrossRef]
37. V. Singh, “Image fusion metrics—a systematic study,” in Proc. 2nd Int. Conf. IoT, Soc., Mobile, Anal. Cloud Comput. Vis. Bio-Eng., 2020, vol. 1, no. 1, pp. 1–7. doi: 10.2139/ssrn.3734738. [Google Scholar] [CrossRef]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools