
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

VKFQ: A Verifiable Keyword Frequency Query Framework with Local Differential Privacy in Blockchain
School of Computer and Communication Engineering, Changsha University of Science and Technology, Changsha, 410114, China
* Corresponding Author: Bo Yin. Email:
Computers, Materials & Continua 2024, 78(3), 4205-4223. https://doi.org/10.32604/cmc.2024.049086
Received 27 December 2023; Accepted 08 February 2024; Issue published 26 March 2024
 View Full Text
View Full Text Download PDF
Download PDFAbstract
With its untameable and traceable properties, blockchain technology has been widely used in the field of data sharing. How to preserve individual privacy while enabling efficient data queries is one of the primary issues with secure data sharing. In this paper, we study verifiable keyword frequency (KF) queries with local differential privacy in blockchain. Both the numerical and the keyword attributes are present in data objects; the latter are sensitive and require privacy protection. However, prior studies in blockchain have the problem of trilemma in privacy protection and are unable to handle KF queries. We propose an efficient framework that protects data owners’ privacy on keyword attributes while enabling quick and verifiable query processing for KF queries. The framework computes an estimate of a keyword’s frequency and is efficient in query time and verification object (VO) size. A utility-optimized local differential privacy technique is used for privacy protection. The data owner adds noise locally into data based on local differential privacy so that the attacker cannot infer the owner of the keywords while keeping the difference in the probability distribution of the KF within the privacy budget. We propose the VB-cm tree as the authenticated data structure (ADS). The VB-cm tree combines the Verkle tree and the Count-Min sketch (CM-sketch) to lower the VO size and query time. The VB-cm tree uses the vector commitment to verify the query results. The fixed-size CM-sketch, which summarizes the frequency of multiple keywords, is used to estimate the KF via hashing operations. We conduct an extensive evaluation of the proposed framework. The experimental results show that compared to the Merkle B+ tree, the query time is reduced by 52.38%, and the VO size is reduced by more than one order of magnitude.Keywords
With the emergence and development of Bitcoin, blockchain technology has evolved beyond digital currencies and has demonstrated significant potential in various fields including finance, the Internet of Things, and healthcare. Blockchain functions as a distributed ledger, maintained by equal participants known as blockchain nodes. When new transactions occur, they are broadcast to all nodes, and the blockchain system utilizes a consensus algorithm to package these transactions into a new block. The consensus process is verified by nodes across the network. Data are stored within blocks, which are linked together through the hash value of the previous block in the block header, creating a chained structure. Consequently, any alteration of data within a block will result in a change in the hash value of that block, ensuring the integrity and immutability of the blockchain.
The decentralized, tamper-proof, and traceable features of blockchain technology allow for secure data sharing. This means that data can be securely shared between different systems, organizations, or individuals. For instance, electronic medical records can be shared across healthcare organizations, making medical services accessible; moreover, transaction information can be shared amongst organizations, facilitating inter-organization money transfers. One of the main problems in data sharing is how to protect individual privacy while allowing efficient data queries. In the context of blockchain, data are uploaded for sharing, and the data requester (DR) can query the blockchain to retrieve the data they need. However, even if the data are anonymized before being uploaded, there is still a risk of privacy leakage. Attackers may use external data sources to perform matching analysis or employ methods like linear programming to reconstruct the anonymized data and infer the privacy information it contains [1].
In this paper, we study verifiable KF queries with local differential privacy in blockchain. Data on blockchain is expanding rapidly these days; in November 2023, for example, over 18.71 million blocks were generated in Ethereum (https://etherscan.io/txs). As storing all the data would put high storage and computing pressure on blockchain nodes, a typical blockchain network contains two classes of nodes: Full nodes and light nodes. The full node stores the complete block, but the light node only holds the block header including the consensus proof and the block hash. There are three roles in blockchain-based sharing systems: Data owner (DO), DR, and cloud service provider (SP). As illustrated in Fig. 1, the SP acts as a full node, storing the data used for sharing and trading, and providing query services. The DR joins the blockchain as a light node. The trustworthiness of the SP is not absolute, and there is a potential risk of tampering. To address this concern, the full node maintains an ADS, which enables query processing and data verification. On the other hand, the light node only maintains the root hash of ADS for data verification. When returning query results to the DR, the SP provides a VO as well. This allows the DR to verify the accuracy of the result based on the held root hash and the received VO.

Figure 1: KF queries with local privacy in blockchain
A KF query aims to find the occurrences of a given keyword such that the value of the numeric attribute falls in a specified range. In many practical applications, numerical attributes, such as a patient’s temperature and heart rate are publicly available, while keyword attributes, such as the medicines purchased by a patient, need to be privacy-protected. Specifically, each data object
Example 1. In a blockchain-based smart healthcare system, patients share their medical records, including body metrics like temperature, blood pressure, and heart rate, as well as symptom information such as dizziness, cough, and chest tightness. Healthcare organizations want to count the frequency of specific symptoms. For instance, a query
Example 2. In blockchain-based investor behavior analysis, investors share information about their investments in various financial products. The blockchain systems store the investment amount and the name of the investor. Financial regulators may need to count the number of times an investor has invested within a particular investment amount range. For example, a query
Although some researchers have studied the privacy protection problem in blockchain, most of them employ anonymous communication to anonymize users, preventing attackers from linking transaction information with user addresses. However, there is a “trilemma” for such anonymous communication-based approaches [2]. Some researchers use cryptographic algorithms to safeguard user identity information, but they do not consider supporting the query processing. There are also some studies on verifiable query processing in blockchains, e.g., numerical range queries and Boolean queries [3–5]. For inter-block queries, current approaches improve search efficiency through skip list [6] and sliding window indexes [7]. Although these approaches [3–7] allow for efficient queries and guarantee the correctness and integrity of the results, they do not use local differential privacy. Moreover, existing approaches cannot support KF queries. The proposed ADS are variants of the Merkle tree, the VO size of which is
To this end, we propose a verifiable keyword frequency query framework with local differential privacy in blockchain (VKFQ), which aims to protect DOs’ privacy on keyword attributes and support efficient and verifiable query processing for KF queries. The framework protects the DO’s privacy of personal data using the local differential privacy technique [8] before the data are uploaded to the blockchain. It also facilitates the calculation of the frequency of a keyword on blockchain data. The framework consists of two main parts: A utility-optimized local differential privacy data-sharing model and a VB-cm ADS. In the data sharing model, each DO independently adds noise to their data object locally, ensuring that the impact of individual data objects on the statistical analysis of the overall dataset remains within the privacy budget (i.e., the upper limit of the privacy loss, lower privacy budget means stronger privacy protection). The perturbed data are then broadcast to the blockchain network. The VB-cm ADS is an inter-block index tree that combines the CM-sketch [9] and the Verkle tree [10]. The CM-sketch is used to summarize the frequency of keywords; as a result, each numerical attribute’s value
The main contributions of this paper are as follows:
• To the best of our knowledge, we are the first to address the verifiable KF query problem in blockchain. Our goal is to support efficient and verifiable query processing while protecting the DO’s privacy. Each data object has both numerical attributes and keyword attributes where the keyword attribute is sensitive and needs to be privacy-protected.
• We propose the VKFQ framework for the KF query, which protects the DO’s keyword using a utility-optimized local differential privacy technique. The framework calculates the estimate of a keyword’s frequency and is efficient in query time and VO size.
• We propose the VB-cm tree as the ADS to support efficient query processing while ensuring privacy protection. The VB-cm tree integrates the CM-sketch with the Verkle tree, to reduce the storage cost and the VO size. Each leaf node stores the fixed-size CM-sketch to summarize the frequency information of a large number of keywords. We propose a query scheme based on the VB-cm tree.
• We conduct extensive experiments to evaluate the efficiency of the VKFQ framework. The experimental results demonstrate that there is a nearly one-order reduction in VO size. The query time and ADS size are lowered by 52.38% and 46.81%, respectively, in comparison to the Merkle B+ tree. The VO size is reduced by more than one order of magnitude.
The rest of the paper is structured as follows. The related work is shown in Section 2. In Section 3, the problem is formulated and the general idea and the preliminaries are presented. Section 4 presents the local differential privacy data sharing model. Section 5 presents the VB-cm ADS. Section 6 describes the experimental design and the results, and the paper’s conclusion is provided in Section 7.
2.1 Privacy Protection in Blockchain
In recent years, extensive research has revealed the risk of privacy leakage in blockchain. For instance, within the Bitcoin system, each node stores the complete history of transaction information to prevent “double spending” and maintain decentralization. Moreover, Ober et al. [11] found that it is possible to link user addresses to transactions by analyzing the Bitcoin transactions. Reid et al. [12] suggested that incorporating external information, such as email addresses and IP addresses, can potentially expose a user’s identity and compromise anonymity. Koshy et al. [13] demonstrated this concept by mapping nearly 1000 Bitcoin addresses to their respective owner IPs using anomalous relay behavior, thus establishing the ownership relationship between Bitcoin addresses and IP addresses. One common approach to preserving privacy is the anonymizing communication such as Tor [14]. However, these communication networks face a “trilemma” [2] where only two of the three objectives, strong anonymity, minimal bandwidth overhead, and low latency, can be met. Biryukov et al. [15] suggested that while some latency can be tolerated in blockchain, integrating Tor introduces new security vulnerabilities, such as the use of DDoS mechanisms to control the flow of user information, thereby hindering the achievement of strong anonymity.
Yang et al. [16] have summarized the commonly used privacy-preserving methods in blockchain, particularly in cryptocurrencies. For instance, Maurer et al. [17] utilized hybrid coins to mix and split transactions, ensuring anonymity. ZeroCoin [18], on the other hand, employed zero-knowledge proofs to preserve user identity information privacy. Similarly, MonroeCoin [19] uses ring signatures to ensure user anonymity. Additionally, several privacy-preserving methods rely on cryptographic techniques. Zhang [20] proposed the VPFT algorithm, which utilizes a crypto-lottery algorithm to secure consumers’ personal information data. However, it does not provide how the encrypted data can be recovered once stored on the blockchain, making it impossible to query the data. Otherwise, Guo et al. [21] proposed a grid location coordinate privacy protection scheme. Attribute encryption as well as order-preserving encryption are employed to safeguard user location privacy. While this scheme allows querying based on the order of encrypted values, the encryption method is more complex than ordinary encryption, and it is more susceptible to statistical analysis attacks due to retaining the ordering information, thereby making it insufficiently secure.
In addition, smart contracts in blockchain can be used for privacy protection, for example, Raj et al. [22] used smart contracts for access control such that only authorized entities had access to a patient’s medical data. Lu et al. [23] proposed secure data storage protocols that used group signature schemes, proxy re-encryption schemes, and smart contracts to achieve privacy protection. However, smart contracts may have security vulnerabilities caused by code errors and cannot be modified after deployment.
2.2 Verifiable Queries in Blockchain
Verifiable queries in blockchain already enable range queries on numerical attributes [3] and keyword Boolean queries [4,5]. Zhang et al. [3] proposed a method that combines the MB and SMB trees, using the larger MB tree as the primary index and the smaller SMB tree to index newly inserted objects, thus enabling batch merging. Dai et al. [4] designed a lightweight verifiable query for account balances and transaction history in the Bitcoin system. They improved the straw man method to ensure that the query results satisfy the correctness and integrity of the data. But the method results in large intermediate data storage overhead. The keyword query scheme under the blockchain hybrid storage framework was proposed in [5]. This scheme overcomes the storage problem caused by a large amount of intermediate data and maintains the complete ADS on the SP, while the chain maintains part of the ADS. The keywords are organized using the idea of an inverted index. If the smart contract only stores the root summary of the MB tree, updating a new data item requires regenerating the proof, which will result in high overhead, even though only the SP needs to send an authenticatable proof of update to the smart contract. If a trapdoor is used to ensure that the DO does not change its commitment when updating the data, the password pairing operation during verification will be much slower than the password operation for hashing.
The vchain framework proposed by Xu et al. [6] works for both keyword Boolean queries and numerical value range queries. By changing the block structure, the attDigest field is added as a digest of the whole record (i.e., the value after encrypting the plaintext using a public key), which is packed and uploaded to the chain by miners. All collection elements are stored in Merkle tree nodes to support boolean queries for keywords, which leads to expensive storage overhead. In contrast, for numerical range queries, numerical attributes are converted to keywords based on the prefix tree. Because vchain becomes linear at worst when searching between blocks, vchain+ [7] is designed, which uses a Sliding Window Accumulator (SWA) index to achieve efficient search. The sliding window idea is used to divide the query into fixed-length subqueries and then construct a Merkle-Trie tree, avoiding the problem of possible failure of inter-block skiplist.
However, all the above approaches do not consider privacy protection and cannot address the KF query problem. Because the problem addressed is different from ours, existing approaches cannot be applied to the KF query.
Definition 1 (KF queries). Each data object is represented as
We formulated the KF query in Definition 1. In this paper, we focus on privacy protection on keyword attributes, while assuming that the numerical attributes are publicly available. Let
After receiving
Because the data query often involves multiple blocks in real applications, to enable inter-block query processing, SP stores
To support the KF query, we design the VB-cm tree as the ADS. VB-cm tree is constructed on
Goals. We need to protect the DO’s privacy. Blockchain is a peer-to-peer network; there is a risk of dishonest nodes (e.g., the SP) tampering with the data, leading to inaccurate query results. To address these concerns, we propose a VKFQ framework that enables the DO to obfuscate keyword information before uploading data to the blockchain network. The blockchain network can then return VO along with the query result, which can be used by the DR to verify the accuracy of the result. The goals of the verifiable KF query under local differential privacy are as follows:
• Privacy: Given a keyword, blockchain nodes including the SP and DR cannot identify the DO who have uploaded the data associated with this keyword based on the data stored in blockchain.
• Correctness: Because the SP computes the frequency estimate
• Integrity: The DR can verify that all
• Query efficiency: The time it takes from when a DR initiates a query to when the DR verifies the query results is reduced.
• Storage overhead: We want to reduce the ADS size and the VO size, and keep the VO size constant even with large volumes of data.
Differential privacy [8] is a technique aimed at safeguarding individual privacy by preventing the disclosure of sensitive personal information during the analysis of personal data, even if an attacker possesses information from other external data sources. The fundamental principle of this technique is to protect personal privacy by introducing noise or perturbation to the data, ensuring that any single modification made by an individual does not significantly impact the overall result. The mathematics of differential privacy is rooted in probability and randomization functions. If a randomized algorithm A, used to perturb the information, satisfies
The probabilistic data structure called CM-Sketch allows for fast estimation of frequency information for elements in large-scale data streams approximately while conserving memory space. It utilizes a two-dimensional matrix to encode a significant amount of element count information. Each row of the matrix consists of an array of counters, with each element being mapped to a specific array using a different hash function. The mapped bits are then incremented by 1. For the estimation of the number of a given element, similar to sketch updating, the counts of the bits of the element in each row are checked. Due to potential hash conflicts and the possibility of different elements being mapped to the same bit, the count in the corresponding bit is also incremented. As a result, the estimated value for the element is determined by taking the smallest value among all the counters. CM-Sketch sacrifices a certain level of accuracy within an acceptable range, which allows for a trade-off between space overhead and accuracy. The width of the two-dimensional array controls the element counting error, while the height controls the probability of the element computation error not exceeding the counting error.
3.2.3 RSA-Based Vector Commitment
Vector Commitment (VC) is a cryptographic primitive used for committing a message
Key Generation Function
Commitment Generation Function
Open Function
Verification Function
4 Utility-Optimized Local Differential Privacy Data Sharing Model
Using differential privacy to encrypt personal data can protect individual privacy and minimize the impact of privacy leakage on the overall data analysis results. The differential privacy method perturbs the dataset before posting it, making it impossible for attackers to determine whether the queried information is from the original or perturbed dataset. That is, an attacker cannot infer from the posted data whether a particular piece of data exists in the original dataset, thereby protecting the privacy of individuals. Modifying certain data will not have much impact on the distribution of the output of a certain algorithm, i.e., for a certain statistical value, the probability of outputting the same statistical value will not change significantly.
Specifically, the purpose of privacy protection in this paper is to collect useful information while ensuring that the keyword information uploaded by the DO is resistant to differential attacks. Useful information is the frequency of keyword appearances, which can be applied to data analysis. SP can collect this useful information from the blockchain network. However, the SP is not entirely trustworthy, and an SP or DR is able to perform a differential attack to localize sensitive information to a DO by using the information obtained from multiple queries. Thus utility-optimized local differential privacy protection is performed before the DO uploads the data. This is because in
In the perturbation phase, the numerical attributes
We set
In the aggregation phase, SP calculates the corresponding frequency estimates of the privacy-protected keywords based on the data uploaded by the DO. In the blockchain network, the uploading of the perturbed keyword frequency information by the DOs is equivalent to broadcasting in the peer-to-peer network. When the SP receives the data
We initialize an all-0 array
The VB-cm tree combines the ideas of the Verkle tree and CM-sketch for efficient and verifiable KF queries. The VB-cm tree has the following advantages. First, it enables fast queries among blocks and reduces the storage cost of the ADS structure. Second, it supports the verification of the correctness and integrity of the query results.
Specifically, after the SP obtains the data with the perturbed keywords and numerical attributes, it uses the CM-sketch to map these keywords evenly to diffchildren with numerical attributerent rows. This reduces the possibility of hash conflicts and also compactly records the frequency. Because we consider inter-block queries, we deposit the sketch

Figure 2: VB-cm tree
The VB-cm tree is constructed on
Compared with the traditional ADS such as the Merkle B+ tree and the Verkle B+ tree, the proposed VB-cm tree is more effective in reducing the query time and VO size. In query time, hashing is employed instead of traversing after finding the block containing the keywords. This allows for a speedy retrieval of the KF data. For VO size, the sketch is utilized to express keyword information rather than the key-value pair. Moreover, a smaller number of nodes are inserted into VO.
There are three types of nodes in the proposed VB-cm tree: Leaf node, intermediate node and root node. The VB-cm tree adds the following fields to nodes: 1)
The field
and
Example 3. Consider the VB-cm tree where node
Algorithm 1 describes the construction process of the VB-cm tree. The construction starts from the leaf node layer by layer upwards. We use

Given a range
Note that the VB-cm tree retains the ordered and linkable structure of the leaf nodes like the B+ tree. Hence, we conduct a depth-first query to find the left-most and right-most leaf nodes based on the query range
Algorithm 2 describes the process of the query processing and the generation of the VO. The top-down query starts from the root node and performs node pruning based on the query range
Example 4. In Fig. 2, the numbers next to each node in the figure are the numerical attributes. Suppose the query range
The verification process contains correctness verification and integrity verification, which is achieved by traversing VO. Recall that VO is returned to the DR along with the query result.
Algorithm 3 describes the process of verification. Based on VO obtained during the query process and

Example 5. We first verify the answer’s correctness. According to the VO obtained in Example 4, and the

Privacy protection. There are potential security vulnerabilities in the system. The SP, as a full node, can locate the DO through the data stored in the blockchain to obtain address information. In addition, the DR can also be an attacker that performs a data reconstruction attack by launching multiple query requests to the SP. That is, an attacker can construct inequalities with KF information and solve linear equations with the goal of noise minimization to solve the approximate solution of the data object saved by the SP, which leads to personal privacy disclosure. Our approach uses the local differential privacy technique to allow the DO to do the noise addition to the data locally. The SP and the DR are unable to determine whether the data is real data from the DO, and therefore it is not possible to determine from which DO the real data was sent. From this, it can be concluded that the user’s privacy is protected to minimize security vulnerabilities.
Correctness and integrity of the query result. For the correctness of the query result, DR can extract all the CM-sketches in the VO and obtain
The value
We run all algorithms on a PC with Inter(R) Core(TM) i7-7700HQ CPU (2.80 GHz) and a RAM of 8 GB. The operating system is Windows 10 and the program code is written using Python 3.8. We measure the performance of the approaches using the following metrics: 1) Query time, the time from the beginning of the query to the end of getting the result verified as correct and integral, 2) Verification time, the time to verify the results after getting them, 3) ADS size, number of bytes occupied by the ADS, and 4) VO size, number of bytes occupied by VO. We compare our proposed VB-cm tree with the Merkle B+ tree and the Verkle B+ tree.
Figs. 3a–3c plot the query time as a function of the number of leaf nodes, the width of the query range, and the dataset size, respectively. The query time grows when the number of leaf nodes increases because it takes longer to perform the search and generate a larger VO. When the width of the query range becomes larger, all approaches see an increase in query time. This is because expanding the query range will result in more leaf nodes in the query results. More time is consumed for verification. When the dataset increases, the query time increases for the Merkle B+ tree and Verkle B+ tree but remains essentially unchanged for the VB-cm tree. The VB-cm tree performs best and the Merkle B+ tree performs worst in Fig. 3. The average query time of the Verkle B+ tree and the Merkle B+ tree is 1.52 times and 2.10 times that of the VB-cm tree, respectively. The main reason for the best performance of the VB-cm tree is the use of CM-sketch, which saves more time when querying the KF by hash mapping than traversing the keywords. The Verkle B+ tree performs better than the Merkle B+ tree because the Merkle B+ tree needs to obtain the hash of all the sibling nodes to generate the VO, whereas the Verkle B+ tree only needs information about the nodes in the path.

Figure 3: Query time
Fig. 4 shows the verification time of the three approaches. The VB-cm tree outperforms the other two approaches. The average verification time of the Verkle B+ tree and the Merkle B+ tree is 1.98 times and 2.67 times longer than that of the VB-cm tree, respectively. This is because both the VB-cm tree and the Verkle B+ tree use the same Verification Function to read VO for verification, and the verification time is proportional to the size of VO. VB-cm tree has the shortest verification time because it uses CM-sketch to aggregate the frequency information of a large number of elements in a fixed-size matrix compared to the counter. The verification time increases with the number of leaf nodes and the width of the query range because more nodes are added to the VO. When the dataset becomes larger, the verification time of the VB-cm tree remains essentially unchanged, and the verification time of the Merkle B+ tree and the Verkle B+ tree increases. This is because the VB-cm tree uses CM-sketch to ensure that VO size is constant.

Figure 4: Verification time
Fig. 5 shows the size of VO. The VB-cm tree performs best and the Merkle B+ tree performs worst. The average VO size of the Verkle B+ tree and the Merkle B+ tree is 9.28 times and 14.9 times larger than that of the VB-cm tree, respectively. This is because the VO size of the Merkle tree is

Figure 5: VO size
Fig. 6a plots the ADS size as a function of the number of leaf nodes. When the number of leaf nodes increases, the ADS size becomes larger. This is because as the increase of leaf nodes in the tree structure, the data contained in the tree increases along with the number of layers, so the bytes occupied by ADS also increase. Fig. 6b shows the effect of dataset size. When the dataset size becomes larger, the size of the Merkle B+ tree and Verkle B+ tree becomes larger, and the size of the VB-cm tree remains the same. This is the VB-cm tree that uses a fixed-size CM-sketch to record the frequency of multiple keywords. The average ADS size of the Verkle B+ tree and the Merkle B+ tree is 1.89 times and 1.88 times larger than that of the VB-cm tree, respectively.
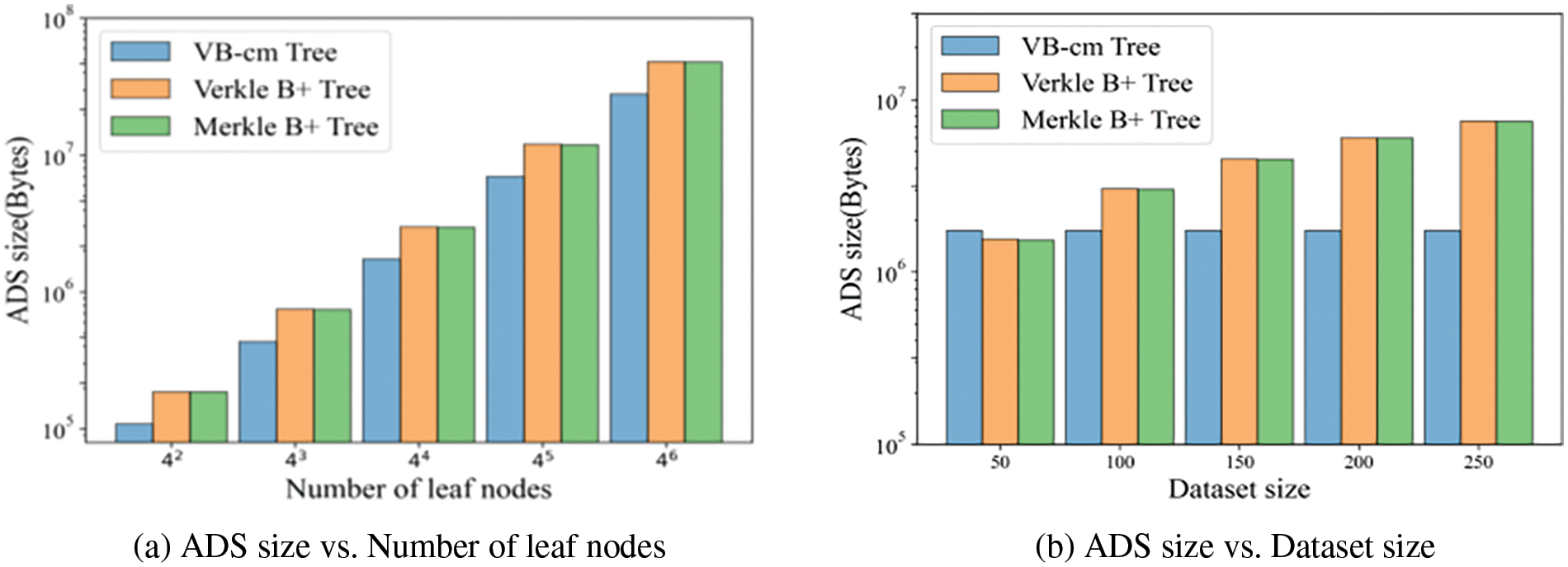
Figure 6: ADS size
The VB-cm tree performs better than the Merkle B+ tree and the Verkle B+ tree on the four metrics. This is because the VB-cm tree stores the frequency information using a CM-sketch of a fixed size without the need to store the keywords and their complete frequency information. The CM-sketch uses hash mapping in the query process, which saves more time than traversing the counters. In addition, the VB-cm tree incorporates the structure of a Verkle tree. To verify the content in a leaf node, the VO contains the nodes in the path from the leaf node to the root without the sibling nodes. As the dataset size increases, the superiority of the VB-cm tree is more obvious. Specifically, the query time, verification time, and VO size grow slightly while those of the other two ADS increase apparently. So we can conclude that the system has good scalability.
In this paper, we have proposed the VKFQ framework for efficient and verifiable KF queries with privacy protection in blockchain. Sensitive data keywords get differential privacy processing. We have proposed the VB-cm tree as the ADS. The VB-cm tree combines the CM-sketch and the Verkle tree to reduce storage costs and VO size. The CM-sketch serves as a summary of the frequency of keywords, from which an estimate of the frequency of keywords is derived. We have presented the query processing and result verification in detail. Extensive experimental results have demonstrated the efficiency of the proposed framework. For instance, there is more than one order of magnitude reduction in the VO size.
The suggested framework is compatible with blockchain architectures that are already in place, like Ethereum. We can add the VB-cm tree to the block where the root is stored in the block header, to support KF queries. The limitation of the framework is that the ADS can only handle KF queries. There are several future directions. We may think about using different kinds of privacy protection techniques such as data encryption technology in our framework. It is also interesting to extend the proposed framework to handle other query operators, i.e., skyline queries and k-nearest neighbor queries.
Acknowledgement: We would like to express thanks to the editor and anonymous reviewers for their appreciated comments that enhanced the worth of the research paper.
Funding Statement: The authors received no specific funding for this study.
Author Contributions: Study conception and design: Y. Ji and B. Yin; data collection: Y. Ji; analysis and interpretation of results: Y. Ji and B. Yin; draft manuscript preparation: Y. Ji and K. Gu. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: All data generated or analyzed during this study are included in this article and are available from the corresponding author upon reasonable request.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. I. Dinur and K. Nissim, “Revealing information while preserving privacy,” in Proc. Twenty-Second ACM SIGMOD-SIGACT-SIGART Symp. on Prin. of Dat. Syst., New York, NY, USA, 2003, pp. 202–210. [Google Scholar]
2. D. Das, S. Meiser, E. Mohammadi, and A. Kate, “Anonymity trilemma: Strong anonymity, low bandwidth overhead, low latency-choose two,” in 2018 IEEE Symp. on Secur. and Priv. (SP), San Francisco, CA, USA, 2018, pp. 108–126. [Google Scholar]
3. C. Zhang, C. Xu, J. Xu, Y. Tang, and B. Choi, “Gem2-tree: A gas-efficient structure for authenticated range queries in blockchain,” in 2019 IEEE 35th Int. Conf. on Data Eng. (ICDE), Macao, China, 2019, pp. 842–853. [Google Scholar]
4. X. Dai et al., “LVQ: A lightweight verifiable query approach for transaction history in bitcoin,” in 2020 IEEE 40th Int. Conf. on Distrib. Computing Syst. (ICDCS), Singapore, 2020, pp. 1020–1030. [Google Scholar]
5. C. Zhang, C. Xu, H. Wang, J. Xu, and B. Choi, “Authenticated keyword search in scalable hybrid-storage blockchains,” in 2021 IEEE 37th Int. Conf. on Data Eng. (ICDE), Chania, Greece, 2021, pp. 996–1007. [Google Scholar]
6. C. Xu, C. Zhang, and J. Xu, “vChain: Enabling verifiable boolean range queries over blockchain databases,” in Proc. 2019 Int. Conf. on Manag. of Data (SIGMOD), New York, NY, USA, 2019, pp. 141–158. [Google Scholar]
7. H. Wang, C. Xu, C. Zhang, J. Xu, Z. Peng and J. Pei, “vChain+: Optimizing verifiable blockchain boolean range queries,” in IEEE 38th Int. Conf. on Data Eng. (ICDE), Kuala Lumpur, Malaysia, 2022, pp. 1927–1940. [Google Scholar]
8. T. Murakami and Y. Kawamoto, “Utility-optimized local differential privacy mechanisms for distribution estimation,” in Proc. 28th USENIX Conf. on Secur. Symp., ser. SEC’19, Santa Clara, CA, USA, 2019, pp. 1877–1894. [Google Scholar]
9. G. Cormode, “Data sketching,” Commun. ACM, vol. 60, no. 9, pp. 48–55, 2017. [Online]. Available: https://api.semanticscholar.org/CorpusID:8697904 (accessed on 02/02/2024). [Google Scholar]
10. J. Kuszmaul, “Verkle trees,” 2019. [Online]. Available: https://api.semanticscholar.org/CorpusID:218475793 (accessed on 02/02/2024). [Google Scholar]
11. M. Ober, S. Katzenbeisser, and K. Hamacher, “Structure and anonymity of the bitcoin transaction graph,” Future Internet, vol. 5, no. 2, pp. 237–250, 2013. doi: 10.3390/fi5020237. [Google Scholar] [CrossRef]
12. F. Reid and M. Harrigan, “An analysis of anonymity in the bitcoin system,” in 2011 IEEE Third Int. Conf. on Priv., Secur., Risk and Trust and 2011 IEEE Third Int. Conf. on Soc. Comput., Boston, MA, USA, 2011, pp. 1318–1326. [Google Scholar]
13. P. Koshy, D. Koshy, and P. Mcdaniel, “An analysis of anonymity in bitcoin using P2P network traffic,” in Financial Cryptography, 2014. [Online]. Available: https://api.semanticscholar.org/CorpusID:225868 (accessed on 02/02/2024). [Google Scholar]
14. R. Dingledine, N. Mathewson, and P. Syverson, “Tor: The second-generation onion router,” in 13th USENIX Secur. Symp. (USENIX Security 04), San Diego, CA, USA, USENIX Association, Aug. 2004. [Google Scholar]
15. A. Biryukov and I. Pustogarov, “Bitcoin over tor isn’t a good idea,” in 2015 IEEE Symp. on Secur. and Priv., San Jose, CA, USA, 2015, pp. 122–134. [Google Scholar]
16. C. Yang, J. Chen, B. Zeng, and L. Liao, “Overview of blockchain privacy protection,” in 2022 IEEE 8th Int. Conf. on Big Data Secur. on Cloud (BigDataSecurityIEEE Int. Conf. on High Perf. and Smart Computing (HPSC) and IEEE Int. Conf. on Intell. Data and Secur. (IDS), Jinan, China, 2022, pp. 212–217. [Google Scholar]
17. F. K. Maurer, T. Neudecker, and M. Florian, “Anonymous coinjoin transactions with arbitrary values,” in 2017 IEEE Trustcom/BigDataSE/ICESS, Sydney, NSW, Australia, 2017, pp. 522–529. [Google Scholar]
18. I. Miers, C. Garman, M. Green, and A. D. Rubin, “Zerocoin: Anonymous distributed e-cash from bitcoin,” in 2013 IEEE Symp. on Security and Privacy, Berkeley, CA, USA, 2013, pp. 397–411. [Google Scholar]
19. N. van Saberhagen, “Cryptonote v 2.0,” 2013. [Online]. Available: https://api.semanticscholar.org/CorpusID:2711472 (accessed on 02/02/2024). [Google Scholar]
20. J. Zhang, “Research on business model governance and consumer privacy protection path of e-commerce industry based on blockchain technology,” in 2023 Int. Conf. on Distrib. Computing and Electrical Circuits and Electron. (ICDCECE), Ballar, India, 2023, pp. 1–6. [Google Scholar]
21. L. Guo and Z. Yan, “A privacy protection scheme for blockchain aggregation platform based on attribute-based and order-preserving encryption,” in 2023 8th Int. Conf. on Computer and Commun. Systems (ICCCS), Guangzhou, China, 2023, pp. 414–423. [Google Scholar]
22. A. Raj and S. Prakash, “A privacy-preserving authentic healthcare monitoring system using blockchain,” Int. J. Softw. Sci. Comput. Intell., vol. 14, no. 1, pp. 1–23, Oct. 2022. doi: 10.4018/IJSSCI.310942. [Google Scholar] [CrossRef]
23. J. Lu, J. Shen, P. Vijayakumar, and B. B. Gupta, “Blockchain-based secure data storage protocol for sensors in the Industrial Internet of Things,” IEEE Trans. Industr. Inform., vol. 18, no. 8, pp. 5422–5431, 2022. doi: 10.1109/TII.2021.3112601. [Google Scholar] [CrossRef]
24. Y. Zhang, Y. Zhu, Y. Zhou, and J. Yuan, “Frequency estimation mechanisms under (ϵ,δ) -utility-optimized local differential privacy,” IEEE Trans. Emerg. Topics Comput., pp. 1–12, 2023. [Google Scholar]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools