
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Machine Learning for Data Fusion: A Fuzzy AHP Approach for Open Issues
1 Chitkara University Institute of Engineering and Technology, Chitkara University, Punjab, 140401, India
2 Department of Networking and Communications, SRM Institute of Science and Technology, Kattankulathur, Chengalpattu, Tamil Nadu, 603203, India
3 Department of Networking and Communications, Faculty of Engineering and Technology, SRM Institute of Science and Technology, Kattankulathur, Chengalpattu, Tamil Nadu, 603203, India
4 Department of Computer Science and Engineering, Vardhaman College of Engineering, Hyderabad, 501218, India
5 Department of Computer Science and Information Engineering, National Yunlin University of Science and Technology, Yunlin, 64002, Taiwan
6 Intelligence Recognition Industry Service Research Center, National Yunlin University of Science and Technology, Yunlin, 64002, Taiwan
* Corresponding Author: Shih-Yu Chen. Email:
Computers, Materials & Continua 2023, 77(3), 2899-2914. https://doi.org/10.32604/cmc.2023.045136
Received 18 August 2023; Accepted 18 October 2023; Issue published 26 December 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
Data fusion generates fused data by combining multiple sources, resulting in information that is more consistent, accurate, and useful than any individual source and more reliable and consistent than the raw original data, which are often imperfect, inconsistent, complex, and uncertain. Traditional data fusion methods like probabilistic fusion, set-based fusion, and evidential belief reasoning fusion methods are computationally complex and require accurate classification and proper handling of raw data. Data fusion is the process of integrating multiple data sources. Data filtering means examining a dataset to exclude, rearrange, or apportion data according to the criteria. Different sensors generate a large amount of data, requiring the development of machine learning (ML) algorithms to overcome the challenges of traditional methods. The advancement in hardware acceleration and the abundance of data from various sensors have led to the development of machine learning (ML) algorithms, expected to address the limitations of traditional methods. However, many open issues still exist as machine learning algorithms are used for data fusion. From the literature, nine issues have been identified irrespective of any application. The decision-makers should pay attention to these issues as data fusion becomes more applicable and successful. A fuzzy analytical hierarchical process (FAHP) enables us to handle these issues. It helps to get the weights for each corresponding issue and rank issues based on these calculated weights. The most significant issue identified is the lack of deep learning models used for data fusion that improve accuracy and learning quality weighted 0.141. The least significant one is the cross-domain multimodal data fusion weighted 0.076 because the whole semantic knowledge for multimodal data cannot be captured.Keywords
In the period of ambiguous abstract data upturn, the massive bulk of data is envisaged, collected, investigated, and processed. By focusing on this data carefully, handy and reliable information can be extracted along with the formation of rules. These rules help in a better way to logically draw the conclusion or decision-making as compared with results drawn from intuition or experience. This big data has characteristics like variety, volume, value, veracity, and velocity. This makes it difficult for traditional techniques to dig out reliable, useful information from the massive amount of complex, tangled, mixed, and imperfect data [1]. Different types of data processing techniques are applied to cope with this huge complex data like data pre-processing, data manipulation, data storage, data visualization, data analytics, data fusion, and data transfer. The current study targets data fusion. It is known by different names in the literature like sensor fusion, data combination, information fusion, decision fusion, multi-sensor fusion, or data aggregation. This is one of the dominant techniques to deal with above mentioned raw data so that useful information is extracted. Fused data is expected to provide more synthetic, consistent, or reliable information as compared to raw original data. Data fusion is used in image processing, intrusion detection, sensor networks, radar systems, etc. Data fusion based on ML algorithms is heading the market in the present era due to its computation and classification capabilities. This methodology helps to hide critical information and can handle issues generated when IoT systems are used with big data. ML helps in choosing the best fusion method to increase overall accuracy for getting information from multiple sensors. Different ML algorithm which is used with data fusion is Support Vector Machine (SVM), Artificial Neural Network (ANN), k-means clustering, k-central clustering, etc. Machine Learning (ML) algorithms can be highly beneficial when used with data fusion, as they can automatically learn from the data and improve their performance over time. This combination of ML and data fusion has found applications in various fields, such as robotics, surveillance, environmental monitoring, medical diagnosis, and more.
The importance of ML algorithms in data fusion applications can be attributed to the following factors:
1. Improved accuracy: ML algorithms can identify patterns and relationships in the fused data that may not be apparent to humans or traditional statistical methods, leading to improved accuracy in predictions, classifications, and decision-making.
2. Handling large volumes of data: Modern applications often generate vast amounts of data from multiple sources. ML algorithms are highly scalable and can efficiently process and analyze these large datasets to extract valuable insights.
3. Adaptability: ML algorithms can adapt to changing data patterns and evolve, making them well-suited for applications where the data sources or underlying processes may change.
4. Reducing uncertainty and noise: Data fusion can help reduce uncertainties and noise in the data by combining information from multiple sources. ML algorithms can further enhance this process by learning to identify and mitigate the effects of noise and uncertainty on the analysis.
5. Real-time processing: ML algorithms can be designed to process data in real-time, enabling faster decision-making and timely responses in applications where time is of the essence, such as emergency response, fraud detection, and autonomous vehicles.
It is essential to know about the open issues in ML and data fusion because addressing these issues can lead to even better performance and more robust applications. The current study is organized into different sections. Section 2 targets the literature review of ML algorithms that have been used for data fusion. Section 3 elaborates on the open issues that are related to data fusion ML-based algorithms. Section 4 mentions the research methodology followed by Section 5 which shows the fuzzy Analytical Hierarchy Process (AHP) implementation. Section 6 gives insight into the discussion and conclusion.
2 Machine Learning Algorithms for Data Fusion
The current study categorizes the literature on ML for data fusion into three types. The categories are signal level, feature level, and decision level data fusion [1,2].
In signal-level fusion, raw data inputs are taken from sensors and the output is reliable and accurate along with capitalization of a few noises. The authors [3] have proposed a hybrid model for fault detection. The model targets multi-sensor data fusion with the help of Short-Term Fourier Transforms (STFT), Support Vector Machine (SVM), and time duration. The authors [4] integrated the Bayesian approach with SVM for data fusion. The authors proposed an SVM algorithm [5] for data fusion along with tuning up the score normalization technique. An optimized Back Propagation Neural Network (BP-NN) has been proposed with speed constrained multi-objective particle swarm optimization (SMPSO) algorithm so that efficiency and adaptability in the large-scale network increase [6]. An ANN-based navigation system was proposed to handle or predict non-linear problems [7]. The authors have proposed a Radial Basis Function (RBF) neural network model that can handle non-linear problems [8]. K-central clustering has been used by the authors for data fusion [9] so that higher accuracy for target tracking and identification in real time can be achieved. Another fast data fusion based on a clustering algorithm has also been proposed [10]. K-means clustering is also in the race for target tracking [11], wireless sensor networks [12], earth observations [13], and uncertain conditions [14].
At the feature level, inputs are in the form of raw data or features and the output is more reliable and polished information for making decisions. For feature fusion SVM is used for land cover classification [15], meta-search engine [16]. Artificial neural network (ANN) was used for online tool wear estimation [17]. Hierarchical fusion systems are used for intrusion detection [18], and building construction [19]. Hybrid methods are used for travel mode choice [20].
At the decision level, different types of data are fused and it generates accurate decision results. The authors proposed multiple SVM models for fusing hyperspectral data and Light Detection And Ranging (LIDAR) data. This is for an anomaly intrusion detection system. Different classifiers are also used by the authors [21] for intrusion detection systems. Unsupervised algorithms like clustering are also used for intrusion systems [22], nuclear power crack inspection [23], crop monitoring [24], and diagnostic applications [25].
3 Machine Learning Algorithms Open Issues
After doing a comprehensive literature review, it shows that there are a lot of issues that are associated when ML algorithms are used with data fusion. A total of 9 issues have been identified and these open issues are summarized in Table 1. DF-MA stands for data fusion-machine learning algorithms open issue.

3.1 Lack of Deep Learning Models
The lack of deep learning models used for data fusion poses a significant challenge in achieving improved accuracy and learning quality in the integration of ML/DL with data fusion. A primary reason for this deficiency is the complexity of designing and training deep learning models tailored to fuse heterogeneous data from diverse sources. Data fusion entails the combination of multiple data sets, which often involves dealing with disparate formats, incomplete or noisy data, and varying levels of reliability. Developing appropriate deep learning architectures that can efficiently learn from such varied data and extract relevant features is a critical and complex task. Furthermore, the need for large amounts of training data and computational resources exacerbates the problem. As a result, the current landscape of ML/DL integration with data fusion lacks the full potential for achieving enhanced accuracy and learning quality. To address this open issue, researchers must focus on developing novel deep-learning architectures, techniques, and methodologies tailored to the unique challenges of data fusion [26–28].
The performance of ML/DL models often comes at the expense of high computational complexity, which can hinder real-time or resource-constrained applications. The fusion process itself involves the combination of data from multiple sources, which can lead to a substantial increase in the volume of data to be processed. This, in turn, exacerbates the computational burden of ML/DL algorithms, making it challenging to achieve both accuracy and efficiency simultaneously. To address this issue, researchers need to develop novel techniques that optimize the trade-off between accuracy and computational efficiency. Potential solutions may involve designing lightweight deep learning architectures, employing model compression techniques, or leveraging distributed and parallel computing paradigms. By focusing on fusion efficiency, researchers can enhance the scalability and applicability of ML/DL-based data fusion systems in a wider range of scenarios, ultimately unlocking their full potential [29,30].
Developing a model that excels in all these aspects simultaneously is challenging, as each criterion often involves a trade-off with another. For example, increasing model accuracy may require complex architectures that could compromise efficiency and adaptability to unstable environments. Additionally, enhancing robustness may involve incorporating redundancy or error-correction mechanisms, which could impact the model’s extensibility. Addressing this issue necessitates a multifaceted approach that encompasses the development of novel ML/DL architectures, optimization techniques, and fusion strategies tailored to the specific requirements of diverse applications. Researchers must focus on identifying the appropriate balance between these criteria to create more versatile and reliable data fusion systems. By establishing a comprehensive framework that encompasses these essential aspects, the potential benefits of ML/DL-based data fusion can be fully realized across various domains and use cases [31,32].
3.4 Data Privacy and Security Issue
Data privacy and security emerge as critical open issues when ML/DL integrates with data fusion, as the process often involves handling sensitive information from multiple sources. As data fusion combines diverse datasets, it can potentially reveal new patterns and insights that may not be apparent when examining individual datasets. This can lead to unintended consequences, such as the exposure of private information or the violation of data protection regulations like GDPR or CCPA. Addressing data privacy and security concerns requires the development and implementation of privacy-preserving techniques and robust security measures. Methods such as differential privacy, federated learning, and secure multi-party computation can help ensure that sensitive information remains protected while still allowing ML/DL models to learn from the fused data. Moreover, establishing clear data governance policies and enforcing access controls can further safeguard privacy and security [33–35].
3.5 Cross Domain Multimodal Data
Multimodal data consists of heterogeneous data types originating from various sources, such as text, images, audio, and video. Each data modality conveys distinct information and requires specialized processing and feature extraction techniques. Consequently, creating a unified representation that encapsulates the complete semantic knowledge of such diverse data becomes a daunting endeavor. Addressing this issue necessitates the development of advanced ML/DL models and fusion strategies capable of effectively combining information from multiple modalities while preserving the inherent semantics of each data type. Techniques such as cross-modal learning, multi-task learning, and domain adaptation can help build more effective and robust representations for multimodal data fusion. Furthermore, leveraging unsupervised or self-supervised learning approaches can aid in capturing latent semantic relationships across different modalities, thereby enhancing the fusion process [36,37].
3.6 Prediction and Decision Making
Prediction and decision-making become increasingly difficult when ML/DL integration with data fusion deals with imperfect, inconsistent, uncertain, and non-linear data. Such data often arise from real-world scenarios, where noise, missing values, conflicting information, and inherent complexity are prevalent. These imperfections pose significant challenges for ML/DL models, as their performance is highly dependent on the quality and consistency of the input data. Training models on noisy or inconsistent data may lead to overfitting, reduced generalization, or incorrect predictions, ultimately impacting the reliability and utility of the data fusion process. To address this open issue, researchers must develop robust ML/DL techniques and fusion strategies that can effectively handle and learn from imperfect data. Approaches such as robust optimization, Bayesian learning, and ensemble methods can help improve model resilience to noise, inconsistencies, and uncertainties. Additionally, incorporating data preprocessing and cleaning techniques, as well as incorporating domain knowledge, can help mitigate data imperfections and enhance the overall quality of the fused data [38,39].
Data conflict emerges as a critical open issue when integrating ML/DL with data fusion, as the process often involves combining data from multiple sources that may provide conflicting or contradictory information. Discrepancies in data can arise from various factors, such as sensor errors, data corruption, or inconsistencies in data collection methods. These conflicts can hinder the performance of ML/DL models, leading to unreliable predictions and decision-making, which may ultimately undermine the benefits of data fusion. Addressing this issue requires the development of conflict resolution strategies and robust ML/DL techniques that can effectively handle and learn from conflicting data. One approach to mitigating data conflicts is to employ data preprocessing and cleaning methods, which can identify and resolve discrepancies before they reach the learning stage. Additionally, incorporating source reliability or trustworthiness into the fusion process can help weigh the contribution of different data sources based on their credibility. Another potential solution is the use of advanced ML/DL models, such as ensemble methods, that can learn from multiple sources and make decisions based on a consensus, thereby minimizing the impact of conflicts. Furthermore, leveraging domain knowledge and context-aware approaches can aid in identifying and resolving data conflicts more effectively [40–42].
In real-world scenarios, the characteristics of data sources and the environment can change over time, affecting the relevance and accuracy of the fused data. To maintain effective decision-making and predictions, fusion models must be capable of adapting to these dynamic changes, which poses a significant challenge for conventional static fusion techniques. Addressing this issue necessitates the development of adaptive ML/DL models and dynamic fusion strategies that can accommodate changes in data types, environments, and time-varying systems. Techniques such as online learning, incremental learning, and transfer learning can help create models that are capable of updating themselves as new data becomes available or conditions change. Moreover, incorporating context-aware approaches and domain knowledge can further enhance the adaptability of these models to dynamic environments. Another potential solution is the use of attention mechanisms, which can learn to weigh different sources and features based on their relevance at a given time. This enables the model to focus on the most relevant information while adapting to changes in the data or environment [43].
Data samples from multiple sources may exhibit variations in terms of distribution, density, and noise levels. These differences can lead to ML/DL models learning suboptimal representations or overfitting to specific data characteristics, ultimately resulting in a large generalization error and reduced performance on unseen data. To address this issue, researchers must develop robust ML/DL techniques and fusion strategies that take sampling differences into account. One possible approach is employing domain adaptation techniques, which enable models to learn more general representations that can be applied across different data distributions. Another potential solution is the use of data preprocessing methods, such as data normalization or resampling, to minimize the impact of sampling differences on the learning process. Furthermore, incorporating ensemble methods, regularization techniques, or dropout strategies can help improve model generalization by reducing overfitting and encouraging the learning of more robust features. Additionally, focusing on unsupervised or semi-supervised learning approaches can help models extract more meaningful information from data with varying sampling characteristics [44].
A similar work is deeply investigated for Unmanned Aerial Vehicles (UAV) revealing the significance of kinematic model error for achieving optimal solution. The method reveals the use of optimal navigation solutions. The method simultaneously processes observations from integrated MIMU/GNSS and MIMU/CNS (Micro-electro-mechanical system-based inertial measurement unit/global navigation satellite system/celestial navigation system) subsystems for the subsequent global fusion. Based on the above, an optimal fusion technique is developed to fuse the filtering results of each subsystem for achieving global optimality [45]. In another study, the authors present a method of distributed state fusion by using the sparse-grid quadrature filter to deal with the fusion estimation problem for multi-sensor nonlinear systems. Here sparse-grid quadrature filter is performed in a distributed manner to process the information. The simulations and experiments in INS/CNS/GNSS (inertial navigation system/celestial navigation system/global navigation satellite system) integration verify the effectiveness of the proposed methodology [46].
A new optimal data fusion method based on the adaptive fading unscented Kalman filter for multi-sensor nonlinear stochastic systems is proposed which has a two-level fusion structure: at the bottom level, an adaptive fading unscented Kalman filter based on the Mahalanobis distance is developed and serves as local filters to improve the adaptability and robustness of local state estimations against process-modeling error; at the top level, an unscented transformation-based multi-sensor optimal data fusion for the case of N local filters is established according to the principle of linear minimum variance to calculate globally optimal state estimation by fusion of local estimations. The proposed methodology is found to be more effective and refrains from the influence of process-modeling error on the fusion solution, leading to improved adaptability and robustness of data fusion for multi-sensor nonlinear stochastic systems [47]. Nevertheless, the information fusion involved in INS/GNSS/CNS integration is still an open issue. Henceforth, a matrix-weighted multisensor data fusion methodology with the two-level structure for INS/GNSS/CNS integrated navigation system is proposed integrating local filters respectively to obtain local optimal state estimations. The approach proposed its significance with matrix-weighted multisensor data fusion methodology in comparison with the federated Kalman filter [48,49].
4.1 Background and Research Gap
The literature shows that the usage of ML algorithms with data fusion can be a costly and timely affair. An integrated framework that allows for the combination of real-world observations and simulation data for optimal result estimation. This could improve the performance of data fusion addressing the limitations as discussed in Section 3. Data fusion is used for military purposes, intrusion detection, target tracking, nuclear power cracks, crop monitoring, etc. When you work on these types of critical areas, you cannot afford to face failure as it involves huge costs, life risks along a huge time for implementation. It becomes important to figure out the open issues that are related to the implementation of ML-based algorithms with data fusion. Now, the important thing is to prioritize these open issues such that the above-mentioned cons can be minimized or zilch. To rank these issues, a multi-criteria decision analysis technique called fuzzy AHP is used [50]. Works relating to software-defined networking (SDN) were used in several controllers to improve the reliability as well as the scalability of networks such as the Internet of Things (IoT). To achieve optimal results in IoT networks, an SDN is employed to reduce the complexity associated with IoT and provide an improved quality-of-service (QoS). The proposed scheme is more flexible for the decision-making process for the selection of appropriate controllers with varying resources [51].
A survey has been conducted with the help of 15 experts to rank the identified nine open issues. These are rated on a scale of 1 to 9 and the current study is quantitative. Two sections are considered in the survey. The first section contains the experts’ profiles whereas the other section contains these open issues. A nine-point Likert scale is used for measuring these open issues variables where nine stands for “tremendous” to one stands for “equal” importance as shown in Table 1. The survey was conducted to rank the identified issues so that success is achieved while implementing data fusion by taking care of issues that should be handled on priority.
Different multi-criteria decision-making (MCDM) techniques exist in the past and they are used to rank the criteria or issues as well as sub-criteria. FAHP is one of the prevailing and powerful techniques that has been used for decision-making. Fuzzy set theory is the basis for doing FAHP. Fuzzy triangular numbers (FTNs) are used to do a pair-wise comparison for identified criteria or open issues [52,53]. FAHP is used to rank the criteria or open issues based on weights that have been calculated. The process of FAHP is explained below:
Step 1: First do the pair-wise comparison for all criteria or sub-criteria. Experts’ opinions are used to do a pairwise comparison with the help of a linguistic scale as mentioned in Table 2. Eq. (1) is used for doing a pairwise comparison.

where
Step 2: Fuzzy synthetic criteria (Fi) is calculated for all criteria with the help of fuzzy synthetic extent values (SVS) using Eq. (2).
Step 3: After calculating Fi, it is important to find out the degree of possibility (DgPs) with the help of Eq. (3). Suppose, F1 = (x1, y1, z1) and F2 = (x2, y2, z2) are two fuzzy matrices. The degree of possibility of F1 ≥ F2 can be defined as:
Step 4: Calculate fuzzy weight (Fwgt) and non-fuzzy weight (NFwgt) with the help of Eqs. (4) and (5), respectively.
where
Initially to start FAHP implementation, firstly open issues or criteria are defined as can be seen in Table 1. Further, a linguistic scale (Table 2) should be developed that will be used by experts for doing a pairwise comparison. Triangular Fuzzy Numbers (TFNs) have been used for doing a pairwise comparison and are shown in Expert 1 in Table 3 along with Data Fusion Multi Criteria (DF-MC).
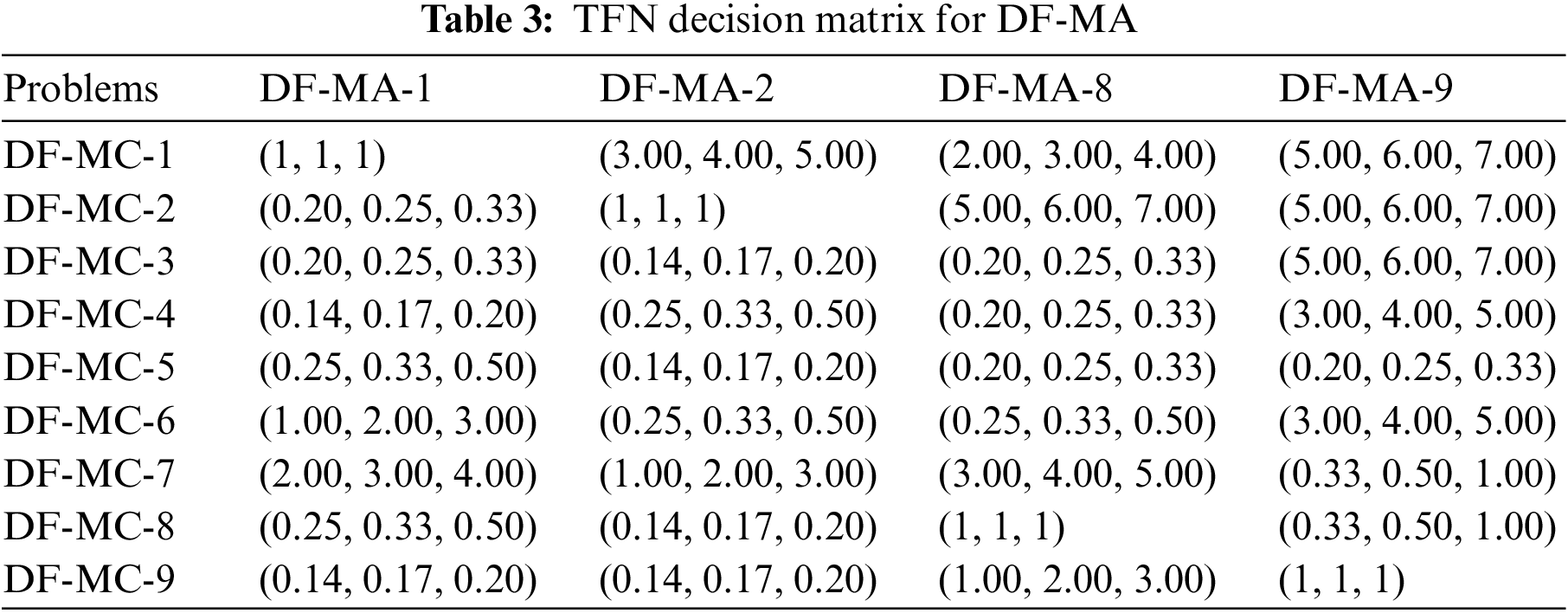
A pairwise comparison by all 15 experts has been done and their aggregated decision matrix result is shown in Table 4. Out of these, six are data analytics experts, four are software developers of industries, two are project managers who have used data fusion in their projects and three are directors of startups.
The important thing after calculating the aggregated TFNs decision matrix is to find out Fi for all open issues with the help of SVs. The results are mentioned in Table 5. After this calculate the Degree of Possibility (DgPs) for all open issues.

The degree of possibility is a measure of how likely or probable a certain decision or outcome is, based on the linguistic terms used in pairwise comparisons between different decision criteria. The degree of possibility can be calculated using fuzzy arithmetic operations, such as addition, multiplication, and comparison. This allows decision-makers to combine different degrees of possibility to make overall decisions, taking into account the uncertainty and imprecision inherent in human decision-making. Overall, the use of degree of possibility in fuzzy AHP allows decision-makers to make more nuanced and realistic decisions, based on linguistic terms and fuzzy numbers, while still maintaining a quantitative and rigorous decision-making framework. After computing the degree of possibility, find out the minimum DgPs, and the results are mentioned in Table 6. The minimum degree of possibility is a threshold value that is used to determine whether a pairwise comparison between two decision criteria is considered meaningful or not. The choice of the minimum degree of possibility depends on the specific context of the decision-making problem and the preferences of the decision-makers. Setting a higher minimum degree of possibility can help ensure that only the most meaningful comparisons are included in the analysis, but it may also result in a smaller set of pairwise comparisons and potentially less information to inform the decision-making process. Overall, the minimum degree of possibility in fuzzy AHP is an important parameter that helps ensure the validity and reliability of the pairwise comparisons used to make decisions, while also balancing the need for meaningfulness and comprehensiveness.
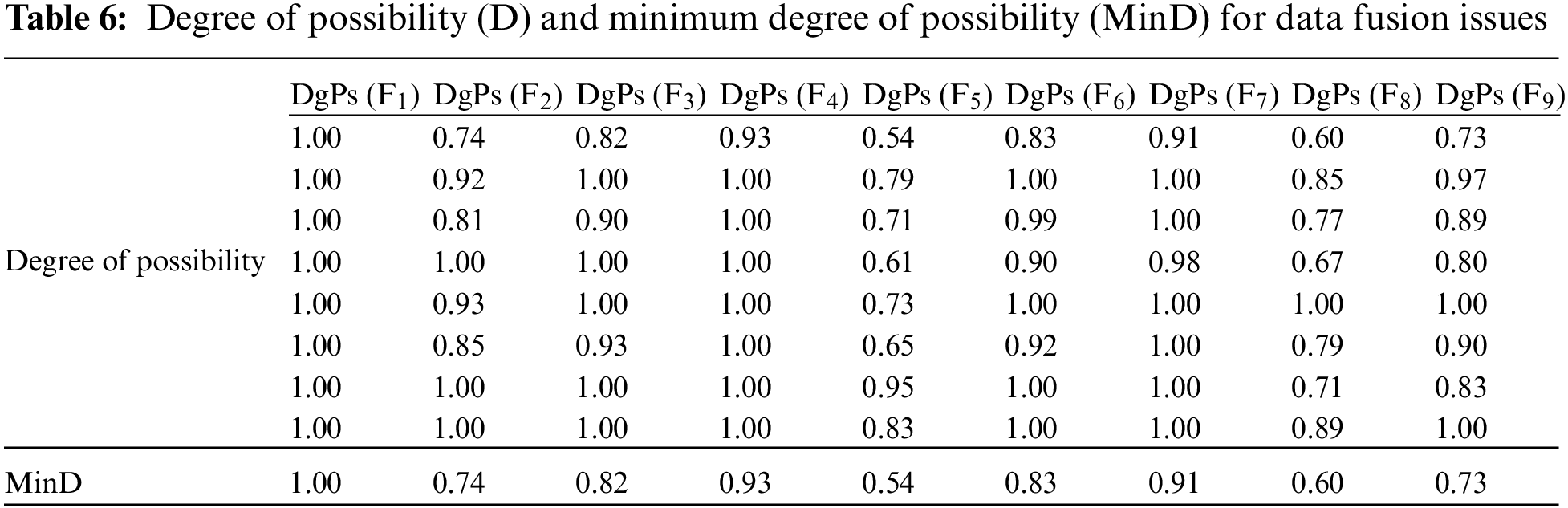
Table 6 displays the Degree of Possibility (DgPs) and Minimum Degree of Possibility (MinD) for nine data fusion issues (F1 to F9). The Degree of Possibility is a measure of how likely a particular issue is to occur, with 1.00 representing certainty and values closer to 0 representing increasing uncertainty. The Minimum Degree of Possibility represents the lowest observed DgPs value for each issue.
From the Table 6, the following observations could be made:
1. All data fusion issues have a Degree of Possibility of 1.00 in at least one instance, which means that each issue is highly likely to occur in certain situations.
2. The Minimum Degree of Possibility (MinD) ranges from 0.54 to 1.00, indicating that some issues have a relatively low likelihood of occurring in certain scenarios (e.g., F4 with MinD of 0.54), while others are highly likely to occur in all situations (e.g., F1 with MinD of 1.00).
3. Data fusion issues F1, F7, and F9 have relatively low Minimum Degrees of Possibility, suggesting that they might be less critical or frequent concerns compared to the other issues.
4. Data fusion issues F2, F3, F5, and F6 have relatively high Minimum Degrees of Possibility, which indicates that these issues are more likely to be encountered and could be considered more important to address.
Use Eqs. (4) and (5) to compute Fwgt and NFwgt for all open issues so that they can be prioritized and managers solve the issue by considering their priority level so that projects will not face failure. These are ranked with the highest weight is ranked highest and the lowest weight is ranked lowest. The ranking results are mentioned in Table 7.
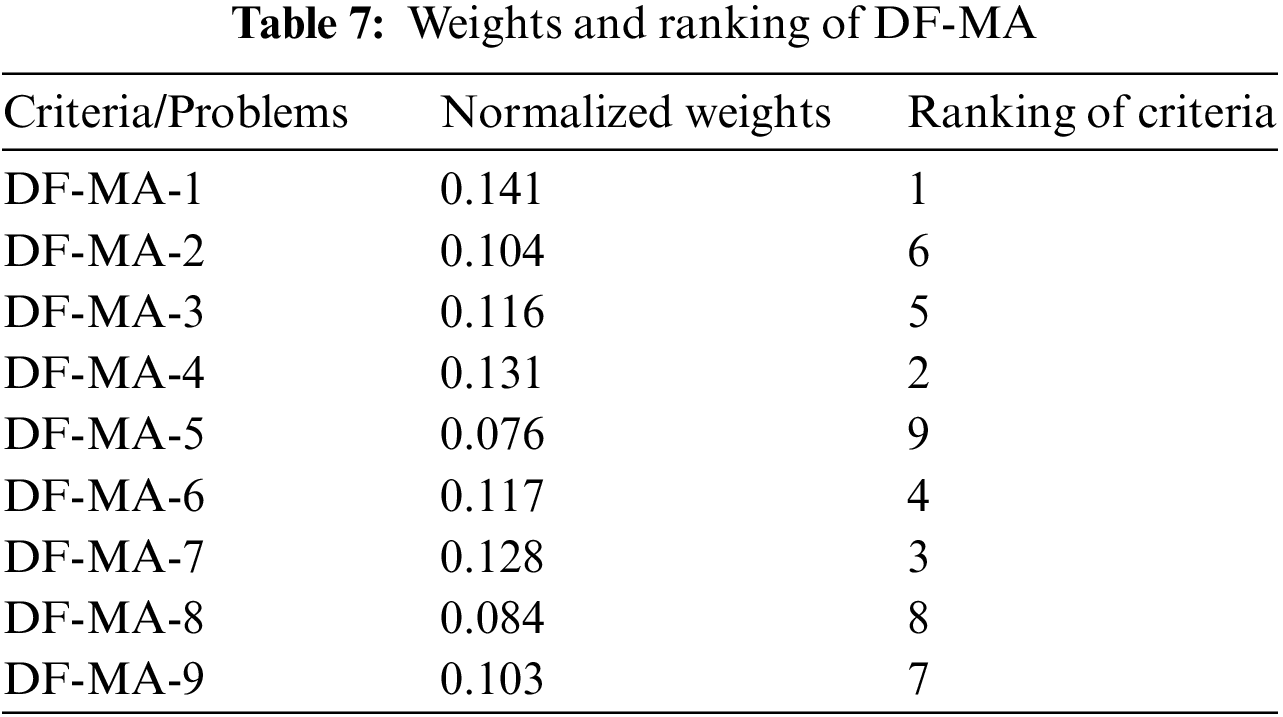
From Table 7, the following observations were noted:
1. The highest priority criterion is DF-MA-1 with a normalized weight of 0.141, indicating that it is the most important criterion to consider.
2. The least important criterion is DF-MA-5 with a normalized weight of 0.076, suggesting that it should be the lowest priority in decision-making.
3. The remaining criteria have varying levels of importance, with DF-MA-4 and DF-MA-7 being relatively more important, while DF-MA-8 and DF-MA-9 are less important.
It is difficult to predict when machine algorithms give birth to data fusion and what factors are needed to ensure efficient, reliable, and high-quality data fusion. Therefore, it is vital to figure out the open issues related to data fusion when using ML algorithms. This research has identified nine issues. It is crucial to prioritize them to ensure the success of data fusion and the accuracy and reliability of the results. FAHP has helped prioritize the open issues. Table 7 shows the data of weights of the issues. The highest weight is ranked highest and the lowest weight is ranked lowest. Based on weights, the issues appear in descending order. The results are DF-MA-1 > DF-MA-4 > DF-MA-7 > DF-MA-6 > DF-MA-3 > DF-MA-2 > DF-MA-9 > DF-MA-8 > DF-MA-5. It shows the most important use of ‘deep learning models that can improve accuracy and learning quality’ (weight = 0.141) followed by ‘data privacy & security issue’ and ‘data confliction.’ When handling ranked open issues, take care when ‘data is imperfect, inconsistent, uncertain and non-linear’ followed by ‘A comprehensive model that satisfied all expected criteria is missing’ and ‘data fusion efficiency.’ The lowest three open issues identified using FAHP are ‘Generalization error is large as sampling differences are not considered extensively’ (weight = 0.103), ‘Dynamic fusion’ (weight = 0.084), and ‘Cross-domain multimodal data fusion is a challenge as whole semantic knowledge for multimodal data cannot be captured’ weighting 0.076. The decision-makers must pay attention to the issues mentioned while doing data fusion. In the future, FAHP + TOPSIS, DEMATEL, and ELECTRE can be used to overcome the vagueness generated by experts’ opinions.
Acknowledgement: The authors would like to thank the anonymous reviewers for their valuable comments. This work was financially supported by the “Intelligent Recognition Industry Service Center” from The Featured Areas Research Center Program within the framework of the Higher Education Sprout Project by the Ministry of Education (MOE) in Taiwan.
Funding Statement: This work was supported in part by the Higher Education Sprout Project from the Ministry of Education (MOE) and National Science and Technology Council, Taiwan (109-2628-E-224-001-MY3, 112-2622-E-224-003) and in part by Isuzu Optics Corporation. Dr. Shih-Yu Chen is the corresponding author.
Author Contributions: The authors confirm contribution to the paper as follows: study conception and design: V. Kukreja; data collection: A. Asha; analysis and interpretation of results: K. Kalaiselvi, K. Deepa Thilak; draft manuscript preparation: S. Hariharan, S. Y. Chen. All authors reviewed the results and approved the final version of the manuscript.
Availability of Data and Materials: Not applicable.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. T. Meng, X. Jing, Z. Yan and W. Pedrycz, “A survey on machine learning for data fusion,” Information Fusion, vol. 57, pp. 115–129, 2020. [Google Scholar]
2. Z. Qin, P. Zhao, T. Zhuang, F. Deng, Y. Ding et al., “A survey of identity recognition via data fusion and feature learning,” Information Fusion, vol. 91, pp. 694–712, 2023. [Google Scholar]
3. T. P. Banerjee and S. Das, “Multi-sensor data fusion using support vector machine for motor fault detection,” Information Sciences, vol. 217, pp. 96–107, 2012. [Google Scholar]
4. S. Challa, M. Palaniswami and A. Shilton, “Distributed data fusion using support vector machines,” in Proc. of the Fifth Int. Conf. on Information Fusion, Annapolis, Maryland, USA, pp. 881–885, 2002. [Google Scholar]
5. M. S. Fahmy, A. F. Atiya and R. S. Elfouly, “Biometric fusion using enhanced SVM classification,” in Proc. of the 4th Int. Conf. on Intelligent Information Hiding and Multimedia Signal Processing, Harbin, China, pp. 1043–1048, 2008. [Google Scholar]
6. S. Li, M. Liu and X. Li, “WSN data fusion approach based on improved BP algorithm and clustering protocol,” in Proc. of the 2015 27th Chinese Control and Decision Conf. (2015 CCDC), Qingdao, China, pp. 1450–1454, 2015. [Google Scholar]
7. K. Kolanowski, A. Świetlicka, R. Kapela, J. Pochmara and A. Rybarczyk, “Multisensor data fusion using Elman neural networks,” Applied Mathematics and Computation, vol. 319, pp. 236–244, 2018. [Google Scholar]
8. A. Singh and K. Gaurav, “Deep learning and data fusion to estimate surface soil moisture from multi-sensor satellite images,” Scientific Reports, vol. 13, pp. 2251, 2023. https://doi.org/10.1038/s41598-023-28939-9 [Google Scholar] [PubMed] [CrossRef]
9. H. Shu, Y. Wang and J. Jiang, “Multi-rada data fusion algorithm based on K-central clustering,” in Proc. of the Fourth Int. Conf. on Fuzzy Sysems and Knowledge Discovery, Haikou, China, pp. 617–621, 2007. [Google Scholar]
10. Z. Li and X. Wang, “High resolution radar data fusion based on clustering algorithm,” in Proc. of the 2nd Int. Workshop on Database Technology and Applications, Wuhan, China, pp. 1–4, 2010. [Google Scholar]
11. H. Wang, T. Liu, Q. Bu and B. Yang, “An algorithm based on hierarchical clustering for multi-target tracking of multi-sensor data fusion,” in Proc. of the 35th Chinese Control Conf. (CCC), Chengdu, China, pp. 5106–5111, 2016. [Google Scholar]
12. F. Wang, K. Wang and F. Jiang, “An improved fusion method of fuzzy logic based on K-mean clustering in WSN,” Sensors and Transducers, vol. 157, no. 10, pp. 20–25, 2013. [Google Scholar]
13. S. S. Sanz, P. Ghamisi, M. Piles, M. Werner, L. Cuadra et al., “Machine learning information fusion in earth observation: A comprehensive review of methods, applications and data sources,” Informnation Fusion, vol. 63, pp. 256–272, 2020. [Google Scholar]
14. M. M. Alyannezhadi, A. A. Pouyan and V. Abolghasemi, “An efficient algorithm for multisensory data fusion under uncertainty condition,” Electrical Systems and Information Technology, vol. 4, no. 1, pp. 269–278, 2017. [Google Scholar]
15. R. Pouteau and B. Stoll, “SVM selective fusion (SELF) for multi-source classification of structurally complex tropical rainforest,” Selected Topics in Earth Observations and Remote Sensing, vol. 5, no. 4, pp. 1203–1212, 2012. [Google Scholar]
16. Y. L. Cao, T. J. Huang and Y. H. Tian, “A ranking SVM based fusion model for cross-media meta-search engine,” Journal of Zhejiang University Science C, vol. 11, no. 11, pp. 903–910, 2010. [Google Scholar]
17. N. Ghosh, Y. B. Ravi, A. Patra, S. Mukhopadhyay, S. Paul et al., “Estimation of tool wear during CNC milling using neural network-based sensor fusion,” Mechanical Systems and Signal Processing, vol. 21, no. 1, pp. 466–479, 2007. [Google Scholar]
18. S. Xiao, Y. Zhang, X. Liu and J. Gao, “Alert fusion based on cluster and correlation analysis,” in Proc. of the Int. Conf. on Convergence and Hybrid Information Technology,, Bushan, South Korea, pp. 163–168, 2008. [Google Scholar]
19. Y. Himeur, A. Alsalemi, A. Al-Kababji, F. Bensaali and A. Amira, “Data fusion strategies for energy efficiency in buildings: Overview, challenges and novel orientations,” Information Fusion, vol. 64, pp. 99–120, 2020. [Google Scholar]
20. X. Chang, J. Wu, H. Liu, X. Yan, H. Sun et al., “Travel mode choice: A data fusion model using machine learning methods and evidence from travel diary survey data,” Transpormetrica A: Transport Science, vol. 15, no. 2, pp. 1587–1612, 2019. [Google Scholar]
21. G. Giacinto, F. Roli and L. Didaci, “Fusion of multiple classifiers for intrusion detection in computer networks,” Pattern Recognition Letters, vol. 24, no. 12, pp. 1795–1803, 2003. [Google Scholar]
22. B. a. Fessi, S. Benabdallah, Y. Djemaiel and N. Boudriga, “A clustering data fusion method for intrusion detection system,” in Proc. of the IEEE Int. Conf. on Computer and Information Technology, Paphos, Cyprus, pp. 539–545, 2011. [Google Scholar]
23. F. C. Chen and M. R. Jahanshahi, “NB-CNN: Deep learning based crack detection using convolutional neural network and naïve bayes data fusion,” IEEE Transactions on Industrial Electronics, vol. 65, no. 5, pp. 4392–4400, 2018. [Google Scholar]
24. M. Maimaitijiang, V. Sagan, P. Sidike, A. M. Daloye, H. Erkbol et al., “Crop monitoring using satellite/UAV data fusion and machine learning,” Remote Sensing, vol. 12, no. 9, pp. 1357–1379, 2020. [Google Scholar]
25. D. Vidhate and P. Kulkarni, “Cooperative machine learning with information fusion for dynamic decision making in diagnostic applications,” in Proc. of the Int. Conf. on Advances in Mobile Networks, Communication and its Applications, Banglore, India, pp. 70–74, 2012. [Google Scholar]
26. M. Maimaitijiang, A. Ghulam, P. Sidike, S. Hartling, M. Maimaitijiang et al., “Unmanned aerial system (UAS)-based phenotyping of soybean using multi-sensor data fusion and extreme learning machine,” Photogrammetry and Remote Sensing, vol. 134, pp. 43–58, 2017. [Google Scholar]
27. J. Wu, L. Zhou, C. Cai, J. Shen, S. K. Lau et al., “Data fusion for MaaS: Opportunities and challenges,” in Proc. of the 22nd Int. Conf. on Computer Supported Cooperative Work in Design, Nanjing, China, pp. 184–189, 2018. [Google Scholar]
28. J. Qi, P. Yang, L. Newcombe, X. Peng, Y. Yang et al., “An overview of data fusion techniques for internet of things enabled physical activity recognition and measure,” Information fusion, vol. 55, pp. 269–280, 2020. [Google Scholar]
29. W. Wang, J. Chen and T. Hong, “Occupancy prediction through machine learning and data fusion of environmental sensing and Wi-Fi sensing in buildings,” Automation in Construction, vol. 94, pp. 233–243, 2018. [Google Scholar]
30. A. R. Pinto, C. Montez, G. Araújo, F. Vasques and P. Portugal, “An approach to implement data fusion techniques in wireless sensor networks using genetic machine learning algorithms,” Information Fusion, vol. 15, no. 1, pp. 90–101, 2014. [Google Scholar]
31. J. Li, D. Hong, L. Gao, J. Yao, K. Zheng et al., “Deep learning in multimodal remote sensing data fusion: A comprehensive review,” Applied Earth Observation and Geoinformation, vol. 112, pp. 102906, 2022. [Google Scholar]
32. D. Lahat, T. Adali and C. Jutten, “Multimodal data fusion: An overview of methods, challenges, and prospects,” IEEE, vol. 103, no. 9, pp. 1449–1477, 2015. [Google Scholar]
33. B. P. L. Lau, S. H. Marakkalage, Y. Zhou, N. U. Hassan, C. Yuen et al., “A survey of data fusion in smart city applications,” Information Fusion, vol. 52, pp. 357–374, 2019. [Google Scholar]
34. J. Zhou, X. Hong and P. Jin, “Information fusion for multi-source material data: Progress and challenges,” Applied Sciences, vol. 9, no. 17, pp. 1–18, 2019. [Google Scholar]
35. Y. Zheng, “Methodologies for cross-domain data fusion: An overview,” IEEE Transactions on Big Data, vol. 1, no. 1, pp. 16–34, 2015. [Google Scholar]
36. J. Gao, P. Li, Z. Chen and J. Zhang, “A survey on deep learning for multimodal data fusion,” Neural Computation, vol. 32, no. 5, pp. 829–864, 2020. [Google Scholar] [PubMed]
37. B. Khaleghi, A. Khamis, F. O. Karray and S. N. Razavi, “Multisensor data fusion: A review of the state-of-the-art,” Information Fusion, vol. 14, no. 1, pp. 28–44, 2013. [Google Scholar]
38. L. Feng, B. Wu, S. Zhu, J. Wang, Z. Su et al., “Investigation on data fusion of multisource spectral data for rice leaf diseases identification using machine learning methods,” Frontiers in Plant Sciences, vol. 11, pp. 1–17, 2020. [Google Scholar]
39. J. J. Braun, “Sensor data fusion with support vector machine techniques,” Sensor Fusion: Architectures and Algorithms, vol. 4731, pp. 98–109, 2002. [Google Scholar]
40. A. K. Raz, P. Wood, L. Mockus, D. A. Delaurentis and J. Llinas, “Identifying interactions for information fusion system design using machine learning techniques,” in Proc. of the 21st Int. Conf. on Information Fusion, Cambridge, UK, pp. 226–233, 2018. [Google Scholar]
41. D. Y. Chang, “Applications of the extent analysis method on fuzzy AHP,” European Journal of Operational Research, vol. 95, no. 3, pp. 649–655, 1996. [Google Scholar]
42. Z. Dan and C. Yi, “Realization and simulation analysis of intelligent data fusion algorithm based on support vector machine,” in Proc. of the Int. Conf. on Information System, Computing and Educational Technology (ICISCET), Montreal, QC, Canada, pp. 323–327, 2022. [Google Scholar]
43. F. Schwenker, “Keynote: Machine learning and data analysis of multimodal affective and pain data,” in Proc. of the IEEE Int. Conf. on Pervasive Computing and Communications Workshops and Other Affiliated Events (PerCom Workshops), Kassel, Germany, pp. 452, 2021. [Google Scholar]
44. S. K. Kakula, A. J. Pinar, M. A. Islam, D. T. Anderson and T. C. Havens, “Novel regularization for learning the fuzzy choquet integral with limited training data,” IEEE Transactions on Fuzzy Systems, vol. 29, no. 10, pp. 2890–2901, 2021. [Google Scholar]
45. H. Li, L. Yu, M. Lyu and Y. Qian, “Fusion deep learning and machine learning for multi-source heterogeneous military entity recognition,” in Proc. of the 2021 IEEE Conf. on Telecommunications, Optics and Computer Science (TOCS), Shenyang, China, pp. 535–539, 2021. [Google Scholar]
46. B. Gao, G. Hu, Y. Zhong and X. Zhu, “Distributed state fusion using sparse-grid quadrature filter with application to INS/CNS/GNSS integration,” IEEE Sensors, vol. 22, no. 4, pp. 3430–3441, 2022. [Google Scholar]
47. B. Gao, G. Hu, S. Gao, Y. Zhong and C. Gu, “Multi-sensor optimal data fusion based on the adaptive fading unscented kalman filter,” Sensors, vol. 18, no. 2, pp. 488, 2018. [Google Scholar] [PubMed]
48. G. Hu, S. Gao, Y. Zhong, B. Gao and A. Subic, “Matrix weighted multisensor data fusion for INS/GNSS/CNS integration,” Proceedings of the Institution of Mechanical Engineers, Part G: Journal of Aerospace Engineering, vol. 230, no. 6, pp. 1011–1026, 2016. [Google Scholar]
49. B. Gao, G. Hu, Y. Zhong and X. Zhu, “Cubature rule-based distributed optimal fusion with identification and prediction of kinematic model error for integrated UAV navigation,” Aero Science and Technology, vol. 109, pp. 106447, 2022. https://doi.org/10.1016/j.ast.2020.106447 [Google Scholar] [CrossRef]
50. M. Ma, Z. Chen, Z. Fang and H. Xu, “Classification algorithm of streaming media big data fusion under multi-task information filtering,” in Proc. of the 2022 Int. Conf. on Artificial Intelligence, Information Processing and Cloud Computing (AIIPCC), Kunming, China, pp. 441–446, 2022. [Google Scholar]
51. J. Ali, R. H. Jhaveri, M. Alswailim and B. H. Roh, “ESCALB: An effective slave controller allocation-based load balancing scheme for multi-domain SDN-enabled-IoT networks,” Journal of King Saud University-Computer and Information Sciences, vol. 35, no. 6, pp. 101566, 2023. [Google Scholar]
52. W. Xu, Y. Pan, X. Chen, W. Ding and Y. Qian, “A novel dynamic fusion approach using information entropy for interval valued ordered datasets,” IEEE Transactions on Big Data, vol. 9, no. 3, pp. 845–859, 2023. [Google Scholar]
53. M. M. Agarwal, M. C. Govil, M. Sinha and S. Gupta, “Fuzzy based data fusion for energy efficient internet of things,” Grid and High Performance Computing, vol. 11, no. 3, pp. 46–58, 2023. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools