
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

Fusion of Hash-Based Hard and Soft Biometrics for Enhancing Face Image Database Search and Retrieval
Department of Computer Science, Faculty of Computing and Information Technology, King Abdulaziz University, Jeddah, 21589, Saudi Arabia
* Corresponding Author: Ameerah Abdullah Alshahrani. Email:
(This article belongs to the Special Issue: Machine Vision Detection and Intelligent Recognition)
Computers, Materials & Continua 2023, 77(3), 3489-3509. https://doi.org/10.32604/cmc.2023.044490
Received 31 July 2023; Accepted 07 November 2023; Issue published 26 December 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The utilization of digital picture search and retrieval has grown substantially in numerous fields for different purposes during the last decade, owing to the continuing advances in image processing and computer vision approaches. In multiple real-life applications, for example, social media, content-based face picture retrieval is a well-invested technique for large-scale databases, where there is a significant necessity for reliable retrieval capabilities enabling quick search in a vast number of pictures. Humans widely employ faces for recognizing and identifying people. Thus, face recognition through formal or personal pictures is increasingly used in various real-life applications, such as helping crime investigators retrieve matching images from face image databases to identify victims and criminals. However, such face image retrieval becomes more challenging in large-scale databases, where traditional vision-based face analysis requires ample additional storage space than the raw face images already occupied to store extracted lengthy feature vectors and takes much longer to process and match thousands of face images. This work mainly contributes to enhancing face image retrieval performance in large-scale databases using hash codes inferred by locality-sensitive hashing (LSH) for facial hard and soft biometrics as (Hard BioHash) and (Soft BioHash), respectively, to be used as a search input for retrieving the top-k matching faces. Moreover, we propose the multi-biometric score-level fusion of both face hard and soft BioHashes (Hard-Soft BioHash Fusion) for further augmented face image retrieval. The experimental outcomes applied on the Labeled Faces in the Wild (LFW) dataset and the related attributes dataset (LFW-attributes), demonstrate that the retrieval performance of the suggested fusion approach (Hard-Soft BioHash Fusion) significantly improved the retrieval performance compared to solely using Hard BioHash or Soft BioHash in isolation, where the suggested method provides an augmented accuracy of 87% when executed on 1000 specimens and 77% on 5743 samples. These results remarkably outperform the results of the Hard BioHash method by (50% on the 1000 samples and 30% on the 5743 samples), and the Soft BioHash method by (78% on the 1000 samples and 63% on the 5743 samples).Keywords
Every day, a massive volume of multimedia data, including texts, photos, and videos, is created on the internet due to social media and search engines’ revolutionary growth. Therefore, there was a sharp concurrent rise in utilizing large photo databases [1,2]. Recently, content-based image retrieval (CBIR) has drawn a lot of attention due to the growing need to enhance the efficiency and capacities of picture search and retrieval to better handle large-scale databases that may contain billions of images. Furthermore, an extremely effective and reliable retrieval method is required for such large-scale data searches. CBIR has numerous applications in several fields. For instance, in the forensics field, it can be used to aid in criminal investigation [3]. The CBIR method aims to search the image database for images similar to the query input image. Pair-wise label similarity is deemed a common essential way to find similar images, where it often measures the distance among features of a picture via Manhattan distance or the k-nearest neighbor algorithm (kNN) [4]. Face image retrieval aims to find the top matches and rank the outcomes based on similarity to a specific query on a face picture database. In large-scale databases, significant demand exists for more effective content-based face picture retrieval in various applications. A practical retrieval algorithm must rank a huge number of pictures precisely and rapidly while working with enormous datasets so that the most related images appear first in the ranked and then retrieved results. Nevertheless, retrieving a person’s facial picture from a sizable dataset among many human facial pictures can be more challenging [3]. It is time- and space-consuming, and in some cases, the image might not seem accurately retrieved as needed because of the striking resemblance between identical faces, such as twin people’s faces or alike people’s faces, as the number increases. In that case, the facial features and shapes of the similar twins’ faces may also be utilized to differentiate between them. Therefore, the system allows obtaining only the relevant images [5]. This shows that extracting discriminative facial features from image pixels is essential for increasing the accuracy of retrieving facial images. In general, a retrieval system, which depends on extracting multiple attributes, can make it easier to distinguish between comparable images in a database and index or rank them according to their similarity. Even though many researchers focus on different and multiple image attributes, achieving the requisite high performance still represents a challenging issue [6].
Moreover, it is still challenging to retrieve an encrypted image from a database due to the fact that it should be instantly accomplished while maintaining particularity [7]. As a rapid fix to that issue, hash technology can efficiently solve the problems of time spent, privacy preservation, and increased storage costs during querying and retrieving images. The primary purpose of a hash function is to assign streamlined representative codes for high-dimensional data. The fundamental procedure of a hash method includes allocating photos with similar content to comparable binary codes, allowing maintenance of the semantic closeness of the images [8].
Recently, multimodal biometric systems have received more attention than unimodal systems [9]. The classification scores are fused using a fusion method, and the result of that fusion will be the final classification [10]. Feature fusion is a critical technique enabling a multimodal biometric system to integrate different biometrics’ capabilities to identify people. This is because it can improve security and overall recognition rates by combining multiple biometric sources at one level, such as scores or features level [9]. Fig. 1 shows the major steps in multimodal biometric score-level fusion systems.
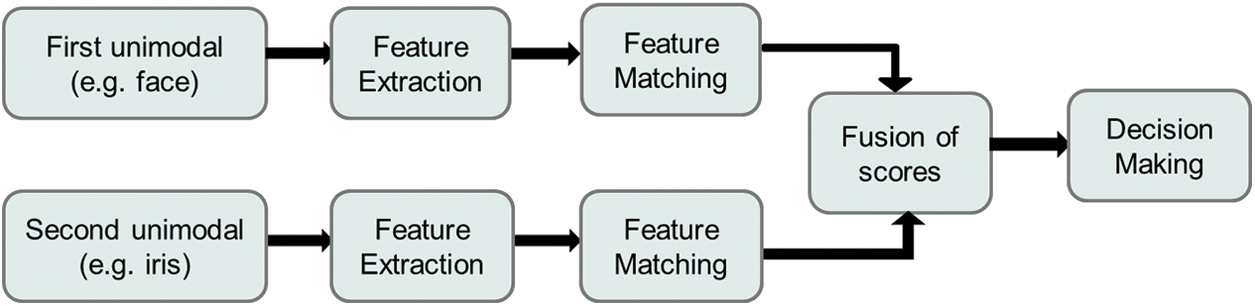
Figure 1: Multimodal biometric score-level fusion
The research is motivated by several aspects. First, human identification is a fundamental component of many applications, and due to the global digital revolution and the sharp rise in social media usage over the past decade, a massive volume of multimedia data demands to be handled with greater effectiveness and better retrieval performance. Second, hashing methods have attracted much interest in the field of retrieving images and have significantly impacted improving image retrieval performance. Third, fusing multiple biometric data sources enhances the overall performance of any system in comparison to unimodal data.
Even though face photo retrieval utilizing a CBIR approach is a well-invested technique for numerous real-world applications, it takes a long time and demands ample storage space, which may adversely affect performance efficiency. This issue is still present even when employing biometric data of very low dimensionality, for instance, face soft biometrics, for retrieving a similar face photo, specifically from extensive databases of uncontrolled face photos. As a result, face hard or soft biometric-based hash codes in isolation and even fusing similarity matching scores of both hard and soft hash codes can be examined, utilized, and compared for performance improvement in face image retrieval. Such facial hard and soft biometric-based hash codes can be generated using hashing methods, such as locality-sensitive hashing (LSH), which many related research studies have effectively used. To the best of our knowledge, the existent research works are still being investigated and comparing the hash-based face image retrieval performance of three counterparts: hard biometric-based hash code (Hard BioHash), soft biometric-based hash code (Soft BioHash), and the match score-level fusion of both hard and soft BioHashes (Hard-Soft BioHash Fusion). In this hash-based face image retrieval, Hard BioHash substitutes the traditional hard face biometrics with their related LSH-based hash codes. In contrast, Soft BioHash replaces the conventional face soft biometrics with their related LSH-based hash codes. Consequently, the primary contribution of this study is as follows:
• To improve face image retrieval performance via the suggested method of Hard-Soft BioHash Fusion, we proved and revealed it in the third experiment in Subsection 5.3.
• To investigate and demonstrate the efficiency of the Hard-Soft BioHash Fusion method as compared with the conventional Hard BioHash approach and its soft biometric-based counterpart method of Soft BioHash, we implement the experiments of those methods and compare the performance of each of them in Section 6.
The remainder of this paper is structured as follows. Section 2 shows relevant studies. Section 3 describes the LSH method and biometrics fusion methods. Section 4 describes the proposed methodology. Details of the experimental setup are provided in Section 5. The results and discussion are demonstrated in Section 6. Lastly, Section 7 presents the conclusion and future works of this study.
This section addresses relevant studies on various facial picture retrieval and recognition methods. The reviewed relevant research can be classified concerning our suggested method into four classifications: conventional methods of face image retrieval, biometric recognition and retrieval using hash methods, face image retrieval utilizing face soft biometrics, and multimodal biometric fusion. Fig. 2 shows the categories of relevant research and highlights the area of our research interest, representing the intersection between all four classifications.
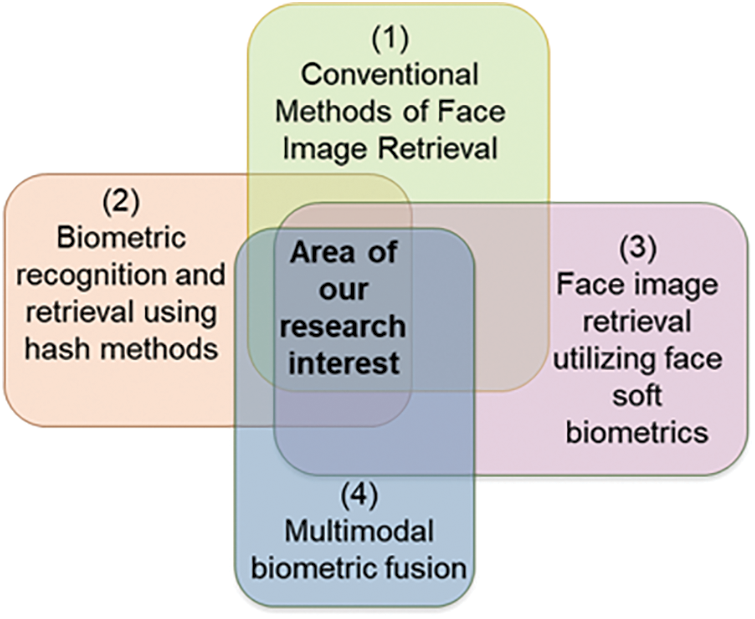
Figure 2: Categories of literature review and the area of our research interest
2.1 Conventional Methods of Face Image Retrieval
Several researchers note that numerous documents now use a picture of a human’s face to identify them. Therefore, using a picture of a face to index and find these documentation papers is important. In [11], they came up with a three-step plan for using face images to find documents. Firstly, a face picture for the query must be detected in the document. Secondly, to pull out features from the face image. Third, to get all documents that have a face picture matching the query document. The result of their method has a mean average precision of 82.66% (MAP). To improve the major drawbacks of previous methods, including productivity, inferior precision, reliability, and the issue of excessive segmentation, the authors of [12] developed a novel method for obtaining face pictures based on the image’s content and employing several metrics to measure similarity. They concluded that their system could function more effectively if various algorithms were applied at various process stages.
There exist numerous real-world uses for large-scale face image retrieval. In [13], their exploration is specifically associated with Hadoop’s impact on large-scale face image retrieval. They introduced a new method for face retrieval by utilizing deep learning based on the Hadoop platform. They used the histogram of oriented gradients (HOG) method and support vector machine (SVM) method to detect faces from the images. For feature extraction, they employed a deep residual network. Their results showed that the retrieval of large-scale facial images could be improved. As for their future work, they suggested that they still need to study the parallel computing models Hadoop and MapReduce, and their applications in large-scale face image retrieval. The main concern of [14] is the impact of the spark processing engine on massive machine learning-based facial image retrieval. They applied Viola&Jones to recognize the faces, the scale-invariant feature transform (SIFT) approach to extract the features, the principal component analysis (PCA) method to reduce the dimensions, HBase to store the data, and finally, the KD-tree query algorithm for the matching. The results of conducting their study on the CelebA dataset indicated the method’s effectiveness. For their future work, they would continue to investigate its other possible applications. In [15], the authors considered the problem that under a certain threshold, massive face image databases might consume a much longer time for retrieval. They applied a fuzzy clustering-based quick retrieval technique on a large database of face photos to obtain a pedigree map and a deep convolutional neural network (DCNN) model for feature extraction. After the node’s center point feature vector was computed, it was stored in the pedigree map. The role of the pedigree map is to speed up retrieval. Their proposed method received improved results and significantly reduced the number of comparisons for images that were retrieved.
2.2 Biometric Recognition and Retrieval Using Hash Methods
Many relevant research studies utilize various methods of hashing for recognition, data safeguarding, and retrieval. The researchers in [16] suggested using a similarity-preserving compression strategy for unsupervised hashing to lighten the storage burden while maintaining high precision. Their experiments with large-scale retrieval showed that their compression method achieved high accuracy with a small amount of storage space. The authors of [1] proposed a new error-corrected deep cross-modal hashing (CMH-ECC) method to accelerate queries for images and reduce the cost of storage space. The cross-modal hashing module (CMH module) trains a deep neural network (DNN) to create intermediate hash codes that would be used in the retrieval process where the error-correcting code module (ECC module) has forward error correction (FEC). The FEC decoder’s role was to discover the nearest codeword that would be used to retrieve the image. Their results showed that this strategy could improve face image retrieval.
Several prerequisites have been proposed for prompt identification and retrieval of the face image [17]. Their suggested deep learning-based hashing for face identification and retrieval employed the FaceNet model for extracting deep features of the face, which then converted the feature vectors to binary hash codes. They concluded that their method retrieved just 48 objects with a hash code of size 64 might frequently contain the matching individual for a specific face picture query. Nevertheless, their algorithm requires more precision to retrieve analogous face pictures at the higher ranks. For improving facial image retrieval from a database, the research study in [8] presented a new iterative method of deep neural decoder cross-modal hashing (DNDCMH). It has two parts: Attribute-based deep cross-model hashing that generates hash code in DNDCMH to improve the retrieval of face images and a neural error-correcting decoder that corrects the hash code that was previously generated. This method works in two stages: the first stage uses an attribute as input for a retrieved face picture, and the second stage retrieves a related face picture for that attribute. Their approach surpassed the performance of other existing cross-modal hashing approaches as per their comparison. However, their retrieval performance is degraded if the number of facial features is increased.
Recently, the research work in [18] introduced a method to improve face image retrieval performance that replaces face soft biometrics with their related hash codes utilizing LSH (Soft BioHash). They concluded that their approach is superior to the traditional method that uses hashing for standard face features with shorter retrieval time and higher accuracy, as it was applied to the database LFW and LFW attributes.
2.3 Face Image Retrieval Utilizing Face Soft Biometrics
The authors suggested a model in [19] that combines the force of traits and hypergraphs into one structure and utilizes it in different face picture retrieval missions. Their model includes tasks comprising trait-based hypergraph learning, attribute adaptation on metrics, and associated feedback for an interactive retrieval process. Hence, their learned distance measure improved retrieval accuracy and speeded up interactive face retrieval. They mainly concluded that the semantic variation among person and machine face perceptions had enormously decreased. The research work [20] explored the viability of merging global face soft biometrics with standard hard biometrics to enhance face identification and authentication capabilities by extracting facial Gabor features from the FERET dataset, along with a suggested small set of six universal soft biometrics to assess the effectiveness of those soft attributes in improving the traditional Gabor-based face recognition algorithm. Therefore, a crowdsourcing platform was used to gather soft biometrics for each individual in the dataset. This work concluded that the performance of face recognition was improved based on identification and verification measures. In [21], the authors concentrated on increasing face image retrieval precision. The DCNN technique was used to retrieve the basic information from the input facial image and an improved grey wolf optimization (GWO) was utilized to extract the best features from the restored features. Their strategy allowed them to solve some existing techniques’ shortcomings while improving retrieval speed and accuracy.
2.4 Multimodal Biometric Fusion
The fusion scheme represents an essential component of the multimodal biometric system. In [22], a proposed novel method was applied to KINECT gait and face images, representing a multimodal fusion biometric system. The proposed method starts with an enrollment step, where features from the gait and face modalities are extracted independently and entered into the system database. Then, the matching feature technique based on kNN is applied during an identification phase. Borda count and logistic regression are the most widely used rank-level fusion techniques applied to investigate the multimodal system’s overall accuracy. Furthermore, the average sum method was used to examine match score-level fusion. The main finding of their study was that using Borda count, logistic regression, and the average sum method gave an accuracy of 93.33%, 96.67%, and 96.67%, respectively. On the other hand [23], Peng et al. showed how to combine the score vectors of a fingerprint and a finger vein at the level. Each unimodal identification system was executed independently to produce a score vector. They divided the score range into interest zones using clustering analysis, and the decisions were made using a decision tree and weighted-sum methods. Their experiments showed that the fusion system outperformed the single-mode identification method.
In [24], they suggested using score-level fusion to improve how well two unimodal systems can recognize. The proposed method consists of three steps: Euclidean distance (ED) to classify the face and iris features separately, normalize the ratings, and apply the sum rule to combine the scores. The experimental results indicated that their fusion approach successfully classified 40 individuals with accuracy scores between 95% and 100%. However, testing it on a large dataset was still needed. In [25], the authors proposed a multimodal biometric identification approach based on the score-level fusion of two modalities, the iris and the fingerprint, to create a vector of scores. Preliminary analysis using the k-means clustering method resulted in the division of the score range into three zones of interest that are pertinent to the suggested identification procedure. The extracted regions were then subject to fusion utilizing two different methods: the first was based on classification by the decision tree combined with the weighted sum (BCC), and the second was based on fuzzy logic (BFL). Their results showed that the three error rates were reduced, and the recognition rate was increased, reaching 95% for the fusion technique based on BCC and 94.44% for BFL. However, this method’s viability still needs to be validated with large datasets. On the other hand, the increasing use of biometric technologies for authentication in various applications, ranging from e-passports to attendance systems, drives the need for rapid retrieval of information from biometric databases. In [26], they employed a data-dependent hashing strategy that utilizes optimized multidimensional spectral hashing with a hash table lookup. Biometric features for the palm, iris, and face are generated using the GIST descriptor; then, they are combined into binary hash code using a bio-inspired cuckoo search method. The multi-biometric database utilized to measure retrieval performance in this study comprises tiny binary codes representing fused features. According to their experiment’s findings, the hit and penetration rates have significantly increased for acceptable recognition accuracy with a retrieval time of 6.90 s, where they attain a penetration rate of 7% with a hit rate of 90%.
LSH is among the common ways to find approximate nearest neighbors in environments with high dimensions. The LSH was first designed for the Hamming distance; it was previously used for other distances, such as the commonly known Euclidean distance. LSH maps the authentic high-dimensional area to the anticipated low-dimensional area utilizing arbitrary hash projections, and it has two main advantages: theoretical guarantees of query accuracy and sub-linear query effectiveness (concerning the amount of data volume) [27]. The LSH family H means the probability distribution P on a hash function family h, where the set of items A and B are used to make the similarity function S [28,29]. It can be defined by:
The concept of LSH is highlighted by the fact that the authentic picture is represented by the LSH method in the form of a low-latitude binary hash code rather than directly saving the high-latitude picture information. A hash code is generated and used to construct an index to match and locate the query image’s nearest neighbors. LSH will then produce a collection of hash tables using the random projection approach [30]. Compared to the total number of entered objects, in the LSH conception, the number of buckets is substantially smaller. Reference [29] and a hash table could be involved with any number of feature vectors and buckets. The general procedure by which LSH creates the indexes that facilitate search and retrieval is shown in Fig. 3.
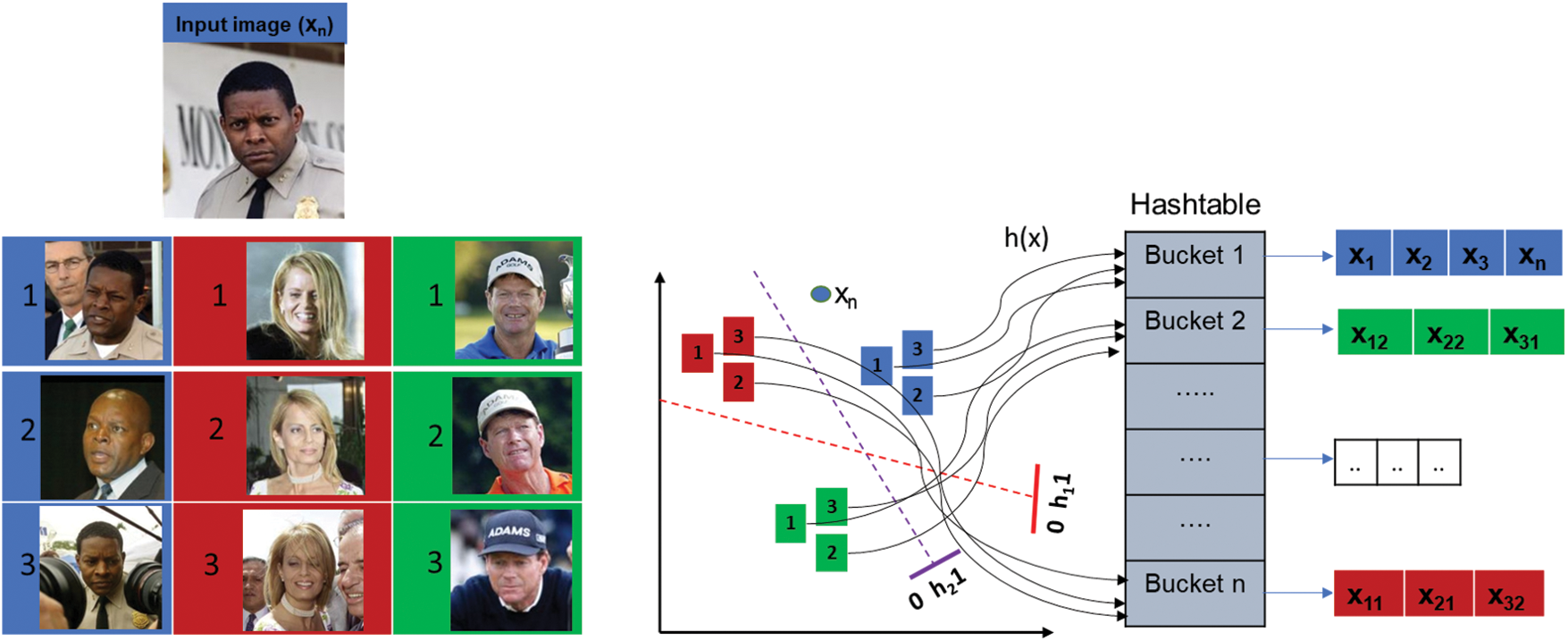
Figure 3: Using LSH to create an image data index and represent each subject by a bucket in this context
Hence, as illustrated in Fig. 3, to achieve retrieval by utilizing a (query) input picture (Xn), the distance between each image in the database and the input image’s hash is calculated to find the most similar images. As a result, there is a higher chance of getting the most similar samples, rather than dissimilar ones, to be hashed with similar hashes and assigned to the same bucket. In Fig. 4, for instance, there are three images where the two images to the right are strikingly similar. Consequently, the distance between h(man1) and h(man2) hash codes of the same subject is considerably closer than the distance between h(man1) and the hash code of another subject of h(woman) since the two photos of the same person seem much more comparable from a semantic standpoint, as shown in Fig. 4. Therefore, after removing the whole data from the pertinent bucket (subject), performing matching on that data linearly, and finding analogous pictures, it is possible to find analogous pictures that meet the query criteria when querying a photo [30].
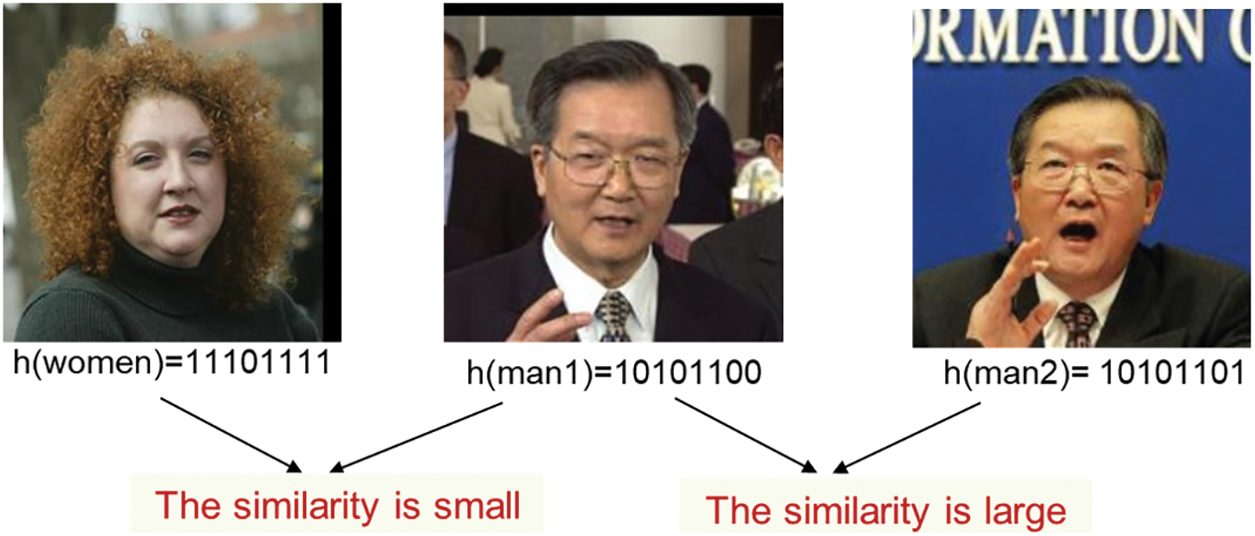
Figure 4: Subject image similarities and their corresponding hash similarities
3.2 Multi-Biometric Fusion Methods
Many decision channels are required when employing multiple biometric modalities. Fusion is a technique used to combine two or more biometric features. Biometric fusion is the term used to describe the design approach that can merge the classified findings from each biometric channel [31]. During the identification or verification process, multimodal biometric fusion is used to fuse various biometric data types for expected improved reliability and performance. Such fusion makes the process more robust and reduces the number of mistakes that may happen [31]. The different levels of multimodal biometric information fusion can be categorized into two main groups (as shown in Fig. 5) based on the kind of multimodal biometric information being fused before or after matching [22].

Figure 5: Categorization of multi-biometric fusion methods
Fusion before matching combines the raw data or raw features before they are compared to a sample to determine the proper identity. Typically, they are named sensor-level and feature-level fusion [22]. When two or more sensors detect the same biometric trait, sensor-level fusion combines the raw data from those readings [31,32]. However, combining two or more pictures from different sensors into a single picture while keeping the key elements of each original image illustrates the extent of sensor-level fusion. It is referred to as data-level or image-level fusion if the image data is combined without further processing. The most fundamental method of image fusion is calculating the average of the images acquired from several sensors [33]. On the other hand, feature-level fusion represents feature sets extracted and combined from multiple samples [31,32].
The fusion after matching involves match score-level, rank-level, and decision-level fusion. The process can be summarized as matching a sample’s biometric modalities to those in the individual biometric dataset. Rank-level fusion, which fuses the outcomes of two or more individuals, generates an indexing of the candidates in the database template. The score-level fusion combines the matching scores from two separate classifiers. It demonstrates the similarity between the testing and training templates. After the identification results from each unique biometric sample have been obtained, a matching score has been calculated for every individual’s sample for each modality (e.g., face and gait) [22]. The match score-level fusion approach performs mathematical operations on various matching scores, such as addition, subtraction, or median, to produce a single matching score [24]. Combining the outcomes of various biometric matches to create a consolidated decision using the decision-level fusion approach is possible. Also, the fuzzy-fusion method can be used both before and after matching. This fusion method is typically used to reduce the dataset size when it is implemented before the matching step. In addition, it can also be used in the post-matching stage to improve recognition performance and boost confidence in the final results [31].
The objective of the proposed study is to improve face photo retrieval performance. Consequently, we examined the proposed Hard-Soft BioHash Fusion’s capability to precisely retrieve face photos compared with the traditional unimodal Hard BioHash and Soft BioHash methods in isolation. We concurrently conducted the same experimentation with the same retrieval scenario for all three approaches to accomplish this goal. Our experimental work constitutes five essential stages. Firstly, a facial image was detected and normalized during the data preprocessing stage; then, it was mapped and formed for the corresponding face soft biometrics. Secondly, we performed an extraction of features and hash creation for the traditional (hard) face features (Hard BioHash), in addition to hash creation for the face soft biometrics (Soft BioHash) introduced in [18]. Thirdly, the Euclidian distance was utilized for retrieving analogous pictures. Fourthly, in the fusion similarity score phase, after the distance metric is generated independently for each modality, match scores are generated by normalizing the resulting scores of each modality and then fusing the normalized scores to get a composite matching score (score-level fusion). After that, we used an arithmetic mean rule to find and retrieve the top 20 most similar face pictures. Fifthly and lastly, the performance assessment was carried out. Fig. 6 demonstrates the methodology embraced in the suggested research investigation.
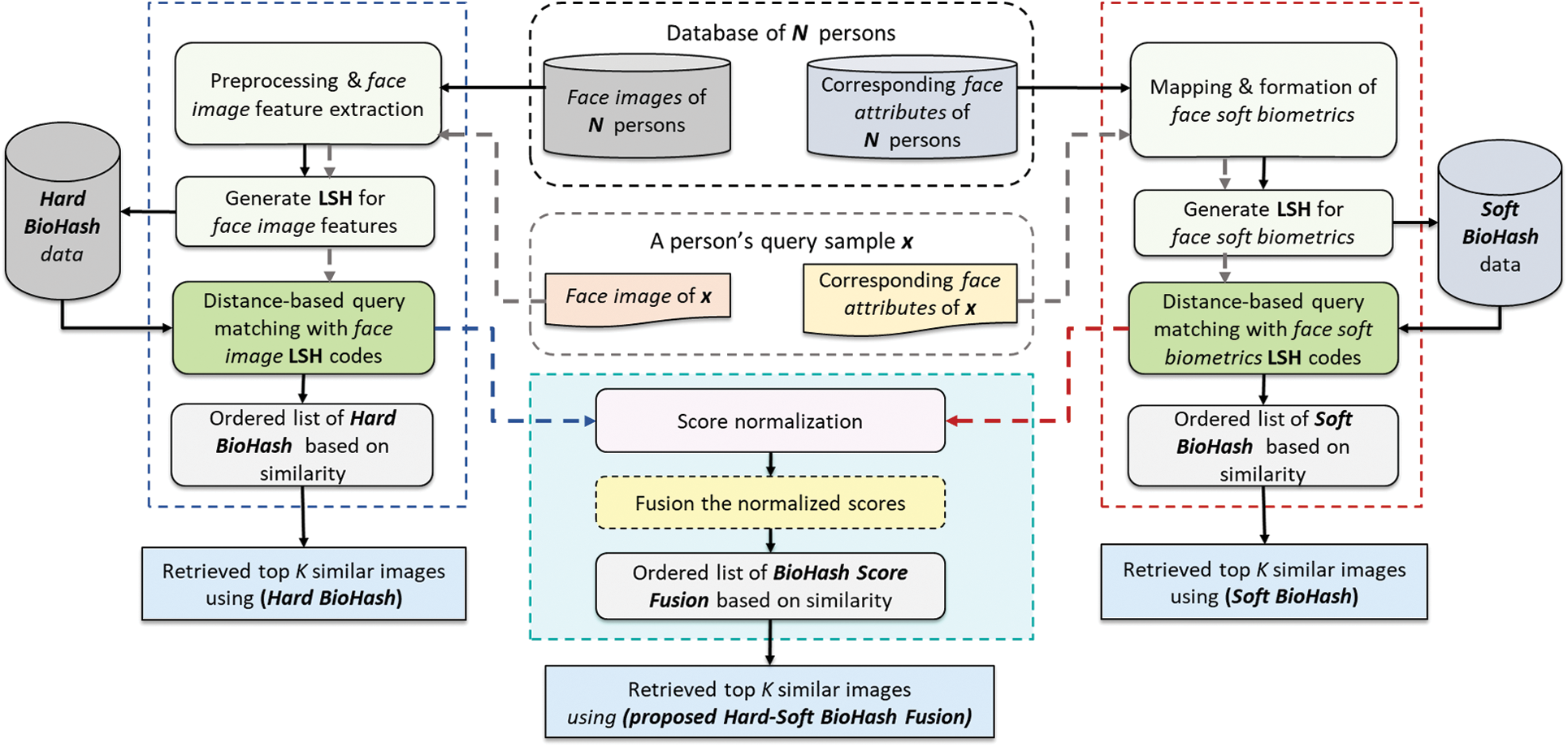
Figure 6: The block diagram of the suggested research method
From the LFW dataset [34], we use only the face images of those that have related face attribute data present in the LFW-attributes dataset [35], as will be covered in more detail in Section 5. A face detection method based on Haar cascades functions was used to detect the subject’s face for each image sample. Next, the background and all other elements are removed, keeping only the face as the area of interest. Then, we cropped the detected face, resized it to 256 × 256 pixels, and transformed it to grayscale as a normalization process. In the LFW-attributes of face traits, which was a ready-created dataset, we reformed all its 73 face attribute data as soft biometric feature vectors and mapped them to the related face images in the LFW dataset. The resulting mapped and reformed face attributes were then utilized as a dataset for face soft biometrics. Note that further information about the procedure for annotating face attribute data can be obtained in [35].
4.2 Feature Extraction and Hash Creation
The discriminatory features of faces are extracted from the normalized face photos by utilizing an assemblage of discrete cosine transform (DCT) coefficients. For the images of size M × N, DCT coefficients are calculated, the picture may be split into overlapped blocks of volume 32 × 32 pixels, and a 2D-DCT process is carried out on every one of these blocks. The dimensions of the frequency coefficient matrix are the same as the DCT block, which is significant because every DCT block has 1023 AC coefficients and one DC coefficient. Consequently, the resulting feature point for each picture is minimized. The DCT coefficients are computed using the following formula:
where u and v are the coordinates in the DCT coefficients, and u = 0, 1,…, M, v = 0, 1,…, N, x, and y are the spatial coordinates in the picture block, the altered block is denoted by F(u,v), while the block element is denoted by f(x,y), MN is the size of the bock, and α(u), α(v) can be defined by:
Then, we created hashes for face soft biometrics (Soft BioHashes) and for features extracted from face images (Hard BioHashes) by using open-source LSHash [36]. We will eventually have both Soft BioHash and Hard BioHash for each sample in each dataset for hash-based retrieval. It should be noted that feature extraction is not performed on the soft biometrics data derived from the face LFW-attributes dataset.
4.3 Measuring the Distance for Analogous Pictures Retrieval
In this step, we obtain the top-k matching (most similar) face pictures for the face hard and soft biometrics queries. The Hamming, Manhattan, Euclidean distance, and other helpful distance measures can be used to determine how close the query picture and database pictures resemble one another. In this work, we used Euclidean distance in the retrieval process. The Euclidean distance (Deuc) between two points X = (x1, x2, …, xp) and Y = (y1, y2, …, yp) can be defined as follows:
Eventually, we used the proposed method of Hard-Soft BioHash Fusion (described in detail in Subsection 5.3) to find and retrieve the top 20 face photos that are more analogous to a face photo query.
4.4 Fusion of Similarity Scores
The score-level fusion method is used to raise the performance of a biometric system as a whole [32]. By fusing scores from several biometric modalities, matching score-level fusion offers a suited rule for calculating a final score. It is possible to consider the matching score-level fusion as the separation of the scores into the Accept/Reject categories or as the combination of the scores to create a single scalar score from multiple [37]. After generating the LSH codes and finding the similarity scores independently for each modality, score normalization is required to convert them from various modalities into a single domain. To get a composite matching score, the output set of normalized scores is fused as score-level fusion using the arithmetic mean rule, also referred to as the sum rule [38,39]. It can be formulated as follows:
where si is the score vector of modality i, and n is the number of modalities.
To assess how well the proposed methods work and see which of the three BioHash methods is superior in finding and retrieving accurate face pictures, we analyze and compare the performance of the Hard BioHash, Soft BioHash, and Hard-Soft BioHash Fusion methods. The metrics described below are used to evaluate each LSH-based retrieval technique from different aspects.
• Accuracy: True positives (TP) and true negatives (TN) represent the ratio of accurate outcomes out of the whole of the tests performed, while (FP) and (FN) stand for false positives and false negatives, respectively. It is a statistical measurement of the precision with which a condition is retrieved or obliterated. The following formula can be used to compute the accuracy:
• Precision: A statistical measure of how well a retrieval method can search for and find the right face image instead of the wrong one, and it can be calculated as the following:
• Recall: A metric gauges a retrieval method’s capacity to consistently and successfully retrieve the correct facial image. It can be defined as the following:
• F1-Score: The following formula is used to determine the F1-Score whenever precision and recall have equal weighting:
• Cumulative match characteristic (CMC): The statistical analysis of the CMC curve for assessing the effectiveness of a biometric identification method depends on the accuracy of each rank. Afterward, the identification performance is defined according to the prorate order of match scores.
In this research’s experimental work, we use the LFW, an uncontrolled environment dataset. This dataset represents a challenge for the content-based face picture retrieval field. It contains an enormous amount of face specimens (LFW dataset) together with a related dataset of traits (LFW soft biometrics attributes dataset).
LFW dataset: is a popular dataset for face photos with more than 13,233 photos of 5,749 individuals. Among those, only 1,680 have two or more pictures [34]. It was created for use in unconstrained face recognition research. Images in this dataset have no restrictions regarding pose, illumination, expression, or occlusion.
LFW soft biometric attribute dataset: consists of 73 attributes acquired for 13,143 LFW face images as soft biometric labels, describing gender, ethnicity, age, face shape/skin color/smiling/frowning, mouth and nose shape/size, eye and eyebrow with/shape/thickness, hair and facial hair color/style, and others [35]. For each label, a positive value shows that an attribute is present, while a negative value shows that it is absent.
To evaluate the capabilities of the suggested approach and the retrieval effectiveness over variance in dataset content and volume, we implemented our approach using two separate groups consisting of 1000 and 5743 specimens of 823 unique persons who hold three pictures or more. Every group comprises, for all included individuals, the same number of samples per individual from both the LFW and LFW-attributes datasets, both describing the individual’s same face image. After that, we divided each subset into 25% for testing and 75% for training. The adopted LSHash model is trained [36] by specifying the hyperparameters: the input vector’s dimensions, hash length, and the total number of hash tables. We conducted three experiments: the first deals with retrieving face pictures utilizing traditional Hard BioHash; the second is based on retrieving face pictures utilizing Soft BioHash; and the third is retrieving face images using the proposed method of Hard-Soft BioHash Fusion.
5.1 First Experiment: Retrieving Face Pictures Utilizing Hard BioHash
As illustrated in Fig. 7, we performed feature extraction using the DCT during this experiment. Then, calculate a hash function h(x) using the LSH dimension reduction method for the features extracted by DCT through the LSHash model [36], where the total number of nascent hash tables is equal to the number of specimens (1000 and 5743), the entered matrices dimension is 32 × 32. The resulting hash is of size 24 bits for the input query, and analogous feature values have been stowed in the same bucket representing one subject through the random projection of the LSH algorithm. The relevant bucket number that stores a similar Hard BioHash data to the Hard BioHash query is acquired. Then, the relevant Hard BioHash data in that bucket are taken out to calculate the similarity. Then, using the Euclidean distance metric to assess the closeness of the Hard BioHash of the query face picture to all other Hard BioHashes stowed in the same bucket in the database, we can return the top 20 face images accordingly.
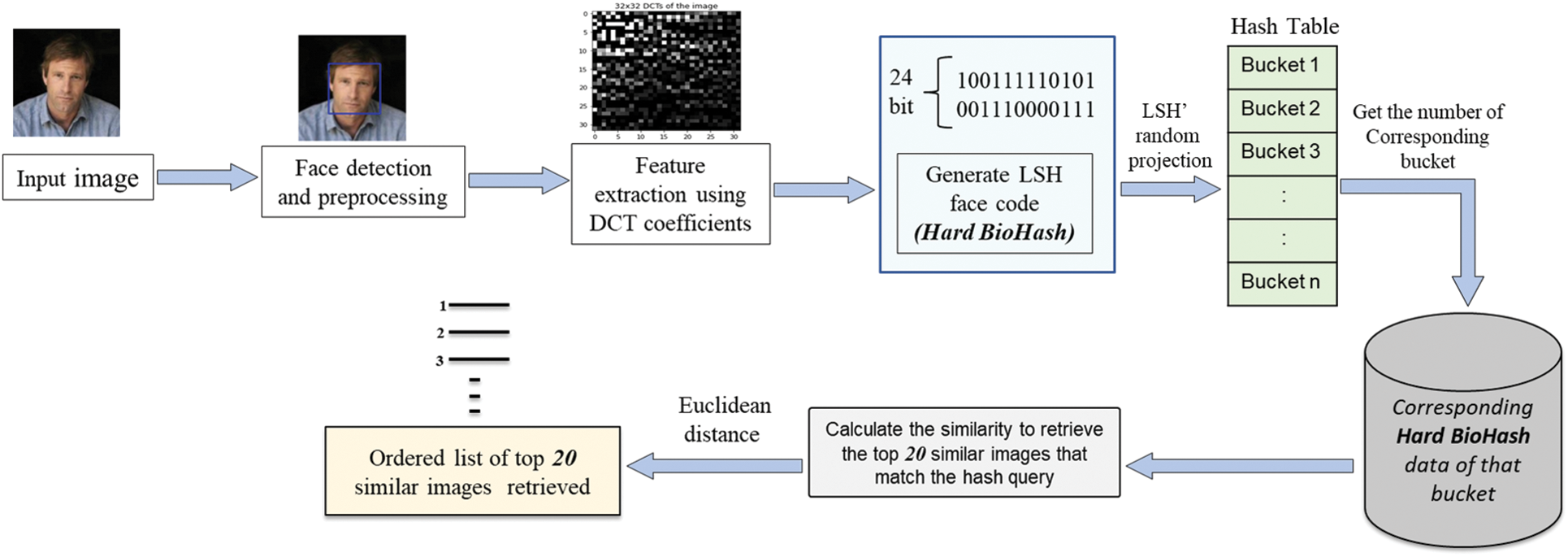
Figure 7: Retrieving face pictures utilizing the Hard BioHash method
5.2 Second Experiment: Retrieving Face Image Utilizing Soft BioHash
As face soft biometrics do not require feature extraction (as shown in Fig. 8), we create the consequent hash code for the mapped and formatted face traits per sample, depending on LSH. The amount of hash tables here is the same amount of attributes (i.e., 73). The hyperparameters are the same as in the first experiment. The LSH technique stores analogous feature values in the same bucket through the random projection of the LSH algorithm. The relevant bucket number that stores Soft BioHash data similar to the Soft BioHash query is acquired. Then, the relevant Soft BioHash data in that bucket are taken out to calculate the similarity. In the end, the top 20 face pictures that match the input Soft BioHash query were finally found using Euclidean distance.
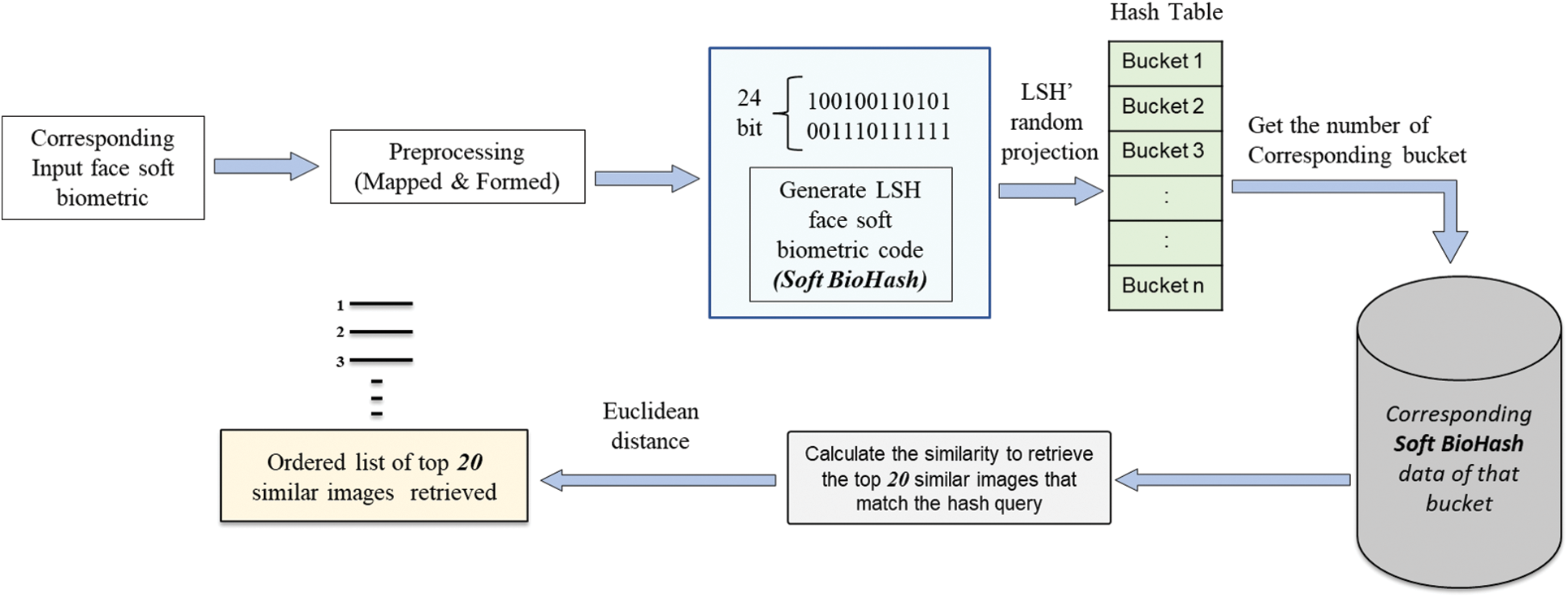
Figure 8: Retrieving face image utilizing the Soft BioHash method
5.3 Third Experiment: Retrieving Face Image Utilizing Proposed Hard-Soft BioHash Fusion
The framework of face retrieval using the suggested method is depicted in Fig. 9. There is a need for score normalization after evaluating match scores from each modality [40]. In general, normalization aims to set the mean and variance of datasets to particular values [23]. Therefore, during this part of the experiment, before combining the scores inferred from the Hard BioHash query and the Soft BioHash query, we use the median and median absolute deviation (MAD) technique as a score normalization that can change the scores of several systems into a common domain. This score normalization can be formulated as follows:
where
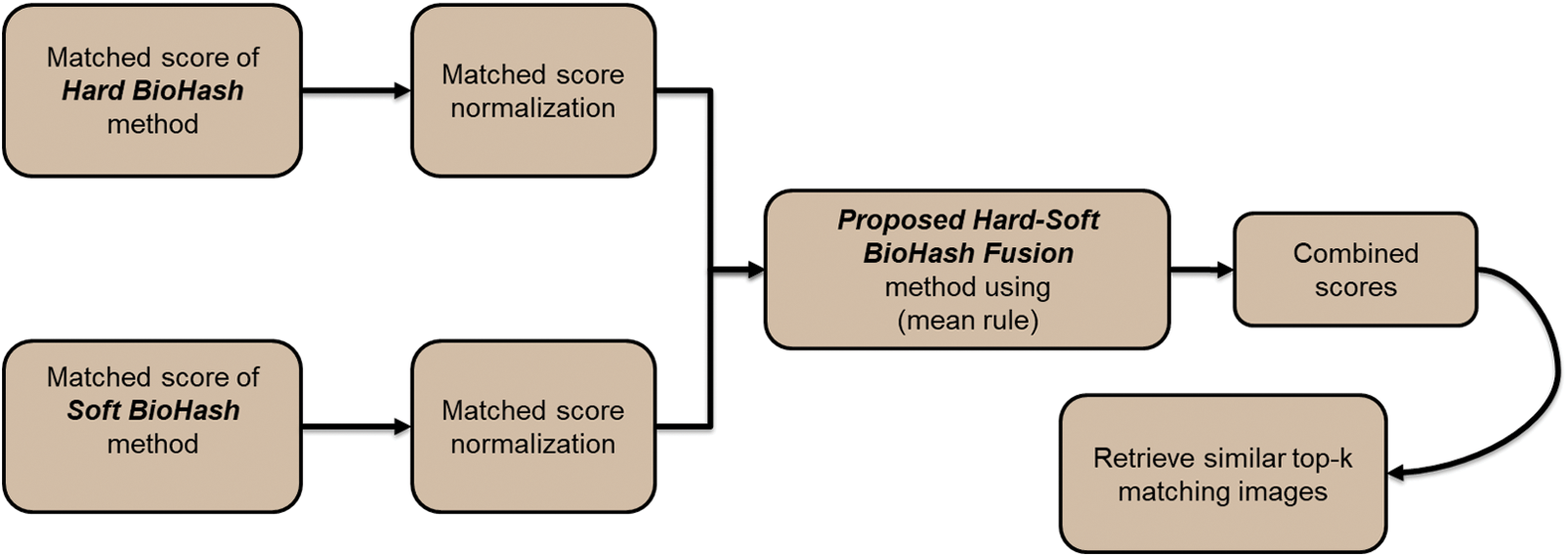
Figure 9: Block illustration of retrieving similar face images using the proposed method
To fuse the resulting normalized scores, we used the arithmetic mean rule to fuse the matching scores and produce a combined score. Then, the top 20 most similar face pictures are retrieved. As shown in Fig. 10, the yellow circles represent the correct images matching the input Hard-Soft BioHash Fusion query. An example of how to fuse the scores at the match score-level based on the arithmetic mean rule is illustrated in Fig. 11.

Figure 10: An example of retrieving the top 20 search results for the query image using the proposed Hard-Soft BioHash Fusion method, where the correct match appears at ranks 1, 3, 6, 8, 10, 12, 14, and 20
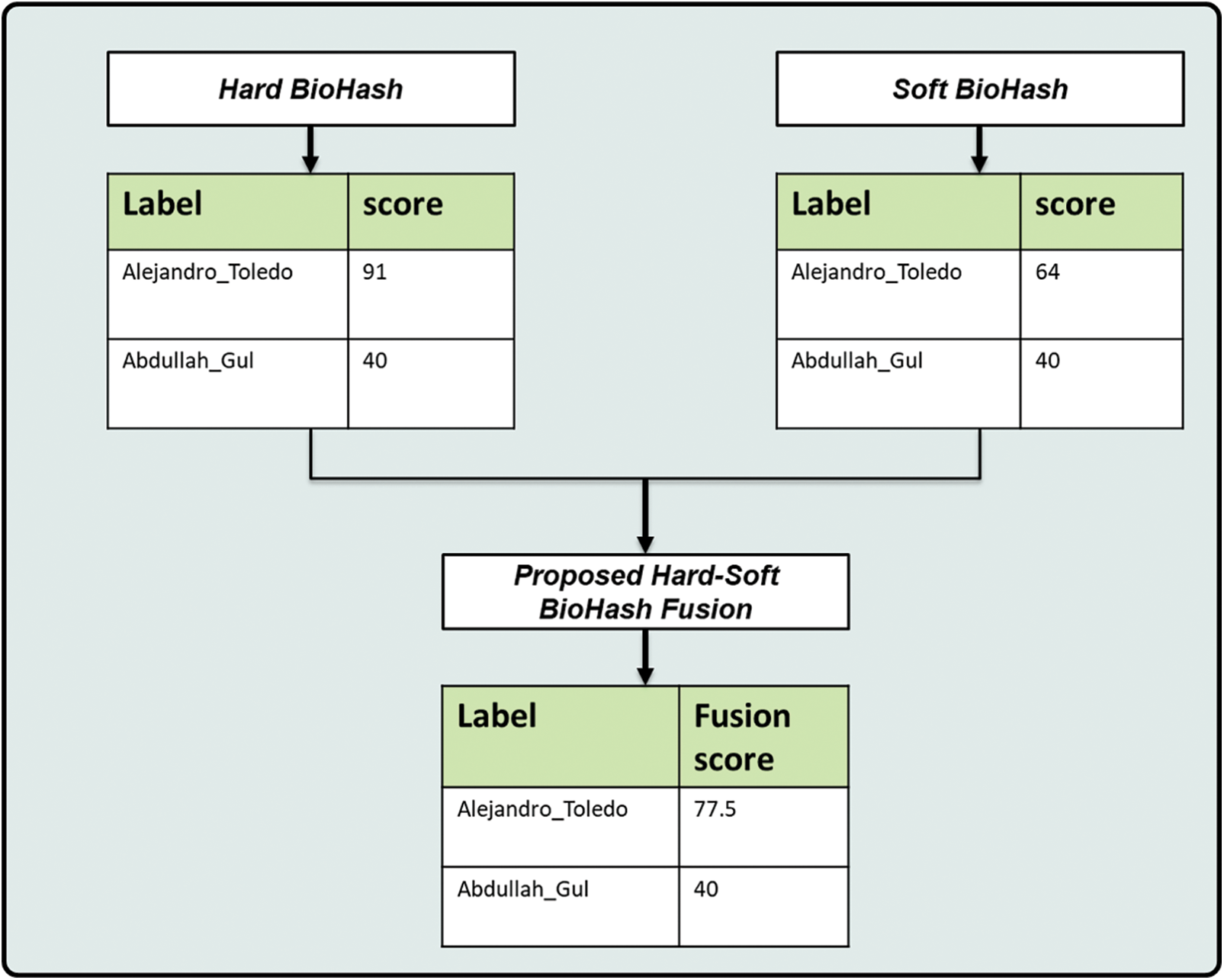
Figure 11: A theoretical example of fusion scores using arithmetic mean rule at match score level
6 Discussion and Result Analysis
The conducted experiments showed promising results, and we concluded that the proposed method (Hard-Soft BioHash Fusion) could be used to search and retrieve face images with significantly augmented performance compared with Hard BioHash and Soft BioHash methods. Table 1 compares the performance accuracy results (20th rank accuracy, avg. accuracy until 20th rank, and avg. accuracy until 60th rank) obtained from the preliminary analysis of the three experiments described in Section 5 with various sizes of specimens. It can be noticed in Table 1 that our suggested approach of Hard-Soft BioHash Fusion is the most possible and efficient, as it outperformed the Hard BioHash and Soft BioHash methods on both subsets (1000 samples subset and 5743 samples subset). For example, in the case of retrieving the top 20 analogous face pictures from the 1000 samples subset, the retrieval accuracy of the proposed fusion approach increased the retrieval performance by 37.4% and 8.8% for Hard BioHash and Soft BioHash, respectively. Similarly, when retrieving the top 20 similar images from the 5743 samples subset, their accuracies were further increased by 47.5% and 14.1%, respectively. In order to show the reliability and stability of the suggested model performance, Table 2 and Fig. 12 demonstrate the performance results in terms of the standard metrics (accuracy, F1-Score, recall, and precision) with the various number of samples (1000 samples subset and 5743 samples subset). As can be observed, Hard-Soft BioHash Fusion yields superior results via all metrics and with various sizes of data specimens.
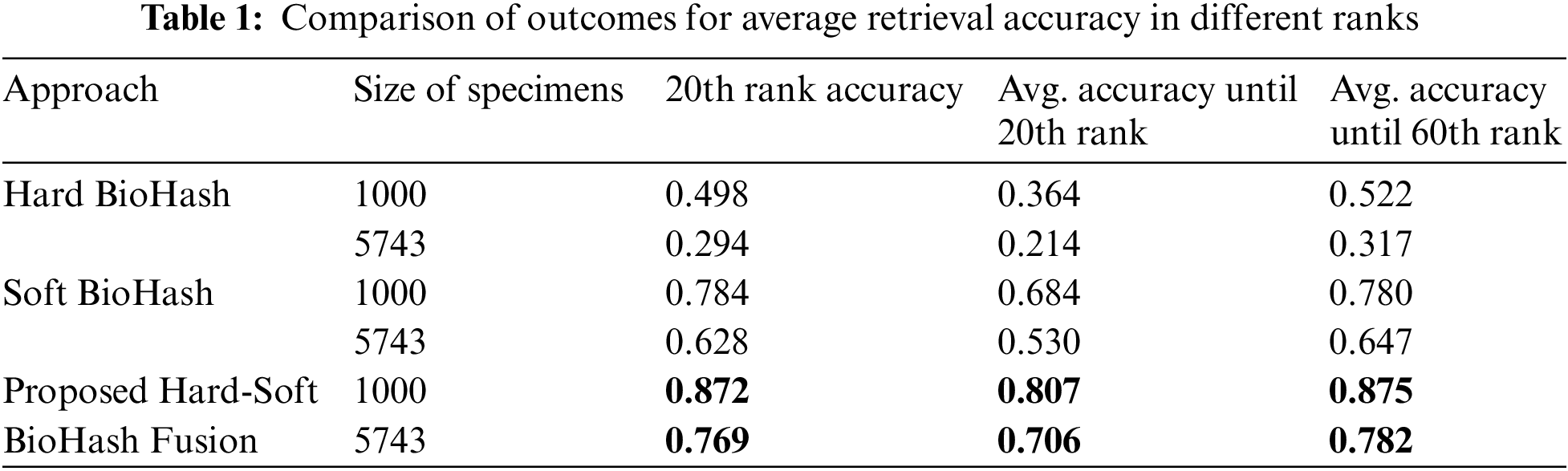
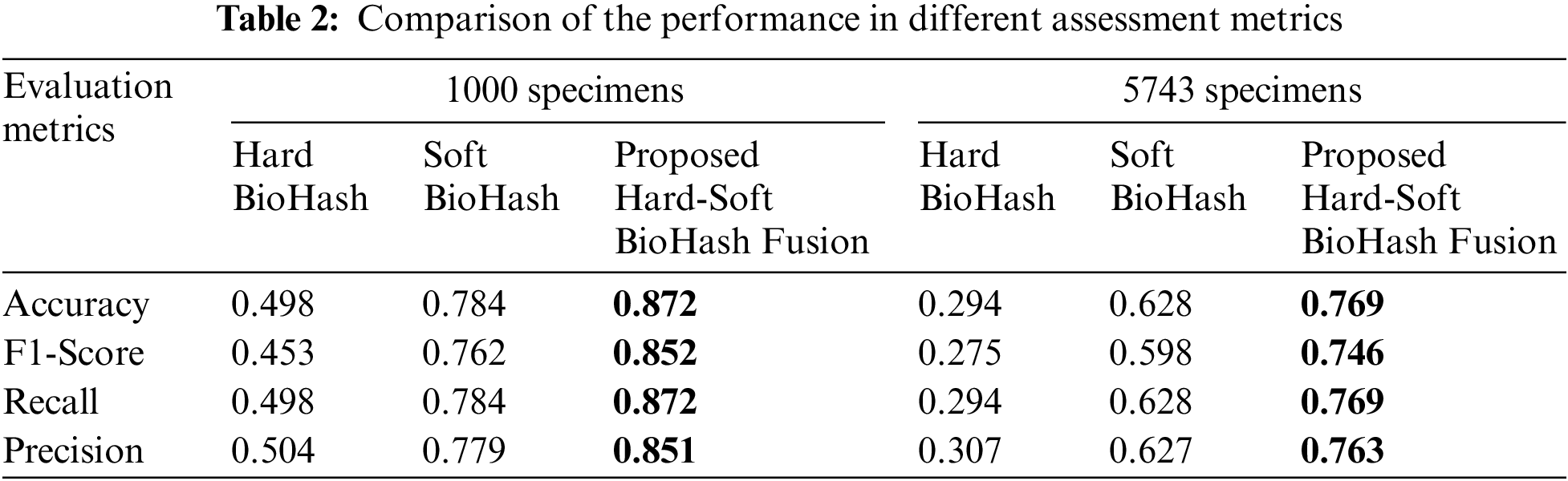
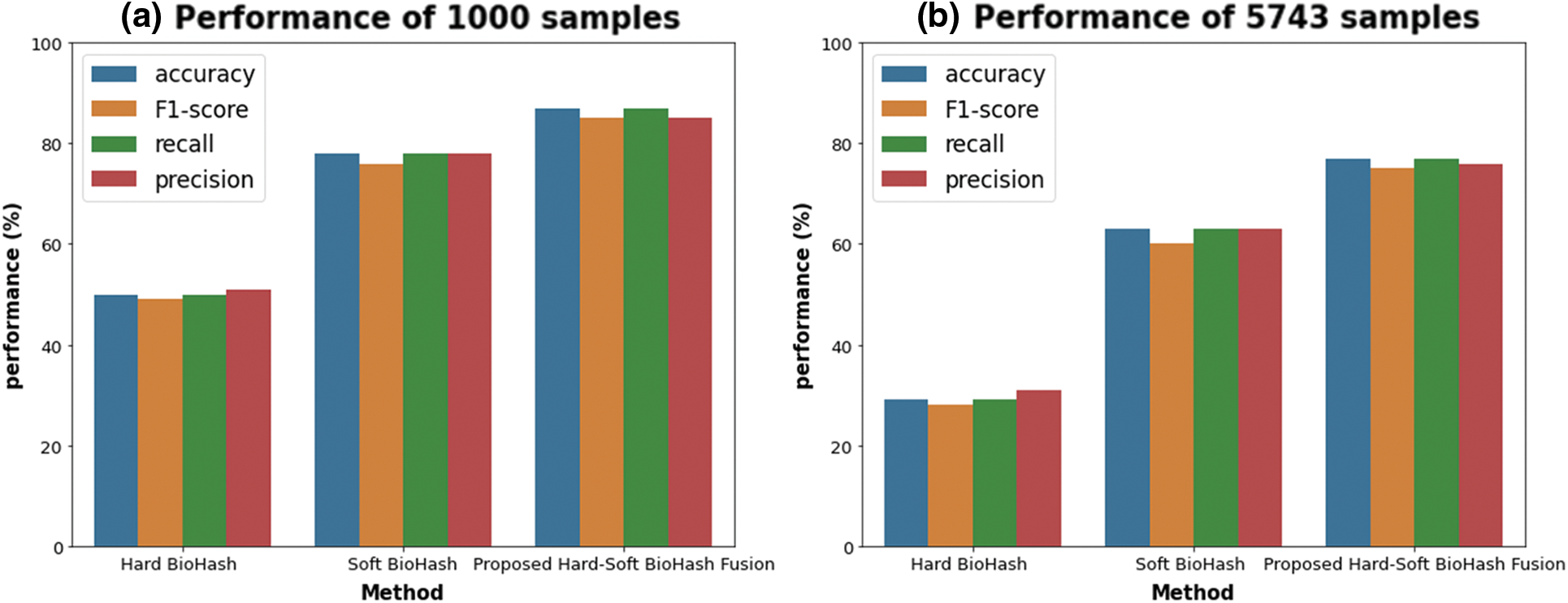
Figure 12: Performance comparison of Hard, Soft BioHash, and proposed Hard-Soft BioHash Fusion approaches with varying typical assessment metrics. (a) When tested on 1000 specimens. (b) When tested on 5743 specimens
The above CMC curves (until 60th rank) are inferred to display the accuracy performance of the Soft BioHash and Hard BioHash methods vs. the proposed Hard-Soft BioHash Fusion when examined on 1000 and 5743 specimens, as depicted in Fig. 13. When tested on 1000 specimens, Fig. 13a shows how accurately the proposed Hard-Soft BioHash Fusion approach performed in comparison to the Soft BioHash and standard Hard BioHash methods, while Fig. 13b depicts the performance of accuracy for the same three methods when tested on 5743 samples. The obtained results show that the proposed Hard-Soft BioHash Fusion method outperforms, by all means, the Soft BioHash and the standered Hard BioHash methods on both datasets of (1000 and 5743) samples throughout the ranks from 1 to 60.
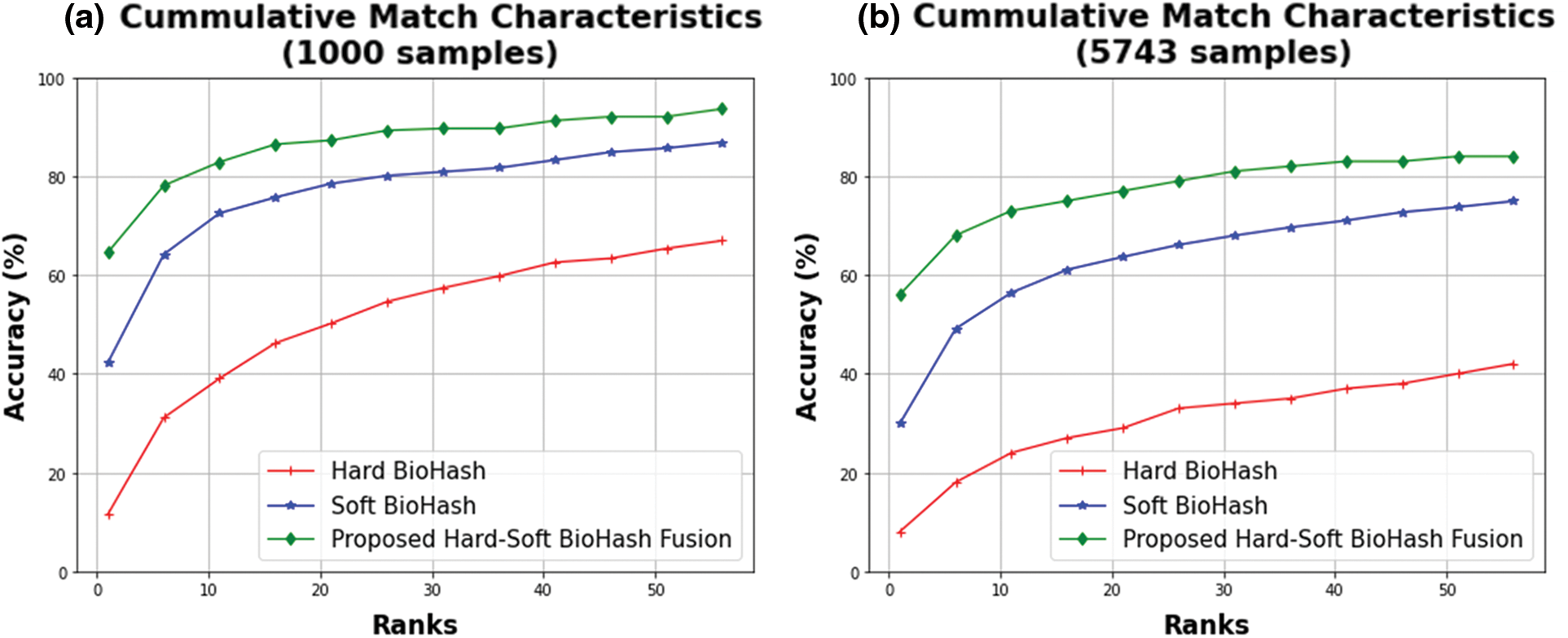
Figure 13: Retrieval performance based on CMC curves that compare the proposed Hard-Soft BioHash Fusion approach with Hard and Soft BioHash approaches when tested on different numbers of data specimens
6.1 Comparative Performance Analyses
Table 3 compares this work with other relevant works that utilized various hash techniques with multi-biometric schemes, including face images. Table 3 provides the types of modalities, datasets, fusion methodology, fusion level, hash method, average retrieval time, and Hard and Soft BioHash fusion availability. Unlike the other compared studies, our research applied biometric hashing to an unconstrained environment dataset, representing a far more realistic and challenging framework for face recognition and content-based face image retrieval. Furthermore, our Hard-Soft BioHash Fusion was uniquely used, where we applied three independent experiments on the LFW and LFW-attributes datasets and examined the impacts of the number of images for each individual on retrieval efficiency. As we merely selected individuals with three pictures or more in the dataset for each experiment, the total number of photos stood at 5743.
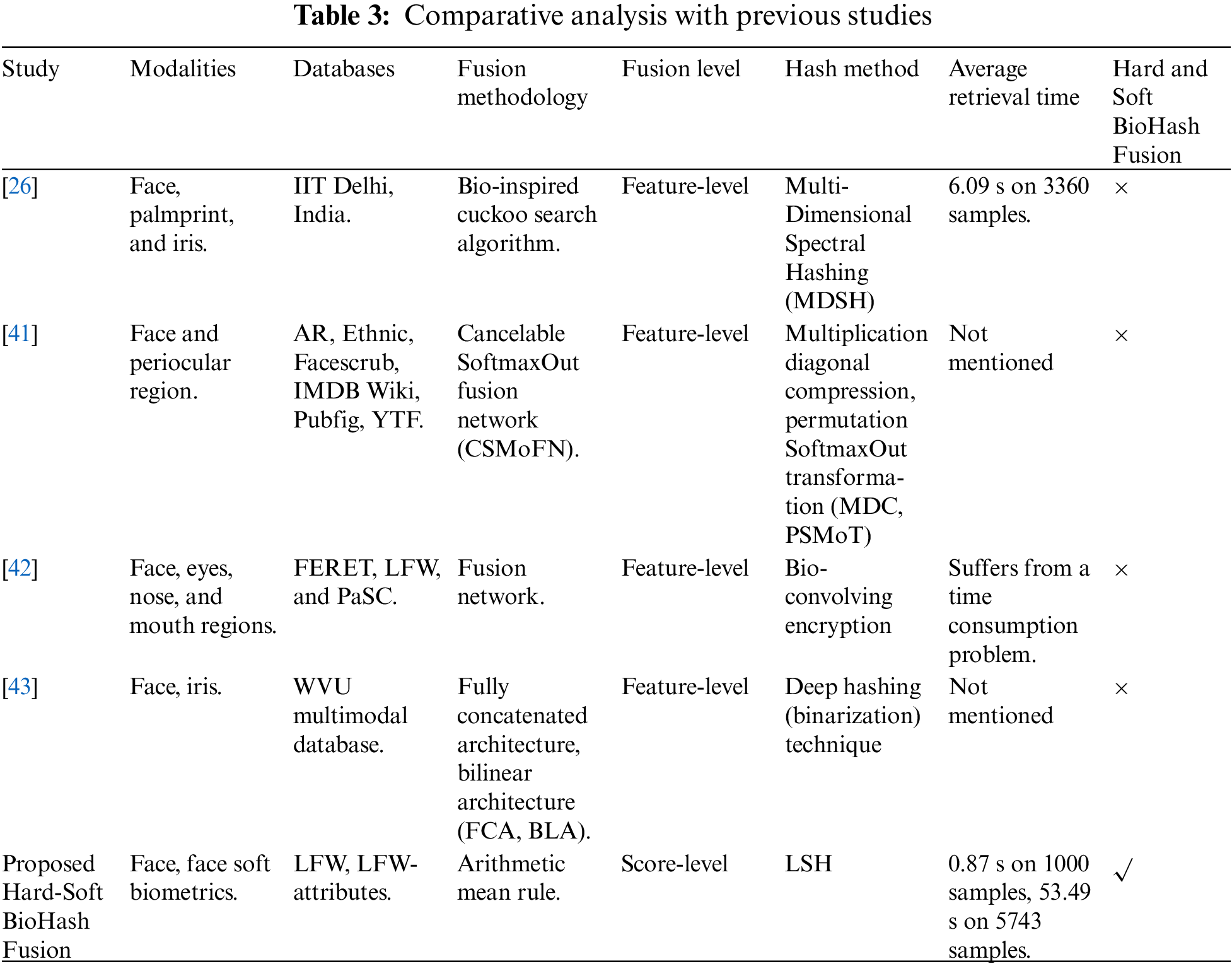
It can be observed from Table 3 that although the studies [26,41–43] have different purposes, they all focused on the feature fusion of multimodal biometrics before utilizing any hash methods. In contrast, our work uniquely focused on fusing multimodal hard and soft biometric hashes (i.e., Hard BioHash and Soft BioHash). However, it is challenging to thoroughly compare all aspects of various multimodal schemes with this research work because of the variations in datasets used, the techniques applied, the circumstances of each work, and the intersection area of interest between this work and the previous works, which is mostly minimal. Thus, it can be emphasized that the efficacy of our proposed Hard-Soft BioHash Fusion method has been successfully proved, as stated in Tables 1 and 2, and has an outperforming performance vs. its unimodal counterparts of the Soft BioHash approach and the standard Hard BioHash approach.
This research work aims to enhance hash-based face picture search and retrieval from large-scale databases. Therefore, we decided to investigate whether the proposed Hard-Soft BioHash Fusion method could more accurately retrieve the face images compared with the Hard BioHash and Soft BioHash methods in isolation. We designed and conducted three different experiments to examine the impact of employing LSH and the proposed fusion approach on the performance of retrieving face images by (1) applying LSH to hard face biometrics, (2) applying LSH to face soft biometrics, and (3) fusing the matching scores of those LSH codes resulting from the preceding two. We have discovered and concluded from the overall obtained performance outcomes that utilizing Hard-Soft BioHash Fusion enhances face image retrieval performance. Nonetheless, designing a system that can annotate soft biometric data in an automatic way for many thousands of face images in a large-scale database remains necessary. For future work, we will consider enhancing the performance by extending our proposed framework to extracting face image features using deep learning techniques, taking into account the cost-effective storage and retrieval time. Moreover, the validity of the proposed method can be expanded for applications on large-scale online databases and using more than two biometric modalities.
Acknowledgement: The authors acknowledge King Abdulaziz University Scientific Endowment for funding this research.
Funding Statement: This research was supported and funded by KAU Scientific Endowment, King Abdulaziz University, Jeddah, Saudi Arabia, grant number 077416-04.
Author Contributions: Proposed method, A.A.A.; software and implementation, A.A.A.; validation, A.A.A.; formal analysis, A.A.A.; investigation, A.A.A.; data manipulation, A.A.A.; writing—preparing the first draft, A.A.A.; reviewing and editing written work, A.A.A., E.S.J., and N.A.; visualization, A.A.A., E.S.J., and N.A.; supervision, E.S.J., and N.A.; acquisition of funding, E.S.J. Each author has reviewed the published version of the manuscript and given their approval.
Availability of Data and Materials: LFW and LFW attributes were the databases utilized in this article. For further information, please refer to [34,35].
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. V. Talreja, F. Taherkhani, M. C. Valenti and N. M. Nasrabadi, “Using deep cross modal hashing and error correcting codes for improving the efficiency of attribute guided facial image retrieval,” in Proc. of the 2018 IEEE Global Conf. on Signal and Information Processing (GlobalSIP), Anaheim, CA, USA, pp. 564–568, 2019. [Google Scholar]
2. M. Sivakumar, N. M. Saravana Kumar and N. Karthikeyan, “An efficient deep learning-based content-based image retrieval framework,” Computer Systems Science and Engineering, vol. 43, no. 2, pp. 683–700, 2022. [Google Scholar]
3. N. Gudur and A. Pradesh, “Efficient retrieval of face image from large scale database using sparse coding Q1 and reranking,” International Journal of Science and Research (IJSR), vol. 3, no. 9, pp. 275–277, 2014. [Google Scholar]
4. K. Nithya and V. Rajamani, “Triplet label based image retrieval using deep learning in large database,” Computer Systems Science and Engineering, vol. 44, no. 3, pp. 2655–2666, 2023. [Google Scholar]
5. G. Kaur and S. Malhotra, “A review: Use of facial marks for twins face identification and image retrieval,” International Journal of Advanced Research in Computer Science, vol. 6, no. 2, pp. 84–87, 2015. [Google Scholar]
6. S. Suchitra and S. Chitrakala, “Face image retrieval of efficient sparse code words and multiple attribute in binning image,” International Journal of Brazilian Archives of Biology and Technology, vol. 60, pp. e17160480, 2017. [Google Scholar]
7. J. Qin, Y. Cao, X. Xiang, Y. Tan, L. Xiang et al., “An encrypted image retrieval method based on simhash in cloud computing,” Computers, Materials & Continua, vol. 63, no. 1, pp. 389–399, 2020. [Google Scholar]
8. F. Taherkhani, V. Talreja, M. C. Valenti and N. M. Nasrabadi, “Error-corrected margin-based deep cross-modal hashing for facial image retrieval,” IEEE Transactions on Biometrics, Behavior, and Identity Science, vol. 2, no. 3, pp. 279–293, 2020. [Google Scholar]
9. W. Kabir, M. O. Ahmad and M. N. S. Swamy, “A multi-biometric system based on feature and score level fusions,” IEEE Access, vol. 7, pp. 59437–59450, 2019. [Google Scholar]
10. Y. Zhang, Z. Wang, X. Zhang, Z. Cui, B. Zhang et al., “Application of improved virtual sample and sparse representation in face recognition,” CAAI Transactions on Intelligence Technology, 2022. [Google Scholar]
11. U. D. Dixit and M. S. Shirdhonkar, “Face-based document image retrieval system,” Procedia Computer Science, vol. 132, pp. 659–668, 2018. [Google Scholar]
12. A. Somnathe, A. Suriya and S. B. Kishor, “A novel content-based facial image retrieval approach using different similarity measurements,” PalArch’s Journal of Archaeology of Egypt/Egyptology, vol. 18, no. 7, pp. 1686–1692, 2021. [Google Scholar]
13. H. Yuanyuan, T. Yuan and X. Taisong, “Large-scale face image retrieval based on hadoop and deep learning,” in 2020 17th Int. Computer Conf. on Wavelet Active Media Technology and Information Processing (ICCWAMTIP), Chengdu, China, pp. 326–329, 2020. [Google Scholar]
14. Y. Zeng, Y. Li, Q. Hu and Y. Tang, “Rapid face image retrieval for large scale based on spark and machine learning,” Journal of Physics: Conference Series, vol. 2026, no. 1, pp. 012026, 2021. [Google Scholar]
15. X. Dong, B. Huang and Y. Zhou, “Research on fast face retrieval optimization algorithm based on fuzzy clustering,” Scientific Programming, vol. 2022, no. 1, pp. 1–7, 2022. [Google Scholar]
16. J. Li, W. W. Ng and X. Tian, “A compression hashing scheme for large-scale face retrieval,” in 2018 Eighth Int. Conf. on Information Science and Technology (ICIST), Cordoba, Granada, and Seville, Spain, pp. 245–251, 2018. [Google Scholar]
17. A. Al Kobaisi and P. Wocjan, “MaxHash for fast face recognition and retrieval,” in 2019 Int. Conf. on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, pp. 652–656, 2019. [Google Scholar]
18. A. A. Ameerah and E. S. Jaha, “Locality-sensitive hashing of soft biometrics for efficient face image database search and retrieval,” Electronics, vol. 12, no. 6, pp. 1360, 2023. [Google Scholar]
19. Y. Fang and Q. Yuan, “Attribute-enhanced metric learning for face retrieval,” EURASIP Journal on Image and Video Processing, vol. 2018, no. 44, pp. 1–9, 2018. [Google Scholar]
20. E. S. Jaha, “Augmenting Gabor-based face recognition with global soft biometrics,” in 2019 7th Int. Symp. on Digital Forensics and Security (ISDFS), Barcelos, Portugal, pp. 1–5, 2019. [Google Scholar]
21. H. Sikkandar and R. Thiyagarajan, “Soft biometrics-based face image retrieval using improved Grey Wolf optimisation,” IET Image Processing, vol. 14, no. 3, pp. 451–461, 2020. [Google Scholar]
22. M. W. Rahman, G. F. Zohra and M. L. Gavrilova, “Score level and rank level fusion for Kinect-based multi-modal biometric system,” Journal of Artificial Intelligence and Soft Computing Research, vol. 9, no. 3, pp. 167–176, 2019. [Google Scholar]
23. J. Peng, J. Wu and Y. Chen, “A score level fusion method on fingerprint and finger vein,” in E3S Web Conf., 2020 Int. Conf. on Energy, Environment and Bioengineering (ICEEB 2020), Xi’an, China, vol. 185, pp. 03035, 2020. [Google Scholar]
24. M. Misar and D. Gharpure, “Score level fusion for multimodal biometric identification,” in AIP Conf. Proc., Pune, India, vol. 2335, no. 1, 2021. [Google Scholar]
25. K. Aizi and M. Ouslim, “Score level fusion in multi-biometric identification based on zones of interest,” Journal of King Saud University-Computer and Information Sciences, vol. 34, no. 1, pp. 1498–1509, 2022. [Google Scholar]
26. R. Balasundaram and G. F. Sudha, “Retrieval performance analysis of multibiometric database using optimized multidimensional spectral hashing based indexing,” Journal of King Saud University-Computer and Information Sciences, vol. 33, no. 1, pp. 110–117, 2021. [Google Scholar]
27. O. Jafari and P. Nagarkar, “Experimental analysis of locality sensitive hashing techniques for high-dimensional approximate nearest neighbor searches,” in Databases Theory and Applications. Cham, Switzerland: Springer, pp. 62–73, 2021. [Google Scholar]
28. Z. Jin, J. Y. Hwang, Y. L. Lai, S. Kim and A. B. J. Teoh, “Ranking-based locality sensitive hashing-enabled cancelable biometrics: Index-of-max hashing,” IEEE Transactions on Information Forensics and Security, vol. 13, no. 2, pp. 393–407, 2017. [Google Scholar]
29. M. Aydar and S. Ayvaz, “An improved method of locality-sensitive hashing for scalable instance matching,” Knowledge and Information Systems, vol. 58, no. 2, pp. 275–294, 2019. [Google Scholar]
30. Y. Luo, W. Li, X. Ma and K. Zhang, “Image retrieval algorithm based on locality-sensitive hash using convolutional neural network and attention mechanism,” Information, vol. 13, no. 10, pp. 446, 2022. [Google Scholar]
31. M. N. Nachappa, A. M. Bojamma and M. C. Aparna, “A review on various fusion techniques in multimodal biometrics,” International Journal of Engineering Research and Technology, vol. 4, no. 21, pp. 1–8, 2016. [Google Scholar]
32. P. Drozdowski, F. Stockhardt, C. Rathgeb, D. Osorio-Roig and C. Busch, “Feature fusion methods for indexing and retrieval of biometric data: Application to face recognition with privacy protection,” IEEE Access, vol. 9, pp. 139361–139378, 2021. [Google Scholar]
33. S. Gundimada, V. K. Asari and N. Gudur, “Face recognition in multi-sensor images based on a novel modular feature selection technique,” Information Fusion, vol. 11, no. 2, pp. 124–132, 2010. [Google Scholar]
34. G. B. Huang, M. Ramesh, T. Berg and E. Learned-miller, Labeled faces in the wild: A database for studying face recognition in unconstrained environments, pp. 1–11, 2008. [Online]. Available: https://hal.inria.fr/inria-00321923/ (accessed on 01/02/2023) [Google Scholar]
35. N. Kumar, A. C. Berg, P. N. Belhumeur and S. K. Nayar, “Attribute and simile classifiers for face verification,” in 2009 IEEE 12th Int. Conf. on Computer Vision, Kyoto, Japan, pp. 365–372, 2009. [Google Scholar]
36. GitHub-kayzhu/LSHash: A fast Python implementation of locality-sensitive hashing, 2020. [Online]. Available: https://github.com/kayzhu/LSHash (accessed on 01/02/2023) [Google Scholar]
37. M. H. Hamd and R. A. Rasool, “Score level fusion technique for human identification,” in IOP Conf. Series: Materials Science and Engineering, Padang, Indonesia, West Sumatera, vol. 990, no. 1, pp. 012021, 2020. [Google Scholar]
38. K. Su, G. Yang, B. Wu, L. Yang, D. Li et al., “Human identification using finger vein and ECG signals,” Neurocomputing, vol. 332, pp. 111–118, 2019. [Google Scholar]
39. R. Dwivedi and S. Dey, “A novel hybrid score level and decision level fusion scheme for cancelable multi-biometric verification,” Applied Intelligence, vol. 49, no. 3, pp. 1016–1035, 2019. [Google Scholar]
40. M. H. Safavipour, M. A. Doostari and H. Sadjedi, “A hybrid approach to multimodal biometric recognition based on feature-level fusion of face, two irises, and both thumbprints,” Journal of Medical Signals and Sensors, vol. 12, no. 3, pp. 177–191, 2022. [Google Scholar] [PubMed]
41. J. Kim, Y. G. Jung and A. B. J. Teoh, “Multimodal biometric template protection based on a cancelable SoftmaxOut fusion network,” Applied Sciences, vol. 12, no. 4, pp. 2023, 2022. [Google Scholar]
42. E. Abdellatef, N. A. Ismail, S. E. S. Abd Elrahman, K. N. Ismail, M. Rihan et al., “Cancelable multi-biometric recognition system based on deep learning,” The Visual Computer, vol. 36, pp. 1097–1109, 2020. [Google Scholar]
43. V. Talreja, M. C. Valenti and N. M. Nasrabadi, “Deep hashing for secure multimodal biometrics,” IEEE Transactions on Information Forensics and Security, vol. 16, pp. 1306–1321, 2020. [Google Scholar]
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools