
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Deep Learning-Based Classification of Rotten Fruits and Identification of Shelf Life
1 Centre for Smart Grid Technologies, School of Electronics Engineering, Vellore Institute of Technology, Chennai, 600127, India
2 School of Electronics Engineering, Vellore Institute of Technology, Chennai, 600127, India
3 Department of Electrical Engineering, Dr. B R Ambedkar National Institute of Technology, Jalandhar, Punjab, 144008, India
* Corresponding Author: Prakash Venugopal. Email:
Computers, Materials & Continua 2024, 78(1), 781-794. https://doi.org/10.32604/cmc.2023.043369
Received 30 June 2023; Accepted 10 November 2023; Issue published 30 January 2024
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The freshness of fruits is considered to be one of the essential characteristics for consumers in determining their quality, flavor and nutritional value. The primary need for identifying rotten fruits is to ensure that only fresh and high-quality fruits are sold to consumers. The impact of rotten fruits can foster harmful bacteria, molds and other microorganisms that can cause food poisoning and other illnesses to the consumers. The overall purpose of the study is to classify rotten fruits, which can affect the taste, texture, and appearance of other fresh fruits, thereby reducing their shelf life. The agriculture and food industries are increasingly adopting computer vision technology to detect rotten fruits and forecast their shelf life. Hence, this research work mainly focuses on the Convolutional Neural Network’s (CNN) deep learning model, which helps in the classification of rotten fruits. The proposed methodology involves real-time analysis of a dataset of various types of fruits, including apples, bananas, oranges, papayas and guavas. Similarly, machine learning models such as Gaussian Naïve Bayes (GNB) and random forest are used to predict the fruit’s shelf life. The results obtained from the various pre-trained models for rotten fruit detection are analysed based on an accuracy score to determine the best model. In comparison to other pre-trained models, the visual geometry group16 (VGG16) obtained a higher accuracy score of 95%. Likewise, the random forest model delivers a better accuracy score of 88% when compared with GNB in forecasting the fruit’s shelf life. By developing an accurate classification model, only fresh and safe fruits reach consumers, reducing the risks associated with contaminated produce. Thereby, the proposed approach will have a significant impact on the food industry for efficient fruit distribution and also benefit customers to purchase fresh fruits.Keywords
Globally, agriculture e plays an important part in the frugality analysis as it is considered to be the backbone of the profitable system for developing countries. Over 70 percent of the pastoral homes depend on husbandry. It contributes about 17% to the total gross domestic product (GDP) and employs around 58% of the population. The share of husbandry in GDP increased to 19.9% in 2020–21 from 17.8% in 2019–20 according to the global analysis. At the moment, people substantially depend on fruits and vegetables for a healthy life. To increase the life expectancy of humans, it is crucial to mitigate the risk of food-borne illnesses. Therefore, separating spoiled produce from fresh ones is imperative to guarantee their safety. The quality discovery of the fruits has become a veritably important task in the husbandry assiduity. High-quality fruits are more likely to have a desirable taste and flavor, which can encourage people to consume more fruits and make healthy eating habits more sustainable. Fresh fruits also have a longer shelf life, which can reduce waste and save money for consumers and retailers. Ensuring high-quality fruits benefits both producers and consumers, making it an important consideration for anyone involved in the production or sale of fruits. Identifying rotten fruits is important for health and safety, quality assurance, economic reasons, sustainability, and consumer satisfaction. The rotten fruits may end up spoiling the fresh fruits which will overall cause a great loss. Segregating rotten fruits manually is a time-consuming, labor-ferocious, less effective and tiring process and thereby technology-driven process are required to meet the task. Implementing this process helps the system to be cost-effective and will reduce the sweat of humans.
Along with relating rotten fruits, conserving them is also important. Knowing the shelf life is important to assure the safety and quality of the fruit. Considering the shelf life of fruit, the period in which the fruits are consumed with good quality Within the shelf life the fruits will remain safe and retain the sensitive, chemical, physical and microbiological characteristics accordingly. The entire analysis can be done from the perspective of computer vision which is an emerging field that empowers a great aspect to comprehend visual data like images and videos. The agriculture and food industries are increasingly adopting computer vision technology to elevate the safety and excellence of fruits and vegetables. This involves detecting rotten produce and forecasting their shelf life. In this research work, Section 2 discusses recent advancements and related work of the proposed method. Section 3 explains the detailed methodology of the proposed approach. Section 4 provides results with a discussion and Section 5 summarizes the proposed work.
Computer vision techniques can be used to develop algorithms that analyze images of fruits to detect signs of rotting or spoilage, such as discoloration, bruising, and mold growth. In computer vision, the segmentation technique is a useful method to detect the quality of any fruits or vegetables. Different segmentation techniques like marker-based segmentation, color-based segmentation and edge detection have been discussed in [1,2] and are used in this work. By training computer vision algorithms on large datasets of images of both fresh and rotten fruits, they can learn to recognize the patterns and features associated with each category and accurately distinguish between them [3]. Additionally, computer vision can be used to analyze the color, texture, and shape of fruits to estimate their ripeness and predict their shelf life. Computer vision technology can be integrated into existing processing and sorting equipment, making it a cost-effective solution for identifying rotten fruits and improving shelf life. Also, machine learning algorithm plays a major role in the fruit grading system. An automatic detection of types of fruits and identification exhibits its quality using machine four machine learning classifiers which are presented in [4] and it includes artificial neural network (ANN), k-nearest neighbor (k-NN), sparse representative classifier (SRC) and support vector machine (SVM). Among these, SVM achieves maximum accuracy of 98.48% in fruit detection and 95.72% in quality grading. However, image classification is one of the tasks in which deep learning algorithms give us good results. In deep learning algorithms, a sequence of neural network layers is utilized to process data, with each layer producing a simplified version of the data that is been transmitted to the subsequent layer. It is all the rage these days because of its superiority in terms of accuracy. The role of deep learning in fruit detection and classification was detailed in [5–7] suggesting that convolution neural networks (CNN) proved exceptional performance by utilizing either new models or pre-trained transfer-learning networks [8]. A computer vision-based technique using deep learning with a specially designed CNN model was proposed [9] to detect fruit freshness from the public data taken from Kaggle. In reference [10], the authors have proposed a CNN model that consists of convolution neural networks to check whether the fruit is rotten or fresh. This model is implemented using Keras but it is designed to classify only three types of fruits namely apples, oranges, and bananas. Similarly, in [11], the Enhanced UNet (En-UNet) based deep learning approach is an improved version of UNet and is utilized to grade the quality of the apple. Reference [12] gave a deep convolution neural network (DCNN) with an AlexNet model-based classification method used to identify whether the fruits are fresh or rotten. Likewise, in [13], an enhanced AlexNet architecture using a transfer learning-based CNN model is utilized to segregate good and bad fruits of apples, oranges, and bananas. Although the aforementioned CNN techniques have achieved good accuracy there is still a research scope to improve the performance by analyzing activation, loss and pooling functions.
Determining the shelf-life of the fruits manually is challenging, expensive and time-consuming and it may cause erroneous results due to human mistakes. Hence, advanced technology-based automated intelligent systems are needed to predict the accurate shelf-life of the fruits. This can be achieved with the help of the latest machine-learning techniques and deep-learning models. The shelf-life prediction is done based on different parameters like temperature, ethylene exposure, humidity, moisture, etc. References [14,15] used a non-destructive thermal imaging technique that uses temperature as the parameter combined with a transfer learning approach to predict the shelf life. In reference [16], an ANN and data fusion-based AI model was proposed to perform the classification based on the shelf life of the apple fruit. A 72% accuracy in the segregation of fruits based on their freshness is implemented using spectroscopy and ensemble machine learning approaches in the work referred to in [17]. A multiple non-linear regression (MNLR) model was proposed in [18] which relates the temperature and maximum shelf life of fruits. Among various deep learning models, CNN was considered to be one of the efficient models in image classification with good accuracy as mentioned in works [19,20]. In reference [21], CNN based approach is used to carry out the fruit grading by analyzing fruit texture, color, and size. Similarly, the freshness of the fruits is determined by analyzing various parameters related to fruits using CNN [22]. The proposed novel CNN approach is compared with the classic CNN model using transfer learning for the identification of various ripping states of banana, and the results show that the proposed CNN model outperformed with 96.14% validation accuracy [23] as mentioned in this work. Moreover, considering the work mentioned in [24], a comparative analysis is made on faster Region-based Convolutional Neural Networks (R-CNN) and you only live once(YOLO) models to predict the shelf life of bananas. One of the major limitations found in the existing literature related to determining the shelf life of fruits are less accurate and designed for one specific fruit. Therefore, there is a larger research scope to propose a unified deep learning model to improve the prediction accuracy of the shelf life of the fruits for different fruit types. This proposed work provides a CNN model and comparison between different pre-trained models after integrating with the built CNN model that helps in the identification task of rotten fruits. It also provides a comparison of different machine learning models that help in the identification of shelf life by considering hue as the parameter [25]. For the rotten fruit discovery, five types of fruits are considered namely, apples, bananas, oranges, papayas and guava. The dataset comprises 10 categories, where each fruit is categorized as either fresh or rotten. The key contribution of this research work is listed below.
• Developed a CNN-based deep learning model using VGG architecture for accurate fruit classification, utilizing a dataset comprising various fruit types, including apples, bananas, oranges, papayas, and guavas also classifying them as rotten or fresh.
• In addition to classification, the research contribution made for accurate prediction of fruit shelf life for bananas using a random forest model by analyzing their color parameters, specifically the hue value.
• The major uniqueness of this work is that it proposes a unified deep learning model to improve the prediction accuracy of shelf-life fruits for different fruit types when compared to the existing research, which examines only determining the shelf life of one fruit type.
In this work, the methodology is a framework for detecting spoiled fruits and estimating their shelf life through computer vision techniques. CNN has demonstrated significant success in image recognition tasks and has been applied to accurately distinguish between fresh and rotten fruits. These deep learning techniques involve analysis with image recognition tasks at an accurate level using this process. For further analysis of this work, implementation and comparison analysis with different deep learning models are done for exhibiting the methodology with real-time data set collected. Shelf-life detection in fruits is very important in the present agricultural needs as the fruit maturity with the environment analysis is required to understand the quality level of fruits and vegetables in the market value. In this work, shelf-life detection of fruits is frame worked with the analysis of deep learning models to give more understanding towards the improved analysis efficiently.
3.1 Convolutional Neural Network Architecture
Machine Learning encompasses deep learning which employs artificial neural networks modeled after the structure and functions of the human brain. The main aspect is the way it mimics the aspect of the human brain of imbibing knowledge in this pattern. It imitates the way the human brain gains a certain type of knowledge. Deep Learning is a powerful tool as it can analyze huge amounts of data in a more efficient way [26]. CNN belongs to the family of ANN in deep learning and specializes in recognizing and classifying images or objects by implementing convolution operations. A CNN is made of 4 layers, namely, convolutional, rectified linear unit (ReLU), pooling and fully connected layer. The convolutional layer is a core structure block of CNN where the majority of calculation occurs. To function effectively, it needs only a few key components, namely input data, a filter, and a feature map. It also has a feature detector which is usually known as a kernel or a filter. The filter size is typically taken as 3 * 3. After every convolution performance, CNN applies a ReLU conversion to the feature map that gives a non-linearity to the model. In the pooling layer, the number of parameters of the inputs is reduced and therefore it is also known as down-sampling the input. This layer helps to reduce complexity, increases the efficiency and limits the chance of over-fitting of the model. At the end of a CNN architecture, the fully connected layer takes the outputs from the preceding layers, flattens them, and produces a unified vector that can be used as the input for the subsequent stage. Different dropout techniques help in a larger aspect to enhance computational efficiency. Fig. 1 exhibits the complete architecture of CNN with the different stages of analysis.

Figure 1: CNN architecture
3.2 Proposed Model for Image Classification
In this work, a CNN model is built for the categorization of rotten and fresh fruits. Fig. 2 exhibits the proposed model for image classification. In this work, the required model which is involved for the image classification consists of three convolutional layers which exhibit the initial layer which holds 32 convolution filters sized at 3 * 3. This model also involves the ReLU activation function, which restricts the activation of all neurons simultaneously with the network analysis by a threshold limit. As in this model, negative input is considered the ReLU function converts it to zero, thereby preventing the corresponding neurons from activation for the input parameters given in the process of classification of fruits at a major level. In this process as in the main network, only a small number of neurons gets activated which makes the computation of the neural network very straightforward for better analysis of the framework of the images taken from the real-time dataset. The input images considered from the real-time data set involve a dimension of 150 * 150 * 3. As in the image dimensions involved in the classification with the neural network, there are convolution layers done efficiently.

Figure 2: Proposed CNN model
The first convolution layer consists of 32 filters with a kernel size of 3 * 3. The large kernel size is not found to be cost efficient which prefers the structure of a smaller kernel size for this neural network where the number of parameters are limited which finally helps to limit the number of unrelated features for the network involved in the methodology. The next step in the process is with the output of the entire neural network involved. Each convolutional layer is directed to the max pooling later where the involvement of pooling size is 2 * 2. Generally max polling layer is involved in minimizing the number of learning parameters which are involved mainly to improvise the computation of speed of the network involved which is also called down-sampling. At the final output, a dropout of 0.2 is added to every structure of a convolution layer created, the addition of this layer involves reducing the overfitting of the model. Avoiding overfitting in the model helps in the larger aspect of the dataset to train the model very effectively with more accuracy. In the CNN model, there are second and third convolutional layers that exhibit the filters of 64 and 128, respectively. There is a feature map of the final structure which is produced by the third convolutional layer with a flattened structure by using a flattened layer. There is found to be the dense layer in the model which is found to be a fully connected layer. The entire model showcasing the different layers for more accuracy is compiled with the Adam optimizer and this shows a loss function for better accuracy parameters in the network which are used in the layer as binary cross–entropy. As in this proposed methodology, deep learning techniques are involved to utilize the neural networks with multiple layers to identify and understand complex patterns and relationships in data. Deep neural networks consist of interconnected nodes or “neurons” arranged in multiple layers, with each layer processing input data and passing the output to the next layer. This gradual transformation of input data leads to a more abstract and sophisticated representation that is used for prediction or classification. Deep learning has demonstrated remarkable performance in a diverse range of applications such as computer vision, natural language processing, speech recognition, and autonomous driving. In this work, to understand the processing data set with real-time analysis, a CNN model is developed and incorporated with pre-trained models, such as VGG16 and InceptionV3 to improve its accuracy and performance.
3.3 Proposed Method for Shelf-Life Detection
The proposed work involves determining the shelf life of fruits which are found to be crucial in ensuring the quality and safety for consumption. Consuming fruits that have exceeded their shelf life may result in food poisoning and other health-related concerns on a larger aspect. The shelf life of a fruit refers to the duration for which it can remain edible. This work aims to identify the shelf life of fruits using hue value as the determining parameter. In this work, the testing process is done based on the real-time dataset of the collected images of the banana fruits from a garden in the eastern Godavari district. Further analysis of the shelf-life detection, can be done by computing for any fruits that change their color evidently during the ripening process of the fruits at this stage. For this real-time analysis in this work, the process of capturing the banana fruits is to overlook each fruit and its important features. An accurate prediction has been generated about the shelf life with the real-time dataset of banana fruits using machine learning algorithms. The segregation of fruits is based on shelf life which involves more advantages of the process like transportation being more effective, and reducing large amounts of wastage and cost which helps in the agricultural domain and farmers at a larger aspect. In addition to this, the sugar content is predicted by the color of the fruit. In this analysis of work, bananas were ripe at a hue value of around 23 to 24 bananas. From this process, the hue values are calculated based on the real-time analysis. In this process, the work involves 60 bananas and a picture of a banana was taken for a particular time. The analysis is based on the ripe category involved for each fruit where 60 bananas from the farm were collected. From this process, the set of bananas indicates that it is not fit for consumption and has reached the end of its life. This analysis has chosen color to be the criteria for identification of its shelf life. Once the fruit is ripe the shops/supermarkets will not accept the fruits as it will cause them a loss. As all the images collected are in the Red, Green, and Blue (RGB), the format is changed to be hue, saturation, and intensity (HSI) format. The conversion is found to be easier to associate the colors with their HSI values than with their RGB values. Once the hue values are recorded for all the bananas on different days then the model classifies the bananas into a corresponding day analysis using its hue value. Finally, to understand the shelf life of the bananas the difference between the ripe day and the predicted day of the banana is done. The dataset images recorded for the ripening process of a single banana are shown in Fig. 3. This learning process has given more insights into the present world as organizations seek to derive insights from the vast amounts of data they generate [27,28]. The mathematical analysis involved for the RGB to HSI conversion involves the following function as mentioned in formula (1).

Figure 3: Real-time day1 to day5 images of a single banana (left to right)
This modeling has been used extensively to optimize the chain process by predicting the process of the fruits that reach the end of their shelf life and thereby there is a reduction of waste in this process. Fig. 4 gives the analysis of the conversion for this process. It can also be used to help identify the optimal storage conditions for different types of fruit, helping to ensure that they remain fresh for as long as possible. For the shelf-life prediction of a fruit using hue value as the key parameter machine learning models are applied namely, Gaussian Naive Bayes and Random Forest.

Figure 4: RGB to HSI conversion
The underlying section elaborates on the pre-trained models that were integrated with the CNN model to enhance its accuracy and performance for the detection of rotten fruits. The results achieved with the various CNN models are discussed in this section. It also explains the machine learning models used for the identification of the shelf life of fruits. The results and analysis of proposed and pre-trained models are explained below.
The CNN model proposed in this study comprises several layers, including a convolutional layer, activation layer, pooling layer, dropout layer, flatten layer, fully connected layer, and output layer. Three convolutional layers were constructed using different convolution filters with a size of 3 * 3. The input image used for training the model was of size 150 * 150 * 3. Additionally, a max pooling layer was implemented with a pool size of 2 * 2. Finally, a dropout, flatten and dense layer were added and the model was compiled to give the results implemented. The accuracy score achieved with this model was 86.6% as shown in Fig. 5.

Figure 5: Accuracy and loss plot for the proposed model
VGG16 is a convolutional neural network architecture for image classification. The model’s architecture is made up of a total of 16 layers, with 13 of them being convolutional layers and the remaining 3 being fully connected layers. In addition, the model has over 138 million trainable parameters. VGG16 architecture is characterized by the basis of the uniformity and simplicity process. It has all the convolutional layers by using a 3 * 3 filter size with a stride of 1 and this creates a max polling layer with a 2 * 2 window and also with a stride of 2 approximately in this process. This results in a very deep network that can learn increasingly complex features at different levels of abstraction. This model gave an accuracy score of 95% as shown in Fig. 6.

Figure 6: Accuracy and loss plot for VGG16
Inception V3 is a type of convolutional neural network design specifically intended for recognizing and categorizing images by utilizing complex convolutional algorithms. The key innovation of Inception V3 is the use of a factorization approach, which aims to reduce the computational cost of convolutional layers without affecting performance. To enhance the image recognition abilities, Inception V3 adopts a technique of replacing certain large convolutional filters with smaller ones, coupled with the use of 1 * 1 convolutions to decrease the feature maps’ complexity before applying larger filters. In addition to this parameter, Inception V3 incorporates other design elements like batch normalization and regularisation to optimize its performance. The accuracy of this model was measured to be 94% as shown in Fig. 7. Comparison of various deep learning models is given in Table 1.

Figure 7: Accuracy and loss plot for Inception V3

The predicted rotten fruits result is shown in Fig. 8.

Figure 8: Prediction of rotten fruits
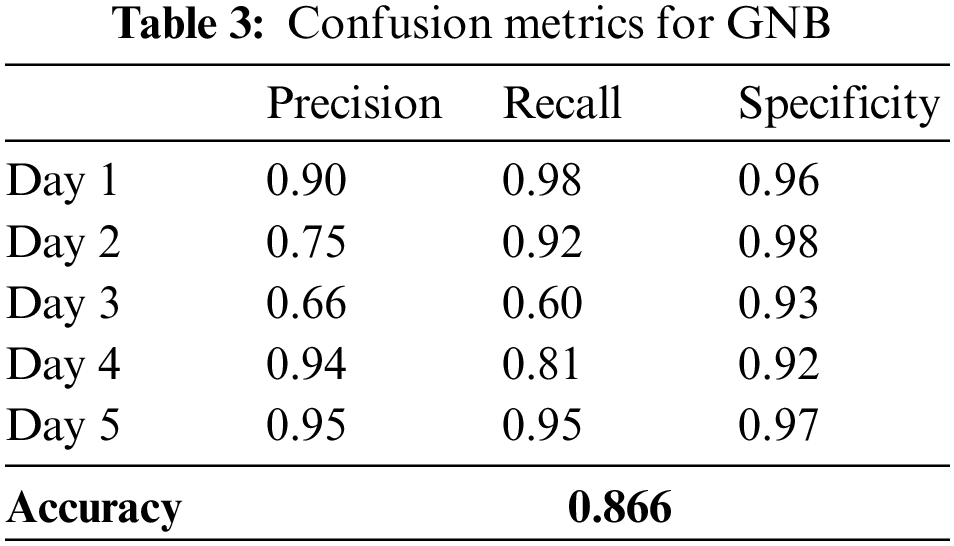
The results and analysis of machine learning models are explained with different comparison models. Gaussian Naïve Bayes (GNB) is considered a major classification algorithm that leverages probability theory. It relies on Bayes’s theorem, which establishes that the likelihood of a hypothesis, such as the class of observation, given a set of evidence or features, is directly proportional to the probability of the evidence conditioned on the hypothesis, multiplied by the prior probability of the hypothesis. To predict a new observation, GNB calculates the posterior probability of each class given the observation’s features using the Bayes theorem and then selects the class with the highest prob ability as the predicted class. This algorithm recorded an accuracy score of 86.6% as shown in Tables 2 and 3.
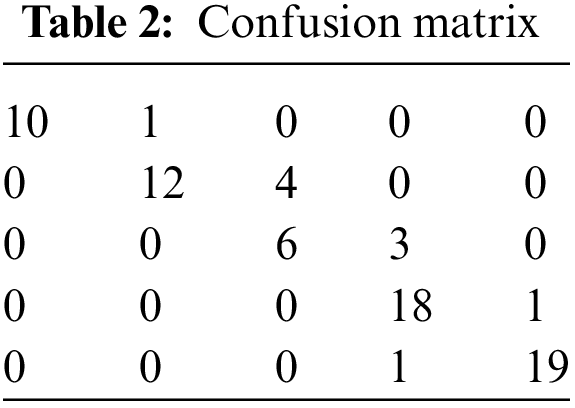
The random forest is a machine learning algorithm that is involved in handling classification and regression tasks which are based on ensemble-based methods that actively combine with various decision trees. These trees are mainly built by using randomly selected subset sections of the required training data and the features involved in the process. Essentially, random forests create a huge number of decision trees and each tree is trained based on the unique process of a random subset of the required features involved along with the training data and this improves a larger way the overall performance of the process involved. During training, each tree is built by recursively partitioning the feature space into regions, where each region corresponds to a leaf node in the tree. The splits are made by selecting the feature that best separates the data based on some criterion, such as the Gini index or the information gain. During prediction, the random forest combines the predictions of all the individual trees to exhibit the required final level of prediction. This algorithm after the training process records an accuracy score of 88% as shown in Tables 4 and 5. Table 6 shows the comparison of the accuracy scores of different machine learning models.



This research work demonstrates the potential applicability of advanced technology in the agriculture and food industries, which not only contributes to ensuring food safety and quality but also promotes sustainability by reducing food waste. By developing an accurate classification model, only fresh and safe fruits reach the consumers, reducing the risks associated with contaminated produce. This contributes to reducing food waste, a critical step toward sustainable agricultural practices. Also, an efficient and timely detection of fresh and rotten fruits enables farmers to increase their fruit production, making a substantial contribution to a nation’s economic value. The integration of deep learning techniques, model comparison, and the innovative approach to shelf-life prediction enriches the fruit quality assessment, with implications for both agricultural practices and consumer well-being. Thereby, the proposed approach will make a significant impact on the food industry for efficient fruit distribution and also benefit the customers in supermarkets to purchase fresh fruits.
Although the proposed CNN model using VGG16 for fruit classification and the random forest model for prediction of fruit shelf life delivers better accuracy there are few limitations and scope for improvement on the proposed models. This work is mainly focused on a limited set of fruit varieties (e.g., apples, bananas, oranges, papayas, and guavas), hence not suitable for other varieties of fruits available in various regions. Also, in shelf-life prediction, only the hue parameter is considered but the fruit ripeness also depends on other factors like texture and aroma which are not considered in this research work. Hence there is a research scope to develop a generic system that can perform the fruit quality and shelf-life prediction for a variety of fruits by considering various real-world environmental factors such as temperature, humidity, and storage conditions.
This work has explained that deep learning can be a very powerful tool for detecting rotten fruits, as it can learn to recognize patterns and features that are not immediately apparent to humans. Through its ability to ensure that only fresh fruits are made available to consumers, this can enhance the safety and quality of food products while minimizing waste. It also shows the capability of machine learning models can analyze datasets on factors such as color, texture, and chemical composition to accurately predict the optimal time to harvest fruits, which can extend their shelf life. The work explains how hue value can be used as a reliable feature for shelf-life prediction. By comparison to GNB, the random forest algorithm provides us with a superior accuracy score. Likewise, the VGG16 model delivers higher accuracy scores and lower loss values in comparison to the other models for the detection of rotten fruits. This highlights the capability of computer vision to leverage deep learning models to automatically learn and extract pertinent features from images, consequently reducing the necessity for manual input while enhancing accuracy. These models are highly valuable in a diverse range of applications.
Acknowledgement: Not applicable.
Funding Statement: The authors received no specific funding for this study.
Author Contributions: The authors confirm their contribution to the paper as follows: study conception and design: S. Sofana Reka, Ankita Bagelikar; relevant paper collection: Ankita Bagelikar, Prakash Venugopal; analysis and interpretation of results: S. Sofana Reka, V. Ravi, Harimurugan Devarajan; draft manuscript preparation: S. Sofana Reka, Prakash Venugopal. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: Not applicable.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. K. Roy, S. S. Chaudhuri, S. Bhattacharjee, S. Manna and T. Chakraborty, “Segmentation techniques for rotten fruit detection,” in Proc. of Int. Conf. on Opto-Electronics and Applied Optics (Optronix), Kolkata, India, pp. 1–4, 2019. [Google Scholar]
2. P. V. Devi and K. Vijayarekha, “Machine vision applications to locate fruits, detect defects and remove noise: A review,” Rasayan Journal of Chemistry, vol. 7, no. 1, pp. 104–113, 2014. [Google Scholar]
3. C. C. Foong, G. K. Meng and L. L. Tze, “Convolutional neural network based rotten fruit detection using ResNet50,” in Proc. of IEEE 12th Control and System Graduate Research Colloquium (ICSGRC), Shah Alam, Malaysia, pp. 75–80, 2021. [Google Scholar]
4. A. Bhargava and A. Bansal, “Automatic detection and grading of multiple fruits by machine learning,” Food Analytical Methods, vol. 13, no. 3, pp. 751–761, 2020. [Google Scholar]
5. C. C. Ukwuoma, Q. Zhiguang, M. B. Bin Heyat, L. Ali, Z. Almaspoor et al., “Recent advancements in fruit detection and classification using deep learning techniques,” Mathematical Problems in Engineering, vol. 2022, no. 1, pp. 1–29, 2022. [Google Scholar]
6. D. Karakaya, O. Ulucan and M. Turkan, “A comparative analysis on fruit freshness classification,” in Proc. of Innovations in Intelligent Systems and Applications Conf. (ASYU), Izmir, Turkey, pp. 1–4, 2019. [Google Scholar]
7. S. Chakraborty, F. M. J. M. Shamrat, M. M. Billah, M. A. Jubair, M. Alauddin et al., “Implementation of deep learning methods to identify rotten fruits,” in Proc. of 5th Int. Conf. on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, pp. 1207–1212, 2021. [Google Scholar]
8. J. Naranjo-Torres, M. Mora, R. Hernández-García, R. J. Barrientos, C. Fredes et al., “A review of convolutional neural network applied to fruit image processing,” Applied Sciences, vol. 10, no. 10, pp. 3443, 2020. [Google Scholar]
9. F. Valentino1, T. W. Cenggoro and B. Pardamean, “A design of deep learning experimentation for fruit freshness detection,” in Proc. of 4th Int. Conf. on Eco Engineering Development, Banten, Indonesia, pp. 1–8, 2020. [Google Scholar]
10. A. Chougule, A. Pawar, R. Kamble, J. Mujawar and A. Bhide, “Recognizing fresh and rotten fruits using deep learning techniques,” in Proc. of Int. Conf. on Innovative Computing and Communications (ICICC), Delhi, India, pp. 205–212, 2021. [Google Scholar]
11. K. Roy, S. S. Chaudhuri and S. Pramanik, “Deep learning based real-time industrial framework for rotten and fresh fruit detection using semantic segmentation,” Microsystem Technologies, vol. 27, no. 9, pp. 3365–3375, 2021. [Google Scholar]
12. U. Amin, M. I. Shahzad, A. Shahzad, M. Shahzad, U. Khan et al., “Automatic fruits freshness classification using CNN and transfer learning,” Applied Sciences, vol. 13, no. 14, pp. 1–17, 2023. [Google Scholar]
13. S. Jana, R. Parekh and B. Sarkar, “Detection of rotten fruits and vegetables using deep learning,” Computer Vision and Machine Learning in Agriculture, vol. 1, no. 1, pp. 31–49, 2021. [Google Scholar]
14. V. Bhole and A. Kumar, “A transfer learning-based approach to predict the shelf life of fruit,” Inteligencia Artificial, vol. 24, no. 67, pp. 102–120, 2021. [Google Scholar]
15. R. Torres-Sánchez, M. T. Martínez-Zafra, N. Castillejo, A. Guillamón-Frutos and F. Artés-Hernández, “Real-time monitoring system for shelf life estimation of fruit and vegetables,” Sensors, vol. 20, no. 7, pp. 1–21, 2020. [Google Scholar]
16. Z. Fathizadeh, M. Aboonajmi and S. R. Hassan-Beygi, “Classification of apples based on the shelf life using ANN and data fusion,” Food Analytical Methods, vol. 14, no. 4, pp. 706–718, 2021. [Google Scholar]
17. H. Chopra, H. Singh, M. S. Bamrah, F. Mahbubani, A. Verma et al., “Efficient fruit grading system using spectrophotometry and machine learning approaches,” IEEE Sensors Journal, vol. 21, no. 14, pp. 16162–16169, 2021. [Google Scholar]
18. M. J. Sousa-Gallagher, A. Tank and R. Sousa, “Emerging technologies to extend the shelf life and stability of fruits and vegetables,” in The Stability and Shelf Life of Food, 2nd ed., vol. 3. Sawston, UK: Woodhead Publishing, pp. 399–430, 2016. [Google Scholar]
19. N. Aherwadi and U. Mittal, “Fruit quality identification using image processing, machine learning, and deep learning: A review,” Advances and Applications in Mathematical Sciences, vol. 21, no. 5, pp. 2645–2660, 2022. [Google Scholar]
20. S. Karamchandani, B. Sekhani, K. Nair and K. Shah, “E-nose for shelf-life prediction of climacteric fruits,” in Proc. of 4th Int. Conf. on Computing, Power and Communication Technologies (GUCON), Kuala Lumpur, Malaysia, pp. 1–4, 2021. [Google Scholar]
21. J. J. Jijesh, D. C. Revathi, M. Shivaranjini and R. Sirisha, “Development of machine learning based fruit detection and grading system,” in Proc. of Int. Conf. on Recent Trends on Electronics, Information, Communication & Technology (RTEICT), Bangalore, India, pp. 403–407, 2020. [Google Scholar]
22. S. S. R. Mamidi, C. A. Munaganuri, T. Gollapall and A. T. V. S. Aditya, “Implementation of machine learning algorithms to identify freshness of fruits,” in Proc. of Third Int. Conf. on Intelligent Computing Instrumentation and Control Technologies (ICICICT), Kannur, India, pp. 1395–1399, 2022. [Google Scholar]
23. N. Saranya, K. Srinivasan and S. K. P. Kumar, “Banana ripeness stage identification: A deep learning approach,” Journal of Ambient Intelligence and Humanized Computing, vol. 13, no. 8, pp. 4033–4039, 2022. [Google Scholar]
24. M. Mukhiddinov, A. Muminov and J. Cho, “Improved classification approach for fruits and vegetables freshness based on deep learning,” Sensors, vol. 22, no. 21, pp. 1–20, 2022. [Google Scholar]
25. A. Sanaeifar, A. Bakhshipour and M. D. L. Guardia, “Prediction of banana quality indices from color features using support vector regression,” Talanta, vol. 148, no. 1, pp. 54–61, 2016. [Google Scholar] [PubMed]
26. M. M. Najafabadi, F. Villanustre, T. M. Khoshgoftaar, N. Seliya, R. Wald et al., “Deep learning applications and challenges in big data analytics,” Journal of Big Data, vol. 2, no. 1, pp. 1–21, 2015. [Google Scholar]
27. J. Qiu, Q. Wu, G. Ding, Y. Xu and S. Feng, “A survey of machine learning for big data processing,” EURASIP Journal on Advances in Signal Processing, vol. 2016, no. 67, pp. 1–16, 2016. [Google Scholar]
28. R. P. França, A. C. B. Monteiro, R. Arthur and Y. Iano, “An overview of deep learning in big data, image, and signal processing in the modern digital age,” in Trends in Deep Learning Methodologies: Algorithms, Applications, and Systems, 1st ed., vol. 1. Cambridge, MA, USA: Academic Press, pp. 63–87, 2020. [Google Scholar]
Cite This Article
 Copyright © 2024 The Author(s). Published by Tech Science Press.
Copyright © 2024 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools