
 Submit a Paper
Submit a Paper Propose a Special lssue
Propose a Special lssue Open Access
Open Access
ARTICLE

PP-GAN: Style Transfer from Korean Portraits to ID Photos Using Landmark Extractor with GAN
1 Department of Computer AI Convergence Engineering, Kumoh National Institute of Technology, Gumi, 39177, Korea
2 Department of Computer Engineering, Kumoh National Institute of Technology, Gumi, 39177, Korea
* Corresponding Author: Sungyoung Kim. Email:
(This article belongs to the Special Issue: Advanced Artificial Intelligence and Machine Learning Frameworks for Signal and Image Processing Applications)
Computers, Materials & Continua 2023, 77(3), 3119-3138. https://doi.org/10.32604/cmc.2023.043797
Received 12 July 2023; Accepted 27 October 2023; Issue published 26 December 2023
 View Full Text
View Full Text Download PDF
Download PDFAbstract
The objective of style transfer is to maintain the content of an image while transferring the style of another image. However, conventional methods face challenges in preserving facial features, especially in Korean portraits where elements like the “Gat” (a traditional Korean hat) are prevalent. This paper proposes a deep learning network designed to perform style transfer that includes the “Gat” while preserving the identity of the face. Unlike traditional style transfer techniques, the proposed method aims to preserve the texture, attire, and the “Gat” in the style image by employing image sharpening and face landmark, with the GAN. The color, texture, and intensity were extracted differently based on the characteristics of each block and layer of the pre-trained VGG-16, and only the necessary elements during training were preserved using a facial landmark mask. The head area was presented using the eyebrow area to transfer the “Gat”. Furthermore, the identity of the face was retained, and style correlation was considered based on the Gram matrix. To evaluate performance, we introduced a metric using PSNR and SSIM, with an emphasis on median values through new weightings for style transfer in Korean portraits. Additionally, we have conducted a survey that evaluated the content, style, and naturalness of the transferred results, and based on the assessment, we can confidently conclude that our method to maintain the integrity of content surpasses the previous research. Our approach, enriched by landmarks preservation and diverse loss functions, including those related to “Gat”, outperformed previous researches in facial identity preservation.Keywords
With the advent of modern technologies, such as photography, capturing the appearances of people has become effortless. However, when these technologies were not developed artists would paint portraits of individuals. Such a painting is called a portrait, and because of the invention of photography, modern portraits have become a new field of art. However, all famous figures from the past were handed down in pictures. The main purpose of paintings is to depict politically famous figures [1], but in modern times, the purpose has expanded to the general public. Although the characteristics of portraits by period and country are very different, most differ greatly from the actual appearance of the characters unless they are surrealistic works. Korean portraits differ considerably depending on time and region. Fig. 1a shows a representative work of portraits from the Goryeo Dynasty. This work is a portrait of Ahn Hyang, a Neo-Confucian scholar from the mid-Goryeo period. Fig. 1b is a portrait of the late Joseon Dynasty, which indicates that there is a large difference in the preservation conditions and drawing techniques. In particular, in Fig. 1b, the “Gat” on the head is clearly visible [2].

Figure 1: The left photo (a) is a portrait of Ahn Hyang (1243~1306) in the mid-Goryeo dynasty and the right photo (b) is a portrait of Lee Chae (1411~1493) in the late Joseon Dynasty
Prior to the Three Kingdoms Period, Korean portrait records were absent, and only a limited quantity of portraits were preserved during the Goryeo Dynasty [3]. In contrast, the Joseon Dynasty produced numerous portraits with different types delineated according to their social status. Furthermore, works from the Joseon era exhibit a superior level of painting, in which facial features are rendered in greater detail than in earlier periods.
A portrait exhibits slight variations in the physical appearance of a person, but it uniquely distinguishes individuals akin to a montage. Modern identification photographs serve a similar purpose and are used as identification cards, such as driver’s licenses and resident registration cards. Old portraits may pique interest in how one appears in such artwork, for which style transfer technology can be used. Korean portraits may be used to provide the style of ID photos; however, the custom of wearing a “Gat” headgear renders transferring the style from Korean portraits to ID photos using previous techniques challenging. While earlier studies have employed global styles or partial styles to transfer onto content images, the distinct styles of texture, attire, and “Gat” must be considered simultaneously for Korean portraits. By independently extracting several styles from the style image, transferring the age, hairstyle, and costume of the person in a portrait onto the ID photos are possible. Fig. 2 showcases the results from the method presented in previous research [4]. The figure distinctly emphasizes the significant challenges encountered when attempting style transfer with multiple styles using CycleGAN [5]. In this study, we introduce a method for high-quality style transfer of Korean portraits, which overcomes the limitations of previous research to accurately preserve facial landmarks and produce realistic results.

Figure 2: Results of style transfer from Korean portraits to ID photos using CycleGAN
Style transfer techniques, such as GAN, are commonly used based on facial datasets, but maintaining the identity of the person is crucial for achieving high-quality results. Existing face-based style transfer studies only consider facial components, such as eyes, nose, mouth, and hair, when transferring styles onto content images. In contrast, this study aims to transfer multiple styles, including Gats and costumes, simultaneously.
To accomplish this, we propose an enhanced GAN-based network for style transfer that generates a mask using landmarks and defines a new loss function to perform style transfer based on facial data. we define the proposed method, “Style Transfer from Korean Portraits to ID Photos Using Landmark Extractor with GAN,” as PP-GAN. The primary contribution of this study is the development of a novel approach to style transfer that considers multiple styles and maintains the identity of a person.
• The possibility of independent and arbitrary style transfer to a network trained with a small dataset has been demonstrated.
• This study is the first attempt at arbitrary style transfer in Korean portraits, which was achieved by introducing a new combination of loss functions.
• The generated landmark mask improved the performance of identity preservation and outperformed previous methods [4].
• New data on upper-body Korean portraits and ID photos were collected for this study.
In Section 2, previous studies related to style transfer are reviewed. In Section 3, the foundational techniques for the method proposed in this paper are explained. Section 4 delves into the architecture, learning strategy, and loss functions of the proposed method in detail. In Section 5, the results of the proposed method and experimental and analytical results through performance metrics are presented. Lastly, Section 6 discusses the conclusions of this research and directions for future studies.
Research on style transfer can be categorized into two main groups: those based on Convolutional Neural Networks (CNN) and those based on General Adversarial Networks (GAN).
AdaIN [6] suggested a method of transferring style at high speed using statistics in feature maps of content and style images. This is one of the earlier studies on style transfers. Huang et al. [7] used the correlation between the content feature map and scaling information of the style feature map for the fusion of content and style. In addition, the order statistics method, called “Style Projection”, demonstrated the advantages and results of fast training speed. Zhu et al. [8] maintained structural distortion and content by presenting a style transfer network that could preserve details. In addition, by presenting the refined network, which modified the VGG-16 [9], the style pattern was preserved via spatial matching of hierarchical structures. Simonyan et al. [10] proposed a new style transfer algorithm that expanded the texture synthesis work. It aimed to create images of similar quality and emphasized a consistent way of creating rich styles while keeping the content intact in the selected area. In addition, it was fast and flexible to process any pair of content and style images. Li et al. [11] suggested a style transfer method for low-level features to express content images in a CNN. Low-level features dominate the detailed structure of new images. A Laplacian matrix was used to detect edges and contours. It shows a better stylized image, which can preserve the details of the content image and remove artifacts. Chen et al. [12] proposed a stepwise method based on a deep neural network for synthesizing facial sketches. It showed better performance by proposing a pyramid column feature to enrich the parts by adding texture and shading. Fast Art-CNN [13] is a structure for fast style transfer performance in the feedforward mode while minimizing deterioration in image quality. It can be used in real-time environments as a method for training deconvolutional neural networks to apply a specific style to content images. Liu et al. [14] proposed an architecture that includes geometric elements in the style transfer. This new architecture can transfer textures into distorted images. In addition, because the content/texture-style/geometry style can be selected to be entered in triple, it provides much greater versatility to the output. Kaur et al. [15] proposed a framework that solves the problem of realistically transferring the texture of the face from the style image to the content image without changing the identity of the original content image. Changes around the landmark are gently suppressed to preserve the facial structure so that it can be transferred without changing the identity of the face. Ghiasi et al. [16] presented a study on neural style transfer capable of real-time inference by combining with a fast style transfer network. It utilized a learning approach that predicts conditional instance normalization parameters for style images, enabling the generation of results for arbitrary content and style images.
APDrawingGAN [17] improved the performance by combining global and regional networks. High-quality results were generated by measuring the similarity between the distance transform and artist drawing. Xu et al. [18] used a generator and discriminator as conditional networks. Subsequently, the mask module for style adjustment and AdaIN [6] for style transfer performed better than the existing GAN. S3-GAN [19] introduced a style separation method in the latent vector space to separate style and content. A style-transferred vector space was created using a combination of separated latent vectors. CycleGAN [5] proposed a method for converting a style to an image without a pair of domains. While training the generator mapping to
Some attempts have been made to maintain facial landmarks in style transfer studies aimed at makeup, aging or changing. In SLGAN [21], a style-invariant decoder was created by a generator to preserve the identity of the content image and introduce a new perceptual makeup loss, resulting in high-quality conversion. BeautyGAN [22] defined instance and perceptual loss to change the makeup style while maintaining the identity of the face, thereby generating high-quality images and maintaining the identity. Paired-CycleGAN [23] trained two generators simultaneously to convert the makeup styles of other people from portrait photos. Stage 1 was used as a pair of powers through image analogy, and as an input of Stage 2, it showed excellent results by calculating identity preservation and style consistency compared to the power of Stage 1. Landmark-CycleGAN [24] showed incorrect results owing to the distortion of the geometrical structure while converting a face image to a cartoon image. To solve this problem, local discriminators have been proposed using landmarks to improve performance. Palsson et al. [25] suggested Group-GAN, which consisted of several models of CycleGAN [5], to integrate pre-trained age prediction models and solve the face aging problem. Wang et al. [26] proposed a method for interconverting edge maps to a CycleGAN-based E2E-CycleGAN network for aging. The old face was generated using the identity feature map and result of converting the edge map using the E2F-pixelHD network. Face-Dancer [27] proposed a model that transfers features from the face of a source image to a target image with the aim of face swapping. This involves transferring the identity of the source image, including its expressions and poses, while preserving the target image. This is significantly different from the method proposed in this paper. Although it claims to maintain identity, the results can be very different from the identity of the source image because it is influenced by the facial components of the target image. The key difference in our paper is that we propose a method that guarantees the identity of the source image itself while transferring the style of the target image.
The VGG-16 [9] network is a prominent computer vision model that attained a 92.7% Top-5 accuracy in the ImageNet Challenge competition by receiving an RGB image with dimensions of 224 × 224 as input, containing 16 layers in a configuration of 13 convolution layers and three FC layers. The convolution filter measures 3 × 3 pixels and maintains fixed strides and padding at 1. The activation function employed in the network is ReLU, and the pooling layer is max pooling, which is set to a fixed stride of 2 on 2 × 2. The closer it is to the input layer, the more low-level information the feature map contains, such as color and texture. of the image, and the closer it is to the output layer, thus providing higher-level information, such as shape. The pre-trained VGG-16 [9] was used in this study to preserve facial and upper-body content and transfer the style efficiently.
The Gram matrix is a valuable tool for representing the color distribution of an image. This enabled the computation of the overall color and texture correlation between the two images. Gatys et al. [28] demonstrated that the style transfer performance can be improved using a Gram matrix on feature maps from various layers. Fig. 3 illustrates the process of calculating the Gram matrix, which involves converting each channel of a color image into a 1D vector, followed by obtaining the matrix by multiplying the
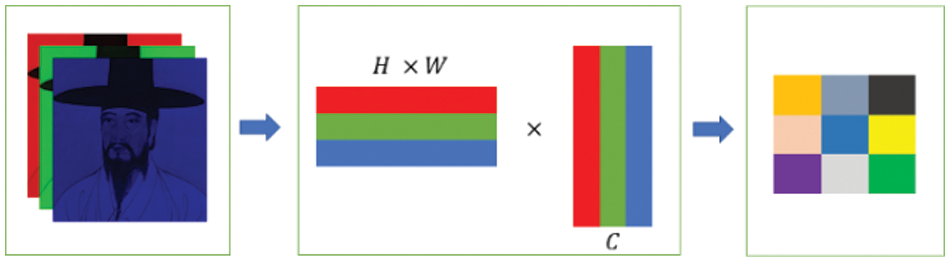
Figure 3: The process of calculating into a Gram matrix for Korean portraits
Facial landmarks, such as the eyes, nose, and mouth, play a vital role in identifying and analyzing facial structures. To detect the landmarks, this study employed the Shape Predictor of 68 face landmarks [29], which generated 68

Figure 4: Masks for eyes, nose, and mouth created by shape predictor 68 face landmarks
Image sharpening is considered a high-frequency emphasis filtering technique, which is employed to enhance image details. High frequency is characterized by the changes in brightness or color occurring locally, and it is useful in identifying facial landmarks. Image sharpening can be achieved using high-boost filtering. It involves generating a high-pass image by subtracting a low-pass image from an input image as shown in Eq. (1). A high-frequency emphasized image is obtained by multiplying the input image with a constant during this process.
Mean filtering is a low-pass filtering technique, and the coefficients of the filter can be determined using Eq. (2). The sharpening strength of the input image is controlled by the value of
To have similar structures between portrait images and ID photos, portrait images are cropped around the faces, as the face occupies a relatively small area. In contrast, ID photos are resized so that they have the same size, both horizontally and vertically, instead of being cropped. However, this resizing can make extracting facial landmarks difficult. Therefore, image sharpening is performed in the present study. This process is necessary to ensure that facial landmarks are extracted well from ID photos, as shown in Fig. 5, where the difference in facial landmark extraction with and without image sharpening is illustrated.

Figure 5: Result of landmark mask generation according to the use of high boost filtering (The first and third columns are the original and the high boost filtered image, respectively, and the second and fourth columns show the masks with the detected landmark for each corresponding image)
The primary objective of the proposed method is to achieve a style transfer of ID photos to Korean portraits. Let
The CycleGAN [5] network is limited in performing style transfer owing to its training over the entire domain. Therefore, the proposed method adopts a Dual I/O generator from BeautyGAN [20], which has a stable discriminator that enables mapping training between two domains and style transfer. Additionally, the proposed method incorporates VGG-16, a Gram matrix, and a landmark extractor to improve performance. Fig. 6 depicts the overall structure of the proposed method.
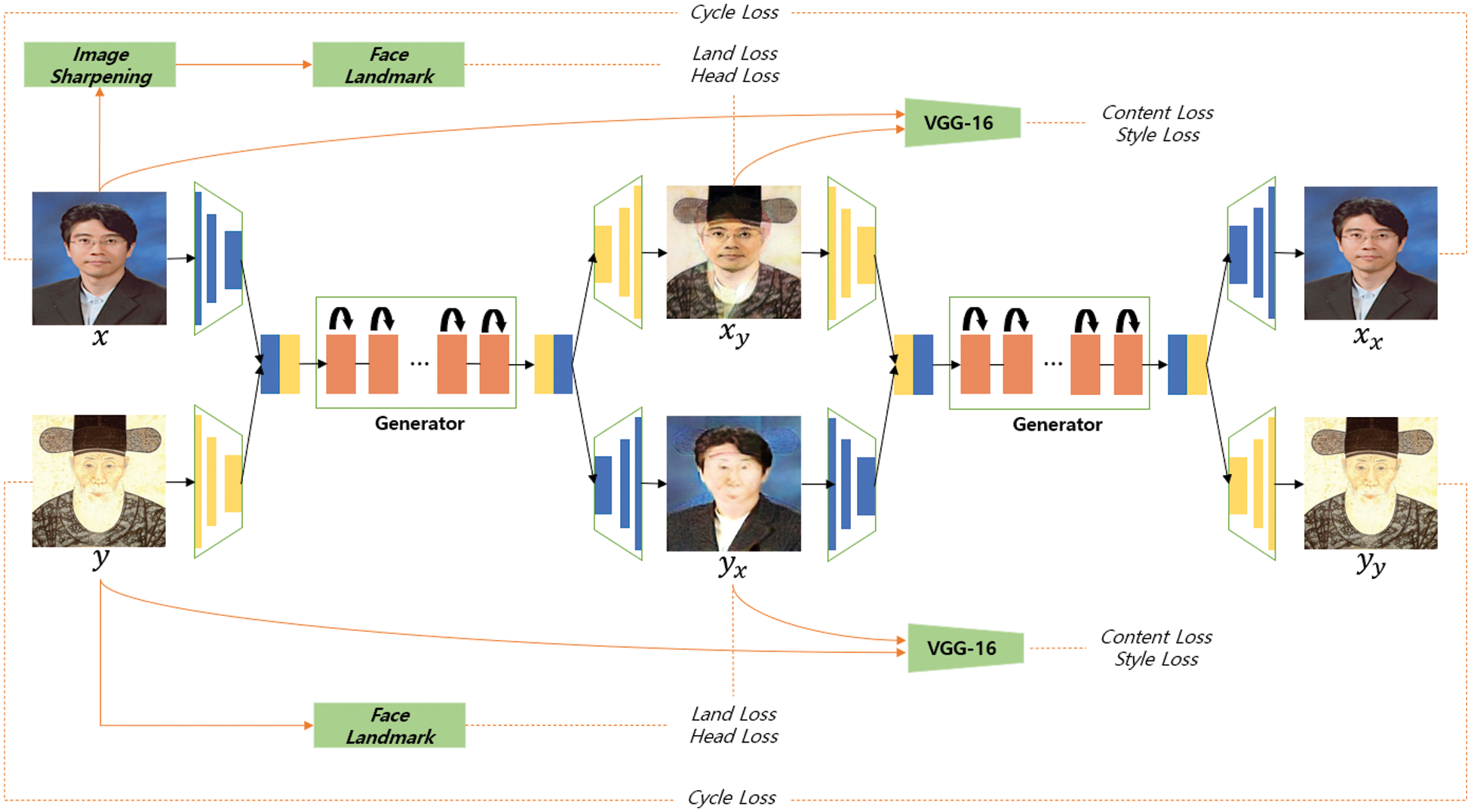
Figure 6: Overall structure of the system proposed in this study
The generator is trained to perform (
The network structure includes two discriminators that are trained to classify the styles of fake and real images generated by the generator. The discriminator consists of five convolution layers and aims to distinguish styles. The input image size is (256, 256, 3), and the network result size is (30, 30, 1). The first four convolution layers, excluding the last layer, perform Spectral Normalization to improve the performance and maintain a stable distribution of the discriminator in a high-dimensional space. The discriminator is defined as follows:
In this study, we propose a loss function for transferring ID photos for arbitrary Korean portrait styles. Six loss functions, including the loss function of the new approach, are used to generate good results.
CycleGAN introduced the concept of setting the result as the input of the generator again through a cycle structure, which should theoretically produce the same output as the original image. Therefore, in this study, we define the recovered result as the cycle loss, which consists of a loss function designed to reduce the difference between the input and output images. In particular, it can be expressed as
The existing style transfer method distorts the shape of the face geometrically, leading to difficulties in recognizing the face shape. To maintain the identity of the character, a new condition is required. Hence, this study defines land loss based on a face landmark mask, which helps in preserving the eyes, nose, and mouth while enhancing the performance of style transfer. Land loss is defined by mathematical expression Eq. (4) in this study.
Land loss is a function that aims to maintain the landmark features of the input and output images generated by the generator. The pairs of images (
The method proposed in this study differs greatly from previous style transfer research, which requires some content of the style target image rather than ignoring it and only considering the color relationship. In particular, for Korean portraits, the style of the Gat and clothes must be considered in addition to image quality, background, and overall color. However, the form of the Gat varies widely, which is difficult to detect due to the differences in wearing position, while the hair of Korean portraits and ID photos have completely different shapes. To address this, a head loss is proposed to minimize the difference between the head area of the result and style images, with the head area divided into the Gat and hair areas, represented by masks
To preserve the overall shape of the character and enhance the performance of style transfer, content loss and Style Loss are defined using a specific layer of VGG-16 in this study. The pre-trained network contained low- and high-level information, such as colors and shapes, which appeared differently depending on the layer location. Low-level information is related to style, and high-level information is related to content. Conversely, high-level layers represent the image characteristics. Therefore, the content and style losses are configured based on the layer characteristics. Style loss is defined using a Gram matrix, which is obtained by computing the inner product of the feature maps. The best set of layers obtained through the experiment is used to define style loss, as shown in Eq. (7), where N and M represent the product and channel of each layer, respectively, and g represents the Gram matrix of the feature map. By training to minimize the difference in the Gram matrix between the feature maps for both sides (
Content loss is defined as a method to minimize linear differences in feature maps at the pixel level. Because the style transfer aims to maintain the content of an image while transferring the style, it is not necessary to consider correlations. The equation for content loss is the same as that in Eq. (8). This is a critical factor in preserving the identity of a person; however, if the weight of this loss is extremely large, it can result in poor style transfer results. Therefore, appropriate hyperparameters must be selected to achieve the desired outcome.
The discriminator loss solely comprised adversarial loss, which followed the GAN structure. The output of the discriminator is a 32 × 32 × 1 result that is evaluated based on PatchGAN [30] to identify whether they are authentic or fake, considering every image PatchGAN [30]. The loss function used to train the discriminator is given by Eq. (9). The loss function is reduced if the patches of
The generator loss is composed of cycle, land, head, style, and content losses, as expressed in Eq. (11). Each loss is multiplied by a different hyperparameter, and the sum of the resulting values is used as the loss function of the generator.
The total loss employed in this study is expressed by Eq. (12) and is composed of the generator and discriminator losses. The generator seeks to minimize the generator loss to generate style transfer outcomes, whereas the discriminator aims to minimize the discriminator loss to enhance its discriminative capability. A trade-off between the generator and discriminator performances is observed, where if one is improved, the other is diminished. Consequently, the total loss is optimized by forming a competitive relationship between the generator and discriminator, which led to superior outcomes.
The experimental environment in this study was conducted on a multi-GPU system using the GeForce RTX 3090 and Ubuntu 18.04 LTS operating system. As TensorFlow 1.x has a minimum version requirement for CUDA, the experiments were carried out using Nvidia-Tensorflow version 1.15.4. Datasets of ID photos and Korean portraits were collected through web crawling using Google and Bing search engines. To improve the training performance, preprocessing was conducted to separate the face area from the whole body of the Korean portraits, which typically feature the entire body. Data augmentation techniques, such as left and right inversion, blur, and noise, were applied to increase the limited number of datasets. Gat preprocessing was also performed, as shown in Fig. 7, to facilitate the feature mapping.

Figure 7: Examples of datasets preprocessing
Table 1 shows the resulting dataset consisting of 1,054 ID photos and 1,736 Korean portraits divided into 96% training and 4% test sets. Owing to the limited number of portraits, a higher ratio of training data was used, and no data augmentation was applied to the test set. As the number of combinations that could be generated from the test data was substantial (
The proposed network was trained for 200 epochs using the Adam Optimizer. The initial learning rate was set to 0.0001 and linearly reduced to zero after 50% of the training epoch for stable learning. To match the equality between the loss functions,

Figure 8: The result of the method proposed in this paper
To perform style loss, this study adopted Conv2_2 and Conv3_2 from the VGG-16 layer, whereas Conv4_1 was used for content loss. Although the front convolution layers contain low-level information, they are sensitive to change and difficult to train because of the large differences in pattern and color between the style and content images. To overcome this problem, this study utilizes a feature map located in the middle to extract low-level information for style transfer. The results of using a feature map not adopted for style loss are presented in Fig. 9 with a smoothing set to 0.8 on the tensorboard. Loss graphs were output for only ten epochs because of the failure of training when layers not used for Style Loss were utilized in the experiment.

Figure 9: Result of a specific feature map experiment of VGG-16 for style loss
• The Conv2_1 layer exhibits a large loss value and unstable behavior during training, indicating that training may not be effective for this layer.
• Conv1_2 is close to zero in most of the losses, but it cannot be said that the training proceeds because the maximum minimum differs by more than
• Conv1_1 exhibits a high loss deviation and instability during training, similar to Conv2_1 and Conv1_2. Moreover, owing to its sensitivity to color, this layer presents challenges for training.
If Conv4_1 is utilized as the style loss layer, it can transfer the style of the image content. However, because the feature map scarcely includes style-related content, the generator may produce images lacking style. Nevertheless, it is observed that transferring the style of the background is feasible as it corresponds to the overall style of the image and can be recognized as content because clothing style is not a prominent feature. Therefore, high-level layers, such as Conv4_1, contain only the style of the background in the character content. The result of utilizing the feature map employed in the content loss for style loss is shown in Fig. 10. In general, most contents of the content image are preserved, whereas the style is marginally transferred. Hence, we proceed with using trainable layers, which results in stable training and enables us to transfer styles while conserving content.

Figure 10: Results when the feature map used for Style Loss is used with the same layer as Content Loss (Column 1: input image; Column 2 and Column 3: output image using Conv4_1)
An ablation study was conducted on four loss functions, excluding Cycle Loss, to demonstrate the effectiveness of the loss function proposed in this study for Generator Loss. The results are presented in Fig. 11, where one row represents the use of the same content and style images. If

Figure 11: Results highlighting the importance of the various loss functions. Column 1 to 4 excluding the loss functions
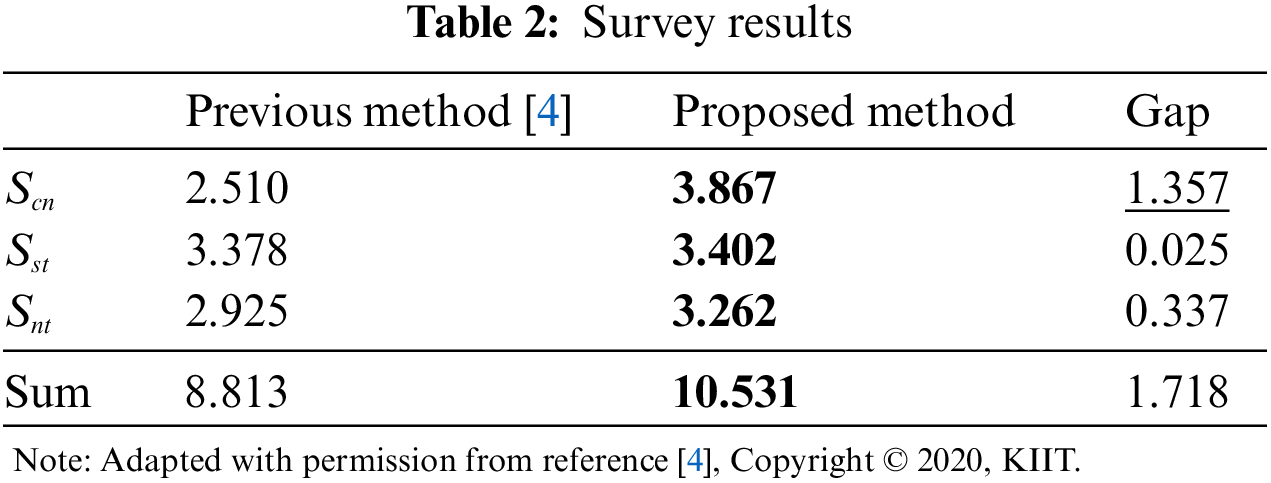
This study conducts a performance comparison with previous research [4] with the same subject, as well as an ablation study. Although there are diverse existing studies on style transfer, the subject of this paper differs significantly from them, leading to a comparison only with a single previous study [4].
Based on CycleGAN [5], evaluation in pairs could not be performed because of the impossibility of arbitrary style transfer. Thus, an evaluation survey was conducted with 59 students of different grades from the Department of Computer Engineering at Kumoh National Institute of Technology to evaluate the performance of the proposed method in terms of three items: the transfer of style (
Peak signal-to-noise ratio (PSNR) and structural similarity index measure (SSIM) are commonly employed to measure performance. However, when conducting style transfer while preserving content, it is crucial to ensure a natural outcome without any significant bias towards either the content or style. Consequently, to compare the performance, we propose new performance indicators that utilize a weighted arithmetic mean, which is further weighted by the median values of the PSNR and SSIM. The final result is obtained by combining the results of both content and style using the proposed performance indicator.
The PSNR is commonly used to assess the quality of images after compression by measuring the ratio of noise to the maximum value, which can be calculated using Eq. (13). The logarithmic denominator in this equation represents the average sum of squares between the original and compressed images, and a lower value indicates a higher PSNR and better preservation of the original image. By contrast, the SSIM is used to evaluate distortions in image similarity between a pair of images by comparing their structural, luminance, and contrast features. Eq. (14) is used to calculate the SSIM, which involves various probability-related definitions such as mean, standard deviation, and covariance.
To evaluate the performance, the indicators are sorted in ascending order, resulting in a sequence of values denoted as [
Table 3 shows the results of the proposed performance indicators based on PSNR and SSIM, which were evaluated based on 1,452 generated results. PSNR values for content and style images are represented by
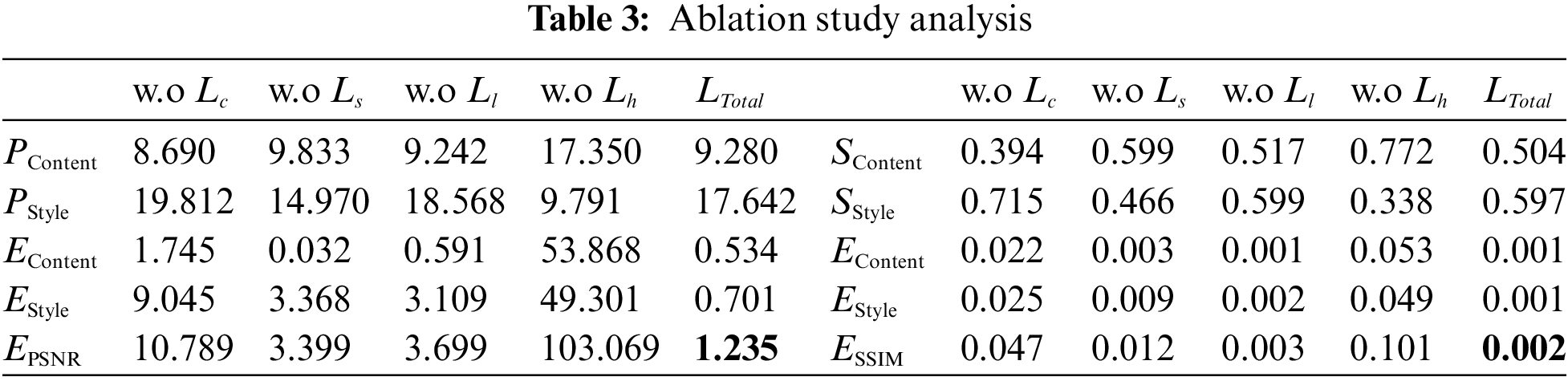
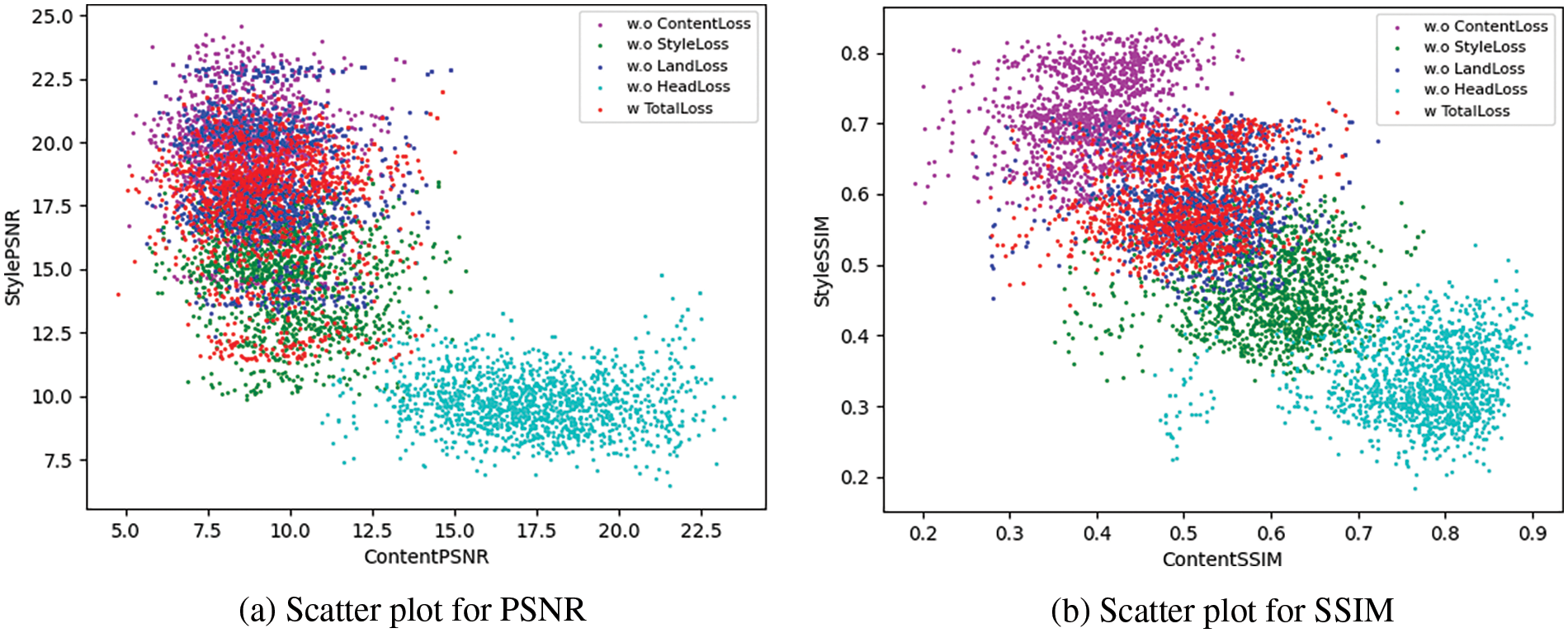
Figure 12: Scatter plot of two metrics (PSNR and SSIM) in terms of content and style for test datasets and their transfer results based on combinations of used loss function combinations
The performance of the style transfer of Korean portraits to ID photos presented in this paper is highly satisfactory. However, there are three issues. First, the dissimilarity in the texture of the images on both sides leads to unsatisfactory results in the reverse direction. While this paper mainly focuses on transferring the Korean portrait style to ID photos, the generator structure allows the transfer of the ID photos style to Korean portraits. Nevertheless, maintaining the shape of the Korean portraits, which are paintings, can pose a challenge. Furthermore, owing to mapping difficulties, only the face may be preserved during style transfer. Second, if the feature map of the Korean portrait dataset does not map well with the ID photos dataset, unsatisfactory results are obtained. This can be attributed to either dataset limitations or faulty preprocessing. For instance, ID photos are front-facing, but Korean portraits may depict characters from other angles. Improper cropping during preprocessing can also lead to different feature maps and poor results. Finally, Korean portrait data are scarce, and using existing data leads to limited and inadequate style representation. Although data augmentation increases the number of data points, the training style remains unchanged, thereby limiting the results.
The objective of this study is to propose a generative adversarial network that utilizes facial feature points and loss functions to achieve arbitrary style transfers while maintaining the original face shape and transferring the Gat. To preserve the characteristics of the face, two loss functions, Land Loss and Head Loss, were defined using landmark masks to minimize the difference and speed up the learning process. Style Loss, which uses a Gram matrix for content loss and style transfer, enables style transfer while preserving the character’s shape. However, if the input images have large differences and the feature maps have significant discrepancies, the results are not satisfactory, and there are color differences in some instances. Additionally, it is noticeable that when hair is prominently displayed in ID photos, the chances of experiencing the ghosting effect increase. To overcome these limitations, it is recommended to define a loss function that considers color differences and aligns the feature map through the alignment of facial landmarks in future studies.
Acknowledgement: The authors thank the undergraduate students, alumni of Kumoh National Institute of Technology, and members of the IIA Lab.
Funding Statement: This work was supported by Metaverse Lab Program funded by the Ministry of Science and ICT (MSIT), and the Korea Radio Promotion Association (RAPA).
Author Contributions: Study conception and design: J. Si, S. Kim; data collection: J. Si; analysis and interpretation of results: J. Si, S. Kim; draft manuscript preparation: J. Si, S. Kim.
Availability of Data and Materials: Data supporting this study cannot be made available due to ethical restrictions.
Ethics Approval: The authors utilized ID photos of several individuals, all of which were obtained with their explicit consent for providing their photos.
Conflicts of Interest: The authors declare that they have no conflicts of interest to report regarding the present study.
References
1. Encyclopedia of Korean culture. http://encykorea.aks.ac.kr/Contents/Item/E0057016/ (accessed on 28/12/2022) [Google Scholar]
2. Cultural heritage administration. http://www.heritage.go.kr/heri/cul/culSelectDetail.do?pageNo=1_1_1_1&ccbaCpno=1113701110000/ (accessed on 17/05/2023) [Google Scholar]
3. Cultural Heritage Administration. https://www.heritage.go.kr/heri/cul/culSelectDetail.do?pageNo=1_1_1_1&ccbaCpno=1121114830000/ (accessed on 17/05/2023) [Google Scholar]
4. J. Si, J. Jeong, G. Kim and S. Kim, “Style interconversion of Korean portrait and ID photo using CycleGAN,” in Proc. of Korean Institute of Information Technology (KIIT), Cheong Ju, Korea, pp. 147–149, 2020. [Google Scholar]
5. J. Zhu, T. Park, P. Isola and A. A. Efros, “Unpaired image-to-Image translation using cycle-consistent adversarial networks,” in Proc. of the IEEE Int. Conf. on Computer Vision (ICCV), Venice, Italy, pp. 2223–2232, 2017. [Google Scholar]
6. X. Huang and S. Belongie, “Arbitrary style transfer in real-time with adaptive instance normalization,” in Proc. of the IEEE Int. Conf. on Computer Vision (ICCV), Seoul, Korea, pp. 1501–1510, 2017. [Google Scholar]
7. S. Huang, H. Xiong, T. Wang, Q. Wang, Z. Chen et al., “Parameter-free style projection for arbitrary style transfer,” arXiv preprint arXiv:2003.07694, 2020. [Google Scholar]
8. T. Zhu and S. Liu, “Detail-preserving arbitrary style transfer,” in Proc. of IEEE Int. Conf. on Multimedia and Expo (ICME), London, UK, pp. 1–6, 2020. [Google Scholar]
9. M. Elad and P. Milanfar, “Style transfer via texture synthesis,” IEEE Transactions on Image Processing, vol. 26, no. 5, pp. 2338–2351, 2017. [Google Scholar] [PubMed]
10. K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” in Proc. of Int. Conf. on Learning Representations (ICLR), San Diego, CA, USA, pp. 1–14, 2015. [Google Scholar]
11. S. Li, X. Xu, L. Nie and T. Chua, “Laplacian-steered neural style transfer,” in Proc. of ACM Int. Conf. on Multimedia, New York, NY, USA, pp. 1716–1724, 2017. [Google Scholar]
12. C. Chen, X. Tan and K. Y. K. Wong, “Face sketch synthesis with style transfer using pyramid column feature,” in Proc. of IEEE Winter Conf. on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, pp. 485–493, 2018. [Google Scholar]
13. B. Blakeslee, R. Ptucha and A. Savakis, “Faster Art-CNN: An extremely fast style transfer network,” in Proc. of IEEE Western New York Image and Signal Processing Workshop (WNYISPW), Rochester, NY, USA, pp. 1–5, 2018. [Google Scholar]
14. X. Liu, X. Li, M. Cheng and P. Hall, “Geometric style transfer,” arXiv preprint arXiv:2007.05471, 2020. [Google Scholar]
15. P. Kaur, H. Zhang and K. Dana, “Photo-realistic facial texture transfer,” in Proc. of IEEE Conf. on Applications of Computer Vision (WACV), Waikoloa, HI, USA, pp. 2097–2105, 2019. [Google Scholar]
16. G. Ghiasi, H. Lee, M. Kudlur, V. Dumoulin and J. Shlens, “Exploring the structure of a real-time, arbitrary neural artistic stylization network,” arXiv preprint arXiv:1705.06830, 2017. [Google Scholar]
17. R. Yi, Y. Liu, Y. Lai and P. Rosin, “APDrawingGAN: Generating artistic portrait drawings from face photos with hierarchical GANs,” in Proc. of the IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, California, USA, pp. 10743–10752, 2019. [Google Scholar]
18. Z. Xu, M. Wilber, C. Fang, A. Hertzmann and H. Jin, “Learning from multi-domain artistic images for arbitrary style transfer,” in Proc. of the ACM/Eurographics Expressive Symp. on Computational Aesthetics and Sketch Based Interfaces and Modeling and Non-Photorealistic Animation and Rendering (Expressive’ 19), Goslar, Germany, pp. 21–31, 2019. [Google Scholar]
19. R. Zhang, S. Tang, Y. Li, J. Guo, Y. Zhang et al., “Style separation and synthesis via generative adversarial networks,” in Proc. of the ACM Int. Conf. on Multimedia, New York, NY, USA, pp. 183–191, 2018. [Google Scholar]
20. R. Yi, Y. J. Liu, Y. K. Lai and P. L. Rosin, “Unpaired portrait drawing generation via asymmetric cycle mapping,” in Proc. of the IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR), Virtual, pp. 8217–8225, 2020. [Google Scholar]
21. D. Horita and K. Aizawa, “SLGAN: Style-and latent-guided generative adversarial network for desirable makeup transfer and removal,” in Proc. of the ACM Int. Conf. on Multimedia in Asia, Tokyo, Japan, pp. 1–8, 2022. [Google Scholar]
22. T. Li, R. Qian, C. Dong, S. Liu, Q. Yan et al., “BeautyGAN: Instance-level facial makeup transfer with deep generative adversarial network,” in Proc. of the ACM Int. Conf. on Multimedia, New York, NY, USA, pp. 645–653, 2018. [Google Scholar]
23. H. Chang, J. Lu, F. Yu and A. Finkelstein, “PairedCycleGAN: Asymmetric style transfer for applying and removing makeup,” in Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, pp. 40–48, 2018. [Google Scholar]
24. R. Wu, X. Gu, X. Tao, X. Shen, Y. W et al., “Landmark assisted cyclegan for cartoon face generation,” arXiv preprint arXiv:1907.01424, 2019. [Google Scholar]
25. S. Palsson, E. Agustsson, R. Timofte and L. V. Gool, “Generative adversarial style transfer networks for face aging,” in Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, pp. 2084–2092, 2018. [Google Scholar]
26. Z. Wang, Z. Liu, J. Huang, S. Lian and Y. Lin, “How old are you? Face age translation with identity preservation using GANs,” arXiv preprint arXiv:1909.04988, 2019. [Google Scholar]
27. F. Rosberg, E. E. Aksoy, F. Alonso-Fernandez and C. Englund, “FaceDancer: Pose-and occlusion-aware high fidelity face swapping,” in Proc. of the IEEE/CVF Winter Conf. on Applications of Computer Vision, Hawaii, Walkoloa, pp. 3454–3463, 2023. [Google Scholar]
28. L. A. Gatys, A. S. Ecker and M. Bethge, “Image style transfer using convolutional neural networks,” in Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), Las Vegas, Nevada, USA, pp. 2414–2423, 2016. [Google Scholar]
29. V. Kazemi and J. Sullivan, “One millisecond face alignment with an ensemble of regression trees,” in Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, pp. 1867–1874, 2014. [Google Scholar]
30. C. Li and M. Wand, “Precomputed real-time texture synthesis with markovian generative adversarial networks,” in Proc. of European Conf. on Computer Vision (ECCV), Amsterdam, Netherlands, pp. 702–716, 2016. [Google Scholar]
Appendix A. Comparison of generated results with similar related works
In this section, we will perform comparative analysis alongside the results of two similar categories: Neural Style Transfer and Face Swap.
In the case of Neural Style Transfer, it involves transferring the style of the entire Style image to the Content image. Therefore, it is unable to produce results such as transferring the Gat or changing the texture of the clothes. For Face Swap, it can extract only the facial features of the ID photos and generate an image on the Korean portrait. However, one of its limitations is that it superimposes the features from the ID photos onto the facial landmarks of the Korean portrait itself, which leads to a loss of original identity. The aim of this study is quite different as it seeks to preserve all aspects of the upper body shape and facial area found in the ID photos, while also transferring the texture of the clothes, the overall color of the picture, and the Gat from the Korean portrait.
Fig. 13 illustrates the visualized results of the methods proposed by Ghiasi et al. [16], Face-Dancer [27], and this study. The results of Ghiasi et al. [16] show a transfer from the ID photos based on the overall style distribution of the Korean portrait images. For Face-Dancer [27], it maintains all content outside the face region of the Korean portrait, and the internal facial features of the ID photos are spatially transformed and transferred onto the face of the Korean portrait. The generated result is not a transfer of the Korean portrait style to the ID photos, but rather a projection of the ID photos onto the Korean portrait itself, hence the preservation of the identity is not maintained.

Figure 13: Comparison of results between neural style transfer, face swap methods and ours (Column 2: Ours, Column 3: G. Ghiasi et al. [16], Column 4: Face-Dancer [27]). Adapted with permission from reference [16], Copyright © 2017, Arxiv., reference [27], Copyright © 2023, IEEE
Cite This Article
 Copyright © 2023 The Author(s). Published by Tech Science Press.
Copyright © 2023 The Author(s). Published by Tech Science Press.This work is licensed under a Creative Commons Attribution 4.0 International License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
 Downloads
Downloads
 Citation Tools
Citation Tools