
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Adaptive Segmentation for Unconstrained Iris Recognition
1 Faculty of Architecture and Design, Al-Zaytoonah University of Jordan, Amman, 11733, Jordan
2 Faculty of Computer Studies, Arab Open University, Riyadh, 11681, Saudi Arabia
3 Faculty of Science and Information Technology, Al-Zaytoonah University of Jordan, Amman, 11733, Jordan
* Corresponding Author: Sally Almanasra. Email:
(This article belongs to the Special Issue: Advances and Applications in Signal, Image and Video Processing)
Computers, Materials & Continua 2024, 78(2), 1591-1609. https://doi.org/10.32604/cmc.2023.043520
Received 04 July 2023; Accepted 04 December 2023; Issue published 27 February 2024
 View Full Text
View Full Text Download PDF
Download PDFAbstract
In standard iris recognition systems, a cooperative imaging framework is employed that includes a light source with a near-infrared wavelength to reveal iris texture, look-and-stare constraints, and a close distance requirement to the capture device. When these conditions are relaxed, the system’s performance significantly deteriorates due to segmentation and feature extraction problems. Herein, a novel segmentation algorithm is proposed to correctly detect the pupil and limbus boundaries of iris images captured in unconstrained environments. First, the algorithm scans the whole iris image in the Hue Saturation Value (HSV) color space for local maxima to detect the sclera region. The image quality is then assessed by computing global features in red, green and blue (RGB) space, as noisy images have heterogeneous characteristics. The iris images are accordingly classified into seven categories based on their global RGB intensities. After the classification process, the images are filtered, and adaptive thresholding is applied to enhance the global contrast and detect the outer iris ring. Finally, to characterize the pupil area, the algorithm scans the cropped outer ring region for local minima values to identify the darkest area in the iris ring. The experimental results show that our method outperforms existing segmentation techniques using the UBIRIS.v1 and v2 databases and achieved a segmentation accuracy of 99.32 on UBIRIS.v1 and an error rate of 1.59 on UBIRIS.v2.Keywords
One of the most authentic forms of biometric identification is iris recognition. This is because the human iris has many unique characteristics, and its texture remains stable throughout the human life span [1]. However, high recognition rates have primarily been reported under ideal image acquisition conditions where a near-infrared (NIR) light source and a “stop-and-stare” camera interface are employed to capture high-resolution iris images at a short distance [2]. In all forms of biometrics identification, when relaxing image framework constraints, the segmentation accuracy significantly degrades. Therefore, the utilization of a time-consuming complex neural network was introduced [3].
In many real-world applications of iris recognition, however, the human subject may be located at a greater distance from the capture system, and the iris image may have a low resolution, be poorly lit, or be blurred. Relatively few studies to date (e.g., [2,4]) have addressed the challenges of unconstrained iris recognition. Although the proposed solutions in these works improve the performance of early iris recognition systems, they continue to have problems with feature extraction and segmentation.
In this study, we propose a reliable segmentation algorithm that correctly segments the inner and outer iris regions to suit recognition systems that capture iris images at long distances (up to eight meters) using a normal light source with a visible wavelength that does not harm human eyes. The proposed method first searches the HSV representation of the iris image for local maxima, which characterizes the sclera area. After the sclera recognition step, the image condition is assessed based on iris characteristics determined globally from the RGB color space. Following this quality assessment process, a Retinex filter is applied to enhance low-quality images and eliminate high-reflection spots from over-illuminated images without degrading high-quality images. Finally, an adaptive threshold is used to identify the external boundary of the iris. The image is then trimmed and converted to the HSV space to locate the pupil area.
The remainder of this paper is structured as follows. In Section 2, we review previously developed iris segmentation techniques. In Section 3, we present our proposed novel segmentation method. In Section 4, we compare our method to previous solutions for two standard iris image databases (UBIRIS.v1 [5] and UBIRIS.v2 [6]). In Section 5, we present the study’s conclusions and make suggestions for future work.
A new model for iris segmentation and localization called Iris Region-Based Convolutional Neural Network (R-CNN) was proposed in [7]. This model was designed to work in non-cooperative environments with visible illumination. The model combines the segmentation and localization tasks into a single framework using an end-to-end multi-task deep neural network approach. The Iris R-CNN model uses the Double-Circle Region Proposal Network (DC-RPN) and Double-Circle Classification and Regression Network (DC-CRN), two novel networks, to identify pupil and iris circles and improve iris localization accuracy. A new region of interest (RoI) pooling operation can be performed across a double-circle region, which is facilitated by the model’s innovative normalization technique for RoIs. Two open datasets, NICE-II and MICHE, were used to train and validate the model. Based on experimental findings, this strategy is more accurate than previous methods. While IrisParseNet achieved higher scores on the NICE-II dataset, Iris R-CNN was more accurate on the MICHE dataset in iris segmentation and localization.
The authors in [8] presented a novel iris segmentation approach using the V-Net architecture for more accurate iris recognition in biometric systems, particularly in challenging, non-cooperative environments. This approach addresses the limitations of traditional methods, which are impacted by factors such as blur, occlusion, and low resolution. The V-Net model precisely localizes iris image boundaries through semantic segmentation mask synthesis, and a color space segmentation technique further enhances the iris boundary points. This approach was applied to the UBIRIS dataset, achieving a 95.6% mean intersection over union (IOU) value, significantly outperforming the U-Net model with 92.3%. While the U-Net-based segmentation shows potential, the V-Net approach is superior in accuracy and quality, indicating the promise of deep learning techniques for biometric recognition systems.
The Hybrid Transformer U-Net (HTU-Net) is a revolutionary technique for comprehensive and precise iris segmentation [9]. This method is particularly useful in general contexts that frequently contain unwanted noise. The HTU-Net approach is unusual because it can simultaneously construct segmentation masks, such as parameterized pupillary and limbic borders, thus increasing the network’s applicability to conventional iris recognition systems. This model combines the advantages of convolution and transformer methods to extract the local intensity characteristics and record long-range associative information. To enhance segmentation by capturing the complete structural context of the iris from a categorical perspective, the researchers developed a unique Multi-Head Dilated Attention technique for feature refinement. Their experimental results demonstrated HTU-Net’s superior performance and improved parameter efficiency compared with previous models across multiple challenging iris image datasets.
Attention Mechanism U-Net++ (AM-UNet++), a cutting-edge iris segmentation technique, was presented in [10] to enhance the precision and effectiveness of iris identification systems. This method is particularly useful for iris photos captured in non-ideal conditions, which contain abundant noise and fluctuation. The AM-UNet++ model increases training time, reduces network parameters, and improves the model’s sensitivity and segmentation accuracy by combining EfficientNetV2 with an attention module included within the down-sampling procedure of the U-shaped network (UNet++). This method not only reduces unnecessary noise but also enhances the detection of the iris region. The model employs a pruning technique to build four performance networks to satisfy iris recognition requirements under various conditions. Studies on databases of iris images illuminated by two near-infrared light sources and one visible light source showed that the performance of AM-UNet++ greatly exceeds the most advanced fusion approach in its segmentation accuracy and effectiveness. However, this method’s network setting requires further optimization and reductions in terms of its hardware and computing requirements.
In [11], the authors presented a novel method, IrisGuideNet, for iris localization and segmentation in iris biometrics. The primary challenge in iris biometrics is dealing with unconstrained conditions, including off-angle images, irregular boundaries, and low-contrast images. IrisGuideNet addresses these issues by incorporating iris-specific features into a convolutional neural network (CNN) to enhance its learning capabilities. This approach reduces the network’s dependence on extensive labeled data, which is often a key limiting factor in model training. The proposed IrisGuideNet model introduces the iris regularization term for guided learning, an iris infusion module to refine predictions, and hybrid loss functions. A deep supervision technique is also used in this approach to maximize the utility of the limited available data. The model was evaluated on multiple datasets and outperformed most of its competitors across multiple database categories; however, this method could be further enhanced to be more lightweight and computationally efficient.
To deal with visual discrepancies caused by different camera sensors, the authors in [12] presented a unique, effective iris segmentation network. Most iris segmentation techniques are designed for a specific image acquisition device and have high computational and storage costs, rendering them unsuitable for low-performance computing devices. To address these problems, the authors develop a fusion feature extraction network combining depth wise separable convolution with conventional convolution methods. This approach reduces the number of parameters and the model’s complexity while maintaining accuracy. They employed a feature extraction method based on a multi-scale context information extraction module to obtain more precise features and multi-scale spatial information and enhance the iris region’s discriminability. A multi-layer feature information fusion module is also recommended to reduce information loss during the down-sampling process. Based on experimental results, the suggested network provides cutting-edge performance with reduced parameters, computational load, and storage space demands. Additionally, this method has strong migration and generalization capabilities, enabling end-users to utilize different acquisition devices in their iris recognition systems.
The authors in [13] presented a robust iris segmentation architecture, Dense-Fully Convolutional Network (DFCN), which improves upon conventional CNNs used in iris recognition systems. Traditional iris segmentation algorithms struggle with adaptability and robustness under non-ideal conditions. To address these issues, the DFCN method incorporates dense blocks and popular optimization techniques to enhance segmentation accuracy. The system’s performance was assessed on the CASIA-Interval-v4, IITD, and UBIRIS.v2 public iris datasets. The regions required manual tagging using Labelme software to address the fact that no eyelash regions were identified in these databases. In terms of accuracy, precision, recall, and other important parameters, DFCN outperforms both traditional and alternative CNN-based iris segmentation methods. Notably, this system performs more effectively on public ground-truth masks than on those that have been manually labeled. However, future studies should focus on developing algorithms that are more resilient to non-ideal conditions and improving labeling techniques.
The model proposed in [14] offered an effective and reliable iris identification approach created specifically for non-ideal imaging conditions, such as photos captured while the iris is in motion or at a distance. Using a pupil segmentation strategy, this method eliminates noise issues such as loss of concentration, gaze deviation, and blockage by eyelids, hair, and glasses. A multi-scale gray-level co-occurrence matrix (MSGLCM) and a multi-range circle Hough transform (MRRCHT) are combined in this approach. The researchers also used pre- and post-processing methods to further increase the segmentation accuracy. A performance evaluation conducted on the CASIA v4.0 (Distance) and MMU v2 databases revealed that this method considerably improved the recognition accuracy and processing time compared with other contemporary techniques. Future enhancements may include the application of advanced denoising techniques.
The Interleaved Residual U-Net (IRUNet) method was introduced in [15], which is intended for iris identification systems in non-ideal situations in which issues such as occlusion, blurring, off-axis images, motion, low image resolution, and specular reflections present segmentation challenges. The iris image’s outer and inner boundaries are precisely localized in this method using iris mask synthesis and semantic segmentation. The outer iris boundary is recovered using saliency points and K-means clustering, while the inner border is recovered using a different set of points on the inner side of the mask. The IRUNet method outperforms other approaches on the CASIA-Iris-Thousand database, with mean IOU values for inner and outer border estimates of 98.9% and 97.7%, respectively. Despite the model’s considerable promise, the authors highlight difficulties caused by inaccurately predicted masks or severe occlusion and recommend further research into reducing the model’s computational demands without compromising accuracy or effectiveness.
In [16], an enhanced iris recognition system was presented, which leverages the Daugman algorithm and multi-level Otsu thresholding to improve image quality and overall performance. The system runs on a Raspberry Pi 4 Model B and takes iris pictures using a Raspberry Pi Camera NoIR. These are improved via multi-level Otsu thresholding, and the Daugman method is then used to localize the iris. Two databases, one containing raw photographs and the other containing improved images, were used to evaluate the system’s accuracy. Compared with the raw picture database (94.23%), the database containing improved photos yielded a higher accuracy rate (96.60%). The researchers concluded that there is a significant improvement in the functionality of the iris recognition system due to the application of multi-level Otsu thresholding. To further improve picture quality and system performance, they recommend using more powerful computer hardware and higher-quality cameras for future studies. The authors also suggested improvements in the iris recognition system’s adaptability could be achieved through improvements in software development and algorithm encoding.
In [17], an effective, unconstrained iris recognition system built around the circular contourlet transform (CCT) was introduced. This system utilizes a CCT-based filter bank for feature extraction, which improves the recognition of anisotropic 2D features in iris images. In contrast to conventional methods, the CCT can reliably capture the multi-scale and multi-phase properties that frequently occur in iris images due to variable eye alignment or varied iris patterns. A shorter feature vector is produced by the system’s feature extraction procedure, thus improving the system’s speed and efficiency, which are essential for practical applications. This approach only uses one sub-band of the eight inputs and five of the seven components from the gray-level co-occurrence matrix to create feature vectors, further reducing computing complexity. Overall, this system offers an iris recognition solution that is relatively efficient, quick, and simple, making it well-suited for practical applications.
In [18], adaptive deep learning was applied in the iris recognition model to enhance human identification. In this method, the iris is segmented using the Hough Transform with K-means clustering and recognized using an enhanced Faster Region CNN (R-CNN). A novel adaptive sailfish optimization technique is used to optimize the Faster R-CNN, increasing the model’s performance. The model was tested on publicly available IIT Delhi and MMU iris datasets. The results demonstrate that this technique achieves improved segmentation accuracy, recognition rate, and computational efficiency compared with conventional models and several state-of-the-art iris recognition models. This method has potential applications in real-time systems, such as secure access to bank accounts, secure financial transactions, wireless device authentication, and forensics. Future research on this model may involve testing on larger datasets.
In [19], the authors proposed a novel fusion-based approach for iris recognition in an unconstrained environment. This technique uses three different models that integrate residual and convolutional blocks to boost iris identification performance for a variety of sensors. Based on the error rate, the best-performing model uses a different arrangement of convolutional and residual blocks from those applied in conventional methods to accelerate weight updates and resolve the vanishing gradient problem. The model is then integrated with a scale-invariant feature transform and Binarized Statistical Information Features to further improve the extraction of iris features. The experimental results, obtained from an analysis of two publicly available iris databases, exhibit error rates of 1.01% and 1.12%, demonstrating a significant improvement over existing methods. Despite these advancements, the study identifies potential challenges, such as the need for larger and more uniformly distributed iris datasets and the capacity to distinguish between numerous iris categories.
In [20], Daugman used a method that assumes the pupil and iris are both round. He used the integro-differential operator in this approach to determine the radius and central point for the external and internal border of the iris. The operator looks for the circular trajectory that has a pixel intensity with the greatest range. Before applying the integro-differential operator, histogram equalization is used to improve the distinction between the pupil, sclera, and iris.
An edge map of the eye was obtained by Wildes et al. using the Canny edge detector [21]. In their approach, this edge map is then subjected to the circular Hough transform. All the points along the edges cast a vote to determine the radius and center coordinates for a specific contour. The intensity of the greyscale image is weighted to provide various orientation ranges. To identify the arcs of the lower and upper eyelids, horizontal points are used to provide more information. In contrast, the vertical edge map is used to identify the circles of the pupil, sclera, and iris edge points. Each point from the vertical edge map contributes to determining the radius and center of each feature, where a circle with an increasing radius is centered at the edge point. The radius is determined by measuring the gap between the points retrieved from the edges that comprise the circumferences and the identified center. The point with the most circumference intersections is determined as the center of the circle. The horizontal edge map is subjected to the parabolic Hough transform with arc parameters rather than circular parameters to identify the top and bottom eyelids.
In [22], Camus et al. localized the external and internal borders of the iris. This was achieved by analyzing the directional changes in image intensity along the radius of the iris. They also use specularity filling to minimize the influence of specular reflections.
In [23], a new sub-iris recognition method was proposed to improve accuracy under non-ideal conditions like off-angle, motion blur, and occlusion. The technique extracts features from sub-regions of the iris using 2D wavelet decomposition. Matching incorporates weights for different sub-iris regions based on quality. The technique achieves higher recognition rates on noisy datasets than prior methods while requiring less time. The study demonstrates the potential of sub-iris methods for robust recognition with non-ideal iris images.
In [24], a new pupil segmentation technique for iris recognition systems was presented. It uses Fast Fourier Transform (FFT) and Radon transform for coarse localization followed by Random sample consensus (RANSAC) circle fitting for refinement. Morphological processing further improves segmentation. On CASIA-Irisv4, the method achieves 99.1% accuracy with fast processing. The study demonstrates efficient and accurate pupil segmentation, which can enhance overall iris recognition performance. The proposed approach has advantages over prior techniques in speed, accuracy, and efficiency.
In the research by Chen et al. [25], an algorithm was proposed based on the adaptive mean shift procedure. This approach allows segmentation from a fine to coarse scale. It then looks for the pupil area within a greyscale image to approximate the iris’s center location. A 2D Gabor filter is used to capture the gradient features. The active contour technique is then applied to accurately determine the iris’s external and internal borders.
In [26], a novel approach for segmenting iris images affected by noise was introduced to determine the high-intensity pixels that represent the sclera area and identify the eye region within the provided images. This approach first analyses the sclera’s chromatic blue, hue, and chromatic red spaces. Following eye recognition, a feature extraction technique based on Zernike moments is implemented on each pixel in the provided image. The collected features are then fed into a learning algorithm that uses a neural circuit and a support vector machine to divide the pixels into two categories: iris-associated and non-iris-associated.
In [27], the authors utilized an altered form of Daugman’s integro-differential operator after applying a circular Gabor filter to obtain the pupil area. The external and internal iris borders are subsequently determined using the integro-differential operator. The upper and lower eyelids are then found using the live-wire approach.
In summary, a wide range of approaches have been used for iris recognition. Each of these techniques has unique characteristics, which are summarized in Table 1.
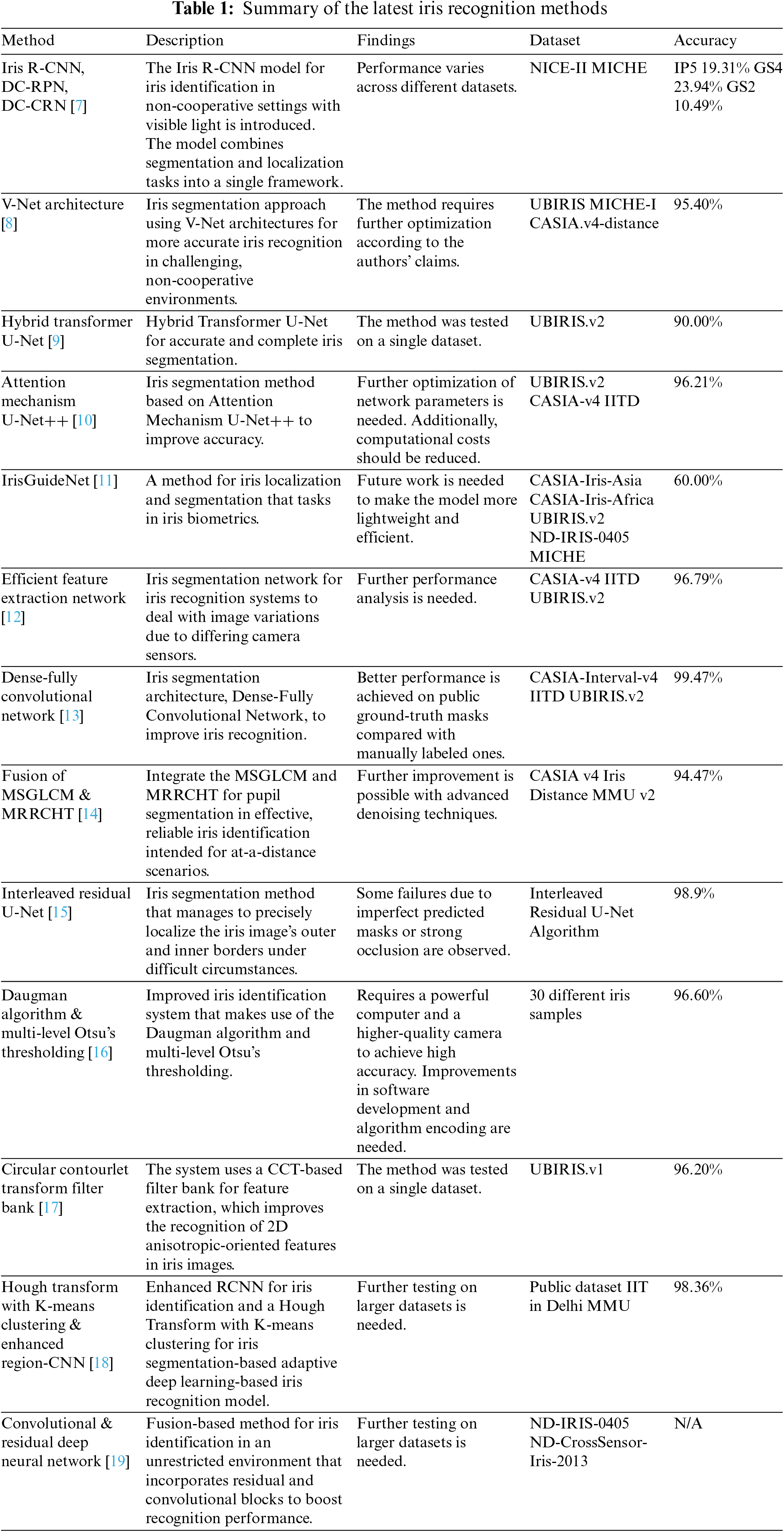
While the reviewed papers cover many iris segmentation and recognition techniques, limitations remain in terms of generalization across diverse datasets and real-world conditions, computational efficiency for practical usage, and accuracy under non-ideal imaging factors like noise, occlusion, and motion blur.
On the other hand, this research aims to tackle some of these gaps by developing an efficient convolutional neural network model for iris recognition that leverages data augmentation to reduce reliance on large, labeled datasets, uses attention mechanisms for improved feature representation, and is designed to be robust to non-ideal imaging conditions through multi-phase training. The goal is to move toward an iris recognition method with strong generalization capabilities across datasets and scenarios for real-world applicability.
Our proposed method first segments the iris image by detecting the sclera. The image is then classified, and a suitable filter is applied. A binary image is obtained by transforming the RGB image for outer ring segmentation. Finally, the HSV color space is utilized to identify the pupil, which is obtained by transforming the resulting image (Fig. 1). In the following sections, we explain each step of the method in detail, and the method’s workflow is summarized in Fig. 2.
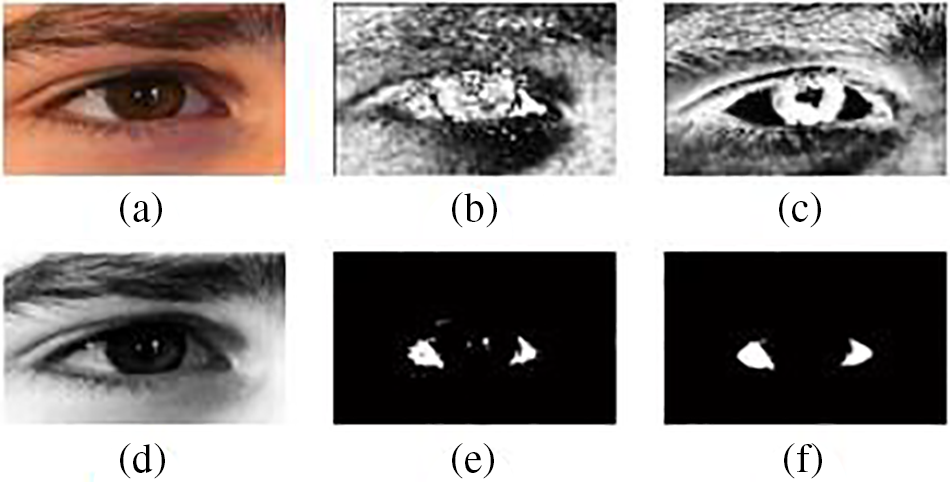
Figure 1: (a) Original image, (b) hue, (c) saturation, (d) value, (e) masked image, and (f) filtered image
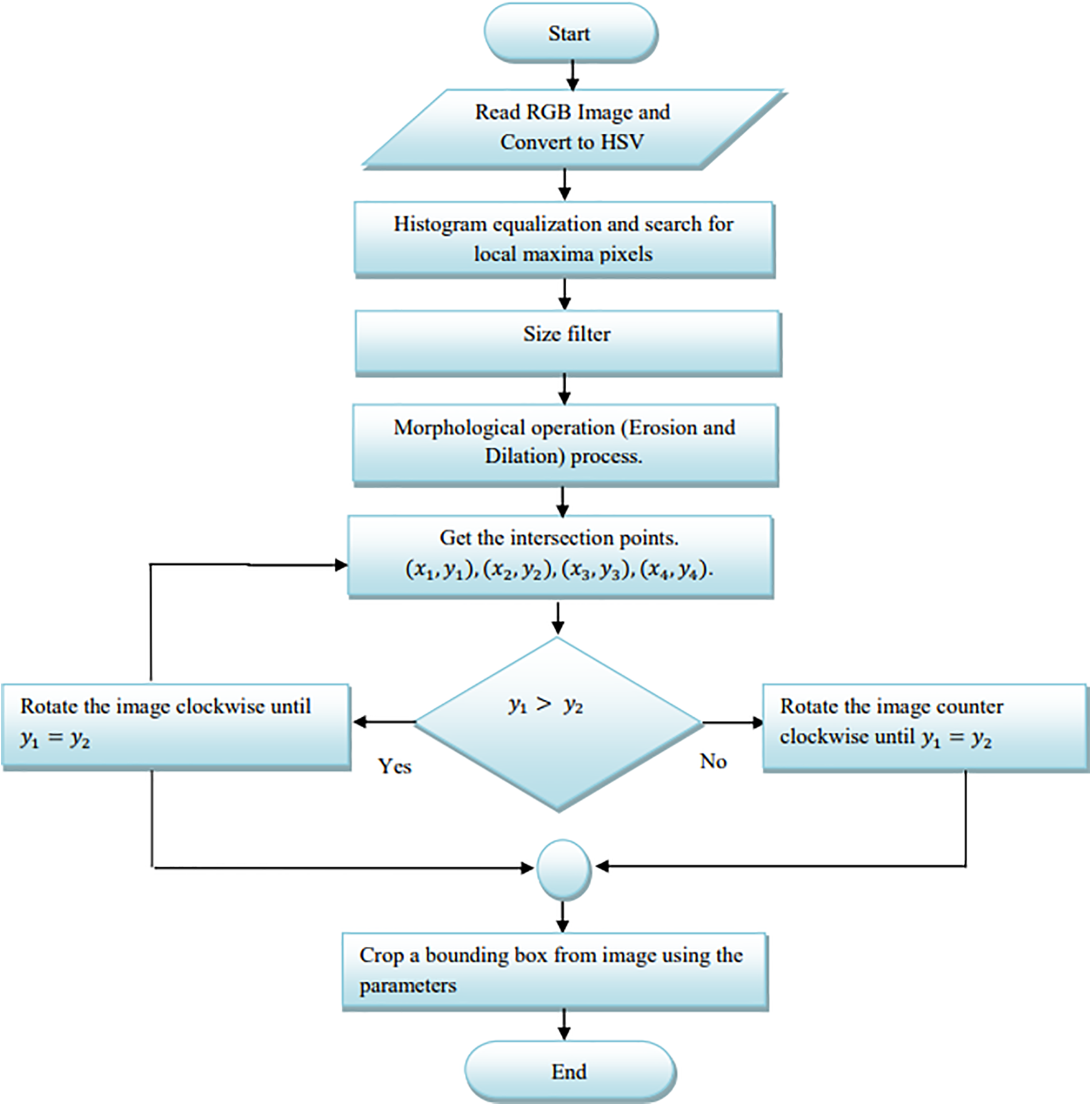
Figure 2: Flow chart for sclera detection
Because of its inherent resilience against reflections, a conversion is performed from RGB to HSV color space, followed by a histogram equalization operation. A search is then conducted to identify local maxima, which correspond to regions characterized by intense color, specifically white pixels. This is achieved by applying the mask equation:
where the H, S, and V thresholds are obtained experimentally. As the resulting binary image is typically non-smooth and contains gaps, we process it using a size filter. Then, we use the dilation and erosion operators to fill the voids and smooth the borders. At this stage in the process, the entire eye image has been split, and only the sclera region has been determined, as shown in Fig. 1. The primary goals of this method are to determine the eye’s angle of rotation, reduce the search area for iris segmentation, and standardize the iris area to a given size. Separate searches are conducted for the sclera’s right, left, lower, and upper sides to identify the five initial black pixels with a consistent spacing of 10 pixels between them. A tangent intersecting the lower and upper observed pixels from the two sides is created using linear polynomial fitting [28]. The RoI forms a rectangle that intersects all of the intersection sites of tangents at points (x1, y1), (x2, y2), (x3, y3), and (x4, y4), as shown in Fig. 3. To reduce the impact of rotation, we rotate the generated image until the y-coordinate y1 is aligned with y2. The RGB version is recreated by applying a multiplication operation on the input and output images and cropping the image to a bounding box with dimensions of x1 – x2 and y3 – y4.
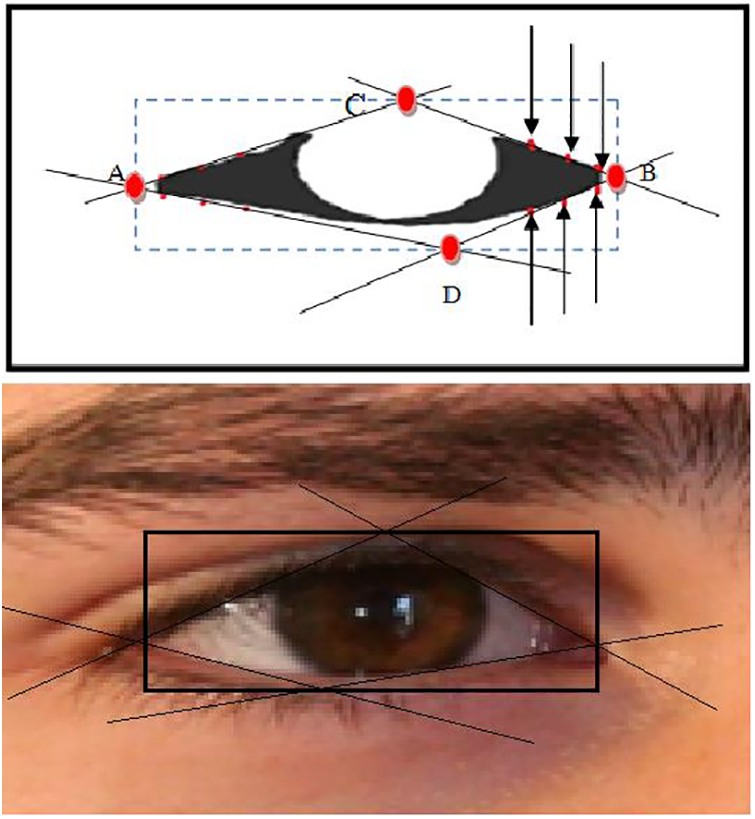
Figure 3: Bounding box. The points A, B, C, and D have coordinates (x1, y1), (x2, y2), (x3, y3), and (x4, y4), respectively
During this stage, the outer iris ring is segmented. Fig. 4 illustrates the flowchart of this step. Based on experiments conducted using 15,000 iris images, we observed that the green and blue values of an RGB iris image are more stable than the red values. If the lighting conditions changed when capturing the same image, the average blue and green values varied by 5%–15%, whereas the mean values of the red channel exhibited fluctuations of 10%–35%.
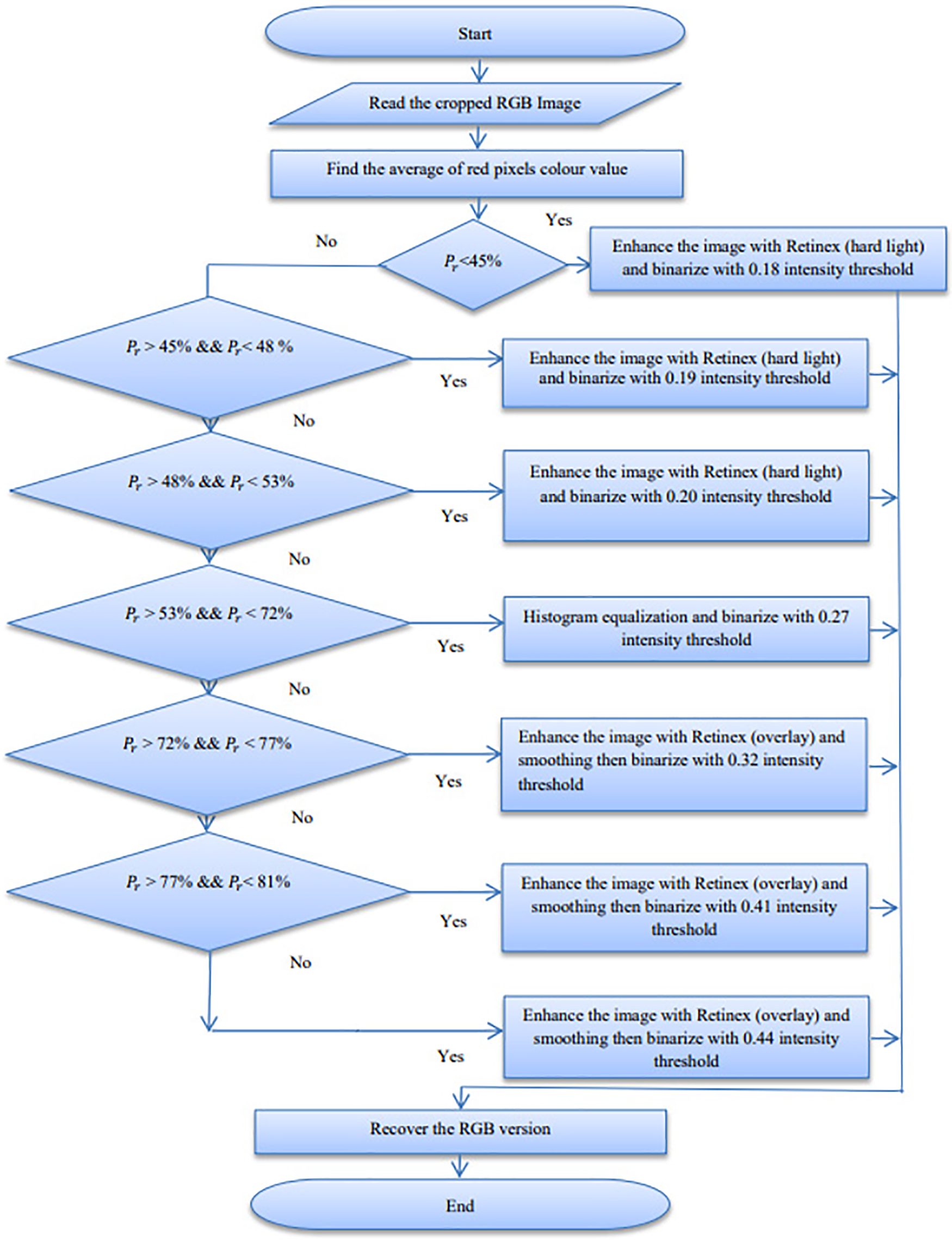
Figure 4: Outer iris segmentation flowchart. The parameter Pr is the normalized average mean of the red value
Based on the mean of the red values, we classified the iris images into seven categories. The first three correspond to dark iris images, inadequately illuminated irises, and images with poor focus. We processed these classes using a Retinex algorithm [29] to enhance their contrast (Fig. 5). The fourth category consists of clear images that do not require preprocessing. The final three categories encompass images featuring specular reflections, light reflections, and those containing glasses. Contrast enhancement was applied to these image groups, followed by a smoothing step.
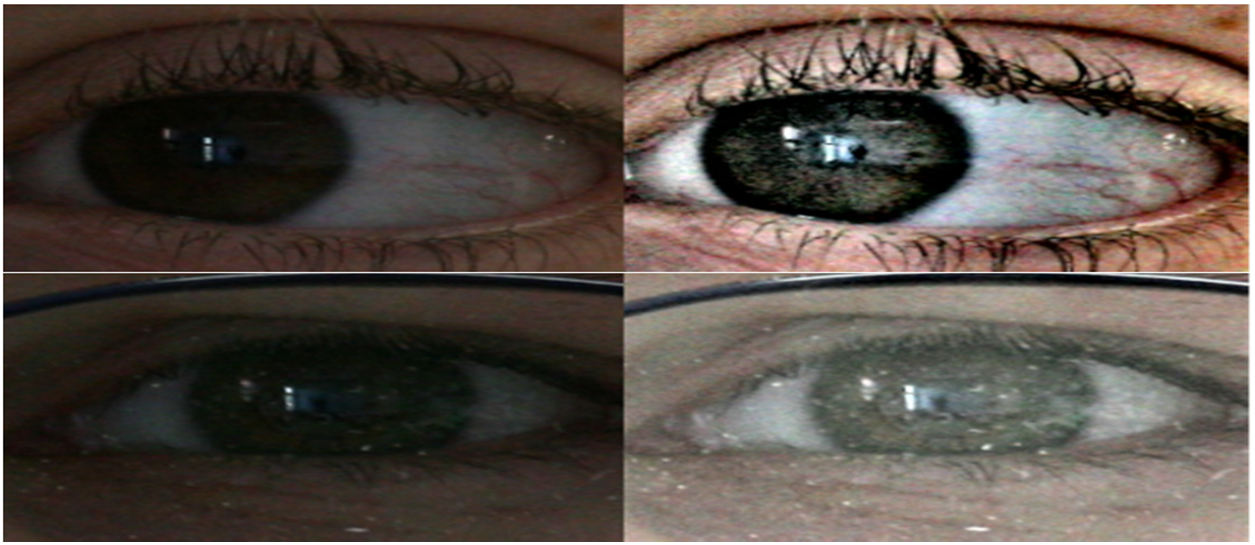
Figure 5: Retinex filter
The pupil is retrieved in this step. To do so, we look for local minima in the HSV color space, as the pupil represents the darkest part of the image. These are defined as regions in which 0.2 < H < 0.8, 0 < S < 0.5, and 0 < V < 0.32. The detected area will not be smooth or circular due to the effects of noise, especially strong reflections. The following filtering steps were then applied:
• Size and area determine the segmented area’s size and identify noise clumps.
• Structure fills the gaps between observed blobs.
• Circle gives the region a circular shape.
After performing this filtering, we then crop the relevant circular area from the input image based on its center and radius values. The result is an iris image that resembles a torus, with occlusions from the eyelashes and eyelids. These areas should be eliminated as they can potentially alter the features that can be recovered from the segmented image.
The locations E(x5, y5), F(x6, y6), G(x7, y7), and H(x8, y8) that correspond to the lower and upper boundaries of the iris are obtained from the sclera detection step (Fig. 6). To remove the top and lower eyelids, a cropping technique can be employed by defining a region located above the upper coordinates (y5 + 5, y6 + 5) and below the lower coordinates (y7, y8). This approach minimizes the potential obstruction caused by the eyelashes, which tend to conceal the corners of the sclera, particularly toward the upper extreme of the image. To account for this effect, an additional five pixels were included in the upper coordinates. This only does not occur if points x5 and x6 are separated by fewer than five pixels; in this instance, cropping is not necessary. A flowchart illustrating the segmentation process of the inner iris is also shown in Fig. 7.
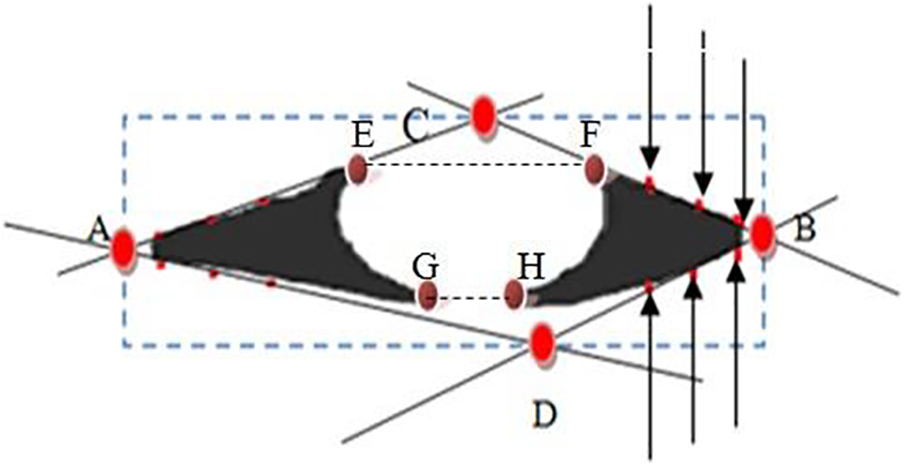
Figure 6: Bounding box
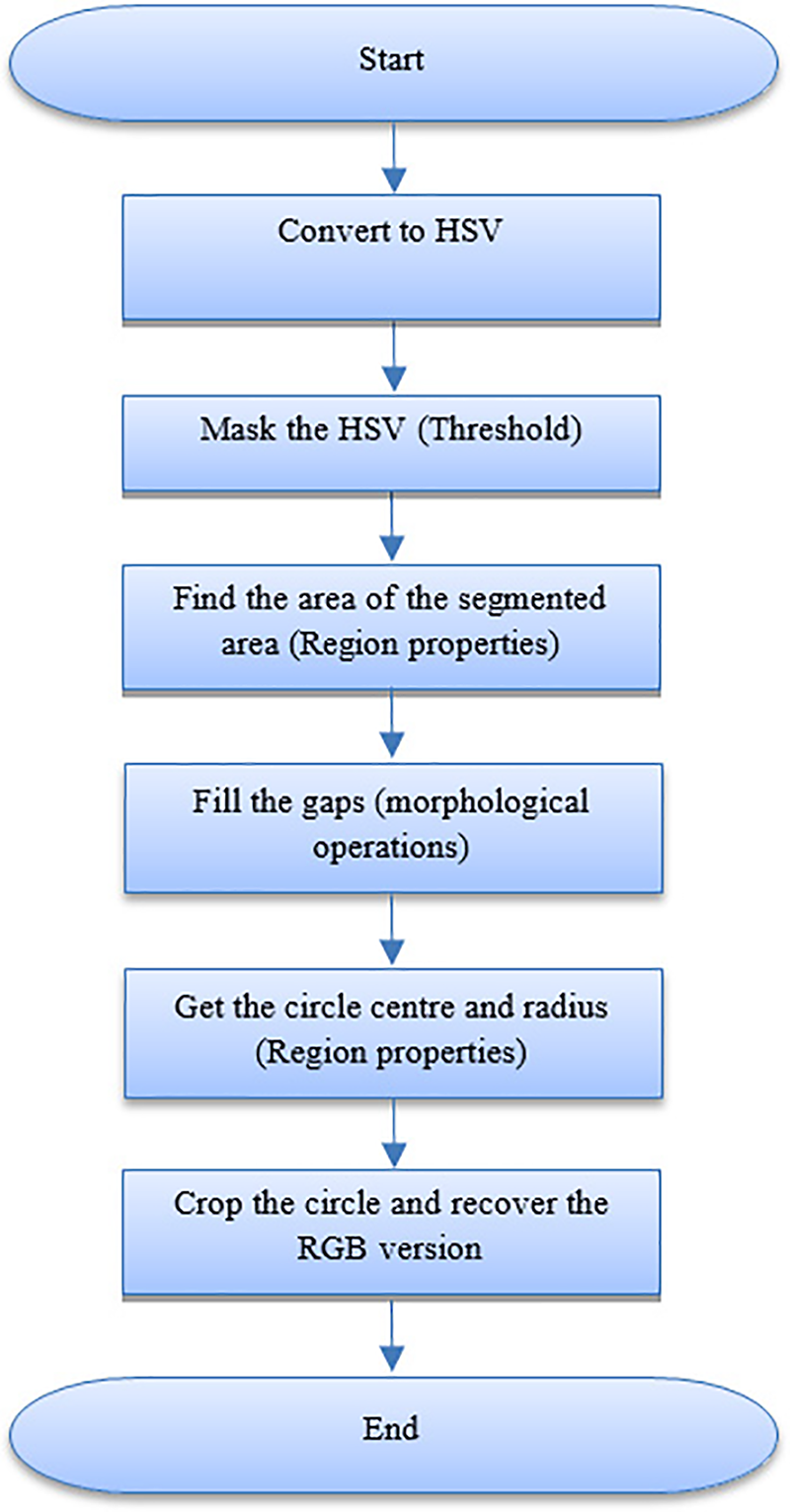
Figure 7: Inner iris segmentation
We tested our segmentation method on the widely used UBIRIS.v1 and UBIRIS.v2 databases. The first database contains a total of 1877 iris images collected from 241 different people. The images in this database were acquired using a Nikon E5700 camera during two sessions. The light source used for the image acquisition emitted visible-wavelength light. The noise-related variables in this dataset include motion blur, occlusion from eyelashes and eyelids, rotation, specular reflections, lack of focus, light reflections, and closed eyes.
Compared to the first version, the noise components were more noticeable in the second. A total of 11,102 iris pictures from 261 people are included in the UBIRIS.v2 database. The test volunteers were instructed to stroll more slowly than usual toward the acquisition camera (Canon EOS 5D). In this database, the subjects were asked to look at pre-placed lateral indicators, which made them turn their heads. The images were acquired using a visible-wavelength light source, and three photos were captured per meter of movement. The iris images in this database were affected by 14 distinct noise variations, including off-angle images, poor focus, rotation, motion blur, obstructions caused by eyelids, eyelashes, glasses, contact lenses, or hair, poor lighting conditions, specular reflections, lighting reflections, partially captured irises, dark irises, and out-of-iris images.
To test our proposed segmentation method, the algorithm was implemented in MATLAB on a workstation with an Intel Core i7 CPU and 16 GB of RAM. The maximum processing time for a single complete iris segmentation in the UBIRIS.v1 was 1.2 s, while the time complexity increased in UBIRIS.v2 to 2.7 s.
Table 2 compares the segmentation accuracy of our method with that of the techniques presented in [17,20,21,22,23] for the whole UBIRIS.v1 database. The segmentation accuracy was determined by visual inspection.
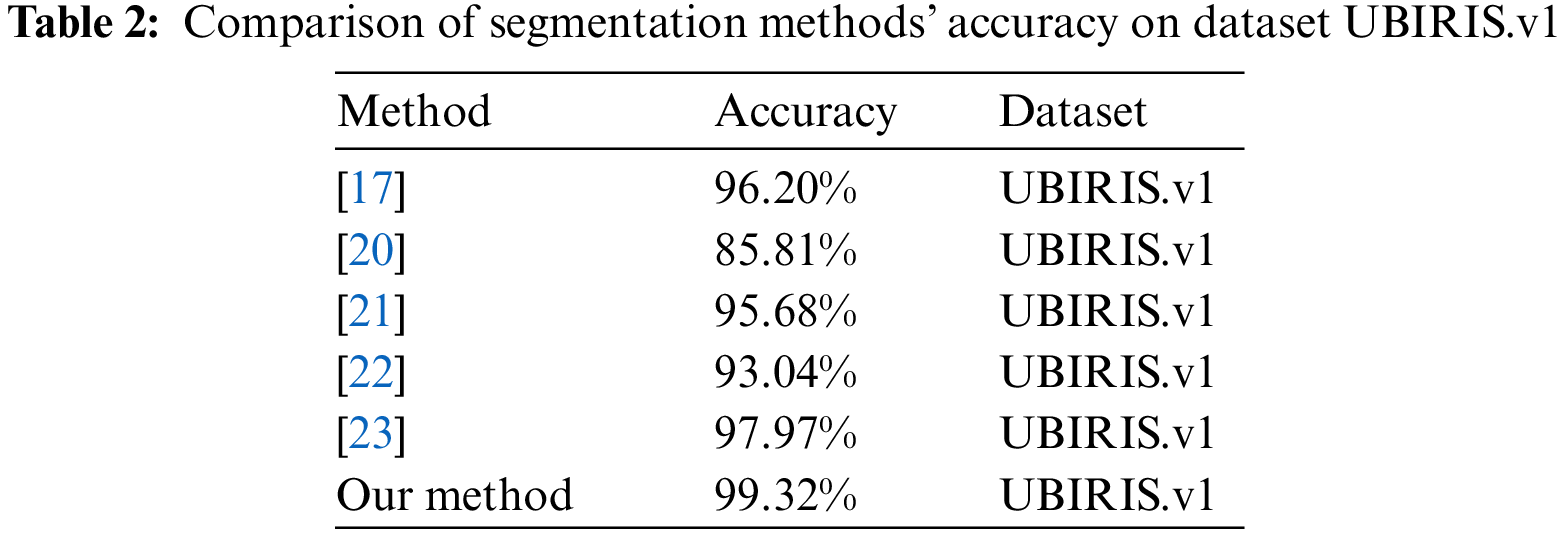
For the two sessions in UBIRIS.v1, our segmentation method achieved the highest accuracy. The fundamental benefit of Daugman’s integro-differential operator method is its parameter value-independent nature; however, the outcomes in Table 1 demonstrate that the approach is noise-sensitive. In particular, the segmentation accuracy drastically declined during the first and second sessions of UBIRIS.v1. When used on high-quality images, the approaches of Wildes et al. [21] and Camus et al. [22], which are based on the circular Hough transform, proved reliable; however, their accuracy markedly decreased on noisy images. The Proenca and Alexandre algorithm [23], based on a circular Hough transform after the application of an instant textural segmentation function, was the best-performing previously published algorithm in this comparison. However, the technique was vulnerable to noise that interfered with the creation of edge maps. Fig. 8 compares the iris segmentation using Daugman’s method and our suggested method.
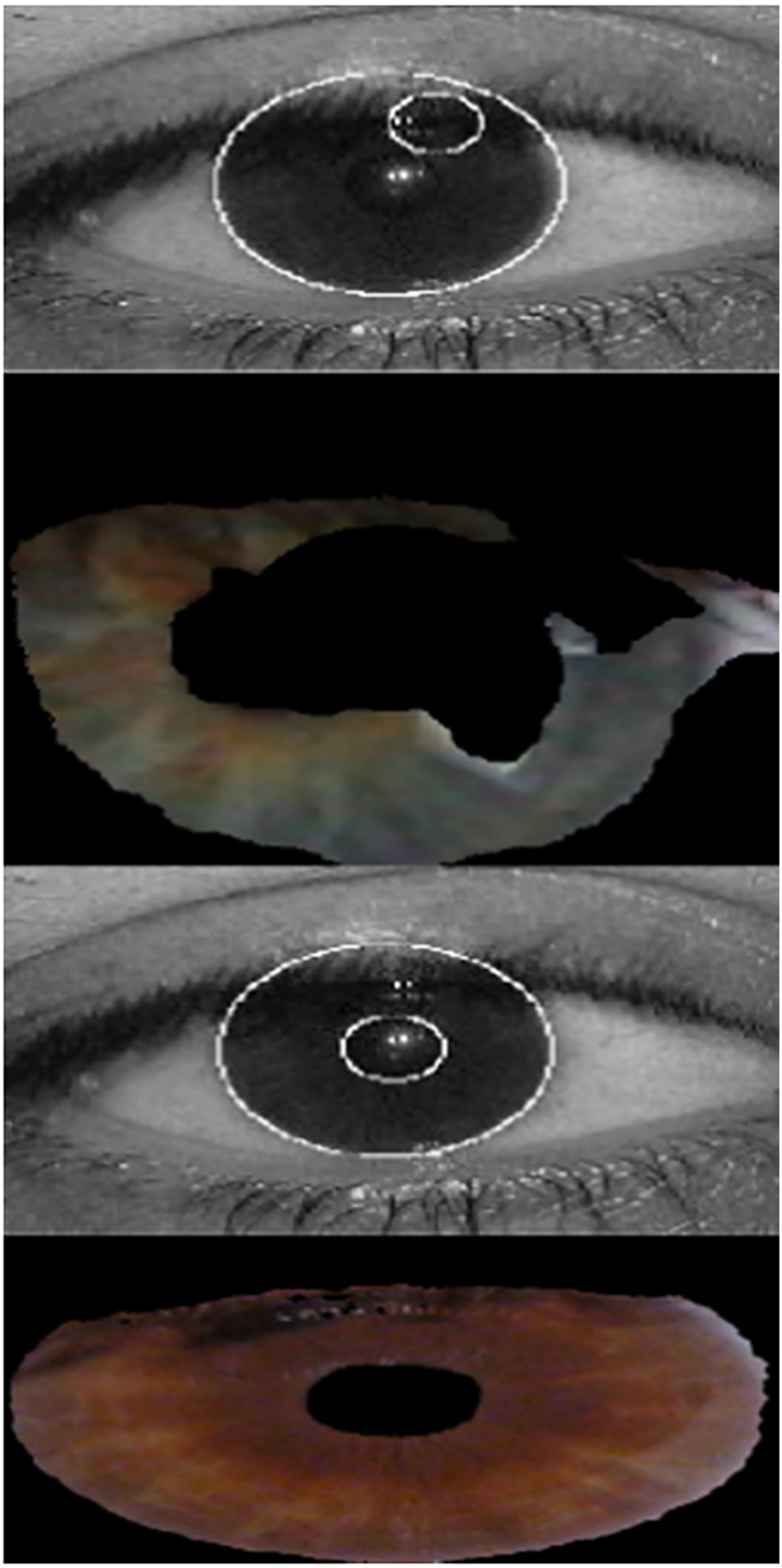
Figure 8: Iris segmentation with Daugman’s method (top two images) and our proposed method (two bottom images)
Table 3 compares the segmentation results of our method with those presented in [25,27,30,31]. For this evaluation, we used the NICE.II database. This includes 1000 images randomly selected from UBIRIS.v2 and their respective manually created templates (ground truth). The error rates shown in Table 3 correspond to the percentage of misclassified pixels.
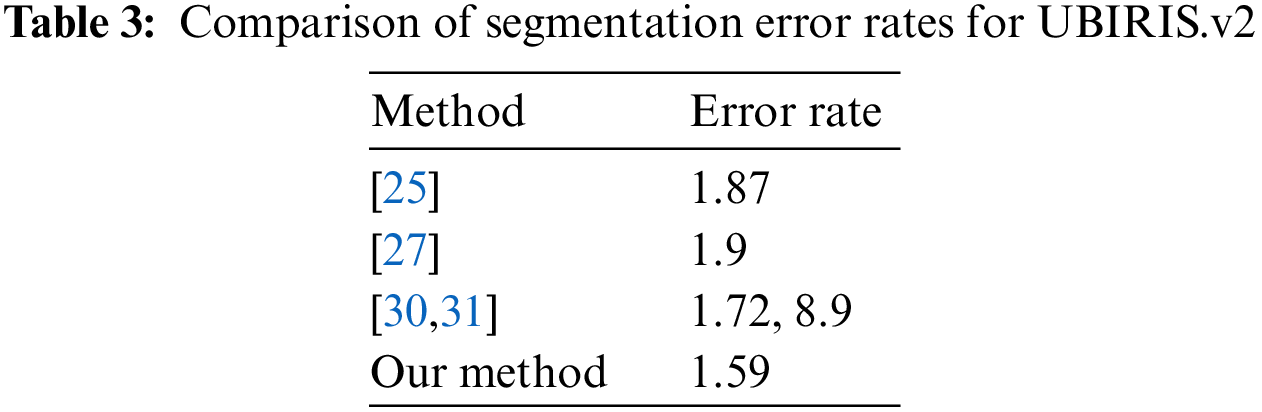
The segmentation accuracy achieved by our method was higher than that of the three previously published methods for two key reasons. First, our approach identifies the sclera in the HSV space, which is less susceptible to reflections than the RGB space. Second, our method classifies the input images based on their quality and applies suitable filters (e.g., dark images are enhanced with a Retinex (hard-light) filter, and images with a high level of reflected light are corrected with a combination of the Retinex (overlay) technique and Gaussian smoothing). This differs from the previous methods, which apply the same filters across all images, regardless of the type of noise they contain. Fig. 9 shows a comparison between the results of our segmentation method and the corresponding template created by human segmentation, and Fig. 10 shows the iris image after each step from the sclera detection phase to the pupil segmentation phase.

Figure 9: Manually segmented (left), segmented with our method (right)
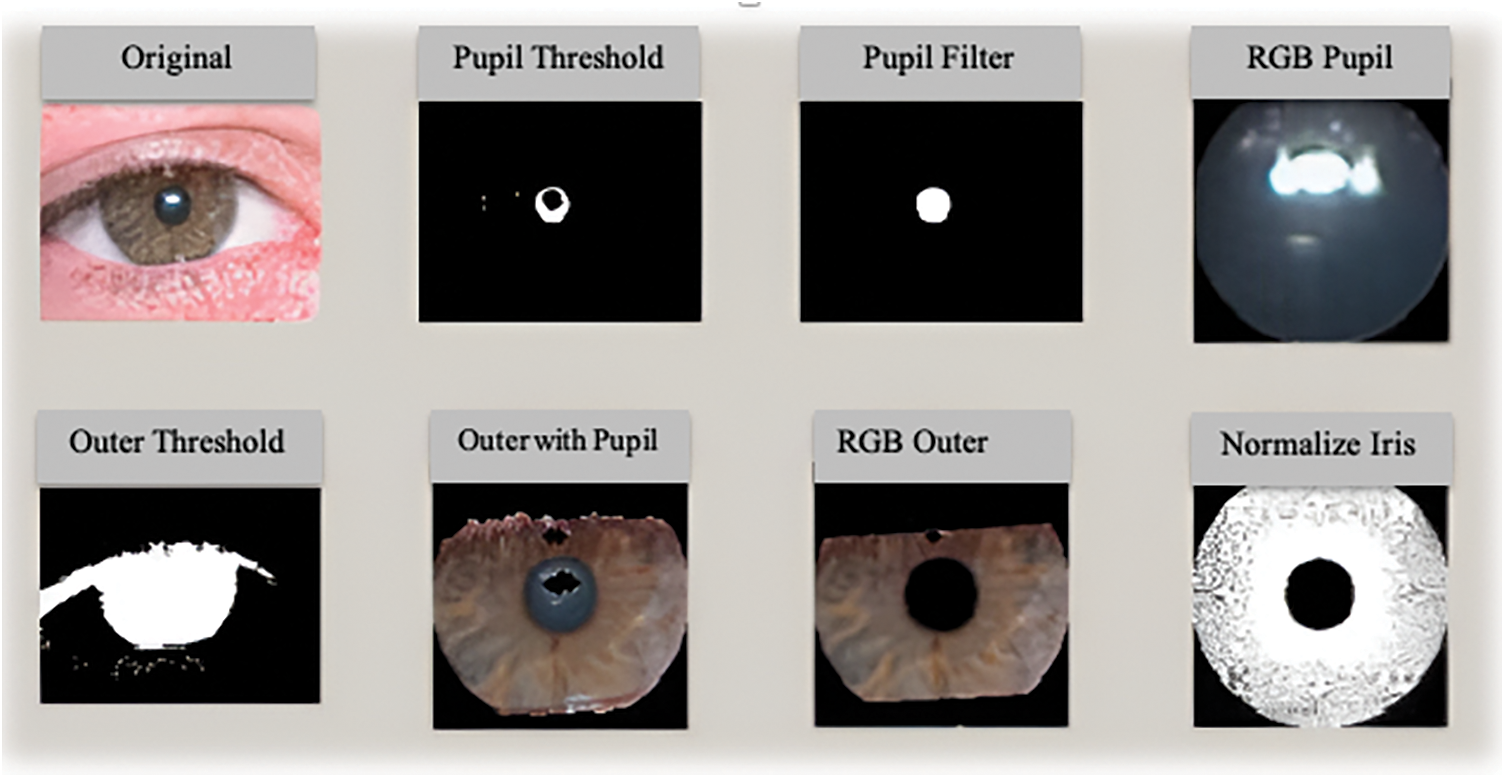
Figure 10: Output of the proposed segmentation algorithm
Our iris recognition system demonstrates strong performance relative to other state-of-the-art techniques and overcomes some limitations of prior methods. However, there is still room for improvement-the system struggles with high false rejection rates when facing major occlusion issues, significant gaze direction changes, or low-lighting capture conditions.
In this research, we proposed a new segmentation algorithm for iris images. The key idea behind our method is to first detect the white sclera part of the eye in the HSV color space, which allows us to isolate the iris region effectively. Before actually segmenting the iris, we have an important quality assessment step-based on features extracted from the RGB image, we judge if the image is low/high quality and accordingly apply a suitable enhancement technique (Retinex filter) to improve contrast. This step sharpens up low-contrast images but avoids unnecessary processing of good-quality images. With the enhanced RGB image, we next use an adaptive thresholding technique to binarize and detect the outer circular iris boundary. Finally, by switching to HSV space and finding local minima representing the darker pupil region, we can segment the complete iris region accurately. We tested our algorithm extensively on the UBIRIS.v1 and UBIRIS.v2 databases which are challenging real-world datasets. Results demonstrate superior performance of our technique compared to previous iris segmentation methods.
Acknowledgement: The authors would like to thank the Arab Open University, Saudi Arabia, and Al-Zaytoonah University, Jordan, for providing the necessary scientific research supplies to implement this research.
Funding Statement: The authors extend their appreciation to the Arab Open University, Saudi Arabia, for funding this work through AOU research fund No. AOURG-2023-009.
Author Contributions: The authors confirm their contribution to the paper as follows: Proposal and implementation and design: Mustafa AlRifaee, Adnan Hnaif; literature review: Ahmad Althunibat, Thamer Alrawashdeh; testing: Sally Almanasra, Mohammad Abdallah. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: The UBIRIS.v1 and UBIRIS.v2 iris image databases used in this study are publicly available for research purposes. The UBIRIS.v1 database can be requested from http://iris.di.ubi.pt/ubiris1.html, and the UBIRIS.v2 database is available at http://iris.di.ubi.pt/ubiris2.html. These standard databases have been widely used to develop and test iris recognition algorithms. The manually created ground truth segmentation data used for the quantitative evaluation of our method is not included in the public databases. This data was created internally during our experiments and is unavailable for public release at the time of publication. However, interested researchers can reproduce the quantitative results using the public UBIRIS databases along with the details provided in the manuscript regarding our experimental setup, evaluation protocol, and performance measures.
Conflicts of Interest: The authors declare they have no conflicts of interest to report regarding the present study.
References
1. J. Daugman, “How iris recognition works,” IEEE Transactions on Circuits and Systems for Video Technology, vol. 14, pp. 21–30, 2004. [Google Scholar]
2. H. Proenca, “On the feasibility of the visible wavelength, at-a-distance and on-the-move iris recognition,” in Proc. of IEEE Workshop on Computational Intelligence in Biometrics: Theory, Algorithms, and Applications, Nashville, TN, USA, pp. 9–15, 2009. [Google Scholar]
3. A. Omaima, T. Abdelfatah and A. Mohammad, “Face recognition system based on different artificial neural networks models and training algorithms,” International Journal of Advanced Computer Science and Applications, vol. 4, no. 6, pp. 40–47, 2013. [Google Scholar]
4. D. S. Jeong, H. A. Park, K. R. Park and J. Kim, “Iris recognition in mobile phone based on adaptive Gabor filter,” Advances in Biometrics, vol. 3832, pp. 457–463, 2005. [Google Scholar]
5. H. Proenca and L. A. Alexandre, “UBIRIS: A noisy iris image database,” in Proc. of 13th Int. Conf. on Image Analysis and Processing, Calgary, Canada, pp. 970–977, 2005. [Google Scholar]
6. H. Proenca, S. Filipe, R. Santos, J. Oliveira and L. A. Alexandre, “The UBIRIS.v2: A database of visible wavelength iris images captured on-the-move and at-a-distance,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 32, pp. 1529–1535, 2010. [Google Scholar] [PubMed]
7. X. Feng, W. Liu, J. Li, Z. Meng, Y. Sun et al., “Iris R-CNN: Accurate iris segmentation and localization in non-cooperative environment with visible illumination,” Pattern Recognition Letters, vol. 155, pp. 151–158, Elsevier B.V, 2022. [Google Scholar]
8. A. Banerjee, C. Ghosh and S. Mandal, “Analysis of V-Net architecture for iris segmentation in unconstrained scenarios,” in SN Computer Science. vol. 3, pp. 1–24, Singapore: Springer, 2022. [Google Scholar]
9. Y. Sun, Y. Lu, Y. Liu and X. Zhu, “Towards more accurate and complete iris segmentation using hybrid transformer U-Net,” in Proc. of IEEE Int. Joint Conf. on Biometrics, Abu Dhabi, United Arab Emirates, pp. 1–10, 2022. [Google Scholar]
10. G. Huo, D. Lin and M. Yuan, “Iris segmentation method based on improved UNet++,” Multimedia Tools and Applications, vol. 81, no. 28, pp. 41249–41269, 2022. [Google Scholar]
11. J. Muhammad, C. Wang, Y. Wang, K. Zhang and Z. Sun, “Iris-GuideNet: Guided localisation and segmentation network for unconstrained iris biometrics,” IEEE Transactions on Information Forensics and Security, vol. 18, pp. 2723–2736, 2023. [Google Scholar]
12. G. Huo, D. Lin and M. Yuan, “Multi-source heterogeneous iris segmentation method based on lightweight convolutional neural network,” IET Image Processing, vol. 17, no. 1, pp. 118–131, 2022. [Google Scholar]
13. Y. Chen, W. Wang, Z. Zeng and Y. Wang, “An adaptive CNNs technology for robust iris segmentation,” IEEE Access, vol. 7, pp. 64517–64532, 2019. [Google Scholar]
14. A. K. Nsaif, S. H. M. Ali, A. K. Nseaf, K. N. Jassim, A. Al-Qaraghuli et al., “Robust and swift iris recognition at distance based on novel pupil segmentation,” Journal of King Saud University—Computer and Information Sciences, vol. 34, no. 10, pp. 9184–9206, 2022. [Google Scholar]
15. Y. H. Li, W. R. Putri, M. S. Aslam and C. Chang, “Robust iris segmentation algorithm in non-cooperative environments using interleaved residual U-Net,” Sensors, vol. 21, no. 4, pp. 1–21, 2021. [Google Scholar]
16. D. T. Virtusio, F. J. D. Tapaganao and R. G. Maramba, “Enhanced iris recognition system using daugman algorithm and multi-level Otsu’s thresholding,” in Proc. of Int. Conf. on Electrical, Computer, and Energy Technologies, Prague, Czech Republic, pp. 1–6, 2022. [Google Scholar]
17. H. N. Fathee, O. N. Ucan, J. M. Abdul-Jabbar and O. Bayat, “Efficient unconstrained iris recognition system based on CCT-like mask filter bank,” Mathematical Problems in Engineering, vol. 2019, pp. 1–10, 2019. [Google Scholar]
18. G. Babu and A. K. Pinjari, “A new design of iris recognition using hough transform with K-means clustering and enhanced faster R-CNN,” Cybernetics and Systems, vol. 53, pp. 1–34, 2022. [Google Scholar]
19. M. Choudhary, V. Tiwari and U. Venkanna, ““Enhancing human iris recognition performance in unconstrained environment using ensemble of convolutional and residual deep neural network models,” Soft Computing. vol. 24, pp. 11477–11491, 2020. [Google Scholar]
20. J. G. Daugman, “High confidence visual recognition of persons by a test of statistical independence,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 15, no. 11, pp. 1148–1161, 1993. [Google Scholar]
21. R. P. Wildes, J. C. Asmuth, G. L. Green, S. C. Hsu, R. J. Kolczynski et al., “A machine vision system for iris recognition,” Machine, Vision and Applications, vol. 9, no. 1, pp. 1–8, 1996. [Google Scholar]
22. T. A. Camus and R. Wildes, “Reliable and fast eye finding in close-up images,” in Proc. of 16th Int. Conf. on Pattern Recognition, Quebec City, QC, Canada, vol. 1, pp. 389–394, 2002. [Google Scholar]
23. H. Proença and L. A. Alexandre, “Iris segmentation methodology for noncooperative recognition,” IEE Proceedings—Vision, Image, and Signal Processing, vol. 153, pp. 199, 2006. [Google Scholar]
24. S. Jamaludin, A. F. M. Ayob, M. F. A. Akhbar, A. A. I. M. Ali, M. M. H. Imran et al., “Efficient, accurate and fast pupil segmentation for pupillary boundary in iris recognition,” Advances in Engineering Software, vol. 175, pp. 103352, 2023. [Google Scholar]
25. R. Chen, X. R. Lin and T. H. Ding, “Iris segmentation for non-cooperative recognition systems,” IET Image Processing, vol. 5, no. 5, pp. 448–456, 2011. [Google Scholar]
26. C. W. Tan and A. Kumar, “Unified framework for automated iris segmentation using distantly acquired face images,” IEEE Transactions on Image Processing, vol. 21, no. 9, pp. 4068–4079, 2012. [Google Scholar] [PubMed]
27. A. Radman, N. Zainal and K. Jumari, “Fast and reliable iris segmentation algorithm,” IET Image Processing, vol. 7, no. 1, pp. 42–49, 2013. [Google Scholar]
28. Al. Mustafa, A. Mohammad, S. I. Mosa and A. M. Ayman, “Unconstrained hand dorsal veins image database and recognition system,” Computers, Materials & Continua, vol. 73, no. 3, pp. 5063–5073, 2022. [Google Scholar]
29. B. Li, S. Wang and Y. Geng, “Image enhancement based on Retinex and lightness decomposition,” in Proc. of 18th IEEE Int. Conf. on Image Processing, Brussels, Belgium, pp. 3417–3420, 2011. [Google Scholar]
30. C. W. Tan and A. Kumar, “Towards online iris and periocular recognition under relaxed imaging constraints,” IEEE Transaction on Image Processing, vol. 22, no. 10, pp. 3751–3765, 2013. [Google Scholar] [PubMed]
31. X. Feng, W. Liu, J. Li, Z. Meng, Y. Sun et al., “Iris R-CNN: Accurate iris segmentation and localization in non-cooperative environment with visible illumination,” Pattern Recognition Letters, vol. 155, pp. 151–158, 2022. [Google Scholar]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools